

Abstract
Listeners possess a remarkable ability to adapt to acoustic variability in the realization of speech sound categories (e.g. different accents). The current work tests whether non-native listeners adapt their use of acoustic cues in phonetic categorization when they are confronted with changes in the distribution of cues in the input, as native listeners do, and examines to what extent these adaptation patterns are influenced by individual cue-weighting strategies. In line with previous work, native English listeners, who use VOT as a primary cue to the stop voicing contrast (e.g. ‘pa’ vs. ‘ba’), adjusted their use of f0 (a secondary cue to the contrast) when confronted with a noncanonical “accent” in which the two cues gave conflicting information about category membership. Native Korean listeners’ adaptation strategies, while variable, were predictable based on their initial cue weighting strategies. In particular, listeners who used f0 as the primary cue to category membership adjusted their use of VOT (their secondary cue) in response to the noncanonical accent, mirroring the native pattern of “downweighting” a secondary cue. Results suggest that non-native listeners show native-like sensitivity to distributional information in the input and use this information to adjust categorization, just as native listeners do, with the specific trajectory of category adaptation governed by initial cue-weighting strategies.
The massive amount of variability inherent to speech requires that listeners make rapid, dynamic adjustments to their definitions of sound categories. Listeners are regularly confronted with dialects and accents in which the “same” sounds are realized differently, and even talkers with similar accents produce the same sounds with different acoustic realizations, due to anatomical differences in the vocal tract. While the details of how listeners resolve the “lack of invariance” problem remain elusive, what is clear is that listeners possess a remarkable amount of perceptual flexibility, rapidly accommodating to foreign accents (e.g. Clarke and Garrett, 2004; Bradlow and Bent, 2008; Baese-Berk et al., 2013), dialectal variation (e.g. Sumner and Samuel, 2009; Trude and Brown-Schmidt, 2012), and degraded speech (e.g. Davis et al., 2005). In contrast to the plasticity found in studies examining native listeners, work on non-native (L2) speech perception has, for the most part, focused on the notoriously stubborn native-language (L1) constraints on L2 sound category formation and perception (Flege, 1995; Best, 1995, among others). This apparent asymmetry between L1 and L2 perceptual flexibility suggests the possibility that L2 listeners may employ qualitatively or quantitatively different adaptation strategies than L1 listeners. In the current work, we examine this possibility by comparing how native and non-native listeners adapt their phonetic categorization strategies in response to different “accents” that vary in the distribution of acoustic cues defining phonetic categories.
Speech perception can be thought of as an example of a general auditory categorization task, with sound categories being mapped onto a multi-dimensional acoustic space (Goudbeek et al., 2005; Holt and Lotto, 2008; Goudbeek et al., 2009; Holt and Lotto, 2010). Speech sounds contrast on many acoustic dimensions (or “cues”), and listeners give different “weights” to these dimensions. For example, the primary cue to the English stop voicing contrast (/p/ vs. /b/, /t/ vs. /d/, and /g/ vs. /k/) is Voice Onset Time (VOT), or the time lapse between the release of the stop closure and the onset of voicing in the following vowel (e.g. Lisker and Abramson, 1964); however, other secondary cues, including fundamental frequency (f0) at vowel onset, also define the contrast, albeit less reliably (e.g. House & Fairbanks, 1953; Kingston & Diehl, 1994; Francis et al., 2008; Kingston et al., 2008; Llanos et al., 2013). Native English speakers’ productions of voiceless stops /p, t, k/ have longer VOTs than voiced stops /b, d, g/; on average, voiceless stops are also produced with slightly higher f0 at vowel onset than voiced stops. However, in contrast to VOT, which consistently separates productions of voiced and voiceless stops, there is a large amount of overlap in the use of f0 between the two categories. These distributional patterns present in speakers’ productions are reflected in listeners’ perception of the contrast, which they primarily distinguish using VOT; secondary cues like f0 can influence categorization decisions, but do so to a much lesser extent (e.g. Whalen et al., 1993; Francis et al., 2008).
Listeners adapt their use of these phonetic dimensions in response to many factors, including the acoustic properties of surrounding auditory stimuli (e.g. selective adaptation: Eimas and Corbit, 1973; contrast effects: Diehl et al., 1978) and the distributional properties of the relevant dimensions (e.g. Clayards et al., 2008, cf. Kleinschmidt and Jaeger, 2015). Whereas listeners may derive stable, “prototypical” cue weights for a contrast based on their long-term experience with acoustic realizations of these sounds aggregated across many speakers and tokens, any given set of weights is unlikely to be optimal for one particular speaker. A successful listener must therefore be able to adapt rapidly to the unpredictable idiosyncrasies of a new speaker. Several lines of research have investigated specific ways in which listeners can be induced to shift their sound categories based on higher-level semantic or lexical information (see Samuel and Kraljic, 2009 for a review). For example, Norris et al. (2003) showed that after words containing an ambiguous sound between [f] and [s] that were lexically disambiguated to be [f], listeners were more likely to subsequently characterize ambiguous sounds on an [f]-[s] continuum as [f] (see also Kraljic and Samuel, 2005; Eisner and McQueen, 2005; Cutler et al., 2008, among many others). Along the same lines, in work by Maye et al. (2008), after listening for twenty minutes to a synthesized English talker whose front vowels were shifted categorically lower in the vowel space, listeners adapted their vowel categories to this idiosyncratic accent. The sort of contextual information that can be used by listeners goes beyond the acoustic level: Bertelson et al. (2003) demonstrated that exposure to audiovisual information during speech can influence subsequent auditory categorization. All of this work demonstrates that listeners shift their criterion for a category boundary on a given dimension after implicitly “learning” idiosyncratic use of cues from contextual information.
In contrast to the “object-based” learning discussed above, in which lexical (or other higher-level) information disambiguates non-prototypical phonetic characteristics, Idemaru and Holt (2011) demonstrated “dimension-based” statistical learning, in which listeners modify their use of a secondary acoustic dimension defining a given sound contrast based on its relationship with a primary acoustic dimension in the input. In particular, Idemaru and Holt (2011) investigated whether listeners would adjust their use of f0 when categorizing the English stop voicing contrast based on short-term changes in the correlation of VOT (the primary cue) and f0 (the secondary cue) in the input. Distributions of stimuli with unambiguously long or short VOT (/p/ vs. /b/) and varying values of f0 were presented to listeners in different blocks (see Figure 2 below for a schematic). One block was characterized by the canonical English correlation of f0 and VOT: tokens with long VOT (i.e. /p/) had high f0, while tokens with short VOT (i.e. /b/) had low f0. This “Canonical” block was followed by a “Reversed” block showing the opposite correlation (long VOT with low f0 and short VOT with high f0). There were no clues or instructions to denote the introduction of this artificial “accent” and since all other aspects of the talker remained the same, participants did not consciously note the change. Despite this lack of explicit knowledge, listeners modified their use of f0 across the two blocks, as demonstrated by their response patterns when categorizing ambiguous /p/~/b/ stimuli. In the context of the Canonical accent, listeners made use of f0 to categorize stimuli with intermediate values of VOT (high f0 elicited more /p/ responses). In the Reversed block, on the other hand, f0 had no effect on categorization responses, suggesting that listeners “downweight” their reliance on a secondary cue (f0) when confronted with noncanonical use of the cue in the input. The authors concluded that listeners recruit what they know to be a more reliable dimension (VOT) as the basis for learning about the distribution of a less reliable dimension (f0) within a given accent, then adjust their use of the secondary dimension accordingly.
Figure 2.

Distribution of stimuli in the Neutral, Canonical, and Reversed blocks. The stimuli are differentiated graphically in this figure (e.g. “covarying” vs. “ambiguous-VOT”); however, within a given block, all stimuli were randomly presented, and these different types of stimuli were undifferentiated from the listeners’ point of view.
A general formulation of dimension-based learning requires that listeners be 1) sensitive to the statistical distribution of secondary phonetic dimensions in the input (even when attention to a given dimension is not directly necessary for the task) and 2) adaptable with respect to these dimensions. Idemaru and Holt’s (2011) native-listener participants demonstrated both of these characteristics: they paid attention to how f0 was used, even when VOT gave unambiguous information about category membership, and modulated their use of f0 when it did not match with the canonical distribution. Whether or not non-native speech perception is characterized by comparable sensitivity and adaptability is an open question. The fact that L1 phonetic patterns exert a strong and (to some extent) predictable influence on L2 perception is uncontroversial. On the other hand, several studies have demonstrated that L2 listeners are able to adjust their cue-weighting strategies in the context of training paradigms designed to direct attention toward relevant acoustic dimensions by exaggerating the contrast (Iverson et al., 2005; Kondaurova and Francis, 2010; Escudero et al., 2011) or to direct attention away from less relevant dimensions via increased variability (Iverson et al., 2005; Kondaurova and Francis, 2010; Lim and Holt, 2011; cf. Holt and Lotto, 2006). However, these tasks are for the most part characterized by explicit feedback over extended training (though the feedback in Lim and Holt (2011) was indirect) Furthermore, in the absence of direct control groups, it is not clear whether or how L1 listeners would also shift categorization in these sorts of paradigms.
In general, the types of adaptation addressed in L1 vs. L2 perceptual learning studies are conceptualized in qualitatively different ways (e.g. L1 category “tuning” vs. L2 “training”). The extent to which these actually constitute distinct processes is an empirical question, and one which is complicated by the fact that the modifications required to shift from non-native to native-like cue weighting strategies are usually much more extensive than the fine-grained perceptual “tuning” elicited by L1 adaptation studies. For example, the well-known difficulty distinguishing the English /r/-/l/ contrast for native Japanese listeners is attributed to the fact that they do not use F3 as a cue to the contrast, as native English listeners do (e.g. Miyawaki et al., 1975; Yamada and Tohkura, 1990; Iverson et al., 2003). L2 perceptual development thus depends on shifting attention to an entirely new dimension (e.g. Francis and Nusbaum, 2002), while L1 category adaptation work has generally focused on small criterion shifts on an already-used dimension (e.g. Norris et al., 2003). The discrepancy between the types of adaptation usually examined in L1 vs. L2 perceptual learning therefore makes it difficult to determine whether any differences in native vs. non-native perceptual learning and plasticity found in previous work reflect fundamentally different processes of accommodation, or whether instead they fall out from the different types of adaptation generally targeted for the two groups in laboratory tasks. Recent results from Reinisch et al. (2013) and Schuhmann (2014) lend support to the latter hypothesis: L2 listeners showed similar shifts on /f/-/s/ continua as L1 listeners, suggesting that L1 and L2 listeners use similar processes for phonetic category adjustment. The languages used in these studies (Dutch and German in Reinisch et al., 2013; German and English in Schuhmann, 2014) have very similar phonetic realizations of the target contrast (/f/-/s/), leaving open the question of whether similar retuning occurs when the L2 contrast does not have a close phonetic match in the L1. In the current work, the target stop contrast is realized very differently in the listeners’ L2 (English) than it is in their L2 (Korean), allowing us to test the generality of adaptation processes in native and non-native perception.
In addition to comparing adaptation of cue weights in L1 vs. L2, the examination of the L2 learners’ adaptation provides an opportunity to test one of the main hypotheses of the account proposed by Idemaru and Holt (2011). In their description of dimension-based learning, Idemaru and Holt (2011) suggest that the primary cue to English stop voicing (VOT) serves as a learning signal for weighting of the secondary cue (f0). This could occur through direct comparison of the two dimensions or by an error signal coming from the category representation activated by the primary cue (Guediche, Blumstein, Fies & Holt, 2014). A prediction of this primary-cue-based learning account is that the pattern of learning (adaptation) should depend on the initial relative cue weights of the listener. This prediction is hard to test with L1 listeners because there is little inter-individual variability in the primacy of VOT as a cue to the English voicing contrast. However, the well-attested variability in non-native (L2) sound perception provides a good potential test ground for the hypothesis.
This hypothesis is further motivated by several previous findings of differential adaptation patterns based on differences in initial categorization strategies. Chandrasekaran et al. (2010) showed that native English listeners’ success in a perceptual learning task targeting Mandarin tonal contrast was correlated with initial attention to cues: in particular, listeners who paid more attention to the trajectory of f0 during a pre-test showed larger effects of training (while training-related effects were not related to listeners’ initial attention to f0 height). Similarly, in work by Wanrooij et al. (2013), L2 Dutch learners responded differently to distributional training on the /?/-/a:/ contrast based on whether or not they used spectral (i.e. F1 and F2) cues to the contrast prior to training. Turning to native listeners, Sawusch and Nusbaum (1983) showed that the same pair of stimuli elicited different directions of contrast effects from different listeners, and that the direction of the effect was predictable from listeners’ initial categorization of the sounds.
In previous work (Schertz et al., 2015), we found substantial variability in native Korean listeners’ cue weighting strategies in distinguishing their L2 English stop contrast: while some Korean listeners used primarily VOT to distinguish the contrast in a forced-choice task, like native English listeners do, most either used primarily f0, or made use of both dimensions (requiring both long VOT and high f0 to categorize stimuli as voiceless /p/). This tendency to rely on f0 likely stems from the fact that the three-way stop contrast in Korean relies heavily on both VOT and f0 (e.g. Cho et al., 2002; Lee and Jongman, 2012). Interestingly, Korean speakers vary both VOT and f0 to an equal extent when distinguishing their L2 English stop contrast in production (Schertz et al., 2015), but this cue use is not necessarily reflected in their perception. The factors underlying these differences in phonetic structure are not yet known; however, recent work by Kong and Yoon (2013) suggests that listeners’ level of English proficiency plays a role, with higher-proficiency speakers using f0 less (i.e. in a more native-like way) than lower-proficiency speakers. Another potential source of variability is the multiple options for mapping the English contrast onto the three-way Korean contrast (e.g. Park and de Jong 2008). Regardless of the sources of these differences, the different cue weighting strategies (i.e. different L2 listeners consider different dimensions as primary) allow us to test the hypothesis that phonetic category modification can occur as a function of one of the dimensions acting as an anchor, and that this anchor dimension is based on listener-specific internal organization of acoustic cues to category membership.
The current work aims to address two issues. First, we examine whether non-native listeners show native-like category adaptation strategies when confronted with changes in the distributional properties of acoustic dimensions via a direct comparison between L1 English and L2 English/L1 Korean listeners. Second, we test the hypothesis that listeners adjust their use of secondary cues to category membership by using a reliable dimension as an “anchor” to extract information about other, less reliable, dimensions. The individual variability which often underlies L2 perception, and in particular the expectation, based on previous work, that L2 Korean listeners will show different cue-weighting strategies for the English stop voicing contrast, allows for a robust test of the prediction that individual differences in categorization strategies lead to categorically different adaptation patterns.
To test these questions, we exposed L1 Korean/L2 English listeners and a control group of L1 English listeners to English sentences containing target syllables beginning with word-initial stops manipulated to covary on two dimensions, VOT and f0, following a modified paradigm of Idemaru and Holt (2011). Although the range and distribution of stimuli along each of the two dimensions remained constant throughout the experiment, the relationship between the dimensions varied by block. In “Canonical” blocks, consistent with the canonical English voicing contrast, VOT and f0 covaried in a positive direction (e.g. long VOT was paired with high f0), while in “Reversed” blocks, they covaried in the opposite direction (e.g. long VOT was paired with low f0).
Following Idemaru and Holt (2011), we expected native English listeners to use VOT as the dominant anchor dimension, adapting their use of f0 (their secondary dimension) in categorizing stimuli with intermediate values of VOT (which should be ambiguous with respect to category membership). Based on Korean perception data reported in Schertz et al. (2015), we expected individual Korean listeners to use different strategies for distinguishing the contrast, with some relying primarily on VOT, some relying primarily on f0, and some relying on the two dimensions to a similar extent. If the same processes drive adaptation in non-native sound categories, regardless of which dimension is dominant, then we would expect different (but symmetrical) patterns of adaptation for the Korean listeners, with the specific pattern determined by these initial individual categorization patterns. To test the hypothesis that listeners use a dominant dimension as an anchor or learning signal, our main comparison of interest is between native English listeners (who use primarily VOT) and those Korean listeners who use primarily f0 (with VOT as a secondary cue). For these Korean listeners, we expect to see the mirror image of native English listeners’ behavior, in particular using f0 as their anchor dimension and adapting their use of VOT when categorizing stimuli with intermediate values of f0.
On the other hand, non-native listeners may not employ native-like category adaptation strategies. Although listeners have been shown to be sensitive to distributional information in their L2, these findings have primarily come from category training tasks with explicit feedback (though see Lim and Holt, 2011 for improved L2 categorization on a videogame task without direct feedback), and these tasks differ substantially from those examining L1 category tuning. Although recent work suggests that L2 listeners show lexically-guided phonetic tuning (Reinisch et al., 2013), this has only been shown for phonetic categories which are virtually identical across the two languages. Furthermore, although we expect most Korean listeners to rely on f0 more than VOT for the English contrast, VOT may still play a significant role, given that VOT is the most reliable indicator of English stop category membership in Koreans’ productions of their L2 English contrast (Schertz et al., 2015).
Methods
Participants
Forty native Korean-speaking undergraduate students at Hanyang University in Seoul (20 male, 20 female, ranging in age from 19 to 29) were paid for their participation. All Korean participants had learned English in school (beginning at a mean age of 9.6 years), but none used it on a regular basis. A control group of twenty-three native English listeners from the University of Arizona (10 male, 13 female, ranging in age from 18 to 26) received course credit for their participation. All listeners reported normal hearing with no speech disorders.
Stimuli
Stimuli consisted of stop-initial target syllables (i.e. a [pa]-[ba] series) embedded in an English carrier sentence. The series of target syllables was created by manipulating a female native English speaker’s production of the syllable [pa]. Using the acoustic analysis software Praat (Boersma and Weenink, 2011), a series of stop-initial syllables varying in VOT and f0 at vowel onset was created, resulting in a set of stimuli spanning a two-dimensional acoustic space: nine steps of VOT, ranging from −20 to 50 ms by nine steps of f0, ranging from 160 to 240 Hz, for a total of 81 stimuli (the ranges for each dimension were chosen based on native Korean listeners’ categorization crossover points from previous work, Schertz et al., 2015). Waveforms and spectrograms of stimuli at the two endpoints of the VOT series, as well as a schematic of the f0 contours in the stimulus range, are given in Figure 1. To create stimuli with positive VOT values, aspiration duration was manipulated using the Time-Domain F0-Synchronous-Overlap-and-Add algorithm (TD-PSOLA, Moulines and Charpentier, 1990) as implemented in Praat. This algorithm manipulates duration of a sound by remapping portions of the original signal onto a new signal, repeating windowed portions of the signal at regular intervals to increase duration and removing portions to decrease duration (for voiced sounds, the windows are based on f0 periods, whereas for voiceless sounds, portions of the sound are simply copied in order to increase duration). To create tokens with negative VOT (i.e. prevoicing), aspiration duration was set to zero (as described above), then consecutive periods of prevoicing were added before the stop burst. F0 was also manipulated using the TD-PSOLA algorithm (as implemented in Praat) to remain at the desired value for the first half of the vowel, then fell linearly to 140 Hz for all stimuli (see Figure 1). Each syllable was then embedded in an English carrier phrase (“I say [target syllable]”), recorded by the same speaker (the carrier phrase was included to keep listeners in an “English mode”).
Figure 1.

Waveforms (above) and spectrograms (below) of a stimulus at the endpoints of the VOT series, with VOT of −20ms (a) and VOT of 50ms (b). Each figure shows the end of the carrier phrase (“say”) along with the target syllable. Each of the nine steps of VOT was crossed with the nine f0 contours schematized in (c) to create 81 stimuli.
As in Idemaru and Holt (2011), these stimuli were distributed among three blocks (Neutral, Canonical, and Reversed); the distribution of stimuli is shown in Figure 2. The Neutral block consisted of “baseline” stimuli spanning the entire covarying VOT-f0 stimulus space (81 stimuli, repeated twice for a total of 162 trials in the block). This block was used to orient listeners to the acoustic space and was not included in any further analyses. The two types of test blocks (Canonical and Reversed) contained a subset of these baseline stimuli. In each block, ten “covarying” stimuli (“exposure stimuli” in Idemaru and Holt, 2011) had extreme values of VOT and f0. Each block also contained two “ambiguous-VOT” stimuli (analogous to the “test stimuli” in Idemaru and Holt, 2011) with intermediate values of VOT (15 ms) with relatively low or high f0 (170 or 230 Hz), and two “ambiguous-f0” stimuli (not included in Idemaru and Holt, 2011) with intermediate values of f0 (200 Hz) and relatively high and low values for VOT (−11 and 41 ms). The four “ambiguous” stimuli were identical in the Canonical and Reversed blocks; the two types of blocks differed only in the correlation of f0 and VOT in the covarying stimuli. In the Canonical block, the covarying stimuli were modeled after the canonical English pattern, such that stimuli with long VOT (i.e voiceless stops, 33, 41, or 51 ms) had high f0 (220, 230, or 240 Hz), while stimuli with short VOT (i.e. voiced stops, 2, −11, or −20 ms) had low f0 (160, 170, or 180 Hz). In the Reversed block, the relationship between VOT and f0 was switched: the Reversed covarying stimuli with long VOT (i.e. voiceless stops) had low f0, while those with short VOT (i.e. voiced stops) had high f0. In total, each test block contained 140 stimuli consisting of ten randomized repetitions of the 14 stimuli (ten covarying plus four ambiguous); the covarying vs. ambiguous stimuli were intermixed within the block and undifferentiated to the listeners. The mixture of the covarying and the ambiguous stimuli within each block makes it possible to test how phonetic categorization of the same ambiguous stimuli varies as a function of whether listeners are exposed to canonically vs. reversely covarying stimuli.
Procedure
The experiments took place at the Hanyang Phonetics and Psycholinguistics Laboratory at Hanyang University, Seoul (for native Korean listeners) and at the Auditory Cognitive Neuroscience Laboratory at the University of Arizona, Tucson (for native English listeners). Participants sat in front of a computer in sound-attenuated booths and received both oral and written instructions in English telling them that they would hear English sentences containing either “pa” or “ba” and that they should press ‘p’ or ‘b’ to indicate which sound they heard. They were told that the experiment would be divided into five blocks, but were not informed that the blocks would be in any way different from one another. The Neutral block was presented first for all participants. This was followed by two blocks of Canonical and two blocks of Reversed (for half the subjects), or two blocks of Reversed and two blocks of Canonical (for the other half), such that each subject completed one Neutral, two Canonical and two Reversed blocks. Each subject heard 162 trials in the Neutral condition (two randomized repetitions of the baseline stimuli) and 280 trials in each of the Canonical and Reversed conditions (ten randomized repetitions of the covarying-plus-ambiguous stimulus set, times two blocks). The covarying stimuli were not differentiated from the ambiguous stimuli for the participants; all stimuli within a given block were randomly intermixed. The experiment took about 25 minutes.
Grouping of participants: Reliance scores
Based on previous work in which Korean listeners were found to use different cue weighting strategies for the English stop voicing contrast (Schertz et al., 2015), participants were expected to show different patterns of categorization for the covarying stimuli: a “VOT group” classifying stimuli with long VOT as voiceless and short VOT as voiced (irrespective of f0), a “f0 group” classifying stimuli with high f0 as voiceless and low f0 as voiced (irrespective of VOT), and a “VOT+f0” group classifying only stimuli with high f0 and long VOT as voiceless and all other stimuli as voiced (schematic in Figure 3). All participants were expected to categorize the covarying stimuli in the Canonical block in the same way, perceiving the long VOT, high f0 (Quadrant I) stimuli as voiceless /p/ and the short VOT, low f0 (Quadrant III) stimuli as voiced /b/. However, different patterns were expected in the covarying stimuli in the Reversed condition (Quadrants II and IV), and we therefore used listeners’ responses to stimuli in these two quadrants to separate them into groups: (1) VOT group (Quadrant II = voiceless and Quadrant IV = voiced); (2) f0 group (Quadrant II = voiced and Quadrant IV = voiceless); and (3) VOT+f0 group, (only Quadrant I = voiceless).
Figure 3.

Schematic of predicted responses for Korean listeners with different primary cue reliance in classifying covarying stimuli (collapsed over Canonical and Reversed blocks).
We calculated a “reliance score” (similar to the “reliance ratio” used by Escudero and Boersma (2004) and Kondaurova and Francis (2010) in their examination of spectral vs. durational cue weighting in the English /i/-/?/ contrast) for each participant by taking the difference between the ratio of “voiceless” response to covarying stimuli in Quadrant II and Quadrant IV. We expected listeners to fall into three groups, with some clustering near 1 (relying exclusively on VOT), some clustering near −1 (relying exclusively on f0), and some clustering around 0 (equal reliance on VOT and f0). Since we predicted that listeners would modify use of their secondary, but not their primary, cue, different adaptation patterns were expected for these different groups; therefore, the subsequent analyses were performed separately for each group.
Statistical analyses
The goal of this work was to assess how listeners adjusted their categorization of the four ambiguous stimuli (i.e., ambiguous-VOT with high or low f0 and ambiguous-f0 with long or short VOT) based on the different distributional information across blocks (i.e. the covarying stimuli in the Canonical vs. Reversed blocks), and how these adaptation patterns differed as a function of listeners’ initial cue weighting strategies. We quantified the use of each cue (VOT, f0) in each block by taking the difference in “voiceless” responses to the high and low versions of the ambiguous stimuli for that cue. For example, the use of f0 for a block was determined by the difference in “pa” responses to the ambiguous-VOT stimulus with high f0 and the ambiguous-VOT stimulus with low f0. Adaptation was then defined as a significant change in the difference score for the Reversed block (as determined by a paired-sample t-test). Cohen’s d was used as a measure of effect size.
Predictions
In line with Idemaru and Holt (2011)’s findings using the same paradigm, English listeners were expected to decrease their reliance on f0 in categorization of ambiguous-VOT stimuli when confronted with noncanonical use of f0. Specifically, we expected greater use of f0 (i.e. a larger f0-difference score) in the Canonical block than in the Reversed block. Since VOT is the primary cue to the stop distinction for native English listeners, and the stimuli were specifically chosen to have unambiguous values of VOT, we did not expect to see any change in listeners’ use of VOT in classifying the ambiguous-f0 stimuli. Therefore, similar VOT-difference scores for the ambiguous-f0 stimuli were expected in the Canonical and the Reversed blocks for native English listeners.
Our primary questions of interest involve the L1 Korean/L2 English listeners. First, we wanted to test whether they showed adaptation at all. If non-native listeners do adapt, we expected that they might show similar adaptation strategies as native listeners (i.e. that category-internal “dimension-based statistical learning” underlies L2 as well as L1 category tuning). In this case, the Koreans using primarily VOT (i.e. those listeners whose cue-weighting strategies reflect those of native English listeners) should show native-like patterns when classifying the ambiguous stimuli (adaptation of f0 but not of VOT). Based on the hypothesis that the dominant cue serves as an anchor for adaption, the Korean f0 group was predicted to show the opposite pattern (adaptation of VOT but not of f0). These polarized adaptation patterns would be due solely to individual differences in initial cue weighting strategies, as the stimuli presented to each group are identical. Since the Korean VOT+f0 group requires both long VOT and high f0 to classify a stimulus as a voiceless stop, the predictions were less clear for this group. However, since they appeared to have more evenly distributed weights between the two cues than the listeners in the other two groups, the change in VOT-difference scores across the two blocks was expected to be comparable to the change in f0-difference scores across blocks.
Results
Grouping of participants
Reliance scores for English and Korean listeners (ratio of “voiceless” responses in Quadrant II minus “voiceless” responses in Quadrant IV) are shown in Figure 4. The Korean listeners clustered in three categories, as expected, with one group showing a greater reliance on f0 (n=16), one group showing a greater reliance on VOT (n=4), and the rest of the listeners (n=20) showing a more equal reliance on both1. The English listeners clustered together, relying primarily on VOT.
Figure 4.
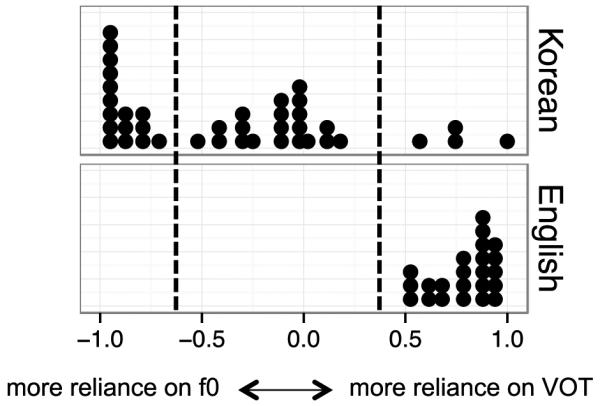
Reliance differences used for grouping of participants: difference in ratio of “voiceless” categorization between covarying stimuli in the Reversed condition, Quadrant II (long VOT, low f0) and Quadrant IV (short VOT, high f0), as shown in Figure 2. Each dot represents one listener. A reliance difference of −1 represents full reliance on f0 in the categorization of covarying stimuli, a reliance difference of 1 represents full reliance on VOT, and 0 represents equal reliance on both dimensions.
Results: L1 English
L1 English control listeners’ responses to the baseline stimuli (Block 1), as well as their responses to the covarying stimuli (pooled across the Canonical and Reversed blocks) are shown in Figure 5. These patterns indicate that English listeners indeed categorized stimuli primarily based on VOT, classifying stimuli with long VOT as voiceless (despite low f0 in the Reversed block in Quadrant II) and stimuli with short VOT as voiced (despite high f0 in the Reversed block in Quadrant IV). Results for the ambiguous test stimuli, shown in the left panel of Figure 6, showed the expected categorization pattern: the f0-difference scores for the ambiguous-VOT test stimuli were greater in the Canonical than in the Reversed block (t(22) = 7.00, p < .001, d = 1.46). This indicates that English listeners made less use of the secondary cue of f0 when exposed to an “accent” showing noncanonical patterning of VOT and f0 (i.e., in the Reversed block). On the other hand, quite a different categorization pattern was observed when listeners categorized ambiguous-f0 stimuli. As can be seen in the right panel of Figure 6, English listeners relied consistently on VOT in categorizing ambiguous-f0 stimuli even in the Reversed block. This is again consistent with the prediction that listeners do not use the secondary cue (f0) as an anchor for adaptation, so that even if f0 information is not canonically matched with VOT in the Reversed block, listeners still use VOT as a reliable cue to the voicing contrast. English listeners made slightly less use of VOT in categorizing ambiguous-f0 stimuli in the Reversed block, an unexpected result based on our predictions. That is, the VOT-difference scores for the ambiguous-f0 stimuli was slightly smaller in the Reversed than in the Canonical block (t(22) = 2.81, p <.05, d = 0.59), although the difference across blocks is much smaller than the effect of f0 on categorization of the ambiguous-VOT stimuli2.
Figure 5.

L1 English control listeners’ performance on responses to baseline stimuli (Block 1) and covarying stimuli (collapsed over both Canonical and Reversed blocks). Each cell represents one stimulus, and the darkness of the cell represents the percentage “voiceless” response in a forced-choice task; the darkest cells elicited 100% ‘pa’ response, while white cells elicited 100% ‘ba.’
Figure 6.
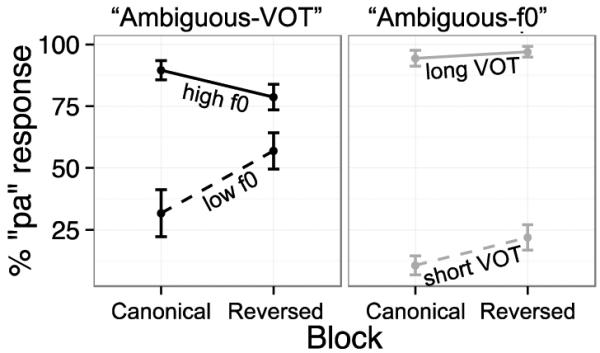
L1 English control listeners’ responses to ambiguous-VOT (left) and ambiguous-f0 (right) stimuli. The y-axis shows percentage ‘pa’ response in a forced-choice (‘ba’-‘pa’) task across blocks. Ambiguous-VOT stimuli with high f0 were classified as mostly ‘pa’ and those with low f0 as mostly ‘ba’ (i.e. a large f0-difference score) in the Canonical block; however, this f0-difference score was greatly diminished in the Reversed block, showing a reduced use of f0 in categorization. For ambiguous-f0 stimuli, listeners showed large VOT-difference scores in both blocks (e.g. classified stimuli with short VOT as ‘ba’ and long VOT as ‘pa’), although this effect was slightly smaller in the Reversed block.
Results: L1 Korean/L2 English listeners
As discussed above, Korean participants were grouped into those listeners who used primarily VOT, primarily f0, or a combination of the two. Each group’s responses to the covarying stimuli (collapsed across the Canonical and Reversed blocks), as well as their baseline cue weights, are shown in Figure 7, and responses to the ambiguous stimuli are shown in Figure 8.
Figure 7.

Native Korean listeners’ responses to covarying stimuli across both the Canonical and Reversed blocks (top) and baseline stimuli (bottom). The graphs show data averaged across all participants in each group (determined by performance on covarying stimuli, see Figure 4). Each cell represents one stimulus, and the darkness of the cell represents the percentage “voiceless” response in a forced-choice (‘ba’/‘pa’) task; the darkest cells elicited 100% ‘pa’ response, while white cells elicited 100% ‘ba.’
Figure 8.

L1 Korean/L1 English listeners’ responses to a forced-choice task on ambiguous-VOT stimuli with intermediate VOT (left) and ambiguous-f0 stimuli with intermediate f0 (right), grouped by categorization strategy. The y-axis shows percentage ‘pa’ response in a forced-choice (‘ba’-‘pa’) task, with performance on Canonical vs. Reversed blocks shown on the x-axis of each panel.
VOT group (n = 4)
As can be seen in the left panel of Figure 8a, the f0-difference scores on ambiguous-VOT stimuli showed a trend toward significance in the expected direction, with an effect size comparable to that of the L1 English listeners (t(3) = 2.92, p =.06, d = 1.45). VOT-difference scores on ambiguous-f0 stimuli were not significantly different between the two blocks (t(3) = −.88, p > .05). Therefore, although there was limited power given the small number of listeners who relied on VOT initially, the trend suggests that 1) these L2 listeners do show adaptation, and 2) the adaptation is comparable to that of native listeners: specifically, these listeners decreased their reliance on the secondary cue (i.e., f0) in the Reversed block, while showing no modulation of VOT (their primary cue) when classifying ambiguous-f0 stimuli across the two blocks.
F0 group (n = 16)
For these listeners, who relied primarily on f0, f0-difference scores on the ambiguous-VOT stimuli were not significantly different between the two blocks (t(15) = 0.52, p > .05) as shown in the left panel of Figure 8b. This indicates that listeners who used f0 as a primary cue to the contrast did so to an equal extent in the context of both Canonical and reversed covariation of VOT and f0. On the other hand, as shown in the right panel of Figure 8b, the VOT-difference scores on the ambiguous-f0 stimuli were significantly greater in the Canonical than in the Reversed block (t(15) = 9.01, p < .001, d = 2.25). Therefore, these L2 listeners showed a clear change in categorization patterns across blocks, and, as with L1 listeners, this adaptation was characterized by a reduction in secondary cue use in the context of the Reversed block.
VOT+f0 group (n = 20)
For listeners in the VOT+f0 group, f0-difference scores were significantly greater in the Canonical than in the Reversed block (t(19) = 5.52, p < .001, d = 1.23) (Figure 8c, left panel). Similarly, for ambiguous-f0 stimuli, the VOT-difference scores were significantly greater in the Canonical than Reversed block (t(19) = 4.81, p < .001, d = 1.07) (Figure 8c, right panel). Unlike listeners in the other two groups, the changes in the use of the two cues were almost identical for these listeners: a within-subjects ANOVA examining the effects of Cue (VOT or f0) and Block (Canonical vs. Reversed) showed only an effect for Block (F(1,19) = 52.43, p < .001), with no effect for Cue (F(1,19) = 1.47, p = .24) and no interaction between Cue and Block (F(1,19) = 2.66, p = .12).
Discussion
The performance of the L2 listeners in the current work suggests that sensitivity and rapid adaptability to changes in distributional information across phonetic categories is a hallmark of non-native, as well as native, speech perception. L2 listeners appear to employ similar dimension-based adaptation strategies to those of native listeners, using more reliable phonetic dimensions to extrapolate information about other, secondary, dimensions defining sound categories. Response patterns of L1 English listeners replicated the results of Idemaru and Holt (2011): L1 listeners, who rely primarily on VOT to distinguish English voiced vs. voiceless stops, decreased their reliance on f0 (their secondary dimension) when exposed to an “accent” in which VOT and f0 were correlated in a noncanonical direction. On the other hand, Korean listeners who relied primarily on f0 to distinguish their L2 English contrast decreased their reliance on VOT (their secondary dimension) when exposed to the same noncanonical accent. As expected, the few Korean listeners who relied primarily on VOT to distinguish the L2 English contrast showed the same trajectory of adaptation as the L1 English listeners did. In both of these cases, while use of the secondary cue decreased in the Reversed block, use of the primary cue (VOT and f0 respectively) appeared to remain stable throughout both blocks, with low values (of VOT or f0) eliciting voiced and high values eliciting voiceless responses3. Korean listeners who relied on both f0 and VOT modulated the use of both cues to a comparable extent, an effect that appears to be driven by an overall decrease in “voiceless” responses in these blocks (see below for further discussion on this point).
The rapid adaptation of L2 categories demonstrated here stands in contrast to the lack of plasticity that characterizes the long-term learning of L2 categories (e.g. Han, 2004). While there have been demonstrations of moderate flexibility in L2 categories with extensive training (e.g. Iverson et al., 2005; Kondaurova and Francis, 2010; Escudero et al., 2011; Lim and Holt, 2011), it is surprising that L2 learners would shift category responses in less than 100 exposures to a non-canonical “accent” with no explicit (or lexical) feedback. In fact, the magnitude of L2 category adaptation appears to be comparable to that of native speakers, mirroring results of Reinisch et al. (2013) and Schuhmann (2014). Together, these findings point to strikingly similar adaptation processes across L1 and L2 listeners, at least in the context of phonetic category “tuning” in response to distributional changes (cf. Pajak et al., to appear).
Listeners’ variable adaptation patterns were predictable from their initial relative cue weights, in line with work showing differential performance on perceptual learning tasks based on initial listening strategy in both L1 (Sawusch and Nusbaum, 1983) and L2 (Chandrasekaran et al., 2010; Wanrooij et al., 2013) listeners. More specifically, the finding follows straightforwardly from the prediction that listeners use a primary dimension as an anchor to adjust use of a secondary dimension (Idemaru and Holt, 2011), by means of bootstrapping from category-internal distributions of phonetic cues. The direct comparison of groups with different initial cue-weighting strategies highlights the fact that the choice of the anchor dimension depends on the relative weight of the dimensions in listeners’ initial definition of the contrast, and that the relative primacy of cues determines the nature of the subsequent category adaptation. In other words, the exact same pattern of distributional changes of phonetic cues in the input may elicit categorically different adaptation strategies, depending solely on variation in listener-specific cue-weighting patterns. One consequence of this result is that even L2 listeners who are similar in accuracy on canonical L2 syllable categorization may have radically different functional categories when confronted with a speaker with a non-canonical accent.
Listeners in the “VOT+f0” group changed the use of both dimensions to an equal extent, lending support to the idea that they do, in fact, weight both dimensions relatively equally. However, the nature of the adaptation differs qualitatively from that of the other two groups. Listeners in the two “unidimensional” (VOT or f0) groups appear to classify both tokens of their ambiguous stimuli at chance in the Reversed block (e.g. in the VOT group, ambiguous-VOT stimuli with both low and high values of f0 are at about 50%); that is, the listeners in both of these groups appear to actually stop using the secondary dimension as a cue to categorization in the Reversed block (see Figure 6). On the other hand, the changes seen in the VOT+f0 group can be more logically interpreted as simply an overall decrease in “voiceless” responses in the Reversed block, caused by a shift in category boundary or decision bias rather than a change in cue weighting. If these listeners were actually decreasing their reliance on one or both of the cues, an increase in “voiceless” responses for low values of each cue (relative to their categorization in the Canonical block) as well as a decrease for high values would be expected; however, only the latter was found. One explanation for this shift depends on the distribution of stimuli in the Reversed block. Recall that the VOT+f0 group required both long VOT and high f0 to identify a given stimulus as voiceless. At the same time, the Reversed block included covarying stimuli with either long VOT paired with low f0 or short VOT paired with high f0 (see Figure 2). Therefore, these listeners were essentially not hearing any good “voiceless” tokens during the Reversed block, which may have caused an overall increase in bias toward choosing “voiced” in these blocks.
The fact that listeners in both the f0 and VOT groups used their primary cue as an anchor from which to bootstrap distributional information about secondary cues from the input demonstrates both the robustness of the primary cues and the flexibility of the secondary cues for each group. The flexibility in the use of VOT by the f0 group is particularly striking. As discussed in the Introduction, there are reasons to expect that VOT might be expected to be an important cue to the L2 English stop contrast, even for those listeners who primarily rely on f0. Most of the native Korean participants in Schertz et al. (2015) showed more reliable differences in VOT than in f0 when producing their L2 English stop contrast (including many of the speakers whose primary cue in perception was f0). Furthermore, given the overwhelming primacy of VOT in native English productions, it might be expected that even for listeners who have a bias toward relying on f0, their experience with the long-term distributional properties of the stop voicing contrast in English likely demonstrate that VOT is an important cue. The current results, however, show that listeners who rely primarily on f0 can be induced to stop using VOT, highlighting its status as a truly secondary cue. The results also show that for this same group of listeners, f0 on its own is a robust enough cue to underly distributional learning: even in the absence of prototypical VOT values, stimuli with high f0 are good enough exemplars of voiceless stops (or stimuli with low f0 are good enough exemplars of voiced stops) to be used to anchor learning of secondary cue distributions.
This work focuses on short-term category adaptation to idiosyncratic distributions of sounds; however, some of the questions brought up may extend more broadly to the long-term structure and acquisition of L2 phonetic categories. Many models of categorization assume that cue weights arise from the distributional properties of the input, as approximated by production data (e.g. Nearey, 1997; Nearey and Hogan, 1986; Lotto, Sato, and Diehl, 2004; Toscano and McMurray, 2010), but in non-native listeners, these distributional regularities may be to a large extent masked by native language biases. The current work shows that these two factors cannot be interpreted independently because listener biases interact in a complex way with changes in distributional information. In particular, if it is the case, as proposed above, that listeners decrease their reliance on secondary dimensions when confronted with the sorts of changing distributional patterns used in the present paradigm, then this implies that certain types of short-term distributional variability will actually reinforce initial listener biases in L2 speech perception, even when these initial biases are not the same as those of native listeners, thus potentially in conflict with the long-term distribution of cues in the language. The fact that the same sorts of distributional changes can result in different adaptation patterns needs to be taken into account when considering the contribution of listener biases and distributional regularities in the initial acquisition and ongoing tuning of L2 phonetic categorization.
The current results provide an example of how multiple factors influence how listeners modify their cue weighting strategies (cf. Holt and Lotto, 2006); in particular, the differential trajectories of adaptation, which can be attributed to the same adaptation strategy, highlight the interaction between of statistical learning and initial biases. The rapid response to short-term changes in the input distribution of stimuli could be modeled in an episodic, exemplar-based model (e.g. Goldinger, 1996; Johnson, 1997; Pierrehumbert, 2001). Similarly, “cue-integration” approaches in which distributional information, but not necessarily individual tokens, is stored (HICAT: Smits, 2001a,b, FLMP: Oden and Massaro, 1978, Toscano and McMurray, 2010) would also be able to accommodate the current findings (and these sorts of models can be computationally difficult to separate from exemplar models in terms of categorization, cf. Smits et al., 2006). One other possibility is that the adaptation occurs due to supervised learning as a result of the primary cue activating a phonemic category representation and an error-signal being generated by the mismatch between expected secondary cue relationship for that category and the actual secondary cue input (Guediche et al., 2014). Regardless of the specific model used, the fact that native and non-native listeners demonstrate the same sensitivity and adaptability to changing distributional information in this task suggests that a unified model may be able to account for both L1 and L2 short-term perceptual learning (cf. Pajak et al., to appear); future work should explore how far this similarity extends to L1 vs. L2 learning more generally.
Conclusion
The non-native listeners in the present work made rapid online shifts in their categorization strategies in response to changes in the input by means of category-internal “dimension-based statistical learning” (Idemaru and Holt, 2011), just as native listeners did. The comparison of native Korean/L2 English listeners who used primarily f0 to distinguish the L2 stop voicing contrast with L1 English listeners who use primarily VOT allowed for a direct test of the hypothesis that these modifications result from listeners’ choice of one acoustic dimension as an “anchor” from which to monitor and learn about potentially idiosyncratic use of other dimensions by the current speaker. As predicted, listeners with different anchor dimensions showed categorically different adaptation strategies; in particular, they stopped using their secondary dimension in categorization when the primary and secondary dimensions gave conflicting information about category membership. The current work demonstrates that the individual variability inherent in foreign sound perception can provide a fruitful perspective from which to explore processes underlying more general category learning and adaptation, and the results highlight the fact that models of auditory category learning need to take into account the potential interactions between listeners’ initial biases and dynamic adaptation to changes in the current listening environment.
Acknowledgements
The authors would like to thank Daejin Kim, Kathy “Nico” Carbonell, Karina Castellanos, and Omar Hussain for their help running subjects, as well as Arthur Samuel, Miquel Simonet, and two anonymous reviewers for helpful feedback on previous versions of this work. This work was supported in part by NSF EAPSI grant #1311026 and NIH-NIDCD grant #R01DC004674.
Footnotes
Further investigation of the factors underlying the individual differences in this population make for an interesting topic for future research. The present groupings do not appear to be predictable based on proficiency or amount of experience with English; however, the group of participants used for this study is not sufficiently large, nor is their experience with English sufficiently heterogeneous, to make claims about this relationship.
We hypothesized that the anomalous change in the use of VOT across blocks may have been related to the fact that there appeared to be a “voiceless” bias for L1 English listeners in this stimulus set (which had been created based on pilot work with Korean listeners); in particular, the 15 ms “ambiguous VOT” tokens were categorized as “pa” 76% of the time in the baseline condition. We therefore ran a follow-up study which exactly replicated the current work but used a modified stimulus space centered around English listeners’ actual VOT boundary on these stimuli (7 ms). This new group of listeners (n=24, from the same population as the original study) showed the expected results, with f0-difference scores on ambiguous-VOT test stimuli greater in the Canonical than the Reversed block (t(23)=6.48, p<.001), but no effect of VOT on the ambiguous-f0 stimuli (t(23)=1.34, p=.19).
An anonymous reviewer suggests that listeners’ primary cue weights may be increasing (concurrent with a decrease in the secondary cue) during the Reversed blocks, a change that would be undetectable in the current experiment (since use of primary cue was already at ceiling, by design of the paradigm used here). This prediction could be tested in future work with a different paradigm.
References
- Baese-Berk M, Bradlow A, Wright B. Accent-independent adaptation to foreign-accented speech. The Journal of the Acoustical Society of America. 2013;133(3):EL174–180. doi: 10.1121/1.4789864. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bertelson P, Vroomen J, de Gelder B. Visual recalibration of auditory speech identification: A McGurk aftereffect. Psychological Science. 2003;14(6):592–597. doi: 10.1046/j.0956-7976.2003.psci_1470.x. [DOI] [PubMed] [Google Scholar]
- Best CT. Speech perception and linguistic experience: Issues in Cross-Language Research. York Press; Timonium, MD: 1995. A direct realist view of cross-language speech perception; pp. 171–204. [Google Scholar]
- Boersma P, Weenink D. Praat: doing Phonetics by computer. 2011 version 5.3: http://www.praat.org. [Google Scholar]
- Bradlow A, Bent T. Perceptual adaptation to non-native speech. Cognition. 2008;106(2):707–729. doi: 10.1016/j.cognition.2007.04.005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chandrasekaran B, Sampath P, Wong P. Individual variability in cue-weighting and lexical tone learning. The Journal of the Acoustical Society of America. 2010;128:456–465. doi: 10.1121/1.3445785. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cho T, Jun S-A, Ladefoged P. Acoustic and aerodynamic correlates of Korean stops and fricatives. Journal of Phonetics. 2002;30(2):193–228. [Google Scholar]
- Clarke CM, Garrett MF. Rapid adaptation to foreign-accented English. Journal of the Acoustical Society of America. 2004;116:3647–3658. doi: 10.1121/1.1815131. [DOI] [PubMed] [Google Scholar]
- Clayards MA, Tanenhaus MK, Aslin RN, Jacobs RA. Perception of speech reflects optimal use of probabilistic speech cues. Cognition. 2008;108(3):804–809. doi: 10.1016/j.cognition.2008.04.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cutler A, McQueen JM, Butterfield S, Norris D. Prelexically-driven perceptual retuning of phoneme boundaries. Proceedings of Interspeech. 2008:2056. 2008. [Google Scholar]
- Davis MH, Johnsrude IS, Hervais-Adelman A, Taylor K, McGettigan C. Lexical information drives perceptual learning of distorted speech: evidence from the comprehension of noise-vocoded sentences. Journal of Experimental Psychology: General. 2005;134(2):222–241. doi: 10.1037/0096-3445.134.2.222. [DOI] [PubMed] [Google Scholar]
- Diehl RL, Elman JL, McCusker SB. Contrast effects on stop consonant identification. Journal of Experimental Psychology: Human Perception and Performance. 1978;4(4):599–609. doi: 10.1037//0096-1523.4.4.599. [DOI] [PubMed] [Google Scholar]
- Eimas PD, Corbit JD. Selective adaptation of linguistic feature detectors. Cognitive Psychology. 1973;4:99–109. [Google Scholar]
- Eisner F, McQueen JM. The specificity of perceptual learning in speech processing. Perception & Psychophysics. 2005;67(2):224–238. doi: 10.3758/bf03206487. [DOI] [PubMed] [Google Scholar]
- Escudero P, Boersma P. Bridging the gap between L2 speech perception research and phonological theory. Studies in Second Language Acquisition. 2004;26:551–585. [Google Scholar]
- Escudero P, Benders T, Wanrooij K. Enhanced bimodal distributions facilitate the learning of second language vowels. The Journal of the Acoustical Society of America. 2011;130(4):EL206–212. doi: 10.1121/1.3629144. [DOI] [PubMed] [Google Scholar]
- Flege JE. Speech perception and linguistic experience: Issues in cross-language research. York Press; Timonium, MD: 1995. Second language speech learning: theory, findings, and problems; pp. 233–277. [Google Scholar]
- Francis A, Kaganovich N, Driscoll-Huber C. Cue-specific effects of categorization training on the relative weighting of acoustic cues to consonant voicing in English. The Journal of the Acoustical Society of America. 2008;124:1234. doi: 10.1121/1.2945161. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Francis A, Nusbaum H. Selective attention and the acquisition of new phonetic categories. Journal of Experimental Psychology: Human Perception and Performance. 2002;28(2):349–366. doi: 10.1037//0096-1523.28.2.349. [DOI] [PubMed] [Google Scholar]
- Goldinger SD. Words and voices: episodic traces in spoken word identification and recognition memory. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1996;22(5):1166–1183. doi: 10.1037//0278-7393.22.5.1166. [DOI] [PubMed] [Google Scholar]
- Goudbeek M, Smits R, Cutler A, Swingley D. Acquiring auditory and phonetic categories. In: Cohen H, Lefebvre C, editors. Handbook of Categorization in Cognitive Science. Elsevier; 2005. pp. 497–513. [Google Scholar]
- Goudbeek M, Swingley D, Smits R. Supervised and unsupervised learning of multidimensional acoustic categories. Journal of Experimental Psychology: Human Perception and Performance. 2009;35(6):1913–1933. doi: 10.1037/a0015781. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Guediche S, Blumstein SE, Fiez JA, Holt LL. Speech perception under adverse conditions: insights from behavioral, computational, and neuroscience research. Frontiers in Systems Neuroscience. 2014;7(126):1–16. doi: 10.3389/fnsys.2013.00126. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Han Z-H. Fossilization in second language acquisition. Multilingual Matters; Clevedon: 2004. [Google Scholar]
- Holt L, Lotto A. Cue weighting in auditory categorization: Implications for first and second language acquisition. The Journal of the Acoustical Society of America. 2006;119:3059–3071. doi: 10.1121/1.2188377. [DOI] [PubMed] [Google Scholar]
- Holt LL, Lotto AJ. Speech perception within an auditory cognitive neuroscience framework. Current Directions in Psychological Science. 2008;17(1):42–46. doi: 10.1111/j.1467-8721.2008.00545.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Holt L, Lotto A. Speech perception as categorization. Attention, Perception, & Psychophysics. 2010;72(5):1218–1227. doi: 10.3758/APP.72.5.1218. [DOI] [PMC free article] [PubMed] [Google Scholar]
- House AS, Fairbanks G. The influence of consonant environment upon the secondary acoustical characteristics of vowels. The Journal of the Acoustical Society of America. 1953;25(1):105–113. [Google Scholar]
- Idemaru K, Holt L. Word recognition reflects dimension-based statistical learning. Journal of Experimental Psychology: Human Perception and Performance. 2011;37(6):1939–1956. doi: 10.1037/a0025641. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Iverson P, Hazan V, Bannister K. Phonetic training with acoustic cue manipulations: A comparison of methods for teaching English /r/-/l/ to Japanese adults. The Journal of the Acoustical Society of America. 2005;118(5):3267–3278. doi: 10.1121/1.2062307. [DOI] [PubMed] [Google Scholar]
- Iverson P, Kuhl P, Akahane-Yamada R, Diesch E, Tohkura Y, Kettermann A, Siebert C. A perceptual interference account of acquisition difficulties for non-native phonemes. Cognition. 2003;87(1):B47–B57. doi: 10.1016/s0010-0277(02)00198-1. [DOI] [PubMed] [Google Scholar]
- Johnson K. Speech perception without speaker normalization: An exemplar model. In: Johnson K, Mullennix JW, editors. Talker variability in speech perception. Academic Press; New York: 1997. pp. 145–166. [Google Scholar]
- Diehl R. Kingston J, editor. Phonetic knowledge. Language. 1994;70(3):419–454. [Google Scholar]
- Kingston J, Diehl R, Kirk C, Castleman W. On the initial perceptual structure of distinctive features: the [voice] contrast. Journal of Phonetics. 2008;36:28–54. doi: 10.1016/j.wocn.2007.02.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kleinschmidt D, Jaeger TF. Robust speech perception: Recognize the familiar, generalize to the similar, and adapt to the novel. Psychological Review. 2015;122(2):148–203. doi: 10.1037/a0038695. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kondaurova MV, Francis AL. The role of selective attention in the acquisition of English tense and lax vowels by native Spanish listeners: comparison of three training methods. Journal of Phonetics. 2010;38:569–587. doi: 10.1016/j.wocn.2010.08.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kong E, Yoon IH. L2 proficiency effect on the acoustic cue-weighting pattern by Korean L2 learners of English: Production and perception of English stops. Journal of the Korean Society of Speech Sciences. 2013;5(4):81–90. [Google Scholar]
- Kraljic T, Samuel AG. Perceptual learning for speech: Is there a return to normal? Cognitive Psychology. 2005;51(2):141–178. doi: 10.1016/j.cogpsych.2005.05.001. [DOI] [PubMed] [Google Scholar]
- Lee H, Jongman A. Effects of tone on the three-way laryngeal distinction in Korean: An acoustic and aerodynamic comparison of the Seoul and South Kyungsang dialects. Journal of the International Phonetic Association. 2012;42(2):145–169. [Google Scholar]
- Lim S-J, Holt L. Learning foreign sounds in an alien world: Videogame training improves non-native speech categorization. Cognitive Science. 2011;35(7):1390–1405. doi: 10.1111/j.1551-6709.2011.01192.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lisker L, Abramson A. A cross-language study of voicing in initial stops: Acoustical measurements. Word. 1964;20:384–422. [Google Scholar]
- Llanos F, Dmitrieva O, Shultz A, Francis AL. Auditory enhancement and second language experience in Spanish and English weighting of secondary voicing cues. Journal of the Acoustical Society of America. 2013;134(3):2213–2224. doi: 10.1121/1.4817845. [DOI] [PubMed] [Google Scholar]
- Lotto AJ, Sato M, Diehl RL. Slifka J, Manuel S, Matthies M, editors. Mapping the task for the second language learner: the case of Japanese acquisition of /r/ and /l/ From Sound to Sense: 50+ Years of Discoveries in Speech Communication. 2004:C381–C386. [Google Scholar]
- Maye J, Aslin RN, Tanenhaus MK. The Weckud Wetch of the Wast: Lexical adaptation to a novel accent. Cognitive Science. 2008;32:543–562. doi: 10.1080/03640210802035357. [DOI] [PubMed] [Google Scholar]
- McGurk H, MacDonald J. Hearing lips and seeing speech. Nature. 1976;264:746–748. doi: 10.1038/264746a0. [DOI] [PubMed] [Google Scholar]
- McQueen JM, Cutler A, Norris D. Phonological abstraction in the mental lexicon. Cognitive Science. 2006;30(6):1113–1126. doi: 10.1207/s15516709cog0000_79. [DOI] [PubMed] [Google Scholar]
- Miyawaki K, Jenkins JJ, Strange W, Liberman AM, Verbrugge R, Fujimura O. An effect of linguistic experience: The discrimination of [r] and [l] by native speakers of Japanese and English. Attention, Perception, & Psychophysics. 1975;18(5):331–340. [Google Scholar]
- Moulines E, Charpentier F. F0-synchronous waveform processing techniques for text-to-speech synthesis using diphones. Speech Communication. 1990;6:453–467. [Google Scholar]
- Nearey T. Speech perception as pattern recognition. Journal of the Acoustical Society of America. 1997;101(6):3241–3254. doi: 10.1121/1.418290. [DOI] [PubMed] [Google Scholar]
- Nearey TM, Hogan JT. Phonological contrast in experimental phonetics: relating distributions of production data to perceptual categorization curves. Experimental Phonology. 1986:141–161. [Google Scholar]
- Norris D, McQueen J, Cutler A. Perceptual learning in speech. Cognitive Psychology. 2003;47(2):204–238. doi: 10.1016/s0010-0285(03)00006-9. [DOI] [PubMed] [Google Scholar]
- Oden GC, Massaro DW. Integration of featural information in speech perception. Psychological Review. 1978;85:172–191. [PubMed] [Google Scholar]
- Pajak B, Fine AB, Kleinschmidt D, Jaeger TF. Learning additional languages as hierarchical inference: Insights from L1 processing. Language Learning. doi: 10.1111/lang.12168. To appear. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Park H, de Jong K. Perceptual category mapping between English and Korean prevocalic obstruents: Evidence from mapping effects in second language identification skills. Journal of Phonetics. 2008;36:704–723. [Google Scholar]
- Pierrehumbert J. Exemplar dynamics: Word frequency, lenition and contrast. In: Bybee J, Hopper P, editors. Frequency effects and the emergence of linguistic structure. Benjamins; Amsterdam: 2001. pp. 323–418. [Google Scholar]
- Reinisch E. Listeners retune phoneme categories across languages. Journal of Experimental Psychology: Human Perception and Performance. 2013;39(1):75–86. doi: 10.1037/a0027979. [DOI] [PubMed] [Google Scholar]
- Samuel AG. Red Herring detectors and speech perception: In defense of selective adaptation. Cognitive Psychology. 1986;18:452–499. doi: 10.1016/0010-0285(86)90007-1. [DOI] [PubMed] [Google Scholar]
- Samuel AG, Kraljic T. Perceptual learning for speech. Attention, Perception, & Psychophysics. 2009;71(6):1207–1218. doi: 10.3758/APP.71.6.1207. [DOI] [PubMed] [Google Scholar]
- Sawusch JR, Nusbaum HC. Auditory and phonetic processes in place perception for stops. Perception & Psychophysics. 1983;34(6):560–568. doi: 10.3758/bf03205911. [DOI] [PubMed] [Google Scholar]
- Schertz J, Cho T, Lotto AJ, Warner N. Individual differences in phonetic cue use in production and perception of a non-native sound contrast. Journal of Phonetics. 2015;52:183–204. doi: 10.1016/j.wocn.2015.07.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schuhmann KS. Perceptual learning in second language learners. 2014. Ph.D. thesis, Stony Brook University.
- Smits R. Evidence for hierarchical categorization of coarticulated phonemes. Journal of Experimental Psychology: Human Perception and Performance. 2001a;27(5):1145–1162. doi: 10.1037//0096-1523.27.5.1145. [DOI] [PubMed] [Google Scholar]
- Smits R. Hierarchical categorization of coarticulated phonemes: a theoretical analysis. Perception & Psychophysics. 2001b;63(7):1109–1139. doi: 10.3758/bf03194529. [DOI] [PubMed] [Google Scholar]
- Smits R, Sereno J, Jongman A. Categorization of sounds. Journal of Experimental Psychology: Human Perception and Performance. 2006;32(3):733–754. doi: 10.1037/0096-1523.32.3.733. [DOI] [PubMed] [Google Scholar]
- Sumner M, Samuel AG. The effect of experience on the perception and representation of dialect variants. Journal of Memory and Language. 2009;60(4):487–501. [Google Scholar]
- Toscano JC, McMurray B. Cue integration with categories: Weighting acoustic cues in speech using unsupervised learning and distributional statistics. Cognitive Science. 2010;34(3):434–464. doi: 10.1111/j.1551-6709.2009.01077.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Trude AM, Brown-Schmidt S. Talker-specific perceptual adaptation during online speech perception. Language and Cognitive Processes. 2012;27(7-8):979–1001. [Google Scholar]
- Wanrooij K, Escudero P, Raijmakers MEJ. What do listeners learn from exposure to a vowel distribution? An analysis of listening strategies in distributional learning. Journal of Phonetics. 2013;41(5):307–319. [Google Scholar]
- Whalen DH, Abramson AS, Lisker L, Mody M. F0 gives voicing information even with unambiguous voice onset times. Journal of the Acoustical Society of America. 1993;93(4):2152–2159. doi: 10.1121/1.406678. [DOI] [PubMed] [Google Scholar]
- Yamada R, Tohkura Y. Perception and production of syllable-initial English /r/ and/l/ by native speakers of Japanese. ICSLP. 1990:757–760. [Google Scholar]