

Abstract
Background
Previous studies have shown that contextual factors and individual socioeconomic status (SES) were associated with mortality in Western developed countries. In Korea, there are few empirical studies that have evaluated the association between SES and health outcomes.
Methods
We conducted cohort study to investigate the socioeconomic disparity in all-cause mortality for patients newly diagnosed with hypertension in the setting of universal health care coverage. We used stratified random sample of Korean National Health Insurance enrollees (2002–2013). We included patients newly diagnosed with hypertension (n = 28,306) from 2003–2006, who received oral medication to control their hypertension. We generated a frailty model using Cox’s proportional hazard regression to assess risk factors for mortality.
Results
A total of 7,825 (27.6%) of the 28,306 eligible subjects died during the study period. Compared to high income patients from advantaged neighborhoods, the adjusted hazard ratio (HR) for high income patients from disadvantaged neighborhoods was 1.10 (95% CI, 1.00–1.20; p-value = 0.05). The adjusted HR for middle income patients who lived in advantaged versus disadvantaged neighborhoods was 1.17 (95% CI, 1.08–1.26) and 1.27 (95% CI, 1.17–1.38), respectively. For low income patients, the adjusted HR for patients who lived in disadvantaged neighborhoods was higher than those who lived in advantaged neighborhoods (HR, 1.35; 95% CI, 1.22–1.49 vs HR, 1.28; 95% CI, 1.16–1.41).
Conclusions
Neighborhood deprivation can exacerbate the influence of individual SES on all-cause mortality among patients with newly diagnosed hypertension.
Electronic supplementary material
The online version of this article (doi:10.1186/s12939-015-0288-2) contains supplementary material, which is available to authorized users.
Keywords: Socioeconomic status, Neighborhood deprivation, All-cause mortality, Hypertension
Background
Hypertension is a chronic disease considered to be a major public health challenge [1–3] and is a key risk factor in the development of stroke, myocardial infarction, heart failure, and renal failure [4]. A socioeconomic gradient of risk factors for hypertension has been observed in a variety of settings. Previous studies that examined socioeconomic disparities related to the incidence or prevalence of hypertension have found that individuals with low income [5, 6], lower education [6–9], blue-collar occupation [6, 7], and living in disadvantaged neighborhoods [10, 11] face a higher probability of dying from complications of hypertension.
Most studies that explain the inverse relationship between socioeconomic status (SES) and risk factors for hypertension have come from the developed countries. The results of these studies demonstrated a relationship between individual socioeconomic characteristics and health status, where higher SES correlated with better health [12–15]. In comparison, other studies have reported that the characteristics of the neighborhoods in which the patients reside and the contextual factors independently affect individual health status. However, other studies have stated that neighborhood characteristics are the result of an aggregation of the relationships between the socioeconomic status and the health status of the individual [16]. An inverse relationship between mortality and neighborhood characteristics was found in Alameda County, 18 counties of Nova Scotia in Canada [17, 18]; in particular, low income individuals living in advantaged neighborhoods had higher mortality rates relative to low income individuals living in disadvantaged neighborhoods. The authors suggested “differential access to resources” as an explanation for these findings [18]. However, because Korea first implemented universal health care coverage in 1989 and has operated by a national tax system, there has been a greater redistribution of income in the population [19], resulting in smaller income inequalities than in the United States.
The aim of this study was to investigate the socioeconomic disparity at both individual and regional levels in all-cause mortality among patients with newly diagnosed hypertension using hierarchical modeling in a setting of universal health care coverage.
Methods
Data source for the study
This study used data from the Korean National Health Insurance (KNHI) claims database from 2002–2013 and the 2005 Korean Census. The National Health Insurance Corporation collects cohort data representative of Korea’s population. These data included the information on 1,025,340 subjects, and represented a stratified random sample selected according to age, sex, region, health insurance type, income quintiles, and individual total medical costs (based on the 2002 data). The database also included the information on reimbursement for each medical service, comprised of basic patient information, an identifier for the clinic or hospital, disease code, costs incurred, results of health screening, past/family health history, health behaviors, and information related to death. We focused especially on the characteristics of the neighborhoods in which patients resided. Ethical approval for this study was granted by the Institutional Review Board of the Graduate School of Public Health, Yonsei University.
Selection of sample population
We identified 131,713 individuals with hypertension between 2002 and 2013 in the KNHI enrollee database. Of these, 38,963 subjects with hypertension (I10-I13; International Classification of Disease, 10th edition) newly diagnosed between 2003 and 2006 were selected. Hypertension patients consisted as following: primary hypertension (n = 24,809; I10), hypertensive heart disease (n = 2,791; I11), hypertensive renal disease (n = 297; I12), and hypertensive heart and renal disease (n = 409; I13). The proportion of patients with primary hypertension was approximately 90% (Additional file 1: Table S1). We confirmed that the diagnoses were new by verifying a lack of hypertension claims between 2002 and 2005, an initial hypertension claim between 2003 and 2006, and an absence of hypertension in the health history prior to the year of diagnosis. We included subject data collected over a minimum of 7 years and a maximum of 10 years. Of the 38,963 subjects initially selected, 10,657 were excluded: 305 patients were less than 20 years-old and 10,352 patients did not take antihypertensive medication. These exclusion criteria were necessary to determine the actual hypertension patients. The final study sample included 28,306 participants (Fig. 1).
Fig. 1.
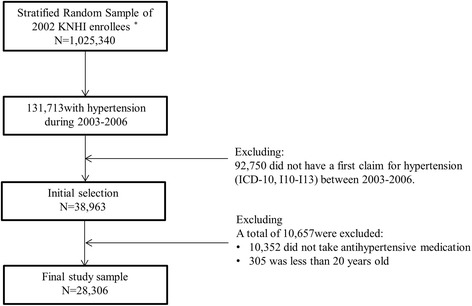
Flowchart for sample selection
Dependent variable
The outcome variable was the survival time from the date of the diagnosis to the date of death or study end-date. We defined mortality as all-cause mortality, as identified from the death certificate data in the national death registry.
Individual SES
We used the average monthly insurance premium as a proxy variable for household income. In Korea, the type of health insurance is classified as national health insurance or medical aid. Individuals qualify for medical aid if their household income is less than $600 per month based on a single household. If the household income is more than $600 per month, individuals qualify for national health insurance. Individuals who have national health insurance provided by their employer pay a monthly insurance premium according to annual salary, and those who are self-employed pay a premium according to property value. Individuals who qualified for the national health insurance were distributed between the 1st percentile and 100th percentile, and those who had medical aid were classified into the 0 percentile. We arbitrarily categorized individual household income into three groups (low, 0–20th percentile; middle, 21st–80th percentile; high, 81st–100th percentile). We divided into five groups as quintile according to household income. When we categorized high and low group using quintile, those belonging upper 20 percentile and lower 20 percentile were categorized to high and low, respectively.
Neighborhood deprivation index
A summary measure was used to characterize the neighborhood-level deprivation. We used the modified Carstairs index [20] for measuring neighborhood deprivation using the census data from 2005. For the original calculation of the Carstairs index in previous studies, four variables from census data were used: 1) residents in households headed by unskilled workers, 2) unemployed males, 3) residents in overcrowded households, and 4) residents without a car. However, because we could not determine ‘residents without a car’ from the census data, according to Lee’s study’ methodology [21], we replaced ‘residents without car’ with ‘residents who rent their homes’. The neighborhood deprivation index was calculated at the Si (city), Gun (county) and Gu (borough) levels by merging the four basic indicators according to the method used for calculating the Carstairs index. Si, Gun, and Gu were geographical units we used to provide coverage across all smaller areas in Korea. We calculated a z-score at the Si, Gun, and Gu levels using the mean and standard deviation of the four indicators. A z-score was calculated by subtracting the mean from the observed value for each indicator, dividing it into the standard deviation, and then summing the four standardized z-scores. Disadvantaged and advantaged neighborhoods were distinguished on the basis of the median neighborhood deprivation index.
Covariates
The covariates for our study were age (20–49, 50–59, 60–69, or ≥70 years), sex, residential area (metropolitan, urban or rural), Charlson Comorbidity Index (CCI) (0, 1, 2, or ≥3) [22], the number of risk factors (none, with diabetes or dyslipidemia, with diabetes and dyslipidemia), disability (normal, mild, severe), and the number of health screenings during the follow-up period (1, 2, 3 or 4). Only the comorbidity component of the CCI was calculated, and all diagnostic information was collected from inpatient and outpatient billing data at the time of diagnosis.
Statistical analysis
Descriptive statistics were computed for all variables. The Chi-square test was used to calculate frequencies and percentages for categorical variables. The survival probability for all-cause mortality was estimated by the Kaplan-Meier product limit method, and the log-rank test was used to stratify SES. To investigate the association between individual-level and regional-level SES and all-cause mortality, we performed survival analysis using a Cox proportional hazards frailty model, which included random effects to deal with the covariates hierarchy denoted. This approach tests for a hospital effect as a random effect [23], which can be thought of as a “frailty”, increasing a region’s susceptibility to short survival time when it is large, and decreasing this susceptibility when it is small. We tested the variance and p-value for mortality among regions and determined that the variance was 0.016 and p-value was 0.003; therefore, we used the frailty model.
The equation λ (t|x) = zλ0(t)exp(xβ) describes the frailty model where x represents the covariates matrix, β is the fixed effect vector, and Z is a random variable representing an unknown random effect related to regions, with the unit mean and variance ξ. These random effects act multiplicatively on the baseline hazard, and large values of ξ reflect a great degree of heterogeneity among regions. For model distribution purposes, we assumed that the frailties were distributed according to a gamma distribution. One attractive feature of the gamma distribution is that it is mathematically tractable [24]. The proportional hazards assumptions were tested using scaled Schoenfeld residuals and no violation was found. All of the statistical analyses were performed using SAS 9.3 software.
Results
Of the 28,306 eligible subjects, 7,825 (27.6%) died during the study period and 20,481 (72.4%) survived (Table 1). There were significant differences between the two groups for all of the individual patient characteristics (age, sex, health insurance type, income, CCI, residential area, number of risk factors, disability, and the number of health screenings during study period).
Table 1.
Baseline characteristics of patients with newly diagnosed hypertension
| Total | Alive | Dead | P-value | |||
|---|---|---|---|---|---|---|
| Characteristics | N = 28,306 | N = 20,481 | (72.4) | N = 7,825 | (27.6) | |
| Age, N (%) | ||||||
| 20 ~ 49 | 5,769 | 5,434 | (94.2) | 335 | (5.8) | <.0001 |
| 50 ~ 59 | 6,251 | 5,588 | (89.4) | 663 | (10.6) | |
| 60 ~ 69 | 7,977 | 6,131 | (76.9) | 1,846 | (23.1) | |
| ≥70 | 8,309 | 3,328 | (40.0) | 4,981 | (60.0) | |
| Sex, N (%) | ||||||
| Male | 13,632 | 9,712 | (71.2) | 3,920 | (28.8) | 0.0001 |
| Female | 14,674 | 10,769 | (73.4) | 3,905 | (26.6) | |
| Health insurance type, N (%) | ||||||
| National health insurance | 27,681 | 20,123 | (72.7) | 7,558 | (27.3) | <.0001 |
| Medical aid | 625 | 358 | (57.3) | 267 | (42.7) | |
| Income, N (%) | ||||||
| Low (≤20th percentile) | 4,801 | 3,192 | (66.5) | 1,609 | (33.5) | <.0001 |
| Middle (21st–80th percentile) | 14,541 | 10,766 | (74.0) | 3,775 | (26.0) | |
| High (≥81st percentile) | 8,964 | 6,523 | (72.8) | 2,441 | (27.2) | |
| Carstairs index, N (%) | ||||||
| Disadvantaged neighborhood (below median) | 15,855 | 11,458 | (72.3) | 4,397 | (27.7) | 0.6101 |
| Advantaged neighborhood (above median) | 12,451 | 9,023 | (72.5) | 3,428 | (27.5) | |
| Combined individual household income level-neighborhood deprivation, N (%) | ||||||
| High-Advantaged neighborhood | 4,177 | 3,050 | (73.0) | 1,127 | (27.0) | <.0001 |
| High-Disadvantaged neighborhood | 4,787 | 3,473 | (72.5) | 1,314 | (27.5) | |
| Middle-Advantaged neighborhood | 6,246 | 4,639 | (74.3) | 1,607 | (25.7) | |
| Middle-Disadvantaged neighborhood | 8,295 | 6,127 | (73.9) | 2,168 | (26.1) | |
| Low-Advantaged neighborhood | 2,028 | 1,334 | (65.8) | 694 | (34.2) | |
| Low-Disadvantaged neighborhood | 2,773 | 1,858 | (67.0) | 915 | (33.0) | |
| Residential area, N (%) | ||||||
| Metropolitan | 12,470 | 9,303 | (74.6) | 3,167 | (25.4) | <.0001 |
| Urban | 12,039 | 8,712 | (72.4) | 3,327 | (27.6) | |
| Rural | 3,797 | 2,466 | (65.0) | 1,331 | (35.0) | |
| Charlson comorbidity index, N (%) | ||||||
| 0–1 | 15,875 | 12,842 | (80.9) | 3,033 | (19.1) | <.0001 |
| 2 | 5,584 | 4,106 | (73.5) | 1,478 | (26.5) | |
| 3 | 3,121 | 1,992 | (63.8) | 1,129 | (36.2) | |
| ≥4 | 3,726 | 1,541 | (41.4) | 2,185 | (58.6) | |
| Number of risk factors, N (%) | ||||||
| None | 11,600 | 7,344 | (63.3) | 4,256 | (36.7) | |
| with diabetes or dyslipidemia | 13,232 | 10,075 | (76.1) | 3,157 | (23.9) | |
| with diabetes and dyslipidemia | 3,474 | 3,062 | (88.1) | 412 | (11.9) | |
| Disability, N (%) | ||||||
| Normal | 25,361 | 18,835 | (74.3) | 6,526 | (25.7) | <.0001 |
| Mild disability | 1,950 | 1,260 | (64.6) | 690 | (35.4) | |
| Severe disability | 995 | 386 | (38.8) | 609 | (61.2) | |
| Number with health screenings during follow-up period, N (%) | ||||||
| 1 | 16,022 | 9,338 | (58.3) | 6,684 | (41.7) | <.0001 |
| 2 | 4,062 | 3,419 | (84.2) | 643 | (15.8) | |
| ≥3 | 8,222 | 7,724 | (93.9) | 498 | (6.1) | |
By Kaplan-Meier analysis, the mean years of survival for low income individuals in disadvantaged neighborhoods was 8.3, while the mean years of survival for low income individuals in advantaged neighborhoods was 7.7 (p-value <0.0001 by log-rank test; Fig. 2).
Fig. 2.
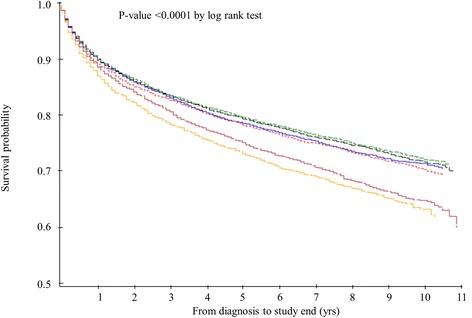
Survival probability for all-cause mortality, stratified to individual household income with advantaged and disadvantaged neighborhoods.  High within Advantaged neighborhoods-8.4 years*;
High within Advantaged neighborhoods-8.4 years*;  Middle within Advantaged neighborhoods-8.6 years*;
Middle within Advantaged neighborhoods-8.6 years*;  Low within Advantaged neighborhoods-7.7 years*;
Low within Advantaged neighborhoods-7.7 years*;  High within Disadvantaged neighborhoods-8.4 years*;
High within Disadvantaged neighborhoods-8.4 years*;  Middle within Disadvantaged neighborhoods-8.7 years*;
Middle within Disadvantaged neighborhoods-8.7 years*;  Low within Disadvantaged neighborhoods-8.3 years*. *, Mean survival
Low within Disadvantaged neighborhoods-8.3 years*. *, Mean survival
Table 2 shows the results from the Cox regression analysis, which did not combine individual and neighborhood SES after controlling for all covariates. Compared to a high income reference group, the adjusted HR for low income and middle income groups was 1.25 (95% CI, 1.17–1.34) and 1.16 (95% CI, 1.10–1.22), respectively. In addition, the adjusted HR of patients in a disadvantaged neighborhood was 1.08 (95% CI, 1.02–1.15), compared with patients in an advantaged neighborhood.
Table 2.
Hazard ratio for all-cause mortality among patients with newly diagnosed hypertension
| Unadjusted | Adjusted | |||
|---|---|---|---|---|
| Characteristics | HR | 95% CI | HR | 95% CI |
| Age | ||||
| 20 ~ 49 | 1.00 | 1.00 | ||
| 50 ~ 59 | 1.88 | (1.65–2.15) | 2.35 | (2.06–2.68) |
| 60 ~ 69 | 4.41 | (3.93–4.96) | 4.85 | (4.31–5.46) |
| ≥70 | 15.49 | (13.87–17.30) | 12.60 | (11.26–14.11) |
| Sex | ||||
| Male | 1.10 | (1.05–1.15) | 1.56 | (1.49–1.63) |
| Female | 1.00 | 1.00 | ||
| Health insurance type | ||||
| National health insurance | 1.00 | 1.00 | ||
| Medical aid | 1.58 | (1.40–1.79) | 0.80 | (0.70–0.91) |
| Income, N (%) | ||||
| Low (≤20th percentile) | 1.27 | (1.19–1.35) | 1.25 | (1.17–1.34) |
| Middle (21st–80th percentile) | 0.95 | (0.90–1.00) | 1.16 | (1.10–1.22) |
| High (≥81st percentile) | 1.00 | 1.00 | ||
| Carstairs index, N (%) | ||||
| Disadvantaged neighborhood (below median) | 1.03 | (0.95–1.10) | 1.08 | (1.02–1.15) |
| Advantaged neighborhood (above median) | 1.00 | 1.00 | ||
| Residential area | ||||
| Metropolitan | 1.00 | 1.00 | ||
| Urban | 1.11 | (1.06–1.17) | 1.04 | (0.98–1.11) |
| Rural | 1.47 | (1.38–1.57) | 1.14 | (1.05–1.24) |
| Charlson comorbidity indexa | ||||
| 0–1 | 1.00 | 1.00 | ||
| 2 | 1.46 | (1.37–1.55) | 1.25 | (1.18–1.34) |
| 3 | 2.15 | (2.01–2.30) | 1.67 | (1.56–1.79) |
| ≥4 | 4.41 | (4.17–4.66) | 2.69 | (2.54–2.85) |
| Number of risk factors | ||||
| None | 1.00 | 1.00 | ||
| with diabetes or dyslipidemia | 0.57 | (0.54–0.60) | 0.63 | (0.60–0.66) |
| with diabetes and dyslipidemia | 0.26 | (0.23–0.29) | 0.36 | (0.33–0.40) |
| Disability | ||||
| Normal | 1.00 | 1.00 | ||
| Mild disability | 1.47 | (1.36–1.59) | 1.11 | (1.03–1.21) |
| Severe disability | 3.00 | (2.77–3.27) | 1.44 | (1.33–1.57) |
| Health screening during follow-up period | ||||
| 1 | 1.00 | 1.00 | ||
| 2 | 0.31 | (0.29–0.34) | 0.39 | (0.36–0.42) |
| ≥3 | 0.11 | (0.10–0.12) | 0.17 | (0.16–0.19) |
acalculated by extracting diabetes, hypertension, and hyperlipidemia from among comorbidity components
The HRs of individual household income for all-cause mortality in disadvantaged and advantaged neighborhoods are shown in Table 3. After stratifying the advantaged and disadvantaged neighborhoods according to the individual household income, the risk for all-cause mortality for patients who lived in a disadvantaged neighborhood was higher than for the individuals who lived in an advantaged neighborhood; this finding was applicable to the high income, middle income and low income groups, even though patients were in the same individual household income group. The adjusted HR of high income patients in an advantaged neighborhood and high income patients in a disadvantaged neighborhood was 1.10 (95% CI, 1.00–1.20; p-value = 0.05), while the adjusted HRs of middle income patients in advantaged neighborhood and disadvantaged neighborhood were 1.17 (95% CI, 1.08–1.26) and 1.27 (95% CI, 1.17–1.38), respectively. The adjusted HR for low income patients who lived in a disadvantaged neighborhood was higher than for those who lived in an advantaged neighborhood (HR, 1.35; 95% CI, 1.22–1.49 vs. HR, 1.28; 95% CI, 1.16–1.41).
Table 3.
HRs of mortality according to individual household income in disadvantaged and advantaged neighborhoods
| Disadvantaged neighborhoodsc | Advantaged neighborhoodsc | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| All-cause mortality | No. of deaths (deaths per 1,000 pya) | HRb | 95% CI | No. of deaths (deaths per 1,000 pya) | HRb | 95% CI | ||||
| Individual household income | ||||||||||
| High (≥81st percentile) | 1,314 | (38.6) | 1.10 | (1.00–1.20)d | 1,127 | (37.8) | 1.00 | |||
| Middle (21st–80th percentile) | 2,168 | (36.4) | 1.27 | (1.17–1.38) | 1,607 | (35.6) | 1.17 | (1.08–1.26) | ||
| Low (≤20th percentile) | 915 | (47.7) | 1.35 | (1.22–1.49) | 694 | (50.7) | 1.28 | (1.16–1.41) | ||
apy, person years
badjusted hazard ratio after controlling for all covariates
cDisadvantaged and advantaged neighborhoods were distinguished on the basis of the mean for neighborhood Carstairs index, with disadvantaged neighborhoods having more-than-mean Carstairs index; a higher Carstairs index represents a more deprived neighborhood
d p-value = 0.05
Discussion
This study evaluated the association between individual income, neighborhood SES, and all-cause mortality in patients with hypertension. Our data showed that individual household income and neighborhood SES are important factors associated with the disparities in all-cause mortality in Korea. Specifically, lower household income and living in a disadvantaged neighborhood increased the risk for all-cause mortality. Moreover, the risk of mortality for all individual household income groups was increased for patients in the disadvantaged neighborhoods relative to the advantaged neighborhoods.
Our results are consistent with previous studies showing that patients in disadvantaged neighborhoods had a higher risk of mortality relative to their income equivalents living in advantaged neighborhoods, even though individuals had the same income level [15, 21, 25–27]. We posed the question, why do low income patients in disadvantaged neighborhoods have higher mortality? Yen and Kaplan [17] suggested “differential access to resources” as an explanation for these findings, and Hook [28] suggested lower “effective income” of low income patients living in advantaged neighborhoods as a reason for less “access to resources.” However, the health insurance programs in Korea provide universal coverage that has improved the accessibility to medical care. In addition, geographical accessibility to health care is better than many other countries because Korea is limited in size and has excellent transportation among its regions. The setting of our study is characterized by universal health care coverage and more equal access to primary education and other social services, suggesting that financial barriers are reduced and that access to resources is a less pronounced determinant of health. Therefore, why do socioeconomic disparities for mortality remain? One possible explanation is that more direct psychosocial factors, such as relative deprivation, hopelessness, lack of control, or loss of respect arising as a consequence of inequality affect individual health [29–31]. In addition, a lack of social cohesion or involvement, possibly linked to psychosocial issues, may contribute to the reduced health of low income patients in the advantaged areas.
Our findings demonstrated that individual household income represents different contextual effects on mortality. The causal linkages between the individual, neighborhood socioeconomic inequality, and poor health outcomes are not fully understood; several possible mechanisms could explain our findings. First, previous studies suggested “access to health care resources” as one possible explanation. However, even though the individual financial barriers for access to health care resources have been reduced, disparities may still exist in access to more expensive health care services, as well as in the number of physicians and the number of medical institutions between the regions. The second possibility is the role SES plays in how health is viewed, which may explain why the higher income individuals living in the more advantaged neighborhoods may be healthier. The ability of high income individuals to use their knowledge, money, power, prestige, and social connections would be reinforced by living in advantaged neighborhoods [32]. In addition, in comparison to low income individuals, high income individuals are quicker to adopt prevention strategies and take advantage of treatment innovations more rapidly [33]. Furthermore, in advantaged areas, health-related knowledge might be more readily shared and cultivated within the network of high income individuals [13]. In contrast, low income individuals are often more socially isolated, which decreases the likelihood of obtaining useful opinions or advice from others [34]. The third possibility is the lack of safe environments in disadvantaged neighborhoods, which reduces the possibility for exercise, thus potentiating an unhealthy lifestyle [35]. Moreover, socio-cultural norms regarding a healthy lifestyle could vary between advantaged and disadvantaged neighborhoods, which could impact the health of individuals and the risk for mortality. For example, studies have shown that environment-related risk factors, such as income, education, and unemployment are associated with mortality risk.
There were several limitations to our study. First, we included only high risk groups with hypertension. Our findings cannot be extrapolated to the general population without hypertension. Second, we could not consider factors such as lifestyle and education, which influence mortality risk, because these factors were not captured by the claims database. In addition, when we selected our study population with hypertension, we could not help using only ICD-10 code and oral antihypertensive medication, but use blood pressure. We did not have the ability to perform actual chart review, and as such, we acknowledge limitations associated with studies lacking detailed physiologic data such as blood pressure. Finally, we did not consider changes in the neighborhood deprivation status for the study participants who moved into a neighborhood with a different status during the study period.
Despite the limitations, our study had several strengths. First, to our knowledge, our study was the first to examine the relationship between individual income, neighborhood SES, and mortality in the context of universal health insurance. We used a prospective design and a relatively large sample, which yielded good statistical power, to detect the effects of neighborhood deprivation, and analyzed the data using a hierarchical frailty model. Second, we analyzed a representative sample of patients with hypertension using the nationwide representative cohort data. Third, we made an effort to increase the homogeneity of our study sample by restricting our study sample to patients who were newly diagnosed with hypertension.
Conclusions
We found that combined effect between individual and neighborhood socioeconomic status on all-cause mortality in patients with newly diagnosed hypertension using a Cox proportional hazard frailty model. Our findings demonstrate how important it is for health professionals and policymakers to understand people within the context of their neighborhoods. The high mortality that we observed among patients of low household income who reside in high deprived neighborhoods suggested that they should focus on public health strategies for these people to reduce health inequalities.
Acknowledgements
The entire study was conducted without external funding.
Abbreviations
- SES
Socioeconomic Status
- KNHI
Korean National Health Insurance
- CCI
Charlson Comorbidity Index
- HR
Hazard Ratio
Additional file
The hypertensive status of subject according to individual household income. (DOCX 15 kb)
Footnotes
Competing interests
The authors declare no conflicts of interest.
Authors’ contributions
The entire study was conducted without external funding. KHC and EP carried out constructing study design, KHC and CMN carried out analyzing data, KHC, EP, SGL, and SL interpreted results, EJL and SJ was scientific advisor, EP guided and directed this study. KHC and EP wrote manuscript. All authors read and approved the final manuscript.
References
- 1.Ezzati M, Lopez AD, Rodgers A, Vander Hoorn S, Murray CJ. Comparative Risk Assessment Collaborating Group. Selected major risk factors and global and regional burden of disease. Lancet. 2002;360(9343):1347–1360. doi: 10.1016/S0140-6736(02)11403-6. [DOI] [PubMed] [Google Scholar]
- 2.Lim SS, Vos T, Flaxman AD, Danaei G, Shibuya K, Adair-Rohani H, et al. A comparative risk assessment of burden of disease and injury attributable to 67 risk factors and risk factor clusters in 21 regions, 1990-2010: a systematic analysis for the Global Burden of Disease Study 2010. Lancet. 2012;380(9859):2224–2260. doi: 10.1016/S0140-6736(12)61766-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Cloutier L, Morris D, Bruneau J, McLean D, Campbell N. World Health Organization celebrates World Health Day, April 7,2013--focusing on hypertension. Can J Cardiovasc Nurs. 2013;23(2):9–11. [PubMed] [Google Scholar]
- 4.Grotto I, Huerta M, Sharabi Y. Hypertension and socioeconomic status. Curr Opin Cardiol. 2008;23(4):335–339. doi: 10.1097/HCO.0b013e3283021c70. [DOI] [PubMed] [Google Scholar]
- 5.Morenoff JD, House JS. Hansen BB, Williams DR, Kaplan GA, Hunte HE. Understanding social disparities in hypertension prevalence, awareness, treatment, and control: the role of neighborhood context. Soc Sci Med. 2007;65(9):1853–1866. doi: 10.1016/j.socscimed.2007.05.038. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Cha SH, Park HS, Cho HJ. Socioeconomic disparities in prevalence, treatment, and control of hypertension in middle-aged Koreans. J Epidemiol. 2012;22(5):425–432. doi: 10.2188/jea.JE20110132. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Leng B, Jin Y, Li G, Chen L, Jin N. Socioeconomic status and hypertension: a meta-analysis. J Hypertens. 2015;33(2):221–229. doi: 10.1097/HJH.0000000000000428. [DOI] [PubMed] [Google Scholar]
- 8.Kautzky-Willer A, Dorner T, Jensby A, Rieder A. Women show a closer association between educational level and hypertension or diabetes mellitus than males: a secondary analysis from the Austrian HIS. BMC Public Health. 2012;30(12):392. doi: 10.1186/1471-2458-12-392. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Erceg M, Ivicević-Uhernik A, Kern J, Vuletić S. Is there any association between blood pressure and education level? The CroHort study. Coll Antropol. 2012;36(Suppl 1):125–129. doi: 10.5671/ca.2012361s.125. [DOI] [PubMed] [Google Scholar]
- 10.Daniel OJ, Adejumo OA, Adejumo EN, Owolabi RS, Braimoh RW. Prevalence of hypertension among urban slum dwellers in Lagos, Nigeria. J Urban Health. 2013;90(6):1016–1025. doi: 10.1007/s11524-013-9795-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Sloggett A, Joshi H. Higher mortality in deprived areas: community or personal disadvantage? BMJ. 1994;309(6967):1470–1474. doi: 10.1136/bmj.309.6967.1470. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Johnson S, Abonyi S, Jeffery B, Hackett P, Hampton M, McIntosh T, et al. Recommendations for action on the social determinants of health: a Canadian perspective. Lancet. 2008;372(9650):1690–1693. doi: 10.1016/S0140-6736(08)61694-3. [DOI] [PubMed] [Google Scholar]
- 13.Roos LL, Magoon J, Gupta S, Chateau D, Veugelers PJ. Socioeconomic determinants of mortality in two Canadian provinces: multilevel modelling and neighborhood context. Soc Sci Med. 2004;59(7):1435–1447. doi: 10.1016/j.socscimed.2004.01.024. [DOI] [PubMed] [Google Scholar]
- 14.Consuegra-Sánchez L, Melgarejo-Moreno A, Galcerá-Tomás J, Alonso-Fernández N, Díaz-Pastor Á, Escudero-García G, et al. Educational Level and Long-term Mortality in Patients With Acute Myocardial Infarction. Rev Esp Cardiol (Engl Ed) 2015;S1885-5857(15):00076–6. doi: 10.1016/j.rec.2014.11.025. [DOI] [PubMed] [Google Scholar]
- 15.Feinglass J, Rydzewski N, Yang A. The socioeconomic gradient in all-cause mortality for women with breast cancer: findings from the 1998 to 2006 National Cancer Data Base with follow-up through 2011. Ann Epidemiol. 2015;S1047-2797(15):00052–00056. doi: 10.1016/j.annepidem.2015.02.006. [DOI] [PubMed] [Google Scholar]
- 16.Roos LL, Walld R. Neighbourhood, family and health care. Can J Public Health. 2007;98(Supple1):S54–S61. doi: 10.1007/BF03403727. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Yen IH, Kaplan GA. Neighborhood social environment and risk of death: multilevel evidence from the Alameda County Study. Am J Epidemiol. 1999;149(10):898–907. doi: 10.1093/oxfordjournals.aje.a009733. [DOI] [PubMed] [Google Scholar]
- 18.Veugelers PJ, Yip AM, Kephart G. Proximate and contextual socioeconomic determinants of mortality: multilevel approaches in a setting with universal health care coverage. Am J Epidemiol. 2001;154(8):725–732. doi: 10.1093/aje/154.8.725. [DOI] [PubMed] [Google Scholar]
- 19.Kim YJ, Jeon JY, Han SJ, Kim HJ, Lee KW, Kim DJ. Effect of socio-economic status on the prevalence of diabetes. Yonsei Med J. 2015;56(3):641–647. doi: 10.3349/ymj.2015.56.3.641. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Morgan O, Baker A. Measuring deprivation in England and Wales using 2001 Carstairs scores. Health Stat Q. 2006;31:28–33. [PubMed] [Google Scholar]
- 21.Lee SG. The effect of neighborhood socioeconomic factors on spatial mortality and individual health status [dissertation] Seoul: Yonsei University; 2002. [Google Scholar]
- 22.Charlson ME, Pompei P, Ales KL, MacKenzie CR. A new method of classifying prognostic comorbidity in longitudinal studies: development and validation. J Chronic Dis. 1987;40(5):373–383. doi: 10.1016/0021-9681(87)90171-8. [DOI] [PubMed] [Google Scholar]
- 23.Andersen PK, Klein JP, Zhang MJ. Testing for centre effects in multi-centre survival studies: a Monte Carlo comparison of fixed and random effects tests. Stat Med. 1999;18(12):1489–1500. doi: 10.1002/(SICI)1097-0258(19990630)18:12<1489::AID-SIM140>3.0.CO;2-#. [DOI] [PubMed] [Google Scholar]
- 24.Andersen PK, Klein JP, Knudsen KM. Tabanera y Palacios R. Estimation of variance in Cox’s regression model with shared gamma frailties. Biometrics. 1997;53(4):1475–1484. doi: 10.2307/2533513. [DOI] [PubMed] [Google Scholar]
- 25.Malmström M, Johansson SE, Sundquist J. A hierarchical analysis of long-term illness and mortality in socially deprived areas. Soc Sci Med. 2001;53(3):265–275. doi: 10.1016/S0277-9536(00)00291-4. [DOI] [PubMed] [Google Scholar]
- 26.Li X, Sundquist J, Zöller B, Sundquist K. Neighborhood deprivation and lung cancer incidence and mortality: a multilevel analysis from Sweden. J Thorac Oncol. 2015;10(2):256–263. doi: 10.1097/JTO.0000000000000417. [DOI] [PubMed] [Google Scholar]
- 27.Vanasse A, Courteau J, Asghari S, Leroux D, Cloutier L. Health inequalities associated with neighbourhood deprivation in the Quebec population with hypertension in primary prevention of cardiovascular disease. Chronic Dis Inj Can. 2014;34(4):181–194. [PubMed] [Google Scholar]
- 28.Hook EB. Letter to the Editor: Re: Neighborhood social environment and risk of death: multilevel evidence from the Alameda County study. Am J Epidemiol. 2000;151(11):1132–1133. doi: 10.1093/oxfordjournals.aje.a010157. [DOI] [PubMed] [Google Scholar]
- 29.Subramanian SV, Belli P, Kawachi I. The macroeconomic determinants of health. Annu Rev Public Health. 2002;23:287–302. doi: 10.1146/annurev.publhealth.23.100901.140540. [DOI] [PubMed] [Google Scholar]
- 30.Elstad JI. The psycho‐social perspective on social inequalities in health. Sociol Health Illness. 1998;20(5):598–618. doi: 10.1111/1467-9566.00121. [DOI] [Google Scholar]
- 31.Boyce WT, Chesterman EA, Winkleby MA. Psychosocial predictors of maternal and infant health among adolescent mothers. Am J Dis Child. 1991;145(3):267–273. doi: 10.1001/archpedi.1991.02160030035017. [DOI] [PubMed] [Google Scholar]
- 32.Link BG, Northridge ME, Phelan JC, Ganz ML. Social epidemiology and the fundamental cause concept: on the structuring of effective cancer screens by socioeconomic status. Milbank Q. 1998;76(3):375–402. doi: 10.1111/1468-0009.00096. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Roos LL, Traverse D, Turner D. Delivering prevention: the role of public programs in delivering care to high-risk populations. Med Care. 1999;37(6):JS264–JS278. doi: 10.1097/00005650-199906001-00020. [DOI] [PubMed] [Google Scholar]
- 34.Chang CM, Su YC, Lai NS, Huang KY, Chien SH, Chang YH, et al. The combined effect of individual and neighborhood socioeconomic status on cancer survival rates. PLoS One. 2012;7(8) doi: 10.1371/journal.pone.0044325. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Li X, Sundquist J, Calling S, Zöller B, Sundquist K. Neighborhood deprivation and risk of cervical cancer morbidity and mortality: a multilevel analysis from Sweden. Gynecol Oncol. 2012;127(2):283–289. doi: 10.1016/j.ygyno.2012.07.103. [DOI] [PubMed] [Google Scholar]