

Abstract
Cryosection brain images in Chinese Visible Human (CVH) dataset contain rich anatomical structure information of tissues because of its high resolution (e.g., 0.167 mm per pixel). Fast and accurate segmentation of these images into white matter, gray matter, and cerebrospinal fluid plays a critical role in analyzing and measuring the anatomical structures of human brain. However, most existing automated segmentation methods are designed for computed tomography or magnetic resonance imaging data, and they may not be applicable for cryosection images due to the imaging difference. In this paper, we propose a supervised learning-based CVH brain tissues segmentation method that uses stacked autoencoder (SAE) to automatically learn the deep feature representations. Specifically, our model includes two successive parts where two three-layer SAEs take image patches as input to learn the complex anatomical feature representation, and then these features are sent to Softmax classifier for inferring the labels. Experimental results validated the effectiveness of our method and showed that it outperformed four other classical brain tissue detection strategies. Furthermore, we reconstructed three-dimensional surfaces of these tissues, which show their potential in exploring the high-resolution anatomical structures of human brain.
1. Introduction
The anatomical structures of the brain tissues are very complex and associated with a number of neurological diseases. Nevertheless, without segmentation, the computer cannot recognize and define a tissue's contour automatically, and the anatomical images are difficult to be used for lateral medical application [1]. Cryosection images in the Chinese Visible Human (CVH) dataset show the true color of the human body in a high spatial resolution and contain more rich and original details of the brain anatomy than other medical imaging, such as CT and MRI [2]. By segmenting CVH brain tissues into cerebrospinal fluid (CSF), gray matter (GM), white matter (WM), or other anatomical structures, we can study human brain and apply it in various fields, such as anatomical education, medical image interpretation, and disease diagnosis [3].
It is known that automatic or semiautomatic segmentation is helpful for alleviating the laborious and time-consuming manual segment; however, much noise is introduced during CVH image acquisition and the image contrast is low at some positions because of the asymmetric illumination. In addition, the CVH dataset has no other similar datasets as atlas for guiding segmentation. So there remains a challenging problem of how to explore new model to segment the whole hundreds of CVH brain images in high accuracy and efficiency.
Currently, most existing brain segmentation algorithms are based on CT or MRI images. According to whether the objects are labeled, these methods can be classified into two categories: unsupervised-based and supervised-based. The unsupervised methods, such as region growing, thresholding, clustering, and statistical models, directly use the image intensity to search the object. For example, the fuzzy c-means method classifies image by grouping similar data that are present into clusters and varying the degree of membership function allows the voxel to belong to the multiple classes [4, 5]. This assumption may not work well as it only considers intensity of image and intensity is not enough to express the intrinsic feature of objects. In addition, some methods estimate distribution of each class with probability density of Gaussian mixture model [6]. These methods need accurate estimation of probability density function and for those images with largely overlapped tissues, it is hard to match real distribution of data in a high accuracy. Other methods, like region growing, extend threshold by combining it with connectivity, but they need seeds for each region and have the problem for determining suitable threshold for homogeneity. Also, the gradient-based segmentation technique like Watershed [7] constructs many dams for segmenting image, but it is easy to produce oversegmentation.
Supervised learning-based segmentation methods are promising as they take expert information (labeled data or atlas) into the procedure of segmentation. These methods have shown remarkable improvements in segmenting CT or MRI brain images. For example, Anbeek et al. [7, 8] proposed applying spatial and intensity features in a population-specific atlas space to label brain voxels. This method achieves high accuracy in the cost of a large set of manually segmented training images. The studies in [9, 10] proposed using cooccurrence texture features of wavelet followed by a classifier (like support vector machine) for brain segmentation, while the performance might vary from different dataset at hand with this kind of low-level feature, especially for the cryosection images that contain many of anatomical structures and morphological changes.
When applying supervised methods to segment the obscure targets, there is a common sense that the key to success is mainly dependent on the choice of data representation used to characterize the input data [11]. Typical features, such as histogram [12], texture [13], and wavelet [10, 14], have been successfully applied to many different occasions. But unfortunately, most of these low-level features are hard to extract and organize salient information from the data and their representation power varied from different datasets. Considering that CVH dataset contains hundreds of brain images with enormous anatomical information of different tissues, due to efficiency, we may not label all the images as training data but just a tiny fraction, so it is crucial to extract better feature representation of the inputs so as to infer the labels distribution of the unknown anatomical structures.
Recently, deep neural networks (DNN) have shown their promising results for feature extraction in many computer vision applications [15, 16]. Contrary to traditional shallow classifiers in which feature engineering is crucial, deep learning methods automatically learn hierarchies of relevant features directly from the raw inputs [17]. There are several DNN-based models such as convolutional neural networks (CNNs) [16], deep belief network (DBN) [18], stacked autoencoder (SAE) [19–21] that have been applied in different tasks. As a typical example of deep models, CNNs alternatingly apply trainable filters and local neighborhood pooling operations on the raw input images, resulting in a hierarchy of increasingly complex features [22, 23].
The first deep autoencoder network was proposed by Hinton and Salakhutdinov in [20]. In contrast to CNNs that apply a series of convolution/pooling/subsampling operations to learn deep feature representations, SAE employs a full connection of units for deep feature learning. SAE contains multiple intermediate layers and millions of trainable parameters that enable it to capture highly nonlinear mapping between input and output, so recently it has been widely applied in some tasks such as image denoising and deconvolution [24, 25], multiple organ detection [26], infant hippocampus segmentation [19], and nuclei regions extraction [27]. Their existing results indicate that the archtecture of SAE is essential for acheiving better performance in a specfic task, which motivates us to investigate the SAE-based feature learning for CVH brain segmentation.
In this paper, we propose a learning-based CVH brain tissues segmentation model that employs unsupervised SAE to automatically learn the deep feature representations and supervised Softmax for classification. Our model is composed of two successive parts: white matter (WM) segmentation module and gray matter (GM)/cerebrospinal fluid (CSF) segmentation module. Specifically, the SAE in two modules takes image patches as input and learns their deep feature representation. These features are then sent to a Softmax classifier for inferring the labels of the center pixels of these patches. To decrease the burden of labeling, only a tiny number of labeled anatomical patches are fed to the network in the training stage. Intuitively, a trained model may be strange to the new patches that contain unknown anatomical structures, but because SAE can learn intrinsic feature representations which are well in eliminating distortion, rotation, and blurring of the input patches, the model can infer the classes of patches that contain unknown anatomical structures. The proposed model was used to segment all 422 CVH brain images at hand. And the segmentation performance of the deep-learned feature was compared with some other representative features (e.g., intensity, PCA, HOG, and AE). Experimental results show that the proposed model achieves higher accuracy in segmenting all three tissues.
The rest of the paper is organized as follows. Section 2 briefly reviews the acquisition of CVH dataset and the details of the proposed model. Section 3 reports the experimental results and analyzes the segmentation performance of different SAE architecture. It also compared the performance of different methods and visualizes the three-dimensional reconstruction results. At last, Section 4 concludes the paper.
2. Material and Methods
2.1. Image Acquisition and Preprocessing
The data utilized in this study are successive cross-sectional images of human brain from the CVH dataset provided by the Third Military Medical University in China. The cadaver is 162 cm in height, 54 kg in weight, and free of organic lesions. Both the donor and her relatives donated their bodies to the Chinese Visible Human program, which follows scientific ethics rules of the Chinese Ethics Department.
The images in CVH dataset are taken of the frozen cadaver. A total of 422 cross-sectional images of the head (number 1074 to number 1495) are selected for this study. As shown in Figure 1, the slice is 0.167 mm per pixel, 0.25 mm thick, and photographed at a resolution of 6,291,456 (3,072 × 2,048) pixels with 24-bit color information in tiff format [28]. In order to reduce computational cost and memory usage, these images are transformed into PNG format and cropped to 1,252 × 1,364 pixels. In the preprocessing stage, skull stripping is applied to each image.
Figure 1.

Preprocessing example of cryosection brain image. (a) Original image without any preprocessing (3,072 × 2,048 pixels). (b) Cropped image (1,252 × 1,364 pixels). (c) Skull stripped image.
2.2. Method Overview
In this work, the CVH brain tissue segmentation problem is formulated as a patch classification task and the architecture of our segmentation model is shown in Figure 2. The model takes patches extracted from the B-channel and V-channel of the original images as input, then SAE is used to extract intrinsic feature representation of the input patches, and the following Softmax classifier generates a labels distribution of these patches based on the deep features. This model on segmenting three brain tissues (CSF, GM, and WM) actually contains two submodels: MODEL 1 and MODEL 2. In MODEL 1, GM and CSF are labeled as the same class, and the segmentation is formulated as a three-class classification task: WM, GM & CSF, and background. Through MODEL 1, WM tissue can be extracted from the region of interest. This segmentation result is helpful to fill the areas of WM into background so as to eliminate the influence of WM. So in MODEL 2, the patches from the WM-eliminated image are taken as inputs, and the image is segmented into CSF, GM, and background. This pipeline has the advantages in that more image patches of the objects with fewer labeled data can be taken as it is quite time-consuming to manually label an image. In the following, we will describe the details of the model.
Figure 2.

Flowchart of our segmentation model.
2.3. Learning Hierarchical Feature Representation by SAE
2.3.1. Single-Layer AE
A single-layer AE [29] is a kind of unsupervised neural network, whose goal is to minimize the reconstruction error from inputs to outputs via two components: encoder and decoder [19]. In the encoding stage, given an input sample , AE will map it to the hidden activation by the following mapping:
| (1) |
where f(z) = 1/(1 + exp(−z)) is a nonlinear activation function; W 1 ∈ ℝ M×N is the encoder weight matrix; is the bias vector. Generally, M < N; then the network is forced to learn a compressed representation of the input vector. This compressed representation can be viewed as features of the input vector. In the decoding stage, AE will reproduce input data from the hidden activation by
| (2) |
where W 2 ∈ ℝ N×M is the decode weight matrix and is the bias vector.
In our model, during the training stage, we minimize the objective function shown in (3) with respect to the weight matrixes W 1 and W 2 and bias vectors and . The objective function includes an average sum-of-square error term to fit the input data and a weight decay term to decrease the magnitude of weight matrices as well as helping prevent over-fitting
| (3) |
where x n denotes the n-th sample in the training set; y n denotes the reconstructed output with input of x n; λ denotes weight decay parameter which controls the relative importance of the two terms; n l denotes the number of layers in the network; s l denotes the number of units in the lth layer; and m denotes the number of training samples.
2.3.2. SAE for Hierarchical Feature Learning
SAE is a type of neural network consisting of multiple layers of AEs in which the output of each layer is wired to the inputs of the successive layer. In this paper we propose a multi-hidden layer SAE which is shown in Figure 3. It is noted that the number of layers in our model is set via cross-validation. For an input vector , the first layer transforms it into a vector that consists of activations of hidden units, and the second layer takes as input to produce a new activated vector ; then the final activated vector that is produced by can be viewed as deep-learned feature representation of the input sample. It is noticed that the model intrinsically handles varying-dimension images through image patches with different sizes. For a specific task, the parameters are usually settled through experiments or experience, and the training and application of SAE will go on those parameters.
Figure 3.
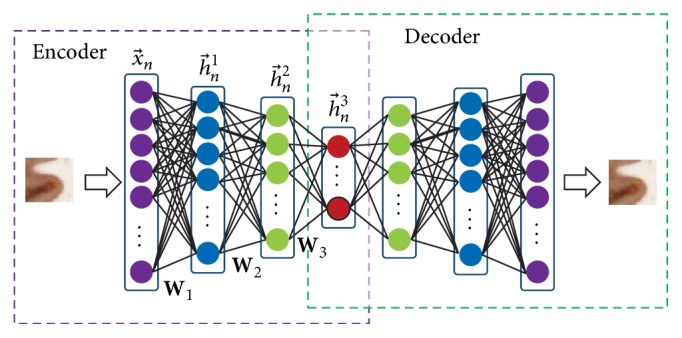
Proposed three-hidden-layer SAE. Note that the number of layers in our model is set via cross-validation.
In our task, we follow the greedy layer-wise training strategy [18, 20, 30] to obtain better parameters of a SAE. That is, we first train the first single AE on the raw input and then train the second AE on the hidden activation vector acquired by the former AE. The subsequent layers are repeated using the output of each layer as input. Once this phase of training is complete, we stack AEs into SAE and train the entire network by a gradient-based optimization method to refine the parameters.
The high-level features learned by SAE are more discriminative compared to hand-crafted feature such as intensity and learning-based feature by single-layer AE. To make an intuitive interpretation, we conducted a dimension reduction experiment to visually examine the distributions of feature vectors from image patches by original intensity and a SAE with three hidden layers, respectively. The experimental result is shown in Figure 4, where the dimensionality of each feature vector is reduced to two by Principal Components Analysis (PCA) for the purpose of visualization. We can see that the features extracted by SAE output a better cluster result than intensity features. It is easier to generate a separation hyperplane for separating different types of samples.
Figure 4.

Two-dimensional feature representation for 500 patches of each brain tissue by (a) intensity + PCA and (b) intensity + three-hidden-layer SAE + PCA; here PCA is just for visualization of principle components.
To further visualize the discriminative ability between AE and SAE, the features learned by each layer of SAE based on cryosection image are shown in Figure 5. As shown in Figure 5(a), it is seen that AE can only learn primitive oriented edge-like features, just like K-means, ICA, or sparse coding do [31]. While SAE can learn higher-level features corresponding to the patterns in the appearance of features in the former layer (as shown in Figure 5(c)), these high-level features are more discriminative for image segmentation task in this paper. Hence, our model employs the SAE instead of both hand-craft features and learning based features by singer-layer AE to extract high-level feature representation for segmenting brain tissues.
Figure 5.

Visualization of learned high-level features of input pixel intensities with three-layer SAE. (a), (b), and (c) Learned feature representation in the first (with 225 units), second (with 144 units), and third (with 81 units) hidden layers, respectively, where the features in the third layer are discriminative for image segmentation task.
2.3.3. SAE Plus Softmax for CVH Brain Tissues Segmentation
For every foreground pixel in the cryosection image, we extract two patches centered at this pixel from its B-channel (in RGB color space) and V-channel (in HSV color space) image, respectively. So ϵ in Figure 2 is 2. The two patches are concatenated together as the input features of SAE, and the features learned by SAE then are sent to a supervised Softmax classifier. The parameters of two SAEs in MODEL 1 and MODEL 2 are roughly consistent. The patch size is set via cross-validation, and layer depth is set among {1,2, 3} considering the balance between computation cost and discriminative power. The number of units in each layer of SAE is experimentally set as 400, 200, and 100, respectively. Thus, the final dimensionality of deep-learned feature is 100. The weight decay λ of two SAEs in MODEL 1 and MODEL 2 is set to 0.003 and 0.005, respectively, which is tuned on the validation set.
2.3.4. Ground Truth and Training Sets Generation
The objective of the proposed model is to automatically segment the three brain tissues of the whole 422 CVH brain image at hand. It is laborious and time-consuming to manually segment all the brain image for an anatomical expert, so the expert only segmented eight CVH brain images which is saturated with abundant anatomical structures as the ground truth for training sets generation and quantitative evaluation.
The patches used for training and testing are extracted from the eight labeled images. The size of each patch is chosen 17 × 17 to achieve relatively best performance which is validated in Section 3.1, so ω in Figure 2 is 17. For MODEL 1, our training sets contain 100,00 WM patches and 90,000 non-WM patches extracted from eight training images. For model 2, the training sets contain 106,000 GM patches and 84,000 CSF patches. These patches are used for SAE and Softmax training in the two models.
3. Experimental Results and Discussion
In the experiments, we firstly focus on evaluating the segmentation performance of features learnt by different SAEs based on cryosection image in order to get the best SAE architecture. Secondly, we compare performances of the proposed model based on the deep-learned features and some famous hand-crafted features such as intensity, PCA, and HOG and one learning-based feature by AE. Then, we present typical segmentation examples and make some discussion. Finally, we build the 3D meshes of three tissues based on our segmentation results.
3.1. Comparison of Different SAE Architectures
The nonlinear mapping between the input and output of SAE is influenced by its multilayer architecture with various input patch sizes and depths. In order to investigate the impact of different SAE architectures on segmentation accuracy, five different SAE architectures are designed and resort to segmentation task. The detailed parameter configurations are shown in Table 1 and the segmentation performances of WM, GM, and CSF are reported in Table 2.
Table 1.
Details of the SAE architectures with different input patch size and layer depth in this study.
| Patch size | Layer 1 | Layer 2 | Layer 3 | Layer 4 | |
|---|---|---|---|---|---|
| 5 × 5 | Layer type | AE | Softmax | — | — |
| Input size | 50 | 25 | — | — | |
| Hidden size | 25 | — | — | — | |
|
| |||||
| 9 × 9 | Layer type | AE | AE | Softmax | — |
| Input size | 162 | 81 | 36 | — | |
| Hidden size | 81 | 36 | — | — | |
|
| |||||
| 13 × 13 | Layer type | AE | AE | Softmax | — |
| Input size | 338 | 150 | 64 | — | |
| Hidden size | 150 | 64 | — | — | |
|
| |||||
| 17 × 17 | Layer type | AE | AE | AE | Softmax |
| Input size | 578 | 400 | 200 | 100 | |
| Hidden size | 400 | 200 | 100 | — | |
|
| |||||
| 21 × 21 | Layer type | AE | AE | AE | Softmax |
| Input size | 882 | 400 | 200 | 100 | |
| Hidden size | 400 | 200 | 100 | — | |
Table 2.
Mean and standard deviation of Dice ratio (in %) for measuring the performance of the three tissue types with five different architectures trained by using different patch sizes of 5 × 5, 9 × 9, 13 × 13, 17 × 17, and 21 × 21, respectively. The experiments were conducted in a leave-one-out manner and eight test results were collected for each tissue.
| Patch size | WM | GM | CSF |
|---|---|---|---|
| 5 × 5 | 92.41 ± 2.85 | 90.36 ± 3.24 | 88.41 ± 3.01 |
| 9 × 9 | 93.95 ± 2.48 | 90.45 ± 2.13 | 89.54 ± 2.57 |
| 13 × 13 | 94.25 ± 2.01 | 91.74 ± 2.51 | 90.14 ± 2.84 |
| 17 × 17 | 96.12 ± 1.63 | 92.24 ± 2.11 | 90.69 ± 2.14 |
| 21 × 21 | 96.64 ± 1.85 | 91.12 ± 2.36 | 90.45 ± 2.04 |
It can be observed from the results that the predictive accuracies are generally higher for the architectures with input patch sizes of 17 × 17 and 21 × 21. The SAEs with larger patch size tend to have a deeper hierarchical structure and more trainable parameters. These learned parameters are capable of capturing the complex relationship between input and output. We can also observe that the architecture with input patch size of 21 × 21 does not generate substantially higher performance, suggesting that larger patch may introduce more image noise and fused anatomical structures. In order to obtain better segmentation performance, in the following we focus on evaluating the performance of our SAE architecture with input patch size of 17 × 17 and depth of 3.
3.2. Comparison of Performances Based on Different Features
In order to provide a comprehensive evaluation of the proposed method and illustrate the effect of high-level features in contrast to low-level features, three representative hand-crafted features such as intensity, PCA [32, 33], and HOG [34] and one learning-based features by AE are used for comparison. These features follow the same segmenting procedures as the deep-learned features. All the segmentation performances are reported in Table 3 using Dice ratio. It can be observed that our model with the features extracted by SAE outperforms other well-known features for segmenting all three types of brain tissue. Specifically, our model yields the best average Dice ratio of 90.69 ± 2.14% (CSF), 91.24 ± 2.01% (GM), and 96.12 ± 1.23% (WM) in a leave-one-out evaluation manner. These results have illustrated the strong discriminative power of the deep-learned features in brain tissues segmentation task.
Table 3.
Mean and standard deviation of Dice ratio (in %) for the segmentations obtained by five feature representation methods.
| Method | CSF | GM | WM |
|---|---|---|---|
| Intensity | 88.76 ± 2.41 | 89.46 ± 2.12 | 95.49 ± 1.96 |
| PCA | 89.31 ± 1.89 | 90.87 ± 2.34 | 95.20 ± 2.01 |
| HOG | 86.77 ± 2.67 | 87.21 ± 2.86 | 94.92 ± 1.89 |
| AE | 88.32 ± 2.37 | 90.26 ± 2.36 | 95.60 ± 1.83 |
| Proposed SAE | 90.69 ± 2.14 | 91.24 ± 2.01 | 96.12 ± 1.23 |
To further demonstrate the advantages of our proposed model, we visually examine the segmentation results on one cryosection image which is shown in Figure 6. (a) shows the original RGB cryosection image and its B- and V-channel images. The ground truth that segmented by experts is shown in (b). (c)–(g) present segmentation results of four methods based on deep-learned features, intensity features, PCA features, HOG features, and AE feautres, respectively. We can see that the segmentation results of the proposed model are quite close to the ground truth. In contrast, other results either generate much oversegmentation or fail to segment tiny anatomical structures accurately. Specifically, WM is only adjacent to the GM and can be easily distinguished from its surroundings, so the WM segmentation DRs are approximate to each other. And the visible results of WM are similar in appearance except the fact that HOG-based method mistakenly introduced a small fraction of CSF into the results. It has some difficulty on GM and CSF segmentation due to the complex anatomical structures and low contrast. HOG and intensity based methods introduce more surrounding non-GM or non-CSF tissue into the ROI of GM or CSF, respectively; thus they produce more defects and fuzzy boundaries for different tissues. In contrast, the GM and CSF tissues generated by our method can be clearly identified with a certain ROI and distinct contours.
Figure 6.

Comparison of the segmentation results with the manually generated segmentation on a cryosection image in CVH dataset. (a) shows the original cryosection and its B-channel (in RGB color space) and V-channel (in HSV color space) image. (b) shows the manual results (CSF, GM, and WM). (c)–(g) show the results by the features of our SAE deep learning, Intensity, PCA, HOG, and AE, respectively.
We then applied our proposed model to segment all 422 brain cryosection images. Typical images in coronal and sagittal viewpoints and their corresponding segmentation results (WM, GM, and CSF) are shown in Figures 7 and 8, respectively. It is remarkably seen that the results of WM and GM change continuously and their morphological distributions are shown clearly; most tiny anatomical structures are well reserved. It is also noticed that the results of CSF seem incomplete and not distributed uniformly. This fact is determined by the characteristics of the cryosection images. These images have such high spatial resolution (0.167 mm per pixel and 0.25 mm per slice) that it can express fine structures of tissues. But since these images were collected from a cadaver, the CSF in the brain no longer flowed in vivo. Due to the effect of gravity, the CSF will gather to some places, rather than uniformly distributing around the surface of brain as in live status. These factors cause the discontinuous distribution of the CSF segmentation results.
Figure 7.

Coronal section images (a) and their corresponding SAE segmentation results of WM, GM, and CSF ((b), (c), and (d)).
Figure 8.

Sagittal section images (a) and their corresponding SAE segmentation results of WM, GM, and CSF ((b), (c), and (d)).
3.3. Three-Dimensional Reconstruction Results
The CVH cryosection slices are 0.167 mm per pixel and 0.25 mm thick, and such high resolution is very helpful for displaying subtle anatomical structures of brain tissues. For a more in-depth understanding of these tissues, the segmented white matter, gray matter, and cerebrospinal fluid images are reconstructed using marching cubes algorithm to produce 3D surface mesh. The reconstruction results in different views are shown in Figure 9. From the surface-rendering reconstruction results, it is seen that the surface of WM is smooth and its sulci and fissures are clearly displayed. The distribution of GM shape is also noticed, but the surface of GM reconstruction results does not look very smooth. The reason for this lies in the fact that the GM and CSF are mixed together because of the ice crystals in the frozen brain slices, so the segmentation of GM is influenced by its surrounding CSF. In spite of it, the sulci and cerebral cisterns are also easy to be recognized in 3D reconstructed WM and GM.
Figure 9.

Three-dimensional surface-rendering reconstruction results of WM, GM, and CSF based on our segmented images.
Benefitting from the increasing development of the 3D reconstruction technology, 3D MRI and PET have now been used in clinic and researches. But because of the resolution limitation and complexity of brain structures of the 2D radiological images (such as CT and MRI), the 3D reconstruction results are usually unsatisfactory and are hard for the guidance of clinic operation. For the work in our paper, we focus on the segmentation and reconstruction of three kinds of CVH brain tissues. The CVH brain images have high spatial resolution of 0.167 mm per pixel and 0.25 mm per slice, after segmentation by the proposed method; the high-quality and high-accuracy 2D brain tissues can get well 3D reconstruction results. Some potential applications of the 3D reconstruction result include the following:
The 3D results can be viewed in any orientation besides the common coronal, sagittal, and transverse orientations. These 3D models (especially for WM and GM) can help obtain the anatomical knowledge of 3D structures and their adjacent relationship in space. In addition, we can identify the structures by comparing radiological image with the anatomical image.
The 3D result in our work is applicable for teaching sectional anatomy since there is rarely direct-viewing model that can make the understanding of anatomical structures easier. The varying viewpoints of the 3D model are helpful for observing the tiny structures in specific positions of human brain, and medical students only need to move their mouse to control the perspective of displaying.
4. Conclusion
We have presented a supervised learning-based CVH brain tissue segmentation method using the deep-learned features with multilayer SAE neural network. The major difference between our proposed feature extraction method and conventional hand-crafted features such as intensity, PCA, and Histogram of Gradient (HOG) is that it can dynamically learn the most informative features adapted to the input dataset at hand. The discriminative ability of our proposed model is evaluated and compared with other types of image features. Experimental results validate the effectiveness of our proposed method and show that it significantly outperforms the methods based on typical hand-crafted features. In addition, the high-resolution 3D tissue surface meshes are reconstructed based on the segmentation results by our method with the resolution of 0.167 mm per pixel and 0.25 mm per slice, much more tiny than the 3 T (even 7 T) MRI brain images. Furthermore, since the procedure of features extraction by our method is independent of the CVH dataset, our method can be easily extended to segment other medical images such as cell images and skin cancer images. CVH dataset contains serial transverse section images of the whole human body, which is large in volume. Pure manual or semiautomatic segmentation of those images is quite time-consuming, so a large proportion of data still remain to be exploited. Though the work in our paper only had segmented the WM, GM, and CSF of the brain tissue, it actually provides a reference for automatically or semiautomatically processing such real-color and high-resolution images.
Recent studies show that neural network can yield more promising performance on image recognition task with deeper hidden layers [35, 36]; we will explore parallel SAE with more hidden layers as well as more training data in the future. In addition, the number of neural units in each hidden layer may affect the segmentation performance in a certain degree. We will further investigate the influence of hidden neural units to segmentation performance. Furthermore, the model uses a classical Softmax classifier to predict labels of the input patches, and we will consider the influence of different classifiers in the future research.
Acknowledgments
This work was partially supported by the Chinese National Science Foundation (NSFC 60903142 and 61190122), the China Postdoctoral Science Foundation (2013T60841, 2012M521677, and Xm201306), and Fundamental Research Funds for the Central Universities (106112015CDJXY120003).
Conflict of Interests
The authors declare that they have no conflict of interests.
References
- 1.Wu Y., Tan L.-W., Li Y., et al. Creation of a female and male segmentation dataset based on chinese visible human (CVH) Computerized Medical Imaging and Graphics. 2012;36(4):336–342. doi: 10.1016/j.compmedimag.2012.01.003. [DOI] [PubMed] [Google Scholar]
- 2.Zhang S.-X., Heng P.-A., Liu Z.-J. Chinese visible human project. Clinical Anatomy. 2006;19(3):204–215. doi: 10.1002/ca.20273. [DOI] [PubMed] [Google Scholar]
- 3.Li M., Zheng X.-L., Luo H.-Y., et al. Automated segmentation of brain tissue and white matter in cryosection images from Chinese visible human dataset. Journal of Medical and Biological Engineering. 2014;34(2):178–187. doi: 10.5405/jmbe.1336. [DOI] [Google Scholar]
- 4.Mahmood Q., Chodorowski A., Persson M. Automated MRI brain tissue segmentation based on mean shift and fuzzy c-means using a priori tissue probability maps. IRBM. 2015;36(3):185–196. doi: 10.1016/j.irbm.2015.01.007. [DOI] [Google Scholar]
- 5.Paul G., Varghese T., Purushothaman K., Singh N. A. Proceedings of the International Conference on Frontiers of Intelligent Computing: Theory and Applications (FICTA) 2013. Vol. 247. Berlin, Germany: Springer; 2014. A fuzzy c mean clustering algorithm for automated segmentation of brain MRI; pp. 59–65. (Advances in Intelligent Systems and Computing). [DOI] [Google Scholar]
- 6.Balafar M. A. Gaussian mixture model based segmentation methods for brain MRI images. Artificial Intelligence Review. 2014;41(3):429–439. doi: 10.1007/s10462-012-9317-3. [DOI] [Google Scholar]
- 7.Anbeek P., Išgum I., van Kooij B. J. M., et al. Automatic segmentation of eight tissue classes in neonatal brain MRI. PLoS ONE. 2013;8(12) doi: 10.1371/journal.pone.0081895.e81895 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Moeskops P., Viergever M. A., Benders M. J. N. L., Išgum I. Evaluation of an automatic brain segmentation method developed for neonates on adult MR brain images. Medical Imaging: Image Processing; March 2015; pp. 1–6. [DOI] [Google Scholar]
- 9.Hussain S. J., Savithri T. S., Devi P. S. Segmentation of tissues in brain MRI images using dynamic neuro-fuzzy technique. International Journal of Soft Computing and Engineering. 2012;1(6):2231–2307. [Google Scholar]
- 10.Demirhan A., Toru M., Guler I. Segmentation of tumor and edema along with healthy tissues of brain using wavelets and neural networks. IEEE Journal of Biomedical and Health Informatics. 2015;19(4):1451–1458. doi: 10.1109/jbhi.2014.2360515. [DOI] [PubMed] [Google Scholar]
- 11.Liao S., Gao Y., Oto A., Shen D. Medical Image Computing and Computer-Assisted Intervention—MICCAI 2013. Vol. 8150. Berlin, Germany: Springer; 2013. Representation learning: a unified deep learning framework for automatic prostate MR segmentation; pp. 254–261. (Lecture Notes in Computer Science). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Nabizadeh N., John N., Wright C. Histogram-based gravitational optimization algorithm on single MR modality for automatic brain lesion detection and segmentation. Expert Systems with Applications. 2014;41(17):7820–7836. doi: 10.1016/j.eswa.2014.06.043. [DOI] [Google Scholar]
- 13.Jirik M., Ryba T., Zelezny M. Texture based segmentation using graph cut and Gabor filters. Pattern Recognition and Image Analysis. 2011;21(2):258–261. doi: 10.1134/s105466181102043x. [DOI] [Google Scholar]
- 14.Nanthagopal A. P., Sukanesh R. Wavelet statistical texture features-based segmentation and classification of brain computed tomography images. IET Image Processing. 2013;7(1):25–32. doi: 10.1049/iet-ipr.2012.0073. [DOI] [Google Scholar]
- 15.Chen W. X., Lin X. Big data deep learning: challenges and perspectives. IEEE Access. 2014;2:514–525. doi: 10.1109/access.2014.2325029. [DOI] [Google Scholar]
- 16.Krizhevsky A., Sutskever I., Hinton G. E., Krizhevsky A. Imagenet classification with deep convolutional neural networks. Proceedings of the Advances in Neural Information Processing Systems (NIPS '12); December 2012; pp. 1097–1105. [Google Scholar]
- 17.Bengio Y. Learning deep architectures for AI. Foundations and Trends in Machine Learning. 2009;2(1):1–127. doi: 10.1561/2200000006. [DOI] [Google Scholar]
- 18.Hinton G. E., Osindero S., Teh Y.-W. A fast learning algorithm for deep belief nets. Neural Computation. 2006;18(7):1527–1554. doi: 10.1162/neco.2006.18.7.1527. [DOI] [PubMed] [Google Scholar]
- 19.Guo Y., Wu G., Commander L. A., et al. Medical Image Computing and Computer-Assisted Intervention—MICCAI 2014. Springer; 2014. Segmenting hippocampus from infant brains by sparse patch matching with deep-learned features; pp. 308–315. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Hinton G. E., Salakhutdinov R. R. Reducing the dimensionality of data with neural networks. Science. 2006;313(5786):504–507. doi: 10.1126/science.1127647. [DOI] [PubMed] [Google Scholar]
- 21.Krizhevsky A., Hinton G. E. Using very deep autoencoders for content-based image retrieval. Proceedings of the 19th European Symposium on Artificial Neural Networks (ESANN '11); April 2011; Bruges, Belgium. pp. 489–494. [Google Scholar]
- 22.Zhang W., Li R., Deng H., et al. Deep convolutional neural networks for multi-modality isointense infant brain image segmentation. NeuroImage. 2015;108:214–224. doi: 10.1016/j.neuroimage.2014.12.061. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Dai J., He K., Sun J. Convolutional feature masking for joint object and stuff segmentation. http://arxiv.org/abs/1412.1283.
- 24.Agostinelli F., Anderson M. R., Lee H. Adaptive multi-column deep neural networks with application to robust image denoising. Proceedings of the Advances in Neural Information Processing Systems (NIPS '13); December 2013; Stateline, Nev, USA. pp. 1493–1501. [Google Scholar]
- 25.Xie J., Xu L., Chen E. Advances in Neural Information Processing Systems. MIT Press; 2012. Image denoising and inpainting with deep neural networks; pp. 341–349. [Google Scholar]
- 26.Shin H.-C., Orton M. R., Collins D. J., Doran S. J., Leach M. O. Stacked autoencoders for unsupervised feature learning and multiple organ detection in a pilot study using 4D patient data. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2013;35(8):1930–1943. doi: 10.1109/TPAMI.2012.277. [DOI] [PubMed] [Google Scholar]
- 27.Xu J., Xiang L., Liu Q., et al. Stacked sparse autoencoder (SSAE) for nuclei detection on breast cancer histopathology images. IEEE Transactions on Medical Imaging. 2015 doi: 10.1109/TMI.2015.2458702. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Zhang S.-X., Heng P.-A., Liu Z.-J., et al. Creation of the Chinese visible human data set. The Anatomical Record Part B: The New Anatomist. 2003;275(1):190–195. doi: 10.1002/ar.b.10035. [DOI] [PubMed] [Google Scholar]
- 29.Qi Y., Wang Y., Zheng X., Wu Z. Robust feature learning by stacked autoencoder with maximum correntropy criterion. Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP '14); May 2014; Florence, Italy. pp. 6716–6720. [DOI] [Google Scholar]
- 30.Amaral T., Silva L. M., Alexandre L. A., Kandaswamy C., Santos J. M., de Sa J. M. Using different cost functions to train stacked auto-encoders. In: Castro F., Gelbukh A., Mendoza M. G., editors. Proceedings of the 12th Mexican International Conference on Artificial Intelligence (MICAI '13); November 2013; Mexico City, Mexico. IEEE; pp. 114–120. [DOI] [Google Scholar]
- 31.Coates A., Ng A. Y., Lee H. An analysis of single-layer networks in unsupervised feature learning. Proceedings of the 14th International Conference on Artificial Intelligence and Statistics (AISTATS '11); April 2011; Fort Lauderdale, Fla, USA. pp. 215–223. [Google Scholar]
- 32.Shlens J. A Tutorial on Principal Component Analysis. Systems Neurobiology Laboratory; 2005. [Google Scholar]
- 33.Zhang Y., Wu L. An MR brain images classifier via principal component analysis and kernel support vector machine. Progress in Electromagnetics Research. 2012;130:369–388. doi: 10.2528/pier12061410. [DOI] [Google Scholar]
- 34.Déniz O., Bueno G., Salido J., De la Torre F. Face recognition using histograms of oriented gradients. Pattern Recognition Letters. 2011;32(12):1598–1603. doi: 10.1016/j.patrec.2011.01.004. [DOI] [Google Scholar]
- 35.Gao S., Zhang Y., Jia K., Lu J., Zhang Y. Single sample face recognition via learning deep supervised autoencoders. IEEE Transactions on Information Forensics and Security. 2015;10(10):2108–2118. doi: 10.1109/tifs.2015.2446438. [DOI] [Google Scholar]
- 36.Jarrett K., Kavukcuoglu K., Ranzato M., LeCun Y. What is the best multi-stage architecture for object recognition?. Proceedings of the 12th International Conference on Computer Vision (ICCV '09); October 2009; Kyoto, Japan. IEEE; pp. 2146–2153. [DOI] [Google Scholar]