

Abstract
An extension to the theory of consensus values is presented. Consensus values are calculated from averages obtained from different sources of measurement. Each source may have its own variability. For each average a weighting factor is calculated, consisting of contributions from both the within- and the between-source variability. An iteration procedure is used and calculational details are presented. An outline of a proof for the convergence of the procedure is given. Consensus values are described for both the case of the weighted average and the weighted regression.
Keywords: components of variance (within- and between-groups), consensus values, convergence proof, Taylor series, weighted average, weighted least squares regression
1. Introduction
The problem of computing consensus values when the errors of measurement involve both internal (within group) and external (between group) components has been discussed in a number of papers [1–4]. The present authors have studied the case of a simple weighted average, as well as that in which the measured quantity y is a linear function of a known variable x.
In the present paper we extend our results to cases in which the error standard deviations are functions, of known form, of the x-variables. We also provide an outline of a proof for convergence of the iterative process described in reference [1].
While our procedure is entirely reasonable, and results in acceptable values, we have no mathematical proof that the weights, which we calculate from the data, are optimal in any well-defined theoretical sense. The problem has been recognized in the literature [5], but we know of no attempt to provide the proof of optimality.
2. Review
If ωi denotes the weight (reciprocal variance) of a quantity, then the general equation for a weighted average is:
| (1) |
If equals the average of ni results from group i (i=1 to m), then
where
= the component of standard deviation within group i (the value can be estimated from the ni results within each group)
σb = the component of standard deviation between groups.
Then the weight ωi of is equal to:
| (2) |
The weight equation, yields:
or
Generally, all σ-values, and consequently the ωi values are unknown. The can be estimated (as ) from the replicate measurements. We derive an estimate for and consequently for the ωi by using the quantity
which we equate to unity. Thus we have
| (3) |
Equation (3) is used in “reverse fashion” to estimate the ωi and from the sample data. This is possible if in eq (2), the are estimated from the within-group variability, so that the only unknown is σb. Note in eq (3) that σb is embedded within each weight and therefore within . The estimated and σb can also be used to estimate the standard deviation of the weighted average, which is equal to . Henceforth, we use the symbol ωi for the sample estimate of ωi.
The same general reasoning holds for the weighted regression case. The variance of a simple weighted average is replaced by the residual mean square from a weighted least squares regression. For a regression with m groups and p coefficients the analogue of eq. (3) is
| (4) |
where ωi is given by eq (2) and is the fitted value.
We now describe the case of a weighted regression with p =2. The fitted value , for the ith group can be written as follows:
| (5) |
or
| (5′) |
where is a weighted average analogous to the weighted average described by eq (1), and and are weighted least squares estimates of the coefficients, α and β. Again, the only unknown is σb, which can now be estimated from sample data by use of eq (4).
A direct solution for σb in either eq (3) or (4) would be extremely complicated since ωi, , and all contain σb. The number of terms m, in both equations will vary depending on the number of groups in a particular sample data set. Furthermore, for the regression case, the and also depend on σb. Therefore an iterative solution was proposed in reference [1]. This iterative procedure is central to the practical solution of either eq (3) or (4). In order that this paper be self-contained, we briefly review the iterative procedure for the regression case using eq (4) with p =2.
3. Iteration Procedure
We define the function:
| (6) |
In view of eqs (2) and (4), the estimate of must be such that . For ease of notation let . Start with an initial value, υ0≈0, and calculate an initial set of weights and then evaluate eq (6). In general, will be different from zero. It is desired to find an adjustment, dυ, such that F(υ0+dυ)=0. Using a truncated Taylor series expansion, one obtains:
Evaluating the partial derivative in this equation, one obtains:
| (7) |
The adjusted (new) value for υ is:
| (8) |
This new value is now used and the procedure is iterated until dυ is satisfactorily close to zero.
The iterative procedure is easily adapted to the computer. The programming steps are as follows:
Evaluate the from the individual groups of data.
Start the iteration process with a value of υ0 just slightly over zero.
Evaluate eq (2) to get estimates of .
Fit eq (5) by a weighted least squares regression of on , and get estimates of the .
Use eq (6) to evaluate F0. If F0<0, then stop the iteration and set υ=0. If not, continue with 6.
Use eq (7) to evaluate dυ.
If dυ is positive and small enough to justify stopping, then stop. If it is positive, but is not small enough, repeat steps 3–7 [using the new υ0 from eq (8)].
The consensus values are the final coefficients of the regression equation. One is also interested in the final value since this is needed to characterize the imprecision of the fit.
For the case of a weighted average [see eq (1)] the above iteration steps are the same, except that in place of step 4, is calculated by eq (1), and steps 5 and 6 use in place of , and unity is used for the p value. The authors have frequently used this procedure for the evaluation of Standard Reference Materials [6].
4. Theoretical Extensions
Once one recognizes the between- as well as the within-group component of variance in the evaluation of consensus values, one can begin to consider functional forms for these components. The within-group component can be of any form, and can be easily handled since the appropriate sample values of the component are simply substituted into the weights described by eq (2). Thereafter, this component does not affect the iteration procedure. See for example reference [7], where the within component of variance refers to a Poisson process. The between-group component, however, affects the iteration procedure and must be handled more carefully. As an example, consider the case where the between-group component of standard deviation is believed to be a linear function of the level of Xi:
| (9) |
Let us assume that we have preliminary estimates, c and d for the γ and δ coefficients. Suppose further that we wish to adjust the estimated value of the variance by a fixed scale factor, say υ′. The desired between-group component of variance is thus:
| (10) |
The weights estimated by eq (2) would then be:
| (2′) |
This newly defined weight can be used in the iteration process. The iteration process proceeds as before, but now the adjustable iteration parameter υ′ is the multiplier needed to make eq (4) true, that is, to make it consistent with the sample data sets. The denominator of eq (7) which is used in iteration step 6 for calculating dυ, needs to be slightly modified since the derivative of F with respect to υ now contains the function described by eq (10).
| (7′) |
All other steps in the iteration process are the same. The final between-group components of variance will be described by eq (10).
5. Example
The iteration process will be used to fit the data of table 1 to a straight line. These are real data taken from a large interlaboratory study for the determination of oxygen in silicon wafers.
Table 1.
Data used in example of iteration process
| X | Y1 | Y2 | Y3 |
|---|---|---|---|
| 0.806 | 2.83 | 2.85 | |
| 1.429 | 4.62 | 5.35 | 5.01 |
| 1.882 | 6.89 | 6.66 | |
| 2.140 | 7.56 | 7.67 | |
| 2.256 | 7.94 | 7.90 | |
| 2.279 | 8.42 | 8.12 | |
| 2.814 | 10.04 | 9.70 | 10.17 |
| 2.957 | 10.34 | 10.05 | |
| 2.961 | 11.09 | 11.07 | |
| 3.108 | 11.63 | 11.69 | |
| 3.124 | 10.87 | 11.01 | |
| 3.403 | 12.40 | 12.22 | |
| 3.466 | 11.94 | 12.17 | 12.92 |
| 3.530 | 12.63 | 12.41 | |
| 3.543 | 12.98 | 13.27 | |
| 3.724 | 12.95 | 12.56 | |
| 3.836 | 13.07 | 13.69 | 13.56 |
| 3.902 | 14.54 | 14.19 | |
| 4.280 | 15.59 | 16.24 | |
| 4.770 | 16.62 | 16.59 |
A preliminary examination of the data indicates that the within error has a constant standard deviation and that the between error has a standard deviation proportional to X. Thus, the error structure for the example is given by the equation:
where υ now stands for the product υ′d2 of eq (2′).
From the replicates, the pooled within standard deviation is readily calculated to be 0.265. The iteration process then yields the following results
Figures 1a and 1b show, respectively, the standard deviations within, and the residuals , as functions of Xi.
Figure 1.
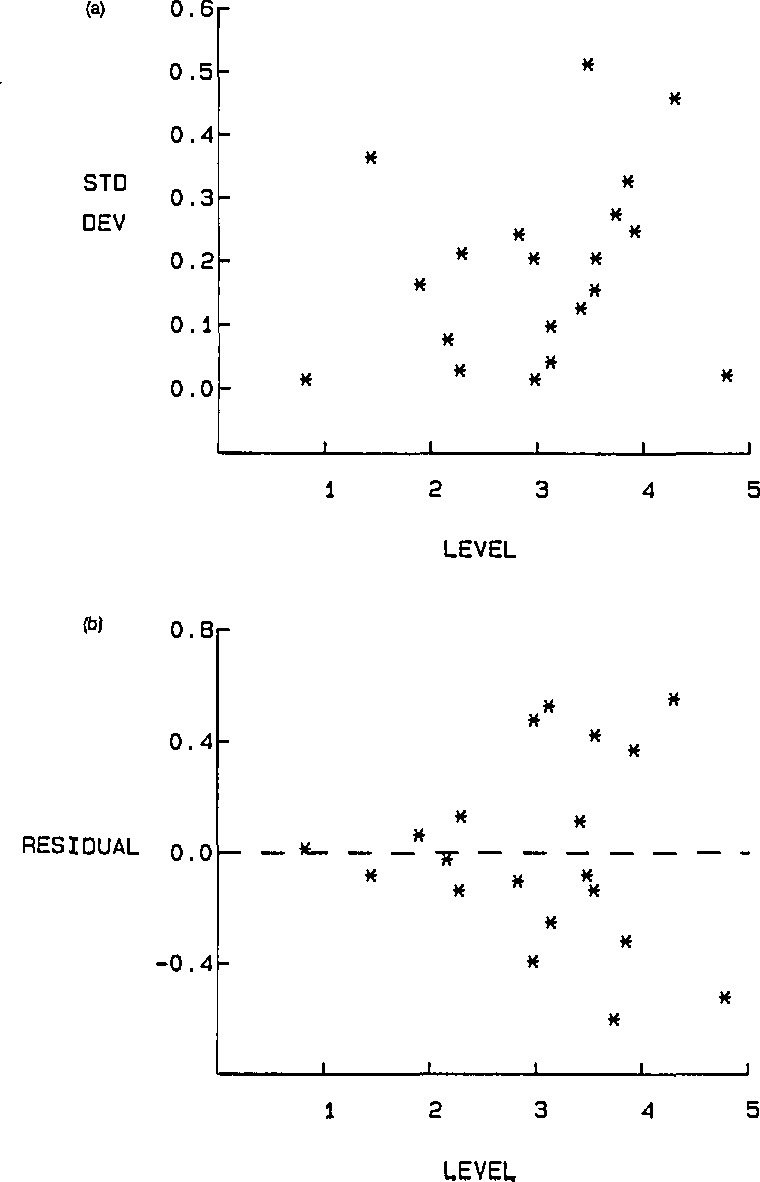
(a) Standard deviations within as a function of X (b) residuals of a function of X.
The figures support the assumpions made concerning the nature of the within and between errors.
Acknowledgments
We wish to thank Miss Alexandra Patmanidou, a graduate student at Johns Hopkins University. She noted that whenever a negative correction in the iteration process is obtained, the process should be terminated and the between-group component of variance set to zero.
Biography
About the authors: Robert C. Paule is a physical scientist and John Mandel is a consulting statistician at the National Measurement Laboratory of NIST.
6. Appendix
6.1 Sketch of Proof of Convergence
The general functional form of the F of eq (6) is as shown in figure 2a or 2b. It is because of the nature of these forms that convergence always occurs.
Figure 2.
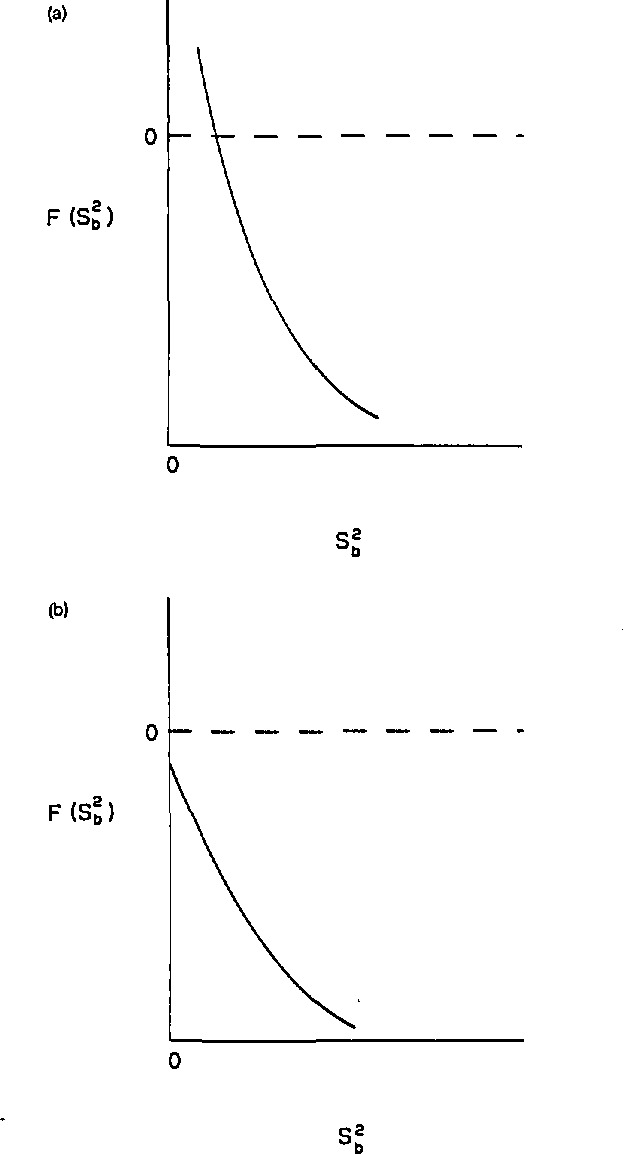
(a) F as a function of where F has a positive root for (b) F as a function of where F does not have a positive root for .
If the functional form of F is as shown in figure 2a, the previously described iterative procedure is used to determine the satisfying the equation . If an initial estimate of is chosen that is very slightly above zero, then convergence of the iteration process always occurs. This is a result of the fact that the first derivative of the function F with respect to is negative, and the second derivative is positive. This means that each iteration will undershoot, since the iteration process extrapolates the slope of the F curve at the current estimate to the F=0 value. Since each new iteration estimate of is the abscissa value of the intersection of the tangent line with the F=0 horizontal line, the iteration process will never overshoot and convergence is obtained.
If the form is that of figure 2b, then there will be no positive solutions for the that is associated with the function F. This represents a situation where the variability between the sample groups is less than that expected from the variability within the sample groups. For this situation F0 is negative and is set to zero (see iteration step 5).
The proof regarding the signs of the first and second derivatives of F with respect to follows. The simple regression case will be considered, with the being constant. (The extension to the variable case is straightforward.)
6.2 Proof That the First Derivative of F is Negative
An examination of eqs (1), (2), (5′). and (6) shows ωi and to be functions of . Equation 5′ also indicates that , , and β are functions of . We start with the first derivative of the F of eq (6)
The derivative of ωi will frequently be encountered in the following material. At this point, it will be convenient to note its value:
Continuing, and making use of eq (5′):
| (A1) |
The last two terms of eq (A1) each contain summations that are equal to zero, so these terms drop out. Next, an examination of the remaining term shows that each product is a positive square, and that the summation is preceded by a minus sign. Thus, the first derivative is negative.
6.3 Proof That the Second Derivative of F is Positive
The evaluation of the second derivative is involved and only an outline of the steps is presented.
| (A2′) |
where
| (A3) |
Evaluation of the first two derivatives on the r.h.s. of eq (A3) yields:
| (A4) |
where W≡Σ ωi.
Evaluation of the last derivative of eq (A3) yields:
| (A5′) |
where
and
Reassembling eq (A5′):
| (A5) |
At this point the running index t can be conveniently changed back to the index i. Finally, the substitution of eq (A5) into (A3), and then eq (A3) into (A2′) yields:
| (A2′ ′) |
This second derivative eq (A2′ ′) is a residual weighted sum of squares from regression. To see this, let
| (A6) |
and substitute into eq (A2′ ′):
The first term on the r.h.s. is the “total” weighted sum of squares of Z. The second term is the weighted sum of squares for the regression of Z on X. Therefore the difference between the two terms is a “residual” sum of squares:
| (A2) |
where is the fitted value of Zi in a weighted regression of Z on X. Thus, the second derivative is positive for ωi>0. The iteration process therefore will never overshoot, and convergence is always assured.
6.4 Extensions
The extension of the convergence proof to the variable case is very similar to that given above. Two basic changes are needed. These changes, which introduce a function of Xi, are in the derivative of ωi, and in the definition of Zi.
and
Equation (10) represents an example of a variable . For that case,
The reader may note that the new Zi contains Xi, and that Zi is regressed on Xi. The argument does not require that this regression “make sense”, only that the sum of squares can be partitioned by a regression process. Again, convergence is obtained.
The weighted average is a special and simple application of the weighted regression case.
8. References
- 1.Paule RC, Mandel J. Consensus Values and Weighting Factors. J Res Natl Bur Stand (US) 1982;87:377. doi: 10.6028/jres.087.022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Mandel J, Paule RC. Interlaboratory Evaluation of a Material with Unequal Numbers of Replicates. Anal Chem. 1970;42:1194. [Google Scholar]; Correction. Anal Chem. 1971;43:1287. [Google Scholar]
- 3.Cohen ER. Determining the Best Numerical Values of the Fundamental Physical Constants; Proceedings of the International School of Physics (Enrico Fermi); 1980. pp. 581–619. Course. [Google Scholar]
- 4.Birge RT. Probable Values of the General Physical Constants. Rev Mod Phys. 1929;1:1. [Google Scholar]
- 5.Cochran WG. The Combination of Estimates from Different Experiments. Biometrics. 1954;10:101. [Google Scholar]
- 6.NIST Standard Reference Materials 1563, 1596, and 1647a.
- 7.Currie LA. The Limit of Precision in Nuclear and Analytical Chemistry. Nucl Instr Meth. 1972;100:387. [Google Scholar]