

Abstract
Background
To extract more information, the properties of infectious disease data, including hidden relationships, could be considered. Here, blood leukocyte data were explored to elucidate whether hidden information, if uncovered, could forecast mortality.
Methods
Three sets of individuals (n = 132) were investigated, from whom blood leukocyte profiles and microbial tests were conducted (i) cross-sectional analyses performed at admission (before bacteriological tests were completed) from two groups of hospital patients, randomly selected at different time periods, who met septic criteria [confirmed infection and at least three systemic inflammatory response syndrome (SIRS) criteria] but lacked chronic conditions (study I, n = 36; and study II, n = 69); (ii) a similar group, tested over 3 days (n = 7); and (iii) non-infected, SIRS-negative individuals, tested once (n = 20). The data were analyzed by (i) a method that creates complex data combinations, which, based on graphic patterns, partitions the data into subsets and (ii) an approach that does not partition the data. Admission data from SIRS+/infection+ patients were related to 30-day, in-hospital mortality.
Results
The non-partitioning approach was not informative: in both study I and study II, the leukocyte data intervals of non-survivors and survivors overlapped. In contrast, the combinatorial method distinguished two subsets that, later, showed twofold (or larger) differences in mortality. While the two subsets did not differ in gender, age, microbial species, or antimicrobial resistance, they revealed different immune profiles. Non-infected, SIRS-negative individuals did not express the high-mortality profile. Longitudinal data from septic patients displayed the pattern associated with the highest mortality within the first 24 h post-admission. Suggesting inflammation coexisted with immunosuppression, one high-mortality sub-subset displayed high neutrophil/lymphocyte ratio values and low lymphocyte percents. A second high-mortality subset showed monocyte-mediated deficiencies. Numerous within- and between-subset comparisons revealed statistically significantly different immune profiles.
Conclusion
While the analysis of non-partitioned data can result in information loss, complex (combinatorial) data structures can uncover hidden patterns, which guide data partitioning into subsets that differ in mortality rates and immune profiles. Such information can facilitate diagnostics, monitoring of disease dynamics, and evaluation of subset-specific, patient-specific therapies.
Keywords: complexity, immunomicrobial interactions, sepsis, immunosuppression, pattern recognition, visual
Introduction
Awareness on the properties of immunological data may improve the study of infectious diseases. Here, infectious disease data-related properties are reviewed, and their desirable and undesirable consequences are considered in the process of developing a method meant to explore host–microbial interactions, which is subsequently pilot-tested.
Infectious disease data may exhibit at least five properties (i) circularity, (ii) ambiguity, (iii) hidden relationships, (iv) dynamics, and (v) complexity. Such features are associated with or may be influenced by compositional, interdependent, and non-linear relationships (1–15).
When antimicrobial immunological data are collected over time and analyzed in three-dimensional (3D) space, circularity is observed (1). Because circular data have no beginning and no end, classic statistics do not apply to such data (2–4).
Infectious disease data can be ambiguous: numerically similar data points may express different biological conditions. For instance, when lymphocyte (L), monocyte (M), or neutrophil (N) counts are analyzed, the same count can be generated by different percents (and vice versa), e.g., a count = 100 cells can consist of 60% N, 20% M, and 20% L (a healthy person), or 90% N, 5% M, and 5% L (a person with an inflammatory disorder).
Ambiguity may also be the result of temporal changes (dynamics) and/or hidden relationships (5). The analysis of complexity may uncover information usually unobserved (6–8).
Complexity involves four features (i) emergence, (ii) irreducibility, (iii) unpredictability, and (iv) autonomy (9–14). Emergence (or novelty) refers to patterns only detected when a complex (system-level) data structure is assembled. “Emergent” patterns may be alternative expressions of hidden relationships (5). Due to irreducibility and unpredictability, emergence cannot be reduced to or explained by any one variable, i.e., no “simple” and/or isolated variable can discriminate. Autonomy is associated with non-linearity: because causes and effects are not coupled, emergence (the effect) is numerically autonomous from the cause(s) (14).
Leukocyte data also exhibit compositional features. “Composition” is the term used since 1986 to describe systems characterized by three or more interacting classes –such as the three predominating cell types of the immune system (L, M, and N). Compositional data are not well described by counts (15). While percents and ratios have been proposed (16), they are not appropriate to analyze leukocyte data because the same ratio can be generated by different percents (and vice versa); e.g., an L/M ratio = 2 is generated both when L = 8%, M = 4%, and N = 88% (acute or recent inflammation) and also when L = 28%, M = 14%, and N = 58% (no inflammation).
To uncover hidden relationships –that is, to prevent ambiguity and detect “emergence” –the literature predicts that discrimination increases when the levels of complexity increase (17, 18). To increase and detect complexity, data combinations may be considered. Because the immune system is inherently combinatorial, approaches that measure combinations (interactions that involve two or more elements) have been proposed since 2000 (19, 20). Because lymphocytes and monocytes interact, at least, in antigen recognition processes (21, 22), they could be measured as interactions, e.g., using the L–M (or M–L) ratio. Because, over time, the same element can perform different functions –e.g., monocytes both promote and destroy neutrophils (23)–, dynamics should also be measured.
In addition, dichotomization should be avoided when interactions are assessed. The “cost of dichotomization” is the phrase used, since 1984, to describe the consequences of a numerical cutoff imposed on continuous data (e.g., leukocyte counts or percents). When a discontinuous (discrete) label is assigned to observations located above/below the cutoff (e.g., “infected”/“non-infected”), a substantial number of false (-positive and -negative) results will occur (24).
Therefore, some practices originated in non-biological fields (where biological complexity is not observed but data independence and linearity may be found) are not justified to study infectious disease data, which include non-linearly distributed data from interdependent leukocytes that, through interactions, perform different functions at different times (25–27).
Because linear classifiers, logistic regressions, as well as decision tree-based methods dichotomize, it is not surprising that such approaches are poorly predictive: when such approaches are analyzed in terms of “area under the curve” (AUC), they show values <75% (28, 29). Dichotomization-, AUC-based evaluations also share an assumption rarely observed in infections: their predictions are only valid when disease prevalence is 50% (30). Because leukocyte–microbial data interactions can include many levels of complexity and/or reveal data ambiguity, only methods that address such problems are desirable (31, 32). However, methods that depend on population metrics (those that utilize confidence intervals) cannot be used in personalized medicine –where patients may differ from the “average patient” (33, 34).
In contrast, approaches that do not assume the whole can be reduced to or predicted from any part (non-reductionist methods) may be adequate to explore infections, especially if they implement data partitioning and foster personalized practices. Such methods could unveil the information potentially embedded in infectious disease-related data (6, 19, 20, 35).
Here, a method that generates leukocyte data combinations (interactions) and investigates several levels of complexity was evaluated in infections. Two questions were asked (i) can blood leukocyte data possess hidden information? and (ii) if usually unobserved patterns are elicited, can complex data structures, derived from blood cells, forecast mortality?
Materials and Methods
Individuals
Two random samples of infected patients admitted to Greek hospitals in 2014, at different time frames, were analyzed. They had no history of chronic diseases but met at least three systemic inflammatory response syndrome (SIRS) criteria (36): body temperature >38°C, heart rate >90 beats/minute, tachypnea or hyperventilation (>20 breaths/minute or PACO2 < 32 mm Hg at sea level), and white blood cell count ≥12,000 or ≤4000/μl. Such criteria characterize sepsis (36). Blood samples were taken at admission from 36 (study I) and 69 (study II) patients aged 31–87, and 30-day, in-hospital mortality was determined. In addition, 7 individuals meeting the same criteria were tested up to three times, daily, from the time of their admission; and 20 non-infected, SIRS-negative individuals were tested once. This study –conceived after patients died or were discharged– was approved by the Scientific Committee of the Thriasio Hospital, Magoula, Greece (protocol 57/16-02-2015) and the University of New Mexico, United States (protocol 13-463-T-HSC). Patient records were de-identified prior to analysis.
Laboratory Methods
Human white blood cell counts and percentages, C-reactive protein (CRP), and conventional blood culture followed by susceptibility testing of the isolated microorganisms were performed. General blood examination was conducted with an automated hematology analyzer (Coulter LH 780 Analyzer, Beckman Coulter International SA, Nyon, Switzerland). Serum CPR was measured with an automated system (BN ProSpec System, Siemens AG, Erlangen, Germany). Blood cultures were performed with the automated Bactec 9249 instrument (Becton Dickinson, NJ, USA). The pathogens isolated from blood were identified and tested for their antimicrobial susceptibility with the automated microbiology system Phoenix 100 (Becton Dickinson, NJ, USA).
Leukocyte Data Structures of Several Complexity Levels
A three-step method partitioned infectious disease data into subsets. It consisted of (i) expansion (a step that augments the number of data structures available for analysis, so that hidden patterns, if present, may be detected), (ii) pattern recognition [a step that removes non-informative structures but keeps those that display distinct patterns (e.g., data inflections) and, based on such patterns, partitions the data into subsets], and (iii) statistical analysis of immune profiles (a step that analyzes leukocyte data, within- and between-subsets).
To implement the first step, dimensionless indicators (DIs) were utilized (5, 37–39). The first step was performed with a proprietary algorithm that creates DIs (5, 37). DIs are the result of any combination of counts, percentages, ratios, or products derived from the primary variables, i.e., data on lymphocytes (L), macrophages/monocytes (M), and/or neutrophils (N). For instance, based on leukocyte percentages, a single number can summarize numerous relationships, e.g., those resulting from calculating [(M/L × N/M)/(N/L × L/M)] over [(M + L/N) × (L + N/M)/(N + M)/L × (M/N)]. Because the resulting number includes all cell types but is not limited to any known biological variable or dimension, the number is dimensionless. While each DI received an identifier (e.g., AAA), DIs had no biological definition.
Dimensionless indicators were used to build and measure many levels of complexity. For instance, in the DI described above, one level of complexity (level I) is measured by each ratio of the first element or “numerator” (M/L, N/M, N/L, and L/M). Two more interactions (of level II complexity) are captured by each product (M/L × N/M, N/L × L/M). Complexity level III is explored by the composite ratio of the numerator, which includes two products [(M/L × N/M)/(N/L × L/M)]. Because the second element (“denominator”) has the same structure, the number of interactions doubles. An additional interaction (complexity level IV) is generated when the numerator and the denominator are simultaneously analyzed. When three DIs are assessed in 3D space, the number of interactions increases three times and, in addition, one more interaction (level V complexity) is produced by the overall 3D relationship. Therefore, in this example, each 3D plot can measure at least (4 × 2 + 1 × 2 + 1 × 3 + 1) 58 interactions, which cover five levels of complexity. However, because some elements include more than one cell type (e.g., M + L), the actual number of interactions and levels of complexity could be higher.
After data subsets were identified in the second step, DIs were not used anymore. Instead, in the third step, input leukocyte data were analyzed statistically. Statistical analyses were also conducted in the second step: when the exact point where 3D inflections occurred was unclear, an open-ended series of statistical tests was conducted, both before and after specific data points were assigned to different subsets. This process identified subsets that revealed the narrowest interval and were orthogonal to one another, detecting data subsets likely to differ at statistically significant levels when, later, leukocyte profiles were investigated. Together, this design (i) did not depend on numerical cutoffs (data partitioning was based on graphic patterns), (ii) did not focus on any one variable, but interactions, (iii) analyzed not one but several data structures, and (iv) conducted statistical tests after (not before) data subsets were distinguished.
When subsets differed statistically in immune profiles and mortality, internal validity was supported. When different populations showed similar patterns, external validity was likely.
Statistical Analysis
The subset corresponding to each data point was determined by linking the identification number of each data point to the spatial patterns observed in 3D plots. Because DIs were hypothetical and showed non-linear relationships, they were biologically uninterpretable and statistically intractable (14). However, after data partitioning revealed orthogonality, statistical tests were justified (40), and leukocyte data were interpretable. Analyses of medians (Mann–Whitney test) or proportions (Chi-square test), as well as 3D plots, were conducted or created with a commercial package (Minitab Inc., State College, PA, USA). Tables S1–S7 in Supplementary Material report the data and statistical test results. The footnotes of Tables S1 and S2 in Supplementary Material describe a procedure that enables readers to reproduce the main findings.
Results
The analysis of separate variables (or variables that did not measure highly complex interactions) failed to discriminate: when data from septic patients were analyzed, blood leukocyte counts, percents, or ratios did not distinguish survivors from non-survivors (Figures 1A–F). CRP data also overlapped across categories (Figures 1G,H).
Figure 1.

Non-partitioning-based (non-combinatorial) analysis of leukocyte and biomarker data. The outcomes reported within 30 days after SIRS+, infected individuals were admitted were not differentiated by input (blood leukocyte) data collected at admission. Both counts (A,B), percentages (C,D), and ratios of leukocyte cell types (E,F) as well as CRP concentrations (G,H) did not distinguish survivors from non-survivors: data overlapping was observed in both studies (blue boxes).
When 3D plots were utilized, not all plots were informative (Figures 2A,B). Even plots that showed perpendicular data inflections did not predict, based on admission data, outcomes observed 30 days later (Figures 2A–D).
Figure 2.

Elimination of non-informative patterns. The combinatorial and three-dimensional (3D) method was not always informative: many plots did not show distinct patterns (A,B), even when a single (one data point-wide) line of observations was detected (C,D).
Yet, some complex, 3D data structures showed a single (one data point-wide) line of observations, which revealed two data segments perpendicular to one another (Figures 3A,B). Therefore, at admission (before microbiological test results were completed), graphic patterns identified two data subsets. When, 2 days later, microbiological test results were available, neither bacterial species nor antibiotic susceptibility patterns explained the observed subsets (Figures S1 and S2 in Supplementary Material). In contrast, 30-day mortality was at least twice higher in the subset located at the right side of the plot (Figures 4A,B). While SIRS-negative, non-infected subjects differed in several aspects (Figure S3 in Supplementary Material), data from such individuals did not show the high-mortality pattern (Figure 4C).
Figure 3.
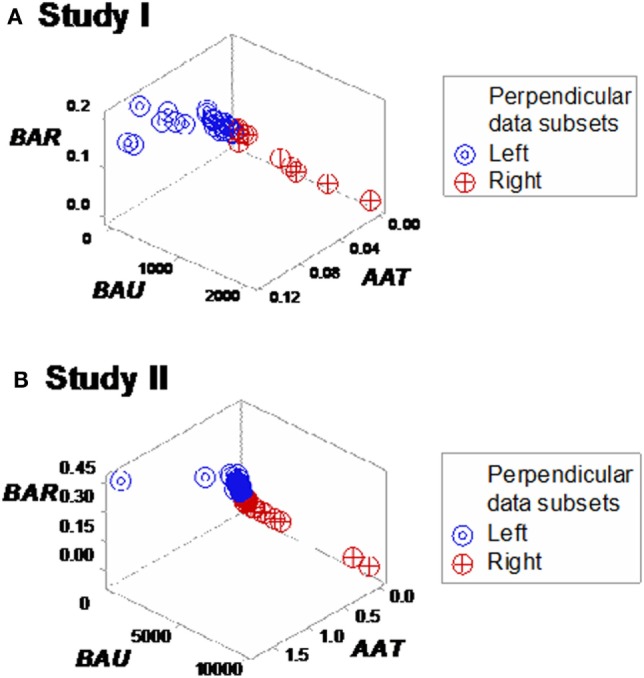
Three-dimensional (combinatorial and partitioning-oriented) analysis of dimensionless indicators derived from leukocyte data (structure I). The large number of combinations the alternative method can generate increased the likelihood of finding some informative plots. Both study I (A) and II (B) displayed a single (one data point-wide) line of observations, which consisted of two segments perpendicular to one another. Such graphic data structure improves detection because data points can only occur along the line.
Figure 4.
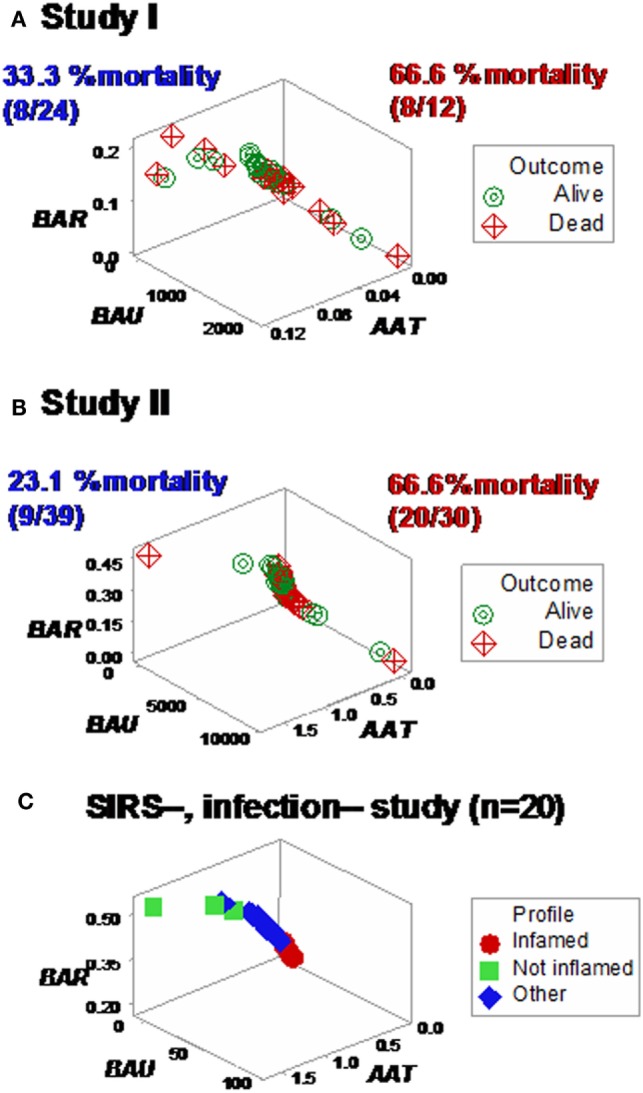
Mortality rates of perpendicular data segments. Both study I (A) and II (B) displayed mortality rates at least twice higher in the subset located on the right side of the plot than in the left subset (66.6% in both studies vs. 33.3 or 23.1%, in study I or II, respectively). Such differences approached or achieved statistical significance [P = 0.057 (study I) or P ≤ 0.01 (study II), Chi-square test]. When the same data structure was utilized to analyze 20 non-infected, SIRS-negative individuals, the high-mortality subset was not observed (C), even though the scale of the critical axis (BAU) was 1000 times smaller than the scale used in (A,B); i.e., the scale facilitated the detection of any pattern, if present.
Neither age nor gender explained mortality (Figures 5A,B; Figure S4 in Supplementary Material). While the median age was higher in the high-mortality subset, the distribution of age values overlapped between the survivor and non-survivor groups, preventing an age-based differentiation of the two subsets (Figures 5C,D).
Figure 5.

Three-dimensional analysis of age data. The age of SIRS+, infected individuals did not explain the mortality rates described in Figure 4. Both study I (A) and II (B) included >65-year-old individuals in the left (low-mortality) subset and <50-year-old individuals in the right (high-mortality) subset. While the median age [large, blue circles (C,D)] was 7–15 years higher in the right subset, any age-based cutoff would result in a large number of errors because the age intervals of survivors and non-survivors overlapped (C,D).
Different shapes –that also revealed a perpendicular data inflection –were seen when both SIRS+, infected groups were assessed with two partially different data structures (Figures 6A,B). Regardless of the data structure used, mortality was higher in the subset located at the right side of the plot [P < 0.001, Chi-square test (n = 105), Table 1]. The high-mortality subset was not observed when non-infected, SIRS-negative individuals were analyzed (Figure 6C).
Figure 6.
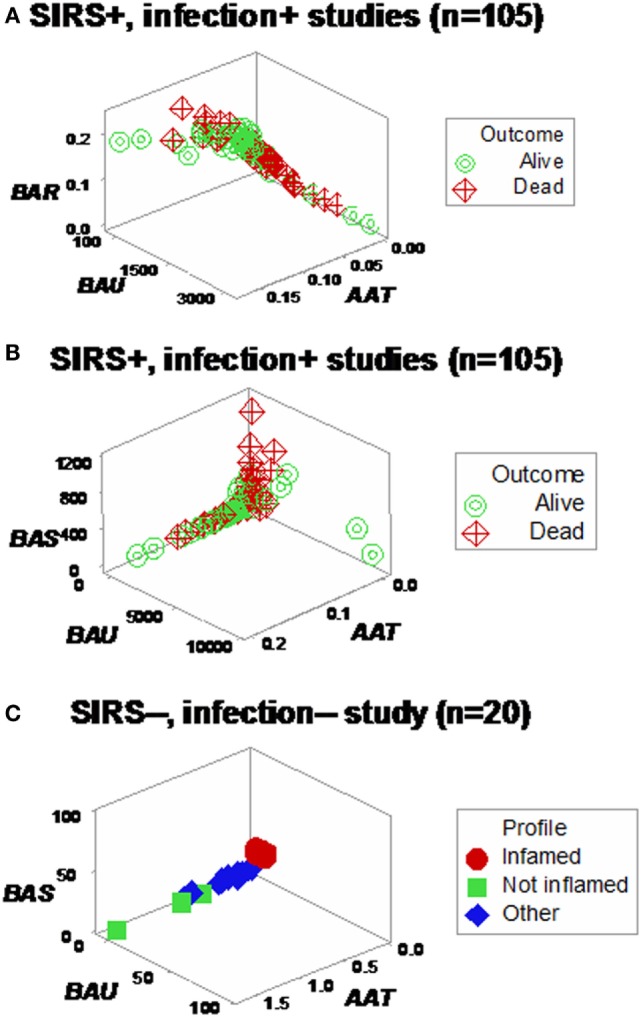
Assessment of redundancy (structure II). When all 105 SIRS+, infection+ individuals were assessed, two (“left” and “right”) perpendicular subsets were observed, which differed in mortality rates: it was 26.1% in the left subset and 54.2% in the right subset (P < 0.004, Chi-square test, Table 1). For clarity, the X and Y axes are scaled down, and three data points are not plotted (A). To prevent errors and improve the chances of extracting more information from the same data, an additional data structure was investigated, which also showed two data subsets orthogonal to one another (B). In contrast, SIRS-negative, non-infected individuals did not present the high-mortality pattern, even though the scale of the Y axis (BAU) was 1000 times smaller than the scale used when SIRS+, infection+ individuals were tested (C).
Table 1.
Mortality rate per subset.
| Population | Outcome | Left subset | Right subset | Pearson Chi-square test |
|---|---|---|---|---|
| Both studies (n = 105) | Survivor | 34 | 27 | |
| Non-survivor | 12 | 32 | ||
| Subtotal | 46 | 59 | ||
| Mortality (%) | 26.1% (12/46) | 54.2% (32/59) | P < 0.004 | |
| Study I (n = 36) | Survivor | 16 | 4 | |
| Non-survivor | 8 | 8 | ||
| Subtotal | 24 | 12 | ||
| Mortality (%) | 33.3% (8/24) | 66.6% (8/12) | P = 0.057 | |
| Study II (n = 69) | Survivor | 30 | 10 | |
| Non-survivor | 9 | 20 | ||
| Subtotal | 39 | 30 | ||
| Mortality (%) | 23.1% (9/39) | 66.6% (20/30) | P < 0.001 |
Some plots detected three subsets in each SIRS+/infection+ study, which differed up to three times in fatalities (Figures 7A,B). Longitudinal analysis of seven SIRS+/infected patients also showed perpendicular data subsets, which, within 24 h, helped differentiate patients (Figures 7C,D). Three data subsets were also displayed by a third set of indicators (Figures 8A–C).
Figure 7.

Study-specific, subset-specific assessment of mortality. When the second data structure was analyzed in each study, three spatial patterns were observed, both in study I (A) and II (B), which showed differences in mortality. When an additional group of seven septic (SIRS+, infection+) individuals was tested over time, three patients were distinguished at day 2 or 3, who displayed (i) a “right” pattern [observable at day 2, two patients (red oval)] or (ii) a “left” pattern [detected at day 3, one patient (purple square) (C)]. When time was not considered, spatial patterns identified three subsets, classified as “left,” “vertical,” and “right” (D).
Figure 8.
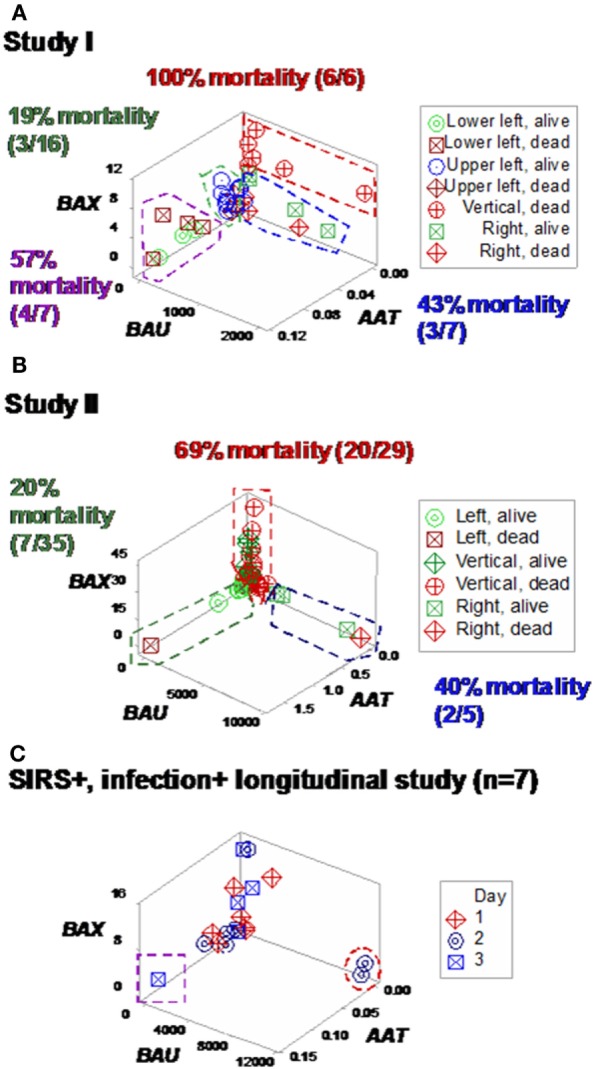
Study-specific, sub-specific assessment of mortality (structure III). At least three profiles were distinguished when a third data structure was explored (A,B). Mortality differed up to five times across subsets. Longitudinal data of septic patients displayed similar patterns, distinguishing at least three individuals [red oval, purple square (C)].
Based on the three (“left,” “vertical,” and “right”) subsets identified in Figures 7A,B, subset-specific immune response profiles were analyzed (Figures 9A,B and 10A,B). Within-subset differences were observed in the “vertical” and “right” subsets. For instance, “right” survivors and non-survivors displayed non-overlapping lymphocyte and neutrophil distributions (Figures 9A,B). Between-subset differences were found in the “left” and “right” data groups, which displayed similar mortality rates (ranging between 22.8 and 36%, Figures 7A,B), but dissimilar (and non-overlapping) neutrophil and monocyte percentages (Figures 9A,B).
Figure 9.
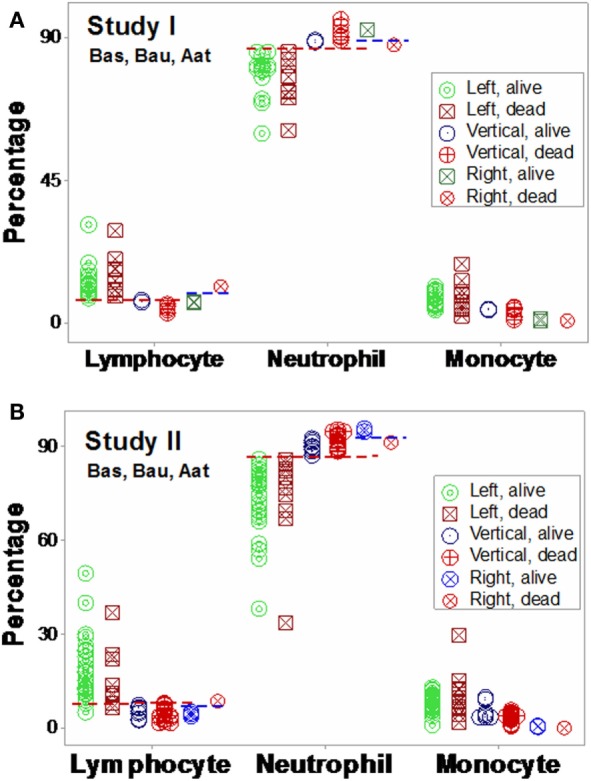
Validation of subsets detected by structure II. The immune profiles of subsets detected in Figures 7A,B were investigated. Both study I (A) and study I (B) showed non-randomly distributed leukocyte profiles, both within- and between-subsets. For instance, in both populations, within-subset differences were observed in the “right” subset, where the lymphocyte and neutrophil percentages did not overlap between survivors and non-survivors [blue horizontal lines (A,B)]. Between-subset differences were also observed, e.g., “left” subset survivors displayed higher L%, higher M%, and lower N% than survivors classified within the remaining subsets [red horizontal lines (A,B)]. Horizontal lines show some data subsets that did not overlap.
Figure 10.
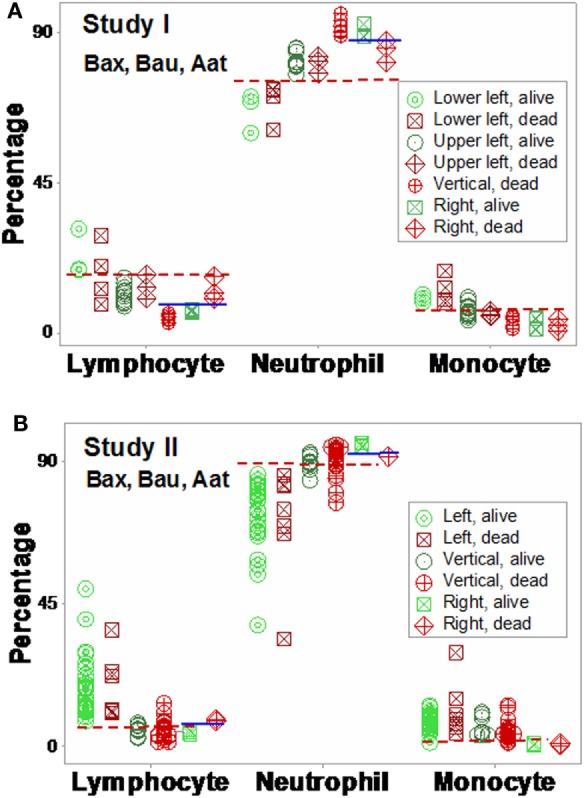
Validation of subsets detected by structure III. The immune profiles of subsets detected in Figures 8A,B were investigated. Discrimination was repeatable, even when a different data structure was utilized. While patterns differed slightly [study I (n = 36) showed four subsets, and one pattern (“vertical”) was only composed of one outcome (non-survivors) (A)], study II (n = 69) detected three subsets, with two outcomes per subset (B). The “left” and “right” subsets of both studies reproduced the information observed in Figure 8: while the “left” subset did not show within-subset differences, the lymphocyte and neutrophil percentage intervals of the “right” subset did not overlap. The “vertical” subset of study II seemed to correspond to both the “vertical” and “lower left” subsets of study I. Horizontal lines show some data subsets that did not overlap.
Mortality was not always predicted by numerical data. For instance, low lymphocyte percentages were found both among survivors (“right” subset) and among non-survivors (“vertical” subset, Figures 9A,B). Discrimination was not data structure-specific: similar findings were observed when a different data structure was investigated (Figures 10A,B).
Additional within- and between-subset differences were noticed when ratios that included data from two or three cell types were evaluated. For instance, “vertical” non-survivors exhibited the highest neutrophil/lymphocyte (N/L) values among all subsets. In contrast, “right” non-survivors displayed lower N/L, lower monocyte/neutrophil (M/N), and lower monocyte/lymphocyte (M/L) values than “right” survivors (Figures 11A,B).
Figure 11.
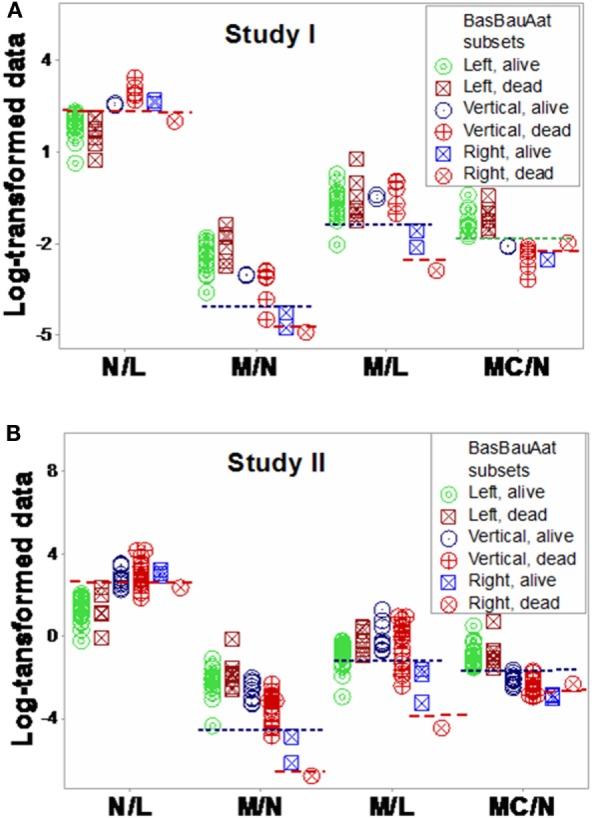
Assessment of immune functions. Based on the subsets detected in Figures 7A,B, interactions involving two or three cell types were investigated. Both study I (A) and study II (B) conveyed similar information. Both survivors and non-survivors of the “left” subset displayed the lowest neutrophil/lymphocyte (N/L) and highest mononuclear cell/neutrophil (MC/N) values. The “right” subset showed the lowest monocyte/neutrophil (M/N) and monocyte/lympohocyte (M/L) values, as well as within-subset differences were not observed in the remaining subsets: “right” non-survivors revealed lower N/L, M/N, and M/L and higher MC/N values than “right” survivors. The “vertical” non-survivors showed the highest N/L and the lowest MC/N values of all non-survivors. Together with the information shown in Figures 9A,B, these patterns support three hypotheses (i) the “right” subset experienced a monocyte-mediated immunosuppression; (ii) the “vertical” subset expressed excessive inflammation, together with low lymphocyte percentages; and (iii) mortality was not due, in the “left” subset, to any of the three disorders observed in the other subsets.
Similar patterns were observed in the longitudinal study of septic patients. While no discrimination was achieved when either information on days or indicators that captured one level of interactions [M/L, neutrophil/mononuclear cell (N/MC) ratios, Figures 12A–F] was assessed, the analysis of two-level interactions [(M/L)/(N/MC)] showed non-overlapping data distributions (Figure 12F). Therefore, the profile shown by one “left” and two “right” patients –identified in Figures 7C and 8C –was at least partially characterized by either (i) a rather late inflammatory profile [low levels of neutrophils/mononuclear cells (low N/MC values), and/or high M/L values, in the “left” patient] or (ii) the opposite profile, revealed by two “right” patients.
Figure 12.

Assessment of disease dynamics. The combinatorial approach also measured disease dynamics, expressed as temporal interactions that included antibiotic–microbial–immunological relationships. Temporal information (days after admission) was not informative when either one or two levels of interactions were measured [N/MC, M/L, and (M/L)/(N/MC) (A–C)]. One-level interactions also failed to discriminate when the spatial patterns shown by Figure 7D were considered (D,E). In contrast, non-overlapping data distributions were observed when both spatial profiles and two-level interactions were assessed, confirming the expectation that discrimination increases when two or more levels of complexity are investigated (F). Horizontal lines denote non-overlapping data distributions (F).
While the data (reported in Tables S1–S4 in Supplementary Material) were not informative prior to data partitioning, after data partitioning, many within- and between-subset comparisons achieved statistical significance (Tables S4–S8 in Supplementary Material). Therefore, the hypothesis that hidden information may be embedded in blood cell data was supported.
Discussion and Conclusion
Infectious disease-related research, including associated syndromes (such as sepsis), may benefit from methods that assess immunological complexity (41). Accordingly, a method meant to estimate complexity was developed and tested. Because it did not assume that the whole can be reduced to or predicted from any part, the combinatorial approach was a non-reductionist method. In contrast, the analysis shown in Figures 1A–H reflected a reductionist approach –it assumed that the analysis of isolated parts could predict or separate outcomes (6, 19, 20). While the reductionist, non-partitioning approach failed to discriminate, the non-reductionist, combinatorial method identified and partitioned data subsets that differed in mortality.
While previous blood cell count-based studies have failed to predict mortality (29, 42), earlier studies had assumed that lymphocytes, neutrophils, or monocytes act independently and, accordingly, such cell types had been analyzed separately. In contrast, the combinatorial method assessed all the observations of all cell types, together.
Hidden data interactions were demonstrated and septic patients were grouped according to their immune profiles. In addition, several problematic properties of infectious disease data were prevented, including those associated with ambiguity and compositions. For example, discrimination was achieved without depending on the white blood cell count (one of the four SIRS criteria), which may be affected by the features of compositional data (15, 36).
While counts, percentages, and simple ratios were not informative per se, when integrated into data structures that captured several levels of complexity, new or more information was retrieved. Because some complex data structures revealed a single (one data point-wide) line of observation, personalized applications were fostered: when any pair of observations –collected over time, from the same individual –are analyzed on a single line, they will exhibit a movement (temporal data directionality), indicating whether the later observation approaches the disease-negative or -positive pole of the data. Such structure prevents data ambiguity because a single line of data point eliminates noise (data variability) from all dimensions, except along the line, while the information reported along the line facilitates (i) monitoring of disease progression (dynamics) and (ii) evaluation of therapies (1, 43).
By detecting data subsets according to graphic patterns, inferences were made without assumptions, and dichotomization was avoided (24). In agreement with reports that have indicated no single biomarker is likely to be diagnostic in personalized medicine (44), analyses that included a single biomarker (CRP) were not informative (Figures 1G,H).
Inferences were based on visualizations that reflected both interactions and dynamics. Here, “interactions” were operationally defined as patterns generated when three variables intersect in 3D space: when one variable increases or decreases in a larger magnitude than the remaining variables, a distinct pattern emerges, e.g., a data inflection, which can be used to separate data subsets (45). Such inflections or bifurcations can reveal a common feature of infections: dynamics. Because homeostatic (feedback and feedforward) processes also occur in infections, they can be used to provide new diagnostic and prognostic information (1, 46).
While some feedback phases may change rapidly and reveal non-linearity (46), the subsets they generate may be perpendicular to one another, as documented here. Thus, infection-related feedback processes may generate a biological equivalent of what, in mathematics, is created by a log-transformation: data, inherently non-linear, can be treated as linear and, consequently, after data subsets perpendicular to one another are observed, statistical analyses can be conducted. When similar data subsets are observed in different populations, the hypothesis of a random event is not defensible –instead, a well-conserved pattern is likely. In such a case, the “transformation” of non-linear immunological data into perpendicular data subsets is not the result of an equation but produced by a well-conserved biological process.
The combinatorial approach also provided explanatory information, of immunological nature, which may support diagnostics and therapy selection (47). Clinicians working in sepsis need new diagnostics: current diagnostic criteria have shown very poor (less than 50%) sensitivity values (48, 49). Clinicians could benefit from earlier evaluations of diagnostic and therapeutic decisions. As shown here, the dynamics of seven septic patients differed over 3 days: two patients revealed a “right” pattern as early as day 2 and (at least) one patient displayed the “left” pattern by day 3 (Figures 7C and 8C). While other factors, not explored (such as the role of empirical antibiotic treatments), prevent to elucidate whether the two “right” patients experienced a better or worse disease progression and/or responsiveness to treatment than the remaining patients, Figure 12F demonstrates that the combinatorial approach can monitor disease dynamics earlier (1 day before in vitro tests are completed), based on in vivo, temporal data that assess not only immunological but also antibiotic–microbial relationships.
The future of therapy, in sepsis, has been indicated to depend on the identification of immune phases or profiles (50–52). Sepsis seems to be a systemic response to infections, which is associated with organ dysfunction (53). Supporting earlier reports, findings revealed dissimilar immune profiles among subsets that also differed in mortality rates (54).
“Vertical” non-survivors displayed an excessive inflammatory response as well as low lymphocyte percentages. When the 3D patterns exhibited by Figures 7A,B were considered, individuals classified within the “vertical” subset displayed higher N% and lower L% than those of the “left” subset (Figures 9A,B). “Vertical” non-survivors showed the highest neutrophil/lymphocyte (N/L) values of all subsets and also higher monocyte/lymphocyte (M/L) values than those of the “right” subset (Figures 11A,B), that is, the “vertical” non-survivor profile was consistent with enhanced lymphocyte apoptosis and delayed monocyte apoptosis; i.e., an immunopathology that may result in protracted inflammation and immunosuppression (55–61).
“Right” non-survivors –unlike the “vertical” ones –exhibited a profile that did not support the hypothesis of mortality induced by low lymphocyte values and excessive inflammation. Instead, “right” non-survivors displayed higher L% than “right” survivors (Figures 9A,B and 10A,B). “Right” non-survivors did not seem to prevent neutrophil recruitment: they showed higher N% than “left” non-survivors (Figures 9A,B and 10A,B). Because “right” non-survivors expressed lower (if not the lowest) M% than observed in all other subsets, a monocyte-related deficiency could be associated, in this subset, with mortality. Homeostatic failures associated with macrophage deficiencies include (i) the limited expression of macrophage-antigen 1 (Mac-1) and (ii) decreased expression of CD11b in dendritic cells (55, 62, 63). Such disruptions can alter trans-membrane permeability and complement fixation functions, without preventing neutrophil release. Furthermore, the “right” subset documented that low lymphocyte values do not characterize all septic cases (51): “right” survivors displayed significantly lower lymphocyte percentages than “left” survivors (Figures 9A,B and Table S7 in Supplementary Material).
“Left” survivors and non-survivors displayed the highest mononuclear cell/neutrophil (MC/N) values observed in this report, differing markedly from the remaining subsets (Figures 11A,B). Unlike other subsets (which revealed several within-subset differences), “left” survivors and non-survivors did not show obvious differences.
The “left” pattern supported three inferences (i) the theory that sepsis may be composed of four stages (sepsis, severe sepsis, septic shock, and refractory septic shock) may be clinically factual, but not scientifically informative; (ii) the proposition that the type of infection determines the outcome of sepsis may not always occur; and (iii) mortality, in the “left” subset, was not explained by the interactions investigated here. Because high MC/N values are typical of late or recurrent inflammations –and they were observed at admission, in the “left” subset –four-stage, clinical-based classifications may miss a late or recurrent process (62).
The “left” profile did not support the hypothesis that the type of infection determines the outcome of sepsis (43). Instead, the opposite view may occur: the immune profile (considered in its broadest meaning, i.e., including homeostatic perspectives) may influence the speed and outcome of antimicrobial responses. In support of the immune-mediated disease hypothesis, Candida sp. and Pseudomonas sp. (opportunistic microbes) infected two individuals classified within the “left” profile (Tables S1 and S2 in Supplementary Material). Because sepsis can occur without apoptosis or necrosis, disorders not typically viewed as inflammatory (e.g., mitochondrial dysfunctions that affect intracellular junctions) cannot be ruled out in the “left” profile, even in the absence of cellular deficits or altered responses (64).
Together, findings supported the view that at least two types of immunosuppression may be found in sepsis: coexisting and not coexisting with excessive inflammation. Two types of immunosuppression have been previously reported in sepsis (65).
Available at admission, this information could support therapy selection. While cytokines that boost the immune response (e.g., granulocyte–macrophage colony-stimulating factor and interleukin-3) may be of interest when the “right subset” profile is observed (52, 66), they may be inadequate in “vertical” immunosuppressions, which coexist with inflammation.
In sum, methods that assess immune complexity appeared to distinguish some sepsis-related sub-syndromes, in real time. Because diagnostic expediency was prioritized, the variables utilized did not cover all biological scales, e.g., cytokines were not investigated. Future studies could assess subcellular variables, as recently described (37).
Offering an alternative to the white blood cell count (a metric prone to ambiguity), complexity-oriented analyses detected and differentiated immunosuppressions. Such analyses can identify patients that differ in mortality risks and help conduct repeated evaluations of diagnosis and therapies. Because immunosuppression matters in infections and also in cancer and transplantation (67, 68), combinatorial analyses may have broad applications.
Two major messages result from this study. The first message refers to Oslerian medicine, that is, to define disease based on clinicopathological correlations derived from organs that express most signs and symptoms –even when disease does not start in such organs. The Oslerian paradigm confuses consequences with causes, resulting in late assessments that ignore pathogenesis (69). When this paradigm is applied with problematic practices –such as numerical cutoffs– and/or assumes that a single biomarker, alone, may capture complex and dynamic interactions, information loss and errors may follow.
The second message is that even leukocyte counts, percents, or simple ratios can be informative when composite metrics are used to explore complexity. While clinical descriptions may not be adequate to monitor disease progression and/or select therapies, immunomicrobial complexity may provide explanatory information, earlier.
Author Contributions
The authors AR and GT conceived the study. SC, AI, ET-G, NC, CS, and TB contributed reagents/materials/data. AR, AH, ALH, and RP analyzed the data. AR, RD, and GT wrote the paper.
Conflict of Interest Statement
While none of the authors received, at any time, any payment or services from a third party for any aspect of the submitted work, they wish to declare that they used a proprietary algorithm subject to a pending patent.
Supplementary Material
The Supplementary Material for this article can be found online at http://journal.frontiersin.org/article/10.3389/fimmu.2016.00217
References
- 1.Rivas AL, Jankowski MD, Piccinini R, Leitner G, Schwarz D, Anderson KL, et al. Feedback-based, system-level properties of vertebrate-microbial interactions. PLoS One (2013) 8(2):e53984. 10.1371/journal.pone.0053984 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Berens P. CircStat: a MATLAB toolbox for circular statistics. J Stat Softw (2009) 31:1–21. 10.18637/jss.v031.i10 [DOI] [Google Scholar]
- 3.Gill J, Hangartner D. Circular data in political science and how to handle it. Polit Anal (2010) 18:316–36. 10.1093/pan/mpq009 [DOI] [Google Scholar]
- 4.Fisher R. Dispersion on a sphere. Proc R Soc Lond A (1953) 217:295–305. 10.1098/rspa.1953.0064 [DOI] [Google Scholar]
- 5.Leitner G, Blum S, Rivas AL. Visualizing the indefinable: three-dimensional complexity of ‘infectious diseases’. PLoS One (2015) 10(4):e0123674. 10.1371/journal.pone.01236742015 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Pinsky MR. Complexity modeling: identify instability early. Crit Care Med (2010) 38:S649–55. 10.1097/CCM.0b013e3181f24484 [DOI] [PubMed] [Google Scholar]
- 7.Namas R, Zamora R, Namas R, An G, Doyle J, Dick TE, et al. Sepsis: something old, something new, and a systems view. J Crit Care (2012) 27:.e1–314. 10.1016/j.jcrc.2011.05.025 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Cedersund G, Roll J. Systems biology: model based evaluation and comparison of potential explanations for given biological data. FEBS J (2009) 276:903–22. 10.1111/j.1742-4658.2008.06845.x [DOI] [PubMed] [Google Scholar]
- 9.de Haan J. How emergence arises. Ecol Complex (2006) 3:293–301. 10.1016/j.ecocom.2007.02.003 [DOI] [Google Scholar]
- 10.San Miguel M, Johnson JH, Kertesz J, Kaski K, Díaz-Guilera A, MacKay RS, et al. Challenges in complex systems science. Eur Phys J Spec Top (2012) 214:245–71. 10.1140/epjst/e2012-01694-y [DOI] [Google Scholar]
- 11.Stephan A. The dual role of ‘emergence’ in the philosophy of mind and in cognitive science. Synthese (2006) 151:485–98. 10.1007/s11229-006-9019-y [DOI] [Google Scholar]
- 12.Huneman P. Determinism, predictability and open-ended evolution: lessons from computational emergence. Synthese (2012) 185:195–214. 10.1007/s11229-010-9721-7 [DOI] [Google Scholar]
- 13.Casadevall A, Fang FC, Pirofski LA. Microbial virulence as an emergent property: consequences and opportunities. PLoS Pathog (2011) 7(7):e1002136. 10.1371/journal.ppat.1002136 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Van Rangenmortel MHV. The rational design of biological complexity: a deceptive metaphor. Proteomics (2007) 7:965–75. 10.1002/pmic.200600407 [DOI] [PubMed] [Google Scholar]
- 15.Aitchison J. The Statistical Analysis of Compositional Data. London: Chapman and Hall; (1986). [Google Scholar]
- 16.Katz JN, King G. A statistical model for multiparty electoral data. Am Polit Sci Rev (1999) 93:15–32. 10.2307/2585758 [DOI] [Google Scholar]
- 17.Robson B. The dragon on the gold: myths and realities for data mining in biomedicine and biotechnology using digital and molecular libraries. J Proteome Res (2005) 3:1113–9. 10.1021/pr0499242 [DOI] [PubMed] [Google Scholar]
- 18.Alfonso I. From simplicity to complex systems with bioinspired pseudopeptides. Chem Commun (2016) 52:239. 10.1039/c5cc07596c [DOI] [PubMed] [Google Scholar]
- 19.Van Rangenmortel MHV. Basic research in HIV vaccinology is hampered by reductionist thinking. Front Immunol (2012) 3:194. 10.3389/fimmu.2012.00194 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Seely AJ, Christou NV. Multiple organ dysfunction syndrome: exploring the paradigm of complex nonlinear systems. Crit Care Med (2000) 28:2193–200. 10.1097/00003246-200007000-00003 [DOI] [PubMed] [Google Scholar]
- 21.Nish S, Medzhitov R. Host defense pathways: role of redundancy and compensation in infectious disease phenotypes. Immunity (2011) 34:629–36. 10.1016/j.immuni.2011.05.009 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Shi F, Zhang JY, Zeng Z, Tien P, Wang FS. Skewed ratios between CD3+ T cells and monocytes are associated with poor prognosis in patients with HBV-related acute-on-chronic liver failure. Biochem Biophys Res Commun (2010) 402:30–6. 10.1016/j.bbrc.2010.09.096 [DOI] [PubMed] [Google Scholar]
- 23.Wynn TA, Chawla A, Pollard JW. Macrophage biology in development, homeostasis and disease. Nature (2013) 496:445–54. 10.1038/nature12034 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Cohen J. The cost of dichotomization. Appl Psychol Meas (1983) 7:249–53. 10.1177/014662168300700301 [DOI] [Google Scholar]
- 25.Koning KK, Mebius RE. Interdependence of stromal and immune cells for lymph node function. Trends Immunol (2012) 33:264–70. 10.1016/j.it.2011.10.006 [DOI] [PubMed] [Google Scholar]
- 26.Shmueli G, Burkom H. Statistical challenges facing early outbreak detection in biosurveillance. Technometrics (2010) 52:39–51. 10.1198/TECH.2010.06134 [DOI] [Google Scholar]
- 27.Barlas Y. Multiple tests for validation of system dynamics type of simulation models. Eur J Oper Res (1989) 42:59–87. 10.1016/0377-2217(89)90059-3 [DOI] [Google Scholar]
- 28.Kobayashi D, Yokota K, Takahashi O, Arioka H, Fukui T. A predictive rule for mortality of inpatients with Staphylococcus aureus bacteraemia: a classification and regression tree analysis. Eur J Intern Med (2014) 25:914–8. 10.1016/j.ejim.2014.10.003 [DOI] [PubMed] [Google Scholar]
- 29.Zhou Y, Dong Y, Zhong Y, Huang J, Lv J, Li J. The cold-inducible RNA-binding protein (CIRP) level in peripheral blood predicts sepsis outcome. PLoS One (2015) 10(9):e0137721. 10.1371/journal.pone.0137721 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Greiner M, Pfeiffer D, Smith RD. Principles and practical application of the receiver-operating characteristic analysis for diagnostic tests. Prev Vet Med (2002) 45:23–41. 10.1016/S0167-5877(00)00115-X [DOI] [PubMed] [Google Scholar]
- 31.Gibbons RD, Hedeker D. Random effects probit and logistic regression models for three-level data. Biometrics (1997) 53:1527–1537. 10.2307/2533520 [DOI] [PubMed] [Google Scholar]
- 32.Amarasingham A, Geman S, Harrison MT. Ambiguity and nonidentifiability in the statistical analysis of neural codes. Proc Natl Acad Sci U S A (2015) 112:6455–60. 10.1073/pnas.1506400112 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Montgomery K. How Doctors Think: Clinical Judgment and the Practice of Medicine. Oxford: Oxford University Press; (2006). [Google Scholar]
- 34.Harvey A, Brand A, Holgate ST, Kristiansen LV, Lehrach H, Palotie A, et al. The future of technologies for personalized medicine. N Biotechnol (2012) 29:625–33. 10.1016/j.nbt.2012.03.009 [DOI] [PubMed] [Google Scholar]
- 35.Burggren W, Monticino MG. Assessing physiological complexity. J Exp Biol (2005) 208:3221–32. 10.1242/jeb.01762 [DOI] [PubMed] [Google Scholar]
- 36.Balk RA. Systemic inflammatory response syndrome (SIRS) where did it come from and is it still relevant today? Virulence (2014) 5:20–6. 10.4161/viru.27135 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Rivas AL, Hoogesteijn AL, Piccinini R. Beyond numbers: the informative patterns of staphylococcal dynamics. Curr Pharm Des (2015) 21:2122–30. 10.2174/1381612821666150310104053 [DOI] [PubMed] [Google Scholar]
- 38.Klinke DJ. Validating a dimensionless number for glucose homeostasis in humans. Ann Biomed Eng (2009) 37:1886–96. 10.1007/s10439-009-9733-y [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Nadell CD, Bucci V, Drescher K, Levin SA, Bassler BL, Xavier JB. Cutting through the complexity of cell collectives. Proc R Soc B (2013) 280:20122770. 10.1098/rspb.2012.2770 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Rodgers JL, Nicewander WA, Toothaker L. Linearly independent, orthogonal, and uncorrelated variables. Am Stat (1984) 38:133–4. 10.2307/2683250 [DOI] [Google Scholar]
- 41.Cohen J, Vincent JL, Adhikari NK, Machado FR, Angus DC, Calandra T, et al. Sepsis: a roadmap for future research. Lancet Infect Dis (2015) 15:581–614. 10.1016/S1473-3099(15)70112-X [DOI] [PubMed] [Google Scholar]
- 42.Lam SW, Leenen LPH, van Solinge WW, Hietbrink F, Huisman A. Evaluation of hematological parameters on admission for the prediction of 7-day in-hospital mortality in a large trauma cohort. Clin Chem Lab Med (2011) 49:493–9. 10.1515/CCLM.2011.069 [DOI] [PubMed] [Google Scholar]
- 43.Fair JM, Rivas AL. Systems biology and ratio-based, real-time disease surveillance. Transbound Emerg Dis (2015) 62:437–45. 10.1111/tbed.12162 [DOI] [PubMed] [Google Scholar]
- 44.Christaki E, Giamarellos-Bourboulis EJ. The beginning of personalized medicine in sepsis: small steps to a bright future. Clin Genet (2014) 86:56–61. 10.1111/cge.12368 [DOI] [PubMed] [Google Scholar]
- 45.Osinga HM, Sherman A, Tsaneva-Atanasova K. Cross-currents between biology and mathematics: the codimension of pseudo-plateau bursting. Discrete Contin Dyn Syst Ser A (2012) 32:2853–77. 10.3934/dcds.2012.32.2853 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Glass L. Dynamical disease: challenges for nonlinear dynamics and medicine. Chaos (2015) 25:097603. 10.1063/1.4915529 [DOI] [PubMed] [Google Scholar]
- 47.Brigandt I. Beyond reduction and pluralism: toward an epistemology of explanatory integration in biology. Erkenntnis (2010) 73:295–311. 10.1007/s10670-010-9233-3 [DOI] [Google Scholar]
- 48.Jolley RJ, Quan H, Jetté N, Sawka KJ, Diep L, Goliath J, et al. Validation and optimisation of an ICD-10-coded case definition for sepsis using administrative health data. BMJ Open (2015) 5:e009487. 10.1136/bmjopen-2015-009487 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Whittaker SA, Mikkelsen ME, Gaieski DF, Koshy S, Kean C, Fuchs BD. Severe sepsis cohorts derived from claims-based strategies appear to be biased toward a more severely ill patient population. Crit Care Med (2013) 41:945–53. 10.1097/CCM.0b013e31827466f1 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Boomer JS, Green JM, Hotchkiss RS. The changing immune system in sepsis: is individualized immuno-modulatory therapy the answer? Virulence (2014) 5:45–56. 10.4161/viru.26516 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Janols H, Wullt M, Bergenfelz C, Björnsson S, Lickei H, Janciauskiene S, et al. Heterogeneity among septic shock patients in a set of immunoregulatory markers. Eur J Clin Microbiol Infect Dis (2014) 33:313–24. 10.1007/s10096-013-1957-y [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Hotchkiss RS, Sherwood ER. Getting sepsis therapy right. Science (2015) 347:1201–2. 10.1126/science.aaa8334 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Vincent JL, Opal SM, Marshall JC, Tracey KJ. Sepsis definitions: time for change. Lancet (2013) 81:774–5. 10.1016/S0140-6736(12)61815-7 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Gogos C, Kotsaki A, Pelekanou A, Giannikopoulos G, Vaki I, Maravitsa P, et al. Early alterations of the innate and adaptive immune statuses in sepsis according to the type of underlying infection. Crit Care (2010) 14:R96. 10.1186/cc9031 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Deutschman CS, Tracey KJ. Sepsis: current dogma and new perspectives. Immunity (2014) 40:463–75. 10.1016/j.immuni.2014.04.001 [DOI] [PubMed] [Google Scholar]
- 56.Vaki I, Kranidioti H, Karagianni V, Spyridaki A, Kotsaki A, Routsi C, et al. An early circulating factor in severe sepsis modulates apoptosis of monocytes and lymphocytes. J Leukoc Biol (2011) 89:343–9. 10.1189/jlb.0410232 [DOI] [PubMed] [Google Scholar]
- 57.Tamayo E, Gomez E, Bustamante J, Gomez-Herreras JI, Fonteriz R, Bobillo F, et al. Evolution of neutrophil apoptosis in septic shock survivors and nonsurvivors. J Crit Care (2012) 27:415.e1. 10.1016/j.jcrc.2011.09.001 [DOI] [PubMed] [Google Scholar]
- 58.Stearns-Kurosawa DJ, Osuchowski MF, Valentine C, Kurosawa S, Remick DG. The pathogenesis of sepsis. Annu Rev Pathol (2011) 6:19–48. 10.1146/annurev-pathol-011110-130327 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Skrupky LP, Kerby PW, Hotchkiss RS. Advances in the management of sepsis and the understanding of key immunologic defects. Anesthesiology (2011) 115:1349–62. 10.1097/ALN.0b013e31823422e8 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60.Leentjens J, Kox M, van der Hoeven JG, Netea MG, Pickkers P. Immunotherapy for the adjunctive treatment of sepsis: from immunosuppression to immunostimulation. Am J Respir Crit Care Med (2013) 187:1287–93. 10.1164/rccm.201301-0036CP [DOI] [PubMed] [Google Scholar]
- 61.Liu JR, Han X, Soriano SG, Auki K. The role of macrophage 1 antigen in polymicrobial sepsis. Shock (2014) 42:532–9. 10.1097/SHK.0000000000000250 [DOI] [PubMed] [Google Scholar]
- 62.Weber GF, Maier SL, Zoennchen T, Breucha M, Seidlitz T, Kutschick I, et al. Analysis of circulating plasmacytoid dendritic cells during the course of sepsis. Surgery (2015) 158:248–54. 10.1016/j.surg.2015.03.013 [DOI] [PubMed] [Google Scholar]
- 63.Levy MM, Fink MP, Marshall JC, Abraham E, Angus D, Cook D, et al. 2001 SCCM/ESICM/ACCP/ATS/SIS international sepsis definitions conference. Crit Care Med (2003) 31:1250–6. 10.1097/01.CCM.0000050454.01978.3B [DOI] [PubMed] [Google Scholar]
- 64.Gomez H, Ince C, De Backer D, Pickkers P, Payen D, Hotchkiss J, et al. A unified theory of sepsis-induced acute kidney injury: inflammation, microcirculatory dysfunction, bioenergetics and the tubular cell adaptation to injury. Shock (2014) 41:3–11. 10.1097/SHK.0000000000000052 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 65.Roquilly A, Villadangos JA. The role of dendritic cell alterations in susceptibility to hospital-acquired infections during critical-illness related immunosuppression. Mol Immunol (2015) 68:120–3. 10.1016/j.molimm.2015.06.030 [DOI] [PubMed] [Google Scholar]
- 66.Weber GF, Chousterman B, He S, Fenn AM, Nairz M, Anzai A, et al. Interleukin-3 amplifies acute inflammation and is a potential therapeutic target in sepsis. Science (2015) 347:1260–5. 10.1126/science.aaa4268 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67.Gobert A, Spano JP. Cancer and immune suppression: from epidemiology to therapeutic challenges. Oncologie (2015) 17:390–6. 10.1007/s10269-015-2547-7 [DOI] [Google Scholar]
- 68.Fernández-Ruiz M, Kumar D, Humar A. Clinical immune-monitoring strategies for predicting infection risk in solid organ transplantation. Clin Transl Immunology (2014) 3:e12. 10.1038/cti.2014.3 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.Loscalzo J, Barabasi AL. Systems biology and the future of medicine. Wiley Interdiscip Rev Syst Biol Med (2011) 3:619–27. 10.1002/wsbm.144 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.