

Abstract
Feature selection plays a critical role in text categorization. During feature selecting, high-frequency terms and the interclass and intraclass relative contributions of terms all have significant effects on classification results. So we put forward a feature selection approach, IIRCT, based on interclass and intraclass relative contributions of terms in the paper. In our proposed algorithm, three critical factors, which are term frequency and the interclass relative contribution and the intraclass relative contribution of terms, are all considered synthetically. Finally, experiments are made with the help of kNN classifier. And the corresponding results on 20 NewsGroup and SougouCS corpora show that IIRCT algorithm achieves better performance than DF, t-Test, and CMFS algorithms.
1. Introduction
As the number of digital documents available on the Internet has been growing significantly in recent years, it is impossible to manipulate manually such enormous information [1]. More and more methods based on statistical theory and machine learning have been proposed, and they are applied successfully to information processing. An effective method for managing the vast amount of data is text categorization, which has been widely applied to many fields such as theme detection, spam filtering, identity recognition, web page classification, and semantic parsing.
The goal of text classification is to assign a new document automatically to a predefined category [2]. A typical text classification framework consists of preprocessing, document representation, feature selection, feature weighting, and classification stages [3]. In the preprocessing stage, it usually contains such tasks as tokenization, stop-word removal, lowercase conversion, and stemming. In the document representation stage, it generally utilizes the vector space model that makes use of the bag-of-words approach [4]. In the feature selection stage, it usually employs the filter methods such as document frequency (DF) [5], mutual information (MI) [6], information gain (IG) [7], and chi-square (CHI) [8]. In the feature weighting stage, it usually uses TF-IDF to calculate the weights of the selected features in each document. And in the classification stage, it always uses some popular classification algorithms, for example, decision trees [9], k-Nearest Neighbors (kNN) [10], and support vector machine (SVM) [11].
The major characteristic of text categorization is that the feature number in the feature space can easily reach up to tens or hundreds of thousands. It can not only increase computational time but also degrade classification accuracy [12]. As a consequence, feature selection plays a critical role in text classification.
The existing experimental results show that IG is one of the most effective feature selection methods, the performance of DF is similar to IG, and MI is the worst [13]. Through comparative analysis, it is easy to find that the performances of DF and IG are good, which means that high-frequency terms are really essential to text classification, while the performance of MI is bad as it is inclined to select low-frequency terms as features. Besides, t-Test method is also based on term frequency [14] and its performance is good. During feature selecting, Categorical Term Descriptor (CTD) method considers the document frequency of IDF and the category information of ICF particularly [15]. Similarly, Strong Class Information Words (SCIW) method selects the terms which have good abilities to distinguish categories [16] and it also considers the category information. Experimental results show that CTD and SCIW both have good accuracies. So we can easily know that feature selection methods based on category information always have good performances. As a result, we draw that high-frequency terms and category information are very important in improving the classification effectiveness. Comprehensively Measure Feature Selection (CMFS) method [1] considers high-frequency terms and category information simultaneously, and it also obtains good results. But it does not consider the interactions between categories. In view of these, we propose a new feature selection algorithm named as feature selection approach based on interclass and intraclass relative contributions of terms (IIRCT), in which term frequency and the interclass relative contribution and the intraclass relative contribution of terms are all considered synthetically.
2. Related Works
To deal with massive documents corpora, many feature selection approaches have been proposed. And their purpose is to select the terms whose classification capabilities are stronger comparatively in feature space. After feature selection, the dimensionality of feature space can be reduced, and the efficiency and accuracy of classifiers can be improved. Its main idea is as follows. Firstly, it uses the feature selection function to compute some important indicators of each word in feature space. And then, it sorts the words in descending order according to above values. Finally, it selects the top m words to construct the feature vector.
In this section, we introduce some symbols used in the following firstly.
tfij is the times that the term t i appears in document d j, namely, term frequency.
is the average frequency of the term t i within a single category C k, and the calculation formula is as follows:
| (1) |
where N is the document number in collection D, N k is the document number in category C k, and I(d j, C k) = {1, d j ∈ C k; 0, d j ∉ C k}, which is an indicator to discriminate whether document d j belongs to category C k.
is the average term frequency of the term t i in collection D, and it is calculated according to
| (2) |
Similarly, N is the document number in collection D.
Then we give the definition of three feature selection methods, which are DF, t-Test, and CMFS, respectively.
2.1. DF
DF method calculates the number of documents which contain the terms in the category to measure the relevance of the terms and the categories. And the terms can be reserved only when they appear in adequate documents. This measurement is based on such an assumption that the terms which have low values of DF have few effects on the classification performance [8]. So DF method always selects terms with high values of DF and removes terms with low values of DF.
DF method is a simple word reduction technology and has good performance. Due to its linear complexity, it can be easily scaled to be used in large-scale corpus.
2.2. t-Test
t-Test [14] is a feature selection approach based on term frequency, which is used to measure the diversity of the distributions of a term between the specific category and the entire corpus. And it is defined as follows:
| (3) |
In (3), is the average frequency of the term t i within a single category C k, is the average term frequency of the term t i in collection D, N k is the document number in category C k, N is the document number in collection D, , and |C| is the category number in collection D.
The following two ways are used alternatively when the main features are finally selected:
| (4) |
| (5) |
where p(C k) = N k/N, N k is the document number in category C k, and N is the document number in collection D.
Generally, the method shown in (4) is always better than that shown in (5) for multiclass problem.
2.3. CMFS
When selecting features, DF method only computes the document frequency of each unique term in one category, and then the highest document frequency of a term in various categories is retained as the term's score. DIA association factor method [17] only calculates the distribution probability of a term in various categories, and then the highest probability of the term can be used as the term's score. Yang et al. [1] noticed that both DF and DIA methods only focus on one respect of the problems (row or column). Thus DF method concentrates on the column of the term-to-category matrix, while DIA focuses on the row of the term-to-category matrix. Based on such observation, a new feature selection algorithm, Comprehensively Measure Feature Selection (CMFS), is proposed by Yang et al. It comprehensively measures the significance of a term both in intercategory and intracategory. And it is defined as follows:
| (6) |
Here, p(t i∣C k) is the probability that the feature t i appears in category C k, and p(C k∣t i) can be considered as the conditional probability that the feature t i belongs to category C k when the feature t i occurs.
To measure the goodness of a term globally, two alternate ways can be used to combine the category-specific scores of a term. And the formulae are as follows:
| (7) |
where p(C k) = N k/N, N k is the document number in category C k, and N is the document number in collection D.
3. IIRCT
In this section, we propose a feature selection approach based on interclass and intraclass relative contributions of terms. In the proposed algorithm, three critical factors, which are term frequency and the interclass relative contribution and the intraclass relative contribution of terms, are all considered synthetically.
3.1. Motivation
At present, a large number of feature selection algorithms emerge. Through studying and analysing them, we can easily find that DF, IG, and t-Test algorithms are inclined to select high-frequency terms as main features, and their performances are good. Among them, DF and IG algorithms are based on document frequency, and t-Test algorithm is based on term frequency. CTD and SCIW algorithms consider the category information, and they both have good accuracies.
Therefore, we conclude the following ones:
A term, which frequently occurs in a single class and does not occur in the other classes, is distinctive. Therefore, it should be given a high score.
A term, which rarely occurs in a single class and does not occur in the other classes, is irrelevant. Therefore, it should be given a low score.
A term, which frequently occurs in all classes, is irrelevant. Therefore, it should be given a low score.
A term, which occurs in some classes, is relatively distinctive. Therefore, it should be given a relatively high score.
From points (1) and (2), it can be seen that high-frequency terms have effects on the classification performance. From points (3) and (4), it can be seen that category information is also a very important factor which influences the classification effect. As a result, we have a conclusion that high-frequency terms and category information are both very important factors in improving the classification performance. In view of these, high-frequency terms and category information are considered synthetically when constructing feature selection function in this paper. When judging whether a word is a high-frequency term, term frequency method is used. While considering category information, we notice that ① if the probability that the feature t i occurs in category C k is higher than other features, t i can represent C k more effectively, ② if the probability that the feature t i occurs in category C k is higher than t i occurs in other categories, t i can represent C k more effectively, ③ if the conditional probability that the feature t i belongs to category C k is higher than t i belongs to other categories when the feature t i occurs, t i can represent C k more effectively. So, the feature selection function constructed in this paper considers the interclass and intraclass relative contributions of terms to measure the category information.
Based on the above, we propose a new feature selection approach, IIRCT, in which term frequency and the interclass relative contribution and the intraclass relative contribution of terms are all considered synthetically.
3.2. Algorithm Implementation
In this section, we firstly introduce some symbols.
TFik is the term frequency of term t i in category C k, and it is calculated according to
| (8) |
where N k is the document number in category C k and tfij is the times that the term t i appears in document d j.
dfik is the document frequency of term t i in category C k.
TFk is the total term frequency of all terms in category C k, and the calculation formula is as follows:
| (9) |
where M k is the term number in category C k.
dfi is the total document frequency of term t i in all categories, and it is calculated according to
| (10) |
where |C| is the category number.
IIRCT algorithm measures the significance of a term from three aspects comprehensively, which are term frequency and the interclass and intraclass relative contributions of terms. Thus, we define comprehensive measurement for each term t i with respect to category C k as follows:
| (11) |
where |C| is the category number, TFik is the term frequency of term t i in category C k, TFk is the total term frequency of all terms in category C k, dfik is the document frequency of term t i in category C k, and dfi is the total document frequency of term t i in all categories.
In view of the probability theory, we can regard TFik/TFk in (11) as the probability that the feature t i occurs in category C k, that is, p(t i∣C k). dfik/dfi in (11) can be considered as the conditional probability that the feature t i belongs to category C k when the feature t i occurs, that is, p(C k∣t i). TFij/TFj in (11) can be considered as the probability that the feature t i occurs in category C j, that is, p(t i∣C j). dfij/dfi in (11) can be considered as the conditional probability that the feature t i belongs to category C j when the feature t i occurs, that is, p(C j∣t i). So (11) can be further represented as follows:
| (12) |
Here, p(t i∣C k) is the probability that the feature t i occurs in category C k, and p(C k∣t i) can be considered as the conditional probability that the feature t i belongs to category C k when the feature t i occurs.
To measure the goodness of a term globally, we construct the following function:
| (13) |
where p(C k) = N k/N which is the probability that category C k occurs in the entire training set, N k is the document number in category C k, and N is the document number in collection D.
3.3. Algorithm Description
According to the above, we present a new feature selection algorithm, IIRCT, based on interclass and intraclass relative contributions of terms. Its pseudocode is as in Pseudocode 1.
Pseudocode 1.

4. Experiments Setup
4.1. Experimental Data
In this paper, we use two popular datasets, 20 NewsGroup and SougouCS.
The 20 NewsGroup corpus, which is collected by Ken Lang, has been widely used in text classification. This corpus contains 19997 newsgroup documents which are nearly evenly distributed among 20 discussion groups, and every group consists of 1,000 documents. All letters are converted into lowercase, and the word stemming is applied. In addition, we use the stop words list to filter words. The details of 20 NewsGroup corpus are as shown in Table 1.
Table 1.
20 NewsGroup corpus.
| Category number | Category name |
|---|---|
| 1 | alt.atheism |
| 2 | comp.graphics |
| 3 | comp.os.ms-windows.misc |
| 4 | comp.sys.ibm.pc.hardware |
| 5 | comp.sys.mac.hardware |
| 6 | comp.windows.x |
| 7 | misc.forsale |
| 8 | rec.autos |
| 9 | rec.motorcycles |
| 10 | rec.sport.baseball |
| 11 | rec.sport.hockey |
| 12 | sci.crypt |
| 13 | sci.electronics |
| 14 | sci.med |
| 15 | sci.space |
| 16 | soc.religion.christian |
| 17 | talk.politics.guns |
| 18 | talk.politics.mideast |
| 19 | talk.politics.misc |
| 20 | talk.religion.misc |
The SougouCS corpus is provided by Sogou Laboratory. The documents of the corpus are from Sohu news website which has a lot of classified information. As the number of web pages in some classes is too small, we only choose 12 classes. And the detail is as shown in Table 2.
Table 2.
SougouCS corpus.
| Category number | Category name |
|---|---|
| 1 | Car |
| 2 | Finance |
| 3 | IT |
| 4 | Health |
| 5 | Sports |
| 6 | Tourism |
| 7 | Education |
| 8 | Culture |
| 9 | Military |
| 10 | Housing |
| 11 | Entertainment |
| 12 | Fashion |
4.2. Document Representation
Documents are represented by vector space model [4]. That is, the content of a document is represented by a vector in the term space. It is illustrated in detail as the following. Consider V(d) = (t 1, w 1(d),…, t i, w i(d),…, t m, w m(d)), where m is the number of the features selected by feature selection algorithms and w i(d) is the weight of feature t i in document d. In experiments, Term Frequency-Inverse Document Frequency (TF-IDF) [18] is used to calculate the weights of the m selected features in each document.
4.3. Classifier Selection
In the experiments, k-Nearest Neighbors (kNN) is used to classify and test documents. And it is also a case-based or instance-based categorization algorithm. At present, kNN is widely used in text classification as it is simple and has low error rate.
The principle of kNN classification algorithm is very simple and intuitive. Giving a test document whose category is unknown, the classification system will find the k-nearest documents by computing the similarities between documents in training data. And then, we will get the category of the test documents according to the k-nearest documents. The similarity measure used for the classifier is the cosine function [19].
In the paper, we set k = 20. And we randomly select 65% instances from each category as training data and the rest as testing data.
4.4. Performance Measures
We measure the effectiveness of classifiers in terms of the combination of precision (p) and recall (r) widely used in text categorization. That is, we use the well-known F 1 function [20] as follows:
| (14) |
For multiclass text categorization, F 1 is usually calculated in two ways. And they are the macroaveraged F 1 (macro-F 1) and the microaveraged F 1 (micro-F 1). Here, we only use macro-F 1, as shown in
| (15) |
where F 1(k) is the F 1 value of the predicted kth category.
5. Results and Discussions
5.1. Results and Discussions on 20 NewsGroup
Figure 1 shows the precision and recall of IIRCT, DF, t-Test, and CMFS on the 20 NewsGroup corpus when 1,500 features are selected in feature space. It can be seen from Figure 1(a) that the precision of IIRCT is higher than that of DF, t-Test, and CMFS. And in some categories, the precision of IIRCT almost reaches up to 95%. Similarly, Figure 1(b) also indicates that the performance of IIRCT is better than that of DF, t-Test, and CMFS, and the recall of most categories has some improvements.
Figure 1.

Precision and recall performance on the 20 NewsGroup corpus.
The numbers 1–20 in Figure 1 can be referred to in Table 1.
Figure 2 shows the macro-F 1 performance of IIRCT, DF, t-Test, and CMFS on the 20 NewsGroup corpus with different feature dimensionalities. From Figure 2, we can conclude that the macro-F 1 of IIRCT is close to that of CMFS when 100 features are selected. But if 200, 500, 1000, 1500, 2000, 2500, 3000, or 3500 terms are selected as features, the macro-F 1 curve of IIRCT is higher than that of DF, t-Test, and CMFS. This means that the performance of IIRCT is better than the other three algorithms. Besides, it can be found that the value of macro-F 1 decreases as the feature number increases. The reason for this is that the boundaries between categories are very clear in the 20 NewsGroup corpus. As a consequence, small amount of features can achieve good classification performance. But with the feature number increasing, many features have a negative impact on classification performance. And the classification effect gets poor.
Figure 2.
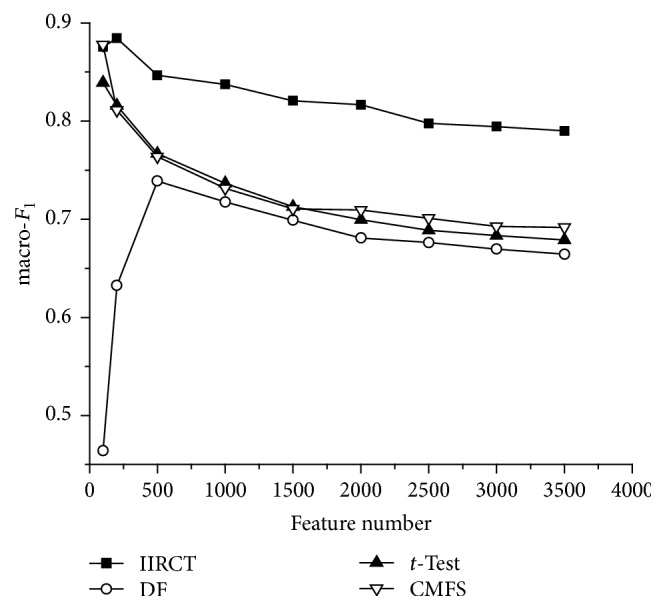
macro-F 1 performance on the 20 NewsGroup corpus.
5.2. Results and Discussions on SougouCS
Figure 3 shows the precision and recall of IIRCT, DF, t-Test, and CMFS on the SougouCS corpus when 4,500 features are selected in feature space. It is clear that, in most categories, the precision and recall of IIRCT have some improvements compared to DF, t-Test, and CMFS. And this means that IIRCT achieves better performance than that of DF, t-Test, and CMFS.
Figure 3.

Precision and recall performance on the SougouCS corpus.
The numbers 1–12 in Figure 3 can be referred to in Table 2.
Figure 4 depicts the macro-F 1 performance of the four algorithms on the SougouCS corpus. From Figure 4, we can know that the macro-F 1 curve of IIRCT lies above the other three curves, which also means IIRCT has better performance than that of DF, t-Test, and CMFS. Besides, it can be found that the value of macro-F 1 is the largest when 4500 features are selected. And when the selected feature number increases or decreases from 4500, the value of macro-F 1 decreases. The reason for this is that, in the SougouCS corpus, some categories, such as fashion and entertainment, have many common words which make the boundaries between categories obscure. When small amount of features is selected, some documents cannot be classified correctly. And when the feature number increases to a certain value, these features make the boundaries between categories clear and improve the classification effect. When the feature number keeps increasing, many features have a negative impact on classification performance. And the classification effect gets poor.
Figure 4.
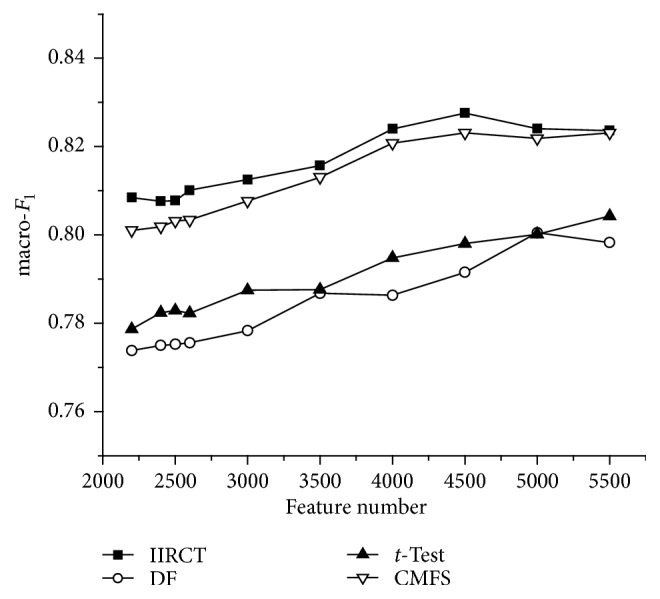
macro-F 1 performance on the SougouCS corpus.
6. Conclusions
Feature selection plays a critical role in text classification and has an immediate impact on text categorization. So we put forward a feature selection approach, IIRCT, based on interclass and intraclass relative contributions of terms in the paper. In our proposed algorithm, term frequency and the interclass and intraclass relative contributions of terms are all considered synthetically. The experimental results on 20 NewsGroup and SougouCS corpora show that IIRCT achieves better performance than DF, t-Test, and CMFS. Therefore, the algorithm proposed in this paper is an effective feature selection method.
Acknowledgments
This research was supported by the National Science Foundation of China under Grants 61402363 and 61272284, Shaanxi Technology Committee Industrial Public Relation Project under Grant 2014K05-49, Natural Science Foundation Project of Shaanxi Province under Grant 2014JQ8361, Education Department of Shaanxi Province Key Laboratory Project under Grant 15JS079, Xi'an Science Program Project under Grant CXY1509(7), and Beilin district of Xi'an Science and Technology Project under Grant GX1625.
Competing Interests
The authors declare that they have no competing interests.
References
- 1.Yang J., Liu Y., Zhu X., Liu Z., Zhang X. A new feature selection based on comprehensive measurement both in inter-category and intra-category for text categorization. Information Processing and Management. 2012;48(4):741–754. doi: 10.1016/j.ipm.2011.12.005. [DOI] [Google Scholar]
- 2.Shang C., Li M., Feng S., Jiang Q., Fan J. Feature selection via maximizing global information gain for text classification. Knowledge-Based Systems. 2013;54:298–309. doi: 10.1016/j.knosys.2013.09.019. [DOI] [Google Scholar]
- 3.Uysal A. K., Gunal S. The impact of preprocessing on text classification. Information Processing and Management. 2014;50(1):104–112. doi: 10.1016/j.ipm.2013.08.006. [DOI] [Google Scholar]
- 4.Zhang B. Analysis and Research on Feature Selection Algorithm for Text Classification. Hefei, China: University of Science and Technology of China; 2010. [Google Scholar]
- 5.Yang K. F., Zhang Y. K., Li Y. Feature selection method based on document frequency. Computer Engineering. 2010;36(17):33–38. [Google Scholar]
- 6.Liu H., Yao Z., Su Z. Optimization mutual information text feature selection method based on word frequency. Computer Engineering. 2014;40(7):179–182. [Google Scholar]
- 7.Shi H., Jia D., Miao P. Improved information gain text feature selection algorithm based on word frequency information. Journal of Computer Applications. 2014;34(11):3279–3282. [Google Scholar]
- 8.Shan S., Feng S., Li X. A comparative study on several typical feature selection methods for Chinese web page categorization. Computer Engineering and Applications. 2003;39(22):146–148. [Google Scholar]
- 9.Quinlan J. R. Induction of decision trees. Machine Learning. 1986;1(1):81–106. doi: 10.1007/bf00116251. [DOI] [Google Scholar]
- 10.Yang Y., Pedersen J. O. A comparative study on feature selection in text categorization. Proceedings of the 14th International Conference on Machine Learning (ICML '97); July 1997; Nashville, Tenn, USA. pp. 412–420. [Google Scholar]
- 11.Cortes C., Vapnik V. Support-vector networks. Machine Learning. 1995;20(3):273–297. doi: 10.1007/BF00994018. [DOI] [Google Scholar]
- 12.Uysal A. K., Gunal S. A novel probabilistic feature selection method for text classification. Knowledge-Based Systems. 2012;36(6):226–235. doi: 10.1016/j.knosys.2012.06.005. [DOI] [Google Scholar]
- 13.Xu Y., Li J.-T., Wang B., Sun C.-M. Category resolve power-based feature selection method. Journal of Software. 2008;19(1):82–89. doi: 10.3724/sp.j.1001.2008.00082. [DOI] [Google Scholar]
- 14.Wang D., Zhang H., Liu R., Lv W., Wang D. t-Test feature selection approach based on term frequency for text categorization. Pattern Recognition Letters. 2014;45(1):1–10. doi: 10.1016/j.patrec.2014.02.013. [DOI] [Google Scholar]
- 15.How B. C., Narayanan K. An empirical study of feature selection for text categorization based on term weightage. Proceedings of the IEEE/WIC/ACM International Conference on Web Intelligence (WI '04); September 2004; Beijing, China. IEEE Computer Society Press; pp. 599–602. [DOI] [Google Scholar]
- 16.Li S. S., Zong C. Q. A new approach to feature selection for text categorization. In: Ren F. J., Zhong Y. X., editors. Proceedings of the 2005 IEEE International Conference on Natural Language Processing and Knowledge Engineering (NLP-KE '05); November 2005; Wuhan, China. IEEE Press; pp. 626–630. [DOI] [Google Scholar]
- 17.Yang J. The Research of Text Representation and Feature Selection in Text Categorization. Changchun, China: Jilin University; 2013. [Google Scholar]
- 18.Salton G., Buckley C. Term-weighting approaches in automatic text retrieval. Information Processing and Management. 1988;24(5):513–523. doi: 10.1016/0306-4573(88)90021-0. [DOI] [Google Scholar]
- 19.Zhou H., Guo J., Wang Y. A feature selection approach based on term distributions. SpringerPlus. 2016;5, article 249 doi: 10.1186/s40064-016-1866-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Sebastiani F. Machine learning in automated text categorization. ACM Computing Surveys. 2002;34(1):1–47. doi: 10.1145/505282.505283. [DOI] [Google Scholar]