

Abstract
Cancer is one of the main causes of threats to human life. Identification of anticancer peptides is important for developing effective anticancer drugs. In this paper, we developed an improved predictor to identify the anticancer peptides. The amino acid composition (AAC), the average chemical shifts (acACS) and the reduced amino acid composition (RAAC) were selected to predict the anticancer peptides by using the support vector machine (SVM). The overall prediction accuracy reaches to 93.61% in jackknife test. The results indicated that the combined parameter was helpful to the prediction for anticancer peptides.
Cancer is the leading cause of death in economically developed countries1. The traditional methods for the treatment of cancer are surgical operation, radiotherapy and chemotherapy. However, radiotherapy and chemotherapy are expensive and cause side effect. Since Swedish scientist Boman first found and determined the antimicrobial peptides primary structure of Hyalophora cecropia in 1972, many studies had shown that the antimicrobial peptides have anti tumor activity2,3. The antimicrobial peptides which have anti tumor activity are called anticancer peptides (ACPs). Anticancer peptides contain 12–50 amino acid residues. Some of these peptides present in membranes with α-helical or β-sheet structures, and the others have particular folds. The mechanism of the action of anticancer peptides includes: necrosis by the cell membrane lytic effect and non-membranolytic4,5,6. Advances in experimental technology have enabled to identify whether a protein belongs to anticancer peptide. However, experimental determination of the anticancer peptide remains time-consuming and laborious. Hence, developing and improving a fast and effective way to predict whether a protein is anticancer peptide would be very necessary. Recently, many methods were focused on the prediction of antimicrobial peptides from primary protein sequences7,8,9. However, the identification of anticancer peptides from primary protein sequences is still at the infant stage. Hajisharifi et al.10 attempted to identify the anticancer peptide based on pseudo amino acid compositions (PseAAC) and the local alignment kernel by using of the Support Vector Machine (SVM). The prediction was made by the 5-fold cross-validation test and the overall success rate was 89.7%. Recently, Chen et al.11 predicted the anticancer peptide with the iACP, the better predictive results were obtained.
In this paper, the amino acid composition (AAC), the average chemical shifts (acACS) and the reduced amino acid composition (RAAC) were selected to predict the anticancer peptides with the same datasets as investigated by Hajisharifi et al.10. The overall prediction accuracy in jackknife test was 93.61% by using the combined parameter AAC + RAAC + acACS for support vector machine (SVM). The predictive results showed significant improvement compared with Hajisharifi’s method.
Results
The prediction of anticancer peptides
In order to predict the anticancer peptides, it is very important to choose a classifier and a set of reasonable information parameters from protein sequence. In this paper, the local amino acids composition (AAC), the average chemical shift (acACS) and the reduced amino acid composition (RAAC) were selected to predict the anticancer peptides.
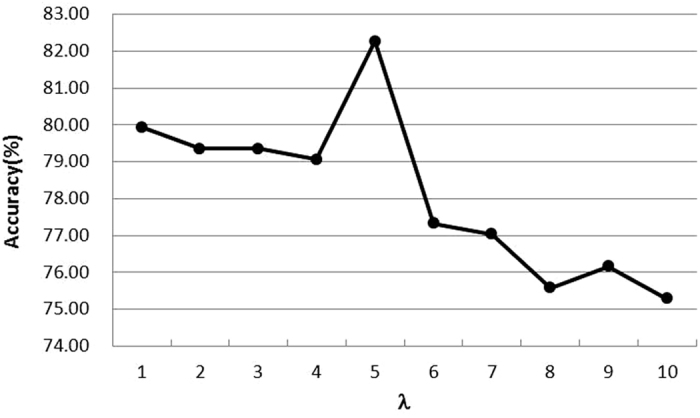
The acACS vectors were formed based on protein sequence, and then the best λ and i were selected. In order to obtain the best performance of predicting anticancer peptides, the combined scheme of chemically shifted atoms and the best λ were optimized with the maximum accuracy. Results in Fig. 1 showed that the accuracy was the best when λ = 5 and in Fig. 2 showed that the prediction result was the best when the combination mode of chemically shifted atoms was 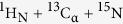 . Therefore, the combination mode chemically shifted
. Therefore, the combination mode chemically shifted 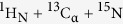 was selected and the correlation factor λ was set to 5 for generating the acACS feature vectors.
was selected and the correlation factor λ was set to 5 for generating the acACS feature vectors.
Figure 1. prediction results with respect to the correlation factor λ of the acACS based on the jackknife test.
The triangle indicates the best results obtained with λ = 5.
Figure 2. Prediction results of different combination schemes of chemical shifts.
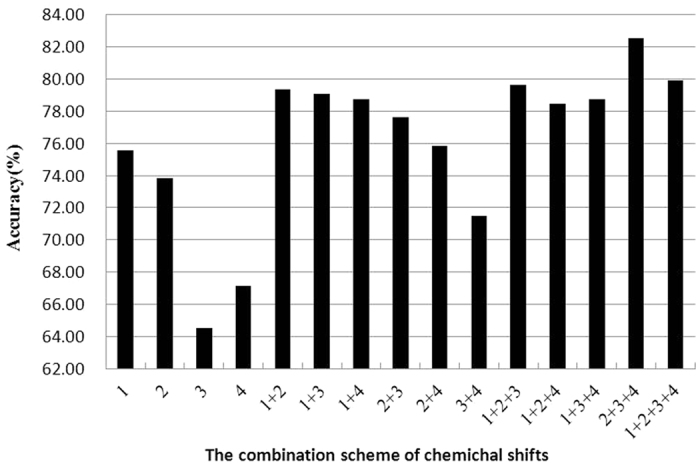
Numbers denote the chemical shifts of atoms: 1 for 1Hα, 2 for 1HN, 3 for 15N, 4 for 13Cα.
For facilitating comparison, the benchmark dataset (see Equation (5)) generated by Hajisharifi et al.10 was employed. The predictive results of anticancer peptides based on AAC, acACS, RAAC, AAC + RAAC, AAC + acACS, RAAC + acACS and AAC + RAAC + acACS by using SVM with jackknife test were recorded in Table 1. The results showed that the combined parameter of AAC + RAAC + acACS was better than other parameters. The overall predictive accuracy (QA) and Matthew’s correlation coefficient (MCC) in jackknife test were 93.61% and 0.867 with the combined parameter of AAC + RAAC + acACS by using of the SVM, respectively. The results indicated that the combined parameter was helpful to the prediction for anticancer peptides.
Table 1. The predictive results of SVM by jackknife test for anticancer peptides.
| Features | sn(%) | sp(%) | QA(%) | MCC |
|---|---|---|---|---|
| AAC | 87.68 | 94.66 | 91.86 | 0.830 |
| RACC | 77.54 | 88.35 | 84.01 | 0.642 |
| acACS | 71.02 | 90.29 | 82.56 | 0.633 |
| AAC + RACC | 86.96 | 97.57 | 93.31 | 0.861 |
| AAC + acACS | 86.23 | 97.57 | 93.02 | 0.856 |
| RACC + acACS | 77.54 | 91.74 | 86.05 | 0.707 |
| AAC + RAAC + acACS | 89.86 | 96.12 | 93.61 | 0.867 |
In order to estimate the effectiveness of the new prediction method, an independent dataset (see Equation (6)) generated by Chen et al.11 was employed. The independent dataset is not absolutely needed for validating a predictor via the jackknife or K-fold cross-validation, since the outcome obtained via the jackknife or K-fold cross-validation with benchmark dataset is actually from a combination of many different independent dataset tests. The combined parameter of AAC + RAAC + acACS was selected to identify the anticancer peptides in the independent dataset. The overall predictive accuracy (QA) and Matthew’s correlation coefficient (MCC) in jackknife test were 89.33% and 0.787 by using of the SVM, respectively. This results showed that the new predictive method was not only able to achieve higher overall success rates, but also more stable.
Evaluation of the predictive performances
In order to evaluate the predictive capability and reliability of the algorithm, the sensitivity (Sn), specificity (Sp), overall predictive accuracy (QA) and Matthew’s correlation coefficients (MCC) are defined by
 |
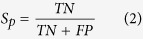 |
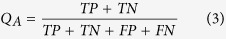 |
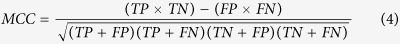 |
where TP denotes the numbers of the correctly recognized positives, FN denotes the numbers of the positives recognized as negatives, FP denotes the numbers of the negatives recognized as positives, TN denotes the numbers of correctly recognized negatives.
Jackknife cross-validation test
In statistical prediction, the following three cross-validation methods are often used to examine a predictor for its effectiveness in practical application: independent dataset test, sub-sampling test, and jackknife cross-validation test12, among the three cross-validation methods, the jackknife test is deemed the most objective, and has been used to examine the performance of various predictors13,14,15,16. Hence the jackknife test was used to evaluate the performance of our method. During the process of jackknife test, each protein is singled out in turn for testing and the remaining proteins are merged for training.
Discussion
Hajisharifi et al.10 used SVM-based classification on the base of their PseAAC parameter and the local alignment kernel as string kernel method in conjunction with 5-fold cross-validation test for the same benchmark dataset (see Equation (5)). For the purpose of comparing the predictive capability of our method, the predicted results of Hajisharifi’s and Chen’s method are enumerated in Table 2 for the same dataset. Compared results show that the performance of our method is more superior to that of Hajisharifi’s method. The sn, sp, QA and MCC of our method are about 5.40%,3.92%,4.49% and 0.095 higher than the predictive results of Hajisharifi’s method with 5-fold cross-validation test, respectively. Although only the sn obtained in our method is higher than that of Chen’s method with 5-fold cross-validation test, the features of anticancer peptides are obtained more comprehensive in our method. At least our method can play a complimentary role to the existing methods in this area.
Table 2. The comparison of the predictive results between this paper and the other methods.
The predictive result indicates that the combined parameter AAC + RAAC + acACS is effective to the prediction of anticancer peptides proteins. From the discussion above, it can be seen that our method has advantage of more comprehensive features and higher predictive success rates. The combined parameter AAC + RAAC + acACS successfully enhance the prediction quality for the anticancer peptides. This method may have broad application in protein and DNA motif identification.
Materials and Method
Datasets
The Benchmark dataset was generated by Hajisharifi et al.10 and can be expressed as
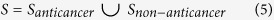 |
where Santicancer consists of 138 anticancer peptides and Snon-anticancer consists of 206 non-anticancer peptides. The anticancer peptides derived from the antimicrobial peptides database (ADP2) and 206 non-anticancer peptides were selected from Universal Protein Resource17.
In order to estimate the effectiveness of the new prediction method, an independent dataset was employed and can be expressed as
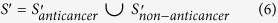 |
where 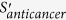 consists of 150 anticancer peptides and
consists of 150 anticancer peptides and 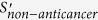 consists of 150 non-anticancer peptides. The samples in
consists of 150 non-anticancer peptides. The samples in 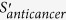 and
and 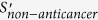 were fetched from the dataset used by Chen et al.11 and none of the sequences in S′ was the same with the sequences in S.
were fetched from the dataset used by Chen et al.11 and none of the sequences in S′ was the same with the sequences in S.
Support Vector Machine (SVM)
The support vector machine (SVM) is a widely used classification method developed based on the statistical learning theory18,19,20,21,22,23,24,25. The SVM is particularly attractive to biological sequence analysis due to its ability to handle noise, large dataset and large input spaces. The SVM model is a representation of the examples as points in space, mapped by a kernel function so that the examples are divided by a clear gap that is widely enough. The new examples are mapped into the same space and predicted according to which side of the gap they fall on. The radial basis kernel function (RBF) was used to obtain the best classification hyperplane. The regularization parameter C and the kernel width parameter γ were tuned via the grid search method. For a brief formulation of SVM and how it works, see the papers26,27. In this paper, the LibSVM algorithm28 has been used to predict the anticancer peptide, which can be downloaded from http://www.csie.ntu.edu.tw/~cjlin/libsvm/.
The local amino acids compositions (AAC)
The information parameters are very important for predicted algorithms. In a sequence-based predictor, the most important issue is the way in which to extract features from primary sequences of proteins29,30,31,32. The primary sequences of proteins are composed of 20 amino acids. The absolute occurrence frequencies of the 20 amino acids in protein are important features. Hence, the absolute occurrence frequencies of the 20 amino acids in protein sequence are considered as the information parameters of a protein and can be defined as
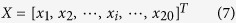 |
where 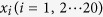 is the absolute occurrence frequencies of the 20 native amino acids and calculated by
is the absolute occurrence frequencies of the 20 native amino acids and calculated by
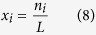 |
where ni is the occurrence number of the 20 native amino acids of the protein; L is the length of the protein.
Analysis of the amino acids compositions
Using the dataset S, we analyzed the average amino acids compositions of anticancer peptides and non-anticancer peptides. The average amino acids compositions can be calculated as follow
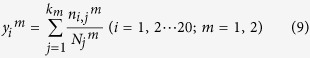 |
where 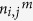 is the number of i-th amino acids of j-th protein in m-th group,
is the number of i-th amino acids of j-th protein in m-th group, 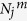 denotes the total number of amino acids of j-th protein in m-th group,
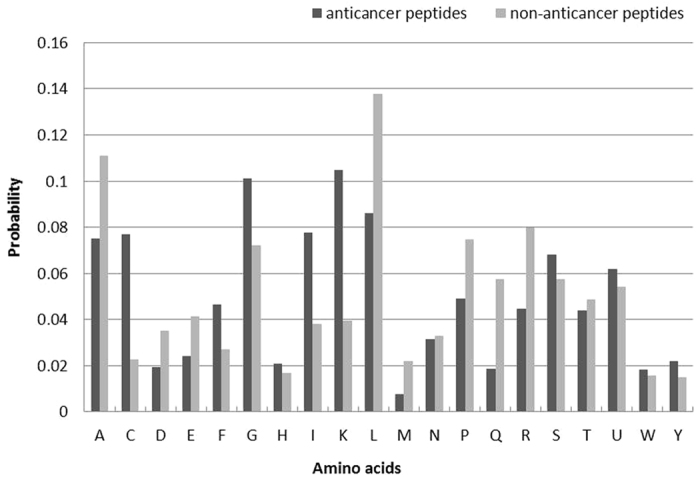
denotes the total number of amino acids of j-th protein in m-th group, 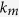 denotes the number of samples in the m-th group (here (k1 = 138, k2 = 206). We calculated the average amino acids compositions of anticancer peptides and non-anticancer peptides by using of Equation (9). The calculate results indicated that the amino acids compositions of anticancer peptides and non-anticancer peptides were different. Hence the amino acids compositions were suitable as features to distinguish anticancer peptides and non-anticancer peptides. The different distribution of the amino acids compositions in anticancer peptides and non-anticancer peptides were shown in Fig. 3.
denotes the number of samples in the m-th group (here (k1 = 138, k2 = 206). We calculated the average amino acids compositions of anticancer peptides and non-anticancer peptides by using of Equation (9). The calculate results indicated that the amino acids compositions of anticancer peptides and non-anticancer peptides were different. Hence the amino acids compositions were suitable as features to distinguish anticancer peptides and non-anticancer peptides. The different distribution of the amino acids compositions in anticancer peptides and non-anticancer peptides were shown in Fig. 3.
Figure 3. The different distribution of the amino acids compositions in anticancer peptides and non-anticancer peptides.
Auto covariance of the average chemical shift (acACS) algorithm
In a predictor, the most important issue is the way in which to extract features from primary sequences of protein. To achieve this, the acACS algorithm is proposed, which uses simple secondary structure information to represent the sample of a protein33. The average chemical shift of a protein has intrinsic correlation with the protein’s secondary structure and the function of this protein. According to this point of view, there must be some relationship among the average chemical shift, protein structure and functions. So the acACS algorithm has been widely applied to predictions of protein attributes, such as predicting protein submitochondrial localization34, the subcellular locations of the mycobacterial proteins and DNA-binding proteins35, as well as for identifying acidic and alkaline enzymes36 and discriminating between bioluminescent and nonbioluminescent proteins37. The acACS algorithm can be obtained from web server at http://202.207.14.87:8032/fuwu/acacs/index.asp.
For a protein P,
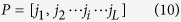 |
where L is the length of the protein sequence p and j represent the 20 native amino acids residues, p is then expressed as follow:
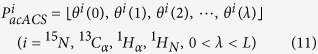 |
where θi(λ) is the correlation factor of the average chemical shift for jl with the average chemical shift for  along the protein sequence. The factor
along the protein sequence. The factor 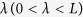 reflects the rank of correlation. The factor i can be the different composition of
reflects the rank of correlation. The factor i can be the different composition of 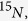
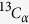 ,
, 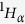 and
and 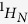 . In order to obtain the best result, an appropriate number for factor λ and i should be determined according to the predicting results.
. In order to obtain the best result, an appropriate number for factor λ and i should be determined according to the predicting results.
The reduced amino acid composition (RAAC)
It was demonstrated that in the definition of global protein structure, the patterns of hydrophobic and hydrophilic residues have major significance. To obtain the hydropathy characteristics, the amino acids were divided into groups using their individual hydropathies according to the ranges of the hydropathy scale. Therefore, a protein sequence with 20 amino acids can be represented by a sequence with 6 characters according to following schemes: Strongly hydrophilic or polar (R, D, E, N, Q, K, H), Strongly hydrophobic (L, I, V, A, M, F), Weakly hydrophilic or weakly hydrophobic (S, T, Y, W), Proline (P), glycine (G) and Cysteine (C)38,39. The dipeptide composition of the six characters were chosen and represented as follow:
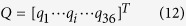 |
where 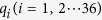 is the absolute occurrence frequencies of the 36 hydropathy dipeptides and calculated by
is the absolute occurrence frequencies of the 36 hydropathy dipeptides and calculated by
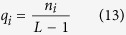 |
where 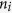 is the occurrence number of the 36 hydropathy dipeptides of the protein, L is the length of the protein.
is the occurrence number of the 36 hydropathy dipeptides of the protein, L is the length of the protein.
Additional Information
How to cite this article: Li, F.-M. and Wang, X.-Q. Identifying anticancer peptides by using improved hybrid compositions. Sci. Rep. 6, 33910; doi: 10.1038/srep33910 (2016).
Acknowledgments
The authors wish to thank the anonymous reviewers for their constructive comments, which were very helpful for strengthening the presentation of this study. This work was supported by National Natural Science Foundation of China (No. 31360206) and Project for Talent Development Foundation of Inner Mongolia Autonomous Region.
Footnotes
Author Contributions F.-M.L. conceived the selection of feature parameters. X.-Q.W. carried out the computation by SVM. F.-M.L. performed the results analysis and wrote the manuscript. All authors reviewed the manuscript.
References
- Jemal A. et al. & Forman D. Global cancer statistics. CA- Cancer J. Clin. 61, 69–90 (2011). [DOI] [PubMed] [Google Scholar]
- Boman H. G. Nilsson I. & Rasmuson B. Inducible antibacterial defence system in Drosophila. Nature 237, 232–235 (1972). [DOI] [PubMed] [Google Scholar]
- Boman H. G. Antibacterial peptides: basic facts and emerging concepts. J. Intern. Med. 254, 197–215 (2003). [DOI] [PubMed] [Google Scholar]
- Cho J. H. Sung B. H. & Kim S. C. Buforins: histone H2A-derived antimicrobial peptides from toad stomach. Biochim. Biophys. Acta 1788, 1564–1569 (2009). [DOI] [PubMed] [Google Scholar]
- Shi S. L. Wang Y. Y. Liang Y. & Li Q. F. Effects of tachypiesin and n-sodium butyrate on proliferation and gene expression of human gastric adenocarcinoma cell line BGC-823. World J. Gastroenterol. 12, 1694–1698 (2006). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen J. et al. Tachyplesin activates the classic complement pathway to kill tumor cells. Cancer Res. 65, 4614–4622 (2005). [DOI] [PubMed] [Google Scholar]
- Xiao X. et al. iAMP-2L: A two-level multi-label classifier for identifying antimicrobial peptides and their functional types. Anal. Biochem. 436, 168–177 (2013). [DOI] [PubMed] [Google Scholar]
- Chen W. & Luo L. F. Classification of antimicrobial peptide using diversity measure with quadratic discriminant analysis. J. Microbiol. Methods 78, 94–96 (2009). [DOI] [PubMed] [Google Scholar]
- Wang P. et al. Prediction of antimicrobial peptides based on sequence alignment and feature selection method. PLoS One 6, e18476 (2011). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hajisharifi Z. et al. Predicting anticancer peptides with Chou’s pseudo amino acid composition and investigating their mutagenicity via Ames test. J. Theor. Biol. 34, 34–40 (2014). [DOI] [PubMed] [Google Scholar]
- Chen W. et al. iACP: a sequence-based tool for identifying anticancer peptides. Oncotarget 7, 16895–16909 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chou K. C. & Zhang C. T. Review: Prediction of protein structural classes. Crit. Rev. Biochem. Mol. Biol. 30, 275–349 (1995). [DOI] [PubMed] [Google Scholar]
- Chen W. Feng P. M. Lin H. & Chou K. C. IRSpotPseDNC: identify recombina-tion spots with pseudo dinucleotide composition. Nucleic Acids Res. 41, e68 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chou K. C. & Shen H. B. Plant-mPLoc:a top-down strategy to augment the power for predicting plant protein subcellular localization. PLoS One 5, e11335 (2010). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lin W. Z. Fang J. A. Xiao X. & Chou K. C. ILoc-animal:amulti-label learning classifier for predicting subcellular localization of animal proteins. Mol. BioSyst. 9, 634–644 (2013). [DOI] [PubMed] [Google Scholar]
- Liu B. et al. Identification of real microRNA precursors with a pseudo structure status composition approach. PLoS One 10, e0121501 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang G. Li X. & Wang Z. APD2: the updated antimicrobial peptide database and its application in peptide design. Nucleic Acids Res. 37, D933–D937 (2009). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cortes C. & Vapnik V. Support-vector networks. Mach. Learn 20, 273–297 (1995). [Google Scholar]
- Guo S. H. et al. iNuc-PseKNC: a sequence-based predictor for predicting nucleosome positioning in genomes with pseudo k-tuple nucleotide composition. Bioinformatics 30, 1522–1529 (2014). [DOI] [PubMed] [Google Scholar]
- Liu B. Fang L. Wang S. & Wang X. Identification of microRNA precursor with the degenerate K-tuple or Kmer strategy. J. Theor. Biol. 385, 153–159 (2015). [DOI] [PubMed] [Google Scholar]
- Liu B. Fang L. Long R. & Lan X. iEnhancer-2L: a two-layer predictor for identifying enhancers and their strength by pseudo k-tuple nucleotide composition. Bioinformatics 32, 362–389 (2016). [DOI] [PubMed] [Google Scholar]
- Liu B. et al. Combining evolutionary information extracted from frequency profiles with sequence-based kernels for protein remote homology detection. Bioinformatics 30, 472–479 (2014). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lin H. et al. iPro54- PseKNC: a sequence-based predictor for identifying sigma-54 promoters in prokaryote with pseudo k-tuple nucleotide composition. Nucleic Acids Res. 42, 12961–12972 (2014). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cao R. Wang Z. Wang Y. & Cheng J. SMOQ: a tool for predicting the absolute residue-specific quality of a single protein model with support vector machines. BMC Bioinform. 15, 120 (2014). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cao R. Wang Z. & Cheng J. Designing and evaluating the MULTICOM protein local and global model quality prediction methods in the CASP10 experiment. BMC Struct. Biol. 14, 13 (2014). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chou K. C. & Cai Y. D. Using functional domain composition and support vector machines for prediction of protein subcellular location. J. Biol. Chem. 277, 45765–45769 (2002). [DOI] [PubMed] [Google Scholar]
- Cai Y. D. & Zhou G. P. Support vector machines for predicting membrane protein types by using functional domain composition. Biophys. J. 84, 3257–3263 (2003). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fan R. E. Chen P. H. & Lin. C. J. Working set selection using second order information for training support vector machines. J. Mach. Learn. Res. 6, 1889–1918 (2005). [Google Scholar]
- Li F. M. & Li Q. Z. Predicting protein subcellular localization using Chou’s pseudo amino acid composition and improved hybrid approach. Protein Pept. Lett. 15, 612–616 (2008). [DOI] [PubMed] [Google Scholar]
- Li F. M. & Li Q. Z. Using pseudo amino acid composition to predict protein subnuclear location with improved hybrid approach. Amino acids 34, 119–125 (2008). [DOI] [PubMed] [Google Scholar]
- Lin H. Deng E. Z. Ding H. & Chen W. iPro54-PseKNC:a sequence-based predictor for identifying sigma-54 promoters in prokaryote with pseudo k-tuple nucleotide composition. Nucleic Acids Res. 42, 12961–12972 (2014). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lin H. et al. Predicting cancerlectins by the optimal g-gap dipeptides. Sci. Rep. 5, 16964 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fan G. L. et al. acACS: Improving the Prediction Accuracy of Protein Subcellular Location and Protein Classification by Incorporating the Average Chemical Shifts Composition. Sci. World J. 864135 (2014). [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fan G. L. & Li Q. Z. Predicting protein submitochondria locations by combining different descriptors into the general form of Chou’s pseudo amino acid composition. Amino Acids 43, 545–555 (2012). [DOI] [PubMed] [Google Scholar]
- Fan G. L. & Li Q. Z. Predict mycobacterial proteins subcellular locations by incorporating pseudo-average chemical shift into the general form of Chou’s pseudo amino acid composition. J. Theor. Biol. 304, 88–95 (2012). [DOI] [PubMed] [Google Scholar]
- Fan G. L. Li Q. Z. & Zuo Y. C. Predicting acidic and alkaline enzymes by incorporating the average chemical shift and gene ontology informations into the general form of Chou’s PseAAC. Process Biochem. 48, 1048–1053 (2013). [Google Scholar]
- Fan G. L. & Li Q. Z. Discriminating bioluminescent proteins by incorporating average chemical shift and evolutionary information into the general form of Chou’s pseudo amino acid composition. J. Theor. Biol. 334, 45–51 (2013). [DOI] [PubMed] [Google Scholar]
- Chen Y. L. & Li Q. Z. Prediction of the subcellular location of apoptosis proteins. J. Theor. Biol. 245, 775–783 (2007). [DOI] [PubMed] [Google Scholar]
- Pánek J. Eidhammer I. & Aasland R. A New Method for Identification of Protein (Sub) Families in a Set of Proteins Based on Hydropathy Distribution in Proteins. Proteins: Struct. Funct. Bioinformatics 58, 923–934(2005). [DOI] [PubMed] [Google Scholar]