

Summary
Quadratic forms capture multivariate information in a single number, making them useful, for example, in hypothesis testing. When a quadratic form is large and hence interesting, it might be informative to partition the quadratic form into contributions of individual variables. In this paper it is argued that meaningful partitions can be formed, though the precise partition that is determined will depend on the criterion used to select it. An intuitively reasonable criterion is proposed and the partition to which it leads is determined. The partition is based on a transformation that maximises the sum of the correlations between individual variables and the variables to which they transform under a constraint. Properties of the partition, including optimality properties, are examined. The contributions of individual variables to a quadratic form are less clear‐cut when variables are collinear, and forming new variables through rotation can lead to greater transparency. The transformation is adapted so that it has an invariance property under such rotation, whereby the assessed contributions are unchanged for variables that the rotation does not affect directly. Application of the partition to Hotelling's one‐ and two‐sample test statistics, Mahalanobis distance and discriminant analysis is described and illustrated through examples. It is shown that bootstrap confidence intervals for the contributions of individual variables to a partition are readily obtained.
Keywords: Corr‐max transformation, collinearity, discriminant analysis, Hotelling, Mahalanobis distance, rotation
1. Introduction
Quadratic forms feature as statistics in various multivariate contexts. Well‐known examples include Hotelling's statistic and the Mahalanobis distance. When the value of a quadratic form is large, then an obvious question is: Which variables cause it to be large? To illustrate, suppose x is an observation that should come from a distribution with mean μ and variance Σ. However, it appears to come from a different distribution because the Mahalonobis distance, equal to the quadratic form , is large. It might be helpful to have a measure of the contribution of individual variables to the size of this quadratic form.
When variables are correlated, it is not immediately apparent that a sensible answer to this question can be given. However, we shall argue that the question can be answered in a meaningful way and we will propose a method of partitioning a quadratic form into contributions from individual variables. This does not imply that there is a “best” way of forming such a partition, other than in some simple situations where arguments of symmetry can be used. However, although a partition of a quadratic form may be arbitrary to a degree, it can still be useful and informative. We show that the partition we propose meets certain optimality criteria.
Our method of forming a partition is based on a transformation that we call the corr‐max transformation. Garthwaite, Critchley, Anaya‐Izquierdo & Mubwandarikwa (2012) focussed on a transformation referred to as the cos‐square transformation, but also proposed a second transformation called the cos‐max transformation. The latter is closely related to the corr‐max transformation that we introduce here. However, while the cos‐max transformation was designed to transform a data matrix, the intended use of the corr‐max transformation is the transformation of a random vector. The cos‐max transformation adjusts a data matrix by a minimal amount while yielding a matrix with orthonormal columns; each of the original variables is associated with exactly one of these columns. The corr‐max transformation yields a vector whose covariance matrix is proportional to the identity matrix, while each of the original variables is associated with exactly one component of the transformed vector. The strength of the associations is measured by correlations and the transformation is chosen to maximise the sum of these correlations (hence our name for the transformation).
Collinearities between variables will reduce the strength of some associations. The variables that are involved in a collinearity can be identified using the cos‐max transformation (Garthwaite et al. 2012). The coordinate axes corresponding to these variables can then be rotated to yield a set of variables with little collinearity. We adapt the corr‐max transformation so that contributions to the quadratic form, as measured by the partition, will only change for those variables that are affected by the rotation. We refer to this feature as the rotation invariance property.
The task of determining which variables have most influence on a Mahalanobis distance has attracted some attention in the literature. The Mahalanobis‐Taguchi system, which features in statistical process control, estimates the covariance matrix Σ from ‘normal’ data and computes the Mahalanobis distances for a set of ‘abnormal’ data points, in order to determine signal‐to‐noise ratios for individual variables and hence identify variables that are useful diagnostics of abnormality (Taguchi & Jugulum 2002; Das & Datta 2007). In ecology, the Mahalanobis distance has been used in the construction of maps that show suitable habitat areas for a particular species. Pixels on the map are equated to points in multidimensional space on the basis of environmental variables and the Mahalanobis distance is used to give a measure of the distance from a point to the mean of the ecological niche. To identify the minimum set of basic habitat requirements for a species, Rotenberry, Preston & Knick (2006) proposed a decomposition of the Mahalanobis distance that exploits the eigenvectors of Σ. Based on work in Rotenberry, Knick & Dunn (2002), they argued that the variables that load heavily on the eigenvectors corresponding to the smallest eigenvalues are the most influential in determining habitat suitability. Calenge, Darmon, Basille & Jullien (2008) added a step to the method of Rotenberry et al. (2006), forming a further eigenvector decomposition with the aim of producing biologically meaningful axes. The decomposition we propose here is simpler to implement and has a straightforward interpretation, making it more likely to be put into practice. Rogers (2015) adopted it as a tool for identifying the key climate variables in determining future changes in the distribution of vector‐borne diseases, illustrating its use through application to dengue, an important tropical disease. He referred to the contributions of variables being measured on the Garthwaite–Koch scale, citing a technical report (Garthwaite & Koch 2013) that forms the basis of the present paper.
In Section 2 we argue that the value of a quadratic form can be meaningfully partitioned into separate contributions of individual variables and give the criteria that determine the corr‐max transformation and our proposed partition. In Section 3 we obtain the transformation and the partition. In Section 4 the transformation is adapted to have the rotation invariance property and ways to exploit this property are suggested. In Section 5 we describe use of the partition in contexts where Hotelling's statistic or Mahalanobis distance arise, and in discriminant problems involving two groups. Bootstrap confidence intervals for the contributions of individual variables can be constructed to quantify uncertainty in these contributions and to increase our insight into the relative importance of these contributions. These ideas are illustrated in Section 6. Concluding comments are given in Section 7.
2. Rationale for a partition
Let Q be the quadratic form
| (1) |
where is an m×1 random vector whose variance is proportional to Σ and where μ is a given m×1 vector that is not necessarily the mean of X. This type of quadratic form arises in various applications. For example, in Hotelling's one‐sample statistic, X would take the value of a sample mean, Σ would be the population variance, and μ would be the hypothesised population mean. The purpose of this paper is to give a method of evaluating the contributions of individual variables to Q. Before doing so, we must first consider whether it is possible, in principle, to meaningfully answer the question, What are the contributions of individual variables to a quadratic form?
Clearly a good answer can easily be given when Σ is the identity matrix: the contribution of each variable is then the square of the corresponding component of x−μ. Extension to the case where Σ is diagonal is obvious. However, if Σ is not diagonal then it is less clear that Q can be partitioned between variables in a meaningful way. To examine this issue, we consider an example.
Specifically, let
and, to aid explanation, suppose the three components of correspond to standardised variables, age (), height (), and weight (). In this example the contribution of age () to Q is always clear, since
If , then height and weight contribute equally to Q, from symmetry. Hence, even though is not diagonal, the contributions of each variable to Q can be determined: age contributes while height and weight each contribute .
To expand this example, suppose to be slightly greater in magnitude than . Then the contribution of age to Q would still be while, in dividing the balance of Q between height and weight, it seems reasonable to give weight slightly the greater portion. Other situations are also readily constructed where common sense can indicate, approximately, the contributions of each variable to Q. Usually though, there will be no partition of Q that is unquestionably better than any alternative. However, it may still be the case that sensible methods of partitioning Q broadly agree on the contributions made by individual variables. We construct a partition that helps interpret the results of some statistical analyses by giving a clearer relationship between the data variables and a test statistic or some other quantity that is based on Q. The transformation that underlies the partition is defined in the next section.
Before ending this section we introduce further notation that will be used in the remainder of the paper. Bold‐face italic capital letters X,Y, , , etc. are m×1 random vectors. Subscripts are added to denote components of the vector: , , etc. The notation is used to denote a generic estimate of the m×m population variance matrix, Σ. Likewise is used to denote the standard unbiased estimate of Σ given by one sample and is used to denote the standard pooled estimate of Σ based on independent samples from two populations that both have variance Σ. The symbols , are used to denote the ith diagonal entries of Σ and , respectively. The symbols D and are used to denote m×m diagonal matrices with ith diagonal entries equal to and , respectively (i=1,…,m). Thus DΣD and have diagonal entries equal to 1. The symbol is used to denote the n×m data matrix whose rows are the n observations and is used to denote the ith column of X. The symbols A, , B, C, H, Ω, Ψ are used to denote m×m matrices and Γ and are used to denote m×m and d×d orthogonal matrices, respectively.
3. The corr‐max transformation
To form our partition, we consider transformations of the form
| (2) |
where W is an m×1 vector and
| (3) |
for any value of X. Then
| (4) |
where , so W yields a partition of Q. The partition will be useful and meaningful if
the components of W are uncorrelated and have identical variances, and
it is reasonable to identify with the ith x‐variable, as the contribution of that x‐variable to Q can then sensibly be defined as .
The following theorem gives the transformation that maximises under the constraints that (2) and (3) hold, where cor(·,·) denotes correlation. Proofs of theorems are given in Appendix A.
Theorem 1
Suppose W=A(X−μ) and var(X)∝Σ. If (3) holds for all X, then the components of W are uncorrelated with identical variances. If, in addition, A is chosen to maximise , then , where D is a diagonal matrix such that DΣD has diagonal entries equal to 1.
We define the corr‐max transformation to be the transformation given by (2) with . From Theorem 1, this transformation yields a W that satisfies requirement (a). For (b), we first note that it is always possible to scale and translate so that it has the same variance and the same mean as , whence the degree to which equates to would primarily be determined by its correlation with . (Perfect correlation would imply that they were identical.) Moreover, scaling and translation do not change the nature of a variable. Otherwise, for example, temperature measurements on the Celsius and Fahrenheit scales would not be equivalent. Hence, the degree to which equates to the ith x‐variable is largely determined by cor. Consequently under a sensible criterion the corr‐max transformation satisfies (b) as fully as possible, since it maximises when the constraint equations (2) and (3) hold. The extent to which the corr‐max transformation satisfies (b) is discussed further in Section 7.
Theorem 1 completes the specification of our partition for the case where Σ is known. To summarise, if X takes the value x and var(X)∝Σ, the corr‐max transformation yields the new vector and the contribution of the ith x‐variable to is defined to be (i=1,…,m).
When Σ is unknown, we replace it in the foregoing method with an estimate, say. In some contexts this type of substitution can have drawbacks but here it seems appropriate, since it yields properties similar to Theorem 1, but in terms of maximising sample correlations, which we denote by , rather than population correlations. This result is given in Theorem 2. Its proof is similar to that of Theorem 1 and is omitted.
Theorem 2
Suppose that the sample variance of X is proportional to and is to be maximised, subject to and for any X. Then and
(5) where is diagonal and has diagonal entries equal to 1.
While the corr‐max transformation yields a sensible method of partitioning Q into contributions of individual variables, other reasonable methods may well give a slightly different partition, but differences should be small when there is a close relationship between each variable and the x‐variable with which it is paired. Information about the strength of these relationships is provided by the correlations between and (i=1,…,m). The following theorem gives a simple means of finding the values of these correlations and, more generally, the correlations and for i=1,…,m;j=1,…,m. It has the interesting implications that and for all i and j, since and are both symmetric matrices.
Theorem 3
Suppose and var(X)∝Σ. Then equals the (i,j)th entry of . Similarly, if and the sample variance of X is proportional to , then equals the (i,j)th entry of .
So far we have only considered the partition of a quadratic form, but the corr‐max transformation also gives a useful partition of the bilinear form , provided var(U)∝Σ and var(V)∝Σ. Theorem 4 gives the relevant result. Its proof follows from the proof of Theorem 1.
Theorem 4
Suppose var(U)∝Σ and var(V)∝Σ where U and V are m×1 random vectors. Let and where A is a square matrix. Under the constraint , both and are maximised when .
Both and are corr‐max transformations, since . From this, and from the theorem, it is reasonable to identify the ith components of and with the ith components of U and V, respectively. Then is our partition of , giving as the contribution of the ith x‐variable to . In Section 5 we use the theorem to form a partition of Fisher's linear discriminant function. When Σ is estimated from data, results corresponding to Theorem 4 hold with .
4. Rotation invariance property
When the correlations between and are weak for some values of i, there will generally be strong collinearities between some of the x‐variables. The standard diagnostic for detecting collinearities are variance inflation factors. Suppose the values of are observed on each of n items (n>m) and let denote the multiple correlation coefficient when is regressed on the other X variables. Then the variance inflation factor for , say, is defined to be . This will be large if is involved in a collinearity. Garthwaite et al. (2012) showed that the x‐variables involved in a collinearity can be identified using the cos‐max transformation. Example 2 in Section 5.2 illustrates this.
Collinear variables can be replaced by non‐collinear variables via orthogonal rotation of coordinate axes. This can clarify the relationship between x‐variables and a quadratic form, as examples will illustrate. Only axes corresponding to collinear variables need be rotated. The results of a rotation are sensitive to scale, so before rotation we scale the x‐variables. This is the same as in principal component analysis, where variables are frequently scaled to have identical variances before applying the principal component transformation (which is an orthogonal rotation).
Here var(X)∝Σ and DΣD has diagonal entries all equal to 1, so the components of D X have identical variances. Let Γ be an m×m orthogonal matrix and put Y=ΓD(X−μ), so that Y is obtained by a re‐scaling of X−μ, followed by an orthogonal rotation. Suppose that we want to apply a transform
| (6) |
in such a manner that there are large correlations between and for i=1,…,m. The components of Y are not all equally important – after rotation some components will have a smaller variance than others and those with smaller variances are deemed to be less important, as in principal components analysis. The corr‐max transformation would choose C to maximise but now, to reflect the differing importance of some variables, we choose C to maximise . This gives greater weight to the with greater variance. Theorem 5 gives the resulting matrix C and properties of the transformation.
Theorem 5
Let Y=ΓD(X−μ) where Γ is a given orthogonal matrix and var(X)∝Σ. Suppose is to be maximised, subject to and , where C is a square matrix. Then:
the components of are uncorrelated and have identical variances;
(7) is equal to the (i, j)th entry of ;
where .
(8)
The transformation from X−μ to will be referred to as the adapted corr‐max transformation. It is identical to the ordinary corr‐max transformation if there is no rotation, that is when Γ=I. If Σ is unknown, we replace it with an estimate, , and put
| (9) |
The contribution of the ith variable to the quadratic form is evaluated as , where is the value taken by the ith component of or .
From equation (8) we obtain the same result whether (a) we multiply D(X−μ) by the rotation matrix Γ and transform the result, or (b) we transform D(X−μ) and multiply the result by Γ. That is, with the adapted corr‐max transformation, the operations of rotation and transformation are commutative.
This property allows us to rotate the coordinate axes corresponding to x‐variables involved in a collinearity while neither affecting the identity of other x‐variables, nor altering assessments of the latter variables’ contributions to the quadratic form. To elucidate, suppose that we want to rotate the first d of the m axes. Then the rotation matrix Γ has the following block‐diagonal form:
| (10) |
where is a d×d orthogonal matrix. Multiplying X by Γ only changes the first d components of X and leaves its other components unchanged, so the latter components are the original variables. Moreover, under the transformation in equation (7), the last m−d components of are unaffected by ; the rotation only changes its first m components. Thus, under the adapted corr‐max transformation, the rotation of selected axes will leave some variables unchanged (those corresponding to unrotated axes) and the contributions of those variables to the quadratic form, as measured by the partition, will also be unchanged. We refer to this as the rotation invariance property.
Ideally, a partition yields orthogonal components that are closely related on a one‐to‐one basis with meaningful quantities. When these quantities cannot be the original x variables because of a collinearity, the rotation invariance property suggests that we might rotate the axes corresponding to variables involved in the collinearity, and then apply the transformation. There should still be close pairwise relationships between each unrotated variable and the variable to which it transforms, as these relationships are not compromised by the rotation. Also, there should now be close relationships between the quantities obtained through rotation and the variables to which they transform.
A rotation is attractive if it yields meaningful quantities. If, say, the only collinearity was between the first two variables, and , a sensible rotation might be
which constructs two new variables, one proportional to the sum of and , and the other proportional to their difference. This will often create variables that have a natural interpretation and the new variables will also have a low correlation if the variance of is similar to the variance of . If rotation is used to counteract more than one distinct collinearity between the x variables, then should have a block diagonal form, with a separate block for each collinearity. An example is given in Section 5.2. When a collinearity involves more than two variables, constructing meaningful variables that have low correlations can be a challenging task. An approach based on orthogonal contrasts that might sometimes be useful is described in Appendix B.
While rotation can be helpful when collinearities are present, we should stress that rotation is never essential. The standard corr‐max transformation of Section 3 can be applied whenever Σ is a positive‐definite matrix, even if Σ contains high correlations, and it will yield a sensible partition of a quadratic form, as we discuss further in Section 7. Hence axes should only be rotated when the new variables that are constructed have an understandable interpretation.
5. Applications
In Section 5.1 we describe some common applications in which the corr‐max transformation yields a partition that quantifies the contributions of individual variables to a test statistic. In Section 5.2 an example is given in which collinearity is present and some x‐axes are rotated while applying the transformation.
5.1. Hotelling , Mahalanobis distance and discriminant analysis
The standard application in which the partition is useful is where a statistic of interest, Θ say, has the form
| (11) |
with an estimate of Σ, var(X)∝Σ and δ a known positive scalar. From equation (5), the corr‐max transformation yields , and the contribution of the ith x‐variable to Θ is evaluated as , where is the value of given by data.
Before the partition can be applied, X, , δ, and μ must be identified and it must be checked that var(X)∝Σ. (The matrix is obtained from .) The individual contributions, for i=1,…,m, then follow automatically. After using the transformation the analyst should examine the correlations between components of and the corresponding components of X; rotation of x‐axes might be considered if some correlations are low. (In our examples we consider rotating axes when correlations are 0.8 or lower.)
In the following four applications, the first three have precisely the form given in (11), while the fourth is closely related to it.
- Hotelling's one‐sample statistic. A random sample of size n is taken from N(μ,Σ), giving a sample mean X and sample covariance . The standard test of the hypothesis is based on Hotelling's one‐sample statistic,
Let the role of X in (11) be played by X, so that var(X)=Σ/n. The partition is obtained by putting , δ=n and .(12) - Hotelling's two‐sample statistic. Two random samples of sizes and are drawn from the multivariate normal distributions, and , that have the same covariance matrix. Then the hypothesis is tested using Hotelling's two‐sample statistic,
where and are the sample means and is the pooled estimate of Σ derived from the two samples. Let the role of X in (11) be played by , so var(X)∝Σ. Put , and μ=0 to obtain the contributions of individual variables to .(13) - Mahalanobis distance. If and are two m×1 vectors, then the Mahalanobis distance between them is
Here and must be independent, but either or both of them could be individual observations, or sample means, or one of them could be a vector of known constants. We suppose (i=1,2) where or (but not both) may equal 0. We also suppose that so, for example, might be the maximum likelihood estimate or an unbiased estimate of Σ. Let , so var(X)∝Σ. Put δ=1 and μ=0. Then the partitioning gives the contributions of individual variables to the Mahalanobis distance.(14) - Fisher's linear discriminant function. Suppose an observation needs to be classified as belonging to one of two classes that are characterised by the multivariate normal distributions and , with sample means and and common estimated covariance matrix . A new observation is classified as belonging to class 1 on the basis of Fisher's linear discriminant function if
Consider the transformations(15)
and(16)
Since and , Theorem 4 applies. Hence the ith components of both and can be identified with the ith x‐variable. Let and denote these components. Because , the contribution of the ith x‐variable to is given by the observed value of .(17)
We use two examples to explore how the transformation and partition work in practice. In the first example we apply the transformation without rotation of variables and consider applications (a), (c) and (d). In the second example, given in the next subsection, we illustrate application (b) and apply the transformation to both rotated and un‐rotated variables.
Example 1
Swiss bank notes Flury & Riedwyl (1988) present data on 100 genuine Swiss 1000‐franc bank notes. Six measurements were made on each note: length (length), left‐ht (height measured on the left), right‐ht (height measured on the right), lower (distance from the inner frame to the lower border), upper (distance from the inner frame to the upper border), and diagonal (length of the diagonal). These measurements are the data values of . Their sample standard deviations are (0.388, 0.364, 0.355, 0.643, 0.649, 0.447) and the reciprocals of these standard deviations form the diagonal entries of . The sample correlation matrix of X is:
(18) where is the sample covariance matrix. It can be seen that no correlation is larger than 0.664. The mean vector for the banknote measurements is .
If the corr‐max transformation is applied to a vector X to yield a vector , the correlations between components of X and the corresponding components of are equal to the diagonal entries of . These diagonal entries are 0.96, 0.90, 0.91, 0.91, 0.91 and 0.98. They are all large, indicating close one‐to‐one relationships between each x‐variable and its corresponding component of , so rotation of x‐variables is unnecessary.
Hotelling's one‐sample statistic might be used to test the hypothesis that the population mean vector is, say, . These values have been chosen so that, for each variable, the hypothesised population mean exceeds the sample mean by 0.1 standard deviations. The value of the test statistic, given by equation (12), is . We have already calculated and . Setting X and μ equal to x and respectively in equation (5) gives . As δ=100, the contribution of the ith x‐variable to is , so the contributions of the six x‐variables are , , , , and . These values sum to 8.75, which differs slightly from because we have listed all contributions to 2 decimals only, and not given their precise values. The actual sum of the contributions equals as the theory tells us. Although for each component the sample mean differs from the hypothesised population mean by an equivalent amount, the last three x‐variables (lower, upper, and diagonal) make larger contributions to the statistic than the first three x‐variables (length, left‐ht and right‐ht).
As an example involving Mahalanobis distance, suppose the measurements for an additional banknote that might be a forgery are . The Mahalonobis distance between and the mean value of X in the sample of 100 genuine banknotes x, is given by equation (14) with and . The value of this distance is 55.69, which gives clear evidence the note is a forgery (p<0.0001). Our partition can be used to determine which characteristics of the new banknote distinguish it from the genuine banknotes. We put and μ=0 in equation (5), to obtain . As δ=1, the contribution of the ith x‐variable to the Mahalanobis distance is the square of the ith component of . These squared values are (8.64 0.87 4.54 16.66 15.12 9.86). Hence the measurements that most distinguish the new banknote from genuine banknotes are (lower) and (upper).
The Swiss bank notes dataset given by Flury & Riedwyl (1988) contained 100 faked bank notes in addition to the 100 genuine notes. As an example that involves Fisher's discriminant rule, we consider the task of using these data to classify a note as genuine or from the same popultation as the fakes. The pooled sample covariance matrix based on all 200 notes is
| (19) |
Table 1 summarises the analysis. The first two rows, and , show the sample means of the genuine and faked bank notes, respectively. The note to be classified is . Equation (15) gives −20.34 as the value of , indicating that the new note should be classified as coming from the same population as the fakes. Applying equations (16) and (17) we obtain and (fourth and fifth rows). The contributions of individual x‐variables to are evaluated as the diagonal entries of , shown in the last row. Unlike the previous two examples, some of these values are negative; negative values suggest the new note is from the same population as the faked notes. The last three variables, lower, upper, and diagonal, underlie the outcome of the discrimination rule, as they make much larger contributions to (in absolute value) than the first three variables.
Table 1.
Values from the discriminant analysis for a Swiss bank note
|
|
|
|
|
|
|
|||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
214.969 | 129.943 | 129.720 | 8.305 | 10.168 | 141.517 | ||||||
|
|
214.823 | 130.300 | 130.193 | 10.530 | 11.133 | 139.45 | ||||||
|
|
214.4 | 130.1 | 130.3 | 9.7 | 11.7 | 139.8 | ||||||
|
|
0.38 | −0.001 | −1.48 | −4.16 | −2.80 | 4.56 | ||||||
|
|
−1.44 | −0.64 | 1.49 | 1.21 | 2.10 | −1.46 | ||||||
|
|
−0.55 | 0.001 | −2.21 | −5.04 | −5.89 | −6.67 |
In Section 1 we noted that Rotenberry et al. (2006) examined eigenvectors corresponding to small eigenvalues in order to determine influential variables on a Mahalanobis distance. Before leaving this example we illustrate their method by applying it to the case where we have 100 genuine banknotes and an additional banknote that might be a forgery. Their approach is to decompose the quadratic form as
where , are the eigenvalues of and are the corresponding eigenvectors. They focus on small eigenvalues because, if is small, then varies little for the X values in the hundred genuine banknotes, so that a large value of is more indicative of forgery. The eigenvalues of the sample covariance matrix of the genuine banknotes are 0.69, 0.36, 0.19, 0.087, 0.080 and 0.041, so interest centres on either just the smallest eigenvalue or the smallest three eigenvalues. The following are the eigenvectors for the three smallest eigenvalues:
| length | left‐ht | right‐ht | lower | upper | diagonal | |
|---|---|---|---|---|---|---|
| Smallest | −0.011 | 0.737 | −0.666 | −0.050 | −0.062 | 0.072 |
| 2 smallest | 0.113 | −0.360 | −0.481 | 0.559 | 0.548 | 0.116 |
| 3 smallest | 0.786 | −0.243 | −0.280 | −0.243 | −0.244 | −0.354 |
Based on just the eigenvector corresponding to the smallest eigenvalue, and (left‐ht and right‐ht) are clearly the most important variables, since in the case of that eigenvector they have much larger coefficients (in absolute value) than the other variables. However, if the three eigenvectors displayed above are all considered relevant, then deciding which x‐variables are important is not clear‐cut and requires the analyst to make an intuitive judgment. Moreover, there is no obvious method of determining the relative quantitative importance of different variables, and with any such method the answers are likely to depend on whether the three smallest eigenvalues or only the very smallest are considered “small”.
5.2. Collinearities, rotation and quadratic forms
Some advantages of the (un‐adapted) corr‐max transformation are diminished when strong collinearities are present: not every X variable will be closely related to the transformed variable with which it is paired. Here we examine a dataset in which collinearities are present and illustrate use of the cos‐max transformation matrix to identify the variables that are collinear. To identify collinearities we apply the cos‐max transformation to data that have been standardised to have means of 0 and variances of 1, making the cos‐max and corr‐max transformations very similar, as will be seen.
The dataset contains two strata whose means will be compared using Hotelling's two‐sample statistic. We partition the test statistic into the contributions of individual variables/variable combinations by applying the adapted corr‐max transformation. The rotation matrix (Γ) we use in the transformation creates meaningful non‐collinear variables from the variables that are involved in the collinearities.
Example 2
Female and male athletes The data relate to the following nine measurements that were made on female and male athletes collected at the Australian Institute of Sport (Cook & Weisberg 1994): Wt (weight), Ht (height), Rcc (red blood cell count), Hg (hemoglobin), Hc (hematocrit), Wcc (white blood cell count), Ferr (plasma ferratin concentration), Bfat (% body fat), and SSF (sum of skin folds). It is assumed that the two groups (females and males) may have different means, and , but have a common covariance matrix Σ. Let denote the pooled estimate of Σ. The pooled correlation matrix, , takes the value
(20)
Under the cos‐max transformation, a data matrix X is transformed to . Let denote the data matrix after variables have been centred and scaled so that the correlation matrix of is . If we put then, as Garthwaite et al. (2012) pointed out, the variance inflation factor for the jth variable () is equal to . Moreover, if is large, indicating a collinearity, then large components of correspond to the variables that underlie the collinearity. In the present example, , so examining the rows of identifies variables involved in collinearities. (When , the corr‐max and cos‐max transformations are the same.)
We put and give the values of the in Table 2. Values greater than 0.80 in absolute value are given in bold‐face type. The last column of the table gives the VIF for each variable, e.g. 8.15 is the VIF for and equals . A VIF above 10 is often treated as indicative of collinearity (Neter, Wasserman & Kutner 1983 p. 392) On this basis, (Bfat) and (SSF) are involved in collinearites and, from the bold‐face numbers in the display of and , there is a collinearity between them. Weaker boundaries for flagging a collinearity have also been proposed; Menard (1995, p. 66) suggests a VIF above 5 should raise concern and O'Brien (2007) reports that boundary values as low as 4 have been suggested as rules of thumb. A boundary of 4 or 5 would indicate one further collinearity, between (Hg) and (Hc).
Table 2.
Rows of and variance inflation factors for data on athletes
|
|
|
|
|
|
|
|
|
|
VIF | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
1.66 | −0.61 | 0.06 | −0.23 | 0.00 | −0.01 | −0.06 | −0.17 | −0.41 | 3.38 | |||||||||
|
|
−0.61 | 1.36 | −0.03 | 0.23 | −0.08 | 0.00 | 0.14 | −0.06 | 0.07 | 2.31 | |||||||||
|
|
0.06 | −0.03 | 1.75 | −0.30 | −0.80 | −0.03 | 0.02 | 0.05 | −0.10 | 3.83 | |||||||||
|
|
−0.23 | 0.23 | −0.30 | 2.09 | −1.12 | 0.00 | −0.04 | 0.04 | 0.00 | 5.82 | |||||||||
|
|
0.00 | −0.08 | −0.80 | −1.12 | 2.48 | −0.08 | 0.06 | −0.09 | 0.22 | 8.15 | |||||||||
|
|
−0.01 | 0.00 | −0.03 | 0.00 | −0.08 | 1.04 | −0.05 | −0.07 | −0.06 | 1.09 | |||||||||
|
|
−0.06 | 0.14 | 0.02 | −0.04 | 0.06 | −0.05 | 1.04 | −0.07 | −0.02 | 1.11 | |||||||||
|
|
−0.17 | −0.06 | 0.05 | 0.04 | −0.09 | −0.07 | −0.07 | 3.27 | −2.43 | 16.64 | |||||||||
|
|
−0.41 | 0.07 | −0.1 | 0.00 | 0.22 | −0.06 | −0.02 | −2.43 | 3.38 | 17.59 |
If the corr‐max transformation is applied to , then the following are the sample correlations between each x variable and the variable to which it transforms:
| Variable: | Wt | Ht | Rcc | Hg | Hc | Wcc | Ferr | Bfat | SSF |
| Correlation: | 0.84 | 0.91 | 0.83 | 0.80 | 0.76 | 0.99 | 0.99 | 0.76 | 0.75 |
The correlations for Hg and Hc are a little low, suggesting that remedial action might be taken to offset both the mild collinearity between this pair of variables as well as the stronger collinearity between Bfat and SSF. To rotate the axes associated with these variable pairs we replace the corr‐max transformation by the adapted corr‐max transformation given by equation (9), with Γ set equal to the following block‐diagonal orthogonal matrix:
| (21) |
We refer to the variables to which Bfat and SSF transform as B+S and B−S, and those from Hg and Hc as H+H and H−H. Rotation dramatically increased the correlations between the new variables and their transformed values while leaving the corresponding correlations of all other variables unchanged. The correlations between the rotated x variables and the variables to which they transform are displayed below. These show a close one‐to‐one relationship between the two sets of variables.
| Variable: | Wt | Ht | Rcc | H+H | H‐H | Wcc | Ferr | B+S | B‐S |
| Correlation: | 0.84 | 0.91 | 0.83 | 0.91 | 0.96 | 0.99 | 0.99 | 0.95 | 0.99 |
Before rotation, the sample means for the female and male athletes ( and ), and the pooled standard deviations (S.D.) were as follows.
| Wt | Ht | Rcc | Hg | Hc | Wcc | Ferr | Bfat | SSF | |
| Female: | 67.34 | 174.59 | 4.405 | 13.560 | 40.48 | 6.994 | 57.0 | 17.85 | 87.0 |
| Male: | 82.52 | 185.51 | 5.027 | 15.553 | 45.65 | 7.221 | 96.4 | 9.25 | 51.4 |
| S. D. | 11.69 | 8.07 | 0.336 | 0.929 | 2.60 | 1.801 | 43.3 | 4.45 | 27.3 |
The reciprocals of the standard deviations constitute the non‐zero (diagonal) entries of the matrix . When Hotelling's test is used to compare the means of the two groups we obtain a statistic equal to 1199.1. This value gives, as you might expect, very clear evidence of differences between the two groups (). However, the question of which quantities contribute most to the value is still relevant.
Putting gives
The partition allows us to evaluate the contributions of individual x‐variables/variable combinations to as proportional to the squares of the components of :
(When multiplied by δ, which here equals 100(102)/(100+102), these sum to the value of the statistic, 1199.1, apart from rounding error.) On the scale given by our partition, the largest contributors to the size of are the average of Bfat and SSF (contributing 24%) and the difference between these same two quantities (contributing 28%). With the other pair of variables whose axes were rotated, Hg and Hc, their average makes a substantial contribution (13%) while the contribution from their difference is only 1%.
6. Bootstrap confidence intervals
The corr‐max transformation gives point estimates of the contributions of individual variables to a quadratic form. Obtaining theoretical results that give interval estimates of these contributions is difficult, but the bootstrap can be used to obtain approximate confidence intervals. We elucidate the procedure through examples.
6.1. Confidence interval for contributions to a Mahalanobis distance
In Example 1 there were 100 genuine Swiss 1000‐franc bank notes and an additional bank note that might be a forgery. The Mahalanobis distance between the potential forgery and the mean of the genuine bank notes was 55.69 and the contributions of the six individual variables were estimated as (8.64 0.87 4.54 16.66 15.12 9.86). To obtain bootstrap confidence intervals for these contributions we generated 100 000 resamples from the 100 genuine bank notes. Each resample was a random sample of size 100 drawn with replacement from the 100 genuine notes.
Each resample was used in the same way as the original sample. The Mahalanobis distance between the potential forgery and the mean of the resample was calculated, with the resample being used to estimate the covariance matrix, . The contributions of individual variables to the Mahalanobis distance were then evaluated using the corr‐max transformation. This gave 100 000 estimates of the contribution of each variable and the kth smallest of these is equated to the (k/1000)th percentile of the bootstrap distribution. The median for a variable's contribution is thus the 50 000th smallest value and the endpoints of an approximate 95% confidence interval are the 2500th smallest and 2500th largest values. (This is the simplest method of forming bootstrap confidence intervals. As is well known, it typically works reasonably well but produces some bias, so work is underway to explore its performance in the current context and compare it with other bootstrap methods.)
Figure 1 gives ‘pseudo‐boxplots’ for the contributions of each of the six variables. As in a conventional boxplot, the ends of the box indicate the interquartile range of the data and the line within the box marks the median. However, we used the whiskers to depict the central 95% confidence interval, rather than the trimmed range. The circles show the point estimates (8.64,…,9.86) given by the actual data. The figure indicates that measurements of the height on the left and right sides (left‐ht and right‐ht) contribute comparatively little to the Mahalanobis distance, while the distances from the inner frame to the lower border (lower) and from the inner frame to the upper border (upper) contribute noticeably more. Other firm conclusions are difficult to make, because there is substantial uncertainty as to the contributions of variables.
Figure 1.
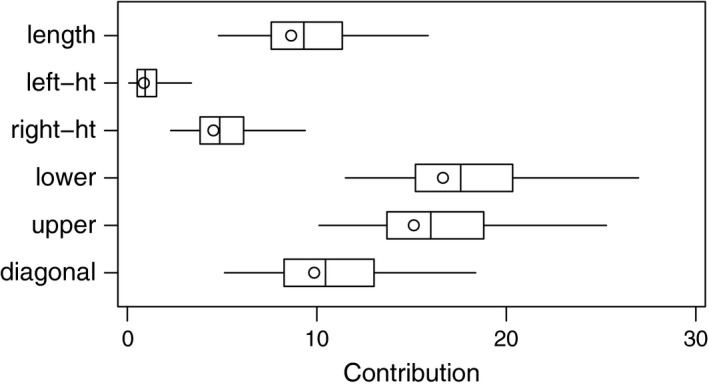
Confidence intervals for the contributions of individual variables to the Mahalanobis distance of a potential banknote forgery.
6.2. Confidence interval for contributions to a two‐sample statistic
Example 2 involves the study of a group of 100 female athletes and a group of 102 male athletes. Nine variables were measured on each athlete and two pairs of variables were rotated to reduce collinearities. The statistic for comparing the two groups was calculated and gave overwhelming evidence that the groups differed. To form bootstrap confidence intervals for the contributions of individual variables to this statistic, the groups must be resampled separately ‐ a resample consists of the measurements of 100 athletes randomly drawn with replacement from the female athletes and 102 athletes drawn with replacement from the male athletes. The statistic was determined for each of 100 000 resamples and the contribution of individual variables/variable combinations to the statistic in each resample was evaluated using the adapted corr‐max transformation.
Pseudo boxplots derived from the results are given in Figure 2. These show that the primary contributions to the statistic are clearly from B+S and B−S, the combination variables that are formed from the sums and differences of Bfat (percentage of body fat) and SSF (sum of skin folds). Other variables contribute noticeably less, but the only variable that clearly makes almost no contribution is the white cell blood count (Wcc). The confidence intervals are skewed to the right and the larger contributions tend to have wider confidence intervals. These appear to be characteristic traits and can also be seen in Figure 1.
Figure 2.

Confidence intervals for the contributions of individual variables to a two‐sample statistic for comparing female and male athletes.
7. Concluding comments
The corr‐max transformation is straightforward to calculate. The matrices and are readily determined and a spectral decomposition gives, say, where Ψ is a diagonal matrix of eigenvalues of and H is an orthogonal matrix whose columns are eigenvectors. After Ψ and have been determined, is set equal to . Hence, the corr‐max transformation and the partition it yields are readily implemented in any programming language that offers matrix functions. To facilitate use of the partition in some important applications, programs have been written in R that determine the contributions of individual variables to a quadratic form in the contexts of Hotelling's one‐sample and two‐sample T tests, Mahalanobis distance, and the classification of an item to one of two populations on the basis of Fisher's linear discriminant function. These programs are available from URL: http://users.mct.open.ac.uk/paul.garthwaite.
The rotation of variables has received much attention in this paper, and further comment is needed to give a balanced perspective on its role in partitioning a quadratic form. As in equation (5), let . When the correlations are high between each component of and the corresponding component of X, then the partition is clearly a sensible way of evaluating the contribution of each x‐variable. When some of these correlations are low, they can sometimes be increased dramatically through rotations that yield interpretable variables. This potential benefit of rotation was illustrated in Section 5.2. However, finding suitable rotations that yield interpretable variables is not always possible. Moreover, even when such rotations can be found, there are attractions in the simplicity of forming a partition that retains the original x‐variables. We briefly return to the athletes data to show that low correlations do not preclude a transparent relationship between the x‐variables and the contributions allocated to them by the partition.
Let denote the difference between an athlete's measurements and the average for their gender. Put , so that the components of are standardized values of each variable. Let . Then is the contribution of the ith variable to the quadratic form Θ in equation (11). We focus on the two most highly correlated variables, Bfat and SSF . The partition uses the following equations (obtained from Table 2) to determine their contribution to Θ.
These formulae show precisely how the contributions of individual variables to Θ are calculated. In particular, the formulae show that the difference between and has a substantial impact on the assessed contributions of Bfat and SSF. This arises from the high correlation between them (the correlation is 0.96), so that a large difference between their standardised differences is unexpected and so increases Θ. The role of the interaction between Bfat and SSF can be further clarified by writing and as,
| (22) |
| (23) |
Written in this way, and seem a very reasonable reflection of the respective contributions of Bfat and SSF to the quadratic form, inasmuch as the large terms in (22) both involve while those in (23) both involve . We should note though, that while our method gives contributions to and that seem reasonable, other methods may give different values that also seem reasonable. We should also note that, in this example, the low correlation on which we focused stems from a single collinearity between just two variables. With multiple collinearities involving several variables, the relationship between the x‐variables and the contributions allocated to them would be less straightforward.
Experiments are often laborious and costly to conduct and the scientists who conduct them would like to glean as much as possible from the data they gather. Not infrequently, a quadratic form is central to a multivariate statistical analysis and then the scientists might reasonably expect the quadratic form to yield more than just a p‐value from a hypothesis test. The method developed in this paper provides a means of learning more about a quadratic form and hence should prove useful. It can always be applied, provided that is positive‐definite, and yields a well‐defined numerical evaluation of the contributions of individual x‐variables to the quadratic farm. With multiple collinearities involving several variables, it can be difficult to judge intuitively whether an evaluation is a sensible reflection of these contributions and then the credibility of an evaluation must stem from the method used to produce it. Our method is derived from a clear, understandable criterion that gives it a sound basis. In our experience the method has never given an evaluation that seems unreasonable and we recommend its use for the decomposition of a quadratic form for any positive‐definite matrix . In reporting results, the method used to obtain the decomposition should be stated so as to define the evaluated contributions unambiguously.
Acknowledgements
The authors thank an associate editor and two referees for helpful comments that led to substantial improvements in this paper. We also thank the University of Adelaide and the Open University for facilitating visits and for their hospitality. PHG benefitted from a travel award from the University of Adelaide. This work was supported by a project grant from the Medical Research Council.
Appendix A. Proofs of theorems
Lemma 1
Suppose that B is a square matrix and tr(B) is to be maximised under the condition that , where Ω is a positive‐definite matrix. Then , the symmetric square‐root of Ω.
Because Ω is positive‐definite, B is of full rank, whence the singular value decomposition theorem gives , where Λ is a diagonal matrix and F and G are orthogonal matrices. Then , so is the unique spectral decomposition of Ω. Also, . Now G and F are orthogonal matrices, so the maximum value that the (i,i)th entry of can take is 1, and it can only equal 1 if the ith columns of G and F are equal. Hence is maximised when G=F. Thus .
Lemma 2
Suppose that E(Y)=0 and , and that is to be maximised, where B is a square matrix and . Then .
Let where k is a scalar. Observe that . Hence we wish to maximise under the constraint that or, equivalently, that . From Lemma 1, , so .
Proof of Theorem 1
For any X, by assumption . Choosing X so that only one entry of (X−μ) is non‐zero shows that the diagonal entries of and are equal. Choosing X so that only two entries of (X−μ) are non‐zero then does the same for off‐diagonal entries, so . Since var(X)∝Σ, it follows that . Consequently the components of W are uncorrelated and have identical variances.
For the next part of the theorem, let and var(X)=k Σ. Then and . Let Z=D{X−E(X)} and put , so that E(Z)=0, var(Z)=k DΣD, and for i=1,…,m. We know that . In addition cor because . Thus . Also the constraint is equivalent to . Hence A must be chosen to maximise , where E(Z)=0, var(Z)∝DΣD and . From Lemma 2, . Thus, and .
Proof of Theorem 3
Let var(X)=k Σ, Z=D{X−E(X)} and put . It then follows that cor. Now var(Z)=k DΣD and Also, . Hence is the (i,j) entry of . Since , both and equal the (i,j)th entry of . Similar reasoning shows that is the (i,j)th entry of .
Proof of Theorem 5
Part (i) follows from reasoning similar to the first steps of the proof of Theorem 1. To prove (ii), let and let V=Y−E(Y), so that E(V)=0 and var(V)∝Φ. Put , so that since . It then follows that . From Lemma 2, is maximised when . Additionally, is the unique symmetric square‐root of . As , it follows that . Part (iii) follows immediately from (ii) and the definition of Y. The proof of (iv) is analogous to the proof of Theorem 3. Part (v) is immediate from equation (7).
Appendix B. Orthogonal matrices from contrasts
Suppose the first four x‐axes are rotated by the transformation , where
| (24) |
and for j=1…,4, so that the are standardised x‐variables. It is readily checked that is an orthogonal matrix. The new variables are
Thus is the difference between the average of the first two variables and the average of the other two variables, and are each proportional to the difference between a pair of variables, and is proportional of the average of the four variables. Consequently may all be meaningful combinations of the x‐variables, although this is obviously context dependent. The point of this example is that the top three rows of form a (non‐unique) set of orthogonal contrasts and contrasts can prove useful when meaningful linear combinations of variables are sought. It is certainly the case that in the analysis of experiments, contrasts among factor levels are commonly constructed for that reason.
More generally, one approach to finding rotation matrices that give meaningful new variables is to look for a set of meaningful orthonormal contrasts. Suppose the first d axes are to be rotated, so that linear combinations of are to be formed. A complete set of orthonormal contrasts consists of d−1 linear combinations
| (25) |
such that , and, for i≠k(k=1,…,d−1), . The set of orthonormal contrasts is not unique, giving flexibility in constructing the . To form a rotation matrix from these contrasts, we set the (i,j)th entry of equal to (i=1,…,d−1;j=1,…,d) and the (d,j)th entry of equal to (j=1,…,d).
References
- Calenge, C. , Darmon, G. , Basille, A. & Jullien, J.‐M. (2008). The factorial decomposition of the Mahalanobis distances in habitat selection studies. Ecology 89, 555–566. [DOI] [PubMed] [Google Scholar]
- Cook, R. D. & Weisberg, S. (1994). An Introduction to Regression Graphics. New York: Wiley. [Google Scholar]
- Das, P. & Datta, S. (2007). Exploring the effects of chemical composition in hot rolled steel product using Mahalanobis distance scale under Mahalanobis‐Taguchi system. Comp. Mater. Sci. 38, 671–677. [Google Scholar]
- Flury, B. & Riedwyl, H. (1988). Multivariate Statistics: A Practical Approach. Cambridge: Cambridge University Press. [Google Scholar]
- Garthwaite, P. H. , Critchley, F. , Anaya‐Izquierdo, K. & Mubwandarikwa, E. (2012). Orthogonalization of vectors with minimal adjustment. Biometrika 99, 787–798. [Google Scholar]
- Garthwaite, P. H. & Koch, I. (2013). Evaluating the contributions of individual variables to a quadratic form. Technical Report 13/07, Statistics Group, The Open University, UK: Available from URL: http://statistics.open.ac.uk/2013_technical_reports. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Menard, S. (1995). Applied Logistic Regression Analysis. Thousand Oaks, CA: Sage. [Google Scholar]
- Neter, J. , Wasserman, W. & Kutner, M. H. (1983). Applied Linear Regression Models. Illinois: Irwin. [Google Scholar]
- O'Brien, R. M. (2007). A caution regarding rules of thumb for variance inflation factors. Qual. Quant. 41, 673–690. [Google Scholar]
- Rogers, D. J. (2015). Dengue: recent past and future threats. Philos. T. Roy. Soc. B 370, 20130562. (doi:10.1098/rstb.2013.0562). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rotenberry, J. T. , Knick, S. T. & Dunn, J. E. (2002). A minimalist approach to mapping species' habitat: Pearson's planes of closest fit In Predicting Species Occurrences: Issues of Accuracy and Scale, Scott J. M., Heglund P. J., Morrison M. L., Haufler J. B., Raphael M. G.l, Wall W. A. & Samson F. B. eds., 281–289. Washington: Island Press. [Google Scholar]
- Rotenberry, J. T. , Preston, K. L. & Knick, S. T. (2006). GIS‐based niche modeling for mapping species habitat. Ecology 87, 1458–1464. [DOI] [PubMed] [Google Scholar]
- Taguchi, G. & Jugulum, R. (2002). The Mahalanobis‐Taguchi Strategy: A Pattern Technology System. New York: Wiley. [Google Scholar]