

Abstract
A word learning paradigm was used to teach children novel words that varied in phonotactic probability and neighborhood density. The effects of frequency and density on speech production were examined when phonetic forms were non-referential (i.e., when no referent was attached) and when phonetic forms were referential (i.e., when a referent was attached through fast mapping). Two methods of analysis were included: (1) kinematic variability of speech movement patterning; and (2) measures of segmental accuracy. Results showed that phonotactic frequency influenced the stability of movement patterning whereas neighborhood density influenced phoneme accuracy. Motor learning was observed in both non-referential and referential novel words. Forms with low phonotactic probability and low neighborhood density showed a word learning effect when a referent was assigned during fast mapping. These results elaborate on and specify the nature of interactivity observed across lexical, phonological, and articulatory domains.
Keywords: Neighborhood density, phonotactic probability, children, motor learning, word learning
Introduction
Classic models of language production posit different levels of representation that include conceptualization of an idea; grammatical, lexical, and phonological formulation; and articulatory implementation (Levelt & Wheeldon, 1994). In this perspective, semantic components of word production are processed at a high order conceptual level. Form is added downstream, first at the lexical level when a word form is selected to match the concept and then at the phonological level where specific sound information is encoded. Finally, articulatory implementation is specified for speech motor output.
There are differing views about interactivity amongst researchers who have investigated the relationship among these distinct levels. For example, Levelt, Roelofs, and Meyer (1999) theorize that semantic, lexical, phonological, and articulatory processing levels are separate and independent stations. Others have posited (Pierrehumbert, 2001; Pisoni, 1997; Johnson, 2006) that lexical, phonological, and phonetic information is bundled as a unit rather than being accessed in a sequential manner. From this perspective information related to form is stored directly with the content. This bottom up approach permits variation in production that would not be observed in a top-down model (Pierrehumbert, 2001).
Models of language production have largely focused on explanations underlying adult behavior, however an inclusive model should also account for developmental processes. When a child learns to produce a new word, she must integrate the form into the existing mental lexicon, map meaning to the form, and then map the form to a sequence of articulatory movements. Both word learning and production of words and non-words have been shown to be sensitive to form related variables, including phonotactic probability and neighborhood density (Mckean, Letts, & Howard, 2013; Metsala & Chisholm, 2010; Storkel & Lee, 2011). An exploration into the way that these factors impact production processes of both referential and non-referential novel words in a single investigation could provide insight into an integrative model of language production that incorporates lexical organization and production mechanisms. We do not know how components of form that are hypothesized to align with the lexicon (i.e., neighborhood density) and with phonetic factors (i.e., phonotactic frequency) interface with articulatory implementation. It is this interface that is the focus of the current investigation.
Phonotactic probability is the likelihood that a sequence of phonemes will occur in a given language (Vitevitch & Luce, 1999). Phoneme sequences that are highly likely to co-occur in the language are referred to as having high phonotactic probability (in English an example is bump as it is a word that has a sequence of sounds “mp” that is highly likely to occur), whereas phoneme sequences with a low likelihood of co-occurrence are said to have low phonotactic probability (e.g., the “mt” in dreamt). Phonotactic probability has been shown to facilitate word recognition (Vitevich & Luce, 1998, 1999), speed and accuracy of production (Munson, Swenson, & Manthei, 2004; Vitevich & Luce, 1998, 1999), as well as word and phoneme learning in both words and non-words (Morisette & Geirut, 2002). Forms with high phonotactic probability are produced more accurately (Edwards, Beckman, & Munson, 2004), recognized more quickly (Luce & Pisoni, 1998), and learned more easily than forms with low phonotactic probability (Storkel, 2001, 2003; Storkel & Rogers, 2000). Infants are also sensitive to the phonotactic patterns in their native language and utilize this information during early word learning (Graf Estes, Edwards, & Saffran, 2011).
Neighborhood density refers to the number of words that are phonemically similar to a given word. One prominent approach to assessing neighborhood density is to determine the number of words that differ by the addition, substitution or deletion of a single phoneme (Vitevitch & Luce, 1999). For example, the word cat has neighbors mat, rat, cap, cot, etc. A word that is found to have many neighbors is said to reside in a dense neighborhood. A word with few neighbors is said to reside in a sparse neighborhood. Neighborhood density specifically relates phonological form to the lexicon. It is a factor that has been found to influence recognition and production of word forms that are established in the mental lexicon. Words from sparse neighborhoods are recognized more accurately and more quickly than words from dense neighborhoods (Garlock, Walley, & Metsala, 2001; Metsala & Chisholm, 2010; Munson, Edwards, & Beckman, 2005; Newman & German, 2005; Storkel & Lee, 2011; Vitevich, 2002, 2003).
Recent investigations have examined the differential effects of neighborhood density and phonotactic probability in word learning. Storkel and Lee (2011) constructed novel words that varied orthogonally in phonotactic probability and neighborhood density. Children learned words that varied in neighborhood density and phonotactic probability in a computer game format. The differential effects of phonotactic probability and neighborhood density were examined both immediately after exposure and again over time. Results showed that when neighborhood density is held constant, there is a facilitative effect of low phonotactic probability in word learning, both immediately and one week later. Neighborhood density was more dynamic in that words from sparse neighborhoods showed an initial advantage in learning while words from dense neighborhoods had an advantage in being retained for long term learning. There is a facilitative effect when the newly acquired entry has more phonological neighbors with which to embed. Storkel and Lee (2011) show that lexical and phonological factors are treated differentially in the word learning process. Overall, for children, low phonotactic probability and low neighborhood density forms show an advantage in early mapping of a new word (Hoover, Storkel, & Hogan, 2010; Storkel & Lee, 2011). It is notable that these studies did not compare production of forms with and without referents and therefore we are unable to draw conclusions about differential effects on forms with and without meaning attached in the mental lexicon.
Approaches to assessing learning of a new word form have focused only minimally on the mapping to articulatory implementation. While articulation has traditionally been viewed as a downstream component of speech production (e.g., Levelt, Roelofs, & Meyer, 1999), current models suggest interactivity between lexical and articulatory processing levels (Baese-Berk & Goldrick, 2009; Frisch & Wright, 2002; Goldrick & Blumestein, 2006; Heisler, Goffman, & Younger, 2010; Hickok, 2012; McMillan, Corley, & Lickley, 2009). The empirical support for such interactivity primarily comes from experiments that integrate linguistic manipulations and speech motor or acoustic analyses. For example, Baese-Berk and Goldrick (2009) found that voice onset time was longer for words that had a minimal pair neighbor in the mental lexicon than for words that did not. McMillan and colleagues (2009) investigated slips of the tongue in a paradigm that resulted in lexical or non-lexical errors. Kinematic findings showed increased variability when the resulting slip of the tongue error was a non-lexical production. These results indicate that lexical factors influence articulatory components of production.
Similar to the MacMillan results, but now as applied to children, the inclusion of a lexical cue also may influence production down to the level of articulatory variability and patterning. Heisler, Goffman, and Younger (2010) examined preschool children's productions in a word learning task and found that a phonetic string with a referent is produced with less kinematic variability than a phonetic string without a referent. In this study, twenty-six children (both typically developing and those meeting exclusionary criteria for specific language impairment) imitated nonsense bisyllabic strings of sounds that would be permissible words in English. These strings of sounds did not have a semantic referent. A learning phase was then implemented in which half of the bisyllabic strings (that were introduced in the pre-test) were taught as words with referents and half were left as controls with no referent attached. The learning phase was receptive or passive in that the children did not say any words, they simply had to listen to the words and watch a computer monitor where the referents were introduced. Finally, the children produced all of the tokens again (both the strings of sounds without referents and the strings of sounds that would now be considered words with referents) in a repetition task. Productions from the initial baseline and productions following the learning phase were analyzed for movement stability and segmental accuracy. Results indicated that children's productions became more stable and more accurate when the word had been learned with a referent. Overall, words that are similar on articulatory grounds are implemented differently as a function of referential status, thus showing that lexical representation influences movement output. However, form variables that impact word learning such as neighborhood density and phonotactic probability were not specifically controlled. Lexical factors interact both with phonological and articulatory implementation factors. However, it is unknown how phonological variables, such as phonotactic probability and neighborhood density, are integrated into the lexical-articulatory interface.
In the current study, we used a novel word learning paradigm (as in Heisler et al., 2010) to examine kinematic variability and phonemic accuracy in novel word forms both with and without referents. In contrast to prior work, phonological forms were explicitly varied in phonotactic probability and neighborhood density to examine the differential effects that phonotactic probability and neighborhood density have on the production of both referential and non-referential novel words. The overarching objective of this work is to evaluate interactions among lexical-semantic, phonological, and articulatory levels of processing as children acquire novel word forms with or without referents.
The goal of the present study is to examine the potentially independent effects of phonotactic probability and neighborhood density on the production of phonetic forms with a semantic referent and phonetic forms without a semantic referent. We include transcription as well as kinematic approaches to evaluate the production of these variables at the implicit level of articulatory implementation as well as incorporating more standard measures of phonetic accuracy and comprehension. As in Heisler et al. (2010), we utilize a word learning paradigm so that we can make direct comparisons between targets with and without semantic representation. This will allow us to see if production variability and accuracy are mediated by phonological and lexical form variables in a learning task.
Consistent with Heisler and colleagues (2010) we expect that children will show sensitivity to lexical status, with novel word forms that are assigned a visual referent produced with greater phonetic accuracy and reduced articulatory variability in comparison with novel words with no visual referent. In the present study, we also incorporate phonological levels into our model, asking whether phonotactic probability and neighborhood density influence phonetic accuracy and articulatory stability. Based on Storkel and Lee (2011), we predict that words in low density neighborhoods will show greater learning effects (i.e., increases in phonetic accuracy) than words in high density neighborhoods. In addition, both referential and non-referential novel words with high phonotactic probability will be produced more accurately. What is less clear, and forms the basis of the current study, is whether phonotactic frequency and neighborhood density will influence speech motor components of production. Incorporating these lexical and phonological factors into the model will specify interactivity at the lexical-phonological-motor interface.
Method
Participants
Twenty typically developing preschool children, all residing in North-Central Indiana, were recruited using flyers and newspaper advertisements. Recruitment was completed in the manner approved by the Institutional Review Board of Purdue University. Of these children, sixteen (eight female) were ultimately included in the study. To be included, children must be able to complete the task and demonstrate learning of the target words in a comprehension probe (to be described in detail below). Of the 20 children originally recruited, four did not complete the study. One child did not learn the target words. Two children did not meet the inclusion requirements when standardized language tests were administered. One child was not able to complete the task.
The mean age of children participating was 4;5 (years; months) (SD = 0;3). Inclusion requirements were that all children perform within expected levels (i.e., scores within 1 SD of the mean). Receptive and expressive vocabulary were assessed via the Peabody Picture Vocabulary Test (PPVT; Dunn & Dunn, 1997; M = 111, SD = 10) and the Expressive Vocabulary Test (EVT; Williams, 1997; M = 111, SD = 10). Expressive language was tested using the Structured Photographic Expressive Language Test-Preschool (SPELT-P; Ohara, Werner, Dawson, & Kresheck, 1983; M (percentile rank) = 50, SD = 30). Speech production was assessed using the Bankson Bernthal Test of Phonology (Bankson & Bernthal, 1990; M = 105, SD = 9). Non-verbal cognitive skills were tested using the Columbia Mental Maturity Scales (Burgemeister, Hollander, Blum, & Lorge, 1972; M = 120, SD = 12). Additionally, all children passed hearing screenings at 20 dB at .5, 1, 2, and 4 kHz, and showed normal structure and function of the oral mechanism (Robbins & Klee, 1987). Parent reports revealed no history of developmental or neurological impairment.
Stimuli
To analyze articulatory lip movements it is obligatory that stimuli contain labial consonants in word initial and word final position. This methodological restriction prohibits us from utilizing stimulus items analogous to other studies that examine word learning in children (Storkel & Lee, 2011). Labial consonants are required in kinematic analyses so that we can visually represent the opening and the closing of the lip movements. A limitation of these articulatory measures that can be applied to young children is that analysis of tongue movement cannot be directly included. Munson (2001) effectively used word medial diphone sequences in a study examining production of words that varied in phonotactic probability. The diphone sequences used in Munson (2001) are amenable to our kinematic analyses and also have been shown to be sensitive to frequency effects on production (Munson, 2001). We therefore adopted high and low frequency diphone sequences in the construction of stimuli in the current study. The diphone sequences permit the required labial phonemes in initial, medial, and final positions, but allow us to modify the phonotactic probability and neighborhood density to make relevant comparisons.
Eight trochaic bisyllabic nonce words were used: /pæptom/, /bompʌm/, /bɑftεb/, /fospɪb/, /pʌmtæm/, /bʌfkɪp/, /fɑmkɪb/, /mofpεb/. Stimuli were divided into two groups, each presented separately in two experimental sessions. All stimuli from Group One (/pæptom/, /bompʌm/, /bɑftεb/, /fospɪb/) had high frequency consonant diphone sequences word medially (Munson, 2001). However, two of the Group One forms have syllables which reside in a dense phonological neighborhood (/pæptom/, /bompʌm/) and two of the forms have syllables which reside in a sparse phonological neighborhood (/bɑftεb/, /fospɪb/). All stimuli from Group Two (/pʌmtæm/, /bʌfkɪp/, /fɑmkɪb/, /mofpεb/) had low frequency diphone sequences word medially; however, two of the forms have syllables which reside in a dense phonological neighborhood (/pʌmtæm/, /bʌfkɪp/) and two of the forms have syllables which reside in a sparse phonological neighborhood (/fɑmkɪb/, /mofpεb/). Diphone sequences were originally used and classified as high or low frequency by Munson (2001). Medial diphone sequences were chosen to avoid any advantage of acquiring initial or final clusters. Due to constraints in controlling for phonotactic frequency and neighborhood density in clusters that contained labial consonants, not all sequences were homorganic. However, this characteristic was balanced across Groups One and Two, with one of the four clusters in each group homorganic and three of the clusters heterorganic.
Incorporating these diphone sequences from Munson (2001), each individual stimulus item was created for use in this study. Phonotactic probability was calculated using four databases: Celex (Burnage, 1990), Hoosier Mental Lexicon (Pisoni, Nusbaum, Luce, & Slowiacek, 1985), Moe, Hopkins, and Rush, (1982), and Storkel and Hoover (2010). Calculations of neighborhood density were obtained from the Washington University Neighborhood Density online database (Sommers, 2002) and the child online calculator established by Storkel and Hoover (2010). Table 1 provides the phonotactic frequency of medial diphone sequences and neighborhood density of syllables for each stimulus item. All databases provided consistent information. Stimuli were produced by the same female talker. They were recorded using PRAAT (Boersma, 2001) and presented in a standard English trochaic stress pattern. Each stimulus item was presented at a normal rate of speech, the duration of each item averaged 1.1 seconds.
Table 1.
Frequency of occurrence of medial diphone sequences and neighborhood density of syllables. Moe et al., HML, and Celex are presented in absolute values. Storkel & Hoover (2010) data are presented as biphone frequency of medial diphone sequences.
| Statistical properties of stimuli: | ||||||
|---|---|---|---|---|---|---|
| Frequency of medial diphone frequencies and neighborhood density(transitional probabilities) by database | ||||||
| Moe | HML | CELEX | S&H | Syllable 1 | Syllable 2 | |
| Word | ||||||
| Group 1 | ||||||
| HPPHND /pæptom/ | 8 | 61 | 33 | .002 | 28 | 22 |
| HPPHND /bompʌm | 41 | 204 | 150 | .009 | 23 | 23 |
| HPPLND /bɑftεb/ | 11 | 20 | 18 | .003 | 2 | 10 |
| HPPLND /fospɪb/ | 10 | 105 | 93 | .003 | 11 | 12 |
| Group 2 | ||||||
| LPPHND /pʌmtæm/ | 1 | 4 | 9 | 0 | 23 | 24 |
| LPPHND /bʌfkɪp/ | 0 | 0 | 0 | 0 | 20 | 21 |
| LPPLND /fɑmkɪb/ | 0 | 4 | 4 | 0 | 5 | 8 |
| LPPLND/fɑmkɪb/ | 0 | 0 | 0 | 0 | 12 | 12 |
Signals Recorded
An Optotrak camera system was used to obtain kinematic recordings. This is a commercially available system designed to record human movement in 3-dimensions with a tracking error of less than 0.1 mm. Three infrared light emitting diodes (IREDs) were placed on the participant's face. One was placed on the upper lip, one on the lower lip, and one on the forehead. Lower lip movement was tracked for analysis. A forehead marker was used for the subtraction of head movement. The kinematic signal was collected at a sampling rate of 250 cycles/second and a time locked acoustic signal at a sampling rate of 16,000 cycles/second. A high quality audio signal was also obtained for transcribing phonetic accuracy.
Stimuli associated with the word learning task were delivered using Microsoft Power Point from a notebook computer. The notebook was connected to a thirty inch monitor and a set of speakers that were placed six-feet in front of the participant.
Session Procedure
Participants attended two experimental sessions with one stimulus set presented in each session. Procedures were identical across both sessions. To test the influence of word learning on speech production, a paradigm was developed which incorporates three phases: a pre-test, a learning phase, and a post-test (Gladfelter & Goffman, 2013; Heisler, Goffman, & Younger, 2010). Comprehension probes (described below) were completed after the post-test phase to ensure that the participants learned the words. Sessions were counterbalanced so half of the participants received stimuli from set one (i.e., high phonotactic frequency) on the first visit, and half of the participants received stimuli from set two (i.e., low phonotactic frequency) on the first visit. There were four counterbalancing conditions for each of the two stimulus sets as shown in Table 2.
Table 2.
Four counterbalancing conditions.
| Counterbalancing conditions | ||||
|---|---|---|---|---|
| Condition | Neighborhood Density | Referential Status | Group 1 High prob. | Group 2 Low prob. |
| 1 | high | word | /pæptom/ | /pʌmtæm/ |
| non-word | /bompʌm/ | /bʌfkɪp/ | ||
| low | word | /bɑftεb/ | /fɑmkɪb/ | |
| non-word | /fospɪb/ | /mofpεb/ | ||
|
| ||||
| 2 | high | non-word | /pæptom/ | /pʌmtæm/ |
| word | /bompʌm/ | /bʌfkɪp/ | ||
| low | non-word | /bɑftεb/ | /fɑmkɪb/ | |
| word | /fospɪb/ | /mofpεb/ | ||
|
| ||||
| 3 | high | word | /pæptom/ | /pʌmtæm/ |
| non-word | /bompʌm/ | /bʌfkɪp/ | ||
| low | non-word | /bɑftεb/ | /fɑmkɪb/ | |
| word | /fospɪb/ | /mofpεb/ | ||
|
| ||||
| 4 | high | non-word | /pæptom/ | /pʌmtæm/ |
| word | /bompʌm/ | /bʌfkɪp/ | ||
| low | word | /bɑftεb/ | /fɑmkɪb/ | |
| non-word | /fospɪb/ | /mofpεb/ | ||
Phase 1: Pre-test
The primary purpose of the pre-test phase was to elicit productions of the four stimulus items prior to any semantic representation being attached. During this phase participants were instructed to look at the large monitor and repeat what they heard. A checkerboard was displayed as the auditory stimulus item was delivered. Each stimulus item was presented fifteen times in quasi-random order (total of 60 items; no more than two consecutive productions of any particular item). Items were presented at the participant's pace with the experimenter controlling stimulus presentation.
Phase 2: Learning phase
During the learning phase, children were instructed to watch the computer monitor and to listen. They were told that this was a listening time when they should not say anything. During this time, stimulus items that were repeated by the children in the pre-test were either paired with a visual referent or presented without a visual referent. Of the four stimulus items, two were assigned referents and two were not. The two without visual referents were presented as they were in phase one, as an auditory stimulus with a checkerboard pattern on the monitor. The two with visual referents were presented in 3-second videos to teach the participants the referents of these items. Referents were unfamiliar objects such as an irregularly shaped piece of plumber's pipe. These novel words were used in a prior study of word learning and were selected because they were not easily named and were unfamiliar to children. Object referents were counterbalanced across participants to avoid any saliency effect the visual stimuli could have on learning or production. Participants heard the name of the object while seeing the referent. During the learning phase, each control and experimental item was presented five times in random order. At this time, participants listened and watched the visual display, but no productions were obtained.
Phase 3: Post-test
Similar to the pre-test phase, all items were presented fifteen times each in quasi-random order for the participant to produce in direct imitation. The pre-test and the post-test differ in that the items taught with referents during the learning phase were presented with a picture of the corresponding referent on the screen, whereas non-referential items continued to be presented with a checkerboard pattern. The post-test allowed for continued learning as the test items were presented with the object referent.
Comprehension Probes
As a final task, a comprehension probe was used to test whether or not the participants sufficiently learned the stimulus items that were taught as referential words. The comprehension probe was conducted with real objects; the two objects used during the learning phase and two foils. Participants were asked to “find the ______”. Participants had a twenty-five percent chance of choosing the correct referent item by chance. All errors were treated equally. All participants included in the analyses were able to identify the referents, as indicated by pointing to the correct object. Foils were similar novel objects that were introduced as other words during the study. In addition similar novel objects that were not previously exposed or named were interspersed.
Analyses
To control for the amount of production practice that each child experienced, the first ten consecutive productions of each stimulus item were analyzed from the pre-test and 10 from the post-test. Items were discarded if they were disfluent or contained missing movement data points. In such cases, the next consecutive item was selected. The need to discard items was minimal and only occurred if a child produced a disfluency or excessive head movement.
Kinematic Signals
Kinematic waveforms were analyzed in Matlab (Mathworks, 1993). A Butterworth filter was used to filter displacement data with a cutoff frequency of 10 Hz (both forward and backward). Superior-inferior movements of the lower lip were included in the kinematic analyses. The Euclidean distance between the forehead and lower lip marker was used to determine lip displacement without the confounding influence of head movement. The 3-point difference method was used to calculate velocity from displacement (Smith et al., 1995). Kinematic waveforms are extracted from the stream of speech and used to assess articulatory patterning variability. This measure allows for the assessment of movement patterning as opposed to phonemic production (which will be analyzed through phonetic transcription).
Extraction of movement sequences
Individual words were extracted from the stream of continuous speech movement. The opening movement of the word initial consonant and the closing movement of the word final consonant were selected by a visual inspection of the kinematic record. An algorithm then determined the maximum displacement value, corresponding with a zero crossing in velocity that occurred within a 25 ms window of the experimenter-selected point. A time locked acoustic signal was then played to confirm that the selection indeed corresponded with the target word form. Figure 1 is an example of how a stimulus item is trimmed from the continuous speech stream.
Figure 1.

This is an example of one production that was extracted from the continuous stream of speech for kinematic analysis. Time is indicated along the x-axis and amplitude of lip movement is indicated along the y-axis.
Movement variability
The spatiotemporal index (STI; Smith et al, 1995) was used as a measure of movement patterning variability. The STI was designed to assess patterning variability when absolute differences in rate and loudness are eliminated. Initially, ten productions of each experimental referential and non-referential novel word were time and amplitude normalized. Amplitude normalization was accomplished by subtracting the mean and dividing by the standard deviation of each displacement record. For time normalization, a spline function (Mathworks, 1993) was used to interpolate each displacement record onto a time base of 1000 points (for a detailed description of this analysis, see Smith, Johnson, McGillem, & Goffman, 2000). Standard deviations were then computed at two-percent intervals across the ten productions. This sum of standard deviations is the STI. The STI was calculated for all pre-test items and all post-test items, as illustrated in Figure 2. This method has been used in other word learning experiments (Gladfelter & Goffman, 2013; Heisler et al., 2010) and has been shown to be a sensitive index of change that may occur from pre-test to post-test during word learning (Heisler et al., 2010).
Figure 2.
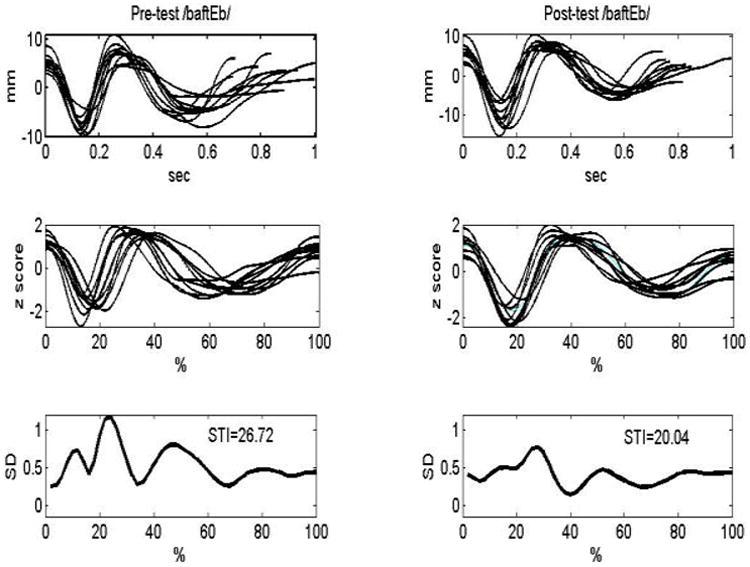
These plots compare the STI analysis for one condition for one child in the pre-test (on the left) and in the post-test (on the right). The top left quadrant shows 10 trimmed tokens of the same form produced in the pre-test from one child. The plot below that on the left shows those trimmed productions, but now they are time and amplitude normalized. The bottom left quadrant shows the STI calculation. The plots on the right show the same child's productions in the post-test.
Transcription Analysis
Digital audio recordings were phonetically transcribed by trained graduate research assistants who were not blind to the purpose of the study. All tokens produced by each child were transcribed. The productions analyzed for movement variability were the same productions utilized for the transcription analysis. A transcription analysis was adapted from Edwards and colleagues (2004) to determine accuracy scores. This type of analysis allows for assessment of graded rather than absolute error rate. For example, in an analysis of absolute error rate, omission of a segment and a voicing error are given equivalent status. Clearly, a voicing error is not equivalent to an omission. An error coding system that allows for graded analysis allows differences in error severity to emerge for comparison.
Following the analysis developed by Edwards and colleagues (2004) each consonant in the entire word was coded for accuracy on three features; place, manner, and voicing. Each feature was equally weighted, for example, accuracy for place, manner, and voicing each receive a point for a total of 3 points for each phoneme. Each vowel was also coded for accuracy on a three point scale; dimension (front, middle, back), height (high, mid, low), and length (tense, lax). One point was awarded for each correct feature; therefore each phoneme could receive a maximum of three points and each word a maximum of eighteen points. This segmental analysis was completed for all items in the pre-test and the post-test. This analysis allowed for the assessment of gradations in error. It is possible that a child produces a manner and voicing error on a phoneme in the pre-test and only a voicing error on a phoneme in the post-test. A gross measure like Percent Consonant Correct (PCC) would view both of these as equal, but the adaptation of the Edwards et al. (2004) procedure allows documentation of incremental changes toward the adult target.
Phonetic transcription reliability
A second trained coder phonetically transcribed the pre- and post-test productions from 5 randomly selected children. The overall transcription reliability was 95%, with a range from 91% to 98%.
Statistical Analysis
There were two major analyses, one for the kinematic data and one for the transcription data. For the kinematic analysis, STI values were compared across conditions in both the pre-test and the post-test. Similarly, for the transcription analysis, error rates were evaluated as a function of condition. For both of these analyses learning was evaluated over the pre- to post-test. Difference scores were the primary index of change as a function of practice and exposure to a visual referent. As in Heisler et al. (2010), difference scores were obtained by subtracting post-test measurements from pre-test measurements (D=y-x). In the kinematic analysis, post-test STI values were subtracted from pre-test values. Similarly, in the transcription analysis, a difference score was obtained between accuracy of pre- vs. post-test productions. These difference scores were evaluated in a 2 (high vs. low neighborhood density) × 2 (high vs. low phonotactic frequency) × 2 (referential vs. non-referential) repeated measures ANOVA. Follow-up two-tailed single sample t-tests were used to determine if mean difference scores differed significantly from zero.
A second set of analyses report on actual segmental accuracy and articulatory variability measures. These include a 2 (high vs. low neighborhood density) × 2 (high vs. low phonotactic frequency) × 2 (referential vs. non-referential) × 2 (pre- vs. post-test) repeated measures ANOVA. Analyzing absolute values is important as it may reveal differences in initial states. For example, one production might be inherently easier or be less variable than another production at pre-test. This information is not captured if we simply look at difference scores or change over time.
For all ANOVAs and t-tests, a .05 level was considered significant. Post hoc comparisons were accomplished using the Tukey HSD procedure, again with a .05 level of significance.
Results
Prior to reviewing results, it is helpful to reconsider our predictions.
1) Previous work has revealed that referential status interacts with articulation, with referential novel words showing lower movement variability than non-referential novel words (Heisler et al., 2010). What is less clear is how other components of lexical and phonological processing also interact with articulation. Delineating the potential interaction between neighborhood density and phonotactic probability and articulation formed the basis of the first set of analyses related to kinematic variability. These analyses specify the nature of interactivity observed across lexical, phonological, and articulatory domains.
(2) Predictions related to phonetic accuracy were more straightforward. Based on previous findings (Edwards et al., 2004; Storkel & Lee 2011), it was expected that both referential and non-referential novel words with high phonotactic probability would be produced with relatively high accuracy. Similarly, it was hypothesized that low neighborhood density would show an overall advantage in learning, with accuracy increasing more over the course of a short term learning experience.
Kinematic Analysis
Kinematic analysis allows us to examine changes in articulatory implementation as a function of phonological, lexical, and semantic factors. Once all target speech movements were extracted from the stream of speech, the STI was calculated for each participant for each nonce string of sounds in both the pre-test and the post-test conditions. The STIs were averaged for all participants by condition in the pre-test and the post-test. These data are presented in Table 3.
Table 3.
Average STIs and accuracy by condition
| Average STI | Average Accuracy | |||
|---|---|---|---|---|
| Pre-test | Post-test | Pre-test | Post-test | |
| Condition | ||||
| High neighborhood density | ||||
| High phonotactic probability | ||||
| Word | 27.7987 | 25.0943 | 96.15 | 94.51 |
| SD | 4.84 | 5.09 | 3.16 | 4.09 |
| Non-word | 28.1848 | 26.1074 | 95.56 | 95.31 |
| SD | 5.76 | 3.47 | 3.49 | 4.11 |
|
| ||||
| High neighborhood density | ||||
| Low phonotactic probability | ||||
| Word | 28.4482 | 28.2728 | 97.36 | 96.74 |
| SD | 5.03 | 5.58 | 4.58 | 4.97 |
| Non-word | 27.7619 | 25.6951 | 96.39 | 96.70 |
| SD | 6.58 | 5.98 | 4.21 | 3.98 |
|
| ||||
| Low neighborhood density | ||||
| High phonotactic probability | ||||
| Word | 29.7122 | 26.7856 | 96.28 | 97.47 |
| SD | 6.91 | 7.16 | 5.53 | 5.02 |
| Non-word | 27.4292 | 24.9584 | 96.94 | 98.19 |
| SD | 6.46 | 4.70 | 3.80 | 3.07 |
|
| ||||
| Low neighborhood density | ||||
| Low phonotactic probability | ||||
| Word | 26.9782 | 23.1193 | 96.07 | 96.35 |
| SD | 6.96 | 5.90 | 3.95 | 4.29 |
| Non-word | 25.3104 | 25.8878 | 97.40 | 97.39 |
| SD | 5.12 | 6.50 | 3.58 | 4.19 |
The first set of analyses was designed to directly evaluate learning effects, both when a token was assigned lexical status and when it was not. In this case, difference scores were calculated for each participant in each condition; D=y-x; D= (post-test)-(pre-test). A negative difference score indicated that kinematic variability had decreased over time, or the child had improved. Figure 3 shows the average difference scores in each condition. A 2 (neighborhood density) × 2 (phonotactic probability) × 2 (referential status) ANOVA was used to determine if mean difference scores varied across conditions for the children. Results revealed no main effect for neighborhood density, F (1, 15) =.029, p=.86. A significant main effect was found for phonotactic probability, F (1, 15) =6.824, p=.019, with high probability tokens showing more change over time. Finally, referential status also showed a significant effect, F (1, 15) =6.032, p=.026, with forms assigned a referent decreasing more in variability in the post-test. There were no significant interactions. These results show that phonotactic probability influenced motor learning from pre-test to post-test. However, there was no effect of neighborhood density on motor learning. These results also indicate that referential status mediated the amount of motor learning (i.e., referential novel words showed a greater effect than non-referential novel words).
Figure 3.

Difference scores from kinematic analysis. Error bars represent standard error.
A difference score that is significantly different from zero indicates that there was a change in performance from pre-test to post-test. If our hypothesis is correct, items that have acquired lexical status should be significantly different from zero. Items in the control condition that do not acquire lexical status should not be significantly different from zero. While the majority of cases were below 0 (see again Figure 3), and thus suggested a degree of learning, the only significant t-test was found in the low neighborhood density, low phonotactic probability, word condition, t (15) =3.032, p=.008. Table 4 provides all of the t-tests that were calculated. Only the low neighborhood density, low phonotactic probability condition evidenced a significant difference in movement variability as a result of word status, indicating a facilitative effect in production as a result of word status.
Table 4.
Results of t-tests for difference scores in the kinematic analysis and transcription analysis.
| T-tests for the difference scores in the kinematic and transcription analyses | ||
|---|---|---|
| Kinematic Analysis | Transcription Analysis | |
| Condition | ||
| High neighborhood density | ||
| High phonotactic probability | ||
| Word | t(15)=1.915, p=.07* | t(15)=2.765, p=.01** |
| Non-word | t(15)=1.319, p=.21 | t(15)=422, p=.68 |
|
| ||
| High neighborhood density | ||
| Low phonotactic probability | ||
| Word | t(15)=.150, p=.88 | t(15)=975, p=.35 |
| Non-word | t(15)=1.097, p=.29 | t(15)=919, p=.37 |
|
| ||
| Low neighborhood density | ||
| High phonotactic probability | ||
| Word | t(15)=2.104, p=.05* | t(15)=-.745, p=.47 |
| Non-word | t(15)=1.271, p=.22 | t(15)=-.877, p=.39 |
|
| ||
| Low neighborhood density | ||
| Low phonotactic probability | ||
| Word | t(15)=3.3032, p=.008** | t(15)=-.522, p=.61 |
| Non-word | t(15)=.391, p=.7 | t(15)=000, p=1.0 |
The primary focus of investigation was within individual change from pre- to post-test. Also of interest was the inherent influence of neighborhood density and phonotactic probability on production. Therefore, a second analysis examined the absolute STI values to determine if neighborhood density, phonotactic probability, referential status, or pre- compared with post-test influenced the stability of motor patterning. These factors were statistically examined in a 2 (neighborhood density) × 2 (phonotactic probability) × 2 (referential status) × 2 (pre-test vs. post-test) ANOVA. Results revealed no significant main effect of neighborhood density, F (1, 15) =2.49, p=.135; phonotactic probability, F (1, 15) =.274, p=.608; or referential status, F (1, 15) =1.106, p=.309. There was, however, a significant main effect of pre- vs. post-test, F(1,15)=17.618, p=.0008. No interactions were significant. Post-test values were significantly lower than pre-test values, indicating a reduction in variability over time regardless of phonological or referential status. This indicates overall effects of motor practice on word learning regardless of referential status; specifically, tokens were produced with less variability with practice.
Transcription
Segmental accuracy
Analysis of the segmental errors made by each individual in the pre-test and the post-test were averaged across conditions and these data are presented in Table 3. To assess phonetic accuracy, the initial goal was to determine an accuracy score (Edwards et al., 2004). This score was obtained for each child in each condition and converted to a percentage. These percentage scores were then arcsine transformed to avoid floor and ceiling effects.
As with the kinematic analysis above, learning effects were the focus, and were assessed in both referential and non-referential novel words across phonotactic probability and neighborhood conditions. To examine these learning effects, difference scores were calculated for each pre-test and post-test pair (D=y-x). Here, a positive difference score means segmental accuracy improved in the post-test condition. The average difference score for each condition is presented in Figure 4. A 2 (neighborhood density) × 2 (phonotactic probability) × 2 (referential status) ANOVA was used to compare mean difference scores. Results revealed a significant main effect for neighborhood, F (1, 15) =6.86, p=.018; children's accuracy decreased from pre- to post- test in dense neighborhoods, but accuracy did not change from pre- to post- test in sparse neighborhoods. There was no significant effect for phonotactic probability, F (1, 15) =.037, p=.85, or for referential status, F (1, 15) =.212, p=.65. No significant interactions were observed.
Figure 4.

Difference scores for segmental analysis. Error bars represent standard error.
We also examined the mean difference scores by condition and their difference from zero. A difference score of zero would indicate that no change occurred from pre-test to post-test, whereas a score significantly above zero indicates a decrease in segmental accuracy from pre-test to post-test. Single sample t-tests were used to examine whether each mean difference score was different from zero. As illustrated in Figure 4, the only significant effect is in the high neighborhood density, high phonotactic probability referential condition, t (16) =2.765, p=.014, where errors increased from pre-test to post-test. The t-tests for all eight conditions are presented in Table 4. Overall, results of these analyses indicate that errors increase in words that are from dense neighborhoods.
As with the kinematic analysis above, we were also interested in determining the absolute influence of neighborhood density, phonotactic probability, and referential status on accuracy. A 2 (neighborhood density) × 2 (phonotactic probability) × 2 (referential status) × 2 (pre- vs. post-test) repeated measures ANOVA was completed on the transformed data. Results revealed a significant main effect for neighborhood density, F(1, 15) =5.348, p=.035, with high density forms produced with lower accuracy than low density forms. There was no significant effect for phonotactic probability, F(1,15)=1.113, p=.308, referential status, F(1,15)=.216, p=.649, or pre- vs. post-test, F(1,15)=.324, p=.578. There was a significant neighborhood density by phonotactic probability interaction, F (1, 15) =6.742, p=.020. Further analysis of this interaction using Tukey HSD revealed that high neighborhood density, high phonotactic probability tokens were produced less accurately than low neighborhood density, high phonotactic probability tokens (p=.015). There were additional interactions, particularly between pre- and post-test performance (high neighborhood density pre-test tokens were produced less accurately than low neighborhood density post-test (p=.0003), high neighborhood density post-test tokens were produced less accurately than low neighborhood density pre-test tokens (p=.002), high neighborhood density post-test tokens were produced less accurately than low neighborhood density post-test tokens (p=.0002), and finally low neighborhood density pre-test tokens were produced more accurately than low neighborhood density post-test tokens (.002). No other interactions were significant. While difficult to interpret these disparate interactions, we can see a general pattern emerge where high neighborhood density forms are less accurate than any other forms to which they are compared.
Discussion
The purpose of this study was to examine the influence of phonotactic probability and neighborhood density on phonological and motor representations in children as a function of word status. A word learning paradigm was used to teach children novel words with and without visual referents; these words varied in phonotactic probability and neighborhood density. Kinematic and transcription measures of production were utilized to draw conclusions about the differential effects of these form variables during the production of referential and non-referential novel words.
Word Learning
We expected that phonetic forms would be produced with less variability when they were learned with an object referent (Heisler et al, 2010) and that forms with low neighborhood density would be most learnable (Strokel & Lee, 2011). Heisler and colleagues (2010) observed that a phonetic string with a referent was produced with more kinematic stability and more segmental accuracy than a phonetic string without a referent. Although that study was procedurally similar to the present one, all stimulus items were constructed with low phonotactic probability combinations and neighborhood density was not controlled for. In the current study phonotactic probability and neighborhood density were systematically manipulated across conditions. The word learning effect was replicated confirming once again that perceptual learning changes production processes, thus giving rise to another major finding of this research. The word learning effect was replicated in the kinematic domain, but only in the low neighborhood density, low phonotactic probability condition.
In the current study, children's productions were more stable when a string of sounds was assigned an object referent in the low neighborhood density, low phonotactic probability condition. This indicates a facilitative production influence for these forms once they are given word status and presumably entered into the mental lexicon. Other investigators have implicated low phonotactic probability, low neighborhood density forms as being facilitative in fast mapping tasks in preschool children (Storkel & Lee, 2011; Hoover et al., 2010). Fewer neighbors may highlight or trigger a given word form as unique and expedite the fast mapping process (Storkel & Lee, 2010; Dumay & Gaskell, 2007). Storkel and Lee (2010) found that words with low phonotactic probability and low neighborhood density were more likely to be accurately identified immediately, but words with high phonotactic probability and high neighborhood density were more likely to be retained long term. This is consistent with our current findings, as we assessed early learning phases and found a facilitative effect of low phonotactic probability and low neighborhood density, now as revealed in more implicit production measures. Connectionist modeling would predict this mapping in the mental lexicon (Dumay & Gaskell, 2007). A new form with low neighborhood density would have little competition, and thus be recognized as a new word and trigger an activation threshold to enter as a lexical item in the mental lexicon. For this reason, new forms with low neighborhood density have an advantage when entering the mental lexicon. In future work, it will be important to evaluate shifts in the effects of both phonological and semantic cues over a more protracted course of learning.
Phonotactic Probability and Production Processes
Our next question focused on the incorporation of a phonological factor into our model, the interaction of phonotactic probability and production of referential and non-referential novel words. We expected that forms with high phonotactic probability would be produced with greater stability since articulation may be influenced by frequency. Findings were that both words and non-words that were high in phonotactic probability were more learnable, as indicated by increased articulatory stability over time as reflected in difference scores. However, overall articulatory stability did not statistically differ as a function of phonotactic probability. Importantly, phonotactic probability showed specific effects on short-term motor learning, but phonetic accuracy was not influenced by this particular phonological factor.
Results of the current study showed that children broadly demonstrated motor learning across conditions. Actual STI values in the kinematic analysis revealed that variability decreased in the post-test, regardless of word status, phonotactic probability, or neighborhood density. Other researchers (Sasisekaran et al., 2010; Walsh et al., 2006) have reported similar results in adult and child participants producing strings of nonce syllables. This rapid reduction of articulatory variability is evident in children as they build a motor representation. Over time, children move toward an increasingly stable articulatory movement pattern while acquiring a new form, even when phonetic accuracy is consistent across productions. Thus, rapid changes in motor implementation serve as a fine-grained index of learning.
The effects of phonotactic probability on motor learning are evident in the kinematic results, both in referential and non-referential conditions. Novel words of high phonotactic probability are more learnable (in terms of speech-motor implementation) than those of low phonotactic probability, regardless of referential status. Thus, it appears phonotactic probability relates more to motor learning in general than to phonetic accuracy or to semantic variables. Although trends in the data suggest that forms with high phonotactic probability are produced with less variability overall, this was not confirmed statistically.
It is important to remember that, in the current study, the control of phonotactic frequency focused on medial clusters. Being less salient than those in initial or final position, medial clusters may be considered particularly difficult. The results could be different if clusters in initial or coda position were analyzed. It would be important to integrate this prosodic aspect of production in future studies.
Neighborhood Density and Word Status
Neighborhood density was found to be the primary factor influencing segmental accuracy of both words and non-words. When a child fast maps a novel form, it is neighborhood density that mediates integration and consolidation in the mental lexicon. Thus neighborhood density affects any possible word form even if it is encountered without a referent. These results are consistent with those reported by Storkel and colleagues (Storkel et al., 2006; Storkel & Lee, 2011), who found that, based on measures of phonetic accuracy, words from low density neighborhoods are relatively more learnable than those from high density neighborhoods. In the present study, words from high density neighborhoods actually decreased in accuracy, likely as a result of competition over the course of short-term learning. Phonetic accuracy but not articulatory variability change as a function of neighborhood density.
Moving to the issue of referential status, more complex interactions relating phonotactic probability, neighborhood density, and speech motor variability emerged. Novel word forms were the most learnable in the speech-motor domain only in the referential condition. That is, a word with low neighborhood density and low phonotactic probability showed the greatest decrease in variability, evidencing a facilitative effect when a referent was assigned. In the prosodic domain, Gladfelter and Goffman (2013) demonstrated that lexical stress also interacts directly with articulation. Iambic nouns are low frequency and trochaic nouns high frequency. Similar to segmental neighborhood effects, low density iambic (weak-strong) word forms are more learnable (as indicated by reductions in kinematic variability and improved performance in a confrontation naming task) than high density trochaic (strong-weak) forms, also for 4-year-old children. In the present work, direct articulatory-lexical connections are also observed in segmental frequency, with low frequency and low density sequences being particularly learnable as evidenced again by decreased articulatory variability over the course of short-term learning. Importantly, this result was only observed when the novel word form was given referential status.
Implications for Developmental Models of Language Production
Traditional models of language production suggest that lexical and phonological processing modules are relatively encapsulated and have minimal interaction with articulation (e.g., Levelt et al., 1999). Researchers associated with these classic models postulate distinct levels of representation for semantic information, the lexicon, phonology, and articulation, which are accessed sequentially during production processes. Alternatively, other investigators have suggested more integrated models in which lexical, phonological and phonetic information is packaged which would have implications for access (Pierrehumbert, 2001; Pisoni, 1997; Johnson, 2006).
Much research on frequency effects, especially neighborhood effects, emphasizes integration between these aspects of phonological acquisition and the developing lexicon. Results of the current study provide support for more integrated relationships across processing levels. These relationships are similar to those suggested by other investigators (Baese-Berk & Goldrick, 2009; Goldrick & Blumstein, 2006; Hickok, 2012; McMillan et al., 2009), who have demonstrated that the lexicon interacts directly with aspects of articulation. In children, we have specified a similar link, with articulatory variability changing as a function of word status (Heisler et al., 2010).
McKean, Letts, and Howard (2013) delineate a developmental trajectory for the influences of phonotactic probability and neighborhood density on children's fast mapping. To summarize this work, infants are able to map frequent sound combinations as an “adaptive strategy” which promotes efficient lexical acquisition (Jusczyk, 1997; Jusczyk, Houston, & Newsome, 1999). At age four, children appear to change strategies and there is a word learning bias towards forms with low phonotactic probability (Storkel et al., 2006). This switch may be explained through increased language competence, in particular a larger core vocabulary. Initially, when entries into the mental lexicon are limited, factors such as phonotactic probability mediate word learning; once a core of vocabulary knowledge is obtained, lexical factors have a larger impact on word learning. The results from the present study are consistent with this proposed developmental trajectory, as these older children no longer show a bias towards learning forms with high phonotactic probability. However, at least at age four and half, there continues to be a facilitative effect for high probability forms in the domain of motor learning.
Turning to neighborhood effects, there appears to be an advantage for the acquisition of forms from sparse neighborhoods early in development (McKean et al., 2013; Storkel, 2006). Storkel and colleagues (2006) found an advantage for learning forms from dense neighborhoods in adults, but a timeline for when this change may occur is not evident from current literature. The present study examined the influence of neighborhood density in four and a half year old children and the bias toward learning words in sparse neighborhoods is supported by our findings.
In terms of production processes, our data support that the form variables of phonotactic probability and neighborhood density that underlie lexical organization and acquisition have a direct impact on production processes and, in some cases, word status amplifies the effect of these factors (such as the case when word status mediates motor learning of high probability forms). These findings provide evidence that information related to articulatory implementation and phonological form are bundled in specific ways with semantic knowledge in the mental lexicon.
Overall, a contribution of the present work is to develop a more integrated model of word learning that incorporates not only phonological and semantic, but also articulatory levels. Prior studies have revealed that referential status influences articulation (Goldrick & Blumstein, 2006; Heisler et al., 2010); these findings are consistent with multiple interactive models that posit an interface across lexical and articulatory levels. Following from these previous results, one possibility is that all higher-level components of language production interact with articulation. The present study was designed to elaborate on the interactive model and to assess whether lexical/phonological and frequency variables would interact with articulation.
The present results do not support broad interactivity across lexical, phonological, and articulatory domains. While we once again demonstrate that referential factors directly link to articulation (see also Goldrick & Blumstein, 2006; Heisler et al., 2010), other components of phonological and lexical processing show more nuanced interactivity. Phonotactic probability connects with articulation, as revealed by shifts in accuracy during short-term learning in high probability contexts. However, this phonological factor does not relate to referential status.
Neighborhood density, as revealed in numerous prior studies (e.g., Storkel et al., 2006; Storkel & Lee, 2011), influences phoneme accuracy. But this lexical-phonological factor does not relate to either speech motor output or to referential status, at least during short-term learning. Thus, prior results that rely on transcription analyses were replicated (Storkel & Lee, 2011), but neighborhood density did not interact with speech motor output. Further, the inclusion of a referent does not facilitate children's capacity to map a new phonological form to an existing neighborhood. In conclusion, it appears that associations across domains of speech production are specific and that models, even those supporting higher levels of interactivity, need to account for differential effects across processing components.
Acknowledgments
This research was supported by National Institutes of Health, National Institute on Deafness and Other Communicative Disorders R01DC04826. We thank Janna Berlin, Diane Brentari, Larry Leonard, David Snow and Barbara Younger for their contributions to the development and completion of this project.
Contributor Information
Lori Heisler, California State University San Marcos.
Lisa Goffman, Purdue University.
References
- Baese-Berk M, Goldrick M. Mechanisms of interaction in speech production. Language and Cognitive Processes. 2009;24:527–554. doi: 10.1080/01690960802299378. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bankson NW, Bernthal JE. Bankson-Bernthal Test of Phonology. Chicago, IL: Riverside Publishing Company; 1990. [Google Scholar]
- Boersma Paul. Praat, a system for doing phonetics by computer. Glot International. 2001;5(9/10):341–345. [Google Scholar]
- Burgemeister BB, Hollander Blum L, Lorge I. Columbia Mental Maturity Scales. New York, NY: Harcourt Brace & Company; 1972. [Google Scholar]
- Burnage G. CELEX: A guide for users. Nijmegen, The Netherlands: CELEX; 1990. [Google Scholar]
- Dunn LM, Dunn LM. Peabody Picture Vocabulary Test-III. Circle Pines, MN: American Guidance Service; 1997. [Google Scholar]
- Edwards J, Beckman ME, Munson B. The interaction between vocabulary size and phonotactic probability effects on children's production accuracy and fluency in nonword repetition. Journal of Speech Language and Hearing Research. 2004;47:1033. doi: 10.1044/1092-4388(2004/034). [DOI] [PubMed] [Google Scholar]
- Frisch SA, Wright R. The phonetics of phonological speech errors: an acoustic analysis of slips of the tongue. Journal of Phonetics. 2002;30:139–162. [Google Scholar]
- Gladfelter A, Goffman L. The influence of prosodic stress patterns and semantic depth on novel word learning in typically developing children. Language Learning and Development. 2013;9:151–174. doi: 10.1080/15475441.2012.684574. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Garlock VM, Walley AC, Metsala JL. Age of acquisition, word frequency, and neighborhood density effects on spoken word recognition by children and adults. Journal of Memory and Language. 2001;45:468–492. [Google Scholar]
- Goldrick M, Blumstein SE. Cascading activation from phonological planning to articulatory processes: evidence from tongue twisters. Language and Cognitive Processes. 2006;21:649–683. [Google Scholar]
- Graf Estes K, Edwards J, Saffran J. Phonotactic Contstraints on Infant Word Learning. Infancy. 2011;16:180–197. doi: 10.1111/j.1532-7078.2010.00046.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Heisler L, Goffman L, Younger B. Lexical and articulatory interactions in children's language production. Developmental Science. 2010;13:722–730. doi: 10.1111/j.1467-7687.2009.00930.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hickok G. Computational Neuroanatomy of Speech Production. Nature Reviews Neuroscience. 2012 doi: 10.1038/nrn3158. online 5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hoover JR, Storkel HL, Hogan TP. A cross sectional comparison of the effects of phonotactic probability and neighborhood density on word learning by preschool children. Journal of Memory and Language. 2010;63:100–116. doi: 10.1016/j.jml.2010.02.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Johnson K. The emergence of social identity and phonology. Journal of Phonetics. 2006;34:485–499. [Google Scholar]
- Jusczyk PW. The discovery of spoken language. Cambridge: The MIT Press; 1997. [Google Scholar]
- Jusczyk PW, Houston DM, Newsome M. The beginnings of word segmentation in English-learning infants. Cognitive Psychology. 1999;39:159–207. doi: 10.1006/cogp.1999.0716. [DOI] [PubMed] [Google Scholar]
- Levelt WJM, Roelofs A, Meyer AS. A theory of lexical access in speech production. Behavioral & Brain Sciences. 1999;22:1–75. doi: 10.1017/s0140525x99001776. [DOI] [PubMed] [Google Scholar]
- Levelt WJM, Wheeldon L. Do speakers have access to a mental syllabary. Cognition. 1994;50:239–269. doi: 10.1016/0010-0277(94)90030-2. [DOI] [PubMed] [Google Scholar]
- Luce PA, Pisoni DB. Recognizing spoken words: The neighborhood activation model. Ear and Hearing. 1998;19:1–36. doi: 10.1097/00003446-199802000-00001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mathworks, Inc. Matlab: High performance numeric computation and visualization software [computer program] Natick, MA: Author; 1993. [Google Scholar]
- McKean C, Letts C, Howard D. Functional reorganization in the developing lexicon: separable and changing influences of phonological variables on children's fast mapping. Journal of Child Language. 2013;40(2):307–335. doi: 10.1017/S0305000911000444. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McMillan CT, Corley M, Lickley JT. Articulatory evidence for feedback and competition in speech production. Language and Cognitive Processes. 2009;24:44–66. [Google Scholar]
- Metsala JL, Chisolm GM. The influence of lexical status and neighborhood density on children's nonword repition. Applied Psycholinguistics. 2011;31:489–506. [Google Scholar]
- Moe S, Hopkins M, Rush L. A vocabulary of first grade children. Springfield, IL: Thomas; 1982. [Google Scholar]
- Morrisette ML, Geirut JA. Lexical organization and phonological change in treatment. Journal of Speech Language and Hearing Research. 2002;45:143–159. doi: 10.1044/1092-4388(2002/011). [DOI] [PubMed] [Google Scholar]
- Munson B. Phonological pattern frequency and speech production in adults and children. Journal of Speech, Language, and Hearing Research. 2001;44:778–792. doi: 10.1044/1092-4388(2001/061). [DOI] [PubMed] [Google Scholar]
- Munson B, Edwards J, Beckman ME. Relationships between nonword repetition accuracy and other measures of linguistic development in children with phonological disorders. Journal of Speech Language and Hearing Research. 2005;48:61. doi: 10.1044/1092-4388(2005/006). [DOI] [PubMed] [Google Scholar]
- Munson B, Swenson CL, Manthei SC. Lexical and phonological organization in children: evidence from repetition tasks. Journal of Speech Language and Hearing Research. 2005;48:108. doi: 10.1044/1092-4388(2005/009). [DOI] [PubMed] [Google Scholar]
- Newman RS, German DJ. Life Span Effects of Lexical Factors on Oral Naming. Language and Speech. 2005;48:123–156. doi: 10.1177/00238309050480020101. [DOI] [PubMed] [Google Scholar]
- Ohara Werner E, Dawson Kresheck J. Structured Photographic Expressive Language Test-Preschool. Dekalb, IL: Janelle Publications Inc; 1983. [Google Scholar]
- Pierrehumbert J. Stochastic Phonology. GLOT. 2001;5:1–13. [Google Scholar]
- Pisoni D. Some thoughts on “normalization” in speech perception. In: Johnson K, Mulennix K, editors. Talker Variability in Speech Processing. Academic Press; San Diego: 1997. pp. 9–32. [Google Scholar]
- Pisoni D, Nusbaum H, Luce P, Slowiacek L. Speech perception, word recognition, and the structure of the lexicon. Speech Communication. 1985;4:75–95. doi: 10.1016/0167-6393(85)90037-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Robbins J, Klee T. Clinical assessment of oropharyngeal motor development in young children. Journal of Speeech and Hearing Disorders. 1987;52:271–277. doi: 10.1044/jshd.5203.271. [DOI] [PubMed] [Google Scholar]
- Sasisekeran J, Smith A, Sadagopan N, Weber-Fox C. Nonword repetition in children and adults: effects on movement coordination. Developmental Science. 2010;13:521–532. doi: 10.1111/j.1467-7687.2009.00911.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Smith A, Goffman L, Zelaznik HN, Ying G, McGillem CM. Spatiotemporal stability and the patterning of speech movement sequences. Experimental Brain Research. 1995;104:493–501. doi: 10.1007/BF00231983. [DOI] [PubMed] [Google Scholar]
- Smith A, Johnson M, McGillem C, Goffman L. On the stability and patterning of speech movements. Journal of Speech, Language, and Hearing Research. 2000;43:277–286. doi: 10.1044/jslhr.4301.277. [DOI] [PubMed] [Google Scholar]
- Sommers M. Washington University in St. Louis Speech and Hearing Lab Neighborhood Database. [Last accessed October, 20, 2013];2002 from http://128.252.27.56/neighborhood/Home.asp.
- Storkel HL. Learning new words: Phonotactic probability in language development. Journal of Speech Language and Hearing Research. 2001;44:1321–1337. doi: 10.1044/1092-4388(2001/103). [DOI] [PubMed] [Google Scholar]
- Storkel HL. Learning new words II: Phonotactic probability in verb learning. Journal of Speech Language and Hearing Research. 2003;46:1312–1323. doi: 10.1044/1092-4388(2003/102). [DOI] [PubMed] [Google Scholar]
- Storkel HL, Armbruster J, Hogan TP. Differentiating phonotactic probability and neighborhood density in adult word learning. Journal of Speech Language and Hearing Research. 2006;49:1175–92. doi: 10.1044/1092-4388(2006/085). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Storkel HL, Hoover JR. An on-line calculator to compute phonotactic probability and neighborhood density based on child corpora of spoken American English. Behavior Research Methods. 2010a;42:497–506. doi: 10.3758/BRM.42.2.497. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Storkel HL, Lee SY. The independent effects of phonotactic probability and neighborhood density on lexical acquisition by preschool children. Language and Cognitive Processes. 2011;26:191–211. doi: 10.1080/01690961003787609. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Storkel HL, Rogers MA. The effect of probabilistic phonotactics on lexical acquisition. Clinical Linguistics and Phonetics. 2000;14:407–425. [Google Scholar]
- Vitevitch M. The influence of phonological similarity neighborhoods on speech production. Journal of Experimental Psychology: Learning, Memory and Cognition. 2002;28:735–747. doi: 10.1037//0278-7393.28.4.735. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vitevitch M. The influence of sublexical and lexical representations on the processing of spoken words in English. Clinical Linguistics and Phonetics. 2003;17:487–499. doi: 10.1080/0269920031000107541. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Vitevitch MS, Luce PA. When words compete: Levels of processing in perception of spoken words. Psychological Science. 1998;9:325–329. [Google Scholar]
- Vitevitch MS, Luce PA. Probabilistic phonotactics and neighborhood activitation in spoken word recognition. Journal of Memory and Language. 1999;40:374–408. [Google Scholar]
- Walsh B, Smith A, Weber-Fox C. Short-term plasticity in children's speech motor systems. Developmental Psychology. 2006;48:660–674. doi: 10.1002/dev.20185. [DOI] [PubMed] [Google Scholar]
- Williams K. Expressive Vocabulary Test. Circle Pines, MN: American Guidance Service; 1997. [Google Scholar]