

Abstract
Urban sound has a huge influence over how we perceive places. Yet, city planning is concerned mainly with noise, simply because annoying sounds come to the attention of city officials in the form of complaints, whereas general urban sounds do not come to the attention as they cannot be easily captured at city scale. To capture both unpleasant and pleasant sounds, we applied a new methodology that relies on tagging information of georeferenced pictures to the cities of London and Barcelona. To begin with, we compiled the first urban sound dictionary and compared it with the one produced by collating insights from the literature: ours was experimentally more valid (if correlated with official noise pollution levels) and offered a wider geographical coverage. From picture tags, we then studied the relationship between soundscapes and emotions. We learned that streets with music sounds were associated with strong emotions of joy or sadness, whereas those with human sounds were associated with joy or surprise. Finally, we studied the relationship between soundscapes and people's perceptions and, in so doing, we were able to map which areas are chaotic, monotonous, calm and exciting. Those insights promise to inform the creation of restorative experiences in our increasingly urbanized world.
Keywords: urban informatics, soundscape, mapping
1. Introduction
Studies have found that long-term exposure to urban noise (in particular, to traffic noise) results into sleeplessness and stress [1], increased incidence of learning impairments among children [2], and increased risk of cardiovascular morbidity such as hypertension [3] and heart attacks [4,5].
Because those health hazards are likely to reduce life expectancy, a variety of technologies for noise monitoring and mitigation have been developed over the years. However, those solutions are costly and do not scale at the level of an entire city. City officials typically measure noise by placing sensors at a few selected points. They do so mainly because they have to comply with the environmental noise directive [6], which requires the management of noise levels only from specific sources, such as road traffic, railways, major airports and industry. To fix the lack of scalability of a typical solution based on sensors, in distinct fields, researchers have worked on ways of making noise pollution estimation cheap. They have worked, for example, on epidemiological models to estimate noise levels from a few samples [7], on capturing samples from smartphones or other pervasive devices [8–12], and on mining geolocated data readily available from social media (e.g. Foursquare, Twitter) [13].
All this work has focused, however, on the negative side of urban sounds. Pleasant sounds have been left out from the urban planning literature, yet they have been shown to positively impact city dwellers’ health [14,15]. Only a few researchers have been interested in the whole ‘urban soundscape’. In the World Soundscape Project,1 for example, composer Raymond Murray Schafer et al. defined soundscape for the first time as an environment of sound (or sonic environment) with emphasis on the way it is perceived and understood by the individual, or by a society [16]. That early work eventually led to a new International Standard, ISO 12913, where soundscape is defined as [the] acoustic environment as perceived or experienced and/or understood by a person or people, in context [17]. Since that work, there remains a number of unsolved challenges though.
First, there is no shared vocabulary of urban sounds. Back in the early days of the World Soundscape Project, scholars collected sound-related terms and provided a classification of sounds [16], but that classification was meant to be neither comprehensive nor systematic. Signal processing techniques for automatically classifying sounds have recently used labelled examples [18,19], but, again, those training labels are not organized in any formal taxonomy.
Second, studying the relationship between urban sounds and people's perceptions is hard. So far, the assumption has been that a good proxy for perceptions is noise level. But perceptions depend on a variety of factors; for example, on what one is doing (e.g. whether one is at a concert). Therefore, policies focusing only on the reduction of noise levels might well fall short.
Finally, urban sounds cannot be captured at scale and, consequently, they are not considered when planning cities [20]. That is because the collection of data for managing urban acoustic environments has mainly been relegated to small-scale surveys [21–24].
To partly address those challenges, we used georeferenced social media data to map the soundscape of an entire city, and related that mapping to people's emotional responses. We did so by extending previous work that captured urban smellscapes from social media [25] with four main contributions:
— We collected sound-related terms from different online and offline sources and arranged those terms in a taxonomy. The taxonomy was determined by matching the sound-related terms with the tags on 1.8 million georeferenced Flickr pictures in Barcelona and London, and by then analysing how those terms co-occurred across the pictures to obtain a term classification (co-occurring terms are expected to be semantically related). In so doing, we compiled the first urban sound dictionary and made it publicly available: in it, terms are best classified into six top-level categories (i.e. transport, mechanical, human, music, nature, indoor), and those categories closely resemble the manual classification previously derived by aural researchers over decades.
— Upon our picture tags, we produced detailed sound maps of Barcelona and London at the level of street segment. By looking at different segment types, we validate that, as one expects, pedestrian streets host people, music and indoor sounds, whereas primary roads are about transport and mechanical sounds.
— For the first time, to the best of our knowledge, we studied the relationship between urban sounds and emotions. By matching our picture tags with the terms of a widely used word-emotion lexicon, we determined people's emotional responses across the city, and how those responses related to urban sound: fear and anger were found on streets with mechanical sounds, whereas joy was found on streets with human and music sounds.
— Finally, we studied the relationship between a street's sounds and the perceptions people are likely to have of that street. Perceptions came from soundwalks conducted in two cities in the UK and Italy: locals were asked to identify sound sources and report them along with their subjective perceptions. Then, from social media data, we determined a location's expected perception based on the sound tags at the location.
2. Methodology
The main idea behind our method was to search for sound-related words (mainly words reflecting potential sources of sound) on georeferenced social media content. To that end, we needed to get hold of two elements: the sound-related words and the content against which to match those words.
2.1. Sound words
We obtained sound-related words from the most comprehensive research project in the field—the World Soundscape Project—and from the most popular crowdsourced online repository of sounds—Freesound.
2.1.1. Schafer's words
The World Soundscape Project is an international research project that initiated the modern study of acoustic ecology. In his book The soundscape, the founder of the project, R. Murray Schafer, coined the term soundscape and emphasized the importance of identifying pleasant sounds and using them to create healthier environments. He described how to classify sounds, appreciating their beauty or ugliness, and offered exercises (e.g. ‘soundwalks’) to help people become more sensitive to sounds. An entire chapter was dedicated to the classification of urban sounds, which was based on literary, anthropological and historical documents. Sounds were classified into six categories: natural, human, societal (e.g. domestic sounds), mechanical, quiet and indicators (e.g. horns and whistles). Our work also used that classification: to associate words with each category, three annotators independently hand-coded the book's sections dedicated to the category, and the intersection of the three annotation sets (which is more conservative than the union) was considered, resulting in a list of 236 English terms.
2.1.2. Crowdsourced words
Freesound is the largest public online collaborative repository of audio samples: 130 K sounds annotated with 1.5 M tags are publicly available through an API. Out of the unique tags (which were 65 K), we considered only those that occurred more than 100 times (the remaining ones were too sparse to be useful), resulting in 2.2 K tags, which still amounted to 76% of the total volume as the tag frequency distribution was skewed. However, those tags covered many topics (including user names, navigational markers, sound quality descriptions and synthesized sound effects) and reflected ambiguous words at times (e.g. ‘fan’ might be a person or a mechanical device) and, as such, needed to be further filtered to retain only words related to sounds or physical sound sources. One annotator manually performed that filtering, which resulted into a final set of 229 English terms.
In addition to that set of words, there is an online repository specifically tailored to urban sounds called Favouritesounds.2 This site hosts crowdsourced maps of sounds for several cities in the world: individuals upload recordings of their favourite sounds, place them on the city map and annotate them with free-text descriptions. By manually parsing the 6 K unique words contained in those descriptions, we extracted 243 English terms.
2.2. Georeferenced content
Having two sets of sound-related words at hand, we needed social media data against which those words had to be matched. 17 M Flickr photos taken between 2005 and 2015 along with their tags were made publicly available in London and Barcelona. In those two cities, we identified each street segment from OpenStreetMap3 (OSM is a global group of volunteers who maintain free crowdsourced online maps). We then collated tags in each segment together by considering the augmented area of the segment's polyline, an area with an extra space of 22.5 m on each side to account for positioning errors typically present in georeferenced pictures [25,26].
We found that, among the three crowdsourced repositories, Freesound words matched most of the picture tags and offered the widest geographical coverage (figure 1), in that they matched 2.12 M tags and covered 141 K street segments in London. In addition, Freesound's words offered a far better coverage than Schafer's did, with a broad distribution of tags over street segments (figure 2).
Figure 1.

Coverage of the three urban sound dictionaries. Number of tags, photos, street segments that had at least one smell word from each vocabulary in Barcelona and London. Each bar is a smell vocabulary. Schafer was extracted from Schafer's book The soundscape, whereas the other two were online repositories. The best coverage was offered by Freesound.
Figure 2.

Number of street segments (y-axis) containing a given number of picture tags that match Freesound terms (x-axis) in London and Barcelona. Many streets had a few tags, and only a few streets have a massive number of them. London has 141 K segments with at least one tag (and 15 tags in each segment, on average), Barcelona 20 K (25 tags per segment on average).
Because the words of the other online repository considerably overlapped with Freesound's (67% Favoritesounds tags are also in Freesound), we worked only with Freesound (to ensure effective coverage) and with Schafer's classification (to allow for comparability with the literature).
2.3. Categorization
To discover similarities, contrasts and patterns, sound words needed to be classified. Schafer already did so. Our Schafer's words are classified into seven main categories—nature, human, society, transport, mechanical, indicators and quiet—and each category might have a subcategory (e.g. society includes the subcategories indoor and entertainment). By contrast, Freesound's words are not classified. However, by looking at which Freesound words co-occur in the same locations, we could discover similarities (e.g. nature words could co-occur in parks, whereas transport words in trafficked streets). The use of community detection to extract word categories had been successfully tested in previous work that extracted categories of smell words [25]. Compared with other clustering techniques (e.g. LDA [27], K-means [28]), a community detection technique has the advantage of being fully non-parametric and quite resilient to data sparsity. Therefore, we also applied it here. We first built a co-occurrence network where nodes were Freesound's words, and undirected edges were weighted with the number of times the two words co-occurred in the same Flickr pictures as tags. The semantic relatedness among words naturally emerged from the network's community structure: semantically related nodes ended up being both highly clustered together and weakly connected to the rest of the network. To determine the clustering structure, we could have used any of the literally thousands of different community detection algorithms that have been developed in the last decade [29]. None of them always returns the ‘best’ clustering. However, because Infomap had shown very good performance across several benchmarks [29], we opted for it to obtain the initial partition of our network [30]. Infomap's partitioning resulted in many clusters containing semantically related words, but it also resulted in some clusters that were simply too big to possibly be semantically homogeneous. To further split those clusters, we applied the community detection algorithm by Blondel et al. [31], which has been found to be the second best performing algorithm [29]. This algorithm stops when no ‘node switch’ between communities increases the overall modularity [32], which measures the overall quality of the resulting partitions.4 The result of those two steps is the grouping of sound words in hierarchical categories. Because a few partitions of words could have been too fine-grained, we manually double-checked whether this was the case and, if so, we merged all those subcommunities that were under the same hierarchical partition and that contained strongly related sound words.
Figure 3 sketches the resulting classification in the form of a sound wheel. This wheel has six main categories (inner circle), each of which has a hierarchical structure with variable depth from 0 to 3. For brevity, the wheel reports only the first level fully (inner circle), whereas it reports samples for the two other levels. Despite spontaneously emerging from word co-occurrences and being fully data-driven, the classification in the wheel strikingly resembles Schafer's. The three categories human, nature and transport are all in both categorizations. The category quiet is missing, because it does not match any tag in Freesound, as one would expect. The remaining categories are all present but arranged at a different level: music and indoor are at the first level in the wheel, whereas they are at the second level in Schafer's categorization; the mechanical category in the wheel collates two of Schafer's categories into one: mechanical and indicator.
Figure 3.

Urban sound taxonomy. Top-level categories are in the inner circle; second-level categories are in the outer ring and examples of words are in the outermost ring. For space limitation, in the wheel, only the first categories (those in the inner circle) are complete, whereas subcategories and words represent just a sample.
Freesound not only offered a classification similar to Schafer's and to recent working groups’ classifications [33,18] (speaking to its external validity), but also offered a richer vocabulary of words. By looking at the fraction tagc/tag of sound words in category c that matched at least one georeference picture tag (tagc) over the total number of tags in the city (tag), we saw that Freesound resulted in a full representation of all sound categories (figure 4), whereas Schafer's resulted in a patchy representation of many categories. Therefore, given its effectiveness, Freesound was chosen as the sound vocabulary for the creation of the urban sound wheel. Only the wheel's top-level categories were used. The full taxonomy is, however, available online5 for those wishing to explore specialized aspects of urban sounds (e.g. transport, nature).
Figure 4.

Fraction tagc/tag of picture tags that matched sound category c over all the tags in the city.
3. Validation
With our sound categorization, we were able to determine, for each street segment j, its sound profile soundj in the form of a six-element vector. Given sound category c, the element soundj,c is
| 3.1 |
where tagj,c is the number of tags at segment j that matched sound category c, and tagj is the total number of tags at segment j. To make sure the sound categories c we had chosen resulted in reasonable outcomes, we verified whether different street types were associated with sound profiles one would expect (§3.1), and whether those profiles matched official noise pollution data (§3.2).
3.1. Street types
One way of testing whether the six-category classification makes sense in the city context is to see which pairs of categories do not tend to co-occur spatially (e.g. nature and transport should be on separate streets). Therefore, for each street segment, we computed the pairwise Spearman rank correlation ρ between the fraction of sound tags in category c1 and that of sound tags in category c2, across all segments (figure 5). That is, we computed ρj(soundj,c1,soundj,c2) across all j's. We found that the correlations were either zero or negative. This meant that the categories were either orthogonal (i.e. the categories of human, indoor, music, mechanical show correlations close to zero) or geographically sorted in expected ways (with ρ=−0.50, nature and transport are seen, on average, on distinct segments).
Figure 5.

Pairwise rank correlations between the fraction of sound tags in category c1 (soundj,c1) and the faction in category c2 (soundj,c2) across all segments j in London.
To visualize the geographical sorting of sounds, we marked each street segment with the sound category that had the highest z-score in that segment (figure 6). The z-scores reflect the extent to which the fraction of sound tags in category c at street segment j deviated from the average fraction of sound tags in c at all the other segments:
| 3.2 |
where μ(soundc) and σ(soundc) are the mean and standard deviation of the fractions of tags in sound category c across all segments. We then reported the most prominent sound at each street segment in figure 6: traffic was associated with street junctions and main roads, nature with parks or greenery spots and human and music with central parts or with pedestrian streets.
Figure 6.

Urban sound maps of London (a) and Barcelona (b). Each street segment is marked with the sound category c that has the highest z-score for that segment (zsoundj,c). In London, natural sounds are found in Regent's Park (1), Hyde Park (2), Green Park (3) and all around the River Thames (9). By contrast, transport sounds are around Waterloo station (4) and on the perimeter of Hyde Park (5). Human sounds are found in Soho (6) and Bloomsbury (7), and music is associated with the small clubs on Camden High Street (8). In Barcelona, natural sounds are found in Montjuic Park (1), Park Guell (2) and Ciutadella Park (3), and on the beaches of Barceloneta (8) and Ronda Litoral (9). By contrast, annoying and chaotic sounds are found on the main road of Avinguda Diagonal (4), on Plaza de Espana (5) and on Avinguda De Les Corts Catalanes (6). Human sounds are found in the historical centre called Gothic/Ciutat Vella (7), and music in the open-air arena of El Forum (10). Only segments with at least five sound tags were considered.
One, indeed, expects that different street types (table 1 reports the most frequent types in OSM) would be associated with different sounds. To verify that, we computed the average z-score of a sound category c for the segments with street type t:
| 3.3 |
where St is the set of segments of (street) type t. Figure 7 reports the average values of those z-scores. Each clock-like representation refers to a street type, and the sound categories unfold along the clock: positive (negative) z-score values are marked in green (red) and suggest a presence of a sound category higher (lower) than the average one. By looking at the positive values, we saw that primary, secondary and tertiary streets (which contain cars) were associated with transport sounds; construction sites with mechanical sounds; footways and tracks (often embedded in parks) were associated with nature sounds; residential and pedestrian streets were associated with human, music and indoor sounds. Then, by looking at the negative values, we learned that primary, secondary, tertiary and construction streets were not associated with nature; and the other street types were not associated with sounds related to transport.
Table 1.
Description of the eight most frequent street types in Open Street Map.
| street type | description |
|---|---|
| footway | designated footpaths mainly or exclusively for pedestrians. This includes walking tracks and gravel paths |
| residential | roads that serve as an access to housing, without function of connecting settlements. Often lined with housing |
| pedestrian | roads used mainly or exclusively for pedestrians in shopping and residential areas. They may allow access of motorized vehicles only for very limited periods of the day |
| track | roads for mostly agricultural or forestry uses. Tracks are often rough with unpaved surfaces |
| primary | a major highway linking large towns, normally with two lanes not separated by a central barrier |
| secondary | a highway which is not part of a major route, but nevertheless forming a link in the national route network, normally with two lanes |
| tertiary | roads connecting smaller settlements or roads connecting minor streets to more major roads |
| construction | active road construction sites. Major road and rail construction schemes that typically require several years to complete |
Figure 7.

Average z-scores of the presence of six sound categories for segments of each street type . Positive values are in green, and negative ones are in red. The first clock-like representation refers to primary roads and shows that transport sounds have z-score of 0.3 (they are present more than average), whereas nature sounds have z-score of −0.3 (they are present less than average). The number of segments per type ranges between 1 and 25 K, with the only exception of the ‘construction’ type that has only 83 segments. Confidence intervals around the average values range between 10−2 and 10−3.
3.2. Noise pollution
The most studied aspect of urban sounds is the issue of noise pollution. Despite the importance of that issue, there are no reliable and high-coverage noise measurement data for world-class cities. There is a great number of participatory sensing applications that manage databases of noise levels in several cities, and some of them are publicly accessible [8–12], but all of them offer a limited geographical coverage of a city.
Barcelona is an exception, however. In 2009, the city council started a project, called Strategic Noise Map, whose main goal was to monitor noise levels and ultimately find new ways of limiting sound pollution. The project has a public API6 that returns noise values at the level of street segment for the whole city. For each segment, we collected the four dB values provided: three yearly averages for the three times of the day (day: from 07.00 to 21.00; evening: from 21.00 to 23.00; and night: from 23.00 to 07.00), and one aggregate value, the equivalent-weighted level (EWL), that averages those three values adding a 5 dB penalty to the evening period, and a 10 dB to the night period. With a practice akin to the one used for air quality indicators [34,35], those noise level values are estimated by a prediction model that is bootstrapped with field measurements [36]. In the case of Barcelona, the model is bootstrapped with 2.300 short-span noise measurements lasting at most 15 min, usually taken during daytime, and with 100 long-span ones lasting from 24 h to a few days.
To see whether noise pollution was associated with specific sound categories, we considered the street segments with at least N tags and computed, across all the segments, the Spearman rank correlations ρj(EWLj, soundj,c) between segment j's EWL values (in dB) and j's fraction of picture tags that matched category c7 (figure 8). The idea was to determine not only which categories were associated with noise pollution but also how many tags were needed to have a significant association. We found that noise pollution was positively correlated (p<0.01) with traffic (0.1<ρ<0.3) and negatively correlated with nature (−0.1<ρ<−0.2), and those results did hold for low values of N, suggesting that only a few hundred tags were needed to build a representative sound profile of a street.
Figure 8.

Spearman correlation between the fraction of tags at segment j that matched category c (soundj,c) and j's noise levels (expressed as equivalent-weighted level values in dB) as the number of tags per street segment (x-axis) increases. All correlations are statistically significant at the level of p<0.01.
4. Emotional and perceptual layers
Sounds can be classified in ways that reflect aspects other than semantics—they may be classified according to, for example, their emotional qualities or the way they are perceived. Therefore, we now show how social media helps extracting the emotional layer (§4.1) and the perceptual layer (§4.2) of urban sound.
4.1. Emotional layer
Looking at a location through the lens of social media makes it possible to characterize places from different points of view. Sound has a highly celebrated link with emotions, especially music sound [38,39], and it has a considerable effect on our feelings and our behaviour.
One way of extracting emotions from georeferenced content is to use a word-emotion lexicon known as EmoLex [40]. This lexicon classifies words into eight primary emotions: it contains binary associations of 6468 terms with the their typical emotional responses. The eight primary emotions (anger, fear, anticipation, trust, surprise, sadness, joy and disgust) come from Plutchik's psychoevolutionary theory [41], which is commonly used to characterize general emotional responses. We opted for EmoLex instead of other commonly used sentiment dictionaries (such as LIWC [42]) as it made it possible to study finer-grained emotions.
We matched our Flickr tags with the words in EmoLex and, for each street segment, we computed its emotion profile. The profile consisted of all Plutchik's primary emotions, in that each of its elements was associated with an emotion:
| 4.1 |
where tagj,e is the number of tags at segment j that matched primary emotion e. We then computed the corresponding z-score:
| 4.2 |
By computing the Spearman rank correlation ρj(zsoundj,c, zemotionj,e), we determined which sound was associated with which emotion. From figure 9, we see that joyful words were associated with streets typically characterized by music and human sounds, whereas they were absent in streets with traffic. Traffic was, instead, associated with words of fear, anticipation and anger. Interestingly, words of sadness (together with those of joy) were associated with streets with music, words of trust with indoors and words of surprise with streets typically characterized by human sounds.
Figure 9.

Correlation between zsoundj,c and zemotionj,e. Each clock-like representation refers to a sound category. The different emotions unfold around the clock, and the emotions that are associated with the sound category are marked in green (positive correlations) or in red (negative emotions). All correlations are statistically significant at the level of p<0.01.
4.2. Perceptual layer
From our social media data, we knew the extent to which a potential source of sound was present on a street. If we knew how people usually perceived that source as well, we could have estimated how the street was likely to be perceived.
One way of determining how people usually perceive sounds in the city context is to run soundwalks. These were introduced in the late 1960s [43] and are still common among acoustic researchers nowadays [44,45]. Therefore, to determine people's perceptions, one of the authors conducted soundwalks across eight areas in Brighton and Hove (UK) and 11 areas in Sorrento (Italy) in April and October. They involved 37 participants (UK: 16 males, five females, μage=38.6, δage=11.5; Italy: 10 males, six females, μage=34.7, δage=7.1) with a variety of backgrounds (e.g. acousticians, architects, planning professionals, local authorities and environmental officers). The experimenter led the participants along a predefined route and stopped at selected locations. At each of the locations, participants were asked to listen to the acoustic environment for two minutes and to complete a structured questionnaire (table 2) inquiring about sound sources’ notability [46], soundscape attributes [46], overall soundscape quality [46,47] and soundscape appropriateness [48]. The questionnaire classified urban sounds into five categories (traffic, individuals, crowds, nature, other) as it is typically done in soundwalks [49,50], and the perceptions of such sounds into eight categories (pleasant, chaotic, vibrant, uneventful, calm, annoying, eventful and monotonous, after Axelsson et al.'s [51] work).
Table 2.
The questionnaire used during the soundwalk. For each question, participants could express their preference on a 10-point ordinal scale.
| question | items | scale extremes (1–10) |
|---|---|---|
| to what extent do you presently hear the following five types of sounds? | Traffic noise (e.g. cars, trains, planes), sounds of individuals (e.g. conversation, laughter, children at play), crowds of people (e.g. passers, sports event, festival), natural sounds (e.g. singing birds, flowing water, wind in the vegetation), other noise (e.g. sirens, construction, industry) | [do not hear at all, …, dominates completely] |
| overall, how would you describe the present surrounding sound environment? | — | [very bad, …, very good] |
| overall, to what extent is the present surrounding sound environment appropriate to the present place? | — | [not at all, …, perfectly] |
| for each of the eight scales below, to what extent do you agree or disagree that the present surrounding sound environment is … | pleasant, chaotic, vibrant, uneventful, calm, annoying, eventful, monotonous | [strongly disagree, …, strongly agree] |
Those soundwalks resulted in 342 tuples, each of which represents a participant's report about sounds and perceptions at a given location. Each tuple had 13 [1,10] values: five values reflecting the extent to which the five sound categories were reported to be present, and the other eight reflecting the extent to which the eight perceptions were reported. More technically, soundk,c is the score for sound category c at tuple k, and perceptionk,f is the score for perception category f at tuple k. The frequency distributions of soundk,c (figure 10) suggest that the participants experienced both streets with only a few sounds, and streets with many. In addition, they rarely experienced crowds and came across traffic and, only at times, nature. Instead, the frequency distributions of perceptionk,f (figure 11) suggest that the participants experienced streets with very diverse perceptual profiles, resulting in the use of the full [1,10] score range for all perceptions.
Figure 10.

Frequency distributions of the survey's scores for sound presence (from 1 to 10) across categories: individuals, crowds, nature, traffic and other. Sounds of individuals are scored in the full 1-to-10 range, whereas sounds of crowds are typically scored with a value of 1 or 2 as they might have been absent most of the time.
Figure 11.

Frequency distributions of the survey's perception scores (from 1 to 10) for each perception category. Most of the perceptions are scored in the full 1-to-10 range.
To see which sounds participants tended to experience together, we computed the rank cross-correlation ρk(soundk,c1,soundk,c2) (figure 12a). Amid crowds, the participants reported high score in the category ‘individuals’. These two sound categories—individuals and crowds—had similar sound profiles so much so that the category ‘crowds’ could be experimentally replaced by the category ‘individuals’ in the specific instance of those soundwalks. Furthermore, as one would expect, the presence of traffic was associated with the absence of individuals, crowds and nature.
Figure 12.

Pairwise rank cross-correlations between the survey's sound scores soundk,c (a) and its perception scores perceptionk,e (b).
To then see which perceptions participants tended to experience together, we computed the rank cross-correlation ρ(perceptionk,f1,perceptionk,f2) (figure 12b). Perceptions meant to have opposite meanings indeed resulted in negative correlations (pleasant versus annoying, eventful versus uneventful, vibrant versus monotonous and calm versus chaos). Interestingly, with their near-zero correlation, pleasantness and eventfulness were orthogonal—when a place was eventful, nothing could have been said about its pleasantness.
To see which sounds participants experienced together with which perception, we computed the rank correlation ρk(soundk,c,perceptionk,f) (figure 14a). On average, vibrant areas tended to be associated with crowds, pleasant areas with individuals, calm areas with nature and annoying and chaotic areas with traffic. In a similar way, Axelsson et al. studied the principal components of their perceptual data [51] and found very similar results: they found that two components best explain most of the variability in the data (figure 13).
Figure 14.

Relationship between sounds and perceptions in the soundwalk survey data. (a) Correlations between the survey's sound scores soundk,c and its perception scores perceptionk,e. Sounds of crowds, for example, are perceived to be pleasant and vibrant but not annoying. (b) Probability p(f|c) that perception f was reported at a location with sound category c.
Figure 13.
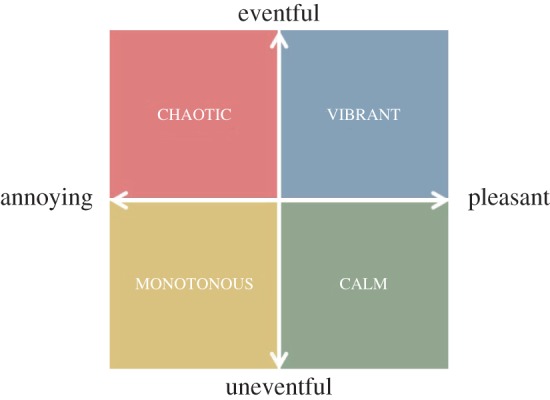
Two principal components describing how study participants perceived urban sound. The combination of the first component ‘uneventful versus eventful’ with the second component ‘annoying versus pleasant’ results in four main ways of perceiving urban sounds: vibrant, calm, monotonous and chaotic [51].
Finally, to map how streets are likely to be perceived, we needed to estimate a street's expected perception given the street's sound profile. The sound profiles came from our social media data, whereas the expected perception could have been computed from our soundwalks’ data. We had already computed the correlations between sounds and perceptions (figure 14a). However, those correlations are not expected values (accounting for, e.g. whether a perception is frequent or rare) but they simply are strength measures. Therefore, we computed the probability of perception f given sound category c as
| 4.3 |
To compute the composing probabilities, we needed to discretize our [1,10] values taken during the soundwalks, and did so by segmenting them into quartiles. We then computed
| 4.4 |
and
| 4.5 |
where Q4(c) is the number of times the sound category c occurred in the fourth quartile of its score; Q4(c*) is the number of times any sound occurred in its fourth quartile; and Q4(c∧f) is the number of times sound c as well as perception f occurred in their fourth quartiles.
The conclusions drawn from the resulting conditional probabilities (figure 14b) did not differ from those drawn from the previously shown sound–perception correlations (figure 14a). As opposed to the correlation values, none of the conditional probabilities were very high (all below 0.33). This is because the conditional probabilities were estimated through the gathering of perceptual data in the wild8 and, as such, the mapping between perception and sound did not result in fully fledged probability values. Those values are best interpreted not as raw values but as ranked values. For example, nature sounds were associated with calm only with a probability 0.34, yet calm is the strongest perception related to nature as it ranks first.
The advantage of conditional probabilities over correlations is that they offer principled numbers that are properly normalized and could be readily used in future studies. They could be used, for example, to draw an aesthetics map, a map that reflects the emotional qualities of sounds. In the maps of figure 15, we associated each segment with the colour corresponding to the perception with the highest value of , where pj(c)=soundj,c, which is the fraction of tags at segment j that matched sound category c. pj( f) is effectively the probability that perception f is associated with street segment j, and the strongest f is associated with j. By mapping the probabilities of sound perceptions in London (figure 15a) and Barcelona (figure 15b), we observed that trafficked roads were chaotic, whereas walkable parts of the city were exciting. More interestingly, in the soundscape literature, monotonous areas have not necessarily been considered pleasant (they fall into the annoying quadrant of figure 13), yet the beaches of Barcelona were monotonous (and rightly so), but might have also been pleasant.
Figure 15.

Perceptual maps of London (a) and Barcelona (b). At each segment, the perception f with the highest probability was reported (i.e. with the highest pj(f)). In London, calm sounds were found in Regent's Park (1), Hyde Park (2), Green Park (3) and all around the River Thames (9). By contrast, chaotic sounds were around Waterloo station (4) and Hyde Park Corner (5). Vibrant sounds were found in Soho (6), Bloomsbury (7) and Camden High Street (8). In Barcelona, calm sounds were found in Montjuic Park (1), Park Guell (2) and Ciutadella Park (3), and on the beach of Barceloneta (8). By contrast, on the beach in front of Ronda Litoral (9), we found monotonous sounds. Chaotic sounds were found on the main road of Avinguda Diagonal (4), on Plaza de Espana (5) and on Avinguda De Les Corts Catalanes (6). Vibrant sounds were found in the historical centre called Gothic/Ciutat Vella (7), and some in the open-air arena of El Forum (10), which was also characterized by chaotic sounds.
5. Discussion
A project called SmellyMaps mapped urban smellscapes from social media [25], and this work—called ChattyMaps—has three main similarities with it. First, the taxonomy of sound and that of smell were both created using community detection algorithms, and both closely resembled categorizations widely used by researchers and practitioners in the corresponding fields. Second, the ways that social media data were mapped onto streets (e.g. buffering of segments, use of longitude/latitude coordinates on the pictures) are the same. Third, in both works, the validation was done with official data (i.e. with air quality data and noise pollution data). However, the two works differ as well, and they do so in three main ways. First, as opposed to SmellyMaps, ChattyMaps studied a variety of urban layers: not only the urban sound layer, but also the emotional, perceptual and sound diversity layers. Second, smell words were derived from smellwalks (as no other source was available), whereas sound words were derived from the online platform of Freesound. Third, because SmellyMaps showed that picture tags were more effective than tweets in capturing geographical-salient information, ChattyMaps entirely relied on Flickr tags.
Our approach comes with a few limitations, mainly because of data biases. The urban soundscape is multifaceted: the sounds we hear and the way we perceive them change considerably with small variations of, for example, space (e.g. simply turning a corner) and time (e.g. day versus night). By contrast, social media data have limited resolution and coverage, and that results in false positives. At times, sound tags do not reflect real sounds because of either misannotations or the figurative use of tags (figure 16a). Fortunately, those cases occur rarely. By manually inspecting 100 photos with sound tags, no false-positive was found: 87 pictures were correctly tagged and 13 referred to sounds that were plausible yet hard to ascertain.
Figure 16.

Examples of ambiguously tagged pictures. (a) Street art in Brick Lane tagged with the term ‘screaming’, and the same location Carriage Drive with Hyde Park tagged with opposing terms related to (b) traffic sounds and (c) nature sounds.
Even when tags refer to sounds likely present in an area, they might do so partially. For example, the tags on the picture of figure 16b consisted of traffic terms (rightly) but not of nature terms, and that was a partial view of that street's soundscape. This risk shrinks as the number of sound tags for the segment increases. Indeed, let us stick with the same example: figure 16c was taken a few metres away from figure 16b, and its tags consisted of nature terms.
To partly mitigate noise at boundary regions, we did two things. First, as described in §2, we added a buffer of 22.5 m around each segment's bounding box. This has been commonly done in previous work dealing with georeferenced digital content [26,25]. It is hard to measure automatically how many tags are needed to get high confidence sound profiles, but we estimated it to be around 20–25 tags (figure 8), if official air quality data are used for validation.
Second, we associated sound distributions (and not individual sounds) with street segments. The six-dimensional sound vector was normalized in [0, 1] to have a probabilistic interpretation. In figure 16b,c, nature sounds were predominant, yet traffic-related sounds varied from 20% to 2% depending on the different parts of that street.
More generally, to have a more comprehensive view of this phenomenon, we determined each segment's sound diversity by computing the Shannon index
| 5.1 |
where soundj,c is the fraction of tags at segment j that matched sound category c. After removing zero diversity values (often associated with segments having only one tag, which made 28% of segments in Barcelona, and 35% segments in London), we saw that the frequency distribution of diversity (figure 17a) had two peaks in 1 (for both cities) and in 1.5 for London and in 2.0 for Barcelona. Then, by mapping those values (figure 18), we saw that the values close to the first peak were associated with parks and suburbs, and those close to the second peak (and higher) were associated with the central parts of the two cities. Furthermore, the diversity did not depend on the number of tags per segment and became stable for segments with at least 10 tags (figure 17b).
Figure 17.

Diversity (entropy) of sound tags. Frequency distribution (a), and how the diversity varies with the number of tags per street segment (b). Segments with zero diversity (28% in Barcelona, 35% in London) were excluded.
Figure 18.

Maps of the diversity of sound tags for each street segment in London (a) and Barcelona (b). Only segments with five or more tags are displayed.
6. Conclusion
We showed that social media data make it possible to effectively and cheaply track urban sounds at scale. Such a tracking was effective, because the resulting sounds were geographically sorted across street types in expected ways, and they matched noise pollution levels. The tracking was also cheap because it did not require the creation of any additional service or infrastructure. Finally, it worked at the scale of an entire city, and that is important, not least because, before our work, there had been nothing in sonography corresponding to the instantaneous impression which photography can create … The microphone samples details and gives the close-up but nothing corresponding to aerial photography [16].
However, whereas landscapes can be static, soundscapes are dynamic [54]. Their perceptions are affected by demography (e.g. personal sensitivity to noise, age), context (e.g. city layout) and time (e.g. day versus night, weekdays versus weekends). Future studies could partly address those issues by collecting additional data and by comparing models of urban sounds generated from social media with those generated from geographic information system techniques.
Nonetheless, no matter what data one has, fully capturing soundscapes might well be impossible. Our work has focused on identifying potential sonic events. To use a food metaphor, if those events are the raw ingredients, then the aural architecture (which comes with the acoustic properties of trees, buildings, streets) is the cooking style, and the soundscape is the dish [54].
To unite hitherto isolated studies in a new synergy, in the future, we will conduct a comprehensive multi-sensory research of cities, one in which visual [55,56], olfactory [25] and sound perceptions are explored together.
The ultimate goal of this work is to empower city managers and researchers to find solutions for an ecologically balanced soundscape where the relationship between the human community and its sonic environment is in harmony, as Schafer famously (and prophetically) remarked in the late 1970s [16].
Acknowledgements
We thank the Barcelona City Council for making the noise pollution data available.
Footnotes
A segment is often a street's portion between two road intersections but, more generally, it includes any outdoor place (e.g. highways, squares, steps, footpaths, cycle-ways).
If one were to apply Blondel's algorithm right from the start, the resulting clusters would be less coherent than those produced by our approach.
Interactive Map of Noise Pollution in Barcelona (http://w20.bcn.cat:1100/WebMapaAcustic/mapa˙soroll.aspx?lang=en).
In computing the correlations, we used the method by Clifford et al. [37] to address spatial autocorrelations.
Data accessibility
Aggregate version of the data is available at http://goodcitylife.org and on Dryad doi:10.5061/dryad.tg735.
Competing interests
We declare we have no competing interests.
Funding
F.A. received funding through the People Programme (Marie Curie Actions) of the European Union's 7th Framework Programme FP7/2007-2013 under REA grant agreement no. 290110, SONORUS ‘Urban Sound Planner’.
References
- 1.Halonen J. et al. 2015. Road traffic noise is associated with increased cardiovascular morbidity and mortality and all-cause mortality in London. Eur. Heart J. 36, 2653–2661. (doi:10.1093/eurheartj/ehv216) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Stansfeld SA. et al. 2005. Aircraft and road traffic noise and children's cognition and health: a cross-national study. Lancet 365, 1942–1949. (doi:10.1016/S0140-6736(05)66660-3) [DOI] [PubMed] [Google Scholar]
- 3.Van Kempen E, Babisch W. 2012. The quantitative relationship between road traffic noise and hypertension: a meta-analysis. J. Hypertens. 30, 1075–1086. (doi:10.1097/HJH.0b013e328352ac54) [DOI] [PubMed] [Google Scholar]
- 4.Hoffmann B. et al. 2006. Residence close to high traffic and prevalence of coronary heart disease. Eur. Heart J. 27, 2696–2702. (doi:10.1093/eurheartj/ehl278) [DOI] [PubMed] [Google Scholar]
- 5.Selander J, Nilsson ME, Bluhm G, Rosenlund M, Lindqvist M, Nise G, Pershagena G. 2009. Long-term exposure to road traffic noise and myocardial infarction. Epidemiology 20, 272–279. (doi:10.1097/EDE.0b013e31819463bd) [DOI] [PubMed] [Google Scholar]
- 6.The European Parliament. 2002. Directive 2002/49/EC: assessment and management of environmental noise. Off. J. Eur. Commun. 189. [Google Scholar]
- 7.Morley D, De HK, Fecht D, Fabbri F, Bell M, Goodman P, Elliott P, Hodgson S, Hansell A, Gulliver J. 2015. International scale implementation of the CNOSSOS-EU road traffic noise prediction model for epidemiological studies. Environ. Pollut. 206, 332–341. (doi:10.1016/j.envpol.2015.07.031) [DOI] [PubMed] [Google Scholar]
- 8.Maisonneuve N, Stevens M, Niessen ME, Hanappe P, Steels L. 2009. Citizen noise pollution monitoring. In Proc. 10th Annual Int. Conf. on Digital Government Research, Puebla, Mexico, 17–21 May 2009, pp. 96–103. Digital Government Society of North America.
- 9.Schweizer I, Bärtl R, Schulz A, Probst F, Mühläuser M. 2011. NoiseMap—real-time participatory noise maps. In Proc. 2nd Int. Workshop on Sensing Applications on Mobile Phones, Seattle, WA, USA, 1 November 2011, pp. 1–5.
- 10.Meurisch C, Planz K, Schäfer D, Schweizer I. 2013. Noisemap: discussing scalability in participatory sensing. In Proc. ACM 1st Int. Workshop on Sensing and Big Data Mining, Rome, Italy, 14 November 2013, pp. 6:1–6:6.
- 11.Becker M. et al. 2013. Awareness and learning in participatory noise sensing. PLoS ONE 8, e81638 (doi:10.1371/journal.pone.0081638) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Mydlarz C, Nacach S, Park TH, Roginska A. 2014. The design of urban sound monitoring devices. In Audio Engineering Society Convention 137, Los Angeles, CA, USA, 9–12 October 2014.
- 13.Hsieh H-P, Yen T-C, Li C-T. 2015. What makes New York so noisy?: reasoning noise pollution by mining multimodal geo-social big data. In Proc. 23rd ACM Int. Conf. on Multimedia (MM), Brisbane, Australia, 26–30 October 2015, pp. 181–184.
- 14.Nilsson ME, Berglund B. 2006. Soundscape quality in suburban green areas and city parks. Acta Acust. United with Acust. 92, 903–911. [Google Scholar]
- 15.Andringa TC, Lanser JJL. 2013. How pleasant sounds promote and annoying sounds impede health: a cognitive approach. Int. J. Environ. Res. Public Health 10, 1439–1461. (doi:10.3390/ijerph10041439) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Schafer RM. 1993. The soundscape: our sonic environment and the tuning of the world. Rochester, VT: Destiny Books. [Google Scholar]
- 17.International Organization for Standardization. 2014. ISO 12913-1:2014 acoustics—Soundscape—part 1: definition and conceptual framework. Geneva, Switzerland: ISO. [Google Scholar]
- 18.Salamon J, Jacoby C, Bello JP. 2014. A dataset and taxonomy for urban sound research. In Proc. 22nd ACM Int. Conf. on Multimedia (MM), Orlando, FL, USA, 3–7 November 2014, pp. 1041–1044.
- 19.Salamon J, Bello J. 2015. Unsupervised feature learning for urban sound classification. In IEEE Int. Conf. on Acoustics, Speech and Signal Processing, Brisbane, Australia, 19–24 April 2015, pp. 171–175 (doi:10.1109/ICASSP.2015.7177954)
- 20.Aletta F, Axelsson Ö, Kang J.2014. Towards acoustic indicators for soundscape design. In Proc. Forum Acusticum Conf., Krakow, Poland, 7–12 September 2014.
- 21.Herranz-Pascual K, Aspuru I, Garcia I. 2010. Proposed conceptual model of environment experience as framework to study the soundscape. In Inter Noise 2010: Noise and Sustainability, Lisbon, Portugal, 13–16 June 2010, pp. 2904–2912. Institute of Noise Control Engineering.
- 22.Schulte-Fortkamp B, Dubois D. 2006. Preface to special issue: recent advances in soundscape research. Acta Acust. United with Acust. 92, I–VIII. [Google Scholar]
- 23.Schulte-Fortkamp B, Kang J. 2013. Introduction to the special issue on soundscapes. J. Acoust. Soc. Am. 134, 765–766. (doi:10.1121/1.4810760) [DOI] [PubMed] [Google Scholar]
- 24.Davies WJ. 2013. Editorial to the special issue: applied soundscapes. Appl. Acoust. 2, 223. [Google Scholar]
- 25.Quercia D, Aiello LM, Schifanella R, McLean K. 2015. Smelly maps: the digital life of urban smellscapes. In Int. AAAI Conf. on Web and Social Media (ICWSM), Oxford, UK, 26–29 May 2015.
- 26.Quercia D, Aiello LM, Schifanella R, Davies A. 2015. The digital life of walkable streets. In Proc. 24th ACM Conf. on World Wide Web (WWW), Florence, Italy, 18–22 May 2015, pp. 875–884.
- 27.Blei DM, Ng AY, Jordan MI. 2003. Latent dirichlet allocation. J. Mach. Learn. Res. 3, 993–1022. [Google Scholar]
- 28.Lloyd SP. 1982. Least squares quantization in PCM. IEEE Trans. Inf. Theory 28, 129–137. (doi:10.1109/TIT.1982.1056489) [Google Scholar]
- 29.Fortunato S. 2010. Community detection in graphs. Phys. Rep. 486, 75–174. (doi:10.1016/j.physrep.2009.11.002) [Google Scholar]
- 30.Rosvall M, Bergstrom CT. 2008. Maps of random walks on complex networks reveal community structure. Proc. Natl Acad. Sci. USA 105, 1118–1123. (doi:10.1073/pnas.0706851105) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Blondel VD, Guillaume J-L, Lambiotte R, Lefebvre E. 2008. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, P10008 (doi:10.1088/1742-5468/2008/10/P10008) [Google Scholar]
- 32.Newman ME. 2006. Modularity and community structure in networks. Proc. Natl Acad. Sci. USA 103, 8577–8582. (doi:10.1073/pnas.0601602103) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Brown A, Kang J, Gjestland T. 2011. Towards standardization in soundscape preference assessment. Appl. Acoust. 72, 387–392. (doi:10.1016/j.apacoust.2011.01.001) [Google Scholar]
- 34.Eeftens M. et al. 2012. Development of land use regression models for PM2.5, PM2.5 absorbance, PM10 and PMcoarse in 20 European study areas; results of the ESCAPE project. Environ. Sci. Technol. 46, 11195–11205. (doi:10.1021/es301948k) [DOI] [PubMed] [Google Scholar]
- 35.Beelen R. et al. 2013. Development of NO2 and NOx land use regression models for estimating air pollution exposure in 36 study areas in Europe—the ESCAPE project. Atmos. Environ. 72, 10–23. (doi:10.1016/j.atmosenv.2013.02.037) [Google Scholar]
- 36.Gulliver J. et al. 2015. Development of an open-source road traffic noise model for exposure assessment. Environ. Model. Softw. 74, 183–193. (doi:10.1016/j.envsoft.2014.12.022) [Google Scholar]
- 37.Clifford P, Richardson S, Hémon D. 1989. Assessing the significance of the correlation between two spatial processes. Biometrics 45, 123–134. (doi:10.2307/2532039) [PubMed] [Google Scholar]
- 38.Kivy P. 1989. Sound sentiment: an essay on the musical emotions, including the complete text of the corded shell. Philadelphia, PA: Temple University Press. [Google Scholar]
- 39.Zentner M, Grandjean D, Scherer KR. 2008. Emotions voked by the sound of music: characterization, classification, and measurement. Emotion 8, 494 (doi:10.1037/1528-3542.8.4.494) [DOI] [PubMed] [Google Scholar]
- 40.Mohammad SM, Turney PD. 2013. Crowdsourcing a word–emotion association lexicon. Comput. Intell. 29, 436–465. (doi:10.1111/j.1467-8640.2012.00460.x) [Google Scholar]
- 41.Plutchik R. 1991. The emotions. Lanham, MD: University Press of America. [Google Scholar]
- 42.Pennebaker J. 2013. The secret life of pronouns: what our words say about us. New York, NY: Bloomsbury. [Google Scholar]
- 43.Southworth M. 1969. The sonic environment of cities. Environ. Behav. 1, 49–70. (doi:10.1177/001391656900100104) [Google Scholar]
- 44.Semidor C. 2006. Listening to a city with the soundwalk method. Acta Acust. United with Acust. 92, 959–964. [Google Scholar]
- 45.Jeon JY, Hong JY, Lee PJ. 2013. Soundwalk approach to identify urban soundscapes individually. J. Acoust. Soc. Am. 134, 803–812. (doi:10.1121/1.4807801) [DOI] [PubMed] [Google Scholar]
- 46.Axelsson Ö, Nilsson ME, Berglund B. 2009. A Swedish instrument for measuring soundscape quality. In Proc. Euronoise Conf., Edinburgh, UK, 26–28 October 2009.
- 47.Liu J, Kang J, Luo T, Behm H, Coppack T. 2013. Spatiotemporal variability of soundscapes in a multiple functional urban area. Landsc. Urban Plann. 115, 1–9. (doi:10.1016/j.landurbplan.2013.03.008) [Google Scholar]
- 48.Axelsson Ö. 2015. How to measure soundscape quality. In Proc. Euronoise Conf., Maastricht, The Netherlands, 31 May–3 June 2015, pp. 1477–1481.
- 49.Aletta F, Margaritis E, Filipan K, Romero VP, Axelsson Ö, Kang J. 2015. Characterization of the soundscape in Valley Gardens, Brighton, by a soundwalk prior to an urban design intervention. In Proc. Euronoise Conf., Maastricht, The Netherlands, 31 May–3 June 2015, pp. 1–12.
- 50.Aletta F, Kang J. 2015. Soundscape approach integrating noise mapping techniques: a case study in Brighton, UK. Noise Mapp. 2, 50–58. (doi:10.1515/noise-2015-0001) [Google Scholar]
- 51.Axelsson Ö, Nilsson ME, Berglund B. 2010. A principal components model of soundscape perception. J. Acoust. Soc. Am. 128, 2836–2846. (doi:10.1121/1.3493436) [DOI] [PubMed] [Google Scholar]
- 52.Watts GR, Pheasant RJ, Horoshenkov KV. 2011. Predicting perceived tranquillity in urban parks and open spaces. Environ. Plann. B 38, 585–594. (doi:10.1068/b36131) [Google Scholar]
- 53.Watts G, Miah A, Pheasant R. 2013. Tranquillity and soundscapes in urban green spaces: predicted and actual assessments from a questionnaire survey. Environ. Plann. B 40, 170–181. (doi:10.1068/b38061) [Google Scholar]
- 54.Blesser B, Salter L. 2009. Spaces speak, are you listening? Experiencing aural architecture. Cambridge, MA: MIT Press. [Google Scholar]
- 55.Quercia D, Schifanella R, Aiello LM. 2014. The shortest path to happiness: recommending beautiful, quiet, and happy routes in the city. In Proc. 25th ACM Conf. on Hypertext and Social Media (HT), Santiago, Chile, 1–4 September 2014, pp. 116–125.
- 56.Quercia D, O’Hare NK, Cramer H. 2014. Aesthetic capital: what makes London look beautiful, quiet, and happy? In Proc. 17th ACM Conf. on Computer Supported Cooperative Work & Social Computing (CSCW), Baltimore, MD, USA, 15–19 February 2014, pp. 945–955.
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
Aggregate version of the data is available at http://goodcitylife.org and on Dryad doi:10.5061/dryad.tg735.