

Abstract
The primary aim of this research was to evaluate the validity, efficacy, and generalization of principles underlying a sound therapy–based treatment for promoting expansion of the auditory dynamic range (DR) for loudness. The basic sound therapy principles, originally devised for treatment of hyperacusis among patients with tinnitus, were evaluated in this study in a target sample of unsuccessfully fit and/or problematic prospective hearing aid users with diminished DRs (owing to their elevated audiometric thresholds and reduced sound tolerance). Secondary aims included: (1) delineation of the treatment contributions from the counseling and sound therapy components to the full-treatment protocol and, in turn, the isolated treatment effects from each of these individual components to intervention success; and (2) characterization of the respective dynamics for full, partial, and control treatments. Thirty-six participants with bilateral sensorineural hearing losses and reduced DRs, which affected their actual or perceived ability to use hearing aids, were enrolled in and completed a placebo-controlled (for sound therapy) randomized clinical trial. The 2 × 2 factorial trial design was implemented with or without various assignments of counseling and sound therapy. Specifically, participants were assigned randomly to one of four treatment groups (nine participants per group), including: (1) group 1—full treatment achieved with scripted counseling plus sound therapy implemented with binaural sound generators; (2) group 2—partial treatment achieved with counseling and placebo sound generators (PSGs); (3) group 3—partial treatment achieved with binaural sound generators alone; and (4) group 4—a neutral control treatment implemented with the PSGs alone. Repeated measurements of categorical loudness judgments served as the primary outcome measure. The full-treatment categorical-loudness judgments for group 1, measured at treatment termination, were significantly greater than the corresponding pretreatment judgments measured at baseline at 500, 2,000, and 4,000 Hz. Moreover, increases in their “uncomfortably loud” judgments (∼12 dB over the range from 500 to 4,000 Hz) were superior to those measured for either of the partial-treatment groups 2 and 3 or for control group 4. Efficacy, assessed by treatment-related criterion increases ≥ 10 dB for judgments of uncomfortable loudness, was superior for full treatment (82% efficacy) compared with that for either of the partial treatments (25% and 40% for counseling combined with the placebo sound therapy and sound therapy alone, respectively) or for the control treatment (50%). The majority of the group 1 participants achieved their criterion improvements within 3 months of beginning treatment. The treatment effect from sound therapy was much greater than that for counseling, which was statistically indistinguishable in most of our analyses from the control treatment. The basic principles underlying the full-treatment protocol are valid and have general applicability for expanding the DR among individuals with sensorineural hearing losses, who may often report aided loudness problems. The positive full-treatment effects were superior to those achieved for either counseling or sound therapy in virtual or actual isolation, respectively; however, the delivery of both components in the full-treatment approach was essential for an optimum treatment outcome.
Keywords: Sound tolerance, loudness discomfort level, hyperacusis, sound therapy
Learning Outcomes: As a result of this activity, the participant will be able to (1) describe a method for creating a placebo sound therapy condition and (2) describe the efficacy of sound therapy and counseling as compared to sound therapy alone, counseling alone, or no treatment.
We report here the findings from a small-scale, randomized, placebo-controlled trial to assess the validity, efficacy, and generality of principles underlying intervention to expand the auditory dynamic range (DR) for loudness among persons with sensorineural hearing losses. The basic treatment principles, described originally by Hazell and Sheldrake in 1992,1 were designed for treatment of debilitating tinnitus and associated hyperacusis. Their treatment protocol, which combined low-level sound therapy with counseling (that encouraged healthy environmental sound exposure), was later incorporated together with Jastreboff's neurophysiological model of tinnitus.2 3 The resulting treatment model and protocol is popularly known today as “tinnitus retraining therapy” (TRT).4 TRT has been used with considerable success globally to treat tinnitus for the past two decades. Over this period, the TRT protocol has been modified to categorize and manage patients with tinnitus differentially based upon the individual patient's hearing status, tinnitus, and sound tolerance complaints.4 Consequently, protocols now exist within TRT for managing sound tolerance complaints, including hyperacusis, misophonia, and phonophobia, usually in association with tinnitus.4 5 6
In this project, the basic principles of the sound therapy intervention, described by Hazell and Sheldrake, 1 were evaluated in a target group of hearing-impaired persons, who were not primarily bothered by tinnitus but were restricted in the use of amplified sound from hearing aids because of their reduced DRs for loudness. Their reduced DRs reflected their elevated audiometric thresholds and, on average, lower-than-normal loudness discomfort levels (LDLs). Our target study group was mostly individuals who would not routinely be seen in a specialty tinnitus and hyperacusis clinic for their sound tolerance conditions. However, their conditions adversely affected their perceived or expected benefit for aided sound. Consequently, they often reported having tried but rejected hearing aid use; assumed they could not tolerate amplified sound and, therefore, never tried hearing aids; or attempted to use amplification, but described using it ineffectually. For these individuals to have been fitted successfully with hearing aids, they typically would have required larger amounts of compression, inordinate decreases in maximum output level, or diminished prescriptive target gains to manage their sound intolerance for amplified sound. The resulting adverse effects of these remedies would variously have manifested as reduced and suboptimal DRs, diminished hearing aid saturation levels (which together with compression effects would give rise to enhanced signal distortion), and inadequate amplification levels set to avoid overstimulation.7 Overamplification, as perceived by the individual with sound tolerance problems, to achieve aided prescriptive target gain levels also may have contributed to hearing aid rejection. Each of these problems alone, or in combination, would confound an otherwise successful hearing aid fitting strategy.
Preliminary to describing our study of this target group, we consider the historical background for conducting this investigation, beginning with early efforts to improve sound tolerance and promote DR expansion among persons with hearing loss by presenting repeated exposures to brief high-intensity sounds.8 9 We then consider Hazell and Sheldrake's low-level sound therapy approach and its evolution as a primary treatment for hyperacusis and decreased sound tolerance.1 4 This background sets the stage for the motivation, purpose, and aims of our research.
Background
Sound Tolerance Training
The idea of modifying sound tolerance among hearing-impaired persons to expand their DRs and, concomitantly, to enhance hearing aid use and benefit is a long-standing challenge in audiology.10 Despite research on this vexing clinical problem for more than half a century, no treatment has proven to be consistently successful for modifying sound tolerance.11 12 13 The primary treatment approach heretofore for expanding the auditory DR comes out of military research and related efforts during World War II. Silverman's early studies of sound tolerance training at the Central Institute for the Deaf are the most extensive and relevant, and the research includes results for normal and hearing-impaired listeners for a range of pure tone and speech stimuli.9 The approach was based on the idea that a listener's tolerance to high-level sounds might be enhanced by brief toughening training exposures to intense sound presented just below the hearing-impaired listener's LDL. Silverman reported ∼10-dB increases in LDLs for both normal and hearing-impaired listeners following brief (several minutes) weekly exposures to high-level pure tones and speech over a 6-week training period.9 Most of the incremental LDL shifts reported by Silverman were achieved between the first and second or third training sessions. Although there was early enthusiasm for Silverman's sound tolerance training strategy,8 the general consensus today is that this approach is not beneficial.11 12 13 It remains unclear whether the resulting incremental LDL shifts from sound tolerance training are real or simply a practice effect.12 Notwithstanding clarification of this issue, sound tolerance training with high-level sounds may be an uncomfortable, if not a painful, protocol that is not practiced clinically today.
Hazell and Sheldrake's Sound Therapy Treatment
In marked contrast to the brief high-level sound exposures used by Silverman for sound tolerance training in normal-hearing and hearing-impaired adults,9 Hazell and Sheldrake's innovative sound therapy strategy evolved from efforts to manage hyperacusis among their patients with tinnitus.1 For the sake of economy, and in the absence of a consensus definition, we will define hyperacusis as a general intolerance to the loudness of sounds that would not typically be bothersome for most individuals.14 Audiologically, hyperacusis manifests as an abnormal reduction in the LDLs, usually below ∼90-dB hearing level (HL) binaurally, across frequencies. Hyperacusis may occur with or without hearing loss or associated tinnitus but is routinely accompanied by subjective reports of sound intolerance. Pain and/or distress may or may not accompany these subjective complaints of reduced sound tolerance.15 16
Hazell and Sheldrake's novel sound therapy protocol for treating patients with tinnitus and primary hyperacusis was implemented with continuous 6-hour exposures, daily, to low-level, high-frequency emphasis broadband noise.1 The noise was produced by behind-the-ear noise maskers fitted with open-canal earmolds. Their sound therapy protocol called for the initial presentation of the noise to be “just audible above the threshold.” Subsequently, their patients were instructed to increase gradually, day by day, the volume settings until a point was reached at which the majority of troubling environmental sounds was tolerated without difficulty. The counseling component of their protocol encouraged their patients “to stop the avoidance of sound in their environment, except when this presented an ordinary risk of damage to the ear.” They also advised their patients not to use sound-attenuating hearing protection during normal daily activities; Hazell and Sheldrake noted that because of the debilitating hyperacusis conditions, hearing protection was in use by 23 of their 30 patients prior to the start of treatment. Hazell and Sheldrake presented only a limited description of counseling in their brief conference proceedings report.1 Sheldrake (personal communication, 2013) indicates counseling was, in fact, an important component of their protocol across three in-clinic treatment sessions. These sessions covered guidance in the theory and application of the desensitizing sound therapy for treatment of hyperacusis, and instruction in the use of the low-level noise maskers for this purpose. Their hyperacusis counseling strategy effectively mirrored that outlined by Sheldrake and colleagues for tinnitus management.17
Hazell and Sheldrake described a remarkable treatment outcome for their hyperacusis group, namely, sizable and statistically significant improvements in LDL judgments across audiometric frequency (excluding 8,000 Hz).1 These positive treatment effects typically reflected expanded DRs, on the order of 8 to 10 dB, which often corresponded to symptomatic improvements in their patients' hyperacusis conditions. Hazell and Sheldrake described good results as being achieved by 10% of the hyperacusis group within 1 month, 53% within 2 months, and 73% within 6 months of beginning treatment. Their other patients either required longer than 6 months for benefit or, in the case of 10% of the group, were not helped by the intervention. Hazell and Sheldrake noted that those patients who benefited from treatment typically sustained their benefits without further use of the noise maskers posttreatment.
Evolution of Hazell and Sheldrake's Sound Therapy Principles for Treatment of Hyperacusis and Diminished Sound Tolerance
Subsequent to Hazell and Sheldrake's obscure but seminal proceedings report,1 Jastreboff and Hazell incorporated sound therapy within a treatment protocol for tinnitus, which in due course was to become known popularly as TRT.2 4 Their TRT protocol has evolved over time to include sound therapy and an expanded counseling protocol in a separate and distinct treatment approach for hyperacusis (i.e., TRT-H). Today, one can find several TRT outcome studies (mostly published in tinnitus conferences proceedings18 19 20) that support Hazell and Sheldrake's early use of low-level sound therapy as a treatment for hyperacusis. A summary of these treatment effects (i.e., treatment-induced incremental LDL shifts) in the TRT literature reveals appreciably larger (∼20-dB) treatment-related LDL shifts for more severely impaired hyperacusis patients compared to the smaller treatment effects reported by Hazell and Sheldrake.1 21 Moreover, sizable but less pronounced secondary treatment effects (i.e., secondary to the primary treatment effects on tinnitus) have been reported for patients with tinnitus treated by TRT.22 These positive secondary treatment effects appear to be largely independent of hearing loss for patients with tinnitus who were able to use noise (or sound) generators for their sound therapy (as long as the audiometric ceiling was not a confounding factor in the measurement range of the LDL values). We also now know that the use of sound generators like the kind worn for TRT sound therapy can affect the elevation of LDLs in normal listeners after 2 to 4 weeks of chronic use without any associated counseling.22 23 The resulting treatment effects reflect average increases in the DR by 6 to 8 dB, which is slightly smaller than that reported by Hazell and Sheldrake in their treatment of hyperacusis with counseling and daily low-level noise exposure.1
Purpose and Aims of This Study
A growing body of evidence suggests that applications of Hazell and Sheldrake's sound therapy and counseling principles may benefit a broad group of hearing-impaired individuals, not just those with debilitating tinnitus and/or primary hyperacusis.1 Of particular interest in this study is the application of those principles to unsuccessful hearing aid users, who were difficult to fit because of their reduced DRs (resulting from some combination of lower-than-normal LDLs and elevated audiometric thresholds). To the extent that Hazell and Sheldrake's counseling and sound therapy principles may be applicable and beneficial for a relatively typical and generic hearing-impaired patient group with mild sound tolerance problems, and there is no reason a priori to believe otherwise, we would predict successful expansion of their DRs, improved sound tolerance and comfort for amplified sounds, and, ultimately, enhanced hearing aid benefit and satisfaction following completion of a successful treatment. That is, the successful treatment would achieve the overarching objectives that Davis et al, early on, had hoped to achieve with high-level sound tolerance training.8 Accordingly, the primary purpose of this study was to evaluate the validity and efficacy of Hazell and Sheldrake's intervention principles and their generalized applicability (i.e., generality) to a relatively traditional sample of individuals with sensorineural hearing impairments whose hearing aid benefit or perceived potential to use hearing aids was limited by their reduced DRs and tolerance for amplified sound.
Of secondary interest in this study was the delineation of the treatment contributions from the counseling and sound therapy components in the full-intervention protocol and the respective treatment dynamics. Counseling represents a significant treatment component in the current TRT-H protocol.4 Refinements in the counseling protocol, with the inclusion of Jastreboff's neurophysiological model, may explain the correspondingly larger incremental LDL shifts obtained by TRT clinicians in relation to those reported by Hazell and Sheldrake.1 22 24 If so, then the counseling principles incorporated in the TRT-H protocol afford a value-added or synergistic contribution when combined with sound therapy and, together, these combined effects are predicted to be greater than those from either sound therapy or counseling alone. Thus, we devised a factorial trial design to control for the treatment effects from counseling separately from those achieved with sound therapy, while also allowing for a comparison of each of these partial treatments with reference to the full-treatment protocol implemented with counseling and sound therapy together. These comparisons were achieved with the use of a double-blind placebo control for the sound therapy component and a no-counseling control, which in combination, also offered a neutral (control) treatment condition for this study.
To summarize, the comprehensive trial design allowed us to address the following aims in a randomized controlled investigational study:
To evaluate the validity, efficacy, and generality of the counseling and sound therapy principles proposed by Hazell and Sheldrake in a targeted sample of hearing-impaired persons, who were not troubled by tinnitus nor debilitating hyperacusis but were affected by diminished DRs that impacted their tolerance for moderately loud and/or amplified sounds.1 Their restricted DRs deterred them from considering amplification or from using hearing aids optimally and/or successfully prior to treatment.
To delineate the contributions of the counseling and the sound therapy components in the treatment protocol by comparing the treatment effects achieved with partial treatment protocols (i.e., counseling combined with placebo sound therapy or sound therapy without counseling) relative to corresponding effects from the full-treatment protocol (i.e., counseling combined with sound therapy) or the control protocol (i.e., placebo sound therapy without counseling).
To characterize the temporal courses and dynamics of the resulting treatment effects for the full, partial, and control treatment protocols.
Methods
Subjects
Ten adults with normal hearing sensitivity provided normative results over a period of almost 1 year to assess learning effects associated with repeated collection of the primary and secondary outcome measures. The normal-hearing volunteers included 8 females (ages 39 to 73 years, with a mean age of 56 years) and 2 males (ages 54 and 60 years, with a mean age of 57 years). These volunteers were recruited locally at the University of Maryland, Baltimore (UMB) under a protocol approved by the institutional Investigational Review Board (IRB). All volunteers provided informed consent.
A total of 32 hearing-impaired adults from the UMB and 4 adults from the University of Alabama (UA) consented, enrolled and, ultimately, completed their assigned treatments in the randomized control trial. The trial protocol and informed consent materials were reviewed and approved by IRBs at UMB and UA. The age range for the 32 participants who completed the trial at UMB was 37 to 84 years, with a mean age of 67.8 years. The participants included 12 women and 20 men in the UMB sample. Four female participants, whose ages ranged from 58 to 79 years, completed the trial at UA. Their mean age was 70.5 years. Most participants, when questioned, were unable to ascribe an onset to their perceived problem or even verbalize the nature of their condition other than to state that they had an ill-defined sound tolerance problem that either confounded or might confound the benefit of hearing aid use.
Recruitment and Eligibility Criteria of Hearing-Impaired Participants for the Trial
Adults with bilateral hearing loss and complaints of reduced sound tolerance, unrelated to primary misophonia (i.e., dislike of or annoyance to specific sounds) or phonophobia (i.e., fear of exposure to specific sounds),4 15 were recruited for this study at UMB from a clinical database and via newspaper advertisements. Recruitment at UA was by known clinical history and direct participant contact. Candidate participants at UMB were initially screened for eligibility by telephone. Prospective candidates who reported unilateral hearing loss only, current use of hearing aids, or a history of otologic surgery were ineligible for the study. Furthermore, anyone who reported tinnitus as his or her primary problem was excluded.
Prospective candidates who confirmed hearing loss in both ears, noted some degree of problem in tolerating moderately loud sounds, and denied current hearing aid use were invited to schedule an eligibility appointment. During the eligibility appointment, ear-specific audiometric thresholds (250, 500, 1,000, 2,000, 3,000, 4,000, 6,000, and 8,000 Hz) and LDL judgments for pure tones (500, 1,000, 2,000, and 4,000 Hz) were measured under earphones (ER-3A) (Etymotic Research, Inc., Elk Grove Village, IL). The pure tone stimuli were produced by a clinical audiometer (Grason-Stadler, model GSI-10) (Grason-Stadler, Eden Prairie, MN), calibrated quarterly according to standard procedures (American National Standards Institute 83.6–1996), and presented to the study candidates via insert earphones (ER-3A). Tympanometry also was conducted with conventional clinical tympanometers (Grason-Stadler, model Tympstar or model 33) to verify normal middle ear function and to rule out confounding middle ear pathology.
The audiometric results for each prospective participant were then evaluated to determine whether he or she met the following inclusion criteria: (1) slight to moderately severe bilateral sensorineural hearing loss of at least 20-dB HL for three frequencies and of at least 30-dB HL for at least one or more frequencies in the range of 500 to 4,000 Hz and (2) LDLs ≤ 90-dB HL in the frequency range 500 to 4,000 Hz for at least two frequencies or a DR ≤ 60 dB for at least two frequencies or sound tolerance complaints for aided or unaided listening for candidates with LDLs below 105-dB HL.
Additional exclusion criteria also were considered in assessing eligibility. Prospective participants were excluded if any of the following criteria were violated. (1) Hearing sensitivity for pure tones was within normal audiometric limits for more than two frequencies in the range 500 to 4,000 Hz. (2) LDLs were ≥ 100-dB HL at more than two frequencies between 500 and 4,000 Hz. This latter exclusion criterion was necessary because one of the indicators of treatment-related change was a measurable increase in the LDL. Accordingly, if baseline LDL values were 100-dB HL or greater, then a significant treatment-related incremental shift in the LDL would have been ceiling limited by audiometer output constraints. (3) The participant's tympanometric test results were clinically abnormal. (4) The candidate could not conform to the test schedule (e.g., anticipation of multiple scheduling conflicts). (5) The participant was incapable of completing the functional outcome measures (e.g., inconsistent responses during preliminary LDL measurements). (6) The participant exhibited or described primary complaints consistent with misophonia or phonophobia. (7) Study personnel determined that the candidate was unlikely to be compliant with the study protocol. Eligible and willing candidates who met the inclusion criteria and who were not disqualified by the exclusion criteria voluntarily consented to enroll in the trial by participating in an informed consent process. This process culminated with each eligible and willing candidate signing an IRB-approved informed consent statement.
Random Treatment Assignments
After providing informed consent, eligible participants were assigned randomly to one of the four experimental treatment groups shown in the 2 × 2 trial design in Table 1. Participants in group 1 were assigned to a treatment grounded in the basic principles described by Hazell and Sheldrake for treatment of hyperacusis.1 This full-treatment protocol was implemented with counseling and conventional sound generators (CSGs). Participants in group 2 were assigned to PSGs and counseling. Participants in group 3 were assigned to CSGs, and those in group 4 were assigned to PSGs, with neither of the latter two treatment groups receiving the counseling component.
Table 1. Study Trial Design and Treatment Groups.
| Sound Generators | Placebo Sound Generators | |
|---|---|---|
| Counseling | Group 1 (n = 11) | Group 2 (n = 9) |
| No Counseling | Group 3 (n = 10) | Group 4 (n = 6) |
Nine participants were assigned randomly to each group at the start of treatment; however, at the end of their treatments three participants were reclassified to account for PSG failures, which rendered their placebo devices conventional in operation as determined by General Hearing Instruments (GHI; Harahan, LA) quality control engineers at posttreatment evaluations. These PSG failures are explained in the appendix (pgs. 106-107). Specifically, one participant was reclassified from PSG group 2 to CSG group 1, and two participants were reclassified from PSG group 4 to CSG group 3. Additionally, two participants, who were randomized to noncounseling treatment, mistakenly received counseling at their initial fitting. One of these participants was moved from group 3 to group 1 and the other participant was moved from group 4 to group 2. Accordingly, after reclassifying for the PSG failures and inadvertent counseling errors, the number of participants evaluated as treated in groups 1, 2, 3, and 4 were 11, 9, 10, and 6, respectively. The presentation of the study findings by treatment group follows from this as-treated reclassification, which we believe is the most sensible presentation of the results based on our knowledge of actual treatments received at the end of the study. This analysis decision does not change the overall pattern of the results, which we will show were virtually identical to those for the as-treated and as-assigned groups after removing the PSG failure participants from the group analyses.
The average audiometric thresholds and LDLs for each as-treated group at baseline are shown in Fig. 1. In general, these baseline results are well matched across groups, reflecting mild-to-moderately severe sloping sensorineural hearing losses and LDLs just below and around 90-dB HL across frequency. The audiometric thresholds were unchanged from baseline to end of treatment.
Figure 1.
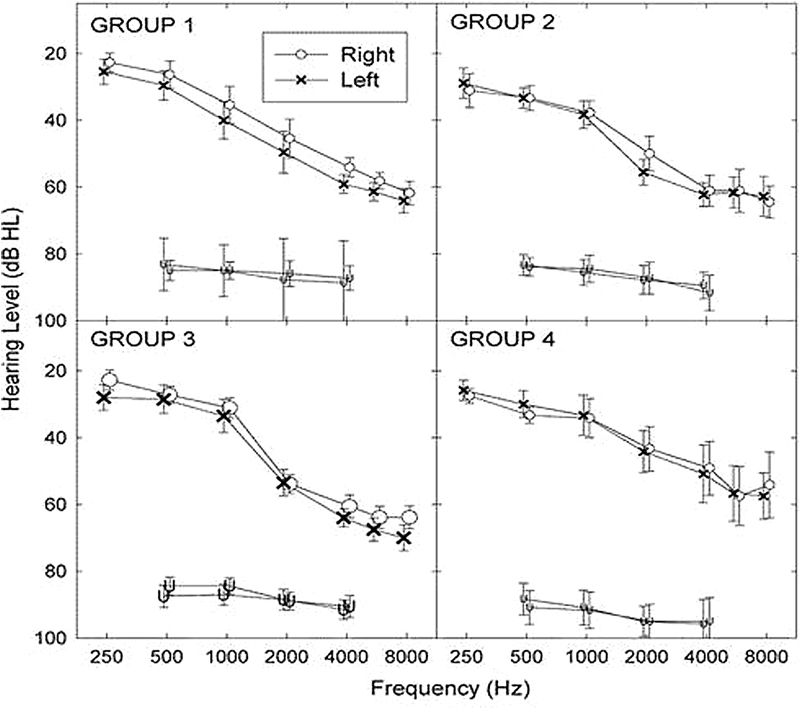
Baseline pure tone air-conduction thresholds and loudness discomfort levels (±1 standard error) for the left and right ears as a function of frequency for each as-treated group identified in the designated panels. Abbreviation: HL, hearing level.
Measurement Protocol
The participants were scheduled for a practice appointment subsequent to completing the informed consent process. This appointment served two primary purposes: (1) to verify that the participants continued to meet eligibility criteria and (2) to familiarize the participants with the study measurement protocol. Subsequently, this same measurement protocol was administered at baseline and at all follow-up measurement visits to assess treatment efficacy. The protocol included measures of audiometric thresholds; LDLs for pure tone, speech, and white-noise stimuli; categorical loudness judgments for warbled tones and speech stimuli; evaluation of word-recognition ability at two presentation levels corresponding to categorical loudness judgments of Comfortable and Loud, but OK for the individual; and tympanometry. The sequence of the test procedures was randomized at each test session. The study measurements were performed in a sound-attenuating test suite (IAC, series 1400 ATT) (IAC - Acoustics, Bronx, New York) with the audiometric equipment previously described.
Ear-specific audiometric thresholds were measured for 250, 500, 1,000, 2,000, 3,000, 4,000, 6,000, and 8,000 Hz, using the modified Hughson-Westlake procedure under earphones (ER-3A).25 Ear-specific LDL values, which represent absolute judgments of loudness discomfort, were measured under earphones (ER-3A) for pure tones presented at 1,000 and 8,000 Hz, for spondee words, and for white noise. Stimulus duration for the tones and noise stimuli was ∼1,000 milliseconds, with an interstimulus interval of ∼400 to 500 milliseconds. Participants were instructed to press the handheld response button when the signal level became uncomfortable. The following instructions were given to each participant: “I am going to present different sounds that get louder and louder in volume. I want you to decide when the sound is at a level that you think is too loud, uncomfortably loud, or annoyingly loud. By ‘too loud,’ I mean when the sound is above the level to which you would choose to listen for any period of time. Push the button when the sound is at a loudness to which you would not listen.” Three LDL estimates were obtained for each stimulus. If there was an intertest difference exceeding 10 dB for a given stimulus, then a fourth estimate was obtained and the outlier was discarded.
Categorical loudness judgments were measured for 500-, 2,000-, and 4,000-Hz pulsed warbled tones (frequency modulation ± 5% of center frequency) per the protocol described by Cox and colleagues for the Contour Test of Loudness.26 Test stimuli were presented in ascending level, with the initial starting level presented one step above the audiometric threshold for that frequency; step size was 5 dB when audiometric threshold was < 50-dB HL and was 2.5 dB when the threshold was ≥ 50-dB HL. Four 200-milliseconds pulses of each warbled tone were presented at each stimulus level. The interstimulus interval was typically 1,000 milliseconds, but varied somewhat based upon the participant response time. Participants responded to the perceived loudness of the signal, after presentation of the series of tones at a given level, by stating the number corresponding to the perceived loudness category (e.g., 1 = Very Soft, 2 = Soft, 3 = Comfortable but Slightly Soft, 4 = Comfortable, 5 = Comfortable but Slightly Loud, 6 = Loud, but OK, 7 = Uncomfortably Loud). The initial presentation level generally yielded a response of Very Soft (category 1). Occasionally, the starting level resulted in a rating of Soft (category 2). When this latter response occurred, the starting level was decreased to audibility threshold. Stimulus intensity subsequently was increased, and a categorical judgment of loudness was obtained for each presentation level until the participant reported a response of Uncomfortably Loud (category 7), which terminated the trial sequence. Three ascending trial sequences were presented at each frequency, with the test frequency selected in random order. The median value for each loudness category was determined from the three trial sequences.
Ear-specific categorical loudness judgments also were obtained under earphones (ER-3A) for recorded spondaic words (Central Institute for the Deaf (CID), W-2 Word Lists). The initial starting level was presented one step above the lowest (best) pure tone threshold across the audiometric frequency range 250 to 8,000 Hz. A 5-dB step size was used for these measurements regardless of the pure tone threshold. Categorical loudness judgments from three ascending trials were measured for each ear; the order of presentation was randomized between the ears. Subsequent to completing the categorical loudness judgments for the recorded spondee speech stimuli, word-recognition ability was measured using recorded Northwestern Auditory Test No. 6 (NU-6) word lists (50-word lists) at presentation levels corresponding to loudness judgments of Comfortable (category 4) and Loud, but OK (category 6).
Some of the study participants at UMB completed a pretreatment sound tolerance questionnaire (personal communication with LaGuinn Sherlock and Sue Erdman) and the Revised NEO Personality Inventory (NEO PI-R, Par Inc., Lutz, FL) during the appointment for the practice session.27 The former instrument was in development at the start of the study and the content is not validated. Therefore, it was not used as a formal baseline nor an outcome measure. The latter psychometric tool was administered to assess personality characteristics that might ultimately be predictive of treatment success or failure. These latter results have not been analyzed formally to date.
Bilateral ear canal impressions, for ordering and fabricating the cases of the custom in-the-ear sound therapy devices, were usually made for the participants at the time of the randomized treatment assignment. This activity was sometimes postponed and performed at a subsequently scheduled practice visit if scheduling or time constraints precluded this step. The sound therapy device order form was completed by a neutral third party (the division administrator), who determined the sound therapy device type (i.e., CSG or PSG) that each participant was assigned to receive based upon a predetermined randomization schedule. The study audiologists were blinded to the device type, as was each study participant.
Participants were scheduled to return for their baseline and treatment visit when their sound therapy devices were ready to be dispensed, typically about 4 weeks after the practice session, but in some cases longer (see the appendix, pg. 107). The baseline test session established LDL values, categorical loudness judgments, and word-recognition performance prior to initiating the assigned treatment protocol for each participant. In addition, baseline auditory brainstem and middle latency response measurements were performed for those participants enrolled in the study at UMB. These results, also measured at follow-up visits throughout the period of treatment, will be described in a separate report.
Counseling Treatment Protocol
Participants assigned to one of the counseling groups (groups 1 and 2) received counseling in a single session. This counseling session followed after the baseline test measurements and preceded the fitting of their CSGs/PSGs. The counseling was performed routinely at UMB and at UA by a single TRT-experienced clinician. The audiologist collecting the study data was not blinded to whether (or not) the participant received counseling as part of his or her treatment.
Counseling followed a structured protocol, which was administered by the counseling audiologist in a checklist format. The content of the counseling protocol was divided into four basic components, which typically required a total time of 1.0 to 1.5 hours to complete. The four components of counseling included: (1) an overview of the counseling protocol and the participant's audiometric results; (2) an overview of relevant auditory anatomy and neurophysiology; (3) an overview of central auditory gain control processes in the context of the participant's sound tolerance problem and his or her limited DR; and (4) an introduction to the importance of sound therapy in treatment of the problem. The counseling was performed with each participant's audiometric and LDL results and with visual aids, using flip charts to display anatomical illustrations and photographs. Additionally, a diagram of Jastreboff's neurophysiological model was presented to help explain the problem of hyperacusis.24 The model was helpful in clarifying hyperacusis and in distinguishing this problem from misophonia/phonophobia; again, our sample did not describe symptoms consistent with either of these latter issues as significant concerns. The counseling content also was void of basic information about tinnitus, which if reported by a participant was an unremarkable secondary issue. Instead, the counseling content was refined and restricted to issues relevant to suprathreshold sound-sensitivity problems, sound intolerance, and associated complaints, including those related to a reduced DR for loudness as a consequence of sensorineural hearing loss.14 These issues, individually and together, were related to adverse effects on the participant's comfortable use of amplification. The objectives of the counseling were explained in terms of isolating and addressing each participant's primary problems, thereby enabling better management to expand his or her reduced DR for loudness. The counseling also clarified the purpose and goals of the study while addressing any study-related questions and concerns expressed by the study participants.
Sound Therapy Devices
All participants were assigned to a sound therapy treatment. The sound therapy treatments were implemented with either CSG or PSG devices via nonoccluding, custom, in-the-ear sound generators (GHI Tranquil model). The CSGs were modified, as described in the appendix, to achieve the desired placebo effect in the PSGs. Two versions of the PSGs were implemented in this study (see the appendix, pgs. 106-108). The typical real-ear frequency responses for both CSGs and PSGs were characterized by a high-frequency emphasis in the range of the ear canal resonance frequencies. Perceptually, the sound output was perceived as a soft seashell-like noise. The CSGs produced the soft noise output continuously at a constant level. In contrast, the PSG devices produced a short-duration dose of the same noise, which is described below.
The novel PSG treatment was crucial to the success of this project in as much as it enabled us to implement the double-blind sound therapy treatment for the trial. The PSG strategy took advantage of normal short-term adaptation processes that may give rise to partial (if not complete) perceptual sound decay for weak sounds. Additionally, other perceptual processes ostensibly contributed to auditory gain recalibration effects, following repeated exposures to the soft sound therapy noise over extended time of use. Specifically, the placebo effect was made plausible because we knew clinically that patients with tinnitus and hyperacusis may experience perceptual attenuation or decay to the noise during sound therapy with CSGs. Consequently, they often report becoming unaware of the low-level sound therapy noise from their CSGs over the course of daily usage. Also, pilot listening to the CSG devices by the investigators, even in quiet conditions corresponding to the Comfortable but Soft presentation levels that were used in this study, revealed normal perceptual attenuation of the noise. Accordingly, the PSGs were designed to decay to silence after ∼60 to 70 minutes of use. The output of the placebo devices was constant in level during the initial 30 to 40 minutes of use and, thereafter, the output was systemically attenuated to silence at a rate of ∼1 dB per minute (see Fig. A3A). The expectation of routine sound decay, consistent with the attenuating PSG function, was reinforced by clinician instruction. Indeed, all participants regardless of device assignment were informed that they may not hear the noise from their devices because of the adaptation effects, especially in noisy sound environments.
Figure 3.
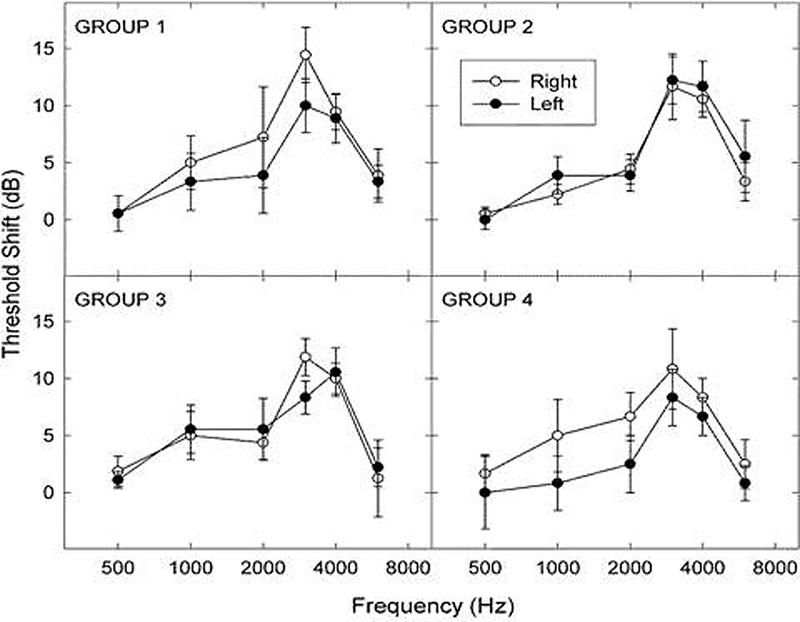
Average masked threshold shifts (±1 standard error) as a function of frequency for groups 1 and 3 and for groups 2 and 4, respectively, when using the conventional sound generators (CSGs) and placebo sound generators (PSGs) at their Comfortable but Slightly Soft use settings.
An innovative and critical feature of the function of the PSG required the output to reset to the initial, steady-state, unattenuated level soon after the device was removed from the ear. This feature was added as a safeguard against untoward revelation of the placebo effect, which might otherwise be revealed to the participant or to the study audiologist during an out-of-the-ear listening check of the PSG output. This novel resetting feature, which operated with a brief resetting time constant of ∼2 to 3 seconds, was critical for double blinding of both the participant and the study audiologist to the conventional or placebo device type. To discourage inadvertent resetting of the PSG output, participants were instructed to insert and position their sound generators (both conventional and placebo) at the start of the day and then to forget about the devices until removed at the end of daily usage (encouraged for at least 8 hours each day).
Sound Therapy Fitting Protocol
Rationale
The essential requirements for sound therapy in this study were to provide the participants a consistent and gentle noise source, consistent with Comfortable but Slightly Soft level (category 3), to facilitate the intended treatment effects from the CSGs, while also minimizing untoward adverse masking effects while in use. An additional requirement for participant use of both the CSG and PSG instruments was to minimize undesirable sound-attenuating occlusion effects while wearing the devices. The latter occlusion effects might otherwise counteract the desired sound-enriching effects of the noise treatment, as well as restrict daily communication while the devices were worn. Specifically, external sound attenuation from wear of a fully occluding device has been shown to induce counterproductive increases in central auditory gain, which enhance loudness and thereby reduce sound tolerance and the DR.22 23 28 To minimize untoward occlusion effects in this study, the CSG and PSG devices were encased in open-canal fitted shells, which allowed speech and environmental sounds to pass virtually unattenuated. Accordingly, a successful CSG sound therapy treatment with an open-canal fit was expected to reduce (central) auditory gain for the participants,1 fostering enhanced sound tolerance and expansion of the auditory DR for loudness.
In planning the use and fitting of the CSGs for this trial, we made the decision to maintain a consistent steady-state volume setting throughout the entire treatment period for each participant. Our treatment protocol therefore differed in an important way from the desensitizing sound therapy protocol originally described by Hazell and Sheldrake and currently recommended in the TRT-H sound therapy protocol for treatment of hyperacusis.1 4 Specifically, the desensitizing sound therapy approach calls for systematic increases in the sound generator volume output over the course of the hyperacusis treatment. Our decision to fix the CSG volume output throughout the period of treatment was, in part, a strategy to offer a known and controlled sound therapy stimulus, which simplified the eventual interpretation of the treatment outcomes. This strategy also was essential for minimizing and controlling the low-level masking produced by the CSGs. Indeed, minimization of low-level masking effects was crucial during the prolonged treatment period for our unaided, audibility-challenged, hearing-impaired participants. Otherwise, their everyday communication and listening abilities, in the absence of useable amplification, would be further compromised by the low-level masking noise from their CSGs. Thus, to the extent that systematic increases in the CSG outputs would necessarily have given rise to incremental low-level masking, each participant's auditory DR would, in turn, have been diminished systematically while the CSGs were in use during the treatment period. Accordingly, we adopted a fixed low-level noise stimulus throughout the period of treatment for groups 1 and 3. Groups 2 and 4 were similarly managed, albeit the outputs of their PSGs were purposely attenuated to silence after ∼60 to 70 minutes of use.
Fitting Procedure
The participants were instructed in the use, fitting, and care of their open-canal sound generators per the treatment protocol described herein. This instruction always followed after the baseline test measures were completed and after a counseling assignment. Initially, the sound generator instruments were positioned within the ear by the study audiologist. Comfortable physical fits were then verified for each participant, and the noise output was adjusted to a volume corresponding to a loudness rating of Comfortable but Slightly Soft. The device volume was set independently for each ear, and a second loudness rating was then obtained with the bilateral devices operational. If the bilateral loudness rating changed, then the volume of each device was adjusted until the participant's rating of the bilateral noise output level was again judged to be Comfortable but Slightly Soft. Next, measurements were performed using a real-ear system (AudioScan, model RM5000) (AudioScan, Dorchester, Ontario, Canada) to document the device output within each ear. The probe tube was placed within the ear canal to a standardized insertion depth of ∼ 28 mm. Measurements were performed with the devices in the ear, first turned off and then turned on. The AudioScan output was turned off so that the resulting difference between the instrument settings in the on and off conditions yielded a measure of the device output within the ear canal. Average real-ear responses for the sound generators used in this study are shown separately for the left and right ears for each treatment group in Fig. 2. These responses reveal the expected high-frequency emphasis, with peak output at 2,000 Hz reflecting the characteristic ear canal resonance.
Figure 2.
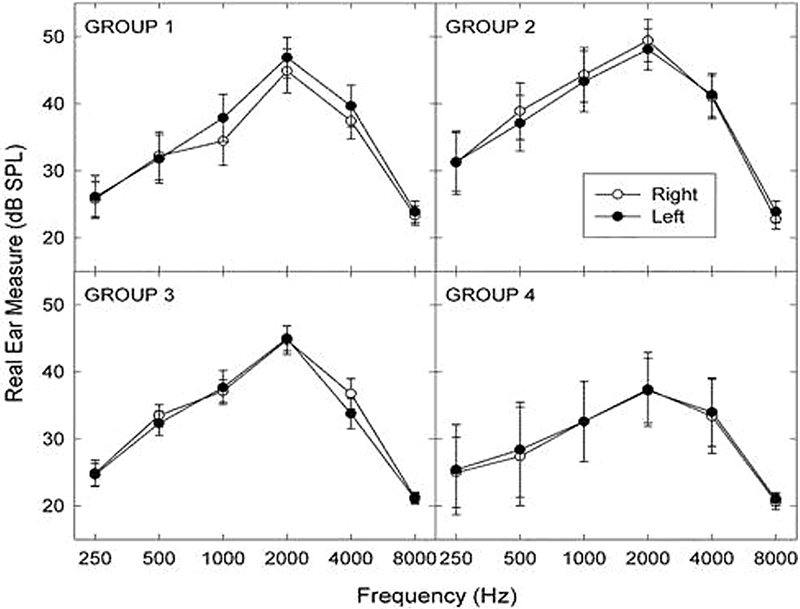
Average real-ear frequency responses (±1 standard error) for the conventional sound generators (CSGs) and placebo sound generators (PSGs) measured for the left and right ears for groups 1 and 3 and for groups 2 and 4, respectively, at Comfortable but Slightly Soft use settings. Abbreviation: SPL, sound pressure level.
Behavioral (audiometric) threshold shifts also were measured with the bilateral CSGs/PSGs situated within the ears and turned on per the treatment protocol. The device-induced masked (audibility) threshold shifts were checked at baseline and at each follow-up appointment to verify expected device output within the ear. (Measurements were made while the PSG outputs were in the steady state, prior to initiation of the decay phase.) Audibility thresholds were measured between 500 and 6,000 Hz using the headphones (Telephonics, model TDH-50) (Telephonics, Farmingdale, NY) encased in supra-aural cushions. The threshold measurements were performed, with and without the treatment devices in use, with the resulting difference in the two sets of thresholds representing the masked threshold shifts. Average masked threshold shifts measured for the sound generators in operation are shown separately for the left and right ears for each treatment group in Fig. 3. Note that the masked threshold shifts mirror the real-ear response patterns shown in Fig. 2. The largest masked threshold shifts, typically between 10 and 15 dB, were produced at 3,000 Hz for each group. Otherwise, the masked threshold shifts were not much more than 5 dB at most frequencies and were not usually reported to be a confounding factor in daily communication for our participants.
CSG/PSG output also was verified electroacoustically during each test session with the AudioScan real-ear system. The CSG or PSG was coupled to an HA-1 coupler and its steady-state output was measured at the participant's use setting. Sound generator outputs were compared at each follow-up session with the baseline measurements at treatment onset to ensure consistent outputs. If a follow-up sound generator-output response varied appreciably from its baseline value, then the CSG/PSG volume setting (set manually by potentiometer adjustment) was verified. If the volume setting was consistent with the baseline value and the output was weak, then a visual inspection of the device was conducted to rule out a cerumen-occluded receiver. Subsequent to these efforts, the treatment device was returned to the manufacturer for repair or replacement if the output response did not closely match the baseline output value.
Participants received written and verbal instruction in the care and use of their CSGs/PSGs. Again, participants were advised to anticipate naturally occurring perceptual attenuation of the low-level noise from their sound generators. Accordingly, they were forewarned and were aware that they might not always detect the outputs from their sound generators. This key information, namely, that perceptual adaptation to the sound generator noise output was normal and should be expected, was emphasized and reinforced at treatment onset and at all follow-up visits for each participant. This knowledge was integral to the successful use of the PSGs, as well as that of the CSG devices. The instruction to the participants, to insert their sound therapy devices within the ears and then to forget them, also was emphasized. The participants practiced correct placement of their CSG/PSG devices in the ears, and proper placement was confirmed by the research audiologist or a graduate assistant at each clinic visit. Participants were provided with a supply of batteries at each test session and instructed to replace the batteries weekly, or as needed, to sustain normal function. Last, participants were instructed to record their CSG/PSG use time each day on a device-use log and to share their logs at each follow-up session for clinician review. The clinician reviewed the daily-use entries to ensure protocol compliance and, if necessary, to counsel the participant if he or she were noncompliant with prescribed use of the device for at least 8 hours daily.
We implemented two follow-up schedules during this study to monitor treatment progress. The two schedules were implemented because the dynamics for the full- and partial-treatment effects were uncertain at the start of this study. Hazell and Sheldrake's early report of their treatment dynamics guided our design of the initial follow-up schedule,1 which coincided with the evaluation of the first-generation CSGs/PSGs (see the appendix, pg. 106). The initial follow-up schedule encompassed a treatment period of about 1 year, which Hazell and Sheldrake reported to have been sufficient to reveal treatment effects for the majority of their patients.1 This early follow-up schedule called for less time between follow-up sessions at the start of treatment, with increasingly longer intervals between follow-up appointments over the course of the assigned treatment protocol. This initial strategy was necessary to monitor and capture rapid treatment effects (i.e., incremental changes in the categorical loudness judgments) that might occur early in the repeated measurements and otherwise be missed. These scheduled follow-up appointments were set at 0.5, 1, 2, 3, 4, 6, 8, 10, and 12 months after the baseline/initial treatment session. Fourteen participants completed the initial follow-up schedule.
After reviewing the treatment dynamics for those participants who benefitted from their interventions during the initial follow-up schedule, we determined that: (1) primary treatment-related changes had generally occurred during the first 6 months of follow-up, which was consistent with Hazell and Sheldrake's findings that 73% of their patients with hyperacusis were treated successfully within 6 months of beginning treatment,1 and (2) these changes would typically have been captured by monthly visits. We therefore modified the follow-up protocol schedule to reduce the burden on the study participants and to allow them to be fitted with hearing aids sooner than was permitted by the original protocol, which called for an additional 6 months of treatment with no further expected improvement from their treatment. The revised follow-up schedule called for monthly follow-up appointments for 6 months after the baseline/initial treatment session. Moreover, the decision was made that the treatment and follow-up protocol could be terminated earlier than 6 months if criterion LDL and/or categorical loudness judgments for Uncomfortably Loud consistently shifted by 10 dB or more for a given measure of uncomfortable loudness at two consecutive follow-up visits. This early termination criterion was developed to allow our participants, who were all hearing aid candidates, the opportunity to be fitted with hearing aids once they had a clinically meaningful change in their sound tolerance. Twenty-two participants completed the revised follow-up schedule.
Participants were interviewed at each follow-up test session to determine whether there were any unexpected changes in their audiometric or sound tolerance conditions, to ascertain any concerns about the fit or function of their CSGs/PSGs, and to evaluate self-reported use time for their sound therapy devices. Compliance with the upcoming schedule and continued interest in study participation also were confirmed, and informed consent was reaffirmed with each participant.
At the termination of their assigned treatments, 10 participants who had not received the full treatment, including counseling and conventional sound therapy, were crossed over to the full-treatment protocol for 6 months. In addition, several of the participants in group 1 who graduated successfully from the full treatment and some participants in other treatment groups who benefited from their treatments elected to try the use of hearing aids at the completion of their successful interventions. Unfortunately, during the funding period for this study, we were only able to follow a few of these individuals in their crossover treatment and/or their postfitting experiences with hearing aids. Case examples of posttreatment functional benefit will be considered for selected participants in a companion report that will address the clinical relevance of the study outcomes.
Statistical Analyses
Along with simple descriptive statistics (i.e., means and standard deviations), the primary statistical analysis applied in this study focused on longitudinal change in the categorical loudness judgments to reveal treatment-related group differences. We performed the primary analysis of longitudinal change using the Proc-Mixed protocol in SAS software (version 9.3, Cary, NC). Longitudinal change in the loudness measures were evaluated and compared, over the course of each treatment, using linear mixed models to evaluate slope inequalities by treatment group assignment. The analyses were stratified by stimulus-frequency condition, 500, 2,000, and 4,000 Hz, for each of the seven Contour loudness categories. Because the study follow-up visits were not equally spaced in time across the participants, the mixed-model design enabled us to explore various covariance matrices to maximize model fit. Additionally, for purposes of post hoc evaluations, the Bonferroni method for correction was used to adjust confidence limits to maintain a consistent α level for all paired comparisons.29 As previously discussed, two different follow-up schedules were evaluated in this study with differing points of treatment termination based on criterion changes in the longitudinal loudness measures. This temporal measurement variation invalidated the standard repeated-measures design, which assumes either that within-participant errors were uncorrelated or that the correlation between observations on the same participants was constant regardless of the time lapse between observations. Accordingly, the mixed-model approach for this longitudinal study incorporated a time-series covariance structure (i.e., spatial power law) to manage the unequally spaced time points in the analysis that otherwise would have been susceptible to underestimates of standard errors and overestimates of time and time-by-treatment effects in a standard repeated-measures analysis.
Both linear and nonlinear (quadratic) functions were evaluated for best fits to the longitudinal data, with minimal difference observed between the two fitting functions. Consequently, for economy of description and interpretation, in the absence of compelling evidence to favor the more complex nonlinear fitting strategy, we adopted the linear-fitting strategy for our primary analyses and for reporting of the study outcomes.
The power analysis for the study also was performed using a mixed-model design for which we modeled between-subjects effects with the four levels (one level for each treatment group) and a within-subjects effect with seven levels (average of time measurements). Both factors were designated as having a linear-up effect pattern, with a conservative detectable mean difference of 1 unit above and below the comparison mean. For example, a 1-unit detectable difference for a reference of a mean of 5 would represent the minimal detectable difference in the range of 4.5 to 5.5 for the comparison mean. Results from this mixed-model power calculation consistently resulted in >80% power for this effect size across samples ranging from 6 to 12 observations (i.e., study participants) per group, which was consistent with various analyses performed on our unbalanced group sizes. This study design therefore is unbalanced in its treatment allocations for the different groups. There is a power decline as the allocation ratio deviates from 1.00; however, this effect is not very prominent and moderate imbalances in group sizes, as occurred in our study, can be utilized without great concern about loss of power or the need to increase total sample size.30
Results
Overview
The results discussed here address the primary and secondary aims listed in the introduction. These findings provide the critical tests of the validity, efficacy, and generality of the intervention principles for treating reduced sound tolerance and related DR problems among our sample of people with hearing loss.1 The results for the ear-specific LDLs and Contour testing are presented as averages across ears and across subjects in each group.
Control Repeated Measures
Consider first the repeated measurements of the categorical loudness judgments measured at monthly intervals over a period of about 1 year from the 10 normal-hearing volunteers. There was no consistent trend of improvement over time for any of our repeated measures for individual participants. The standard deviations across sessions for the categorical loudness judgments, averaged across participants, were 5.4, 4.5, and 10.4 dB at 500, 2,000, and 4,000 Hz, respectively.
Changes in Loudness Discomfort with Treatment
The focus of the treatment effects in this study was on the change in the categorical loudness judgments from baseline to end of treatment. These treatment effects were the primary outcome measure of interest. The LDL judgments were used as a secondary outcome measure to supplement the categorical loudness data for purposes of establishing treatment termination. Incremental changes from baseline of 10 dB or more at two consecutive follow-up visits for either (or both) the 1,000-Hz LDL judgments or the Uncomfortably Loud categorical judgments, averaged for the 500- and 2,000-Hz measurement conditions, qualified a participant to terminate and graduate successfully from the assigned treatment. Based on these criteria for treatment termination, 82% of the individuals receiving full treatment in group 1, 25 and 40% of the participants in partial-treatment groups 2 and 3, respectively, and 50% of the control participants in group 4 were treated successfully at the conclusion of their as-treated group assignments. The latter result for group 4 should be interpreted cautiously because only six participants contributed to this result.
The magnitudes of the treatment-related changes (in decibels) are shown for each group in Fig. 4 for the Uncomfortably Loud categorical judgments, averaged for the 500-, 2,000- and 4,000-Hz frequency conditions. Also shown for comparison are the corresponding mean changes in the LDL judgments for 1,000 Hz for each group. These data were analyzed in three ways to enable comparison of the results by the: (1) as-assigned (at treatment onset); (2) as-treated (as determined at treatment end); and (3) dropped participant group designations. The latter designation reflects the deletion of the three participants with PSG failures from the analysis. The trends are similar for all three analyses. The mean changes for group 1 for both the Uncomfortably Loud and LDL judgments in Fig. 4 were consistently greater than those measured for the other groups. Indeed, the group 1 changes in judgments of Uncomfortably Loud posttreatment averaged ∼15 and 10 dB, respectively, whereas the corresponding changes for the other groups typically averaged ∼ 5 dB or less. Similarly, the efficacy rates for the as assigned and dropped participant analyses were virtually unchanged for group 1 (78 and 80%, respectively) from their as-treated efficacy rate (82%). These treatment-related changes for the Uncomfortably Loud judgments are clinically significant, reflecting incremental shifts in loudness discomfort in excess of a full category for full-treatment group 1.
Figure 4.
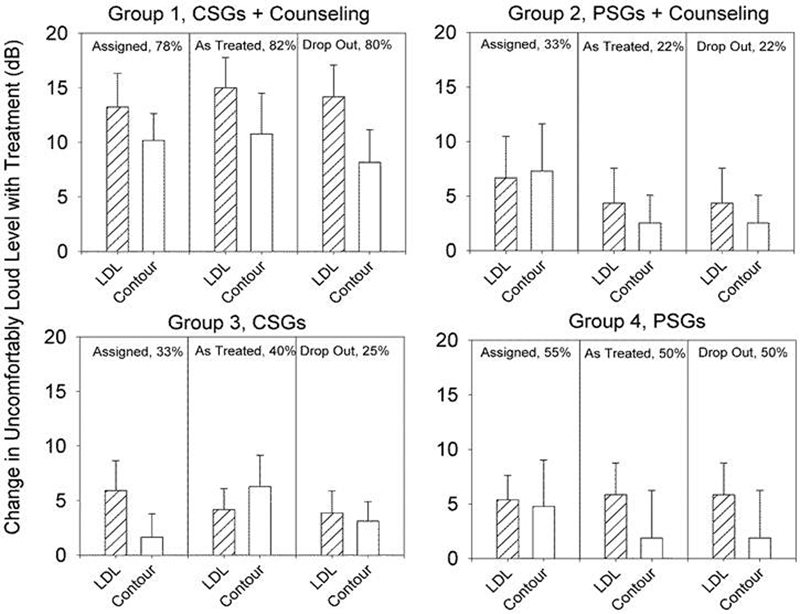
Treatment change by group for LDL (1,000 Hz) and Uncomfortably Loud categorical judgments (averaged for 500, 2,000, and 4,000 Hz) between baseline and end of treatment. Shown are the average change values (±1 standard error) for the participants in the as assigned, as treated, and dropped from analysis treatment groups. Abbreviations: CSG, conventional sound generator; LDL, loudness discomfort level; PSG, placebo sound generator.
Changes in Loudness Growth with Treatment
The average loudness-growth functions measured at baseline and at the end of treatment for group 1 are consistent with the positive treatment effects described above. These results and those of the other treatment groups are shown in Fig. 5 for the as-treated categorical-loudness judgments at 500, 2,000, and 4,000 Hz. The end-of-treatment function for each group reflects average results measured over the last pair of treatment visits (for which consistent performance was required to terminate treatment). Again, the largest treatment effects are apparent for group 1, for whom the divergence of the baseline and end-of-treatment functions was greatest. For 500 Hz, this divergence begins with the judgments of Comfortable but Slightly Soft and increases systemically with increasing loudness category; whereas for 2,000 and 4,000 Hz, the separation of the baseline and end-of-treatment functions is evident across all categories from Very Soft to Uncomfortably Loud, and systematically diverges to a greater extent with increasing loudness category. Consequently, the end-of-treatment loudness-growth function for group 1 is extended to higher levels and, therefore, spans a larger range of levels than does the steeper pretreatment baseline function. Accordingly, the shallower end-of-treatment function for group 1 represents an enhanced DR for loudness relative to the steeper baseline function. A similar but less prominent effect of treatment is observed in the corresponding loudness-growth functions for group 3, which was treated with CSGs alone. The treatment effects for group 2 were relatively smaller than those for group 3, and those for group 4 were negligible. Again, group 2 participants were assigned counseling and PSGs, whereas participants in control group 4 were assigned no counseling and PSGs. The trends for the baseline and end-of-treatment loudness-growth functions for the respective groups were largely invariant of the measurement frequency condition, reflecting the generality of the treatment effects across frequency.
Figure 5.
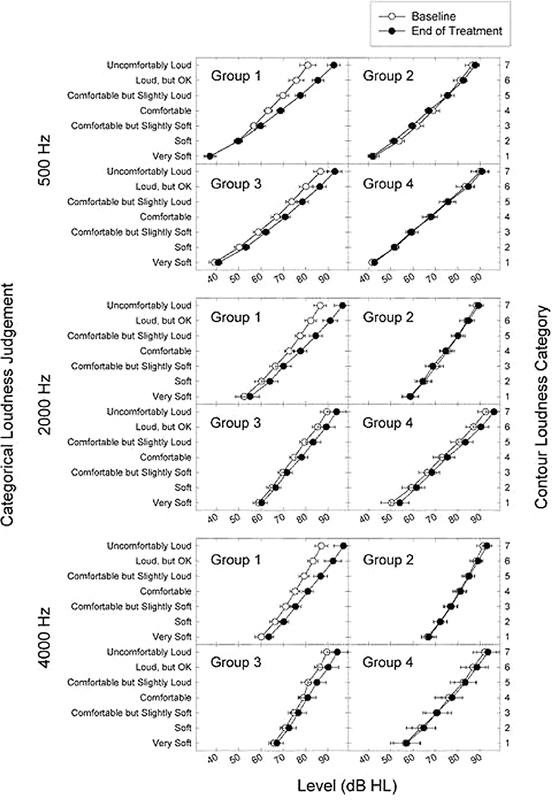
Mean baseline and end-of-treatment loudness-growth functions (±1 standard error), measured for a pulsed-warbled tone are presented by group in separate panels for 500, 2,000, and 4,000 Hz. The end-of-treatment functions were constructed by averaging the resulting judgment levels for each loudness category across the last two study visits for each participant. Abbreviation: HL, hearing level.
A two-way analysis of variance comparing the baseline versus end-of-treatment judgments across Contour loudness category (1 to 7) for each frequency condition confirmed the observable trends in the loudness-growth functions shown in Fig. 5. Specifically, the baseline versus end-of-treatment loudness-growth functions for group 1 were significantly different (p < 0.001) for each frequency condition. Likewise, the baseline and end-of-treatment loudness-growth functions were significantly different for group 3 for 500 Hz (p = 0.013) and for 4,000 Hz (p = 0.008). In contrast, loudness growth was not significantly different between baseline and end-of-treatment for any frequency condition for groups 2 and 4. No interactions were obtained for any treatment group, precluding the isolation of an effect for a specific loudness category. Categorical effects of the treatments, however, are suggested by the increasing separation of the baseline and end-of-treatment functions with increasing loudness category for group 1 and, to a lesser degree, for group 3.
Thus, group 1, which was assigned to full treatment, achieved the most prominent intervention effects as measured by overall changes in loudness growth between baseline and treatment termination. These treatment effects were significant statistically and were consistently measured across frequency at 500, 2,000, and 4,000 Hz. Significant but less prominent treatment effects also were measured at 500 and 4,000 Hz for group 3, which received sound therapy alone via CSGs. No significant treatment effect was measured for control group 4, which was treated only with PSGs, nor for group 2, which was assigned counseling in combination with PSGs. Accordingly, we may surmise from this evidence that CSGs, which were assigned for both groups 1 and 3 but not for groups 2 and 4, were integral to treatment success.
The conclusion that CSGs were integral to treatment success is highlighted in Table 2 in which mean change values are quantified between the baseline and end-of-treatment loudness-growth functions from Fig. 5. For each group, the mean change in decibels is presented for the end-of-treatment loudness judgments relative to the corresponding baseline judgments for each Contour loudness category stratified by measurement frequency. Also shown are the mean change values for each loudness category, stratified by measurement frequency, and the corresponding grand mean change values, averaged across measurement frequency, for each group; the summation of the mean change values by frequency and the total of these grand mean values for each group are shown at the bottom of each column. The latter total grand mean value represents a comprehensive index, estimated across category and frequency, of the respective overall treatment change achieved by each group. The resulting comprehensive index values of treatment change were 40.66, −0.25, 22.95, and 10.17 dB for groups 1, 2, 3, and 4, respectively. The large and moderate index values of overall treatment change for groups 1 and 3, respectively (in relation to the negligible and small index values for groups 2 and 4), confirm the importance of sound therapy in the treatment protocol.
Table 2. Mean Treatment Change between Baseline and End-of-Treatment Loudness Judgments for Each Group as a Function of Contour Loudness Category for Each Measurement Frequency.
| Group 1 | ||||
|---|---|---|---|---|
| Contour Loudness Category | Frequency (Hz) |

|
||
| 500 | 2000 | 4000 | ||
| 1 | −0.06 | 2.61 | 3.35 | 1.97 |
| 2 | 0.06 | 3.69 | 3.92 | 2.56 |
| 3 | 3.01 | 3.69 | 4.38 | 3.69 |
| 4 | 5.57 | 5.06 | 5.68 | 5.44 |
| 5 | 7.84 | 6.99 | 7.33 | 7.39 |
| 6 | 9.60 | 8.81 | 8.92 | 9.11 |
| 7 | 11.65 | 10.00 | 9.89 | 10.51 |
| ∑Δ | 37.67 | 40.85 | 43.47 | 40.66† |
| Group 2 | ||||
| Contour Loudness Category | Frequency (Hz) |
|
||
| 500 | 2000 | 4000 | ||
| 1 | −0.63 | −0.21 | 0.61 | −0.07 |
| 2 | −2.29 | −0.69 | 0.13 | −0.95 |
| 3 | −2.15 | −1.39 | 0.29 | −1.08 |
| 4 | −1.88 | −0.76 | 0.64 | −0.67 |
| 5 | 0.14 | 0.00 | 0.42 | 0.19 |
| 6 | 1.39 | 0.69 | 0.99 | 1.02 |
| 7 | 1.32 | 0.90 | 1.75 | 1.32 |
| ∑Δ | −4.10 | −1.46 | 4.82 | −0.25† |
| Group 3 | ||||
| Contour Loudness Category | Frequency (Hz) |
|
||
| 500 | 2000 | 4000 | ||
| 1 | 1.69 | 1.44 | 1.25 | 1.46 |
| 2 | 3.00 | 1.69 | 1.67 | 2.12 |
| 3 | 3.38 | 2.00 | 1.88 | 2.42 |
| 4 | 3.81 | 3.25 | 1.88 | 2.98 |
| 5 | 4.75 | 3.88 | 3.89 | 4.17 |
| 6 | 6.31 | 3.81 | 3.89 | 4.67 |
| 7 | 6.44 | 4.31 | 4.65 | 5.13 |
| ∑Δ | 29.38 | 20.38 | 19.10 | 22.95† |
| Group 4 | ||||
| Contour Loudness Category | Frequency (Hz) |
|
||
| 500 | 2000 | 4000 | ||
| 1 | 1.15 | 3.65 | 0.52 | 1.77 |
| 2 | −0.52 | 2.19 | 1.25 | 0.97 |
| 3 | −0.52 | 1.98 | −0.31 | 0.38 |
| 4 | 0.63 | 2.40 | 1.46 | 1.49 |
| 5 | 0.42 | 2.81 | 0.83 | 1.35 |
| 6 | 1.46 | 3.33 | 1.77 | 2.19 |
| 7 | 0.83 | 3.75 | 1.46 | 2.01 |
| ∑Δ | 3.44 | 20.10 | 6.98 | 10.17† |
Corresponding grand mean change values, averaged across measurement frequency for each loudness category.
The summation of the mean change values across category for each frequency and the overall grand mean change value.
The comprehensive index values of treatment change estimated for each group in Table 2 represent summary outcome measures of overall treatment-related change in the categorical loudness judgments. The index value for each group can be applied in a factorial analysis using the equations shown in Table 3 to evaluate formally the respective treatment effects from counseling and conventional sound therapy in this study.31 The important outcome from this factorial analysis is that the treatment effect for sound therapy (53.68 dB) is much larger than that for counseling (7.29 dB) in this study. Additionally, it is notable that the full-treatment effect for group 1 (40.66 dB) is fourfold that of the control effect for group 4 (10.17 dB). Moreover, a relative estimate of the placebo contribution in the treatment effects can be garnered from a comparison of the sum of the comprehensive index values for PSG-assigned groups 2 and 4 (9.92 dB) in comparison with the corresponding summed values for CSG-assigned groups 1 and 3 (63.61 dB). This comparison reveals a negligible role for the placebo, which is less than a sixth of the magnitude achieved with conventional sound therapy for otherwise similar treatment assignments.
Table 3. Factorial Analysis Applied in the Evaluation of the Counseling and Sound Therapy Treatment Effects.
| Sound Generators | ||
|---|---|---|
| Counseling | + | − |
| + | Group 1 (40.66 dB) | Group 2 (−0.25 dB) |
| − | Group 3 (22.95 dB) | Group 4 (10.17 dB) |
Note: Comprehensive index values of treatment change (from Table 2) are shown by group for treatment assignments with or without counseling in combination with conventional sound generators or placebo sound generators. Counseling effect = group 1 index value + group 2 index value − (group 3 index value + group 4 index value) = 7.29 dB; and sound therapy effect = group 1 index value + group 3 index value − (group 2 index value + group 4 index value) = 53.68 dB.
Treatment Dynamics
We used linear mixed models to evaluate significant mean differences in treatment change (in decibels) from baseline to end of treatment for each group (shown in Fig. 5). The p values for time × group interactions were calculated for each of the seven Contour loudness categories, stratified by measurement frequency. The longitudinal treatment effects for group 1 were the only ones yielding statistically significant differences from the dynamic treatment effects of the other groups. The longitudinal treatment-related changes in the categorical loudness judgments for group 1 provide further support for the validity and efficacy of the full treatment. Significant time × group interactions were evident early, beginning with the Soft categorical loudness judgments for the 2,000- and 4,000-Hz warble-tone frequency conditions. The time × group interactions for the 500-Hz warble-tone condition for group 1 were significantly different for categories greater than Comfortable but Slightly Loud compared to groups 2 and 3, and were greater than category Loud compared to group 4. For the 2,000-Hz warble-tone condition, group 1 was significantly different from groups 2 and 3 for categories greater than Soft and was different from group 4 for categories greater than Comfortable. For the 4,000-Hz warble-tone conditions, group 1 was significantly different from groups 2 and 3 for categories greater than Soft and was different from group 4 for categories greater than Comfortable but Slightly Soft, with the exception of their Comfortable judgments. The larger response variation for group 4, which consisted of a smaller number of as-treated participants (n = 6) contributing to the average treatment effects, likely accounts for the fewer number of conditions yielding statistically significant differences from group 1. Group 4 also exhibited larger DRs and shallower mean loudness-growth functions at baseline than were measured for any other group; this characteristic feature of their results also may be a factor in their statistics.
The corresponding dynamics that characterize these longitudinal treatment effects (i.e., mean treatment change in decibels from baseline to end of treatment) were described for each group by calculating a slope value. The slope values were estimated as a linear change from baseline (in decibels per month) over the time of treatment. Slope values were calculated for each loudness category independently for 500, 2,000, and 4,000 Hz. The intercept values for corresponding combinations of loudness category and frequency condition were not significantly different across the four treatment groups at baseline. Thus, on average, the four treatment groups began their judgments of loudness from similar starting points for each pairing of Contour loudness category and frequency condition. The slope values for group 1 increased systematically with increasing loudness category for each frequency condition, ranging from 0.11 to 1.56, 0.33 to 1.61, and 0.62 to 1.61 dB/mo at 500, 2,000, and 4,000 Hz, respectively. The slope values were significantly different from a 0 slope for loudness categories greater than Comfortable at 500 Hz and for all Contour loudness categories at both 2,000 and 4,000 Hz. Thus, significant dynamic effects measured for group 1 were more prominently revealed at 2,000 and 4,000 Hz than at 500 Hz, but the full-treatment effects generalized across frequency.
The only significant slope values measured in this study for any of the other treatment groups were those for group 2 for Contour categories Loud, but OK and Uncomfortably Loud, respectively, at 2,000 and 4,000 Hz; these slope values were less than one third of the magnitude of the corresponding slope values for group 1. The appreciably greater slope values and dynamic treatment effects for group 1, compared to those measured for the other treatment groups, are highlighted in Fig. 6. Shown are best-fitting linear functions that represent the average treatment change in the Uncomfortably Loud categorical judgments across 7 months of treatment for each group assignment. This 7-month window captured primary treatment changes across participants with differing treatment periods (5 to 12 months) and also corresponded generally to our criterion for treatment termination across the individual participants in group 1. Within each group, the functions are shown to be similar for 500, 2,000, and 4,000 Hz. The full-treatment dynamics are clearly superior to the smaller effects obtained for the partial and control treatments. The dynamics for control group 4, which are virtually unchanged over the treatment period, are noteworthy in as much as these findings are consistent with the isolated PSG assignment and, therefore, with the implementation of a successful placebo control for the sound therapy treatment in this study.
Figure 6.
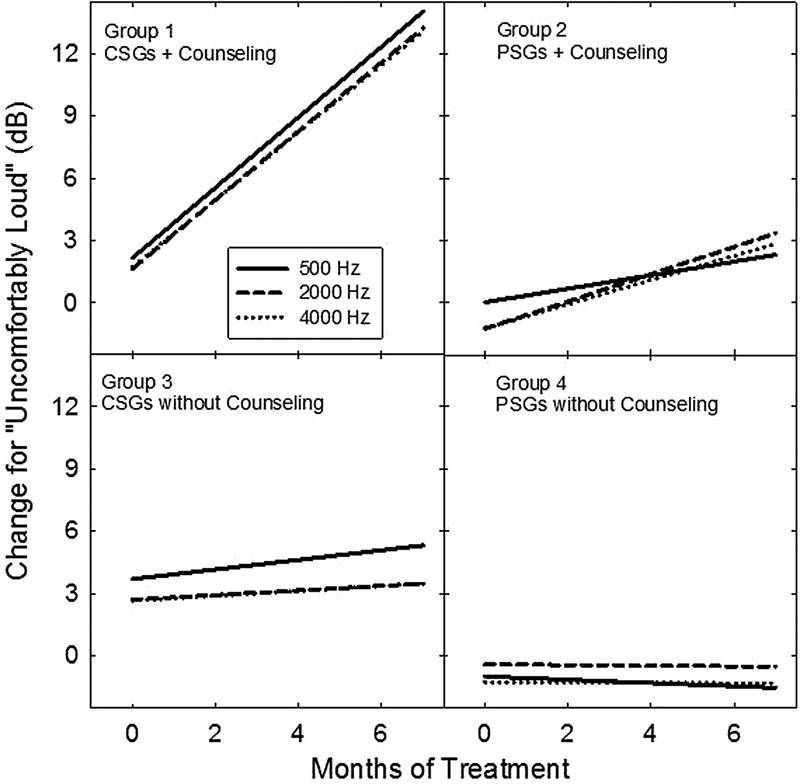
Best-fitting linear-regression functions for each group highlight mean treatment dynamics for changes in Uncomfortably Loud categorical judgments (normalized relative to baseline values measured just prior to treatment onset) over time of treatment shown in months. The parameter in each group panel is measurement frequency (500, 2,000, and 4,000 Hz), identified by line type in the inset legend. Abbreviations: CSG, conventional sound generator; PSG; placebo sound generator.
The normalized (to baseline) treatment dynamics for group 1, averaged across 500, 2,000, and 4,000 Hz, are shown in Fig. 7 for each of the seven Contour loudness categories. The dynamic effects are shown again across the initial 7 months of treatment. The slope values increased systematically from a low value of 0.29 dB/mo for the Very Soft categorical judgments to a high value of 1.66 dB/mo for the Uncomfortably Loud categorical judgments. The slope value for the comfortable judgments was 0.70 dB/mo. This range of slope values reflects a minimum average treatment change of 2.03 dB for the Very Soft categorical judgments and a maximum average treatment change of 11.62 dB for the Uncomfortably Loud judgments over this 7-month treatment window. By contrast, the isolated effects of counseling for group 2 and of sound therapy for group 3 over this same treatment period typically averaged ∼3 dB or less for the Uncomfortably Loud categorical judgments. Again, these various analyses reveal that the treatment dynamics are much more robust for full-treatment group 1 than for either of the partial treatment groups or for the control treatment group.
Figure 7.
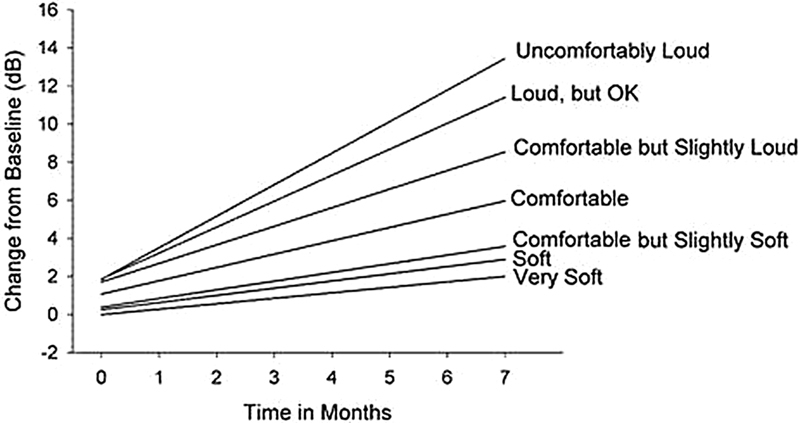
Best-fitting (normalized to baseline) linear-regression functions characterize group 1 full-treatment dynamics for each of the seven loudness categories. Changes in the loudness judgments are shown for each category from Very Soft to Uncomfortably Loud over time of treatment in months.
Discussion
The primary aim of this study was to assess the validity of the basic principles underlying Hazell and Sheldrake's protocol for hyperacusis1; their generality for the treatment of a diminished DR and related primary complaints among our sample of hearing-impaired individuals who, prior to treatment, were unsuccessful hearing aid users because of their associated sound tolerance problems; and the efficacy of the intervention protocol, incorporating CSGs and counseling specific to a diminished DR as a consequence of reduced sound tolerance and hearing loss (aim 1). Our secondary study aims were to delineate the contributions from the counseling and sound therapy components to the full-treatment protocol by comparing the treatment effects for each of the partial treatments with the effects obtained for full treatment (aim 2) and to characterize the associated treatment dynamics for the respective treatment assignments (aim 3). For purposes of comparison, we also measured the treatment effect and dynamics for a control condition that was void of the counseling component and included a placebo sound therapy component. The study outcomes are considered next in terms of these primary and secondary aims.
Aims
Aim 1: Treatment Validity, Efficacy, and Generality
The positive results for full-treatment group 1 support the validity and efficacy of the basic intervention principles for treatment of hyperacusis and related sound tolerance complaints associated with a reduced DR. The treatment effects also generalize to our sample of hearing-impaired listeners who, on average, were borderline for their hyperacusis condition. Specifically, the analyses presented above consistently revealed the full-treatment protocol to be superior in efficacy to both of the partial treatments and to the control treatment. Indeed, the combination of the as-treated efficacy rates for individuals in group 2, who received counseling and used PSGs, and for the individuals in group 3, who received no counseling and used CSGs, were 25 and 40%, respectively, whereas the efficacy rate for those in group 1 was 82%. The efficacy for control group 4 (PSGs without any counseling), albeit 50%, must be viewed cautiously in light of having only six contributing participants in the analysis at treatment end. Thus, in comparison with the efficacy rate for full-treatment group 1, the efficacy rates for each of the partial treatment assignments were diminished by at least 40%. Moreover, almost invariably across the various conditions evaluated statistically, group 1 alone showed positive and highly significant treatment change over time for the categorical loudness judgments, and these positive effects were typically uniform across frequency. Thus, in terms of aim 1, the categorical loudness judgments among the group 1 participants consistently provided substantive support for the treatment benefits of the combined counseling and sound therapy principles originally described by Hazell and Sheldrake and subsequently incorporated into the TRT-H protocol by Jastreboff and Hazell.1 4
Aim 2: Contributions from the Counseling and Sound Therapy Components
The second aim of this research was to delineate the relative contributions of the counseling and sound therapy components to the full treatment. The treatment-related changes in loudness growth for group 3 (revealed in the comprehensive values of treatment change in Table 2) were the only ones, other than those measured for group 1, that were different among the four treatment groups in this study. That the conventional sound therapy treatment (with CSGs) in isolation yielded a treatment benefit for group 3 is not surprising. We and others, beginning with Hazell and Sheldrake,1 have documented positive treatment effects from use of low-level sound therapy among normal-hearing volunteers22 23 and in various patient groups.22 32 33 These positive treatment-related changes have been ascribed to effects on central auditory gain control processes induced by the low-level noise input. We do not know the specific site(s) nor nature of the neuronal mechanisms that are responsible for these sound-induced treatment effects, and these processes continue to be speculative. The treatment effects ascribed to counseling were, on average, negligible in our analysis based on the results from group 2, who received counseling in combination with sound therapy from PSGs. Similarly, the treatment effects for group 4, from the PSGs in isolation, were small.
In the virtual absence of an isolated counseling effect, and with only a small to moderate effect from conventional sound therapy alone, one wonders how these components together contributed to the much larger full-treatment effect achieved by group 1. As noted above, the average treatment efficacy rate from counseling, assuming negligible treatment effects from their PSGs for group 2, was 25%, whereas the efficacy rate for group 3, which received sound therapy alone from CSGs, was 40%. In aggregate, the additive contributions from these partial treatment contributions, when measured in isolation, accounted for an efficacy rate (65%) that was 17% less than when these individual components were offered together, simultaneously, in the full-treatment protocol for group 1 (82%). However, the 17% difference between the additive effects of the partial treatments and the efficacy estimate for full treatment may or may not be sensible. Again, combining the partial-treatment efficacy rates is seemingly problematic when one considers that the control efficacy rate for the small number of participants in group 4 (n = 6) was 50% for the PSG treatment offered in isolation. Results are needed from larger patient samples to obtain more precise estimates of efficacy for the partial treatment groups, which on average were smaller than for the PSG treatment effect for control group 4.
In contrast, evidence of a synergistic, rather than additive treatment effect for counseling and sound therapy in the full-treatment protocol seems more compelling. Consider again the comprehensive index values of treatment change in Table 2 (also shown by group in Table 3). The additive index values for groups 2 (−0.25 dB) and 3 (22.95 dB), which were assigned counseling plus PSGs and CSGs alone, respectively, summed to 22.70 dB, whereas full-treatment group 1 achieved an index value of 40.66 dB. Thus, the aggregate effects of counseling and sound therapy in the full-treatment protocol were almost twofold the additive treatment effects of these individual components in isolation. It is remarkable that the effects of counseling for group 2, which were smaller in magnitude than the effects of the placebo control treatment for group 4, somehow served to amplify the effects of sound therapy by a factor of two when combined in the full-treatment protocol.
The presumptive mechanisms by which the counseling and sound therapy components contribute to the TRT-H treatment for primary hyperacusis have been explained by Jastreboff and Hazell in the context of Jastreboff's neurophysiological model.4 24 Hyperacusis in its purest form is assumed in the model to be an anomalous condition or phenomenon that primarily, if not exclusively, affects the auditory pathways. They assume no involvement of key nonauditory brain structures such as the limbic and autonomic nervous systems, which are conjectured to be activated to varying degrees among persons who suffer misophonia and phonophobia. To the extent that hyperacusis and the related sound tolerance conditions among our participants can be represented in this study as an isolated problem of the auditory pathways, the full-treatment effects, including the effect from counseling, seem surprising. In this study, the synergistic counseling effects, when considered within the context of the full-treatment results for group 1, were effectively equivalent in magnitude to ∼6 dB in terms of the treatment-related incremental shift in the Uncomfortably Loud categorical judgments. This estimate of the phantom counseling effect and its contributions to the full treatment effect is in agreement with at least one estimate of the incremental LDL change from counseling alone after 12 months of TRT.34 We can derive this estimate of the counseling effect in the full-treatment protocol based on a known treatment effect of ∼6 dB for normal-hearing subjects in sound therapy-alone studies.22 23 However, the measurable counseling effect in this study was virtually absent in terms of the estimate of the comprehensive index of treatment change for group 2 (see Tables 2 and 3). We suppose this phantom counseling effect might somehow be mediated outside of the classical auditory pathways by top-down cognitive processes, ostensibly via corticofugal efferent modulation. These feedback efferent processes may be involved in facilitating and augmenting the effects of the sound therapy. We and others have conceived the mechanism of sound therapy to operate through, or on, an anomalous auditory gain control process, probably mediated within the central auditory pathways.10 Theoretically, sound therapy down-regulates the abnormally elevated central-neuronal activity that gives rise to the reduced sound tolerance condition, and the counseling somehow augments or reinforces the effects of sound therapy.
Alternatively, as discussed earlier, additive efficacy rates for counseling and sound therapy do not necessarily rule out two independent additive processes contributing to the full treatment. The counseling contribution to the full treatment would presumably be from cognitive sources and the sound therapy contribution would derive from operations on central auditory pathway processes.
Baguley and Andersson have been critical of the idea that hyperacusis is an isolated problem of the auditory pathways.15 They argue that this notion is too simplistic and that hyperacusis likely involves an associated component of distress, with contributions from nonauditory processes, including the limbic and autonomic nervous systems and other brain structures. If so, then hyperacusis would be better represented in the Jastreboff model as a combined condition with misophonia (i.e., an emotional response to sound characterized by dislike or annoyance to specific sounds), which may often evolve into an associated condition with primary hyperacusis.24 35 Indeed, Hazell et al analyzed 187 consecutive patients with a diagnosis of decreased sound tolerance and concluded that virtually all of these patients had some degree of misophonia.36 Consistent with the complex nature of the hyperacusis problem is recent evidence from neuroimaging studies suggesting that mild hyperacusis likely involves neuronal activity in multiple central nervous system structures within the midbrain, thalamus, and primary auditory cortex.37 Accordingly, the underlying treatment mechanisms and the sites on which the counseling and sound therapy components in our full-treatment protocol achieved their effects almost certainly include actions on structures and processes within and external to the classical auditory pathways. Consequently, we might reasonably conjecture that the phantom counseling effect discussed previously may be due to a counseling-induced reduction in the participant's level of distress or anxiety over the course of the full treatment. Unfortunately, we do not have data to support or refute this idea. However, anecdotally, few if any of our participants noted sound-related distress or anxiety at baseline as a major issue.
Notwithstanding the multiple issues that cloud the understanding of the relative contributions of the counseling and sound therapy components, it is evident that these two treatment components, when offered together, substantially augment full-treatment efficacy. Simply put, this means that the full-treatment approach is better than either of the partial treatments delivered in isolation. Both treatment components are necessary to achieve an optimum outcome for alleviating mild or subclinical conditions of hyperacusis and related sound tolerance complaints that restrict the DR for persons with mild-to-moderately severe sensorineural hearing losses.
Aim 3: Treatment Dynamics
Our third aim was to characterize the dynamics for the full treatment, each partial treatment, and the control treatment. Group 1 yielded significantly different longitudinal treatment effects relative to the treatment dynamics of the other groups; these longitudinal effects generalized across frequency from 500 to 4,000 Hz. The associated slope values further highlighted the prominent positive dynamics of the treatment effects over time of treatment for group 1, which were routinely different from a zero slope across all loudness categories for 2,000 and 4,000 Hz and across categories Soft through Uncomfortably Loud for 500 Hz. The slope values for group 2 for categories Loud, but OK and Uncomfortably Loud at 2,000 and 4,000 Hz were the only values among any of the other treatment groups reaching statistical significance. Thus, on average, the full-treatment protocol yielded a superior outcome when compared to the dynamic effects for either of the partial treatments or for the control treatment. Moreover, these full-treatment dynamics and the positive treatment effects may have been underestimated in as much as our revised follow-up schedule curtailed treatment as soon as consistent shifts of ≥10 dB were measured in the loudness judgments.
Finally, we noted in the presentation of the slope values that the dynamic treatment effects for counseling in effective isolation (group 2) and for sound therapy (group 3) were small but positive. When these average partial effects were summed together for the Uncomfortably Loud categorical judgments, the resulting projection after 7 months of treatment is that the summed partial effects amount to less than half of their combined full-treatment effects (i.e., 4.9 dB versus 11.6 dB, respectively). This analysis of the treatment dynamics also indicates that the combined counseling and sound therapy contributions in the full treatment are likely synergistic rather than additive.
Summary and Conclusions
Notwithstanding the small scale of this randomized controlled trial and the uneven group sizes in our as-treated analyses, the overwhelmingly positive full-treatment effects, the subtle but positive treatment effects achieved for conventional sound therapy alone, and the negligible and small effects measured for the counseling (combined with PSGs) and the control protocols, respectively, are consistent with the nature and efficacy of each treatment type in this study. Accordingly, in aggregate, the study outcome data and our analyses lend substantive support for the validity, efficacy, and generality of the full-intervention approach and the underlying treatment principles described by Hazell and Sheldrake for remediating mild degrees of hyperacusis and expanding the auditory DR for loudness among the hearing-impaired persons sampled in this study.1
Our full-treatment findings for group 1 (1) replicate both the magnitude and dynamics of the uncontrolled treatment effects reported by Hazell and Sheldrake1 and (2) are in agreement with a growing literature that reveals various forms of enriched, wideband sound therapy, in combination with counseling, may significantly enhance sound tolerance in clinical populations.22 This literature includes the Neuromonics approach for tinnitus treatment, which Davis and colleagues report yields incremental LDL shifts equivalent to those reported for patients treated with TRT.38 39
Noreña and Chery-Croze described surprisingly large and rapid treatment effects for a sound therapy-alone protocol among a group of hearing-impaired subjects with varying degrees of high-frequency deficits and primary hyperacusis.33 Their sound therapy approach, which used a weighted, temporally complex, pure tone composite stimulus tailored to the frequencies of the hearing loss, called for daily exposure under headphones to the low-level composite stimulation for 1 to 3 hours. Most of their treatment effects, based on incremental changes in categorical loudness judgments, were obtained within a couple of weeks of beginning treatment and were on the order of that measured for our full-treatment group 1. These rapid treatment effects for sound therapy alone deserve further study. Indeed, one wonders whether counseling combined with Noreña and Chery-Croze's sound therapy approach might further enhance their treatment benefit. Clearly, counseling contributed significantly to an optimum full-treatment benefit in the current study—whether by virtue of participant understanding of the intervention and goals of the treatment, promotion of participant treatment compliance, encouragement of participant motivation, top-down modulation and/or reinforcement of the sound therapy effects, reduction in associated distress, or some other way.
The findings from our study potentially have broad clinical relevance for managing and treating sensorineural hearing loss, with implications of the intervention principles extending beyond the treatment of hyperacusis and tinnitus. Consider that our participants, on average, were representative of a subgroup of patients whom Jastreboff and Jastreboff have distinguished from individuals suffering primary hyperacusis.35 They describe this subgroup as having decreased sound tolerance/no tinnitus, with average LDLs of ∼ 85-dB HL. This subgroup presumably corresponds to hyperacusis category 1 on the Hyperacusis Network Web site (see http://www.hyperacusis.net/hyperacusis). The main concerns among our study sample were consistent with their hearing losses and nominal sound intolerance, as revealed by their borderline-reduced LDLs, which together diminished their DRs. These problems are consistent with those of patients whom one might routinely manage in a traditional hearing aid/audiological practice. Indeed, the most prominent problems among our sample of participants were reported when amplification was fitted unsuccessfully or dismissed without trial because of perceived or potential sound intolerance. The full-treatment protocol as described in this study may, therefore, offer benefit for widespread treatment of diminished DR and sound-intolerance conditions across the general hearing-impaired population. This benefit includes the treatment of persons with classical loudness recruitment for whom no intervention has previously been available. If so, then we have achieved with low-level sound therapy the long-standing, elusive clinical goal and tool originally sought by Davis et al and Silverman, who championed the repeated presentation of brief high-level sound exposures to expand the auditory DRs of hearing-impaired persons.8 9
Finally, we have focused exclusively on group results to address the study aims in this report. We also acquired unique case results that highlight compelling treatment effects and benefits for individual participants over their course of treatment and postintervention. This evidence will be considered in a separate report that provides a deeper discussion of the clinical relevance of the full-treatment protocol and associated implications of the intervention.
Acknowledgments
This research was supported by a Public Health Service research award (parent grant NIDCD R01DC04678) from the National Institutes of Health to Craig Formby and by a pair of companion supplement awards, including dedicated support for Monica Hawley. Work was started while Craig Formby, Monica Hawley, LaGuinn Sherlock and Susan Gold were at the University of Maryland, Baltimore. We gratefully acknowledge student assistance in conducting this study from Kimberly Block, Justine Cannova, Allyson Segar, and Christine Gmitter. We also thank Charles Schroder for his aid in randomizing and maintaining documentation of the blinded treatment assignments for our study participants, and Karen Tucker for preparing multiple drafts of this manuscript. General Hearing Instruments, Inc. and the affiliated authors' roles in this project were restricted to development, production, and quality-assurance testing of the sound generator treatments; preparation of the information contained in the appendix, describing the sound generator products; and collaboration with clinical study staff to achieve double blinding of the sound therapy treatment assignments and maintenance of the associated records and product documentation.
Appendix: Design/Implementation of The Placebo Sound Therapy Treatment
First-Generation Placebo Devices
The implementation of the PSGs by GHI was integral to the success of this clinical trial. The placebo activation, triggered by in- and out-of-the ear detection circuitry, was achieved with two different strategies in this project. The first-generation PSGs were implemented with a gold-plated shell or case. The purpose of this unique shell design was to optimize the detection and capture of electrical activity emitted from the skin of the external ear and ear canal. Specifically, this electrical signal activated and powered the placebo-detection circuitry by maximizing electrical conductivity and shell-surface contact with the skin. The resulting voltage signal from the human body then could be optimized for detection of the placebo device within the ear and for activation of the placebo circuitry.
The detection strategy was implemented with a detector circuit that used an integrated circuit (IC) timer. A voltage applied to the timer input produced a pulse at the output of the timer. The input signal to the timer was the small voltage signal produced from the skin of the external ear and ear canal. For this small electrical skin signal to be usable for control of the placebo circuitry, the signal had to be maximized for detection and transformed to a higher voltage. Two large conductivity plates served to maximize the collection of the small voltage signal from the skin. The plates were implemented on the acrylic shell surface of the placebo device as pictured in Fig. A1A. One plate detected the body voltage and the other established a ground-plane reference to the body. Gold, because of its excellent properties of electrical conductivity, was selected as the material for constructing the plates. The application of the gold to the acrylic shell was achieved through a mercury-free sputtering process. The initial step in the process was to mask the shell surface to outline the two plates; a base metal then was applied to the shell to optimize the adherence of the gold material; and, finally, the gold was deposited electronically onto the base-metal surface of the shell to achieve the plates. Two 1-mm holes were then drilled through the gold-plating material to connect the plates and the internal placebo circuitry via a pair of gold-plated pins.
Figure A1.
Photographs of first-generation sound generators/placebo sound generator shells. (A) Unworn device prior to participant use. (B) Worn device at end of treatment when placebo device failure was determined by General Hearing Instruments (GHI, Harahan, LA) for the participant assigned to group 2 but moved to as-treated group 1. Note the significant erosion of the gold plating from the surface of the failed worn device, which precluded normal placebo function.
Despite the elegance of the gold-plating process and the placebo design, two primary modes of device failure were identified over the period of use of the first-generation PSGs. One failure mode was associated with the wear and loss of the electrically conductive epoxy adhesive connections between the gold-surface pins and plates. This problem was readily resolved by cleaning the shell surface and reapplying the conductive epoxy. The second and appreciably more serious failure mode occurred when the bond between the base metal and the acrylic shell was eroded or disrupted. The causes of this latter form of device failure were multifaceted and resulted from any one or a combination of the following factors, including rough handling of the device; acids in the cerumen of the ear canal that disrupted the acrylic-base bond; excessive cleaning of the shell and/or application of abrasive cleaning products; and flawed bonding of the base metal to the acrylic material of the shell during the sputtering process.
The latter failure mode is obvious when comparing the pictures of unworn (Fig. A1A) and worn (Fig. A1B) failed first-generation PSGs. Note the significant erosion of the gold plating from the surface of the worn failed device in Fig. A1B in relation to the unworn device shown in Fig. A1A. In the absence of the gold plating, little or no residual contact was achieved between the connective pins and the base metal on the surface of the shell. Although we suppose it may have been possible for such damaged PSGs to continue to function via pin conductivity alone, this seems highly unlikely given the unique placebo design, which required a consistent voltage path of sufficient strength, maximized by the gold plating, to activate the placebo circuitry. We know that significant damage or erosion to the gold-plated surface of failed devices, like that shown in Fig. A1B, consistently rendered the placebo function inoperable. Consequently, these failed PSGs acted as conventional (nondecaying) sound generators. This conventional operation by the failed placebo units was measured and confirmed by the manufacturer using standard quality control and failure assessment methods posttreatment.
Fortunately, only 5 of the 17 participants who were fitted with first-generation sound therapy treatments were assigned to PSGs. There was no indication of undue damage or wear to the device cases for two of the five participants assigned to the placebo devices, and GHI engineers confirmed that the placebo operation remained functional for both of their PSGs at treatment end. We do not know at what point in treatment the damaged PSGs failed for the three affected participants; however, the failures appear to have occurred early in treatment because of unexpectedly robust treatment effects (of the kind measured for full treatment).
The first-generation devices also were problematic economically in that they were costly to manufacture and required extended periods of time to produce. The first-generation gold-plated shells, used for both conventional and placebo devices, were made in batches of 10 or more at an added cost of $50.00 per shell. A batch of 10 or more shells for a processing run by the outside vendor required an accumulation of at least five study participants and their acrylic shells prior to placing a batch order for application of the gold-plating. Moreover, at least a month was allotted for the outside vendor to gold-plate the shells and return the plated shells to GHI, which in turn typically required an additional 2 weeks to build and ship a pair of devices to the study center to start/restart treatment. Thus, literally months went by for some participants between the time they were enrolled in the study and the time at which they began treatment with their assigned sound generator. This problem was further confounded for a period of almost 1 year during which no devices were built or repaired because of Hurricane Katrina damage to the GHI manufacturing operation and facilities in New Orleans, Louisiana.
Second-Generation Placebo Devices
In light of the above problems with the first-generation PSGs, GHI re-engineered the placebo instruments. The detector circuitry for the second-generation PSGs relied on detection of skin capacitance rather than skin voltage and was sensitive to skin proximity and touch. Consequently, dual plating on the device shell was not required as was the case for the first-generation devices. Instead, a 6-mm-round contact pin was mounted into the helix of the shell, which provided sufficient capacitive pickup and stability within the ear to prevent undesirable resetting of the placebo circuitry. This pin-contact configuration, as visualized from the outside of the shell, is shown in Fig. A2. The conducting-pin contact transmitted the skin-conductance signal to the placebo detector circuitry, which was implemented with a charge-transfer q-touch IC (Quantum Research Group, model QT 100) (Atmel, San Jose, CA). Upon insertion of the PSG into the ear, the QT 100 IC self calibrated to obtain threshold and reference capacitance levels. The output of the QT 100 IC, which triggered placebo detection within the ear and, ultimately, activation of the circuitry that controlled the sound-decay process, then remained active while in the ear until there was a change in capacitance below a prescribed threshold level. The capacitance change was monitored for 10 counts (i.e., 70 milliseconds per count or circuit cycle of the QT 100 IC) to prevent erroneous readings of the capacitance change. Upon removal of the PSG from the ear, a large change (decrease) in the skin-capacitance level was detected and the QT 100 IC recalibrated to the out-of-the ear state. The IC remained idle until the PSG was returned to the ear, which reinitiated detection of another incremental change in skin capacitance. This incremental change in capacitance reactivated the self-calibrate in-the-ear state of the PSG circuitry. Thus, if device contact with the skin of the ear was lost for a period of time > 700 milliseconds, then the PSG unit recalibrated.
Figure A2.
Photograph of second-generation sound generator shell.
Operationally, if the PSG was removed from the ear for more than ∼1 second, then the placebo-detection circuitry triggered a process of resetting such that within ∼3 second of its removal from the ear the PSG output was restored to its original, full-on, steady-state volume setting. This operational strategy was integral to successful double blinding of both the clinician and study participant as to sound therapy treatment assignment. Specifically, subsequent to the clinician performing a listening check to confirm the out-of-the-ear device output, reinsertion of the PSG within the ear activated the IC detection circuitry to recalibrate for in-the-ear operation. In turn, this recalibration process retriggered activation of the placebo output decay process, which was controlled with circuitry described below. This latter circuitry was common to both the first- and second-generation placebo devices.
Placebo Device Circuitry
The first- and second-generation detection circuits activated the same volume control circuitry for the PSGs. Both detection circuits generated an output voltage, either high or low, to designate whether the placebo devices were operating in an in-the-ear or out-of-the-ear status, respectively. This control-voltage signal was applied to the gates of a quad MOSFET switch (Analog Devices, model AD6783) (Analog Devices, Norwood, MA) to regulate: an electronic volume control (Sound Design Technologies, model lv-560) (Sound Design Technologies, Burlington, Ontario, Canada); the up and down electronic volume-control logic (i.e., for augmentation or attenuation of the noise output), and the time constants of the electronic volume control. The time constants controlled the timing of: (1) the rapid restoration of the full-on steady-state volume output after removal of the PSG from the ear and (2) activation of the sound decay function after 30 to 40 minutes of in-the-ear placebo operation. At power on, a high pulse applied to the gate of the quad MOSFET switch put the electronic volume control into the volume up mode with a very fast time constant (i.e., seconds). This rapid activation of the volume-up mode set the noise output to the clinician-set maximum volume. The circuit remained in this state until the PSG was inserted into the ear, at which time the quad MOSFET switch activated the volume-down mode of the electronic volume control with a very long time constant (i.e., minutes). The output of the PSG remained constant for 30 to 40 minutes, subsequent to which the circuit triggered a decrease in the noise volume (as the countdown capacitors charged and discharged between one- and two-thirds voltage regulators). This decay process systematically attenuated the noise output of the placebo device below the audibility threshold of the participant. The duration of the sound-decay process, subsequent to its initiation, was usually complete within 20 to 30 minutes. The duration of the decay ultimately was dependent on the magnitude of the participant's dynamic range set by the placebo output steady-state suprathreshold noise levels and the threshold-dependent subaudible noise levels. The PSG remained in the subaudible silent state until removed from the ear, which in turn generated a reset pulse to the volume circuitry to restore maximum noise output.
A transconductance block, housed within the electronic volume control circuit, was used as a feedback resistance to control the gain of a linear-d amplifier (Sound Design Technology, model gs-3024). The analog output of this amplifier was then routed to the input of a pulse width modulator (Knowles Electronics, model cd3418) (Knowles Electronics, Itasca, IL), which converted the analog signal into an on/off pulsed-duty-cycle signal. This latter signal then was sent through a set-screw volume control, which attenuated the full-on, steady-state maximum output from the electronic volume control circuit to regulate the amount of noise delivered to the participant. The same signal was routed to the receiver for control of the acoustical output of the PSG.
An example of a typical output-decay response versus time-after-activation (upper graph of decay curve) function for the resulting analog PSG is shown in Fig. A3A. Shown in Figs. A3B and A3C are typical frequency response (lower left graph) and output response (lower right graph displaying dynamic range) curves for this PSG.
Figure A3.
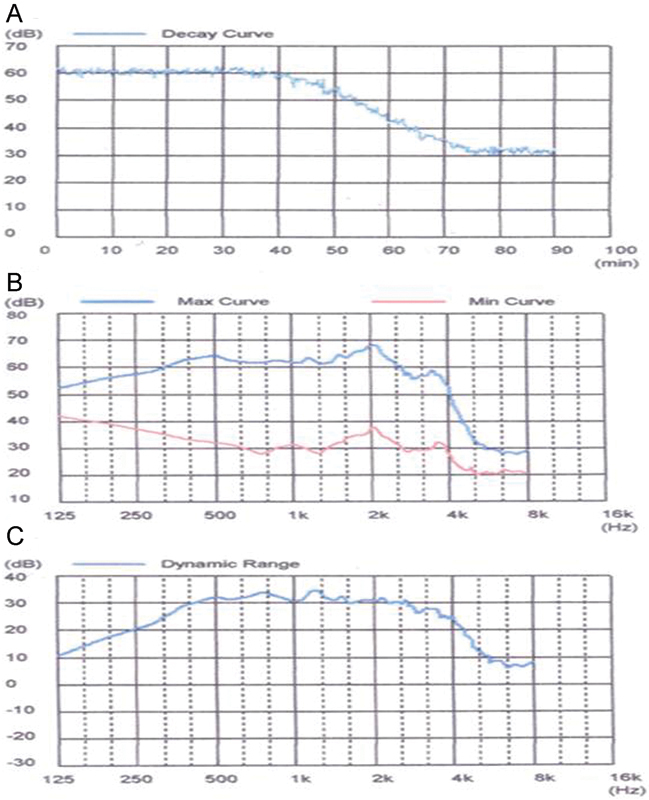
Output decay response curve (A), frequency response curves at minimum and maximum output settings (B), and dynamic range response (C) of a typical placebo sound generator used in this study.
References
- 1.Hazell J WP Sheldrake J B Hyperacusis and tinnitus In: Aran J M Dauman R, eds. . Tinnitus 91. Proceedings of the Fourth International Tinnitus Seminar Amsterdam/New York: Kugler Publications; 1992245–248. [Google Scholar]
- 2.Jastreboff P J, Hazell J WP. A neurophysiological approach to tinnitus: clinical implications. Br J Audiol. 1993;27(1):7–17. doi: 10.3109/03005369309077884. [DOI] [PubMed] [Google Scholar]
- 3.Jastreboff P J, Gray W C, Gold S L. Neurophysiological approach to tinnitus patients. Am J Otol. 1996;17(2):236–240. [PubMed] [Google Scholar]
- 4.Jastreboff P J, Hazell J. Cambridge, UK: Cambridge University Press; 2004. Tinnitus Retraining Therapy: Implementing the Neurophysiological Model. [Google Scholar]
- 5.Jastreboff P J, Jastreboff M M. Tinnitus Retraining Therapy (TRT) as a method for treatment of tinnitus and hyperacusis patients. J Am Acad Audiol. 2000;11(3):162–177. [PubMed] [Google Scholar]
- 6.Jastreboff M M, Jastreboff P J. Decreased sound tolerance and tinnitus retraining therapy (TRT) Aust N Z Audiol. 2002;21:74–81. [Google Scholar]
- 7.Sammeth C A, Birman M, Hecox K E. Variability of most comfortable and uncomfortable loudness levels to speech stimuli in the hearing impaired. Ear Hear. 1989;10(2):94–100. doi: 10.1097/00003446-198904000-00003. [DOI] [PubMed] [Google Scholar]
- 8.Davis H Hudgins C V Marquis R J et al. The selection of hearing aids Laryngoscope 19465685–115., 135–163 [DOI] [PubMed] [Google Scholar]
- 9.Silverman S R. Tolerance for pure tones and speech in normal and defective hearing. Ann Otol Rhinol Laryngol. 1947;56(3):658–677. doi: 10.1177/000348944705600310. [DOI] [PubMed] [Google Scholar]
- 10.Formby C, Gold S L. Modification of loudness discomfort level: evidence for adaptive chronic auditory gain and its clinical relevance. Semin Hear. 2002;23(1):21–34. [Google Scholar]
- 11.Schmitz H D. Loudness discomfort level modification. J Speech Hear Res. 1969;12(4):807–817. doi: 10.1044/jshr.1204.807. [DOI] [PubMed] [Google Scholar]
- 12.Byrne D Dirks D Effects of acclimatization and deprivation on non-speech auditory abilities Ear Hear 199617(3, Suppl):29S–37S. [DOI] [PubMed] [Google Scholar]
- 13.Lindley G. Adaptation to loudness: implications for hearing aid fittings. Hear J. 1999;52:50–57. [Google Scholar]
- 14.Goldstein B, Shulman A. Tinnitus-hyperacusis and the loudness discomfort test—a preliminary report. Int Tinnitus J. 1996;2:83–89. [PubMed] [Google Scholar]
- 15.Baguley D M, Andersson G. Oxford, UK: Plural Publishing; 2007. Hyperacusis: Mechanisms, Diagnosis, and Therapies. [Google Scholar]
- 16.Formby C, Gold S L, Keaser M L, Block K L, Hawley M L. Secondary benefits from tinnitus retraining therapy (TRT): clinically significant increases in loudness discomfort level and in the auditory dynamic range. Semin Hear. 2007;28(4):276–294. [Google Scholar]
- 17.Sheldrake J B, Wood S M, Cooper H R. Practical aspects of the instrumental management of tinnitus. Br J Audiol. 1985;19(2):147–150. doi: 10.3109/03005368509078967. [DOI] [PubMed] [Google Scholar]
- 18.Reich G Vernon J, eds. Proceedings of the Fifth International Tinnitus Seminar Portland, OR: American Tinnitus Association; 1995 [Google Scholar]
- 19.Hazell J WP, ed. Proceedings of the Sixth International Tinnitus Seminar London, UK: The Tinnitus and Hyperacusis Centre; 1999 [Google Scholar]
- 20.Patuzzi R, ed. Proceedings of the Seventh International Tinnitus Seminar Perth, Australia: The University of Western Australia; 2002 [Google Scholar]
- 21.Formby C, ed. Hyperacusis and Related Sound Tolerance Complaints: Differential Diagnosis, Treatment Effects, and Models Semin Hear 2007;28(4):(Monograph) [Google Scholar]
- 22.Formby C, Sherlock L P, Gold S L, Hawley M L. Adaptive recalibration of chronic auditory gain. Semin Hear. 2007;28(4):295–302. [Google Scholar]
- 23.Formby C, Sherlock L P, Gold S L. Adaptive plasticity of loudness induced by chronic attenuation and enhancement of the acoustic background. J Acoust Soc Am. 2003;114(1):55–58. doi: 10.1121/1.1582860. [DOI] [PubMed] [Google Scholar]
- 24.Jastreboff P J. Portland, OR: American Tinnitus Association; 1994. Clinical implication of the neurophysiological model of tinnitus; pp. 500–507. [Google Scholar]
- 25.Carhart R, Jerger J F. Preferred method for clinical determination of pure-tone thresholds. J Speech Hear Disord. 1959;24:330–345. [Google Scholar]
- 26.Cox R M, Alexander G C, Taylor I M, Gray G A. The contour test of loudness perception. Ear Hear. 1997;18(5):388–400. doi: 10.1097/00003446-199710000-00004. [DOI] [PubMed] [Google Scholar]
- 27.Costa P T, Jr, McCrae R R. Odessa, FL: Psychological Assessment Resources, Inc.; 1992. NEO PI-R Professional Manual. [Google Scholar]
- 28.Munro K J, Blount J. Adaptive plasticity in brainstem of adult listeners following earplug-induced deprivation. J Acoust Soc Am. 2009;126(2):568–571. doi: 10.1121/1.3161829. [DOI] [PubMed] [Google Scholar]
- 29.Muller K E, Fetterman B A. Cary, NC: SAS Institute Inc.; 2002. Regression and ANOVA: An Integrated Approach Using SAS Software; pp. 330–333. [Google Scholar]
- 30.Piantadosi S. Hoboken, NJ: John Wiley & Sons; 2005. Clinical Trials: A Methodologic Perspective. 2nd ed. [Google Scholar]
- 31.Gordis L. Philadelphia, PA: Saunders; 2009. Epidemiology. 4th ed. [Google Scholar]
- 32.Dauman R, Bouscau-Faure F. Assessment and amelioration of hyperacusis in tinnitus patients. Acta Otolaryngol. 2005;125(5):503–509. doi: 10.1080/00016480510027565. [DOI] [PubMed] [Google Scholar]
- 33.Noreña A J, Chery-Croze S. Enriched acoustic environment rescales auditory sensitivity. Neuroreport. 2007;18(12):1251–1255. doi: 10.1097/WNR.0b013e3282202c35. [DOI] [PubMed] [Google Scholar]
- 34.McKinney C J, Hazell J WP, Graham R L. London, UK: The Tinnitus and Hyperacusis Centre; 1999. Changes in loudness discomfort level and sensitivity to environmental sound with habituation based therapy; pp. 499–501. [Google Scholar]
- 35.Jastreboff P J, Jastreboff M M. Hamilton, Ontario, Canada: Decker; 2004. Decreased sound tolerance; pp. 8–15. [Google Scholar]
- 36.Hazell J WP Sheldrake J B Graham R L Decreased sound tolerance: predisposing factors, triggers and outcomes after TRT In: Patuzzi R, ed. Proceedings of the Seventh International Tinnitus Seminar Crawley, Perth, Australia: University of Western Australia; 2002255–261. [Google Scholar]
- 37.Gu J W, Halpin C F, Nam E C, Levine R A, Melcher J R. Tinnitus, diminished sound-level tolerance, and elevated auditory activity in humans with clinically normal hearing sensitivity. J Neurophysiol. 2010;104(6):3361–3370. doi: 10.1152/jn.00226.2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Davis P B, Paki B, Hanley P J. Neuromonics tinnitus treatment: third clinical trial. Ear Hear. 2007;28(2):242–259. doi: 10.1097/AUD.0b013e3180312619. [DOI] [PubMed] [Google Scholar]
- 39.Gold S L, Formby C, Frederick E A, Suter C. Crawley, Perth, Australia: University of Western Australia; 2002. Incremental shifts in loudness discomfort level among tinnitus patients with and without hyperacusis; pp. 170–172. [Google Scholar]