

Abstract
We describe a method for removing the effect of confounders to reconstruct a latent quantity of interest. The method, referred to as “half-sibling regression,” is inspired by recent work in causal inference using additive noise models. We provide a theoretical justification, discussing both independent and identically distributed as well as time series data, respectively, and illustrate the potential of the method in a challenging astronomy application.
Keywords: machine learning, causal inference, astronomy, exoplanet detection, systematic error modeling
We assay a method for removing the effect of confounding noise, based on a hypothetical underlying causal structure. The method does not infer causal structures; rather, it is influenced by a recent thrust to try to understand how causal structures facilitate machine learning tasks (1).
Causal graphical models as pioneered by (2, 3) are joint probability distributions over a set of variables , along with directed graphs (usually, acyclicity is assumed) with vertices , and arrows indicating direct causal influences. By the causal Markov assumption, each vertex is independent of its nondescendants, given its parents.
There is an alternative view of causal models, which does not start from a joint distribution. Instead, it assumes a set of jointly independent noise variables, one for each vertex, and a “structural equation” for each variable that describes how the latter is computed by evaluating a deterministic function of its noise variable and its parents (2, 4, 5). This view, referred to as a functional causal model (or nonlinear structural equation model), leads to the same class of joint distributions over all variables (2, 6), and we may thus choose either representation.
The functional point of view is useful in that it often makes it easier to come up with assumptions on the causal mechanisms that are at work, i.e., on the functions associated with the variables. For instance, it was recently shown (7) that assuming nonlinear functions with additive noise renders the two-variable case identifiable (i.e., a case where conditional independence tests do not provide any information, and it was thus previously believed that it is impossible to infer the structure of the graph based on observational data).
In this work we start from the functional point of view and assume the underlying causal graph shown in Fig. 1. In the present paper, are random variables (RVs) defined on the same underlying probability space. We do not require the ranges of the RVs to be , and, in particular, they may be vectorial; we use as placeholders for the values these variables can take. All equalities regarding RVs should be interpreted to hold with probability one. We further (implicitly) assume the existence of conditional expectations.
Fig. 1.

We are interested in reconstructing the quantity Q based on the observables X and Y affected by noise N, using the knowledge that . Note that the involved quantities need not be scalars, which makes the model more general than it seems at first glance. For instance, we can think of N as a multidimensional vector, some components of which affect only X, some only Y, and some both X and Y.
Note that, although the causal motivation was helpful for our work, one can also view Fig. 1 as a directed acyclic graph (DAG) without causal interpretation, i.e., as a directed graphical model. We need Q and X (and, in some cases, also N) to be independent (denoted by ), which follows from the given structure no matter whether one views this as a causal graph or as a graphical model.
In the section Half-Sibling Regression, we present the method. Following this, we describe the application and provide experimental results, and conclusions. Note that the present work extends a conference presentation (8). Proofs that are contained in ref. 8 have been relegated to Supporting Information.
Half-Sibling Regression
Suppose we are interested in the quantity Q, but, unfortunately, we cannot observe it directly. Instead, we observe Y, which we think of as a degraded version of Q that is affected by noise N. Clearly, without knowledge of N, there is no way to recover Q. However, we assume that N also affects another observable quantity (or a collection of quantities) X. By the graph structure, conditional on Y, the variables Q and X are dependent (in the generic case); thus X contains information about Q once Y is observed (although ). This situation is quite common if X and Y are measurements performed with the same apparatus, introducing the noise N. In the physical sciences, this is often referred to as “systematics,” to convey the intuition that these errors are not simply due to random fluctuations but are caused by systematic influences of the measuring device. In our application below, both types of errors occur, but we will not try to tease them apart. Our method addresses errors that affect both X and Y, for instance by acting on N, no matter whether we call them random or systematic.
We need to point out a fundamental limitation at the beginning. Even from infinite data, only partial information about Q is available, and certain degrees of freedom remain. In particular, given a reconstructed Q, we can always construct another one by applying an invertible transformation to it, and incorporating its inverse into the function computing Y from Q and N. This includes the possibility of adding an offset, which we will see below.
The intuition behind our approach is as follows. Because , X cannot predict Q and thus Q’s influence on Y. It may contain information, however, about the influence of N on Y, because X is also influenced by N. Now suppose we try to predict Y from X. As argued above, whatever comes from Q cannot be predicted; hence only the component coming from N will be picked up. Trying to predict Y from X is thus a vehicle to selectively capture N’s influence on Y, with the goal of subsequently removing it, to obtain an idealized estimate of Q referred to as .
Definition 1.
| [1] |
We first show that reconstructs Q (up to its expectation ) at least as well as does.
Proposition 1. For any RVs that satisfy , we have
The above also holds true if we subject Y to some transformation before substituting it into [1] and Proposition 1. Note that it is conceivable that our procedure might benefit from such a transformation; however, finding it is not a topic of the present paper. See also the discussion on the function g following [2].
Proof. We have
Note that the two terms related by the inequality in Proposition 1 differ exactly by the amount . This is due to Lemma 1 (Supporting Information) and the law of total variance .
Our method is surprisingly simple, and although we have not seen it in the same form elsewhere (including standard works on error modeling, e.g., ref. 9), we do not want to claim originality for it. Related tricks are occasionally applied in practice, often using factor analysis to account for confounding effects (10–15). However, those methods usually aim at removing spurious associations between at least two variables (which could erroneously be attributed to a nonexisting causal influence of one variable on another one), whereas our method aims at reconstructing a single variable of interest. Common to these methods and ours is the idea that removal of the disturbing influence is enabled by the fact that it perturbs several or even a large number of variables at the same time, and by strong assumptions about how the disturbance acts (such as linearity or parametric models). Note that our variable X is referred to as “negative controls” in ref. 15.
We next propose an assumption that allows for a practical method to reconstruct Q up to an additive offset. The assumption allows a theoretical analysis that provides insight into why and when our method works.
Additive Systematic Error.
Inspired by recent work in causal inference, we use nonlinear additive noise models (7). Specifically, we assume that there exists a function f such that
| [2] |
We do not consider the more general form because, without additional information, g would not be identifiable. Note, moreover, that, although for ref. 7, the input of f is observed and we want to decide if it is a cause of Y, in the present setting, the input of f is unobserved (16) and the goal is to recover Q, which, for ref. 7, played the role of the noise.
Complete Information.
For an additive model [2], our intuition can be formalized: In this case, we can predict the additive component in Y coming from N, remove the confounding effect of N, and thus reconstruct Q (up to an offset)—which is exactly what we want.
Proposition 2. Suppose are RVs, and f is a measurable function. If there exists a function ψ such that
| [3] |
i.e., can in principle be predicted from X perfectly, then we have
| [4] |
If, moreover, the additive model assumption [2] holds, with RVs and , then
| [5] |
In our main application below, N will be systematic errors from an astronomical spacecraft and telescope, Y will be a star under analysis, and X will be a large set of other stars. In this case, the assumption that has a concrete interpretation: It means that the device can be self-calibrated based on measured science data only (17) (as opposed to requiring separate calibration data).
Proposition 2 provides us with a principled recommendation on how to remove the effect of the noise and reconstruct the unobserved Q up to its expectation : We need to subtract the conditional expectation (i.e., the regression) from the observed Y (Definition 1). The regression can be estimated from observations using (linear or nonlinear) off-the-shelf methods. We refer to this procedure as “half-sibling regression” to reflect the fact that we are trying to explain aspects of the child Y by regression on its half-sibling(s) X to reconstruct properties of its unobserved parent Q.
Note that is a function of x, and is the RV . Correspondingly, [4] is an equality of RVs. By assumption, all RVs live on the same underlying probability space. If we perform the associated random experiment, we obtain values for X and N, and [4] tells us that, if we substitute them into m and f, respectively, we get the same value with probability 1. Eq. 5 is also an equality of RVs, and the above procedure therefore not only reconstructs some properties of the unobservable RV Q—it reconstructs, up to the mean , and with probability 1, the RV itself.
In practice, of course, the accuracy will depend on how well the assumptions of Proposition 2 hold. If the following conditions are met, we may expect that the procedure should work well:
-
i)
X should be (almost) independent of Q—otherwise, our method could possibly remove parts of Q itself and thus throw out the baby with the bath water. A sufficient condition for this to be the case is that N be (almost) independent of Q, which often makes sense in practice, e.g., if N is introduced by a measuring device in a way independent of the underlying object being measured. Clearly, we can only hope to remove noise that is independent of the signal; otherwise, it would be unclear what is noise and what is signal. A sufficient condition for , finally, is that the causal DAG in Fig. 1 correctly describes the underlying causal structure.
Note, however, that Proposition 2, and thus our method, also applies if N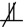 Q, as long as (see Prediction Based on Noneffects).
Q, as long as (see Prediction Based on Noneffects).
-
ii)
The observable X is chosen such that Y can be predicted as well as possible from it; i.e., X contains enough information about , and, ideally, N acts on both X and Y in similar ways such that a “simple” function class suffices for solving the regression problem in practice.
This may sound like a rather strong requirement, but we will see that, in our astronomy application, it is not unrealistic: X will be a large vector of pixels of other stars, and we will use them to predict a pixel Y of a star of interest. In this kind of problem, the main variability of Y will often be due to the systematic effects due to the instrument N also affecting other stars, and thus a large set of other stars will indeed allow a good prediction of the measured Y.
Note that it is not required that the underlying structural equation model be linear—N can act on X and Y in nonlinear ways, as an additive term .
In practice, we never observe N directly, and thus it is hard to tell whether the assumption of perfect predictability of from X holds true. We now relax this assumption.
Incomplete Information.
We now provide a stronger result for [1], including the case where does not contain all information about X.
Proposition 3. Let f be measurable, be RVs with , and . The expected squared deviation between and satisfies
| [6] |
Note that Proposition 2 is a special case of Proposition 3: if there exists a function ψ such that , then the right-hand side of [6] vanishes. Proposition 3 drops this assumption, which is more realistic: Consider the case , where R is another RV. In this case, we cannot expect to reconstruct the variable from X exactly.
There are, however, two settings where we would still expect good approximate recovery of Q: (i) If the standard deviation (SD) of R goes to zero, the signal of N in X becomes strong and we can approximately estimate from X; see Proposition 4. (ii) Alternatively, we observe many different effects of N. In the astronomy application below, Q and R are stars, from which we get noisy observations Y and X. Proposition 5 below shows that observing many different helps reconstructing Q, even if all depend on N through different functions and their underlying (independent) signals do not follow the same distribution. The intuition is that, with increasing number of variables, the independent “average” out, and thus it becomes easier to reconstruct the effect of N.
Proposition 4. Assume that and let
where R, N, and Q are jointly independent, , , g is invertible, and . Then
where .
Proof. We have for that
for some that is bounded in s (the implications follow from the continuous mapping theorem). (The notation denotes convergence in probability with respect to the measure P of the underlying probability space.) This implies
because
( convergence follows because f is bounded). However, then
Proposition 5. Assume that and that satisfies
where all , N, and Q are jointly independent, , for all i, , and
is invertible with uniformly equicontinuous. Then
where we define .
Prediction Based on Noneffects of the Noise Variable.
Although Fig. 1 shows the causal structure motivating our work, our analysis does not require a directed arrow from N to X. For the method to work in the sense of Propositions 2 and 3, we need additivity [2], , and 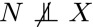 , to ensure that X contains information about N. We can represent this by an undirected connection between the two (Fig. 2), and note that such a dependence may arise from an arrow directed in either direction, and/or another confounder that influences both N and X. (Imagine that N is noise induced by a CCD, and X is a nearby thermometer. Both X and N will be affected by the unobserved true temperature T on the CCD and any amplifiers. The measured temperature does not have a causal effect on N, but nevertheless, it contains information about N that the regression can use.)
, to ensure that X contains information about N. We can represent this by an undirected connection between the two (Fig. 2), and note that such a dependence may arise from an arrow directed in either direction, and/or another confounder that influences both N and X. (Imagine that N is noise induced by a CCD, and X is a nearby thermometer. Both X and N will be affected by the unobserved true temperature T on the CCD and any amplifiers. The measured temperature does not have a causal effect on N, but nevertheless, it contains information about N that the regression can use.)
Fig. 2.

Causal structure from Fig. 1 when relaxing the assumption that X is an effect of N.
Knowledge about a possibly complex causal structure can help in choosing the right regression inputs X. Recall that the Markov Blanket of a node contains its parents, its children, and its children’s other parents (2). Ideally, we would want X to comprise the largest possible subset of N’s Markov Blanket containing information about N, subject to the constraint that (for an example, see Fig. S1).
Fig. S1.

Example for Prediction based on Noneffects of the Noise Variable. The condition that the regression input X should satisfy rules out its component . As a consequence, although is contained in N’s Markov blanket, it is no longer useful as a regression input when predicting Y, because it only contains information about Y conditional on . In the end, we are left with only for prediction of Y.
Half-Sibling Regression for Time Series
Above, we have modeled the data as an independent and identically distributed (i.i.d.) sample. In practice, however, the data may be drawn from random processes that inherit a time structure. We now generalize the i.i.d. method to the time series setting.
Model Assumptions.
Suppose we are given two time series, , , with an ordered discrete index set, say , that are generated according to the structural equation
| [7] |
with three unobserved time series , , and that are independent of each other. Fig. 3 shows an example with order one processes. As before, our goal is to reconstruct the hidden time series .
Fig. 3.

Special case of the time series model. , , and are (jointly) independent of each other, but each one may be autocorrelated. Regressing on unblocks only paths avoiding : the estimate of does not regress out any variability caused by and is more accurate than the i.i.d. estimate . Regressing on unblocks two paths: one avoiding , and the other not. The first may enhance the estimate of ; the second, however, may worsen it. In general, the contribution of both parts cannot be separated. However, they can for particular time series .
Exploiting the Time Dependencies.
Contrary to the i.i.d. case, , , and are now influenced by their own past , , and , respectively, whereas and are only influenced by and , respectively, as in the i.i.d. case. This may induce a time dependency in both and . We will now focus on how to exploit them to improve the reconstruction of .
In the i.i.d. case, we estimated with . In principle, we can now use the time dependency of by regressing on the whole future and past of . This leads to the possibly improved estimator . In some situations, it may also be useful to exploit the time dependency of . However, contrary to the regression of on [or ], blindly regressing onto may regress out parts of and deteriorate the results. To see this, consider Fig. 3: Although the covariates do not contain any information about , the covariate , for example, does; see d separation (3). Therefore, regressing on other values , , can, in general, remove information of from . This may change, however, if we make additional assumptions about . This is the purpose of Signals with Compact Support.
Signals with Compact Support.
We now assume that can be expressed as ; that is, we replace the first equation in [7] with
| [8] |
where , , and are jointly independent for all choices of , and , and h is a fixed function. Denoting by a window of width around , we further assume that
| [9] |
where c is a constant. In the example of exoplanet search described below, we use , and . corresponds to the stellar brightness (which is variable), and the signal of interest, , is the multiplicative change in the observed brightness due to a partial occlusion of the observed star by a planet passing through the line of sight between star and telescope. Such transits are centered around some and have a length , which we think of as an RV. The RVs for describe the shape of the transit. Eq. 9, however, also covers additive effects, using and . We assume that is unknown and that can be bounded by some α: . The goal is to detect the transits, i.e., the regions where . We now describe the method that we will later apply to the exoplanet data set.
Method.
In the i.i.d. case, we proposed to predict each from the other stars and then use the residuals as a reconstruction for (up to its mean). If we are really interested in the detection of transits rather than in reconstructing , we can attempt to filter out the autoregressive (AR) component of that comes from and , as long as this does not affect . Consider with , as above. Here, δ specifies the size of windows in past and future that we will use as regression inputs. Define . We further write . The method consists of the following steps.
Half-Sibling Regression for Time Series
-
i)
Choose a test set containing those points where we want to predict, with indices . Construct a training set, with indices , containing all those points that are separated by more than from the test set.
-
ii)
Regress on and using all for training and hyperparameter tuning. Use the resulting model for predicting from and for all .
In principle, may be a singleton, in which case we build a model for a single test point. If we have to do this for every possible choice of that point, computational requirements become rather large. In practice, we thus use a test set that contains roughly a third of the data, which means we need to carry out the above procedure three times to build models for all possible test points.
Because the signal of interest differs from c only on a compact support, we are able to prove that the method does not destroy any relevant information about the transits in , as long as we carefully choose the parameters α and δ.
Proposition 6. Assume that, for any , we have with as in [9]. Assume further that with constructed by half-sibling regression for time series as described above; here, ϕ is well defined if we assume that the conditional distribution of given and does not depend on t. Then
| [10] |
As a consequence, we can use to correct the observed , and we never remove any information about the transit . The proof is immediate because, for a fixed , we have that , , and for , as well as and , are independent of .
In general, will not be independent of for ; in other words, correction of using (e.g., by subtraction) may distort the signal outside of the transit time window . This is visualized in Fig. 4. In practice, the training set usually contains more than one transit. In this case, we cannot prove [10]. However, we would only expect a real distortion of the transit signal if the transits are abundant and thus form a significant fraction of the training set; again, see Fig. 4.
Fig. 4.

Simulated transit reconstruction using half-sibling regression for time series, but without regressing on . From bottom to top: , , with , and . The estimate was trained using ridge regression with regularization parameter . Transits were also present in the training set. Note that the transit itself is preserved. However, some artifacts (here: bumps) are introduced to the right and left of the transit.
Applications
Synthetic I.I.D. Data.
We first analyze two simulated data sets.
Increasing relative strength of N in a single X.
We consider 20 instances (each time we sample 200 i.i.d. data points) of the model and , where f and g are randomly chosen sigmoid functions and the variables N, Q, and R are normally distributed. The SD for R is chosen uniformly between 0.05 and 1, and the SD for N is between 0.5 and 1. Because Q can be recovered only up to a shift in the mean, we set its sample mean to zero. The distribution for R, however, has a mean that is chosen uniformly between and 1, and its SD is chosen from the vector . Proposition 4 shows that, with decreasing SD of R, we can recover the signal Q. SD zero corresponds to the case of complete information (Proposition 2). For regressing Y on X, we use the function gam (penalized regression splines) from the R package mgcv; Fig. 5 shows that this asymptotic behavior can be seen on finite data sets.
Fig. 5.

(Left) We observe a variable with invertible function g. If the variance of R decreases, the reconstruction of Q improves because it becomes easier to remove the influence of the noise N from the variable by using X; see Proposition 4. (Right) A similar behavior occurs with increasing the number d of predictor variables ; see Proposition 5. Both plots show 20 scenarios, each connected by a thin line.
Increasing number of observed variables.
Here, we consider the same simulation setting as before, this time simulating for . We have shown, in Proposition 5, that, if the number of variables tends to infinity, we are able to reconstruct the signal Q. In this experiment, the SD for and Q is chosen uniformly between 0.05 and 1; the distribution of N is the same as above. It is interesting to note that even additive models (in the predictor variables) work as a regression method (we use the function gam from the R package mgcv on all variables and its sum ). Fig. 5 shows that, with increasing d, the reconstruction of Q improves.
Exoplanet Light Curves.
The field of exoplanet search has recently become one of the most popular areas of astronomy research. This is largely due to the Kepler space observatory launched in 2009. Kepler observed a small fraction of the Milky Way in search of exoplanets. The telescope was pointed at the same patch of sky for more than 4 y (Fig. 6 and Fig. S2). In that patch, it monitored the brightness of 150,000 stars (selected from among 3.5 million stars in the search field), taking a stream of half-hour exposures using a set of Charge-Coupled Device (CCD) imaging chips.
Fig. 6.

View of the Milky Way with position of the Sun and depiction of the Kepler search field. Image courtesy of © Jon Lomberg.
Fig. S2.

Kepler search field as seen from Earth, located close to the Milky Way plane, in a star-rich area near the constellation Cygnus. Image courtesy of NASA/Carter Roberts/Eastbay Astronomical Society.
Kepler detects exoplanets using the transit method. Whenever a planet passes in front of their host star(s), we observe a tiny dip in the light curve (Fig. S3). This signal is rather faint, and, for our own planet as seen from space, it would amount to a brightness change smaller than , lasting less than half a day, taking place once a year, and visible from about half a percent of all directions. The level of required photometric precision to detect such transits is one of the main motivations for performing these observations in space, where they are not disturbed by atmospheric effects and it is possible to observe the same patch almost continuously using the same instrument.
Fig. S3.

Sketch of the transit method for exoplanet detection. As a planet passes in front of its host star, we can observe a small dip in the apparent star brightness. Image courtesy of NASA Ames.
For planets orbiting stars in the habitable zone (allowing for liquid water) of stars similar to the Sun, we would expect the signal to be observable, at most, every few months. We thus have very few observations of each transit. However, it has become clear that there are a number of confounders introduced by spacecraft and telescope leading to systematic changes in the light curves that are of the same magnitude or larger than the required accuracy. The dominant error is pointing jitter: If the camera field moves by a fraction of a pixel (for Kepler, the order of magnitude is 0.01 pixels), then the light distribution on the pixels will change. Each star affects a set of pixels, and we integrate their measurements to get an estimate of the star’s overall brightness. Unfortunately, the pixel sensitivities are not precisely identical, and, even though one can try to correct for this, we are left with significant systematic errors. Overall, although Kepler is highly optimized for stable photometric measurements, its accuracy falls short of what is required for reliably detecting Earth-like planets in habitable zones of Sun-like stars.
We obtained the data from the Mikulski Archive for Space Telescopes (see archive.stsci.edu/index.html). Our system, which we abbreviate as cpm (Causal Pixel Model), is based on the assumption that stars on the same CCD share systematic errors. If we pick two stars on the same CCD that are far away from each other, they will be light years apart in space, and no physical interaction between them can take place. The light curves (Fig. S4) nevertheless have similar trends, caused by systematics. We use linear ridge regression (see Supporting Information) to predict the light curve of each pixel belonging to the target star as a linear combination of a set of predictor pixels. Specifically, we use 4,000 predictor pixels from about 150 stars, which are selected to be closest in magnitude to the target star. (The exact number of stars varies with brightness, as brighter stars have larger images on the CCD and thus more pixels.) This is done because the systematic effects of the instruments depend somewhat on the star brightness; e.g., when a star saturates a pixel, blooming takes place, and the signal leaks to neighboring pixels. To rule out any direct optical cross-talk by stray light, we require that the predictor pixels are from stars sufficiently far away from the target star (at least 20 pixels distance on the CCD), but we always take them from the same CCD (note that Kepler has a number of CCDs, and we expect that systematic errors depend on the CCD). We train the model separately for each month, which contains about 1,300 data points. (The data come in batches, which are separated by larger errors, since the spacecraft needs to periodically redirect its antenna to send the data back to Earth.) Standard regularization is used to avoid overfitting, and parameters (regularization parameter and number of input pixels) were optimized using cross-validation. Nonlinear kernel regression was also evaluated but did not lead to better results. This may be due to the fact that the set of predictor pixels is relatively large (compared with the training set size), and, among this large set, it seems that there are sufficiently many pixels that are affected by the systematics in a rather similar way as the target.
Fig. S4.

Stars on the same CCD share systematic errors. A and B show pixel fluxes (brightnesses) for two stars: KIC 5088536 (A) and KIC 5949551 (B); here, KIC stands for Kepler Input Catalog. Both stars lie on the same CCD but are far enough apart so that there is no stray light from one affecting the other. Each panel shows the pixels contributing to the respective star. Note that there exist similar trends in some pixels of these two stars, caused by systematic errors.
If we treat the data as i.i.d. data, our method removes some of the intrinsic variability of the target star. This is due to the fact that the signals are not i.i.d., and time acts as a confounder. If, among the predictor stars, there exists one whose intrinsic variability is very similar to the target star, then the regression can attenuate variability in the latter. This is unlikely to work exactly, but, given the limited observation window, an approximate match (e.g., stars varying at slightly different frequencies) will already lead to some amount of attenuation. Because exoplanet transits are rare, it is very unlikely (but not impossible) that the same mechanism will remove some transits.
Note that, for the purpose of exoplanet search, the stellar variability can be considered a confounder as well, independent of the planet positions that are causal for transits. To remove this, we use as additional regression inputs also the past and future of the target star (see Proposition 6). This adds an AR component to our model, removing more of the stellar variability and thus increasing the sensitivity for transits. In this case, we select an exclusion window around the point of time being corrected, to ensure that we do not remove the transit itself. Below, we report results where the AR component uses as inputs the three closest future and the three closest past time points, subject to the constraint that a window of ±9 h around the considered time point is excluded. Choosing this window corresponds to the assumption that time points earlier than −9 h or later than +9 h are not informative for the transit itself. Smaller windows allow more accurate prediction, at the risk of damaging slow transit signals. Our code is available at https://github.com/jvc2688/KeplerPixelModel.
To give a view on how our method performs, cpm is applied on several stars with known transit signals. After that, we compare them with the Kepler Presearch Data Conditioning (PDC) method (see keplergo.arc.nasa.gov/PipelinePDC.shtml). PDC builds on the idea that systematic errors have a temporal structure that can be extracted from ancillary quantities. The first version of PDC removed systematic errors based on correlations with a set of ancillary engineering data, including temperatures at the detector electronics below the CCD array, and polynomials describing centroid motions of stars. The current PDC (18, 19) performs principal component analysis (PCA) on filtered light curves of stars, projects the light curve of the target star on a PCA subspace, and subsequently removes this projection. PCA is performed on a set of relatively quiet stars close in position and magnitude. For non-i.i.d. data, this procedure could remove temporal structure of interest. To prevent this, the PCA subspace is restricted to eight dimensions, strongly limiting the capacity of the model (20).
In Fig. 7, we present corrected light curves for three typical stars of different magnitudes, using both cpm and PDC. In our theoretical analysis for the i.i.d. case, we dealt with additive noise, and could deal with multiplicative noise, e.g., by log transforming. In practice, neither of the two models is correct for our application. If we are interested in the transit (and not the stellar variability), then the variability is a multiplicative confounder. At the same time, other noises may be better modeled as additive (e.g., CCD noise). In practice, we calibrate the data by dividing by the regression estimate and then subtracting 1, i.e.,
Effectively, we thus perform a subtractive normalization, followed by a divisive one. This works well, taking care of both types of contaminations.
Fig. 7.

Corrected fluxes using our method, for three example stars, spanning the main magnitude (brightness) range encountered. We consider a bright star (A), a star of moderate brightness (B), and a relatively faint star (C). SAP stands for Simple Aperture Photometry (in our case, a relative flux measure computed from summing over the pixels belonging to a star). In A−C, Top shows the SAP flux (black) and the cpm regression (red), i.e., our prediction of the star from other stars. Middle shows the cpm flux corrected using the regression (for details, see Applications, Exoplanet Light Curves), and Bottom shows the PDC flux (i.e., the default method). The cpm flux curve preserves the exoplanet transits (little downward spikes), while removing a substantial part of the variability present in the PDC flux. All x axes show time, measured in days since January 1, 2009.
The results illustrate that our approach removes a major part of the variability present in the PDC light curves, while preserving the transit signals. To provide a quantitative comparison, we ran cpm on 1,000 stars from the whole Kepler input catalog (500 chosen randomly from the whole list, and 500 random G-type Sun-like stars), and estimated the Combined Differential Photometric Precision (CDPP) for cpm and PDC. CDPP is an estimate of the relative precision in a time window, indicating the noise level seen by a transit signal with a given duration. The duration is typically chosen to be 3 h, 6 h, or 12 h (21). Shorter durations are appropriate for planets close to their host stars, which are the ones that are easier to detect. We use the 12-h CDPP metric, because the transit duration of an Earth-like planet is roughly 10 h. Fig. 8 presents our CDPP comparison of cpm and PDC, showing that our method outperforms PDC. This is no small feat, because PDC incorporates substantial astronomical knowledge (e.g., in removing systematic trends). It should be noted, however, that PDC’s runtime is much smaller than that of cpm.
Fig. 8.

Comparison of the proposed method (cpm) to the Kepler PDC method in terms of CDPP (see Applications, Exoplanet Light Curves). A shows our performance (red) vs. the PDC performance in a scatter plot, as a function of star magnitude (note that larger magnitude means fainter stars, and smaller values of CDPP indicate a higher quality as measured by CDPP). B bins the same dataset and shows box plots within each bin, indicating median, top quartile, and bottom quartile. The red box corresponds to cpm, and the black box refers to PDC. C shows a histogram of CDPP values. Note that the red histogram has more mass toward the left (i.e., smaller values of CDPP), indicating that our method overall outperforms PDC, the Kepler “gold standard.”
Conclusion
We have assayed half-sibling regression, a simple yet effective method for removing the effect of systematic noise from observations. It uses the information contained in a set of other observations affected by the same noise source. We have analyzed both i.i.d. and time series data. The main motivation for the method was its application to exoplanet data processing, which we discussed in some detail, with rather promising results. However, we expect that it will have applications in other domains as well.
Our method may enable astronomical discoveries at higher sensitivity on the existing Kepler satellite data. Moreover, we anticipate that methods to remove systematic errors will further increase in importance: By May 2013, two of the four reaction wheels used to control the Kepler spacecraft were dysfunctional, and, in May 2014, NASA announced the K2 mission, using the remaining two wheels in combination with thrusters to control the spacecraft and continue the search for exoplanets in other star fields. Systematic errors in K2 data are significantly larger because the spacecraft has become harder to control. In addition, NASA is planning the launch of another space telescope for 2017. The Transiting Exoplanet Survey Satellite (tess.gsfc.nasa.gov/) will perform an all-sky survey for small (Earth-like) planets of nearby stars. To date, no Earth-like planets orbiting Sun-like stars in the habitable zone have been found. This is likely to change in the years to come, which would be a major scientific discovery. In particular, although the proposed method treats the problem of removing systematic errors as a preprocessing step, we are also exploring the possibility of jointly modeling systematics and transit events. This incorporates additional knowledge about the events that we are looking for in our specific application, and it has already led to promising results (20).
Further Proofs
Proof of Proposition 2: Due to [3], we have
To show the second statement, consider the conditional expectation
Using and [4], we get
Recalling Definition 1 completes the proof.
Before proving Proposition 3, we observe that is a good approximation for whenever is almost determined by X.
Lemma 1. For any two RVs , we have
| [S1] |
Here, is the RV with , and is the RV with . Then [S1] turns into
| [S2] |
Proof of Lemma 1: Note that, for any RV Z, we have
by the definition of variance, applied to the variable . Hence
where both sides are functions of X. Taking the expectation w.r.t. X on both sides yields
where we have used the law of total expectation on the right-hand side.
Proof of Proposition 3: We rewrite the argument of the square in [6] as
Here, the last step uses , which follows from .
The result follows using Lemma 1 with .
Proof of Proposition 5: By Kolmogorov’s strong law, we have for
that
for some that are uniformly bounded in d (the implication follows from uniform equicontinuity, implication by the continuous mapping theorem). This implies
because
[The convergence of the right hand side follows from and boundedness of .] However, then
A Note on Related Work
In its supplement, ref. 15 assays a related idea for the case of linear relations with multivariate variables. In this work, Y is a vector of log expression levels of some genes of interest, and the generating model
| [S3] |
is assumed, where X represents some factors of interest, e.g., some vector-valued disease state, W denotes some unobserved covariates (such as sample quality), E is a random noise term, and β and α are matrices of regression coefficients. is the unwanted term because W may be a latent common cause of X and Y which makes the estimation of the regression vector β difficult. The correction method assumes that there are some control genes that are not influenced by the factors X of interest, that is, the restriction of [S3] to those genes reads
W is estimated from via factor analysis, which allows removal of the unwanted term from [S3]. Unlike ours, the method is restricted to linear models.
A crucial feature of our approach is that an explicit estimation of the noise term N is not necessary, which is particularly convenient when it influences Y in a nonlinear way.
The method of ref. 15 has recently been further developed (22).
Ridge Regression
Suppose we are given an i.i.d. sample from , . Then, for any (regularization parameter), the solution to the problem
is given by (e.g., ref. 23)
where the matrix and the matrix contain the data points.
For a light curve of duration 3 mo, our approach took about 7 h on a single core (Ivy Bridge x86_64 3.0 GHz), training the 3 mo separately, i.e., about 2 h for each month comprising around 1,300 data points. We had to solve about 1,300 linear systems of dimension about 1,300 for a 1-mo light curve. There were four parameters to be tuned: the number of predictor pixels, autoregression window size, and L2 regularization parameters for both components (regression from the other stars, and autoregression on past and future of the light curve itself). The parameters were tuned by first considering a representative subset of around 20 light curves and performing cross-validation. This led to different values for each light curve, but we found that we were able to choose a set of values uniform across the light curves that led to essentially the same cross-validation errors. We thus used these values for all light curves. We found that the results were robust with respect to changing the regularization parameter by an order of magnitude (up or down).
Acknowledgments
We thank Stefan Harmeling, James McMurray, Oliver Stegle, and Kun Zhang for helpful discussion, and the anonymous reviewers for helpful suggestions and references. D.W.H., D.W., and D.F.-M. were partially supported by NSF (IIS-1124794) and NASA (NNX12AI50G) and the Moore-Sloan Data Science Environment at NYU. C.-J.S.-G. was supported by a Google Europe Doctoral Fellowship in Causal Inference. J.P. was supported by the Max Planck ETH Center for Learning Systems.
Footnotes
The authors declare no conflict of interest.
This paper results from the Arthur M. Sackler Colloquium of the National Academy of Sciences, “Drawing Causal Inference from Big Data,” held March 26−27, 2015, at the National Academies of Sciences in Washington, DC. The complete program and video recordings of most presentations are available on the NAS website at www.nasonline.org/Big-data.
This article is a PNAS Direct Submission.
This article contains supporting information online at www.pnas.org/lookup/suppl/doi:10.1073/pnas.1511656113/-/DCSupplemental.
References
- 1.Schölkopf B, et al. On causal and anticausal learning. In: Langford J, Pineau J, editors. Proceedings of the 29th International Conference on Machine Learning (ICML) Omnipress; New York: 2012. pp. 1255–1262. [Google Scholar]
- 2.Pearl J. Causality. Cambridge Univ Press; New York: 2000. [Google Scholar]
- 3.Spirtes P, Glymour C, Scheines R. Causation, Prediction, and Search. 2nd Ed MIT Press; Cambridge, MA: 1993. [Google Scholar]
- 4.Aldrich J. Autonomy. Oxf Econ Pap. 1989;41(1):15–34. [Google Scholar]
- 5.Hoover KD. Causality in economics and econometrics. In: Durlauf SN, Blume LE, editors. Economics and Philosophy. 2nd Ed. Vol 6 Palgrave Macmillan; New York: 2008. [Google Scholar]
- 6.Peters J, Mooij J, Janzing D, Schölkopf B. Causal discovery with continuous additive noise models. J Mach Learn Res. 2014;15(Jun):2009–2053. [Google Scholar]
- 7.Hoyer P, Janzing D, Mooij JM, Peters J, Schölkopf B. Nonlinear causal discovery with additive noise models. In: Koller D, Schuurmans D, Bengio Y, Bottou L, editors. Advances in Neural Information Processing Systems. Vol 21. MIT Press; Cambridge, MA: 2009. pp. 689–696. [Google Scholar]
- 8.Schölkopf B, et al. Removing systematic errors for exoplanet search via latent causes. In: Bach F, Blei D, editors. Proceedings of the 32nd International Conference on Machine Learning. Microtome; Brookline, MA: 2015. pp. 2218–2226. [Google Scholar]
- 9.Taylor JR. An Introduction to Error Analysis: The Study of Uncertainties in Physical Measurements. 2nd Ed Univ Science Books; Herndon, VA: 1997. [Google Scholar]
- 10.Price AL, et al. Principal components analysis corrects for stratification in genome-wide association studies. Nat Genet. 2006;38(8):904–909. doi: 10.1038/ng1847. [DOI] [PubMed] [Google Scholar]
- 11.Yu J, et al. A unified mixed-model method for association mapping that accounts for multiple levels of relatedness. Nat Genet. 2006;38(2):203–208. doi: 10.1038/ng1702. [DOI] [PubMed] [Google Scholar]
- 12.Johnson WE, Li C, Rabinovic A. Adjusting batch effects in microarray expression data using empirical Bayes methods. Biostatistics. 2007;8(1):118–127. doi: 10.1093/biostatistics/kxj037. [DOI] [PubMed] [Google Scholar]
- 13.Kang HM, Ye C, Eskin E. Accurate discovery of expression quantitative trait loci under confounding from spurious and genuine regulatory hotspots. Genetics. 2008;180(4):1909–1925. doi: 10.1534/genetics.108.094201. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Stegle O, Kannan A, Durbin R, Winn JM. Accounting for non-genetic factors improves the power of eQTL studies. In: Vingron M, Wong L, editors. Research in Computational Molecular Biology: 12th Annual International Conference, RECOMB 2008. Springer; New York: 2008. pp. 411–422. [Google Scholar]
- 15.Gagnon-Bartsch JA, Speed TP. Using control genes to correct for unwanted variation in microarray data. Biostatistics. 2012;13(3):539–552. doi: 10.1093/biostatistics/kxr034. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Janzing D, Peters J, Mooij J, Schölkopf B. Identifying confounders using additive noise models. In: Bilmes J, Ng AY, editors. 25th Conference on Uncertainty in Artificial Intelligence. AUAI Press; Corvallis, OR: 2009. pp. 249–257. [Google Scholar]
- 17.Padmanabhan N, et al. An improved photometric calibration of the Sloan Digital Sky Survey imaging data. Astrophys J. 2008;674(2):1217–1233. [Google Scholar]
- 18.Stumpe MC, et al. Kepler Presearch Data Conditioning I—Architecture and algorithms for error correction in Kepler light curves. Publ Astron Soc Pac. 2012;124:985–999. [Google Scholar]
- 19.Smith JC, et al. Kepler Presearch Data Conditioning II—A Bayesian approach to systematic error correction. Publ Astron Soc Pac. 2012;124:1000–1014. [Google Scholar]
- 20.Foreman-Mackey D, et al. A systematic search for transiting planets in the K2 data. Astrophys J. 2015;806(2):215. [Google Scholar]
- 21.Christiansen JL, et al. The derivation, properties, and value of Kepler’s combined differential photometric precision. Publ Astron Soc Pac. 2012;124:1279–1287. [Google Scholar]
- 22.Jacob L, Gagnon-Bartsch JA, Speed TP. Correcting gene expression data when neither the unwanted variation nor the factor of interest are observed. Biostatistics. 2016;17(1):16–28. doi: 10.1093/biostatistics/kxv026. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Hastie T, Tibshirani R, Friedman J. The Elements of Statistical Learning; Data Mining, Inference and Prediction. 2nd Ed Springer; New York: 2009. [Google Scholar]