

Summary
The estimation of average treatment effects based on observational data is extremely important in practice and has been studied by generations of statisticians under different frameworks. Existing globally efficient estimators require non-parametric estimation of a propensity score function, an outcome regression function or both, but their performance can be poor in practical sample sizes. Without explicitly estimating either functions, we consider a wide class calibration weights constructed to attain an exact three-way balance of the moments of observed covariates among the treated, the control, and the combined group. The wide class includes exponential tilting, empirical likelihood and generalized regression as important special cases, and extends survey calibration estimators to different statistical problems and with important distinctions. Global semiparametric efficiency for the estimation of average treatment effects is established for this general class of calibration estimators. The results show that efficiency can be achieved by solely balancing the covariate distributions without resorting to direct estimation of propensity score or outcome regression function. We also propose a consistent estimator for the efficient asymptotic variance, which does not involve additional functional estimation of either the propensity score or the outcome regression functions. The proposed variance estimator outperforms existing estimators that require a direct approximation of the efficient influence function.
Keywords: Global semiparametric efficiency, Propensity score, Sieve estimator, Treatment effects
1. Introduction
Studying the effect of an intervention or a treatment is central to experimental scientists. While a randomized trial is a gold standard to identify average treatment effects, it may be infeasible, or even unethical, to conduct in practice. Observational studies are common in econometrics, social science, and public health, where the participation of intervention is only observed rather than manipulated by scientists. A typical concern for inferring causality in an observational study is confounding, where individual characteristics such as demographic factors can be related to both the treatment selection and the outcome of interest. In these cases, a simple comparison of sample averages from the two intervention groups can lead to a seriously biased estimate of the population average treatment effects.
When the treatment selection process depends entirely on observable covariates, there are two broad classes of strategies for estimating average treatment effects, namely outcome regression and propensity score estimation. When a linear model is assumed for the outcome given covariates, the coefficient for treatment status provides an estimate of average treatment effects when all relevant confounders are controlled and when there is no effect modifiers. In general, more complex regression models can be used for predicting unobservable potential outcomes, while the average treatment effects can be estimated by averaging predicted outcomes (Oaxaca; 1973; Blinder; 1973). An alternative class of strategies is based on the propensity score, which is the probability of receiving treatment given covariates. Rosenbaum and Rubin (1983) showed that adjusting the true propensity score can remove all bias due to confounding. They also showed that the true propensity score balances the covariate distributions between the two treatment arms. Propensity score can be used for subclassification (Rosenbaum and Rubin; 1984; Rosenbaum; 1991), matching (Rosenbaum and Rubin; 1985; Abadie and Imbens; 2006), and weighting (Rosenbaum; 1987; Hirano et al.; 2003). However, propensity score based methods may not be efficient in general.
To study efficient estimation, semiparametric efficiency bounds were derived independently by Robins et al. (1994) and Hahn (1998). Interestingly, the efficient influence function for the average treatment effects involves both the propensity score and the outcome regression functions. This motivated subsequent development of methods involving a combination of propensity score and outcome regression modeling (Robins et al.; 1994; Hahn; 1998; Bang and Robins; 2005; Qin and Zhang; 2007; Cao et al.; 2009; Tan; 2010; Graham et al.; 2012; Vansteelandt et al.; 2012). Recently, Chan (2013), Han and Wang (2013) and Chan and Yam (2014) considered methods that can accommodate multiple non-nested models of the propensity score and outcome regression at the same time. Many recent methods focus on improving covariate balance within the propensity score and outcome regression frameworks (Qin and Zhang; 2007; Tan; 2010; Chan; 2012; Graham et al.; 2012; Vansteelandt et al.; 2012; Han and Wang; 2013; Chan and Yam; 2014). Imai and Ratkovic (2014) argue that the estimation of propensity score parameters with a specification of outcome model does not align well with the original spirit of propensity score methodology as discussed in Rubin (2007). They proposed a covariate balancing propensity score method for the estimation of propensity score parameters, which balances covariates for an overidentified moment restriction without assuming an outcome model.
All methods mentioned so far require specification of either a propensity score model, an outcome model, or both. Consistency of the estimators requires some underlying models to be correctly specified. Since the estimand of interest is the average treatment effects, and the propensity score or the outcome models are just intermediate steps, it is natural to question whether the correctness of the intermediate models were necessary for producing correct inference. Nonparametric estimators are developed to provide valid inference in large samples without relying on parametric assumptions in the intermediate steps of estimation. Hahn (1998), Hirano et al. (2003), Imbens et al. (2006), Chen et al. (2008) have considered various nonparametric estimators for the average treatment effects. Although the validity of estimation does not rely on any parametric assumption on the propensity score and outcome models, their methods require sieve approximations of those unknown conditional functions, as these functions appear explicitly in the semiparametric efficient inference functions (Robins et al.; 1994; Hahn; 1998). An important observation has been made by Hirano et al. (2003) that the celebrated inverse probability weighted estimator of Horvitz and Thompson (1952) is globally semiparametric efficient when a sieve maximum likelihood propensity score estimator is used. Global semiparametric efficiency is more desirable than local semiparametric efficiency which requires the correct specification of parametric models. An implication of Hirano et al. (2003) is that global efficiency can be achieved by solely estimating the propensity score nonparametrically, without requiring to estimate the outcome model, which also appears in the efficient influence function. An efficient estimator is adapted from the Horvitz-Thompson estimator, a simple estimator used by decades of statisticians. Alternatively, Imbens et al. (2006) and Chen et al. (2008) showed that globally efficient estimators can be constructed from nonparametric estimators of the outcome model only. A combination of nonparametric estimators of the propensity score and outcome models can also produce globally efficient estimators (Imbens et al.; 2006; Chen et al.; 2008).
The existing globally efficient estimators do not require correct specification of propensity score or outcome regression models in large samples, but the need to specify a nonparametric approximation of either or both functions is still present. It has been shown that estimators for average treatment effects can have substantial bias when either functions are poorly estimated (Kang and Schafer; 2007; Ridgeway and McCaffrey; 2007). It is natural to question whether nonparametric estimation of these functions is even necessary, and whether they can be replaced by an alternative simple balancing criterion which is inherited from the unknown propensity score function. Although estimators that improve balance of covariate distribution are discussed in recent papers (Qin and Zhang; 2007; Tan; 2010; Graham et al.; 2012; Vansteelandt et al.; 2012; Han and Wang; 2013; Imai and Ratkovic; 2014; Chan and Yam; 2014), their methods require parametric modeling of the propensity score model or the outcome model. Nonparametric methods for improving covariate balance have been studied widely in the survey sampling literature (Deming and Stephan; 1940; Deville and Särndal; 1992; Kim and Park; 2010; Hainmueller; 2012). The recent paper of Hainmueller (2012) focused on using the implied weights of the raking estimator of Deming and Stephan (1940) to preprocess data for estimating the treatment effects on the treated. Since he focused on preprocessing, he did not study statistical inference and estimation efficiency.
There are two substantial gaps in the literature of nonparametric inference for average treatment effects that we aim to fill in this article. First, we show that a broad class of calibration estimators which solely targets on covariate balancing can attain semiparametric efficiency bound without explicitly estimating the propensity score or outcome regression functions. Compared to the seminal paper of Hirano et al. (2003) who showed that globally efficient estimation can be achieved by a nonparametric adaptation of a simple estimator by Horvitz and Thompson (1952), which has been used by statisticians for decades, we show that a globally efficient estimator can be adapted from another class of simple estimators pioneered by Deming and Stephan (1940). However, our work contains three very different conceptual aspects compared to existing survey calibration methods. The first important difference is that the proposed weights minimize a distance measure from a set of misspecified, uniform weights, whereas the original survey calibration estimators minimizes distance from the design weights, which are the unknown inverse propensity score weights for the evaluation problem. Therefore, our formulation does not involve the estimation of the unknown propensity score function. By minimizing the distance to uniform baseline weights, we improve robustness by avoiding extreme weights that typically ruin the performance of Horvitz-Thompson estimators with maximum likelihood estimated weights. The uniform baseline weights are misspecified unless the treatment is randomized, and the usual theory for survey calibration that requires a correctly specified baseline weights are therefore inapplicable. The mathematical proofs for the theorems are therefore very different from the existing results. Second, we reformulate the problem as the dual of the original calibration problem, which is a separable programming problem subject to linear constraints. The dual, as discussed in the optimization literature, is an unconstrained convex optimization problem. This reformulation allows us to provide a simple and stable algorithm for practical usage and streamlines the mathematical proofs. Third, we consider a growing number of moment conditions as opposed to a fixed number of moment conditions for survey calibration. The growing number of moment conditions is necessary for removing asymptotic bias associated with misspecified design weights while at the same time attaining global efficiency.
An equally important contribution of our paper is a novel nonparametric variance estimator for interval estimation and hypothesis testing. While there are plenty of point estimators for estimating average treatment effects, the problem of nonparametric estimation of efficient variance has received little attention because it is difficult. A consistent plugged-in estimator proposed by Hirano et al. (2003) involves the squared inverse of estimated propensity score function and can perform extremely poorly in small samples as shown in the simulation studies given in the online supplementary materials. In a local semiparametric efficiency framework, consistent variance estimation often requires both the propensity score and outcome regression models to be correctly modeled despite point estimators that are often doubly robust. Due to these difficulties, many authors proposed novel point estimators while leaving the variance estimation unattended. Bootstrapping may be used but is typically computationally intensive and may not be practical to implement for large data sets. Others have suggested that the estimated weights shall be treated as fixed weights (see for example, Section 3.4 of Hainmueller, 2012). However, statistical inference can be very misleading. The variability of the estimated weights can be substantial, and in fact we illustrate using a real example in Section 5.2 to show that the standard error of the treatment effects can be underestimated by more than five fold if the weights are treated as fixed. Our proposed variance estimator is both novel and important for statistical inference in practice. It does not require direct nonparametric estimation of either the propensity score or outcome regression models. This is in contrast to Hirano et al. (2003), whose point estimator does not require nonparametric estimation of outcome regression function but that additional functional estimation is required for interval estimation. We show that the proposed estimator is consistent to the semiparametric variance bound and its validity does not depend on any parametric models; it outperforms existing estimators which require direct approximation of the efficient influence function.
The paper is organized as follows. In Section 2, we shall introduce the notations and a class of the calibration estimators, explain the philosophical and practical differences between calibration and propensity score modeling, and study the large sample properties of the calibration estimators. A consistent asymptotic variance estimator is proposed in Section 3. In Section 4, we study three extensions of the problem: the estimation of weighted average treatment effects, treatment effects on the treated, and the estimation for multiple comparison groups. Analyses of the National Health and Nutrition Examination Survey and the famous Lalonde (1986) data for the effect of job training on income are presented in Section 5. Some final remarks are given in Section 6.
The proposed methods can be implemented through an open-source R package ATE available from the Comprehensive R Archive Network (http://cran.r-project.org/package=ATE).
2. Point Estimation
2.1. Notations and basic framework
Let T be a binary treatment indicator. We define Y (1) and Y (0) to be the potential outcomes when an individual is assigned to the treatment or control group respectively. The population average treatment effects is defined as τ ≜
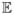 (Y (1) − Y (0)). The estimation of τ is complicated by the fact that Y (1) and Y (0) cannot be observed jointly. The potential outcome Y (1) is only observed when T = 1, and Y (0) is only observed when T = 0. The observed outcome can be represented as Y = TY (1) + (1 − T)Y (0). In addition to (T, Y), we assume that a vector of covariates X is observed for everyone, and T is typically dependent on (Y (1), Y (0)) through X. We assume the full data {(Ti, Yi(1), Yi(0), Xi), i = 1, …, N} are independent and identically distributed, and the observed data is {(Ti, Yi, Xi), i = 1, …, N}. The following assumption is often made for the identification of t:
(Y (1) − Y (0)). The estimation of τ is complicated by the fact that Y (1) and Y (0) cannot be observed jointly. The potential outcome Y (1) is only observed when T = 1, and Y (0) is only observed when T = 0. The observed outcome can be represented as Y = TY (1) + (1 − T)Y (0). In addition to (T, Y), we assume that a vector of covariates X is observed for everyone, and T is typically dependent on (Y (1), Y (0)) through X. We assume the full data {(Ti, Yi(1), Yi(0), Xi), i = 1, …, N} are independent and identically distributed, and the observed data is {(Ti, Yi, Xi), i = 1, …, N}. The following assumption is often made for the identification of t:
Assumption 1. (Unconfounded Treatment Assignment) Given X, T is independent of (Y (1), Y (0)).
Based on Assumption 1, the semiparametric efficiency bound for estimating t has been developed by Robins et al. (1994) and Hahn (1998). Let π(x) ≜
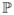 (T = 1|X = x) be the non-missing probability, also known as the propensity score, and m1(x) ≜
[Y (1)|X = x], m0(x) ≜
[Y (0)|X = x] are the conditional mean functions. Conventional statistical methods for estimating τ involves modeling of π(X), (m1(X), m0(X)) or both, based on different representations of τ:
(T = 1|X = x) be the non-missing probability, also known as the propensity score, and m1(x) ≜
[Y (1)|X = x], m0(x) ≜
[Y (0)|X = x] are the conditional mean functions. Conventional statistical methods for estimating τ involves modeling of π(X), (m1(X), m0(X)) or both, based on different representations of τ:
| (1) |
| (2) |
| (3) |
The inverse probability weighted estimators (Horvitz and Thompson; 1952; Hirano et al.; 2003) have been constructed based on (1); the regression prediction estimators (Oaxaca; 1973; Cheng; 1994; Imbens et al.; 2006) have been proposed based on (2); and the augmented inverse probability weighted estimators (Robins et al.; 1994; Bang and Robins; 2005; Cao et al.; 2009) have been proposed based on (3).
Based on Assumption 1, another important feature for the propensity score π(X) is that
| (4) |
Recently, many authors have proposed estimators by combining (1) and (4) in various creative manners under the propensity score framework, see Qin and Zhang (2007), Tan (2010), Chan (2012), Graham et al. (2012), Vansteelandt et al. (2012), Han and Wang (2013), Imai and Ratkovic (2014) and Chan and Yam (2014). Since (4) often defines an overidentifying set of moment restrictions, estimation is generally done within the generalized method of moments or the empirical likelihood framework. These methods require modeling and estimation of the propensity score but the proposed method does not.
2.2. A general class of calibration estimators
Let D(v, v0) be a distance measure, for a fixed v0 ∈ ℝ, that is continuously differentiable in v ∈ ℝ, nonnegative, strictly convex in v and D(v0, v0) = 0. The general idea of calibration as in Deville and Särndal (1992) is to minimize the aggregate distance between the final weights w = (w1, …, wN) to a given vector of design weights d = (d1, …, dN) subject to moment constraints. The minimum distance estimation is closely related to generalized empirical likelihood as discussed in Newey and Smith (2004). In survey applications, the design weights are known inverse probability weights. In the estimation of average treatment effects, the inverse probability weights are di = π(Xi)−1 if Ti = 1 or di = (1 − p(Xi))−1 if Ti = 0, for i = 1, …, N, which are unknown and need to be estimated. A recent paper by Chan and Yam (2014) discussed the calibration methods with design weights estimated by maximum likelihood approach. Here we consider a different formulation. To circumvent the need to estimate the design weights, we consider a vector of misspecified uniform design weights d* = (1, 1, …, 1), and construct weights w by solving the following constrained minimization problem:
subject to the empirical counterparts of (4), that are
The choice of uniform design weights is based on a few observations. First, if the counterfactual variables are observable for everyone, we can estimate τ by the sample mean of Y (1) − Y (0) which assigns equal weights. Also, the need for estimating π(x) is not needed when the design weights are assumed to be uniform. Moreover, by minimizing the aggregate distance from constant weights, the dispersion of final weights is controlled and extreme weights are less likely to obtain. In contrast, extreme weights cause instability in Horvitz-Thompson estimators with maximum likelihood weights under model misspecification. However, the choice of uniform design weights also poses unique challenges. When the number of matching conditions is fixed, Hellerstein and Imbens (1999) showed that an empirical likelihood calibration estimator with misspecified design weights yields inconsistent estimators in general. To circumvent this theoretical difficulty, we consider matching uK which is a K(N)-dimensional function of X, K(N) increases to infinity when N goes to infinity yet with K(N) = o(N).
The constrained optimization problem stated above is equivalent to two separate constrained optimization problems:
| (5) |
and
| (6) |
Furthermore, to efficiently implement the method, we consider the dual problems of (5) and (6). The reason is that the primal problems (5) and (6) are convex separable programming with linear constraints, and Tseng and Bertsekas (1987) showed that the dual problems are unconstrained convex maximization problems that can be solved by efficient and stable numerical algorithms.
Let D(v) = D(v, 1), f(v) = D(1 − v) and its derivative be f′(v), ∀v ∈ ℝ. The dual solutions are given as follows. For i such that Ti = 1, 1
where ρ′ is the first derivative of a strictly concave function
| (7) |
and γ̂K ∈ ℝK maximizes the following objective function
| (8) |
Similarly, for i such that Ti = 0,
and β̂K ∈ ℝK maximizes the following objective function
| (9) |
According to the first order conditions of the maximizations of (8) and (9), we can easily check that the linear constraints in (5) and (6) are satisfied. We define the proposed empirical balancing estimator for τ to be
The relationship (7) between ρ(v) and f(v) = D(1−v) is shown in Appendix B, where we also show that strict convexity of D is equivalent to strict concavity of ρ. Since the dual formulation is equivalent to the primal problem and will simplify the following discussions, we shall express the estimator in terms of ρ(v) in the rest of the discussions. When ρ(v) = −exp(−v), the weights are equivalent to the implied weights of exponential tilting (Kitamura and Stutzer; 1997; Imbens et al.; 1998). When ρ(v) = log(1 + v), the weights correspond to empirical likelihood (Owen; 1988; Qin and Lawless; 1994). When ρ(v) = −(1 − v)2/2, the weights are the implied weights of the continuous updating estimator of generalized method of moments (Hansen et al.; 1996), and also minimizes the squared distance function. When ρ(v) = v − exp(−v), the weights are equivalent to the inverse of a logistic function.
Despite the close connections with generalized empirical likelihood, the calibration estimator has several important differences compared to the generalized empirical likelihood literature. In econometrics, generalized empirical likelihood is often employed for estimating a p-dimensional parameter by specifying a q-dimensional estimating equation, where q > p ≥ 1. However, we are not estimating the target parameter τ by directly solving an overidentified estimating equation. The calibration conditions in (5) and (6) can be regarded as a K-dimensional moment restriction with a degenerate parameter of interest, and (8) and (9) are essentially degenerate cases of generalized empirical likelihood with only the auxiliary parameters λ and β appearing but not the target parameter τ. Even though the generalized empirical likelihood estimation problem is undefined because the moment restrictions are not functions of target parameters, implied weights can still be constructed. In econometrics, the generalized empirical likelihood estimators are usually solutions to saddlepoint problems and can be difficult to compute. In our case, λ̂ and β̂ are solutions to unconstrained convex maximization problems rather than a saddlepoint problem and can be computed by a fast and stable Newton-type algorithm. Moreover, the generalized empirical likelihood literature mainly deals with a fixed number of moment restrictions, but the dimension K of moment restrictions increases with N in our present consideration. Furthermore, the moment restrictions are misspecified for finite K in our case, but most theoretical results for generalized empirical likelihood are derived under a correct model specification and are therefore inapplicable.
2.3. Philosophical differences and practical implications
Although the calibration weights in Section 2.2 are also constructed from moment balancing conditions as in certain propensity score methodologies, there is a fundamental difference in the modeling philosophy that leads to important practical implications in the estimation of average treatment effects. Philosophically, the calibration weights are constructed without any reference to a propensity score model. It ignores the explicit link between the weights in the treated and the control groups that are present in propensity score modeling. Practically, it leads to an exact three-way balance between the treated, the controls and the combined group for finite samples as well as asymptotically, whereas finite-sample exact three-way balance is not guaranteed for propensity score modeling in general. Furthermore, calibration can be viewed as a unification of the existing globally efficient estimations that are constructed from different modeling strategies as discussed in the online supplementary material.
To illustrate the first idea, we consider a general class of weighting estimators . If the true propensity score π(X) is known, we set w1(X) = (π(X))−1 and w0(X) = (1 − p(X))−1, so that the corresponding weighting estimator is an unbiased estimator for τ based on (1). The propensity score setting confines the weight functions w1(x) and w0(x) in the following relationship:
| (10) |
When a propensity score model π(x; γ) is assumed, and γ̂ is an estimate of γ, the Horvitz-Thompson estimator sets w1(x) = π−1(x; γ̂) and w0(x) = (1 − π(x; γ̂))−1. It follows that (10) is satisfied. Under model misspecification, and can be very different from 1, therefore it has been suggested that w1(x) = [C1π(x; γ̂)]−1 and w0(x) = [C0(1 − π(x; γ̂))]−1 which are ratio-type inverse probability weighting estimators. However, these weight functions do not satisfy (10) unless C1 = C0 = 1. In fact, the ratio-type inverse probability weighting estimator is a special calibration estimator that requires propensity score modeling to be discussed in Section 6. The class of calibration estimators in Section 2.2 does not rely on propensity score modeling in the first place, and the weights w1(x) = ρ′(γ̂TuK(x)) and w0(x) = ρ′(β̂TuK(x)) do not satisfy (10) in general. We note that one of the two weights can correspond to the inverse probability weight from a propensity score model, but it is generally impossible to have both sets of weights to be consistent with a single propensity score model. Therefore, for any fixed K, the calibration estimator for the average treatment effects cannot be locally efficient. Despite this seemingly undesirable property, we shall show that τ̂ is globally semiparametric efficient when K is allowed to increase with N. Existing globally efficient estimators are all locally efficient for any fixed dimension of approximation, but the calibration estimator sacrifices local efficiency by ignoring the link (10), while achieving exact three-way balance in finite samples. Note that the true propensity score attains the exact three-way balance in (4), but the estimated propensity scores typically do not achieve exact three-way balance in finite samples. While the Horvitz-Thompson estimator with maximum likelihood weights is globally efficient and three-way balance should hold for extremely large samples, the balance can be quite poor for practical sample sizes. In our current proposal, the exact three-way balance holds for finite samples as well as asymptotically, which is a reason why our asymptotic results for the point and variance estimators hold well even for finite samples.
To further illustrate the balancing properties of estimators, suppose that π(γTx) is a propensity score model. The expression (4) leads to
| (11) |
| (12) |
| (13) |
Suppose we estimate γ by solving each of the just-identified system of estimating equations defined by moment conditions (11), (12) and (13), and denote the corresponding estimators to be γ̂1, γ̂2 and γ̂3; that is, γ̂j satisfies , for j = 1, 2, 3. Note that, however, for j ≠ j′. The covariate balancing propensity score of Imai and Ratkovic (2014) shares the same spirit of γ̂3, and the inverse probability tilting method of Graham et al. (2012) shares the same spirit of γ̂1. In general, matching one set of moment conditions creates two-way balance, but does not guarantee three-way balance between the treated, the controls and the combined group. However, a lack of three-way balance can adversely affect the quality of the final estimate since the average treatment effects is defined for the combined population, and the data for Y (1) and Y (0) are only available for the treated and controls respectively. We shall further illustrate this point by the simulation studies in the online supplementary materials. On the other hand, four-or-more-way balance is not necessary because asymptotic efficiency is attained by three-way balance as shown in Theorem 1 in Section 2.4.
Since b3 = b1 − b2, balancing any two systems out of (11), (12) and (13) can lead to a balance of the remaining system. Therefore, by considering an overidentified combined system of estimating functions b1 and b2, one can estimate γ by using generalized method of moments or empirical likelihood, and we denote the corresponding estimator by γ̂12. However, it is typical that
because the generalized method of moment estimator does not solve that corresponding overidentified system exactly, and therefore the exact three-way balance is typically not achieved.
For the calibration estimator, however,
by construction, and exact three-way balance can naturally be achieved.
Several remarks are in order. First, when the propensity score model is misspecified, which is likely in practice, γ̂j converges in probability to , j = 1, 2, 3, which are different in general. Therefore, covariate balancing based on one of (11), (12) or (13) can lead to very different results. For balancing an over-identified system of equations using the empirical likelihood, there is no guarantee that the γ estimate is -consistent (Schennach; 2007) under a misspecified propensity score model. Calibration is similar to using γ̂1 for reweighting the treated and γ̂2 for reweighting the controls when the propensity score model is misspecified, but our proposed non-parametric calibration method does not involve propensity score estimation.
Despite the dissimilarities in the weighting aspects compared to propensity score methodologies, calibration can be viewed as a unification of the existing globally efficient estimation that are constructed from two very different strategies: weighting and prediction. Let m̃1(X) and m̃0(X) be weighted least square estimators for Y against uK(X) among the treated and controls with weights p̂K(X) and q̂K(X) respectively. It follows that
The first equality holds from the score equation of weighted least squares, and the second equality holds because of the exact three-way balance. Therefore, our proposed calibration unifies the weighting and the prediction estimators by a rather unexpected way of relaxing the estimation of propensity score and outcome regression functions.
2.4. Large sample properties of calibration estimators
To show the large sample properties, we need the following technical assumptions in addition to Assumption 1.
Assumption 2.
[Y (1)2] < ∞ and
[Y (0)2] < ∞.Assumption 3. The support
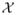 of r-dimensional covariate
X
is a Cartesian product of r compact intervals.
of r-dimensional covariate
X
is a Cartesian product of r compact intervals.Assumption 4. π(x) is uniformly bounded away from 0 and 1, i.e. there exist some constants such that
where
is the support of
X.Assumption 5. π(x) is s-times continuously differentiable, where s > 13r.
Assumption 6. m0(x) and m1(x) are t-times continuously differentiable, where .
Assumption 7. K = O (Nν) and .
Assumption 8. ρ ∈ C3(ℝ) is a strictly concave function defined on ℝ i.e. ρ″(γ) < 0, ∀γ ∈ ℝ, and the range of ρ′ contains [η2, η1] which is a subset of the positive real line.
Assumptions 1–7 or their analogues also appeared in Hahn (1998), Hirano et al. (2003) and Imbens et al. (2006). Assumption 1 is required for the identification of the average treatment effects. Assumption 2 is required for the finiteness of asymptotic variance. Assumptions 3 and 4 are required for uniform boundedness of approximations. Assumption 4 is an overlap condition that is necessary for the nonparametric identification of the average treatment effects in the population. If there exists a region of X such that the probability of receiving treatment is 0 or 1, the treatment effects cannot be identified unless some extrapolatory modeling assumptions are imposed. In that case, one could define a subpopulation with a sufficient overlap so that the average treatment effects can be estimated nonparametrically within this subpopulation. Assumptions 5 and 6 are required for controlling the remainder of approximations with a given basis function. They are standard assumptions for multivariate smoothing where the order of smoothness required increases with the dimension of X. There is usually no a-priori reason to believe that the π(x), m1(x) and m0(x) are not smooth in x. Also the dimension of X is not restricted by the assumptions, unlike in the kernel estimation of π(x) discussed in Chen et al. (2013), in which their assumptions imply that the dimension of X cannot be greater than 4. Assumption 7 is required for controlling the stochastic order of the residual terms, which is desirable in practice because K grows very slowly with N so that a relatively small number of moment conditions is sufficient for the proposed method to perform well. Assumption 8 is a mild assumption on ρ which is chosen by the statisticians and includes all the important special cases considered in the literature. In contrast, the theoretical results for Hahn (1998), Hirano et al. (2003), Imbens et al. (2006) and Chen et al. (2008) were developed only for linear or logistic models for propensity score.
Define μ0 ≜
[Y (0)], μ1 ≜
[Y (1)],
and
, which are finite by Assumption 2. We have the following theorem.
Theorem 1
Under Assumptions 1–8, we have
;
-
, where
attains the semi-parametric efficiency bound as shown in Robins et al. (1994) and Hahn (1998).
A detailed proof of Theorem 1 will be provided in the supplementary materials. We note that our global efficiency result is substantially more general than existing results in the literature, in which global efficiency for weighting estimators has only been established for two particular estimators for the propensity score: the series least square estimator (Hahn; 1998; Chen et al.; 2008), and the maximum likelihood series logit estimator (Hirano et al.; 2003; Imbens et al.; 2006). The proof of lemma B.2 in Chen et al. (2008) relies crucially on the least square property of the projection of T on the approximation basis. The validity of the result in Hirano et al. (2003) requires a key fact about the least square projection of
onto a transformed approximation basis
, where π*(x) is defined in terms of the limit of a maximum likelihood estimator under a logistic regression model. Their projection argument yields an asymptotically negligible residual term only when the series maximum likelihood logit estimator is used. We are able to establish the global efficiency results for any strictly concave ρ satisfying Assumption 8 because we employed a different and more delicate projection argument. We studied a weighted least square projection of −
(Y (1)|X = x) and −
(Y (0)|X = x) onto the original approximation basis uK(x), where ρ only enters the weights of the projection, but not the approximation basis. Our projection argument yields an asymptotically negligible residual term when the weights of the projection are bounded from above and below, which was established under our regularity conditions. Theorem 1 holds even when the ρ functions used for computing p̂K and q̂K are different. However, we do not recommend this in practice, because each ρ(v) corresponds to a measure of distance D(v) from the unit weight, and usually there is not any justifiable reason for choosing a different measure for the two treatment groups.
3. A nonparametric variance estimator
By Theorem 1, the proposed estimator attains the semiparametric efficiency bound with the following asymptotic variance: . Since the variance involves unknown functions π(x), m1(x) and m0(x), plug-in estimators typically involve nonparametric estimation of functions other than π(x), as in Hirano et al. (2003). One of the advantages of our proposed point estimator is that we do not need to directly estimate those functions, and it would be nice to have a variance estimator that also does not involve any additional estimates of nonparametric functions. Moreover, existing nonparametric estimators that require estimation of π(x) often fail in practice, as illustrated in Table 4 of the online supplementary materials. A particular thorny issue is that the asymptotic variance estimators often depend on the squared inverse of estimated propensity score, and the instability caused by extreme inverse weights is even magnified. In this section, we shall study a consistent asymptotic variance estimator that can be computed easily from the point estimator and avoids the problem of extreme weights.
Define
where θ ≜ (λ, β, τ)T. Also define θ̂K ≜ (λ̂K, β̂K, τ̂K)T, and . Note that θ̂K satisfies
Taylor series expansion on the left hand side at yields
| (14) |
where θ̃K = (λ̃K, β̃K, τ̃K)T lies on the line joining θ̂K and . We shall show in the supplementary materials that
| (15) |
where
and
However, note that we are only interested in the limiting behavior of , which is the last element of when N ↑ ∞, this leads us to consider the last row of which is
where
Since (the zero vector), by (3.55) in the supplementary materials we can get:
| (16) |
where . This motivates us to define our estimator for the asymptotic variance by:
where
Although the construction of the proposed variance estimator did not start with a direct approximation of the influence function, the variance estimator can be written as where
which is an estimator of the efficient influence function:
| (17) |
Comparing φeff and φ̂CAL, the proposed variance estimator would have a good performance if −LKgK1(T, X; λ̂)+RKgK2(T, X; β̂) is a good but indirect approximation of (T −π(X))β(X). This is particularly true because of approximation results that are established in the proof of Theorem 1 for the terms (29) and (30) given in Appendix A. In summary, we have the following theorem:
Theorem 2
Under Assumptions 1–8 with Assumption 2 being strengthened to
(Y4(1)) < ∞ and
(Y4(0)) < ∞, V̂K is a consistent estimator for the asymptotic variance Vsemi.
The proof of Theorem 2 is given in the supplementary materials. The strengthened condition in Theorem 2 is mainly used in (3.71) in the supplementary materials so as to ensure the consistency of the asymptotic variance; and this condition is mild and naturally holds for practical samples. The results illuminated the advantages of using the proposed variance estimator for statistical inference. We note that the proposed variance estimator can pair with any globally efficient estimators for valid inference, since all of them are asymptotically equivalent. However, the computation of the proposed estimator only requires intermediate input from the calibration estimation and does not require direct estimation of propensity score or outcome regression function, therefore it pairs naturally with the calibration estimators.
4. Related estimation problems
In this section we illustrate that calibration weighting can be easily extended to several related problems. All proofs of the main theorems in this section are very similar to that of Theorem 1, and they are omitted. The estimators for asymptotic variances in this section, namely
, and Vjl for i, l ∈
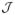 = {0, …, J − 1}, J ≥ 2, and their corresponding consistent estimation results can be derived similarly by using the approach founded in Section 3.
= {0, …, J − 1}, J ≥ 2, and their corresponding consistent estimation results can be derived similarly by using the approach founded in Section 3.
4.1. Weighted average treatment effects
Our estimator can be easily extended to estimate a weighted average treatment effects
where g is a known function of the covariates. To estimate , we can define and , with λ̂K and β̂K being replaced by maximizers of slightly different objective functions:
and
where . Therefore, p̂K and q̂K satisfies
| (18) |
and
Define . The following theorem states that is efficient.
Theorem 3
Under Assumptions 1–8, |g| is bounded from above and that
[g(X)] > 0. Then we have
;
, where attaining the semi-parametric efficiency bound as shown in Theorem 4 of Hirano et al. (2003).
4.2. Treatment effects on the treated
To estimate the average treatment effects among the treated subpopulations, we estimate
where the last equality follows from Assumption 1. Therefore, when the propensity score is known, τATT is a special case of τWATE with g(x) = π(x), and one can estimate τATT by . Following Theorem 3, we have the following results for .
Corollary 4
Under Assumptions 1–8, we have
;
, where attaining the semi-parametric efficiency bound as shown in Theorem 2 of Hahn (1998).
Note that
(Y(1)|T = 1) is estimated by
where p̂K satisfies (18) with g(x) = π(x), and this estimate is more efficient than the estimator
when π(x) is known, because one can calibrate the treated subpopulation to
and use the full data to improve estimation efficiency.
When π(x) is unknown, however, the weighted average treatment effects estimator cannot be used. Since we want to estimate the subpopulation of the treated, it is natural to calibrate the control group to the treated by redefining the objective function:
where . The calibration estimator for estimating the treatment effects on the treated is . The next theorem states that τ̂ATT is globally efficient when the propensity score is unknown.
Theorem 5
Under Assumptions 1 to 8, we have
;
, where attaining the semi-parametric efficiency bound as shown in Theorem 1 of Hahn (1998).
4.3. Multiple treatment groups
The calibration methods can also be easily generalized to situations with multiple treatment groups. Let Ti ∈
= {0, …, J − 1} where J ≥ 2 is an integer. Define μj =
[Y(j)], mj(x) =
[Y(j)|X = x], πj(x) =
(T = j|X = x),
, j ∈
, and τjl = μj − μl which is the average treatment effects between treatments j and l. Calibration weights can be defined for any j ∈
by
where maximizes the objective function:
That is, we calibrate moments of uK(X) for each group to the full data. Estimators for μj, j ∈
are defined as
and the estimator for the average treatment effects between treatment j and l is τ̂jl ≜ μ̂j − μ̂l.
Theorem 6
Under Assumptions 1 to 8 with π(x) and (m1(x), m0(x)) replaced by πj(x) and mj(x) for j ∈
, respectively,
;
, where .
Estimators for the weighted average treatment effects and the treatment effects of the treated can also be easily extended to multiple treatment groups.
5. Data analysis
5.1. A childhood nutrition study
We studied the performance of various weighting estimators using the 2007–2008 National Health and Nutrition Examination Survey (NHANES), which is a study designed to assess the health and nutrition statuses of children and adults in the United States. We studied whether participation of the National School Lunch or the School Breakfast programs (hereinafter, “school meal programs”) would lead to an increase in body mass index (BMI) for children and youths aged at 4 to 17. The school meal programs are intended to address the problem of insufficient food access of children in low-income families. However, a potential unintended consequence of the program is excessive food consumption which may cause childhood obesity. We analyzed 2330 children and youth at ages between 4 and 17, with a median age of 10, with 1284 (55%) participated in school meal programs.
Covariates in the data include: child age, child gender, race (black, Hispanic versus others), families above 200% of the federal poverty level, participation in Special Supplemental Nutrition Program for Women, Infants and Children, participation in the Food Stamp Program, a childhood food security measurement which is an indicator of two or more affirmative responses to eight child-specific questions in the NHANES Food Security Questionnaire Module, health insurance coverage, and the age and sex of survey respondents (usually an adult in the family). The estimated average difference in BMI between participants and non-participants, together with standard error estimates and imbalance measures, are all given in Table 1. Direct comparison showed that the mean BMI of participants was significantly higher than that of non-participants, indicating that the program may lead to excessive food consumption. This particular finding has a policy implication in that there is a need to redesign the school meal programs to promote a healthier diet. Using a logistic propensity score model with a linear covariate specification, the Horvitz-Thompson estimators using maximum likelihood estimation and the covariate balancing propensity score estimates of Imai and Ratvokic (2014) both yielded a consistent, but opposite conclusion that the participation in school meal programs led to a significantly lower BMI and possible malnutrition. This particular finding has policy implications in that current school meal programs may fail in reducing the health disparities for poorer children. The inverse propensity score weighted estimates (IPW) were much closer to zero than the corresponding Horvitz-Thompson estimators, yielding a non-significant difference in BMI between the participants and the non-participants. The use of different propensity score weighting estimators leads to an inconclusive finding. The calibration estimators gave a consistent result that there is a negligible mean BMI difference between the participants and the non-participants. A policy implication is that the current school meal programs are implemented in an appropriate manner that provides assistance for the needed without an unintended consequence of increasing childhood obesity.
Table 1.
The difference in average BMI between participants and non-participants of school meal programs: NHANES 2007–2008 data
| Estimate | SE | 95% C. I. | Imbalance ×100 | ||||
|---|---|---|---|---|---|---|---|
| (1,0) | (1,F) | (0,F) | Total | ||||
| Naive | 0.53 | 0.21 | (0.11,0.95) | 103 | 47 | 57 | 127 |
| HT(MLE) | −1.48 | 0.51 | (−2.50, −0.46) | 49 | 16 | 57 | 63 |
| HT(CBPS) | −1.38 | 0.50 | (−2.38, −0.38) | 42 | 20 | 36 | 53 |
| IPW(MLE) | −0.14 | 0.24 | (−0.62,0.34) | 7 | 7 | 26 | 16 |
| IPW(CBPS) | −0.1 | 0.23 | (−0.56,0.36) | 10 | 11 | 12 | 17 |
| CAL(ET) | −0.04 | 0.22 | (−0.48,0.40) | 0 | 0 | 0 | 0 |
| CAL(EL) | −0.06 | 0.22 | (−0.50,0.38) | 0 | 0 | 0 | 0 |
| CAL(Q) | 0 | 0.22 | (−0.44,0.44) | 0 | 0 | 0 | 0 |
| CAL(IL) | −0.08 | 0.22 | (−0.52,0.36) | 0 | 0 | 0 | 0 |
SE: standard error; CI: confidence interval; HT: Horvitz-Thompson estimator; IPW: inverse probability weighting estimator; CAL: calibration estimator; MLE: maximum likelihood estimator; CBPS: covariate balancing propensity score; ET: exponential tilting; EL: empirical likelihood; Q: quadratic; IL: inverse logistic. Standardized covariate imbalance between treated and controls (10), treated and full data (1F), control and full data (0F) and total imbalance are reported.
5.2. A job training study
We further demonstrate the performance of various weighting estimators by estimating the treatment impact of a labor training program data previously analyzed in Lalonde (1986) and Dehejia and Wahba (1999), among many others.
The National Supported Work (NSW) Demonstration was a randomized experiment implemented in the mid-1970s to study whether a systematic job training program would increase post-intervention income levels among workers. Both intervention and control groups were present in the original NSW study. Lalonde (1986) examined the extent to which analyses using observational data sets as controls would agree with the unbiased results of a randomized experiment. His nonexperimental estimates were based on two observational cohorts: the Panel Study of Income Dynamics (PSID) and Westat’s Matched Current Population Survey –Social Security Administration File (CPS). Detailed description of the two data sets was given in Lalonde (1986) and Dehejia and Wahba (1999).
Dehejia and Wahba (1999) and others had analyzed the data set using different propensity score methodologies. Since calibration estimators are weighting estimators, we again limit our comparison only to other weighting estimators based on propensity score modeling. We combined the three data sets and created a group variable G having four categories: G = 1 for the treated in the NSW data (N = 185), G = 2 for the controls in the NSW data (N = 260), G = 3 for the PSID data (N = 2490) and G = 4 for the CPS data (N = 15992). Categories 2, 3 and 4 all served as control data because individuals in those groups did not participate in the job training program offered in NSW. However, Categories 2, 3, 4 had substantially different covariate distributions. We considered the four categories in the combined data to illustrate that the calibration methodology can be applied to handle multiple treatment groups. We studied whether PSID and CPS can be used as the controls in the original NSW data, and we compared the estimates for the average treatment effects in the NSW study population, which was treatment effects on the treated. We noted that the treated and the control groups in the NSW data should have the same covariate distribution because of randomization. Using this information, we calibrated the weights of the four groups to the combined covariate distribution of groups 1 and 2. We also compared our results to calibration estimators with weights calibrated to the treatment group G = 1 only. Since there were four nominal group categories, we used the multinomial logit model for propensity score modeling. Two covariate configurations were considered, where the calibration estimators matched the same variables as in the propensity score models. The first (linear) specification included age, an indicator for black race (black), an indicator for Hispanic race (hisp), years of education (ed), an indicator for being married (married), an indicator for not having an academic degree (nodegr), income in 1974 (re74), income in 1975 (re75), an indicator for zero income in 1974 (u74), and an indicator for zero income in 1975 (u75). The second specification included all variables in the linear specification with the following additional higher-order variables: age2, age3, ed2, re742, re752, ed×re74 and u74×black. These variables were included in the final models for either PSID or CPS data in Dehejia and Wahba (1999).
We estimated the average difference of income in 1978 between the treatment group (G = 1) and the control groups (G = 2, 3, 4). We further examined the evaluation bias defined as the estimated mean difference of outcome between the NSW control group (G = 2) and the observational control groups (G = 3, 4). The results are shown in Table 2. Direct comparisons were known to be severely biased, and had a huge evaluation bias. All weighting estimators greatly reduced the estimated evaluation bias, but the Horvitz-Thompson and inverse probability weighted estimator can yield very different estimates under the same model. Also, the estimates can change dramatically in comparing the two specifications of propensity score models. The calibration estimators yielded very similar estimates for both model specifications. Calibration to the combined NSW group had lower estimated standard errors compared to calibration only to the treated group. However, the estimates for the two calibration procedures were slightly different, probably because they were referring to two slightly different populations. This was possibly due to the fact that the analysis file of Dehejia and Wahba (1999) removed observations with a missing 1974 income, and the missingness may be different in the treatment and control groups. Hence, the NSW treated and controls may not have the same covariate distribution. In general, the standard errors of the propensity score estimators were much larger than that of the calibration estimators.
Table 2.
Average treatment effects and evaluation biases for the Lalonde (1986) data.
| (a) Treatment effects | |||||||
|---|---|---|---|---|---|---|---|
| Estimators | Model | NSW data | PSID data | CPS data | |||
| Estimates | SE | Estimates | SE | Estimates | SE | ||
| Unweighted | 1794 | 671 | −15205 | 657 | −8498 | 583 | |
| HT | 1 | 1600 | 827 | 2421 | 917 | 551 | 862 |
| HT | 2 | 1936 | 872 | 2136 | 1018 | 1071 | 711 |
| IPW | 1 | 1702 | 734 | 310 | 1095 | 1515 | 1014 |
| IPW | 2 | 1287 | 863 | −830 | 1207 | 1534 | 745 |
| CAL | 1 | 1572 | 667 | 2557 | 716 | 1233 | 668 |
| CAL* | 1 | 1712 | 707 | 2425 | 743 | 1406 | 675 |
| CAL | 2 | 1454 | 642 | 2504 | 699 | 1178 | 754 |
| CAL* | 2 | 1874 | 705 | 2285 | 795 | 1527 | 738 |
| (b) Evaluation biases | |||||||
| Unweighted | −17000 | 391 | −10292 | 349 | |||
| HT | 1 | 626 | 809 | −1244 | 710 | ||
| HT | 2 | 342 | 998 | −724 | 917 | ||
| IPW | 1 | −1485 | 926 | −279 | 527 | ||
| IPW | 2 | 2624 | 1085 | −261 | 577 | ||
| CAL | 1 | 986 | 556 | −338 | 487 | ||
| CAL* | 1 | 712 | 600 | −306 | 512 | ||
| CAL | 2 | 1049 | 605 | −276 | 617 | ||
| CAL* | 2 | 411 | 677 | −347 | 592 | ||
SE: standard error; CI: confidence interval; HT: Horvitz-Thompson estimator with propensity score estimated from maximum likelihood; IPW: ratio-type inverse probability weighting estimator with propensity score estimated from maximum likelihood estimation; CAL: calibration with exponential tilting, moments are calibrated to the combined NSW group; CAL*: calibration with exponential tilting, moments are calibrated to the NSW treatment group. Two model specifications are considered, 1: linear in covariates; 2: linear and higher-order covariates as in Dehajia and Wahba (1999). Standard errors for HT and IPW estimators were calculated by bootstrapping with 1000 replicates.
An advantage of using weighting estimators is that statisticians can graphically assess whether covariate balance is achieved. Figure 1 shows the weighted distributions of the four continuous covariates age, education (ed), income in 1974 (re74) and income in 1975 (re75). We compared the IPW and the calibration weighted distributions for the PSID and CPS data, with the empirical distributions of the combined NSW sample. Propensity score modeling and calibration were done using the non-linear model specification as in Dehejia and Wahba (1999). The calibration weighted distributions in both PSID and CPS data were close to the empirical distributions from the NSW data. However, the IPW weighted distributions showed a substantial difference for some variables, such as age, re74 and re75 in the PSID data and ed in the CPS data. Even when we matched a small number of moment constraints, the calibration weights performed well in matching the full covariate distributions between the non-experimental groups and the NSW data.
Fig. 1.

Weighted covariate distributions for the Lalonde (1986) data
Solid lines (
 ): Empirical distribution from the NSW data. Dashed lines (------): Calibration weighted distributions. Dotted lines (···········): Inverse probability weighted distributions. CDF: Cumulative distribution function.
): Empirical distribution from the NSW data. Dashed lines (------): Calibration weighted distributions. Dotted lines (···········): Inverse probability weighted distributions. CDF: Cumulative distribution function.
We further examined the performance of the proposed standard error estimators by comparing them to bootstrap estimates based on 1000 replications and standard error estimates that treat the weights as given and fixed. The corresponding results for the calibration estimator under the linear specification are given in Table 3. The proposed standard error estimates were very close to the bootstrap standard errors, but the standard error estimators which treated the weights as if they were fixed can greatly underestimate the variability of the calibration estimators. For instance, when we ignored the variability of the estimated weights, the standard error estimates for the CPS data were much smaller because of their large sample sizes. However, the true estimation variability can be more than 6 times larger because the weights were constructed by calibrating to the combined NSW data which had a much smaller sample size. Therefore, ignoring estimation variability of calibration weights can lead to a misleading inference. For a correct inference, one cannot rely on variance estimates that treat the weights as fixed, which was suggested in Section 3.4 of Hainmueller (2012).
Table 3.
Comparisons of standard error estimates for the Lalonde (1986) data.
| (a) Treatment Effects | |||
|---|---|---|---|
| NSW data | PSID data | CPS data | |
| Proposed | 667 | 716 | 668 |
| Bootstrap | 672 | 737 | 666 |
| Fixed | 643 | 300 | 111 |
| (b) Evaluation Biases | |||
| Proposed | 556 | 487 | |
| Bootstrap | 612 | 500 | |
| Fixed | 254 | 92 | |
Bootstrap estimates were based on 1000 replicates.
6. Discussions
We studied a large class of calibration estimators for efficient inference of the average treatment effects. Calibration weights removes imbalance in pretreatment covariates among the treated, controls and the combined group. By directly modifying the misspecified uniform weights, we do not directly model or estimate the propensity score. We show that balancing covariate distribution alone can achieve global semiparametric efficiency, and we also propose a consistent asymptotic variance estimator which outperforms other estimators that involve direct approximation of the influence function.
While we considered calibration estimators that modify the uniform weights, calibration can be constructed to modify the Horvitz-Thompson weights. However, this formulation requires an additional direct modeling and estimation of propensity score. If π̂(x) is an estimated propensity score function, a class of calibration weights can be defined by
where λ̂K ∈ ℝk maximizes the objective function
and
where β̂K ∈ ℝK maximizes the objective function
This type of calibration procedure is discussed in detail in Chan and Yam (2014). We now focus on the special case that K = 1 and u ≜ uK ≡ 1, together with λ and β being set as scalar parameters. The balancing equation for the treated becomes
Therefore, and the corresponding calibration weight is . Similarly, . This yields the ratio-type IPW estimator. Therefore, the construction of IPW from HT estimators can be viewed as a calibration procedure. When π̂ is a series logit estimator, Hirano et al. (2003) and Imbens et al. (2006) show that the ratio-type IPW estimator is globally asymptotically efficient. Note that u is one-dimensional regardless of sample sizes. Therefore, when π is estimated by a series logit estimator, global efficiency can be achieved when uK has a fixed dimension. However, our global efficiency results require uK to have an increasing dimension with N because propensity score was not directly estimated.
In practice, we suggest to choose uK(X) to be the first and possibly higher moments of candidate covariates. When the covariate distributions of the treated and the controls differ only by a mean shift, matching the first moment of X would be sufficient for removing imbalance. When the variances differ, one can also match the second moment. Matching moments of covariate distributions are intuitive to non-statisticians. We can also graphically check whether the choice of uK(X) is sufficient as in Figure 1. A noticeable difference in the weighted distributions comparing the treated and the controls would suggest that additional moment conditions are needed. Furthermore, we can choose K by a graphical method or by cross-validation. Since the parameter K controls the number of moment conditions for matching to eliminate the bias from confounding, the choice of K is therefore analogous to the selection of number of confounders in regression modeling, for which a graphical method was discussed in Crainiceanu et al. (2008). Inspired by that paper, we propose the following graphical method for choosing K. From the unweighted sample, we calculate the total standardized imbalance measure for each candidate uK(X), and rearrange them in a descending order of the imbalance measure. Then for k = 1, 2, …, we plot the point estimates and the 95% confidence intervals by matching the first k moment conditions. The bias would vanish when enough moment conditions are balanced, therefore the difference between consecutive point estimates will stabilize. Identify a region such that the the difference between consecutive point estimates is small, and within this region we can choose K such that the corresponding confidence interval is the shortest. Alternatively, K can be chosen by cross-validation. The moment conditions are matched in a training subset of the full data, while the weights are created in a complementary testing set and a total imbalance measure is calculated for the test data. This process is repeated over different partitions of data, and we choose K such that the average imbalance measure is minimized. While K can be chosen by the above methods, we would like to remark that Theorems 1 and 2 hold for a broad ranges of K and our simulation results given in the online supplementary materials show that the performance of the calibration estimators are insensitive to the choice of K when all relevant covariates are included. This is because our estimator involves the summation of linear functions of p̂K(Xi) and q̂K(Xi), and the summation of functions of nonparametric estimators are typically insensitive to the selection of the tuning parameter (Maity et al.; 2007), known as the double-smoothing phenomenon.
Supplementary Material
Acknowledgments
The authors thank Profs. Gareth Roberts, Piotr Fryzlewicz, two associate editors and three reviewers for their insightful comments and suggestions, which have led to substantial improvements. The first author-K. C. G. Chan is supported by US National Institutes of Health grant R01HL122212. The second author-Phillip Yam acknowledges the financial supports from The Hong Kong RGC GRF 404012 with the project title: Advanced Topics In Multivariate Risk Management In Finance And Insurance, and Direct Grants for Research 2010/2011 with project code: 2060422, 2011/2012 with project code: 2060444, and 2014/15 with project code: 4053141 all offered by CUHK. The third author-Zheng Zhang acknowledges the financial supports from the Chinese University of Hong Kong and the UGC of HKSAR. The present work constitutes part of his research study leading to his PhD thesis in CUHK.
Appendix A. Asymptotic expansion of the calibration estimators
The technical proofs for the lemmas and theorems are given in the supplementary materials. Here we present an asymptotic expansion of the empirical balancing estimator, which will be the key to these proofs.
Define
Now we have the following decomposition of our empirical balancing estimator in Theorem 1(b),
| (19) |
| (20) |
| (21) |
| (22) |
| (23) |
| (24) |
| (25) |
| (26) |
| (27) |
| (28) |
| (29) |
| (30) |
| (31) |
| (32) |
Since and have a symmetric structure, we only need to consider the terms (19), (21), (23), (25), (27) and (29), and then apply the similar arguments to the terms (20), (22), (24), (26), (28) and (30). We shall show that the sum (31) + (32) asymptotically follows a normal distribution, while all the remaining terms are of order op(1). A key challenge of the proof is to show the asymptotic order of (29) and (30), because they link all the unknown functions (π(x), m1(x), m0(x)) with the calibration weights and balancing moment conditions. This is overcome by using a novel weighted projection argument.
Appendix B. Dual formulation of calibration estimators
We derive the dual of the constrained optimization problem (5) by using the methodology introduced in Tseng and Bertsekas (1987); the dual of (6) follows by a similar argument. Define EK×N ≜ (uK(X1), …, uK(XN)), si ≜ 1 − TiNpi, i = 1, …, N, s ≜ (s1, …, sN)T and f(v) ≜ D(1 − v), then we can rewrite the problem (5) as
For every j ∈ {1, …, N}, we define the conjugate convex function (Tseng and Bertsekas; 1987) of Tjf (·) to be
where the third equality follows by noting that Tf(1−TNpj) = Tf (1 − Npj), and satisfies the first order condition:
By defining ρ(z) ≜ f((f′)−1 (z)) + z − z · (f′)−1 (z), then
By Tseng and Bertsekas (1987), the dual problem of (5) is
where Ej is the j-th column of EK×N, i,e., Ej = uK(Xj).
Since D is strictly convex, f″(v) = D″(1 − v), and hence f is also strictly convex and f′ is strictly increasing. Note that
differentiating with respect to v both sides of the latter equation yields:
which also implies
since f″ > 0. Further differentiating with respect to v of the above equation, we get ρ″(f′(v)) f″(v) = −1, which implies
By also working backward, the convexity of D is equivalent to the concavity of ρ.
Contributor Information
Kwun Chuen Gary Chan, Department of Biostatistics, University of Washington.
Sheung Chi Phillip Yam, Department of Statistics, Chinese University of Hong Kong.
Zheng Zhang, Department of Statistics, Chinese University of Hong Kong.
References
- Abadie A, Imbens GW. Large sample properties of matching estimators for average treatment effects. Econometrica. 2006;74(1):235–267. [Google Scholar]
- Bang H, Robins JM. Doubly robust estimation in missing data and causal inference models. Biometrics. 2005;61(4):962–973. doi: 10.1111/j.1541-0420.2005.00377.x. [DOI] [PubMed] [Google Scholar]
- Blinder AS. Wage discrimination: reduced form and structural estimates. Journal of Human resources. 1973;8(4):436–455. [Google Scholar]
- Cao W, Tsiatis AA, Davidian M. Improving efficiency and robustness of the doubly robust estimator for a population mean with incomplete data. Biometrika. 2009;96(3):723–734. doi: 10.1093/biomet/asp033. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chan KCG. Uniform improvement of empirical likelihood for missing response problem. Electronic Journal of Statistics. 2012;6:289–302. [Google Scholar]
- Chan KCG. A simple multiply robust estimator for missing response problem. Stat. 2013;2(1):143–149. [Google Scholar]
- Chan KCG, Yam SCP. Oracle, multiple robust and multipurpose calibration in a missing response problem. Statist Sci. 2014;29(3):380–396. [Google Scholar]
- Chen SX, Qin J, Tang CY. Mann–whitney test with adjustments to pretreatment variables for missing values and observational study. J R Statist Soc B. 2013;75(1):81–102. [Google Scholar]
- Chen X, Hong H, Tarozzi A. Semiparametric efficiency in gmm models with auxiliary data. Ann Statist. 2008;36(2):808–843. [Google Scholar]
- Cheng PE. Nonparametric estimation of mean functionals with data missing at random. J Am Statist Ass. 1994;89(425):81–87. [Google Scholar]
- Crainiceanu CM, Dominici F, Parmigiani G. Adjustment uncertainty in effect estimation. Biometrika. 2008;95(3):635–651. [Google Scholar]
- Dehejia R, Wahba S. Causal effects in nonexperimental studies: reevaluating the evaluation of training programs. J Am Statist Ass. 1999;94(448):1053–1062. [Google Scholar]
- Deming W, Stephan F. On a least squares adjustment of a sampled frequency table when the expected marginal totals are known. Ann Math Statist. 1940;11(4):427–444. [Google Scholar]
- Deville J, Särndal C. Calibration estimators in survey sampling. J Am Statist Ass. 1992;87(418):376–382. [Google Scholar]
- Graham B, Pinto C, Egel D. Inverse probability tilting for moment condition models with missing data. The Review of Economic Studies. 2012;79(3):1053–1079. [Google Scholar]
- Hahn J. On the role of the propensity score in efficient semiparametric estimation of average treatment effects. Econometrica. 1998;66(2):315–331. [Google Scholar]
- Hainmueller J. Entropy balancing for causal effects: A multivariate reweighting method to produce balanced samples in observational studies. Political Analysis. 2012;20(1):25–46. [Google Scholar]
- Han P, Wang L. Estimation with missing data: beyond double robustness. Biometrika. 2013;100(2):417–430. [Google Scholar]
- Hansen L, Heaton J, Yaron A. Finite-sample properties of some alternative GMM estimators. Journal of Business & Economic Statistics. 1996;14(3):262–280. [Google Scholar]
- Hellerstein JK, Imbens GW. Imposing moment restrictions from auxiliary data by weighting. Review of Economics and Statistics. 1999;81(1):1–14. [Google Scholar]
- Hirano K, Imbens G, Ridder G. Efficient estimation of average treatment effects using the estimated propensity score. Econometrica. 2003;71(4):1161–1189. [Google Scholar]
- Horvitz DG, Thompson DJ. A generalization of sampling without replacement from a finite universe. J Am Statist Ass. 1952;47(260):663–685. [Google Scholar]
- Imai K, Ratkovic M. Covariate balancing propensity score. J R Statist Soc B. 2014;76(1):243–263. [Google Scholar]
- Imbens G, Newey W, Ridder G. Unpublished manuscript. University of California Berkeley; 2006. Mean-squared-error calculations for average treatment effects. [Google Scholar]
- Imbens G, Spady R, Johnson P. Information theoretic approaches to inference in moment condition models. Econometrica. 1998;66(2):333–357. [Google Scholar]
- Kang J, Schafer J. Demystifying double robustness: a comparison of alternative strategies for estimating a population mean from incomplete data. Statist Sci. 2007;22(4):523–539. doi: 10.1214/07-STS227. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kim JK, Park M. Calibration estimation in survey sampling. International Statistical Review. 2010;78(1):21–39. [Google Scholar]
- Kitamura Y, Stutzer M. An information-theoretic alternative to generalized method of moments estimation. Econometrica. 1997;65(4):861–874. [Google Scholar]
- Lalonde R. Evaluating the econometric evaluations of training programs. American Economic Review. 1986;76:604–620. [Google Scholar]
- Maity A, Ma Y, Carroll RJ. Efficient estimation of population-level summaries in general semiparametric regression models. J Am Statist Ass. 2007;102(477):123–139. [Google Scholar]
- Newey WK, Smith RJ. Higher order properties of gmm and generalized empirical likelihood estimators. Econometrica. 2004;72(1):219–255. [Google Scholar]
- Oaxaca R. Male-female wage differentials in urban labor markets. International economic review. 1973;14(3):693–709. [Google Scholar]
- Owen A. Empirical likelihood ratio confidence intervals for a single functional. Biometrika. 1988;75(2):237–249. [Google Scholar]
- Qin J, Lawless J. Empirical likelihood and general estimating equations. Ann Statist. 1994;22:300–325. [Google Scholar]
- Qin J, Zhang B. Empirical-likelihood-based inference in missing response problems and its application in observational studies. J R Statist Soc B. 2007;69(1):101–122. [Google Scholar]
- Ridgeway G, McCaffrey DF. Comment: Demystifying double robustness: A comparison of alternative strategies for estimating a population mean from incomplete data. Statist Sci. 2007;22(4):540–543. doi: 10.1214/07-STS227. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Robins J, Rotnitzky A, Zhao L. Estimation of regression coefficients when some regressors are not always observed. J Am Statist Ass. 1994;89(427):846–866. [Google Scholar]
- Rosenbaum PR. Model-based direct adjustment. J Am Statist Ass. 1987;82(398):387–394. [Google Scholar]
- Rosenbaum PR. A characterization of optimal designs for observational studies. J R Statist Soc B (Methodological) 1991;53(3):597–610. [Google Scholar]
- Rosenbaum PR, Rubin DB. The central role of the propensity score in observational studies for causal effects. Biometrika. 1983;70(1):41–55. [Google Scholar]
- Rosenbaum PR, Rubin DB. Reducing bias in observational studies using subclassification on the propensity score. J Am Statist Ass. 1984;79(387):516–524. [Google Scholar]
- Rosenbaum PR, Rubin DB. Constructing a control group using multivariate matched sampling methods that incorporate the propensity score. The American Statistician. 1985;39(1):33–38. [Google Scholar]
- Rubin DB. The design versus the analysis of observational studies for causal effects: parallels with the design of randomized trials. Statist Med. 2007;26(1):20–36. doi: 10.1002/sim.2739. [DOI] [PubMed] [Google Scholar]
- Schennach S. Point estimation with exponentially tilted empirical likelihood. Ann Statist. 2007;35(2):634–672. [Google Scholar]
- Tan Z. Bounded, efficient and doubly robust estimation with inverse weighting. Biometrika. 2010;97(3):661–682. [Google Scholar]
- Tseng P, Bertsekas DP. Relaxation methods for problems with strictly convex separable costs and linear constraints. Mathematical Programming. 1987;38(3):303–321. [Google Scholar]
- Vansteelandt S, Bekaert M, Claeskens G. On model selection and model misspecification in causal inference. Statistical methods in medical research. 2012;21(1):7–30. doi: 10.1177/0962280210387717. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.