

Abstract
Introduction
The use of a medical data registry allows institutions to effectively manage information for many different investigations related to the registry, as well as evaluate patient's trends over time, with the ultimate goal of recognizing trends that may improve outcomes in a particular patient population.
Methods
The purpose of this article is to illustrate our experience with a stroke patient registry at a comprehensive stroke center and highlight advantages, disadvantages, and lessons learned in the process of designing, implementing, and maintaining a stroke registry. We detail the process of stroke registry methodology, common data element (CDE) definitions, the generation of manuscripts from a registry, and the limitations.
Advantages
The largest advantage of a registry is the ability to prospectively add patients, while allowing investigators to go back and collect information retrospectively if needed. The continuous addition of new patients increases the sample size of studies from year to year, and it also allows reflection on clinical practices from previous years and the ability to investigate trends in patient management over time.
Limitations
The greatest limitation in this registry pertains to our single-entry technique where multiple sites of data entry and transfer may generate errors within the registry.
Lessons Learned
To reduce the potential for errors and maximize the accuracy and efficiency of the registry, we invest significant time in training competent registry users and project leaders. With effective training and transition of leadership positions, which are continuous and evolving processes, we have attempted to optimize our clinical research registry for knowledge gain and quality improvement at our center.
Keywords: stroke, registries, methodology, epidemiological methods, common data elements, source data verification
Introduction
Single-center registries of medical data are commonly created for clinical investigations across a variety of medical conditions, including stroke.1–5 Over the past 30 years, the use of registries has been demonstrated to improve the quality of care, patient prognosis, and hospitalization costs by systematically delineating standards of care by which institutions are expected to abide. This holds true for stroke patient registries6–8 as well as for other medical registries.9–11 Additionally, registries are utilized to report hospital-level data for ‘Get with the Guidelines’12 (a multicenter effort to document and improve outcomes in patients with stroke and cardiovascular disease) and for maintenance of The Joint Commission Primary Stroke Center certification.
Despite the value in medical stroke registries, there are many limitations to establishing and maintaining an up-to-date and accurate medical data registry. Some of these shortcomings include incompleteness in registry data,13 difficulties with prospective data collection during patient hospitalization,14 errors in data collection and management,15 and poor standardization in definitions among common data elements (CDEs).15–18
The purpose of this article is to illustrate the advantages, limitations, and lessons learned during the creation of the registry used by the stroke program at the Tulane Medical Center, as well as how the center strives to minimize these limitations in the production and maintenance of the registry.
Methods
Patients and research personnel
The clinical registry was originally developed using a four-page case report form (CRF) to initiate data collection in preparation for the application for Primary Stroke Center certification and to address a specific study question related to the safety and efficacy of combined anti-platelet therapy during the acute phase of ischemic stroke.19 The larger registry includes all but a handful of data points requested by ‘Get with the Guidelines-Stroke’12 and all of the data points needed for reporting to The Joint Commission. The Joint Commission requires that all certified Primary Stroke Centers maintain these data on their patient population, treatment rates, and other information for quality improvement.
After the approval of the initial four-page CRF by the Tulane Medical Center Institutional Review Board in 2009, the expanded stroke registry was approved in 2011 to allow for inclusion of all patients who had a stroke diagnosis since the start of the stroke program in July 2008.
This center includes a 350-bed tertiary care center in downtown New Orleans, LA, serving a predominantly Medicare and Medicaid, African American population. See Table 1 and several recent publications for a description of the patient population.20–22 The stroke service evaluates approximately 500 patients with a stroke diagnosis each year (<15% transfers from outside hospitals) and are staffed by board-certified vascular neurologists. The stroke program meets the criteria of a comprehensive stroke center, offering 24/7/365 neurosurgical and endovascular care to its patients. Data from these patients are collected prospectively as described below. The senior leadership position is held by the Stroke Director, a vascular neurology fellowship-trained academic neurologist. Two hospital employees participate in data collection for the stroke registry, but they are not funded specifically for this activity. Neurology residents and medical students are also encouraged to participate. Their duties are described in the ‘Creating a Primary Registry’ section. Despite receiving no dedicated funding, the program has expanded yearly from three students in year 1 to nearly 20 active members by year 5.
Table 1.
Patient population.
| Diagnosis | Year 1 | Year 2 | Year 3 | Year 4 | First 6 months of Year 5 |
|---|---|---|---|---|---|
| No. ischemic stroke | 185 | 261 | 309 | 291 | 174 |
| No. treated with IV tPA (%) | 27 (14.6) | 69 (26.4) | 75 (24.3) | 100 (34.4) | 78 (44.8) |
| No. treated with IA tPA (%) | 4 (2.2) | 18 (6.9) | 16 (5.2) | 16 (5.5) | 10 (5.7) |
| No. TIA | 62 | 74 | 79 | 74 | 33 |
| No. intracerebral hemorrhage | 38 | 57 | 60 | 58 | 34 |
IV tPA, intravenous tissue plasminogen activator; IA tPA, intra-arterial tissue plasminogen activator; TIA, transient ischemic attack.
Creating a primary registry
Each CDE is defined in a codebook in an effort to standardize variable definitions and to increase inter-rater reliability of data acquisition. While some CDEs are straightforward and objective (admission vital signs), other more subjective data points (pre-admission ambulatory status) achieve legitimacy through consistency with the National Institute of Neurological Disease and Stroke (NINDS) stroke-specific CDE standards.23 Despite this standardization in CDEs being released after preparing the registry, the definitions used for the registry match those used in the CDE online module. This precise labeling and classifying has allowed collaboration with other institutional stroke registries so that registry variables can be synchronized between centers and parameters adjusted between respective institutions. The aim of this is to ultimately build larger studies and corroborate findings with those of other institutions.
Consecutive patients evaluated at the center with a high clinical suspicion for stroke are prospectively added to a ledger by the stroke program coordinator. Once the diagnosis of stroke is confirmed, either clinically or via imaging, eligible patients are assigned a registry code number. Core measures and key clinical CDEs including, but not limited to, baseline demographics, stroke classification, laboratory data, and other admission information (the sum of which comprises nearly half the total number of CDEs in our registry) are collected prospectively by the stroke program coordinator onto a standardized paper version of our CRF (see Figure 1). In the days following admission, a board-certified vascular neurologist will document onto this CRF key imaging and management data.
Figure 1.
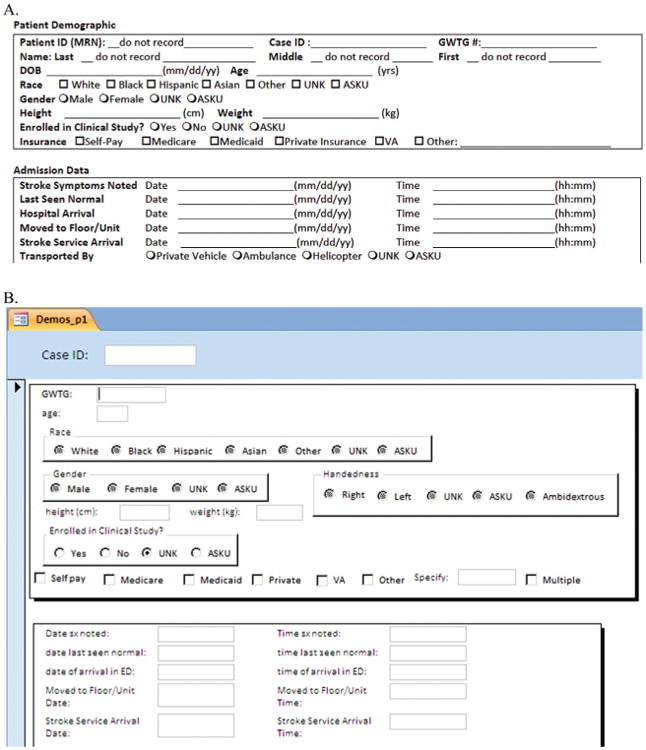
View of the paper and digital versions of our case report form (CRF).
A. Representative view of the paper case report form on which data are collected.
B. Screen view of the digital data collection tool (Microsoft Access 2007). Shown is a representative page in the collection tool that corresponds to the common data elements (CDEs) collected in the case report form (part A).
Key CDEs are selected for initial collection based on the ability to use responses as a filter for future studies. If an investigator establishes an ancillary project idea based on subpopulations of the registry, the key CDEs can aide in guiding the investigator to establish what additional information needs to be collected as well as how it should be collected. This is followed by applying for expedited Institutional Review Board (IRB) approval for the ancillary study, and additional needed variables can be collected from the electronic medical record and chart using a study-specific CRF (see further discussion in Supplementary Data Abstraction for details). The remaining data regarding a patient's hospitalization, complications during stay, and outcome at the time of discharge and at 3 months are collected retrospectively onto the CRF by other research team members (medical student volunteers, residents, nurse practitioners, faculty) trained in data collection. The only 90-day outcome measure collected is the modified Rankin Scale (mRS) score, a seven-point scale serving as the most commonly used functional outcome measure in neurological studies.24 Because The Joint Commission requires collection of the 90-day mRS and follow-up phone calls for disease-specific certification, our stroke program coordinator obtains the 90-day mRS by a structured and validated telephone interview, except when a patient was seen in the stroke clinic within the ± 7-day range and the mRS is documented.
Reconciliation of CDEs
Once the CDEs have been gathered onto the paper version of our CRF, potentially inaccurate data points are validated manually by a more experienced research team member. In the event that inaccurate data are suspected, the medical record would be reviewed by a more experienced member of the research team and the variable of interest would be corrected on the CRF with a time/date stamp indicating when the reconciliation was made as well as the initials of the reviewing team member. After all data on a paper CRF have been reviewed in this manner, the CRF data are then transcribed via single-entry into a secure, password-protected electronic master spreadsheet – Figure 1 – where a second reconciliation process occurs after the data are electronically transferred. Prior to analysis, each CDE used in a given research study is then sorted from smallest to largest (for continuous variables) or A to Z (for text variables) in order to identify any gross transcription errors (a letter or word in the place of a number). This process is followed by identification of any continuous numerical data that lie beyond two standard deviations for that particular CDE (classified as ‘potentially erroneous data’). These data are validated or corrected using source data verification (SDV) once a second review of that patient's medical record has occurred. After all data have been accurately collected and entered into this master electronic spreadsheet, it is then transferred to a statistical software package for analysis where the statistical files become recognized by the research team as the updated primary registry. Each of these phases in primary registry creation has been approved by the Tulane Medical Center IRB.
Supplementary data abstraction
Once the primary registry is established, a researcher can posit a study question that he/she would like to investigate. The study question is discussed with all investigators who would be involved in the data abstraction, analysis, and drafting of the manuscript, and then formed into a testable hypothesis by methodologists. The research team is then able to anticipate all quantifiable CDEs necessary to answer this question, which includes data collected in the primary registry as well as data necessitating re-review of patient medical records. The CDEs that are needed for the study question are used to create a supplemental CRF to collect the additional data. The new variables of interest are strictly defined and added to the master code book by the project PI. Once IRB approval has been granted for the proposed study, data collection with the supplemental CRF begins where it goes through the same series of SDV as described above to ensure data validity. Once these additional data have been gathered and validated in a supplemental electronic spreadsheet, they can be added to the secure master electronic spreadsheet. A summary of our data collection and interpretation methods can be found in Figure 2.
Figure 2.

Summary of methods.
Advantages
In an attempt to minimize some of the errors inherent to registry production and maintenance, the following three objectives were applied to the medical data registry:
The same CDEs are collected accurately and completely;
Each CDE has a standardized definition; and
Data which can be queried for future investigations are provided.
Objective 1 ensures the abstraction of accurate, verifiable, complete, and relevant information. However, less controllable sources of data error still exist, such as errors in laboratory results and other medical data documentation from electronic medical records. The completeness of information is valuable for two reasons:
All of the important facts for a given patient during their hospitalization are collected; and
Each of these facts is collected across all patients in the registry, reducing bias in data abstraction.
Objective 2 provides the framework for reliable and simple information. Simple but concrete definitions, standardized within the literature, are required to study specific associations between variables and to permit collaboration with other investigators when combining variables with the same definition.
Objective 3 facilitates economical and timely information abstraction. It is important to consider the timeliness of information abstraction as this is commonly a rate-limiting step in any methodology. It may take an experienced data abstractor up to 90 min to complete one CRF and an additional 30 min to validate and transcribe these data into an electronic master spreadsheet. Not all data from a given patient can be collected in a timely manner; therefore, fundamental CDEs must be collected quickly for screening purposes and then reviewed retrospectively if any more specific questions regarding that CDE should arise. All of these key points within Objective 3 provide for flexible data that can be utilized in many different forms from reporting to ‘Get with the Guidelines’, creating reports for internal quality assurance, tracking changes within our institution, and contributing to scientific research.
These objectives are compliant with the MDR-OK categorization protocol (for mergeable data, dataset standardized, rules for data collection, observations associated over time, and knowledge of Outcomes) from a previous review that outlines effective medical data registry protocol25 and is consistent with the recommendations of the American Heart Association.26
The stroke registry serves a key function, as it provides a foundation upon which other studies can originate, as well as generate new hypotheses. Because the registry also provides a foundation for ideas to cultivate, data abstractors may notice anecdotal trends or grow curious about certain functions pertaining to strokes. This encourages a team approach to discussing novel study ideas, providing students with the opportunity to design and implement a scientific investigation, and allowing faculty members to cultivate their mentoring skills.
The largest advantage of having a registry is the ability to prospectively add patients to the registry, while allowing investigators to collect information retrospectively if needed. The continuous addition of new patients increases the sample size of our studies from year to year. Furthermore, the combination of prospective and retrospective data collection methods has been suggested as the most efficacious means for gathering data in terms of completeness and accuracy.13
Impact on quality improvement
Furthermore, the use of this registry has allowed investigations into this center's practices in order to implement internal quality improvement measures. Whenever a question regarding complications or outcomes is raised by hospital staff, the registry is queried to obtain the needed data. For example, an emergency department (ED) nurse expressed concern for treating a patient who woke up with stroke symptoms with a thrombolytic. The registry was queried after IRB approval, and we were able to report complication rates for this group of patients and compare them to complication rates of patients treated within the American Heart Association guidelines; the results were similar. While neither research objectives nor quality improvement can be identified as the primary purpose of this registry, the registry has certainly afforded our institution both types of information. In an additional example, we examined whether outcomes were compromised by prolonged length of stay in the ED.27 We found that it was not the amount of time spent by a patient in the ED, but rather the presence in the ED during the nursing shift change that was associated with increased frequency of pneumonia.27 This is one of the best examples of a research query at this center that led to a change in hospital management; however, many small changes have been implemented following research queries of the registry. While significant, these have not always resulted in publications through peer-reviewed journals.
Limitations
As in all investigations and clinical data registries, there are drawbacks to our registry. One primary pitfall is that there is no specific study in mind while collecting the information for the registry. This leaves the team at the liberty of the treating physician as to whether specific laboratory values are collected, imaging studies are ordered, and so on. Much of the information within the registry is retrospective, which can create problematic issues if aspects of patient care needed for research purposes are not included within the medical record.
While there are advantages to the checks and balances of multiple points of data entry, there is a limitation to this feature as well. The multiple points of data transfer increase the likelihood that human error can affect the data transfer and also increase the total time spent on the process, thereby decreasing efficacy.15 Because screening of data for irregularities is confined to outliers and gross typographical errors, it is possible that minor errors may go undetected if they fall within a normal distribution for a specific data point. Over half of the errors in clinical data gathering are due to data entry technique according to a recent study, but there is still a substantial portion of errors that are generated during the reconciliation process that appears to be dependent on the knowledge of research personnel.28 One unique feature of the registry is the similarity of the paper and digital versions of our data collection tool (see Figure 1). Because the two forms are nearly identical with regard to the data copied from the paper version to the electronic version, we have found that this reduces the risk of human error during transcription.
Furthermore, the use of multiple team members in the abstraction of similar data points may risk inter-abstractor reliability (meaning lack of consensus in definitions of data elements between abstractors may lead to inaccurate gathering of these data)29 and potentially lead to abstractor drift (meaning small changes in understanding CDEs by a given abstractor may result in unforeseen discrepancies in data collection). We strive to minimize this with the implementation of a very specific codebook of CDE definitions. Because the majority of our CDEs are collected prospectively by the Stroke Program Coordinator and a trained vascular neurologist, this leaves little room for potential error with our remaining data abstractors. These errors may be reduced with the implementation of a double-entry approach,30 but such a methodology may not be efficient in large patient populations with large quantities of data.31
We also implement a mandatory training period of all new research personnel whereby a more experienced supervisor (usually a senior medical student with two or more years of experience with our team) is required to monitor any new data abstractors and data entry personnel until such a time when the junior student can carry out these tasks accurately, effectively, and without further assistance. During this time, the senior team member also allocates a sufficient amount of time educating junior team members regarding general aspects of stroke pathophysiology, clinical diagnosis, laboratory and imaging studies, and management. Bi-monthly meetings with research personnel on our team also afford us the opportunity to review and discuss clinical data and their definitions in an open setting as well as an opportunity to assess the status of our new and ongoing investigations.
Another disadvantage is that this is a single center that can only offer insight into a specific population of patients who present to our institution. This limitation prohibits our ability to generalize our results to other centers and other studies. Our center is very unique in that it serves patients in the New Orleans area regardless of insurance status, and the source population of New Orleans (being in the ‘Stroke Belt’) is not a representative sample of the United States.32 This is why we have made clear, specific variable definitions so that we can combine our registry with other registries to increase sample size and improve our generalizability.
Lessons Learned
In establishing a stroke registry, we have learned many lessons regarding initiation of the registry, developing CDE definitions, and commencing projects from the registry. One factor pertains to the responsibility of the research project leader, which may be a double-edged sword. While the leadership experience gained by medical students and residents in piloting an independent study, working with a team from start to finish, and presenting results in peer-reviewed journals and at conferences is invaluable, follow-through and keeping deadlines can be challenging due to conflicting obligations. We have learned that communication of goals and interests is paramount, which fosters a true teamwork approach where students, residents, and faculty work closely together to complete projects in a timely manner. Bi-monthly meetings to communicate the status of the registry and related projects, and the dissemination of meeting minutes and a running list of projects, papers, and abstract deadlines have helped in establishing and re-establishing expectations and resource utilization.
We have also learned that investing the time to carefully train research personnel with regard to data collection techniques, variable definition classification, and data entry greatly reduces the errors in data collection. At this center, all members of the research team are required to be certified in the NIH Stroke Scale examination33 as well as undergo IRB training and certification. New members also go through a period of proper training and supervision from a more experienced team member as explained above. In an attempt to maintain data accuracy, we also limit the reconciliation of data errors to trained and experienced clinical personnel, such as upper level medical students and residents who understand the biological and statistical meaning of these data elements and can more easily recognize outliers, errors, and inconsistencies (e.g., the erroneous coding of a patient who expired when he or she was discharged to home).
We have learned that it is important to inform faculty and residents at your center about your registry. They should know which data elements are included so that they can assist in the collection of information from patients and effectively dictate these pertinent elements in their patient notes. At our center, we keep other faculty and residents informed about our registry by inviting them to our bi-monthly research meetings and actively discussing the results of our research at regularly scheduled vascular conferences, grand rounds, and other meetings. We have also created templates for admission and discharge notes, which include the most important CDEs.
The main lesson learned in this process is that data are more effectively and accurately collected when a stroke coordinator or other trained clinical personnel collect the majority of patient information prospectively, rather than retrospectively via chart review. Because of the active, prospective collection of data by this team member, with many elements collected for reporting to The Joint Commission for maintaining Primary Stroke Center certification, any uncommon data elements needed for the registry that are not intuitively gathered by residents or medical students (such as a specific history of liver disease) can be collected by the coordinator before the patient might be lost to follow-up.
It is worth disclosing that in the generation of this registry, methods and protocols have been actively evolving. The lessons learned during the early phases of registry production have already been applied to the current phase. For instance, we began the data abstraction process in 2008 with an almost entirely retrospective approach using a limited version of a CRF (approximately four pages in length with just over 350 CDEs). In January 2011, the CRF was significantly revised for a number of reasons in order to improve the efficacy and completeness of our data collection. The revised CRF now includes more data points that can be used for research queries (approximately 18 pages in length with over 1,000 CDEs) and is better organized with respect to the order of information collection. From our experience, while there are more data to be abstracted, the improvement in organization has dramatically shortened the time necessary for data collection and improves the accuracy and completeness in each of the CDEs of the registry.
Future Directions
Stroke is a leading cause of disability and death in the US population,34 and research with the use of registries has grown to be an effective way to improve the care and quality of life of individuals who suffer from this disease.6, 35–37
Now that the Tulane Medical Center's primary registry has been ongoing for several years (since 2008), future directions of the registry are under discussion. Currently, in the Electronic Health Records (EHR) being used, data cannot be captured by electronic means. Instead, all information must be abstracted through manual searches with individual data point abstraction. The center is actively looking into the adoption of a new EHR system to meet the objectives of meaningful use (in improving patient health care), which may help with future data collection when ultimately implemented. The next immediate step involves improving the integrity of our data abstraction and SDV. Currently, our data entry methodology involves several points of data transfer using a single-entry technique, which has been associated with a low risk of data error. While we recognize that double-entry would reduce this rate of error, we agree with other investigations which have demonstrated that double-entry is not cost-effective due to limited time and personnel. Furthermore, we restrict ourselves to an SDV process limited to identifying outliers in our data. In the future, we can improve the accuracy of our registry by performing a random selection of non-outlier data elements for SDV. In addition, we hope to inspire other centers to develop their own stroke registries with well-defined variable definitions that are consistent with the literature and with other stroke center registries.
Acknowledgments
Funding: This project was supported by Award Numbers 5 T32 HS013852-10 from The Agency for Healthcare Research and Quality (AHRQ) and 3 P60 MD000502-08S1 from The National Institute on Minority Health and Health Disparities (NIMHD), National Institutes of Health (NIH), and 13PRE13830003 from the American Heart Association.
Footnotes
Conflict of interest: The content is solely the responsibility of the authors and does not necessarily represent the official views of the AHRQ or the NIH.
References
- 1.Kunitz SC, Gross CR, Heyman A, Kase CS, Mohr JP, Price TR, et al. The pilot stroke data bank: definition, design, and data. Stroke. 1984;15:740–6. doi: 10.1161/01.str.15.4.740. http://dx.doi.org/10.1161/01.STR.15.4.740. [DOI] [PubMed] [Google Scholar]
- 2.Mohr JP, Caplan LR, Melski JW, Goldstein RJ, Duncan GW, Kistler JP, et al. The harvard cooperative stroke registry: a prospective registry. Neurology. 1978;28:754–6. doi: 10.1212/wnl.28.8.754. http://dx.doi.org/10.1212/WNL.28.8.754. [DOI] [PubMed] [Google Scholar]
- 3.Rosati RA, McNeer JF, Starmer CF, Mittler BS, Morris JJ, Jr, Wallace AG. A new information system for medical practice. Arch Intern Med. 1975;135:1017–24. http://dx.doi.org/10.1001/archinte.1975.00330080019003. [PubMed] [Google Scholar]
- 4.Ding D, Lu CZ, Fu JH, Hong Z. Predictors of vascular events after ischemic stroke: the China ischemic stroke registry study. Neuroepidemiology. 2010;34:110–16. doi: 10.1159/000268823. http://dx.doi.org/10.1159/000268823. [DOI] [PubMed] [Google Scholar]
- 5.Turin TC, Kita Y, Rumana N, Takashima N, Ichikawa M, Sugihara H, et al. Diurnal variation in onset of hemorrhagic stroke is independent of risk factor status: Takashima stroke registry. Neuroepidemiology. 2010;34:25–33. doi: 10.1159/000255463. http://dx.doi.org/10.1159/000255463. [DOI] [PubMed] [Google Scholar]
- 6.Schwamm LH, Fonarow GC, Reeves MJ, Pan W, Frankel MR, Smith EE, et al. Get with the guidelines-stroke is associated with sustained improvement in care for patients hospitalized with acute stroke or transient ischemic attack. Circulation. 2009;119:107–15. doi: 10.1161/CIRCULATIONAHA.108.783688. http://dx.doi.org/10.1161/CIRCULATIONAHA.108.783688. [DOI] [PubMed] [Google Scholar]
- 7.LaBresh KA. Quality of acute stroke care improvement framework for the paul coverdell national acute stroke registry: facilitating policy and system change at the hospital level. Am J Prev Med. 2006;31:S246–50. doi: 10.1016/j.amepre.2006.08.012. http://dx.doi.org/10.1016/j.amepre.2006.08.012. [DOI] [PubMed] [Google Scholar]
- 8.George MG, Tong X, McGruder H, Yoon P, Rosamond W, Winquist A, et al. Paul coverdell national acute stroke registry surveillance - four states, 2005-2007. MMWR Surveill Summ. 2009;58:1–23. [PubMed] [Google Scholar]
- 9.Jakobsen E, Palshof T, Osterlind K, Pilegaard H. Data from a national lung cancer registry contributes to improve outcome and quality of surgery: Danish results. Eur J Cardiothorac Surg. 2009;35(2):348–352. doi: 10.1016/j.ejcts.2008.09.026. http://dx.doi.org/10.1016/j.ejcts.2008.09.026. [DOI] [PubMed] [Google Scholar]
- 10.Larsson S, Lawyer P, Garellick G, Lindahl B, Lundstrom M. Use of 13 disease registries in 5 countries demonstrates the potential to use outcome data to improve health care's value. Health Aff (Millwood) 2012;31:220–7. doi: 10.1377/hlthaff.2011.0762. http://dx.doi.org/10.1377/hlthaff.2011.0762. [DOI] [PubMed] [Google Scholar]
- 11.Maas AI. Traumatic brain injury: simple data collection will improve the outcome. Wien Klin Wochenschr. 2007;119:20–2. doi: 10.1007/s00508-006-0759-y. http://dx.doi.org/10.1007/s00508-006-0759-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Xian Y, Fonarow GC, Reeves MJ, Webb LE, Blevins J, Demyanenko VS, et al. Data quality in the American Heart Association get with the guidelines-stroke (gwtgstroke): results from a national data validation audit. Am Heart J. 2012;163(3):392–8. 398–e391. doi: 10.1016/j.ahj.2011.12.012. http://dx.doi.org/10.1016/j.ahj.2011.12.012. [DOI] [PubMed] [Google Scholar]
- 13.Yoon SS, George MG, Myers S, Lux LJ, Wilson D, Heinrich J, et al. Analysis of data-collection methods for an acute stroke care registry. Am J Prev Med. 2006;31(6):S196–201. doi: 10.1016/j.amepre.2006.08.010. http://dx.doi.org/10.1016/j.amepre.2006.08.010. [DOI] [PubMed] [Google Scholar]
- 14.Braunschweig CA. Creating a clinical nutrition registry: prospects, problems, and preliminary results. J Am Diet Assoc. 1999;99:467–70. doi: 10.1016/S0002-8223(99)00115-7. http://dx.doi.org/10.1016/S0002-8223(99)00115-7. [DOI] [PubMed] [Google Scholar]
- 15.Arts DG, De Keizer NF, Scheffer GJ. Defining and improving data quality in medical registries: a literature review, case study, and generic framework. J Am Med Inform Assoc. 2002;9:600–11. doi: 10.1197/jamia.M1087. http://dx.doi.org/10.1197/jamia.M1087. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Siegler JE, Martin-Schild S. Early neurological deterioration (end) after stroke: the end depends on the definition. Int J Stroke. 2011;6:211–12. doi: 10.1111/j.1747-4949.2011.00596.x. http://dx.doi.org/10.1111/j.1747-4949.2011.00596.x. [DOI] [PubMed] [Google Scholar]
- 17.Albright KC, Martin-Schild S, Bockholt HJ, Howard G, Alexandrov A, Sline MR, et al. No consensus on definition criteria for stroke registry common data elements. Cerebrovasc Dis Extra. 2011;1:84–92. doi: 10.1159/000334146. http://dx.doi.org/10.1159/000334146. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Davis FG, Bruner JM, Surawicz TS. The rationale for standardized registration and reporting of brain and central nervous system tumors in population-based cancer registries. Neuroepidemiology. 1997;16:308–16. doi: 10.1159/000109703. http://dx.doi.org/10.1159/000109703. [DOI] [PubMed] [Google Scholar]
- 19.Leung LY, Albright KC, Boehme AK, Tarsia J, Shah KR, Siegler JE, et al. Short-term bleeding events observed with clopidogrel loading in acute ischemic stroke patients. J Stroke Cerebrovasc Dis. 2013;22(7):1184–9. doi: 10.1016/j.jstrokecerebrovasdis.2013.03.001. http://dx.doi.org/10.1016/j.jstrokecerebrovasdis.2013.03.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Siegler JE, Boehme AK, Albright KC, Martin-Schild S. Ethnic disparities trump other risk factors in determining delay to emergency department arrival in acute ischemic stroke. Ethn Dis. 2013;23:29–34. [PMC free article] [PubMed] [Google Scholar]
- 21.Siegler JE, Boehme AK, Kumar AD, Gillette MA, Albright KC, Beasley TM, et al. Identification of modifiable and nonmodifiable risk factors for neurologic deterioration after acute ischemic stroke. J Stroke Cerebrovasc Dis. 2012;22(7):e207–13. doi: 10.1016/j.jstrokecerebrovasdis.2012.11.006. http://dx.doi.org/10.1016/j.jstrokecerebrovasdis.2012.11.006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Kumar AD, Boehme AK, Siegler JE, Gillette M, Albright KC, Martin-Schild S. Leukocytosis in patients with neurologic deterioration after acute ischemic stroke is associated with poor outcomes. J Stroke Cerebrovasc Dis. 2013;22(7):e111–7. doi: 10.1016/j.jstrokecerebrovasdis.2012.08.008. http://dx.doi.org/10.1016/j.jstrokecerebrovasdis.2012.08.008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Saver JL, Warach S, Janis S, Odenkirchen J, Becker K, Benavente O, et al. Standardizing the structure of stroke clinical and epidemiologic research data: the National Institute of Neurological Disorders and Stroke (NINDS) Stroke Common Data Element (CDE) project. Stroke. 2012;43:967–973. doi: 10.1161/STROKEAHA.111.634352. http://dx.doi.org/10.1161/STROKEAHA.111.634352. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.van Swieten JC, Koudstaal PJ, Visser MC, Schouten HJ, van Gijn J. Interobserver agreement for the assessment of handicap in stroke patients. Stroke. 1988;19:604–7. doi: 10.1161/01.str.19.5.604. http://dx.doi.org/10.1161/01.STR.19.5.604. [DOI] [PubMed] [Google Scholar]
- 25.Drolet BC, Johnson KB. Categorizing the world of registries. J Biomed Inform. 2008;41(6):1009–20. doi: 10.1016/j.jbi.2008.01.009. http://dx.doi.org/10.1016/j.jbi.2008.01.009. [DOI] [PubMed] [Google Scholar]
- 26.Bufalino VJ, Masoudi FA, Stranne SK, Horton K, Albert NM, Beam C, et al. The American Heart Association's recommendations for expanding the applications of existing and future clinical registries: a policy statement from the American Heart Association. Circulation. 2011;123:2167–79. doi: 10.1161/CIR.0b013e3182181529. http://dx.doi.org/10.1161/CIR.0b013e3182181529. [DOI] [PubMed] [Google Scholar]
- 27.Jones EM, Albright KC, Fossati-Bellani M, Siegler JE, Martin-Schild S. Emergency department shift change is associated with pneumonia in patients with acute ischemic stroke. Stroke. 2011;42:3226–30. doi: 10.1161/STROKEAHA.110.613026. http://dx.doi.org/10.1161/STROKEAHA.110.613026. [DOI] [PubMed] [Google Scholar]
- 28.Johnson CM, Nahm M, Shaw RJ, Dunham A, Newby K, Dolor R, et al. Can prospective usability evaluation predict data errors? AMIA Annu Symp Proc. 2010;2010:346–50. [PMC free article] [PubMed] [Google Scholar]
- 29.Reeves MJ, Mullard AJ, Wehner S. Inter-rater reliability of data elements from a prototype of the paul coverdell national acute stroke registry. BMC Neurol. 2008;8:19. doi: 10.1186/1471-2377-8-19. http://dx.doi.org/10.1186/1471-2377-8-19. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Paulsen A, Overgaard S, Lauritsen JM. Quality of data entry using single entry, double entry and automated forms processing-an example based on a study of patient-reported outcomes. PLoS One. 2012;7(4):e35087. doi: 10.1371/journal.pone.0035087. http://dx.doi.org/10.1371/journal.pone.0035087. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Day S, Fayers P, Harvey D. Double data entry: what value, what price? Control Clin Trials. 1998;19(1):15–24. doi: 10.1016/s0197-2456(97)00096-2. http://dx.doi.org/10.1016/S0197-2456(97)00096-2. [DOI] [PubMed] [Google Scholar]
- 32.Howard G. Why do we have a stroke belt in the southeastern united states? A review of unlikely and uninvestigated potential causes. Am J Med Sci. 1999;317(3):160–7. doi: 10.1097/00000441-199903000-00005. [DOI] [PubMed] [Google Scholar]
- 33.Lyden P, Raman R, Liu L, Grotta J, Broderick J, Olson S, et al. NIHSS training and certification using a new digital video disk is reliable. Stroke. 2005;36:2446–9. doi: 10.1161/01.STR.0000185725.42768.92. http://dx.doi.org/10.1161/01.STR.0000185725.42768.92. [DOI] [PubMed] [Google Scholar]
- 34.Towfighi A, Saver JL. Stroke declines from third to fourth leading cause of death in the United States: historical perspective and challenges ahead. Stroke. 2012;42:2351–5. doi: 10.1161/STROKEAHA.111.621904. http://dx.doi.org/10.1161/STROKEAHA.111.621904. [DOI] [PubMed] [Google Scholar]
- 35.Hsieh FI, Lien LM, Chen ST, Bai CH, Sun MC, Tseng HP, et al. Get with the guidelines-stroke performance indicators: surveillance of stroke care in the Taiwan stroke registry: get with the guidelines-stroke in Taiwan. Circulation. 2010;122:1116–23. doi: 10.1161/CIRCULATIONAHA.110.936526. http://dx.doi.org/10.1161/CIRCULATIONAHA.110.936526. [DOI] [PubMed] [Google Scholar]
- 36.California Acute Stroke Pilot Registry Investigators. The impact of standardized stroke orders on adherence to best practices. Neurology. 2005;65(3):360–5. doi: 10.1212/01.wnl.0000171706.68756.b7. http://dx.doi.org/10.1212/01.wnl.0000171706.68756.b7. [DOI] [PubMed] [Google Scholar]
- 37.Centers for Disease Control and Prevention (CDC) Use of a registry to improve acute stroke care-seven states, 2005-2009. MMWR Morb Mortal Wkly Rep. 2011;60(07):206–10. [PubMed] [Google Scholar]