

Abstract
Learning non-native speech categories is often considered a challenging task in adulthood. This difficulty is driven by cross-language differences in weighting critical auditory dimensions that differentiate speech categories. For example, previous studies have shown that differentiating Mandarin tonal categories requires attending to dimensions related to pitch height and direction. Relative to native speakers of Mandarin, the pitch direction dimension is under-weighted by native English speakers. In the current study, we examined the effect of explicit instructions (dimension instruction) on native English speakers' Mandarin tone category learning within the framework of a dual-learning systems (DLS) model. This model predicts that successful speech category learning is initially mediated by an explicit, reflective learning system that frequently utilizes unidimensional rules, with an eventual switch to a more implicit, reflexive learning system that utilizes multidimensional rules. Participants were explicitly instructed to focus and/or ignore the pitch height dimension, the pitch direction dimension, or were given no explicit prime. Our results show that instruction instructing participants to focus on pitch direction, and instruction diverting attention away from pitch height resulted in enhanced tone categorization. Computational modeling of participant responses suggested that instruction related to pitch direction led to faster and more frequent use of multidimensional reflexive strategies, and enhanced perceptual selectivity along the previously underweighted pitch direction dimension.
Keywords: category learning, instruction, computational modeling, dual-learning systems
Overview
Speech categorization involves the mapping of continuous, highly variable, multidimensional acoustic cues to discrete category representations (Holt & Lotto, 2010). Several non-native speech categories are challenging to learn in adulthood (Iverson et al., 2003). Feature-based models attribute this difficulty to cross-language differences in the relative weighting of acoustic dimensions underlying the non-native speech category. Despite the difficulty, there is overwhelming evidence that adults can acquire non-native speech categories with auditory training (Bradlow, Akahane-Yamada, Pisoni, & Tohkura, 1999a; Bradlow, Pisoni, Akahane-Yamada, & Tohkura, 1997; Francis, Kaganovich, & Driscoll-Huber, 2008b; Francis & Nusbaum, 2002; Francis, Nusbaum, & Fenn, 2007; Hattori & Iverson, 2009; Ingvalson, Barr, & Wong, 2013; Ingvalson, Holt, & McClelland, 2012; Iverson, Hazan, & Bannister, 2005a; Kondaurova & Francis, 2010; Lively, Logan, & Pisoni, 1993a; Lively, Pisoni, Yamada, Tohkura, & Yamada, 1994; Logan, Lively, & Pisoni, 1991; Wang, Jongman, & Sereno, 2003; Wang, Spence, Jongman, & Sereno, 1999a; Wong, Perrachione, & Parrish, 2007). In the current study we examine the impact of dimensional priming on the acquisition of a non-native phonetic contrast (tone). Previous studies have shown that native speakers of American English have considerable difficulty in perceiving and producing this phonetic contrast (Wang, 2003; Wang, 2003; Wang, 1999).
Recent work has largely focused on mechanisms underlying speech learning in adults. Mechanistically, attention-to-dimension (A2D) models, which derive from the Generalized Context Model (GCM), posit that speech learning in adulthood involves attentional restructuring of the dimensions that underlie the perceptual space used in categorization (Kondaurova, 2010; Francis, 2008; Francis, 2008; Francis, 2002). Learning, per A2D, involves focusing attention onto previously unattended dimensions, and/or withdrawing attention from irrelevant dimension (Kondaurova & Francis, 2010). Attention (or withdrawal of attention) stretches (or shrinks) the perceptual space along that dimension. This allows for greater discriminability of speech sounds that vary substantially on the attended dimension. A well-studied example of a challenging speech sound category distinction is lexical tones. In tone languages like Mandarin, pitch pattern differences within a syllable can change the meaning of the word (e.g., /ma/ with a high-rising tone means “mother,” while /ma/ with a high-falling tone means “to scold”).Multidimensional scaling studies show that similar acoustic dimensions underlie tone perception across languages, irrespective of the language's tonal inventory (Chandrasekaran, Gandour, & Krishnan, 2007; Francis, Ciocca, Ma, & Fenn, 2008a; Gandour & Harshman, 1978). However, the relative weighting of dimensions is language-dependent. For example, previous studies have found that when disambiguating tones, pitch height (average F0) and pitch direction (average slope) are two dominant dimensions identified to be used by both tone language and non-native (English) speakers (Chandrasekaran, et al., 2007; Francis, et al., 2008a; Gandour & Harshman, 1978). The pitch height dimension is weighted similarly by both groups; however, pitch direction is weighted more by tone language speakers, relative to English speakers, likely driven by the increased relevance of this acoustic dimension in disambiguating lexical tones in contour tone languages (Chandrasekaran, et al., 2007; Francis, et al., 2008a; Gandour & Harshman, 1978). Although difficult, with training, non-native listeners can learn to increase their relative attention to pitch direction (Chandrasekaran, Sampath, & Wong, 2010). Laboratory training paradigms largely utilize trial-by-trial feedback and/or high variability (multiple speakers) training to teach L2 speech categories (Bradlow, Akahane-Yamada, Pisoni, & Tohkura, 1999b; Lim & Holt, 2011; Lively, Logan, & Pisoni, 1993b; Tricomi, Delgado, McCandliss, McClelland, & Fiez, 2006; Zhang et al., 2009), but see (Iverson, Hazan, & Bannister, 2005b; Jamieson & Morosan, 1986) Feedback is thought to enhance learning by reducing errors, and multiple-speaker training results in learners refocusing their attention to cues that are relevant for distinguishing speech categories and/or reducing attention to irrelevant cues (Bradlow & Bent, 2008).
The goal of this paper is two-fold. First, we examine the extent to which explicit instructions to attend to acoustic dimensions underlying lexical tone perception can impact Mandarin tone categorization in English speakers with no prior exposure to Mandarin. The role of instruction on non-native speech learning is unclear. On one hand, several studies have shown significant learning of new auditory and speech categories with no explicit instructions provided to learners (Lim & Holt, 2011; Vlahou, Protopapas, & Seitz, 2012). For example, significant learning (and generalization) has been demonstrated in a videogame-based auditory training paradigm, where learning occurs incidentally by mapping between new speech categories, visual information, and motor responses (Lim & Holt, 2011). Given these studies, we could predict that instructions will not modulate learning performance. On the other hand, more explicit training methods such as perceptual fading have been previously employed to train adult learners on new phonetic contrast. In this method, critical dimension(s) are exaggerated so that listeners learn to focus attention on the new dimension(s) (Jamieson & Morosan, 1986; McCandliss, Fiez, Protopapas, Conway, & McClelland, 2002; McClelland, Fiez, & McCandliss, 2002). In a study examining non-speech category learning, passive exposure to greater distributional variability along an over-weighted dimension enhanced cue-weighting (Holt & Lotto, 2006). Further, a phonetic training study compared various methods of modifying cue weighting, that ranged from explicit attention to critical dimensions, or increasing variability on irrelevant dimensions, found similar learning across training methods (Iverson, et al., 2005a). To anticipate, we find that explicit instructions to attend to the pitch direction dimension (the dimension that is underweighted by English speakers relative to Mandarin speakers) enhances learning relative to a no instruction control condition, and two conditions that instruct listeners to focus on the pitch height dimension. A second goal of this paper was to examine the mechanisms underlying the effect of instruction. We employ computational models that allow the examination of perceptual and decisional strategies used by participants. Our models explore the processing locus of the effect of dimensional priming and ask whether the explicit dimension instruction affect decisional processes, perceptual processes, or both.
Our computational modeling approach derives from dual-learning systems theory (DLS; Ashby, Alfonso-Reese, Turken, & Waldron, 1998; Chandrasekaran, Koslov, & Maddox, 2014a; Maddox & Chandrasekaran, 2014a). DLS assumes that speech category learning involves a competition between a reflective system that is rule-based and relies on executive function processes in the prefrontal cortex, and a reflexive system that is procedural and relies upon dopamine-mediated reward signals in the striatum (Chandrasekaran, et al., 2014a; Maddox & Chandrasekaran, 2014a; Yi, Maddox, Mumford, & Chandrasekaran, 2014)1. The DLS approach derives from Ashby and Townsend's (1986) General Recognition Theory that is a multidimensional extension of signal detection theory (Green & Swets, 1967). Signal detection theory postulates that behavior is determined from decisional but also perceptual processing. Signal detection theory assumes that repeated presentations of the same physical stimulus yield unique perceptual effects. Thus, over trials each physical stimulus is represented by a distribution of perceptual effects. Although the family of distribution is not specified, it is common to assume a normally distributed set of perceptual effects. Normal distributions are characterized by the mean and the variance. The mean denotes the average perceptual effect and the variance denotes the error or noise in the perceptual process.
Thus, the DLS approach dissociates perceptual from decisional processes and includes parameters that separately estimate aspects of perceptual processing from aspects of decisional processing (Maddox & Ashby, 1996, 1998; Maddox, Ashby, & Waldron, 2002). This allows us to determine whether explicit instruction to focus on pitch direction affects decision processes, but also might lead to more accurate perceptual processing in the form of smaller perceptual noise estimates. A number of studies in the literature suggest that perceptual noise is reduced decisional forms of selectivity are operative (Goldstone, 1994; Maddox, 2001a, 2002b; Maddox, et al., 2002; Maddox & Dodd, 2003b). Given that English speakers naturally weight pitch height we do not predict any difference in perceptual noise along the pitch height dimension as a function of explicit dimension prime condition. However, it is likely that explicit dimensional instruction to pitch direction will lead to enhanced perceptual processing along that dimension and thus smaller estimates of perceptual noise. We predict that explicit instruction to the pitch direction dimension will speed the transition from simple unidimensional reflective, rule-based strategies (e.g. rules related to pitch height) to a more optimal reflexive strategy that weights both dimensions (equally) during decision (Chandrasekaran, et al., 2014a; Maddox & Chandrasekaran, 2014a; Maddox, Chandrasekaran, Smayda, & Yi, 2013; Maddox et al., 2014).
We now briefly review the DLS model and the evidence suggesting that it underlies non-native speech category learning.
The Dual-Learning Systems Theoretical Framework
Fast and accurate categorization determines how efficiently we organize the sensory world. The systems involved in category learning have been an important focus of research (Allen & Brooks, 1991; Ashby, et al., 1998; Ashby & Maddox, 2010; Brooks, 1978; Erickson & Kruschke, 1998; Estes, 1986, 1994; Homa, Sterling, & Trepel, 1981; Keri, 2003; Knowlton & Squire, 1993; Medin & Schaffer, 1978; Nomura et al., 2007; Nomura & Reber, 2008; Nosofsky, 1986; Nosofsky, Palmeri, & McKinley, 1994; Rosch, 1978; Seger & Miller, 2010; Smith & Medin, 1981; Smith et al., 2012). Much of what we know about the learning systems underlying category learning comes from the visual domain. An extensive body of behavioral, neuropsychological and neuroimaging work (reviewed in Chandrasekaran, et al., 2014a) suggests that visual category learning is mediated by at least two neural systems: a reflective (rule-based) learning system that actively generates verbal rules, is pre-frontally-mediated and relies heavily on executive function and working memory, and a reflexive (procedural-based) learning system that involves pre-decisional integration of information across dimensions, is striatally-mediated and does not rely on executive function and working memory. When the optimal classification rule is easily verbalizable, the reflective learning system dominates. This system uses a feedback-based strategy that tests and discards rules until a rule that maximizes accuracy is uncovered. When the optimal classification rule is not verbalizable and instead is based on a pre-decisional integration of information, the reflexive learning system dominates. This feedback-based system learns by implicitly mapping motor responses to complex stimulus patterns as a function of reinforcement.
DLS posits that the learning systems are competitive in nature, are dissociable, and show an initial bias toward reflective (verbal rule) processing that only gives way to reflexive processing when the optimal classification rule is reflexive. Nearly all of this work has been conducted in the visual domain, but recently, this theoretical framework has been extended to speech category learning. In the next section, we address the question of whether speech category learning is reflective or reflexive-optimal.
Speech Category Learning in Adulthood: Reflective and Reflexive
We propose that non-native speech category learning is optimally learned by the reflexive system. This hypothesis is supported by at least three lines of evidence. First, speech categories typically are difficult to verbalize, have multiple dimensions, and are highly variable. Further, the redundancy and variability of cues available during speech perception prevents a simple one-to-one mapping of cues to categories (Liberman, Cooper, Shankweiler, & Studdert-Kennedy, 1967; Lisker, 1986). Second, a recent behavioral dissociation study revealed that speech category learning was enhanced under training procedures that enhance reflexive learning, and was attenuated under training procedures that enhance reflective learning (Chandrasekaran, Yi, & Maddox, 2014b). Chandrasekaran et al (2014b) used the dissociation logic to investigate the extent to which lexical tone category learning in native English speakers is mediated by the reflective or reflexive learning system. We manipulated the richness of feedback, timing of feedback, and the nature of the training stimuli (high variability versus low variability). Across all three manipulations, learning was enhanced under conditions that boost reflexive learning. For example, we found that classification accuracy was lower when the feedback provided was richer or delayed, both of which lead to worse reflexive category learning in the visual domain (Maddox, Ashby, & Bohil, 2003; Maddox & Ing, 2005; Maddox, Love, Glass, & Filoteo, 2008). Classification accuracy was also lower under low-variability training, which was achieved by blocking the multiple talkers used during training. Finally, a recent neuroimaging study (Yi, et al., 2014) found that successful speech category learning was associated with greater use of reflexive strategies (as determined from computational modeling) and increased activation in the putamen (a sub-structure within the striatum). Taken together, these data provide strong support for our claim that non-native speech category learning is dominated by the reflexive system.
Given the competitive nature of the reflexive and reflective learning systems, one could predict that explicit instruction would not be beneficial in a reflexive-optimal task. As pointed to earlier, explicit instruction may lead to the persistence of reflective strategies, consequently lowering performance on a reflexive-optimal task. However, several lines of evidence point to the use of the reflective system early in training. For example, computational modeling studies indicate that early in training, unidimensional rule-based strategies dominate (Maddox & Chandrasekaran, 2014). Successful learners eventually transition to multidimensional learning strategies. However, in some learners, this transition from simple, reflective unidimensional strategies to reflexive multidimensional strategies does not happen. Such learners perseverate (‘get stuck’) with simple rules that help achieve only partial learning success. For example, older adults are poorer at learning Mandarin tone categories because they perseverate with unidimensional strategies, likely driven by an age-related deficit in executive functioning (Maddox, et al., 2013). Given these findings, we predict that explicit instruction would help (not hurt) speech learning by allowing a focus of attention to the unattended dimension, thereby allowing a transition to more optimal strategies that integrate multiple dimensions.
The Current Study
The current study focuses on Mandarin tone learning by native English speakers under different explicit dimension priming conditions. Two dimensions, pitch height, and pitch direction are important for discerning tone categories across languages (see Figure 1). For example, on the pitch height-direction continuum, the four Mandarin tone categories can be differentiated as “high-level”, “low-rising”, “low-dipping”, and “high-falling”. The pitch height dimension (average pitch across the syllable) is important for distinguishing the low tone (T3) from the high tone (T1); the pitch direction dimension is important in distinguishing rising tone (T2) from falling tone (T4). Five monosyllabic Mandarin Chinese words (bu, di, lu, ma, and mi) that are minimally contrasted by the four tone categories were used in the experiment, and each was produced in citation form with the four Mandarin tones by two male and two female native speakers of Mandarin Chinese. This yielded a total of 80 unique exemplars. A scatter-plot of these 80 stimuli in the two-dimensional pitch height-pitch direction space is displayed in Figure 1a. Scatter-plots of the 40 stimuli spoken by a two male and two female speakers are displayed in Figures 1b and 1c, respectively. Note that no simple reflective, verbalizable rule-based strategy can be applied to accurately separate the stimuli into the four tone categories. Rather a reflexive, non-verbalizable strategy is necessary.
Figure 1.
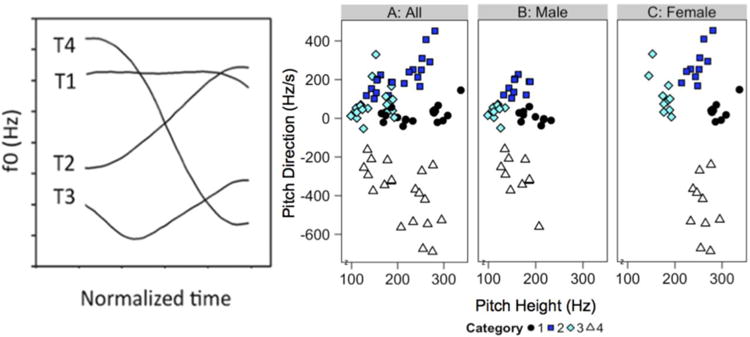
(Left panel) Sample fundamental frequency contours of four Mandarin tones (T1: high-level; T2: low-rising; T3: low-dipping; T4: high-falling) produced by a male native Mandarin speaker. (Right panel) (a) Scatterplot of all stimuli. (b) Scatterplot of male-talker stimuli. (C)
Scatterplot of female-talker stimuli. Stimuli dimensions (Pitch Height and Pitch Direction) were normalized between 0 and 1.
Across conditions (see Table 1), participants were given explicit instructions to attend to acoustic dimensions underlying tone perception. In the Control (None) condition, no explicit dimension instruction were provided. Participants were simply instructed to do their best. In the Both condition, participants were told that good task performance could be achieved by generating rules related to changes in pitch height and pitch direction. In the Height condition, participants were told that good task performance could be achieved by generating rules related to changes in pitch height. In the Direction condition, participants were told that good task performance could be achieved by creating rules related to changes in pitch direction. Additionally, in the Direction-not-Height condition, participants were told that good task performance could be achieved by creating rules related to changes in pitch direction while explicitly ignoring pitch height. As outlined earlier, pitch direction is underweighted by native English speakers, but is critical to accurately disambiguate tones. We predict that participants in the Direction and Direction-not-Height conditions will obtain superior performance relative to the Control (None) condition. In addition, as derived from the DLS theoretical approach, we also predict that the locus of this performance advantage will be due to enhanced utilization of multidimensional, reflexive decision processes that take account of both variation in pitch height and pitch direction. Specifically, DLS predicts that explicit instruction to the pitch direction dimension will speed the transition from simple unidimensional reflective, rule-based strategies (that dominate early learning) to an optimal reflexive strategy that weights both dimensions. An alternate prediction is that explicit instructions may broadly lead to a persistence of reflective strategies, resulting in lower accuracies in the speech category learning task. This prediction is based on the fact that previous studies have shown that speech learning may be reflexive-optimal, and persistence of reflective strategies may not allow the transfer of control to the reflexive system. This may particularly be true for the over-weighted ‘height-only’ condition. It is possible that explicit instruction to focus on this dimension may hurt performance more than providing no instruction at all.
Table 1.
Means and standard deviations of frequency for each tone produced by each speaker.
| Speaker | Tone Category | Mean Pitch Height, Hz (SD) | Mean Pitch Direction, Hz/s (SD) | Sex |
|---|---|---|---|---|
| 1 | 1 | 173.68 (9.35) | 21.44 (33.05) | Male |
| 1 | 2 | 149.41 (13.78) | 164.75 (51.73) | Male |
| 1 | 3 | 107.88 (6.25) | 26.62 (23.95) | Male |
| 1 | 4 | 137.36 (8.99) | -259.82 (93.87) | Male |
| 2 | 1 | 215.60 (13.83) | -13.24 (19.56) | Male |
| 2 | 2 | 171.90 (20.87) | 158.46 (52.92) | Male |
| 2 | 3 | 124.76 (7.51) | 35.46 (58.48) | Male |
| 2 | 4 | 185.80 (15.61) | -354.53 (146.99) | Male |
| 3 | 1 | 278.85 (2.13) | 35.16 (6.76) | Female |
| 3 | 2 | 242.03 (14.34) | 243.01 (59.85) | Female |
| 3 | 3 | 170.61 (24.24) | 149.09 (155.93) | Female |
| 3 | 4 | 266.77 (24.30) | -420.95 (143.25) | Female |
| 4 | 1 | 303.37 (23.94) | 38.36 (79.30) | Female |
| 4 | 2 | 253.87 (30.08) | 308.40 (136.67) | Female |
| 4 | 3 | 182.45 (7.94) | 80.63 (32.10) | Female |
| 4 | 4 | 252.50 (17.59) | -512.26 (209.20) | Female |
With respect to perceptual processes, we predict that explicit instruction to the pitch direction dimension should lead to enhanced perceptual selectivity in the form of reduced perceptual noise along that dimension. This would suggest more veridical percept of this dimension as a function of dimension prime condition. In addition, given that English speakers weight pitch height strongly even before training, we do not predict any difference in perceptual selectivity along the pitch height dimension as a function of dimension prime condition
Method
Participants
One hundred fifteen individuals from The University of Texas at Austin community received course credit or were paid $8 per hour for their participation. Informed consent was obtained from all participants, and the experiment was approved for ethics procedures using human participants. Participants who reported having learned a tone language were excluded (n = 3 from the Both condition; n = 2 from the Direction condition; n = 1 from the Height condition; and n = 3 from the Control condition). Therefore, a total of 106 participants were used in the final analysis, with 19 in the Control condition, 21 in the Height only condition, 20 in the Direction only condition, 21 in the Both condition, and 25 in the Direction-not-Height condition. To ensure that participants in each of our experimental conditions were homogeneous with respect to music training, given the recent results of Smayda et al. (2015), we ran several one-way ANOVA's on measures of music training between conditions (Smayda, Chandrasekaran, & Maddox, 2015). We found no difference between conditions for hours practiced per week [F(4,92) = 2.24, p = 0.07], years played [F(4,97) = 2.20, p = 0.07], number of instruments currently playing [F(4,94) = 1.94, p = 0.11], and of those who played an instrument, the age they began playing [F(4,43) = 0.74, p = 0.57].
Stimuli
Stimuli consisted of the four Mandarin tones, tone 1 (T1), tone 2 (T2), tone 3 (T3), and tone 4 (T4) in the context of five syllables found in both Mandarin Chinese and English (“bu”, “di”, “lu”, “ma”, “mi”) spoken by two male and two female talkers (all originally from Beijing) for a total of 80 stimuli. All stimuli were RMS amplitude and duration normalized (70 dB, 0.4 s) using the software Praat (Perrachione, Lee, Ha, & Wong, 2011; Wong, Perrachione, Gunasekera, & Chandrasekaran, 2009). While duration and amplitude envelope are potentially useful cues to disambiguate lexical tones, behavioral studies (Howie, 1976) as well as multidimensional scaling (MDS) analyses have shown that dimensions related to pitch, especially height and direction, are used primarily to distinguish tone categories (Chandrasekaran, Gandour, & Krishnan, 2007; Francis, et al., 2008a; Gandour, & Harshman, 1978). Therefore, we represent the stimuli used in this experiment using a space that varies on pitch height [frequency in Hz] and pitch direction [(end Hz – start Hz)/duration (seconds)]. Five native speakers of Mandarin were asked to identify the tone categories (they were given four choices) and rate their quality and naturalness. High identification (>95%) was achieved across all 5 native speakers. Speakers rated these stimuli as highly natural. A scatter-plot of the 80 stimuli in the pitch height-pitch direction space is displayed in Figure 1A. Scatter-plots of the 40 stimuli spoken by male and female speakers are displayed in Figure 1B and 1C, respectively. In addition, the means and standard deviations of each tone spoken by each speaker are presented in Table 1.
Procedure
On each trial, participants were presented with a single exemplar from one of four Mandarin tone categories (T1, T2, T3, or T4) and instructed to categorize the stimulus into one of four equally likely categories. Participants were instructed that high levels of accuracy were possible, but that the task would be difficult and would take practice. Participants were given corrective feedback on each trial and exposed to multiple talkers throughout the training program. No explicit instruction regarding the tone category structure was given. Participants listened to each of the 80 unique stimuli (4 tone categories × 5 syllables × 4 talkers) once in each block in a random order, and completed a total of six blocks of training. The task was run using the E-Prime software (Psychology Software Tools, Inc., Sharpsburg, PA), and stimuli were presented through Sennheiser HD 280 Pro headphones that were connected to the computer. Participants generated a response by pressing one of four number button keys on the left side of the computer keyboard, labeled “1”, “2”, “3”, or “4”. Following the response, feedback was provided for 1 s on the computer screen and consisted of the word “Correct.” or “No.” A 1-s ITI followed the feedback.
In each condition, we manipulated the presentation of an extra screen of instructions before participants began the task, cueing them to certain features of the stimuli. For example, the extra instructional screen for the pitch height condition read: “HINT: Prior participants have found that creating rules related to changes in the level of pitch led to good task performance.” In a pilot study conducted prior to this experiment, we queried native English participants on their understanding of the terms ‘level’ and ‘direction’ as they relate to pitch. These terms were consistently interpreted as ‘height’ (“level refers to whether pitch is high or low) and ‘direction’ (“direction refers to whether pitch rises or falls”). The exact dimensional instruction for each condition can be found in Table 2. In the control condition, no extra instructional screen was presented. Critically, this is the only manipulation we made to the procedure across conditions.
Table 2.
Explicit dimension instruction presented in the extra instructional screen for each condition.
| Condition | Explicit Dimensional Instruction: |
|---|---|
| Control | (No extra screen was presented.) |
| Both | “Prior participants have found that creating rules related to changes in the level of pitch and changes in pitch direction led to good task performance.” |
| Height | “Prior participants have found that creating rules related to changes in the level of pitch led to good task performance.” |
| Direction | “Prior participants have found that creating rules related to changes in pitch direction led to good task performance.” |
| Direction-not-Height | “Prior participants have found that creating rules related to changes in pitch direction led to good task performance. Prior participants have found that creating rules related to changes in level of pitch of the tone led to poor task performance.” |
Results
Accuracy
First we present accuracy analyses comparing block-by-block training across the explicit dimension priming groups to determine whether the dimension instruction had any effect on subsequent learning. Across all participants (N = 106), the average performance in the first learning block was 33% (SD = 16%) and 58% (SD = 11%) in the final block. Group-by-block performance is plotted in Figure 2.
Figure 2.

Group-by-block performance in the speech learning task. The x-axis represents each successive learning block. The y-axis represents proportion of accurate responses per block for each group. Individual bars represent different groups. Participants in the Both and Height conditions do not perform better than the Control group, but those in the Direction and Direction-not-Height condition perform better. Error bars denote standard errors.
By the final block, there was a performance advantage for the Direction (n = 20; M = 63%; SE = 2.5%) and the Direction-not-Height (n = 25; M = 62%; SE = 2%) prime groups over the Control (n = 19; M = 52%; SE = 3%) group. The Both (n = 21; M = 55%; SE = 2%) and Height (n = 21; M = 56%; SE = 2%) prime groups did not display a significant advantage over the Control group. To assess the validity of these observations, we employed a generalized linear mixed effects model to analyze the results statistically, using the statistical computing package R (Team, 2014) in conjunction with the package lme4 (Bates et al., 2014). This analysis was designed to estimate the log odds of producing a correct response given each trial and explicit verbal prime group. The dependent variable was trial-by-trial accuracy for individual participants coded as “correct” or “incorrect”, with the reference level set as “incorrect”. The fixed effects included the explicit dimensional instruction group (Control, Both, Height, Direction, Direction-not-Height, with the reference level set as Control), the trial number (1 to 480), and the interaction term between the two factors. The model was corrected for the random intercept for each participant. The Direction group by trial interaction was significant, b = 0.00095, SE = 0.00024, z = 3.95, p < 0.0001, suggesting that, relative to the Control group, there was increasing odds of producing a correct response for each successive trial. In other words, the learning rate was higher for the Direction group than for the Control group. The Direction-not-Height group by trial interaction was also significant, b = 0.00089, SE = 0.00023, z = 3.93, p < 0.0001, suggesting that the learning rate for this group was higher than for the Control group. The Both group by trial interaction was not significant, b = 0.00028, SE = 0.00023, z = 1.20, p = 0.23, failing to provide evidence that the Both group had a different learning rate from that of the Control group. The Height group by trial interaction was also not significant, b = -0.00028, SE = 0.00023, z = -1.20, p = 0.23. The trial effect was significant, b = 0.0024, SE = 0.00017, z = 14.31, p < 0.0001, attesting to the robust learning effect for each successive trial for the Control group. No group effect was found to be significant (Direction: b = 0.19, SE = 0.30, z = 0.61, p = 0.54; Direction-not-Height: b = 0.10, SE = 0.29, z = 0.36, p = 0.72; Both: b = 0.026, SE = 0.30, z = 0.088, p = 0.93; Height: b = 0.18, SE = 0.30, z = 0.62, p = 0.54), suggesting that there were no initial differences in learning across groups. In summary, these results strongly suggest that the Direction and Direction-not-Height-dimension instruction led to significantly faster learning relative to the Control condition, but also that such advantage was not observed for the Both or Height dimension instructions.
Computational Modeling Overview
Computational modeling description
The accuracy-based analyses suggest that explicit dimensional instruction to attend to pitch direction or to attend to pitch direction and ignore pitch height led to better Mandarin tone learning than instructions to attend to both dimensions, attend to pitch height, or no instructions simply to do your best. Accuracy rates provide an excellent source of information regarding how well an individual is performing in a task, but tell us nothing about the perceptual and decisional processing locus of the performance advantage. To provide insights onto these important issues, we utilized computational models of the task that allow us to characterize the nature of the response strategy an individual is applying in a given task, and allow us to estimate the magnitude of trial-by-trial perceptual variability (referred to as perceptual noise). These perceptual noise estimates will allow us to determine whether verbally presented instruction affect decisional, but also perceptual processes (Goldstone, 1994; Maddox, 2001a, 2002b; Maddox, et al., 2002; Maddox & Dodd, 2003b). As outlined above, we predict that the direction and direction-not-height instruction to speed the transition from reflective to reflexive decision strategies. Given that pitch direction is underweighted in native English speakers but is critical for Mandarin tone category learning, it is also likely that the pitch direction dimension instruction might also lead to enhanced perceptual processing in the form of less perceptual variability (noise) along the pitch direction dimension. Fortunately, the computational models provide a powerful tool for separately exploring perceptual and decisional processing and allow us to explore how perceptual and decisional processes change with experience.
Decision processing assumptions
We apply a series of decision bound models originally developed for application in the visual domain (Ashby & Maddox, 1993; Maddox & Ashby, 1993) and recently extended to the auditory domain by Maddox and Chandrasekaran (Maddox & Chandrasekaran, 2014a; Maddox, et al., 2013; Maddox, et al., 2014) on a block-by-block basis at the individual participant level because of problems with interpreting fits to aggregate data (Ashby, Maddox, & Lee, 1994; Estes, 1956; Maddox, 1999). We assume that the points in the two-dimensional (pitch height vs. pitch direction) space displayed in Figure 1a accurately describes the average (or mean) perceptual effects for each stimulus and, based on the results from our earlier work (Maddox & Chandrasekaran, 2014a), we also assume that participants operate independently on the male (Figure 1b) and female (Figure 1c) perceptual spaces. Our previous computational modeling studies show that native English speakers show an inherent bias towards a reflective strategy of using separate perceptual spaces by the sex of the talker, likely driven by the bias towards F0 height. The variance explained by assuming separate spaces is significantly greater than using a single perceptual space {Maddox, 2014 #278}. We estimate parameters associated with the decision strategy being utilized by the participant. Each model assumes that decision-bounds (or category boundaries created by the participant as they learn the categories) were used to classify stimuli into each of the four Mandarin tone categories (T1, T2, T3, or T4). Note that as long as the major dimensions are known, these modeling procedures can be applied to any type of speech category structure so this offers an exciting new approach to the study of speech category learning.
Here we provide a brief description of the decision processing assumptions of each model. Details are available in numerous previous publications (Ashby & Maddox, 1993; Maddox & Ashby, 1993; Maddox & Chandrasekaran, 2014a; Maddox, et al., 2013; Maddox, et al., 2014). We applied three types of models: reflexive, reflective and random responder. The first is a computational model of the reflexive category learning system. This is instantiated with the Striatal Pattern Classifier (SPC; Ashby & Waldron, 1999). The SPC is a computational model whose processing is consistent with the neurobiology of the reflexive category learning system and is thought to underlie reflexive-optimal classification performance (Ashby & Waldron, 1999; Chandrasekaran, et al., 2014a; Maddox & Chandrasekaran, 2014a; Maddox, et al., 2013; Maddox, et al., 2014; Nomura et al., 2006; Seger, 2008; Seger & Cincotta, 2005). Responses from a hypothetical participant using the SPC are displayed in Figure 3a. The second class is models of the reflective category learning system. The conjunctive models assume that the participant sets criteria along the pitch height and pitch direction dimensions that are then combined to determine category membership. Responses from a hypothetical participant using a conjunctive strategy are displayed in Figure 3b. Unidimensional models assume that the participant sets criteria along the pitch height or pitch direction dimension that are then used to determine category membership. For example, the UniDimensional_Height model assumes that the participant sets three criteria along the pitch height dimension, which are used to separate the stimuli into those that are of low, medium-low, medium-high, or high pitch height. Importantly, this model ignores the pitch direction dimension. Although a large number of versions of this model are possible, we explored the eight variants of the model that made the most reasonable assumptions regarding the assignment of category labels to the four response regions. Using the convention that the first, second, third and fourth category labels are associated with low, medium-low, medium-high and high pitch height, respectively, the 8 variants were: 3214, 3412, 3241, 3421, 2314, 4312, 2341, and 4321. For example, the 3214 version of the model assumes that low pitch heights are associated with category 3, medium-low pitch heights are associated with category 2, medium-high pitch heights are associated with category 1, and high pitch heights are associated with category 4. Responses from a hypothetical participant using a unidimensional strategy along pitch height are displayed in Figure 3c. The Unidimensional_Direction model assumes that the participant sets three criteria along the pitch direction dimension. The model assumes that the three criteria along the pitch direction dimension are used to separate the stimuli into those that are of low slope, medium-low slope, medium-high slope, or high pitch direction slope. Importantly, this model ignores the pitch height dimension. Although a large number of versions of this model are possible, we explored the two variants of the model that made the most reasonable assumptions regarding the assignment of category labels to the four response regions. Using the convention that the first, second, third and fourth category labels are associated with low, medium-low, medium-high and high pitch direction, respectively, the 2 variants were: 4312 and 4132. For example, the 4312 version of the model assumes that low pitch directions are associated with category 4, medium-low pitch directions are associated with category 3, medium-high pitch directions are associated with category 1, and high pitch directions are associated with category 2. Responses from a hypothetical participant using a unidimensional strategy along pitch direction are displayed in Figure 3d. The third model is a random responder model that assumes that the participant guesses on each trial.
Figure 3.
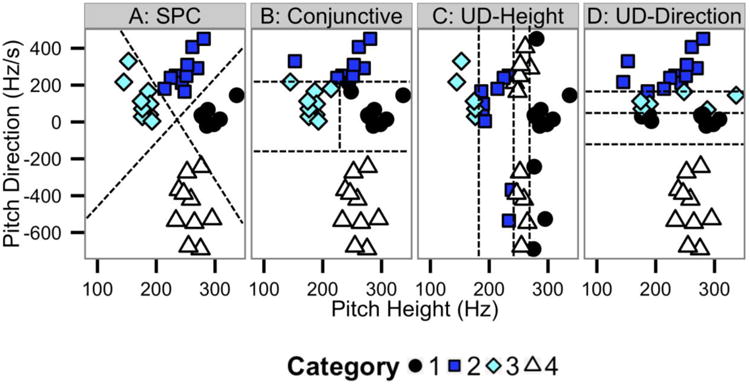
Scatterplots of the responses along with the decision boundaries that separate response regions from a hypothetical participant using a version of the (A) Striatal Pattern Classifier, (B) Conjunctive rule-based, (C) Unidimensional_Height, and (D) Unidimensional_Direction models as applied to the female talker stimuli shown in Fig 1c.
Perceptual processing assumptions
As outlined in the Introduction, the dual learning systems modeling framework utilized here is derived from signal detection theory. Signal detection theory assumes that behavior is a function of perceptual processing and decisional processing. The decision processing assumptions explored in this work are outlined above. Perceptually, signal detection theory assumes that repeated presentations of the same physical stimulus yield unique perceptual effects. Thus, over trials a physical stimulus is represented by a distribution of perceptual effect. The most common assumption, and the one made here, is that the distribution is normally distributed. For simplicity and to reduce the number of free parameters in our modeling, we assume that the pitch height-pitch direction values shown in Figures 1a-c represent the mean perceptual effects that remain unchanged throughout the task. The variability in the percepts across trials is determined by estimating a perceptual variance along the pitch height dimension and a perceptual variance along the pitch direction dimension. These are also referred to as perceptual “noise” because they represent “error” or noise in the system. We assume that the perceptual variance along pitch height is identical across all 80 stimuli and that the perceptual variance along pitch direction is identical across all 80 stimuli, but that these values can differ across pitch height and pitch direction (referred to as a stimulus invariant perceptual representation; Ashby & Maddox, 1992; Maddox, 2001b, 2002a; Maddox & Dodd, 2003a). We also assume that the perceptual noise along the pitch height and pitch direction dimensions are uncorrelated (referred to as perceptual independence Ashby, 1988; Ashby & Townsend, 1986). In other words, while we estimate the perceptual variability along the pitch height dimension separately from that along the pitch direction dimension, we assume those variability estimates are constant across stimuli (stimulus invariance), and that the perceptual covariance between pitch height and pitch direction is zero (perceptual independence).
The models were fit to the Mandarin tone category learning data from each trial on a block-by-block basis by maximizing negative log-likelihood and the best fitting model was identified by comparing AIC values for each model (Akaike, 1974). AIC penalizes models with more free parameters. For each model, i, AIC is defined as:
| (1) |
where Li is the maximum likelihood for model i, and Vi is the number of free parameters in the model. Smaller AIC values indicate a better fit to the data.
Computational Modeling Results
The presentation of the results is divided into two parts. First, we examine decision processes by summarizing the results associated with the nature of individuals' decision strategies and how they change with experience and as a function of the explicit dimensional prime condition. Second, we examine perceptual processes. In particular we are interested in exploring how perceptual variability (noise) along the pitch direction dimension changes with experience and as a function of the explicit dimensional prime instructions.
Decisional strategies results
As outlined in the Introduction section, research suggests that pitch height is a language-universal dimension, and that native English speakers largely focus on this dimension when learning Mandarin tonal categories. With experience however, and we argue under targeted explicit dimensional priming instructions to focus on the pitch direction dimension, many individuals learn to spread their attention to the pitch direction dimension. Because optimal Mandarin tone learning requires the application of reflexive decision strategies that focus on both pitch height and pitch direction, we hypothesize that explicit dimensional instruction to focus on the pitch direction dimension should lead to a faster shift from reflective strategy use to reflexive strategy use. Figure 4 displays the proportion of participants in each block whose data was best fit by the reflexive, one of the three reflective or the random responder model separately by explicit dimension prime condition. A visual examination of Figure 4 supports our prediction. Reflexive strategy use occurs sooner and more frequently in the Direction and Direction-not-Height conditions relative to the Control, Height or Both conditions.
Figure 4.
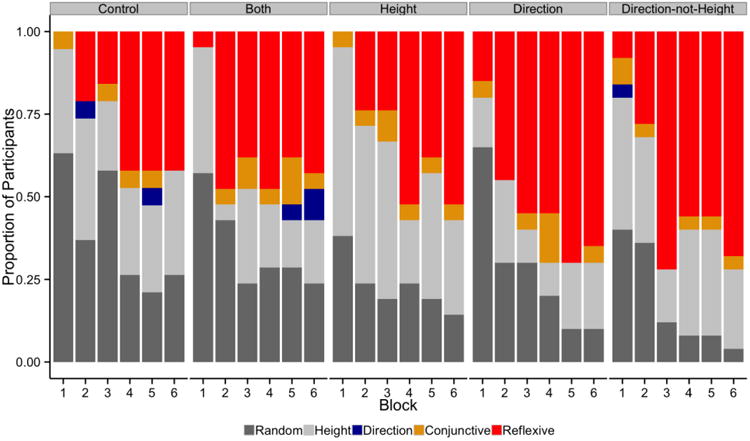
Strategy use as estimated by computational modeling, across explicit dimensional prime groups and learning blocks. Each panel corresponds to one prime group, whereas the colors correspond to modeled response strategies.
As a more direct test of this hypothesis we examined a number of aspects of the modeling results. First, we determined the first block of trials for which the SPC (a model of reflexive processing) provided the best fit of the data. If individuals given explicit dimensional instruction to focus on the pitch direction dimension show enhanced reflexive processing then they should use reflexive strategy sooner than individuals who were not told to focus on the pitch direction dimension. Second, we determined the total number of blocks (out of 6) for which the SPC provided the best account of the data. If individuals given explicit dimensional instruction to focus on the pitch direction dimension show enhanced reflexive processing then they should use reflexive strategies (as measured by the SPC) in more blocks of trials. Data from these two measures is displayed in Figure 5. An ANOVA examining the first block for which the SPC was utilized across pre-training instruction conditions was significant [F(4, 101) = 3.063, p < 0.05, partial η2 = 0.108]. Post hoc analyses revealed that the SPC was used significantly sooner in the Direction condition than in the Control and Height conditions (both p's < 0.05), and that the SPC was used significantly sooner in the Direction-not-Height condition than in the Control and Height conditions (both p's < 0.05). In addition, the first use of the SPC did not differ significantly across the Direction and Direction-not-Height conditions (p = 0.75). An examination of the total number of SPC blocks uses revealed a similar pattern. An ANOVA examining the total number of SPC blocks was significant [F(4, 101) = 2.404, p = 0.05, partial η2 = 0.087]. Post hoc analyses revealed that the SPC was used significantly more often in the Direction condition than in the Control and Height conditions (both p's < 0.05), and that the SPC was used significantly more often in the Direction-not-Height condition than in the Control (p < 0.05) and marginally more often than in the Height condition (p = 0.07). In addition, the total number of SPC blocks did not differ significantly across the Direction and Direction-not-Height conditions (p = 0.99). These findings establish that individuals given instructions to attend to pitch direction use reflexive strategies sooner and with greater regularity than individuals told to “do their best” or to “focus on pitch height”.
Figure 5.
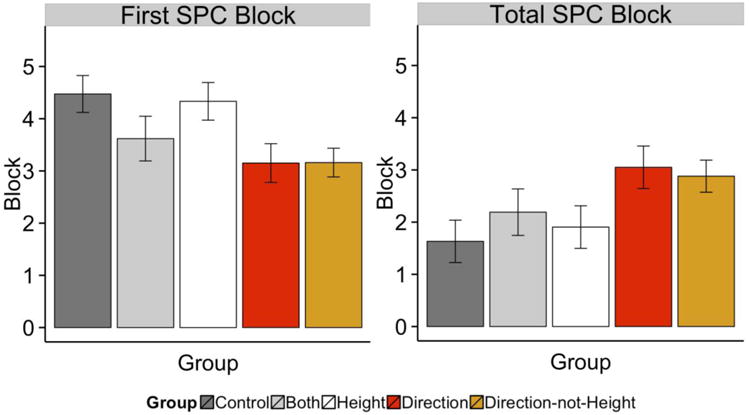
Striatal pattern classifier (SPC) strategy use across groups. (left) The first block for which the SPC provided the best account of the data in each group. Participants in the Direction and Direction-not-Height were best fit by the SPC earlier than the Control group. (right) Total number of blocks for which SPC use was identified as the best fitting model for each group. Error bars denote standard errors.
Perceptual variance results
In this section we examine the effects of explicit dimensional instruction on perceptual processing. Specifically, we ask whether explicit instruction to focus on pitch direction led to enhanced perceptual processing in the form of smaller perceptual noise estimates. A number of studies in the literature (Goldstone, 1994; Maddox, 2001a, 2002b; Maddox, et al., 2002; Maddox & Dodd, 2003b) suggests that perceptual noise is reduced when decisional forms of selectivity are operative. Given that English speakers naturally weight pitch height we do not predict any difference in perceptual noise along the pitch height dimension as a function of dimension prime condition. However, it is likely that explicit dimensional instruction to pitch direction should lead to enhanced perceptual processing along that dimension and thus smaller estimates of perceptual noise. Because we focus on the perceptual variability estimates, we wanted to focus on the model that best accounted for the data. In the present application the most general model, and the one that provides the best account of the data, is the striatal pattern classifier (SPC). Thus, we examined the perceptual noise estimates on a block-by-block basis from the SPC for each participant.
Figure 6 displays the block-by-block average perceptual noise estimates for pitch height (Figure 6a) and pitch direction (Figure 6b) for each explicit dimension prime condition. A 5 dimension prime condition × 6 block mixed ANOVA was conducted on the pitch height perceptual noise estimates. The main effect of block was significant [F(5, 505)=10.299, p < 0.001, partial η2 = 0.093] but the main effect of condition [F(4, 101) < 1.0] and the interaction were non-significant [F(20, 505) =1.123, p = 0.322, partial η2 = 0.043]. Not surprisingly, perceptual noise estimated declined with learning but did not differ across explicit dimension prime conditions. A 5 dimension prime condition × 6 block mixed ANOVA was conducted on the pitch direction perceptual noise estimates. The main effect of condition [F(4, 101)=2.823, p < 0.029, partial η2 = 0.101], block [F(5, 505) =16.242, p < 0.001, partial η2 = 0.139], and the interaction [F(20, 505) = 1.658, p = 0.037, partial η2 = 0.062] were all significant. As expected, the perceptual noise estimates in the Direction and Direction-not-Height conditions were significantly smaller than in the Control condition (both p's < 0.05). In addition, the perceptual noise estimates in the Height and Both conditions did not differ significantly from the Control condition (both p's > 0.30). Perceptual noise estimates declined with experience but at different rates depending upon the explicit dimension prime condition.
Figure 6.
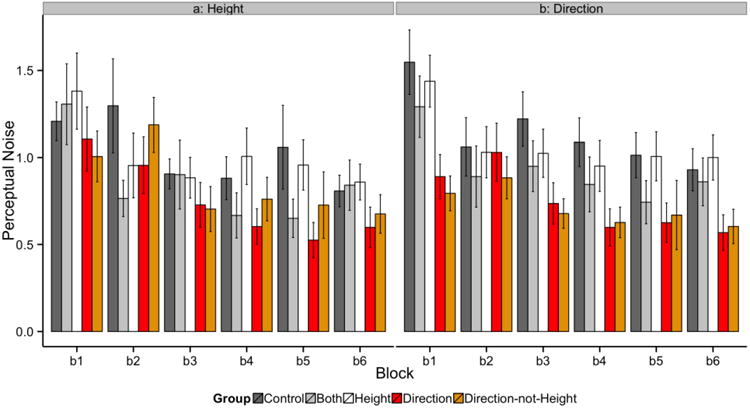
Block-by-block average perceptual noise estimates for (a) pitch height and pitch direction (b) for each explicit dimension prime condition.
To summarize, the model-based analyses led to a number of interesting conclusions and explanations for the learning advantage associated with explicit instruction to focus on pitch direction. First, explicit instruction to focus on the (initially underweighted) pitch direction dimension led to faster and more frequent use of reflexive-optimal decision strategies relative to the conditions that included explicit instruction to focus on pitch height or no instruction. A fast transition to reflexive strategies and more consistent use of those strategies is optimal and will speed learning. Second, explicit instruction to focus on the pitch direction dimension led to enhanced perceptual processing and large reductions in perceptual noise along the pitch direction dimension relative to the conditions that included explicit instruction to focus on pitch height or no instruction. Reduced perceptual noise along the relevant pitch direction dimension is optimal and will also speed learning.
Discussion
We examined the impact of explicit dimensional instruction on the learning of Mandarin tone categories by native English speakers. We found that instruction that focused the learner towards the initially under-weighted pitch direction dimension enhanced speech learning relative to instruction that focused the learning on the pitch height dimension or to a no prime control condition. Computational modeling results with the dual-learning systems model suggest that explicit dimensional instruction to focus on pitch direction affected decisional processes and enhanced perceptual selectivity along the pitch direction dimension. From a decision processing perspective, explicit instruction to focus on pitch direction led to a faster shift from simple unidimensional reflective strategies (primarily based on the pitch height dimension) to the more optimal, multidimensional reflexive strategies, and to greater use of these reflexive strategies across learning blocks. Explicitly instructing participants to focus on already highly weighted dimensions (in the height-only and both-conditions) did not impair performance relative to control (no instruction). This suggests a stable, inherent bias towards using pitch height as a cue that is not modulated on the basis of instruction. Improving categorization accuracy seems to critically dependent on directing instruction towards the underweighted pitch dimension. Explicit instruction impact perceptual processes as well; explicit instruction to focus on pitch direction led to enhanced perceptual selectivity along the pitch direction dimension, in the form of reduced perceptual noise. Although a similar reduction in perceptual noise with training was evidenced along the pitch height dimension, the reduction was not contingent on condition. Two other results are note-worthy.
The effect of explicit instruction on speech learning has not been systematically studied in previous research. Previous research has shown that both explicit and implicit training procedures can enhance speech learning. Both types of training procedures are also associated with large inter-individual differences in learning success. Our results suggest multiple routes to successful learning; optimal training procedures that target explicit learning may be beneficial especially during early learning.
Attention-to-Dimensions
It is important to note that these behavioral data are consistent with DLS but also with another popular theoretical approach, namely the attention-to-dimensions approach (A2D; Francis & Nusbaum, 2002). In the context of lexical tones, A2D predicts stretching and shrinking of the perceptual space along the pitch direction and pitch height dimensions, respectively. Stretching a dimension enhances the difference between two non-identical stimuli along that dimension making them more dissimilar and thus more easily discriminated. Shrinking a dimension attenuates the difference between two non-identical stimuli along that dimension making them more similar and thus more difficult to discriminate. A2D predicts that explicit instruction to pitch direction should stretch the perceptual space along that dimension leading to improved performance, as observed. Although both approaches are consistent with the observed accuracy results, we focus the theoretical analyses on the DLS approach because it provides a computational basis for understanding the psychological processes that are affected by the explicit dimension instruction. In particular, the DLS approach dissociates perceptual from decisional processes and includes parameters that separately estimate aspects of perceptual processing from aspects of decisional processing. A2D, like other exemplar-based models, does not distinguish between perceptual and decisional influences (Maddox & Ashby, 1996, 1998; Maddox, et al., 2002). This allows us to determine whether explicit instruction to focus on pitch direction affect decision processes, perceptual processes or both. Even so, A2D is an important approach that is also consistent with the results presented in this study.
Explicit Cueing may Bootstrap Reflexive Learning Processes
Several lines of evidence suggest that speech categories are optimally learned through implicit, procedural-learning mechanisms. For example, in a videogame training paradigm, participants are immediately rewarded if they are accurate (Lim & Holt, 2011; Liu & Holt, 2011; Wade & Holt, 2005). Due to the time constraints of the videogame, developing explicit rules regarding speech categories is challenging. Similarly, in a previous study we demonstrated that training manipulations that targeted implicit learning processes, led to enhanced learning over trials, relative to training manipulations that targeted more explicit learning (Chandrasekaran, et al., 2014b). Finally, difficult categorization problems, such as the learning of the subtle Hindi retroflex-dental contrast are achieved by incidental training approaches (Vlahou, et al., 2012). Given this emerging view, our finding that explicit instructions improve speech learning is intriguing.
Our results are not incompatible with these findings. We propose that dimensional priming may help bootstrap reflexive processes. Early in training, explicit instruction may enhance focus on a previously underutilized dimension. This may help bootstrap more implicit, reflexive learning that requires both dimensions to disambiguate categories. Further, the reflexive system is critically dependent on reinforcement (via positive feedback). If a prime can increase initial success in learning via reflective learning, this would result in more positive feedback, and provide scaffolding for the reflexive learning system (Crossley & Ashby, in press). It is relevant to note that learning occurs in both systems, with a shift in relative balance determining the dominance of one system over the other (Chandrasekaran, et al., 2014a; Maddox & Chandrasekaran, 2014b; Yi, et al., 2014). Adults are inherently biased towards reflective, rule-based processes during learning. Usually, such a bias results in the development of simple rules that can be quickly tested and possibly discarded for more complex rules. The computational modeling results suggest that this is true of our current dataset as well. Irrespective of dimensional instruction, there is a tendency to predominantly use unidimensional rules at the beginning of training. In the case of Mandarin tone learning, the unidimensional rule utilizes the pitch height dimension that is already heavily weighted by native English speakers. Successful learners shift away from this simple unidimensional rule to multidimensional, reflexive strategy that we have found is optimal for successful learning.
The development of multidimensional strategies by increasing the weighting on the pitch direction dimension is important for several reasons: tones in Mandarin vary substantially on this dimension (Wang, et al., 2003; Wang, Spence, Jongman, & Sereno, 1999b), so this additional cue captures more of the variance. Additionally, the pitch direction dimension is substantially more resistant to talker variability. Shifting to a reflexive strategy may also be advantageous. This strategy places less demands on executive attention and working memory. This may allow learners to allocate cognitive resources towards other processes (for e.g. vocabulary in learning novel words disambiguated by tones).
Future Direction
Future studies would need to examine generalizability of these results to other speech categories. Most speech categories do not have easily identifiable dimensions or dimensions that could be primed by simple, verbalizable rules. A characteristic finding in several speech learning studies is extreme individual variability in learning success. Based on our results, we posit that such variability could result from an inability to switch from simple, unidimensional rules to multidimensional, reflexive strategies. Thus, priming may allow more learners to move away from sub-optimal rules, towards more reinforcing learning behavior. Ultimately, the key to optimal learning would most likely require individualization. For example, dimensional instruction may be most useful early in training and may have less value later in training. Thus, the duration and extent of priming may need to be individualized in order to maximize learning potential.
Conclusion
Our results show that dimensional instruction enhance speech learning. Critically, not all instruction enhance learning; only instruction that direct attention towards an underweighted dimension results in superior learning. Computationally, such priming allows the learner to focus on an underweighted dimension, and thereby developing multidimensional strategies that may capture more variance in the perceptual space and resist talker variability.
Acknowledgments
This work was supported by NIDA grant DA032457 to WTM, and NIDCD grant DC013315 to BC. We thank the Maddox Lab RAs and especially Seth Koslov for assistance with all data collection.
Footnotes
Although we describe the systems as prefrontal and striatal, they are more accurately defined as cortico-striatal loops. The prefrontal system involves the executive cortico-striatal loop that connects the prefrontal cortex with the head of the caudate nucleus, whereas the striatal system involves the sensorimotor cortico-striatal loop that connects high level visual areas with the body and tail of the caudate/putamen (Alexander, DeLong, & Strick, 1986; Seger, 2008).
References
- Akaike H. A new look at the statistical model identification. Transactions on Automatic Control. 1974;19:716–723. [Google Scholar]
- Alexander GE, DeLong MR, Strick PL. Parallel organization of functionally segregated circuits linking basal ganglia and cortex. Annual Review of Neuroscience. 1986;9:357–381. doi: 10.1146/annurev.ne.09.030186.002041. [DOI] [PubMed] [Google Scholar]
- Allen SW, Brooks LR. Specializing the operation of an explicit rule. Journal of Experimental Psychology: General. 1991;120:3–19. doi: 10.1037//0096-3445.120.3.278. [DOI] [PubMed] [Google Scholar]
- Ashby FG. Estimating the parameters of multidimensional signal detection theory from simultaneous ratings on separate stimulus components. Perception & psychophysics. 1988;44:195–204. doi: 10.3758/bf03206288. [DOI] [PubMed] [Google Scholar]
- Ashby FG, Alfonso-Reese LA, Turken AU, Waldron EM. A neuropsychological theory of multiple systems in category learning. Psychological Review. 1998;105:442–481. doi: 10.1037/0033-295x.105.3.442. [DOI] [PubMed] [Google Scholar]
- Ashby FG, Maddox WT. Complex decision rules in categorization: Contrasting novice and experienced performance. Journal of Experimental Psychology: Human Perception and Performance. 1992;18(1):50. [Google Scholar]
- Ashby FG, Maddox WT. Relations between prototype, exemplar, and decision bound models of categorization. Journal of Mathematical Psychology. 1993;37:372–400. [Google Scholar]
- Ashby FG, Maddox WT. Human category learning 2.0. Annals of the New York Academy of Sciences. 2010 doi: 10.1111/j.1749-6632.2010.05874.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ashby FG, Maddox WT, Lee WW. On the dangers of averaging across subjects when using multidimensional scaling or the similarity-choice model. Psychological Science. 1994;5(3):144–151. [Google Scholar]
- Ashby FG, Townsend JT. Varieties of perceptual independence. Psychological Review. 1986;95:124–150. [PubMed] [Google Scholar]
- Ashby FG, Waldron EM. On the nature of implicit categorization. Psychon Bull Rev. 1999;6(3):363–378. doi: 10.3758/bf03210826. [DOI] [PubMed] [Google Scholar]
- Bates D, Maechler M, Bolker B, Walker S, Christensen RHB, Singmann H, et al. Rcpp L. R Foundation for Statistical Computing. Vienna: 2014. Package ‘lme4’. [Google Scholar]
- Bradlow AR, Akahane-Yamada R, Pisoni DB, Tohkura Y. Training Japanese listeners to identify English /r/ and /l/: long-term retention of learning in perception and production. Perception & psychophysics. 1999a;61(5):977–985. doi: 10.3758/bf03206911. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bradlow AR, Akahane-Yamada R, Pisoni DB, Tohkura Yi. Training Japanese listeners to identify English/r/and/l: Long-term retention of learning in perception and production. Perception & psychophysics. 1999b;61(5):977–985. doi: 10.3758/bf03206911. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bradlow AR, Bent T. Perceptual adaptation to non-native speech. Cognition. 2008;106(2):707–729. doi: 10.1016/j.cognition.2007.04.005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bradlow AR, Pisoni DB, Akahane-Yamada R, Tohkura Y. Training Japanese listeners to identify English /r/ and /l/: IV. Some effects of perceptual learning on speech production. The Journal of the Acoustical Society of America. 1997;101(4):2299–2310. doi: 10.1121/1.418276. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brooks L. Nonanalytic concept formation and memory for instances. Hillsdale, NJ: Erlbaum; 1978. [Google Scholar]
- Chandrasekaran B, Gandour JT, Krishnan A. Neuroplasticity in the processing of pitch dimensions: a multidimensional scaling analysis of the mismatch negativity. Restorative neurology and neuroscience. 2007;25(3-4):195–210. [PMC free article] [PubMed] [Google Scholar]
- Chandrasekaran B, Koslov SR, Maddox WT. Toward a dual-learning systems model of speech category learning. Front Psychol. 2014a;5:825. doi: 10.3389/fpsyg.2014.00825. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chandrasekaran B, Sampath PD, Wong PC. Individual variability in cue-weighting and lexical tone learning. The Journal of the Acoustical Society of America. 2010;128(1):456–465. doi: 10.1121/1.3445785. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chandrasekaran B, Yi HG, Maddox WT. Dual-learning systems during speech category learning. Psychon Bull Rev. 2014b;21(2):488–495. doi: 10.3758/s13423-013-0501-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Erickson MA, Kruschke JK. Rules and exemplars in category learning. Journal of Experimental Psychology: Learning, Memory, and Cognition. 1998;127:107–140. doi: 10.1037//0096-3445.127.2.107. [DOI] [PubMed] [Google Scholar]
- Estes WK. The problem of inference from curves based on group data. Psychological Bulletin. 1956;53:134–140. doi: 10.1037/h0045156. [DOI] [PubMed] [Google Scholar]
- Estes WK. Array models for category learning. Cognitive Psychology. 1986;18:500–549. doi: 10.1016/0010-0285(86)90008-3. [DOI] [PubMed] [Google Scholar]
- Estes WK. Classification and cognition. New York: Oxford University Press; 1994. [Google Scholar]
- Francis AL, Ciocca V, Ma L, Fenn K. Perceptual learning of Cantonese lexical tones by tone and non-tone language speakers. Journal of Phonetics. 2008a;36(2):268–294. [Google Scholar]
- Francis AL, Kaganovich N, Driscoll-Huber C. Cue-specific effects of categorization training on the relative weighting of acoustic cues to consonant voicing in English. The Journal of the Acoustical Society of America. 2008b;124(2):1234–1251. doi: 10.1121/1.2945161. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Francis AL, Nusbaum HC. Selective attention and the acquisition of new phonetic categories. Journal of experimental psychology Human perception and performance. 2002;28(2):349–366. doi: 10.1037//0096-1523.28.2.349. [DOI] [PubMed] [Google Scholar]
- Francis AL, Nusbaum HC, Fenn K. Effects of training on the acoustic phonetic representation of synthetic speech. Journal of speech, language, and hearing research: JSLHR. 2007;50(6):1445–1465. doi: 10.1044/1092-4388(2007/100). [DOI] [PubMed] [Google Scholar]
- Gandour JT, Harshman RA. Crosslanguage differences in tone perception: a multidimensional scaling investigation. Language and speech. 1978;21(1):1–33. doi: 10.1177/002383097802100101. [DOI] [PubMed] [Google Scholar]
- Goldstone R. Influences of categorization on perceptual discrimination. Journal of Experimental Psychology: General. 1994;123:178–200. doi: 10.1037//0096-3445.123.2.178. [DOI] [PubMed] [Google Scholar]
- Green DM, Swets JA. Signal detection and psychophysics. New York: Wiley; 1967. [Google Scholar]
- Hattori K, Iverson P. English /r/-/l/ category assimilation by Japanese adults: individual differences and the link to identification accuracy. The Journal of the Acoustical Society of America. 2009;125(1):469–479. doi: 10.1121/1.3021295. [DOI] [PubMed] [Google Scholar]
- Holt LL, Lotto AJ. Cue weighting in auditory categorization: Implications for first and second language acquisitiona) The Journal of the Acoustical Society of America. 2006;119(5):3059–3071. doi: 10.1121/1.2188377. [DOI] [PubMed] [Google Scholar]
- Holt LL, Lotto AJ. Speech perception as categorization. Attention, Perception, & Psychophysics. 2010;72(5):1218–1227. doi: 10.3758/APP.72.5.1218. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Homa D, Sterling S, Trepel L. Limitations of exemplar-based generalization and the abstraction of categorical information. Journal of Experimental Psychology: Human Learning and Memory. 1981;7:418–439. doi: 10.1037//0278-7393.10.4.638. [DOI] [PubMed] [Google Scholar]
- Howie J. Acoustical studies of Mandarin vowels and tones. Cambridge, UK: Cambridge University Press; 1976. [Google Scholar]
- Ingvalson EM, Barr AM, Wong PC. Poorer phonetic perceivers show greater benefit in phonetic-phonological speech learning. Journal of speech, language, and hearing research: JSLHR. 2013;56(3):1045–1050. doi: 10.1044/1092-4388(2012/12-0024). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ingvalson EM, Holt LL, McClelland JL. Can native Japanese listeners learn to differentiate/r-l/on the basis of F3 onset frequency? Bilingualism. 2012;15(2):434–435. doi: 10.1017/S1366728912000041. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Iverson P, Hazan V, Bannister K. Phonetic training with acoustic cue manipulations: a comparison of methods for teaching English /r/-/l/ to Japanese adults. The Journal of the Acoustical Society of America. 2005a;118(5):3267–3278. doi: 10.1121/1.2062307. [DOI] [PubMed] [Google Scholar]
- Iverson P, Hazan V, Bannister K. Phonetic training with acoustic cue manipulations: A comparison of methods for teaching English/r/-/l/to Japanese adults. The Journal of the Acoustical Society of America. 2005b;118(5):3267–3278. doi: 10.1121/1.2062307. [DOI] [PubMed] [Google Scholar]
- Iverson P, Kuhl PK, Akahane-Yamada R, Diesch E, Tohkura Yi, Kettermann A, Siebert C. A perceptual interference account of acquisition difficulties for non-native phonemes. Cognition. 2003;87(1):B47–B57. doi: 10.1016/s0010-0277(02)00198-1. [DOI] [PubMed] [Google Scholar]
- Jamieson DG, Morosan DE. Training non-native speech contrasts in adults: Acquisition of the English/ð/-/θ/contrast by francophones. Perception & psychophysics. 1986;40(4):205–215. doi: 10.3758/bf03211500. [DOI] [PubMed] [Google Scholar]
- Keri S. The cognitive neuroscience of category learning. Brain Research Reviews. 2003;43(1):85–109. doi: 10.1016/s0165-0173(03)00204-2. [DOI] [PubMed] [Google Scholar]
- Knowlton BJ, Squire LR. The learning of categories: Parallel brain systems for item memory and category level knowledge. Science. 1993;262:1747–1749. doi: 10.1126/science.8259522. [DOI] [PubMed] [Google Scholar]
- Kondaurova MV, Francis AL. The role of selective attention in the acquisition of English tense and lax vowels by native Spanish listeners: comparison of three training methods. Journal of phonetics. 2010;38(4):569–587. doi: 10.1016/j.wocn.2010.08.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liberman AM, Cooper FS, Shankweiler DP, Studdert-Kennedy M. Perception of the speech code. Psychological Review. 1967;74(6):431. doi: 10.1037/h0020279. [DOI] [PubMed] [Google Scholar]
- Lim Sj, Holt LL. Learning Foreign Sounds in an Alien World: Videogame Training Improves Non - Native Speech Categorization. Cognitive science. 2011;35(7):1390–1405. doi: 10.1111/j.1551-6709.2011.01192.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lisker L. “Voicing” in English: a catalogue of acoustic features signaling/b/versus/p/in trochees. Language and speech. 1986;29(1):3–11. doi: 10.1177/002383098602900102. [DOI] [PubMed] [Google Scholar]
- Liu R, Holt LL. Neural changes associated with nonspeech auditory category learning parallel those of speech category acquisition. Journal of Cognitive Neuroscience. 2011;23(3):683–698. doi: 10.1162/jocn.2009.21392. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lively SE, Logan JS, Pisoni DB. Training Japanese listeners to identify English /r/ and /l/. II: The role of phonetic environment and talker variability in learning new perceptual categories. The Journal of the Acoustical Society of America. 1993a;94(3 Pt 1):1242–1255. doi: 10.1121/1.408177. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lively SE, Logan JS, Pisoni DB. Training Japanese listeners to identify English/r/and/l/. II: The role of phonetic environment and talker variability in learning new perceptual categories. The Journal of the Acoustical Society of America. 1993b;94(3):1242–1255. doi: 10.1121/1.408177. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lively SE, Pisoni DB, Yamada RA, Tohkura Y, Yamada T. Training Japanese listeners to identify English /r/ and /l/. III. Long-term retention of new phonetic categories. The Journal of the Acoustical Society of America. 1994;96(4):2076–2087. doi: 10.1121/1.410149. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Logan JS, Lively SE, Pisoni DB. Training Japanese listeners to identify English /r/ and /l/: a first report. The Journal of the Acoustical Society of America. 1991;89(2):874–886. doi: 10.1121/1.1894649. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Maddox WT. On the dangers of averaging across observers when comparing decision bound models and generalized context models of categorization. Perception & psychophysics. 1999;61(2):354–375. doi: 10.3758/bf03206893. [DOI] [PubMed] [Google Scholar]
- Maddox WT. Separating perceptual processes from decisional processes in identification and categorization. Perception & psychophysics. 2001a;63:1183–1200. doi: 10.3758/bf03194533. [DOI] [PubMed] [Google Scholar]
- Maddox WT. Separating perceptual processes from decisional processes in identification and categorization. Perception & Psychophysics. 2001b;63(7):1183–1200. doi: 10.3758/bf03194533. [DOI] [PubMed] [Google Scholar]
- Maddox WT. Learning and attention in multidimensional identification and categorization: Separating low-level perceptual processes and high-level decisional processes. Journal of Experimental Psychology: Learning, Memory, and Cognition. 2002a;28(1):99. doi: 10.1037/0278-7393.28.1.99. [DOI] [PubMed] [Google Scholar]
- Maddox WT. Learning and attention in multidimensional identification, and categorization: Separating low-level perceptual processes and high-level decisional processes. Journal of Experimental Psychology: Learning, Memory, and Cognition. 2002b;28:99–115. doi: 10.1037/0278-7393.28.1.99. [DOI] [PubMed] [Google Scholar]
- Maddox WT, Ashby FG. Comparing decision bound and exemplar models of categorization. Perception & psychophysics. 1993;53:49–70. doi: 10.3758/bf03211715. [DOI] [PubMed] [Google Scholar]
- Maddox WT, Ashby FG. Perceptual separability, decisional separability, and the identification-speeded classification relationship. J Exp Psychol Hum Percept Perform. 1996;22(4):795–817. doi: 10.1037//0096-1523.22.4.795. [DOI] [PubMed] [Google Scholar]
- Maddox WT, Ashby FG. Selective attention and the formation of linear decision boundaries: comment on McKinley and Nosofsky (1996) J Exp Psychol Hum Percept Perform. 1998;24(1):301–321. doi: 10.1037//0096-1523.24.1.301. discussion 322-339. [DOI] [PubMed] [Google Scholar]
- Maddox WT, Ashby FG, Bohil CJ. Delayed feedback effects on rule-based and information-integration category learning. J Exp Psychol Learn Mem Cogn. 2003;29(4):650–662. doi: 10.1037/0278-7393.29.4.650. [DOI] [PubMed] [Google Scholar]
- Maddox WT, Ashby FG, Waldron EM. Multiple attention systems in perceptual categorization. Memory & Cognition. 2002;30(3):325–339. doi: 10.3758/bf03194934. [DOI] [PubMed] [Google Scholar]
- Maddox WT, Chandrasekaran B. Tests of a Dual-systems Model of Speech Category Learning. Biling (Camb Engl) 2014a;17(4):709–728. doi: 10.1017/S1366728913000783. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Maddox WT, Chandrasekaran B. Tests of a Dual-systems Model of Speech Category Learning. Bilingualism. 2014b;17(4):709–728. doi: 10.1017/S1366728913000783. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Maddox WT, Chandrasekaran B, Smayda K, Yi HG. Dual systems of speech category learning across the lifespan. Psychol Aging. 2013;28(4):1042–1056. doi: 10.1037/a0034969. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Maddox WT, Chandrasekaran B, Smayda K, Yi HG, Koslov S, Beevers CG. Elevated depressive symptoms enhance reflexive but not reflective auditory category learning. Cortex. 2014;58:186–198. doi: 10.1016/j.cortex.2014.06.013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Maddox WT, Dodd JL. Separating perceptual and decisional attention processes in the identification and categorization of integral-dimension stimuli. Journal of Experimental Psychology: Learning, Memory, and Cognition. 2003a;29(3):467. doi: 10.1037/0278-7393.29.3.467. [DOI] [PubMed] [Google Scholar]
- Maddox WT, Dodd JL. Separating perceptual and decisional attention processes in the identification and categorization of integral-dimension stimuli. Journal of Experimental Psychology: Learning, Memory, & Cognition. 2003b;29(3):467–480. doi: 10.1037/0278-7393.29.3.467. [DOI] [PubMed] [Google Scholar]
- Maddox WT, Ing AD. Delayed Feedback Disrupts the Procedural-Learning System but Not the Hypothesis-Testing System in Perceptual Category Learning. Journal of Experimental Psychology: Learning, Memory, & Cognition. 2005;31(1):100–107. doi: 10.1037/0278-7393.31.1.100. [DOI] [PubMed] [Google Scholar]
- Maddox WT, Love BC, Glass BD, Filoteo JV. When more is less: feedback effects in perceptual category learning. Cognition. 2008;108(2):578–589. doi: 10.1016/j.cognition.2008.03.010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McCandliss BD, Fiez JA, Protopapas A, Conway M, McClelland JL. Success and failure in teaching the [r]-[l] contrast to Japanese adults: Tests of a Hebbian model of plasticity and stabilization in spoken language perception. Cognitive, Affective, & Behavioral Neuroscience. 2002;2(2):89–108. doi: 10.3758/cabn.2.2.89. [DOI] [PubMed] [Google Scholar]
- McClelland JL, Fiez JA, McCandliss BD. Teaching the/r/–/l/discrimination to Japanese adults: behavioral and neural aspects. Physiology & Behavior. 2002;77(4):657–662. doi: 10.1016/s0031-9384(02)00916-2. [DOI] [PubMed] [Google Scholar]
- Medin DL, Schaffer MM. Context theory of classification learning. Psychological Review. 1978;85:207–238. [Google Scholar]
- Nomura EM, Maddox WT, Filoteo JV, Gitelman DR, Parrish TB, Mesulam MM, Reber PJ. MTL and caudate contributions to visual category learning: combining fMRI adn computational modeling; Paper presented at the Society for Neuroscience; Atlanta, GA. 2006. [Google Scholar]
- Nomura EM, Maddox WT, Filoteo JV, Ing AD, Gitelman DR, Parrish TB, et al. Reber PJ. Neural correlates of rule-based and information-integration visual category learning. Cereb Cortex. 2007;17(1):37–43. doi: 10.1093/cercor/bhj122. [DOI] [PubMed] [Google Scholar]
- Nomura EM, Reber PJ. A review of medial temporal lobe and caudate contributions to visual category learning. Neurosci Biobehav Rev. 2008;32(2):279–291. doi: 10.1016/j.neubiorev.2007.07.006. [DOI] [PubMed] [Google Scholar]
- Nosofsky RM. Attention, similarity, and the identification-categorization relationship. Journal of Experimental Psychology: General. 1986;115:39–57. doi: 10.1037//0096-3445.115.1.39. [DOI] [PubMed] [Google Scholar]
- Nosofsky RM, Palmeri TJ, McKinley SC. A rule-plus-exception model of classification learning. Psychological Review. 1994;101:53–79. doi: 10.1037/0033-295x.101.1.53. [DOI] [PubMed] [Google Scholar]
- Perrachione TK, Lee J, Ha LY, Wong PC. Learning a novel phonological contrast depends on interactions between individual differences and training paradigm design. The Journal of the Acoustical Society of America. 2011;130(1):461–472. doi: 10.1121/1.3593366. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rosch E. Principles of categorization. Hillsdale: Erlbaum; 1978. [Google Scholar]
- Seger CA. How do the basal ganglia contribute to categorization? Their roles in generalization, response selection, and learning via feedback. Neurosci Biobehav Rev. 2008;32(2):265–278. doi: 10.1016/j.neubiorev.2007.07.010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Seger CA, Cincotta CM. The Roles of the Caudate Nucleus in Human Classification Learning. Journal of Neuroscience. 2005;25(11):2941–2951. doi: 10.1523/JNEUROSCI.3401-04.2005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Seger CA, Miller EK. Category learning in the brain. Annu Rev Neurosci. 2010;33:203–219. doi: 10.1146/annurev.neuro.051508.135546. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smayda K, Chandrasekaran B, Maddox WT. Enhanced cognitive and perceptual processing: A computational basis for the musician advantage in speech learning. Frontiers in Psychology. 2015;6 doi: 10.3389/fpsyg.2015.00682. http://doi.org/10.3389/fpsyg.2015.00682. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smith EE, Medin DL. Categories and concepts. Cambridge, MA: Harvard University Press; 1981. [Google Scholar]
- Smith JD, Berg ME, Cook RG, Murphy MS, Crossley MJ, Boomer J, et al. Grace RC. Implicit and explicit categorization: a tale of four species. Neurosci Biobehav Rev. 2012;36(10):2355–2369. doi: 10.1016/j.neubiorev.2012.09.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Team RC. R: a language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing; 2012; 2014. Open access available at: http://cran.r-project.org. [Google Scholar]
- Tricomi E, Delgado MR, McCandliss BD, McClelland JL, Fiez JA. Performance feedback drives caudate activation in a phonological learning task. Journal of Cognitive Neuroscience. 2006;18(6):1029–1043. doi: 10.1162/jocn.2006.18.6.1029. [DOI] [PubMed] [Google Scholar]
- Vlahou EL, Protopapas A, Seitz AR. Implicit training of nonnative speech stimuli. Journal of Experimental Psychology: General. 2012;141(2):363. doi: 10.1037/a0025014. [DOI] [PubMed] [Google Scholar]
- Wade T, Holt LL. Incidental categorization of spectrally complex non-invariant auditory stimuli in a computer game task. The Journal of the Acoustical Society of America. 2005;118(4):2618–2633. doi: 10.1121/1.2011156. [DOI] [PubMed] [Google Scholar]
- Wang Y, Jongman A, Sereno JA. Acoustic and perceptual evaluation of Mandarin tone productions before and after perceptual training. The Journal of the Acoustical Society of America. 2003;113(2):1033–1043. doi: 10.1121/1.1531176. [DOI] [PubMed] [Google Scholar]
- Wang Y, Spence MM, Jongman A, Sereno JA. Training American listeners to perceive Mandarin tones. The Journal of the Acoustical Society of America. 1999a;106(6):3649–3658. doi: 10.1121/1.428217. [DOI] [PubMed] [Google Scholar]
- Wang Y, Spence MM, Jongman A, Sereno JA. Training American listeners to perceive Mandarin tones. The Journal of the Acoustical Society of America. 1999b;106(6):3649–3658. doi: 10.1121/1.428217. [DOI] [PubMed] [Google Scholar]
- Wong PC, Perrachione TK, Gunasekera G, Chandrasekaran B. Communication disorders in speakers of tone languages: etiological bases and clinical considerations. Paper presented at the Seminars in speech and language. 2009 doi: 10.1055/s-0029-1225953. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wong PC, Perrachione TK, Parrish TB. Neural characteristics of successful and less successful speech and word learning in adults. Human brain mapping. 2007;28(10):995–1006. doi: 10.1002/hbm.20330. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yi HG, Maddox WT, Mumford JA, Chandrasekaran B. The Role of Corticostriatal Systems in Speech Category Learning. Cereb Cortex. 2014 doi: 10.1093/cercor/bhu236. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhang Y, Kuhl PK, Imada T, Iverson P, Pruitt J, Stevens EB, et al. Nemoto I. Neural signatures of phonetic learning in adulthood: a magnetoencephalography study. Neuroimage. 2009;46(1):226–240. doi: 10.1016/j.neuroimage.2009.01.028. [DOI] [PMC free article] [PubMed] [Google Scholar]