

Abstract
Undirected graphical models, or Markov networks, are a popular class of statistical models, used in a wide variety of applications. Popular instances of this class include Gaussian graphical models and Ising models. In many settings, however, it might not be clear which subclass of graphical models to use, particularly for non-Gaussian and non-categorical data. In this paper, we consider a general sub-class of graphical models where the node-wise conditional distributions arise from exponential families. This allows us to derive multivariate graphical model distributions from univariate exponential family distributions, such as the Poisson, negative binomial, and exponential distributions. Our key contributions include a class of M-estimators to fit these graphical model distributions; and rigorous statistical analysis showing that these M-estimators recover the true graphical model structure exactly, with high probability. We provide examples of genomic and proteomic networks learned via instances of our class of graphical models derived from Poisson and exponential distributions.
Keywords: graphical models, model selection, sparse estimation
1. Introduction
Undirected graphical models, also known as Markov random fields, are an important class of statistical models that have been extensively used in a wide variety of domains, including statistical physics, natural language processing, image analysis, and medicine. The key idea in this class of models is to represent the joint distribution as a product of clique-wise compatibility functions. Given an underlying graph, each of these compatibility functions depends only on a subset of variables within any clique of the underlying graph. Popular instances of such graphical models include Ising and Potts models (see references in Wainwright and Jordan (2008) for a varied set of applications in computer vision, text analytics, and other areas with discrete variables), as well as Gaussian Markov Random Fields (GMRFs), which are popular in many scientific settings for modeling real-valued data. A key modeling question that arises, however, is: how do we pick the clique-wise compatibility functions, or alternatively, how do we pick the form or sub-class of the graphical model distribution (e.g. Ising or Gaussian MRF)? For the case of discrete random variables, Ising and Potts models are popular choices; but these are not best suited for count-valued variables, where the values taken by any variable could range over the entire set of positive integers. Similarly, in the case of continuous variables, Gaussian Markov Random Fields (GMRFs) are a popular choice; but the distributional assumptions imposed by GMRFs are quite stringent. The marginal distribution of any variable would have to be Gaussian for instance, which might not hold in instances when the random variables characterizing the data are skewed (Liu et al., 2009). More generally, Gaussian random variables have thin tails, which might not capture fat-tailed events and variables. For instance, in the finance domain, the lack of modeling of fat-tailed events and probabilities has been suggested as one of the causes of the 2008 financial crisis (Acemoglu, 2009).
To address this modeling question, some have recently proposed non-parametric extensions of graphical models. Some, such as the non-paranormal (Liu et al., 2009; Lafferty et al., 2012) and copula-based methods (Dobra and Lenkoski, 2011; Liu et al., 2012a), use or learn transforms that Gaussianize the data, and then fit Gaussian MRFs to estimate network structure. Others, use non-parametric approximations, such as rank-based estimators, to the correlation matrix, and then fit a Gaussian MRF (Xue and Zou, 2012; Liu et al., 2012b). More broadly, there could be non-parametric methods that either learn the sufficient statistics functions, or learn transformations of the variables, and then fit standard MRFs over the transformed variables. However, the sample complexity of such classes of non-parametric methods is typically inferior to those that learn parametric models. Alternatively, and specifically for the case of multivariate count data, Lauritzen (1996); Bishop et al. (2007) have suggested combinatorial approaches to fitting graphical models, mostly in the context of contingency tables. These approaches, however, are computationally intractable for even moderate numbers of variables.
Interestingly, for the case of univariate data, we have a good understanding of appropriate statistical models to use. In particular, a count-valued random variable can be modeled using a Poisson distribution; call-times, time spent on websites, diffusion processes, and life-cycles can be modeled with an exponential distribution; other skewed variables can be modeled with gamma or chi-squared distributions. Here, we ask if we can extend this modeling toolkit from univariate distributions to multivariate graphical model distributions? Interestingly, recent state of the art methods for learning Ising and Gaussian MRFs (Meinshausen and Bühlmann, 2006; Ravikumar et al., 2010; Jalali et al., 2011) suggest a natural procedure deriving such multivariate graphical models from univariate distributions. The key idea in these recent methods is to learn the MRF graph structure by estimating node-neighborhoods, or by fitting node-conditional distributions of each node conditioned on the rest of the nodes. Indeed, these node-wise fitting methods have been shown to have strong computational as well as statistical guarantees. Here, we consider the general class of models obtained by the following construction: suppose the node-conditional distributions of each node conditioned on the rest of the nodes follows a univariate exponential family. By the Hammersley-Clifford Theorem (Lauritzen, 1996), and some algebra as derived in Besag (1974), these node-conditional distributions entail a global multivariate distribution that (a) factors according to cliques defined by the graph obtained from the node-neighborhoods, and (b) has a particular set of compatibility functions specified by the univariate exponential family. The resulting class of MRFs, which we call exponential family MRFs, broadens the class of models available off the shelf, from the standard Ising, indicator-discrete, and Gaussian MRFs.
Thus the class of exponential family MRFs provides a principled approach to model multivariate distributions and network structures among a large number of variables; by providing a natural way to “extend” univariate exponential families of distributions to the multivariate case, in many cases where multivariate extensions did not exist in an analytical or computationally tractable form. Potential applications for these exponential family graphical models abound. Networks of call-times, time spent on websites, diffusion processes, and life-cycles can be modeled with exponential graphical models; other skewed multivariate data can be modeled with gamma or chi-squared graphical models; while multivariate count data such as from website visits, user-ratings, crime and disease incident reports, and bibliometrics could be modeled via Poisson graphical models. A key motivating application for our research is multivariate count data from next-generation genomic sequencing technologies (Mortazavi et al., 2008). This technology produces read counts of the number of short RNA fragments that have been mapped back to a particular gene; and measures gene expression with less technical variation than, and is thus rapidly replacing, microarrays (Marioni et al., 2008). Univariate count data is typically modeled using Poisson or negative binomial distributions (Li et al., 2011). As Gaussian graphical models have been traditionally used to understand genomic relationships and estimate regulatory pathways from microarray data, Poisson and negative-binomial graphical models could thus be used to analyze this next-generation sequencing data. Furthermore, there is a proliferation of new technologies to measure high-throughput genomic variation in which the data is not even approximately Gaussian (single nucleotide polymorphisms, copy number, methylation, and micro-RNA and gene expression via next-generation sequencing). For this data, a more general class of high-dimensional graphical models could thus lead to important breakthroughs in understanding genomic relationships and disease networks.
The construction of the class of exponential family graphical models also suggests a natural method for fitting such models: node-wise neighborhood estimation via sparsity constrained node-conditional likelihood maximization. A main contribution of this paper is to provide a sparsistency analysis (or analysis of variable selection consistency) for the recovery of the underlying graph structure of this broad class of MRFs. We note that the presence of non-linearities arising from the generalized linear models (GLM) posed subtle technical issues not present in the linear case (Meinshausen and Bühlmann, 2006). Indeed, for the specific cases of logistic, and multinomial respectively, Ravikumar et al. (2010); Jalali et al. (2011) derive such a sparsistency analysis via fairly extensive arguments, but which were tuned to the specific cases; for instance they used the fact that the variables were bounded, and the specific structure of the corresponding GLMs. Here we generalize their analysis to general GLMs, which required a subtler analysis as well as a slightly modified M-estimator. We note that this analysis might be of independent interest even outside the context of modeling and recovering graphical models. In recent years, there has been a trend towards unified statistical analyses that provide statistical guarantees for broad classes of models via general theorems (Negahban et al., 2012). Our result is in this vein and provides structure recovery for the class of sparsity constrained generalized linear models. We hope that the techniques we introduce might be of use to address the outstanding question of sparsity constrained M-estimation in its full generality.
There has been related work on the simple idea above of constructing joint distributions via specifying node-conditional distributions. Varin and Vidoni (2005); Varin et al. (2011) propose the class of composite likelihood models where the joint distribution is a function of the conditional distributions of subsets of nodes conditioned on other subsets. Besag (1974) discuss such joint distribution constructions in the context of node-conditional distributions belonging to exponential families, but for special cases of joint distributions such as pairwise models. In this paper, we consider the general case of higher-order graphical models for the joint distributions, and univariate exponential families for the node-conditional distributions. Moreover, a key contribution of the paper is that we provide tractable M-estimators with corresponding high-dimensional statistical guarantees and analysis for learning this class of graphical models even under high-dimensional statistical regimes.
Additionally, we note that a preliminary abridged version of this paper appeared at (Yang et al., 2012). In this manuscript, we provide a more in depth theoretical analysis along with several novel developments. Particularly, we provide a novel analytic framework on the sparsistency of our M-estimators that provide tighter finite-sample bounds, simpler proofs, and less restrictive assumptions than that of (Yang et al., 2012); these innovations are discussed further in Section 3.2. Further, we highlight and study several instances of our framework, relating our work to the existing literature on Gaussian MRFs and Ising models, as well as introducing two novel instances, the Poisson MRF and Exponential MRF. For each of these cases, we provide specific corollaries on conditions necessary for sparsistent recovery of the underlying graph structure. Finally, we also provide a greatly expanded experimental analysis of our class of MRFs and their M-estimators compared to that of (Yang et al., 2012). Focusing on two novel instances of our model, the Poisson and Exponential MRF, we study the theoretical rates, graph structural recovery, and robustness of our estimators through simulated examples. Further, we provide an additional case study on protein signaling networks using the Exponential MRF in Section 4.2.2.
2. Exponential Family Graphical Models
Suppose X = (X1, …, Xp) is a random vector, with each variable Xi taking values in a set 𝒳. Let G = (V,E) be an undirected graph over the set of nodes V := {1, …, p} corresponding to the p variables . The graphical model over X corresponding to G is a set of distributions that satisfy Markov independence assumptions with respect to the graph G (Lauritzen, 1996). By the Hammersley-Clifford theorem (Clifford, 1990), any such distribution that is strictly positive over its domain also factors according to the graph in the following way. Let 𝒞 be a set of cliques (fully-connected subgraphs) of the graph G, and let {ϕc(Xc)}c∈𝒞 be a set of clique-wise sufficient statistics. With this notation, any strictly positive distribution of X within the graphical model family represented by the graph G takes the form:
| (1) |
where {θc} are weights over the sufficient statistics. An important special case is a pairwise graphical model, where the set of cliques 𝒞 consists of the set of nodes V and the set of edges E, so that
| (2) |
As previously discussed, an important question is how to select the form of the graphical model distribution, which under the above parametrization in (1), translates to the question of selecting the class of sufficient statistics, ϕ. As discussed in the introduction, it is of particular interest to derive such a graphical model distribution as a multivariate extension of specified univariate parametric distributions such as negative binomial, Poisson, and others. We next outline a subclass of graphical models that answer these questions via the simple construction: set the node-conditional distributions of each node conditioned on the rest of the nodes as following a univariate exponential family, and then derive the joint distribution that is consistent with these node-conditional distributions. Then, in Section 3, we will study how to learn the underlying graph structure, or the edge set E, for this general class of “exponential family” graphical models. We provide a natural sparsity-encouraging M-estimator, and sufficient conditions under which the M-estimator recovers the graph structure with high probability.
2.1 The Form of Exponential Family Graphical Models
A popular class of univariate distributions is the exponential family, whose distribution for a random variable Z is given by
| (3) |
with sufficient statistics B(Z), base measure C(Z), and log-normalization constant D(θ). Such exponential family distributions include a wide variety of commonly used distributions such as Gaussian, Bernoulli, multinomial, Poisson, exponential, gamma, chi-squared, beta, and many others; any of which can be instantiated with particular choices of the functions B(·), and C(·). Such exponential family distributions are thus used to model a wide variety of data types including skewed continuous data and count data. Here, we ask if we can leverage this ability to model univariate data to also model the multivariate case. Let X = (X1, X2, …, Xp) be a p-dimensional random vector; and let G = (V,E) be an undirected graph over p nodes corresponding to the p variables. Could we then derive a graphical model distribution over X with underlying graph G, from a particular choice of univariate exponential family distribution (3) above?
Consider the following construction. Set the distribution of Xr given the rest of nodes XV\r to be given by the above univariate exponential family distribution (3), and where the canonical exponential family parameter θ is set to a linear combination of k-th order products of univariate functions {B(Xt)}t∈N(r), where N(r) is the set of neighbors of node r according to graph G. This gives the following conditional distribution:
| (4) |
where C(Xr) is specified by the exponential family, and D̄(XV\r) is the log-normalization constant. Notice that we use the notation D̄(·) in case when we express the log-partition function in terms of random variables. That is, D̄(XV\r) := D(θ(XV\r)) where θ(XV\r) is the canonical parameter θ derived from XV\r.
By the Hammersley-Clifford theorem, and some elementary calculation, this conditional distribution can be shown to specify the following unique joint distribution P(X1, …, Xp):
Proposition 1 Suppose X = (X1, X2, …, Xp) is a p-dimensional random vector, and its node-conditional distributions are specified by (4) given an undirected graph G. Then its joint distribution P(X1, …, Xp) belongs to the graphical model represented by G, and is given by
| (5) |
where A(θ) is the log-normalization constant.
Note that the function D(·) (and hence D̄(·)) in (4) is the log-partition function of the node-conditional distribution, while the function A(·) in (5) in turn is the log-partition function of the joint distribution. Proposition 1, thus, provides an answer to our earlier question on selecting the form of a graphical model distribution given a univariate exponential family distribution. When the node-conditional distributions follow a univariate exponential family as in (4), there exists a unique graphical model distribution as specified by (5). One question that remains, however, is whether the above construction, beginning with (4), is the most general possible. In particular, note that the canonical parameter of the node-conditional distribution in (4) is a tensor factorization of the univariate sufficient statistic, which seems a bit stringent. Interestingly, by extending the argument from (Besag, 1974), which considers the special pairwise case, and the Hammersley-Clifford Theorem, we can show that indeed (4) and (5) have the most general form.
Theorem 2 Suppose X = (X1, X2, …, Xp) is a p-dimensional random vector, and its node-conditional distributions are specified by an exponential family,
| (6) |
where the function E(XV\r), the canonical parameter of exponential family, depends on the rest of all random variables except Xr (and hence the log-normalization constant D̄(XV\r)). Further, suppose the corresponding joint distribution factors according to the graph G, with the factors over cliques of size at most k. Then, the conditional distribution in (6) necessarily has the tensor-factorized form in (4), and the corresponding joint distribution has the form in (5).
Theorem 2 thus tells us that under the general assumptions that:
the joint distribution is a graphical model that factors according to a graph G, and has clique-factors of size at most k, and
its node-conditional distribution follows an exponential family,
it necessarily follows that the conditional and joint distributions are given by (4) and (5) respectively.
An important special case is when the joint graphical model distribution has clique factors of size at most two. From Theorem 2, the conditional distribution is given by
| (7) |
while the joint distribution is given as
| (8) |
For many classes of models (e.g. general Ising, discrete CRFs), the log-partition function of the joint distribution, A(·), has no analytical form, and might even be intractable to compute, while the function D(·) typically is more amenable, and available in analytical form, since it is the log-partition function of a univariate exponential family distribution.
When the univariate sufficient statistic function B(·) is a linear function B(Xr) = Xr, then the conditional distribution in (7) is precisely a generalized linear model (McCullagh and Nelder, 1989) in canonical form,
| (9) |
where the canonical parameter of GLMs becomes θr + Σt∈N(r) θrt Xt. At the same time, the joint distribution has the form:
| (10) |
where the log-partition function A(·) in this case is defined as
| (11) |
We will now provide some examples of our general class of “exponential family” graphical model distributions, focusing on the case in (10) with linear functions B(Xr) = Xr. For each of these examples, we will also detail the domain, Θ := {θ : A(θ) < +∞}, of valid parameters that ensure that the density is normalizable. Indeed, such constraints on valid parameters are typically necessary for the distributions over countable discrete or continuous valued variables.
2.2 Gaussian Graphical Models
The popular Gaussian graphical model (Speed and Kiiveri, 1986) can be derived as an instance of the construction in Theorem 2, with the univariate Gaussian distribution as the exponential family distribution. The univariate Gaussian distribution with known variance σ2 is given by
where Z ∈ ℝ, so that it can be seen to be an exponential family distribution of the form (3), with sufficient statistic , and base measure . Substituting these in (10), we get the distribution:
| (12) |
which can be seen to be the multivariate Gaussian distribution. Note that the set of parameters {θrt}(r,t)∈E entails a precision matrix that needs to be positive definite for a valid probability distribution.
2.3 Ising Models
The Ising model (Wainwright and Jordan, 2008) in turn can be derived from the construction in Theorem 2 with the Bernoulli distribution as the univariate exponential family distribution. The Bernoulli distribution is a member of the exponential family of the form (3), with sufficient statistic B(X) = X, and base measure C(X) = 0, and with variables taking values in the set 𝒳 = {0, 1}. Substituting these in (10), we get the distribution:
| (13) |
where we have ignored the singleton term, i.e. set θr = 0 for simplicity. The form of the multinomial graphical model, an extension of the Ising model, can also be represented by (10) and has been previously studied in Jalali et al. (2011) and others. The Ising model imposes no constraint on its parameters, {θrt}, for normalizability, since there are finitely many configurations of the binary random vector X.
2.4 Poisson Graphical Models
Poisson graphical models are an interesting instance with the Poisson distribution as the univariate exponential family distribution. The Poisson distribution is a member of the exponential family of the form (3), with sufficient statistic B(X) = X and C(X) = −log(X!), and with variables taking values in the set 𝒳 = {0, 1, 2, …}. Substituting these in (10), we get the following Poisson graphical model distribution:
| (14) |
For this Poisson family, with some calculation, it can be seen that the normalizability condition, A(θ) < +∞, entails θrt ≤ 0 ∀ r, t. In other words, the Poisson graphical model can only capture negative conditional relationships between variables.
2.5 Exponential Graphical Models
Another interesting instance uses the exponential distribution as the univariate exponential family distribution, with sufficient statistic B(X) = −X and C(X) = 0, and with variables taking values in 𝒳 = {0} ⋃ ℝ+. Such exponential distributions are typically used for data describing inter-arrival times between events, among other applications. Substituting these in (10), we get the following exponential graphical model distribution:
| (15) |
To ensure that the distribution is valid and normalizable, so that A(θ) < +∞, we then require that θr > 0, θrt ≥ 0 ∀ r, t. Because of the negative sufficient statistic, this implies that the exponential graphical model can only capture negative conditional relationships between variables.
3. Statistical Guarantees on Learning Graphical Model Structures
In this section, we study the problem of learning the graph structure of an underlying exponential family MRF, given i.i.d. samples. Specifically, we assume that we are given n samples of random vector , from a pairwise exponential family MRF,
| (16) |
The goal in graphical model structure recovery is to recover the edges E* of the underlying graph G = (V, E*). Following Meinshausen and Bühlmann (2006); Ravikumar et al. (2010); Jalali et al. (2011), we will approach this problem via neighborhood estimation: where we estimate the neighborhood of each node individually, and then stitch these together to form the global graph estimate. Specifically, if we have an estimate N̂(r) for the true neighborhood N*(r), then we can estimate the overall graph structure as
| (17) |
Remark. Note that the node-neighborhood estimates N̂(r) might not be symmetric (i.e. there may be a pair (r, s) ∈ V × V, with r ∈ N̂(s), but s ∉ N̂(r)). The graph-structure estimate in (17) provides one way to reconcile these neighborhood estimates; see Meinshausen and Bühlmann (2006) for some other ways to do so (though as they note, these different estimates have asymptotically identical sparsistency guarantees: given exponential convergence in the probability of node-neighborhood recovery to one, the probability that the node-neighborhood estimates are symmetric, and hence that the different “reconciling” graph estimates would become identical, also converges to one.)
The problem of graph structure recovery can thus be reduced to the problem of recovering the neighborhoods of all the nodes in the graph. In order to estimate the neighborhood of any node in turn, we consider the sparsity constrained conditional MLE. Note that given the joint distribution in (16), the conditional distribution of Xr given the rest of the nodes is reduced to a GLM and given by
| (18) |
Let θ*(r) be a set of parameters related to the node-conditional distribution of node Xr, i.e. where be a zero-padded vector, with entries for t ∈ N*(r) and , for t ∉ N*(r). In order to infer the neighborhood structure for each node Xr, we solve the ℓ1 regularized conditional log-likelihood loss:
| (19) |
where Ω is the parameter space in ℝ × ℝp−1, and ℓ(θ(r); X1:n) is the conditional log-likelihood of the distribution (18):
Note that the parameter space Ω might be restricted, and strictly smaller than ℝ × ℝp−1; for Poisson graphical models, θrt ≤ 0 for all r, t ∈ V for instance.
Given the solution θ̂(r) of the M-estimation problem above, we then estimate the node-neighborhood of r as N̂(r) = {t ∈ V\r : θ̂rt ≠ 0}. In what follows, when we focus on a fixed node r ∈ V, we will overload notation, and use θ ∈ ℝ × ℝp−1 as the parameters of the conditional distribution, suppressing dependence on the node r.
3.1 Conditions
A key quantity in the analysis is the Fisher information matrix, , which is the Hessian of the node-conditional log-likelihood. In the following, we again will simply use Q* instead of where the reference node r should be understood implicitly. We also use S = {(r, t) : t ∈ N*(r)} to denote the true neighborhood of node r, and Sc to denote its complement. We use to denote the d × d sub-matrix of Q* indexed by S where d is the number of neighborhoods of node r again suppressing dependence on r. Our first two conditions, mirroring those in Ravikumar et al. (2010), are as follows.
(C1) (Dependency condition) There exists a constant ρmin > 0 such that so that the sub-matrix of Fisher information matrix corresponding to true neighborhood has bounded eigenvalues. Moreover, there exists a constant ρmax < ∞ such that .
These condition can be understood as ensuring that variables do not become overly dependent. We will also need an incoherence or irrepresentable condition on the Fisher information matrix as in Ravikumar et al. (2010).
(C2) (Incoherence condition) There exists a constant α > 0, such that .
This condition, standard in high-dimensional analyses, can be understood as ensuring that irrelevant variables do not exert an overly strong effect on the true neighboring variables.
A key technical facet of the linear, logistic, and multinomial models in Meinshausen and Bühlmann (2006); Ravikumar et al. (2010); Jalali et al. (2011), used heavily in their proofs, was that the random variables {Xr} there were bounded with high probability. Unfortunately, in the general exponential family distribution in (18), we cannot assume this explicitly. Nonetheless, we show that we can analyze the corresponding regularized M-estimation problems under the following mild conditions on the log-partition functions of the joint and node-conditional distributions.
(C3) (Bounded Moments) For all r ∈ V, the first and second moments are bounded, so that
for some constants κm, κv. Further, the log-partition function A(·) of the joint distribution (16) satisfies:
for some constant κh, and where er ∈ ℝp2 is an indicator vector that is equal to one at the index corresponding to θr, and zero everywhere else. Further, it holds that
where Ār(η; θ*) is a slight variant of (11):
| (20) |
for some scalar variable η.
(C4) For all r ∈ V, the log-partition function D(·) of the node-wise conditional distribution (18) satisfies: there exist functions κ1(n, p) and κ2(n, p) (that depend on the exponential family) such that, for all θ ∈ Θ and X ∈ 𝒳, |D″(a)| ≤ κ1(n, p) where a ∈ [b, b+4κ2(n, p) max{log n, log p}] for b := θr + 〈θ\r, XV\r〉. Additionally, |D‴(b)| ≤ κ3(n, p) for all θ ∈ Θ and X ∈ 𝒳. Note that κ1(n, p),κ2(n, p) and κ3(n, p) are functions that might be dependent on n and p, which affect our main theorem below.
Conditions (C3) and (C4) are the key technical components enabling us to generalize the analyses in Meinshausen and Bühlmann (2006); Ravikumar et al. (2010); Jalali et al. (2011) to the general exponential family case. It is also important to note that almost all exponential family distributions including all our previous examples can satisfy (C4) with mild functions κ1(n, p), κ2(n, p) and κ3(n, p), as we will explicitly show later in this section. Comparing to the assumption in Yang et al. (2012) that requires ‖θ*‖2 ≤ 1 for some exponential families, this will be much less restrictive condition on the minimum values of θ* permitted to achieve variable selection consistency.
3.2 Statement of the Sparsistency Result
Armed with the conditions above, we can show that the random vector X following a exponential family MRF distribution in (16) is suitably well-behaved:
Proposition 3 Suppose X is a random vector with the distribution specified in (16). Then, for ∀r ∈ V,
where δ ≤ min{2κv/3, κh + κv}, and c is a positive constant.
We recall the notation that the superscript indicates the sample and the subscript indicates the node; so that X(i) is the i-th sample, while is the s-th variable/node of this random vector.
Proposition 4 Suppose X is a random vector with the distribution specified in (16). Then, for ∀r ∈ V,
where δ is any positive real value, and c is a positive constant.
These propositions are key to the following sparsistency result for the general family of pairwise exponential family MRFs (16).
Theorem 5 Consider a pairwise exponential family MRF distribution as specified in (16), with true parameter θ* and associated edge set E* that satisfies Conditions (C1)-(C4). Suppose that , where d is the maximum neighborhood size. Suppose also that the regularization parameter is chosen such that for some constants M1, M2 > 0. Then, there exist positive constants L, c1, c2 and c3 such that if n ≥ Ld2κ1(n, p)(κ3(n, p))2 log p(max{log n, log p})2, then with probability at least 1 – c1(max{n, p})−2 – exp(−c2n) – exp(−c3n), the following statements hold.
(Unique Solution) For each node r ∈ V, the solution of the M-estimation problem in (19) is unique, and
(Correct Neighborhood Recovery) The M-estimate also recovers the true neighborhood exactly, so that N̂(r) = N*(r).
Note that if the neighborhood of each node is recovered with high probability, then by a simple union bound, the estimate in (17), Ê = ⋃r∈V ⋃t∈N̂(r) {(r, t)} is equal to the true edge set E* with high-probability.
In the following subsections, we investigate the consequences of Theorem 5 for the sparsistency of specific instances of our general exponential family MRFs.
3.3 Statistical Guarantees for Gaussian MRFs, Ising Models, Exponential Graphical Models
In order to apply Theorem 5 to a specific instance of our general exponential family MRFs, we need to specify the terms κ1(n, p), κ2(n, p) and κ3(n, p) defined in Condition (C4). It turns out that we can specify these terms for the Gaussian graphical models, Ising models and Exponential graphical model distributions, discussed in Section 2, in a similar manner, since the node-conditional log-partition function D(·) for all these distributions can be upper bounded by some constant independent of n and p. In particular, we can set κ1(n, p) := κ1, κ2(n, p) := ∞ and κ1(n, p) := κ3 where κ1 and κ3 now become some constants depending on the distributions.
(Gaussian MRFs) Recall that the node-conditional distribution for Gaussian MRFs follow a univariate Gaussian distribution:
Note that following (Meinshausen and Bühlmann, 2006), we assume that for all r ∈ V. The node-conditional log-partition function D(·) can thus be written as , so that |D″(η)| = 1 and D‴(η) = 0. We can thus set κ1 = 1 and κ3 = 0.
(Ising Models) For Ising models, node-conditional distribution follows a Bernoulli distribution:
The node-conditional log-partition function D(·) can thus be written as D(η) := log (1 + exp(η)), so that for any η, and . Hence, we can set κ1 = κ3 = 1/4.
(Exponential Graphical Models) Lastly, for exponential graphical models, we have
The node-conditional log-partition function D(·) can thus be written as D(η) := −log η, with η = θr + Σt∈N(r) θrtXt. Recall from Section 2.5 that the node parameters are strictly positive θr > 0, and the edge-parameters are positive as well, θrt ≥ 0, as are the variables themselves Xt ≥ 0. Thus, under the additional constraint that θr > a0 where a0 is a constant smaller than , we have that η := θr + Σt∈N(r) θrtXt ≥ a0. Consequently, and . We can thus set and .
Armed with these derivations, we recover the following result on the sparsistency of Gaussian, Ising and Exponential graphical models, as a corollary of Theorem 5:
Corollary 6 Consider a Gaussian MRF (12) or Ising model (13) or Exponential graphical model (15) distribution with true parameter θ*, and associated edge set E*, and which satisfies Conditions (C1)-(C3). Suppose that . Suppose also that the regularization parameter is set so that for some constant M > 0. Then, there exist positive constants L, c1, c2 and c3 such that if , then with probability at least 1 –c1 (max{n, p})−2–exp(−c2n) – exp(−c3n), the statements on the uniqueness of the solution and correct neighborhood recovery, in Theorem 5 hold.
Remarks. As noted, our models and theorems are quite general, extending well beyond the popular Ising and Gaussian graphical models. The graph structure recovery problem for Gaussian models was studied in Meinshausen and Bühlmann (2006) especially for the regime where the neighborhood sparsity index is sublinear, meaning that d/p → 0. Besides the sublinear scaling regime, Corollary 6 can be adapted to entirely different types of scaling, such as the linear regime where d/p → α for some α > 0 (see Wainwright (2009) for details on adaptations to sublinear scaling regimes). Moreover, with κ1 and κ3 as defined above, Corollary 6 exactly recovers the result in Ravikumar et al. (2010) for the Ising models as a special case.
Also note that Corollary 6 provides tighter finite-sample bounds than the results of Yang et al. (2012). In particular, a sample size complexity necessary on λn to achieve sparsistent recovery here is , which is faster as compared to in Yang et al. (2012).
3.4 Statistical Guarantees for Poisson Graphical Models
We now consider the Poisson graphical model. Again, to derive the corresponding corollary of Theorem 5, we need to specify the terms κ1(n, p), κ2(n, p) and κ3(n, p) defined in Condition (C4). Recall that the node-conditional distribution of Poisson graphical models has the form:
The node-conditional log-partition function D(·) can thus be written as D(η) := exp η, with η = θr + Σt∈N(r) θrtXt. Noting that the variables {Xt} range over positive integers, and that feasible parameters θrt are negative, we obtain
where p′ = max{n, p}. Suppose that we restrict our attention on the subfamily where θr ≤ a0 for some positive constant a0. Then, if we choose κ2(n, p) := 1/(4 log p′), we then obtain θr + 4κ2(n, p) log p′ ≤ a0 + 1, so that setting κ1(n, p) := exp(a0 + 1) would satisfy Condition (C4). Similarly, we obtain D‴(θr + 〈θ\r, XV\r〉) = exp (θr + 〈θ\r, XV\r〉) ≤ exp(a0 + 1), so that we can set κ3(n, p) to exp(a0 + 1).
Armed with these settings, we recover the following corollary for Poisson graphical models:
Corollary 7 Consider a Poisson graphical model distribution as specified in (14), with true parameters θ*, and associated edge set E*, that satisfies Conditions (C1)-(C3). Suppose that . Suppose also that the regularization parameter is chosen such that for some constants M1, M2 > 0. Then, there exist positive constants L, c1, c2 and c3 such that if , then with probability at least 1 – c1(max{n, p})−2 – exp(−c2n) – exp(−c3n), the statements on the uniqueness of the solution and correct neighborhood recovery, in Theorem 5 hold.
4. Experiments
We evaluate our M-estimators for exponential family graphical models, specifically for the Poisson and exponential distributions, through simulations and real data examples. Neighborhood selection was performed for each M-estimator with an ℓ1 penalty to induce sparsity and non-negativity or non-positivity constraints to enforce appropriate restrictions on the parameters. Optimization algorithms were implemented using projected gradient descent (Daubechies et al., 2008; Beck and Teboulle, 2010), which since the objectives are convex, is guaranteed to converge to the global optimum. Further details on the optimization problems used for our M-estimators are given in the Appendix E.
4.1 Simulation Studies
We provide a small simulation study that corroborates our sparsistency results; specifically Corollary 6 for the exponential graphical model, where node-conditional distributions follow an exponential distribution, and Corollary 7 for the Poisson graphical model, where node-conditional distributions follow a Poisson distribution. We instantiated the corresponding exponential and Poisson graphical model distributions in (15) and (14) for 4 nearest neighbor lattice graphs (d = 4), with varying number of nodes, p ∈ {64, 100, 169, 225}, and with identical edge weights for all edges: for exponential MRF, and , and, for Poisson MRF, and . We generated i.i.d. samples from these distributions using Gibbs sampling, and solved our sparsity-constrained M-estimation problem by setting , following our corollaries; c = 3 for exponential MRF, and 15 for Poisson MRF. We repeated each simulation 50 times and measured the empirical probability over the 50 trials that our penalized graph estimate in (17) successfully recovered all edges, that is, P(Ê = E*). The left panels of Figure 1(a) and Figure 1(b) show the empirical probability of successful edge recovery. In the right panel, we plot the empirical probability against a re-scaled sample size β = n/(log p). According to our corollaries, the sample size n required for successful graph structure recovery scales logarithmically with the number of nodes p. Thus, we would expect the empirical curves for different problem sizes to more closely align with this re-scaled sample size on the horizontal axis, a result clearly seen in the right panels of Figure 1. This small numerical study thus corroborates our theoretical sparsistency results.
Figure 1.

Probabilities of successful support recovery for the (a) exponential MRF, grid structure with parameters and , and the (b) Poisson MRF, grid structure with parameters and . The empirical probability of successful edge recovery over 50 replicates is shown versus the sample size n (left), and verses the re-scaled sample size β = n/(log p) (right). The empirical curves align for the latter, thus verifying the logarithmic dependence of n on p as obtained in our sparsistency analysis.
We also evaluate the comparative performance of our M-estimators for recovering the true edge structure from the different types of data. Specifically, we consider the three typical examples in our unified neighborhood selection approach: the Poisson M-estimator, the Exponential M-estimator, and the well-known Gaussian M-estimator by (Meinshausen and Bühlmann, 2006). In order to extensively compare their performances, we compute the receiver-operator-curves for the overall graph recovery by varying the regularization parameter, λn. In Figure 2, the same graph structures for the exponential MRF ( and ) and the Poisson MRF ( and ) with 4 nearest neighbors, are used as in the previous simulation. Moreover, we focus on the high-dimensional regime where n < p. As shown in the figure, exponential and Poisson M-estimators outperform and have significant advantage over Gaussian neighborhood selection approach if the data is generated according to exponential or Poisson MRFs. One interesting phenomenon we observe is that exponential and Poisson M-estimators perform similarly regardless of the underlying graphical model distribution. This likely occurs as our estimator maximizes the conditional likelihoods by fitting penalized GLMs. Note that GLMs assume that the conditional mean of the regression model follows an exponential family distribution. As both the Poisson distribution and the exponential distribution have the same mean, the rate parameter, λ, we would expect GLM-based methods that fit conditional means to perform similarly.
Figure 2.

Receiver-operator curves (ROC) computed by varying the regularization parameter, λn. High-dimensional data is generated according to (a) the Exponential MRF with (n, p) = (150, 225) and to (b) the Poisson MRF with (n, p) = (100, 225). Results are compared for three M-estimators: that of the Poisson, exponential, and Gaussian distributions.
As discussed at end of Section 2, the exponential and Poisson graphical models are able to capture only negative conditional dependencies between random variables, and our corresponding M-estimators are computed under this constraint. In our last simulation, we evaluate the impact of this restriction when the true graph contains both positive and negative edge weights. As there does not exist a proper MRF related to the Poisson and exponential distributions with both positive and negative dependencies, we resort to generating data from via a copula transform. In particular, we first generate multivariate Gaussian samples from N(0, Σ) where Θ = Σ−1 is the precision matrix corresponding to the 4 nearest neighbor grid structure previously considered. Specifically, Θ has all ones on the diagonal and with equal probabilities. We then use a standard copula transform to make the marginals of the generated data approximately Poisson. Figure 3 again present receiver operator curves (ROC) for the three different classes of M-estimators on the copula transformed data, transformed to the Poisson distribution. In the left of Figure 3, we consider signed support recovery where we define the true positive rate as . In the right, on the other hand, we ignore the positive edges so that true positive rate is now . Note that the false positive rate is also defined similarly. As expected, the results indicate that our Poisson and exponential M-estimators fail to recover the edges with positive conditional dependencies recovered by the Gaussian M-estimator. However, when attention is restricted to negative conditional dependencies, our method outperforms the Gaussian M-estimator. Notice also that for the exponential and Poisson M-estimators, the highest false positive rate achieved is around 0.15. This likely occurs due to the constraints enforced by our M-estimators that force the weights of potential positive conditional dependent edges to be zero. Thus, while the restrictions on the edge weights may be severe, for the purpose of estimating negative conditional dependencies with limited false positives, the Poisson and exponential M-estimators have an advantage.
Figure 3.

Receiver-operator curves (ROC) computed by varying the regularization parameter, λn, for data, (n, p) = (200, 225), generated via Poisson copula transform according to a network with both positive and negative conditional dependencies. Left plot denotes results on overall edge recovery, while right plot denotes recovery of the edges with negative weights corresponding to negative conditional dependencies.
4.2 Real Data Examples
To demonstrate the versatility of our family of graphical models, we also provide two real data examples: a meta-miRNA inhibitory network estimated by the Poisson graphical model, Figure 4, and a cell signaling network estimated by the exponential graphical model, Figure 5.
Figure 4.
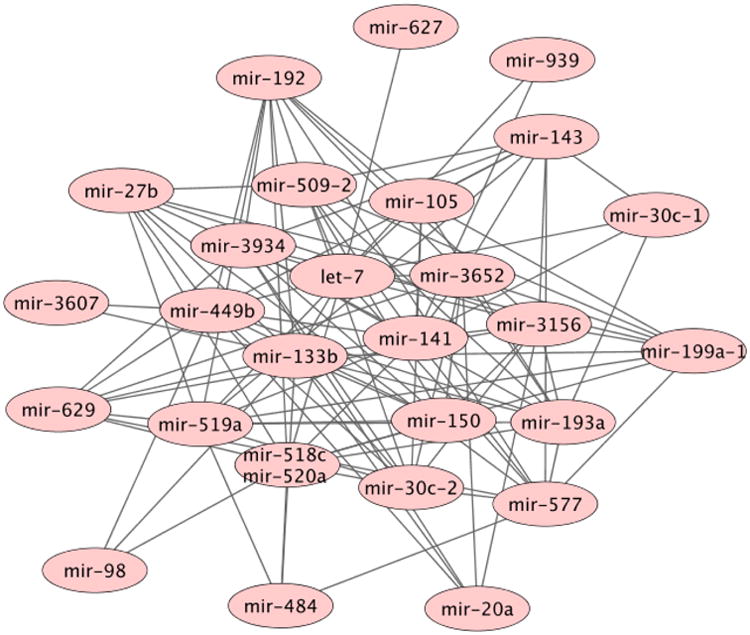
Meta-miRNA inhibitory network for breast cancer estimated via Poisson graphical models from miRNA-sequencing data. Level III data from TCGA was processed into tightly correlated clusters, meta-miRNAs, with the driver miRNAs identified for each cluster taken as the set of nodes for our network. The Poisson network reveals major inhibitory relationships between three hub miRNAs, two of which have been previously identified as tumor suppressors in breast cancer.
Figure 5.

Cell signaling network estimated from flow cytometry data via exponential graphical models (left) and Gaussian graphical models (right). The exponential graphical model was fit to un-transformed flow cytometry data measuring 11 proteins, and the Gaussian graphical model to log-transformed data. Estimated negative conditional dependencies are given in red. Both networks identify PKA (protein kinase A) as a major inhibitor, consistent with previous results.
When applying our family of graphical models, there is always a question of whether our model is an appropriate fit for the observed data. Typically, one can assess model fit using goodness-of-fit tests. For the Gaussian graphical model, this reduces to testing whether the data follows a multivariate Gaussian distribution. For general exponential family graphical models, testing for goodness-of-fit is more challenging. Some have proposed likelihood ratio tests specifically for lattice systems with a fixed and known dependence structure (Besag, 1974). When the network structure is unknown, however, there are no such existing tests. While we leave the development of an exact test to future work, we provide a heuristic that can help us understand whether our model is appropriate for a given dataset.
Recall that our model assumes that conditional on its node-neighbors, each variable is distributed according to an exponential family. Thus, if the neighborhood is known, our conditional models are simply GLMs, for which the goodness-of-fit can be assessed compared to a null model by a likelihood ratio test (McCullagh and Nelder, 1989). When neighborhoods must be estimated, and specifically when estimated via an ℓ1-norm penalty, the resulting ratio of likelihoods no longer follow a chi-squared distribution (Bühlmann, 2011). Recently, for the ℓ1 linear regression case, Lockhart et al. (2014) have shown that the difference in the residual sums of squares follows an exponential distribution. Similar results have not yet been extended to the penalized GLM case. In the absence of such tests, we propose a simple heuristic: for each node, first estimate the node-neighborhood via our proposed M-estimator. Next, assuming the neighborhood is fixed, fit a GLM and compare the fit of this model to that of a null model (only an intercept term) via the likelihood ratio test. One can then heuristically assess the overall goodness-of-fit by examining the fit of a GLM to all the nodes. This procedure is clearly not an exact test, and following from Lockhart et al. (2014), it is likely conservative. In the absence of an exact test, which we leave for future work, this heuristic provides some assurances about the appropriateness of our model for real data.
4.2.1 Poisson Graphical Model: Meta-miRNA Inhibitory Network
Gaussian graphical models have often been used to study high-throughput genomic networks estimated from microarray data (Pe'er et al., 2001; Friedman, 2004; Wei and Li, 2007). Many high-throughput technologies, however, do not produce even approximately Gaussian data, so that our class of graphical models could be particularly important for estimating genomic networks from such data. We demonstrate the applicability of our class of models by estimating a meta-miRNA inhibitory network for breast cancer estimated by a Poisson graphical model. Level III breast cancer miRNA expression (Cancer Genome Atlas Research Network, 2012) as measured by next generation sequencing was downloaded from the TCGA portal (http://tcga-data.nci.nih.gov/tcga/). MicroRNAs (miRNA) are short RNA fragments that are thought to be post-transcriptional regulators, predominantly inhibiting translation. Measuring miRNA expression by high-throughput sequencing results in count data that is zero-inflated, highly skewed, and whose total count volume depends on experimental conditions (Li et al., 2011). Data was processed to be approximately Poisson by following the steps described in (Allen and Liu, 2013). In brief, the data was quantile corrected to adjust for sequencing depth (Bullard et al., 2010); the miRNAs with little variation across the samples, the bottom 50%, were filtered out; and the data was adjusted for possible over-dispersion using a power transform and a goodness of fit test (Li et al., 2011). We also tested for batch effects in the resulting data matrix consisting of 544 subjects and 262 miRNAs: we fit a Poisson ANOVA model (Leek et al., 2010), and only found 4% of miRNAs to be associated with batch labels; and thus no significant batch association was detected. As several miRNAs likely target the same gene or genes in the same pathway, we expect there to be strong positive dependencies among variables that cannot be captured directly by our Poisson graphical model which only permits negative conditional relationships. Thus, we will use our model to study inhibitory relationships between what we term meta-miRNAs, or groups of miRNAs that are tightly positively correlated. To accomplish this, we further processed our data to form clusters of positively correlated miRNAs using hierarchical clustering with average linkage and one minus the correlation as the distance metric. This resulted in 40 clusters of tightly positively correlated miRNAs. The nodes of our meta-miRNA network were then taken as a the medoid, or median centroid defined as the miRNA closest in Euclidean distance to the cluster centroid, in each group.
A Poisson graphical model was fit to the meta-miRNA data by performing neighborhood selection with the sparsity of the graph determined by stability selection (Liu et al., 2010). The heuristic previously discussed was used to assess goodness-of-fit for our model. Out of the 40 node-neighborhoods tested via a likelihood ratio test, 36 exhibited p-values less than 0.05, and 34 were less than 0.05/40, the Bonferroni-adjusted significance level. These results show that the Poisson GLM is a significantly better fit for the majority of node-neighborhoods than the null model, indicating that our Poisson graphical model is appropriate for this data. The results of our estimated Poisson graphical model, Figure 4 (left), are consistent with the cancer genomics literature. First, the meta-miRNA inhibitory network has three major hubs. Two of these, miR-519 and miR-520, are known to be breast cancer tumor suppressors, suppressing growth by reducing HuR levels (Abdelmohsen et al., 2010) and by targeting NF-KB and TGF-beta pathways (Keklikoglou et al., 2012) respectively. The third major hub, miR-3156, is a miRNA of unknown function; from its major role in our network, we hypothesize that miR-3156 is also associated with tumor suppression. Also interestingly, let-7, a well-known miRNA involved in tumor metastasis (Yu et al., 2007), plays a central role in our network, sharing edges with the five largest hubs. This suggests that our Poisson graphical model has recovered relevant negative relationships between miRNAs with the five major hubs acting as suppressors, and the central let-7 miRNA and those connected to each of the major hubs acting as enhancers of tumor progression in breast cancer.
4.2.2 Exponential Graphical Model: Inhibitory Cell-Signaling Network
We demonstrate our exponential graphical model, derived from the univariate exponential distribution, using a protein signaling example (Sachs et al., 2005). Multi-florescent flow cytometry was used to measure the presence of eleven proteins (p = 11) in n = 7462 cells. This data set was first analyzed using Bayesian Networks in Sachs et al. (2005) and then using the graphical lasso algorithm in Friedman et al. (2007). Measurements from flow-cytometry data typically follow a left skewed distribution. Thus to model such data, these measurements are typically normalized to be approximately Gaussian using a log transform after shifting the data to be non-negative (Herzenberg et al., 2006). Here, we demonstrate the applicability of our exponential graphical models to recover networks directly from continuous skewed data, so that we learn the network directly from the flow-cytometry data without any log or such transforms. Our pre-processing is limited to shifting the data for each protein so that it consists of non-negative values. For comparison purposes, we also fit a Gaussian graphical model to the log-transformed data.
We then learned an exponential and Gaussian graphical model from this flow cytometry data using stability selection (Liu et al., 2010) to select the sparsity of the graphs. The goodness-of-fit heuristic previously described was used to assess the appropriateness of our model. Out of the eight connected node-neighborhoods, the likelihood ratio test was statistically significant for seven neighborhoods, indicating that our exponential GLM is a better fit than the null model. The estimated protein-signaling network is shown on the right in Figure 5 with that of the Gaussian graphical model fit to the log-transformed data on the left. Estimated negative conditional dependencies are shown in red. Recall that the exponential graphical model restricts the edge weights to be non-negative; because of the negative inverse link, this implies that only negative conditional associations can be estimated. Notice that our exponential graphical model finds that PKA, protein kinase A, is a major protein inhibitor in cell signaling networks. This is consistent with the inhibitory relationship of PKA as estimated by the Gaussian graphical model, right Figure 5, as well as its hub status in the Bayesian network of (Sachs et al., 2005). Interestingly, our exponential graphical model also finds a clique between PIP2, Mek, and P38, which was not found by Gaussian graphical models.
5. Discussion
We study what we call the class of exponential family graphical models that arise when we assume that node-wise conditional distributions follow exponential family distributions. Our work broadens the class of off-the-shelf graphical models from classical instances such as Ising and Gaussian graphical models. In particular, our class of graphical models provide closed form multivariate densities as extensions of several univariate exponential family distributions (e.g. Poisson, exponential, negative binomial) where few currently exist; and thus may be of further interest to the statistical community. Further, we provide simple M-estimators for estimating any of these graphical models from data, by fitting node-wise penalized conditional exponential family distributions, and show that these estimators enjoy strong statistical guarantees. The statistical analyses of our M-estimators required subtle techniques that may be of general interest in the analysis of sparse M-estimation.
There are many avenues of future work related to our proposed models. We assume that all conditional distributions are members of an exponential family. To determine whether this assumption is appropriate in practice for real data, a goodness-of-fit procedure is needed. While we have proposed a heuristic to this effect, more work is needed to determine a rigorous likelihood ratio test for testing model fit. For several instances of our proposed class of models, specifically those with variables with infinite domains, severe restrictions on the parameter space are sometimes needed. For instance, the Poisson and exponential graphical models studied in Section 4, could only model negative conditional dependencies, which may not always be desirable in practice. A key question for future work is whether these restrictions can be relaxed for particular exponential family distributions. Finally, while we have focused on single parameter exponential families, it would be interesting to investigate the consequences of using multi-parameter exponential family distributions. Overall, our work has opened avenues for learning Markov networks from a broad class of univariate distributions, the properties and applications of which leave much room for future research.
Acknowledgments
We would like to acknowledge support for this project from ARO W911NF-12-1-0390, NSF IIS-1149803, IIS-1320894, IIS-1447574, and DMS-1264033 (PR and EY); NSF DMS-1264058 and DMS-1209017 (GA); and the Houston Endowment and NSF DMS-1263932 (ZL).
Appendix A. Proof of Theorem 2
The proof follows the development in Besag (1974), where they consider the case with k = 2. We define Q(X) as Q(X) := log(P(X)/P(0)), for any X = (X1, …, Xp) ∈ 𝒳p where P(0)) denotes the probability that all random variables take 0. Given any X, also denote X̄r:0 := (X1, …, Xr−1, 0, Xr+1, …, Xp). Now, consider the following the most general form for Q(X):
| (21) |
since the joint distribution has factors of at most size k. By the definition of Q and some algebra (See Section 2 of Besag (1974) for details), it can then be seen that
| (22) |
Now, consider the simplifications of both sides of (22). For notational simplicity, we fix r = 1 for a while. Given the form of Q(X) in (21), we have
| (23) |
By given the exponential family form of the node-conditional distribution specified in the statement, right-hand side of (22) become
| (24) |
Setting Xt = 0 for all t ≠ 1 in (23) and (24), we obtain
Setting Xt2 = 0 for all t2 ∉ {1, t},
Recovering the index 1 back to r yields
Similarly,
| (25) |
From the above three equations, we obtain
More generally, by considering non-zero triplets, and setting Xv = 0 for all v ∉ {r, t, u}, we obtain
| (26) |
so that by a similar reasoning we can obtain
More generally, we can show that
Thus, the k-th order factors in the joint distribution as specified in (21) are tensor products of (B(Xr) – B(0)), thus proving the statement of the theorem.
Appendix B. Proof of Proposition 3
By the definition of (20) with the following simple calculation, the moment generating function of becomes
Suppose that a ≤ 1. Then, by a Taylor Series expansion, we have for some ν ∈ [0, 1]
where the inequality uses Condition (C3). Note that since the derivative of log-partition function is the mean of the corresponding sufficient statistics and Ār(0; θ) = A(θ), by assumption. Thus, by the standard Chernoff bounding technique, for all positive a ≤ 1,
With the choice of , we obtain
provided that δ ≤ 2κv/3, as in the statement.
Appendix C. Proof of Proposition 4
Let be the zero-padded parameter with only one non-zero coordinate, which is 1, for the sufficient statistics Xr so that ‖v̄‖2 = 1. A simple calculation shows that
By a Taylor Series expansion and Condition (C3), we have for some ν ∈ [0, 1]
where the inequality (i) uses the fact that v̄ has only nonzero element for the sufficient statistics Xr. Thus, again by the standard Chernoff bounding technique, for any positive constant a, , and by setting a = δ log η we have
where , as claimed.
Appendix D. Proof of Theorem 5
In this section, we sketch the proof of Theorem 5 following the primal-dual witness proof technique in Wainwright (2009); Ravikumar et al. (2010). We first note that the optimality condition of the convex program (19) can be written as
| (27) |
where Ẑ is a length p vector: Ẑ\r ∈ ∂‖θ̂\r‖1 is a length (p – 1) subgradient vector where Ẑrt = sign(θ̂rt) if θ̂rt ≠ 0, and |Ẑrt| ≤ 1 otherwise; while Ẑr, corresponding to θr, is set to 0 since the nodewise term θr is not penalized in the M-estimation problem (19).
Note that in a high-dimensional regime with p ≫ n, the convex program (19) is not necessarily strictly convex, so that it might have multiple optimal solutions. However, the following lemma, adapted from Ravikumar et al. (2010), shows that nonetheless the solutions share their support set under certain conditions. We first recall the notation S = {(r, t) : t ∈ N*(r)} to denote the true neighborhood of node r, and Sc to denote its complement.
Lemma 8 Suppose that there exists a primal optimal solution θ̂ with associated subgradient Ẑ such that ‖ẐSc‖∞ < 1. Then, any optimal solution θ̃ will satisfy θ̃Sc = 0. Moreover, under the condition of ‖ẐSc‖∞ < 1, if is invertible, then θ̂ is the unique optimal solution of (19).
Proof This lemma can be proved by the same reasoning developed for the special cases Wainwright (2009); Ravikumar et al. (2010) in our framework; As in the previous works, for any node-conditional distribution in the form of exponential family, we are solving the convex objective with ℓ1 regularizer (19). Therefore, the problem can be written as an equivalent constrained optimization problem, and by the complementary slackness, for any optimal solution θ̃, we have 〈Ẑ, θ̃〉 = ‖θ̃‖1. This simply implies that for all index j for which |Ẑj| < 1, θ̃j = 0 (See Ravikumar et al. (2010) for details). Therefore, if there exists a primal optimal solution θ̂ with associated subgradient Ẑ such that ‖ẐSc‖∞ < 1, then, any optimal solution θ̃ will satisfy θ̃Sc = 0 as claimed.
Finally, we consider the restricted optimization problem subject to the constraint θSC = 0. For this restricted optimization problem, if the Hessian, , is positive definite as assumed in the lemma, then, this restricted problem is strictly convex, and its solution is unique. Moreover, since all primal optimal solutions of (19), θ̃, satisfy θ̃Sc = 0 as discussed, the solution of the restricted problem is the unique solution of (19).
We use this lemma to prove the theorem following the primal-dual witness proof technique in Wainwright (2009); Ravikumar et al. (2010). Specifically, we explicitly construct a pair (θ̂, Ẑ) as follows (denoting the true support set of the edge parameters by S):
Recall that θ(r) = (θr, θ\r) ∈ ℝ × ℝp−1. We first fix θSc = 0 and solve the restricted optimization problem: (θ̂r, θ̂S, 0) = arg minθr∈ℝ, (θS,0)∈ℝp−1 {ℓ(θ; X1:n)+λn‖θS‖1}, and ẐS = sign(θ̂S).
We set θ̂Sc = 0.
We set ẐSc to satisfy the condition (27) with θ̂ and ẐS.
By construction, the support of θ̂ is included in the true support S of θ*, so that we would finish the proof of the theorem provided (a) θ̂ satisfies the stationary condition of (19), as well as the condition ‖ẐSc‖∞ < 1 in Lemma 8 with high probability, so that by Lemma 8, the primal solution θ̂ is guaranteed to be unique; and (b) the support of θ̂ is not strictly within the true support S. We term these conditions strict dual feasibility, and sign consistency respectively.
We will now rewrite the subgradient optimality condition (27) as
where Wn := −∇ℓ(θ*; X1:n) is the sample score function (that we will show is small with high probability), and Rn is the remainder term after coordinate-wise applications of the mean value theorem; , for some θ̄(j) on the line between θ̂ and θ*, and with being the j-th row of a matrix.
Recalling the notation for the Fisher information matrix Q* := ∇2ℓ(θ*; X1:n), we then have
From now on, we provide lemmas that respectively control various terms in the above expression: the score term Wn, the deviation θ̂ − θ*, and the remainder term Rn. The first lemma controls the score term Wn:
Lemma 9 Suppose that we set λn to satisfy for some constant κ4 ≤ min{2κv/3, 2κh + κv}. Suppose also that . Then, given a incoherence parameter α ∈ (0, 1],
where p′ := max{n, p}.
The next lemma controls the deviation θ̂ – θ*.
Lemma 10 Suppose that and . Then, we have
| (28) |
for some constant c1 > 0.
The last lemma controls the Taylor series remainder term Rn:
Lemma 11 If , and , then we have
| (29) |
for some constant c1 > 0.
The proof then follows from Lemmas 9, 10 and 11 in a straightforward fashion, following Ravikumar et al. (2010). Consider the choice of regularization parameter . For a sample size greater , the conditions of Lemma 9 are satisfied, so that we may conclude that with high probability. Moreover, with a sufficiently large sample size such that for some constant L′ > 0 depending only on ρmin, ρmax, κ4 and α, it can be shown that the remaining condition of Lemma 11 (and hence the milder condition in Lemma 10) in turn is satisfied. Therefore, the resulting statements (28) and (29) of Lemmas 10 and 11 hold with high probability.
Strict dual feasibility
Following Ravikumar et al. (2010), we obtain
Correct sign recovery
To guarantee that the support of θ̂ is not strictly within the true support S, it suffices to show that . From Lemma 10, we have as long as . This completes the proof.
D.1 Proof of Lemma 9
For a fixed t ∈ V\r, we define for notational convenience so that
Consider the upper bound on the moment generating function of , conditioned on ,
where the last equality holds by the second-order Taylor series expansion. Consequently, we have
First, we define the event: . Then, by Proposition 4, we obtain . Provided that a ≤ κ2(n, p), we can use Condition (C4) to control the second-order derivative of log-partition function and we obtain
with probability at least 1 – c1p′−2. Now, for each index t, the variables satisfy the tail bound in Proposition 3. Let us define the event for some constant κ4 ≤ min{2κv/3, 2κh + κv}. Then, we can establish the upper bound of probability by a union bound:
as long as . Therefore, conditioned on ξ1, ξ2, the moment generating function is bounded as follows:
The standard Chernoff bound technique implies that for any δ > 0,
Setting Yields
Suppose that for large enough n; thus setting :
and by a union bound, we obtain
Finally, provided that , we obtain
where we use the fact that the probability of occurring event 𝒜 is upper bounded by .
D.2 Proof of Lemma 10
In order to establish the error bound for some radius B, several works (e.g. Negahban et al. (2012); Ravikumar et al. (2010)) proved that it suffices to show F(uS) > 0 for all s.t. ‖uS‖2 = B where
Note that F(0) = 0, and for , F(uS) ≤ 0. From now on, we show that F(uS) is strictly positive on the boundary of the ball with radius B = Mλn√d where M > 0 is a parameter that we will choose later in this proof. Some algebra yields
| (30) |
where q* is the minimum eigenvalue of for some v ∈ [0, 1]. Moreover,
where y ∈ ℝd s.t ‖y‖2 = 1. Similarly as in the previous proof, we consider the event ξ1 with probability at least 1 – c1p′−2. Then, since all the elements in vector is smaller than 4log p′, for all i. At the same time, by Condition (C4), . Note that is a convex combination of and θ̂S, and as a result, we can directly apply the Condition (C4). Hence, conditioned on ξ1, we have
As a result, assuming that . Finally, from (30), we obtain
which is strictly positive for . Therefore, if , then
which completes the proof.
D.3 Proof of Lemma 11
In the proof, we are going to show that . Then, since the conditions of Lemma 11 are stronger than those of Lemma 10, from the result of Lemma 10, we can conclude that
as claimed in Lemma 11.
From the definition of Rn, for a fixed t ∈ V\r, can be written as
where is some point in the line between θ̂\r and , i.e., for vt ∈ [0, 1]. By another application of the mean value theorem, we have
for a some point between and . Similarly in the previous proofs, conditioned on the event ξ1, we obtain
Performing some algebra yields
with probability at least 1 – c1p′−2, which completes the proof.
Appendix E. Optimization Problems for Poisson and Exponential Graphical Model Neighborhood Selection
We propose to fit our family of graphical models by performing neighborhood selection, or maximizing the ℓ1-penalized log-likelihood for each node conditional on all other nodes. For several exponential families, however, further restrictions on the parameter space are needed to ensure a proper Markov Random Field. When performing neighborhood selection, these can be imposed by adding constraints to the penalized generalized linear models. We illustrate this by providing the optimization problems solved by our Poisson graphical model and exponential graphical model M-estimator that are used in Section 4.
Following from Section 3, the neighborhood selection problem for our family of models maximizes the likelihood of a node, Xr, conditional on all other nodes, XV\r. This conditional likelihood is regularized with an ℓ1 penalty to induce sparsity in the edge weights, θ(r) a p – 1 dimensional vector, and constrained to enforce restrictions, θ(r) ∈ 𝒞, needed to yield a proper MRF:
where ℓ (Xi,r|Xi,V\r; θ(r)) is the conditional log-likelihood for the exponential family. For the Poisson graphical model, the edge weights are constrained to be non-positive. This yields the following optimization problem:
Similarly, the edge weights of the exponential graphical are restricted to be non-negative yielding
Note that we neglect the intercept term, assuming this to be zero as is common in other proposed neighborhood selection methods (Meinshausen and Bühlmann, 2006; Ravikumar et al., 2010; Jalali et al., 2011). Both of the neighborhood selection problems are concave problems with a smooth log-likelihood and linear constraints. While there are a plethora of optimization routines available to solve such problems, we have employed a projected gradient descent scheme which is guaranteed to converge to a global optimum (Daubechies et al., 2008; Beck and Teboulle, 2010).
Contributor Information
Eunho Yang, Email: EUNHYANG@US.IBM.COM, IBM T.J. Watson Research Center, Yorktown Heights, NY 10598, USA.
Pradeep Ravikumar, Email: PRADEEPR@CS.UTEXAS.EDU, Department of Computer Science, University of Texas, Austin, Austin, TX 78712, USA.
Genevera I. Allen, Email: GALLEN@RICE.EDU, Department of Statistics, Rice University, Houston, TX 77005, USA.
Zhandong Liu, Email: ZHANDONL@BCM.EDU, Department of Pediatrics-Neurology, Baylor College of Medicine, Houston, TX 77030, USA.
References
- Abdelmohsen K, Kim MM, Srikantan S, Mercken EM, Brennan SE, Wilson GM, de Cabo R, Gorospe M. mir-519 suppresses tumor growth by reducing hur levels. Cell Cycle. 2010;9(7):1354–1359. doi: 10.4161/cc.9.7.11164. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Acemoglu D. The crisis of 2008: Lessons for and from economics. Critical Review. 2009;21(2-3):185–194. [Google Scholar]
- Allen GI, Liu Z. A local poisson graphical model for inferring networks from sequencing data. IEEE Trans NanoBioscience. 2013;12(1):1–10. doi: 10.1109/TNB.2013.2263838. [DOI] [PubMed] [Google Scholar]
- Beck A, Teboulle M. Gradient-based algorithms with applications to signal recovery problems. Convex Optimization in Signal Processing and Communications. 2010:42–88. [Google Scholar]
- Besag J. Spatial interaction and the statistical analysis of lattice systems. Journal of the Royal Statistical Society Series B (Methodological) 1974;36(2):192–236. [Google Scholar]
- Bishop YM, Fienberg SE, Holland PW. Discrete Multivariate Analysis. Springer Verlag; 2007. [Google Scholar]
- Bühlmann P. Statistics for High-dimensional Data. Springerverlag; Berlin Heidelberg: 2011. [Google Scholar]
- Bullard J, Purdom E, Hansen K, Dudoit S. Evaluation of statistical methods for normalization and differential expression in mrna-seq experiments. BMC Bioinformatics. 2010;11(1):94. doi: 10.1186/1471-2105-11-94. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cancer Genome Atlas Research Network. Comprehensive molecular portraits of human breast tumours. Nature. 2012;490(7418):61–70. doi: 10.1038/nature11412. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Clifford P. Disorder in Physical Systems. Oxford Science Publications; 1990. Markov random fields in statistics. [Google Scholar]
- Daubechies I, Fornasier M, Loris I. Accelerated projected gradient method for linear inverse problems with sparsity constraints. Journal of Fourier Analysis and Applications. 2008;14(5):764–792. [Google Scholar]
- Dobra A, Lenkoski A. Copula gaussian graphical models and their application to modeling functional disability data. Annals of Applied Statistics. 2011;5(2A):969–993. [Google Scholar]
- Friedman J, Hastie T, Tibshirani R. Sparse inverse covariance estimation with the lasso. Biostatistics. 2007;9(3):432–441. doi: 10.1093/biostatistics/kxm045. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Friedman N. Inferring cellular networks using probabilistic graphical models. Science. 2004;303(5659):799–805. doi: 10.1126/science.1094068. [DOI] [PubMed] [Google Scholar]
- Herzenberg LA, Tung J, Moore WA, Herzenberg LA, Parks DR. Interpreting flow cytometry data: a guide for the perplexed. Nature Immunology. 2006;7(7):681–685. doi: 10.1038/ni0706-681. [DOI] [PubMed] [Google Scholar]
- Jalali A, Ravikumar P, Vasuki V, Sanghavi S. On learning discrete graphical models using group-sparse regularization. Inter Conf on AI and Statistics (AISTATS) 2011;14 [Google Scholar]
- Keklikoglou I, Koerner C, Schmidt C, Zhang JD, Heckmann D, Shavinskaya A, Allgayer H, Gückel B, Fehm T, Schneeweiss A, et al. Microrna-520/373 family functions as a tumor suppressor in estrogen receptor negative breast cancer by targeting nf-κb and tgf-β signaling pathways. Oncogene. 2012;31:4150–4163. doi: 10.1038/onc.2011.571. [DOI] [PubMed] [Google Scholar]
- Lafferty J, Liu H, Wasserman L. Sparse nonparametric graphical models. Statistical Science. 2012;27(4):519–537. [Google Scholar]
- Lauritzen SL. Graphical Models. Oxford University Press; USA: 1996. [Google Scholar]
- Leek JT, Scharpf RB, Bravo HC, Simcha D, Langmead B, Johnson WE, Geman D, Baggerly K, Irizarry RA. Tackling the widespread and critical impact of batch effects in high-throughput data. Nature Reviews Genetics. 2010;11(10):733–739. doi: 10.1038/nrg2825. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li J, Witten DM, Johnstone IM, Tibshirani R. Normalization, testing, and false discovery rate estimation for rna-sequencing data. Biostatistics. 2011 doi: 10.1093/biostatistics/kxr031. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Liu H, Lafferty J, Wasserman L. The nonparanormal: Semiparametric estimation of high dimensional undirected graphs. Journal of Machine Learning Research. 2009;10:2295–2328. [PMC free article] [PubMed] [Google Scholar]
- Liu H, Roeder K, Wasserman L. Stability approach to regularization selection (stars) for high dimensional graphical models. Arxiv preprint arXiv:1006.3316. 2010 [PMC free article] [PubMed] [Google Scholar]
- Liu H, Han F, Yuan M, Lafferty J, Wasserman L. High dimensional semiparametric gaussian copula graphical models. Arxiv preprint arXiv:1202.2169. 2012a [Google Scholar]
- Liu H, Han F, Yuan M, Lafferty J, Wasserman L. The nonparanormal skeptic. International Conference on Machine learning (ICML) 2012b;29 [Google Scholar]
- Lockhart R, Taylor J, Tibshirani RJ, Tibshirani R. A significance test for the lasso. Annals of Statistics. 2014;42(2):413–468. doi: 10.1214/13-AOS1175. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Marioni JC, Mason CE, Mane SM, Stephens M, Gilad Y. Rna-seq: an assessment of technical reproducibility and comparison with gene expression arrays. Genome Research. 2008;18(9):1509–1517. doi: 10.1101/gr.079558.108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- McCullagh P, Nelder JA. Monographs on statistics and applied probability 37. Chapman and Hall/CRC; 1989. Generalized Linear Models. [Google Scholar]
- Meinshausen N, Bühlmann P. High-dimensional graphs and variable selection with the Lasso. Annals of Statistics. 2006;34:1436–1462. [Google Scholar]
- Mortazavi A, Williams BA, McCue K, Schaeffer L, Wold B. Mapping and quantifying mammalian transcriptomes by rna-seq. Nature Methods. 2008;5(7):621–628. doi: 10.1038/nmeth.1226. [DOI] [PubMed] [Google Scholar]
- Negahban S, Ravikumar P, Wainwright MJ, Yu B. A unified framework for high-dimensional analysis of m-estimators with decomposable regularizers. Statistical Science. 2012;27:538–557. [Google Scholar]
- Pe'er D, Regev A, Elidan G, Friedman N. Inferring subnetworks from perturbed expression profiles. Bioinformatics. 2001 Jun;17(Suppl 1):S215–S224. doi: 10.1093/bioinformatics/17.suppl_1.s215. [DOI] [PubMed] [Google Scholar]
- Ravikumar P, Wainwright MJ, Lafferty J. High-dimensional ising model selection using ℓ1-regularized logistic regression. Annals of Statistics. 2010;38(3):1287–1319. [Google Scholar]
- Sachs K, Perez O, Pe'er D, Lauffenburger DA, Nolan GP. Causal protein-signaling networks derived from multiparameter single-cell data. Science. 2005;308(5721):523–529. doi: 10.1126/science.1105809. [DOI] [PubMed] [Google Scholar]
- Speed TP, Kiiveri HT. Gaussian Markov distributions over finite graphs. Annals of Statistics. 1986;14(1):138–150. [Google Scholar]
- Varin C, Vidoni P. A note on composite likelihood inference and model selection. Biometrika. 2005;92:519–528. [Google Scholar]
- Varin C, Reid N, Firth D. An overview of composite likelihood methods. Statistica Sinica. 2011;21:5–42. [Google Scholar]
- Wainwright MJ. Sharp thresholds for high-dimensional and noisy sparsity recovery using ℓ1-constrained quadratic programming (Lasso) IEEE Trans Information Theory. 2009;55:2183–2202. [Google Scholar]
- Wainwright MJ, Jordan MI. Graphical models, exponential families, and variational inference. Foundations and Trends® in Machine Learning. 2008;1(1-2):1–305. [Google Scholar]
- Wei Z, Li H. A markov random field model for network-based analysis of genomic data. Bioinformatics. 2007;23(12):1537–1544. doi: 10.1093/bioinformatics/btm129. [DOI] [PubMed] [Google Scholar]
- Xue L, Zou H. Regularized rank-based estimation of high-dimensional nonparanormal graphical models. Annals of Statistics. 2012;40:2541–2571. [Google Scholar]
- Yang E, Ravikumar P, Allen GI, Liu Z. Graphical models via generalized linear models. Neur Info Proc Sys (NIPS) 2012;25 [Google Scholar]
- Yu F, Yao H, Zhu P, Zhang X, Pan Q, Gong C, Huang Y, Hu X, Su F, Lieberman J, et al. let-7 regulates self renewal and tumorigenicity of breast cancer cells. Cell. 2007;131(6):1109–1123. doi: 10.1016/j.cell.2007.10.054. [DOI] [PubMed] [Google Scholar]