

Abstract
In this article, we construct a generalization of the Blum–François Beta-splitting model for evolutionary trees, which was itself inspired by Aldous' Beta-splitting model on cladograms. The novelty of our approach allows for asymmetric shares of diversification rates (or diversification ‘potential’) between two sister species in an evolutionarily interpretable manner, as well as the addition of extinction to the model in a natural way. We describe the incremental evolutionary construction of a tree with n leaves by splitting or freezing extant lineages through the generating, organizing and deleting processes. We then give the probability of any (binary rooted) tree under this model with no extinction, at several resolutions: ranked planar trees giving asymmetric roles to the first and second offspring species of a given species and keeping track of the order of the speciation events occurring during the creation of the tree, unranked planar trees, ranked non-planar trees and finally (unranked non-planar) trees. We also describe a continuous-time equivalent of the generating, organizing and deleting processes where tree topology and branch lengths are jointly modelled and provide code in SageMath/Python for these algorithms.
Keywords: random evolutionary trees, Beta-splitting model(s), speciation and extinction model, binary search trees
1. Introduction
In the last couple of decades, many models of random evolutionary trees have been introduced and studied, as reviewed by Mooers & Heard [1] and Morlon [2]. Most of them are formulated in terms of (constant or variable) individual species diversification rates mirroring the influence of particular features such as species age, trait, available niche space, etc. In this way, they propose an evolutionary explanation for the shapes and branch lengths observed in some reconstructed real trees. Many of these models cannot jointly model the branch lengths and the tree topologies or shapes, are quite complex to analyse and have limited identifiability [2]. Note that, although we adopt here the terminology of evolutionary biology, the same kind of questions appear in other domains such as developmental biology (with cell lineage diagrams, cf. [1, p. 48]) or epidemiology [3]. The model developed in this paper may thus be of interest in these other contexts.
Even though the branch lengths of a phylogenetic tree give potentially precise indications on the individual diversification rates, their estimations may be subject to appreciable errors due to the difficulty of their reconstruction. On the other hand, the tree topology has a discrete nature that is somewhat easier to handle (for computation or comparison purposes, for example), and it already brings a lot of information on the phenomena shaping the clade diversity [1]. In particular, many works focus on the balance of a tree, measured by a diverse class of indices (e.g. Colless index, cf. [4] and Sackin index, cf. [5]). Of course many diversification mechanisms can lead to the same phylogenetic tree balance [6] and so such indices cannot be used on their own to characterize the way the reconstructed tree was generated. However, they may be used to rule out some scenarii. For example, several papers [1,7,8] point out the fact that the reconstructed trees of the TreeBase database are on average much more unbalanced than expected under the most well-known model of speciation, the Yule model [9]. In this model, every species branches into two species at the same rate (which may vary in time but remains identical for all species), and there is no extinction. The Yule model is the best known example of an evolutionarily interpretable model of speciation due to the following three features:
— it is based on an incremental evolutionary construction whereby the tree grows by splitting one of the current leaf nodes which represent the set of extant lineages,
— it can be defined jointly on the product space of tree topologies and branch lengths, and
— the distribution it induces on coarser resolutions of the tree space can be obtained.
Several models introduced in the literature are not evolutionarily interpretable in the above sense. The main objective of this paper is to formulate an evolutionarily interpretable parametric family of models that includes the Yule model as well as many others in the literature that originally lacked evolutionary interpretability.
Aldous [10] introduces a one-parameter family of random cladograms, called the Beta-splitting model. Here a cladogram is defined as a binary tree shape with a specified number of tips (or leaves) in which there is no ‘left’ and ‘right’ ordering of the child nodes of an internal node (in other words, the tree is non-planar and unranked as defined below). The leaves are labelled by the sampled species, or by for simplicity. The parameter modulates the shape and balance of the tree produced by this model by determining the split distribution of a node subtending m leaves. More precisely, Aldous' recursive construction involves a fixed n, the number of leaf nodes representing the extant species in a tree with at least two leaves and , a symmetric probability distribution (i.e. ) which specifies the numbers i and of descendants along the two branches emanating from the root node of the tree. Once this split is fixed, the construction carries on recursively in the two subtrees pending from the root, with respective numbers of leaf nodes i and , and stops when all subtrees considered have only one leaf. In the Beta-splitting model with , the split distribution takes the form
| 1.1 |
for , where is a normalizing factor given by
This Markov branching model has now become a reference in the literature [6,8,11], in particular, because it provides a family of random tree topologies indexed by a single parameter, which contains the most commonly used Yule tree () and proportional to distinguishable arrangements (or PDA) model in which every cladogram is equally likely (). The parameter β tunes the balance of the tree, since ‘’ corresponds to the totally unbalanced tree or comb, whereas the generated trees become more and more balanced as β tends to infinity. Aldous [7] also proposes a measure of the balance of a tree which has the advantage of being independent of the tree size, at least for large n's: the median of the split distribution . This measure is used to perform maximum-likelihood estimation of β or to compare the global balance of several trees [7,8].
Unfortunately, Aldous, being unable to find an appropriate underlying process (cf. [10, Section 4.3]) in his own words, ‘resort(s) to pulling a model out of thin air’ [10, Section 3]. Since the number of leaf nodes has to be known before recursive splitting begins, Aldous' Beta-splitting model is not based on an incremental evolutionary construction or defined jointly on the product space of tree topologies and branch lengths for every value of , and thus lacks evolutionary interpretability in our sense.
Subsequently, several other families of random tree topologies have been introduced, in particular Ford's alpha-model [12] in which branches are added one after another to the tree until it has the desired number of leaves. The parameter there serves to give a weight to each existing edge in the tree and then choose which one will be split to insert the next edge. Ford's alpha-model also lacks evolutionary interpretability since new species can arise not just from the currently extant leaf lineages but from any ancestral lineage that is currently extinct. Blum & François [8] introduced an evolutionary Beta-splitting model based on ideas of Kirkpatrick & Slatkin [13], and Aldous [10]. The idea is that the ‘speciation potential’ is shared between the two offspring species in a random way, as may occur, for example, in the cases where speciation is influenced by available niche or geographical space that is shared between the two new species. In this model, a (rooted binary non-planar) tree is constructed incrementally by starting from a single node (the root) with speciation rate (or ‘potential’) 1. When this first species branches, a parameter is sampled in according to a Beta distribution (the definition of the Beta distribution is recalled below). Then the first offspring species is given the speciation rate , and the second the speciation rate . The next species to split is thus the first one with probability , or the second one with probability . Carrying on the construction, upon the split of a species with speciation rate λ, a new parameter is sampled independently of the previous ones according to the same Beta distribution, and the two sister species receive the speciation rates and . Then, each species is the next one to branch with a probability equal to its speciation rate/potential.
Though the Blum–François and the Aldous Beta-splitting models coincide for , in general they do not yield the same distribution on cladograms. See the supplementary material of Blum & François [8] for a discussion of the relationships between the two families of processes. Nevertheless, the principles behind the two constructions are similar and the Blum–François model offers an approximate evolutionary construction of Aldous' Beta-splitting model, with a slightly restricted range of parameters ( instead of ). Below, we argue that the range of topologies covered by the Blum–François model is quite wide as well, since ‘’ corresponds to the totally unbalanced trees while ‘’ corresponds to highly balanced trees. For the reasons expounded in this paragraph, we feel that this model has not yet received the attention it deserves in the phylogenetics community (or other communities as explained earlier), in particular because it is only sketchily described in Blum & François [8].
In this article, we extend the Blum–François model by allowing asymmetric Beta-distributions for the split distribution. That is, the fraction of ‘speciation potential’ allocated to the first offspring species is now distributed according to a Beta distribution, for some and . Of course this lack of symmetry makes sense only if we distinguish a first and second (or later ‘left’ and ‘right’) offspring species. This distinction appears naturally when we think of speciation as being the creation of a new species and the continuation of the mother species, in which case the two species will not play a symmetric role and have a priori no reason to speciate at the same rate (e.g. [14]). In the context of transmission trees in epidemiology [15], the left branch keeps track of the infector and its ‘infection potential’, while the right branch keeps track of the infectee and its ‘infection potential’ for each infection event recorded by the internal branch. The same distinction is true of cell lineage diagrams where the left branch can track the sister cell upon division using some measurable feature such as having more DNA damage than the sister cell along the right branch [16].
In order to formalize more precisely how these Beta-splits create a given topology of interest, we consider four types of (rooted binary) trees:
— Ranked planar trees: In this case, we distinguish the left and right child nodes of an internal node, and every internal node is labelled by an integer keeping track of the ordering in which the splits occur during the construction of the tree. Since a binary tree with n leaves has internal nodes, the labels thus run from 1 (the root) to (the last split).
— Unranked planar trees: Left and right child nodes are distinguished, but the internal nodes are not labelled (so that the order of the splits is not recorded).
— Ranked non-planar trees: In this case, the internal nodes are ranked and labelled according to the splitting order, but left and right child nodes play equivalent roles.
— Trees: Unranked and non-planar trees. Aldous' cladograms are such trees whose leaves are further labelled by the n taxa.
Indeed, as explained above, planarity can be interesting when the two sister species do not necessarily evolve according to the same mechanisms. The ranking of the internal nodes is a way to include some information on relative speciation times without keeping track of the full set of speciation times (e.g. [17]). Furthermore, various tree shape statistics are functions of the unranked non-planar trees or cladograms without leaf labels. Explicit expressions for the probability of any tree at each of these four resolutions are not available in the literature for the Beta-splitting models of Aldous or Blum–François. Thus, another contribution of this paper is the set of explicit expressions for the probability of any tree at the resolutions of ranked planar and unranked planar trees for any α and β and for the probability of any tree at the resolutions of ranked non-planar and unranked non-planar trees for any .
We first focus on the finest of these four tree resolutions, that of ranked planar trees. We introduce the generalization of the Blum–François Beta-splitting model by decomposing the construction of a random ranked planar tree with n leaves into two steps. First, we sample a generating sequence , which is a realization of a sequence of independent and identically distributed random variables which, at each step i, will determine the choice of the next leaf to be split and the fraction of ‘speciation potential’ allocated to the left child of that former leaf. Once this generating sequence is fixed, we define a (non-random) organizing process that turns the generating sequence into a ranked planar binary tree with the desired number of leaves. Each of these leaves is labelled by a subinterval of whose length is the speciation potential of the corresponding species. The intervals take part in the choice of the next leaf to be split. This construction enables us to add species extinction by a similar mechanism, thanks to a deleting process that encodes the freezing of some leaf nodes with a given probability . A frozen leaf can no longer evolve, and thus represents a species which is either extinct or no longer able to diversify. See the next section for a precise description of the generating, organizing and deleting processes.
Our next task is to describe the distribution on ranked planar trees corresponding to a given pair of parameters , as well as the distribution on the three coarser tree resolutions induced by this construction. We provide several examples in the case of Blum & François [8], in particular to discuss the balance of the trees obtained as a function of β. For completeness, we also propose a continuous-time process of leaf splitting and freezing such that the shape of the tree obtained after N events (regardless of branch lengths) has the same distribution as that obtained through the generating, organizing and deleting processes after N steps. Finally, in the electronic supplementary material, we give SageMath/Python code to produce these trees at several resolutions as well as a demonstration of the code for the case of the Yule process with four leaves.
In the electronic supplementary material, we also discuss a reversibility result describing how to choose a pair of sibling leaves (a cherry) in an unranked planar tree with leaves created through the generating and organizing processes with n steps, in such a way that the tree with n leaves obtained by removing this cherry has the same law as a tree we would have obtained from the GO processes with only steps. This last result is on sampling consistency of our evolutionarily interpretable Beta-splitting model, which unlike Aldous' model (cf. [10, Section 6.3]), does not naively satisfy equivalence in distribution between (i) constructing a tree with leaves and then removing one leaf at random and (ii) constructing a tree directly with n leaves. Our result shows that in the unranked case (planar or non-planar), there is a natural but non-uniform way of choosing a terminal split to remove to obtain a tree with the same distribution as if it had been produced directly with the reduced number of leaves.
Let us end this section with some notation. To match the standard definition of the Beta distribution, for any we call the distribution on with density , where
| 1.2 |
If , this distribution is symmetric: if , then .
In all that follows, we shall consider the distribution (for ), with density proportional to . This choice corresponds to the density used in the Aldous and Blum–François Beta-splitting models in the symmetric case .
2. An evolutionary construction
We fix .
2.1. The generating sequence
Let be a sequence of independent and identically distributed (i.i.d.) random variables, with the distribution. Let also be a sequence of i.i.d. random variables with the uniform distribution on , that is independent of . Thus, each of these variables takes its values in . We call the generating sequence. It will be the basis of an incremental construction of a ranked planar binary tree with n leaves and internal nodes.
Remark 2.1
Here we use the distribution, because it gives us a two-parameter family with a wide range of possible behaviours for the corresponding trees (as we shall see later). In general, we may take to be a sequence of i.i.d. variables with some common distribution F on . Even more generally, we may take a sequence with an arbitrary dependence of each on the previous values .
2.2. The organizing map
Let us now describe the deterministic mapping that takes a realization of the generating sequence and turns it into a planar binary tree in which the internal nodes are labelled by an integer and the leaves are labelled by a subinterval of . As we shall see below, the integer labels of the internal nodes will give the order in which these nodes have been split during the construction. The interval labels of the leaves will form a partition of the interval and will be used to decide which leaf is split and becomes an internal node in the next step.
Let be a realization of the generating sequence. The organizing map proceeds incrementally as follows, until the tree created has n leaves. We start with a single root node, labelled by the interval .
— Step 1: Split the root into a left leaf labelled by and a right leaf labelled by . Change the label of the root to the integer 1.
— Step 2: If , split the left child node of the root into a left leaf and a right leaf, respectively, labelled by and . If , then instead split the right child node of the root into left and right leaves with respective labels , . Label the former leaf that is split during this step by 2.
— Step i: Find the leaf whose interval label contains . Change its label to the integer i and split it into a left leaf with label and a right leaf with label .
— Stop at the end of Step .
In words, at each step i the labels of the leaves form a partition of the interval . We find the next leaf to be split by checking which interval contains the corresponding and then is used to split the interval of that former leaf, say with length ℓ, into two intervals of lengths and . The internal node just created is then labelled by i to record the order of the splits. At the end of step i, the tree has leaves, and so we stop the procedure at step . Figure 1 shows an example of such construction for .
Figure 1.
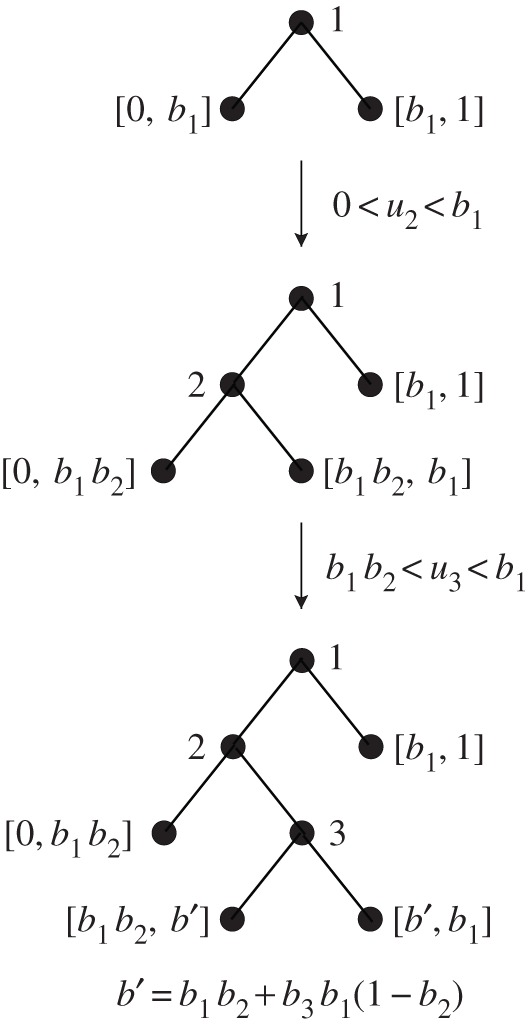
An example of construction for .
Note that once the realization of the generating sequence has been fixed, the creation of the ranked planar binary tree has no extra randomness. Below, we shall study the random tree obtained under the assumption that the generating sequence is a sequence of i.i.d. pairs , where and .
2.3. Generating, organizing and deleting process
We can complete the organizing procedure to obtain an incremental construction of a tree with splitting (or reproduction) and freezing (or death) events. In this new process, freezing will correspond for example to a species becoming extinct (so that it cannot speciate later): such a leaf will be marked with a star and cannot be chosen to split in later steps. For this, we need to augment the generating sequence to include two more coordinates, which will decide whether the next step is a split or a freezing, and which leaf is frozen in the second case.
More precisely, let and be two independent sequences of i.i.d. random variables with a uniform distribution on (independent of ). Let also be a fixed number corresponding to the probability that the next event is a freezing event and not a split. We augment the generating sequence into the following sequence of quadruples .
Let now be a realization of the new generating sequence. Again, we start with a single root node, labelled by the interval and proceed incrementally, until the tree created has n active (i.e. not frozen) leaves or no active leaves. At each step i, we decide to freeze if and split otherwise. If , then we freeze the leaf node whose interval label contains by marking it with a star (if it was already marked, then nothing changes). If , we find the leaf node whose interval label contains as before. If the corresponding leaf is still active, we split it according to the procedure described in the organizing map. If that leaf is frozen, then the event is cancelled. Alternatively, we can have a construction where the distribution is conditional over the currently active leaf intervals.
Figure 2 gives an example of realization of the generating, organizing and deleting process. Of course, this procedure is particular in the sense that we may have chosen more general distributions for the variables dictating the choice of the leaf becoming frozen.
Figure 2.

Example of a realization of the generating, organizing and deleting process. Here, we only record the labels of the internal nodes (the split ranking) and the stars indicating a frozen leaf, but each leaf is also labelled by an interval as in the organizing process. We start with a single node. During the first step, and so the node is split and becomes labelled by 1. Next, and belongs to the interval labelling the left leaf, so that this leaf becomes frozen. During the third step, whatever the value of , the affected leaf chosen according to where or sits lies among the frozen leaves and so nothing happens. The next two steps are such that and the leaves chosen to split are both active. In the final step, and belongs to the interval labelling the right child leaf of node 3, which therefore becomes frozen.
3. Properties of the Beta-splitting evolutionary trees
Keeping track of the generating sequence is useful to carry on the incremental construction and add new leaves to the tree. However, in most applications the object of interest is the (unlabelled) ranked planar binary tree obtained by keeping the labels of the internal nodes (giving the ranking of the splits) and by erasing the leaf nodes' interval labels whose widths give their speciation potentials that are yet to be observed. Thus, this is the random tree of interest in this section.
3.1. Probability of a given tree
All trees here are rooted and binary. First, let us give the probability of obtaining a given tree through the random generating and the non-random organizing processes.
For a given (unlabelled) ranked planar tree, and an internal node labelled by i, let us write (resp., ) for the number of internal nodes in the left (resp., right) subtree below node i. In particular, if node i subtends two leaves, then .
Theorem 3.1
For any unlabelled ranked planar binary tree τ with n leaves, we have
3.1 where was defined in (1.2).
Proof outline. —
Remember that if a leaf is labelled by an interval , the probability that it is split during the ith step is , the probability that the uniform random variable falls within . If it is chosen to split, it is given label i and the left and right leaves created are labelled by intervals of respective lengths and . Then these intervals may split later, but into intervals of lengths that are always proportional to or (respectively). Now the probability of the tree τ is the product of the probabilities of choosing a given leaf to split at each step, each of which is equal to the length of the interval labelling that leaf. As a consequence, each split occurring in the left subtree below node i brings in another in the product, or another if the split occurs in the right subtree below node i. Averaging over the possible values of the 's, which are independent random variables, yields the result. ▪
Remark 3.2
This construction is different from Aldous' interpretation in terms of splitting intervals that starts by uniformly scattering the given n leaf nodes as ‘particles’ on the unit interval and splitting the interval at a random point with density f. This splitting is repeated recursively on subintervals exactly as we do, i.e. splitting each interval at a point , where the X's are independent with density f. Splitting stops when each subinterval contains only one leaf particle while splits that result in one of the intervals being empty (without any leaf particles in it) are not allowed. See the supplementary material of Blum & François [8] for a discussion on the relationship between Aldous' Beta-splitting model and this incremental construction.
3.2. Examples
In all the examples given below, we focus on the symmetric case . Some of the formulae given below are easily generalized to the case .
The most important example is the case , which corresponds to the Yule model of pure births that is used in many models of phylogenies.
Recall that is related to the Gamma function Γ by the equality
| 3.2 |
and that if . Using (3.1) with , we have
| 3.3 |
where the second equality is obtained by observing that is the number of internal nodes of the tree rooted at node i, which is the left or the right subtree below the mother node of i. Hence, each term in the numerator of the product cancels with the term in the denominator that corresponds to the left child node of i, except if and the left child node of i is a leaf. But in this case, by convention. The same holds true for each of the . Likewise, the terms in the denominator which are not compensated by some term in the numerator are those corresponding to internal nodes having no mother nodes. But the only such node is the root (), with . This gives us the result.
Remark 3.3
This construction is very different from the standard evolutionary construction of the Yule tree, in which the next leaf to split is chosen uniformly at random among the current set of leaves. Here the choice of the next split is dictated by the lengths of the intervals labelling the current leaves, which will all be distinct with probability one. However, averaging over the law of the generating sequence (when ) yields the same distribution on ranked planar binary trees.
Using the above property of the Gamma function, we can also give explicit values for the probability of a tree when is a non-negative integer: if , then
| 3.4 |
Thirdly, when β is a non-negative integer, we have
As a consequence, another example in which the probability of a tree has an explicit form is the case where , with :
To the best of our knowledge, the cases and correspond to no well-studied models of trees.
To see how the global shape of the tree (and in particular its balance) evolves as β goes from to , let us consider the two extreme cases. The corresponding processes cannot be defined directly as and lie out of the range of the possible β's, but we can capture the essence of the resulting (random) tree by taking limits in β. First, as , the distribution gives more and more weight to the boundaries 0 and 1. In the limit, the random variables should then take the values 0 or 1, each with probability . In this case, the root is first split into a leaf with label and another leaf with label or (i.e. an interval reduced to a single point). The leaf that receives the label is the left one with probability . Next, the uniform random variable belongs to the interval with probability one, so that the leaf labelled by is necessarily that chosen to split. Again, it is split into two leaves with labels and or , implying that the next leaf to split is that inheriting the full interval with probability one. The reasoning can be carried on until step . Hence, morally the tree corresponding to is a fully unbalanced tree, with a single backbone from which the n leaves are hanging. The backbone is extended at each step by choosing one of the two leaves created in the previous step, each with probability . See figure 3 for an example with .
Figure 3.
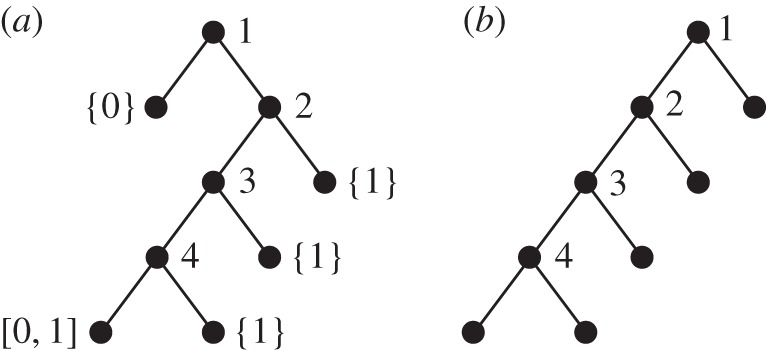
(a) An example of realization of a tree corresponding to the limiting case , and (b) the comb which is the only possible non-planar tree that can be generated in this case.
Let us now consider the limit . Using (3.4) and the fact that as (meaning that the ratio of both terms tends to 1), we can pass to the limit and obtain that
Because in the balanced trees the internal nodes below a given node are equally split between the left and right subtrees hanging from that node, the sum decreases with i faster than in more unbalanced trees. This means that for very large β's, approximately balanced trees will have much higher probabilities than unbalanced ones. For instance, any of the fully unbalanced trees will have probability
On the other hand, if is a power of 2, the probability of any of the fully balanced trees is equal to
Indeed, any subtree pending from a node at level (level 0 being that of the root, level that of all the leaves) has leaves, and so internal nodes below its root. Furthermore, there are internal nodes at level k. Together with (3.1), this gives us the result.
Using the results obtained in the next section, we can further compute the probability of producing a fully unbalanced (unranked non-planar) tree as being equal to
Likewise, the probability of producing a fully balanced tree with tips is given by
Table 1 gives a few examples of these probabilities for different values of and .
Table 1.
Probability of sampling a comb tree or a fully balanced tree for different values of n and β. As explained in the text, larger values of β correspond to higher probabilities of sampling a balanced tree.
| n | 4 | 8 | 32 | 1024 | |
|---|---|---|---|---|---|
| comb | 1 | 1 | 1 | 1 | |
| balanced | 0 | 0 | 0 | 0 | |
| comb | |||||
| balanced | |||||
| comb | |||||
| balanced |
Finally, we have shown that the family of Beta-splitting trees defined in Blum & François [8] and generalized in this article includes a one-parameter family containing the classical Yule (ranked planar) tree. For small β's (close to ), the corresponding trees are unbalanced with high probability, whereas for large β's the tree distribution is concentrated on balanced trees. The family of Beta-splitting trees indexed by thus covers a very wide range of possible topologies.
4. Other tree resolutions
Recall that a tree in this paper is always rooted and binary. Up to now we have focused on ranked planar trees with n leaves that keep records of the order in which splits occur and give an asymmetric role to the left and right child nodes of an internal node. These many trees are in bijective correspondence with permutations of through the increasing binary tree-lifting operation (see [18, Ex. 17, p. 132]). However, we may be interested in coarser resolutions of the trees generated by our Beta-splitting procedure, especially those resolutions of interest to evolutionary biologists. To the best of our knowledge, explicit formulae for the probability of any tree at these resolutions are not available in the literature as a function of α and β (even for the symmetric case when ). This is because the cardinality of the inverse image from a fine to a coarser tree resolution needs to be computed for any tree in the coarser resolution. Such probabilities can be directly useful in simulation-intensive inference.
4.1. Probability of unranked planar trees
Here, we keep the lack of symmetry between the child nodes, but do not record the order of the splits. As explained in the Introduction, this may be of interest, for example, if we assume that there is a lack of symmetry between the two species created during a speciation event, say due to one species being the ancestor and other being the descendant, but we do not want to reconstruct the temporal order in which the speciation events occurred. In the context of transmission trees, we may only be interested in the infector–infectee relation for each transmission event and not in the ranking of transmission events given by their relative temporal order.
Since we do not label the internal nodes, let denote the set of all internal nodes of a planar tree and let us extend the notation and , , for the number of internal nodes in the left and right subtrees below node i to this unlabelled case. The probability of obtaining a given (unranked) planar binary tree through the Beta-splitting generating and organizing processes is given by the following lemma.
Lemma 4.1
Let be a planar binary tree. We have
Indeed, recall that the second product in the right-hand side of the first equality above is the probability of a given ranked planar tree corresponding to the unranked tree . Since it does not depend on the ranking, there remains to count the number of ranked trees whose unranking gives . Now, to rank the internal nodes of , at each split we have to decide which of the remaining integer labels go to the left or to the right subtree below the corresponding node. This gives us choices, hence the first product term in . This product of binomial coefficients is called the shape functional [19], the Catalan coefficient [20] and is the solution to an enumerative combinatorial exercise [21, ch. 3, Ex. 1.b, p. 312].
As in the case (see the derivation of (3.3)), the simplification leading to the last equality comes from the fact that is the number of internal nodes of the subtree rooted at node i, so that most factorial terms cancel out in the product over .
4.2. Probability of ranked non-planar trees
In this case, we keep the ranking but give a symmetric role to the left and right child nodes of an internal node. These trees are termed evolutionary relationships by Tajima [22], who shows that there are ranked planar trees for a given ranked non-planar tree , where is the number of cherry nodes, i.e. sub-terminal nodes with two child nodes. For a quick justification of Tajima's result, suppose we want to turn the ranked non-planar tree into a planar tree. For each of the internal nodes of , there are two choices for the child node that is said to be ‘left’ except if they are both leaves (i.e. the internal node is a cherry node). Indeed, in this case they carry no ranking that would make them distinguishable.
Since the probability of a ranked non-planar tree does not depend on the planarity, provided , the probability of is simply the product of the probability of a corresponding ranked planar tree, times the number of ranked planar trees corresponding to . That is,
Note that when , we need to sum over all ranked planar trees that map to the ranked non-planar tree (since in this case ), and this may not be computationally feasible for large n.
4.3. Probability of trees
This is the case of (rooted binary) unranked non-planar trees or simply trees (also called phylogenetic tree shapes). There are unranked planar trees that correspond to a tree t, where is the number of internal nodes of t that have isomorphic left and right subtrees. See Sainudiin et al. [23] for a proof by induction. And all these unranked planar trees that correspond to t have the same probability provided . One can intuitively understand this by noting that there are two unranked planar embeddings for each internal node of t that does not have isomorphic subtrees on its left and right descendant nodes. Thus, the probability of a tree t if is
Once again if we need to sum over all unranked planar trees that map to the (unranked non-planar) tree t and this may not be computationally feasible for large n.
5. Continuous-time process
Up to now we have described the generating–organizing–deleting process in discrete time over ranked planar trees and given the probabilities over various equivalence classes of trees. However, one may want to formulate a continuous-time version of this process in order to have a more precise description of the evolutionary relationships including how much time elapsed between two speciation or extinction events.
To do so, recall that we fix two parameters characterizing the way in which leaf intervals are split, and the probability of a freezing during the next event (if , only splits occur). Let us also fix a rate of events. One way to formulate a continuous-time generating–organizing–deleting process is the following: suppose the current interval length of the jth active leaf is . Then each active leaf j splits at rate or becomes frozen at rate . When a split occurs, the internal node created during the event is labelled by the first integer N larger than all integer labels in the current tree, and the two leaves created are labelled by intervals that are obtained by splitting the (former) interval label of node N using (that is, if that interval is , the new leaves are labelled by and as before).
Lemma 5.1
The discrete tree embedded in the continuous-time planar ranked tree stopped after the nth event has the same law as the ranked planar tree obtained from the generating, organizing and deleting process stopped after the nth effective event. By effective event, we mean an event affecting an active leaf and therefore leading to a change in the tree.
Proof.
Let us write for the sum over all active leaves of their interval lengths , and for the union of the corresponding intervals. Hence, is the length of the set corresponding to all frozen leaves. Let us check for both random trees that, conditionally on the current state of the process:
(i) The next (effective) event is a split with probability or a freezing with probability δ.
(ii) If it is a split, then the probability that leaf j is chosen to split is .
(iii) If it is a freezing, then the probability that leaf j is chosen to freeze is also .
The result is an easy consequence of the construction of continuous-time jump processes for the tree embedded in the continuous-time procedure (in essence, if we have a countable collection of events such that event i happens at rate , then the first event to occur is the jth one with probability ).
For the tree constructed from the discrete process ‘restricted’ to the effective events, observe first that the coordinates of the organizing process are recorded in the ranked planar tree only through the choices of the next leaf to be affected. Also, the coordinates appear only through the types of the next events to occur. As a consequence, the law of the tree emanating from this construction depends only on the probabilities that each of these quantities belongs to a given set, conditionally on the fact that the leaf chosen is active. That is, the probability that the next effective event is a freezing is
since and are independent. Likewise, the probability of the next effective event being a split is , which proves (i). Next, conditionally on the next event being a split, the probability that leaf j is chosen is (again by the independence of and )
This proves (ii), and (iii) can be obtained in the same way. Points (i)–(iii) then enable us to conclude that the topologies and rankings of both trees have the same law.
There remains to show that, conditionally on the topology and ranking, the interval labels of the leaves are identical in distribution. Note that they are not a priori identical with probability one since the continuous-time construction uses the variables whereas the discrete-time construction uses the variables , where are the random indices of the effective events. But the event that depends only on the generating sequence , since it depends only on the current length of all active leaves. Consequently, and are independent random variables (recall that all components of are independent of each other). A simple argument then shows that the law of is the same as the law of , which in turn guarantees that the interval labels of the leaves are also equal in law. Lemma 5.1 is proved. ▪
Supplementary Material
Acknowledgments
R.S. thanks Mike Steel for posing the problem and R.S. and A.V. thank Hélène Morlon for generous introductions to models of diversification. They also thank the referees for their careful reading of the manuscript.
Data accessibility
The code developed for this work is given in the electronic supplementary material. It is also publicly shared at https://cloud.sagemath.com/projects/2c5f7f68-e689-4c70-a4b4-5b5d4dc4f93f/files/2015-10-27-082849.sagews.
Authors' contributions
R.S. and A.V. designed the model, studied its properties and drafted the manuscript. R.S. coded the algorithm. All authors gave final approval for publication.
Competing interests
We declare we have no competing interests.
Funding
R.S. was partly supported by a Sabbatical Grant from College of Engineering (University of Canterbury, New Zealand), External Consulting for Wynyard Group (Christchurch, New Zealand), and a Visiting Scholarship at Department of Mathematics (Cornell University, USA). R.S. and A.V. were supported in part by the chaire Modélisation Mathématique et Biodiversité of Veolia Environnement-École Polytechnique-Museum National d'Histoire Naturelle-Fondation X.
References
- 1.Mooers AO, Heard SB. 1997. Inferring evolutionary process from phylogenetic tree shape. Quart. Rev. Biol. 72, 31–54. (doi:10.1086/419657) [Google Scholar]
- 2.Morlon H. 2014. Phylogenetic approaches for studying diversification. Ecol. Lett. 17, 508–525. (doi:10.1111/ele.12251) [DOI] [PubMed] [Google Scholar]
- 3.Colijn C, Gardy J. 2014. Phylogenetic tree shapes resolve disease transmission patterns. Evol. Med. Public Health 1, 96–108. (doi:10.1093/emph/eou018) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Colless DH. 1982. Review of phylogenetics: the theory and practice of phylogenetic systematics. Syst. Zool. 31, 100–104. (doi:10.2307/2413420) [Google Scholar]
- 5.Sackin MJ. 1972. ‘Good’ and ‘bad’ phenograms. Syst. Zool. 21, 225–226. (doi:10.2307/2412292) [Google Scholar]
- 6.Jones GR. 2011. Tree models for macroevolution and phylogenetic analysis. Syst. Biol. 60, 735–746. (doi:10.1093/sysbio/syr086) [DOI] [PubMed] [Google Scholar]
- 7.Aldous D. 2001. Stochastic models and descriptive statistics for phylogenetic trees, from Yule to today. Stat. Sci. 16, 23–34. (doi:10.1214/ss/998929474) [Google Scholar]
- 8.Blum MGB, François O. 2006. Which random processes describe the tree of life? A large-scale study of phylogenetic tree imbalance. Syst. Biol. 55, 685–691. (doi:10.1080/10635150600889625) [DOI] [PubMed] [Google Scholar]
- 9.Yule GU. 1924. A mathematical theory of evolution, based on the conclusions of Dr. J.C. Willis. Phil. Trans. R. Soc. Lond. B 213, 21–87. (doi:10.1098/rstb.1925.0002) [Google Scholar]
- 10.Aldous D. 1996. Probability distributions on cladograms. In Random discrete structures, pp. 1–18. Berlin, Germany: Springer.
- 11.Phillimore AB, Price TD. 2008. Density-dependent cladogenesis in birds. PLoS Biol. 6, e71 (doi:10.1371/journal.pbio.0060071) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Ford DJ. 2005. Probabilities on cladograms: introduction to the alpha model. (http://arxiv.org/abs/math/0511246)
- 13.Kirkpatrick M, Slatkin M. 1993. Searching for evolutionary patterns in the shape of a phylogenetic tree. Evolution 47, 1171–1181. (doi:10.2307/2409983) [DOI] [PubMed] [Google Scholar]
- 14.Hagen O, Hartmann K, Steel M, Stadler T. 2015. Age-dependent speciation can explain the shape of empirical phylogenies. Syst. Biol. 64, 432–440. (doi:10.1093/sysbio/syv001) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Sainudiin R, Welch D. 2015. The transmission process. UCDMS Research Report 2015/4, School of Mathematics and Statistics, University of Canterbury, Christchurch, New Zealand.
- 16.Stewart EJ, Madden R, Paul G, Taddei F. 2005. Aging and death in an organism that reproduces by morphologically symmetric division. PLoS Biol. 3, e45 (doi:10.1371/journal.pbio.0030045) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Ford D, Matsen FA, Stadler T. 2009. A method for investigating relative timing information on phylogenetic trees. Syst. Biol. 58, 167–183. (doi:10.1093/sysbio/syp018) [DOI] [PubMed] [Google Scholar]
- 18.Flajolet P, Sedgewick R.. 2009. Analytic combinatorics. New York, NY: Cambridge University Press. [Google Scholar]
- 19.Dobrow RP, Fill JA. 1995. On the Markov chain for the move-to-root rule for binary search trees. Ann. Appl. Probab. 5, 1–19. (doi:10.1214/aoap/1177004824) [Google Scholar]
- 20.Sainudiin R. 2012. Sequence A185155, The on-line encyclopedia of integer sequences, published electronically, February 2012.
- 21.Stanley RP. 1997. Enumerative combinatorics, vol. 1. Cambridge Studies in Advanced Mathematics, no. 19 Cambridge, UK: Cambridge University Press. [Google Scholar]
- 22.Tajima F. 1983. Evolutionary relationship of DNA sequences in finite populations. Genetics 105, 437–460. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Sainudiin R, Fischer M, Cleary S, Griffiths RC. 2015. Some distributions on finite rooted binary trees. UCDMS Research Report 2015/2, School of Mathematics and Statistics, University of Canterbury, Christchurch, New Zealand.
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
The code developed for this work is given in the electronic supplementary material. It is also publicly shared at https://cloud.sagemath.com/projects/2c5f7f68-e689-4c70-a4b4-5b5d4dc4f93f/files/2015-10-27-082849.sagews.