

Abstract
When being searched for and then (if found) pursued by a predator, a prey animal has a choice between choosing very randomly among hiding locations so as to be hard to find or alternatively choosing a location from which it is more likely to successfully flee if found. That is, the prey can choose to be hard to find or hard to catch, if found. In our model, capture of prey requires both finding it and successfully pursuing it. We model this dilemma as a zero-sum repeated game between predator and prey, with the eventual capture probability as the pay-off to the predator. We find that the more random hiding strategy is better when the chances of repeated pursuit, which are known to be related to area topography, are high. Our results extend earlier results of Gal and Casas, where there was at most only a single pursuit. In that model, hiding randomly was preferred by the prey when the predator has only a few looks. Thus, our new multistage model shows that the effect of more potential looks is opposite. Our results can be viewed as a generalization of search games to the repeated game context and are in accordance with observed escape behaviour of different animals.
Keywords: game theory, escape, repeated games, behavioural ecology
1. Introduction
When a predator finds its prey but is unsuccessful in its pursuit, it has two choices. It can give up the attempt to again find and then catch this prey and move to another patch or it can persist in its endeavour. We call the probability of the predator adopting the second choice its persistence, which we label as parameter β. This persistence parameter is related to the so-called ‘give-up time’, and we view it as an exogenous, fixed, parameter in our repeated game model of combined search for and pursuit of prey. Giving-up times have been studied for decades within behavioural ecology as a specific case of economic decisions at the individual level [1] and shown to depend on both internal (satiation level, number of ripe eggs, etc.) and external variables (number and quality of prey in patches, predation risk) [2]. Persistence is known to be related to the topography of the pursuit arena, for example, it was found in [3] that ‘…compared with a flat surface, leaf litter … reduced the likelihood of secondary pursuits, after initial escape of the prey, to nearly zero’. With the inclusion of a persistence probability, this paper can be viewed as a repeated game extension of the single stage game of Gal & Casas [4], where an unsuccessful pursuit ended the game. Our main result is that when the persistence probability is high, the prey should hide more randomly (distributed over more potential locations) rather than more concentrated on the best sites for fleeing.
From the point of view of the field of ‘search games’ (e.g. [5]), the importance of this paper is the introduction of models and techniques from the area of repeated games, which hitherto have not been part of the field. Such an extension of existing models is required to analyse persistent attacks of a predator.
2. Search games and biological contexts
This section places our work within the two contexts of search games (in the applied mathematics and operational research literatures) and behavioural ecology.
2.1. Search games
There is an extensive literature on search games where the hider chooses to locate at one of a finite number of locations (called cells, boxes, etc.) and then the searcher looks sequentially into these boxes to try to find the hider. These boxes may be heterogeneous in the cost of searching and in the probability that a hider can be overlooked even if his location is searched. The literature on this aspect of our model has been discussed in [4]. A new aspect of search games that appears in this paper is that of persistence of attacks—if the prey escapes, the predator may attempt to find it again. The closest to this repetition of search is in the model of Alpern et al. [6,7], where during the search the prey (hider) may attempt to flee the search region. The prey will succeed in this attempt if the predator is in a cruise search mode, but not if he is in an ambush mode. In those models, a successful flight by the prey is definitely followed by a renewed attempt by the predator to find it. (We use the term ‘flight’ as fleeing from the hiding location, not necessarily in the air.) So in our context, we would say that those models had maximum persistence, a β value of 1.
The problem of where to hide food (in discrete packages such as nuts) rather than where to hide oneself, has been analysed in a search game played between a scatter hoarder such as a squirrel and a pilferer in [8]. The squirrel has limited digging energy and has to decide between placing nuts deeply hidden in one place or alternatively widely scattered at shallower depths. This problem is somewhat analogous to the problem of the prey hiding in a good location or randomly choosing among less good locations. Of course the pay-offs are of a different kind as the prey either gets caught or not; while the squirrel either has enough nuts left to survive the winter, or not. Also, there is no pursuit phase in the squirrel's problem.
The search game models in [6,7] had no pursuit phase, and the issue raised there concerned the optimal alternation between cruise search and ambush search. Following those papers, Zoroa et al. [9,10] advanced the theory of search games to include ambush. A ‘silent predator’ (whose approach is not observable by the prey) was considered in [11]. More biological models were considered by Broom [12] and Pitchford [13]. The only one of these papers to touch on repeated games is the study of Zoroa et al. [10].
2.2. Persistent attacks and prey escape tactics in the animal world
There is a paucity of ethological studies reporting the fleeing behaviour of prey under persistent attacks by their natural enemies, in contrast with the well-studied case of a single attack, followed by escape [14]. In fact, the number of predator–prey interactions with a rapid sequence of repeated attacks on the same prey by the same predator abound in nature, and older literature provides lengthy descriptions of such interactions, from pompilid wasps pursuing spiders to falcons attacking passerine prey (see Fabre’s description in [4] for the first case and [15] for the second case). These descriptions often lack crucial information to formalize them as repeated games, and are not quantified. In the following, we first report the findings of a few studies, conducted mainly with lizards [16] and grasshoppers [17] as prey and humans as predators. We then describe one biological interaction in more detail. We use this example to formalize the backbone of our theoretical study and describe in less detail a further example in the discussion.
The survey of the less than a dozen studies on prey escape under persistent attack show that prey switch tactics once they realize that the predator is repeatedly attacking them [17]. The chosen tactics range from shorter flight initiation distance, longer flight distance, extended use of cover, use of more protective cover and higher latency to emerge from cover. Prey indeed adjust continuously the costs and benefits of their decisions, and switching to a different tactic has a price. For example, lizards running into rock crevices rather than moving a bit further experience a thermal cost [16] and grasshoppers hiding down grass stems rather than chipping plant pieces and eating them in the open do not have access to food [17]. Because these examples use humans as the predator, the experiments are conducted in a way to enable prey to escape. Also, these studies do not provide a map of the environment and hence an appreciation of the number of hiding places available to the prey. This aspect does matter as it defines the number of possible hiding locations [4].
The most comprehensive knowledge of both the geometry of the spatial arena and the occurrence of repeated attacks and fleeing displayed by both antagonists is available for a leafminer larva–parasitic wasp interaction. This system has been studied in depth and only the relevant information is provided here.
Movements by both wasp and host larva produce vibrations of the leaf tissues in which the caterpillar lives, which may be sensed by both actors [18,19]. The wasp flies toward the visual appearance of the mines due to the white spots, thereafter called windows, which are feeding locations of a couple of square millimetres where only the cuticle of the leaf remains. The feeding larva is below the window, and can be seen through the translucent cuticle. The number of windows increases during larval development [20]. The wasp lands on the leaf and the game begins. Leaf vibrations cause the larvae to cease feeding and to become ‘alert’. On the one hand, vibrations produced by the host during escape are useful to the parasitoid female, as a trigger to continue the hunt [19]. On the other hand, vibrations produced by a hunting parasitoid at the leaf's surface are also useful to the host, which remains alert. The wasp tries to sting the larva by inserting the ovipositor violently in one of the windows, the other areas of the mine being too tough to penetrate. A successful search ends with the larva being parasitized and the wasp laying an egg.
Let us now formalize that biological example as a repeated search game. We consider that the white spots on the mine are the locations under which the hider hides. This number can reach easily over 100. For simplicity, we assume that the larva is hiding under only one window. In reality, a large larva can be simultaneously under a few windows. A look starts when the wasp explores a given window with its antenna. There are then different possibilities depending on whether the larva is hiding there. If the hider is somewhere else, the wasp moves to another window or inserts the ovipositor to explore the location more carefully (these less frequent cases are classified as searching). In either of these cases the wasp then moves to another location. If the larva was under the search window, either the wasp does not sense it and moves to another window or the wasp pursues the larva by violently inserting its ovipositor. So, overlooking the hider is a possibility which implies the end of that look, as the wasp is changing location, but its rare occurrence is not implemented in our model. For a given pursuit, there are two possible events. First, the wasp might hit the larva and the game ends. Alternatively, the wasp might merely touch the larva or produce strong leaf vibrations. Both actions lead to the escape of the larva, which relocates itself with uniform probability under any of the windows. A change of windows by the larva terminates the look, irrespective whether the wasp persists searching at the actual location. A change of window by the wasp also terminates the look. If both remain in the same location, the behavioural sequence starts anew, but within the same look.
3. Review of basic game G(k, 0)
All the games we study are zero-sum two-person games. The pay-off function is always the probability that the searcher eventually finds and captures the hider. Thus, the searcher is the maximizer and the hider is the minimizer. Such games have a value, denoted by v, and optimal mixed strategies for each player. The optimal strategy for the searcher will guarantee that the capture probability (pay-off) is at least v and the optimal strategy for the hider will guarantee that the capture probability is at most v. The pair of optimal strategies form a Nash equilibrium, though of a special type. The details of the general form of search games can be found in [5].
Before describing the general game G(k, β) with persistence probability β, we review what we call the basic game studied in [4]. There is no persistence of attack, the persistence probability β is 0, which is why the second parameter (for β) describing the game is 0. There are n locations 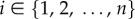 for the hider to hide in. If the hider stays at location i, then the probability of capture, in case that the searcher looks at this location is pi, where p = (p1, … , pn) is a known vector capture probability, with the locations ordered so that
for the hider to hide in. If the hider stays at location i, then the probability of capture, in case that the searcher looks at this location is pi, where p = (p1, … , pn) is a known vector capture probability, with the locations ordered so that 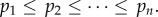 Thus, location 1 is always the location where it is hardest to catch the hider. The searcher is limited to looking in k out of the n possible locations of the hider. Since the time taken to find the hider is not important in our model, a pure strategy for the searcher is a simple subset
Thus, location 1 is always the location where it is hardest to catch the hider. The searcher is limited to looking in k out of the n possible locations of the hider. Since the time taken to find the hider is not important in our model, a pure strategy for the searcher is a simple subset 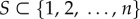 of cardinality k. If the hider's location i belongs to the searched set S, the hider is captured with probability pi; otherwise he is not captured. The pay-off to the searcher (hider) is 1(0) if the hider is captured and 0(1) otherwise.
of cardinality k. If the hider's location i belongs to the searched set S, the hider is captured with probability pi; otherwise he is not captured. The pay-off to the searcher (hider) is 1(0) if the hider is captured and 0(1) otherwise.
In terms of pure strategies, where the hider chooses location i and the searcher looks at each location in the set S, the pay-off (probability of capture) is given by
| 3.1 |
A mixed strategy for the hider is a probability distribution h = (h1, … ,hn) over the locations, so that 0 ≤ hi ≤ 1 and h1 +… hn = 1. For the searcher, it is a probability distribution over the subsets of {1,2, … ,n} of cardinality k. A simpler representation of a search strategy, shown to be equivalent in [4], is an n-vector r = (r1, … , rn) satisfying
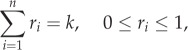 |
3.2 |
where ri is the probability that 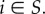 (Note that the extreme points of the set of all such points r have k coordinates equal to 1 and the rest equal to 0, and thus can be identified with particular k-sets S.)
(Note that the extreme points of the set of all such points r have k coordinates equal to 1 and the rest equal to 0, and thus can be identified with particular k-sets S.)
It is useful to observe that in games of hide and seek (called search games in the literature [5]), pure strategies are generally not very good for either player. If the hider always goes to the same location, the searcher will always look there first; if the searcher always searches locations in the same order, the hider will choose a location not searched or searched late (if capture time enters the pay-off). An exception to this is the Type II solution of theorem 3.1, where the hider always chooses location 1 (the best location for escape) and the searcher always looks there first (or in the first k looks). But in any case the prevalence of mixed strategies as Nash equilibria (optimal strategies) in search games is in stark contrast with the pure strategies which are sufficient as evolutionary stable strategies in asymmetric animal contests [21]. It should be noted in any case that the ‘pure’ strategies in [21] are behavioural and involve randomization. In addition, during any round of our game neither player knows about the choice made by the other player so there is no asymmetry of knowledge.
In terms of mixed strategies r (for the searcher) and h (for the hider), the capture probability (pay-off) is given by the following formula, which is, however, never explicitly used in finding the solution.
| 3.3 |
That is, the hider will be captured if for some location i: the hider hides at location i, the searcher looks in location i and the search successfully catches the hider in the pursuit stage at location i.
The solution to the basic game G(k, 0), as given in [4], can be summarized in the following result from Gal & Casas [4], where
| 3.4 |
Theorem 2.1. —
(Gal–Casas) The value of the game G(k, 0) is given by
3.5 The optimal strategies come in two types, mixed (Type I) and pure (Type II).
Type I solution. If k < p1/λ (that is, v = kλ) then the unique optimal search strategy satisfies ri = kλ/pi, and the unique optimal hiding strategy satisfies hi = λ/pi, i = 1, … , n (the hider makes all locations equally attractive for the searcher).
Type II solution. If
(that is,
) then any optimal search strategy satisfies r1 = 1 (
) and
for
and the uniquely optimal hiding strategy is to hide at location 1, that is, h1 = 1.
4. The game with persistence of attack, G(k, β)
This section covers the more general game, G(k, β), with an arbitrary persistence probability β.
4.1. Framework
We now extend the game of Gal & Casas [4] to multiple periods. When the persistence β is 1, we have a repeated game, and when β < 1, the game is mathematically equivalent to a discounted repeated game, where β plays the role of the discount factor.
The repeated game G(k, β) has an unlimited number of stages played at the same n locations. In each stage, the pure strategies are the same as in the basic game G(k, 0) discussed in the previous section: the hider chooses a location to hide in and the searcher chooses a subset S of cardinality k to inspect. There is no influence of previous play in earlier stages, except in the variation discussed in the final section, where the hider cannot return to a location where he has previously hidden. There are three possible outcomes:
(1) If the searcher does not find the hider, then the game ends with zero pay-off for the searcher and a pay-off of one to the hider. (hider wins.)
(2) If the searcher finds the hider and successfully pursues it (captures it), then the game ends with a pay-off of one to the searcher and a pay-off of zero to the hider. (searcher wins.)
(3) If the searcher finds the hider but does not catch it, then there are two possibilities. With probability 1−β the predator gives up and the game ends with a win for the hider. With the persistence probability β the process restarts with the hider finding a new location.
The value v (0 ≤ v ≤ 1) is the probability that the searcher eventually captures the hider, with best play on both sides. We will show that there exist optimal strategies for both players which are usually unique. The dynamics of the game can be seen in figure 1.
Figure 1.

Flowchart of the dynamics of the repeated game. (Online version in colour.)
4.2. Basic lemmas for G(k, β)
The value v of the game G(k, β), with persistence β, will be later shown to be the solution of the basic equation
| 4.1 |
We now present several auxiliary results.
Lemma 4.1. —
The LHS of (4.1) is (continuous) strictly monotonic increasing in v. Thus, equation (4.1) has a unique positive root v, 0 < v ≤ 1.
Proof. —
The left-hand side (LHS) of equation (4.1) can be written as
so it is a strictly monotonic increasing function of v for v > 0. This function continuously increases from 0 to at least n as v increases from 0 to 1. Since k ≤ n, it follows by continuity that there exists a unique root for equation (4.1). ▪
Definition 4.2. —
Let v1 satisfy
4.2 so
4.3
It immediately follows from Lemma 4.1 that
Lemma 4.3. —
As v increases from 0 to v1, LHS of (4.1) continuously increases from 0 to M given by
4.4 Also, as persistence β increases from 0 to 1, M increases from
to n.
Lemma 4.4. If k < M then for any i
4.5
Proof. —
By lemma 4.3 if k < M then v < v1 so v < p1 + (1 – p1)βv. Since the right-hand side of (4.5) is a convex combination of 1, and βv ≤ 1 and pi ≥ p1, the result follows. ▪
4.3. Type I solutions of G(k, β)
A Type I solution for G(k, β) is a pair (h*r*) such that h* is the hiding strategy that makes all locations equally attractive for the searcher to visit for each stage independent of history and r* is the search strategy that makes all locations equally attractive to hide at for each stage independent of history. We now show that these strategies are optimal if k is smaller than the threshold M.
Theorem 4.5 (Type I). —
If k ≤ M (see (4.4)), then the solution of the game G(k, β) is of Type I:
The optimal strategies, unique for k < M, are
4.6 and
4.7 The value v of the game is the unique solution of equation (4.1), as guaranteed by lemma 4.1.
Proof. Assume that k < M. First note that for all i,
by lemma 4.4.
We now show that
guarantees capture probability equal to v which solves equation (4.1) against any hiding strategy. To obtain the minimum probability of capture, achievable by the hider, if the searcher uses r* the hider has to solve the corresponding Markov decision process (MDP) [22] with just two states (a ‘free’ state and an absorbing state ‘capture’) and a finite action space for the hider. In this MDP there are no costs involved except for a cost 1 which is paid by the hider if the searcher visits the hider's location (and the process then enters into the absorbing state ‘capture’). By the basic theory of MDP we need to take into account only deterministic stationary strategies for the hider, i.e. always hiding at the same location, say j. For any such j, the probability of capture if the searcher uses r* is
by (4.7).
Next we show that
keeps the probability of capture to at most v against any search strategy. In order to obtain the maximum probability of capture achievable by the searcher if the hider uses h* we have to solve an analogous two-state MDP for the searcher. Again, we need to consider only deterministic stationary search strategies of searching only a set of k locations, say i1, … ,ik. For any such set of locations, the probability of capture if the hider uses h* is calculated as follows. The probability of another round of the process is
4.8 Thus, the overall probability of capture is
4.9 by (4.8) and (4.6).
In order to calculate (4.9) observe that for any dj > 0, j = 1, … ,k, with cj = y(1−dj), we have
Denote now
and
then
so the expression given by (4.9) is equal to v. Thus, the hiding strategy h* assures the probability of capture at most v given by equation (4.1). We have thus shown that v is the value of the game and (h*, r*)) is a Nash equilibrium.
We next show that
is the unique search strategy that guarantees the pay-off v given by (4.1). Assume that there exists a location j with
Then by hiding at j the hider would make the searcher's pay-off
Thus, in order to guarantee pay-off v all ri would have to satisfy
But r has to satisfy (3.2) so by (4.1) and lemma 4.1, we must have equality. We have thus proved the uniqueness of r*.
We now prove the uniqueness of h*:
If
4.10 then the searcher can get more than v by using a vector r with
, for all
and
where θ is a small positive number. Thus, the pay-off for the searcher using R is
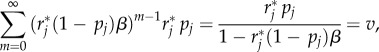
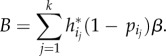



4.4. The persistent predator: G(k, 1)
We now consider the special case where the persistence probability β is 1 – the game always repeats after a successful escape of the prey.
Corollary. —
The optimal solution of the persistent predator game G(k, 1), for any k, 1 ≤ k ≤ n, is always of Type I.
Proof —
Our basic equation with β = 1 is
If β = 1 then M = n so k ≤ M. Thus, the Type I solution is optimal.
Moreover, the solution is unique except for the trivial case k = n in which any hiding strategy leads to a loss of 1 for the hider because the hider always gets caught, eventually.
Also If k < n then υ ≤ k/n because if the hider hides with probability 1/n at each location, then the probability of capture in the repeated game is at most k/n.
Note that basic equation for υ can be written as
Since the RHS is increasing in k, it follows that υ is super-linear in k.
The optimal strategies are:
and
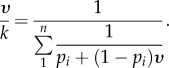
4.5. Type II solution for general β and k ≥ M
Here we show that if k ≥ M, where M is given by (4.4), then the optimal solution is Type II: always hide at the most favourable location, i.e. at location 1 which has the smallest pi.
Theorem 4.6 (Type II). —
Suppose k ≥ M, where M is given by (4.4). Then v = v1 given by (4.3), and an optimal solution for the hider is to hide at location 1 (Type II). For the searcher it is optimal to use an r1 vector satisfying
and
Proof. By (4.6), hiding at location 1 guarantees v1 for the hider. Also, the vector r1, which guarantees v1 against any hiding location, is feasible by (4.4) which implies that
4.6. The ranges of Type I and II solutions
Here we show that, in general, there is a cut-off value of the persistence probability β above which the game G(k, β) has only Type I (mixed) solutions and below which it has only Type II (pure) solutions. Sometimes there are only Type I solutions.
Theorem 4.7. —
For a given k ≤ n Let βk denote the solution of the equation
4.11 Then
(1) if β > βk, then there are only Type I solutions to the game G(k, β).
(2) if β < βk, then there are only Type II solutions to the game G(k, β).
(3) If the equation (4.11) has no solution, then there are only Type I solutions to the game G(k, β).
Proof. M given by (4.4) is monotonic increasing with β. Thus, β > βk implies that k < M. Hence theorem 4.5 implies that the unique solution of G(k, β) is of Type I. Similarly, β < βk implies that k > M so theorem 4.7 implies that the solution of G(k, β) is of Type II.
If (4.11) has no solution, then it must mean that the right-hand side w1 of (4.11) is always greater than k (because for β = 1 the w1 equals n) so there are always only Type I solutions to the game G(k, β).▪
Note that  because the denominator of (4.4) is decreasing with β.
because the denominator of (4.4) is decreasing with β.
Example 4.8. —
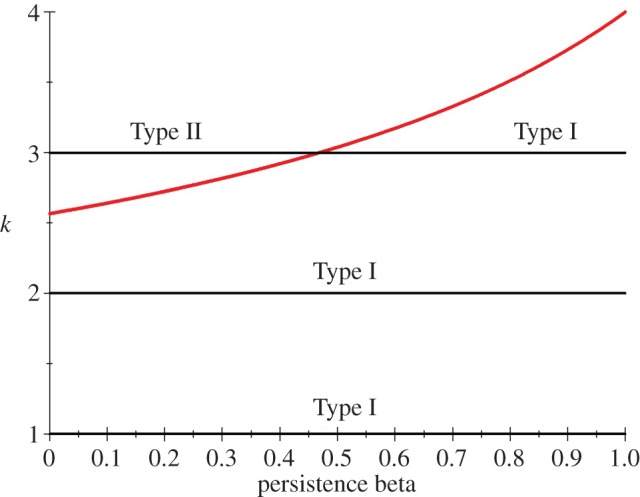
In order to illustrate both types of solution for G(k, β), we consider first an example with four hiding location and take the capture probability vector to be
Figure 2 shows which strategy type is optimal for
We plot the curve k = w(β) which gives the least value of k, as a real number, for which Type II strategies are optimal. So, for example, when β = 0.1, Type II strategies are optimal for k > 2.6. But as k is always an integer in our model (the number of searches), this effectively means that for β = 0.1 Type II strategies are optimal only when k = 3 (or in the trivial case k = 4, where all locations are searched). For k equal to 1 or 2, the figure shows that Type I strategies are optimal for any persistence probability β. If we fix k = 3, the line at height 3 intersects w(β) at about β3 = 0.469, which is thus the cut-off value of β for Type II strategies and Type I strategies. That is, when β < 0.469 the solution to G(3, β) is of Type II, whereas for β > 0.469 the solution is of Type I.
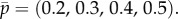
Figure 2.
Plot of k = w(β) for capture probabilities 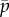 . (Online version in colour.)
. (Online version in colour.)
Example 4.9. —
We now consider a larger arena with nine hiding locations, with capture probabilities given by the vector
Figure 3 plots the curve k = w(β) which again gives the least k, as a real number, for which Type II strategies are optimal. Since in our model k is the integer giving the number of searches, figure 3 only has implications for integer values of k, which are drawn as horizontal lines. The intersection of the curve w(β) with the horizontal line at height k is called βk, and for β ≤ βk the solution for k searches is of Type II because there the line of height k is above the curve k = w(β). For β ≥ βk, the solution for k searches is of Type I. Note that for k = 1,2 we only have Type I solutions, but for higher k we have both types.
Figure 3.
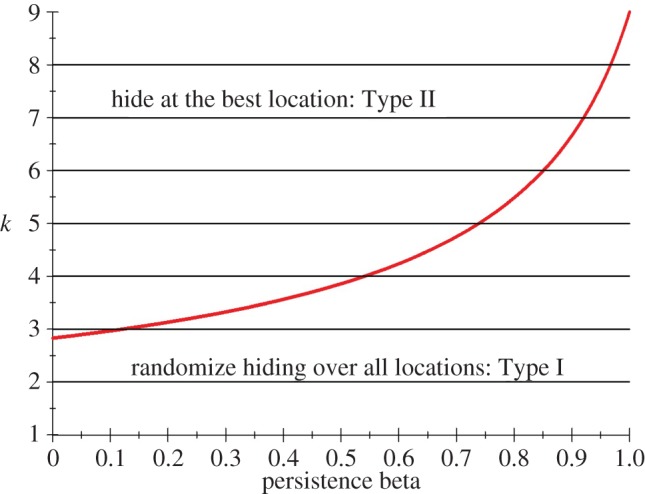
Plot of k = w(β) for capture probabilities 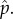 (Online version in colour.)
(Online version in colour.)
Remark 4.10. —
Note that in general if
(or, equivalently, p1 > jλ) then G(k, β) has only Type I solutions for all k ≤ j. This follows from theorem 4.7 because the right-hand side of (4.11) at β = 0 is greater than j so no solutions for (4.11) exist if k ≤ j. So for example if p = (0.5,0.5,1,1) we have equality for j = 3 so we have only Type I solutions for k = 1 and 2, and if k = 3 only Type I solutions for β > 0.
4.7. An alternative approach to the repeated game
An alternative way of obtaining some of the results about the game G(k, β) is to reduce it to a one-stage game by changing the capture probabilities. Suppose the value of the game G(k, β) is known to be some number v. If the hider hides at a location i and the searcher visits it then the pay-off to the searcher can be written as
because the searcher wins immediately (pay-off 1) with probability pi and with probability (1 − pi)β he gets to play the game (with value v) again. The remaining probability can be ignored as it gives him pay-off 0. It follows that the multi-period game G(k, β) is equivalent to the one-stage game (β = 0) with capture probabilities qi.
Using (3.5) of theorem 3.1 with qi replacing pi we get the implicit equation
| 4.12 |
where
The implicit equation (4.12) can be solved by using lemmas 4.1 and 4.3. Solutions with the minimum in the first coordinate give Type I solutions and those with the minimum in the second coordinate give Type II solutions.
5. Discussion
We first address here the biological significance of our findings and end the paper with an enhancement of our analysis by accounting for the possibility that prey do not return to locations where they were previously found but escape capture.
Persistence in the search leads to more randomization in the prey choice of hiding locations. In the one-stage game of Gal & Casas [4], a larger parameter k means more potential searches. It also means that prey is more likely to hide at the best location, in other words there is less randomization in the hiding locations. The persistence game of this paper implies, for k fixed, more potential searches for bigger β. Therefore, bigger β means prey is more likely to be found—but in this case it is less likely to hide at the best location. This implies more randomization, so the effect of more searches due to persistence is the opposite. This can be seen in figure 3, where increasing k (going up) leads into the Type II region, whereas increasing β (going right) leads into the Type I region.
Despite an extensive search, we were unable to find descriptions of biological interactions in which the arena was mapped with sufficient precision to identify hiding locations, enabling us to test the predictions of the model. In the only case for which we have sufficient information, the leafminer case detailed in the introduction, the very large number of ovipositor insertions leads to a full randomization of the fleeing locations of the caterpillar location (see [18] and [19]). By contrast, there is ample evidence that persistence of attacks leads to increased randomness in other characteristics of prey escape for several biological systems [23]. For example, the distribution of angle of fleeing in cockroaches increases in variance with an increasing degree of persistence of attacks [23]. In all cases, increasing randomness in prey escape hampers any learning process in the persistent predator.
A predator–prey interaction for which several of the key ingredients of the game are known is the attack behaviour of polar bears and the Inuit on seals at breathing holes. Polar bears (Ursus maritiums) hunting ringed seals (Phoca hispida) use different approaches at different times of the year with still-hunts, also called sit and wait predation, being a common occurrence [24]. Hunting seals with harpoons at breathing holes belongs to the traditional way of hunting for the Inuit, and is very similar to the technique used by bears [25]. Both polar bears and the Inuit may wait quietly for seals at their breathing holes for hours, making minimal movement, as sound is well transmitted through ice in water. Seals do not use holes if they hear noises at the surface. Just before surfacing, seals also produce ‘phantom’ signals by exhaling air. The bubbles move the water surface and a misled hunter might then launch a premature attack and miss the wary prey. The attacked seal then avoids using that hole due to potential danger but needs to swim rapidly to another, safer hole before oxygen depletion. Alternatively, it can wait to re-use the same hole until the predator gives up and moves away. In summer, the number of breathing holes is large. In winter, the number of breathing holes is reduced as each hole has to be maintained actively and maintaining all the holes of summer requires too much effort. Indeed, a hole is excavated through ice which can exceed 2 m in thickness [26] and a thick cap can form within a few hours. The home range of ringed seals overlap extensively and multiple seals use the breathing holes [26]. From the map produced by [26] one can estimate the density of breathing holes at approximately 2–3 breathing holes per square kilometre. Finding a hole of several tens of centimetres diameter at such low density in a nearly featureless landscape is not an easy task for bears, nor for humans. Information about rapid changes of hunting holes by bears and humans is very scant in the literature, so that this example cannot be further used, despite containing all the major ingredients, as basis for modelling persistent search and attack.
5.1. Improving the realism of the repeated search model
Our model includes two assumptions that might be relaxed. The first is that the available hiding locations do not change over time and the second is that once the prey successfully evades the predator, he will not be captured before he finds a new hiding location.
Up to now, we have been assuming that in the multi-stage games the available hiding locations remain the same over time. However, we now consider the implications of the opposite assumption, namely that if the prey successfully escapes after being found at location j, he may not return to that location in the next stage of the game. This restriction on prey strategies is in accordance with two detailed biological examples: a wary seal might prefer to swim to a different breathing hole and a wary caterpillar might have stopped in its mine and relocated itself somewhere else. As this restriction is a complicating feature, we explore the consequences of the ‘no return’ assumption in the simplest setting, a two-stage game of four locations and full persistance β = 1 in the first stage. We consider the example where the capture probability vector is 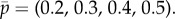 In the version with the no-return assumption, the optimal hiding strategy in stage 1 is given by
In the version with the no-return assumption, the optimal hiding strategy in stage 1 is given by 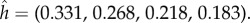 In the unrestricted version (where the hider can return to a previously occupied location), the optimal hiding strategy in stage 1 is given by
In the unrestricted version (where the hider can return to a previously occupied location), the optimal hiding strategy in stage 1 is given by 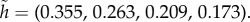 Note that when return is prohibited, the optimal probability of hiding at the best location, location 1, goes down from 0.355 (in the unrestricted case) to 0.331. The intuition for this decreased probability is that hiding at location 1 in the first stage now has the disadvantage that this good location is no longer available in the second stage. Of course, if the probability of hiding at location 1 goes down, this must be compensated by increasing some of the other probabilities. But it is interesting to note, in this respect, that the ratios
Note that when return is prohibited, the optimal probability of hiding at the best location, location 1, goes down from 0.355 (in the unrestricted case) to 0.331. The intuition for this decreased probability is that hiding at location 1 in the first stage now has the disadvantage that this good location is no longer available in the second stage. Of course, if the probability of hiding at location 1 goes down, this must be compensated by increasing some of the other probabilities. But it is interesting to note, in this respect, that the ratios 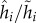 form an increasing sequence (0.931, 1.018, 1.046, 1.058). In terms of the value (probability that predator wins), it goes up from
form an increasing sequence (0.931, 1.018, 1.046, 1.058). In terms of the value (probability that predator wins), it goes up from 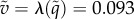 in the unrestricted game to
in the unrestricted game to 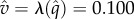 in the game where the prey is restricted to no-return strategies. Of course it is well known that, in zero-sum games, restricting the strategies of one player results in a lower expected pay-off for that player, so the direction of change is not surprising.
in the game where the prey is restricted to no-return strategies. Of course it is well known that, in zero-sum games, restricting the strategies of one player results in a lower expected pay-off for that player, so the direction of change is not surprising.
The second assumption that might be relaxed concerns the ability of the prey to safely reach any new hiding location once he has escaped pursuit by the predator at location i. This models the situation where the prey is only vulnerable to capture while in one of the hiding locations. This is the same as in the model of Zoroa et al. [10]. However, it is possible in theory to incorporate a probability pij that the prey will be captured when changing from location i to location j. This could model the cover in the region between the hiding locations. Clearly, locations i where the numbers pij and pji are high would then become less attractive to hide at. Another version of this type of modelling could be to impose a network structure on the hiding locations, so that if hiding in location i in one period the prey could only move to an adjacent location i′ in the next period.
Both these altered models could be investigated in future research, and we thank an anonymous referee for suggesting modifications of our model in such directions.
5.2. Conclusion
This work is the first to extend search games to repeated games. It thus expands greatly the number of observed searcher–hider interactions played repeatedly by the same pair of agents in the same environment and also highlights the opposite inferences drawn when incorporating multiple bouts of search and escape, in comparison with those obtained in one-stage games. Our next goal is to further increase the realism of search games by developing stochastic search games to deal with the giving up time of persistent, learning predators.
Acknowledgement
We thank I. Stirling and A. Derocher for sharing their insights on polar bear attacks on seals and two referees for insightful comments.
Authors' contributions
The mathematical parts were developed and written mainly by S.G. and S.A., whereas the biological parts were analysed and written mainly by J.C. All authors contributed equally to the writing of the successive drafts.
Competing interests
We declare we have no competing interests.
Funding
S.A. thanks the Air Force Office of Scientific Research (grant FA9550-14-1-0049).
References
- 1.Davies NB, Krebs JR, West SA. 2012. An introduction to behavioral ecology, 4th edn New York, NY: Wiley. [Google Scholar]
- 2.Stephens DW, Krebs JR. 1986. Foraging theory. Princeton, NJ: Princeton University Press. [Google Scholar]
- 3.Morice S, Pincebourde S, Darboux F, Kaiser W, Casas J. 2013. Predator–prey pursuit–evasion games in structurally complex environments. Integr. Comp. Biol. 53, 767–779. ( 10.1093/icb/ict061) [DOI] [PubMed] [Google Scholar]
- 4.Gal S, Casas J. 2014. Succession of hide–seek and pursuit–evasion at heterogeneous locations. J. R. Soc. Interface 11, 20140062 ( 10.1098/rsif.2014.0062) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Alpern S, Gal S. 2003. The theory of search games and rendezvous. Dordrecht, The Netherlands: Kluwer Academic Publishers. [Google Scholar]
- 6.Alpern S, Fokkink R, Timmer M, Casas J. 2011. Ambush frequency should increase over time during optimal predator search for prey. J. R. Soc. Interface 8, 1665–1672. ( 10.1098/rsif.2011.0154) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Alpern S, Fokkink R, Gal S, Timmer M. 2013. On search games that include ambush. SIAM J. Control Optim. 51, 4544–4556. ( 10.1137/110845665) [DOI] [Google Scholar]
- 8.Alpern S, Fokkink R, Lidbetter T, Clayton N. 2012. A search game model of the scatter hoarder's problem. J. R. Soc. Interface 9, 869–879. ( 10.1098/rsif.2011.0581) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Zoroa N, Fernndez-Sez MJ, Zoroa P. 2011. A foraging problem: sit-and-wait versus active predation. Eur. J. Oper. Res. 208, 131–141. ( 10.1016/j.ejor.2010.08.001) [DOI] [Google Scholar]
- 10.Zoroa N, Fernández-Sáez MJ, Zoroa P. 2015. Ambush and active search in multistage predator–prey interactions. J. Optim. Theory Appl. 166, 626–643. ( 10.1007/s10957-014-0620-9) [DOI] [Google Scholar]
- 11.Arcullus R. 2013. A discrete search–ambush game with a silent predator. In Search theory. A game theoretic perspective, pp. 249–266. New York, NY: Springer. [Google Scholar]
- 12.Broom M. 2013. Interactions between searching predators and hidden prey. In Search theory. A game theoretic perspective, pp. 233–248. New York, NY: Springer. [Google Scholar]
- 13.Pitchford J. 2013. Applications of search in biology: some open problems. In Search theory: A game theoretic perspective, pp. 295–303. New York, NY: Springer. [Google Scholar]
- 14.Cooper WE Jr, Blumstein DT. 2015. Escaping from predators: an integrative view of escape decisions. Cambridge, UK: Cambridge University Press. [Google Scholar]
- 15.Rudebeck G. 1951. The choice of prey and modes of hunting of predatory birds with special reference to their selective effect. Oikos 3, 200–231. ( 10.2307/3565185) [DOI] [Google Scholar]
- 16.Martin J, Lopez P. 2003. Changes in the escape responses of the lizard Acanthodactylus erythrurus under persistent predatory attacks. Copeia 2003, 408–413. ( 10.1643/0045-8511%282003%29003%5B0408%3ACITERO%5D2.0.CO%3B2) [DOI] [Google Scholar]
- 17.Bateman PW, Fleming PA. 2014. Switching to Plan B: changes in the escape tactics of two grasshopper species (Acrididae: Orthoptera) in response to repeated predatory approaches. Behav. Ecol. Sociobiol. 68, 457–465. ( 10.1007/s00265-013-1660-0) [DOI] [Google Scholar]
- 18.Meyhöfer R, Casas J, Dorn S. 1997. Vibration-mediated interactions in a host–parasitoid system. Proc. R. Soc. Lond. B 264, 261–266. ( 10.1098/rspb.1997.0037) [DOI] [Google Scholar]
- 19.Djemai I, Casas J, Magal C. 2004. Parasitoid foraging decisions mediated by artificial vibrations. Anim. Behav. 67, 567–571. ( 10.1016/j.anbehav.2003.07.006) [DOI] [Google Scholar]
- 20.Pincebourde S, Casas J. 2015. Warming tolerance across insect ontogeny: influence of joint shifts in microclimates and thermal limits. Ecology 96, 986–997. ( 10.1890/14-0744.1) [DOI] [PubMed] [Google Scholar]
- 21.Selten R. 1980. A note on evolutionarily stable strategies in asymmetric animal conflicts. J. Theor. Biol. 84, 93–101. ( 10.1016/S0022-5193(80)81038-1) [DOI] [PubMed] [Google Scholar]
- 22.Puterman ML. 1994. Markov decision processes: discrete stochastic dynamic programming. New York, NY: John Wiley & Sons, Inc. [Google Scholar]
- 23.Domenici P, Blagburn JM, Bacon JP. 2011. Animal escapology I: theoretical issues and emerging trends in escape trajectories. J. Exp. Biol. 214, 2463–2473. ( 10.1242/jeb.029652) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Stirling I. 1974. Midsummer observations on the behavior of wild polar bears (Ursus maritimus). Can. J. Zool. 52, 1191–1198. ( 10.1139/z74-157) [DOI] [Google Scholar]
- 25.Hall CF. 1864. Life with the Esquimaux, 2 vols London, UK: Sampson, Low, Son, and Marston. [Google Scholar]
- 26.Kelly BP, Badajos OH, Kunnasranta M, Moran JR, Martinez-Bakker M, Wartzok D, Boveng P. 2010. Seasonal home ranges and fidelity to breeding sites among ringed seals. Polar Biol. 33, 1095–1109. ( 10.1007/s00300-010-0796-x) [DOI] [Google Scholar]