

Abstract
Causal structure learning from time series data is a major scientific challenge. Extant algorithms assume that measurements occur sufficiently quickly; more precisely, they assume approximately equal system and measurement timescales. In many domains, however, measurements occur at a significantly slower rate than the underlying system changes, but the size of the timescale mismatch is often unknown. This paper develops three causal structure learning algorithms, each of which discovers all dynamic causal graphs that explain the observed measurement data, perhaps given undersampling. That is, these algorithms all learn causal structure in a “rate-agnostic” manner: they do not assume any particular relation between the measurement and system timescales. We apply these algorithms to data from simulations to gain insight into the challenge of undersampling.
1 Introduction
Dynamic causal systems are a major focus of scientific investigation in diverse domains, including neuroscience, economics, meteorology, and education. One significant limitation in all of these sciences is the difficulty of measuring the relevant variables at an appropriate timescale for the particular scientific domain. This challenge is particularly salient in neuroimaging: standard fMRI experiments sample the brain’s bloodflow approximately every one or two seconds, though the underlying neural activity (i.e., the major driver of bloodflow) occurs much more rapidly. Moreover, the precise timescale of the underlying causal system is unknown; it is almost certainly faster than the fMRI measurements, but it is unknown how much faster.
In this paper, we aim to learn the causal structure of a system that evolves at timescale τS, given measurements at timescale τM. We focus on the case in which τS is faster than τM to an unknown degree. We assume that the underlying causal structure can be modeled as a directed graphical model G without simultaneous influence. There has been substantial work on modeling the statistics of time series, but relatively less on learning causal structure, and almost all of that assumes that the measurement and causal timescales match [1–5]. The problem of causal learning from “under-sampled” time series data was explicitly addressed by [6, 7 ], but they assumed that the degree of undersampling—i.e., the ratio of τS to τM —was both known and small. In contrast, we focus on the significantly harder challenge of causal learning when that ratio is unknown.
We provide a formal specification of the problem and representational framework in Section 2. We then present three different Rate-Agnostic Structure Learning (RASL) algorithms in Section 3. We finish in Section 4 by exploring their performance on synthetic data.
2 Representation and Formalism
A dynamic causal graphical model consists of a graph G over random variables V at the current time t, as well as nodes for V at all previous (relative) timesteps that contain a direct cause of a variable at the current timestep.1 The Markov order of the system is the largest k such that , where superscripts denote timestep. We assume throughout that the “true” underlying causal system is Markov order 1, and that all causally relevant variables are measured.2 Finally, we assume that there are no isochronal causal edges ; causal influences inevitably take time to propagate, and so any apparent isochronal edge will disappear when measured sufficiently finely. Since we do not assume that the causal timescale _S is known, this is a relatively innocuous assumption.
G is thus over 2V nodes, where the only edges are , where possibly i = j. There is additionally a conditional probability distribution or density, P(Vt|Vt−1), which we assume to be time-independent. We do not, however, assume stationarity of P(Vt). Finally, we assume appropriate versions of the Markov (“Variable V is independent of non-descendants given parents”) and Faithfulness/Stability (“The only independencies are those implied by Markov”) assumptions, such that the graph and probability distribution/density mutually constrain each other.
Let {t0, t1, …, tk, …} be the measurement timesteps. We undersample at rate u when we measure only timesteps {t0, tu, …, tuk, …}; the causal timescale is thus “undersampled at rate 1.” We denote the causal graph resulting from undersampling at rate u by Gu. To obtain Gu, we “unroll” G1 by introducing nodes for Vt−2 that bear the same graphical and parametric relations to Vt−1 as those variables bear to Vt, and iterate until we have included Vt−u. We then marginalize out all variables except those in Vt and Vt−u.
Marginalization yields an Acyclic Directed Mixed Graph (ADMG) Gu containing both directed and bidirected edges [8]. in Gu iff there is a directed path from to in the unrolled graph. Define a trek to be a pair of directed paths (π1, π2) such that both have the same start variable. in Gu iff there is a trek between and with length(π1) = length(π2) = k < u. Clearly, if a bidirected edge occurs in Gm, then it occurs in Gu for all u ≥ m.
Unrolling-and-marginalizing can be computationally complex due to duplication of nodes, and so we instead use compressed graphs that encode temporal relations in edges. For an arbitrary dynamic causal graph H, ℋ is its compressed graph representation: (i) ℋ is over non-time-indexed nodes for V; (ii)Vi → Vj in ℋ iff in H; and (iii) Vi ↔ Vj in ℋ iff in H. Compressed graphs can be cyclic (Vi ⇄ Vj for and ), including self-cycles. There is clearly a 1-1 mapping between dynamic ADMGs and compressed graphs.
Computationally, the effects of undersampling at rate u can be computed in a compressed graph simply by finding directed paths of length u in 𝒢1. More precisely, in 𝒢u iff there is a directed path of length u in 𝒢1. Similarly, in 𝒢u iff there is a trek with length(π1) = length(π2) = k < u in 𝒢1. We thus use compressed graphs going forward.
3 Algorithms
The core question of this paper is: given ℋ = 𝒢u for unknown u, what can be inferred about 𝒢1? Let ⟦ℋ⟧ = {𝒢1 : ∃u 𝒢u = ℋ} be the equivalence class of 𝒢1 that could, for some undersample rate, yield ℋ. We are thus trying to learn ⟦ℋ⟧ from ℋ. An obvious brute-force algorithm is: for each possible 𝒢1, compute the corresponding graphs for all u, and then output all 𝒢u = ℋ. Equally obviously, this algorithm will be computationally intractable for any reasonable n, as there are 2n2 possible 𝒢1 and u can (in theory) be arbitrarily large. Instead, we pursue three different constructive strategies that more efficiently “build” the members of ⟦ℋ⟧ (Sections 3.2, 3.3, and 3.4). Because these algorithms make no assumptions about u, we refer to them each as RASL—Rate Agnostic Structure Learner—and use subscripts to distinguish between different types. First, though, we provide some key theoretical results about forward inference that will be used by all three algorithms.
3.1 Nonparametric Forward Inference
For given 𝒢1 and u, there is an efficient algorithm [9] for calculating 𝒢u, but it is only useful in learning if we have stopping rules that constrain which 𝒢1 and u should ever be considered. These rules will depend on how 𝒢1 changes as u → ∞. A key notion is a strongly connected component (SCC) in 𝒢1: a maximal set of variables S ⊆ V such that, for every X, Y ∈ S (possibly X = Y), there is a directed path from X to Y. Non-singleton SCCs are clearly cyclic and can provably be decomposed into a set of (possibly overlapping) simple loops (i.e., those in which no node is repeated): σ1, …, σs [10]. Let ℒS be the set of those simple loop lengths.
One stopping rule must specify, for given 𝒢1, which u to consider. For a single SCC, the greatest common divisor of simple loop lengths (where gcd(ℒS) = 1 for singleton S) is key: gcd(ℒS) = 1 iff ∃f s.t. ∀u > f[𝒢u = 𝒢f]; that is, gcd() determines whether an SCC “converges” to a fixed-point graph as u → ∞. We can constrain u if there is such a fixed-point graph, and Theorem 3.1 generalizes [9, Theorem 5] to provide an upper bound on (interesting) u. (All proofs found in supplement.)
Theorem 3.1
If gcd(ℒS) = 1, then stabilization occurs at f ≤ nF + γ+ d + 1.
where nF is the Frobenius number,3 d is the graph diameter, and γ is the transit number (see supplement). This is a theoretically useful bound, but is not practically helpful since neither γ nor nF have a known analytic expression. Moreover, gcd(ℒS) = 1 is a weak restriction, but a restriction nonetheless. We instead use a functional stopping rule for u (Theorem 3.2) that holds for all 𝒢:
Theorem 3.2
If 𝒢u = 𝒢v for u > v, then ∀w > u∃kw < u[𝒢w = 𝒢kw].
That is, as u increases, if we find a graph that we previously encountered, then there cannot be any new graphs as u → ∞. For a given 𝒢1, we can thus determine all possible corresponding undersampled graphs by computing 𝒢2, 𝒢3, … until we encounter a previously-observed graph. This stopping rule enables us to (correctly) constrain the u that are considered for each 𝒢1.
We also require a stopping rule for 𝒢1, as we cannot evaluate all 2n2 possible graphs for any reasonable n. The key theoretical result is:
Theorem 3.3
If 𝒢1 ⊆ 𝒥1, then ∀u[𝒢u ⊆ 𝒥u].
Let be the graph resulting from adding the edges in E to 𝒢1. Since this is simply another graph, it can be undersampled at rate u; denote the result . Since can always serve as 𝒥1 in Theorem 3.3, we immediately have the following two corollaries:
Corollary 3.4
If 𝒢u ⊈ ℋ, then Corollary 3.5
If ∀u[𝒢u ⊈ ℋ], then ∀E,
We thus have a stopping rule for some candidate 𝒢1: if 𝒢u is not an edge-subset of ℋ for all u, then do not consider any edge-superset of 𝒢1. This stopping rule fits very cleanly with “constructive” algorithms that iteratively add edge(s) to candidate 𝒢1. We now develop three such algorithms.
3.2 A recursive edgewise inverse algorithm
The two stopping rules naturally suggest a recursive structure learning algorithm with ℋ as input and ⟦ℋ⟧ as output. Start with an empty graph. For each edge e (of n2 possible edges), construct 𝒢1 containing only e. If 𝒢u ⊈ ℋ for all u, then reject; else if 𝒢u = ℋ for some u,4 then add 𝒢1 to ⟦ℋ⟧; else, recurse into non-conflicting graphs in order. Effectively, this is a depth first search (DFS) algorithm on the solution tree; denote it as RASLre for “recursive edgewise.” Figure 1a provides pseudo-code, and Figure 1b shows how one DFS path in the search tree unfolds. We can prove:
Figure 1.

RASLre algorithm 1a specification, and 1b search tree example
Theorem 3.6
The RASLre algorithm is correct and complete.
One significant drawback of RASLre is that the same graph can be constructed in many different ways, corresponding to different orders of edge addition; the search tree is actually a search lattice. The algorithm is thus unnecessarily inefficient, even when we use dynamic programming via memoization of input graphs.
3.3 An iterative edgecentric inverse algorithm
To minimize multiple constructions of the same graph, we can use RASLie (“iterative edgewise”) which generates, at stage i, all not-yet-eliminated 𝒢1 with exactly i edges. More precisely, at stage 0, RASLie starts with the empty graph; if ℋ is also empty, then it adds the empty graph to ⟦ℋ⟧. Otherwise, it moves to stage 1. In general, at stage i + 1, RASLie (a) considers each graph 𝒢1 resulting from a single edge addition to an acceptable graph at stage i; (b) rejects 𝒢1 if it conflicts (for all u) with ℋ; (c) otherwise keeps 𝒢1 as acceptable at i + 1; and (d) if ∃u[𝒢u = ℋ], then adds 𝒢1 to ⟦ℋ⟧. RASLie continues until there are no more edges to add (or it reaches stage n2 + 1). Figure 2 provides the main loop (Figure 2a) and core function of RASLie (Figure 2c), as well as an example of the number of graphs potentially considered at each stage (Figure 2b). RASLie provides significant speed-up and memory gains over RASLre (see Figure 3).
Figure 2.

RASLie algorithm (a) main loop; (b) example of graphs considered; and (c) core function.
Figure 3.
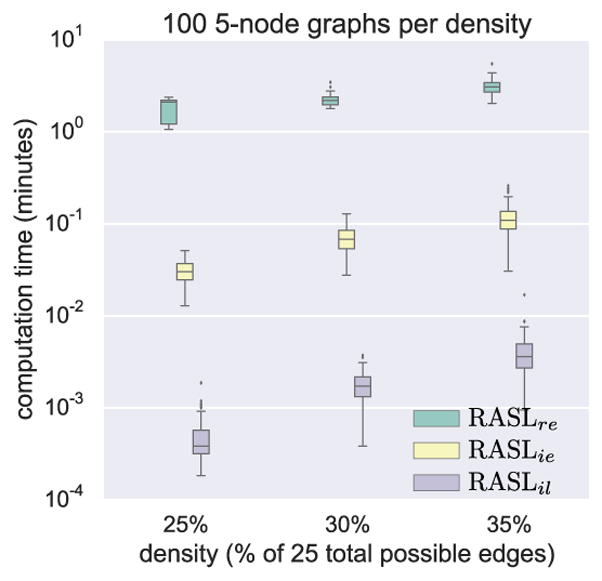
Run-time comparison.
We optimize RASLie by tracking the single edges that could possibly still be added; for example, if a single-edge graph is rejected in stage 1, then do not consider adding that edge at other stages. Additional conflicts can be derived analytically, further reducing the graphs to consider. In general, absence of an edge in ℋ implies, for the corresponding (unknown) u, absence of length u paths in all 𝒢1 ∈ ⟦ℋ⟧. Since we do not know u, we cannot directly apply this constraint. However, lemmas 3.7 and 3.8 provide useful, special case constraints for u > 1 (implied by a single bidirected edge).
Lemma 3.7
If u > 1, then ∀V ↛ W ∈ ℋ, 𝒢1 cannot contain any of the following paths: .
Lemma 3.8
If u > 1, then ∀V↮ W ∈ ℋ ∄ T[V ← T → W] ∈ 𝒢1
3.4 An iterative loopcentric inverse algorithm
RASLie yields results in reasonable time for ℋ with up to 8 nodes, though it is computationally demanding. We can gain further computational advantages if we assume that ℋ is an SCC. This assumption is relatively innocuous, as it requires only that our time series be generated by a system with (appropriate) feedback loops. As noted earlier, any SCC is composed of a set of simple loops, and so we modify RASLie to iteratively add loops instead of edges; call the resulting algorithm RASLil for “iterative loopwise.” More precisely, RASLil uses the same algorithm as in Figure 2, but successively attempts to add non-conflicting simple loops, rather than non-conflicting edges. RASLil also incorporates the additional constraints due to lemmas 3.7 and 3.8.
RASLil is surprisingly much faster than RASLie even though, for n nodes, there are simple loops (compared to n2 edges). The key is that introducing a single simple loop induces multiple constraints simultaneously, and so conflicting graphs are discovered at a much earlier stage. As a result, RASLil checks many fewer graphs in practice. For example, consider the 𝒢1 in Figure 1, with corresponding ℋ for u = 3. RASLre constructs (not counting pruned single edges) 28,661 graphs; RASLie constructs only 249 graphs; and RASLil considers only 47. For u = 2, these numbers are 413, 44, and 7 respectively. Unsurprisingly, these differences in numbers of examined graphs translate directly into wall clock time differences (Figure 3).
4 Results
All three RASL algorithms take a measurement timescale graph ℋ as input. They are therefore compatible with any structure learning algorithm that outputs a measurement timescale graph, whether Structural Vector Autoregression (SVAR) [11], direct Dynamic Bayes Net search [12], or modifications of standard causal structure learning algorithms such as PC [1, 13] and GES [14]. The problem of learning a measurement timescale graph is a very hard one, but is also not our primary focus here. Instead, we focus on the performance of the novel RASL algorithms.
First, we abstract away from learning measurement timescale structure and assume that the correct ℋ is provided as input. For these simulated graphs, we focus on SCCs, which are the most scientifically interesting cases. For simplicity (and because within-SCC structure can be learned in parallel for a complex ℋ [9]), we employ single-SCC graphs. To generate random SCCs, we (i) build a single simple loop over n nodes, and (ii) uniformly sample from the other n(n − 1) possible edges until we reach the specified density (i.e., proportion of the n2 total possible edges). We employ density in order to measure graph complexity in an (approximately) n-independent way.
We can improve the runtime speed of RASLre using memoization, though it is then memory-constrained for n ≥ 6. Figure 3 provides the wall-clock running times for all three RASL algorithms applied to 100 random 5-node graphs at each of three densities. This graph substantiates our earlier claims that RASLil is faster than RASLie, which is faster than RASLre. In fact, each is at least an order of magnitude faster than the previous one.
RASLre would take over a year on the most difficult problems, so we focus exclusively on RASLil. Unsurprisingly, run-time complexity of all RASL algorithms depends on the density of ℋ. For each of three density values (20%, 25%, 30%), we generated 100 random 6-node SCCs, which were then undersampled at rates 2, 3, and 4 before being provided as input to RASLil. Figure 4 summarizes wall clock computation time as a function of ℋ’s density, with different plots based on density of 𝒢1 and undersampling rate. We also show three examples of ℋ with a range of computation runtime. Unsurprisingly, the most difficult ℋ is quite dense; ℋ with densities below 50% typically require less than one minute.
Figure 4.
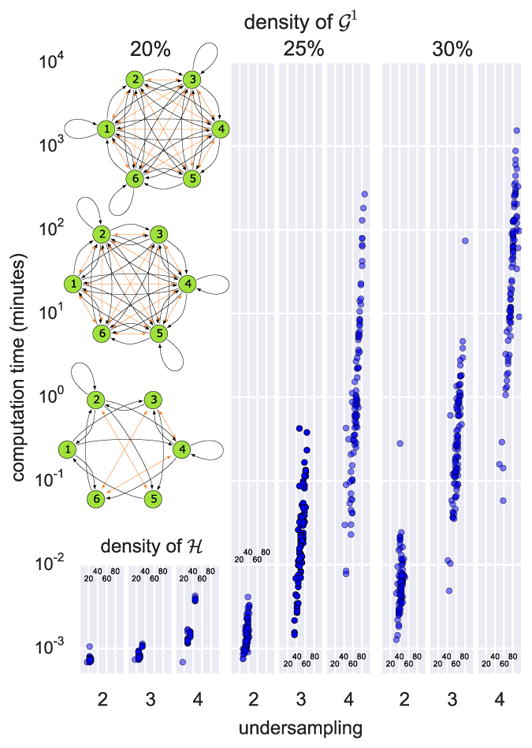
Run-time behavior.
4.1 Equivalence classes
We first use RASLil to determine ⟦ℋ⟧ size and composition for varying ℋ; that is, we explore the degree of underdetermination produced by undersampling. The worst-case underdetermination occurs if ℋ is a super-clique with every possible edge: ∀ X, Y[X → Y & X ↔ Y]. Any SCC with gcd(ℒS) = 1 becomes a super-clique as u → ∞ [9], so ⟦ℋ⟧ contains all such graphs for super-clique ℋ. We thus note when ℋ is a super-clique, rather than computing the size of ⟦ℋ⟧.
Figures 5 and 6 plot equivalence class size as a function of both 𝒢1 density and the true undersampling rate. For each n and density, we (i) generated 100 random 𝒢1; (ii) undersampled each at indicated u; (iii) passed 𝒢u = ℋ to RASLil; and (iv) computed the size of ⟦ℋ⟧. Interestingly, ⟦ℋ⟧ is typically quite small, sometimes even a singleton. For example, 5-node graphs at u = 2 typically have singleton ⟦ℋ⟧ up to 40% 𝒢1 density. Even 10-node graphs often have a singleton ⟦ℋ⟧ (though with relatively sparse 𝒢1). Increased undersampling and density both clearly worsen underdetermination, but often not intractably so, particularly since even nonsingleton ⟦ℋ⟧ can be valuable if they permit post hoc inspection or analysis.
Figure 5.

Size of equivalence classes for 100 random SCCs at each density and u ∈ {2, 3, 4}.
Figure 6.

Size of equivalence classes for larger graphs n ∈ 7, 8, 10 for u ∈ 2, 3
To focus on the impact of undersampling, we generated 100 random 5-node SCCs with 25% density, each of which was undersampled for u ∈ {2, …, 11}. Figure 7 plots the size of ⟦ℋ⟧ as a function of u for these graphs. For u ≤ 4, singleton ⟦ℋ⟧ still dominate. Interestingly, even u = 11 still yields some non-superclique ℋ.
Figure 7.

Effect of the undersampling rate on equivalence class size.
Finally, 𝒢1 ∈ ⟦ℋ⟧ iff ∃ u[𝒢u = ℋ], but the appropriate u need not be the same for all members of ⟦ℋ⟧. Figure 8 plots the percentages of u-values appropriate for each 𝒢1 ∈ ⟦ℋ⟧, for the ℋ from Figure 5. If actually utrue = 2, then almost all 𝒢1 ∈ ⟦ℋ⟧ are because of 𝒢2; there are rarely 𝒢1 ∈ ⟦ℋ⟧ due to u > 2. If actually utrue > 2, though, then many 𝒢1 ∈ ⟦ℋ⟧ are due to 𝒢u where u ≠ utrue. As density and utrue increase, there is increased underdetermination in both 𝒢1 and u.
Figure 8.

Distribution of u for 𝒢u = ℋ for 𝒢1 ∈ ⟦ℋ⟧ for 5- and 6-node graphs
4.2 Synthetic data
In practice, we typically must learn ℋ structure from finite sample data. As noted earlier, there are many algorithms for learning ℋ, as it is a measurement timescale structure (though small modifications are required to learn bidirected edges). In pilot testing, we found that structural vector autoregressive (SVAR) model [11] optimization provided the most accurate and stable solutions for ℋ for our simulation regime. We thus employ the SVAR procedure here, though we note that other measurement timescale learning algorithms might work better in different domains.
To test the two-step procedure—SVAR learning passed to RASLil—we generated 20 random 6-node SCCs for each density in {25%, 30%, 35%}. For each random graph, we generated a random transition matrix A by sampling weights for the non-zero elements of the adjacency matrix, and controlling system stability (by keeping the maximal eigenvalue at or below 1). We then generated time series data using a vector auto-regressive (VAR) model [11] with A and random noise (σ = 1). To simulate undersampling, datapoints were removed to yield u = 2. SVAR optimization on the resulting time series yielded a candidate ℋ that was passed to RASLil to obtain ⟦ℋ⟧.
The space of possible ℋ is a factor of larger than the space of possible 𝒢1, and so SVAR optimization can return an ℋ such that ⟦ℋ⟧ = ∅. If RASLil returns ∅, then we rerun it on all ℋ* that result from a single edge addition or deletion on ℋ. If RASLil returns ∅ for all of those graphs, then we consider the ℋ* that result from two changes to ℋ, then three changes. This search through the 3-step Hamming neighborhood of ℋ essentially always finds an ℋ* with ⟦ℋ*⟧ ≠ ∅.
Figure 9 shows the results of the two-step process, where algorithm output is evaluated by two error-types: omission error: the number of omitted edges normalized to the total number of edges in the ground truth; comission error: number of edges not present in the ground truth normalized to the total possible edges minus the number of those present in the ground truth. We also plot the estimation errors of SVAR (on the undersampled data) to capture the dependence of RASLil estimation errors on estimation errors for ℋ. Interestingly, RASLil does not significantly increase the error rates over those produced by the SVAR estimation. In fact, we find the contrary (similarly to [6]): the requirement to use an ℋ that could be generated by some undersampled 𝒢1 functions as a regularization constraint that corrects for some SVAR estimation errors.
Figure 9.
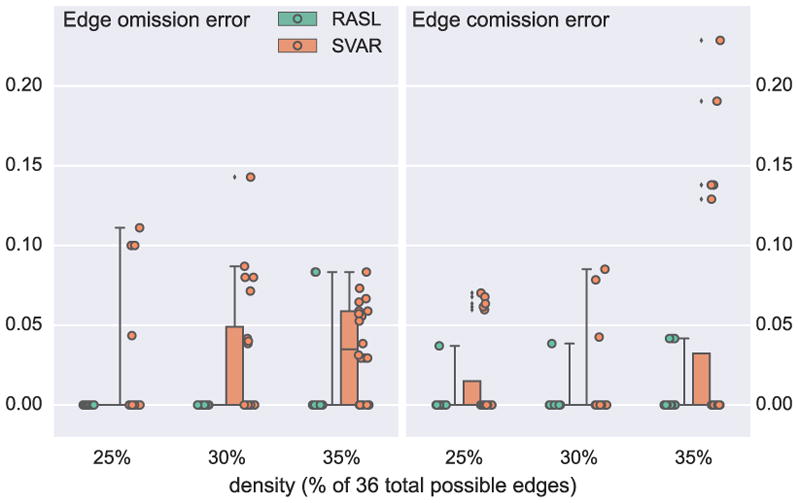
The estimation and search errors on synthetic data: 6-node graphs, u = 2, 20 per density.
5 Conclusion
Time series data are widespread in many scientific domains, but if the measurement and system timescales differ, then we can make significant causal inference errors [9, 15]. Despite this potential for numerous errors, there have been only limited attempts to address this problem [6, 7], and even those methods required strong assumptions about the undersample rate.
We here provided the first causal inference algorithms that can reliably learn causal structure from time series data when the system and measurement timescales diverge to an unknown degree. The RASL algorithms are complex, but not restricted to toy problems. We also showed that underdetermination of 𝒢1 is sometimes minimal, given the right methods. ⟦ℋ⟧ was often small; substantial system timescale causal structure could be learned from undersampled measurement timescale data. Significant open problems remain, such as more efficient methods when ℋ has ⟦ℋ⟧ = ∅. This paper has, however, expanded our causal inference “toolbox” to include cases of unknown undersampling.
Acknowledgments
This work was supported by awards NIH R01EB005846 (SP); NSF IIS-1318759 (SP); NSF IIS-1318815 (DD); & NIH U54HG008540 (DD) (from the National Human Genome Research Institute through funds provided by the trans-NIH Big Data to Knowledge (BD2K) initiative).
Footnotes
We use difference equations in our analyses. The results and algorithms will be applicable to systems of differential equations to the extent that they can be approximated by a system of difference equations.
More precisely, we assume a dynamic variant of the Causal Sufficiency assumption, though it is more complicated than just “no unmeasured common causes.”
For set B of positive integers with gcd(B) = 1, nF is the max integer with for αi ≥ 0.
This check requires at most min(eu, eℋ) + 1 (fast) operations, where eu, eℋ are the number of edges in 𝒢u, ℋ, respectively. This equality check occurs relatively rarely, since 𝒢u and ℋ must be non-conflicting.
The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Contributor Information
Sergey Plis, Email: s.m.plis@gmail.com, The Mind Research Network, Albuquerque, NM.
David Danks, Email: ddanks@cmu.edu, Carnegie-Mellon University, Pittsburgh, PA.
Cynthia Freeman, Email: cynthiaw2004@gmail.com, The Mind Research Network, CS Dept., University of New Mexico, Albuquerque, NM.
Vince Calhoun, Email: vcalhoun@mrn.org, The Mind Research Network, ECE Dept., University of New Mexico, Albuquerque, NM.
References
- 1.Moneta A, Chlaß N, Entner D, Hoyer P. Causal search in structural vector autoregressive models. Journal of Machine Learning Research: Workshop and Conference Proceedings, Causality in Time Series (Proc. NIPS2009 Mini-Symposium on Causality in Time Series); 2011. pp. 95–114. [Google Scholar]
- 2.Granger CWJ. Investigating causal relations by econometric models and cross-spectral methods. Econometrica: Journal of the Econometric Society, pages. 1969:424–438. [Google Scholar]
- 3.Thiesson B, Chickering D, Heckerman D, Meek C. Arma time-series modeling with graphical models. Proceedings of the Twentieth Conference Annual Conference on Uncertainty in Artificial Intelligence (UAI-04); Arlington, Virginia. AUAI Press; 2004. pp. 552–560. [Google Scholar]
- 4.Voortman Mark, Dash Denver, Druzdzel Marek. Learning why things change: The difference-based causality learner. Proceedings of the Twenty-Sixth Annual Conference on Uncertainty in Artificial Intelligence (UAI); Corvallis, Oregon. AUAI Press; 2010. pp. 641–650. [Google Scholar]
- 5.Friedman Nir, Murphy Kevin, Russell Stuart. Learning the structure of dynamic probabilistic networks. 15th Annual Conference on Uncertainty in Artificial Intelligence; San Francisco. Morgan Kaufmann; 1999. pp. 139–147. [Google Scholar]
- 6.Plis Sergey, Danks David, Yang Jianyu. Mesochronal structure learning. Proceedings of the Thirty-First Conference Annual Conference on Uncertainty in Artificial Intelligence (UAI-15); Corvallis, Oregon. AUAI Press; 2015. [PMC free article] [PubMed] [Google Scholar]
- 7.Gong Mingming, Zhang Kun, Schoelkopf Bernhard, Tao Dacheng, Geiger Philipp. Discovering temporal causal relations from subsampled data. Proc. ICML; 2015. pp. 1898–1906. [Google Scholar]
- 8.Richardson T, Spirtes P. Ancestral graph markov models. The Annals of Statistics. 2002;30(4):962–1030. [Google Scholar]
- 9.Danks David, Plis Sergey. Learning causal structure from undersampled time series. JMLR: Workshop and Conference Proceedings; 2013. pp. 1–10. [Google Scholar]
- 10.Johnson Donald B. Finding all the elementary circuits of a directed graph. SIAM Journal on Computing. 1975;4(1):77–84. [Google Scholar]
- 11.Lütkepohl Helmut. New introduction to multiple time series analysis. Springer Science & Business Media; 2007. [Google Scholar]
- 12.Murphy K. PhD thesis. UC Berkeley; 2002. Dynamic Bayesian Networks: Representation, Inference and Learning. [Google Scholar]
- 13.Glymour Clark, Spirtes Peter, Scheines Richard. Erkenntnis Orientated: A Centennial Volume for Rudolf Carnap and Hans Reichenbach. Springer; 1991. Causal inference; pp. 151–189. [Google Scholar]
- 14.Chickering David Maxwell. Optimal structure identification with greedy search. The Journal of Machine Learning Research. 2003;3:507–554. [Google Scholar]
- 15.Seth Anil K, Chorley Paul, Barnett Lionel C. Granger causality analysis of fmri bold signals is invariant to hemodynamic convolution but not downsampling. Neuroimage. 2013;65:540–555. doi: 10.1016/j.neuroimage.2012.09.049. [DOI] [PubMed] [Google Scholar]