

Abstract
A difficulty in using Simultaneous Perturbation Stochastics Approximation (SPSA) is its performance sensitivity to the step sizes chosen at the initial stage of the iteration. If the step size is too large, the solution estimate may fail to converge. The proposed adaptive stepping method automatically reduces the initial step size of the SPSA so that reduction of the objective function value occurs more reliably. Ten mathematical functions each with three different noise levels were used to empirically show the effectiveness of the proposed idea. A parameter estimation example of a nonlinear dynamical system is also included.
Keywords: Stochastic approximation, Optimization, Direct method, Noisy function, Parameter estimation
Background
Simultaneous Perturbation Stochastic Approximation (SPSA) (Spall 1992) is an optimization algorithm that uses only objective function measurements in the search of solutions. Applications of SPSA include model-free predictive control (Dong and Chen 2012a, b; Ko et al. 2008), signal timing for vehicle timing control (Spall and Chin 1997), air traffic network (Kleinman et al. 1997), and marine vessel traffic management (Burnett 2004). More applications are mentioned in the introductory article by Spall (1998b). SPSA has been used successfully in many optimization problems that have high-dimensional input parameter space and the objective value is not deterministic (SPSA 2001).
In this optimization method, the initial design parameter vector of D-dimensions is perturbed simultaneously in every dimension, i.e. by adding and subtracting a perturbation vector of D-dimensions, thus obtaining an estimate of the gradient vector g. Unlike the traditional finite differencing approach, it only takes two function evaluations to obtain the estimate of the gradient. Yet, the number of iteration needed for convergence to the optimum is said to be more or less the same with Finite-Difference Stochastic Approximation (FDSA) (Kiefer and Wolfowitz 1952), which in essence is an approximate steepest-descent method that uses finite-differencing to approximate the partial derivatives along each of the D parameters. Thus, the number of function evaluations of SPSA is D-fold smaller compared to FDSA (Spall 1998b). An extension to this method exists to include second-order (Hessian) effects to accelerate convergence (Spall 2000, 2009; Zhu and Spall 2002). However, we will not treat this enhancement here.
The problem solved by SPSA in this paper can be formulated as following.
| 1 |
where is the objective function and is a D-dimensional vector of parameters. We assume that each element in the vector is a real number and has upper and lower bounds that defines the Cartesian product domain . The SPSA and FDSA procedures are in the general recursive form:
| 2 |
where is the estimate of the gradient vector at iteration k based on the measurements of the objective function. The is the step size at iteration k. Equation (2) is analogous to the gradient descent algorithm in nonlinear programming, in which is the gradient of the objective function . The difference is that in Eq. (2), represent gradients stochastically and the effect of the noise or deviation from the true gradient is expected to cancel out as the iteration count k increases. The step sizes are normally prescribed in SPSA and FDSA as a function of k just like the Simulated-Annealing’s (Kirkpatrick et al. 1983) cooling schedule. This is because these methods do not assume deterministic responses in the measurements of the objective function values. Thus, unlike the nonlinear programming counterparts, adaptation of step sizes based on gradients and amount of descent achieved (such as in the line search) is usually not done in the stochastic approximation optimization methods. The rationale of the Eq. (2) is intuitively depicted in Fig. 1 for one variable case.
Fig. 1.
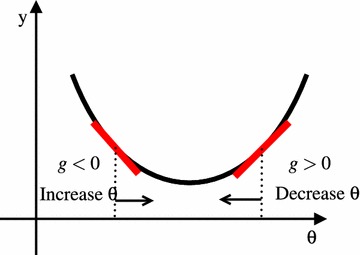
Objective value minimization using gradient descent (one variable): if gradient g is positive at then move to , if gradient g is negative then move to
Under appropriate conditions, the iteration in Eq. (2) will converge to the optimum in some stochastic sense. The hat symbol indicates an “estimate”. Thus, denotes the estimate of the optimum at iteration k. Let denote a measurement of the objective function at parameter value denoted by “” and be some small positive number. The measurements are assumed to contain some noise, i.e. . In SPSA, the component of the gradient vector is formed from a ratio involving the individual components in the perturbation vector and the difference in the two corresponding measurements. For two-sided simultaneous perturbations, we have
| 3 |
where the D-dimensional random perturbation vector
| 4 |
follows a specific statistical distribution criterion. Here, i is the parameter index. A simple choice for each component of is to use Bernoulli 1 distribution, which is essentially a random switching between +1 and 1. The Bernoulli distribution is proven to be an optimal distribution for the simultaneous perturbation (Sadegh and Spall 1997). Note also that in the Eq. (3), we do not evaluate . The recursive equation (2) proceeds with only the responses from the two perturbed inputs and .
The choice of and is critical to the performance of SPSA and suggested values can be found in Spall (1998a). At given iteration k:
| 5 |
| 6 |
where , , , , , , .
The setting for and above are not optimal in the asymptotic sense, but are adapted to finite iteration settings. In practice, one of the drawbacks of SPSA is that one has to find good values for a and c, as both affect the performance of the algorithm Spall (2003, pp. 165–166) (Altaf et al. 2011; Shen et al. 2012; Radac et al. 2011; Easterling et al. 2014; Taflanidis and Beck 2008). However, for c, we have a tangible measure, which is the output measurement error (Spall 1998a), to select a proper value up front. If the function response is noiseless, c is usually not a critical parameter. On the other hand, a is more problematic, because no clear measure exists. It is possible to work with instead of a, but a priori assignment of its value is still non-trivial if little is known about the function that we are trying to optimize.
A larger value of a generally produces better results compared to a smaller value of a. However, this also increases the chance that the optimization diverges to a worse solution than the starting point. Very often, the user of SPSA has to find as big a as possible that would not cause divergence.
To avoid divergence, an adaptation called “blocking” exists (Easterling et al. 2014; Spall 1998a) in which the objective values at is evaluated in addition to the two perturbations. If the new objective function value is “significantly worse” than the current objective function value, the updating of does not happen. The extra function evaluation at each iteration increases the cost of iteration by 33 %. In addition, a problem dependent threshold parameter to block the update needs to be set up by the user.
Another way to mitigate divergence is to modify the gradient approximation by “scaling” and “averaging” (Andradóttir 1996; Xu and Wu 2013). However, the methods proposed in the literature require set up of additional threshold parameters critical to their performance. Furthermore, their methods require additional gradient estimations per iteration.
Stochastic Gradient Descent (SGD) methods use noisy information of the gradient of the objective functions. On the other hand, Stochastic Approximation methods such as FDSA and SPSA only uses measurement of noisy objective values. Therefore, adaptive determination of step sizes based on (approximate) gradients and inverse Hessians in SGD literature (such as in Zeiler (2012), Bottou (2010)) may not be directly applicable to or feasible in SPSA. Convergence conditions also differ between the two. Although this does not exclude the possibility of successful import of ideas from SGD literature, in this paper, we will not delve into this direction.
This paper provides a solution to determine the appropriate values of a by introducing an adaptive scheme as discussed in “Adaptive initial step sizes” section. It does not require any additional objective function evaluations per iteration nor extra problem dependent parameters to set up.
Adaptive initial step sizes
To remedy the sensitivity to a, we propose an adaptive stepping algorithm. At the end of each iteration k, we perform the adjustment described in Algorithm 1.

The condition requires that at least one of the two parameter perturbations produce a better (smaller) measurement of the objective function than that of initial guess of parameters to proceed without modifying a. Therefore, at each iteration k, the smaller of the two measurements of the objective function values of perturbed parameters is compared to that of the initial value at iteration . If the measurements of the objective values of the perturbed parameters are larger, is reset to , which is the point that gave the minimum in the history of iteration and a is reduced to half of its previous value. A pseudocode of the proposed SPSA with the adaptive initial step is shown in Algorithm 2. The difference between the standard SPSA and our SPSA is in line 10.

Comments on convergence
Currently available theories of stochastic algorithms are almost all based on asymptotic properties with , and SPSA is no exception. For given conditions Spall (2003, p. 183), SPSA is proven to converge to a local optima almost surely. However, under limited function evaluation budget, we frequently encounter situations in which SPSA returns worse solution than the initial i.e. divergence. The method we propose is a practical remedy conceived in a finite k setting. We will show, in the next section, its effectiveness empirically via numerical experiments with k in the order of .
For to converge to the optimal solution in infinite steps, the following conditions are required for and (Spall 1992): for all k; as ; , and . With Algorithm 1, is not guaranteed. For example, if the reduction of a happens in every iteration k, the sum is convergent. In practice, the numbers of function evaluations are finite, and reductions of a are expected to happen only a limited number of times. Therefore, this violation is expected to pose little problem.
The intention of the proposed method is not to modify the asymptotic convergence rate of the original SPSA algorithm Spall (2003, pp. 186–188). The adaptive step takes place only if it is suspected that the objective value has become larger than at the starting point . The probability of Algorithm 1 taking place is expected to go to zero under reasonable signal-to-noise ratio as decreases. The worst situation that can happen is that the every perturbation produces worsening moves and no improvement is obtained compared to the starting point . In “Computational results” section, we will confirm empirically what we have described about the convergence in finite k settings ().
Another reason to take the objective value at the starting point as the threshold value to judge divergence is that if we update this value with , where , we may risk picking a point that is too low due to the noise incurred in the measurement y. This in turn inhibits further improvement of for lower objective values.
In the following section, the smallest output of mathematical functions will be sought using the standard SPSA and our adaptive initial stepping SPSA. This will show the sensitivity of the function value in the final iteration to the initial step size and so the sensitivity to a, and how the adaptive initial stepping substantially mitigates the difficulty to find the proper initial perturbation magnitude.
Computational results
In this section, we will compare the original SPSA and our modified SPSA as described in Algorithm 2 using 10 analytical test functions and a parameter estimation example of a nonlinear dynamic system.
Test functions
To see the effect of the new adaptive stepping algorithm in SPSA, the minimum points of ten different mathematical test functions were sought. Except for Griewank function, the following conditions were applied. The functions’ responses were minimized from arbitrary starting points (D-dimensional product space with lower bound -2 and upper bound 2). If exceeded in any of its D dimensions, that parameter was replaced by -10 if it was less than -10 or was replaced by 10 if it was larger than 10. For Griewank function, it was randomly started from . If exceeded in any of its D dimensions, that parameter was replaced by −600 if it was less than −600 or was replaced by 600 if it was larger than 600. For all ten functions, the iteration was stopped when 2000 evaluations of the objective function were reached. For convenience, we will label our proposed algorithm as “A_SPSA” and the standard SPSA as “SPSA”.
The optimizations for each of the ten objective functions were started from 20 different starting points. After the 2000 iterations, the distributions of objective values were plotted with respect to . Eleven different values of between and (up to for Griewank) were used to make the plot. The dimensions of the functions were set to be 20, i.e. .
The definitions of the ten functions are given in the following. The Rosenbrock function is described as
| 7 |
The Sphere function is described as
| 8 |
The Schwefel function is described as
| 9 |
The Rastrigin function is described as
| 10 |
The Skewed Quartic function Spall (2003, ex. 6.6) is described as
| 11 |
where the matrix in the Skewed Quartic function is a square matrix with upper triangular elements set to 1 and the lower triangular elements set to zero. The Griewank function is described as
| 12 |
The Ackley function is described as
| 13 |
The Manevich function is described as
| 14 |
The Ellipsoid function is described as
| 15 |
The Rotated Ellipsoid function is described as
| 16 |
Each of Figs. 2, 3, 4, 5, 6, 7, 8, 9, 10 and 11 show three different cases of noisy measurements of the outputs. The subfigures (a) have no noise added, subfigures (b) and (c) have Gaussian noise added to the true output with standard deviation of 0.1 and 1.0 respectively. In all the three noise levels of the ten functions, was used.
Fig. 2.
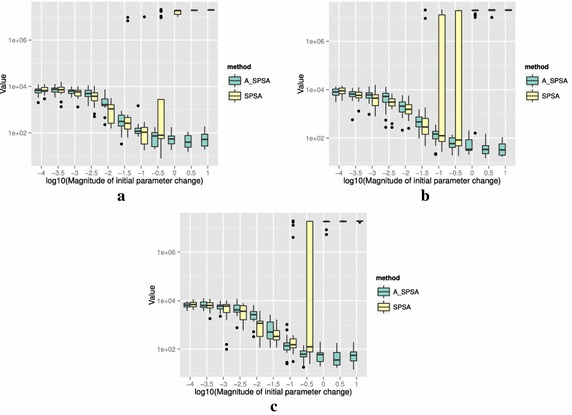
Initial parameter change and distribution of responses after 2000 function evaluations for “Rosenbrock”. a No noise, b σ = 0.10, c σ = 1.0
Fig. 3.

Initial parameter change and distribution of responses after 2000 function evaluations for “Sphere”. a No noise, b σ = 0.10, c σ = 1.0
Fig. 4.

Initial parameter change and distribution of responses after 2000 function evaluations for “Schwefel”. a No noise, b σ = 0.10, c σ = 1.0
Fig. 5.

Initial parameter change and distribution of responses after 2000 function evaluations for “Rastrigin”. a No noise, b σ = 0.10, c σ = 1.0
Fig. 6.

Initial parameter change and distribution of responses after 2000 function evaluations for “Skewed Quartic”. a No noise, b σ = 0.10, c σ = 1.0
Fig. 7.

Initial parameter change and distribution of responses after 2000 function evaluations for “Griewank”. a No noise, b σ = 0.10, c σ = 1.0
Fig. 8.
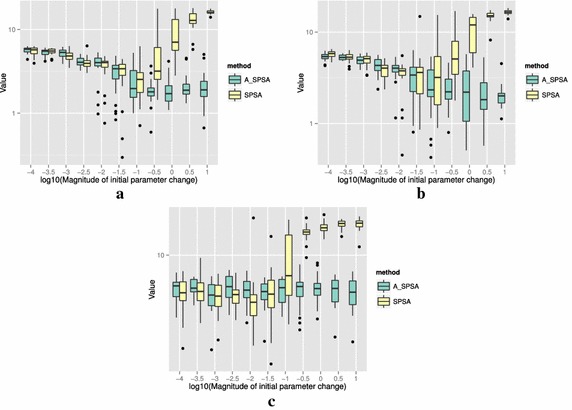
Initial parameter change and distribution of responses after 2000 function evaluations for “Ackley”. a No noise, b σ = 0.10, c σ = 1.0
Fig. 9.
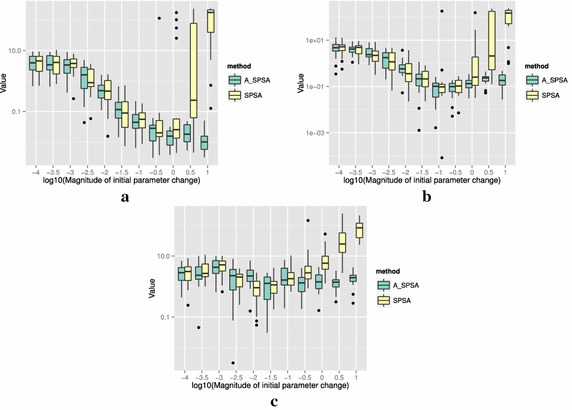
Initial parameter change and distribution of responses after 2000 function evaluations for “Manevich”. a No noise, b σ = 0.10, c σ = 1.0
Fig. 10.
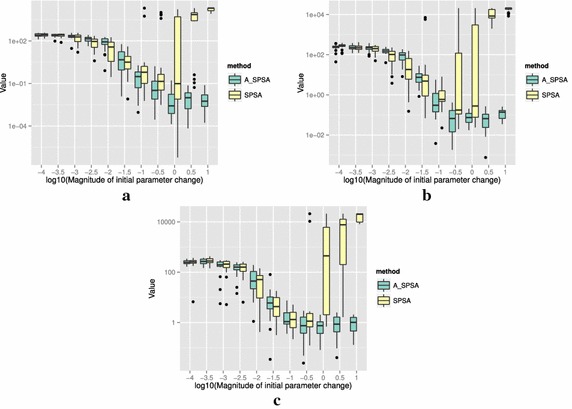
Initial parameter change and distribution of responses after 2000 function evaluations for “Ellipsoid”. a No noise, b σ = 0.10, c σ = 1.0
Fig. 11.

Initial parameter change and distribution of responses after 2000 function evaluations for “Rotated Ellipsoid”. a No noise, b σ = 0.10, c σ = 1.0
A general trend observed from the figures is that when the initial step size is large, the original SPSA tends to diverge to big objective values. The SPSA with the proposed initial step size reduction, on the other hand, effectively mitigates this divergence problem producing smaller objective values in general as the (a priori) initial step size is increased. This is because if the two function evaluations in the iteration are not smaller than the starting point value , the algorithm will reduce the step size (by halving a) and restart at , which is the point that gave the smallest output in the history of iterations. However, note that the iteration index k in and is not reinitialized. For the ten functions tested, A_SPSA achieved its best performance when was close to 10 or 100 for Griewank function. This indicates that one can simply set the minimum perturbation close to the magnitude of the difference between upper and lower bound of the parameter in consideration. This may not be a guarantee for the best results but doing so does not cause the optimization to diverge to large responses and the results achieved are not substantially worse than the cases with best settings for a.
As mentioned earlier, the value for c is important when the measurements of y contain noise. Figure 12 shows how the choice of c affects the outcome of optimizations. The figure shows the case of the 20 dimensional Sphere Function with Gaussian noise having standard deviation . Among the three values of c, namely 0.01, 0.1 and 1.0, gave the best results for A_SPSA. At , however, A_SPSA showed little improvement in the objective value regardless of magnitude. This is caused by a becoming prematurely too small in the divergent early iterations. On the other hand, the standard SPSA showed a good reduction at , and . at both and 1.0. This implies that for A_SPSA, a range of values of good c can be narrower than that of the standard SPSA. On the other hand, the choice of (and therefore a) is much easier for A_SPSA. We can, for example, let (U − L), where min(U − L) is the minimum difference between upper and lower bounds of the domain of parameter vector . In practice, it is better to scale all the input dimensions to fall in similar or equal intervals.
Fig. 12.

Effect of choice of c to the final response of “Sphere” with Gaussian noise of after 2000 function evaluations. a c = 0.01, b c = 0.10, c c = 1.00
Figure 13 shows the results of optimizing the Rosenbrock and Rastrigin functions using three different values of multiplication factor of a: 0.1, 0.5, and 0.9. The difference in multiplication factor does not change the general trend that larger produces better results and that divergence does not occur. One could tune the value of the multiplication factor, but the default value of 0.5 that we showed in the Algorithm 1 generally produces satisfactory results compared to other values of multiplication factors between 0 and 1. The Fig. 13 (b) also shows that may not be an optimal setting since smaller value is shown to produce better optimization results when the reduction rate is slow at 0.9. This implies that in a bumpy (highly multimodal) function like Rastrigin, the slow decrease in a can adversely affect the minimization of the objective value by a large number of resets to . The opposite is true with Rosenbrock function in (a), in which the slow reduction factor 0.9 gave the best result at .
Fig. 13.

Effect of choice of the reduction factor of a to the responses after 2000 function evaluations. a Rosenbrock (no noise), b Rastrigin (no noise)
For all the mathematical functions tested in this paper, optimization using SPSA diverges almost surely if the is large. However, A_SPSA and SPSA give closely matching results when the initial step sizes are relatively small (i.e., the left hand side of the plots in Figs. 2, 3, 4, 5, 6, 7, 8, 9, 10 and 11). This is because, in cases that divergence does not happen, the adaptation of a does not take place in A_SPSA and therefore SPSA and A_SPSA have identical behavior. This is a confirmation that Algorithm 1 does not alter, in any significant way, the finite sample convergence characteristics of the original SPSA when the divergence does not manifest.
Nonlinear dynamics example
We consider a parameter estimation problem with Lorenz attractor. Its nonlinear dynamics is described as
| 17 |
| 18 |
| 19 |
We seek to identify the system parameters by minimizing the one-time-step-ahead prediction error of the state given the current state . We use fourth-order Runge–Kutta method to obtain .
Let us denote as one-time-step-ahead prediction given by the estimated system with parameters . Then, we can define the prediction error as
| 20 |
Thus, the optimization to be solved is
| 21 |
The index k above is the same as the index k in the SPSA algorithms. So the SPSA iteration proceeds along with the time steps of the dynamic system to compute .
We set the true parameters to be and pretend to not to know them. We set the time increment to be and simulate from to 20, obtaining target state with . We let and at each value of we run both A_SPSA and SPSA 20 times.
For this problem, we set the parameter space as three-dimensional product space . The initial state is . The initial guess (starting point) of the parameter set is a random pick from .
Figure 14 show the box plots of final when started from different values of . The smallest median of final is obtained at for SPSA and and 1000 for A_SPSA. The best medians of final obtained for A_SPSA () is smaller compared to that of SPSA (). However, both SPSA and A_SPSA had some runs that did not converge to the above mentioned near-zero values even at these .
Fig. 14.
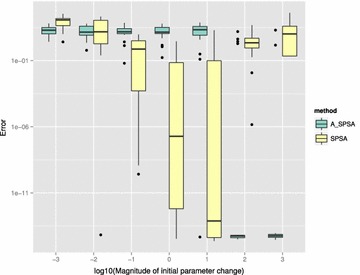
Initial parameter change and distribution of (after 8000 function evaluations)
Again, for A_SPSA, the best setting were obtained when was set to large values near the order of magnitude of the distance between upper and lower bound of the domain, while for SPSA, the best was at an interior value between and .
Figure 15 shows the trajectory of the reference Lorenz attractor and the simulation of the Lorenz attractor whose system parameters s, r, and b were successfully identified by A_SPSA. The time t is run from 0 to 20 starting from the same initial condition used in the identification. The figure shows excellent match.
Fig. 15.

State evolution of the target and identified Lorenz attractor, to 20
Figure 16 shows the box plots of parameters estimated by A_SPSA and SPSA starting at their best settings. The corresponding statistics are shown in Tables 1 and 2. The boxes appear collapsed as single horizontal lines at medians since the spaces between first quartiles and third quartiles are very narrow. Some non-converging cases are visible as dots on the figure. The figure and the tables show that the parameter estimates are more consistent from run to run in A_SPSA than that of SPSA as A_SPSA has narrower first and third quartile differences.
Fig. 16.

Distribution of the parameters identified by A_SPSA and SPSA. a A_SPSA with , b SPSA with
Table 1.
Statistics of identified Lorenz Attractor parameters by 20 SPSA runs at
| Method | s | r | b | Pred. Err. | |
|---|---|---|---|---|---|
| 1 | A_SPSA: 0 | Min.: 0.00 | Min.: 8.017 | Min.: 0.000 | Min.: 0.0000 |
| 2 | SPSA: 20 | 1st Qu.: 10.00 | 1st Qu.: 28.000 | 1st Qu.: 2.642 | 1st Qu.: 0.0000 |
| 3 | Median: 10.00 | Median: 28.000 | Median: 2.667 | Median: 0.0000 | |
| 4 | Mean: 55.94 | Mean: 45.534 | Mean: 2.311 | Mean: 1.3645 | |
| 5 | 3rd Qu.: 11.11 | 3rd Qu.: 36.817 | 3rd Qu.: 2.667 | 3rd Qu.: 0.1017 | |
| 6 | Max.: 477.04 | Max.: 328.504 | Max.: 3.261 | Max.: 19.6773 |
Table 2.
Statistics of identified Lorenz attractor parameters by 20 A_SPSA runs at
| Method | s | r | b | Pred. Err. | |
|---|---|---|---|---|---|
| 1 | A_SPSA: 20 | Min.: 0.000 | Min.: 0.000 | Min.: 0.0000 | Min.: 0.0000 |
| 2 | SPSA: 0 | 1st Qu.: 10.000 | 1st Qu.: 28.000 | 1st Qu.: 2.6667 | 1st Qu.: 0.0000 |
| 3 | Median: 10.000 | Median: 28.000 | Median: 2.6667 | Median: 0.0000 | |
| 4 | Mean: 68.069 | Mean: 31.816 | Mean: 24.8487 | Mean: 1.2328 | |
| 5 | 3rd Qu.: 10.000 | 3rd Qu.: 28.000 | 3rd Qu.: 2.6667 | 3rd Qu.: 0.0000 | |
| 6 | Max.: 500.000 | Max.: 156.811 | Max.: 438.8246 | Max.: 15.6654 |
Conclusion
With the adaptive initial step algorithm, one can avoid divergence in SPSA iterations. Moreover, with a large initial step size, the SPSA algorithm with the adaptive initial step algorithm was able to find equal or better solutions compared to the original SPSA for all the ten mathematical function minimization problems that we have tested. In the nonlinear dynamics example, the new algorithm was able to find system parameters more precisely. The proposed method may not eliminate the need of tuning the parameters of SPSA algorithms, but it facilitates the process by eliminating the risk of solution divergence and reducing the trial-and-error effort. Further testing of the algorithm with different test functions, noise distributions, and industrial use-cases would be beneficial. The improvement proposed in this paper is expected to be valuable when the objective functions are costly to evaluate or if the algorithm is employed inside another algorithm such as machine learning or target tracking, for manual tuning of the parameters would be cumbersome in such cases. As a future work, it would be beneficial to investigate under what conditions the probability of the proposed adaptation (i.e. going into if-branch in Algorithm 1) happening tends to zero as iteration k tends to infinity.
Authors’ contributions
KI has conceived the Algorithm 1, conducted the numerical experiments, and has written this manuscript. TD has provided guidance by supervising the progress of the research, and has reviewed the manuscript for intellectual feedback and editing.
Acknowledgements
The authors would like to thank James C. Spall for constructive comments on the proposed method. Keiichi Ito has been funded by the Institute for the Promotion of Innovation through Science and Technology (IWT) through the Baekeland Mandate program. This research has also been funded by the Interuniversity Attraction Poles Programme BESTCOM initiated by the Belgian Science Policy Office.
Competing interests
Keiichi Ito is employed at Noesis Solutions, a private company, which has interests in optimization methods.
References
- Altaf MU, Heemink AW, Verlaan M, Hoteit I. Simultaneous perturbation stochastic approximation for tidal models. Ocean Dyn. 2011;61:1093–1105. doi: 10.1007/s10236-011-0387-6. [DOI] [Google Scholar]
- Andradóttir S. A scaled stochastic approximation algorithm. Manag Sci. 1996;42(4):475–498. doi: 10.1287/mnsc.42.4.475. [DOI] [Google Scholar]
- Bottou L (2010) Large-scale machine learning with stochastic gradient descent. In: Proceedings of COMPSTAT’2010. Springer, pp 177–186
- Burnett R (2004) Application of stochastic optimization to collision avoidance. In: Proceedings of the American control conference. Massachusetts, USA, Boston, pp 2789–2794
- Dong N, Chen Z. A novel ADP based model-free predictive control. Nonlinear Dyn. 2012;69(1–2):89–97. doi: 10.1007/s11071-011-0248-3. [DOI] [Google Scholar]
- Dong N, Chen Z. A novel data based control method based upon neural network and simultaneous perturbation stochastic approximation. Nonlinear Dyn. 2012;67(2):957–963. doi: 10.1007/s11071-011-0039-x. [DOI] [Google Scholar]
- Easterling D, Watson L, Madigan M, Castle B, Trosset M. Parallel deterministic and stochastic global minimization of functions with very many minima. Comput Optim Appl. 2014;57(2):469–492. doi: 10.1007/s10589-013-9592-1. [DOI] [Google Scholar]
- Kiefer J, Wolfowitz J. Stochastic estimation of the maximum of a regression function. Ann Math Stat. 1952;23:452–466. [Google Scholar]
- Kirkpatrick S, Gelatt CD, Vecchi MP. Optimization by simulated annealing. Science. 1983;220(4598):671–680. doi: 10.1126/science.220.4598.671. [DOI] [PubMed] [Google Scholar]
- Kleinman NL, Hill SD, Ilenda VA (1997) SPSA/SIMMOD optimization of air traffic delay cost. In: Proceedings of the American control conference. Albuquerque, New Mexico, USA, pp 1121–1125
- Ko HS, Lee KY, Kim HC. A simultaneous perturbation stochastic approximation (SPSA)-based model approximation and its application for power system stabilizers. Int J Control Autom Syst. 2008;6(4):506–514. [Google Scholar]
- Radac M, Precup R, Petriu E, Preitl S. Application of IFT and SPSA to servo system control. IEEE Trans Neural Netw. 2011;22(12):2363–2375. doi: 10.1109/TNN.2011.2173804. [DOI] [PubMed] [Google Scholar]
- Sadegh P, Spall JC (1997) Optimal random perturbations for stochastic approximation using a simultaneous perturbation gradient approximation. In: Proceedings of the American control conference. Albuquerque, NM, USA, pp 3582–3586
- Shen X, Yao M, Jia W, Yuan D (2012) Adaptive complementary filter using fuzzy logic and simultaneous perturbation stochastic approximation algorithm. Measurement 45(5):1257–1265. doi:10.1016/j.measurement.2012.01.011. http://www.sciencedirect.com/science/article/pii/S0263224112000267
- Spall JC. Multivariate stochastic approximation using a simultaneous perturbation gradient approximation. IEEE Trans Autom Control. 1992;37(3):332–341. doi: 10.1109/9.119632. [DOI] [Google Scholar]
- Spall JC. Implementation of the simultaneous perturbation algorithm for stochastic optimization. IEEE Trans Aerosp Electron Syst. 1998;34(3):817–823. doi: 10.1109/7.705889. [DOI] [Google Scholar]
- Spall JC. An overview of the simultaneous perturbation method for efficient optimization. Johns Hopkins APL Tech Dig. 1998;19(4):482–492. [Google Scholar]
- Spall JC. Adaptive stochastic approximation by the simultaneous perturbation method. Trans Autom Control. 2000;45(10):1839–1853. doi: 10.1109/TAC.2000.880982. [DOI] [Google Scholar]
- Spall JC. Introduction to stochastic search and optimization, estimation, simulation and control. New York: Wiley-Interscience; 2003. [Google Scholar]
- Spall JC. Feedback and weighting mechanisms for improving jacobian estimates in the adaptive simultaneous perturbation algorithm. IEEE Trans Autom Control. 2009;54(6):1216–1229. doi: 10.1109/TAC.2009.2019793. [DOI] [Google Scholar]
- Spall JC, Chin DC. Traffic-responsive signal timing for system-wide traffic control. Transp Res. 1997;5(Part C):153–163. [Google Scholar]
- SPSA (2001) Simultaneous perturbation stochastic approximation: a method for system optimization. http://www.jhuapl.edu/SPSA/index.html
- Taflanidis A, Beck J (2008) Stochastic subset optimization for optimal reliability problems. Probab Eng Mech 23(2–3):324–338. doi:10.1016/j.probengmech.2007.12.011. http://www.sciencedirect.com/science/article/pii/S0266892007000501. 5th international conference on computational stochastic mechanics
- Xu Z, Wu X. A new hybrid stochastic approximation algorithm. Optim Lett. 2013;7(3):593–606. doi: 10.1007/s11590-012-0443-2. [DOI] [Google Scholar]
- Zeiler MD (2012) ADADELTA: an adaptive learning rate method. arXiv:1212.5701v1 [cs.LG]
- Zhu X, Spall JC. A modified second-order SPSA optimization algorithm for finite samples. Int J Adapt Control Signal Process. 2002;16:397–409. doi: 10.1002/acs.715. [DOI] [Google Scholar]