

Abstract
Background and Objective:
In the analysis of dichotomous type response variable, logistic regression is usually used. However, the performance of logistic regression in the presence of sparse data is questionable. In such a situation, a common problem is the presence of high odds ratios (ORs) with very wide 95% confidence interval (CI) (OR: >999.999, 95% CI: <0.001, >999.999). In this paper, we addressed this issue by using penalized logistic regression (PLR) method.
Materials and Methods:
Data from case-control study on hyponatremia and hiccups conducted in Christian Medical College, Vellore, Tamil Nadu, India was used. The outcome variable was the presence/absence of hiccups and the main exposure variable was the status of hyponatremia. Simulation dataset was created with different sample sizes and with a different number of covariates.
Results:
A total of 23 cases and 50 controls were used for the analysis of ordinary and PLR methods. The main exposure variable hyponatremia was present in nine (39.13%) of the cases and in four (8.0%) of the controls. Of the 23 hiccup cases, all were males and among the controls, 46 (92.0%) were males. Thus, the complete separation between gender and the disease group led into an infinite OR with 95% CI (OR: >999.999, 95% CI: <0.001, >999.999) whereas there was a finite and consistent regression coefficient for gender (OR: 5.35; 95% CI: 0.42, 816.48) using PLR. After adjusting for all the confounding variables, hyponatremia entailed 7.9 (95% CI: 2.06, 38.86) times higher risk for the development of hiccups as was found using PLR whereas there was an overestimation of risk OR: 10.76 (95% CI: 2.17, 53.41) using the conventional method. Simulation experiment shows that the estimated coverage probability of this method is near the nominal level of 95% even for small sample sizes and for a large number of covariates.
Conclusions:
PLR is almost equal to the ordinary logistic regression when the sample size is large and is superior in small cell values.
KEY WORDS: Logistic regression, maximum likelihood, penalized maximum likelihood, profile penalized confidence interval
Introduction
For analyzing binary type response variable, logistic regression is commonly used. Logistic regression enables researchers to estimate the effect of the exposure variable after adjusting for the effect of other potential confounding variables. An example of such binary type response variable is the case-control study finding the association between alcohol intake and heart disease after adjusting for confounding factors such as smoking, age, and gender.[1] Usually in logistic regression, the measure of association such as odds ratio (OR) is estimated by using the maximum-likelihood estimation (MLE) method. A common problem in estimating OR in logistic regression whenever with empty cell frequency in k × k table or with a small number of frequency count, is the failure of maximum likelihood estimate to converge [OR: >999.999; 95% confidence interval (CI): <0.001, >999.999].[2] This predominantly occurs in small to medium size datasets where the regression coefficient of at least one covariate value becomes infinitely large. Sparse data or separation data occur when the response variable is perfectly separated by a single covariate or linear combination of variables.[3] The problem of separation is by no means negligible and may occur even if the variable values are low in numbers.[4]
A simple example of separation is a k × k table with “empty cell” frequency. Table 1 presents the data on diabetics and obesity that were collected by the US National Institute of Diabetics and Digestive and Kidney Diseases.[5] One of the aims of the study was to find the association between obesity and diabetes after adjusting for age, number of pregnancies, blood pressure, etc. In this data, the separation is due to the presence of few/zero count values between obesity and diabetes. In the presence of separation, the model may converge but produce huge values of regression coefficients and standard error (SE) and CI may present with infinite values (OR: >999.999; 95% CI: <0.001, >999.999). This is due to the nonexistence of maximum likelihood estimates that makes it difficult for researchers to make appropriate decisions.
Table 1.
Distribution of obesity among diabetics in the US National Institute of Diabetes and Digestive and Kidney Diseases data
| Frequency | Diabetics | Total | |
|---|---|---|---|
| No | Yes | ||
| Obesity | |||
| Underweight | 2 (100.00) | 0 (0.00) | 2 |
| Normal | 21 (91.30) | 2 (8.70) | 23 |
| Over weight | 35 (81.40) | 8 (18.60) | 43 |
| Obese | 74 (56.06) | 58 (43.94) | 132 |
| Total | 132 (66.0%) | 68 (34.0%) | 200 |
Some of the existing solutions that have been in practice for the problem of separation exclude the variable from the analysis. The second commonly used method is making modifications (usually by adding 0.5) in the data to eliminate the problem (Yates’ correction in bivariate analysis for categorical data). But both these methods were strictly not recommended as they would lead to misleading results. Another alternative approach in the analysis of sparse/separation data is the exact logistic regression.[6,7] The idea behind this method is the same as the exact inference (Fisher's exact test) in 2 × 2 table. The exact logistic regression is based on the “exact permutational distributions of the sufficient statistics that correspond to the parameters of interest, conditional on fixing the sufficient statistics of the remaining parameters at their observed value.”[3] Although this method is shown to be another option as compared to the above two, it is not used in regular practice due to the computational difficulty, provision of degenerate estimates, and not allowing the inclusion of continuous type covariates.[3]
This paper disseminates the strategy and method of handling separated data in logistic regression using penalized maximum likelihood estimation method (PMLE).[4] We also examine the characteristics of this approach with the presence of separation data for small to large sample sizes with a different number of covariates using simulation.
Methods
Data
The data used in this paper is from a case control study on hyponatremia and hiccups conducted in Christian Medical College, Vellore, Tamil Nadu, India.[8] The main aim of the hyponatremia study was to find an association between hyponatremia and hiccups after adjusting for potential confounding factors such as gender, age, renal disease, and creatine level in hospitalized patients. The dataset consists of 50 subjects with hiccups (cases) and 50 subjects without hiccups (controls). The hiccups groups were subdivided according to the severity of the disease so that among 50 subjects with hiccups, 23 subjects had mild hiccups, 12 subjects had moderate hiccups, and 15 subjects had a severe kind of hiccups. For an illustrative purpose, we have chosen 23 mild hiccup cases and 50 controls from the dataset and other confounding factors were randomly generated based on the given estimated values. Data were analyzed using SAS 9.2 for windows (SAS Institute, Inc., Cary, NC, 2000) software.[9]
Maximum likelihood and penalized maximum likelihood estimates
Basically, the likelihood function is the joint probability of each data point under an assumed distribution for the outcome. The probability mass function of the Bernoulli random variable is written as f(y,p) = py (1 - p)1-y ; y = 0,1 & 0 ≤p ≤1. The logistic regression model is 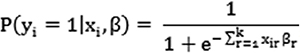 , with i = 1, 2…; n denotes n observations, r = 1, 2.., k denotes k-1 independent variables with r = 1 denoting the constant. The maximum likelihood estimate for the unknown parameter βr is obtained in such a way that it maximizes the probability of observing the data such that the likelihood function
, with i = 1, 2…; n denotes n observations, r = 1, 2.., k denotes k-1 independent variables with r = 1 denoting the constant. The maximum likelihood estimate for the unknown parameter βr is obtained in such a way that it maximizes the probability of observing the data such that the likelihood function 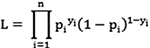 . The log likelihood (logL) is determined by taking the natural log of the likelihood function logL = ∑(yi logpi +(1-yi)log(1-pi)). The maximum likelihood estimate is obtained by solving the score equation,
. The log likelihood (logL) is determined by taking the natural log of the likelihood function logL = ∑(yi logpi +(1-yi)log(1-pi)). The maximum likelihood estimate is obtained by solving the score equation,
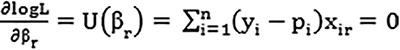 .
.
The problem in maximum likelihood estimate in the case of separation is that the function cannot have one maximum [Figure 1a]. Hence, the idea behind penalized maximum likelihood estimate for logistic regression is that the method penalizes the likelihood by half of the logarithm of the determinant of the information matrix (I), that is, 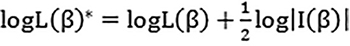 .[10] So, the modified score function becomes U(βr)* = ∑ni=1 (yi –pi +hi (1/2–pi)xir) = 0. Thus, the penalized maximum likelihood estimate provides a solution to the problem of separation in Figure 1b. For the calculation of CI, we used profile likelihood based CI as compared to asymptomatic based Wald-type confidence interval that is inaccurate in the presence of separation.[11] For comparing models fitted by maximum likelihood and penalized maximum likelihood for logistic regression, we used Akaike information criterion (AIC) and −2 log likelihood (−2logL) methods.[12] Given the different models, the one with smaller AIC/−2 logL fits the data better than the one with larger AIC/−2 logL values. Details of the software for execution of penalized logistic regression (PLR) are given below.
.[10] So, the modified score function becomes U(βr)* = ∑ni=1 (yi –pi +hi (1/2–pi)xir) = 0. Thus, the penalized maximum likelihood estimate provides a solution to the problem of separation in Figure 1b. For the calculation of CI, we used profile likelihood based CI as compared to asymptomatic based Wald-type confidence interval that is inaccurate in the presence of separation.[11] For comparing models fitted by maximum likelihood and penalized maximum likelihood for logistic regression, we used Akaike information criterion (AIC) and −2 log likelihood (−2logL) methods.[12] Given the different models, the one with smaller AIC/−2 logL fits the data better than the one with larger AIC/−2 logL values. Details of the software for execution of penalized logistic regression (PLR) are given below.
Figure 1.
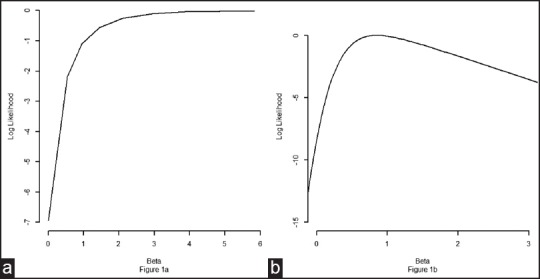
(a and b) Profile of log likelihood and penalized log likelihood function under complete separation
Simulation study
A simulation experiment was conducted to study the empirical performance of PLR with respect to coverage probability. Coverage probability is defined as the probability that the procedure produces an interval that covers the true (regression coefficient) value. In order to investigate the performance of this method in the presence of complete and quasi separations, we created 1,000 datasets, each with different sample of sizes n = (30, 75, 150) and with a different number of covariates k = (2, 3, 4). We used Monte Carlo method to obtain the 95% coverage probability of PLR. We conducted the simulation experiment by using SAS 9.2 for windows (SAS Institute, Inc., Cary, NC, 2000) statistical software. The R, STATA, and SAS codes for doing PLR are given in the appendix.
Results
Twenty three cases and 50 controls were selected for the analysis of ordinary logistic regression and PLR. Table 2 shows the demographic and clinical characteristics of the subjects. The primary exposure factor hyponatremia was present in nine (39.13%) of the cases and in four (8.0%) of the controls. Of the 23 hiccup cases, all were males and among the controls, 46 (92.0%) were males. Renal disease was present in five (21.74%) of the cases and seven (14.0%) of the controls. The mean [standard deviation (SD)] age of the subjects in the hiccups group was 51.61 (12.27) years and in the control group was 49.34 (11.94) years. The mean (SD) creatine level was more in the cases, that is, 2.23 (1.52) mg/dL than in the control group 1.45 (0.72) mg/dL. Our primary interest in this paper is to find the association between hyponatremia and hiccups after adjusting the potential confounders with the presence of separation due to zero cell frequency in the cross tabulation between gender and the disease group.
Table 2.
Distribution of each of the predictor variables with the outcome in hiccups data
| Variable | Hiccups | |
|---|---|---|
| Yes* | No | |
| n = 23 (31.51%) | n = 50 (68.49%) | |
| Hyponatremia | ||
| Yes | 9 (39.13) | 4 (8.00) |
| No | 14 (60.87) | 46 (92.00) |
| Gender | ||
| Male | 23 (100.0) | 46 (92.00) |
| Female | 0 (0.00) | 4 (8.00) |
| Renal disease | ||
| Present | 5 (21.74) | 7 (14.00) |
| Absent | 18 (78.26) | 43 (86.00) |
| Age (years): mean (SD) | 51.61 (12.27) | 49.34 (11.94) |
| Creatine (mg/dL): mean (SD) | 2.23 (1.52) | 1.45 (0.72) |
*We only considered mild hiccups cases from the original paper
Table 3 presents the results of the association between hiccups and its corresponding risk factors with 95% CI using both ordinary logistic regression and PLR methods. In the analysis of hiccups data, complete separation between gender and the disease group led to an infinite maximum likelihood estimate of gender (OR: >999.999; 95% CI: <0.001, >999.999) and intercept (OR: 47287; 95% CI: -) with large standard errors, whereas there is a finite and consistent regression coefficient for gender (OR: 5.35; 95% CI: 0.42, 816.48) and the intercept (OR: 0.05; 95% CI: 0.00, 1.30) using PLR. After adjusting for gender, age, and clinical characteristics, hyponatremia was associated with nearly 7.9 (95% CI: 2.06, 38.86) times higher risk of developing hiccups that is statistically significant (P value = 0.0057) using the penalized maximum likelihood method. Rather, there is an overestimation of OR: 10.76 (95% CI: 2.17, 53.41) between hyponatremia and hiccups by using ordinary logistic regression (P value = 0.0036). There is a statistically significant effect of the creatine level on hiccups in both the methods [OR: 2.16; 95% CI (1.16, 5.58)] using penalized methods (P value = 0.0493) and OR: 2.62; 95% CI (1.10, 6.27) the ordinary logistic regression method (P value = 0.0301)).
Table 3.
Results of analysis of hiccups data by maximum likelihood and penalized maximum likelihood logistic regression methods
| Variable | Ordinary logistic regression | Penalized logistic regression | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| beta | SE | P value | OR | 95% CI of OR | beta | SE | P value | OR | 95% CI* of OR | |
| Intercept | −14.15 | 377.90 | 0.9701 | 47287.44 | — | −3.08 | 2.09 | 0.1412 | 0.05 | (0.00, 1.30) |
| Hyponatremia: Yes | 2.38 | 0.82 | 0.0036 | 10.76 | (2.17, 53.41) | 2.06 | 0.75 | 0.0057 | 7.88 | (2.06, 38.86) |
| Gender: Male | 12.86 | 377.90 | 0.9729 | >999.999 | (<0.001, >999.999) | 1.68 | 1.82 | 0.3561 | 5.35 | (0.42, 816.48) |
| Renal disease: Present | 0.06 | 0.79 | 0.9346 | 1.07 | (0.23, 5.02 | 0.16 | 0.75 | 0.8309 | 1.17 | (0.25, 4.81) |
| Age (years) | −0.03 | 0.03 | 0.3481 | 0.97 | (0.91, 1.03) | −0.02 | 0.03 | 0.4856 | 0.98 | (0.92, 1.03) |
| Creatine (mg/dL) | 0.96 | 0.44 | 0.0301 | 2.62 | (1.10, 6.27) | 0.77 | 0.39 | 0.0493 | 2.16 | (1.16, 5.58) |
| AIC | 80.82 | 70.02 | ||||||||
| −2 Log L | 68.82 | 58.02 | ||||||||
SE – Standard error; OR – Odds ratio; CI – Confidence interval; *Profile penalized likelihood-based CI
It is also noted that point estimates for each of the risk factors by the penalized maximum likelihood method was considerably smaller than the maximum likelihood estimates owing to the bias correction property of the penalized maximum likelihood method. In addition to this, the width of the 95% CI of the penalized maximum likelihood estimates was narrow as compared to the maximum likelihood estimates. PLR had a lower AIC and −2 log L values as compared to ordinary logistic regression using maximum likelihood estimate. This shows that PLR is preferred over ordinary logistic regression in the presence of separation.
It is also evident from the results of the simulation study that the estimated coverage probabilities of the CI of PLR were almost near the nominal level of 95% [Table 4]. This is even true for the studies with complete/nearly separated data with small sample sizes and an increased number of covariates. Instead, the coverage probabilities of ordinary logistic regression of almost 100% (where it is expected to be nearly 95%) indicates that this method is a poor choice when there is a presence of separation in the data. Thus, the simulation study implies that penalized maximum likelihood logistic regression can be applied for separated data even for small number of observations with increased number of covariates.
Table 4.
Results of the simulation study for different sample sizes and number of covariates – coverage probability of 95% CI
| N | K | Coverage probability of 95% CI (based on penalized logistic regression) (%) |
Coverage probability of 95% CI (based on ordinary logistic regression) (%) |
|---|---|---|---|
| 30 | 2 | 93.9 | 100 |
| 3 | 94.5 | 100 | |
| 4 | 93.4 | 100 | |
| 75 | 2 | 94.7 | 100 |
| 3 | 97.7 | 100 | |
| 4 | 96.8 | 100 | |
| 150 | 2 | 94.7 | 100 |
| 3 | 93.7 | 100 | |
| 4 | 94.7 | 100 |
Figure 2 plots the profile penalized maximum likelihood estimates for the effect of hyponatremia on hiccups, along with 95% CI. The circle denotes the point estimate with indications for lower limit (LL) and upper limit (UL).
Figure 2.
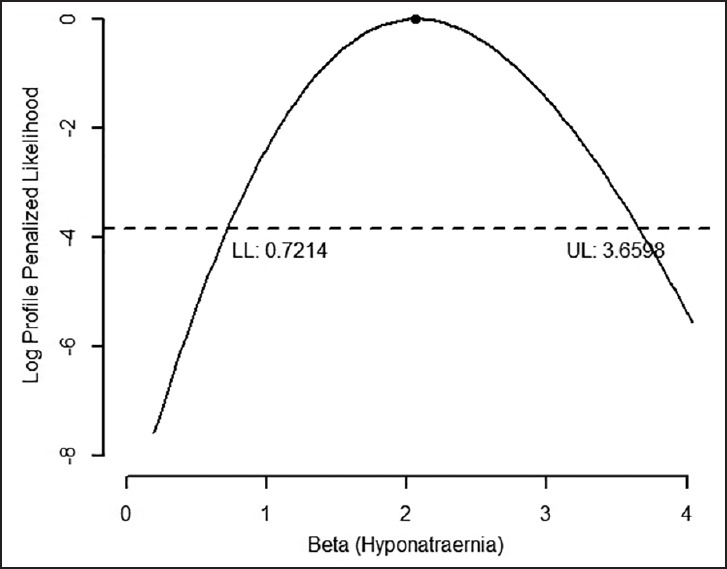
Profile penalized maximum likelihood estimates for the effect of hyponatremia on hiccups, along with 95% confidence interval
Discussion
In the analysis of the data, while the researcher may want to adjust for the effects of all confounding factors, including gender, omission of this risk factor cannot be considered here. Hence, we used the penalized maximum likelihood logistic regression method that provided a reasonable estimate of the effect of each of the risk factors on the disease status and greatly improved the interpretation as compared to the conventional method. All the ORs were nearly greater than 1; however, only hyponatremia and creatine level were statistically significant in both the models. The estimated OR of hyponatremia on hiccups is easily interpretable. After adjusting for all the confounding factors, hyponatremia was significantly associated with hiccups (PMLE OR: 7.88; 95% CI: 2.06, 38.86 as compared to MLE OR: 10.76; 95% CI: 2.17, 53.41). Excluding the covariate - gender, in both ordinary logistic regression and PLR models, the effect of hyponatremia on hiccups was lower as compared to the model with the presence of gender (PMLE OR: 6.95; 95% CI: 1.91,29.80 as compared to MLE OR: 8.62; 95% CI: 2.00,37.20).
Initially, the PMLE method was introduced to reduce the bias of maximum likelihood estimate in generalized linear models.[13] Currently, this method is used in many situations such as in multinomial logistic regression where it was suggested that this method was superior to other methods in small samples and equivalent to maximum likelihood estimate when the sample size increases;[14] in the analysis of complete/nearly separated data in logistic regression;[4] in the analysis of diagnostic and prognostic prediction models[15] where it has been shown that PMLE leads to smaller prediction error as compared to other methods such as bootstrapping technique. PLR has been used for finding the association between coronary heart disease (CHD) and smoking.[16] Comparison between maximum likelihood estimate and penalized maximum likelihood estimate were also done for separation case in which one of the cells in 2 × 2 table was equal to zero. Double penalized MLE has also been proposed for separation and multicollinearity in multiple logistic regressions.[17]
In many medical researches, in dealing with binary type response variables the presence of separation is unavoidable. It arises most often when the sample size is small or strong relationships are present. The PMLE method is simple and easy-to-use and can be implemented via the most of the popular softwares. It also gives meaningful results that enable researchers to make appropriate decisions about important risk factors. In our data, the effect of gender on hiccups could not be studied using the conventional method while it would have been possible by using the penalized method (OR: 5.35; 95% CI: 0.42, 816.48). Thus, PLR provides an attractive, finite, and consistent regression coefficient against the conventional method. The OMLE method is approximately equal to the conventional method when the sample size is large and the cell frequency is more or equally distributed and is superior in small cell values. Hence, a recommendation can be made to always use PLR as compared to the ordinary logistic regression method.[18] The goal of considering the separation variable in the analysis is two pronged:firstly, how its impact on the exposure variable of interest as a co-variate or a confounder, for example: hyponatremia in this study; and secondly its effect on the outcome variable (OR and 95% CI).[4] The PLR analysis provides the correct estimate of OR and its 95% CI for the separation variables as compared to ordinary logistic regression analysis. However, many times the 95% CI is still wider despite its significance.
Hence, in the analysis of logistic regression with the presence of separation/sparse data the researchers need to make out two important points of information. One is that we need to review carefully the contingency table of separation variable and the outcome. It should provide biologically important data. Here in our example, men are more likely to have hiccups as compared to women. Second, we should not throw away such useful information due to a wider CI. The author should also provide the contingency table for the separation variable and the outcome to convey this message. Thus, the application of PLR in this study has provided a better picture of the effect of hyponatremia on hiccups after adjusting for other confounding variables.
Software details
PLR can be done using SAS, STATA, and R statistical software. In SAS, Proc logistic procedure with keyword “firth” was used to estimate the parameter of the covariates using PLR.[9] In STATA, “firthlogit” command is used to implement Firth-based PLR.[19] The “logistf” library in R software also has the function to perform PLR.[20]
Financial support and sponsorship
This research received no specific grant from any funding agency in the public, commercial or not-for-profit sectors.
Conflicts of interest
There are no conflicts of interest.
Appendix
Appendix.
R codes
### The R codes are case-sensitive
### To use penalized logistic regression, install the package “logistf” install.packages(“logistf”)
library(logistf)
### How to input data:
### Please note the double slash in the directory. Copy the directory and insert one more slash.
### If MAC users ignore the above
### The following command is to read the data which is in Documents folder
hic <- read.csv(“C:\\Users\\ljey\\Documents\\Hiccups data.csv”, sep=”,”, header=T)
hic # This command will display the data
names(hic) # This command will display the names of the variables
### How to run the penalized regression
model <- logistf(Disease~Exposure+gender+renal+age+creatine, data=hic)
summary (model)
### To calculate OR with 95% CI
exp(model$coef[1]);exp(model$ci.lower[1]);exp(model$ci.upper[1])
exp(model$coef[2]);exp(model$ci.lower[2]);exp(model$ci.upper[2])
exp(model$coef[3]);exp(model$ci.lower[3]);exp(model$ci.upper[3])
exp(model$coef[4]);exp(model$ci.lower[4]);exp(model$ci.upper[4])
exp(model$coef[5]);exp(model$ci.lower[5]);exp(model$ci.upper[5])
exp(model$coef[6]);exp(model$ci.lower[6]);exp(model$ci.upper[6])
SAS codes:
/* To import data into SAS*/
proc import datafile=” C:\Users\ljey\Documents\Hiccups data.csv”
out=hic_data;
run;
/* To run penalized logistic regression in SAS*/
proc logistic descending data=hic_data;
model disease=exposure gender renal age creatine/firth clparm=PL;
run;
STATA codes:
/*To import data in STATA*/
import delimited “C:\Users\ljey\Documents\Hiccups data.csv “
/* To run penalized logistic regression in STATA*/
firthlogit disease exposure gender renal age creatine
/* To calculate OR with 95% CI*/
firthlogit, or
References
- 1.Schlesselman JJ. New York, USA: Oxford University Press; 1982. Case Control Studies: Design, Conduct, Analysis; pp. 181–2. [Google Scholar]
- 2.Paul DA. Convergence Failures in Logistic Regression. SAS Glob. FORUM360AD. [Last accessed on 2015 Jan 3]. Available from: http://www2.sas.com/proceedings/forum2008/360-2008.pdf .
- 3.Zorn C. A solution to separation in binary response models. Polit Anal. 2005;13:157–70. [Google Scholar]
- 4.Heinze G, Schemper M. A solution to the problem of separation in logistic regression. Stat Med. 2002;21:2409–19. doi: 10.1002/sim.1047. [DOI] [PubMed] [Google Scholar]
- 5.Shahbaba B. Biostatistics with R. An Introduction to Statistics through Biological Data. Springer. 2011:246–8. [Google Scholar]
- 6.Cox DR, Snell EJ. 2nd ed. Chapman & Hall/CRC; 1989. Analysis of Binary Data. [Google Scholar]
- 7.Mehta CR, Patel NR. Exact logistic regression: Theory and examples. Stat Med. 1995;14:2143–60. doi: 10.1002/sim.4780141908. [DOI] [PubMed] [Google Scholar]
- 8.George J, Thomas K, Jeyaseelan L, Peter JV, Cherian AM. Hyponatraemia and hiccups. Natl Med J India. 1996;9:107–9. [PubMed] [Google Scholar]
- 9.Statistical Analysis Software, SAS/STAT. [Last accessed on 2015 Jan 3]. Available from: http://www.sas.com/en_us/software/analytics/stat.html .
- 10.Hilbe JM. 1st ed. Boca Raton: Chapman & Hall/CRC; 2009. Logistic Regression Models; pp. 554–5. [Google Scholar]
- 11.Stryhn H, Christensen J. Confidence Intervals by the Profile Likelihood Method with Applications in Veterinary Epidemiology. Contributed paper at ISVEE X (November 2003, Chile) 2003. http://people.upei.ca/hstryhn/stryhn208.pdf .
- 12.Akaike H. Parzen E, Tanabe K, Kitagawa G. Selected Papers of Hirotugu Akaike. New York: Springer; 1998. Information theory and an extension of the maximum likelihood principle; pp. 199–213. [Google Scholar]
- 13.Firth D. Bias reduction of maximum likelihood estimates. Biometrika. 1993;80:27–38. [Google Scholar]
- 14.Bull SB, Mak C, Greenwood CM. A modified score function estimator for multinomial logistic regression in small samples. Comput Stat Data Anal. 2002;39:57–74. [Google Scholar]
- 15.Moons KG, Donders AR, Steyerberg EW, Harrell FE. Penalized maximum likelihood estimation to directly adjust diagnostic and prognostic prediction models for overoptimism: A clinical example. J Clin Epidemiol. 2004;57:1262–70. doi: 10.1016/j.jclinepi.2004.01.020. [DOI] [PubMed] [Google Scholar]
- 16.Eyduran E. Usage of penalized maximum likelihood estimation method in medical research: An alternative to maximum likelihood estimation method. J Res Med Sci. 2008;13:325–30. [Google Scholar]
- 17.Shen J, Gao S. A solution to separation and multicollinearity in multiple logistic regression. J Data Sci. 2008;6:515–31. [PMC free article] [PubMed] [Google Scholar]
- 18.Paul DA. Logistic Regression for Rare Events Statistical Horizons 2012. [Last accessed on 2015 Jan 3]. Available from: http://www.statisticalhorizons.com/logisticregression-for-rare-events .
- 19.Coveney J. FIRTHLOGIT: Stata Module to Calculate Bias Reduction in Logistic Regression. 2008. [Last accessed on 2015 Jan 3]. Available from: http://econpapers.repec.org/software/bocbocode/s456948.htm .
- 20.Heinze G, Ploner M. Versions DD (Former, (Former Versions) HS. Logistf: Firth's Bias Reduced Logistic Regression. 2013. [Last accessed on 2015 Jan 3]. Available from: http://cran.r-project.org/web/packages/logistf/index.html .