

Summary
Background
A critical consideration when applying the results of a clinical trial to a particular patient is the degree of similarity of the patient to the trial population. However, similarity assessment rarely is practical in the clinical setting. Here, we explore means to support similarity assessment by clinicians.
Methods
A scale chart was developed to represent the distribution of reported clinical and demographic characteristics of clinical trial participant populations. Constructed for an individual patient, the scale chart shows the patient’s similarity to the study populations in a graphical manner. A pilot test case was conducted using case vignettes assessed by clinicians. Two pairs of clinical trials were used, each addressing a similar clinical question. Scale charts were manually constructed for each simulated patient. Clinicians were asked to estimate the degree of similarity of each patient to the populations of a pair of trials. Assessors relied on either the scale chart, a summary table (aligning characteristics of 2 trial populations), or original trial reports. Assessment time and between-assessor agreement were compared. Population characteristics considered important by assessors were recorded.
Results
Six assessors evaluated 6 cases each. Using a visual scale chart, agreement between physicians was higher and the time required for similarity assessment was comparable
Conclusion
We suggest that further research is warranted to explore visual tools facilitating the choice of the most applicable clinical trial to a specific patient. Automating patient and trial population characteristics extraction is key to support this effort.
Keywords: Data representation, clinical decision support systems, patient similarity, visual scale
1. Introduction
To make evidence-based decisions, doctors must keep their knowledge up to date. However, digesting the rapidly accumulating published evidence is challenging at best. It has been estimated that over 600 hours per month would be needed for a primary care physician to go over all relevant new publications [1]. Indeed, most physicians do not regularly perform literature searches when in need of information, and turn to reviews if they do [2]. To cope with information overload, many clinicians choose to rely on high-level aggregate and summary data knowledge bases of published research. These resources are extremely valuable, however they cannot fully account for the variability and diversity between patients and within populations forming the original publications on which they are based.
Implementing evidence-based practice entails applying the (aggregate –level) conclusions of a successful clinical trial to a particular patient, despite the built-in limitations of such approach. A critical consideration when doing so is the degree to which the study population is representative of the patient. The more similar the patient to the participants of a study, the stronger the justification for relying on that study when considering an intervention. When more than one clinical trial assessing a diagnostic or therapeutic question is available, clinicians have to choose which one to rely on. This involves comparing them in light of the characteristics of a patient in question. Hence, to evaluate available evidence in context of a particular patient, the physician sometimes has to refer to the original reported results of clinical trials rather than rely on high-level summary resources. However, as mentioned, this is hardly feasible in practice using traditional methods.
How can one tell if a patient and a trial population are similar? What patient characteristics are relevant for the assessment of similarity, and what is their relative importance? There is no well-established, comprehensive list of such attributes available. Moreover, both the relevance and importance of various attributes are case-specific. Characteristics cardinal to the evaluation of one clinical question may have little if any relevance to another. For example, gender is a major determinant in the workup of urinary tract infection [3] but probably has a small effect if any on the management of tinnitus.
As documented by McDonald [4], physicians use heuristics to fill in information lacunas such as those involved in determining clinical trial applicability. However, heuristics have been shown to involve substantial biases that may adversely affect rational decision making [5]. As heuristics are used whenever uncertainty is present, reducing bias entails reducing uncertainty.
To date, efforts to help doctors cope with the problems of having too little evidence at hand, or too much evidence to handle, have been focused on improving their efficient access to evidence. Yet, when it comes to digesting clinical trials, these efforts seem to fall short of doctors’ needs. Real time similarity assessment in the clinical setting is impractical when attempted to be performed manually because of time constraints. This calls for means to facilitate comparing a patient to a clinical trial population, and trial populations to each other, allowing clinicians to draw more valid conclusions from these trials regarding their patients.
Experiments of using graphical representation of medical information have been conducted for improving patient education [6–9] and interpreting laboratory data [10, 11]. Some clinically-relevant extremely complex information types, such as genetic and microbiome analyses are typically reported using graphic representation [12]. New ways to graphically present clinical practice guidelines have been suggested [13] and novel representation of timelines [14], clinic encounters [15] and intensive care unit electronic health record data explored [16]. Scale charts such as forest plots are commonly used for meta-analysis reports. However, by and large, studies of graphical tools as means to represent clinical information are sparse. A tool for comparing an attribute of a target population to the distribution of the corresponding attribute in a clinical trial population has been suggested [17], but it only allows one attribute at a time to be compared.
In an attempt to provide better ways of approaching and evaluating the relevance of clinical trials, we developed a visual summary scale chart to compare the characteristics of a patient to those of trial populations. In this work, we present the approach and report the results of a pilot case study evaluation of it.
2. Objectives
We explore here the potential for trial-patient relationship digestion and representation using a visual scale tool. Appreciating that distribution measures of the characteristics of a trial population may be as important as the mean in this context, we aimed to communicate both in an intuitive and space-efficient way in the graphic representation.
In the exploratory case study conducted, we aimed to assess the performance of the scale chart in terms of the time needed to complete the task of similarity assessment, as well as the reproducibility of the assessment as measured by between-assessor agreement.
3. Methods
We conducted a case study to compare a summary table of clinical trials to a graphical representation of their populations relative to a patient’s characteristics for facilitated similarity assessment.
The visual chart used was designed to follow the format of the table almost always found in trials which lists the baseline characteristics of participants (often referred to as “Table 1”). The use of horizontal bars to represent distribution measures was inspired by the commonly used graphic representation of normal value ranges in lab reports. The bars are also similar to those found in forest plots, which physicians reading meta-analyses are used to seeing. Designing the scale chart, we made an attempt to reduce the information burden by limiting the displayed content to the minimum necessary.
Two pairs of clinical trials, each addressing a similar clinical question were selected. The first [17, 18] assessed the benefit of fibrates in preventing cardiovascular outcomes and the second [19,20] compared the combination of an angiotensin converting enzyme inhibitor (ACE-I) and an angiotensin receptor blocker (ARB) versus ACE-I alone for prevention of cardiovascular outcomes. The papers were chosen as they address common conditions and common therapeutic choices.
We simulated a case where a clinician has to select the more appropriate of two studies to rely on when caring for a specific patient. Demographic and clinical data of trial populations, as well as inclusion and exclusion criteria, were manually extracted from the published reports to a spreadsheet (Microsoft Excel 2010, Microsoft Inc.). One of the studies [21] reported separately the participant data for the intervention and control groups. For each variable, an average value across the two groups was computed for the entire study population. These data were used to populate a summary table (► Table 1) aligning the two studies constituting each pair one next to the other to facilitate comparison of their populations.
Table 1.
Baseline characteristics of trials and patient
| Characteristic | Blue | Orange | Patient | |
|---|---|---|---|---|
| Age mean±SD | 64.05±11 | 62.75±14.4 | 40 | |
| Men% | 78.7 | 53.9 | female | |
| Ethnic origin% | European | 90.55 | 100 | black |
| Black | 5 | 0 | ||
| Other | 4.45 | 0 | ||
| NYHA class (%) | ii | 24.1 | 33.5 | class ii |
| iii | 72.85 | 66.5 | ||
| iv | 3.05 | 0 | ||
| LV ejection fraction (%) mean±SD | 28±7.5 | 29.8±7.65 | 40 | |
| Heart rate (beats/min) mean±SD | 73.55±13.1 | 67.8±8.6 | 98 | |
| Blood pressure (mm Hg) mean±SD | Systolic | 125.15±18.6 | 125.4±8.1 | 96 |
| Diastolic | 75.1±10.75 | 81±6.45 | 58 | |
| Body-mass index (kg/m2) mean±SD | 27.85±5.3 | n/a | 21 | |
| Time on HD monthes mean±SD | n/a | 93.95±16.1 | None | |
| Body surface area mean±SD | n/a | 1.88±0.115 | 1.7 | |
| Delta body weight, kg mean±SD | n/a | 2.75±0.8 | n/a | |
| Heart-failure cause % | Ischaemic | 62.4 | n/a | idiopathic |
| Idiopathic | 26.2 | n/a | ||
| Hypertensive | 6.5 | n/a | ||
| Hospital admission for CHF | 77.1 | n/a | yes | |
| Myocardial infarction | 55.65 | 56.9 | no | |
| Current angina pectoris | 20.25 | n/a | no | |
| Stroke | 8.65 | n/a | no | |
| Diabetes mellitus | 29.75 | 29 | no | |
| Hypertension | 48.2 | n/a | no | |
| Atrial fibrillation | 26.95 | n/a | yes | |
| Pacemaker | 9.1 | n/a | no | |
| Current smoker | 16.85 | 12 | no | |
| previous smoker | n/a | 26.95 | no | |
| PCI | 14.75 | n/a | no | |
| CABG | 24.45 | n/a | no | |
| Implantable cardioverter-defibrillator | 3.95 | n/a | no | |
| Cancer | 6 | n/a | no | |
| Medical treatment % | ||||
| ACE inhibitor | 99.9 | 100 | yes | |
| Diuretic | 90.05 | n/a | yes | |
| ⍰ blocker | 55.45 | 60.95 | no | |
| Spironolactone | 17.15 | n/a | yes | |
| Digoxin/digitalis glycoside | 58.4 | 51.5 | no | |
| Calcium antagonist | 10.45 | n/a | no | |
| Other vasodilators | 36.75 | n/a | no | |
| Nitrates | n/a | 48 | no | |
| Oral anticoagulant | 38.1 | n/a | no | |
| Antiarrhythmic agent | 12.55 | n/a | no | |
| Amiodarone | n/a | 19.15 | no | |
| Aspirin | 51.45 | 63.85 | yes | |
| Other antiplatelet agent | 3.25 | 32.75 | no | |
| Lipid-lowering drug | 41.2 | n/a | statin | |
| Statin | n/a | 67.95 | statin | |
| Hemoglobin, g/dl mean±SD | n/a | 11.4±0.65 | 10 | |
| Albumin, g/dl mean±SD | n/a | 3.915±0.58 | 3.1 | |
| PTH, ng/l mean±SD | n/a | 245.9±36 | 220 | |
Exclusion: not specified
The population of the summary table involved some editing to the format in which baseline characteristics were reported in the original articles. In some cases, categories were merged. For example, the Education categories “some college” and “college degree or higher” were replaced by a single category “at least some college”. A study reported separately the percentage of participants over 75 years of age, while its pair did not. In this case, since age was included as a characteristic of the population, the information on this subset of participants was omitted when constructing the summary table in an attempt to avoid information overload. In other cases, where an attribute was available in only one study but was considered by us to be clinically important, it was used in the summary table and an indication of data being unavailable in the corresponding study was added (e.g., “Hospital admission for CHF”).
For each simulated patient, a scale chart based on the same data was manually created. Colored bars (with each trial represented by a different color) for each reported characteristic represented trial population mean (or median) and/or distribution (standard deviation, inter-quartile range or relative fraction of categories). On the bars appeared numerical values of the mean/median and the distribution measure used. The bars were positioned in relation to a vertical line representing the simulated patient so as to show the patient’s position on the trial population distribution (► Figure 1). The numeric/categorical value of each characteristic of a patient appeared in a text box adjunct to the vertical bar. As the scale chart was focused on comparing patient and study population values using the same metric, units were omitted to reduce the information burden on assessors.
Fig. 1.
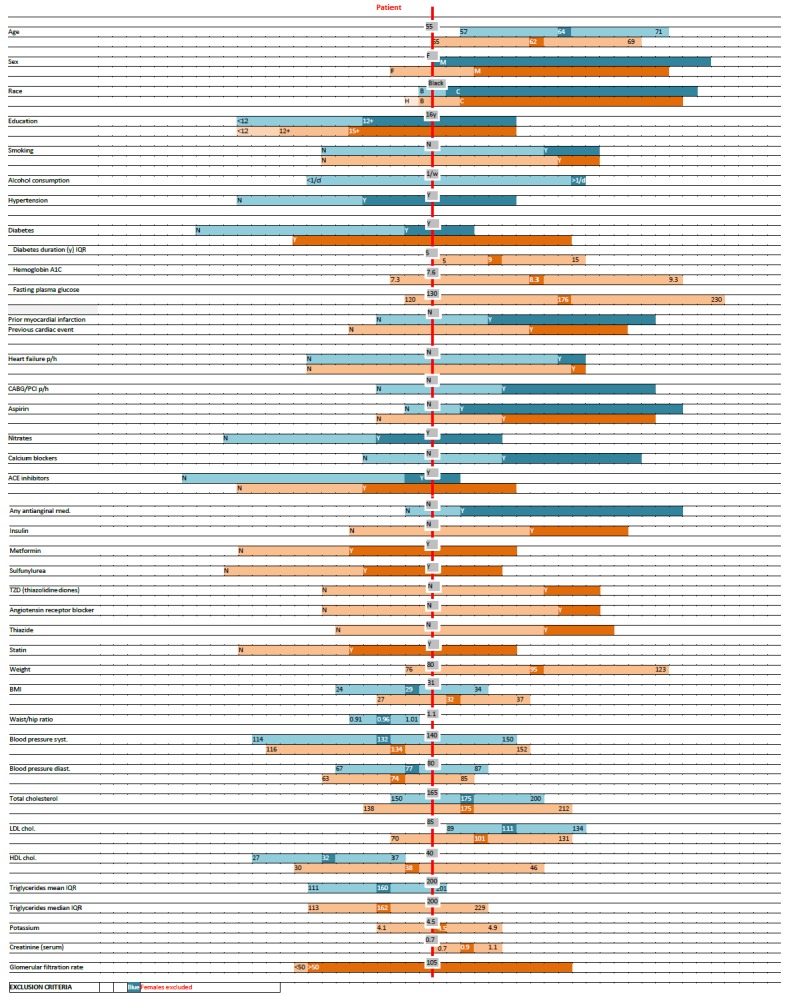
An example of a Scale Chart comparing a patient’s characteristics (red vertical line, grey boxes) to the distribution of reported population characteristics of two clinical trials (blue and orange horizontal bars). Each bar represents the mean or median and the standard deviation or interquartile range (IQR), as indicated, for continuous variables, and relative frequency for categorical variables. Horizontal bars are aligned to correspond to the patient’s characteristics. Different tones are used for different categories.
Clinicians working at the National Institutes of Health (NIH) were approached and asked to use the assessment tools. Assessors were presented with data from two pairs of clinical trials, each addressing a similar clinical question. For each pair, they were provided with either (a) the relevant parts in the original publications containing data for similarity assessment, including the methods section and the table outlying baseline patient characteristics; (b) the summary table (► Table 1) or; (c) the scale chart (► Figure 1). Assessors were provided a 1 page tutorial on the use of the scale chart, which did not include data from the trials assessed. Abstracts of the published trial reports were also available to the participating clinicians. Each physician was presented with 3 simulated case vignettes describing patient demographics and prior medical history. Case vignettes were composed by one of the authors (AC), and attempted to describe patients likely to be encountered in the clinic.. Each participant evaluated 3 casesper trial pair (a total of 6 case vignettes).
Based on the information provided, and disregarding trial outcome, clinicians were asked to assess the similarity between each simulated patient described in the vignettes and each of the corresponding 2 clinical trials, by assigning a score between 0 and 100 on a scale. As we had no particularly good reason to prefer one evaluation scale over another, we chose a percentage scale, which physicians commonly use. Case order was changed between participants. Participants were asked to time their assessments.
We further collected information about the attributes on which assessors based their conclusion. For each pair of trials, clinicians were asked to mark those reported participant population characteristics that they considered clinically important for the purpose of similarity assessment and also to indicate whether they considered the exclusion criteria to be relevant in this context. This was done using checking characteristics on a pre-generated list. In the list, for the sake of simplicity, some categories of characteristics were merged. For instance, the smoking sub-categories “current”, “past” and “never” were merged to “Current smoking status”.
Statistical analysis was done using SPSS Statistics 20 (IBM Inc.) We used the between-assessor agreement as the gold standard for comparing the quality of the similarity assessments based on the different tools used by assessors. For each patient presented, and for each of the assessment tools studied, the difference in the similarity assessment between any two participating clinicians was computed. Student’s t-test was used to compare means. Qualitative judgements were compared using the Kruskal-Wallis rank sum test.
4. Results
Considerable differences in the choice of parameters reported in the baseline characteristics table of the studies used were noted. In the first pair of trials, the summary table included 45 parameters. Of those, the relevant information was not reported for 10 and 21 parameters in the “Blue” and “Orange” study, respectively. A similar pattern was observed in the second pair of trials, where out of a total of 50 parameters in the summary table, 22 and 10 parameters were not available for comparison in the “Blue” and “Orange” studies, respectively. Some of these were sub-categories of parameters, such as “Total cholesterol interquartile range”.
There were a total of six participants: 4 attending physicians (3 internists and 1 cardiologist), 1 intern and 1 final year medical student. A total of 36 cases were assessed. The average time needed to complete the assessment of 3 case vignettes using the 3 modalities was 19, 20 and 21 minutes for the published baseline participant characteristics, scale chart and summary table, respectively. However, the time participants required to complete the entire questionnaire ranged from about 20 to 44 minutes.
Similarity assessments (within each case, across modalities) varied considerably between clinicians, with a mean range of 57±9%. Wide gaps were also evident between numeric assessments of each of the two participants assessing the same case vignette using the same tool, yet the greatest agreement (i.e., smallest mean difference) was found between assessors using the scale graphic representation (► Figure 2, upper panel). Mean between-assessor differences were 24±19%, 18±12%, and 31±23%, respectively (all differences statistically significant with p≤0.01). When comparing the agreement between assessors as to the qualitative selection of the more applicable trial of each pair presented, we found it to be highest when the scale chart was used, however this finding was not statistically significant (► Figure 2, lower panel).
Fig. 2:

Numerical similarity-degree assessment-difference between each two clinicians assessing the same case vignette using the same assessment tool. Error bars represent ± 1 standard error of mean (upper panel); Overall degree of between-assessor agreement on the more similar trial of each pair of trials presented using the same assessment tool (lower panel).
There was poor agreement between clinicians as to the relevance of reported population characteristics to similarity assessment, as shown in ► Figure 3. Participants unanimously agreed on only one characteristic (a medical background of diabetes) for the first pair of trials, whereas no unanimous agreement was found on any characteristic for the second pair. Of the entire list of characteristics to be considered, only 15 of 38 and 10 of 45 characteristics from each paper, respectively, were considered important by the majority of clinicians, and only six of these were common to both pairs (namely: Age, sex, body-mass index, presence of diabetes, presence of hypertension, and current smoking status).
Fig. 3.

Between-assessor agreement on trial population characteristics important for similarity assessment (dark and light bars represent the first and second pairs of trials, respectively). The majority of characteristics were not viewed as important by most assessing physicians.
5. Discussion
Methods for helping clinicians efficiently digest evidence and apply it in everyday practice are desperately needed to overcome the time pressure and cognitive load associated with clinical work. To this end, we show preliminary evidence in this pilot study that our knowledge visualization tool produces better between-physician agreement when assessing the similarity between a patient and a study population and when choosing the more applicable of a pair of trials.
Our results are limited owing to the small number of participating clinicians and small number of cases assessed. Although we had anticipated that the time needed for clinicians to perform the assessment would be shorter using the visual scale, our results show that using the published participant baseline characteristics table was actually the fastest way to arrive at a conclusion. One explanation for this finding may be suboptimal design of the visual tool. Alternative visualization formats can be explored, like heatmaps [20] or radial charts [21], which are growingly used for multivariate data. A notable limitation of the visual scale is that it is impractical for handing more than two trials at a time. Alternative designs could be superior in this aspect as well. Future versions of the tool, perhaps presenting less data, may be more intuitively interpreted by physicians. For instance, an interactive process, in which the physician first defines those parameters she wishes to compare, could allow for a more concise visual chart to be displayed. Another explanation relates to physicians’ lack of experience using the scale chart. Participating clinicians only received a 1 page tutorial on the use of the scale chart, whereas they have far more experience using the conventional data presentation. It may very well be that for an advantage in assessment time to be demonstrable, repeated use of the visual tool will be required. We were surprised to find less agreement between clinicians when using the summary table, which we had expected would facilitate comparison between trials by aligning their reported population characteristics.
Manual construction of scale charts is tedious and impractical, but automatic data extraction (of both patient and trial population) and translation methods are technically feasible and may facilitate adoption of the scale charts. Structured patient characteristics may be extracted from an electronic health record system in a standardized format. Participant characteristics for clinical trials can be obtained in XML format when they have been included in the trial listing on ClinicalTirals.gov. Provided that data are properly reported (especially eligibility criteria), the whole process could eventually be automated, including the assignment of a numeric or categorical score representing the degree to which a patient and a trial population are similar. Inconsistent reporting of participant characteristics in terms of the characteristics chosen, subcategories used and the units of measure reported is a challenge. In our case, less than half of the parameters in the summary tables could be directly compared between the studies in each pair. This is a surprising finding since each pair of trials related to a similar clinical condition, and thus one would expect that similar characteristics would be reported. Our findings indicate that not all reported characteristics are regarded as being important (or relevant) in the assessment of similarity. Only a minor part of the reported trial characteristics was considered important by the majority of assessing clinicians and those characteristics varied between trial pairs and participants. This may suggest that the set of reported characteristics published as part of an article could be reduced, whereas other characteristics could be reported only in supplemental material. As noted, an interface allowing the user to define the list of characteristics to be displayed will eliminate information considered by the user to be irrelevant or redundant, which will result in a less crowded and easier to use visual chart. Assigning differential weights to attributes to reflect their relative contribution to an overall similarity measure may improve the validity of the similarity assessment. However such weights may vary on a trial by trial and patient by patient basis and data to support their valid assignment is lacking. Currently, we assume that physicians assign differential weighing, but this is probably done implicitly and weights may not be quantifiable. Hence, having weights assigned to selected parameters automatically or by the querying doctor is a matter requiring further research.
Finally, when comparing an individual patient to a group of trial participants, the mean or median value of a specific characteristic may be insufficient. The diversity within a trial population should also be taken in consideration when assessing similarity. The recently introduced GIST score [17] aims to support doing so. If the diversity within a trial population is high, then some correction may be needed, such as dividing the measure of difference in a characteristic by its variance in the trial population. Ideally, similarity should be assessed based on individual participant data (using trials’ original, complete databases) rather than on reported aggregated data. However, individual-level participant data are not currently available to use by clinicians for this purpose.
6. Conclusions
Assessing the applicability of clinical trials to the management of specific patients is key in clinical decision making but is challenged by data overload and time restriction. The proposed visual scale is a preliminary attempt to facilitate the direct application of clinical trials to patient care. Further research is needed to validate and refine this approach, and a more structured scheme of reporting trial population characteristics allowing for automating the comparison process is warranted.
Acknowledgments
This project was supported in part by an appointment to the Research Participation Program for the Centers for Disease Control and Prevention: National Center for Environmental Health, Division of Laboratory Sciences, administered by the Oak Ridge Institute for Science and Education through an agreement between the Department of Energy and DLS. Dr. Cimino was supported in part by research funds from the National Library of Medicine and the NIH Clinical Center.
Footnotes
Clinical Relevance Statement
We propose a visual scale representation of characteristics of clinical trial populations and individual patients. This tool is intended to be used by a clinician caring for a patient to select clinical trials with populations most representative of that patient. Automatic construction of visual scales may be useful in supporting at scale individualized evidence-based medicine at the point of care.
Conflict of Interest
The authors declare that they have no conflict of interest in the research.
Human Subjects Protections
Human and/or animal subjects were not included in the project.
References
- 1.Alper BS, Hand JA, Elliott SG, Kinkade S, Hauan MJ, Onion DK, et al. How much effort is needed to keep up with the literature relevant for primary care? J Med Libr Assoc JMLA 2004; 92(4):429–437. [PMC free article] [PubMed] [Google Scholar]
- 2.Williamson JW, German PS, Weiss R, Skinner EA, Bowes F. Health science information management and continuing education of physicians. A survey of U.S. primary care practitioners and their opinion leaders. Ann Intern Med 1989; 110(2):151–160. [DOI] [PubMed] [Google Scholar]
- 3.Gupta K, Hooton TM, Naber KG, Wullt B, Colgan R, Miller LG, et al. International clinical practice guidelines for the treatment of acute uncomplicated cystitis and pyelonephritis in women: A 2010 update by the Infectious Diseases Society of America and the European Society for Microbiology and Infectious Diseases. Clin Infect Dis Off Publ Infect Dis Soc Am 2011; 52(5): e103-e120. doi:10.1093/cid/ciq257. [DOI] [PubMed] [Google Scholar]
- 4.McDonald CJ. Medical heuristics: the silent adjudicators of clinical practice. Ann Intern Med 1996; 124(1 Pt 1): 56–62. [DOI] [PubMed] [Google Scholar]
- 5.Tversky A, Kahneman D. Judgment under Uncertainty: Heuristics and Biases. Science 1974; 185(4157):1124–1131. doi:10.1126/science.185.4157.1124. [DOI] [PubMed] [Google Scholar]
- 6.Gaissmaier W, Wegwarth O, Skopec D, Müller A-S, Broschinski S, Politi MC. Numbers can be worth a thousand pictures: individual differences in understanding graphical and numerical representations of health-related information. Health Psychol Off J Div Health Psychol Am Psychol Assoc 2012; 31(3):286–296. doi:10.1037/a0024850. [DOI] [PubMed] [Google Scholar]
- 7.Tait AR, Voepel-Lewis T, Zikmund-Fisher BJ, Fagerlin A. Presenting research risks and benefits to parents: does format matter? Anesth Analg 2010; 111(3):718–723. doi:10.1213/ANE.0b013e3181e8570a. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Hawley ST, Zikmund-Fisher B, Ubel P, Jancovic A, Lucas T, Fagerlin A. The impact of the format of graphical presentation on health-related knowledge and treatment choices. Patient Educ Couns 2008; 73(3):448–455. doi:10.1016/j.pec.2008.07.023. [DOI] [PubMed] [Google Scholar]
- 9.Edwards A, Thomas R, Williams R, Ellner AL, Brown P, Elwyn G. Presenting risk information to people with diabetes: evaluating effects and preferences for different formats by a web-based randomised controlled trial. Patient Educ Couns 2006; 63(3):336–349. doi:10.1016/j.pec.2005.12.016. [DOI] [PubMed] [Google Scholar]
- 10.Bauer DT, Guerlain S, Brown PJ. The design and evaluation of a graphical display for laboratory data. J Am Med Inform Assoc JAMIA 2010; 17(4):416–424. doi:10.1136/jamia.2009.000505. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Henry JB, Kelly KC. Comprehensive graphic-based display of clinical pathology laboratory data. Am J Clin Pathol 2003; 119(3):330–336. [DOI] [PubMed] [Google Scholar]
- 12.Arumugam M, Raes J, Pelletier E, Le Paslier D, Yamada T, Mende DR, et al. Enterotypes of the human gut microbiome. Nature 2011; 473(7346):174–180. doi:10.1038/nature09944. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Shiffman RN. Representation of Clinical Practice Guidelines in Conventional and Augmented Decision Tables. J Am Med Inform Assoc 1997; 4(5):382–393. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Plaisant C, Mushlin R, Snyder A, Li J, Heller D, Shneiderman B. LifeLines: using visualization to enhance navigation and analysis of patient records. Proc AMIA Annu Symp AMIA Symp 1998: 76–80. [PMC free article] [PubMed] [Google Scholar]
- 15.Rathod RH, Farias M, Friedman KG, Graham D, Fulton DR, Newburger JW, et al. A novel approach to gathering and acting on relevant clinical information: SCAMPs. Congenit Heart Dis 2010; 5(4):343–353. doi:10.1111/j.1747–0803.2010.00438.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Pickering BW, Herasevich V, Ahmed A, Gajic O. Novel Representation of Clinical Information in the ICU. Appl Clin Inform 2010; 1(2):116–131. doi:10.4338/ACI-2009–12-CR-0027. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Weng C, Li Y, Ryan P, Zhang Y, Liu F, Gao J, et al. A distribution-based method for assessing the differences between clinical trial target populations and patient populations in electronic health records. Appl Clin Inform 2014; 5(2):463–479. doi:10.4338/ACI-2013–12-RA-0105. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Rubins HB, Robins SJ, Collins D, Fye CL, Anderson JW, Elam MB, et al. Gemfibrozil for the secondary prevention of coronary heart disease in men with low levels of high-density lipoprotein cholesterol. Veterans Affairs High-Density Lipoprotein Cholesterol Intervention Trial Study Group. N Engl J Med 1999; 341(6):410–418. doi:10.1056/NEJM199908053410604. [DOI] [PubMed] [Google Scholar]
- 19.ACCORD Study Group. Ginsberg HN, Elam MB, Lovato LC, Crouse JR, Leiter LA, et al. Effects of combination lipid therapy in type 2 diabetes mellitus. N Engl J Med 2010; 362(17):1563–1574. doi:10.1056/NEJMoa1001282. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Metsalu T, Vilo J. ClustVis: a web tool for visualizing clustering of multivariate data using Principal Component Analysis and heatmap. Nucleic Acids Res 2015; 43(W1): W566-W570. doi:10.1093/nar/gkv468. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Albo Y, Lanir J, Bak P, Rafaeli S. Off the Radar: Comparative Evaluation of Radial Visualization Solutions for Composite Indicators. IEEE Trans Vis Comput Graph 2016; 22(1):569–578. doi:10.1109/TVCG.2015.2467322. [DOI] [PubMed] [Google Scholar]