

Abstract
The problem of constructing Bayesian optimal discriminating designs for a class of regression models with respect to the T-optimality criterion introduced by Atkinson and Fedorov (1975a) is considered. It is demonstrated that the discretization of the integral with respect to the prior distribution leads to locally T-optimal discriminating design problems with a large number of model comparisons. Current methodology for the numerical construction of discrimination designs can only deal with a few comparisons, but the discretization of the Bayesian prior easily yields to discrimination design problems for more than 100 competing models. A new efficient method is developed to deal with problems of this type. It combines some features of the classical exchange type algorithm with the gradient methods. Convergence is proved and it is demonstrated that the new method can find Bayesian optimal discriminating designs in situations where all currently available procedures fail.
Keywords: Design of experiment, Bayesian optimal design; model discrimination; gradient methods; model uncertainty
1 Introduction
Optimal design theory provides useful tools to improve the accuracy of statistical inference without any additional costs by carefully planning experiments before they are conducted. Numerous authors have worked on the construction of optimal designs in various situations. For many models optimal designs have been developed explicitly [see the monographs of Pukelsheim (2006); Atkinson et al. (2007)] and several algorithms have been developed for their numerical construction if the optimal designs are not available in explicit form [see Yu (2010); Yang et al. (2013) among others]. On the other hand the construction of such designs depends sensitively on the model assumptions and an optimal design for a particular model might be inefficient if it is used in a different model. Moreover, in many experiments it is often not obvious which model should be finally fitted to the data and model building is an important part of data analysis. A typical and very important example are Phase II dose-finding studies, where various nonlinear regression models of the form
| (1.1) |
have been developed for describing the dose-response relation [see Pinheiro et al. (2006)], but the problem of model uncertainty arises in nearly any other statistical application. As a consequence, the construction of efficient designs for model identification has become an important field in optimal design theory. Early work can be found in Stigler (1971), who determined designs for discriminating between two nested univariate polynomials by minimizing the volume of the confidence ellipsoid for the parameters corresponding to the extension of the smaller model. Several authors have worked on this approach in various other classes of nested models [see for example Dette and Haller (1998) or Song and Wong (1999) among others].
A different approach to the problem of constructing optimal designs for model discrimination is given in a pioneering paper by Atkinson and Fedorov (1975a), who proposed the T-optimality criterion to construct designs for discriminating between two competing regression models. Roughly speaking their approach provides a design such that the sum of squares for a lack of fit test is large. Atkinson and Fedorov (1975b) extended this method for discriminating a selected model η1 from a class of other regression models, say {η2, . . . , ηk}, k ≥ 2. In contrast to the work Stigler (1971) and followers the T-optimality criterion does not require competing nested models and has found considerable attention in the statistical literature with numerous applications including such important fields as chemistry or pharmacokinetics [see e.g. Atkinson et al. (1998), Ucinski and Bogacka (2005), López-Fidalgo et al. (2007), Atkinson (2008), Tommasi (2009) or Foo and Duffull (2011) for some more recent references]. A drawback of the T-optimality criterion consists of the fact that – even in the case of linear models – the criterion depends on the parameters of the model η1. This means that T-optimality is a local optimality criterion in the sense of Chernoff (1953), and that it requires some preliminary knowledge regarding the parameters. Consequently, most of the cited papers refer to locally T-optimal designs. Although there exist applications where such information is available [for example in the analysis of dose response studies as considered in Pinheiro et al. (2006)], in most situations such knowledge can be rarely provided. Several authors have introduced robust versions of the classical optimality criteria such as Bayesian or minimax D-optimality criteria in order to determine efficient designs for model discrimination, which are less sensitive with respect to the choice of parameters [see Pronzato and Walter (1985); Chaloner and Verdinelli (1995); Dette (1997)]. The robustness problem of the T-optimality criterion has been already mentioned in Atkinson and Fedorov (1975a), who proposed a Bayesian approach to address the problem of parameter uncertainty in the T-optimality criterion. Wiens (2009) imposed (linear) neighbourhoud structures on each regression response and determined least favorable points in these neighbourhouds in order to robustify the locally T-optimal design problem. Dette et al. (2012) considered polynomial regression models and determined explicitly Bayesian T-optimal discriminating designs for the criterion introduced by Atkinson and Fedorov (1975a). Their results indicate the difficulties arising in Bayesian T-optimal design problems.
The scarcity of literature on Bayesian T-optimal discriminating designs can be explained by the fact that in nearly all cases of practical interest these designs have to be found numerically, and even this is a very hard problem. These numerical difficulties become even apparent in the case of locally T-optimal designs. Atkinson and Fedorov (1975a) proposed an exchange type algorithm, which has a rather slow rate of convergence and has been used by several authors. Braess and Dette (2013) pointed out that, besides its slow convergence, this algorithm does not yield the solution of the optimal discriminating design problem, if more than 5 model comparisons are under consideration. These authors developed a more efficient algorithm for the determination of locally T-optimal discriminating designs for several competing regression models by exploring relations between optimal design problems and (nonlinear) vector-valued approximation theory. Although the resulting algorithm provides a substantial improvement of the exchange type methods it cannot deal with Bayesian optimality criteria in general, and the development of an efficient procedure for this purpose is a very challenging and open problem.
The goal of the present paper is to fill this gap. We utilize the fact that in applications the integral with respect to the prior distribution has to be determined by a discrete approximation and we show that the discrete Bayesian T-optimal design problem is a special case of the local T-optimality criterion for a very large number of competing models considered as in Braess and Dette (2013). The competing models arise from the different support points used for the approximation of the prior distribution by a discrete measure, and the number of model comparisons in the resulting criterion easily exceeds the 200. Therefore the algorithm in Braess and Dette (2013) does not provide a solution of the corresponding optimization problem, and we propose a new method for the numerical construction of Bayesian T-optimal designs with substantial computational advantages. Roughly speaking, the support points of the design in each iteration are determined in a similar manner as proposed in Atkinson and Fedorov (1975a) but for the calculation of the corresponding weights we use a gradient approach. It turns out that the new procedure is extremely efficient and is able to find Bayesian T-optimal designs with a few number of iterations.
The remaining part of this paper is organized as follows. In Section 2 we give an introduction into the problem of designing experiments for discriminating between competing regression models and also derive some basic properties of locally T-optimal discriminating designs. In particular we show how the Bayesian T-optimal design problem is related to a local one with a large number of model comparisons [see Section 2.2]. Section 3 is devoted to the construction of new numerical procedures (in particular Algorithm 3.2), for which we prove convergence to a T-optimal discriminating design. Our approach consists of two steps consecutively optimizing with respect to the support points (Step 1) and weights of the design (Step 2). For the second step we also discuss two procedures to speed up the convergence of the algorithm. The results are illustrated in Section 4 calculating several Bayesian T-optimal discriminating designs in examples, where all other available procedure do not provide a numerical solution of the optimal design problem. For example, the new procedure is able to solve locally T-optimal designs with more than 240 model comparisons as they are arising frequently in Bayesian T-optimal design problems. In particular we illustrate the methodology calculating Bayesian T-optimal discriminating designs for a dose finding clinical trial which has recently been discussed in Pinheiro et al. (2006). The corresponding R-package will be provided in the CRAN library. Finally all proof are deferred to an appendix in Section 5.
2 T-optimal discriminating designs
Consider the regression model (1.1), where x belongs to some compact set and observations at different experimental conditions are independent. For the sake of transparency and a clear representation we assume that the error ε is normally distributed. The methodology developed in the following discussion can be extended to more general error structures following the line of research in López-Fidalgo et al. (2007), but details are omitted for the sake of brevity.
Throughout this paper we consider the situation where ν different models, say
| (2.1) |
are available to describe the dependency of Y on the predictor x. In (2.1) the quantity θi denotes a di-dimensional parameter, which varies in a compact space, say Θi (i = 1, . . . , ν). Following Kiefer (1974) we consider approximate designs that are defined as probability measures, say ξ, with finite support. The support points x1, . . . , xk of a design ξ give the locations where observations are taken, while the weights ω1, . . . , ωk describe the relative proportions of observations at these points. If an approximate design is given and n observations can be taken, a rounding procedure is applied to obtain integers ni (i = 1, . . . , k) from the not necessarily integer valued quantities ωin such that . We are interested in designing an experiment, such that a most appropriate model can be chosen from the given class {η1, . . . , ην} of competing models.
2.1 T-optimal designs
In the case of ν = 2 competing models Atkinson and Fedorov (1975a) proposed to fix one model, say η1(·, θ1), with corresponding parameter and to maximize the functional
| (2.2) |
in the class of all (approximate) designs. Roughly speaking, these designs maximize the power of the test of the hypothesis “η1 versus η2”. Note that the resulting optimal design depends on the parameter for the first model, which has to be fixed by the experimenter. This means that these designs are local in the sense of Chernoff (1953). It was pointed out by Dette et al. (2013) that locally T-optimal designs may be very sensitive with respect to misspecification of . In a further paper Atkinson and Fedorov (1975b) generalized their approach to construct optimal discriminating designs for more than 2 competing regression models and suggested the criterion
| (2.3) |
This criterion determines a “good” design for discriminating the model η1 against η2, . . . , ην, where the parameter has the same meaning as before. As pointed out by Tommasi and López-Fidalgo (2010) and Braess and Dette (2013) there are many situations, where it is not clear which model should be considered as fixed and these authors proposed a symmetrized Bayesian (instead of minimax) version of the T-optimality criterion, that is
| (2.4) |
where the quantities pi,j denote nonnegative weights reflecting the importance of the comparison between the the model ηi and ηj. We note again that this criterion requires the specification of the parameter , whenever the corresponding weight pi,j is positive. Throughout this paper we will call a design maximizing one of the criteria (2.2) - (2.4) locally T-optimal discriminating design, where the specific criterion under consideration is always clear from the context. For some recent references discussing locally T-optimal discriminating designs we refer to Ucinski and Bogacka (2005), López-Fidalgo et al. (2007), Atkinson (2008), Tommasi (2009) or Braess and Dette (2013) among many others. For the formulation of the first results we require the following assumptions.
Assumption 2.1
For each i = 1, . . . , ν the functions ηi(·, θi) is continuously differentiable with respect to the parameter θi ∈ Θi,.
Assumption 2.2
For any design ξ such that TP(ξ) > 0 and weight pi,j ≠ 0 the infima in (2.4) are attained at a unique points in the interior of the set Θj.
For a design ξ we also introduce the notation
| (2.5) |
which is used in the formulation of the following result.
Theorem 2.1
If Assumption 2.1 is satisfied, then the design ξ* is a locally TP-optimal discriminating design, if and only if there exist distributions on the sets defined in (2.5) such that the inequality
| (2.6) |
is satisfied for all . Moreover, there is equality in (2.6) for all support points of the the locally TP-optimal discriminating design ξ*.
Theorem 2.1 provides an extension of the corresponding theorem in Braess and Dette (2013), and the proof is similar and therefore omitted. For designs ξ, ζ on we introduce the function
| (2.7) |
where ζ is an experimental design and the set is defined in (2.5). Using Lemma 5.1 from the appendix it is easy to check that
where ξ(α) = (1 – α)ξ + αζ denotes the convex combination of the designs ξ and ζ. If Assumption 2.2 is satisfied, the function Q simplifies to
which plays an important role in the subsequent discussion. In particular we need also the following extension of Theorem 2.1.
Theorem 2.2
If Assumption 2.1 is satisfied and the design ξ is not TP-optimal, then there exists a design ζ*, such that the inequality Q(ζ*, ξ) > TP(ξ) holds.
In order to obtain a more manageable condition of this result let denote a measure on the set for which the function
attains its minimal value, and define
| (2.8) |
Note that the function in (2.8) simplifies to
| (2.9) |
if both Assumptions 2.1 and 2.2 are satisfied.
Corollary 2.3
If Assumption 2.1 is satisfied and the design ξ is not TP-optimal then there exists a point such that
2.2 Bayesian T-optimal designs
As pointed out by Dette et al. (2012) locally T-optimal designs are rather sensitive with respect to misspecification of the unknown parameters , and it might be appropriate to construct more robust designs for model discrimination. The problem of robustness was already mentioned in Atkinson and Fedorov (1975a) and these authors proposed a Bayesian version of the T-optimality criterion which reads in the situation of the criterion (2.4) as follows
| (2.10) |
Here for each i = 1, . . . , ν the measure denotes a prior distribution for the parameter θi in model ηi, such that all integrals in (2.10) are well defined. Throughout this paper we will call any design maximizing the criterion (2.10) a Bayesian T-optimal discriminating design. For (two) polynomial regression models Bayesian T-optimal discriminating designs have been explicitly determined by Dette et al. (2013), and their results indicate the intrinsic difficulties in the construction of optimal designs with respect to this criterion.
In the following we will link the criterion (2.10) to the locally T-optimality criterion (2.4) for large number of competing models. For this purpose we note that in nearly all situations of practical interest an explicit evaluation of the integral in (2.10) is not possible and the criterion has to be evaluated by numerical integration approximating the prior distribution by a measure with finite support. Therefore we assume that the prior distribution in the criterion is given by a discrete measure with masses at the points . The criterion in (2.10) can then be rewritten as
| (2.11) |
which is a locally T-optimality criterion of the from (2.4). The only difference between the criterion obtained form the Bayesian approach and (2.4) consists in the fact that the criterion (2.11) involves substantially more comparisons of the functions ηi and ηj. For example, if this approach is used for a Bayesian version of the criterion (2.2) we obtain
| (2.12) |
This is the locally T-optimality criterion (2.4) with , and pi,j = 0 otherwise. Thus, instead of making only one comparison as required for the locally T-optimality criterion, the Bayesian approach (with a discrete approximation of the prior) yields a criterion with comparisons, where denotes the number of support points used for the approximation of the prior distribution. Moreover, for each support point of the prior distribution in the criterion (2.11) (or (2.12)) the infimum has to be calculated numerically, which is computationally expensive. Consequently, the computation of Bayesian T-optimal discriminating design problems is particularly challenging. In the following sections we provide an efficient solution of this problem.
3 Calculating locally T-optimal designs
Braess and Dette (2013) proposed an algorithm for the numerical construction of locally T-optimal designs, which is based on vector-valued Chebyshev approximation. This algorithm is quite difficult both in terms of description and implementation. Moreover, it requires substantial computational resources and is therefore only able to deal with a small number of comparisons in the T-optimality criterion. The purpose of this section is to develop a more efficient method which is able to deal with a large number of comparisons in the the criterion and avoids the drawbacks of the procedures in Atkinson and Fedorov (1975a) and Braess and Dette (2013). As pointed out in Section 2.2 methods solving this problem are required for the calculation of Bayesian T-optimal discriminating designs. Recall the definition of the function Ψ in (2.8) and note that under Assumption 2.1 it follows from Corollary 2.3 that there exists a point , such that the inequality
holds, whenever ξ is not a locally T-optimal discriminating design. The algorithm of Atkinson and Fedorov (1975a) uses this property to construct a sequence of designs which converges to the locally T-optimal discriminating design. For further reference it is stated here.
Algorithm 3.1 (Atkinson and Fedorov (1975a))
Let ξ0 denote a given (starting) design and let be a sequence of positive numbers, such that . For s = 0, 1, . . . define
where .
It can be shown that this algorithm converges in the sense that , where ξ* denotes a locally T-optimal discriminating design. However, a major problem of Algorithm 3.1 is that it yields a sequence of designs with an increasing number of support points. As a consequence the resulting design (after applying some stopping criterion) is concentrated on a large set of points. Even if this problem can be solved by clustering or by determining the extrema of the final function Ψ(x, ξs), it is much more difficult to deal with the accumulation of support points during the iteration. Moreover, Braess and Dette (2013) demonstrated that in many cases the iteration process may take several hundred iterations for obtaining a locally T- optimal discriminating design with a required precision, resulting in a high computational complexity for the recalculation of the optimum values
| (3.1) |
in the optimality criterion (2.4). These authors also showed that Algorithm 3.1 may not find the optimal design if there are too many model comparisons involved in the T-optimality criterion (2.4).
Therefore, we propose the following alternative basic procedure for the calculation of locally T-optimal discriminating designs as an alternative to Algorithm 3.1. Roughly speaking, it consists of two steps treating the maximization with respect to support points (Step 1) and weights (Step 2) separately, where two methods implementing the second step will be given below [see Section 3.1 and 3.2 for details].
Algorithm 3.2
Let ξ0 denote a starting design such that TP(ξ0) > 0 and define recursively a sequence of designs (ξs)s=0,1,... as follows:
-
(1)
Let denote the support of the design ξs. Determine the set of all local maxima of the function Ψ(x, ξs) on the design space and define .
-
(2)We define as the design supported at (with a vector w of weights) and determine the locally TP-optimal design in the class of all designs supported at , that is we determine the vector ω[s+1] maximizing the function
(here wx denotes the weights at the point ). All points in with vanishing components in the vector of weights ω[s+1] will be be removed and the new set of support points will also be denoted by . Finally the design ξs+1 is defined as the design with the set of support points and the corresponding nonzero weights.
Theorem 3.3
Let Assumption 2.1 be satisfied and let (ξs)s=0,1,... denote the sequence of designs obtained by Algorithm 3.2, then
where ξ* denotes a locally T-optimal discriminating design.
A proof of Theorem 3.3 is deferred to Section 5. Note that the algorithm adds all local maxima of the function Ψ(x, ξs) as possible support points of the design in the next iteration. Consequently, in the current form Algorithm 3.2 also accumulates too many support points. To avoid this problem, it is suggested to remove at each step those points from the support, whenever their weight is smaller than m0.25, where m denote the working precision of the software used in the implementation (which is 2.2 × 10−16 for R). Note also that this refinement does not affect the convergence of the algorithm from a practical point of view. A more important question is the implementation of the second step of the procedure, that is the maximization of function g(ω). Before we discuss two computationally efficient procedures for this purpose in the following sections, we state an important property of the function Ψ(x, ξs+1) obtained in each iteration.
Lemma 3.4
At the end of each iteration of Algorithm 3.2 the function Ψ(x, ξs+1) attains one and the same value for all support points of the design ξs+1.
3.1 Quadratic programming
Let denote the set obtained in the first step of Algorithm 3.2 and define ξ as a design supported at with corresponding weights ω1, . . . , ωn (which have to be determined in Step 2 of the algorithm by maximizing the function
where is defined in (3.1). For this purpose we suggest to linearize the functions in the neighborhood of point . More precisely, we consider the function
where dj is the dimension of the parameter space Θj, Ω = diag(ω1, . . . , ωn) and the matrices , and the vectors are defined by
respectively. Obviously the minimum with respect to αi,j is achieved by which gives
where
The matrix Q(ω) depends on ω, but if we ignore this dependence and take the matrix as fixed, then we end up with a quadratic programming problem, that is
| (3.2) |
This problem is solved iteratively until convergence, substituting each time the solution obtained in the previous iteration instead of . We note that a similar idea has also been proposed by Braess and Dette (2013).
Remark 3.5
In the practical implementation of the procedure it is recommended to perform only a few iterations of this step such that an improvement in the difference between the value of the criterion of the starting design in Step 2 and the design obtained in the iteration of (3.2) is observed. This will speed up the convergence of the procedure substantially. In this case equality of the function Ψ at the support points of the calculated design (as stated in Lemma 3.4) is only achieved approximately.
Formally, the convergence of the algorithm is only proved if the iteration (3.2) is performed until convergence. However, in all examples considered so far, we observed convergence of the procedure, even if only a few iterations of (3.2) are used. In our R program the user can specify the number of iterations used in this part of the algorithm. Thus, if any problem regarding convergence is observed, the number of iterations should be increased (of course at a cost speed of the algorithm).
3.2 A gradient method
A further option for the second step in Algorithm 3.2 is a specialized gradient method, which is used for the function
| (3.3) |
where is defined in (3.1). For it s description we define the functions
and iteratively calculate a sequence of vectors (ω(γ))γ=0,1,.... At the beginning we choose (for example equal weights). If ω(γ) = (ω(γ),1, . . . , ω(γ),n) is given, we proceed for γ = 0, 1, . . . as follows. We determine indices k̄ and ḵ corresponding to max1≤k≤n vk(ω(γ)) and min1≤k≤n vk(ω(γ)), respectively, and define
| (3.4) |
where the vector is given by
The vector ω(γ+1) of the next iteration is then defined by . The following theorem shows that the generated sequence of vectors converges to a maximizer of the function g in (3.3) and is proved in the Appendix.
Theorem 3.6
The sequence converges to a vector ω* ∈ arg max g(ω).
Remark 3.7
It is worthwhile to mention that the one dimensional optimization problem (3.4) is computationally rather expensive. In the implementation we use a linearization of the optimization problem, which is obtained in a similar way a described in Section 3.1.
4 Implementation and numerical examples
We have implemented the procedure for the calculation of the locally T-optimal discriminating design in R, where the user has to specify the weights pi,j and the corresponding preliminary information regarding the parameters . To be precise, we call
the comparison table for the locally T-optimal discriminating design problem under consideration. This table has to be specified by the experimenter. Because the Bayesian T-optimal design problem with a discrete prior can be reduced to a locally T-optimal one with a large number of model comparisons, we now describe the corresponding table for the Bayesian T-optimality criterion. For illustration purposes we consider the case ν = 2. The Bayesian T-optimality criterion is given in (2.12), where the prior for the parameter θ1 puts masses at the points . This criterion can be rewritten as a local T-optimality criterion of the form (2.4), i.e.
| (4.1) |
where comparison table is given by
| (4.2) |
, and . The extension of this approach to more than two models is easy and left to the reader. We now illustrate the new method in two examples calculating Bayesian T-optimal discriminating designs. We have implemented both procedures described in Section 3.1 and 3.2 and the results were similar. For this reason we only represent the Bayesian T-optimal discriminating designs calculated by Algorithm 3.2, where the quadratic programming method was used in Step 2 [see Section 3.1 for details].
4.1 Bayesian T-optimal discriminating designs for exponential models
Consider the problem of discriminating between the two regression models
| (4.3) |
where the design space is given by the interval [0, 10]. Exponential models of the form (4.3) are widely used in applications. For example, the model η2 is frequently fitted in agricultural sciences, where it is called Mitscherlichs growth law and used for describing the relation between the yield of a crop and the amount of fertilizer. In fisheries research this model is called Bertalanffy growth curve and used for the description of the length of a fish in dependence of its age [see Ratkowsky (1990)]. Optimal designs for exponential regression models have been determined by Han and Chaloner (2003) among others. In the following we will demonstrate the performance of the new algorithm in calculating Bayesian T-optimal discriminating designs for the two exponential models. Note that it make only sense to consider the Bayesian version of T12, because the model η2 is obtained as a special case of η1 for θ1,4 = 1. It is easy to see that the locally T-optimal discriminating designs do not depend on the linear parameters of η1 and we have chosen and for these parameters. For the parameters and we considered independent prior distributions supported at the points
| (4.4) |
where μ3 = 0.8, μ4 = 1.5 and different values of the variance σ2 are investigated. The corresponding weights at these points are proportional (in both cases) to
| (4.5) |
We note that this yields 25 terms in the Bayesian optimality criterion (2.12). Bayesian T-optimal discriminating designs are depicted in Table 1 for various values of σ2, where an equidistant design at 11 points 0, 1, . . . , 10 was used as starting design.
Table 1.
Bayesian T-optimal discriminating designs for the two exponential models in (4.3). The support points and weights of the independent prior distributions for the parameters and are given by (4.4) and (4.5), respectively.
| σ 2 | Optimal design | σ 2 | Optimal design | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 0.0 | 0.000 | 0.441 | 1.952 | 10.000 | 0.285 | 0.000 | 0.453 | 1.758 | 10.000 | |
| 0.209 | 0.385 | 0.291 | 0.115 | 0.207 | 0.396 | 0.292 | 0.105 | |||
| 0.1 | 0.000 | 0.452 | 1.877 | 10.000 | 0.3 | 0.000 | 0.452 | 1.747 | 4.951 | 10.000 |
| 0.209 | 0.391 | 0.290 | 0.110 | 0.207 | 0.396 | 0.292 | 0.003 | 0.102 | ||
| 0.2 | 0.000 | 0.455 | 1.811 | 10.000 | 0.4 | 0.000 | 0.446 | 1.651 | 4.699 | 10.000 |
| 0.208 | 0.394 | 0.291 | 0.107 | 0.200 | 0.384 | 0.290 | 0.060 | 0.066 | ||
A typical determination of the optimal design takes between 0.03 seconds (in the case σ2 = 0) and 1.4 seconds (in the case σ2 = 0.4) CPU time on a standard PC (with an intel core i7-4790K processor). The algorithm using the procedure described in Section 3.2 in step 2 requires between 0.11 seconds (in the case σ2 = 0) and 11.6 seconds (in the case σ2 = 0.4) CPU time. We observe that for small values of σ2 the optimal designs are supported at 4 points, while for σ2 ≥ 0.285 the Bayesian T-optimal discriminating design is supported at 5 points. The corresponding function Ψ from the equivalence Theorem 2.1. is shown in Figure 1.
Figure 1.

The function on the left hand side of inequality (2.6) in the equivalence Theorem 2.1 for the numerically calculated Bayesian T-optimal discriminating designs. The competing regression models are given in (4.3).
4.2 Bayesian T-optimal discrimination designs for dose finding studies
Non-linear regression models have also numerous applications in dose response studies, where they are used to describe the dose response relationship. In these and similar situations the first step of the data analysis consists in the identification of an appropriate model, and the design of experiment should take this task into account. For example, for modeling the dose response relationship of a Phase II clinical trial Pinheiro et al. (2006) proposed the following plausible models
| (4.6) |
where the designs space (dose range) is given by the interval . In this reference some prior information regarding the parameters for the models is also provided, that is
Locally optimal discrimination designs for the models in (4.6) have been determined by Braess and Dette (2013) in the case pi,j = 1/6, (1 ≤ j < i ≤ 4), which means that the resulting local T-optimality criterion (2.4) consists of 6 model comparisons.
We begin with an illustration of the new methodology developed in Section 3 calculating again the locally T-optimal discriminating design for this scenario. The proposed algorithm needs only four iterations for the calculation of a design, say ξ4, which has at least efficiency
The function Ψ(·, ξ1) after the first iteration is displayed in Figure 2, where we used the same starting design as in Braess and Dette (2013). The support points of ξ1 are shown as circles and we can see that function Ψ(x, ξ1) attains one and the same value, which is represented with dotted line, for all support points. We finally note that the algorithm proposed in Braess and Dette (2013) needs 9 iterations to find a design with the same efficiency.
Figure 2.
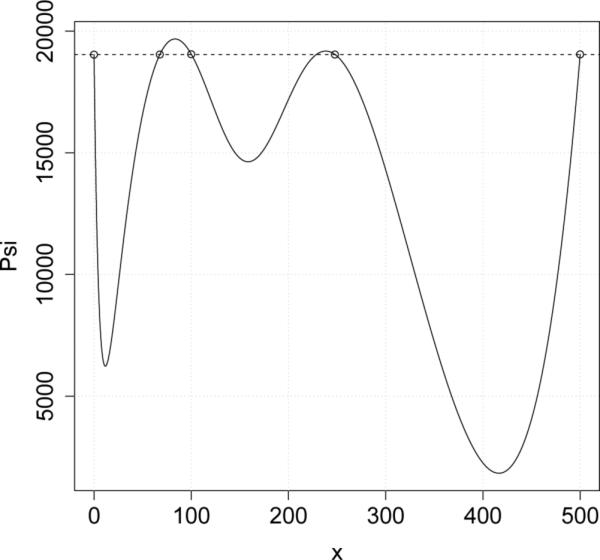
The function Ψ(·, ξ1) after the first iteration of Algorithm 3.2
We now investigate Bayesian T-optimal discriminating designs for a similar situation. For the sake of a transparent representation we only specify a prior distribution of the four-dimensional parameter for the calculation of the discriminating design, while and are considered as fixed. In order to obtain a design which is robust with respect to model misspecification we chose a prior discrete prior with 81 points in . More precisely, the support points of the prior distribution are given by the points
| (4.7) |
where
and different values for σ2 are considered. The weights at the corresponding points are proportional (normalized such that their sum is 1) to
| (4.8) |
where ∥·∥2 denotes the Euclidean norm. The resulting Bayesian optimality criterion (2.11) consist of 246 model comparisons. In this case the method of Braess and Dette (2013) fails to find the Bayesian T-optimal discriminating design. Bayesian T-optimal discriminating designs have been calculated by the new Algorithm 3.2 for various values of σ2 and the results are shown in Table 2. A typical determination of the optimal design takes between 0.09 seconds (in the case σ2 = 0) and 7.8 seconds (in the case σ2 = 372) CPU time on a standard PC. The algorithm using the procedure described in Section 3.2 in Step 2 requires between 0.75 seconds (in the case σ2 = 0) and 37.1 seconds (in the case σ2 = 372) CPU time. For small values the Bayesian T-optimal discriminating designs are supported at 4 points including the boundary of the design space. The smaller (larger) interior support point is increasing (decreasing) if σ2 is increasing. For larger values of σ2 even the number of support points of the optimal design increases. For example, if σ2 = 352 or 372 the Bayesian T-optimal discriminating design has 5 or 6 points (including the boundary points of the design space). These observations are in line with the theoretical finding of Braess and Dette (2007) who showed that the number of support points of Bayesian D-optimal designs can become arbitrarily large with an increasing variability in the prior distribution. The corresponding functions from the equivalence Theorem 2.1 are shown in Figure 3.
Table 2.
Bayesian T-optimal discriminating designs for the models in (4.6). The weights in the criterion (2.10) are given by pi,j = 1/6; 1 ≤ i < j ≤ 4 and the support and masses of the prior distribution are defined by (4.7) and (4.8), respectively.
| σ 2 | optimal design | σ 2 | optimal design | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.000 | 78.783 | 241.036 | 500.0 | 332 | 0 000 | 92.692 | 222.735 | 500.0 | ||
| 0.255 | 0.213 | 0.357 | 0.175 | 0.260 | 0.240 | 0.344 | 0.156 | ||||
| 202 | 0.000 | 84.467 | 234.134 | 500.0 | 352 | 0.000 | 91.743 | 129.322 | 221.118 | 500.0 | |
| 0.257 | 0.225 | 0.351 | 0.167 | 0.260 | 0.214 | 0.036 | 0.336 | 0.154 | |||
| 302 | 0.000 | 91.029 | 225.713 | 500.0 | 372 | 0.000 | 89.881 | 129.590 | 170.306 | 220.191 | 500.0 |
| 0.259 | 0.237 | 0.345 | 0.159 | 0.260 | 0.170 | 0.091 | 0.019 | 0.310 | 0.150 | ||
Figure 3.

The function on the left-hand side of inequality (2.6) in the equivalence Theorem 2.1 for the numerically calculated Bayesian T-optimal discriminating designs. The competing regression models are given in (4.6).
5 Proofs
5.1 An auxiliary result
Lemma 5.1
Let φ(v, y) be a twice continuously differentiable function of two variables and , where is a compact set. Denote by the set of all points where the minimum is attained and let be an arbitrary direction. Then
| (5.1) |
Proof
See Pshenichny (1971), p. 75.
5.2 Proofs
Proof of Theorem 2.2
Assume without loss of generality that pi,j > 0 for all i, j = 1, . . . , ν. Let ξ* denote any locally T-optimal discriminating design and let θ = (θi,j)i,j=1,...,ν denote the vector consisting of all θi,j ∈ Θi,j(ξ*). We introduce the function
| (5.2) |
and consider the product measure
| (5.3) |
where μij are measures on the sets defined by (2.5). Similarly, we define as the product measure of the measures in Theorem 2.1. From this result we have
where the sup and inf are calculated in the class of designs ζ on and product measures μ on , respectively. It now follows that the characterizing inequality (2.6) in Theorem 2.1 is equivalent to the inequality
Consequently, any non-optimal design must satisfy the opposite inequality.
Proof of Corollary 2.3
Let ξ denote a design such that TP(ξ) > 0 and recall the definition of the set in (2.5). We consider for a vector , the function φ is defined in (5.2) and product measures μ(dθ) of the form (5.3) on Θ*(ξ). Now the well known minimax theorem and the definition of the function Q in (2.7) yields
where the infimum is calculated with respect to all measures μ of the form (5.3) and the supremum is calculated with respect to all experimental designs ζ on . Note that is compact by assumption and it can be checked that the set Θ*(ξ) is also compact as a closed subset of a compact set. Consequently all suprema and infima are achieved and there exists a design ζ* supported at the set of local maxima of the function Ψ(x, ξ), such that
The assertion of Corollary 2.3 now follows from Theorem 2.2.
Proof of Theorem 3.3
Obviously, the inequality
holds for all s as optimization with respect to ω occurs on a larger set. Moreover, the sequence TP(ξs) is bounded from above by TP(ξ*) and has a limit, which is denoted by . Consequently, there exists a subsequence of designs, say ξsj, j = 1, 2, . . . converging to a design, say ξ**. Note that TP is upper semi-continuous as the infimum of continuous functions, which implies . Now, assume that TP(ξ**) < TP(ξ*), then ξ** is not locally T-optimal and by Theorem 2.2 there exists a constant δ > 0 such that
where the function Q is defined in (2.7). Therefore for sufficiently large j, say, j ≥ N we obtain (using again the lower semi-continuity of supζ Q(ζ, ξ)) that
whenever j ≥ N. Note that by construction the sequence is increasing and therefore
| (5.4) |
In order to estimate the right hand side we consider for j ≥ N and α ∈ [0, 1] the design
where ζj is the measure for which the function Q(ζ, ξsj) attains its maximal value in the class of all experimental designs supported at the local maxima of the function Ψ(x, ξsj), and define
By construction of ξsj+1 is the best design supported at , and (5.4) yields
| (5.5) |
We introduce the notations , and note that
A Taylor expansion gives
where K is an absolute upper bound of the second derivative. Therefore it follows from (5.5) that
which gives for L > N + 1
The left hand side of this inequality converges to the finite value T(ξ**) – T(ξsN) as L → ∞, while the right hand side converges to infinity. Therefore we obtain a contradiction to our assumption TP(ξ**) < TP(ξ*), which proves the assertion of Theorem 3.3.
Proof of Lemma 3.4
Fix t ∈ {1, . . . , n} and note that . Under Assumptions 2.1 and 2.2 we obtain by formula (5.1)
The condition is the necessary condition for weight optimality and consequently it follows from the definition of the function that this function attains one and the same value for all support points of the design .
Proof of Theorem 3.6
The proof is similar to the proof of Theorem 3.3. Denote
where the vector is calculated at the γth iteration. Since the sequence g(ω(γ)) is bounded and increasing (by construction) it converges to some limit, say g**. Consequently there exists a subsequence of vector of weights, say converging to a vector, say . Note that g is upper semi-continuous as the infimum of continuous functions, which implies . Now, assume that , then it follows by an application of Theorem 2.1 with that there exists a constant δ > 0 such that
Here the vector is defined in the same way as , where ω(γ) is replaced by ω = ω**. Therefore for sufficiently large j, say, j ≥ N we obtain (using the lower semi-continuity of g) that h(γj, 0) > δ and a Taylor expansion yields
where is the value α* from the γjth iteration and K is an absolute upper bound of the second derivative. Using the same arguments as in the proof of Theorem 3.3 we obtain a contradiction, which proves the assertion of the theorem.
Acknowledgements
Parts of this work were done during a visit of the second author at the Department of Mathematics, Ruhr-Universität Bochum, Germany. The authors would like to thank M. Stein who typed this manuscript with considerable technical expertise. The work of H. Dette and V. Melas was supported by the Deutsche Forschungsgemeinschaft (SFB 823: Statistik nichtlinearer dynamischer Prozesse, Teilprojekt C2). The research of H. Dette reported in this publication was also partially supported by the National Institute of General Medical Sciences of the National Institutes of Health under Award Number R01GM107639. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health. V. Melas was also partially supported by Russian Foundation of Basic Research (Project 12.01.00747a).
Contributor Information
Holger Dette, Ruhr-Universität Bochum, Fakultät für Mathematik, 44780 Bochum, Germany, holger.dette@rub.de.
Viatcheslav B. Melas, St. Petersburg State University, Department of Mathematics, St. Petersburg, Russia, vbmelas@post.ru
Roman Guchenko, St. Petersburg State University, Department of Mathematics, St. Petersburg, Russia, romanguchenko@ya.ru.
References
- Atkinson A, Donev A, Tobias R. Optimum Experimental Designs, with SAS (Oxford Statistical Science Series) 2nd edition Oxford University Press; USA: 2007. [Google Scholar]
- Atkinson AC. Examples of the use of an equivalence theorem in constructing optimum experimental designs for random-effects nonlinear regression models. Journal of Statistical Planning and Inference. 2008;138(9):2595–2606. [Google Scholar]
- Atkinson AC, Bogacka B, Bogacki MB. D- and T -optimum designs for the kinetics of a reversible chemical reaction. Chemometrics and Intelligent Laboratory Systems. 1998;43:185–198. [Google Scholar]
- Atkinson AC, Fedorov VV. The designs of experiments for discriminating between two rival models. Biometrika. 1975a;62:57–70. [Google Scholar]
- Atkinson AC, Fedorov VV. Optimal design: Experiments for discriminating between several models. Biometrika. 1975b;62:289–303. [Google Scholar]
- Braess D, Dette H. On the number of support points of maximin and Bayesian D-optimal designs in nonlinear regression models. Annals of Statistics. 2007;35:772–792. [Google Scholar]
- Braess D, Dette H. Optimal discriminating designs for several competing regression models. Annals of Statistics. 2013;41(2):897–922. [Google Scholar]
- Chaloner K, Verdinelli I. Bayesian experimental design: A review. Statistical Science. 1995;10(3):273–304. [Google Scholar]
- Chernoff H. Locally optimal designs for estimating parameters. Annals of Mathematical Statistics. 1953;24:586–602. [Google Scholar]
- Dette H. Designing experiments with respect to “standardized” optimality criteria. Journal of the Royal Statistical Society, Ser. B. 1997;59:97–110. [Google Scholar]
- Dette H, Haller G. Optimal designs for the identification of the order of a Fourier regression. Annals of Statistics. 1998;26:1496–1521. [Google Scholar]
- Dette H, Melas VB, Shpilev P. T-optimal designs for discrimination between two polynomial models. Annals of Statistics. 2012;40(1):188–205. [Google Scholar]
- Dette H, Melas VB, Shpilev P. Robust T-optimal discriminating designs. Annals of Statistics. 2013;41(4):1693–1715. doi: 10.1214/15-AOS1333. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Foo LK, Duffull S. Optimal design of pharmacokinetic-pharmacodynamic studies. In: Bonate PL, Howard DR, editors. Pharmacokinetics in Drug Development, Advances and Applications. Springer; 2011. [Google Scholar]
- Han C, Chaloner K. D- and c-optimal designs for exponential regression models used in pharmacokinetics and viral dynamics. Journal of Statistical Planning and Inference. 2003;115:585–601. [Google Scholar]
- Kiefer J. General equivalence theory for optimum designs (approximate theory). Annals of Statistics. 1974;2(5):849–879. [Google Scholar]
- López-Fidalgo J, Tommasi C, Trandafir PC. An optimal experimental design criterion for discriminating between non-normal models. Journal of the Royal Statistical Society, Series B. 2007;69:231–242. [Google Scholar]
- Pinheiro J, Bretz F, Branson M. Analysis of dose-response studies: Modeling approaches. In: Ting N, editor. Dose Finding in Drug Development. Springer-Verlag; New York: 2006. pp. 146–171. [Google Scholar]
- Pronzato L, Walter E. Robust experimental design via stochastic approximation. Mathematical Biosciences. 1985;75:103–120. [Google Scholar]
- Pshenichny BN. Necessary Conditions of an Extremum. Marcel Dekker; New York: 1971. [Google Scholar]
- Pukelsheim F. Optimal Design of Experiments. SIAM; Philadelphia: 2006. [Google Scholar]
- Ratkowsky D. Handbook of Nonlinear Regression Models. Dekker; New York: 1990. [Google Scholar]
- Song D, Wong WK. On the construction of grm-optimal designs. Statistica Sinica. 1999;9:263–272. [Google Scholar]
- Stigler S. Optimal experimental design for polynomial regression. Journal of the American Statistical Association. 1971;66:311–318. [Google Scholar]
- Tommasi C. Optimal designs for both model discrimination and parameter estimation. Journal of Statistical Planning and Inference. 2009;139:4123–4132. [Google Scholar]
- Tommasi C, López-Fidalgo J. Bayesian optimum designs for discriminating between models with any distribution. Computational Statistics & Data Analysis. 2010;54(1):143–150. [Google Scholar]
- Ucinski D, Bogacka B. T -optimum designs for discrimination between two multiresponse dynamic models. Journal of the Royal Statistical Society, Ser. B. 2005;67:3–18. [Google Scholar]
- Wiens DP. Robust discrimination designs, with Matlab code. Journal of the Royal Statistical Society, Ser. B. 2009;71:805–829. [Google Scholar]
- Yang M, Biedermann S, Tang E. On optimal designs for nonlinear models: A general and efficient algorithm. Journal of the American Statistical Association. 2013;108:1411–1420. [Google Scholar]
- Yu Y. Monotonic convergence of a general algorithm for computing optimal designs. The Annals of Statistics. 2010;38(3):1593–1606. [Google Scholar]