

Abstract
Objectives
This study develops neural network models to improve the prediction of diabetes using clinical and lifestyle characteristics. Prediction models were developed using a combination of approaches and concepts.
Methods
We used memetic algorithms to update weights and to improve prediction accuracy of models. In the first step, the optimum amount for neural network parameters such as momentum rate, transfer function, and error function were obtained through trial and error and based on the results of previous studies. In the second step, optimum parameters were applied to memetic algorithms in order to improve the accuracy of prediction. This preliminary analysis showed that the accuracy of neural networks is 88%. In the third step, the accuracy of neural network models was improved using a memetic algorithm and resulted model was compared with a logistic regression model using a confusion matrix and receiver operating characteristic curve (ROC).
Results
The memetic algorithm improved the accuracy from 88.0% to 93.2%. We also found that memetic algorithm had a higher accuracy than the model from the genetic algorithm and a regression model. Among models, the regression model has the least accuracy. For the memetic algorithm model the amount of sensitivity, specificity, positive predictive value, negative predictive value, and ROC are 96.2, 95.3, 93.8, 92.4, and 0.958 respectively.
Conclusions
The results of this study provide a basis to design a Decision Support System for risk management and planning of care for individuals at risk of diabetes.
Keywords: Diabetes, Decision Support Techniques, Neural Networks, Early Diagnosis
I. Introduction
Diabetes is a chronic disease that poses a great challenge for health systems worldwide. On average, about 8.3% of people are diagnosed with diabetes around the world [1]. In the United States alone, 25.8 million individuals had diabetes in 2011, and 79 million more were at a high risk to develop the disease [2,3]. According to recent estimates, about 7 million Iranians have been diagnosed with diabetes. The prevalence of diabetes in the Iranian urban population is rapidly growing by 8.6% annually [1].
The average lifetime costs of direct medical treatment for a diabetic patient were estimated to be approximately $85,000 in 2012 in the United States [4]. The burden of this disease on the economy far exceeds the direct medical costs in the health sector because diabetes reduces the quality of life and labor productivity.
Type 2 diabetes (T2D) is the most common type of diabetes, accounting for 95% of all cases [3]. In T2D patients, insulin is not sufficiently produced or insulin is incapable of permeating cells [5]. This type of diabetes is dependent on lifestyle; therefore, it can be managed or even prevented by early diagnosis and lifestyle modifications. Delayed diagnosis and control of diabetes significantly increases the risk of secondary complications, such as cardiovascular diseases, kidney failure, and sight problems, as well as lower extremity and foot problems [6,7,8]. However, half of people with diabetes are not aware of their disease [9,10]. In the majority of cases, diabetes is diagnosed in the advanced stage requiring medications. Therefore, timely diagnosis at an early stage of disease using clinical indicators and lifestyle indicators such as body mass index (BMI) can save lives and health resources. The importance of early diagnosis has been recognized since the early 1990s by disease management and population health programs [11]. These initiatives use prediction models to determine the risk of onset and progression of diseases [12,13]. Kaiser Permanente in the United States and the United Kingdom's National Health Service (NHS) have successfully applied disease prediction models to manage the risk of progression and avoid further resource consumption [14]. A wide set of techniques are employed to develop prediction models, including artificial neural networks (ANNs), meta-heuristic algorithms, mathematical models, regression models, and so forth [15]. Meta-heuristic algorithms and mathematical models are used to assist in the diagnosis of diabetes [16,17]. Genetic algorithms and memetic algorithms are two commonly used prediction models in diabetes care, though ANNs are more common than other models [18]. ANN models improve the accuracy of results; however, the designing and training of neural networks are challenging. One of the most important challenges is assigning weights in an ANN structure, which has a direct effect on the performance of output models [19]. Other parameters of NNs, such as inputs, the number of hidden layers and their nodes, the number of memory taps, and learning rates could also affect ANN performance. Researchers try to choose appropriate values for parameters by combining ANNs with other optimization methods, such as the genetic algorithm and simulated annealing. Mahmoudabadi et al. [20] reported an ANN which is optimized by the Levenberg-Marquardt (LM) algorithm and the genetic algorithm. Cho [21] developed a hybrid model using the concepts of fuzzy logic and the genetic algorithm.
In this study we used algorithms to develop prediction models using demographic and clinical indicators. In the first step, genetic algorithms were developed, followed by the use of a memetic algorithm to update the weights of the neural network and to improve prediction accuracy. The accuracy of prediction models based on genetic algorithms and memetic algorithms are compared with multivariate regression models.
The remainder of this paper is organized as follows. In Section II we present the modeling methods. Section III provides modeling results and analysis. In Section IV we discuss our results and provide policy recommendations for healthcare decision makers.
II. Methods
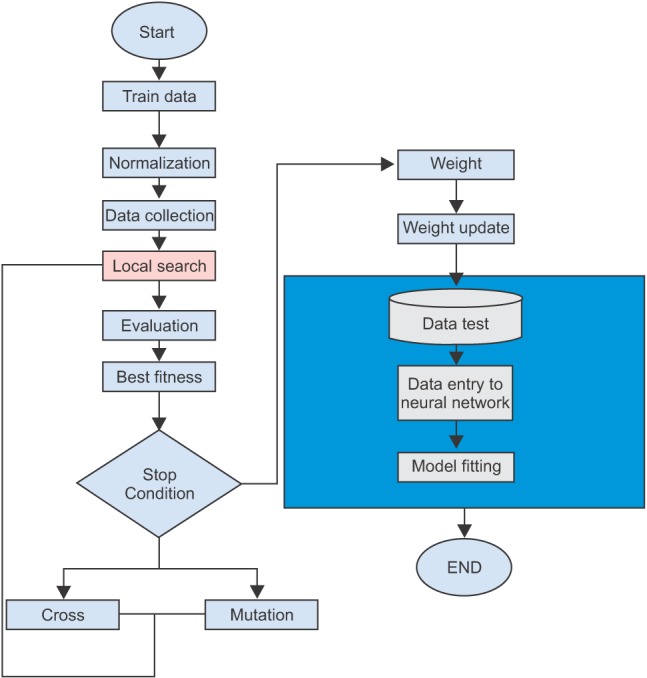
Using neural networks and algorithms, prediction models were developed in five steps. These steps are shown in Figure 1. First, we present an overview of the research method and then present the details of models.
Figure 1. Steps to develop predictive models.

In the first step shown in Figure 1, data on the clinical indicators and lifestyle characteristics of individuals was collected from the clients of a diabetes clinic in Hamedan University of Medical Sciences (UMSHA), Hamedan, Iran. Data for 75% of these individuals was used to develop models and other 25% was used to test the models. In the 'pre-process' step, the maximum and minimum of each characteristic were normalized in a range from -1 to +1. In the next step, neural network models were developed using these normalized characteristics. Parameters obtained by trial and error and from previous studies were used to calculate the optimal parameters for neural networks. In the 'update weight' step, the optimal parameters were used to update the weight and improve the accuracy of prediction using memetic algorithms. Models produced using algorithms were compared with multivariate regression models in terms of accuracy of prediction. The accuracy of models was estimated using a confusion matrix and receptor operating curve (ROC). In the 'post-process' step, participants' characteristics were converted from a normalized range to actual values. Below, we present the models step by step with empirical data from patients served in the diabetes clinic in UMSHA.
1. Model Development
In diabetes care, prediction models use demographic factors, health state, and clinical indicators to predict the onset and progression of the disease [12,13]. Therefore, to provide a basis for model development, data for demographic and clinical characteristics was collected from 545 non-diabetic and patients diagnosed with diabetes. Diabetic patients were registered in the diabetes clinic. Characteristics of interest were age, fasting blood sugar (FBS), diastolic blood pressure, BMI, and change in body weight. Of the participants, 345 had diabetes, and 170 were non-diabetic. Detailed demographic and clinical characteristics information of both groups is presented in Table 1.
Table 1. Characteristics of diabetic and non-diabetic individuals.

FBS: fasting blood sugar, DBP: diastolic blood pressure, BMI: body mass index.
In the first step, the values of characteristics for all individuals were normalized for the purpose of classification and accuracy of diagnosis. This was done using a min-max method in formula (1).
| (1) |
Here, Xmax and Xmin represent the maximum and minimum of characteristics, respectively. The values of characteristics were converted to a range from –1 to +1. The normalized value of each characteristic was fed to a neural network. The algorithms of the neural network received the normalized values through the first layer neuron and trained and classified them as diabetic (+1) and non-diabetic (–1). In the training step, to ensure high accuracy, different models of transfer function and error function were trained. These models are presented in Table 2.
Table 2. Parameters of neural network models.

The best model with the highest accuracy in training and testing was a neural network with 7 neurons, a learning rate 0.57, and a momentum rate 0.76. More information about this model is given in row 2 in Table 2. We present more information about the parameters of this model in Table 3.
Table 3. Parameters of the best neural network model.

MSE: mean square error.
The algorithms of neural networks have a capacity to analyze incomplete data and complex situations [15,16]. It is paramount to choose the appropriate weight and bias for neural networks; otherwise, the accuracy of the neural networks will be compromised. In this study, to obtain a higher accuracy rate, after the training of neural networks, a memetic algorithm was used to update weights and improve accuracy [14]. Weights and bias were respectively inserted in an array (Figure 2) by which the chromosomes of the genetic algorithms and memetic algorithms were made.
Figure 2. Encoding of chromosome.
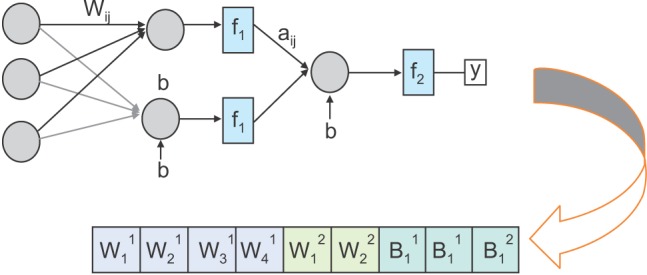
Figure 3 presents a process map by which memetic algorithms were implemented. A memetic algorithm is a combination of a genetic algorithm and a local search. A classic genetic algorithm is efficient in finding a response level; however, it is slow in finding an optimum response. Therefore, a genetic algorithm can be improved by the addition of local search algorithms. A memetic algorithm bridges between a local search and a genetic search. Memetic algorithms compared with their counterparts have a faster search process and find more accurate solutions for complex problems. The parameters of memetic algorithm were tested using the following criteria and ranges:
Figure 3. Implementation process of memetic algorithm.
- Cross rate (CR): the recommended range for CR is 80%–95%. In some cases, 60% is also appropriate.
- Mutation rate (MR): it is usually a small figure (0.2%–0.5%).
- Initial population (IP): The recommended size of the IP is 20–30; however, in some studies an IP size equal to a chromosome size is recommended.
Since analysis of the combinations of all above conditions of CR, MR, and IP would be difficult, combinations were analyzed using the Taguchi test (Table 4), and the best combination was chosen.
Table 4. Combinations of parameters analysed by Taguchi test.

Among the combinations analyzed by the Taguchi test, the best combination was a CR of 0.9 and an MR of 0.05, which resulted in 90% training accuracy and 88% test accuracy (see row 6 in Table 4). By using these parameters for the memetic algorithm, the training accuracy and test accuracy improved to 92.84% and 93.23%, respectively.
2. Model Testing
A confusion matrix and ROC were used to analyze the accuracy of the models. We used 25% of the collected data to test the models [22]. ROC is a measure of accuracy. It has two dimension, the x-axis represents specificity and the yaxis represents sensitivity [16]. Sensitivity and specificity are common parameters to check the accuracy of tests in medical sciences. As sensitivity and specificity are insufficient to test the prediction accuracy, we also used positive predictive value (PPV), negative predictive value (NPV), positive likelihood ratio (LR+), and negative likelihood ratio (LR–).
III. Results
In this section, we present the results of models in terms of their accuracy. We also compare the accuracy of models based on the genetic algorithm and memetic algorithm with a logistic regression model. Results from the confusion matrix are presented in Table 5. This matrix compares the prediction accuracy of the models based on the genetic algorithm and the memetic algorithm with that of logistic regression models.
Table 5. Comparison of models using confusion matrix.

PPV: positive predictive value, NPV: negative predictive value, LR+: positive likelihood ratio, LR–: negative likelihood ratio.
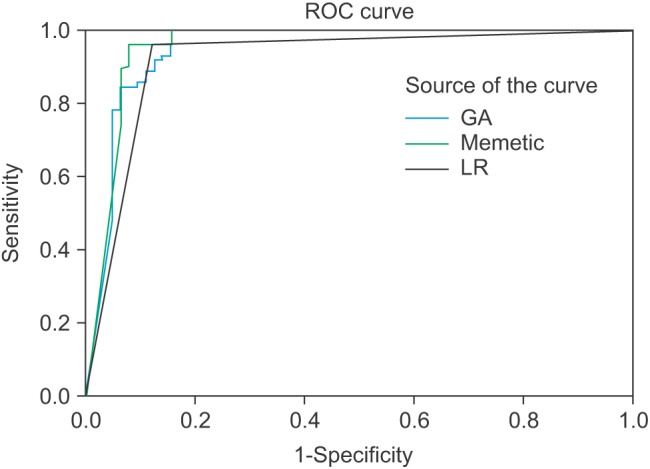
As seen in Table 5, the models based on genetic and memetic algorithms showed high sensitivity. The model based on the memetic algorithm showed the highest sensitivity. The regression model showed the lowest specificity. The memetic algorithm model showed the highest values for PPV, NPV, and LR+ and lowest value (close to zero) of LR–. This model is therefore more accurate than the other models. The ROC analysis results are shown in Figure 4. In Figure 4, a model has the higher accuracy when it is close to the top left corner (0, 1). This point shows the highest overlap between a prediction model and an actual model.
Figure 4. Analysis of model using receiver operating characteristic curve (ROC). GA: genetic algorithm model, LR: logistic regression model.
IV. Discussion
This paper presented models developed based on neural networks and memetic algorithms to assist in diabetes prediction. These models were developed based on patient demographic, lifestyle indicators, and clinical characteristics. In this study, we also aimed to improve the accuracy of models. For this purpose we used the memetic algorithm to update the weight of neural networks. Having improved the weight of neural network models, we obtained a memetic algorithm model that achieved 93% prediction accuracy. This model was able to provide a more accurate prediction than the other two other models considered in this study. These findings confirm previous research results, such as those obtained by Wang et al. [23] with regard to the improved accuracy of prediction models using neural networks. They also reported more accurate prediction by neural network models in comparison to regression models [17]. However, these findings are not unexpected given the fact that the prediction of diabetes is a non-linear problem, and neural networks can model such problems more accurately than regression models. This comparison between models suggests that providers should more often use neural network models in healthcare issues in which regression models are dominant.
We introduced algorithms that can be used in developing a decision support tool for diabetes care management in Iran. As the empirical model developed in this study takes into consideration a wider set of characteristics related to health state and lifestyle, it is suitable for preventive and health monitoring programs. The model could facilitate the identification of individuals at high risk of becoming diabetic using FBS, blood pressure, BMI, and weight change measurements. These characteristics are not considered in real life practice for the diagnosis and prediction of diabetes.
This study had some limitations. The memetic algorithms in comparison require longer training time and more powerful processors than logistic regression models. Also, the quality of data limited the research quality somewhat.
The models developed in this study could certainly be improved. The accuracy of the memetic algorithm model could be improved by new data and training. The use of these models by other researchers may improve the reliability of models and thus help save resources.
In this study memetic algorithms were applied to update weights and improve the prediction accuracy of neural network models for diabetes prediction. Our preliminary analysis using parameters obtained by trial and error and from previous studies found that the prediction accuracy of neural networks was 88%. The use of the memetic algorithm improved this accuracy to 93.2%. Among the generic algorithm, memetic algorithm, and logistic regression models, the memetic algorithm model showed the highest prediction accuracy. For the memetic algorithm model the sensitivity, specificity, PPV, NPV, and ROC values were 96.2, 95.3, 93.8, 92.4, and 0.958, respectively, which makes it the most accurate model. Our study confirmed previous findings with regard to the low comparative accuracy of prediction by regression models. This paper also presented a prediction model which might be helpful in the development of computer-based decision support for real life diabetes care practices.
Footnotes
Conflict of Interest: No potential conflict of interest relevant to this article was reported.
References
- 1.International Diabetes Federation. IDF diabetes atlas. 6th ed. Brussels, Belgium: International Diabetes Federation; 2013. [Google Scholar]
- 2.Centers for Disease Control and Prevention. National Diabetes Fact Sheet: national estimates and general information on diabetes and prediabetes in the United States, 2011 [Internet] Atlanta (GA): US Department of Health and Human Services, Centers for Disease Control and Prevention; 2011. [cited at 2016 Mar 1]. Available from: http://www.cdc.gov/diabetes/pubs/pdf/ndfs_2011.pdf. [Google Scholar]
- 3.Pei E, Li J, Lu C, Xu J, Tang T, Ye M, et al. Effects of lipids and lipoproteins on diabetic foot in people with type 2 diabetes mellitus: a meta-analysis. J Diabetes Complicat. 2014;28(4):559–564. doi: 10.1016/j.jdiacomp.2014.04.002. [DOI] [PubMed] [Google Scholar]
- 4.Zaugg SD, Dogbey G, Collins K, Reynolds S, Batista C, Brannan G, et al. Diabetes numeracy and blood glucose control: association with type of diabetes and source of care. Clin Diabetes. 2014;32(4):152–157. doi: 10.2337/diaclin.32.4.152. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Nielsen DS, Krych L, Buschard K, Hansen CH, Hansen AK. Beyond genetics: Influence of dietary factors and gut microbiota on type 1 diabetes. FEBS Lett. 2014;588(22):4234–4243. doi: 10.1016/j.febslet.2014.04.010. [DOI] [PubMed] [Google Scholar]
- 6.Manzella D, Grella R, Abbatecola AM, Paolisso G. Repaglinide administration improves brachial reactivity in type 2 diabetic patients. Diabetes Care. 2005;28(2):366–371. doi: 10.2337/diacare.28.2.366. [DOI] [PubMed] [Google Scholar]
- 7.Zhuo X, Zhang P, Barker L, Albright A, Thompson TJ, Gregg E. The lifetime cost of diabetes and its implications for diabetes prevention. Diabetes Care. 2014;37(9):2557–2564. doi: 10.2337/dc13-2484. [DOI] [PubMed] [Google Scholar]
- 8.Chavey A, Ah Kioon MD, Bailbe D, Movassat J, Portha B. Maternal diabetes, programming of beta-cell disorders and intergenerational risk of type 2 diabetes. Diabetes Metab. 2014;40(5):323–330. doi: 10.1016/j.diabet.2014.02.003. [DOI] [PubMed] [Google Scholar]
- 9.Mohan D, Raj D, Shanthirani CS, Datta M, Unwin NC, Kapur A, et al. Awareness and knowledge of diabetes in Chennai: the Chennai Urban Rural Epidemiology Study [CURES-9] J Assoc Physicians India. 2005;53:283–287. [PubMed] [Google Scholar]
- 10.Hadaegh F, Bozorgmanesh MR, Ghasemi A, Harati H, Saadat N, Azizi F. High prevalence of undiagnosed diabetes and abnormal glucose tolerance in the Iranian urban population: Tehran Lipid and Glucose Study. BMC Public Health. 2008;8:176. doi: 10.1186/1471-2458-8-176. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Ofman JJ, Badamgarav E, Henning JM, Knight K, Gano AD, Jr, Levan RK, et al. Does disease management improve clinical and economic outcomes in patients with chronic diseases? A systematic review. Am J Med. 2004;117(3):182–192. doi: 10.1016/j.amjmed.2004.03.018. [DOI] [PubMed] [Google Scholar]
- 12.Baan CA, Ruige JB, Stolk RP, Witteman JC, Dekker JM, Heine RJ, et al. Performance of a predictive model to identify undiagnosed diabetes in a health care setting. Diabetes Care. 1999;22(2):213–219. doi: 10.2337/diacare.22.2.213. [DOI] [PubMed] [Google Scholar]
- 13.Asche C, LaFleur J, Conner C. A review of diabetes treatment adherence and the association with clinical and economic outcomes. Clin Ther. 2011;33(1):74–109. doi: 10.1016/j.clinthera.2011.01.019. [DOI] [PubMed] [Google Scholar]
- 14.Billings J, Blunt I, Steventon A, Georghiou T, Lewis G, Bardsley M. Development of a predictive model to identify inpatients at risk of re-admission within 30 days of discharge (PARR-30) BMJ Open. 2012;2(4):e001667. doi: 10.1136/bmjopen-2012-001667. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Gray AR, MacDonell SG. A comparison of techniques for developing predictive models of software metrics. Inf Softw Technol. 1997;39(6):425–437. [Google Scholar]
- 16.Narasingarao MR, Sridhar GR, Madhu K, Rao AA. A clinical decision support system using multi-layer perceptron neural network to predict quality of life in diabetes. J Assoc Physicians India. 2010;4(1):127–133. [PubMed] [Google Scholar]
- 17.Karan O, Bayraktar C, Gumuskaya H, Karlik B. Diagnosing diabetes using neural networks on small mobile devices. Expert Syst Appl. 2012;39(1):54–60. [Google Scholar]
- 18.Kang JO, Chung SH, Suh YM. Prediction of hospital charges for the cancer patients with data mining techniques. J Korean Soc Med Inform. 2009;15(1):13–23. [Google Scholar]
- 19.Tahmasebi P, Hezarkhani A. A hybrid neural networksfuzzy logic-genetic algorithm for grade estimation. Comput Geosci. 2012;42:18–27. doi: 10.1016/j.cageo.2012.02.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Mahmoudabadi H, Izadi M, Menhaj MB. A hybrid method for grade estimation using genetic algorithm and neural networks. Comput Geosci. 2009;13(1):91–101. [Google Scholar]
- 21.Cho SB. Fusion of neural networks with fuzzy logic and genetic algorithm. Integr Comput Aided Eng. 2002;9(4):363–372. [Google Scholar]
- 22.Smith AD, Bolam JP. The neural network of the basal ganglia as revealed by the study of synaptic connections of identified neurones. Trends Neurosci. 1990;13(7):259–265. doi: 10.1016/0166-2236(90)90106-k. [DOI] [PubMed] [Google Scholar]
- 23.Wang C, Li L, Wang L, Ping Z, Flory MT, Wang G, et al. Evaluating the risk of type 2 diabetes mellitus using artificial neural network: an effective classification approach. Diabetes Res Clin Pract. 2013;100(1):111–118. doi: 10.1016/j.diabres.2013.01.023. [DOI] [PubMed] [Google Scholar]