

Abstract
Gamma-aminobutyric acid type-A receptors (GABAARs) belong to multisubunit membrane spanning ligand-gated ion channels (LGICs) which act as the principal mediators of rapid inhibitory synaptic transmission in the human brain. Therefore, the category prediction of GABAARs just from the protein amino acid sequence would be very helpful for the recognition and research of novel receptors. Based on the proteins' physicochemical properties, amino acids composition and position, a GABAAR classifier was first constructed using a 188-dimensional (188D) algorithm at 90% cd-hit identity and compared with pseudo-amino acid composition (PseAAC) and ProtrWeb web-based algorithms for human GABAAR proteins. Then, four classifiers including gradient boosting decision tree (GBDT), random forest (RF), a library for support vector machine (libSVM), and k-nearest neighbor (k-NN) were compared on the dataset at cd-hit 40% low identity. This work obtained the highest correctly classified rate at 96.8% and the highest specificity at 99.29%. But the values of sensitivity, accuracy, and Matthew's correlation coefficient were a little lower than those of PseAAC and ProtrWeb; GBDT and libSVM can make a little better performance than RF and k-NN at the second dataset. In conclusion, a GABAAR classifier was successfully constructed using only the protein sequence information.
1. Introduction
Gamma-aminobutyric acid (GABA) is a major human brain inhibitory neurotransmitter and plays a principal role in the regulation of pituitary gland function. GABA is made up of a four-carbon chain flexible carbon skeleton (Figure 1), which can adopt a number of conformations when interacting with many macromolecular receptor targets. This characteristic of GABA can provide many selective ligands by producing conformationally restricted analogues [1]. GABA is mainly synthesized in the hypothalamus as well as within the pituitary gland and stored in the anterior lobe and intermediate lobe cells, the GABA-synthesizing enzyme is glutamic acid decarboxylase (GAD) which is relevant to TCA cycle [2], and the direct substrate is glutamate [3] (Figure 2). In addition to GAD, the GABA level is also related to glutamine-glutamate (Gln-Glu) cycling [4], in which glutaminase and glutamine synthetase play a key role in keeping the cycling balance. Gln is first converted to Glu and then to GABA in the cycle, or Glu solution is catalyzed to GABA; this process is known to play a significant role in the regulation of neurogenesis, and the release of GABA is mainly produced from Purkinje cells in the cerebellar cortex via special regulatory mechanism [5–7].
Figure 1.
GABA conformation.
Figure 2.
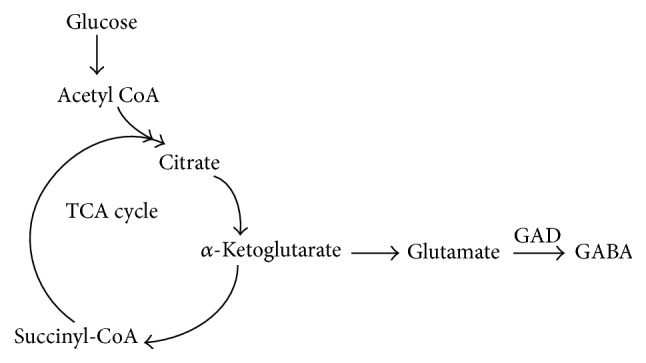
Model of direct GABA production.
GABA can specifically interact with the postsynaptic GABA receptor in human central nervous system (CNS) [8]; the specific binding of GABA to synaptic membrane fractions is saturable. Three types of GABA receptors are expressed in human, namely, the ionotropic GABAA receptor (GABAAR), the metabotropic GABAB receptor (such as G protein-coupled receptor) [9], and another ionotropic GABAC receptor, among them GABAAR is relevant to epilepsy [10]. These receptors belong to the Cys-loop superfamily of ligand-gated ion channels (LGICs) and exhibit a long (about 200 a.a.) extracellular amino terminus, which is thought to be responsible for ligand channel interactions. The amino terminus forms agonist or antagonist binding sites, four transmembrane (TM) domains, and a large intracellular domain between TM3 and TM4 for phosphorylating regulation and localization at synapses, and five TM2 domains in a cycle form the lining segment of the ion channel (Figure 3). The extracellular amino terminus contains a conserved motif, called the Cys-loop (13-amino acid disulfide loop), which is characterized by 2 cysteine residues spaced by 13 different amino acid residues [11]; the amino terminus incorporates neurotransmitters and some modulator binding sites. For example, the extracellular domain of GABAAR β2 subunits contains the amino acid residue “CMMDLRRYPLDEQNC” (C stands for cysteine). For the structural details of Cys-loop receptors see review [12].
Figure 3.
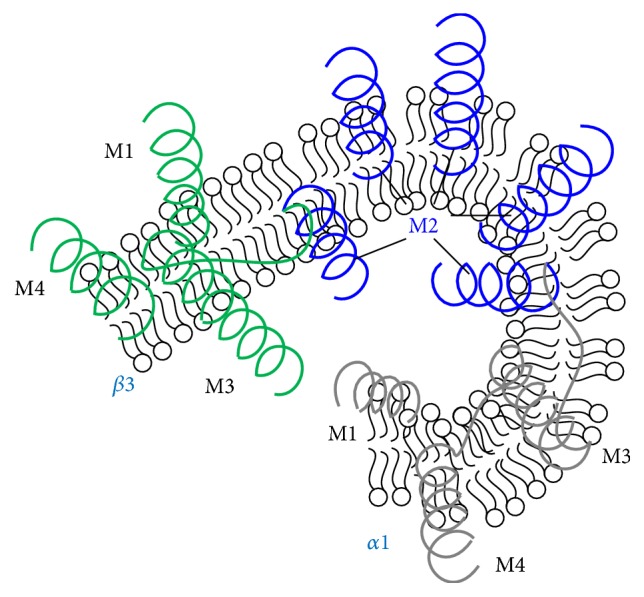
GABAAR modulation patterns of transmembrane domain, a homology model of the transmembrane domains of a GABAAR showing the five-M2-helix domains forming the chloride ion channel (blue) and M1, M3, and M4 helices for single α1 (grey) or β3 (green) subunit. The helices may embed into the postsynaptic membrane in mammalian CNS.
GABAARs form pentameric chloride channels comprising various combinations from eight kinds of subunits (α, β, γ, δ, ε, θ, π, and ρ), each of which comprises several subtypes [13]. These receptors belong to a superfamily of pentameric ligand-gated ion channels (pLGICs) with five-membered ring structures; pLGICs are also known as Cys-loop receptors including two classes: the cation-selective (e.g., nicotinic acetylcholine receptors and serotonin type 3 receptors) and anion-selective (e.g., glycine receptors (GlyRs) and GABAARs) [14]. According to their extracellular domain, pentameric receptors can be further divided into these containing only one conserved Cys-loop and those containing an additional disulfide bond that links the β9-β10 strands in Loop C. Human GABAAR subunits are encoded by 19 different genes, namely, α1–6, β1–3, γ1–3, δ, ε, θ, π, and ρ1–3; among these subunits, the crystallization shows that human GABAAR β3 subunit is unique to eukaryotic Cys-loop receptors [15]. The α1–α6 subunits are encoded by GABRA1 to GABRA6 genes; the α1 subtype is widely expressed in the whole brain, whereas α2, α3, α4, α5, and α6 subtypes are expressed in specific brain areas [16]. Most of the pentameric GABAARs in the human brain are typically composed of two α subunits, two β subunits, and one γ subunit, and the GABA binding sites are located in the α-β subunit interface [17]. The α1, β2, and γ2 subunits are expressed most abundantly in human brain [18], and the subunit variants may thus influence ion channel gating, expression, and GABA receptor trafficking to the cell surface. The GABRA1 and GABRA6 genes are located in human chromosome 5, whereas GABRA2 and GABRA3 are located in chromosome 4 and GABRA4 and GABRA5 are located in chromosome X and chromosome 15, respectively [19]. These genes have been proposed to affect certain drug targets and the regulation of neuronal activities in human brain [20]. Several antiepileptic drugs (AEDs) such as phenobarbital and gabapentin bind to GABAARs in the CNS with a confined area distribution, and the alterations in GABAAR subunits may regulate the responses elicited by AEDs [21]. Several AEDs exert agonistic effects on GABAARs. AEDs may react with GABAARs comprising distinct subunits in diverse manners, and the composition and function of α subunits may influence the treatment efficacy of different AEDs [22]. Targeted proteins of AEDs are involved in the regulation of extracellular K+ and intracellular Cl− homeostasis, cell volume, and pH, all of which are important for maintaining normal brain activity [23].
GABAAR subunit mutations or genetic variations can lead to its dysfunctions, which have been thought to participate in the pathomechanisms of epilepsy [24], in which multiple GABAAR epilepsy mutations result in protein misfolding and may cause degradation or retention of the protein molecules in cells; Kang et al. found that mutant GABAAR γ2 subunits accumulate and aggregate intracellularly, activated caspase-3, and caused widespread and age-dependent neurodegeneration; these findings suggested the epilepsy-associated mutant γ2 subunit played important role in neurodegeneration [25]. The gene mutations or genetic variation of the α1, α6, β2, β3, γ2, or δ subunits (GABRA1, GABRA6, GABRB2, GABRB3, GABRG2, and GABRD, resp.) compromises hyperpolarization through GABAARs, and these variations have been associated with human epilepsy with or without febrile seizures [26].
Support vector machine (SVM) is a kind of supervised machine learning algorithms that have been broadly applied for classification and regression analysis [27–32], which is also a type of sparse kernel machines that rely on various data to predict unknown class labels and which has linear or nonlinear learning model for binary classifier [33–35]. Random forest (RF) is an ensemble machine learning technique based on random decision trees for classification and other tasks. Relying on the feature, a data point can be divided into a special category and is assigned a prediction. RF has been broadly applied in novel protein and target identification [36, 37], because it combines the merits of bagging idea and feature selection [38]. Another decision tree learning is gradient boosting decision tree (GBDT), which has been very successfully applied for many fields such as smart city concept [39], and its major advantage is ability to find nonlinear interactions automatically through decision tree learning with the minimality error. GBDT is generally regarded as one of the best out-of-the-box classifiers which has the ability to generalize and can combine weak learners into a single strong learner; it has gradually acquired popularity in the field of machine learning methods although it still possesses many disadvantages [40–43].
Here, we performed an in silico analysis on the GABAARs according to sequence information and other physicochemical features, including hydrophobicity, normalized van der Waals volume, polarity, polarizability, charge, surface tension, secondary structure, and solvent accessibility. Twenty natural amino acids can be divided into 3 different groups based on each of the above eight properties, and thus 188-dimensional (188D) feature vectors of proteins were constructed with an ensemble classifier [44], which performed well in membrane protein prediction [45]. We employed PseAAC and ProtrWeb methods for human GABAAR to adapt to the web server limit of sequence amounts; we also applied libSVM, RF, GBDT, and widely used k-nearest neighbor (k-NN) algorithms to make comparisons of performance with dataset at rigorous cd-hit filtration [46].
Since motif, a conserved short pattern of a protein [47], is one of the fundamental function units of molecular evolution, with regard to DNA, a motif may act as a protein-binding site; in proteins, a motif may directly correspond to the active site of an enzyme or a structural unit of the protein. Therefore, we also conducted motif analysis.
2. Materials and Methods
2.1. Data Retrieval and Treatment
All the primary sequences of both GABAAR and the control Pfam proteins (in FASTA files) were retrieved from the UniProt database (http://www.uniprot.org/); the raw data are preprocessed by cd-hit program (http://cd-hit.org) to merge the sequence similarities and reduce the complexity [46]. To avoid bias in the classifier, we set the identity at 90% similarity and obtained the results of 2353 GABAAR sequences as positive dataset; the negative samples were obtained from the control proteins when the positive ones were deleted, and 10652 entries were obtained as negative dataset. When the four classifiers performance was measured, cd-hit was set at rigorous 40% identity and gained 360 GABAARs and 9598 non-GABAARs.
2.2. Prediction Analysis for Potential GABAAR Proteins
Machine learning is often employed in the bioinformatics and proteomics problem. Several important techniques facilitate the protein classification and identification, such as imbalanced classification strategies [48], ensemble learning [49–51], samples selection strategies [52, 53], features reduction, and ranking methods [54–56].
To predict the potential GABAAR from the amino acid sequences, we constructed a classifier according to the GABAAR protein features. First, we extracted the feature vectors from positive versus negative protein sequence dataset by using a novel machine-learning-based method developed by our group, we transformed all the positive and negative sequences into the corresponding protein family (Pfam) information, and the obtained features included sequence evolutional information, k-skip-n-gram model, physicochemical properties, and local PsePSSM [57]. Altogether, we assembled 188D feature vectors. Afterward, the resulting feature vectors were imported into Weka (http://www.cs.waikato.ac.nz/ml/weka/), which is a machine learning workbench used for automatic classification via visualization and cross-validation analysis [58, 59]. After several preliminary trials with the same dataset, we selected random forest method and set the parameters as default.
2.3. Conserved Motif Analysis of Human GABAAR Proteins
Conserved motif analyses were implemented using the online MEME Suite (http://meme-suite.org/, 4.11.1 version), a powerful motif-based sequence analysis tool, which integrated a set of web-based tools including Gene Ontology database for studying sequence motifs in proteins, DNA, and RNA [60]. Currently, the MEME Suite has added six new tools and reached thirteen since the “Nucleic Acids Research” Web Server Issue in 2009. Human GABAAR sequences in FASTA format were used as a file input. The maximum motif width, minimal motif width, and maximum number of motifs were set to 50, 6, and 9, respectively. The remaining parameters were set as default values.
2.4. Pseudo-Amino Acid Composition and ProtrWeb Analysis
Chou et al. [61–63] had proposed the concept of PseAAC to describe global or long-range sequence-order protein information early in 2001; their original design objective was to improve protein subcellular localization prediction and membrane protein type prediction. Since then, the PseAAC approach alone or incorporating other properties had rapidly penetrated many areas of computational proteomics. As the most intuitive features for protein biochemical reactions, the physicochemical properties of amino acids significantly influence the protein classification. Features that incorporate appropriate physicochemical properties can contain much valuable information for improving the performance of predictors. Single feature extraction of our own method has inevitably its own shortcomings and does not always perform well on all circumstances. Thus, we also used the concept of PseAAC and ProtrWeb (http://protrweb.scbdd.com/) to construct feature vectors for human GABAAR proteins (58 entries) and other proteins (58 entries) in this study.
PseAAC is a web server that can generate numerous pseudo-amino acid compositions including sequence-order information in addition to the conventional 20D amino acid composition. It is a classification algorithm based on the amino acid composition and physicochemical characteristics of proteins; the server was designed in a flexible way to identify various pseudo-amino acid composition information for a given protein sequence by selecting different parameters and their combinations. PseAAC provides three PseAA modes and six amino acid characters for user to choose. ProtrWeb [64] is also a web server based on the R package routine protr, the first version of which was developed in November 2013. This server is dedicated to calculate protein sequence-derived structural and physicochemical descriptors such as amino acid composition. n-gram and k-skip are based on permutation and combination theory. ProtrWeb can be applied in various protein prediction studies, including protein structural and functional classes, protein subcellular locations, protein-protein interactions, and receptor-ligand interactions. ProtrWeb offers 12 types of commonly used descriptors presented in the web such as amino acid composition, dipeptide composition, and pseudo-amino acid composition. Recently, some studies have shown that the long-range sequence-order effects of DNA [65] can improve the performance of computational predictors [66].
To extract features from the physicochemical properties of proteins by using PseAAC, we considered all six physiochemical properties: hydrophobicity, hydrophilicity, mass, pK1 (alpha-COOH), pK2 (NH3), and pI (at 25°C). We selected type 2 PseAA mode, set Lambda parameter at 10, and set the weight factor as default. The results were shown as 80-dimensional (80D) data for each protein. For ProtrWeb, we chose amino acid composition (20 Dim) and pseudo-amino acid composition (50 Dim) adapted to the restricted parameter measure.
2.5. Prediction Ability Comparison of Four Classifiers on the 40% Identity cd-Hit Filtration Data
We extracted 188D feature vectors from 360 GABAARs and 9598 non-GABAARs as input to Weka performing category via RF, k-NN, and SVM algorithm which was implemented using libSVM. GBDT classifier was carried out by python program developed by ourselves; the above 4 classifiers have the parameters set as default.
Four common measurements were used to illuminate the performance quality of the predictor more intuitively. Sensitivity (Sn), specificity (Sp), accuracy (Acc), and Matthew's correlation coefficient (MCC) were adopted to evaluate the above three methods and four classifiers. These methods are formulated as follows:
| (1) |
where TP, TN, FP, and FN stand for the numbers of true positive, true negative, false positive, and false negative, respectively.
3. Results
3.1. Searching the Protein Family Number
To determine the Pfam families of GABAARs, we ran the program with the positive and negative protein sequences (GABAARs versus non-GABAARs) and obtained nonredundant Pfam numbers after combining the same ones (Table 1). The negative group was very large; thus, we only listed the positive ones.
Table 1.
Pfam accession numbers (83 entries) for GABAARs as positive group.
| PF00008, PF00012, PF00018, PF00022, PF00028, PF00053, PF00055, PF00057, PF00059, PF00060, PF00069 |
| PF00078, PF00084, PF00087, PF00090, PF00100, PF00130, PF00147, PF00163, PF00168, PF00169, PF00209 |
| PF00226, PF00240, PF00270, PF00271, PF00335, PF00387, PF00388, PF00397, PF00400, PF00454, PF00520 |
| PF00564, PF00621, PF00627, PF00643, PF00651, PF00665, PF00754, PF00850, PF00892, PF01082, PF01352 |
| PF01436, PF01479, PF01498, PF01529, PF02072, PF02140, PF02214, PF02259, PF02260, PF02460, PF02891 |
| PF02931, PF02932, PF02991, PF03144, PF03416, PF03521, PF04849, PF06220, PF07645, PF07690, PF07707 |
| PF08007, PF08266, PF08377, PF08625, PF08771, PF09279, PF09497, PF11865, PF11938, PF12248, PF12448 |
| PF12662, PF13499, PF15311, PF15974, PF16457, PF16492 |
3.2. Reclassification of Positive and Negative Proteins
We obtained the 188D (this work), 80D (from PseAAC), and 70D (from ProtrWeb) feature vector dataset from both positive and negative groups and used them as input to the Weka explorer (RF algorithm). The results showed that the correctly classified rates were 96.8%, 95.7%, and 94.8%. The confusion matrix is shown in Table 2, and the four common measurement values are illustrated in Figure 4.
Table 2.
Confusion matrix classifier (RF) from three kinds of feature vector extraction algorithms.
| PseAAC | ProtrWeb | This work | ||||
|---|---|---|---|---|---|---|
| Human GABAARs | Human non-GABAARs | Human GABAARs | Human non-GABAARs | GABAAR proteins | Non-GABAAR proteins | |
| Positive cases | 55 | 2 | 55 | 3 | 2007 | 76 |
| Negative cases | 3 | 56 | 3 | 55 | 346 | 10576 |
Figure 4.
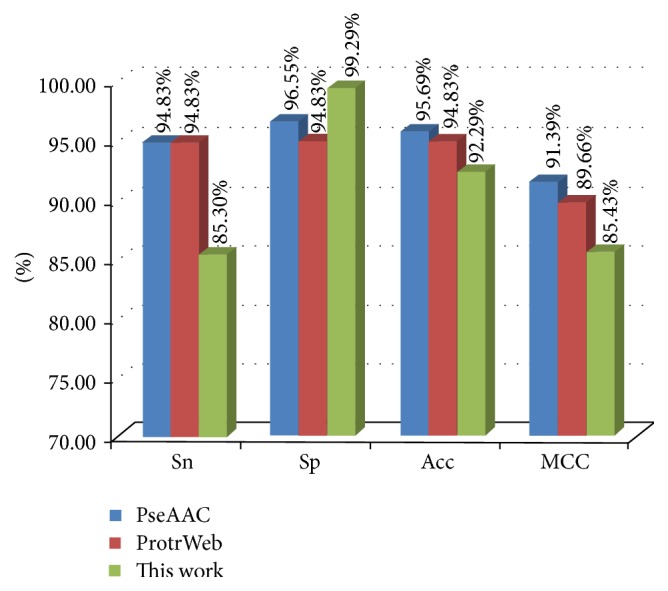
Sn, Sp, Acc, and MCC values listed from PseAAC, ProtrWeb, and our work. Note: PseAAC and ProtrWeb only include human 58 GABAARs and 58 non-GABAARs because of the web amount limitation; our method contains all the GABAARs and non-GABAARs (2353 versus 10652).
3.3. Four Classifiers' Prediction Ability Comparison
On the four classifiers, they all performed well and got high correctly classified rate over 96%, but GBDT and libSVM had a little better performance than RF and k-NN assessed from all the indicators (Table 3).
Table 3.
Classification results for four classifiers based on 360 GABAARs and 9598 non-GABAARs.
| Classifier | Sensitivity (%) | Specificity (%) | Accuracy (%) | MCC | Correctly classified rate |
|---|---|---|---|---|---|
| GDBT | 51.39 | 99.66 | 75.52 | 0.5828 | 0.9791 |
| RF | 41.39 | 99.86 | 70.63 | 0.5085 | 0.9775 |
| libSVM | 58.89 | 97.76 | 78.32 | 0.6148 | 0.9635 |
| k-NN | 51.94 | 98.17 | 75.06 | 0.5651 | 0.9650 |
3.4. Conserved Motif Analysis of Human GABAAR
To reveal the evolutionary correlation of GABAARs from the conserved motifs, 92 human protein sequences were analyzed by using MEME software. The nine most significant and conserved motifs are shown in Figure 5 and Table 4.
Figure 5.

Motifs of human GABAARs found by the MEME system (for details see Table 3). (a) Locations of the nine discovered motifs (showing the top 32 sequences). (b) Nine motif logos found by MEME.
Table 4.
Human conserved motifs of GABAARs found by MEME system (in regular expression).
| Motif | Width | E-value | Best possible match |
|---|---|---|---|
| 1 | 50 | 1.6e − 1592 | L[KRS]R[KNR][IMV]GYF[IV][IL]QTY[IL]P[CS][IT][LM][TI][VT][IV]LS [WQ]VSFW[IL]N[RK][DE][SA][VS][PA]AR[TV][VAS][LF]G[IV] TTVLTMTT |
|
| |||
| 2 | 50 | 8.6e − 1477 | T[TV]PN[KR][LM][LI]R[IL]F[PD][DN]GT[VLI]LYT[LM]R[LI]T[ITV]TA [EA]C[PN][ML][DQ]L[ES][DNR][FY]P[ML]D[EAT][HQ][AST]CPL[KE] [FL][EG]SY[GA]Y |
|
| |||
| 3 | 32 | 1.9e − 816 | P[KR][VI][SA]Y[VAI][TK]A[MI]DW[FY][IL]AVC[FY][AV]FVF[SL]AL [LI]E[YF]A[TA][VL]NY |
|
| |||
| 4 | 29 | 2.4e − 804 | L[TR]L[ND]N[LR][ML][AV]SK[IL]W[TV]PDT[FY]F[HRV]N[GS]KKS[FIV] AHN[MV] |
|
| |||
| 5 | 50 | 3.7e − 1083 | GYDNRLRP[GN][FL]G[GE][PR][PI][TV][EQ][VI]XT[DN]I[YD][VI][TA] S[FI][GD][PS][VI]S[DE][TV][ND]M[ED]YTI[DT][VI][FY][FL]RQ [SKT]WKDER |
|
| |||
| 6 | 29 | 1.7e − 538 | [DS][VI]S[KA]ID[KR][YW]SRI[VFL]FPV[AL]FG[LF]FN[LV]VYW[AVL] [YTV]Y[LV] |
|
| |||
| 7 | 29 | 3.5e − 413 | Q[FY][DS][LFI][VL]G[QL][TR][VN][GST][TS]E[TI][VI]K[STF]STG[ED] Y[VPT][VIR][ML][TS][VLA][YHS]FH |
|
| |||
| 8 | 29 | 2.4e − 262 | [AFG][RS][LQS][VMY][LGP][AQT][NPS][IS][QLV][EKQ]DE[ALT][KN] [DN]N[IT]T[IV]FTRILD[RG]LLD |
|
| |||
| 9 | 41 | 5.8e − 174 | [TY]W[LK]RGN[DE]S[VL][RK][GT][LD]E[HK][LI][RS]L[AS]Q[YF][TL] I[EQ]R[YF][FH]T[LT][VS]T[RL][SA][QF][QY][ES][TS][GT][NG][YW] [TY][RN] |
4. Discussion
The primary structures of amino acid sequences are often the basis for understanding the three-dimensional conformation and functional properties of proteins [67], which exhibit an intimate relationship between their primary structure and function [68]. Twenty natural α-amino acids commonly constitute the primary sequences of proteins [69, 70]. Amino acids are biologically important organic nitrogenous compounds in the natural world. These compounds contain amine (-NH2) and carboxylic acid (-COOH) functional groups which link with the same carbon atom called α-carbon, usually along with a side-chain (called R group) specific to each amino acid. The elements of carbon, hydrogen, oxygen, and nitrogen are essential for an amino acid, though other elements are found in the R group. Amino acids can be classified in many ways, such as according to the core structure and side-chain group properties. However, 20 standard and encoding α-carbon amino acids are usually classified into five main groups on the basis of biochemistry [71], namely, a hydrophobe, if the side-chain is nonpolar; a hydrophile, if it is polar but uncharged; aromatic, if it includes an aromatic ring; acidic, if it is negatively charged; and basic, if it is positively charged.
Previous research has extracted information on protein feature according to composition, position, or physicochemical properties [31]. In our work, we adopted 188D algorithm to extract feature vectors by combining amino acid compositions with physicochemical properties in a protein functional classifier [72]. This 188D method includes amino acid composition (20D) and eight types of physicochemical properties, that is, hydrophobicity (21D), normalized van der Waals volume (21D), polarity (21D), polarizability (21D), charge (21D), surface tension (21D), secondary structure (21D), and solvent accessibility (21D). The CTD model was employed to describe global information about the protein sequence, where C represents the percentage of each type of hydrophobic amino acid in an amino acid sequence, T represents the frequency of one hydrophobic amino acid followed by another amino acid with different hydrophobic properties, and D represents the first, 25%, 50%, 75%, and last position of the amino acids that satisfy certain properties in the sequence; for details, see [44]. In addition to this 188D feature vector extraction method, we used two web-based servers, PseAAC and ProtrWeb, for 80D and 70D feature vectors, respectively. The limited amount of sequence on the web allowed the analysis of only human GABAARs and the corresponding non-GABAARs by using the last two methods.
The abnormities of GABAARs are associated with the pathology and progression of several neurological and psychiatric diseases, such as autism, schizophrenia [73], and alcoholism [74], particularly in epilepsy [75–79], Dravet syndrome [80], asthma [81], breast cancer [82], some psychiatric diseases [83], Alzheimer disease [84], and other neurodegenerative diseases. It is recently reported that GABAAR may be involved in apoptosis in preeclampsia [85]. Human GABAARs conserved motifs analyses indicate that motifs 1, 3, and 6 are the frame of neurotransmitter-gated ion channel transmembrane region, which form the ion channel for cation transporter by the construction of transmembrane helix. Motifs 2, 4, and 5 are also composed of neurotransmitter-gated ion channel extracellular ligand binding domain by linking closely and forming a pentameric arrangement in the structure [86]. Various GABA receptor genes are associated with many mental-disorder-related phenotypes. Alterations in GABAergic inhibitory actions, such as the subunit amount, composition, and gene expression of GABAARs, may demonstrate neurophysiologic and functional consequences related to mental disorders. Some studies on protein prediction using Chou's method have been reported in 2011 because of the importance of GABAARs [11]. However, similar studies on GABAARs are rarely reported since then.
The current results showed that our method reached the most correctly classified instances at 96.8%; it suggested that our 188D algorithm performed well for classification and could correctly discriminate both positive and negative samples with relative high specificity. However, the Sn, Acc, and MCC indexes were lower than those of the PseAAC and ProtrWeb methods; this might be due to the large dataset size of our work. But the lowest value was higher than 85%. Overall, our project, which is mainly based on physicochemical properties, can reflect the characteristics of protein sequences and can be applied in the prediction of GABAARs classification. Definitely, it needs to develop more precise methods based on 188D.
Acknowledgments
The work was supported by the Natural Science Foundation of Fujian Province of China (no. 2016J01152) and National Natural Science Foundation of China (no. 61573235, no. 61272315, and no. 61302139).
Competing Interests
The authors declare that there are no competing interests.
References
- 1.Locock K. E. S., Yamamoto I., Tran P., et al. γ-aminobutyric acid(C) (GABAC) selective antagonists derived from the bioisosteric modification of 4-aminocyclopent-1-enecarboxylic acid: amides and hydroxamates. Journal of Medicinal Chemistry. 2013;56(13):5626–5630. doi: 10.1021/jm4006548. [DOI] [PubMed] [Google Scholar]
- 2.Mayerhofer A., Höhne-Zell B., Gamel-Didelon K., et al. Gamma-aminobutyric acid (GABA): a para- and/or autocrine hormone in the pituitary. The FASEB Journal. 2001;15(6):1089–1091. doi: 10.1096/fj.00-0546fje. [DOI] [PubMed] [Google Scholar]
- 3.Okai N., Takahashi C., Hatada K., Ogino C., Kondo A. Disruption of pknG enhances production of gamma-aminobutyric acid by Corynebacterium glutamicum expressing glutamate decarboxylase. AMB Express. 2014;4(1, article 20):1–8. doi: 10.1186/s13568-014-0020-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Pereira F. C., Rolo M. R., Marques E., et al. Acute increase of the glutamate-glutamine cycling in discrete brain areas after administration of a single dose of amphetamine. Annals of the New York Academy of Sciences. 2008;1139:212–221. doi: 10.1196/annals.1432.040. [DOI] [PubMed] [Google Scholar]
- 5.Rigby M., Cull-Candy S. G., Farrant M. Transmembrane AMPAR regulatory protein γ-2 is required for the modulation of GABA release by presynaptic AMPARs. The Journal of Neuroscience. 2015;35(10):4203–4214. doi: 10.1523/jneurosci.4075-14.2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Zonouzi M., Scafidi J., Li P., et al. GABAergic regulation of cerebellar NG2 cell development is altered in perinatal white matter injury. Nature Neuroscience. 2015;18(5):674–682. doi: 10.1038/nn.3990. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Irie T., Kikura-Hanajiri R., Usami M., Uchiyama N., Goda Y., Sekino Y. MAM-2201, a synthetic cannabinoid drug of abuse, suppresses the synaptic input to cerebellar Purkinje cells via activation of presynaptic CB1 receptors. Neuropharmacology. 2015;95:479–491. doi: 10.1016/j.neuropharm.2015.02.025. [DOI] [PubMed] [Google Scholar]
- 8.Zukin S. R., Young A. B., Snyder S. H. Gamma-aminobutyric acid binding to receptor sites in the rat central nervous system. Proceedings of the National Academy of Sciences of the United States of America. 1974;71(12):4802–4807. doi: 10.1073/pnas.71.12.4802. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Olsen R. W., Sieghart W. International union of pharmacology. LXX. Subtypes of γ-aminobutyric acidA receptors: classification on the basis of subunit composition, pharmacology, and function. Update. Pharmacological Reviews. 2008;60(3):243–260. doi: 10.1124/pr.108.00505. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Fritschy J.-M. Epilepsy, E/I balance and GABAA receptor plasticity. Frontiers in Molecular Neuroscience. 2008;1, article 5 doi: 10.3389/neuro.02.005.2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Mohabatkar H., Mohammad Beigi M., Esmaeili A. Prediction of GABAA receptor proteins using the concept of Chou's pseudo-amino acid composition and support vector machine. Journal of Theoretical Biology. 2011;281(1):18–23. doi: 10.1016/j.jtbi.2011.04.017. [DOI] [PubMed] [Google Scholar]
- 12.Miller P. S., Smart T. G. Binding, activation and modulation of Cys-loop receptors. Trends in Pharmacological Sciences. 2010;31(4):161–174. doi: 10.1016/j.tips.2009.12.005. [DOI] [PubMed] [Google Scholar]
- 13.Pöltl A., Hauer B., Fuchs K., Tretter V., Sieghart W. Subunit composition and quantitative importance of GABAA receptor subtypes in the cerebellum of mouse and rat. Journal of Neurochemistry. 2003;87(6):1444–1455. doi: 10.1046/j.1471-4159.2003.02135.x. [DOI] [PubMed] [Google Scholar]
- 14.Grenningloh G., Gundelfinger E., Schmitt B., et al. Glycine vs GABA receptors. Nature. 1987;330(6143):25–26. doi: 10.1038/330025b0. [DOI] [PubMed] [Google Scholar]
- 15.Miller P. S., Aricescu A. R. Crystal structure of a human GABAA receptor. Nature. 2014;512(7514):270–275. doi: 10.1038/nature13293. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Sieghart W., Sperk G. Subunit composition, distribution and function of GABA(A) receptor subtypes. Current Topics in Medicinal Chemistry. 2002;2(8):795–816. doi: 10.2174/1568026023393507. [DOI] [PubMed] [Google Scholar]
- 17.Torkkeli P. H., Liu H., French A. S. Transcriptome analysis of the central and peripheral nervous systems of the spider Cupiennius salei reveals multiple putative Cys-loop ligand gated ion channel subunits and an acetylcholine binding protein. PLoS ONE. 2015;10(9) doi: 10.1371/journal.pone.0138068.e0138068 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Reid C. A., Berkovic S. F., Petrou S. Mechanisms of human inherited epilepsies. Progress in Neurobiology. 2009;87(1):41–57. doi: 10.1016/j.pneurobio.2008.09.016. [DOI] [PubMed] [Google Scholar]
- 19.Simon J., Wakimoto H., Fujita N., Lalande M., Barnard E. A. Analysis of the set of GABAA receptor genes in the human genome. The Journal of Biological Chemistry. 2004;279(40):41422–41435. doi: 10.1074/jbc.m401354200. [DOI] [PubMed] [Google Scholar]
- 20.Chou I.-C., Lee C.-C., Tsai C.-H., et al. Association of GABRG2 polymorphisms with idiopathic generalized epilepsy. Pediatric Neurology. 2007;36(1):40–44. doi: 10.1016/j.pediatrneurol.2006.09.011. [DOI] [PubMed] [Google Scholar]
- 21.Bethmann K., Fritschy J.-M., Brandt C., Löscher W. Antiepileptic drug resistant rats differ from drug responsive rats in GABAA receptor subunit expression in a model of temporal lobe epilepsy. Neurobiology of Disease. 2008;31(2):169–187. doi: 10.1016/j.nbd.2008.01.005. [DOI] [PubMed] [Google Scholar]
- 22.SidAhmed-Mezi M., Kurcewicz I., Rose C., et al. Mass spectrometric detection and characterization of atypical membrane-bound zinc-sensitive phosphatases modulating GABAA receptors. PLoS ONE. 2014;9(6) doi: 10.1371/journal.pone.0100612.e100612 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Uwera J., Nedergaard S., Andreasen M. A novel mechanism for the anticonvulsant effect of furosemide in rat hippocampus in vitro. Brain Research. 2015;1625:1–8. doi: 10.1016/j.brainres.2015.08.014. [DOI] [PubMed] [Google Scholar]
- 24.Fisher J. L. The anti-convulsant stiripentol acts directly on the GABAA receptor as a positive allosteric modulator. Neuropharmacology. 2009;56(1):190–197. doi: 10.1016/j.neuropharm.2008.06.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Kang J.-Q., Shen W., Zhou C., Xu D., Macdonald R. L. The human epilepsy mutation GABRG2(Q390X) causes chronic subunit accumulation and neurodegeneration. Nature Neuroscience. 2015;18(7):988–996. doi: 10.1038/nn.4024. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Hirose S. Mutant GABA(A) receptor subunits in genetic (idiopathic) epilepsy. Progress in Brain Research. 2014;213:55–85. doi: 10.1016/b978-0-444-63326-2.00003-x. [DOI] [PubMed] [Google Scholar]
- 27.Ding H., Guo S.-H., Deng E.-Z., et al. Prediction of Golgi-resident protein types by using feature selection technique. Chemometrics and Intelligent Laboratory Systems. 2013;124:9–13. doi: 10.1016/j.chemolab.2013.03.005. [DOI] [Google Scholar]
- 28.Li W.-C., Deng E.-Z., Ding H., Chen W., Lin H. iORI-PseKNC: a predictor for identifying origin of replication with pseudo k-tuple nucleotide composition. Chemometrics and Intelligent Laboratory Systems. 2015;141:100–106. doi: 10.1016/j.chemolab.2014.12.011. [DOI] [Google Scholar]
- 29.Lin H., Chen W., Ding H. AcalPred: a sequence-based tool for discriminating between acidic and alkaline enzymes. PLoS ONE. 2013;8(10) doi: 10.1371/journal.pone.0075726.e75726 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Yuan L.-F., Ding C., Guo S.-H., Ding H., Chen W., Lin H. Prediction of the types of ion channel-targeted conotoxins based on radial basis function network. Toxicology in Vitro. 2013;27(2):852–856. doi: 10.1016/j.tiv.2012.12.024. [DOI] [PubMed] [Google Scholar]
- 31.Liu B., Zhang D., Xu R., et al. Combining evolutionary information extracted from frequency profiles with sequence-based kernels for protein remote homology detection. Bioinformatics. 2014;30(4):472–479. doi: 10.1093/bioinformatics/btt709. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Chen J., Wang X., Liu B. IMiRNA-SSF: improving the identification of MicroRNA precursors by combining negative sets with different distributions. Scientific Reports. 2016;6 doi: 10.1038/srep19062.19062 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Besga A., Gonzalez I., Echeburua E., et al. Discrimination between Alzheimer’s disease and late onset bipolar disorder using multivariate analysis. Frontiers in Aging Neuroscience. 2015;7, article 231 doi: 10.3389/fnagi.2015.00231. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Yang Q., Zou H.-Y., Zhang Y., et al. Multiplex protein pattern unmixing using a non-linear variable-weighted support vector machine as optimized by a particle swarm optimization algorithm. Talanta. 2016;147:609–614. doi: 10.1016/j.talanta.2015.10.047. [DOI] [PubMed] [Google Scholar]
- 35.Wang R., Xu Y., Liu B. Recombination spot identification Based on gapped k-mers. Scientific Reports. 2016;6, article 23934 doi: 10.1038/srep23934. [DOI] [PMC free article] [PubMed] [Google Scholar] [Retracted]
- 36.Sharma A. K., Kumar S., Harish K., Dhakan D. B., Sharma V. K. Prediction of peptidoglycan hydrolases—a new class of antibacterial proteins. BMC Genomics. 2016;17(1, article 411) doi: 10.1186/s12864-016-2753-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Li Z. C., Huang M. H., Zhong W. Q., et al. Identification of drug-target interaction from interactome network with ‘guilt-by-association’ principle and topology features. Bioinformatics. 2016;32(7):1057–1064. doi: 10.1093/bioinformatics/btv695. [DOI] [PubMed] [Google Scholar]
- 38.Jones J. J., Wilcox B. E., Benz R. W., et al. A plasma-based protein marker panel for colorectal cancer detection identified by multiplex targeted mass spectrometry. Clinical Colorectal Cancer. 2016;15(2):186–194.e13. doi: 10.1016/j.clcc.2016.02.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Semanjski I., Gautama S. Smart city mobility application—gradient boosting trees for mobility prediction and analysis based on crowdsourced data. Sensors. 2015;15(7):15974–15987. doi: 10.3390/s150715974. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.Johnson R., Zhang T. Learning nonlinear functions using regularized greedy forest. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2014;36(5):942–954. doi: 10.1109/TPAMI.2013.159. [DOI] [PubMed] [Google Scholar]
- 41.Singh K. P., Gupta S. In silico prediction of toxicity of non-congeneric industrial chemicals using ensemble learning based modeling approaches. Toxicology and Applied Pharmacology. 2014;275(3):198–212. doi: 10.1016/j.taap.2014.01.006. [DOI] [PubMed] [Google Scholar]
- 42.Chen Y., Jia Z., Mercola D., Xie X. A gradient boosting algorithm for survival analysis via direct optimization of concordance index. Computational and Mathematical Methods in Medicine. 2013;2013:8. doi: 10.1155/2013/873595.873595 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Decruyenaere A., Decruyenaere P., Peeters P., Vermassen F., Dhaene T., Couckuyt I. Prediction of delayed graft function after kidney transplantation: comparison between logistic regression and machine learning methods. BMC Medical Informatics and Decision Making. 2015;15, article 83 doi: 10.1186/s12911-015-0206-y. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Lin C., Zou Y., Qin J., et al. Hierarchical classification of protein folds using a novel ensemble classifier. PLoS ONE. 2013;8(2) doi: 10.1371/journal.pone.0056499.e56499 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Zou Q., Li X., Jiang Y., Zhao Y., Wang G. Binmempredict: a web server and software for predicting membrane protein types. Current Proteomics. 2013;10(1):2–9. doi: 10.2174/1570164611310010002. [DOI] [Google Scholar]
- 46.Huang Y., Niu B., Gao Y., Fu L., Li W. CD-HIT Suite: a web server for clustering and comparing biological sequences. Bioinformatics. 2010;26(5):680–682. doi: 10.1093/bioinformatics/btq003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Liu C., Su P., Li R., et al. Molecular cloning, expression pattern, and molecular evolution of the spleen tyrosine kinase in lamprey, Lampetra japonica . Development Genes and Evolution. 2015;225(2):113–120. doi: 10.1007/s00427-015-0492-5. [DOI] [PubMed] [Google Scholar]
- 48.Song L., Li D., Zeng X., Wu Y., Guo L., Zou Q. nDNA-prot: identification of DNA-binding proteins based on unbalanced classification. BMC Bioinformatics. 2014;15, article 298 doi: 10.1186/1471-2105-15-298. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Zou Q., Guo J., Ju Y., Wu M., Zeng X., Hong Z. Improving tRNAscan-SE annotation results via ensemble classifiers. Molecular Informatics. 2015;34(11-12):761–770. doi: 10.1002/minf.201500031. [DOI] [PubMed] [Google Scholar]
- 50.Lin C., Chen W., Qiu C., Wu Y., Krishnan S., Zou Q. LibD3C: ensemble classifiers with a clustering and dynamic selection strategy. Neurocomputing. 2014;123:424–435. doi: 10.1016/j.neucom.2013.08.004. [DOI] [Google Scholar]
- 51.Zou Q., Wang Z., Guan X., Liu B., Wu Y., Lin Z. An approach for identifying cytokines based on a novel ensemble classifier. BioMed Research International. 2013;2013:11. doi: 10.1155/2013/686090.686090 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Wei L., Liao M., Gao Y., Ji R., He Z., Zou Q. Improved and promising identification of human microRNAs by incorporatinga high-quality negative set. IEEE/ACM Transactions on Computational Biology and Bioinformatics. 2014;11(1):192–201. doi: 10.1109/tcbb.2013.146. [DOI] [PubMed] [Google Scholar]
- 53.Zeng X., Yuan S., Huang X., Zou Q. Identification of cytokine via an improved genetic algorithm. Frontiers of Computer Science. 2015;9(4):643–651. doi: 10.1007/s11704-014-4089-3. [DOI] [Google Scholar]
- 54.Zou Q., Zeng J., Cao L., Ji R. A novel features ranking metric with application to scalable visual and bioinformatics data classification. Neurocomputing. 2016;173:346–354. doi: 10.1016/j.neucom.2014.12.123. [DOI] [Google Scholar]
- 55.Ding H., Liang Z. Y., Guo F. B., Huang J., Chen W., Lin H. Predicting bacteriophage proteins located in host cell with feature selection technique. Computers in Biology and Medicine. 2016;71:156–161. doi: 10.1016/j.compbiomed.2016.02.012. [DOI] [PubMed] [Google Scholar]
- 56.Tang H., Chen W., Lin H. Identification of immunoglobulins using Chou's pseudo amino acid composition with feature selection technique. Molecular BioSystems. 2016;12(4):1269–1275. doi: 10.1039/c5mb00883b. [DOI] [PubMed] [Google Scholar]
- 57.Wei L., Zou Q., Liao M., Lu H., Zhao Y. A novel machine learning method for cytokine-receptor interaction prediction. Combinatorial Chemistry & High Throughput Screening. 2016;19(2):144–152. doi: 10.2174/1386207319666151110122621. [DOI] [PubMed] [Google Scholar]
- 58.Frank E., Hall M., Trigg L., Holmes G., Witten I. H. Data mining in bioinformatics using Weka. Bioinformatics. 2004;20(15):2479–2481. doi: 10.1093/bioinformatics/bth261. [DOI] [PubMed] [Google Scholar]
- 59.Smith T. C., Frank E. Introducing machine learning concepts with WEKA. In: Mathé E., Davis S., editors. Statistical Genomics. Vol. 1418. Berlin, Germany: Springer; 2016. pp. 353–378. (Methods in Molecular Biology). [DOI] [PubMed] [Google Scholar]
- 60.Bailey T. L., Johnson J., Grant C. E., Noble W. S. The MEME Suite. Nucleic Acids Research. 2015;43(W1):W39–W49. doi: 10.1093/nar/gkv416. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61.Chou K.-C. Prediction of protein cellular attributes using pseudo-amino acid composition. Proteins. 2001;43(3):246–255. doi: 10.1002/prot.1035. [DOI] [PubMed] [Google Scholar]
- 62.Shen H.-B., Chou K.-C. PseAAC: a flexible web server for generating various kinds of protein pseudo amino acid composition. Analytical Biochemistry. 2008;373(2):386–388. doi: 10.1016/j.ab.2007.10.012. [DOI] [PubMed] [Google Scholar]
- 63.Liu B., Liu F., Wang X., Chen J., Fang L., Chou K. Pse-in-One: a web server for generating various modes of pseudo components of DNA, RNA, and protein sequences. Nucleic Acids Research. 2015;43(W1):W65–W71. doi: 10.1093/nar/gkv458. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64.Xiao N., Cao D.-S., Zhu M.-F., Xu Q.-S. Protr/ProtrWeb: R package and web server for generating various numerical representation schemes of protein sequences. Bioinformatics. 2015;31(11):1857–1859. doi: 10.1093/bioinformatics/btv042. [DOI] [PubMed] [Google Scholar]
- 65.Chen W., Feng P.-M., Deng E.-Z., Lin H., Chou K.-C. iTIS-PseTNC: a sequence-based predictor for identifying translation initiation site in human genes using pseudo trinucleotide composition. Analytical Biochemistry. 2014;462:76–83. doi: 10.1016/j.ab.2014.06.022. [DOI] [PubMed] [Google Scholar]
- 66.Liu B., Liu F. L., Fang L. Y., Wang X. L., Chou K.-C. repDNA: a Python package to generate various modes of feature vectors for DNA sequences by incorporating user-defined physicochemical properties and sequence-order effects. Bioinformatics. 2015;31(8):1307–1309. doi: 10.1093/bioinformatics/btu820. [DOI] [PubMed] [Google Scholar]
- 67.Au L., Green D. F. Direct calculation of protein fitness landscapes through computational protein design. Biophysical Journal. 2016;110(1):75–84. doi: 10.1016/j.bpj.2015.11.029. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 68.Hopper J. T. S., Robinson C. V. Mass spectrometry quantifies protein interactions-from molecular chaperones to membrane porins. Angewandte Chemie—International Edition. 2014;53(51):14002–14215. doi: 10.1002/anie.201403741. [DOI] [PubMed] [Google Scholar]
- 69.Kržišnik K., Urbic T. Amino acid correlation functions in protein structures. Acta Chimica Slovenica. 2015;62(3):574–581. doi: 10.17344/acsi.2015.1538. [DOI] [PubMed] [Google Scholar]
- 70.Olivera-Nappa A., Andrews B. A., Asenjo J. A. Mutagenesis Objective Search and Selection Tool (MOSST): an algorithm to predict structure-function related mutations in proteins. BMC Bioinformatics. 2011;12, article 122 doi: 10.1186/1471-2105-12-122. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 71.Pinheiro C. B., Shah M., Soares E. L., et al. Proteome analysis of plastids from developing seeds of Jatropha curcas L. Journal of Proteome Research. 2013;12(11):5137–5145. doi: 10.1021/pr400515b. [DOI] [PubMed] [Google Scholar]
- 72.Cai C. Z., Han L. Y., Ji Z. L., Chen X., Chen Y. Z. SVM-Prot: web-based support vector machine software for functional classification of a protein from its primary sequence. Nucleic Acids Research. 2003;31(13):3692–3697. doi: 10.1093/nar/gkg600. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 73.Glausier J. R., Lewis D. A. Selective pyramidal cell reduction of GABA(A) receptor α1 subunit messenger RNA expression in schizophrenia. Neuropsychopharmacology. 2011;36(10):2103–2110. doi: 10.1038/npp.2011.102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 74.Onori N., Turchi C., Solito G., Gesuita R., Buscemi L., Tagliabracci A. GABRA2 and alcohol use disorders: no evidence of an association in an Italian case-control study. Alcoholism: Clinical and Experimental Research. 2010;34(4):659–668. doi: 10.1111/j.1530-0277.2009.01135.x. [DOI] [PubMed] [Google Scholar]
- 75.Yuan H., Low C.-M., Moody O. A., Jenkins A., Traynelis S. F. Ionotropic GABA and glutamate receptor mutations and human neurologic diseases. Molecular Pharmacology. 2015;88(1):203–217. doi: 10.1124/mol.115.097998. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 76.Richetto J., Labouesse M. A., Poe M. M., et al. Behavioral effects of the benzodiazepine-positive allosteric modulator SH-053-2′F-S-CH3 in an immune-mediated neurodevelopmental disruption model. The International Journal of Neuropsychopharmacology. 2014;18(4):1–11. doi: 10.1093/ijnp/pyu055. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 77.Hatch R. J., Reid C. A., Petrou S. Enhanced in vitro CA1 network activity in a sodium channel β1(C121W) subunit model of genetic epilepsy. Epilepsia. 2014;55(4):601–608. doi: 10.1111/epi.12568. [DOI] [PubMed] [Google Scholar]
- 78.Kumari R., Lakhan R., Kalita J., Garg R. K., Misra U. K., Mittal B. Potential role of GABAA receptor subunit; GABRA6, GABRB2 and GABRR2 gene polymorphisms in epilepsy susceptibility and pharmacotherapy in North Indian population. Clinica Chimica Acta. 2011;412(13-14):1244–1248. doi: 10.1016/j.cca.2011.03.018. [DOI] [PubMed] [Google Scholar]
- 79.Murashima Y. L., Yoshii M. New therapeutic approaches for epilepsies, focusing on reorganization of the GABAA receptor subunits by neurosteroids. Epilepsia. 2010;51(3):131–134. doi: 10.1111/j.1528-1167.2010.02627.x. [DOI] [PubMed] [Google Scholar]
- 80.Chiron C. Current therapeutic procedures in Dravet syndrome. Developmental Medicine and Child Neurology. 2011;53(supplement 2):16–18. doi: 10.1111/j.1469-8749.2011.03967.x. [DOI] [PubMed] [Google Scholar]
- 81.Gallos G., Yim P., Chang S., et al. Targeting the restricted α-subunit repertoire of airway smooth muscle GABAA receptors augments airway smooth muscle relaxation. American Journal of Physiology—Lung Cellular and Molecular Physiology. 2012;302(2):L248–L256. doi: 10.1152/ajplung.00131.2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 82.Sizemore G. M., Sizemore S. T., Seachrist D. D., Keri R. A. GABA(A) receptor Pi (GABRP) stimulates basal-like breast cancer cell migration through activation of extracellular-regulated kinase 1/2 (ERK1/2) Journal of Biological Chemistry. 2014;289(35):24102–24113. doi: 10.1074/jbc.M114.593582. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 83.Sinclair L. I., Dineen P. T., Malizia A. L. Modulation of ion channels in clinical psychopharmacology: adults and younger people. Expert Review of Clinical Pharmacology. 2010;3(3):397–416. doi: 10.1586/ecp.10.21. [DOI] [PubMed] [Google Scholar]
- 84.Al Mansouri A. S., Lorke D. E., Nurulain S. M., et al. Methylene blue inhibits the function of α7-nicotinic acetylcholine receptors. CNS and Neurological Disorders—Drug Targets. 2012;11(6):791–800. doi: 10.2174/187152712803581010. [DOI] [PubMed] [Google Scholar]
- 85.Lu J., Zhang Q., Tan D., et al. GABA A receptor π subunit promotes apoptosis of HTR-8/SVneo trophoblastic cells: implications in preeclampsia. International Journal of Molecular Medicine. 2016;38(1):105–112. doi: 10.3892/ijmm.2016.2608. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 86.Hanek A. P., Lester H. A., Dougherty D. A. Photochemical proteolysis of an unstructured linker of the GABAAR extracellular domain prevents GABA but not pentobarbital activation. Molecular Pharmacology. 2010;78(1):29–35. doi: 10.1124/mol.109.059832. [DOI] [PMC free article] [PubMed] [Google Scholar]