

Abstract
This paper presents new theoretical results on the backpropagation algorithm with smoothing regularization and adaptive momentum for feedforward neural networks with a single hidden layer, i.e., we show that the gradient of error function goes to zero and the weight sequence goes to a fixed point as n (n is iteration steps) tends to infinity, respectively. Also, our results are more general since we do not require the error function to be quadratic or uniformly convex, and neuronal activation functions are relaxed. Moreover, compared with existed algorithms, our novel algorithm can get more sparse network structure, namely it forces weights to become smaller during the training and can eventually removed after the training, which means that it can simply the network structure and lower operation time. Finally, two numerical experiments are presented to show the characteristics of the main results in detail.
Keywords: Feedforward neural networks, Adaptive momentum, Smoothing regularization, Convergence
Background
A multilayer perceptron network trained with a highly popular algorithm known as the error back-propagation (BP) has been dominating in the neural network literature for over two decades (Haykin 2008). BP uses two practical ways to implement the gradient method: the batch updating approach that accumulates the weight corrections over the training epoch before performing the update, while the online learning approach updates the network weights immediately after each training sample is processed (Wilson and Martinez 2003).
Note that training is usually done by iteratively updating of the weights that reduces error value, which is proportional to the negative gradient of a sum-square error (SSE) function. However, during the training of feedforward neural networks (FNN) with SSE, the weights might become very large or even unbounded. This drawback can be addressed by adding a regularization term to the error function. The extra term acts as a brute-force to drive unnecessary weights to zero to prevent the weights from taking too large values and then it can be used to remove weights that are not needed, and is also called penalty term (Haykin 2008; Wu et al. 2006; Karnin 1990; Reed 1993; Saito and Nakano 2000).
There are four main different penalty approaches for BP training: weight decay procedure (Hinton 1989), weight elimination (Weigend et al. 1991), approximate smoother procedure (Moody and Rognvaldsson 1997) and inner product penalty (Kong and Wu 2001).
In the weight decay procedure, the complexity penalty term is defined as the squared norm of the weight vector, and all weights in the multilayer perceptron are treated equally. In the weight elimination procedure, the complexity penalty represents the complexity of the network as function of weight magnitudes relative to a pre-assigned parameter (Reed 1993).
In approximate smoother procedure, this penalty term is used for a multilayer perceptron with a single hidden layer and a single neuron in the output layer. Compared with the earlier methods, it does two things. First, it distinguishes between the roles of weights in the hidden layer and those in the output layer. Second, it captures the interactions between these two sets of weights, however, it is much more demanding in computational complexity than weight decay or weight elimination methods. In Kong and Wu (2001) the inner-product form is proposed and its efficiency in general performance of controlling the weights is demonstrated. Convergence of the gradient method for the FNN has been considered by Zhang et al. (2015, 2009), Wang et al. (2012) and Shao and Zheng (2011).
The convergence of the gradient method with momentum is considered in Bhaya and Kaszkurewicz (2004), Torii and Hagan (2002), Zhang et al. (2006), in Bhaya and Kaszkurewicz (2004) and Torii and Hagan (2002) under the restriction that the error function is quadratic. Inspired by Chan and Fallside (1987), Zhang et al. (2006) considers the convergence of a gradient algorithm with adaptive momentum, without assuming the error function to be quadratic as in the existing results. However, in Zhang et al. (2006), the strong convergence result is based on the assumption that the error function is uniformly convex, which still seems a little intense.
The size of a hidden layer is one of the most important considerations when dealing with real life tasks using FNN. However, the existing pruning methods may not prune the unnecessary weights efficiently, so how to efficiently simplify the network structure becomes our main task.
Recently, considerable attention has been paid to the sparsity problems and a class of regularization methods was proposed which take the following form:
| 1 |
where is a loss function, is a data set, and is the regularization parameter. When h is in the linear form and the loss function is square loss, is normally taken as the norm of the coefficient of linear model.
For , (1) becomes regularization and can be understood as a penalized least squares with penalty , which yields the most sparse solutions, but for large data analysis it faces the problem of combinatory optimization (Davis 1994; Natarajan 1995). In order to deal with such difficulty, Tibshirani (1996) proposed regularization where and is the norm of n dimensional Euclidean space , which just needs to solve a quadratic programming problem but is less sparse than the regularization. At the same time Donoho (1995, 2005) proved that under some conditions the solutions of the regularizer are equivalent to those of the , so the hard NP optimization problem can be avoided in the regularizer. In order to find a new regularizer which is more sparse than the regularizer while it is still easier to be solved than the regularizer, in Xu et al. (2010) a modified regularizer is proposed of the following form:
| 2 |
where is the tuning parameter. As shown in Xu et al. (2010), regularizer has a nonconvex penalty and possesses many promising properties such as unbiasedness, sparsity, oracle properties and can be taken as a representative of the regularizer. Recently, we develop a novel method to prune FNNs through modify the usual regularization term by smoothing technique. The new algorithm not only removes the oscillation of the gradient value, but also get better pruning, namely the final weights to be removed are smaller than those produced through the usual regularization (Wu et al. 2014; Fan et al. 2014).
The focus of this paper is on extension of regularization beyond its basic concept though its augmentation with a momentum term. Also, there are some other applications of FNNs for optimization problems, such as the generalized gradient and recurrent neural network methods shown as Liu et al. (2012) and Liu and Cao (2010)
It is well known that a general drawback of gradient based BP learning process is its slow convergence. To accelerate learning, a momentum term is often added (Haykin 2001; Chan and Fallside 1987; Qiu et al. 1992; Istook and Martinez 2002). By adding momentum to the update formula, the current weight increment is a linear combination of the gradient of the error function and the previous weight increment. As a result, the updates respond not only to the local gradient but also to recent gradient in the error function. Selected reports discuss the NN training with momentum term in the literature (Torii and Hagan 2002; Perantonis and Karras 1995; Qian 1999).
As demonstrated in Torii and Hagan (2002), there always exists a momentum coefficient that will stabilize the steepest descent algorithm, regardless of the value of the learning rate (we will define it below). In addition, it shows how the value of the momentum coefficient changes the convergence properties. Momentum acceleration, its performance in terms of learning speed and scalability properties is evaluated and found superior to the performance of reputedly fast variants of the BP algorithm in several benchmark training tasks in Perantonis and Karras (1995). Qian (1999) shows that in the limit of continuous time, the momentum parameter is analogous to the mass of Newtonian particles that move through a viscous medium in a conservative force field.
In this paper, a modified batch gradient method with smoothing regularization penalty and adaptive momentum algorithm (BGSAM) is proposed. It damps oscillations present in the regularization and in the adaptive momentum algorithm (BGAM). In addition, without the requirement that the error function is quadratic or uniformly convex, we present a comprehensive study of the weak and strong convergence for BGSAM which offers an effective improvement in real life application.
The rest of this paper is arranged as follows. The algorithm BGSAM is described in “Batch gradient method with smoothing L1/2 regularization and adaptive momentum (BGSAM)” section. In “Convergence results” section, the convergence results of BGSAM are presented, and the detailed proofs of the main results are stated in the “Appendix”. The performance of BGSAM is compared to BGAM and the experimental results shown in “Numerical experiments” section. Concluding remarks are in “Conclusions” section.
Batch gradient method with smoothing regularization and adaptive momentum (BGSAM)
Batch gradient method with regularization and adaptive momentum (BGAM)
Here and below, some definitions and notations used in e.g. Wu et al. (2006), Shao and Zheng (2011), and Wu et al. (2006), Shao and Zheng (2011) have been re-defined and used without repeatedly citing the references. We consider a FNN with three layers, and we denote the numbers of neurons of the input, hidden and output layers by p, q and 1, respectively. Suppose that is the given set of J training samples. Let be the weight vector between the hidden units and the output unit, and be the weight vector between the input units and the hidden unit i. To simplify the presentation, we combine the weight vectors, and write and we define a matrix . We also define a vector function , for
| 3 |
Let be a given transfer function for the hidden and output nodes, which is typically, but not necessarily, a sigmoid function. Then for each input , the actual output vector of the hidden layer is and the final output of the network is
| 4 |
For a fixed W, the output error function with the regularization penalty term is
| 5 |
where , , , is the penalty coefficient, and denotes the absolute value. The gradient of the error function is
| 6 |
where
The gradient of the error function with respect to and are, respectively, given by
| 7 |
| 8 |
where and .
The detailed BGAM algorithm is presented as follows. We denote , starting from an arbitrary initial value and , and the weights are updated iteratively by
| 9 |
The learning rate is assumed constant and satisfies , and is the momentum coefficient vector of the n-th training. It consists of coefficients for each , and for each . Similar to Shao and Zheng (2011), for every , after each training epoch it is chosen as
| 10 |
where is the momentum factor. Compared with the traditional algorithm, the BGAM has better pruning performance, but we notice that this usual regularization term used in this part involves in absolute values and it is not differentiable at the origin, which will cause difficulty in the convergence analysis. More importantly, it causes oscillations of the error function and the norm of gradient. In order to overcome these drawbacks we improved the BGAM algorithm as follows:
Smoothing regularization and adaptive momentum (BGSAM)
This section introduces a modified algorithm with smoothing regularization and adaptive momentum term. The network structure is the same as the description in part of last subsection (BGAM). We modify the usual regularization term at the origin (i.e. we replace the absolute values of the weights by a smooth function in a neighborhood of the origin). Then we use a smooth function f(x) to approximate |x|. We get the following error function with a smoothing regularization penalty term:
| 11 |
where , , , is the penalty coefficient. Here, by smoothing we mean that, in a neighborhood of the origin, we replace the absolute values of the weights by a smooth function of the weights. For definiteness and simplicity, we choose f(x) as a piecewise polynomial function such as:
| 12 |
where a is a small positive constant. and denotes the absolute value. Then, from the definition of f(x) immediately yields
The gradient of the error function with respect to W as in (6), and the gradients of the error function with respect to and are then as follows:
| 13 |
| 14 |
where .
For BGSAM algorithm, we denote . Starting with an initial value and , the weights are updated iteratively by
| 15 |
Here the learning rate , the momentum coefficient vector of the n-th training and other coefficients are the same as the description of algorithm BGAM. For each , after each training epoch it is chosen as (10).
Convergence results
The following assumptions are needed to introduce the relating convergence theorems of BGSAM.
- (A1)
|g(t)|, , are uniformly bounded for .
- (A2)
There exists a bounded region such that .
- (A3)
, where and is a constant defined in (16) below.
Assume conditions (A1)–(A2) is valid. Then there are some positive constants – such that
| 16 |
Theorem 1
If assumptions are valid for any arbitrary initial value and , the error function be defined by (1), and let the learning sequence 1 be generated by the iteration algorithm (15), then we have the following convergence
-
(i)
. Moreover, (A4) if there exists a compact set such that and the set contains finite points also holds, then we have the following convergence
-
(ii)
where .
Numerical experiments
This section presents the simulations that verify the performance of BGAM and BGSAM. Our theoretical results are experimentally verified with the 3-bit parity problem, which is a typical benchmark problem in area of the neural networks.
The two algorithms (BGAM and BGSAM) are implemented by the networks with the structure 5-7-1 (input , hidden and output nodes, see Fig. 1). Each of the two algorithms are carried out fifty trials for 3-bit parity problem and then take the mean values, and the termination criterion is that the error is 1e6 or 3000 iterations. For the network with linear output, we set the transfer function for hidden neurons to be and that for output layer to be . For the network with nonlinear output, the transfer functions for both hidden and output neurons are . The inputs and the ideal outputs are shown in Table 1.
Fig. 1.
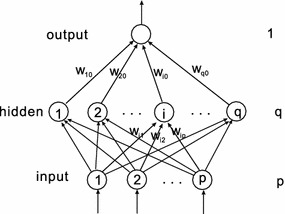
Feedforward neural network with one hidden layer and one output
Table 1.
3-bit parity problem
| Input | Output | Input | Output | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | −1 | 1 | 1 | −1 | −1 | −1 | 1 |
| 1 | 1 | −1 | −1 | 0 | −1 | 1 | 1 | −1 | 0 |
| 1 | −1 | 1 | −1 | 0 | −1 | −1 | 1 | −1 | 1 |
| −1 | −1 | −1 | −1 | 0 | −1 | 1 | −1 | −1 | 1 |
The performance results of BGAM and BGSAM are shown in the following figures. Figures 2, 3 and 4 present the comparison results for learning rate , penalty parameter and momentum term with 0.01, 0.0006 and 0.03, respectively.
Fig. 2.

The curve of error function
Fig. 3.

The curve of norm of gradient
Fig. 4.

The curve of norm of weight
From Figs. 2 and 3, it can be seen that the error function decreases monotonically and the norm of the gradient of the error function approaches zero as depicted by the convergence theorem, respectively. Also Fig. 3 show us that our modified algorithm overcomes the drawbacks of numerical oscillations, i.e., for BGSAM the norm of gradient curve is much smoother than BGAM. The reason as the following: Since the derivative of |x| jumps from to near the , the learning process of BGAM will oscillate when a weight is close to zero, whic prevents it from getting further closer to zero. And on the contrary, the derivative of f(x), which is a smooth approximation of |x|, is smooth and equal to zero at the origin, and will not cause any oscillation in the learning process when is close to zero. In the meantime, it can be seen that BGSAM convergence faster than BGAM. Fig. 4 demonstrates that the effectiveness of the algorithm BGSAM in controlling the magnitude of weights is better than BGAM.
Conclusions
In this paper, the smoothing regularization term with adaptive momentum is introduced into the batch gradient learning algorithm to prune FNN. First, it removes the oscillation of the gradient value. Second, the convergence results for three-layer FNN are proved under certain relaxed conditions. Third, the algorithm is applied to a 3-bit parity problem and the related results are supplied to support the theoretical findings above. Finally, this new algorithm will also effective for other types neural networks or big data processing.
Authors’ contributions
This work was carried out by the three authors, in collaboration. All authors read and approved the final manuscript.
Acknowledgements
This work was supported by National Science Foundation of China (Nos. 11201051, 11501431, 11302158) and National Science Foundation for Tian yuan of China (No. 11426167), and the Science Plan Foundation of the Education Bureau of Shaanxi Province. The authors are grateful to the anonymous reviewers and editors for their profitable comments and suggestions, which greatly improves this paper.
Competing interests
The authors declare that they have no competing interests.
Appendix
In the following section three useful lemmas are given for convergence analysis for BGSAM algorithm. For the sake of description, we introduce the following notations:
| 17 |
Using the error function (11) we have
Lemma 1
(Wu et al. 2010, Lemma 1) Suppose thatis continuous and differentiable on a compact set, and thatcontains only finite number of points. If a sequencesatisfies
then, there existssuch that.
The above lemma is crucial for the strong convergence analysis, and it basically follows the same proof as Lemma 1 in Wu et al. (2010). So its proof is omitted.
Now, we give the proofs of Theorem1 through the following 4 steps.
Step 1. We show the following inequalities holds
| 18 |
| 19 |
Proof
With the assumption (A1), (16) and the definition of G(x), it is easy to show that there exists a positive constant such that (18) holds.
By the Lagrange mean value theorem, (A1) and (16), we obtain that
| 20 |
where is between and .
Furthermore, in terms of (9) and (10) we can show that
| 21 |
On the basis of the above inequalities (20) and (21) we immediately have (19).
Step 2. We show the following monotonicity of the sequence
| 22 |
Proof
According to the definition of and , we get
| 23 |
By the Taylor mean value theorem with Lagrange remainder to g(t) at the point , we obtain
| 24 |
where each lies on the segment between and , .
Together with (10) and (14), we get
| 25 |
where , and is between and .
Using (10) and (13), we obtain
| 26 |
Apply the Taylor mean value theorem with Lagrange remainder, we have
| 27 |
where , and is a constant between and .
Substituting (25) and (26) into (27) and using the Lagrange mean value theorem for f(x), we have
| 28 |
where is between and .
According to (21) and (28) we can conclude
| 29 |
Set , and . Note that
It follows from (16), (18), (19) and the Cauchy-Schwartz inequality that
| 30 |
where ,
Similarly, we can evaluate as follows:
| 31 |
where .
Similarly, we obtain
| 32 |
where .
Using , from (29)–(32) and (A3) we can obtain
| 33 |
There holds (n = 1,2,...).
Step 3. we show
Proof
From Step 2, we know that the nonnegative sequence is monotone and it is also bounded. Hence, there must exist such that .
Taking , it follows from Assumption (A3) that . and using (33), we get
Since , it gives that
Let , it holds that
This results in
Thus
| 34 |
Step 4. Add the assumption (A4), we show where .
Proof
Note that the error function E(W) defined in (11) is continuous and differentiable. According to (21) and (34), we get
i.e.
| 35 |
According to the assumption (A4), (34), (35) and Lemma 1, there exists a point , such that
| 36 |
Now, we proved the Theorem 1 by Step 1–Step 4.
Contributor Information
Qinwei Fan, Email: qinweifan@126.com.
Wei Wu, Email: wuweiw@dlut.edu.cn.
Jacek M. Zurada, Email: jacek.zurada@louisville.edu
References
- Bhaya A, Kaszkurewicz E. Steepest descent with momentum for quadratic functions is a version of the conjugate gradient method. Neural Netw. 2004;17:65–71. doi: 10.1016/S0893-6080(03)00170-9. [DOI] [PubMed] [Google Scholar]
- Chan LW, Fallside F. An adaptive training algorithm for backpropagation networks. Comput Speech Lang. 1987;2:205–218. doi: 10.1016/0885-2308(87)90009-X. [DOI] [Google Scholar]
- Davis G (1994) Adaptive nonlinear approximations, Ph.D. thesis, New York University
- Donoho DL. De-noising by soft-thresholding. IEEE Trans Inf Theory. 1995;41:613–627. doi: 10.1109/18.382009. [DOI] [Google Scholar]
- Donoho DL (2005) Neighborly polytopes and the sparse solution of underdetermined systems of linear equations, Technical report, Statistics Department, Stanford University
- Fan QW, Wei W, Zurada JM. Convergence of online gradient method for feedforward neural networks with smoothing regularization penalty. Neurocomputing. 2014;131:208–216. doi: 10.1016/j.neucom.2013.10.023. [DOI] [Google Scholar]
- Haykin S. Neural networks: a comprehensive foundation. 2. Beijing: Tsinghua University Press, Prentice Hall; 2001. [Google Scholar]
- Haykin S. Neural networks and learning machines. Upper Saddle River: Prentice-Hall; 2008. [Google Scholar]
- Hinton GE. Connectionist learning procedures. Artif Intell. 1989;40(1–3):185–234. doi: 10.1016/0004-3702(89)90049-0. [DOI] [Google Scholar]
- Istook E, Martinez T. Improved backpropagation learning in neural networks with windowed momentum. Int J Neural Syst. 2002;12(3–4):303–318. doi: 10.1142/S0129065702001114. [DOI] [PubMed] [Google Scholar]
- Karnin ED. A simple procedure for pruning back-propagation trained neural networks. IEEE Trans Neural Netw. 1990;1:239–242. doi: 10.1109/72.80236. [DOI] [PubMed] [Google Scholar]
- Kong J, Wu W. Online gradient methods with a punishing term for neural networks. Northeast Math J. 2001;173:371–378. [Google Scholar]
- Liu QS, Cao JD. A recurrent neural network based on projection operator for extended general variational inequalities. IEEE Trans Syst Man Cybern B Cybern. 2010;40(3):928–938. doi: 10.1109/TSMCB.2009.2033565. [DOI] [PubMed] [Google Scholar]
- Liu QS, Guo ZS, Wang J. A one-layer recurrent neural network for constrained pseudoconvex optimization and its application for dynamic portfolio optimization. Neural Netw. 2012;26:99–109. doi: 10.1016/j.neunet.2011.09.001. [DOI] [PubMed] [Google Scholar]
- Moody JE, Rognvaldsson TS (1997) Smoothing regularizers for projective basis function networks. In: Advances in neural information processing systems 9 (NIPS 1996). http://papers.nips.cc/book/advances-in-neuralinformation-processing-systems-9-1996
- Natarajan BK. Sparse approximate solutions to linear systems. SIAM J Comput. 1995;24:227–234. doi: 10.1137/S0097539792240406. [DOI] [Google Scholar]
- Perantonis SJ, Karras DA. An efficient constrained learning algorithm with momentum acceleration. Neural Netw. 1995;8(2):237–249. doi: 10.1016/0893-6080(94)00067-V. [DOI] [PubMed] [Google Scholar]
- Qian N. On the momentum term in gradient descent learning algorithms. Neural Netw. 1999;12(1):145–151. doi: 10.1016/S0893-6080(98)00116-6. [DOI] [PubMed] [Google Scholar]
- Qiu G, Varley MR, Terrell TJ. Accelerated training of backpropagation networks by using adaptive momentum step. IEEE Electron Lett. 1992;28(4):377–379. doi: 10.1049/el:19920236. [DOI] [Google Scholar]
- Reed R. Pruning algorithms-a survey. IEEE Trans Neural Netw. 1993;4(5):740–747. doi: 10.1109/72.248452. [DOI] [PubMed] [Google Scholar]
- Saito K, Nakano R. Second-order learning algorithm with squared penalty term. Neural Comput. 2000;12(3):709–729. doi: 10.1162/089976600300015763. [DOI] [PubMed] [Google Scholar]
- Shao H, Zheng G. Convergence analysis of a back-propagation algorithm with adaptive momentum. Neurocomputing. 2011;74:749–752. doi: 10.1016/j.neucom.2010.10.008. [DOI] [Google Scholar]
- Tibshirani R. Regression shrinkage and selection via the Lasso. J R Stat Soc B. 1996;58:267–288. [Google Scholar]
- Torii M, Hagan MT. Stability of steepest descent with momentum for quadratic functions. IEEE Trans Neural Netw. 2002;13(3):752–756. doi: 10.1109/TNN.2002.1000143. [DOI] [PubMed] [Google Scholar]
- Wang J, Wu W, Zurada JM. Computational properties and convergence analysis of BPNN for cyclic and almost cyclic learning with penalty. Neural Netw. 2012;33:127–135. doi: 10.1016/j.neunet.2012.04.013. [DOI] [PubMed] [Google Scholar]
- Weigend AS, Rumelhart DE, Huberman BA (1991) Generalization by weight elimination applied to currency exchange rate prediction. In: Proceedings of the international joint conference on neural networks, vol 1, pp 837–841
- Wilson DR, Martinez TR. The general inefficiency of batch training for gradient descent learning. Neural Netw. 2003;16:1429–1451. doi: 10.1016/S0893-6080(03)00138-2. [DOI] [PubMed] [Google Scholar]
- Wu W, Shao H, Li Z. Convergence of batch BP algorithm with penalty for FNN training. Lect Notes Comput Sci. 2006;4232:562–569. doi: 10.1007/11893028_63. [DOI] [Google Scholar]
- Wu W, Li L, Yang J, Liu Y. A modified gradient-based neuro-fuzzy learning algorithm and its convergence. Inf Sci. 2010;180:1630–1642. doi: 10.1016/j.ins.2009.12.030. [DOI] [Google Scholar]
- Wu W, Fan QW, Zurada JM, et al. Batch gradient method with smoothing regularization for training of feedforward neural networks. Neural Netw. 2014;50:72–78. doi: 10.1016/j.neunet.2013.11.006. [DOI] [PubMed] [Google Scholar]
- Xu Z, Zhang H, Wang Y, Chang X, Liang Y. regularizer. Sci China Inf Sci. 2010;53:1159–1169. doi: 10.1007/s11432-010-0090-0. [DOI] [Google Scholar]
- Zhang NM, Wu W, Zheng GF. Convergence of gradient method with momentum for two-layer feedforward neural networks. IEEE Trans Neural Netw. 2006;17(2):522–525. doi: 10.1109/TNN.2005.863460. [DOI] [PubMed] [Google Scholar]
- Zhang H, Wu W, Liu F, Yao M. Boundedness and convergence of online gradient method with penalty for feedforward neural networks. IEEE Trans Neural Netw. 2009;20(6):1050–1054. doi: 10.1109/TNN.2009.2020848. [DOI] [PubMed] [Google Scholar]
- Zhang HS, Zhang Y, Xu DP, Liu XD. Deterministic convergence of chaos injection-based gradient method for training feedforward neural networks. Cogn Neurodyn. 2015;9(3):331–340. doi: 10.1007/s11571-014-9323-z. [DOI] [PMC free article] [PubMed] [Google Scholar]