

Abstract
Copula modelling has in the past decade become a standard tool in many areas of applied statistics. However, a largely neglected aspect concerns the design of related experiments. Particularly the issue of whether the estimation of copula parameters can be enhanced by optimizing experimental conditions and how robust all the parameter estimates for the model are with respect to the type of copula employed. In this paper an equivalence theorem for (bivariate) copula models is provided that allows formulation of efficient design algorithms and quick checks of whether designs are optimal or at least efficient. Some examples illustrate that in practical situations considerable gains in design efficiency can be achieved. A natural comparison between different copula models with respect to design efficiency is provided as well.
Keywords: copulas, design measure, Fisher information, stochastic dependence, clinical trials
AMS Subject Classification: 62K05
1. Introduction
Due to their flexibility in describing dependencies and the possibility of separating marginal and joint effects copula models have become a popular device for coping with multivariate data. in many areas of applied statistics eg. for insurances,[1] econometrics,[2] medicine,[3] marketing,[4] spatial extreme events,[5] time series analysis,[6] even sports [7] and particularly in finance.[8]
The concept of copulas, however, has only been rarely employed in experimental design with notable exceptions of spatial design in [9,10], and sequential trials in [11]. The design question for copula parameter estimation has to our knowledge just been raised in [12], where a brute-force simulated annealing optimization was employed for the solution of a specific problem. By this paper we provide the necessary theory for fully embedding the situation into optimal design theory. Particularly we provide a Kiefer–Wolfowitz type equivalence theorem [13] in Section 5 as a basis for a substantial analysis of the arising issues in the example sections.
To be more concrete, let us consider a vector of control variables, where is a compact set. The results of the observations and of the expectations in a regression experiments are the vectors:
where is a certain unknown vector of marginal parameters to be estimated and are known functions. Let us call the marginal cumulative distributions of each for all and the joint probability density function of the random vector , where are unknown (copula) parameters. In the remainder of the paper we will focus on the case , but generalizations of our results are possible.
Definition 2.
Let . A two-dimensional copula (or 2-copula) is a bivariate function with the following properties:
(1)
Now let be a joint cumulative distribution function (cdf) with marginal cdfs and . According to Sklar's theorem [14] there exists then a 2-copula C such that
| (2) |
for all reals , . If and are continuous, then C is unique; otherwise, C is uniquely defined on . Conversely, if C is a 2-copula and and are distribution functions, then the function given by Equation (2) is a joint distribution with marginals and .
2. Design issues
We need to quantify the amount of information on both (trend and copula) sets of parameters α and β respectively from the regression experiment embodied in the Fisher information matrix, which for an elemental information at a particular control x in the sense of Atkinson et al. [15] is a matrix defined as
| (3) |
where the submatrix is the matrix with the th element defined as
| (4) |
and the submatrices and are defined accordingly. Here we model the dependence between and with a copula function and find the joint density of the random variables from
Definition 4.
For a concrete (discrete) experiment with N independent observations at support points the corresponding total information matrix is
with so-called design weights .
The aim of approximate optimal design theory is concerned with finding an optimal design measure , such that it maximizes some scalar function , the so-called design criterion. In the following we will consider only D-optimality, that is, the criterion , if M is non-singular. There exist several well written monographs on optimal design theory and its application, but in this paper we follow mainly the style and notation of Silvey.[16]
3. Equivalence theory
The cornerstone of a theoretical investigation into optimal design is usually the formulation of a Kiefer–Wolfowitz type equivalence relation, which is given in the following theorem. It is a generalized version of a theorem given without proof in [17] and follows from a multivariate version of the basic theorem given in [16], its full proof can be found in the Appendix.
Theorem 3.1.
Denote by fixed values (local guesses) for the parameter vector. Then, the following properties are equivalent:
is D-optimal;
minimize over all .
This theorem provides simple checks for D-optimality through the maxima of
which is usually called sensitivity function. It also allows us the use of standard design algorithms such as of the Fedorov-Wynn-type,[18,19] which will yield an optimal approximate design .
Note that these resulting optimal designs will now depend not only upon the marginal model structure, but also upon the chosen copula and through the induced nonlinearities potentially also on the unknown parameter values for α and β, which is why we are resorting to localized designs around the values . A sensitivity analysis with respect to the effect of these choice on a particular example can be found in [20].
Definition 6.
For the comparison of designs define D-Efficiency of the design ξ with respect to the design as the ratio
(5) where is the number of the model parameters. We will report all our findings in percentage losses of these D-efficiencies.
4. Examples
A main question now of course concerns whether ignorance or wrong guesses of copula function and/or parameters may lead to inefficiencies of the designs.
4.1. Tools
For that purpose let us here give the list of copulas used in our examples (for more details see, eg. [21] or [22]). We provide the copula function along with the so-called Kendall's τ, which is a dependence measure that allows us to conveniently relate different copulas (for a definition and a more exhaustive comparison see [23]).
Definition 8.
with .
with and .
with and .
with and .
with and .
with and .
4.2. The linear case
Let us first consider a simple example reported in [18]. For each design point , we may observe an independent pair of random variables and , such that
which is linear in β and has dependence described by the product copula with Gaussian margins. Since this case is covered by Theorem 1, we were able to compute the optimal design by a standard algorithm and we display it in Figure 1 along with its sensitivity function. As rather typical is supported on only a small number (here four) of design points, smaller than the number of parameters. From the sensitivity function we can see that it is indeed optimum as it reaches (and not exceeds) the number of parameters at all design points. Furthermore our optimal design coincides with the one reported in [18], namely
| (6) |
Figure 1.
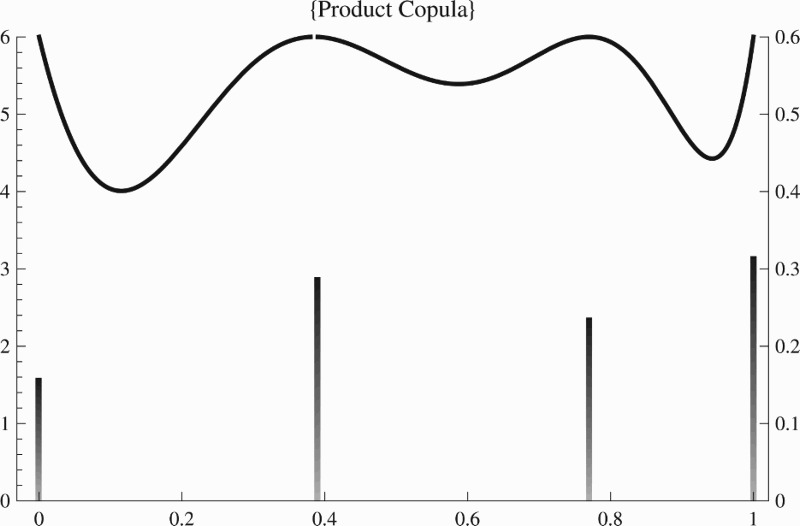
Sensitivity function (left axis) and optimal design (right axis) for the Fedorov example.
Let us consider a more general case, for which the joint distribution is described by a Gaussian copula and we thus allow the random variables and to be dependent. In this case the joint probability function of the random vector is simply
| (7) |
where denotes the bivariate normal cdf with correlation and Φ denotes the cdf of the standard normal distribution (see [24]).
Our computations gave rise to the following
Corollary 4.2
For different values of α the optimal design is the same as for the independence case, which is the Gaussian case with .
Note, that the sensitivity function now has a different scaling (with a maximum at 7) as we have an additional copula parameter. This corollary, however, is hardly surprising as this fact coincides with the classic findings for the multivariate Gaussian distribution by Krafft and Schaefer.[25]
But now for a contrast consider the FGM copula. Following our approach, we must calculate the density corresponding to the function:
which eventually leads to expressions like
for the information matrix. These integrals are not analytically solvable, but we can evaluate them numerically and we can use the algorithm in order to find the optimum designs.
Not surprisingly those optimal designs do depend upon the choice of (i.e. the assumed dependence) – and similar calculations can be performed for other copula functions as well. Some results are subsumed in Table 1, which displays the loss in D-efficiency that occurs by using the optimal design from Equation (6) compared to the respective optimal designs for various copula models and Kendall's τ. It can be seen that these losses are generally quite small for all considered copulas.
Table 1. Losses in D-efficiency (in bold) by ignoring the dependence in per cent.
| FGM | Clayton | Frank | ||||
|---|---|---|---|---|---|---|
| τ | D-eff | D-eff | D-eff | |||
| 0.29 | n.d. | – | −1.37 | 0.10 | ||
| 0.23 | n.d. | – | −0.90 | 0.10 | ||
| 0.59 | n.d. | – | −0.45 | 0.10 | ||
| 0.68 | 0.10 | 0.16 | 0.45 | 0.10 | ||
| 0.39 | 0.22 | 0.13 | 0.90 | 0.10 | ||
| 0.28 | 0.35 | 0.34 | 1.37 | 0.10 | ||
| n.d. | – | 1.08 | 0.11 | 3.51 | 0.11 | |
| n.d. | – | 6.00 | 0.27 | 14.13 | 0.16 | |
4.3. A binary bivariate model
In order to better investigate the role of the copula parameter, we analyse a more elaborate example with potential applications in clinical trials. Let us formally introduce the model. We consider a bivariate binary response , with four possible outcomes where 1 usually represents a success and 0 a failure (of eg. a drug treatment). For a single observation denote the joint probabilities of and by for . In a clinical trial context and could represent efficacy and toxicity of a tested drug.
Now, define
| (8) |
The complete log-likelihood for the bivariate binary model is then given by
| (9) |
where and are the parameters associated with the respective margins and the log-likelihood for a single observation is given by
| (10) |
As shown in [26] the Fisher information matrix for a single observation can then be written as
| (11) |
where , and . Some useful formulae for calculating information matrices in copula models can also be found in [27].
A particular case of the introduced model has already been analysed in [17]. In that work, the authors assume the marginal probabilities of success given by the models
| (12) |
with and ‘localized’ parameters and . The considered joint cdf is the Gumbel cdf, which corresponds to the following choice for the probability of success :
that is, in terms of copulas, the FGM copula.
In [17], the choice of this model is highlighted by arguing that it allows for dependence between efficacy and toxicity and it is claimed that including estimation of α rather then independently analysing efficacy and toxicity is preferable. We reanalyse this example studying both the role of the copula parameter and the impact of a particular type of dependence structure on the D-optimal designs obtained.
To get a clearer idea of the role played by the copula parameter, let us first focus on the benchmark case of independence, described both by the Product copula and the FGM copula with . However, using these two copulas has substantially different interpretation and effect. In the one case (Product copula) we completely ignore potential dependence, whereas in the other case (FGM copula) we allow for its estimation, but assume it inexistent.
In a second step, to examine the impact of the dependence structure, we compare the model analysed in [17] with the more general ones proposed in [12]. Those have the same assumptions on the marginals probabilities as in [17], as well as same design space and initial parameter for the betas, but the dependencies are instead represented by using the copulas Frank, Gumbel, and Clayton. Note that in [12] the authors employed a brute-force simulated annealing algorithm for their calculations and had no means for checking definitive optimality, which is now possible through the equivalence theorem (Theorem 5.1) provided.
Now, using the D-optimal designs for the FGM copula and for the Product copula as benchmarks, we note the losses in D-efficiency in per cent as reported respectively in Table 2 (Product copula) and in Table 3 (FGM). In both cases, the losses are much stronger than in the previous example.
Table 2. Losses in D-efficiency (in bold) by ignoring the dependence in per cent (product copula).
| Frank | Clayton | Gumbel | ||||
|---|---|---|---|---|---|---|
| τ | D-eff | D-eff | D-eff | |||
| 1.00 | 1.72 | 0.24 | 1.75 | 1.12 | 0.95 | |
| 5.00 | 1.31 | 1.68 | 1.49 | 1.84 | 1.29 | |
| 10.00 | 1.87 | 3.98 | 0.71 | 3.00 | 2.31 | |
| 15.00 | 2.89 | 6.42 | 2.84 | 4.21 | 2.99 | |
| 20.00 | 3.10 | 8.89 | 9.48 | 5.45 | 3.25 | |
Table 3. Losses in D-efficiency (in bold) in per cent with respect to the FGM copula ().
| Frank | Clayton | Gumbel | ||||
|---|---|---|---|---|---|---|
| τ | D-eff | D-eff | D-eff | |||
| 1.00 | 0.01 | 0.24 | 2.42 | 1.12 | 0.87 | |
| 5.00 | 0.36 | 1.68 | 1.13 | 1.84 | 0.5 | |
| 10.00 | 3.18 | 3.98 | 1.34 | 3.00 | 2.84 | |
| 15.00 | 5.63 | 6.42 | 5.54 | 4.21 | 5.13 | |
| 20.00 | 6.24 | 8.89 | 13.94 | 5.45 | 6.12 | |
Analysing these results by focusing on the Frank and the Gumbel copulas, one can notice that lower losses in Table 3 correspond to the lower values of τ. Conversely, the losses already become much higher in Table 3 for a moderate level of the association τ. Moreover, looking at the results for the Clayton copula, we even have lower losses by ignoring the dependence for almost all the levels of the association τ. This suggests, at first glance, that it is not generally preferable to insert a dependence parameter to be estimated, since this might increase the losses when the model is chosen badly.
Interestingly, if the copula parameter is not estimated, that is, if the model is just a four parameter model, the optimal designs found are almost the same for all the investigated copulas, and can be represented by
Evidently, the structure of the dependence has an impact as soon as its parameter requires estimation. In Figure 2 we display the designs and sensitivity functions for a representative case contrasting the very different optimal designs for a Clayton and a Gumbel copula with identical Kendall's τ. It will therefore be of great practical value to compare different copulas with respect to their optimal design properties (as well as eventually to be able to efficiently discriminate between them).
Figure 2.
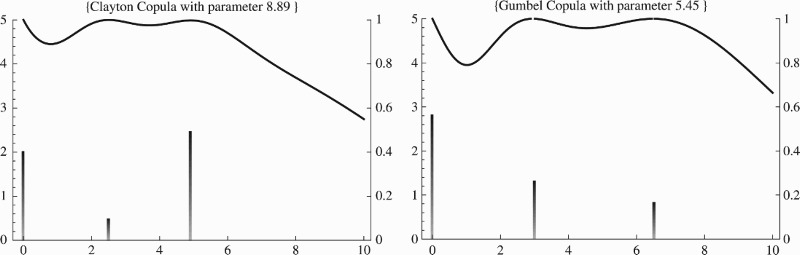
The optimal designs and the sensitivity functions for the binary example (Clayton left, Gumbel right). The copula parameters chosen correspond to Kendall's .
A first such step of comparing different copula models was taken in [12] where the authors evaluate designs for various copula choices against each other (in their Table 8). However, they have been using the same parameter values for all the copulas without considering the different meaning of the copula parameter for various copula families. Therefore, we instead provide in Table 4 an improved comparison between different dependence structures along the same Kendall's τ values by exploiting the relationship between the copula parameter to the measure of concordance τ. Thanks to this comparison, now the pure impact of the choice of the copula is highlighted. It turns out, that even in extreme case the efficiency losses are only small to moderate. They are greatest if Frank or Gumbel are used instead of Clayton, which may be explained by their opposing representations of tail dependencies.
Table 4. Losses in D-efficiency (in bold) by comparing the true copula model with the assumed one for a fixed Kendall's τ.
| True Copula | Frank | Clayton | Gumbel | |||
|---|---|---|---|---|---|---|
| Assumed Copula | Clayton | Gumbel | Frank | Gumbel | Frank | Clayton |
| 2.24 | 0.67 | 1.99 | 2.70 | 0.82 | 2.75 | |
| 0.26 | 0.03 | 0.26 | 0.11 | 0.03 | 0.15 | |
| 1.09 | 0.11 | 1.04 | 1.28 | 0.14 | 1.57 | |
| 4.27 | 0.02 | 3.87 | 4.08 | 0.01 | 4.73 | |
| 8.24 | 0.01 | 10.91 | 10.96 | 0.01 | 8.43 | |
4.4. A more flexible model
Let us now allow the strength of the dependence itself be dependent upon the regressors x, a situation completely covered by our equivalence theorem. Thus here the copula parameters themselves become model-dependent such as, for example, in [28]. As in our context only positive associations (between efficacy and toxicity) make sense we consider in the following the τ modelled by a logistic:
| (13) |
which takes values in for .
Considering the Archimedian copulas Clayton and Gumbel , the following relationships between the Kendall's τ and the copula parameters hold:
Then, we model the current probability of success by a convex combination of the Clayton and the Gumbel copulas
and when we link them at the same τ values we end up with
The added flexibility of such a model is that the impact of the dependence structure and the association level is reflected by two different parameters. While the parameter is strictly related to the structure of the dependence, the parameter is only related to the measure of association Kendall's τ.
In Table 5 we report the efficiency losses with respect to the independence case (Product Copula). By fixing three localized values , we assume three different intervals for τ. Corresponding to these intervals we fixed four localized values . From the table it is clear that when the range of the τ increases, the losses in terms of D-efficiency can become quite substantial. By focusing on the various localized values for , it is evident that also the structure of the dependence plays a big role in the design obtained. Here, we can see that when the highest weight in the convex combination is on the Clayton copula, the efficiency losses are lowest.
Table 5. Losses in D-efficiency for the convex combination model in per cent (in bold).
| Loss in D-eff. | Loss in D-eff. | Loss in D-eff. | |
| 11.15 | 31.97 | 47.22 | |
| 6.51 | 25.11 | 40.33 | |
| 2.50 | 17.20 | 32.27 | |
| 1.11 | 10.90 | 24.96 |
5. Discussion
In general, our theory forms the basis to investigate further showcase examples from the literature, like, for example, in [29] or eventually treat mixed discrete/continuous type models like in [30]. Particularly for the latter, but also quite generally the methods provided in this paper can thus be expected to be valuable for real applications from clinical trials, environmental sampling, industrial experiments, etc.
Although here we provide only examples on limited types of copulas, we might expect similar or greater effects for some more non-symmetric copulae (see eg. [31]), which are subject to our current investigations.
Note that in the convex combination example by focusing on we could find designs with the sole purpose of efficiently discriminating between different copula models, which we plan to do future research on.
Acknowledgements
We thank F. Durante, M. Stehlík, L. Pronzato, J. Rendas and E.P. Klement for fruitful discussions and a referee for constructive remarks.
Appendix
Equivalence theorem
For all the basics in what follows cf.[16] For a given vector of parameters , let be the set of the information matrices generated as ξ ranges over the class of all set of probability distribution on . Then is the convex hull of .
Let us now recall the definition of two derivatives that will play an important role in our theory.
Definition A ((Gâteaux and Fréchet derivative)).
Considering two elements and in the Gâteaux derivative of φ at in the direction of is:
the Fréchet derivative of φ at in the direction of is:
The following are the properties of the derivatives that we defined before: the concavity of φ implies that
is a non-increasing function of ϵ in . Hence when φ is concave, exists if we allow the value .
It is clear that if we put in the previous equation, we obtain: .
According to the definitions of Fréchet and Gâteaux derivatives, we can stress the following relationship between them: . Then, if we assume the differentiability of φ it is clear that for scalars
Theorem A.2.
Suppose to have a fixed parameters vector a concave function φ on which is also differentiable at all points of where so where a φ optimal measure exists.
Then the following are equivalent:
is φ-optimal;
.
Proof.
Let us prove the theorem by double implications.
is φ-optimal. This means that is maximal.
For the properties of the function φ, the following relation holds:for and all .
and this means, from the definition of the Fréchet derivative, that
for all .
Since are elements of the convex hull , the condition (iii) follows directly from the hypothesis.
But, according to the hypothesis, we have that for the design
Hence
that means that , . According to the definition of the matrices , any M can be written as , where and for every .
for every .
for every , then is φ-optimal.
D-optimality
Let consider now as design criterion the following function:
A design that maximizes such a φ function is called D-optimal design.
In the case of D-optimality the Fréchet and the Gâteaux derivatives have the following expression:
Gâteaux derivative
Hence, .
Fréchet derivative
where is the number of the model parameters.
We are ready now to give an equivalence theorem which holds in the particular case of the D-criterion.
Theorem A.3.
For a fixed parameters vector the following properties are equivalent:
is D-optimal;
minimize over all .
Proof.
The proof comes directly from the Theorem A.1 by imputing the Fréchet derivative for the D-criterion.
Funding Statement
This work has been supported by the project ANR-2011-IS01-001-01 ‘DESIRE’ and Austrian Science Fund (FWF) I 833-N18.
Disclosure statement
No potential conflict of interest was reported by the authors.
ORCID
W.G. Müller http://orcid.org/0000-0002-3564-766X
References
- Valdez EA. Understanding relationships using copulas. N Am Actuar J. 1998;2(1):1–25. [Google Scholar]
- Trivedi PK, Zimmer DM. Copula modeling: an introduction for practitioners. Found Trends Econ. 2006;1(1):1–111. [Google Scholar]
- Nikoloulopoulos AK, Karlis D. Multivariate logit copula model with an application to dental data. Stat Med. 2008;27(30):6393–6406. doi: 10.1002/sim.3449. [DOI] [PubMed] [Google Scholar]
- Danaher PJ, Smith MS. Modeling multivariate distributions using copulas: applications in marketing. Mark Sci. 2011;30(1):4–21. [Google Scholar]
- Wadsworth JL, Tawn JA. Dependence modelling for spatial extremes. Biometrika. 2012;99(2):253–272. [Google Scholar]
- Patton AJ. A review of copula models for economic time series. J Multivariate Anal. 2012;110:4–18. [Google Scholar]
- McHale I, Scarf P. Modelling the dependence of goals scored by opposing teams in international soccer matches. Stat Model. 2011;11(3):219–236. [Google Scholar]
- Cherubini U, Luciano E, Vecchiato W. Copula methods in finance. Chichester: Wiley; 2004. [Google Scholar]
- Li J, Bárdossy A, Guenni L, Liu M. A copula based observation network design approach. Environ Model Softw. 2011;26(11):1349–1357. [Google Scholar]
- Pilz J, Kazianka H, Spöck G. Some advances in Bayesian spatial prediction and sampling design. Spat Statist. 2012;1:65–81. [Google Scholar]
- Schmidt R, Faldum A, Witt O, Gerß J. Adaptive designs with arbitrary dependence structure. Biom J. 2014;56(1):86–106. doi: 10.1002/bimj.201200234. [DOI] [PubMed] [Google Scholar]
- Denman NG, McGree JM, Eccleston JA, Duffull SB. Design of experiments for bivariate binary responses modelled by Copula functions. Comput Statist Data Anal. 2011;55(4):1509–1520. [Google Scholar]
- Kiefer J, Wolfowitz J. The equivalence of two extremum problems. Canad J Math. 1960;12:363–366. [Google Scholar]
- Sklar A. Fonctions de répartition à n dimensions et leurs marges. Publications de l'Institut de Statistique de Paris. 1959;8:229–231. [Google Scholar]
- Atkinson AC, Fedorov VV, Herzberg AM, Zhang R. Elemental information matrices and optimal experimental design for generalized regression models. J Statist Plann Inference. 2014;144:81–91. [Google Scholar]
- Silvey SD. Optimal design (science paperbacks) London: Chapman & Hall; 1980. [Google Scholar]
- Heise MA, Myers RH. Optimal designs for bivariate logistic regression. Biometrics. 1996;52(2):613–624. [Google Scholar]
- Fedorov VV. The design of experiments in the multiresponse case. Theory Probab Appl. 1971;16(2):323–332. [Google Scholar]
- Wynn HP. The sequential generation of D-optimum experimental designs. Ann Math Statist. 1970;41(5):1655–1664. [Google Scholar]
- Perrone E. A study on robustness in the optimal design of experiments for copula models. In: Steland A, Rafajłowicz E, Szajowski K, editors. Stochastic models, statistics and their applications. Springer Proceedings in Mathematics & Statistics, Vol. 122. Wrocław, Poland: Springer International Publishing; 2015. p. 335–342.
- Nelsen RB. An introduction to copulas (Springer series in statistics) 2nd ed. New York: Springer; 2007. [Google Scholar]
- Durante F, Sempi C. Copula theory: an introduction. In: Bickel P, Diggle P, Fienberg S, Gather U, Olkin I, Zeger S, Jaworski P, Durante F, Härdle WK, Rychlik T, editors. Copula theory and its applications. Lecture Notes in Statistics, chapter 1, Vol. 198. Berlin, Heidelberg: Springer; 2010. p. 3–31.
- Michiels F, De Schepper A. A copula test space model: how to avoid the wrong copula choice. Kybernetika. 2008;44(6):864–878. [Google Scholar]
- Meyer C. The bivariate normal copula. Comm Statist Theory Methods. 2013;42(13):2402–2422. [Google Scholar]
- Krafft O, Schaefer M. D-optimal designs for a multivariate regression model. J Multivariate Anal. 1992;42(1):130–140. [Google Scholar]
- Dragalin V, Fedorov V. Adaptive designs for dose-finding based on efficacy–toxicity response. J Statist Plann Inference. 2006;136(6):1800–1823. [Google Scholar]
- Schepsmeier U, Stöber J. Derivatives and Fisher information of bivariate copulas. Stat. Papers. 2014;55(2):525–542. [Google Scholar]
- Noh H, Ghouch AE, Bouezmarni T. Copula-based regression estimation and inference. J Amer Statist Assoc. 2013;108(502):676–688. [Google Scholar]
- Oakes D, Ritz J. Regression in a bivariate copula model. Biometrika. 2000;87(2):345–352. [Google Scholar]
- de Leon AR, Wu B. Copula-based regression models for a bivariate mixed discrete and continuous outcome. Stat Med. 2011;30(2):175–185. doi: 10.1002/sim.4087. [DOI] [PubMed] [Google Scholar]
- Klement EP, Mesiar R. How non-symmetric can a copula be? Comment Math Univ Carolin. 2006;47(1):141–148. [Google Scholar]