

Abstract
We propose a novel automated volumetric segmentation method to detect and quantify retinal fluid on optical coherence tomography (OCT). The fuzzy level set method was introduced for identifying the boundaries of fluid filled regions on B-scans (x and y-axes) and C-scans (z-axis). The boundaries identified from three types of scans were combined to generate a comprehensive volumetric segmentation of retinal fluid. Then, artefactual fluid regions were removed using morphological characteristics and by identifying vascular shadowing with OCT angiography obtained from the same scan. The accuracy of retinal fluid detection and quantification was evaluated on 10 eyes with diabetic macular edema. Automated segmentation had good agreement with manual segmentation qualitatively and quantitatively. The fluid map can be integrated with OCT angiogram for intuitive clinical evaluation.
OCIS codes: (110.4500) Optical coherence tomography, (100.0100) Image processing, (100.2960) Image analysis, (170.4470) Ophthalmology
1. Introduction
Diabetic retinopathy (DR) is a microvascular disease characterized by hyperpermeability, capillary occlusion, and neovascularization [1]. These pathophysiologic changes can lead to macular edema and proliferative diabetic retinopathy, which are responsible for most of the vision loss associated with this disease [2]. Therefore early detection and monitoring of these complications is important in preventing permanent visual impairment.
Optical coherence tomography (OCT) [3] is commonly used in clinical ophthalmology to detect diabetic macular edema (DME) and assess treatment response by mapping the total retinal thickness [4–10]. The retinal thickness correlates with vascular leakage, but can also paradoxically decrease due to ischemic atrophy, which happens not infrequently in the setting of DME. Retinal fluid volume, not retinal thickness, would be a more accurate indication of vascular permeability in DME.
Direct detection of retinal fluid has been performed qualitatively through laborious visual inspection of sequential OCT cross sections. Thus, an automated image processing algorithm that detects and quantifies retinal fluid would be necessary to make this practical in clinical settings. A few state-of-the-art algorithms [11–18] provided fluid segmentation methods on clinical two dimensional (2D) OCT images. These have been used to classify the fluid associated abnormalities based on extraordinary retinal layer texture and structure gradient in DME. To the best of our knowledge, no fully-automated algorithm capable of a generalized and robust application has been validated to identify fluid-filled regions in a three dimensional (3D) fashion.
In this paper, we present and validate an automated volumetric segmentation algorithm based on fuzzy level-set method [19] to identify and quantify retinal fluid, including intraretinal fluid (IRF) and subretinal fluid (SRF), on OCT structural images. Our proposed method uses OCT angiography volume scans [20–22], where structural OCT is simultaneously acquired. Finally, by registering the structural (fluid accumulation) and functional (blood flow) information into a single 3D volume, clinicians can intuitively evaluate pathological structures and microvascular dysfunction simultaneously.
2. Materials and method
2.1 Patient selection and data acquisition
Participants diagnosed with DME and varied levels of retinopathy severity were recruited from the Casey Eye Institute. An informed consent was obtained and the protocol was approved by the Institutional Review Board at the Oregon Health & Science University. The study was conducted in compliance with the Declaration of Helsinki.
Two volumetric data sets were collected from single eyes of participants with DME within a visit. All of the data was acquired using a commercial spectral domain OCT system (RTVue-XR; Optovue, Fremont, CA) with a center wavelength 840 nm, a full-width half-maximum bandwidth of 45 nm, and an axial scan rate of 70 kHz [23]. A single volumetric data set contained two volumetric raster scans covering a 3 × 3 mm area with a 2 mm depth. In the fast transverse scanning direction, 304 axial scans were sampled to obtain a single 3 mm B-scan. Two repeated B-scans were captured at a fixed position before proceeding to the next location. A total of 304 locations along a 3 mm distance in the slow transverse direction were sampled to form a 3D data cube. All 608 B-scans in each data cube were acquired in 2.9 seconds. Blood flow information was acquired using the split-spectrum amplitude-decorrelation (SSADA) between consecutive B-scans [23, 24]. The SSADA algorithm detected blood flow by calculating the signal amplitude-decorrelation between consecutive B-scans. OCT structural images were obtained by averaging two repeated B-scans. The structural and angiography data were generated simultaneously on each scan. For each volumetric data set, two volumetric raster scans, including one x-fast scan and one y-fast scan were registered and merged through an orthogonal registration algorithm [25]. The digital resolution is 10 × 10 × 3.0μm3/pixel.
One eye of sixteen DME participants was scanned. Ten eyes had retinal fluid in the macular scans based on clinician grading. These were used to test the automated algorithm.
2.2 Algorithm overview
Figure 1 summarizes the algorithm. A pre-processing step was first performed to prepare the tissue region for segmentation. Fluid segmentation using fuzzy level-set method followed. Finally, post-processing steps were applied to remove artifacts. The following three sections will describe the process in detail. The algorithm was implemented with custom software written in Matlab 2011a (Mathworks, Natick, MA) installed on a workstation with Intel(R) Xeon(R) CPU E3-1226 v3 @ 3.30GHz and 16.0 GB RAM.
Fig. 1.

Overview of the automated volumetric retinal fluid detection algorithm. ILM: inner limiting membrane, BM: Bruch’s membrane, IS/OS: junction of inner and outer photoreceptor segments.
2.3 Pre-processing
The retina was defined as the region between inner limiting membrane (ILM) and Bruch’s membrane (BM). Three dimensional structural OCT data (Fig. 2(A)) was flattened using ILM plane (Fig. 2(B)). The junction of inner and outer photoreceptor segments (IS/OS) defined the boundary between IRF and SRF.
Fig. 2.

(A) Original OCT structural volume. (B) OCT structural volume flattened according to the inner limiting membrane (ILM) boundary. B-scans (x and y-axes) and C-scans (z-axis) were indicated with red, green and blue, respectively.
All aforementioned layer boundaries were segmented by the directional graph search method (Fig. 3), published in [26]. Because of the tissue damage inherent to DME, automatic layer segmentation is likely to fail even with robust algorithms. By using the graph search based segmentation method, ILM and BM can be automatically detected with a high degree of precision (Fig. 3(A)), while IS/OS requires some manual intervention in the data with SRF (Fig. 3(B)).
Fig. 3.
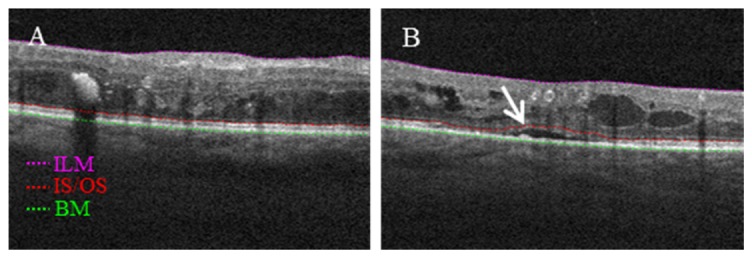
(A) An example B-frame showing inner limiting membrane (ILM), Bruch’s membrane (BM) and junction of inner and outer photoreceptor segments (IS/OS) boundaries used in this study can be automatically segmented. (B) An example B-frame with subretinal fluid showing IS/OS needs be manually corrected in the position pointed by a white arrow.
2.4 Retinal fluid segmentation
In this stage, a fuzzy level-set method, (combination of fuzzy C-means (FCM) and level set method) is implemented. Briefly, the intensity of retinal fluid is lower than retinal tissues, so fluid region can be clustered using FCM scored by probability. Then, the boundary of the retinal fluid can be detected by level-set method. Fuzzy level-set method is applied frame by frame on C-scans (z-axis) and B-scans (x and y-axes) to identify fluid filled regions (Fig. 2(B)). Therefore, three separate volumetric segmentation results are obtained. The synthetic candidates are combined by voting the three volumetric segmentation results for each voxel.
2.4.1 Fuzzy level-set method
Level-set methods are widely used in image segmentation [27–29], and has recently been applied to detect abnormality in OCT en face images [30]. Level-set method represents the boundary of interest in image I as contour ϕ = 0 (i.e. level-set curve), where the level-set function ϕ, is a function of time and spatial coordinates in I. ϕ was initialized with an estimate of the segmentation and evolves to get the accurate boundary. For example, in our implementation the evolution of ϕ was described by [19] and [31].
| (1) |
where δ is the Dirac function, div is the divergence operator, μ, λ, Rb are estimated based the FCM result.
The first term has two purposes. It smooths the level-set when ϕ is too steep (|Δϕ|>1) and also makes the level-set steeper when ϕ is too smooth (|Δϕ|<1). The second and the third term on the right hand side of Eq. (1) are responsible for driving the zero level curves towards the boundary of interest.
Typically, a Gaussian smoothing operator is used to calculate the boundary weight g [19, 31]. However, considering that the dominate noise in OCT images is the speckle noise [32], we used median operator M instead
| (2) |
The median operator suppresses the noise while maintaining the edge sharpness in OCT images.
A drawback of the traditional level-set method is that its performance is subject to optimal configuration of the controlling parameters (μ, λ and Rb) and appropriate initialization of ϕ (an estimate of the segmentation). This requires substantial manual intervention [19]. The fuzzy level-set based method achieves full automation by first obtaining a probabilistic clustering result using the FCM. This clustering information is then used to determine the initialization and controlling parameters.
On OCT structural images, retinal fluid has a low intensity value compared to the high intensity of surrounding retinal tissue. Based on this intensity contrast, FCM assigns every pixel a probability of belonging to both the fluid and tissue cluster, by minimizing a cost function
| (3) |
where K is a predetermined number of clusters, N is the number of pixels, pi,j is the probability of I(j) belong to the i-th cluster, m is a initialized parameter (m>1) (in this study, m = 2). C(i) is the center of mass of the i-th cluster, and the C of the low intensity cluster is initialized using the mean intensity of vitreous region (above the ILM, top dark area in Fig. 3(A)). The pi,j and C(i) was updated by Eq. (4) during the iteration of the segmentation process.
| (4) |
The probability map pi,j of the lowest intensity cluster (Fig. 4(B)) contains retinal fluid, vitreous, shadows of vessels, and other low intensity regions in or below retina. FCM results were used to initialize ϕ and calculate controlling parameters (μ, λ, Rb in Eq. (1)) for level-set evolution. (detailed implementation can be found in [19]).
Fig. 4.

(A) OCT structural B-scan (y-axis) image of a participant with severe macular edema. (B) Lowest intensity cluster generated by applying fuzzy C-means (FCM) on image (A). (C) Retinal fluid delineated by applying fuzzy level-set method on image (A).
The fuzzy level-set based segmentation method is fully-automated and self-adaptive for images with quality variation. In these DME cases, it detected retinal fluid boundaries (shown in red on the B-scan (y-axis) Fig. 4(C)) with few remaining artifacts, which were filtered out in the following steps.
2.4.2 Voting of cross-sectional segmentations
Each voxel at location ω = (x, y, z) has a segmentation result for each of the three cross-sectional orientations (SYZ, SXZ and SYZ). These segmentations vary among the orientations due to differences in image contrast and bulk motion artifacts (Fig. 5, the regions outlined by yellow). In order to improve segmentation accuracy, a voting rule was used to automatically determine the segmentation results for each voxel. If a voxel was identified as belonging to retinal fluid in at least two of the cross-sectional orientations, it was considered to be “true” retinal fluid; otherwise, it was considered as retinal tissue. An example shown in Fig. 5 indicates the segmentation errors are dramatically reduced in the integrated results.
Fig. 5.

Illustration of improving retinal fluid segmentation accuracy by voting of cross-sectional segmentations. (A1) (B1) and (C1) are the segmentation results obtained by applying the fuzzy level-set method on C-scan and two B-scans, respectively. (A2) (B2) and (C2) are the segmentation results represented on a C-scan extracted from (A1) (B1) and (C1). (A3) (B3) and (C3) show a zoomed in perspective of the yellow square region in (A2) (B2) and (C2). (D1) is the segmentation result after voting. (D2) shows a zoomed in perspective of the yellow square region in D1. It can be seen that D2 has much less error than (A3) (B3) and (C3).
2.5 Post-processing
Voting of the results on three cross-sectional orientations improved the accuracy of segmentation. However, some segmentation artifacts still remain (Fig. 5(D1)). Areas of retinal thickening or areas under vascular shadow have low intensity on OCT and can be misclassified as retinal fluid.
Morphological characteristics can distinguish retinal thickening from retinal fluid. Generally, retinal fluid appears as a near-round region with smooth boundaries on OCT cross sections, while retinal thickening has boundaries that change sharply (Fig. 6(A) and 6(B1), marked with white arrows). The smoothness of the boundary quantified by both the shape descriptor [33] and polar coordinates, in addition to the aspect ratio of the region, are all used to remove retinal thickening segmentation errors (Fig. 6(A), 6(B1) and 6(B2), marked with green arrows).
Fig. 6.

Structural OCT B-scan images overlaid with SSADA (blue) and retinal fluid segmentation results (outlined by red). (A) Before post-processing results where segmentation artifacts due to retinal thickening (white arrow, green arrow) and vascular shadow (purple arrow) can be seen in the square regions. (B1) and (B2) showed the zoomed in perspective of the yellow and blue square regions in A. (C) After post-processing image where artifacts contained in the square regions have been removed.
Shape descriptors were reflected by the contour inflexion points of the detected regions [31]. The contour C of the detected region was expressed using two parametric functions x(l) and y(l): C = (x(l), y(l)). where l is a normalized parameter ranging from [0, 1], which represents the length variable. Curvature in variation levels were computed using Eq. (5).
| (5) |
where, X(l, σ1) and Y(l, σ1) are smoothed curves using Gaussian filter g(l, σ1), X'(·) and X”(·) are first and second derivatives of length l, respectively, and similarly for Y'(·) and Y”(·). The zero-crossing of τ(l,σ1) indicates the curvature inflexion.
Since we express the curve in polar coordinates, the curve variation can also be reflected in a one-dimensional sequence, following
| (6) |
where (Xo, Yo) is the center of detected region. The inflexion of R(l,σ2) is another parameter to evaluate smoothness.
In our study, σ1 = 12, σ2 = 6 were used in Eqs. (5) and (6). Zero-crossings of τ(l,σ1) and inflexions of R(l,σ2) above the preset thresholds are identified as artifacts. Furthermore, the aspect ratio of the region, the ratio(r) between major axis and minor axis of the minimum enclosing ellipse, was also assessed.
Hemoglobin in perfused vessels absorbs and scatters the incident light of OCT and creates a vascular shadow. The SSADA angiogram, computed using the same OCT scan, can identify these blood vessels. By targeting the low intensity area associated with the vessels from the angiogram, we removed segmentation errors caused by vascular shadowing. Figure 6(A) and 6(B2) provide an example of how we removed the detected regions (indicated by purple arrows). This region can be differentiated as a segmentation error because the far left and far right points both fall within the vascular shadowing.
In the final step, the boundaries of volumetric detected regions were smoothed. We rejected the clutters with dimension smaller than 3 pixels on each axis. Therefore, the smallest fluid volume we can resolve is 30 × 30 × 9.0µm3.
2.6 Quantification and visualization
The fluid volumes were calculated as the product of the number of detected voxels and the voxels dimension (10 × 10 × 3.0μm3) in each scan. Fluid thickness maps were generated by calculating the product of the number of detected voxels and voxel size in each axial position. This was then projected on 2D en face maps. Fluid voxels above the IS/OS reference plane were classified as IRF and those below as SRF. This allowed separate volume calculations and thickness maps of IRF and SRF to be made.
Three-dimensional rendering of retinal fluid were constructed by 3D visualization module of ImageJ (1.49, http://imagej.nih.gov/ij/). This 3D rendering showing the retinal fluid (blue) and OCT angiogram (sepia) can be combined to visualize the retinal fluid in relation to vasculature. Here, en face OCT angiogram was created by projecting the maximum SSADA flow signals internal to BM boundary [20].
2.7 Verification of results
To evaluate the accuracy of the proposed method, we compared our segmentation results with ground truth which is the manually corrected segmentation results. An expert human grader manually corrected the boundaries detected by automated algorithm through the whole volumetric data set. The correction was done on the OCT orientation with the clearest fluid boundaries for contouring. During correction, the grader compared the structural OCT frames at all three orientations to make a grading decision, and use an editing tool incorporated in the same software interface to delineate the correct fluid boundary. The smallest fluid region that the editing tool could resolve was 9 pixels. In order not to introduce too much error during contouring, the regions smaller than this were neglected.
Jaccard similarity metric (J) [34] was used for comparison, which is defined as
| (7) |
where S is our automated segmentation results, G is the ground truth that is the manually corrected results based on S. The Jaccard coefficient ranges from 0 to 1, where 1 denotes the two were identical and 0 if they were completely different. Errors rates were also computed by comparison to ground truth. False positive error was the ratio of the total number of automatically segmented pixels that were not included in the manual segmentation result to the total number of ground truth pixels. False negative error was the ratio of the total number of manually segmented pixels that were not included in the automated segmentation result to the total number of ground truth pixels. Difference between the automated segmentation results and ground truth is described as the total number of false positive and false negative errors.
We also conducted the same evaluations described above on the fuzzy level-set algorithm using the fast-axis orientation. Paired Wilcoxon rank-sum tests were performed to compare the performance between our proposed algorithm using three different orientations and the simple 2D processing using one orientation only.
We assessed intra-visit repeatability of the proposed method using and intra-class correlation (ICC).
3. Results
The results from automated fuzzy level-set algorithm were compared with the results from manual correction (ground truth). Data from a single eye of 10 participants with DME were analyzed. The results from two representative cases were shown in Fig. 7 and Fig. 8. The first case (Fig. 7) has IRF only and shows the high image contrast between IRF and surrounding tissues. The second case carries both IRF and SRF, and also diffused retinal thickening. It represents a challenging case with low contrast between retinal fluid and thickening. The fuzzy level-set algorithm automatically outlined the boundary of fluid space. The algorithm required about 26 minutes of processing time on an Intel Xeon CPU (E3-1226, 3.3 GHz), of which 73% of the time was spent on the iteration of fuzzy level-set segmentation. Segmentation of each orientation required 6 minutes of processing time.
Fig. 7.

Segmentation results compared to ground truth. (A1) and (B1) are original images on C-scan and B-scan. (A2) and (B2) are segmentation results of our proposed method. (A3) and (B3) are ground truth delineated by human expert. Yellow arrows identify the false positive segmentation results corrected by an expert human grader.
Fig. 8.

Segmentation results compared ground truth in a case with both IRF and SRF. (A1) and (B1) are original images on C-scan and B-scan. (A2) and (B2) are segmentation results of our proposed method. (A3) and (B3) are ground truth delineated by human expert. Yellow arrows identify the false negative segmentation results corrected by an expert human grader. Green arrows identify the rejected regions by both automated algorithm and manual correction.
A qualitative comparison between both B-scans and C-scans shows a very small difference between the fuzzy level-set algorithm and expert grading. This difference is due to false positive segmentation where the boundaries between IRF spaces are indistinct (Fig. 7(B2)) and the retinal thickening cause extremely low intensity (Fig. 7(A2)). Some difference was due to false negative segmentation (Fig. 8(A2) and 8(B2)) where the real fluid detected region may be excluded in the step of removing clutters (see 2.5 post-processing). Fluid regions appearing as black holes on C-scans were infrequently missed by the manual grading. This is due to the indistinct size and boundary of small fluid regions (indicated by green arrows in Fig. 8).
Quantitatively, the proposed method agreed well with manual grading, which is significantly higher than the same processing using one orientation only (Tables 1 and 2). Repeatability of retinal fluid measurement was computed from the 2 sets of OCT scans obtained from each eye. The automated method has excellent repeatability as measured by ICC (0.976).
Table 1. The retinal fluid volumes detected by our proposed algorithm and ground truth.
| Case | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Fluid Volume (mm3) | Ground truth | 0.286 | 0.290 | 0.051 | 0.022 | 0.020 | 0.027 | 0.059 | 0.232 | 0.139 | 0.052 |
|
| |||||||||||
| Fuzzy level-set | 0.297 | 0.336 | 0.048 | 0.024 | 0.019 | 0.020 | 0.065 | 0.246 | 0.132 | 0.051 | |
|
| |||||||||||
| Differencea | 0.037 | 0.068 | 0.009 | 0.005 | 0.005 | 0.007 | 0.021 | 0.044 | 0.023 | 0.006 | |
a Difference is the total number of false positive and false negative errors
Table 2. Agreement between automated segmentation and ground truth.
| Our proposed method | Fuzzy level-set on fast-axis | P-valuea | |
|---|---|---|---|
| Jaccard similarity metric | 0.811 ± 0.052 | 0.724 ± 0.049 | 0.005 |
|
| |||
| False positive error | 0.092 ± 0.036 | 0.136 ± 0.461 | 0.005 |
|
| |||
| False negative error | 0.121 ± 0.061 | 0.232 ± 0.077 | 0.008 |
a P-values were based on paired Wilcoxon rank-sum test.
To visualize the segmented fluid spaces better, the thicknesses of IRF and SRF were projected separately on 2D map (Fig. 9(A) and 9(B)), and 3D volumetric fluid were rendered separately (Fig. 9(D) and 9(E)). The detected IRF in the case shown stays together in the same region, appearing in petaloid pattern. The detected SRF are shown as a large dome shape, which corresponds to the classical pattern. An en face composite map combining fluid volume map and angiogram presents the vasculature and the fluid cysts in an intuitive fashion and highlights the relationship between the vascular and anatomic changes in DR (Fig. 9(C) and 9(F)).
Fig. 9.

Quantification of volumetric spaces of retinal fluid. (A) Thickness maps of intraretinal fluid (IRF). (B) Thickness maps of subretinal fluid (SRF). (C) En face retinal OCT angiogram. (D) 3D rending of IRF volume. (E) 3D rending of SRF volume. (F) OCT angiogram overlaid with retinal fluid thickness map.
4. Discussion and conclusion
We developed an automated volumetric segmentation method to quantify retinal fluid (IRF and SRF) on OCT which involves three main steps: (1) segment and flatten retinal layers; (2) identify retinal fluid space using a fully automated and self-adaptive model (fuzzy level-set method) on OCT cross-sections from three orthogonal directions (two types of B-scans and C-scans); (3) remove remaining artifacts by identifying morphological characteristics and vascular shadowing. We showed that the proposed algorithm can detect and quantify the retinal fluid in DME eyes with a varied image contrasts. The fuzzy level-set algorithm agreed with expert human grading very well. Our technique offers a major advance in providing clinically valuable quantitative measurements of IRF and SRF.
The clinical relevance of IRF and SRF on OCT is well established. Resolution or stabilization of IRF and SRF was a main indicator of disease activity for the studies of DME, neovascular aged-related macular degeneration (AMD) and retinal vein occlusion [35–40]. Current OCT platforms provide retinal thickness and volume measurements, but the retinal fluid volume may be a more robust and accurate biomarker of disease activity compared to retinal thickness and volume. Numerous factors such as atrophy and fibrosis, in addition to vascular permeability, influence retinal volume. An automated segmentation technique that provides a quantitative measurement of retinal fluid could offer a more precise tool in the management of macular diseases with hyperpermeability.
Despite its clear applicability, automated detection of volumetric retinal fluid has been a poorly explored area. No commercial system offers this function, leaving the identification of fluid space to subjective assessment or manual delineation. Carera Fernandez [17] applied active contours (a gradient vector flow snake model) to extract fluid regions in retinal structure of AMD patients. This method is slow and requires substantial grader input, including initial boundary location estimation. Wilkins [41] described an approach for automated segmentation of retinal fluid on Cirrus OCT of cystoid macular edema. This method applies an empirical thresholding cutoff on the contrast enhance images by bilateral filtering, sparse details were presented on the assessment of the segmentation reliability. Chiu [16] recently presented a fully automated algorithm based on a kernel regression classification method to identify fluid-filled region in real world spectral domain OCT images of eyes with severe DME. However, this algorithm did not yet distinguish between intraretinal from subretinal fluid or focal from diffuse retinal thickening. All aforementioned algorithms were developed for 2D OCT images only. Quellec [13] and Chen [14] introduced an approach working on volumetric data set using prior information to classify the fluid associated abnormalities based on feature- and layer-specific properties in comparison with the normal appearance of macula. Unfortunately this method did not provide a clean measurement of fluid-filled space.
Compared to the previously reported methods using 2D images, our method makes full use of the volumetric information by operating detection on three directions. The voting process increases the accuracy of detecting true fluid voxels. The remaining false positives are rejected using morphological characteristics and OCT angiography.
There are several reasons leading to the use of level-set segmentation on 2D instead of 3D. First, the time cost of segmentation step using 2D algorithm is lower than 3D algorithm. This is because the complexity of 2D algorithm [O(n2)] is lower than 3D algorithm [O(n3)]. Second, the segmentation of each frame is independent; therefore, parallel computing could further shorten the processing time. Furthermore, the 2D algorithm can easily incorporate manual grading results, making the trouble-shooting easier compared to 3D approach.
In our proposed method, we removed the dependence on parameter tuning and the needs for initialization by using a rigorous classification algorithm. This classification assumes that the retinal fluid filled regions have similar reflectance to the vitreous region. The classification initialized by the intensity of vitreous avoids the process of data training for searching optimal parameters, so that it has a strong self-adaptive capacity. This is critical in applying the method to real world clinical situations where a wide variability of image quality and pathology exists. Due to its self-adaptive capability, this classification method would enable utilizing data sets acquired from multiple different clinical OCT systems. Although our method was developed on the OCT angiography scan pattern from a commercial spectral domain OCT (Optovue RTV-ue XR Avanti) it can be applied easily to other OCT devices that generates volumetric scans. The removal of vascular shadowing artifact can be modified by use of other criterion as described in [41].
In summary, this novel algorithm can automatically detect and quantify retinal fluid space accurately, offering an alternative and possibly more meaningful way to evaluate diabetic macular edema than total retinal thickness and volume.
Acknowledgments
This work was supported by NIH grants DP3 DK104397, R01 EY024544, R01 EY023285, P30-EY010572, NSFC (Grant No. 61471226), Natural Science Foundation for Distinguished Young Scholars of Shandong Province (Grant No. JQ201516) and unrestricted grant from Research to Prevent Blindness. Financial interests: Yali Jia has a significant financial interest in Optovue. This potential conflicts of interest have been reviewed and managed by Oregon Health & Science University. Yali Jia has potential patent interest in the subject of this article. Other authors do not have financial interest in the subject of this article.
References and links
- 1.Frank R. N., “Diabetic Retinopathy,” N. Engl. J. Med. 350(1), 48–58 (2004). 10.1056/NEJMra021678 [DOI] [PubMed] [Google Scholar]
- 2.Antonetti D. A., Klein R., Gardner T. W., “Diabetic Retinopathy,” N. Engl. J. Med. 366(13), 1227–1239 (2012). 10.1056/NEJMra1005073 [DOI] [PubMed] [Google Scholar]
- 3.Huang D., Swanson E. A., Lin C. P., Schuman J. S., Stinson W. G., Chang W., Hee M. R., Flotte T., Gregory K., Puliafito C. A., Fujimoto J., “Optical coherence tomography,” Science 254(5035), 1178–1181 (1991). 10.1126/science.1957169 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Hee M. R., Puliafito C. A., Duker J. S., Reichel E., Coker J. G., Wilkins J. R., Schuman J. S., Swanson E. A., Fujimoto J. G., “Topography of diabetic macular edema with optical coherence tomography,” Ophthalmology 105(2), 360–370 (1998). 10.1016/S0161-6420(98)93601-6 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Sadda S. R., Tan O., Walsh A. C., Schuman J. S., Varma R., Huang D., “Automated detection of clinically significant macular edema by grid scanning optical coherence tomography,” Ophthalmology 113(7), 1187 (2006). 10.1016/j.ophtha.2005.12.020 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Browning D. J., Glassman A. R., Aiello L. P., Beck R. W., Brown D. M., Fong D. S., Bressler N. M., Danis R. P., Kinyoun J. L., Nguyen Q. D., Bhavsar A. R., Gottlieb J., Pieramici D. J., Rauser M. E., Apte R. S., Lim J. I., Miskala P. H., Diabetic Retinopathy Clinical Research Network , “Relationship between optical coherence tomography-measured central retinal thickness and visual acuity in diabetic macular edema,” Ophthalmology 114(3), 525–536 (2007). 10.1016/j.ophtha.2006.06.052 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Lammer J., Scholda C., Prünte C., Benesch T., Schmidt-Erfurth U., Bolz M., “Retinal thickness and volume measurements in diabetic macular edema: a comparison of four optical coherence tomography systems,” Retina 31(1), 48–55 (2011). 10.1016/j.ophtha.2006.06.052 [DOI] [PubMed] [Google Scholar]
- 8.Krzystolik M. G., Strauber S. F., Aiello L. P., Beck R. W., Berger B. B., Bressler N. M., Browning D. J., Chambers R. B., Danis R. P., Davis M. D., Glassman A. R., Gonzalez V. H., Greenberg P. B., Gross J. G., Kim J. E., Kollman C., Diabetic Retinopathy Clinical Research Network , “Reproducibility of macular thickness and volume using Zeiss optical coherence tomography in patients with diabetic macular edema,” Ophthalmology 114(8), 1520–1525 (2007). 10.1016/j.ophtha.2006.10.055 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Yannuzzi L. A., Ober M. D., Slakter J. S., Spaide R. F., Fisher Y. L., Flower R. W., Rosen R., “Ophthalmic fundus imaging: today and beyond,” Am. J. Ophthalmol. 137(3), 511–524 (2004). 10.1016/j.ajo.2003.12.035 [DOI] [PubMed] [Google Scholar]
- 10.Regatieri C. V., Branchini L., Carmody J., Fujimoto J. G., Duker J. S., “Choroidal thickness in patients with diabetic retinopathy analyzed by spectral-domain optical coherence tomography,” Retina 32(3), 563–568 (2012). 10.1097/IAE.0B013E31822F5678 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Mimouni M., Nahum Y., Levant A., Levant B., Weinberger D., “Cystoid macular edema: a correlation between macular volumetric parameters and visual acuity,” Can. J. Ophthalmol. 49(2), 183–187 (2014). 10.1016/j.jcjo.2013.11.004 [DOI] [PubMed] [Google Scholar]
- 12.Beausencourt E., Remky A., Elsner A. E., Hartnett M. E., Trempe C. L., “Infrared scanning laser tomography of macular cysts,” Ophthalmology 107(2), 375–385 (2000). 10.1016/S0161-6420(99)00056-1 [DOI] [PubMed] [Google Scholar]
- 13.Quellec G., Lee K., Dolejsi M., Garvin M. K., Abràmoff M. D., Sonka M., “Three-dimensional analysis of retinal layer texture: identification of fluid-filled regions in SD-OCT of the macula,” IEEE Trans. Med. Imaging 29(6), 1321–1330 (2010). 10.1109/TMI.2010.2047023 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Chen X., Niemeijer M., Zhang L., Lee K., Abràmoff M. D., Sonka M., “Three-dimensional segmentation of fluid-associated abnormalities in retinal OCT: probability constrained graph-search-graph-cut,” IEEE Trans. Med. Imaging 31(8), 1521–1531 (2012). 10.1109/TMI.2012.2191302 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Lang A., Carass A., Swingle E. K., Al-Louzi O., Bhargava P., Saidha S., Ying H. S., Calabresi P. A., Prince J. L., “Automatic segmentation of microcystic macular edema in OCT,” Biomed. Opt. Express 6(1), 155–169 (2015). 10.1364/BOE.6.000155 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Chiu S. J., Allingham M. J., Mettu P. S., Cousins S. W., Izatt J. A., Farsiu S., “Kernel regression based segmentation of optical coherence tomography images with diabetic macular edema,” Biomed. Opt. Express 6(4), 1172–1194 (2015). 10.1364/BOE.6.001172 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Fernández D. C., “Delineating fluid-filled region boundaries in optical coherence tomography images of the retina,” IEEE Trans. Med. Imaging 24(8), 929–945 (2005). 10.1109/TMI.2005.848655 [DOI] [PubMed] [Google Scholar]
- 18.Zheng Y., Sahni J., Campa C., Stangos A. N., Raj A., Harding S. P., “Computerized assessment of intraretinal and subretinal fluid regions in spectral-domain optical coherence tomography images of the retina,” Am. J. Ophthalmol. 155(2), 277–286 (2013). 10.1016/j.ajo.2012.07.030 [DOI] [PubMed] [Google Scholar]
- 19.Li B. N., Chui C. K., Chang S., Ong S. H., “Integrating spatial fuzzy clustering with level set methods for automated medical image segmentation,” Comput. Biol. Med. 41(1), 1–10 (2011). 10.1016/j.compbiomed.2010.10.007 [DOI] [PubMed] [Google Scholar]
- 20.Jia Y., Bailey S. T., Hwang T. S., McClintic S. M., Gao S. S., Pennesi M. E., Flaxel C. J., Lauer A. K., Wilson D. J., Hornegger J., Fujimoto J. G., Huang D., “Quantitative optical coherence tomography angiography of vascular abnormalities in the living human eye,” Proc. Natl. Acad. Sci. U.S.A. 112(18), E2395–E2402 (2015). 10.1073/pnas.1500185112 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Hwang T. S., Jia Y., Gao S. S., Bailey S. T., Lauer A. K., Flaxel C. J., Wilson D. J., Huang D., “Optical Coherence Tomography Angiography Features of Diabetic Retinopathy,” Retina 35(11), 2371–2376 (2015). 10.1097/IAE.0000000000000716 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Hwang T. S., Gao S. S., Liu L., Lauer A. K., Bailey S. T., Flaxel C. J., Wilson D. J., Huang D., Jia Y., “Automated quantification of capillary nonperfusion using optical coherence tomography angiography in diabetic retinopathy,” JAMA Ophthalmol. 5658, 1–7 (2016). 10.1001/jamaophthalmol.2015.5658 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Gao S. S., Liu G., Huang D., Jia Y., “Optimization of the split-spectrum amplitude-decorrelation angiography algorithm on a spectral optical coherence tomography system,” Opt. Lett. 40(10), 2305–2308 (2015). 10.1364/OL.40.002305 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Jia Y., Tan O., Tokayer J., Potsaid B., Wang Y., Liu J. J., Kraus M. F., Subhash H., Fujimoto J. G., Hornegger J., Huang D., “Split-spectrum amplitude-decorrelation angiography with optical coherence tomography,” Opt. Express 20(4), 4710–4725 (2012). 10.1364/OE.20.004710 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Kraus M. F., Potsaid B., Mayer M. A., Bock R., Baumann B., Liu J. J., Hornegger J., Fujimoto J. G., “Motion correction in optical coherence tomography volumes on a per A-scan basis using orthogonal scan patterns,” Biomed. Opt. Express 3(6), 1182–1199 (2012). 10.1364/BOE.3.001182 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Zhang M., Wang J., Pechauer A. D., Hwang T. S., Gao S. S., Liu L., Liu L., Bailey S. T., Wilson D. J., Huang D., Jia Y., “Advanced image processing for optical coherence tomographic angiography of macular diseases,” Biomed. Opt. Express 6(12), 4661–4675 (2015). 10.1364/BOE.6.004661 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Chan T. F., Vese L. A., “Active contours without edges,” IEEE Trans. Image Process. 10(2), 266–277 (2001). 10.1109/83.902291 [DOI] [PubMed] [Google Scholar]
- 28.Cremers D., Rousson M., Deriche R., “A review of statistical approaches to level set segmentation: integrating color, texture, motion and shape,” Int. J. Comput. Vis. 72(2), 195–215 (2007). 10.1007/s11263-006-8711-1 [DOI] [Google Scholar]
- 29.Min H., Jia W., Wang X. F., Zhao Y., Hu R. X., Luo Y. T., Xue F., Lu J. T., “An Intensity-Texture model based level set method for image segmentation,” Pattern Recognit. 48(4), 1547–1558 (2015). 10.1016/j.patcog.2014.10.018 [DOI] [Google Scholar]
- 30.Mohammad F., Ansari R., Wanek J., Francis A., Shahidi M., “Feasibility of level-set analysis of enface OCT retinal images in diabetic retinopathy,” Biomed. Opt. Express 6(5), 1904–1918 (2015). 10.1364/BOE.6.001904 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.C. Li, C. Xu, C. Gui, and M. D. Fox, “Level set evolution without re-initialization: a new variational formulation,” in Computer Vision and Pattern Recognition, 2005. CVPR 2005. IEEE Computer Society Conference on (IEEE, 2005), pp.430–436. [Google Scholar]
- 32.Szkulmowski M., Gorczynska I., Szlag D., Sylwestrzak M., Kowalczyk A., Wojtkowski M., “Efficient reduction of speckle noise in Optical Coherence Tomography,” Opt. Express 20(2), 1337–1359 (2012). 10.1364/OE.20.001337 [DOI] [PubMed] [Google Scholar]
- 33.Mokhtarian F., Mackworth A., “Scale-based description and recognition of planar curves and two-dimensional shapes,” IEEE Trans. Pattern Anal. Mach. Intell. 8(1), 34–43 (1986). 10.1109/TPAMI.1986.4767750 [DOI] [PubMed] [Google Scholar]
- 34.Liu L., Gao S. S., Bailey S. T., Huang D., Li D., Jia Y., “Automated choroidal neovascularization detection algorithm for optical coherence tomography angiography,” Biomed. Opt. Express 6(9), 3564–3576 (2015). 10.1364/BOE.6.003564 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Massin P., Duguid G., Erginay A., Haouchine B., Gaudric A., “Optical coherence tomography for evaluating diabetic macular edema before and after vitrectomy,” Am. J. Ophthalmol. 135(2), 169–177 (2003). 10.1016/S0002-9394(02)01837-8 [DOI] [PubMed] [Google Scholar]
- 36.Otani T., Kishi S., Maruyama Y., “Patterns of diabetic macular edema with optical coherence tomography,” Am. J. Ophthalmol. 127(6), 688–693 (1999). 10.1016/S0002-9394(99)00033-1 [DOI] [PubMed] [Google Scholar]
- 37.Eriksson U., Alm A., Bjärnhall G., Granstam E., Matsson A. W., “Macular edema and visual outcome following cataract surgery in patients with diabetic retinopathy and controls,” Graefes Arch. Clin. Exp. Ophthalmol. 249(3), 349–359 (2011). 10.1007/s00417-010-1484-9 [DOI] [PubMed] [Google Scholar]
- 38.Weiss J. N., Bynoe L. A., “Injection of tissue plasminogen activator into a branch retinal vein in eyes with central retinal vein occlusion,” Ophthalmology 108(12), 2249–2257 (2001). 10.1016/S0161-6420(01)00875-2 [DOI] [PubMed] [Google Scholar]
- 39.Wang M., Munch I. C., Hasler P. W., Prünte C., Larsen M., “Central serous chorioretinopathy,” Acta Ophthalmol. 86(2), 126–145 (2008). 10.1111/j.1600-0420.2007.00889.x [DOI] [PubMed] [Google Scholar]
- 40.Dugel P. U., Rao N. A., Ozler S., Liggett P. E., Smith R. E., “Pars Plana Vitrectomy for Intraocular Inflammation-related Cystoid Macular Edema Unresponsive to Corticosteroids. A preliminary Study,” Ophthalmology 99(10), 1535–1541 (1992). 10.1016/S0161-6420(92)31769-5 [DOI] [PubMed] [Google Scholar]
- 41.Wilkins G. R., Houghton O. M., Oldenburg A. L., “Automated segmentation of intraretinal cystoid fluid in optical coherence tomography,” IEEE Trans. Biomed. Eng. 59(4), 1109–1114 (2012). 10.1109/TBME.2012.2184759 [DOI] [PMC free article] [PubMed] [Google Scholar]