

Abstract
Objectives:
In natural hearing, cochlear mechanical compression is dynamically adjusted via the efferent medial olivocochlear reflex (MOCR). These adjustments probably help understanding speech in noisy environments and are not available to the users of current cochlear implants (CIs). The aims of the present study are to: (1) present a binaural CI sound processing strategy inspired by the control of cochlear compression provided by the contralateral MOCR in natural hearing; and (2) assess the benefits of the new strategy for understanding speech presented in competition with steady noise with a speech-like spectrum in various spatial configurations of the speech and noise sources.
Design:
Pairs of CI sound processors (one per ear) were constructed to mimic or not mimic the effects of the contralateral MOCR on compression. For the nonmimicking condition (standard strategy or STD), the two processors in a pair functioned similarly to standard clinical processors (i.e., with fixed back-end compression and independently of each other). When configured to mimic the effects of the MOCR (MOC strategy), the two processors communicated with each other and the amount of back-end compression in a given frequency channel of each processor in the pair decreased/increased dynamically (so that output levels dropped/increased) with increases/decreases in the output energy from the corresponding frequency channel in the contralateral processor. Speech reception thresholds in speech-shaped noise were measured for 3 bilateral CI users and 2 single-sided deaf unilateral CI users. Thresholds were compared for the STD and MOC strategies in unilateral and bilateral listening conditions and for three spatial configurations of the speech and noise sources in simulated free-field conditions: speech and noise sources colocated in front of the listener, speech on the left ear with noise in front of the listener, and speech on the left ear with noise on the right ear. In both bilateral and unilateral listening, the electrical stimulus delivered to the test ear(s) was always calculated as if the listeners were wearing bilateral processors.
Results:
In both unilateral and bilateral listening conditions, mean speech reception thresholds were comparable with the two strategies for colocated speech and noise sources, but were at least 2 dB lower (better) with the MOC than with the STD strategy for spatially separated speech and noise sources. In unilateral listening conditions, mean thresholds improved with increasing the spatial separation between the speech and noise sources regardless of the strategy but the improvement was significantly greater with the MOC strategy. In bilateral listening conditions, thresholds improved significantly with increasing the speech-noise spatial separation only with the MOC strategy.
Conclusions:
The MOC strategy (1) significantly improved the intelligibility of speech presented in competition with a spatially separated noise source, both in unilateral and bilateral listening conditions; (2) produced significant spatial release from masking in bilateral listening conditions, something that did not occur with fixed compression; and (3) enhanced spatial release from masking in unilateral listening conditions. The MOC strategy as implemented here, or a modified version of it, may be usefully applied in CIs and in hearing aids.
Keywords: Bilateral implant, Bilateral processing, Cochlear efferents, Hearing aid, Interaural level differences, Sound processor, Spatial release from masking, Speech intelligibility, Speech reception threshold
In natural hearing, cochlear mechanical compression is dynamically adjusted via the medial olivocochlear efferent reflex (MOCR). These adjustments likely help understanding speech in noisy environments and are not available to the users of cochlear implants (CIs). The present study presents a bilateral CI sound processing strategy that reinstates some of the effects of the contralateral MOCR to CI users using frequency-specific, contralaterally controlled dynamic compression. The new strategy facilitates understanding speech in competition with speech-shaped noise in the bilateral and unilateral listening conditions tested, and produces significant spatial release from masking. The strategy may be usefully applied in hearing prostheses.
INTRODUCTION
Listeners with normal hearing have a remarkable ability to process sounds over a very wide range of acoustic pressures. This is achieved, at least in part, thanks to the mechanical response properties of the basilar membrane (BM). The velocity of BM vibration grows with increasing sound level at a compressive rate of ~0.2 dB/dB (Robles & Ruggero 2001), an effect that serves to compress a wide range of acoustic pressures into a narrower range of BM (and eventually neural) responses (Bacon 2004). The compressive growth rate of BM velocity, however, is not fixed in time and depends on the state of activation of the medial olivocochlear (MOC) efferents. Activation of MOC efferents inhibits BM responses for low- and moderate-level sounds and much less so (or not at all) for high-level sounds (e.g., see Fig. 2 in Cooper & Guinan 2006). MOC efferents thus linearize BM input/output curves. MOC efferents may be activated in a reflexive manner by ipsilateral and contralateral sounds (Guinan et al. 2003; Guinan 2006). Therefore, in acoustic binaural hearing, BM compression in our two ears is probably coupled and dynamically adjusted via the ipsilateral and the contralateral MOC reflex (MOCR; Guinan et al. 2003; Guinan 2006). Here, we present and assess the merits of a binaural cochlear implant (CI) sound coding strategy inspired by the dynamic control of BM mechanical compression provided by the contralateral MOCR.
CIs can enable useful hearing for profoundly deaf persons via direct electrical stimulation of the auditory nerve. Similarly to the functioning of the normal ear, where BM compression contributes to accommodate a wide range of acoustic pressure into a narrower range of neural responses (Bacon 2004), the sound processor in a CI (Fig. 1) includes an instantaneous back-end compressor in each frequency channel of processing to map the wide dynamic range of sounds in the environment into the relatively narrow dynamic range of electrically evoked hearing (Wilson et al. 1991). In the fitting of modern CIs, the amount and endpoints of the compression* are adjusted for each frequency channel and its associated intracochlear electrode(s). Unlike what happens in the normal ear, where BM compression is almost certainly dynamic by action of the MOCR, compression in the CI once set is fixed for all sound inputs. Furthermore, because the electrical stimulation delivered with the CI is independent from cochlear mechanical processes, the adjustment of compression provided by the contralateral MOCR in natural hearing is unavailable to CI users (Wilson et al. 2005).
Fig. 1.
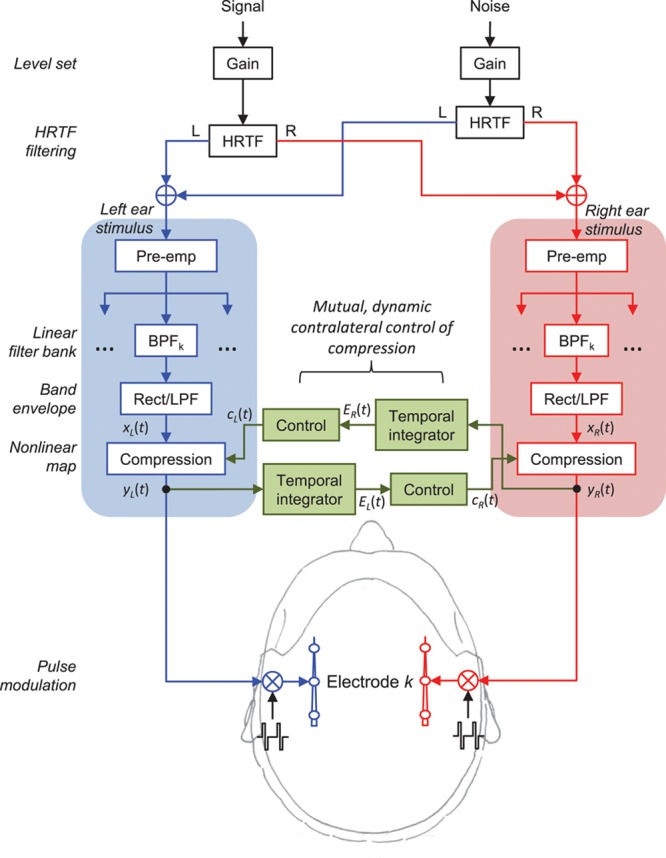
Signal processing block diagram. The diagram illustrates how the target speech and noise signals were HRTF filtered to simulate free-field stimuli at the left and right ears, and how the stimulus at each ear was processed through corresponding STD and MOC processors (processing is only shown for the kth channel). Note that STD and MOC processors were identical except that MOC processors included contralateral control of back-end compression. See text for further details. MOC indicates medial olivocochlear reflex; STD, standard strategy.
The MOCR likely facilitates the intelligibility of speech in noisy environments. In quiet backgrounds, the inhibition of BM responses caused by the MOCR impairs the detectability of low-intensity pure tones (Aguilar et al. 2014). In noisy backgrounds, by contrast, the MOCR restores the effective dynamic range of auditory nerve fibers to values observed in quiet (see Fig. 5 in Guinan 2006). Furthermore, by inhibiting BM responses, and hence the effective driving force of neural responses, the MOCR probably increases the number of auditory nerve fibers that work within their response dynamic range and below saturation. Altogether, this almost certainly improves the neural coding of speech embedded in noise (Brown et al. 2010; Chintanpalli et al. 2012; Clark et al. 2012), thus facilitating the intelligibility of speech in noisy environments (Kim et al. 2006; Brown et al. 2010; Clark et al. 2012). Furthermore, Kim et al. measured the intelligibility improvement in speech-shaped noise when the speech and noise sources were spatially separated by 90 degrees relative to a condition where they were colocated at 0 degrees azimuth and found it to be significantly correlated with the strength of the contralateral MOCR. This suggests that a second possible benefit of the MOCR is to increase spatial release from masking. In other words, the unmasking effects of the MOCR could be greater for spatially separated than for colocated speech and noise sound sources, although the mechanism underlying this potential benefit is yet unknown. As explained above, MOCR effects are unavailable to CI users, and this might contribute to the greater difficulty experienced by CI users understanding speech in noisy environments and their diminished spatial release from masking compared with normal-hearing listeners (Ihlefeld & Litovsky 2012).
Here, we present a binaural CI sound coding strategy (the MOC strategy) inspired by the dynamic contralateral control of BM compression provided in natural hearing by the contralateral MOCR. Speech in noise intelligibility with the MOC strategy is compared with intelligibility measured with a pair of functionally independent CI sound processors (one per ear), a condition very close to the current clinical standard (the STD strategy). The comparisons are made for unilateral and bilateral listening conditions and for various spatial configurations of the speech and noise sources. It will be shown that the MOC strategy significantly improves intelligibility in speech-shaped noise for spatially separated speech and noise sources, both in unilateral and bilateral listening conditions. It will be further shown that the MOC strategy also produced significant spatial release from masking in the bilateral listening conditions where the STD strategy did not.
MATERIALS AND METHODS
The MOC and STD Strategies
The STD and MOC sound processing strategies were identical with the exception of the back-end compression stage (Fig. 1). The processors in the two strategies included a high-pass pre-emphasis filter (first-order Butterworth filter with a 3-dB cutoff frequency of 1.2 kHz); a bank of sixth-order Butterworth band-pass filters whose 3-dB cutoff frequencies followed a modified logarithmic distribution between 100 and 8500 Hz; envelope extraction via full-wave rectification and low-pass filtering (fourth-order Butterworth low-pass filter with a 3-dB cutoff frequency equal to a fourth of the ear-specific pulse rate given in Table 1 or 400 Hz, whichever was lower); a logarithmic compression function (fixed for STD and dynamic for MOC processors); and continuous interleaved sampling of compressed envelopes (Wilson et al. 1991). The number of filters in the bank was identical to the number of active electrodes in the implant (Table 1), and equal between the left- and right-ear processors.
TABLE 1.
Demographic information for the five cochlear implant users tested with the STD and MOC strategies
The back-end compression function in all processors was as follows (Boyd 2006):
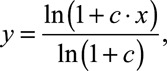 |
(1) |
where x and y are the input and output amplitudes to/from the compressor, respectively, both of them assumed to be within the interval [0,1]; and c is a parameter that determines the amount of compression. For the STD processors, c was fixed at 1000, the value in the clinical processors of the participants used in the present study, and was identical at the two ears. For the MOC processors, however, c varied dynamically in time depending upon the time-weighted output energy from the corresponding frequency channel in the contralateral processor (on-frequency inhibition), as depicted in Figure 1 and explained as follows.
For the natural MOCR, the more intense the contralateral stimulus, the greater the inhibition of cochlear mechanical responses (Hood et al. 1996; Maison et al. 1997; Backus & Guinan 2006). On the other hand, it seems reasonable that the amount of MOCR inhibition depends on the output from the cochlea rather than on the acoustic stimulus (Froud et al. 2015). Inspired by this, we assumed that the instantaneous value of c(t) for any given frequency channel in an MOC processor was inversely related to the time-weighted output energy from the corresponding channel in the contralateral MOC processor, E(t) (Fig. 1). In other words, we assumed a relationship between c(t) and E(t) such that the greater the contralateral output energy, E(t), the smaller the value of c(t), the more linear Equation (1), and the greater the inhibition of processor output amplitude. Notably, the relationship between c(t) and E(t) was such that in the absence of contralateral energy, MOC processors behaved as STD ones. In other words, for E(t) = 0, c(t) became equal to 1000 (the value used in the STD processors) and there was no contralateral inhibition.
Figure 2A illustrates the shapes of the compression function (Eq. 1) for different values of the contralateral energy, E, and corresponding values of the c parameter. The amount of inhibition in the MOC strategy was selected ad hoc from a range of values tested in pilot measures (see “Discussion”) and is shown in Figure 2B, C. Inhibition here is defined as the ratio (in dB) between the processor’s output amplitude in the absence of a contralateral stimulus (i.e., for E(t) = 0) and the corresponding output amplitude in the presence of a contralateral stimulus (vertical arrow in Fig. 2A). Note that the amount of contralateral inhibition in the MOC processors (1) was greater for lower than for higher input levels (Fig. 2C), as in the natural MOCR (e.g., Fig. 2A in Cooper & Guinan 2006); (2) was greater the higher the output energy (Fig. 2B); and (3) was negligible for low contralateral energy values (Fig. 2B), as intended.
Fig. 2.
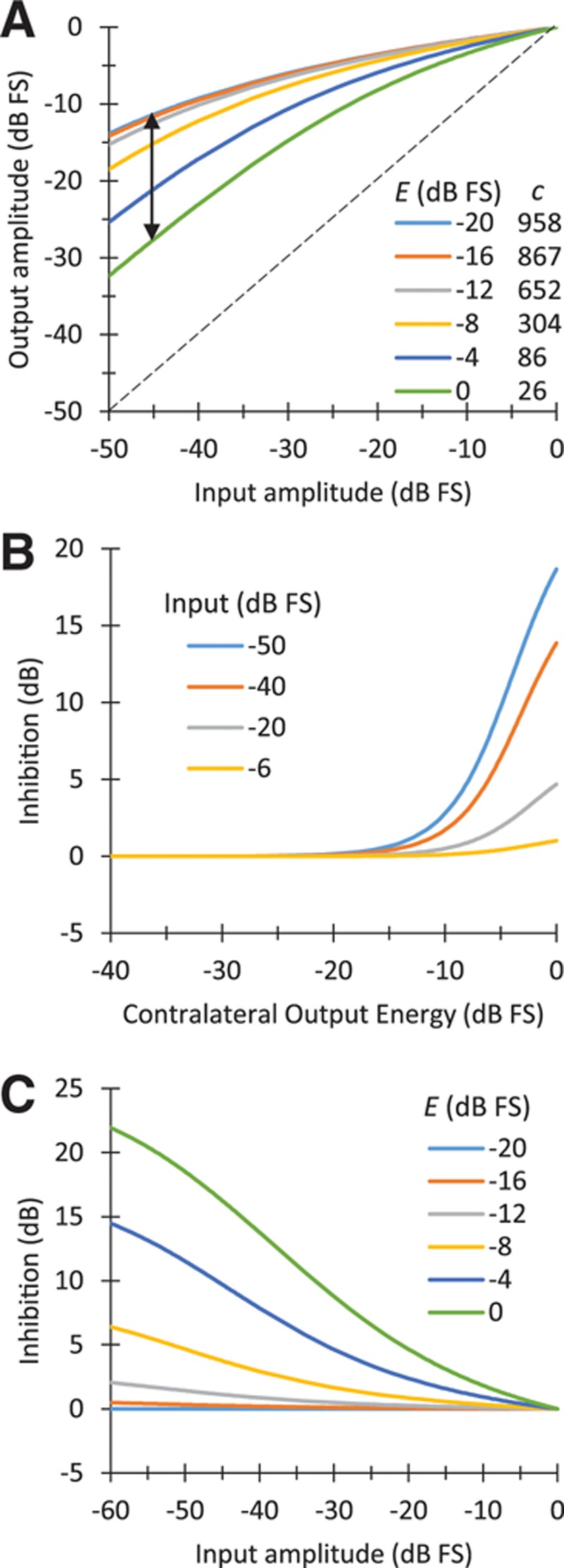
The characteristics of the dynamic back-end compression in the MOC strategy. A, Range of instantaneous compression functions (Eq. 1) for six different values of the contralateral energy (E) linearly distributed from −20 to 0 dB FS and corresponding values of the parameter c, as shown in the inset. The double-headed vertical arrow illustrates the amount of inhibition for an input level of −45 dB FS. B, Inhibition (in dB) a function of contralateral output energy, for four fixed input amplitudes (in dB FS) indicated in the inset. C, Inhibition (in dB) as a function of input amplitude for the same six values of E (in dB FS) shown in (A). dB FS means dB re unity. FS indicates full scale; MOC, medial olivocochlear reflex.
Inspired by the exponential time-course of activation and deactivation of the MOC effect (Backus & Guinan 2006), in the MOC strategy, the instantaneous output energy from the contralateral processor, E(t), was calculated as the root mean square output amplitude integrated over a preceding exponentially decaying time window (temporal integrator in Fig. 1). The time constants of activation of the natural MOCR are of the order of 60 to 300 msec (Backus & Guinan 2006). Here, however, we used an integration time constant of 2 msec in an attempt to produce an effect for transient speech features. The implications of using a shorter-than-natural time constant will be discussed below.
Further details on the MOC strategy can be found elsewhere (Lopez-Poveda 2015).
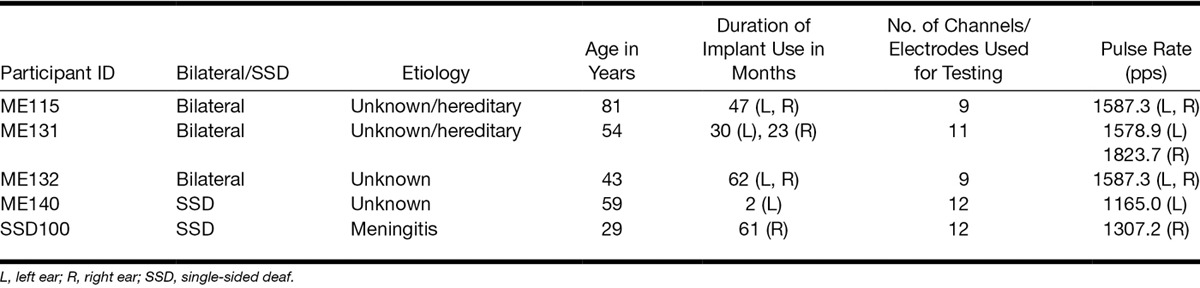
Participants
Five users (2 females) of MED-EL CIs participated in the experimental testing of the MOC strategy (Table 1). Three of them (1 female) were bilateral CI users; the other 2 participants were single-sided deaf (SSD) unilateral CI users, and they both had audiometric thresholds within 20 dB HL (American National Standards Institute 1996) in the nonimplanted ear. The median duration of implant use for all eight ears tested was 47 months. Participants had between 9 and 12 active electrodes in their implants. Informed consent was obtained from all participants before testing. Testing procedures were approved by the Western Institutional Review Board (Puyallup, WA).
Procedures
To compare intelligibility in speech-shaped noise with MOC and STD strategies, we asked participants to recognize sentences in simulated free-field conditions in the presence of a steady noise with a speech-like spectrum. Performance was measured using the speech reception threshold (SRT), defined as the signal-to-noise ratio (SNR) at which 50 percent of the sentences are recognized. The conditions included listening with one or both ears, in multiple spatial configurations.
Unilateral listening involved listening with the self-reported better ear (bilateral CI users) or with the implanted ear alone (SSD CI users). In unilateral listening, the electrical stimulus delivered to the test ear was always calculated as if the listeners were wearing a pair of MOC or STD processors, as appropriate. Furthermore, in unilateral listening, the signal was always presented in front of or ipsilateral to the test ear, as no benefit of MOC processing was expected for signals presented contralateral to the test ear (see below).
Bilateral listening involved listening with the two implants (bilateral CI users) or combining acoustic stimulation for the normal-hearing ear with electrical stimulation for the implanted ear (SSD CI users). For SSD CI users, acoustic thresholds are elevated in the normal-hearing ear when the implanted ear is stimulated electrically, an effect probably due to an inhibition of cochlear mechanical responses in the normal-hearing ear by activation of the contralateral MOCR with the electrical stimulus delivered in the implant (James et al. 2001; Lin et al. 2013). We assumed that this was indeed the case. Consequently, in bilateral listening, the electrical stimulus delivered in the implanted ear of SSD CI users was calculated as if these listeners were wearing a pair of processors (one per ear) and the acoustic stimulus delivered in the normal-hearing ear was unprocessed (i.e., identical to the stimulus that a normal-hearing person would have had at that ear for the corresponding speech-noise spatial configuration).
Before any testing, electrical current levels at maximum comfortable loudness (MCL) were measured using the method of adjustment. Minimum stimulation levels (i.e., thresholds) were set to 0, 5, or 10 percent of MCL values, according to each participant’s clinical fitting (Boyd 2006). Processor volumes were set using the STD strategy to ensure that sounds at the two ears were perceived as comfortable and equally loud. Threshold and MCL levels, as well as processor volumes, remained identical for the MOC strategy to ensure that contralateral inhibition produced the corresponding reductions in stimulation amplitudes (i.e., reduced loudness or audibility) relative to the STD condition (Fig. 2A).
SRTs were measured using the hearing-in-noise test (HINT; Nilsson et al. 1994). Speech was presented at a fixed level of −20 dB full-scale (FS; where 0 dB FS corresponds to a sinusoid with peak amplitude at unity†) in competition with adaptive steady, speech-shaped HINT noise. Thirty sentences were presented for each test condition. The first 10 sentences were always the same and were included to give listeners an opportunity to become familiar with the processing strategy tested during that run. The SNR changed in 4-dB steps between sentences 1 and 14 and 2-dB steps between sentences 14 and 30. The SRT was calculated as the mean of the final 17 SNRs (the 31st SNR was calculated and used in the SRT estimate but not actually presented).
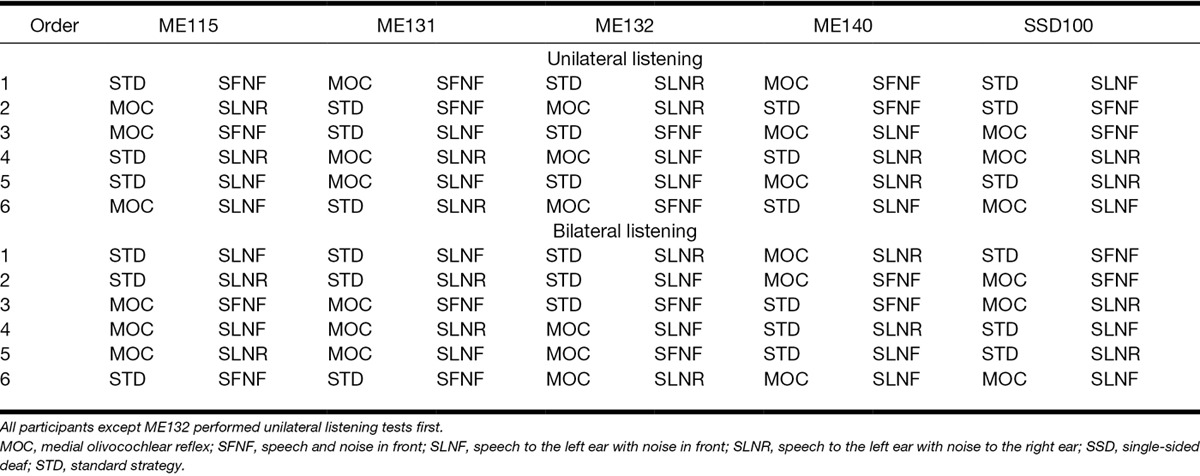
SRTs were measured for three spatial configurations of target speech and noise masker. As outlined in Figure 1, these were achieved by convolving monophonic recordings with generic diffuse-field equalized head-related transfer functions (HRTFs) for a Knowles Electronics Manikin for Acoustic Research (KEMAR; Gardner & Martin 1995). Spatial configurations included a condition referred to as speech front, noise front (SFNF) with the speech and noise sources colocated in front of the listener at 0 degrees azimuth; a condition referred to as speech left, noise front (SLNF) with the speech and noise sources at 270 and 0 degrees azimuth, respectively; and a condition referred to as speech left, noise right (SLNR) with the speech and noise sources at 270 and 90 degrees azimuth, respectively. Speech was actually presented to the self-reported better ear for the bilateral CI users and to the implanted ear for the SSD CI users; however, the “speech-left” nomenclature was chosen by convention. As explained above, participants were tested with both ears together (bilateral/SSD) and with one implant alone (unilateral). One SRT was obtained for each strategy and spatial configuration, amounting 12 SRT measurements per subject in total: 2 strategies (MOC and STD) × 3 spatial configurations (SLNR, SLNF, and SFNF) × 2 listening conditions (unilateral and bilateral). Unilateral listening tests were administered separately from bilateral listening tests. All participants except ME132 performed unilateral listening tests first. The test order was otherwise different across participants, as shown in Table 2.
TABLE 2.
Test order per participant
The MATLAB software environment (R2013a, The Mathworks, Inc.) was used to perform all signal processing and implement all test procedures, including the presentation of electric and acoustic stimuli. Stimuli were generated digitally (at 20 kHz sampling rate, 16-bit quantization), processed through the corresponding coding strategy, and the resulting electrical stimulation patterns delivered using the Research Interface Box 2 (RIB2; Department of Ion Physics and Applied Physics at the University of Innsbruck, Innsbruck, Austria) and each patient’s implanted receiver/stimulator(s). Acoustic signals were presented to SSD CI users via Sony MDR-V600 circumaural headphones using an analog output port from a National Instruments PCIe-6351 data acquisition card, a Mackie 1402-VLZ audio mixer and a headphone buffer (HB6) and programmable attenuator (PA4) made by Tucker-Davis Technologies. The amount of acoustic attenuation was adjusted to produce equally loud speech compared with a STD processor in the implanted ear.
RESULTS
Example Electrical Stimulation Patterns
Figure 3A–D presents example channel output signals (plots of processor output amplitude as a function of time for individual frequency channels) for the STD (top panels) and the MOC (middle panels) strategies, and for two spatial configurations of signal and noise sources: SFNF (left panels) and SLNR (right panels). The stimulus was a −20 dB FS, 2-kHz pure tone in continuous white noise at 0 dB SNR. Both the noise and the tone were filtered through appropriate HRTFs to mimic free-field conditions, as shown in Figure 1. To facilitate the analysis, Figure 3E, F illustrates corresponding electrical stimulation patterns (plots of peak electrical current amplitude versus frequency channel number) at time ~29 msec indicated by the vertical dotted lines in Figure 3A–D; that is, well after the effects of dynamic compression became stable. An identical noise token (i.e., frozen noise) was used to facilitate visual comparison across strategies and conditions.
Fig. 3.
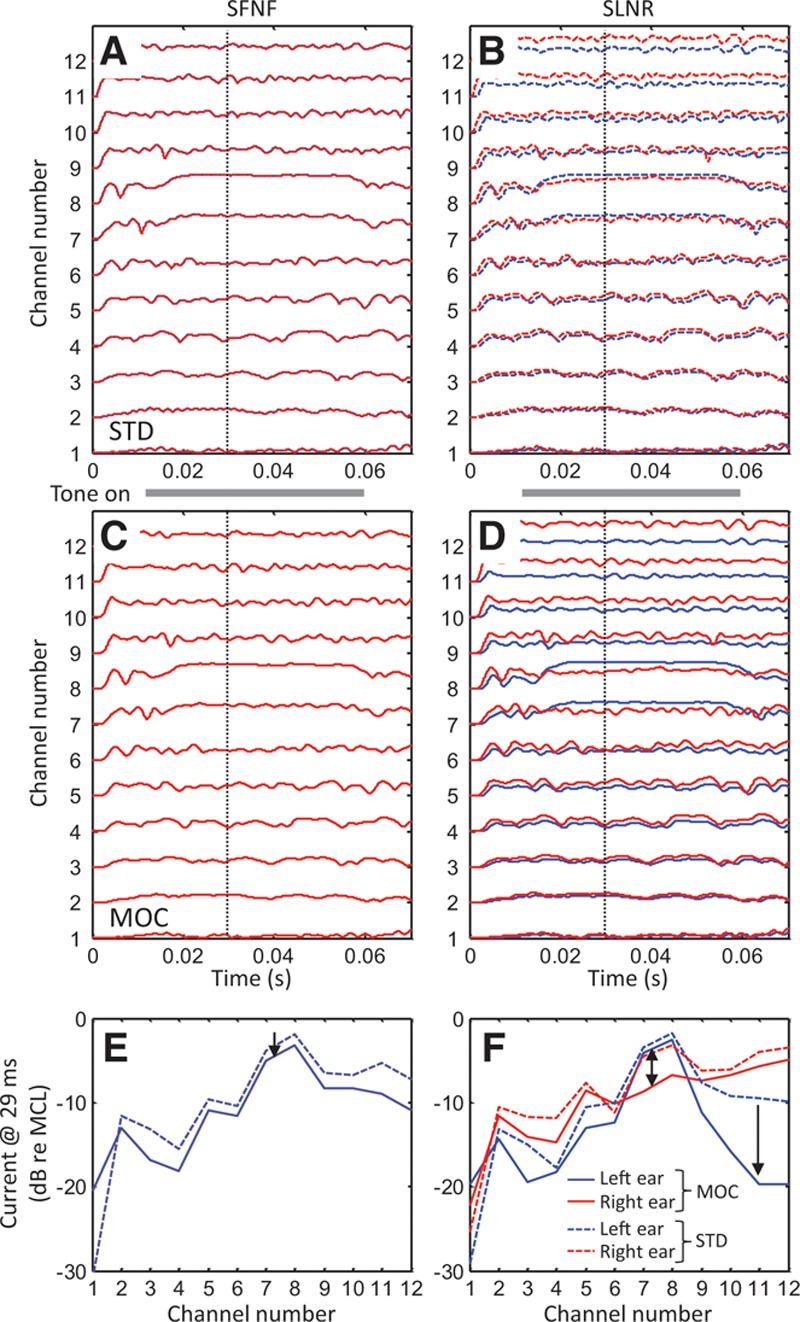
Bilateral electrical stimulation patterns generated with the STD and MOC strategies. The stimulus was a −20 dB FS, 2-kHz pure tone signal in continuous white noise at 0 dB SNR. The tone had 10-msec onset and offset ramps and was on over the time period from 10 to 60 msec, as indicated by the thick gray bar between the top two panels. Panels on the left and on the right illustrate results for the SFNF and SLNR spatial configurations, respectively. A–D, Electrical current amplitude as a function of time for each frequency channel for the STD (A, B) and the MOC (C, D) strategy. E–F, Electrical current amplitude at time 29 msec (vertical dotted lines in A–D) as a function of frequency channel number. Channels 1 and 12 are the lowest and highest in frequency, respectively. Blue and red traces illustrate results for the left and the right ears, respectively. Note the overlap between the red and blue traces in (A), (C), and (E). MOC indicates medial olivocochlear reflex; SFNF, speech front, noise front; SLNR, speech left, noise right; SNR, signal-to-noise ratio; STD, standard strategy.
When the signal and the noise are both in front of the listener and identical at the input of the two processors (SFNF condition, left panels in Fig. 3), electrical stimulation patterns are identical at the two ears, hence the overlap between the patterns at the left (blue trace) and right ears (red trace). While the overlap occurs for both strategies, peak output amplitudes are higher for the STD than for the MOC strategy (i.e., the dashed traces are above the continuous traces in Fig. 3E). This result is obtained because, with identical stimuli at the two ears, the two MOC processors inhibit each other by the same amount, linearizing the compression functions in each of the processors and thereby reducing the current amplitude compared with the STD strategy. Perceptually, this linearization might reduce audibility slightly (downward pointing arrow in Fig. 3E) but in doing so, it may increase the number of auditory nerve fibers that function within their dynamic range (Guinan 2006; Chintanpalli et al. 2012).
Figure 3F shows corresponding peak electrical stimulation patterns for a condition where the signal and the noise are presented to the left and right ears, respectively (SLNR condition). In this case, the acoustic head-shadow effect increases the SNR at the left ear compared with the SFNF condition. This explains that, for the STD strategy (dashed traces), the output from the channel containing the greatest signal energy (#8) is higher for the left than for the right ear, whereas the output from the channels containing the greatest noise energy (#9 to #12) is higher on the right ear. The stimulation patterns for the MOC strategy are notably different. Because of mutual contralateral inhibition, the interaural current difference for the signal channel (#8) is greater than for the STD strategy (double arrow in Fig. 3F). In addition, the processor for the left ear conveys less noise, as seen in the reduction of amplitudes in channels containing the highest levels of energy from the noise (downward pointing arrow in Fig. 3F). As a result, the left-ear processor conveys mostly the signal while the right-ear processor conveys mostly the noise. In perceptual terms, these changes might (1) increase the SNR for the ear on the same side as the signal; (2) increase the apparent spatial separation between the signal and the noise, compared with the STD strategy. Although not shown, similar observations are obtained with other lateral positions of the signal and noise sources.
Figure 4 shows example bilateral “electrodograms” (i.e., graphical representations of processors’ output amplitudes as a function of time and frequency-channel number) for a speech signal in competition with noise and for the STD and MOC strategies. In this example, the disyllabic Spanish word diga was uttered in simulated free-field conditions by a female speaker located on the left side of the head (at 270 degrees azimuth) while a noise source located on the right side of the head (at 90 degrees azimuth) generated speech-shaped noise (SLNR condition). The speech and noise tokens were presented at the same level (−20 dB FS), hence the SNR was 0 dB. Approximate spectrograms for the word and the noise are shown in Figure 4A and B, respectively, as the output from the processors’ filter banks (BPF in Fig. 1). As shown in Figure 1, up to the filter bank stage, signal processing was identical and linear for the STD and MOC strategies.
Fig. 4.
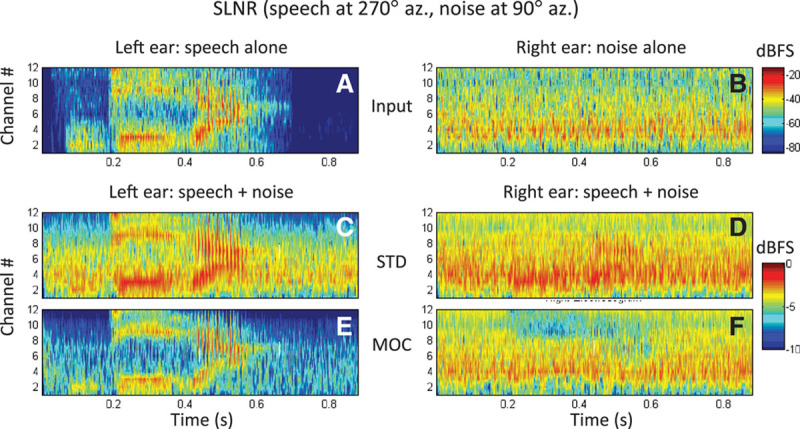
Bilateral electrodograms for the SLNR spatial configuration generated with the STD and MOC strategies. The stimulus is the Spanish word diga at −20 dB FS in speech-shaped noise at 0 dB SNR. Each panel illustrates output amplitude (color scale, in dB FS) as a function of time (abscissa) and channel number (ordinate). In all panels, output amplitudes are shown for 12 channels (with channel #1 being the lowest in frequency) but the color shading has been interpolated across channels to make the plot look like a spectrogram. A, Magnitudes at the output of the left-ear linear filter bank (Fig. 1) for the speech alone. B, Magnitudes at the output of the right-ear linear filter bank for the noise alone. Note that the plots in (A) and (B) can be thought of as acoustic spectrograms of the word and noise tokens alone at the left and right ears, respectively. C, D, Electrodograms for the left- and right-ear STD processors, respectively. E, F, Corresponding electrodograms for the left- and right-ear MOC processors, respectively. Note the different decibel range illustrated by the two color bars: the narrower range (bottom) illustrates the compressed range of output amplitudes while the broader range (top) illustrates the range of input amplitudes. FS indicates full scale; MOC, medial olivocochlear reflex; SLNR, speech left, noise right; SNR, signal-to-noise ratio; STD, standard strategy.
For the STD strategy (middle row), the fixed compression in the left ear amplifies the noise and reduces the effective SNR in that ear compared with the acoustic (unprocessed) stimulus (compare Fig. 4C with Fig. 4A). Similarly, the fixed compression in the right ear amplifies the word in the right ear; while this might improve the SNR in the right ear, the SNR remains negative in this ear (Fig. 4D). By contrast, the MOC strategy delivers a lower-amplitude but clear word to the left ear (Fig. 4E), the ear nearest to the speech source. This is because at 0 dB SNR, the spectro-temporal distribution of the word’s energy is more sparse than that of the noise and so the word features in the left ear are comparatively higher in amplitude than the noise in the right ear and inhibit the noise in the right ear more than the other way round. This also enhances the interaural current difference at the times and in the channels where the word features occur. Furthermore, in this particular spatial configuration, where the noise is at 90 degrees azimuth, the noise energy is higher on the right ear and thus inhibits the noise in the left ear at the times and in the frequency channels where the stronger speech features do not occur. As a result, the MOC strategy delivers a slightly lower-amplitude but clear word in the left ear (Fig. 4E), spectro-temporal word-modulated noise in the right ear (Fig. 4F), and less overall noise. Some of these benefits are admittedly most obvious for this particular spatial configuration (SLNR) but still hold for other spatial configurations (not shown). Furthermore, we have shown elsewhere that similar effects occur for a speech source presented in competition with another speech source (Lopez-Poveda 2015; Lopez-Poveda et al. 2016).
Altogether, the electrodograms suggest that the MOC strategy could facilitate the perception of speech in noisy backgrounds both in bilateral listening if the CI user were able to pay attention to the better ear, and also in unilateral listening so long as the target signal is on the same side of the head as the CI. The MOC strategy could also enhance the lateralization of speech, and possibly spatial segregation, in situations with multiple spatially nonoverlapping sound sources. In the next section, it is experimentally shown that this was actually the case.
Speech-in-Noise Intelligibility Tests
Figure 5 shows individual (left panels) and mean SRTs (right panels) measured with the STD and MOC strategies in unilateral (top) and bilateral (bottom) listening for the three spatial configurations of speech and noise sources.
Fig. 5.
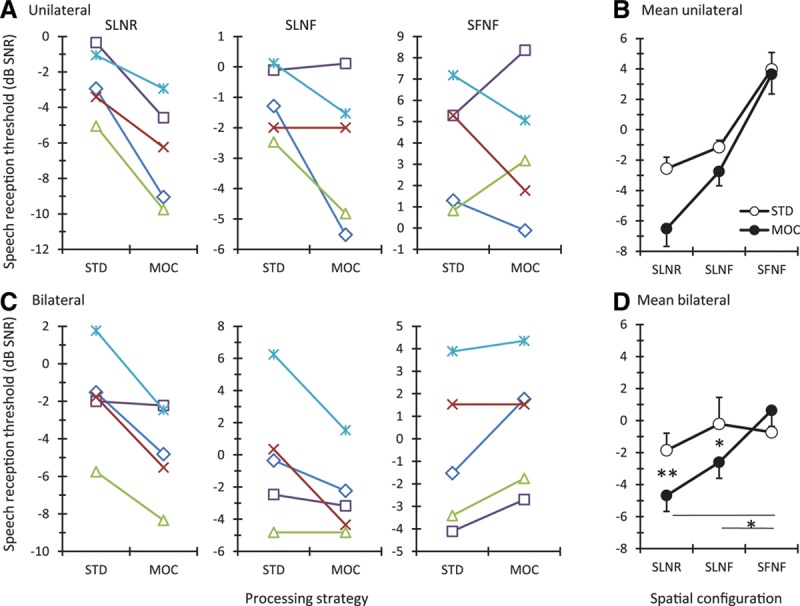
Speech reception thresholds measured with the STD and MOC strategies. A, C, Individual scores for bilateral and unilateral listening, respectively. Each symbol is for a different participant: ME115 (multiplication), ME131 (asterisk), ME132 (diamond), ME140 (square), and SSD100 (triangle). Each panel is for a different spatial speech-noise configuration, as indicated at the top. B, D, Mean scores (N = 5) for unilateral and bilateral listening, respectively. Error bars depict one standard error of the mean. Asterisks indicate statistically significant pairwise differences at 95% (*) and 99% (**) confidence levels. MOC indicates medial olivocochlear reflex; SFNF, speech and noise in front; SLNF, speech to the left ear with noise in front; SLNR, speech to the left ear with noise to the right ear; SSD, single-sided deaf; STD, standard strategy.
The mutual MOCR-inspired inhibition between the MOC processors significantly improved mean SRTs for spatially separated speech and noise sources. In unilateral listening (Fig. 5B), a two-way repeated measures analysis of the variance indicated significant main effects of processing strategy [F(1, 4) = 11.41, p = 0.028] and spatial configuration [F(2, 8) = 159.80, p < 0.001]. The interaction between the two variables was not significant [F(2, 8) = 3.62, p = 0.08]. In contrast, when using two ears (Fig. 5D), a significant interaction was observed [F(2, 8) = 18.84, p < 0.001]. Post hoc pairwise comparisons (using the Holm-Sidak method) indicated that the mutual inhibition between the MOC processors significantly aided speech recognition in bilateral listening (SRTs improved compared with the STD strategy) when the signal and the masker were at different spatial locations, for both the signal left and noise front (SLNF; p = 0.015) and signal left and noise right (SLNR; p = 0.007) spatial configurations. The mutual inhibition also produced significant spatial release from masking in the bilateral listening conditions, something that did not occur with fixed compression (STD strategy) (SRT comparisons for the factor “spatial configuration” within the MOC strategy produced the following p values: SFNF versus SLNR, p < 0.001; SFNF versus SLNF, p = 0.015; SLNF versus SLNR, p = 0.061). The facilitating effect of contralateral inhibition for spatially separate speech and noise sources also can be seen in the results for the individual subjects (Fig. 5A, C).
As a control, the bilateral CI users also were asked to recognize monosyllabic words in quiet using the same spatial arrangements as in the SRT measures (signal left and signal front). In this case, no differences were observed between processing strategies for either bilateral [F(1, 2) = 0.03, p = 0.873] or unilateral listening [F(1, 2) = 1.00, p = 0.423]. Altogether, the results show that the two processing strategies produced comparable results in quiet and that the MOC strategy improved speech recognition in speech-shaped noise.
DISCUSSION
A binaural CI sound coding strategy has been proposed to mimic some of the effects of the contralateral MOCR with CIs. The approach involves a frequency-specific, contralateral control of dynamic compression inspired by the natural control of BM compression provided by the MOCR. The present results show that, on average, this strategy can (1) improve the recognition of speech presented in competition with steady noise by bilateral CI users or SSD CI users in bilateral listening conditions, (2) improve the recognition of speech presented in competition with noise in unilateral CI users when the target speech is on the CI side of the user, and (3) produce significant spatial release from masking for the studied conditions.
For most individual participants, intelligibility was better or comparable with the MOC than with the STD strategy for conditions where the speech and noise sources were spatially separated (SLNR and SLNF in Fig. 5A, C); for colocated sources, by contrast, some participants benefited from the MOC strategy while others did not (SFNF condition in Fig. 5A, C). The reason for the latter result is uncertain and we can only conjecture. Compared with the STD strategy, the MOC strategy enhances the SNR in the better ear (Fig. 4) and also the depth of amplitude modulations within individual frequency channels (the latter effect emerges from having a more linear system and although it has not been explicitly shown here, it has been reported in Fig. 15 of Lopez-Poveda 2015). In addition, the MOC strategy delivers less overall electrical current than the STD strategy, something that may increase the proportion of auditory nerve fibers functioning within their dynamic range. These effects may be regarded as positive for improving intelligibility. Delivering less current, however, reduces loudness perception. Indeed, participants voluntarily reported stimuli to sound softer with the MOC than with the STD strategy. This might have compromised audibility and hence intelligibility in some conditions. No attempt was made to compensate for the reduction in loudness using a higher volume in the MOC than in the STD strategy because one implicit aim of the present study was to test the notion that the natural MOCR improves intelligibility even though it reduces auditory sensitivity (Chintanpalli et al. 2012). As a result, intelligibility with the MOC strategy probably depended on a tradeoff between the positive effects just mentioned and the potentially negative effects of loudness reduction. That SRTs were comparable or better with the MOC than with the STD strategy for all participants for the SLNR and SLNF spatial configurations suggests that the positive effects of MOC processing, particularly the SNR enhancement, outdid any negative effect of loudness reduction in the spatial configurations where there was a better ear. For the SFNF condition, there was no better ear because the input signals were identical at the left- and right-ear processors in that case. Furthermore, loudness was probably reduced more in this condition than in the other spatial configurations also because the input signals were identical at the two ears (e.g., notice the lower peak amplitude in the signal channel #8 for the MOC strategy in Fig. 3E compared with Fig. 3F). Therefore, the idiosyncratic results observed for the SFNF conditions may be due to different participants being more or less sensitive to the negative effects of loudness reduction. It should be noted, however, that having identical input signals at the two ears would be unlikely (not to say impossible) in real-world listening with the MOC strategy, as any asymmetry in the positioning of the pair of MOC processors may suffice to create a “better ear” effect that might compensate for any reduction in loudness. Furthermore, normal-hearing listeners and CI users benefit from listening at an angle of their interlocutor and naturally move or orient their heads in search for a better SNR thus creating a better-ear effect (Grange 2015). In other words, the results obtained in the present SFNF condition may not be representative of real-world listening with or without CIs. It might also be possible to compensate for the negative effects of loudness reduction in the MOC strategy using a higher volume.
For bilateral CI users, listening with enhanced interaural level differences improves the intelligibility of a talker presented to one side of the head in the presence of a masker talker on the other side (Brown 2014). We have shown that for different input signals at the two ears, the MOC strategy enhances the interaural current difference in a frequency specific manner (Fig. 3F; see also Lopez-Poveda et al. 2016). Therefore, one might wonder whether the better intelligibility with the MOC strategy is the result of enhanced interaural current differences rather than or in combination with the other previously mentioned positive effects, particularly with the enhanced SNR in the better ear. Disentangling the relative contributions of each effect for the improved intelligibility is not possible because in the MOC strategy all of the effects in question are concomitant and occur as a result of contralateral inhibition (for example, in Fig. 4, the MOC strategy simultaneously provides a better SNR in the left ear and a larger interaural current difference at any time instant and for every frequency channel).
In the MOC strategy, the strength of the effects just described may be increased or decreased depending on the amount of contralateral inhibition. As explained in the “Materials and Methods,” here the amount of contralateral inhibition was selected ad hoc from a range of values tested in pilot measures seeking to improve intelligibility. A comparison with the amount of inhibition caused by the natural contralateral MOC is not straight forward. As shown in Figure 2, the actual inhibition in the MOC strategy varied nonlinearly depending on the input and output levels to/from the back-end compressor for each frequency channel, and these depended on the level of the stimulus and the distribution of its energy across frequency channels. Figure 2B shows that for a pure-tone stimulus with a level of −20 dB FS, the inhibition was at most 5 dB and typically less (gray line in Fig. 2B). In chinchillas, for a 60-dB-SPL tone at the characteristic frequency, electrical stimulation of the MOC bundle inhibits BM responses by ~5 dB (e.g., Fig. 2B in Cooper & Guinan 2006). It is hard to say whether −20 dB FS for a CI user corresponds to 60 dB SPL for a healthy chinchilla, but (1) humans and chinchillas have similar hearing ranges, and (2) these two levels are typically used for testing speech perception in normal hearing and CI user populations because they sound comfortably loud. Therefore, in so far as a comparison with the natural contralateral MOCR is possible, the inhibition used in our MOC strategy was in line with the inhibition of BM responses caused by the natural MOCR.
We note that the mimicking of the MOCR actions in this study was limited to modulating compression on the contralateral sides in like-channels of processing. For example, a change in energy in a band-pass channel on one side would produce a change in the compression function for the same band-pass channel on the contralateral side. Thus, effects of the dynamic changes in compression produced by the control signals from the contralateral side were evaluated, but other aspects of the MOCR in normal hearing were not evaluated, including (1) the slow time courses for activation and deactivation of the reflex (Backus & Guinan 2006), (2) the half-octave frequency shift in the site of action of the MOCR (Lilaonitkul & Guinan 2009b), and (3) the greater inhibition by the MOCR in the apical region of the cochlea compared with other regions (Lilaonitkul & Guinan 2009a; Aguilar et al. 2013). In our MOC strategy, we used on-frequency contralateral inhibition, a fast time course of activation, and all cochlear regions were weighted equally (see “Materials and Methods”). Preliminary testing using longer time-constants of activation for the contralateral inhibition suggested the possibility for greater benefits than those reported here. Further research is necessary to test the perceptual effects of closer mimicking of the contralateral MOCR function on compression with CIs.
The natural MOCR may be activated by ipsilateral and contralateral stimuli (Guinan et al. 2003; Guinan 2006). The focus here was on mimicking some contralateral MOCR effects but the ipsilateral MOCR may by itself improve understanding speech in competition with noise (Brown et al. 2010; Clark et al. 2012; Chintanpalli et al. 2012). Incidentally, the present condition for identical stimuli at the two ears (SFNF in Figs. 3 and 5) would be a very rough approximation to mimicking the effects of the ipsilateral MOCR on compression with CIs. No significant benefit from dynamic compression was observed in this condition on average (Fig. 5B, D), but some participants benefited from it in unilateral listening (SFNF condition in Fig. 5A). This suggests that frequency-specific, ipsilateral control of dynamic compression might also be advantageous by itself or in combination with contralateral control. Further research is necessary to test these possibilities.
Hearing aids restore audibility, but their users still have great difficulties understanding speech in noisy acoustic environments, such as restaurants or workplaces (Kochkin 2002). Hearing aid users who suffer from outer hair cell dysfunction also show reduced or absent cochlear mechanical compression (Ruggero et al. 1990; Lopez-Poveda & Johannesen 2012; Johannesen et al. 2014) and thus possibly reduced MOCR effects. For these hearing aid users, compression is a fundamental aspect of hearing aid processing. The present results show that recognition of speech presented in competition with noise can be improved with frequency-specific, contralateral control of compression. The MOC strategy as implemented, or a modified version of it, may be usefully applied also in hearing aids.
There exist other binaural sound processing strategies for auditory prostheses. Some of them use binaural interaction to detect and maximize desired sound features or signals. For example, there are binaural strategies that detect and enhance interaural sound localization cues (Francart et al. 2013), the SNR (Blamey 2012), or a signal of interest (Patricio Mejia et al. 2009). Other strategies, typically referred to as “binaural beamformers,” consist of processing the acoustic stimulus for improving the SNR before the actual sound coding takes place (reviewed by Baumgärtel et al. 2015a, 2015b). For bilateral CI users, binaural beamformers can improve SRTs by about 5 to 7 dBs in spatially realistic multi-talker or cafeteria-type scenarios, and about 10 dB in conditions involving a spatially separated single competing talker (e.g., Fig. 2 in Baumgärtel et al. 2015a). Although test conditions were different, this benefit seems higher than that provided by the MOC strategy (3 and 4 dB for the SLNR condition in bilateral and unilateral listening, respectively). Existing binaural strategies and beamformers, however, require the use of multiple adaptive microphones, speech detection and enhancement algorithms, and/or making assumptions about the characteristics of the target and/or the interferer sounds, or their spatial location (Baumgärtel et al. 2015b). Like some of those strategies and beamformers, the MOC strategy can enhance the SNR (Fig. 4) and the interaural level differences (Fig. 3). Unlike those strategies and beamformers, however, the enhancements in the MOC strategy emerge naturally from its physiologically inspired functioning rather than from detection and enhancement (or suppression) of particular sound features or signals. Furthermore, the implementation of the MOC strategy in a device would require a single microphone per processor, no complex preprocessing or assumptions about the signal of interest or its location, and probably less interaural data exchange.
Binaural strategies that involve the linking of compression across the ears have been proposed for use in hearing aids (Kollmeier et al. 1993; Kates 2008). One such strategy is inspired by the contralateral MOCR (Kates 2009). One implementation of that strategy involves using the weighted sum of the input amplitudes at the two ears to control the compression separately in each ear (Fig. 13.3 in Kates 2008). An alternative implementation consists of linking the left- and right-ear compressors so that the gain applied at the two ears is the same at each time instant and equal to the minimum of the gains that would have been applied at each ear when compression was independent (Fig. 13.4 in Kates 2008). An analysis of the output signals from these strategies revealed that they can reduce the noise, at least for positive SNRs in a SLNR spatial configuration (Kates 2008). Compared with having independent compression at the two ears, a two-channel version of the second strategy improved speech in noise intelligibility for normal-hearing listeners for binaural listening and for monaural listening to the ear with the better SNR (Wiggins & Seeber 2013), and a multichannel version of the same strategy decreased the target-to-masker spatial separation required for normal-hearing listeners to perform at the threshold of intelligibility (Schwartz & Shinn-Cunningham 2013). To our knowledge, it remains to be shown that these strategies provide a benefit for hearing aid users or that they may be adapted for use in CIs. The MOC strategy differs from the strategies of Kates (2009) at least in (1) that compression is controlled using the contralateral output rather than the input, and (2) it is designed to control the back-end compression in a CI rather than the compression in a hearing aid. Nonetheless, the results for Kates’ strategies are broadly consistent with the present results and thus support the idea that MOC-inspired contralateral control of dynamic compression can improve speech in noise intelligibility and spatial release from masking.
Admittedly, the MOC strategy is only a rough experimental CI model of the contralateral MOCR. Nevertheless, the present results support the idea, reviewed in the “Introduction,” that the contralateral MOCR plays an important role for understanding speech in competition with noise despite its causing a small reduction in audibility. They further suggest that the contralateral MOCR might be partly responsible for spatial release from masking and provide a hypothetical mechanism for how this might happen (Fig. 4). The effects of the MOCR are absent for electrically stimulated ears and this would be consistent with the diminished spatial release from masking experienced by CI users (Ihlefeld & Litovsky 2012). The roles of the contralateral MOCR possibly go beyond those explored here. The MOCR may for example be essential for normal development of cochlear active mechanical processes (Walsh et al. 1998) or for minimizing deleterious effects of noise exposure on cochlear function (Maison et al. 2013).
The present results were made possible with the unique stimulus controls provided by the CI. Additional theories and putative mechanisms of hearing could be evaluated with those controls.
ACKNOWLEDGMENTS
We thank Enzo L. Aguilar, Peter T. Johannesen, Peter Nopp, Patricia Pérez-González, and Peter Schleich for insightful discussions.
The value of c, the parameter that controls the back-end compression function (Eq. 1), is typically equal for all processing channels. The amount of compression, however, can be different across electrodes because for a fixed acoustic input range and a fixed value of c, the lowest (threshold) and highest (maximum comfortable level) electrical current delivered by the implant can differ across electrodes.
The digital signals at the input of the processors always had instantaneous peak amplitudes within the range (−1, +1) to avoid clipping and associated distortion.
This research was funded by European Regional Development Funds, by the Spanish Ministry of Economy and Competitiveness (Grants BFU2009-07909 and BFU2012-39544-C02) to E.A.L.-P. and by MED-EL GmbH.
E.A.L.-P. conceived the processor and the study. A.E.-M. and J.S.S. implemented the sound processors and testing tools. R.D.W. collected the data. E.A.L.-P., A.E.-M., and J.S.S. analyzed the data. E.A.L.-P. and J.S.S. wrote the manuscript. All authors designed the testing conditions and revised the manuscript.
Portions of this article were presented at the 167th Meeting of the Acoustical Society of America on May 5–9, 2014, in Providence, Rhode Island, and at the Bernstein Sparks Workshop, 13th International Conference on Cochlear Implants on June 18–21, 2014, in Munich, Germany.
To protect the intellectual property, the University of Salamanca has filed applications to the Spanish Patent Office (WO2013/164511A1) and to the European Patent Office (WO2015/169649A1) related to the present research.
The authors have no conflicts of interest to disclose.
REFERENCES
- Aguilar E., Eustaquio-Martin A., Lopez-Poveda E. A.Contralateral efferent reflex effects on threshold and suprathreshold psychoacoustical tuning curves at low and high frequencies. J Assoc Res Otolaryngol(2013)14341–357. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Aguilar E., Johannesen P. T., Lopez-Poveda E. A.Contralateral efferent suppression of human hearing sensitivity. Front Syst Neurosci(2014)8251. [DOI] [PMC free article] [PubMed] [Google Scholar]
- American National Standards Institute American National Standards Institute S3.6 Specification for Audiometers(1996)New York, NY: American National Standards Institute. [Google Scholar]
- Backus B. C., Guinan J. J., JrTime-course of the human medial olivocochlear reflex. J Acoust Soc Am(2006)1195 Pt 12889–2904. [DOI] [PubMed] [Google Scholar]
- Bacon S. P.Bacon S. P., Fay R. R., Popper A. N.Overview of auditory compression. In Compression: From Cochlea to Cochlear Implants(2004)New York, NY: Springer; 1–17. [Google Scholar]
- Baumgärtel R. M., Hu H., Krawczyk-Becker M., et al. Comparing binaural pre-processing strategies II: Speech intelligibility of bilateral cochlear implant users. Trends Hear. 2015a;19:1–18. doi: 10.1177/2331216515617917. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Baumgärtel R. M., Krawczyk-Becker M., Marquardt D., et al. Comparing binaural pre-processing strategies I: Instrumental evaluation. Trends Hear. 2015b;19:1–16. doi: 10.1177/2331216515617916. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Blamey P.Binaural noise reduction US Patent 2012/0128164 A1(2012)
- Boyd P. J.Effects of programming threshold and maplaw settings on acoustic thresholds and speech discrimination with the MED-EL COMBI 40+ cochlear implant. Ear Hear(2006)27608–618. [DOI] [PubMed] [Google Scholar]
- Brown C. A.Binaural enhancement for bilateral cochlear implant users. Ear Hear(2014)35580–584. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brown G. J., Ferry R. T., Meddis R.A computer model of auditory efferent suppression: Implications for the recognition of speech in noise. J Acoust Soc Am(2010)127943–954. [DOI] [PubMed] [Google Scholar]
- Chintanpalli A., Jennings S. G., Heinz M. G., et al. Modeling the anti-masking effects of the olivocochlear reflex in auditory nerve responses to tones in sustained noise. J Assoc Res Otolaryngol(2012)13219–235. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Clark N. R., Brown G. J., Jürgens T., et al. A frequency-selective feedback model of auditory efferent suppression and its implications for the recognition of speech in noise. J Acoust Soc Am(2012)1321535–1541. [DOI] [PubMed] [Google Scholar]
- Cooper N. P., Guinan J. J., JrEfferent-mediated control of basilar membrane motion. J Physiol(2006)576Pt 149–54. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Francart T., Wouters J., van Dijk B.Localization in a bilateral hearing device system Patent US8503704B2(2013) [Google Scholar]
- Froud K. E., Wong A. C., Cederholm J. M., et al. Type II spiral ganglion afferent neurons drive medial olivocochlear reflex suppression of the cochlear amplifier. Nat Commun(2015)67115. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gardner W. G., Martin K. D.HRTF measurements of a KEMAR. J Acoust Soc Am(1995)973907–3908. [Google Scholar]
- Grange J. A. Realising the head-shadow benefit to cochlear implant users(2015)PhD Thesis, Cardiff University. [Google Scholar]
- Guinan J. J., JrOlivocochlear efferents: Anatomy, physiology, function, and the measurement of efferent effects in humans. Ear Hear(2006)27589–607. [DOI] [PubMed] [Google Scholar]
- Guinan J. J., Jr, Backus B. C., Lilaonitkul W., et al. Medial olivocochlear efferent reflex in humans: Otoacoustic emission (OAE) measurement issues and the advantages of stimulus frequency OAEs. J Assoc Res Otolaryngol(2003)4521–540. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hood L. J., Berlin C. I., Hurley A., et al. Contralateral suppression of transient-evoked otoacoustic emissions in humans: Intensity effects. Hear Res(1996)101113–118. [DOI] [PubMed] [Google Scholar]
- Ihlefeld A., Litovsky R. Y.Interaural level differences do not suffice for restoring spatial release from masking in simulated cochlear implant listening. PLoS One(2012)7e45296. [DOI] [PMC free article] [PubMed] [Google Scholar]
- James C., Blamey P., Shallop J. K., et al. Contralateral masking in cochlear implant users with residual hearing in the non-implanted ear. Audiol Neurootol(2001)687–97. [DOI] [PubMed] [Google Scholar]
- Johannesen P. T., Pérez-González P., Lopez-Poveda E. A.Across-frequency behavioral estimates of the contribution of inner and outer hair cell dysfunction to individualized audiometric loss. Front Neurosci(2014)8214. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kates J. M.Digital Hearing Aids(2008)San Diego, CA: Plural Publishing [Google Scholar]
- Kates J. M.Binaural compression system US Patent 7630507B2(2009) [Google Scholar]
- Kim S. H., Frisina R. D., Frisina D. R.Effects of age on speech understanding in normal hearing listeners: Relationship between the auditory efferent system and speech intelligibility in noise Speech Commun(2006)48862 [Google Scholar]
- Kochkin S.Consumers rate improvements sought in hearing instruments. Hear Rev(2002)918–22. [Google Scholar]
- Kollmeier B., Peissig J., Hohmann V.Real-time multiband dynamic compression and noise reduction for binaural hearing aids. J Rehabil Res Dev(1993)3082–94. [PubMed] [Google Scholar]
- Lilaonitkul W., Guinan J. J., Jr Human medial olivocochlear reflex: Effects as functions of contralateral, ipsilateral, and bilateral elicitor bandwidths. J Assoc Res Otolaryngol. 2009a;10:459–470. doi: 10.1007/s10162-009-0163-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lilaonitkul W., Guinan J. J., Jr Reflex control of the human inner ear: A half-octave offset in medial efferent feedback that is consistent with an efferent role in the control of masking. J Neurophysiol. 2009b;101:1394–1406. doi: 10.1152/jn.90925.2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lin P., Lu T., Zeng F. G.Central masking with bilateral cochlear implants. J Acoust Soc Am(2013)133962–969. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lopez-Poveda E. A.Sound enhancement for cochlear implants. EU Patent WO 2015/169649A1(2015)
- Lopez-Poveda E. A., Johannesen P. T.Behavioral estimates of the contribution of inner and outer hair cell dysfunction to individualized audiometric loss. J Assoc Res Otolaryngol(2012)13485–504. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lopez-Poveda E. A., Eustaquio-Martin A., Stohl J. S., et al. Roles of the contralateral efferent reflex in hearing demonstrated with cochlear implants. Adv Exp Med Biol(2016)In press [DOI] [PubMed] [Google Scholar]
- Maison S., Micheyl C., Collet L.Medial olivocochlear efferent system in humans studied with amplitude-modulated tones. J Neurophysiol(1997)771759–1768. [DOI] [PubMed] [Google Scholar]
- Maison S. F., Usubuchi H., Liberman M. C.Efferent feedback minimizes cochlear neuropathy from moderate noise exposure. J Neurosci(2013)335542–5552. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nilsson M., Soli S. D., Sullivan J. A.Development of the hearing in noise test for the measurement of speech reception thresholds in quiet and in noise. J Acoust Soc Am(1994)951085–1099. [DOI] [PubMed] [Google Scholar]
- Patricio Mejia J., Carlile S., Dillon H. A.Method and system for enhancing the intelligibility of sounds. US Patent 2009/0304188A1(2009)
- Robles L., Ruggero M. A.Mechanics of the mammalian cochlea. Physiol Rev(2001)811305–1352. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ruggero M. A., Rich N. C., Robles L., et al. A. Axelsson, H. Borchgrevink, P. A. Hellström, D. Henderson, R. P. Hamernik, R. Salvi.The effects of acoustic trauma, other cochlear injury, and death on basilar-membrane responses to sound. In Scientific Basis of Noise-Induced Hearing Loss(1990)New York, NY: Thieme Medical Publishers; 23–35. [Google Scholar]
- Schwartz A. H., Shinn-Cunningham B. G.Effects of dynamic range compression on spatial selective auditory attention in normal-hearing listeners. J Acoust Soc Am(2013)1332329–2339. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Walsh E. J., McGee J., McFadden S. L., et al. Long-term effects of sectioning the olivocochlear bundle in neonatal cats. J Neurosci(1998)183859–3869. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wiggins I. M., Seeber B. U.Linking dynamic-range compression across the ears can improve speech intelligibility in spatially separated noise. J Acoust Soc Am(2013)1331004–1016. [DOI] [PubMed] [Google Scholar]
- Wilson B. S., Finley C. C., Lawson D. T., et al. Better speech recognition with cochlear implants. Nature(1991)352236–238. [DOI] [PubMed] [Google Scholar]
- Wilson B. S., Schatzer R., Lopez-Poveda E. A., et al. Two new directions in speech processor design for cochlear implants. Ear Hear(2005)264 Suppl73S–81S. [DOI] [PubMed] [Google Scholar]