

Abstract
In stepped cluster designs the intervention is introduced into some (or all) clusters at different times and persists until the end of the study. Instances include traditional parallel cluster designs and the more recent stepped‐wedge designs. We consider the precision offered by such designs under mixed‐effects models with fixed time and random subject and cluster effects (including interactions with time), and explore the optimal choice of uptake times. The results apply both to cross‐sectional studies where new subjects are observed at each time‐point, and longitudinal studies with repeat observations on the same subjects.
The efficiency of the design is expressed in terms of a ‘cluster‐mean correlation’ which carries information about the dependency‐structure of the data, and two design coefficients which reflect the pattern of uptake‐times. In cross‐sectional studies the cluster‐mean correlation combines information about the cluster‐size and the intra‐cluster correlation coefficient. A formula is given for the ‘design effect’ in both cross‐sectional and longitudinal studies.
An algorithm for optimising the choice of uptake times is described and specific results obtained for the best balanced stepped designs. In large studies we show that the best design is a hybrid mixture of parallel and stepped‐wedge components, with the proportion of stepped wedge clusters equal to the cluster‐mean correlation. The impact of prior uncertainty in the cluster‐mean correlation is considered by simulation. Some specific hybrid designs are proposed for consideration when the cluster‐mean correlation cannot be reliably estimated, using a minimax principle to ensure acceptable performance across the whole range of unknown values. © 2016 The Authors. Statistics in Medicine published by John Wiley & Sons Ltd.
Keywords: cluster studies, stepped‐wedge designs, intra‐cluster correlation, optimal design
1. Introduction
In a ‘stepped’ cluster design, an intervention is introduced into some or all of the clusters at (possibly) different uptake‐times during the study. Once introduced into a cluster, the intervention persists until the end of the study. We assume that outcome‐data is collected in all clusters throughout the duration of study and that interest centres on the contrast between the treated (post‐intervention) and control (pre‐intervention) conditions. This class of study design includes some traditional parallel cluster designs 1 with ongoing patient recruitment (where one group of clusters receives the intervention at the start, and the remainder at the end, or not at all) as well as the recent ‘stepped‐wedge’ designs in which the intervention is introduced into all clusters but at staggered (often regularly spaced) time‐points 2, 3, 4, 5. Some other examples feature in Figure 1. Stepped‐wedge designs offer a potential advantage over parallel designs in that each cluster functions as its own control. This can be useful when a high proportion of the variation occurs at the cluster level, but it must be set against the temporal confounding that may arise because the number of clusters exposed to the intervention increases over the course of the study. The tension between cluster‐level effects and temporal confounding is a critical factor for the performance of stepped designs 6.
Figure 1.
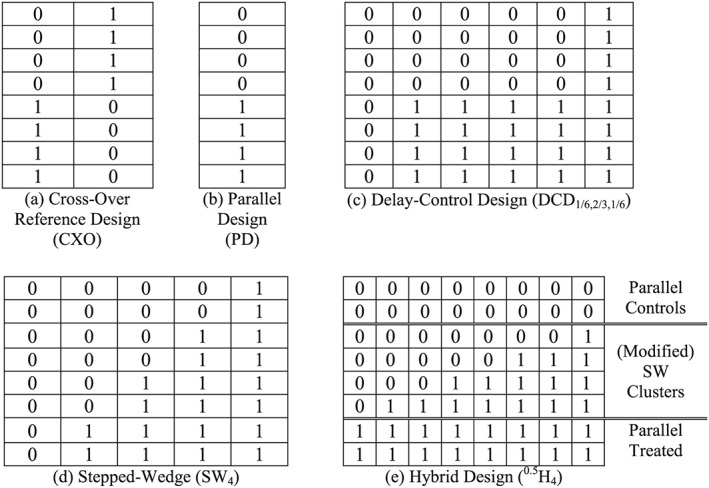
Schematic for some designs with eight clusters. The horizontal direction represents time and the total duration of the study (which is the same for each design) is equally divided between the columns. The rows represent clusters. So each cell represents the observation‐times in a single cluster over one fixed time period. Treated cells are denoted by 1, and Controls by 0.
We suppose that a study for a cluster‐level intervention is planned to take place in K clusters and that each cluster contributes m outcome measurements (observations) at each of T regularly‐spaced time‐points. The discussion here applies to two main types of cluster study: (i) longitudinal (cohort) studies where Km subjects are recruited at the beginning of the study, with repeat observations at each time‐point; and (ii) cross‐sectional studies where KTm different subjects are recruited during the course of the study, and each contributes a single observation on the main outcome measure. We exclude ‘open’ cohort designs – i.e. longitudinal studies with significant drop‐out and/or ongoing recruitment. Instances of these two types are provided by two paradigms: (i) studies of a health intervention in a closed population (such as a care‐home) where the same subjects are monitored over a period of time 7, 8; and (ii) service‐delivery studies in hospital in‐patient or emergency departments where a single outcome measure is obtained from each member of a continuously changing patient population 9, 10. Further instances of each type are enumerated in a recent review 4. In either case we assume that the frequency and timing of data‐collection are already settled, and focus on the choice of intervention uptake‐times: specifically the impact of this choice on the statistical performance of the intervention effect estimate.
The observations are described by a linear mixed effects model with fixed time and random cluster effects due to Hussey and Hughes 11, with the addition of random cluster‐specific time components and subject‐level components for longitudinal studies 12. Even without these additions, the Hussey and Hughes model has been found useful for the design of stepped studies 13, 14. It is directly applicable when the outcome is continuous, and approximately for binary outcomes when m is large 11. It was used also in a recent paper that addresses the optimal design of stepped‐wedge studies 15, although under conditions that exclude most of the optimal designs in the present study.
Some designs using eight clusters are illustrated in Figure 1. In each particular design the number of observation‐times in each cell is constant, with treatment status coded as 1 if exposed and 0 if unexposed to the intervention. The total number of observations in each cluster (mT = M) is the same for all designs. This means that the cell‐sizes may differ between designs. Thus a cell in Figure 1b – the parallel design – contains twice as many observations as a cell in Figure 1a.
In most of these examples the number of treated clusters grows over the course of the study. An exception is the cross‐over design in Figure 1(a). This design is often not practical because the intervention is withdrawn in some clusters halfway through the study. However it is useful as a reference design against which the relative efficiency of other designs can be calibrated. The ‘Delay‐Control Design’ – a terminology suggested by an anonymous referee – in Figure 1c is an elaboration of the parallel design in which all clusters contribute baseline control observations and all receive the intervention towards the end of the study. A stepped‐wedge design arises if all clusters receive the intervention with uptake times evenly spaced throughout the study. The stepped‐wedge in Figure 1d has eight clusters but only g = 4 uptake times. Alternatives with g = 2 or 8 are also available. The final design (Figure 1e) is motivated by an optimality result described later. It represents a 50:50 hybrid combination of a parallel design in the top and bottom two clusters with a stepped‐wedge‐type layout in the middle four clusters, although with reduced time before the first and after the last uptake point.
The paper contains two main sections. In section 2 a generic expression for the precision of the treatment effect estimate is obtained. This leads to a simple graphical method for comparing the efficiency of designs. Section 3 is concerned with the optimal choice of uptake times when the numbers of clusters and observation time‐points are both fixed, and includes some suggestions for practical design choices.
2. The precision of the effect estimate under a linear mixed effects model
2.1. The model
Each cluster i (i = 1,…,K) generates m measurements at every time‐point j (j = 1,…,T) according to the following model:
| (1) |
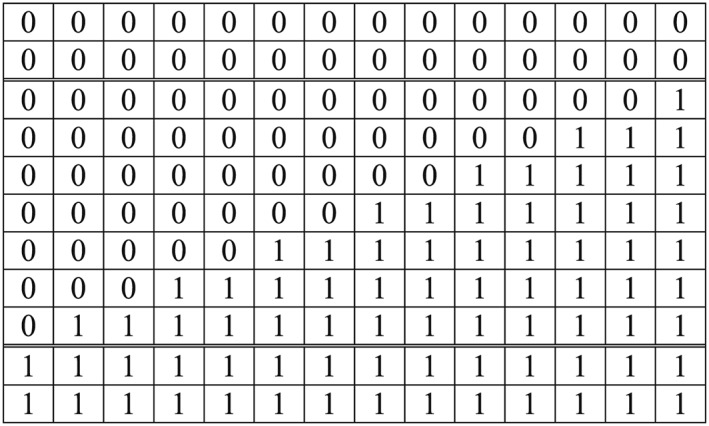
Here has variance and is the outcome for the lth observation (l = 1,…,m) at time j in cluster i; c 1,…,cK are mutually independent random cluster effects (variance ); t 1,…,tT are fixed time‐effects; s l(i) and (st)l(i)j are within‐cluster random effects with variances and respectively; (ct)ij represents cluster‐level fluctuations of the time‐effect with variance so that η CT = 1 − η C − η S − η ST; θ is the intervention effect whose estimation is the purpose of the analysis; and Jij is a binary variable (as in Figure 1) which indicates whether or not the intervention is present at time j in cluster i. The random components in this model are as in Teerenstra et al. 12. Note that we use M = Tm to denote the total number of observations in each cluster. The number of time parameters is dictated by the number of observation times (T), and this may be greater than the number of columns in the representation used in Figure 1. However, the main precision formula below applies also for models with a single time‐parameter for each column.
This formulation covers two important cases:
Cross‐sectional study with no within‐cluster time effects: η S = 0, η CT = 0. At each time‐point m (new) subjects are observed within each cluster. The (st) component combines variation between subjects (within clusters) and within‐subject measurement error. Here ηC is the conventional intra‐cluster correlation coefficient (ICC).
Longitudinal/Cohort study: η S > 0. Within each cluster, the same group of m subjects is measured at every time‐point. The s‐component describes variation between subjects (within clusters); the (st)‐component describes variation within‐subjects (including measurement error); the (ct)‐component describes cluster‐level time effects.
In this work we consider the performance of the best linear unbiased estimate of θ in model (1). This can depend only on the means of the observations at each time‐point in each cluster, i.e. on . The Yijs obey a model (2) of the form proposed by Hussey and Hughes 11 and which is the basis of our development. This is:
| (2) |
where , with variance , and , with variance , are independent random components. The variance of Yij can be partitioned as
with . The quantity ρ is the correlation between Yij‐values obtained in the same cluster at different times, and corresponds to the ICC for the Yijs. Unlike ICCs for the individual observations , ρ can easily be large (i.e. close to 1), particularly if ηCT = 0.
2.2. The cluster‐mean correlation
The efficiency of a stepped cluster design turns on the quantity R, defined by , from which . The value of R has a simple interpretation in terms of the Yij as the proportion of the variance of a cluster‐mean that comes from random effects that are independent of time (i.e. from the ci and sl(i)). In many circumstances this definition is aligned with that for the correlation between the means of two replicate sets of observations – say – from the same cluster i, although the nature of the replication must be carefully considered. For a cross‐sectional study with ηS = 0, ηCT = 0 the replicate set simply entails the recruitment of a new set of subjects in the same cluster. Moreover, in this case, , furnishing a direct connection with ηC, the ICC for the individual observations. A similar interpretation in longitudinal studies is possible if the ‘replicate set’ is taken to require new observations at the same times on the same subjects rather than a set of measurements on new subjects.
In all cases we refer to R as the cluster‐mean correlation (CMC). In general 0 ≤ R ≤ 1 and large values of R (i.e. close to 1) are possible even in cross‐sectional studies with a small ICC (ηC) for the individual observations. This feature is illustrated in Figure 2.
Figure 2.
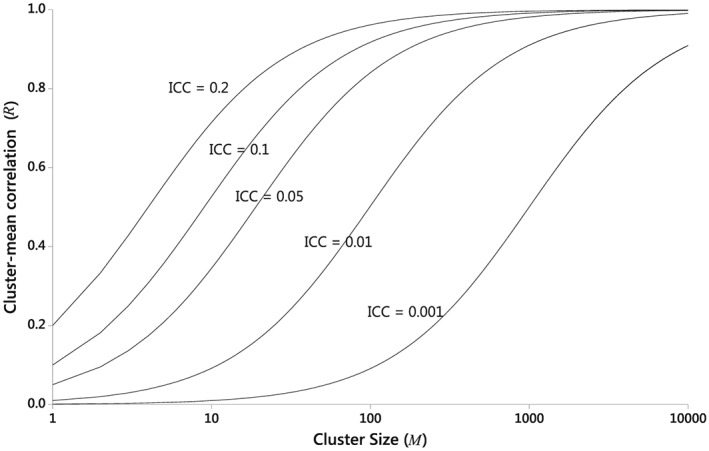
The cluster‐mean correlation (R) as a function of cluster‐size (M = Tm) in cross‐sectional studies with individual‐observation ICC (ηC) = 0.001, 0.01, 0.05, 0.10, 0.20.
2.3. A precision formula
The performance of the design can be identified with the precision of the best linear unbiased estimate (BLUE) of the treatment effect θ in model (1), with known variances. The BLUE under model (1) is also the BLUE under the Hussey and Hughes model (2), so that the following result can be applied:
(Precision of the effect estimate) Under the model in (2) the BLUE of θ has precision given by:
| (3) |
where is the CMC and aD and bD are constants, specific to the particular design D, that depend on the distribution of the treatment indicator Jij over the units in the study.
Specifically we have
and
making use of the ‘dot‐bar’ notation, so that means and means .
In the language of the analysis of variance, aD is the ‘within‐columns’ variance of the binary variable J ij, and bD is the ‘between‐rows’ variance of Jij, under a probability model in which equal weight is assigned to each point of the (i,j) lattice. The result (3) is established in Appendix A under the conditions of model (2), and provides a straightforward method to calculate the precision for any configuration of Jijs.
The argument in appendix also shows that the precision expression (3) holds for a model with linear constraints on the tj parameters, provided that the resulting model is rich enough to represent an initial level, together with a separate time‐effect for each uptake point. If the design is represented as in Figure 1, the minimum requirement is a separate time parameter for each column.
(Extension to fixed cluster effects). If the cluster effects (γi) are treated as fixed, the precision of the estimate of θ is recovered by setting R(T,ρ) = 1 in expression (3).
The result (3) is formally equivalent to an expression given by Hussey and Hughes 11. However, these authors do not expose the important relationship with the CMC.
2.4. Precision for some particular designs
The design coefficients aD and bD in (3) are presented for some particular designs in Table 1 below. The calculations are outlined in Appendix B. In some cases these expressions apply strictly only if certain divisibility conditions on T and K are met. For example, the results for the g‐step stepped‐wedge design require that T be a multiple of (g + 1), and K a multiple of g. Where a required condition does not hold, the results may be regarded as approximations whose validity improves in larger studies.
Table 1.
Design coefficients for some selected designs. These determine the precision using equation (3) and the design effect using equation (5). The final column represents the asymptotic relative efficiency (ARE) of the design (compared to CXO) when the number of observations is large.
Cluster Cross‐Over design (CXO): For this design it is assumed that both K and T are even. Initially there are K/2 intervention clusters and K/2 control clusters. Halfway through the study each cluster crosses over to the alternative condition.
Parallel Design (PD): This is a classic design for a cluster‐randomised trial. An even number of clusters is assumed, equally divided between treated and control conditions.
Delay‐Control Design (DCDp,q,r): A parallel layout runs only for a proportion q of the study duration, preceded by a period (proportion p) in which all clusters remain in the control condition, and followed by a period (proportion r) in which the treatment is present in all clusters (p + q + r = 1). The PD (= DCD0,1,0) and the ANCOVA design 12 (= DCD0.5,0.5,0) are covered as special cases. The design coefficients (aD,bD) depend only on the proportion of time (q) occupied by the parallel layout.
For both the PD and the DCD it is possible to vary the proportion of control clusters within the parallel layout from the 50% assumed here. The effect would be to reduce both design coefficients – and hence the precision – by the factor 4s(1 − s) ≤ 1 where s is the (new) proportion of control clusters.
Stepped‐Wedge design with g steps (SWg): This is the ‘standard’ stepped‐wedge design. The clusters are divided into g equal groups. Initially all clusters are untreated. The uptake time is the same for all clusters in any one group. In the first group this occurs when a fraction of the total study time equal to 1/(g + 1) has elapsed and T/(g + 1) observation time‐points have passed. The uptake times in the remaining groups occur at time‐fractions 2/(g + 1), 3/(g + 1),…, etc. until all clusters are exposed. During the final part of the study (from time‐fraction g/(g + 1) to the end) all clusters are exposed to the intervention.
Modified SW design (MSWg): In this modification of the SWg design the time period before the first (and after the last) uptake point is equal to one half of the time between consecutive uptake points – as in the middle four clusters in Figure 1e. Because a MSW − b MSW R > a SW − b SW R for all values of R, the MSWg design generates greater precision than the conventional SWg design, although the relative advantage diminishes as g increases.
Stepped‐Wedge/Parallel Hybrid designs (βHg): These designs achieve the maximum precision over stepped designs with overall balance between treated and control observations, a result established below in section 3. In the βHg hybrid, Kβ clusters are assigned to a modified stepped‐wedge layout with g uptake points, and the remaining K(1 − β) clusters to a concurrent parallel layout.
2.5. Precision‐ratio plots
Using the CXO as a reference design, the efficiency of any stepped design, D, may be defined as a precision ratio from (3):
| (4) |
The performance of the design when T is large is captured by the asymptotic relative efficiency (ARE) as R → 1 (= 4aD − 4bD) as given in the final column of Table 1. The fact that this is zero for the PD reflects the generally poor performance of parallel cluster trials with large cluster sizes 16. The other designs all have non‐zero AREs so that there is no upper limit to the precision that can be obtained by increasing the number of observations in each cluster.
Figure 3 shows the precision‐ratio as a function of the CMC, R, for the designs in Figure 1. When R is small, the PD outperforms the other designs, but is the worst design when R = 1. The SW4 design performs relatively well for large R but is dominated by MSW4. Similarly DCD with q = 2/3 is dominated by 0.5H4. Over the range the 0.5H4 design gives the best precision among these designs. Outside this range PD (for smaller R) or MSW4 (larger R) are best. If the value of R is uncertain the 0.5H4 design might be preferred as a compromise design, at least on statistical grounds, because it performs reasonably well throughout the range.
Figure 3.
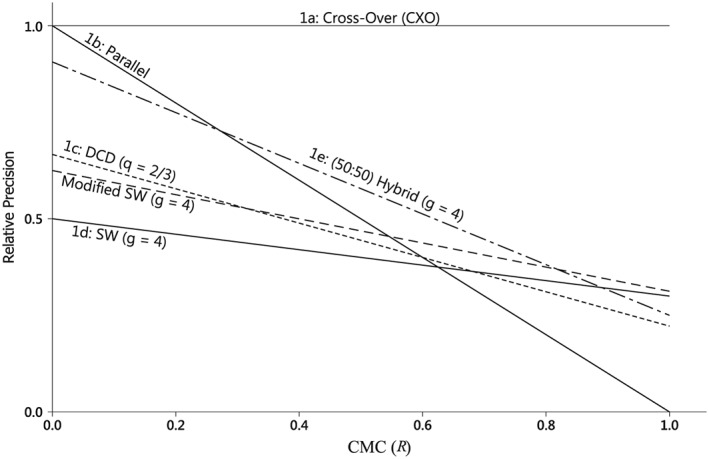
Precision–ratio plots. The relative precision of some stepped designs compared to the cross‐over design is plotted against the cluster‐mean correlation parameter R. Designs 1a to 1e are those illustrated for eight clusters in Figure 1. The Modified SW design corresponds to two copies of the middle four clusters in Figure 1e.
This approach can inform the choice between any two candidate designs: for example, that between a stepped‐wedge and parallel design 14, 16, 17, 18, 19, 20, 21, 22. From (4) the stepped‐wedge is the more efficient only if R > r 0 where the threshold r 0 satisfies
This implies that for a standard SWg design, and if an MSWg is used. In general, a SW design – of either type – can be better than a PD only if the cluster‐mean correlation R exceeds ½. In a cross‐sectional study, where the ICC of a single observation (i.e. ηC) is generally small, this translates into a useful rule of thumb: to prefer the SW option only if the ICC is greater than 1/M.
2.6. Design effects
A design effect is the ratio of the precision of the treatment effect estimate in an individually randomised trial (RCT) to that in the cluster trial, and is convenient for sample size calculations. For a CXO design under model (1) the components ci and sl(i) cancel out in the treatment‐effect estimate and the design effect is just mη CT + η ST. It follows that the design effect for a general design D is given by
| (5) |
For a parallel cross‐sectional (PD) design with M observations per cluster and no cluster‐level time effects (ηS = ηCT = 0) the formula (5) becomes (1 − η C)/(1 − R) and yields the well‐known design effect [1 + (M − 1)η C] 1. Published stepped‐wedge design effects 14 can also be obtained in this way.
3. Finding the best design
In many traditional designs the intervention is introduced (into some of the clusters) at a single time‐point in the study. This is not true of stepped‐wedge designs for which a number (g) of different uptake times will be required. Normally these are equally spaced in time, yet they can be chosen so as to optimise the performance of the design. To this end, we assume that the study will involve T observation times within each of K clusters with observations Yij generated by the model (2). The problem is to choose a configuration of uptake times in the clusters to achieve the best possible precision for the treatment effect estimate. Note that it is possible for an uptake time to occur before the start of the study (in a pure ‘treated’ cluster), or, notionally, after it has finished (in a pure ‘control’ cluster).
Mathematically we must find the values of the Jijs (= 0 or 1) that maximise the expression for Π in (3), subject to the irreversibility constraint that j > j′ ⇒ Jij ≥ J ij′ for all i. First suppose that the clusters have been numbered according to the order in which their uptake times occur (so that i < i′ ⇒ Jij ≥ Ji′j for all j). This ordering has been implicitly assumed in the examples in Figure 1 above, with the cluster index i taken as increasing in the upwards direction and the time index j as increasing from left to right. Also it is convenient to map the design points (i,j) on to a lattice in the x‐y plane by setting
The x–y design lattice is contained in a unit square centred on the origin (see Figure 4).
Figure 4.
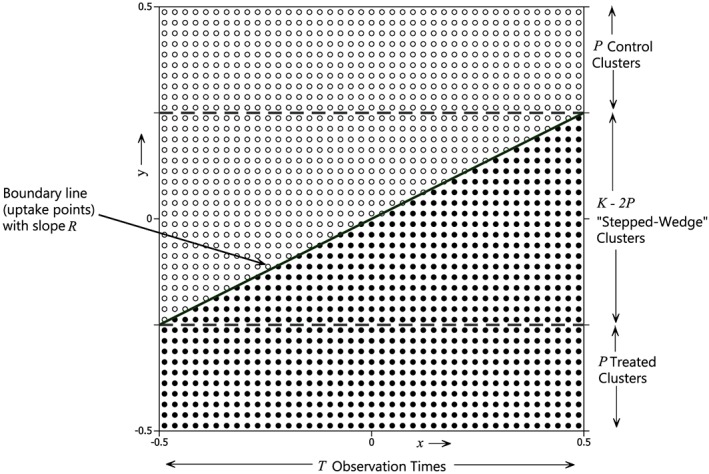
A best balanced design. The boundary line (of slope R) divides the treated (●) from the untreated (○) points, and contains the uptake points in the ‘stepped‐wedge’ clusters. If T/(K − 2P) is an even integer, the design is a Hybrid design as defined above in section 2.
With these definitions an alternative expression to (3) for the precision is given by
| (6) |
a result derived in Appendix C. Unlike (3) (which holds for any configuration of the Jijs) the expression (6) is valid in the presence of the irreversibility constraint, and where the clusters follow the suggested ordering.
3.1. An algorithm for optimal designs
Suppose that J • • (the total number of treated time‐points over all clusters) is fixed. Then, in view of (6), the precision is maximised by nominating treated points one by one, beginning with (i, j) = (1, T) and in decreasing order of the quantity (Rxj – yi), until exactly J • • are included in the treated set. Any ambiguity in the ordering caused by tied values can be resolved arbitrarily because tied points contribute the same amount to the expression in (6). In geometrical terms this is achieved by moving a straight line of slope R upwards until exactly J • • points lie on or beneath it (as, for example, in Figure 4). In this way designs with the best precision are determined for each of the (TK − 1) possible values of J • •. The overall optimum can then be obtained by maximising the best precision over J • •, using (6). This algorithm is easily implemented in a spreadsheet programme and can assist with the design of practical studies.
3.2. Best balanced designs
Practical experience with this algorithm shows: (i) that the optimal design is not always unique; and (ii) that when the number of design points is an even number there may still be no optimal design with overall balance between the treatment arms – i.e. for which . Notwithstanding (ii) it turns out that the design with greatest precision among those that satisfy the balance condition (the best balanced design, or BBD) is often approximately optimal, especially when both T and K are large.
The BBD can be determined from the algorithm above by setting .
(Best Balanced Design) Suppose that the number of design points, TK, is even. A design in which the treated points consist of those for which yi < Rxj together with half of the points (if there are any) for which yi = Rxj is a best balanced design.
In such a design, the boundary between the treated and untreated lattice‐points is a straight line through the origin with slope R. An example is shown in Figure 4. The first group of P clusters receive the intervention at the start of the study (i.e. they are ‘Treated’ clusters) where P is the label of the last cluster for which the point (x 1 ,yP) lies on, or just below, the boundary line y = Rx. This condition translates into the inequalities:
The last P clusters are ‘control clusters’ and do not receive the intervention at all. The K − 2P clusters in the middle participate in a genuine stepped study with equal intervals of time between the uptake points. In some cases the design for these middle clusters corresponds exactly to a MSW(K − 2P) design, though this requires that T = 2(K − 2P)l for some integer l, where l is the number of time‐points in each cluster before the first uptake time (and 2l is the number between two successive uptake times). In the general case, the correspondence to the MSW design is only approximate.
This result shows that the best balanced design when T is large approximates to a hybrid design RHRK in which a stepped‐wedge layout is followed in a proportion of the clusters equal to the CMC, R, and a parallel layout in the remaining clusters.
3.3. Examples of optimal design
Consider the design of a study in 10 clusters over six observation times. The design lattice contains 60 (=10 × 6) points. The observations within each cluster are either unique measurements on 6m separate subjects, or they could be six repeat measurements on the same m subjects. The value of m need not be separately specified because the statistical design issues depend only on the CMC, R.
Best balanced designs for this problem are shown in Figure 5 for the full range of R‐values from 0 to 1. For each design the range of validity includes both end‐points, so that, for instance, design (a) – a parallel layout – and design (b) are both BBDs when R = 0.12. The BBDs are unique except at these isolated end‐points. In a majority of cases the BBD is also an optimal design. Exceptions include design (b) for R = 0.2, and design (h) for R = 1. In each case conversion to optimality is achieved by modifying the treated set either to exclude the circled point or to include the boxed point. By repeated application of the optimality algorithm with R = 0(0.001)1 it was found that the BBD is optimal in 77.5% of cases, and achieved a relative efficiency of at least 98.83% for all values of R, with the worst case at R = 0.6. The mean relative efficiency of the BBDs was 99.92% – a minimal loss of efficiency compared to the true optimum.
Figure 5.
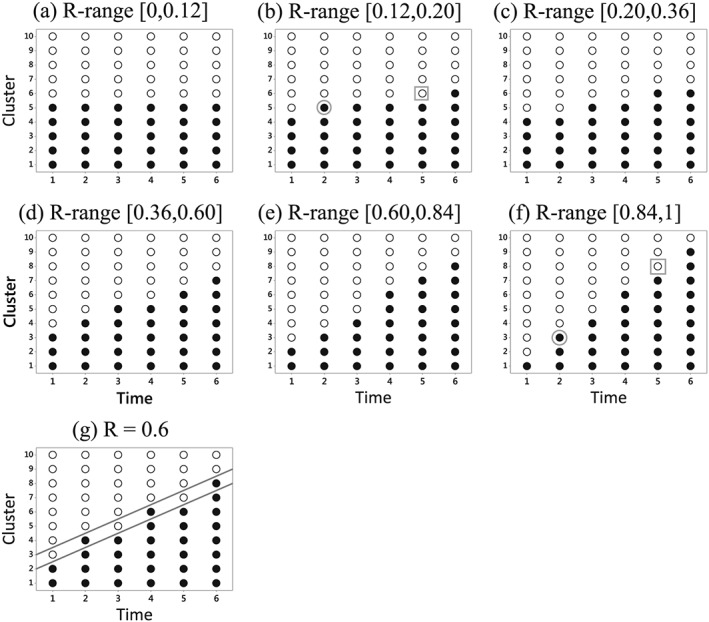
BBDs for 10 clusters over six time‐points. The boxed and circled points in (b) and (f) relate to overall optimal designs for particular R‐values as discussed in the text.
The case with R = 0.6 is complex: designs (d), (e), and (g) are just three out of 20 possible BBDs in this case. The other seventeen BBDs are obtained by choosing different sets of three treated points from the six design points along the diagonal indicated in Figure 5(g), whose slope (=0.6) exactly matches the value of R. Design (g) has been singled out here because it is an example of an exact hybrid design (0.6H3). However, none of these 20 BBDs is fully optimal when R = 0.6. An optimal design in this case omits all six diagonal points from the treated set.
All the examples shown include pure ‘control’ clusters and pure ‘treated’ clusters as part of the optimal design. This is a common feature of optimal stepped designs as defined here, but is specifically excluded in recent work by Lawrie et al. 15.
3.4. Admissible designs for large studies
When T and K are large, the precision for the best balanced design approximates to that of the overall optimal design, with an error of small order in the quantity min(T,K). This is shown in Appendix D– by means of an integral approximation to (6). It follows that the efficiency (relative to the CXO) of the overall optimal design for a large study is that of a hybrid design in which g is large (i.e. RH∞). From Table 1 this is
| (7) |
This quadratic is plotted in Figure 6 and represents the boundary of the feasible region for stepped designs. The admissible designs (i.e. those that are not dominated by any other stepped design) are the hybrid designs, and generate tangents to the boundary curve. The parallel (R = 0) and stepped‐wedge (R = 1) designs are both admissible. The region of the unit square in Figure 6 above the quadratic curve is not attainable by any stepped design.
Figure 6.
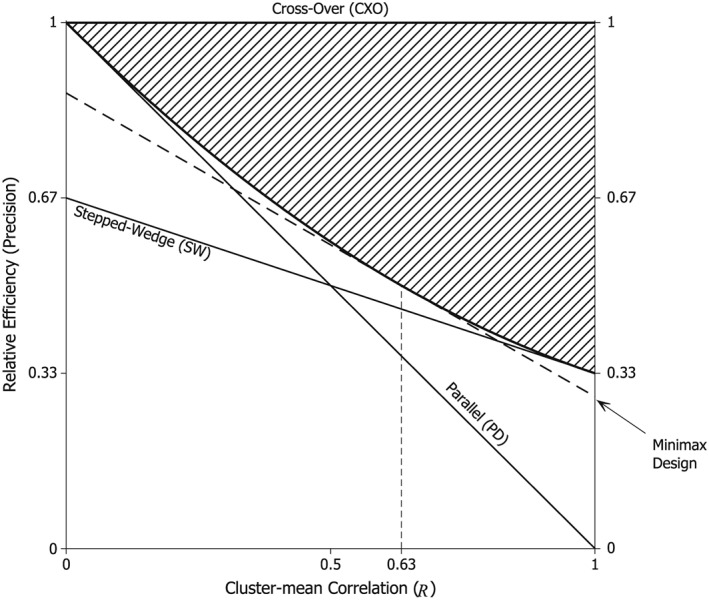
The relative efficiency of cluster designs for large studies as a function of the cluster‐mean correlation R. Three feasible (and admissible) stepped designs are shown: PD, SW (solid lines) and Minimax – i.e. 0.634H∞ – (broken line). The shaded region is prohibited by the irreversibility constraint and bounded by the quadratic curve .
Hybrid designs do not appear to have been widely used in practice. We are aware of only one example 23. However they offer an appealing compromise between the parallel and stepped‐wedge designs given that these can offer optimal precision only at the extreme ends of the range for the cluster‐mean correlation (i.e. when R = 0 and 1, respectively). An appropriate hybrid design can improve the precision of the treatment estimate in all other cases.
3.5. Minimax designs
Where reliable information about the CMC is not available it makes sense to choose an admissible design that minimises the maximum possible loss of precision relative to the optimal design. For large studies this is a hybrid design (the ‘minimax hybrid’) where , the proportion of SW clusters, is given by
At the minimax solution the relative loss of precision is the same at both ends of the range for R (i.e. at R = 0 and R = 1) because of the convexity of the quadratic boundary curve in Figure 6. So satisfies , from which . The precision of the minimax design is at least (≈86.6%) of the available precision at all values of R.
In practice a near‐minimax design can be constructed if about 63.4% of the clusters are allocated to a stepped‐wedge layout with the remainder in a parallel layout. The extent to which this can be achieved depends on the number of clusters in the study. Ideally, 63.4% of K should be close to a whole number of clusters (the SW component), with the residue equal to an even number (for the Parallel component). Some possible near‐minimax designs are shown in Table 2.
Table 2.
Performance of some near‐minimax hybrid designs alongside minimax (0.634H∞), PD and SW∞ for comparison. The relative precisions are computed with reference to the best possible designs in large studies. When R = 0 this is a parallel design (PD), when R = 1 it is a MSW with a notionally infinite value of g.
| Design label | No. of parallel clusters | No. of SW clusters | Total no. of clusters | Proportion of SW clusters (β) | No. of SW uptake points (g) | Relative precision at R = 0 | Relative precision at R = 1 | Worst relative precision (WRP) |
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 5 | 0.600 | 3 | 85.3 | 82.7 | 82.7 |
| 2 | 2 | 4 | 6 | 0.667 | 4 | 83.3 | 87.5 | 83.3 |
| 3 | 4 | 6 | 10 | 0.600 | 6 | 87.3 | 83.7 | 83.7 |
| 4 | 4 | 7 | 11 | 0.636 | 7 | 86.0 | 86.4 | 86.0 |
| 5 | 4 | 8 | 12 | 0.667 | 8 | 84.7 | 88.5 | 84.7 |
| 6 | 6 | 9 | 15 | 0.600 | 9 | 87.7 | 83.9 | 83.9 |
| 7 | 6 | 10 | 16 | 0.625 | 5 | 85.9 | 85.3 | 85.3 |
| 8 | 6 | 10 | 16 | 0.625 | 10 | 86.7 | 85.8 | 85.8 |
| 9 | 6 | 12 | 18 | 0.667 | 6 | 84.4 | 88.3 | 84.4 |
| Minimax | 0.634 | ∞ | 86.6 | 86.6 | 86.6 | |||
| PD | 0 | 100.0 | 0.0 | 0.0 | ||||
| SW∞ | 1 | ∞ | 66.7 | 100.0 | 66.7 |
Any of the designs in Table 2 can be ‘scaled up’ to larger numbers of clusters (rows) and observation periods (columns) without the affecting the precision relative to the CXO design, which can depend only on β and g. The best performance in the table is achieved by design 4, illustrated in Figure 7. Note that the 50:50 Hybrid in Figure 1e achieves a worst‐case relative precision (WRP) of 75%. Even the simplest five‐cluster design in the table (design 1) achieves a WRP of nearly 83%. This design was encountered above (Figure 5(g)) as a BBD for the case K = 10, T = 6.
Figure 7.
A near‐Minimax design with 11 (groups of) clusters (row 4 from Table 2). It achieves at least 99.25% of the precision of the large‐study minimax design (0.634H∞) for any value of R.
3.6. Design performance when R is uncertain – a simulation study
In practice the likely performance of a chosen design depends on the degree of uncertainty in the prior estimate of the CMC. This was investigated using a class of prior distributions for R of the form:
where R 0 is the median CMC value, and prior uncertainty is characterised by the variance parameter τ 2. Values of τ2 were chosen to correspond to three different coefficients of variation of the quantity R/(1 − R): 0.25 (low uncertainty); 0.5 (medium uncertainty); and 1.0 (high uncertainty). In view of the relation the prior is consistent with a similar level of uncertainty for ρ (or ηC). In particular, this analysis applies directly to the case of a cross‐sectional study with uncertain ICC.
Table 3 shows the results of a simulation study for the distribution of the relative precision of some particular design‐choices compared to the BBD at the true value of R. Centiles from the distribution are displayed, alongside the WRP. The designs considered are: (i) BB0 – the best balanced design at the median‐estimate, R 0; the near‐minimax hybrid design 6H3; (iii) Mmx – the true‐minimax design for large studies (= 0.634H∞). Two cases are shown: (i) a ‘small’ study with 10 clusters and six observation times (for which the BBDs are shown in Figure 5); and (ii) the limiting case of large studies (T, K → ∞), for which the BBDs are hybrid designs.
Table 3.
Performance of best balanced and near‐minimax designs under prior uncertainty for the CMC, R, (a) for 10 clusters with six observation times and (b) in the limiting case of large studies. The prior median is denoted by R 0, and CV is the coefficient of variation of the quantity R/(1 − R). the designs considered are: BB0 – the BBD at R 0; .6H3 – a near‐minimax hybrid design (design 1 in Table 2); Mmx (= .634H∞) – the minimax design in large studies. Entries are the centiles (from 9999 simulations) of the relative precision of the stated design compared to the BBD at the true value of R. WRP is the relative precision at the least favourable value of R (=0 or 1 in all cases).
| (a) K = 10, T = 6 | (b) Limiting case: T, K → ∞ | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CV = 0.25 | CV = 0.5 | CV = 1.0 | CV = 0.25 | CV = 0.5 | CV = 1.0 | |||||||||||
| BB0 | .6H3 | BB0 | .6H3 | BB0 | .6H3 | BB0 | .6H3 | Mmx | BB0 | .6H3 | Mmx | BB0 | .6H3 | Mmx | ||
| R 0 = 0.1 | cent50 | 1.000 | 0.884 | 1.000 | 0.884 | 1.000 | 0.884 | 1.000 | 0.881 | 0.895 | 1.000 | 0.881 | 0.895 | 0.999 | 0.881 | 0.895 |
| cent25 | 1.000 | 0.879 | 0.998 | 0.876 | 0.994 | 0.871 | 1.000 | 0.877 | 0.891 | 0.999 | 0.874 | 0.888 | 0.998 | 0.870 | 0.883 | |
| cent10 | 0.998 | 0.876 | 0.993 | 0.870 | 0.978 | 0.864 | 1.000 | 0.874 | 0.888 | 0.998 | 0.869 | 0.883 | 0.991 | 0.864 | 0.877 | |
| cent5 | 0.997 | 0.874 | 0.990 | 0.868 | 0.962 | 0.861 | 0.999 | 0.872 | 0.886 | 0.996 | 0.867 | 0.880 | 0.981 | 0.861 | 0.874 | |
| cent1 | 0.994 | 0.871 | 0.978 | 0.864 | 0.910 | 0.858 | 0.998 | 0.870 | 0.883 | 0.991 | 0.863 | 0.877 | 0.944 | 0.858 | 0.871 | |
| WRP | 0.000 | 0.853 | 0.000 | 0.853 | 0.000 | 0.853 | 0.190 | 0.827 | 0.866 | 0.190 | 0.827 | 0.866 | 0.190 | 0.827 | 0.866 | |
| R 0 = 0.3 | cent50 | 1.000 | 0.936 | 1.000 | 0.936 | 0.997 | 0.936 | 0.999 | 0.931 | 0.949 | 0.998 | 0.931 | 0.949 | 0.994 | 0.931 | 0.949 |
| cent25 | 1.000 | 0.927 | 0.996 | 0.921 | 0.985 | 0.912 | 0.998 | 0.924 | 0.941 | 0.994 | 0.917 | 0.933 | 0.985 | 0.907 | 0.922 | |
| cent10 | 0.998 | 0.921 | 0.985 | 0.910 | 0.959 | 0.893 | 0.997 | 0.917 | 0.933 | 0.988 | 0.905 | 0.920 | 0.959 | 0.889 | 0.903 | |
| cent5 | 0.995 | 0.917 | 0.977 | 0.903 | 0.928 | 0.884 | 0.995 | 0.913 | 0.929 | 0.981 | 0.899 | 0.914 | 0.928 | 0.881 | 0.895 | |
| cent1 | 0.988 | 0.911 | 0.959 | 0.893 | 0.837 | 0.871 | 0.991 | 0.906 | 0.922 | 0.960 | 0.888 | 0.902 | 0.853 | 0.870 | 0.883 | |
| WRP | 0.472 | 0.853 | 0.472 | 0.853 | 0.472 | 0.853 | 0.510 | 0.827 | 0.866 | 0.510 | 0.827 | 0.866 | 0.510 | 0.827 | 0.866 | |
| R 0 = 0.5 | cent50 | 1.000 | 0.977 | 1.000 | 0.977 | 0.997 | 0.971 | 0.999 | 0.968 | 0.990 | 0.997 | 0.967 | 0.989 | 0.990 | 0.961 | 0.984 |
| cent25 | 1.000 | 0.969 | 0.997 | 0.963 | 0.975 | 0.952 | 0.997 | 0.962 | 0.983 | 0.990 | 0.956 | 0.977 | 0.973 | 0.941 | 0.962 | |
| cent10 | 1.000 | 0.963 | 0.979 | 0.951 | 0.932 | 0.925 | 0.994 | 0.956 | 0.977 | 0.980 | 0.944 | 0.962 | 0.949 | 0.919 | 0.938 | |
| cent5 | 0.998 | 0.959 | 0.963 | 0.941 | 0.902 | 0.913 | 0.992 | 0.953 | 0.973 | 0.973 | 0.936 | 0.954 | 0.928 | 0.907 | 0.925 | |
| cent1 | 0.985 | 0.953 | 0.932 | 0.924 | 0.846 | 0.893 | 0.987 | 0.945 | 0.964 | 0.954 | 0.920 | 0.937 | 0.881 | 0.888 | 0.903 | |
| WRP | 0.694 | 0.853 | 0.694 | 0.853 | 0.694 | 0.853 | 0.750 | 0.827 | 0.866 | 0.750 | 0.827 | 0.866 | 0.750 | 0.827 | 0.866 | |
| R 0 = 0.7 | cent50 | 1.000 | 0.985 | 1.000 | 0.983 | 1.000 | 0.975 | 0.999 | 0.969 | 0.997 | 0.997 | 0.968 | 0.995 | 0.991 | 0.961 | 0.988 |
| cent25 | 1.000 | 0.980 | 1.000 | 0.973 | 0.980 | 0.960 | 0.998 | 0.963 | 0.993 | 0.991 | 0.957 | 0.986 | 0.976 | 0.940 | 0.969 | |
| cent10 | 1.000 | 0.974 | 0.985 | 0.964 | 0.951 | 0.935 | 0.995 | 0.957 | 0.987 | 0.983 | 0.942 | 0.974 | 0.957 | 0.914 | 0.946 | |
| cent5 | 1.000 | 0.971 | 0.972 | 0.959 | 0.934 | 0.921 | 0.993 | 0.953 | 0.984 | 0.977 | 0.933 | 0.965 | 0.944 | 0.899 | 0.932 | |
| cent1 | 0.989 | 0.966 | 0.949 | 0.941 | 0.895 | 0.901 | 0.989 | 0.945 | 0.977 | 0.963 | 0.916 | 0.950 | 0.915 | 0.875 | 0.911 | |
| WRP | 0.813 | 0.853 | 0.813 | 0.853 | 0.813 | 0.853 | 0.837 | 0.827 | 0.866 | 0.837 | 0.827 | 0.866 | 0.837 | 0.827 | 0.866 | |
| R 0 = 0.9 | cent50 | 1.000 | 0.926 | 1.000 | 0.926 | 1.000 | 0.926 | 1.000 | 0.901 | 0.936 | 0.999 | 0.901 | 0.936 | 0.998 | 0.901 | 0.936 |
| cent25 | 1.000 | 0.918 | 1.000 | 0.911 | 1.000 | 0.901 | 0.999 | 0.892 | 0.928 | 0.998 | 0.885 | 0.921 | 0.995 | 0.875 | 0.912 | |
| cent10 | 1.000 | 0.911 | 0.998 | 0.900 | 0.979 | 0.887 | 0.999 | 0.885 | 0.921 | 0.996 | 0.873 | 0.910 | 0.985 | 0.857 | 0.895 | |
| cent5 | 1.000 | 0.907 | 0.991 | 0.894 | 0.966 | 0.880 | 0.998 | 0.881 | 0.918 | 0.993 | 0.867 | 0.904 | 0.972 | 0.850 | 0.888 | |
| cent1 | 0.999 | 0.902 | 0.978 | 0.887 | 0.933 | 0.873 | 0.997 | 0.875 | 0.912 | 0.984 | 0.857 | 0.895 | 0.933 | 0.841 | 0.880 | |
| WRP | 0.720 | 0.853 | 0.720 | 0.853 | 0.720 | 0.853 | 0.730 | 0.827 | 0.866 | 0.730 | 0.827 | 0.866 | 0.730 | 0.827 | 0.866 | |
The BB0 designs show excellent relative precision for medium or low uncertainty about R: the median (cent50) relative precision is at least 99% and the 5th centile as least 95% in all cases. Under higher levels of uncertainty there is some deterioration in performance, even in large studies. Even so the 5th centile still exceeds 90% in all tabulated cases. In general, performance is somewhat better for values of R 0 towards the ends rather than the middle of the range.
Nevertheless the low values of the WRP for many of the BB0 designs (it can be as low as 0 when R 0 is small) highlight the need for caution if the prior information is unreliable. In this case a more robust choice is the near‐minimax design .6H3. In the small study its WRP of 85.3% guarantees acceptable performance even when the CMC is very low. In large studies, it is inferior to the true minimax design (0.634H∞) by less than 4 percentage points (i.e. 0.04) at every centile of the distribution of relative precision. Improved near‐minimax designs are available in Table 2.
4. Comments
The mixed effects model (1) is a vehicle to express a certain correlation‐structure with additive fixed effects for time and treatment, including subject‐level effects and variation within clusters over time. This structure could be further enriched – for example by using time series models for the development of subject and cluster effects over time, or by using cluster by treatment interaction terms to model variation in treatment effects across clusters. In its current form the model expresses the tension between cluster‐effects and time‐effects for the design of cluster studies in a form susceptible to exact analysis. At the design stage, the correlations are assumed known and, following the strategy of Hussey and Hughes 11, we use the model to compute the precision of unbiased linear estimates of a fixed treatment effect. This approach is moment‐based and makes no explicit distributional assumption, although it is clearly justifiable when the data are normally distributed with the prescribed correlation‐structure. In some other cases, where central limiting arguments can be deployed, it approximates to the best approach – for example, for binary outcomes when m is large. The additivity requirement in the model can be relaxed within a generalised linear mixed model, with fixed and random effects on a transformed scale. Then our results may still apply approximately if these effects are relatively small, permitting a linear approximation on the natural scale.
Several aspects of this work offer potential applications in the design of both cross‐sectional cluster studies (where each subject provides a single outcome measurement) and of cohort designs (where repeated measures are taken on the same subjects). First, the expression for precision in terms of the CMC leads to a convenient graphical tool for comparing the performance of competing study designs, and provides a simple approach to the computation of design effects which are useful in sample size calculations. Second, the class of hybrid designs emerge as admissible designs, at least in large studies, in the sense that any design not of this form is (weakly) dominated by at least one design that is. Cross‐sectional studies can often be conceptualised as a series of observations taken over a large number of weeks or months, in which case the hybrid results may be directly applicable. Third, a simple search algorithm is proposed for finding optimal designs when the ‘large‐study’ results are inapplicable. This is often the case in cohort studies, where the number of observation times is limited to the (usually small) number of repeat measures on each subject.
The precise nature of the optimal design depends on the value of the CMC which, in common with the traditional ICC, may be difficult to predict with certainty. An alternative strategy is to look for a design that reduces the possible loss of precision because of an unknown CMC. For this purpose the near‐minimax hybrids of section 3.5 are offered as practical alternatives to more traditional designs.
Acknowledgements
The authors acknowledge financial support from The Medical Research Council Midland Hub for Trials Methodology Research [grant number G0800808] and The National Institute for Health Research (NIHR) Collaborations for Leadership in Applied Health Research and Care for West Midlands (CLAHRC WM).
Appendix A. The precision of the treatment effect estimate (equation 3)
A.1.
We outline a derivation for the precision of the BLUE for θ in model (2). Without loss of generality, take σ2 = 1.
Consider a transformation of the observation matrix Y (with elements Yij) given by
where H is a T × T orthogonal matrix (i.e. HTH = IT) with first row given by . (Throughout we use the conventional notation that the superscript T denotes matrix transposition. This is not to be confused with T, the time‐dimension in the model.) Also define the K × T matrices Z and η by Z T = HJ T, η T = Hε T. Then a model for the transformed observations corresponding to (2) is
| (A1) |
where {η ij; 1 ≤ i ≤ K, 1 ≤ j ≤ T} is a set of uncorrelated random variables with mean zero and variance (1 − ρ). The orthogonality of H implies that the elements of the matrix U are uncorrelated with one another. Thus, as j varies from 1 to T, the expressions in (A1) represent a series of T linear regression models for Uij on Zij, with intercepts (Ht)j and common slope θ. For j = 1, the error variance is ; for 2 ≤ j ≤ T, the error variance is (1 − ρ). The estimation problem for θ reduces to that of finding the common slope in a set of uncorrelated regressions. The precision of the pooled estimate for θ is just the sum of the precisions of the BLUEs in the separate models. In a simple linear regression model with explanatory variables xi the precision of the slope estimate is . Hence the precision of the pooled estimate is given by:
| (A2) |
from which (3) follows. The last equality holds because , and
Fixed cluster effects
If the cluster effects γi are treated as fixed, the regression model for U i1 in (A1) is not identifiable and does not yield an estimate for θ. Its contribution to the precision of the pooled estimate is zero, which is tantamount to setting R = 1 in the expression (A2).
Time‐effects modelling
The model in (1) has one parameter for each of the T observation times in the study. However, the argument can be extended to show that the expression (A2) holds under more restrictive time‐effects models. To be precise, if the T × 1 vector of time effects is modelled as t = Xβ for some design matrix X, where β is a vector of unknown parameters, the result (A2) holds provided that the vector JT1K (whose jth element is J • j) lies in the column‐space of X. In a stepped design this amounts to the requirement that the model is rich enough to include a separate time parameter for any period in which no cluster experiences an uptake event. For the designs in Figure 1, it means that (A2) remains true provided the model includes at least one time‐parameter for each of the columns depicted in the corresponding figure.
Appendix B. Design coefficients for standard designs (Table 1)
B.1.
As indicated in section 2, the design coefficients, aD and bD may be interpreted in terms of variances generated by a uniform probability measure on the lattice points {(i, j); 1 ≤ i ≤ K, 1 ≤ j ≤ T}. Under this probability measure we have a D = E j vari(J ij|j)≡ varij J ij − varj E i(J ij|j) and .
CXO: The row (i.e. cluster) mean , a constant for all i, and, under the uniform measure on the lattice points, the conditional distribution of Jij for fixed j is Binomial(1, ½). So, for this design, and b BCO = 0.
PD: Here the distribution of is Binomial(1, ½), as is the conditional distribution of Jij for fixed j. Hence .
The following result is useful for calculating coefficients for stepped‐wedge and DCD‐designs.
Lemma
Suppose that aD and bD are the design coefficients for a design D with layout matrix J containing nJ columns. Let D′ be the design obtained when J is augmented to include n 0 additional columns of zeros and n 1 additional columns of 1 s. This amounts to adding baseline observations and post‐implementation observations in all clusters. Then the design coefficients for D′ are given by a D′ = qa D, b D′ = q 2 b D where is the proportion of the columns in the new layout occupied by the original matrix J.
To prove this, note that the row means under D′ are given by , with variance . Also the variances within the added columns are zero, so that a D′ = E j vari(J′ ij|j) = (1 − q) × 0 + qE j vari(J ij|j) = qa D as required.
DCDp,q,r: A straightforward application of the lemma to the case where the (unaugmented) base design is parallel (PD) shows that .
An important consequence of the lemma is that the design coefficients for any design are unaffected when initial baseline observation periods are exchanged for post‐implementation periods and vice versa. In either case they depend only on the proportion, q, of time‐points devoted to the central part of the design.
Stepped‐wedge designs
MSWg: Consider a truncated version of the SWg design in which the first column of control observations is absent. If there is just one cluster in each group, the corresponding J‐matrix is square. For example, when g = 4, . In this layout the proportion of post‐implementation periods is and there are no baseline periods. Hence, from the lemma, the design coefficients will be the same as those for the corresponding MSW design in which the baseline and post‐implementation proportions are both equal to . In the truncated layout, the row and column means are identical, and uniformly distributed on the set . This distribution has variance . The proportion of 1s in J is so that . Hence .
SW: The coefficients for SWg can be obtained in a similar way. Here an extra baseline period is added to the truncated design. Using the lemma, the design coefficients are given by:
and
Transposed layouts and hybrid designs
Consider the design layout JT obtained by interchanging the rows and columns of J. The design coefficients for the transposed layout can be expressed as and where π is the proportion of 1 s in the layout, using the fact that var J ij = π(1 − π).
The layout for a hybrid design, βHg, can be written as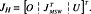
Here O and U represent matrices of 0 s and 1 s respectively, and JMSW is the layout for a MSWg design. Using the MSW coefficients (in conjunction with the result of the lemma) the hybrid design coefficients are obtained as and .
Appendix C. Derivation of equation (6)
C.1.
First note that the quantities aD and bD that feature in (3) can be expressed as:
Now assume that the clusters are labelled according to the order in which they receive the intervention. Then, for any value of j, we have Jij = 1 only for the first J •j clusters, where is the total number of clusters that have received the intervention by time j. Similarly, for each value of i, we have Jij = 1 only for the last J i• time‐points. It follows that and . (For the second expression we observe the convention that a sum is null if the lower limit exceeds the upper limit. This delivers the correct result when J i• = 0.)
Using these expressions we find that
and
Thus which, on substituting in (3), gives the desired result.
Appendix D. Unconstrained optimal design of large stepped studies
D.1.
It is shown in section 3.1 that the optimal uptake boundary corresponds to a line segment of slope R in the x–y plane of the form y – Rx = η, for some value of η. Let A(η) be the area of the region in the unit square below the line segment – i.e. the region occupied by the treated units. Then J • • ~ TKA(η) and
The right‐hand side has a turning value when the derivative with respect to η is zero. I.e. when− 2ηA′ (η) − RA′ (η) + 2RA(η)A′ (η) = 0, where .
Dividing through by A′(η) we find that the maximum precision is obtained when
This equation is clearly satisfied when η = 0 because A(0) = ½, and the solution corresponds to a balanced design. Detailed consideration of the functional form of A(η) – which is straightforward but not given here – reveals that the equation has no other root. Thus the optimal design is approximately balanced when T and K are large, as claimed in section 3.4.
Girling, A. J. , and Hemming, K. (2016) Statistical efficiency and optimal design for stepped cluster studies under linear mixed effects models. Statist. Med., 35: 2149–2166. doi: 10.1002/sim.6850.
References
- 1. Campbell MJ, Walters SJ. How to Design, Analyse and Report Cluster Randomised Trials in Medicine and Health Related Research. Wiley: Chichester, UK, 2014. [Google Scholar]
- 2. Mdege ND, Man M‐S, Taylor CA, Torgerson DJ. Systematic review of stepped wedge cluster randomized trials shows that design is particularly used to evaluate interventions during routine implementation. Journal of Clinical Epidemiology 2011; 64:936–948. [DOI] [PubMed] [Google Scholar]
- 3. Brown CA, Lilford RJ. The stepped wedge trial design: a systematic review. BMC Medical Research Methodology 2006; 6:54. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4. Beard E, Lewis JJ, Copas A, Davey C, Osrin D, Baio G, Thompson JA, Fielding KL, Omar RZ, Ononge S, Hargreaves J, Prost A. Stepped wedge randomised controlled trials: systematic review of studies published between 2010 and 2014. Trials 2015; 16:353. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5. Hemming K, Haines TP, Chilton PJ, Girling AJ, Lilford RJ. The stepped wedge cluster randomised trial: rationale, design, analysis, and reporting. BMJ 2015; 350:h391. [DOI] [PubMed] [Google Scholar]
- 6. Baio G, Copas A, Ambler G, Hargreaves J, Beard E, Omar RZ. Sample size calculation for a stepped wedge trial. Trials 2015; 16:354. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7. Leontjevas R, Gerritsen DL, Smalbrugge M, Teerenstra S, Vernooij‐Dassen MJ, Koopmans RT. A structural multidisciplinary approach to depression management in nursing‐home residents: a multicentre, stepped‐wedge cluster‐randomised trial. Lancet 2013; 381:2255–2264. [DOI] [PubMed] [Google Scholar]
- 8. Muntinga ME, Hoogendijk EO, van Leeuwen KM, van Hout HP, Twisk JW, van der Horst HE, Nijpels G, Jansen AP. Implementing the chronic care model for frail older adults in the Netherlands: study protocol of ACT (frail older adults: care in transition). BMC Geriatrics 2012; 12:19. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9. Pearse RE. K. Protocol 13PRT/7655:Enhanced PeriOperative Care for High‐risk patients (EPOCH) Trial (ISRCTN80682973). The Lancet 2013. http://www.thelancet.com/protocol-reviews/13PRT‐7655 [Google Scholar]
- 10. Dainty KN, Scales DC, Brooks SC, Needham DM, Dorian P, Ferguson N, Rubenfeld G, Wax R, Zwarenstein M, Thorpe K, Morrison LJ. A knowledge translation collaborative to improve the use of therapeutic hypothermia in post‐cardiac arrest patients: protocol for a stepped wedge randomized trial. Implementation Science 2011; 6:4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11. Hussey MA, Hughes JP. Design and analysis of stepped wedge cluster randomized trials. Contemporary Clinical Trials 2007; 28:182–191. [DOI] [PubMed] [Google Scholar]
- 12. Teerenstra S, Eldridge S, Graff M, de Hoop E, Borm GF. A simple sample size formula for analysis of covariance in cluster randomized trials. Statistics in Medicine 2012; 31:2169–2178. [DOI] [PubMed] [Google Scholar]
- 13. Hemming K, Taljaard M. Relative efficiencies of stepped wedge and cluster randomized trials were easily compared using a unified approach. Journal of Clinical Epidemiology 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14. Woertman W, de Hoop E, Moerbeek M, Zuidema SU, Gerritsen DL, Teerenstra S. Stepped wedge designs could reduce the required sample size in cluster randomized trials. Journal of Clinical Epidemiology 2013; 66:752–758. [DOI] [PubMed] [Google Scholar]
- 15. Lawrie J, Carlin JB, Forbes AB. Optimal stepped wedge designs. Statistics & Probability Letters 2015; 99:210–214. [Google Scholar]
- 16. Hemming K, Girling A, Martin J, Bond SJ. Stepped wedge cluster randomized trials are efficient and provide a method of evaluation without which some interventions would not be evaluated. Journal of Clinical Epidemiology 2013; 66:1058–1059. [DOI] [PubMed] [Google Scholar]
- 17. Hemming K, Girling A. The efficiency of stepped wedge vs. cluster randomized trials: stepped wedge studies do not always require a smaller sample size. Journal of Clinical Epidemiology 2013; 66:1427–1428. [DOI] [PubMed] [Google Scholar]
- 18. de Hoop E, Woertman W, Teerenstra S. The stepped wedge cluster randomized trial always requires fewer clusters but not always fewer measurements, that is, participants than a parallel cluster randomized trial in a cross‐sectional design Reply. Journal of Clinical Epidemiology 2013; 66:1428–1428. [DOI] [PubMed] [Google Scholar]
- 19. Keriel‐Gascou M, Buchet‐Poyau K, Rabilloud M, Duclos A, Colin C. A stepped wedge cluster randomized trial is preferable for assessing complex health interventions. Journal of Clinical Epidemiology 2014; 67:831–833. [DOI] [PubMed] [Google Scholar]
- 20. Viechtbauer W, Kotz D, Spigt M, Arts ICW, Crutzen R. Response to Keriel‐Gascou et al.: Higher efficiency and other alleged advantages are not inherent to the stepped wedge design. Journal of Clinical Epidemiology 2014; 67:834–836. [DOI] [PubMed] [Google Scholar]
- 21. Kotz D, Spigt M, Arts ICW, Crutzen R, Viechtbauer W. Use of the stepped wedge design cannot be recommended: a critical appraisal and comparison with the classic cluster randomized controlled trial design. Journal of Clinical Epidemiology 2012; 65:1249–1252. [DOI] [PubMed] [Google Scholar]
- 22. Mdege ND, Kanaan M. Response to Keriel‐Gascou et al. Addressing assumptions on the stepped wedge randomized trial design. Journal of Clinical Epidemiology 2014; 67:833–834. [DOI] [PubMed] [Google Scholar]
- 23. Hughes JP, Goldenberg RL, Wilfert CM, Valentine M, Mwinga KG, Guay LA, Mimiro F. Design of the HIV Prevention Trials Network (HPTN) Protocol 054: a cluster randomized crossover trial to evaluate combined access to Nevirapine in developing countries. UW Biostatistics Working Paper Series 2003; Working Paper 195.