

Abstract
Multichannel amplitude compression is widely used in hearing aids. The preferred compression speed varies across individuals. Moore (2008) suggested that reduced sensitivity to temporal fine structure (TFS) may be associated with preference for slow compression. This idea was tested using a simulated hearing aid. It was also assessed whether preferences for compression speed depend on the type of stimulus: speech or music. Twenty-two hearing-impaired subjects were tested, and the stimulated hearing aid was fitted individually using the CAM2A method. On each trial, a given segment of speech or music was presented twice. One segment was processed with fast compression and the other with slow compression, and the order was balanced across trials. The subject indicated which segment was preferred and by how much. On average, slow compression was preferred over fast compression, more so for music, but there were distinct individual differences, which were highly correlated for speech and music. Sensitivity to TFS was assessed using the difference limen for frequency at 2000 Hz and by two measures of sensitivity to interaural phase at low frequencies. The results for the difference limens for frequency, but not the measures of sensitivity to interaural phase, supported the suggestion that preference for compression speed is affected by sensitivity to TFS.
Keywords: hearing aids, compression speed, temporal fine structure
Introduction
People with cochlear hearing loss usually experience loudness recruitment and the associated reduced dynamic range (Fowler, 1936; Moore, 2004, 2007; Steinberg & Gardner, 1937). Most modern hearing aids incorporate some form of multichannel amplitude compression or automatic gain control (AGC) to deal with this. In principle, AGC can make low-level sounds audible while preventing high-level sounds from becoming uncomfortably loud. However, controversy continues about the “best” way to implement AGC, and in particular whether it should be fast acting or slow acting.
There are several factors that affect the usefulness and acceptability of hearing aids. One factor is the extent to which hearing aids improve the ability to understand speech in quiet and in the presence of background sounds (Dillon, 2012). A second factor is sound quality, which is important both for speech sounds and for other sounds such as music. Poor sound quality is a major reason for rejection of hearing aids (Kochkin, 1996, 2010). In this study, we assessed the preferences for sound quality of 22 hearing-impaired subjects for fast relative to slow compression, using a simulated hearing aid. The study was intended to answer two questions: (a) Are preferences for slow versus fast compression consistent for speech and music stimuli? For example, if an individual prefers slow compression for speech, will they also prefer slow compression for music? (b) Are preferences for compression speed related to sensitivity to temporal fine structure (TFS), as hypothesized by Moore (2008).
The speed of response of an AGC system is usually measured using a sound whose level changes abruptly between two values, 55 and 90 dB sound pressure level (SPL). The time taken for the gain to decrease to within 3 dB of its steady value following an increase in level is called the attack time, ta. The time taken for the gain to increase to within 4 dB of its steady value following a decrease in level is called the recovery time or release time, tr (ANSI, 2003). The range of attack and release times currently implemented in hearing aids is large (ta = 0.5–2,000 ms, tr = 10–5,000 ms), and there is currently no consensus as to the best compression speed (Moore, 2008). Compression is often described as fast or slow acting, depending on the values of ta and tr. Systems described as fast usually have ta from 0.5 to 20 ms and tr from 5 to 150 ms. Fast compression causes changes in gain within the time course of a single word and so is also known as “syllabic” compression. Systems described as slow usually have ta from 10 to 2,000 ms and tr from 500 to 5,000 ms. Slow compression causes little change in gain over the time course of individual words and is also known as automatic volume control. Both fast and slow compression have strengths and limitations; see Moore (2008) for a review.
Gatehouse, Naylor, and Elberling (2006a) reviewed 13 studies investigating the effect of compression speed in hearing aids. Four showed no effect, three showed that fast compression was superior to slow compression, three showed that slow compression was superior to fast compression, and three showed that the best time constants varied across subjects. The diversity of results across studies is probably partly a result of the great variety of evaluation criteria. Some studies focused on speech intelligibility in quiet, some on speech intelligibility in noise, some on subjective ratings of sound quality or speech intelligibility, and some on paired-comparison judgments of preference. A problem with most of the studies is that the amount of compression was not adjusted to suit the hearing loss of the individual being tested. Often, the amount of compression (as determined by the compression ratio [CR]) was greater than would typically be used in practice and did not vary with frequency in an appropriate way.
Gatehouse, Naylor, and Elberling (2003, 2006a, 2006b) conducted a study that overcame many of the problems of earlier studies. They tested 50 subjects in a within-subjects, randomized, blind, crossover evaluation of five different hearing-aid signal-processing schemes, two with linear amplification and three with two-channel AGC differing only in release time constants. The frequency-dependent gain and compression were adjusted appropriately for each subject. Outcome measures included the intelligibility of speech in steady noise and fluctuating noise (ICRA noise; Dreschler, Verschuure, Ludvigsen, & Westermann, 2001). They also measured the cognitive ability of their subjects using a visual digit-monitoring task and a visual letter-monitoring task. They found a significant interaction between cognitive ability, the temporal characteristics of the noise (steady or fluctuating), and the release time constants. They reported that “listeners with greater cognitive ability derive greater benefit from temporal structure in background noise when listening via fast time constants, one of whose effects is to facilitate ‘listening in the gaps’” (Gatehouse et al., 2003, p. S77). In other words, the ability to listen in the dips of a fluctuating masker could be facilitated by fast compression, as found previously by Moore, Peters, and Stone (1999), but this happened mainly for subjects with greater cognitive ability.
Gatehouse et al. (2006a) reported that slow compression was preferred to fast compression for subjective listening comfort, but for reported and measured speech intelligibility, the converse was true. There was no significant effect of compression speed for overall satisfaction. Gatehouse et al. (2006a) also reported that there were clear individual differences in the patterns of benefit. The majority of subjects ranked fast compression as either their most preferred or least preferred option, whereas slow compression most frequently received intermediate rankings.
Moore, Füllgrabe, and Stone (2011) used a paired-comparison procedure and a simulated hearing aid to compare preferences for slow versus fast compression, using both speech and music stimuli. The subjects had mild hearing losses, and the simulated hearing aid was programmed to suit the individual hearing losses using the CAM2 procedure (Moore, Glasberg, & Stone, 2010). They found slight mean preferences for slow compression for both speech and music, but the effect occurred mainly for an input level of 80 dB SPL, and not for input levels of 50 and 65 dB SPL. They did not present individual results but reported that there were marked individual differences.
Moore (2008) suggested that individual differences in best compression speed might be related to sensitivity to the TFS of the waveforms evoked by sounds on the basilar membrane. Hearing-impaired subjects perform more poorly than normal-hearing subjects on tasks that are thought to rely on sensitivity to TFS, for example, discrimination of harmonic and frequency-shifted tones (Hopkins & Moore, 2007, 2010a; Moore, 2014), interaural phase discrimination (Hopkins & Moore, 2011; Lacher-Fougère & Demany, 2005), and detection of low-rate frequency modulation (Buss, Hall, & Grose, 2004; Moore & Skrodzka, 2002; Strelcyk & Dau, 2009). Hopkins, Moore, and Stone (2008) and Hopkins and Moore (2010a) reported high variability in the ability of hearing-impaired subjects to use TFS information, some being completely insensitive to TFS information and others having a similar ability to use TFS as people with normal hearing.
Moore (2008) suggested that hearing-aid users with good TFS sensitivity may benefit more from fast than from slow compression, as TFS information may be important for listening in the dips of a fluctuating background (Moore & Glasberg, 1987), and fast compression increases the audibility of signals in the dips (Moore et al., 1999). This argument may not be completely correct because the ability to use TFS information does not seem to be related to the magnitude of masking release (the difference between speech identification scores for speech in a steady and a fluctuating background; Bernstein, Summers, Iyer, & Brungart, 2012; Freyman, Griffin, & Oxenham, 2012; Füllgrabe, Moore, & Stone, 2015; Oxenham & Simonson, 2009). However, high sensitivity to TFS is associated with a better ability to understand speech at low speech-to-background ratios (Füllgrabe et al., 2015), perhaps because TFS information is useful for perceptual segregation of the target and background sounds (Lunner, Hietkamp, Andersen, Hopkins, & Moore, 2012). Dip listening becomes more important and effective at low speech-to-background ratios (Bernstein & Grant, 2009). Hence, the greater audibility of low-level parts of the signal provided by fast compression may be beneficial for listeners with good sensitivity to TFS. More generally, high sensitivity to TFS may be associated with less reliance on temporal envelope cues and hence more resistance to the envelope distortion produced by fast-acting multichannel compression (Souza, 2002; Stone & Moore, 1992, 2004; Stone, Moore, Füllgrabe, & Hinton, 2009).
In contrast, people with poor TFS sensitivity may rely mainly on temporal envelope information in different frequency channels, and for them, it may be important to avoid the temporal envelope distortion that is introduced by fast compression. Hence, slow compression may be the preferred option for people with poor sensitivity to TFS. It should be noted that preservation of temporal envelope cues may be important for people with poor TFS sensitivity for many types of acoustic signals, not just speech in background sounds.
Hopkins, King, and Moore (2012) tested the hypothesis that the best compression speed for speech intelligibility depends on the availability of original TFS information. The intelligibility of speech in the presence of a background talker was measured for normal-hearing subjects listening via a simulated hearing aid using either fast or slow compression followed by a simulation of threshold elevation and loudness recruitment (Moore & Glasberg, 1993). The input signals were either unprocessed or were tone vocoded to remove the original TFS information. If the best compression speed depends on the availability of original TFS information, there should be an interaction between speed of compression and processing condition. As expected, performance was better for the nonvocoded stimuli than for the vocoded stimuli. Performance was better with fast compression than with slow compression. The interaction between compression speed and processing condition was not significant, so the results did not support the idea that the availability of original TFS information affected the compression speed that gave the best intelligibility.
Hopkins et al. (2012) pointed out a limitation of their study, namely that tone-vocoded signals (like any audio signals) contain both envelope and TFS information. The TFS in a vocoded signal is different from that of the original signal, but the TFS that is present nevertheless conveys information about the spectro-temporal structure of the original signal (Moore, 2014; Shamma & Lorenzi, 2013; Søndergaard, Decorsière, & Dau, 2012). Thus, the loss of ability to use TFS information associated with cochlear hearing loss is not simulated using vocoder processing. The normal-hearing subjects in the study of Hopkins et al. would have been able to use TFS information in both the nonvocoded and vocoded signals.
The present study used hearing-impaired subjects to assess whether relative preferences for fast versus slow compression were related to sensitivity to TFS. We chose to focus initially on preferences because preferences seem to be mainly based on sound quality, and sound quality is important for the initial acceptance of hearing aids (Kochkin, 1996, 2010). A paired-comparison task was used; on each trial, the same stimulus segment was presented twice in succession, once processed with fast compression and once with slow compression. Because hearing aids are often used for listening to music as well as for listening to speech (Kochkin, 2010; Leek, Molis, Kubli, & Tufts, 2008; Madsen & Moore, 2014), we used both speech stimuli and music stimuli. The results were intended to assess whether different compression speeds would be preferred for speech and for music. To avoid complications associated with independent hearing-aid processing at the two ears, preference judgments were obtained using monaural presentation. This is comparable with the situation with monaural aiding but may not adequately represent bilateral aiding. The effects of bilateral aiding will be addressed in future studies.
All subjects were assessed for their sensitivity to TFS, using three tasks. Two of these tasks assessed sensitivity to interaural phase at low frequencies. It was thought to be reasonable to include these tasks because scores on a task assessing sensitivity to interaural phase have been shown to be reasonably highly correlated with scores on a monaural test of sensitivity to TFS conducted at the same center frequency (Moore, Vickers, & Mehta, 2012). Initially, we attempted to use the TFS1 test (Moore & Sek, 2009; Sek & Moore, 2012) to assess sensitivity to TFS at medium frequencies. However, we found that several hearing-impaired subjects could not perform this task at all, consistent with the results of Hopkins and Moore (2007). Hence, we decided to use a measure of the difference limen for frequency (DLF) at 2000 Hz as the third task. Although the DLF could in principle be determined by either a place mechanism or a temporal mechanism (using TFS), there is evidence that, for normal-hearing subjects, a temporal mechanism dominates for a frequency of 2000 Hz (Moore, 1973, 2014; Moore & Ernst, 2012; Sek & Moore, 1995). Hence, DLFs that are larger than normal at 2000 Hz probably indicate a reduced ability to use TFS information.
Method
Subjects
Twenty-two subjects (14 men) with moderate-to-severe sensorineural hearing loss were paid to participate. The number of subjects was chosen such that a correlation as small as .36 between a measure of TFS sensitivity and preference scores would be significant based on a one-tailed test. Their ages ranged from 56 to 87 years, with a mean of 73 years. Twenty were current users of multichannel compression hearing aids, and two did not use hearing aids. Audiometric thresholds were measured for all audiometric frequencies from 0.25 to 10 kHz, using a Grason-Stadler GSI61 audiometer (Eaden Prairie, MN), following the procedure recommended by the British Society of Audiology (2004). Telephonics TDH50 headphones (Farmington, NY) were used for audiometric frequencies up to 8 kHz, and Sennheiser HDA200 headphones (Wedemark, Germany) were used for the frequency of 10 kHz. Only the better ear of each subject was tested using the paired-comparison procedure. The mean and individual audiograms for the ears used for the preference judgments are shown in Figure 1. The hearing loss in the test ear ranged from 8 to 60 dB at 500 Hz, 6 to 64 dB at 1000 Hz, 26 to 70 dB at 2 kHz, and 48 to 74 dB at 4000 Hz. Eighteen subjects were native speakers of British English, and four were native speakers of Polish.
Figure 1.
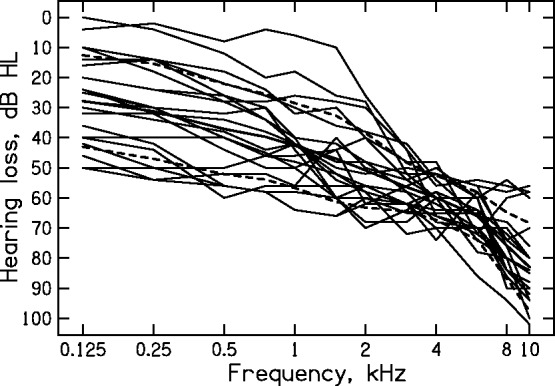
Individual audiograms (thin lines) of the test ears of the subjects. The thick line shows the mean audiogram, and the dashed lines show ± one standard deviation (SD) around the mean.
Simulated Hearing Aid
The simulated hearing aid was the same as described by Moore, Füllgrabe, and Stone (2010) and Moore and Sek (2013). Briefly, the aid included a digital filter for overall shaping of the frequency response prior to splitting the signal into five channels, with independent compression in each channel. The lower and upper edge frequencies of channels 1 to 5, respectively, were 100 and 707 Hz, 707 and 1414 Hz, 1414 and 2828 Hz, 2828 and 5657 Hz, and 5657 and 10574 Hz. Five channels were used to achieve a compromise between having sufficient flexibility to implement the frequency-dependent insertion gains (IGs) and CRs required to match the prescription for each subject while avoiding the reduction of spectral and temporal contrast that can occur when many channels are used (Bor, Souza, & Wright, 2008; Plomp, 1988; Stone & Moore, 2008).
The IGs for a 65-dB speech-shaped noise and the CRs for the five channels were set according to the CAM2 prescription method (Moore, Glasberg, et al., 2010), modified slightly as described in Moore and Sek (2013, 2016). The version of the software used, called CAM2A, was 1.0.7.0. The compression thresholds were chosen to be representative of those used by default in the fitting software of some hearing-aid manufacturers. The compression thresholds (CTs) were set to 49, 41, 40, 34, and 28 dB SPL for channels 1 to 5, respectively.
To simulate fast compression, the attach and release times were set to 10 and 100 ms, respectively, for all channels. To simulate slow compression, the attack and release times were set to 50 and 3000 ms, respectively, for all channels. The CR was limited to 3 when fast compression was used because there is evidence that with fast compression high CRs can lead to reduced speech intelligibility (Verschuure et al., 1996). The CR was allowed to have any value up to 10 when slow compression was used. Table 1 compares the CRs for slow and fast compression for each channel of the simulated hearing aid, showing the arithmetic mean across subjects (and corresponding SDs), the geometric mean across subjects, and the maximum and the minimum values. For all channels above the first, the mean CR was greater for slow than for fast compression. The consequences of this are discussed later.
Table 1.
Comparison of Compression Ratios for SLOW and FAST Compression, for Each Channel of the Simulated Hearing Aid.
| SLOW |
FAST |
|||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Channel | Ar. Mean | SD | GeoMean | Max | Min | Ar. Mean | SD | GeoMean | Max | Min |
| 1 | 1.3 | 0.3 | 1.2 | 2.1 | 1.0 | 1.3 | 0.35 | 1.2 | 2.1 | 1.0 |
| 2 | 3.1 | 1.5 | 2.8 | 6.7 | 1.4 | 2.5 | 0.54 | 2.5 | 3.0 | 1.4 |
| 3 | 3.1 | 1.2 | 2.9 | 6.9 | 1.5 | 2.5 | 0.47 | 2.5 | 3.0 | 1.5 |
| 4 | 5.5 | 2.8 | 4.9 | 10 | 2.0 | 3.0 | 0.08 | 3.0 | 3.0 | 2.0 |
| 5 | 4.8 | 1.5 | 4.6 | 7.8 | 2.1 | 2.8 | 0.25 | 2.8 | 3.0 | 2.1 |
Note. Ar. Mean = arithmetic mean; SD = standard deviation; GeoMean = geometric mean; Max = maximum; Min = minimum.
It should be noted that the slow compression would have had little effect on the ongoing fluctuations in amplitude for speech at a given level, but it would have resulted in the application of gains that varied with overall level, which is important because three overall levels were used (see later for details). Prior to the onset of the stimuli, the IG values in each channel were at their maximum values (equal to the IG at the CT). However, the use of an attack time of 50 ms for the slow compressor meant that the gain values were fairly rapidly reduced for the higher level stimuli.
All processing was performed offline, using at least 24-bit precision. Stimuli were generated via an Echo Indigo 24-bit sound card (Echo Digital Audio, Santa Barbara, CA), using a sampling rate of 44.1 kHz, and were presented via Sennheiser HDA200 headphones (Wedemark, Germany). The response of the headphones was measured on an acoustic manikin (Burkhard & Sachs, 1975), and digital filtering was used to adjust this response so that it resembled the diffuse-field response of the ear, thus ensuring that the correct IGs were obtained in the ear canal. The prescribed IGs and the CRs could be set very accurately in the software. Also, the output of the headphones for frequencies up to 10 kHz is rather consistent across individual ears (Han & Poulsen, 1998). Thus, the prescriptions were probably implemented more accurately here than would be the case in a clinical setting with real hearing aids.
IGs were reduced for the inexperienced subjects according to the CAM2A recommendations. The reductions averaged 1 to 3 dB for frequencies up to 4 kHz and increased to about 4 dB at 6 kHz, 8 dB at 8 kHz, and 10 dB at 10 kHz; the gain reductions varied only slightly with input level.
Stimuli
The speech stimuli for the English-speaking subjects were digitally recorded segments of running speech (connected discourse) obtained from one male and one female talker of British English. The recordings were a subset of those described by Moore, Stone, Füllgrabe, Glasberg, and Puria (2008). Examples of the spectra of the speech stimuli are given in that article. The recordings were edited to remove pauses for breath and extraneous sounds, but natural-sounding gaps of between 100 and 300 ms were left. One 4.8-s segment of speech was selected for each talker. The speech stimuli for the Polish-speaking subjects were digitally recorded meaningful sentences describing realistic situations. Four short sentences were concatenated to produce a 7.8-s sample of male speech and a 8.9-s sample of female speech. The level of the speech at the input to the simulated hearing aid was 50, 65, or 80 dB SPL.
The music signals were as follows: a 7.3-s segment of a jazz trio (piano, bass, and drums); a 5.6-s segment of a classical orchestra (including brass instruments and cymbals); a 3.5-s segment extracted from track 27 of the compact disc produced by Bang & Olufsen called “Music for Archimedes” (CD B&O 101), consisting of a xylophone (anechoic recording); and an 8.3-s segment of a male singing (a counter-tenor accompanied by guitar and recorder). The long-term average spectra of the first three signals are shown in Moore et al. (2011). For all four music signals, the input level to the simulated hearing aid was 50, 65, or 80 dB SPL.
Paired-Comparison Procedure
The procedure was similar to that described by Moore and Sek (2013). On each trial, the same segment of sound was presented twice in succession, once processed with fast compression and once with slow. The time interval between the two segments was 1.25 s. The possible orders were used equally often, and the order was randomized across trials. Within a given pair of sounds, the only difference between the sounds was in the compression speed; the input level was always the same. The subject was asked to indicate which of the two was preferred and by how much, using a slider on the screen. The continuum was labeled “1 much better,” “1 moderately better,” “1 slightly better,” “equal,” “2 slightly better,” “2 moderately better,” and “2 much better.” The next pair was stimuli was presented 1 s after the subject had entered their response.
Within each block of trials, all six types of signals were presented (Classical music, Jazz, Male singing, Percussion, Female speech, and Male speech), and the input level was kept constant. The 12 pairs of sounds (6 signal types × 2 presentation orders [fast compression first or slow compression first]) were presented in random order. Two blocks of trials were used for each subject and each input level. The order of presentation of input levels across blocks was random.
For a given trial, if fast compression (FAST) was preferred, the slider position was coded as a negative number, and if slow compression (SLOW) was preferred, the slider position was coded as a positive number. For example, if the order on a given trial was SLOW first and FAST second, and the participant set the slider position midway between “2 slightly better” and “2 moderately better,” the score for that trial was assigned a value of −1.5. The overall score for each compression speed and stimulus type (e.g., classical music) was obtained by averaging all of the subscores obtained for that speed and stimulus type. A score of −3 would indicate a very strong and perfectly consistent preference for FAST, whereas a score of +3 would indicate a very strong and perfectly consistent preference for SLOW. A score of 0 would indicate no preference.
Measurement of DLFs
The method used to measure DLFs was similar to that described by Moore and Vinay (2009) and Moore and Ernst (2012). A two-interval, two-alternative forced-choice task was used. One interval contained four successive 2000-Hz tones. The other interval contained four successive tones whose frequency alternated between 2000 Hz and 2000 Hz + Δf. The subject had to choose the interval in which they heard a fluctuation in pitch. Each tone lasted 400 ms, including 20-ms raised-cosine ramps. The silent gap between the tones within an interval was 100 ms. The silent gap between intervals was 400 ms.
Each ear was tested separately. Initially, the absolute threshold at 2000 Hz was measured using the two-alternative forced-choice method implemented in the TFS1 software (Sek & Moore, 2012). Three estimates were obtained for each ear, and the final estimate was based on the average of the three. For measurement of the DLF, the level of each test tone was set 30 dB above the measured threshold, that is, to 30 dB sensation level (SL). No level roving was used. The value of Δf was varied adaptively to determine the DLF. For the first run for each subject, the starting value of Δf was 100 Hz. For subsequent runs, the starting value of Δf was set to four times the threshold estimate for the first run. Following two correct responses in a row, the value of Δf was decreased, while following one incorrect response, it was increased. This procedure tracks the 70.7% correct point on the psychometric function. The value of Δf was changed by a factor of 1.953 (1.253) until one turnpoint had occurred, by a factor of 1.5625 (1.252) until the second turnpoint had occurred, and by a factor of 1.25 thereafter. The procedure continued until eight turnpoints had occurred. The threshold was estimated as the geometric mean of the values of Δf at the last six turnpoints. Four estimates were obtained for each ear, and the final estimate was obtained as the geometric mean of the four.
Measurement of Interaural Phase Sensitivity—The TFS-LF (Low Frequency) test
The TFS-LF test (Hopkins & Moore, 2010b; Sek & Moore, 2012) uses a two-interval, two-alternative forced-choice task, with a similar temporal structure to that described for the measurement of the DLFs. The tone durations and silent gaps were as described for the DLFs. All of the tones in one interval were in phase at the two ears. In the other interval, the first and third tones were in phase at the two ears, but the second and fourth tones had an interaural phase difference (IPD) of ϕ in the TFS only (the envelopes of the tones were synchronous in the two ears). The subject was asked to indicate the interval in which the tones appeared to move within the head.
The test frequency was fixed at 500 Hz. Initially, the absolute threshold at 500 Hz was measured for each ear using the two-alternative forced-choice method implemented in the TFS software (Sek & Moore, 2012). Three estimates were obtained for each ear, and the final estimate was based on the average of the three. The level of the test tones in each ear was set to 30 dB SL. The value of ϕ was varied adaptively to determine the IPD at threshold, using the same procedure as for the DLFs. The starting value of ϕ was 180°. The threshold was estimated as the geometric mean of the values of ϕ at the last six turnpoints. Five estimates were obtained, and the final estimate was obtained as the geometric mean of the five.
The adaptive procedure terminated if the procedure called for the largest possible value of ϕ (180°) twice before the second turnpoint or any time after the second turnpoint. This happened consistently for six of the subjects. The thresholds for those subjects were thus indeterminate but are plotted at an arbitrary value of 180° when the results are presented. When the adaptive procedure terminated, the procedure switched to a nonadaptive procedure where 40 trials were run with ϕ fixed at 180°. The obtained scores were all only a little above the chance value of 50% (range 53% to 58.5% correct).
Measurement of Interaural Phase Sensitivity—The TFS-Adaptive Frequency Test
To obtain an estimate of interaural phase sensitivity for all subjects, we used a modified version of the TFS-LF test in which the IPD was fixed at 180°, and the frequency of the test tone was adaptively varied to determine the highest frequency at which the task could be performed. The task is based on the assumption that, for each subject, there is a frequency above which sensitivity to interaural phase worsens markedly (Brughera, Dunai, & Hartmann, 2013; Hughes, 1940). The procedure is intended to track the highest frequency at which changes in IPD can be detected. The time pattern of the stimuli was the same as for the TFS-LF test. All subjects could perform the task when the frequency was made sufficiently low. We refer to the modified test as the TFS-AF test, where AF stands for adaptive frequency (Füllgrabe, Harland, Sek, & Moore, 2016). A comparable task has been used by Ross, Fujioka, Tremblay, and Picton (2007) and by Grose and Mamo (2010).
The starting frequency was 500 Hz. The level of the tones in each ear for this frequency was set to 30 dB SL, using the absolute threshold measured with the TFS software. Because the absolute thresholds varied with frequency, the absolute thresholds at other frequencies were estimated from the measured audiometric thresholds for each ear. For each audiometric frequency, the absolute threshold in dB HL was converted to level in dB SPL by adding the minimum audible pressure for monaural listening, as predicted by the loudness model of Moore and Glasberg (2007). Interpolation was used to estimate the absolute threshold in dB SPL at frequencies between the audiometric frequencies, and the level of the test tones in each ear was adjusted so that the SL remained constant at about 30 dB SL as the frequency was changed. The frequency was adjusted using the same rules as used for changing Δf in the DLF task, and the threshold was estimated as the geometric mean frequency at the last six turnpoints. Five estimates were obtained, and the final estimate was obtained as the geometric mean of the five. The lowest frequency allowed in the software was 30 Hz, and all subjects achieved thresholds of 200 Hz or above.
Results
Compression Speed Preferences for Speech
As described earlier, a score of −3 would indicate a very strong and perfectly consistent preference for FAST, whereas a score of +3 would indicate a very strong and perfectly consistent preference for SLOW. A score of 0 would indicate no preference. The pattern of results was similar across levels. To get an overview of the individual preference scores, the scores were averaged across the three levels. The average preference scores for the male talker and the female talker were highly correlated (r = .91, p < .001). This indicates that the subjects were consistent in their ratings across talkers. In what follows, only the mean ratings across talkers are considered.
Figure 2 shows individual and mean preferences for speech. On average, SLOW was preferred over FAST, but only by 0.46 scale units. There were distinct individual differences. Ten subjects showed a preference for SLOW of 0.5 scale units or more, while five subjects showed a preference for FAST of 0.5 scale units or more.
Figure 2.

Mean preference scores for speech for each subject. Error bars show ± 1 SD. The bar at the right shows the mean.
SD = standard deviation.
Compression Speed Preferences for Music
Again, the pattern of the preference scores was similar across levels, and the results were initially averaged across the three levels. The preference scores were reasonably consistent across all music types except for the solo percussion instrument. The scores for the latter were not significantly correlated with scores for any of the other music types. Also, the scores for the percussion instrument fell within a narrow range (−0.2 to +0.53) for all except two subjects. This may have happened because the percussion instrument was generally described as sounding unpleasant regardless of whether fast or slow compression was used. Therefore, in what follows, we consider only the mean scores across the three other music types: jazz, classical, and man singing with guitar.
Figure 3 shows individual and mean preferences for music. On average, SLOW was preferred over FAST, by 0.55 scale units. There were again distinct individual differences. Nine subjects showed a preference for SLOW of 0.5 scale units or more, and the rest showed very small preferences for SLOW or no clear preference.
Figure 3.

As Figure 2, but for music.
Similarity of Preferences for Speech and Music
Although the mean preference for SLOW relative to FAST was slightly greater for the music than for the speech stimuli, the pattern of preferences across subjects was highly correlated for the two stimulus types (r = .89, p < .01), as can be seen in Figure 4. However, it is noteworthy that subjects whose preference scores for speech were negative (indicating slight preferences for FAST) gave preference scores for music that were in the range 0 to 0.4, indicating no clear preference for SLOW versus FAST. Subjects with preference scores greater than 1 for speech, indicating relatively strong preferences for SLOW, also gave reasonably strong positive preference scores for music.
Figure 4.

Scatterplot of preference scores for music against preference scores for speech. Each symbol shows the scores for one subject. The dashed diagonal line indicates where the scores would lie if preferences for FAST versus SLOW were equal for speech and for music.
Effects of Level on Preferences
Figure 5 shows mean preference ratings across subjects for each level, separately for the speech and music stimuli. An overall slight preference for SLOW occurred for all three levels for both stimulus types. A within-subjects analysis of variance was conducted on the preference scores with factors level and stimulus type. Neither of the main effects was significant, but there was a significant interaction between level and stimulus type: F(2,42) = 15.3, p < .001. The interaction reflects the fact that the relative preference for SLOW was greater for speech than for music at the 65-dB SPL level, but not at the two other levels.
Figure 5.

Mean preferences across subjects for speech (cross-hatched bars) and music (diagonally shaded bars) for each input level. Error bars show ± 1 SD.
SPL = sound pressure level; SD = standard deviation.
The pattern of results differs somewhat from that found by Moore et al. (2011) using a similar procedure, simulated hearing aid, and stimuli. They also found slight mean preferences for slow compression for both speech and music, but the effect occurred mainly for the input level of 80 dB SPL, and not for input levels of 50 and 65 dB SPL. The discrepancy may be related to the fact that their subjects generally had smaller hearing losses than those of the subjects used here. For example, at 4 kHz, the hearing losses of their subjects ranged from 20 to 65 dB, with a mean of 44 dB, whereas the hearing losses of the subjects used here ranged from 48 to 74 dB, with a mean of 59 dB. CAM2A prescribes higher CRs for greater hearing losses, so the effects of compression speed might have been larger and more noticeable for the subjects used here.
TFS-LF and TFS-AF Scores
Figure 6 is a scatterplot of scores for the TFS-AF test (in hertz) against scores for the TFS-LF test (in degrees). Scores for the latter are plotted as diamonds at 180° for the six subjects for whom the threshold could not be reliably determined because the adaptive procedure called for a value of ϕ greater than 180° (three of the diamonds are superimposed, as, by coincidence, three subjects had thresholds on the TFS-AF test of 200 Hz). The six subjects for whom thresholds could not be determined reliably using the TFS-LF test all had thresholds on the TFS-AF test close to 500 Hz or at 200 Hz, so it is not surprising that the adaptive procedure could not be completed using the TFS-LF test with a fixed frequency of 500 Hz. Of the remaining subjects, six had thresholds below (i.e., worse than) 500 Hz but were still able to complete the adaptive procedure in the TFS-LF test. For the 16 subjects who were able to complete both the TFS-LF and the TFS-AF tasks, there was a strong negative correlation between the two (r = −.91, p < .01), indicating good consistency across the two tests; good interaural phase sensitivity is associated with a low threshold in degrees on the TFS-LF test and a high threshold in hertz on the TFS-AF test.
Figure 6.

Scatterplot of scores for the TFS-AF test (frequency in hertz) against scores for the TFS-LF test (IPD in degrees). Circles show results for subjects who could complete both adaptive procedures. Diamonds show results for subjects who could not complete the TFS-LF adaptive procedure; for these subjects, the scores for the TFS-LF test are plotted at the maximum possible IPD of 180°.
TFS-AF = temporal fine structure-adaptive frequency; TFS-LF = temporal fine structure-low frequency; IPD = interaural phase difference.
Previous results have suggested that sensitivity to interaural phase declines with increasing age (Grose & Mamo, 2010; Moore, Glasberg, Stoev, Füllgrabe, & Hopkins, 2012; Moore, Vickers, et al., 2012; Ross et al., 2007), even when audiometric thresholds remain within the normal range. For the present results, the TFS-AF thresholds were negatively correlated with age, as expected (r = −.2), but the correlation was not significant (p > .05), perhaps because the effects of age were swamped by the effects of hearing loss. The TFS-AF thresholds were significantly negatively correlated with the absolute threshold for the test ear at 500 Hz (r = .43, p < .05).
Relationship of Compression Speed Preferences to Sensitivity to TFS
Because we were testing the hypothesis that the relative preference for SLOW would increase with decreasing sensitivity to TFS, one-tailed tests were used to assess the significance of correlations. The logarithms of the DLFs for the test ears were weakly correlated with preference scores: r = .36, p = .05 for speech and r = .39, p < .05 for music. This is illustrated in Figures 7 and 8. Large DLFs, indicating poor sensitivity to TFS, were associated with greater preferences for SLOW. Scores on the TFS-AF test, which could be completed by all subjects, were not significantly correlated with compression speed preferences for either speech or music (both r = −.06, p > .05). The DLFs for the test ears were not significantly correlated with the TFS-AF test scores (r = −.17, p > .05). This is not surprising, as the two tests were conducted using stimuli in very different frequency regions.
Figure 7.

Scatterplot of preference scores for speech against DLFs at 2000 Hz.
DLFs = difference limens for frequency.
Figure 8.

Scatterplot of preference scores for music against DLFs at 2000 Hz.
DLFs = difference limens for frequency.
The DLFs ranged from about 15 to 50 Hz, with a geometric mean of 24 Hz. Moore and Ernst (2012) measured DLFs for normal-hearing subjects using a similar task, except that they roved the level of every tone, whereas no roving was used here. Their DLFs at 2000 Hz for a level of 70 dB SPL ranged from 12 to 31 Hz with a geometric mean of 15 Hz. Their DLFs were, on average, smaller than those found here, despite their use of level roving, which would tend to increase the DLFs, consistent with the idea that the hearing loss of our subjects was associated with larger-than-normal DLFs. Some previous results have suggested that DLFs increase with increasing age (Konig, 1957; Moore, 2014). However, in the present results, there was no significant correlation between the DLFs and age (r = .08, p > .05), perhaps because the effects of age were swamped by the effects of hearing loss. The correlation between the DLFs and the audiometric thresholds at 2 kHz in the test ear was significant (r = .56, p < .01).
Comparison of CRs for SLOW and FAST
One complication in interpreting the results is that the CR was allowed to have any value up to 10 for SLOW, but the CR was limited to 3 for FAST. For all channels above the first, the mean CR was greater for SLOW than for FAST, as shown in Table 1. This might have affected the preference judgments. However, the slow compression had a release time that was so long that the compression would have had little effect on the ongoing amplitude fluctuations in the stimuli, even when the CR was above 3 (Stone & Moore, 1992, 2007). Therefore, the dynamic changes in the stimuli were effectively independent of the CR used for SLOW.
As noted earlier, the main effect of the slow compression was to compensate for differences in overall level of the stimuli. Because of the different maximum CRs used for SLOW and FAST and the way that CAM2A compensates for limitations in the CR, the output level was expected to be slightly higher for SLOW than for FAST for the 50 dB SPL input level and slightly lower for SLOW than for FAST for the 80 dB SPL input level; the output levels should have been well matched for SLOW and FAST for the input level of 65 dB SPL. To quantify these effects, the CAM2A software was used to generate a recommended fitting for an audiogram corresponding to the average for the test ears of the present subjects (with the CR restricted to 3 for FAST and 10 for SLOW). The simulated hearing aid was programmed with the two fittings. The output was then determined for each stimulus (except the percussion instrument) for each input level. The results are given in Table 2. The differences in output level between SLOW and FAST were in the expected direction but were generally small. Output levels were very well matched for the input level of 65 dB SPL.
Table 2.
Differences in Root-Mean-Square Output Level (FAST−SLOW) in dB for Each Signal (Excluding the Percussion Instrument) and Each Input Level.
| Input level, dB SPL | |||
|---|---|---|---|
| Stimulus | 50 | 65 | 80 |
| Male talker | −2.0 | −0.1 | 4.3 |
| Female talker | −2.0 | −0.5 | 4.0 |
| Classical | −2.0 | 0.8 | 6.4 |
| Jazz | −1.9 | −0.1 | 2.4 |
| Man singing | −1.6 | 0.0 | 0.8 |
| M | −1.9 | 0.0 | 3.6 |
Note. SPL = sound pressure level.
If the preferences were determined by level (or loudness), one might have expected the preferences to differ most from zero for the lowest and highest levels, and to be least different from zero for the medium input level, for which the output levels were well matched. In fact, the overall mean preferences (across speech and music) showed a nonsignificant trend in the opposite direction; mean preference values were 0.41, 0.66, and 0.51 for the input levels of 50, 65, and 80 dB SPL, respectively (see Figure 5). It can be concluded that the preference judgments were probably not determined by level or loudness. The dominant factor was probably related to the fact that FAST reduced the ongoing envelope fluctuations in the stimuli, while SLOW did not.
Discussion
Consistent with the research reviewed in the introduction, there were distinct individual differences among hearing-impaired subjects in preferences for SLOW relative to FAST. On average, the relative preference for SLOW was slightly greater for music than for speech, but the difference was not significant, t(21) = 0.65, p > .05. The pattern of preferences across subjects was similar for speech and music. The general preference for SLOW is consistent with previous results obtained using preference judgments (Gatehouse et al., 2006a; Moore et al., 2011).
Comparisons of slow and fast compression in terms of speech intelligibility have led to mixed results. Gatehouse et al. (2006a, 2006b) reported that the intelligibility of speech in steady or modulated background noise heard via a two-channel compression hearing aid was, on average, better for fast than for slow compression. However, Moore, Füllgrabe, et al. (2010), using a five-channel simulated hearing aid, found that the intelligibility of speech in a background of two competing talkers was, on average, slightly better for slow than for fast compression. Lunner and Sundewall-Thoren (2007), using two-channel hearing aids, found that subjects with low cognitive ability performed better with slow than with fast compression for speech in both steady noise and modulated noise. Subjects with high cognitive ability showed similar performance with fast and slow compression for speech in unmodulated noise but performed better with fast compression for speech in modulated noise. Hopkins et al. (2012), using a six-channel simulated hearing aid with normal-hearing subjects listening to a simulation of hearing impairment, found that performance for understanding speech in a single competing talker was consistently better with fast than with slow compression. This underlines the need for caution when interpreting results obtained using simulations of hearing loss.
Based on the present results, the use of slow compression seems to be a “safe” option for music listening because several subjects showed relatively clear preferences for SLOW, while none showed a clear preference for FAST. This is consistent with the finding of Kirchberger and Russo (2016) that the quality of prerecorded music was rated higher when it was subjected to linear amplification than when it was subjected to fast-acting compression, as slow-acting compression is similar to linear amplification over short time scales. Thus, it seems reasonable to use slow compression as the default option for a “music” program in a hearing aid. However, for speech, five subjects showed a clear preference for FAST. This finding, combined with previous results suggesting clear individual differences in the relative benefit of slow and fast compression for the intelligibility of speech in fluctuating background sounds, suggests that there is no “safe” option for speech. To determine the most appropriate compression speed for everyday listening to speech, it is necessary either to assess subjective preferences for different compression speeds or to assess speech intelligibility for different compression speeds, or (preferably) both.
The preferences were not related to the measures of sensitivity to IPD at low frequencies. A possible reason is that some of the subjects had near-normal hearing at low frequencies, and for them, little compression was applied at low frequencies. It would be desirable to repeat this study using subjects with greater hearing losses at low frequencies. There were weak but significant correlations between the DLFs at 2000 Hz and preferences for compression speed for both speech and music. Thus, sensitivity to TFS may have a weak influence on preferences for compression speed. However, other factors, such as cognitive ability (Gatehouse et al., 2006a, 2006b; Lunner & Sundewall-Thoren, 2007), may also play a role.
Conclusions
Preferences for compression speed among hearing-impaired subjects listening via a simulated five-channel hearing aid fitted using the CAM2A method showed clear individual differences. For speech, SLOW was preferred by more subjects than FAST, but 5 out of 22 subjects showed clear preferences for FAST. For music, about half of the subjects showed a preference for SLOW, and half showed no clear preference. Preferences were correlated for speech and music, but subjects who showed no clear preference or a preference for FAST for speech showed no clear preference for music. The preferences for both speech and music were weakly correlated with DLFs at 2000 Hz, suggesting a weak role of sensitivity to TFS; poor sensitivity to TFS is associated with a greater preference for SLOW. Measures of the sensitivity to interaural phase at low frequencies were not correlated with preferences for compression speed for either speech or music. Slow compression seems to be a safe default option for a music program in hearing aids. However, there appears to be no safe option for speech.
Acknowledgments
We thank Michael Stone, Christian Füllgrabe, and Brian Glasberg for their contributions to this work. We also thank Andrew Oxenham and two anonymous reviewers for helpful comments on an earlier version of this article.
Declaration of Conflicting Interests
The authors declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: The authors receive royalties from sales of the CAM2A hearing-aid fitting software.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the MRC (UK; Grant G0701870) and by the H.B. Allen Charitable Trust (UK).
References
- ANSI (2003) ANSI S3.22-2003, specification of hearing aid characteristics, New York, NY: Author. [Google Scholar]
- Bernstein J. G., Summers V., Iyer N., Brungart D. S. (2012) Set-size procedures for controlling variations in speech-reception performance with a fluctuating masker. Journal of the Acoustical Society of America 132, 2676–2689. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bernstein J. G. W., Grant K. W. (2009) Auditory and auditory-visual intelligibility of speech in fluctuating maskers for normal-hearing and hearing-impaired listeners. Journal of the Acoustical Society of America 125, 3358–3372. [DOI] [PubMed] [Google Scholar]
- Bor S., Souza P., Wright R. (2008) Multichannel compression: Effects of reduced spectral contrast on vowel identification. Journal of Speech, Language, and Hearing Research 51, 1315–1327. [DOI] [PMC free article] [PubMed] [Google Scholar]
- British Society of Audiology (2004) Pure tone air and bone conduction threshold audiometry with and without masking and determination of uncomfortable loudness levels, Reading, England: British Society of Audiology. [Google Scholar]
- Brughera A., Dunai L., Hartmann W. M. (2013) Human interaural time difference thresholds for sine tones: The high-frequency limit. Journal of the Acoustical Society of America 133, 2839–2855. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Burkhard M. D., Sachs R. M. (1975) Anthropometric manikin for acoustic research. Journal of the Acoustical Society of America 58, 214–222. [DOI] [PubMed] [Google Scholar]
- Buss E., Hall J. W., III, Grose J. H. (2004) Temporal fine-structure cues to speech and pure tone modulation in observers with sensorineural hearing loss. Ear and Hearing 25, 242–250. [DOI] [PubMed] [Google Scholar]
- Dillon H. (2012) Hearing aids, 2nd ed Turramurra, Australia: Boomerang Press. [Google Scholar]
- Dreschler W. A., Verschuure H., Ludvigsen C., Westermann S. (2001) ICRA noises: Artificial noise signals with speech-like spectral and temporal properties for hearing instrument assessment. Audiology 40, 148–157. [PubMed] [Google Scholar]
- Fowler E. P. (1936) A method for the early detection of otosclerosis. Archives of Otolaryngology 24, 731–741. [Google Scholar]
- Freyman R. L., Griffin A. M., Oxenham A. J. (2012) Intelligibility of whispered speech in stationary and modulated noise maskers. Journal of the Acoustical Society of America 132, 2514–2523. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Füllgrabe, C., Harland, A. J., Sek, A. P., & Moore, B. C. J. (2016). Development of a new method for determining binaural sensitivity to temporal fine structure. Manuscript submitted for publication. [DOI] [PubMed]
- Füllgrabe C., Moore B. C. J., Stone M. A. (2015) Age-group differences in speech identification despite matched audiometrically normal hearing: Contributions from auditory temporal processing and cognition. Frontiers in Aging Neuroscience 6, article 347, 1–25. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gatehouse S., Naylor G., Elberling C. (2003) Benefits from hearing aids in relation to the interaction between the user and the environment. International Journal of Audiology 42(Suppl. 1): S77–S85. [DOI] [PubMed] [Google Scholar]
- Gatehouse S., Naylor G., Elberling C. (2006a) Linear and nonlinear hearing aid fittings – 1. Patterns of benefit. International Journal of Audiology 45, 130–152. [DOI] [PubMed] [Google Scholar]
- Gatehouse S., Naylor G., Elberling C. (2006b) Linear and nonlinear hearing aid fittings – 2. Patterns of candidature. International Journal of Audiology 45, 153–171. [DOI] [PubMed] [Google Scholar]
- Grose J. H., Mamo S. K. (2010) Processing of temporal fine structure as a function of age. Ear and Hearing 31, 755–760. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Han L. A., Poulsen T. (1998) Equivalent threshold sound pressure levels for Sennheiser HDA 200 earphone and Etymotic Research ER-2 insert earphone in the frequency range 125 Hz to 16 kHz. Scandinavian Audiology 27, 105–112. [DOI] [PubMed] [Google Scholar]
- Hopkins K., King A., Moore B. C. J. (2012) The effect of compression speed on intelligibility: Simulated hearing-aid processing with and without original temporal fine structure information. Journal of the Acoustical Society of America 132, 1592–1601. [DOI] [PubMed] [Google Scholar]
- Hopkins K., Moore B. C. J. (2007) Moderate cochlear hearing loss leads to a reduced ability to use temporal fine structure information. Journal of the Acoustical Society of America 122, 1055–1068. [DOI] [PubMed] [Google Scholar]
- Hopkins K., Moore B. C. J. (2010a) The importance of temporal fine structure information in speech at different spectral regions for normal-hearing and hearing-impaired subjects. Journal of the Acoustical Society of America 127, 1595–1608. [DOI] [PubMed] [Google Scholar]
- Hopkins K., Moore B. C. J. (2010b) Development of a fast method for measuring sensitivity to temporal fine structure information at low frequencies. International Journal of Audiology 49, 940–946. [DOI] [PubMed] [Google Scholar]
- Hopkins K., Moore B. C. J. (2011) The effects of age and cochlear hearing loss on temporal fine structure sensitivity, frequency selectivity, and speech reception in noise. Journal of the Acoustical Society of America 130, 334–349. [DOI] [PubMed] [Google Scholar]
- Hopkins K., Moore B. C. J., Stone M. A. (2008) Effects of moderate cochlear hearing loss on the ability to benefit from temporal fine structure information in speech. Journal of the Acoustical Society of America 123, 1140–1153. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hughes J. W. (1940) The upper frequency limit for the binaural localization of a pure tone by phase difference. Philosophical Transactions of the Royal Society of London, B 128, 293–305. [Google Scholar]
- Kirchberger M., Russo F. A. (2016) Dynamic range across music genres and the perception of dynamic compression in hearing-impaired listeners. Trends in Hearing 20, 1–16. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kochkin S. (1996) Customer satisfaction and subjective benefit with high performance hearing aids. Hearing Reviews 3, 16–26. [Google Scholar]
- Kochkin S. (2010) MarkeTrak VIII: Consumer satisfaction with hearing aids is slowly increasing. Hearing Journal 63, 19–20, 22, 24, 26, 28, 30–32. [Google Scholar]
- Konig E. (1957) Pitch discrimination and age. Acta Otolaryngologica 8, 475–489. [DOI] [PubMed] [Google Scholar]
- Lacher-Fougère S., Demany L. (2005) Consequences of cochlear damage for the detection of interaural phase differences. Journal of the Acoustical Society of America 118, 2519–2526. [DOI] [PubMed] [Google Scholar]
- Leek M. R., Molis M. R., Kubli L. R., Tufts J. B. (2008) Enjoyment of music by elderly hearing-impaired listeners. Journal of the American Academy of Audiology 19, 519–526. [DOI] [PubMed] [Google Scholar]
- Lunner T., Hietkamp R. K., Andersen M. R., Hopkins K., Moore B. C. J. (2012) Effect of speech material on the benefit of temporal fine structure information in speech for young normal-hearing and older hearing-impaired participants. Ear and Hearing 33, 377–388. [DOI] [PubMed] [Google Scholar]
- Lunner T., Sundewall-Thoren E. (2007) Interactions between cognition, compression, and listening conditions: Effects on speech-in-noise performance in a two-channel hearing aid. Journal of the American Academy of Audiology 18, 604–617. [DOI] [PubMed] [Google Scholar]
- Madsen S. M. K., Moore B. C. J. (2014) Music and hearing aids. Trends in Hearing 18, 1–29. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Moore B. C. J. (1973) Frequency difference limens for short-duration tones. Journal of the Acoustical Society of America 54, 610–619. [DOI] [PubMed] [Google Scholar]
- Moore B. C. J. (2004) Testing the concept of softness imperception: Loudness near threshold for hearing-impaired ears. Journal of the Acoustical Society of America 115, 3103–3111. [DOI] [PubMed] [Google Scholar]
- Moore B. C. J. (2007) Cochlear hearing loss: Physiological, psychological and technical issues, 2nd ed Chichester, England: Wiley. [Google Scholar]
- Moore B. C. J. (2008) The choice of compression speed in hearing aids: Theoretical and practical considerations, and the role of individual differences. Trends in Amplification 12, 103–112. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Moore B. C. J. (2014) Auditory processing of temporal fine structure: Effects of age and hearing loss, Singapore: World Scientific. [DOI] [PubMed] [Google Scholar]
- Moore B. C. J., Ernst S. M. (2012) Frequency difference limens at high frequencies: Evidence for a transition from a temporal to a place code. Journal of the Acoustical Society of America 132, 1542–1547. [DOI] [PubMed] [Google Scholar]
- Moore B. C. J., Füllgrabe C., Stone M. A. (2010) Effect of spatial separation, extended bandwidth, and compression speed on intelligibility in a competing-speech task. Journal of the Acoustical Society of America 128, 360–371. [DOI] [PubMed] [Google Scholar]
- Moore B. C. J., Füllgrabe C., Stone M. A. (2011) Determination of preferred parameters for multi-channel compression using individually fitted simulated hearing aids and paired comparisons. Ear and Hearing 32, 556–568. [DOI] [PubMed] [Google Scholar]
- Moore B. C. J., Glasberg B. R. (1987) Factors affecting thresholds for sinusoidal signals in narrow-band maskers with fluctuating envelopes. Journal of the Acoustical Society of America 82, 69–79. [DOI] [PubMed] [Google Scholar]
- Moore B. C. J., Glasberg B. R. (1993) Simulation of the effects of loudness recruitment and threshold elevation on the intelligibility of speech in quiet and in a background of speech. Journal of the Acoustical Society of America 94, 2050–2062. [DOI] [PubMed] [Google Scholar]
- Moore B. C. J., Glasberg B. R. (2007) Modeling binaural loudness. Journal of the Acoustical Society of America 121, 1604–1612. [DOI] [PubMed] [Google Scholar]
- Moore B. C. J., Glasberg B. R., Stoev M., Füllgrabe C., Hopkins K. (2012) The influence of age and high-frequency hearing loss on sensitivity to temporal fine structure at low frequencies. Journal of the Acoustical Society of America 131, 1003–1006. [DOI] [PubMed] [Google Scholar]
- Moore B. C. J., Glasberg B. R., Stone M. A. (2010) Development of a new method for deriving initial fittings for hearing aids with multi-channel compression: CAMEQ2-HF. International Journal of Audiology 49, 216–227. [DOI] [PubMed] [Google Scholar]
- Moore B. C. J., Peters R. W., Stone M. A. (1999) Benefits of linear amplification and multi-channel compression for speech comprehension in backgrounds with spectral and temporal dips. Journal of the Acoustical Society of America 105, 400–411. [DOI] [PubMed] [Google Scholar]
- Moore B. C. J., Sek A. (2009) Development of a fast method for determining sensitivity to temporal fine structure. International Journal of Audiology 48, 161–171. [DOI] [PubMed] [Google Scholar]
- Moore B. C. J., Sek A. (2013) Comparison of the CAM2 and NAL-NL2 hearing-aid fitting methods. Ear and Hearing 34, 83–95. [DOI] [PubMed] [Google Scholar]
- Moore B. C. J., Sek A. (2016) Comparison of the CAM2A and NAL-NL2 hearing-aid fitting methods for participants with a wide range of hearing losses. International Journal of Audiology 55, 93–100. [DOI] [PubMed] [Google Scholar]
- Moore B. C. J., Skrodzka E. (2002) Detection of frequency modulation by hearing-impaired listeners: Effects of carrier frequency, modulation rate, and added amplitude modulation. Journal of the Acoustical Society of America 111, 327–335. [DOI] [PubMed] [Google Scholar]
- Moore B. C. J., Stone M. A., Füllgrabe C., Glasberg B. R., Puria S. (2008) Spectro-temporal characteristics of speech at high frequencies, and the potential for restoration of audibility to people with mild-to-moderate hearing loss. Ear and Hearing 29, 907–922. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Moore B. C. J., Vickers D. A., Mehta A. (2012) The effects of age on temporal fine structure sensitivity in monaural and binaural conditions. International Journal of Audiology 51, 715–721. [DOI] [PubMed] [Google Scholar]
- Moore B. C. J., Vinay (2009) Enhanced discrimination of low-frequency sounds for subjects with high-frequency dead regions. Brain 132, 524–536. [DOI] [PubMed] [Google Scholar]
- Oxenham A. J., Simonson A. M. (2009) Masking release for low- and high-pass-filtered speech in the presence of noise and single-talker interference. Journal of the Acoustical Society of America 125, 457–468. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Plomp R. (1988) The negative effect of amplitude compression in multichannel hearing aids in the light of the modulation-transfer function. Journal of the Acoustical Society of America 83, 2322–2327. [DOI] [PubMed] [Google Scholar]
- Ross B., Fujioka T., Tremblay K. L., Picton T. W. (2007) Aging in binaural hearing begins in mid-life: Evidence from cortical auditory-evoked responses to changes in interaural phase. Journal of Neuroscience 27, 11172–11178. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sek A., Moore B. C. J. (1995) Frequency discrimination as a function of frequency, measured in several ways. Journal of the Acoustical Society of America 97, 2479–2486. [DOI] [PubMed] [Google Scholar]
- Sek A., Moore B. C. J. (2012) Implementation of two tests for measuring sensitivity to temporal fine structure. International Journal of Audiology 51, 58–63. [DOI] [PubMed] [Google Scholar]
- Shamma S., Lorenzi C. (2013) On the balance of envelope and temporal fine structure in the encoding of speech in the early auditory system. Journal of the Acoustical Society of America 133, 2818–2833. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Søndergaard P. L., Decorsière R., Dau T. (2012) On the relationship between multi-channel envelope and temporal fine structure. In: Dau T., Jepsen M. L., Poulsen T., Dalsgaard J. C. (eds) Speech perception and auditory disorders, Ballerup, Denmark: The Danavox Jubilee Foundation, pp. 363–370. [Google Scholar]
- Souza P. E. (2002) Effects of compression on speech acoustics, intelligibility, and sound quality. Trends in Amplification 6, 131–165. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Steinberg J. C., Gardner M. B. (1937) The dependence of hearing impairment on sound intensity. Journal of the Acoustical Society of America 9, 11–23. [Google Scholar]
- Stone M. A., Moore B. C. J. (1992) Syllabic compression: Effective compression ratios for signals modulated at different rates. British Journal of Audiology 26, 351–361. [DOI] [PubMed] [Google Scholar]
- Stone M. A., Moore B. C. J. (2004) Side effects of fast-acting dynamic range compression that affect intelligibility in a competing speech task. Journal of the Acoustical Society of America 116, 2311–2323. [DOI] [PubMed] [Google Scholar]
- Stone M. A., Moore B. C. J. (2007) Quantifying the effects of fast-acting compression on the envelope of speech. Journal of the Acoustical Society of America 121, 1654–1664. [DOI] [PubMed] [Google Scholar]
- Stone M. A., Moore B. C. J. (2008) Effects of spectro-temporal modulation changes produced by multi-channel compression on intelligibility in a competing-speech task. Journal of the Acoustical Society of America 123, 1063–1076. [DOI] [PubMed] [Google Scholar]
- Stone M. A., Moore B. C. J., Füllgrabe C., Hinton A. C. (2009) Multi-channel fast-acting dynamic-range compression hinders performance by young, normal-hearing listeners in a two-talker separation task. Journal of the Audio Engineering Society 57, 532–546. [Google Scholar]
- Strelcyk O., Dau T. (2009) Relations between frequency selectivity, temporal fine-structure processing, and speech reception in impaired hearing. Journal of the Acoustical Society of America 125, 3328–3345. [DOI] [PubMed] [Google Scholar]
- Verschuure J., Maas A. J. J., Stikvoort E., de Jong R. M., Goedegebure A., & Dreschler W. A. (1996) Compression and its effect on the speech signal. Ear and Hearing 17, 162–175. [DOI] [PubMed] [Google Scholar]