

Abstract
Disease progression and drug response may vary significantly from patient to patient. Fortunately, the rapid development of high-throughput ‘omics’ technologies has allowed for the identification of potential biomarkers that may aid in the understanding of the heterogeneities in disease development and treatment outcomes. However, mechanistic gaps remain when the genome or the proteome are investigated independently in response to drug treatment. In this article, we discuss the current status of pharmacogenomics in precision medicine and highlight the needs for concordant analysis at the proteome and metabolome levels via the more recently-evolved fields of pharmacoproteomics, toxicoproteomics, and pharmacometabolomics. Integrated ‘omics’ investigations will be critical in piecing together targetable mechanisms of action for both drug development and monitoring of therapy in order to fully apply precision medicine to the clinic.
Keywords: Pharmacogenomics, Proteomics, Biomarker, Precision medicine
Background
Too many patients suffer from diseases with no known cure or effective treatment. Therapeutic modalities may be efficacious in some individuals or be associated with treatment failure and toxicities in others. It is well known that heterogeneities of disease presentation, genetics, and environment all contribute to the variability in drug response. With the vast improvements in technologies such as genome sequencing, big-data analysis, and electronic health records, healthcare is being revolutionized from a “one-size-fits-all” approach to a focus on the individual patient. In his 2015 State of the Union address, U.S. President Obama announced the Precision Medicine Initiative. The goal of the precision medicine approach is to integrate genetic and environmental information to have the ability to classify subpopulations of patients based on their susceptibility to particular diseases and/or their responses to particular treatments. In this manner, diagnostic testing can be used to optimize therapies for an individual. In support of this initiative, Congress recently approved the largest funding increase for biomedical research in 12 years, giving the NIH a $2 billion increase that contained $200 million for the Precision Medicine Initiative in 2016 [1]. A main mission of the initiative will be the assembly of a national research participant cohort of over 1 million Americans [2]. Data collected from the cohort will ideally allow for the identification of pharmacogenomic drug-gene relationships as well as the discovery of new biomarkers and therapeutic targets. This initiative comes at a time when technological advances have shifted biomedical studies from single genes, proteins, and metabolites to all-encompassing genomes, proteomes, and metabolomes. This review will highlight how recent progressions in both genomics and proteomics have contributed to and will continue to be simultaneously necessary for the administration of therapeutic regimens with the highest probability of success.
Pharmacogenomics
With advances in sequencing technology and follow-ups to the Human Genome Project, such as the International HapMap Project and the 1000 Genomes Project, much of the focus for precision medicine thus far has been in the field of genomics. While a patient’s response to a drug is affected by many factors, such as drug dose, adherence and compliance to a dosing regimen, and drug–drug interactions, genetic variation in genes encoding for drug-metabolizing enzymes and transporter proteins also plays a significant role. Such genetic variation may drastically impact drug pharmacokinetics through modulation of drug absorption, distribution, metabolism, or elimination. With standard doses of implicated drugs, individuals with this type of genetic variation may experience adverse drug reactions due to drug concentrations that may either be toxic or non-efficacious. For example, single nucleotide polymorphisms (SNPs), particularly within genes encoding for the cytochrome P450 family of enzymes, have been widely implicated in aberrant drug metabolism [3].
Pharmacogenomics approaches and applications
Genetic mutations influencing drug metabolism may be explored in a targeted single-gene manner (pharmacogenetics) or in a more global, whole-genome manner (pharmacogenomics) [4]. Single gene-drug responses, also known as candidate-gene studies, were traditionally the focus of investigations and have resulted in most of the well-established pharmacogenetic markers to date. However, improvements in broad-range sequencing technologies, including the completion of the Human Genome Project, have allowed for the increasing application of pharmacogenomic, genome-wide association studies. Such approaches allow largely unbiased investigation into genes or genetic pathways that may be involved in drug response. In vivo human experiments are ideal for these studies when they can be performed safely. Typically, patient samples are grouped by phenotype, such as patients who experienced efficacious drug effects versus no effect, or patients who experienced particular adverse reactions or toxic effects from standard doses. DNA is analyzed by broad, high-throughput sequencing approaches such as SNP microarrays, digital PCR, and next-generation sequencing. Data quality checks are critical to determine SNPs that were successfully genotyped, and appropriate allele frequency models are used to calculate accurate odds ratios and pinpoint candidate SNPs [5]. Animal studies and in vitro cell line approaches are practical alternatives for pharmacogenomic studies when drug toxicity is of concern [6, 7]. In particular, lymphoblastoid cell lines transformed with the human Epstein–Barr virus, resulting in immortalized B lymphocytes, have shown tremendous utility as a model to assess germline genetic contribution to both positive and adverse drug responses [8]. The NCI-60 cancer cell panel is also widely used to investigate the effect of somatic mutations on drug response [9].
A hallmark genome-wide drug response study in human patients was reported in 2008 by the Study of the Effectiveness of Additional Reductions in Cholesterol and Homocysteine (SEARCH) Collaborative Group, which sought to determine reasons for rare cases of statin-induced myopathy and rhabdomyolysis [10]. Assessment of over 300,000 SNP locations by bead array in patients taking equivalent doses of simvastatin revealed a strong correlation of myopathy (defined as elevated serum creatine kinase levels) with a particular SNP on the SLCO1B1 gene, which encodes a protein involved in the hepatic uptake of various drugs. The finding led the group to further sequencing of other regions on SLCO1B1 and resulted in the identification of several other common variants of the gene that were strongly associated with statin-induced myopathy. A recent pilot study showed that patients who received SLCO1B1 genetically-guided statin therapy management were more likely to comply with dosing regimens and lower their LDL-cholesterol [11].
Genome-wide pharmacogenomic studies have more recently been applied in a wide variety of clinical applications, including investigations into drug concentrations and related effects of additional cholesterol- and lipid-lowering molecules [12–14], anti-depressants [15, 16], and cancer treatments [17, 18]. While most traditional cancer genomics initiatives focused on identifying the somatic mutations that drive tumor progression, it is now also recognized that germline variation among patients may significantly impact their response to cancer treatments. Initially, candidate-gene studies established associations such as CYP2D6 polymorphisms and poor outcomes of breast cancer after tamoxifen treatment [19], or toxicity-inducing UGT1A1 polymorphisms with irinotecan treatment of colon cancer [20]. Both of these pharmacogenetic associations have since been used to guide dosages of these drugs in a clinical setting [21, 22] and are included in expert consensus guidelines offered by the Clinical Pharmacogenetics Implementation Consortium (CPIC) [23]. Currently, there are increasing genome-wide association studies which serve to discover novel genetic biomarkers associated with variant cancer drug efficacy or toxicity in a broad, high-throughput manner. An unprecedented genome-wide study into the genetic association of variable outcomes of 5-fluorouracil and oxaliplatin (FOLFOX) treatments for colorectal cancer patients used SNP array technology to reveal seven SNPs significantly correlated with gastrointestinal, hematological, and neurological adverse drug reactions [24]. Recently, a similarly-designed study found two SNPs associated with myelosuppression in non-small cell lung cancer patients receiving platinum-based therapies [25]. Such associations would likely have never been discovered without the use of unbiased genome-wide approaches. However, functional studies are needed to further understand the pathways and mechanisms associated with these genetic aberrations in order to consider them for clinical use.
Future directions for pharmacogenomics
Future directions for pharmacogenomics studies will likely involve incorporation of epigenetic factors such as DNA methylation and histone modification into assessment of drug response. Epigenetics may explain heterogeneities in phenotype when genotype is identical. Epigenetic modifications have largely been implicated in cancer, among other diseases, and represent an important class of drug targets [26, 27]. Indeed, DNA methylation has been shown to play a significant role in regulating the expression of members of the cytochrome P450 superfamily of enzymes, which is responsible for the metabolism of over 75 percent of commonly-prescribed pharmaceuticals [28–30]. While significant evidence exists in the literature for the epigenetic regulation of genes involved in the absorption, distribution, metabolism, and excretion (ADME) of drugs [31], the clinical relevance of this regulation remains to be seen. Combined broad-screening genomic and epigenetic studies are emerging [32] and will be critical to directly link genotypes with phenotypes. Additionally, increased accessibility to next generation sequencing will allow for the identification and analysis of novel, unique variants that may be missed by the SNP array-based methods [33]. In 2012, Price et al. described the first use of whole exome sequencing to identify novel, non-CYP2C19 genetic variants correlated to aberrant platelet responsiveness to clopidogrel [34]. More recently, whole exome sequencing also led to genetic determinants in exceptional responders to targeted anticancer therapy of pazopanib and everolimus in advanced solid tumors [35]. Indeed, as sequencing costs continue to decrease, pharmacogenetic testing in the clinic may shift from targeted assays for specific drugs to pre-emptive, broad-scale testing models using interpretive guides from such resources as CPIC [23, 36].
Pharmacoproteomics
While the aforementioned genomic studies have provided an abundance of advancing information and clinical utility, it is at the protein level that cellular processes are functionally regulated. Expression levels of genes and their transcripts do not necessarily correlate with corresponding protein abundance [37]. While there are an estimated 19,000 protein-coding genes in the human genome [38], it is likely that the number of proteins is near or into the millions, taking into consideration the vast opportunities for posttranslational modification that exponentially increase the diversity of the human proteome. Additionally, while DNA sequencing approaches provide static snapshots of cellular processes, the more dynamic nature of proteins makes them ideal for studying kinetic responses to drug treatments. Thus, it would be beneficial for wide-scale genomic studies to be paired with analysis of the proteome. Indeed, a major limitation of the aforementioned genome-wide associated pharmacogenomics studies is the lack of understanding of the true biological mechanisms and complete cellular pathways underlying the identified genetic associations. Precision medicine should therefore encompass both pharmacogenomics and pharmacoproteomics, a more recently-emerged field which uses proteomic technologies for drug discovery and development [39]. Notably, analysis of the translation step between genome and proteome is referred to as transcriptomics. The transcriptome may be measured by such technologies as mRNA microarrays and RNA-seq [40]. As correlation between mRNA and protein may be low, transcriptomics may also be a critical component of integrated ‘omics’ approaches [41].
The term ‘pharmacoproteomics’ was not introduced in the literature until the early 2000s [39, 42, 43], near the beginning of a rapid growth period in the general field of proteomics and its technologies. While the number of publications termed with ‘pharmacogenomics’ or ‘pharmacogenetics’ approaches well into the 10,000–20,000 range, a PubMed search in June 2016 revealed only 166 results for pharmacoproteomics, with the first having been published as a conference summary in 2002 [44]. Even today, there exists no standard definition for this branch of proteomics. This review will primarily focus on pharmacoproteomics as the use of proteomic analyses in drug discovery and development.
Although many discovered therapeutic targets enter the preclinical testing phase, the number of drugs that are eventually approved for human use is relatively miniscule, especially for oncology treatments [45]. Drug failure is often due to poor pharmacokinetic properties such as low bioavailability, poor absorption, pre-mature metabolism, or adverse side effects. Pharmacoproteomics gives us the potential to study drug mechanisms at the proteome level while at the same time investigating toxicity and resistance, or perhaps discovering new drug targets, early in the drug development process. In this manner, drugs with flawed properties can be saved from further development, while newer, better-performing drugs can be discovered and moved forward.
Pharmacoproteomics approaches and applications
Experimental workflows in proteomics approaches to drug screening and development, like genomics approaches, may be broadly classified as targeted or global. Targeted approaches may involve affinity-based or activity-based profiling techniques, which employ chemically-engineered probes to capture proteins of interest. Detailed discussion of targeted methods can be found in several informative book chapters and review articles [46–48]. While global methods are more challenging from a bioinformatics standpoint, they are advantageous because they provide unbiased, large-scale analyses and may reveal unexpected relationships among seemingly unrelated pathways. A typical in vitro workflow involves treating cells with the drug of interest, lysing the cells, digesting proteins into peptides, and then analyzing the entire proteome by mass spectrometry techniques. Stable isotope labeling with amino acids in cell culture (SILAC) is often used for accurate quantification [49]. Protein abundance is compared across drug-treated and untreated (control) conditions in order to probe the phenotypic pathways induced by the drug. Initial studies were likely biased towards the most abundant proteins, as analytical depth suffered with earlier analytical technologies. Advances in mass spectrometry, such as sensitivity, sample preparation methods, and data analysis capabilities, now allow for the identification of over 10,000 proteins in a cell line [50, 51], though current resolutions may remain too limited to detect some low-abundance markers in blood or tissue [52]. Furthermore, protein and peptide enrichment techniques permit the assessment of post-translational modifications such as phosphorylation, as demonstrated by Klammer et al. with their identification of a protein phosphorylation signature to predict response to the antineoplastic agent dasatinib in non-small cell lung cancer cell lines [53]. Notably, protein or antibody arrays are another major technique to study proteomics that may offer increased analytical sensitivities [54]. However, because such arrays require preconceiving of the proteins to be investigated, the ‘open architecture’ of mass spectrometry may be more advantageous for global, discovery studies.
A leading study in the pharmacoproteomic field, described by Ong et al. [55], utilized quantitative proteomic analysis of SILAC-labeled cell lysates to identify specific protein interactions and targets of small molecules, including kinase inhibitors and immunophilin binders. Several investigations have since followed similar methods to identify targets of anti-cancer agents [56–58]. Results have often demonstrated that pharmaceutical compounds elicit pharmacological effects through multiple protein targets that may be unrelated by genetic sequence, highlighting the importance of the broad proteomic approach to piece together complete mechanisms [59]. Furthermore, identification of multiple protein targets may lead to novel combinatorial therapies, particularly in cancer. A recent study utilized pharmacoproteomic approaches to identify and verify combined therapy towards B cell receptor (BCR) pathways and heat shock protein 90 (Hsp90) in diffuse large B cell lymphoma [60]. Pharmacoproteomics methodologies have been applied to a variety of other disease states, such as diabetes and neurovascular disease [61]. In particular, quantitative proteomics may shed light on the interaction of small molecules with the complex blood brain barrier [62].
Toxicoproteomics
Adverse reactions are a significant cause of drug failure in the drug development pipeline. Toxicoproteomic studies incorporate similar global protein expression technologies as described above but typically focus on either acute or chronic toxicity of the small molecule(s) in question [63]. Toxicoproteomics seeks to determine how chemical exposure modifies proteins or protein expression as a form of preclinical risk assessment. Quick and efficient identification of a molecule’s toxic effect means it may be spared from further progression down the pipeline, saving money and allowing for focus shifts to alternative molecules. Furthermore, identified protein changes may translate into new biomarkers that may be used to monitor treated patients for signatures of chemical toxicity. In terms of anticancer agents, toxicoproteomic studies aid in the detection of toxicity for ideally cancer cells only when compared to proteomic signatures of treated normal cells. A comprehensive compilation of published toxicoproteomic studies on drugs both in vitro (humans and animals) and in vivo (animals) is provided by Rabilloud and Lescuyer [64]. Analyses are sometimes targeted toward specific organ systems, often the liver or kidney [65], though it is important to consider that even the most targeted of drugs may have significant impacts system-wide. Notably, toxicoproteomic studies extend beyond the application of drug development and may be used to assess the toxic effects of other chemical agents such as environmental toxins and engineered nanomaterials.
Pharmacometabolomics
Metabolomics involves the broad characterization of small molecule metabolites in the cell or body fluid, representing the final culmination of gene expression, protein expression, and environmental influences in order to characterize a metabolic signature of a sample or patient. In similar fashion to the aforementioned fields of study, pharmacometabolomics entails the comparison of this metabolic signature before and after drug exposure [66]. Outcomes of these studies may allow for better understanding of the mechanisms underlying heterogeneities in drug response. Approaches may be targeted toward a pathway of interest or non-targeted and may utilize a variety of technical platforms. A recent study utilized GC–MS and NMR to identify distinct sets of metabolites indicative of survival and of disease progression in serum from lung cancer patients undergoing standard chemotherapy or radiation regimens [67]. Another recent study used a targeted LC–MS/MS approach to investigate signatures of such compounds as amino acids, acylcarnitines, and lipids in serum upon neoadjuvant trastuzumab-paclitaxel treatment in HER2-positive breast cancer patients. This group found that patients with favorable response to therapy exhibited significantly higher amounts of spermidine and lower amounts of tryptophan when compared to poor responders [68]. However, larger studies are needed to clinically validate these potential biomarkers.
Integration of pharmacogenomics and pharmacoproteomics
It is clear that research findings from the ‘omics’ fields of study, i.e. pharmacogenomics, transcriptomics, pharmacoproteomics, and associated areas of toxicoproteomics and pharmacometabolomics, should not be taken individually but instead should inform and complement one another (Fig. 1). Until recently, simultaneously-combined genomics and proteomics studies (‘proteogenomics’) had rarely been undertaken. However, advancements in systems pharmacology technologies and data management have allowed for what should be considered just the beginning of such complementing studies. One large initiative with this approach in mind is the National Cancer Institute’s Clinical Proteomic Tumor Analysis Consortium (CPTAC) [69]. The goal of the program is to identify potential cancer biomarker candidates by integrating genomic and proteomic analyses. In the “targeting genome to proteome” approach, cancer-related genome alterations first identified by genomic studies are then targeted at the protein level by proteomic measurements. In the “mapping proteome to genome” approach, broad-scale genomic and proteomic measurements are conducted simultaneously and then integrated. To date, this initiative has allowed for the unprecedented identification of protein pathways associated with genomically-annotated breast cancer samples [70] and our study on ovarian cancer samples [71]. These studies have identified novel therapeutic targets by linking genotype to phenotype, and ideally, further studies may compare the same genome and/or proteome data before and after treatment with new therapies geared toward these targets. CPTAC centers, including ours, are actively developing assays to detect and correlate candidate biomarkers. The resulting databases, as well as assay details, are posted to a free online repository in order to foster collaboration and standardization. Furthermore, in July 2016, NCI announced the launch of the Applied Proteogenomics OrganizationaL Learning and Outcomes (APOLLO) Network, a tri-agency coalition involving CPTAC, the Department of Veterans Affairs, and the Department of Defense. Through APOLLO, cancer patients will be screened for both genomic and proteomic abnormalities in order to match the patients to personalized, targeted therapies. Initially, the program will focus on a cohort of 8000 patients to investigate the genomics- and proteomics-based individualization of lung cancer treatment.
Fig. 1.
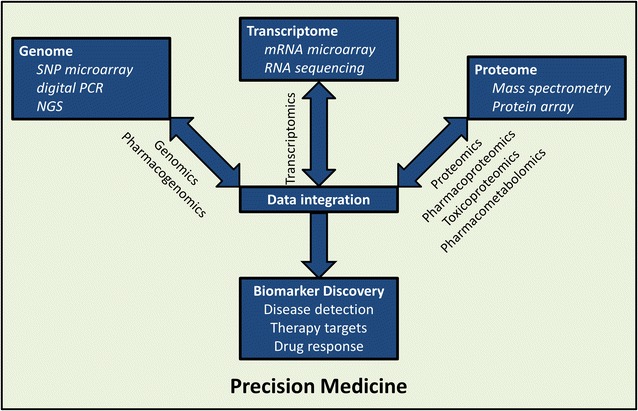
Integration of ‘omics’ technologies for precision medicine. The realization of precision medicine via the discovery and development of biomarkers for disease detection, therapy, and prediction of drug response will involve the integration of technologies which analyze control and disease-relevant samples at the genomic, transcriptomic, and proteomic levels. This schematic details some examples of such technologies. NGS next-generation sequencing
Another joint initiative stems from two additional NIH-funded multi-institution networks: the Pharmacogenomics Research Network [72] and the Pharmacometabolomics Research Network [73]. Concurrent genomic and metabolomics studies are conducted to, for instance, investigate whether genetic mutations identified as correlated with aberrant drug response are also associated with metabolites indicated for the same drug response. This approach has been coined by the networks as “pharmacometabolomics-informed-pharmacogenomics” and thus far has been applied to investigate heterogeneities in responses from pharmaceutical agents including aspirin and selective serotonin reuptake inhibitors [74]. Kaddurah-Daouk and Weinshilboum, along with the Pharmacometabolomics Research Network, provide an informative compilation of affiliated pharmacometabolomic studies in a recent review [75].
Challenges in clinical translation
While exciting advancements are paving the way for combined ‘omics’ investigations, several barriers still remain to translate resultant biomarkers into clinical practice. Practically, challenges remain in the proteomic assessment of complex tissue and body fluids, and a majority of studies conducted to date are in vitro. Thus, identified candidates may need further verification via orthogonal, targeted approaches in more clinically-relevant matrices. Data management continues to prove challenging with the tremendous amount of data that is generated by high-throughput and broad-screening technologies. Integration of data from various experiments amongst the collaborative networks in a logistical and standardized way will be imperative in order for investigators to feed off of one another to progress discoveries.
Furthermore, once data is mined and potential biomarkers are identified, those candidate markers must be progressed forward to independent validation studies before they can be translated into the realm of clinical diagnostics. Further investigations should assess: (a) the utility of the markers in clinical outcomes studies, (b) how measurements of the markers should be interpreted and acted upon, and (c) the cost-effectiveness of implementing the monitoring of the markers. The lack of such clinical validation studies remains a significant obstacle for the implementation of pharmacogenomic and pharmacoproteomic markers alike and is a large reason that testing of many well-established pharmacogenetic polymorphisms is not widely utilized and reimbursed [36].
For similar reasons, FDA approval of assays detecting laboratory-discovered proteomic and genomic biomarkers is slow. In the case of pharmacogenomics, there is a combined desire for the FDA’s inclusion of genetic test indications on the drug label in addition to FDA approval of the corresponding genetic test itself. Progress has been made steadily, and currently more than 100 drug labels contain pharmacogenetic information specifying genetic biomarkers that may be indicated for safe use of the drug [76, 77]. As of this publication, twelve commercial nucleic acid-based assays are FDA cleared or approved in the ‘drug metabolizing enzyme’ category [78], many for CYP2C9 for the identification of warfarin sensitivity. However, some hospital laboratories conducting pharmacogenetic testing are using laboratory-developed tests (LDTs). It remains to be seen how upcoming changes in FDA oversight of LDTs will impact pharmacogenetic testing [79, 80]. On the pharmacoproteomic side, challenges in approving proteomic biomarkers for clinical practice often include limitations in both analytical performance (i.e. precision, accuracy, sensitivity, specificity) and clinical performance, perhaps due to complexities in both sample preparation and spectra analysis methods [81, 82]. These limitations have raised issues of reproducibility with proteomics and have made harmonization of assays difficult across multiple laboratory sites. However, a recent significant multi-center study has demonstrated that standardization of both analytical and pre-analytical protocols can make possible the reproducibility of mass spectrometric measurement of proteins [83]. Further, genomic and transcriptomic technologies are currently universally considered highly reproducible [84].
Future outlook and conclusions
Many diseases are in need of biomarker discovery of targets for treatment and monitoring and could therefore benefit tremendously from integrated ‘omics’ approaches. Cancer may be one of the most appropriate immediate focuses due to its inherent complexity and the large number of cancer genomes which have already been sequenced through collaborative efforts (i.e. the Cancer Genome Atlas [85] and the International Cancer Genome Consortium [86]). Other critical applications include the growing health problems in our nation of diabetes and metabolic syndrome. Longitudinal gathering of genomic, transcriptomic, and proteomic data among patients at-risk for these disorders may provide insight into the mechanisms behind disease progression and reveal targets for disease detection, treatment, and monitoring. Further advances in integrated data management will be critical for these studies to be successful.
As genomic and proteomic methodologies prove their analytical performance and clinical utility, become more accessible and routine, and perhaps more portable [87], one may imagine a treatment model by which such measurements may be taken at the bedside. Pharmacogenetic screening for risks of adverse drug reactions would guide drug prescription and dosing on the front end of treatment, while pharmacoproteomic measurements taken before, during, and after interventional therapy would aid in monitoring triggered phenotypic changes. Standardization of both detection methodologies and electronic healthcare databases will be critical such that patients can be followed longitudinally throughout this process.
In conclusion, personalized ‘omics’ approaches, both at the genome and proteome levels, are actively improving our understanding of disease and drug mechanisms and are allowing for the discovery, detection, and monitoring of novel biomarkers for a variety of complex diseases and their treatments. By integrating pharmacoproteomic profiles with pharmacogenomics databases, precision medicine may be eventually fulfilled via diagnosing testing to identify the right therapeutic regimen for the right patient.
Authors’ contributions
All authors were involved in the drafting and revising of the manuscript. Both authors read and approved the final manuscript.
Competing interests
The authors declare that they have no competing interests.
Availability of data and materials
Data sharing is not applicable to this article as no datasets were generated or analyzed for this manuscript.
Abbreviations
- SNP
single nucleotide polymorphism
- SEARCH
Study of the Effectiveness of Additional Reductions in Cholesterol and Homocysteine
- CPIC
Clinical Pharmacogenetics Implementation Consortium
- FOLFOX
folinic acid, fluorouracil, and oxaliplatin
- ADME
absorption, distribution, metabolism, and excretion
- SILAC
stable isotope labeling with amino acids in cell culture
- BCR
B cell receptor
- Hsp90
heat shock protein 90
- CPTAC
Clinical Proteomic Tumor Analysis Consortium
- APOLLO
Applied Proteogenomics OrganizationaL Learning and Outcomes
Contributor Information
Allison B. Chambliss, Email: achambl2@jhmi.edu, Email: abchambl@usc.edu
Daniel W. Chan, Email: dchan@jhmi.edu
References
- 1.Kaiser J. Senate panel approves $2 billion raise for NIH in 2016. Sci Mag. 2015 [Google Scholar]
- 2.Collins FS, Varmus H. A new initiative on precision medicine. N Engl J Med. 2015;372:793–795. doi: 10.1056/NEJMp1500523. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Rogers JF, Nafziger AN, Bertino JS., Jr Pharmacogenetics affects dosing, efficacy, and toxicity of cytochrome P450-metabolized drugs. Am J Med. 2002;113:746–750. doi: 10.1016/S0002-9343(02)01363-3. [DOI] [PubMed] [Google Scholar]
- 4.Evans WE, Relling MV. Moving towards individualized medicine with pharmacogenomics. Nature. 2004;429:464–468. doi: 10.1038/nature02626. [DOI] [PubMed] [Google Scholar]
- 5.Wang WY, Barratt BJ, Clayton DG, Todd JA. Genome-wide association studies: theoretical and practical concerns. Nat Rev Genet. 2005;6:109–118. doi: 10.1038/nrg1522. [DOI] [PubMed] [Google Scholar]
- 6.Welsh M, Mangravite L, Medina MW, Tantisira K, Zhang W, Huang RS, McLeod H, Dolan ME. Pharmacogenomic discovery using cell-based models. Pharmacol Rev. 2009;61:413–429. doi: 10.1124/pr.109.001461. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Penny MA, McHale D. Pharmacogenomics and the drug discovery pipeline: when should it be implemented? Am J Pharmacogenomics. 2005;5:53–62. doi: 10.2165/00129785-200505010-00005. [DOI] [PubMed] [Google Scholar]
- 8.Wheeler HE, Dolan ME. Lymphoblastoid cell lines in pharmacogenomic discovery and clinical translation. Pharmacogenomics. 2012;13:55–70. doi: 10.2217/pgs.11.121. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Niu N, Wang L. In vitro human cell line models to predict clinical response to anticancer drugs. Pharmacogenomics. 2015;16:273–285. doi: 10.2217/pgs.14.170. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Search Collaborative Group SLCO1B1 variants and statin-induced myopathy—a genomewide study. N Engl J Med. 2008;359:789–799. doi: 10.1056/NEJMoa0801936. [DOI] [PubMed] [Google Scholar]
- 11.Li JH, Joy SV, Haga SB, Orlando LA, Kraus WE, Ginsburg GS, Voora D. Genetically guided statin therapy on statin perceptions, adherence, and cholesterol lowering: a pilot implementation study in primary care patients. J Pers Med. 2014;4:147–162. doi: 10.3390/jpm4020147. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Tardif JC, Rheaume E, Lemieux Perreault LP, Gregoire JC, Feroz Zada Y, Asselin G, et al. Pharmacogenomic determinants of the cardiovascular effects of dalcetrapib. Circ Cardiovasc Genet. 2015;8:372–382. doi: 10.1161/CIRCGENETICS.114.000663. [DOI] [PubMed] [Google Scholar]
- 13.Hu M, Tomlinson B. Pharmacogenomics of lipid-lowering therapies. Pharmacogenomics. 2013;14:981–995. doi: 10.2217/pgs.13.71. [DOI] [PubMed] [Google Scholar]
- 14.Aslibekyan S, Straka RJ, Irvin MR, Claas SA, Arnett DK. Pharmacogenomics of high-density lipoprotein-cholesterol-raising therapies. Expert Rev Cardiovasc Ther. 2013;11:355–364. doi: 10.1586/erc.12.134. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Ji Y, Schaid DJ, Desta Z, Kubo M, Batzler AJ, Snyder K, et al. Citalopram and escitalopram plasma drug and metabolite concentrations: genome-wide associations. Br J Clin Pharmacol. 2014;78:373–383. doi: 10.1111/bcp.12348. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Lin E, Lane HY. Genome-wide association studies in pharmacogenomics of antidepressants. Pharmacogenomics. 2015;16:555–566. doi: 10.2217/pgs.15.5. [DOI] [PubMed] [Google Scholar]
- 17.Wheeler HE, Maitland ML, Dolan ME, Cox NJ, Ratain MJ. Cancer pharmacogenomics: strategies and challenges. Nat Rev Genet. 2013;14:23–34. doi: 10.1038/nrg3352. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.McLeod HL. Cancer pharmacogenomics: early promise, but concerted effort needed. Science. 2013;339:1563–1566. doi: 10.1126/science.1234139. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Schroth W, Antoniadou L, Fritz P, Schwab M, Muerdter T, Zanger UM, et al. Breast cancer treatment outcome with adjuvant tamoxifen relative to patient CYP2D6 and CYP2C19 genotypes. J Clin Oncol. 2007;25:5187–5193. doi: 10.1200/JCO.2007.12.2705. [DOI] [PubMed] [Google Scholar]
- 20.Cote JF, Kirzin S, Kramar A, Mosnier JF, Diebold MD, Soubeyran I, Thirouard AS, Selves J, Laurent-Puig P, Ychou M. UGT1A1 polymorphism can predict hematologic toxicity in patients treated with irinotecan. Clin Cancer Res. 2007;13:3269–3275. doi: 10.1158/1078-0432.CCR-06-2290. [DOI] [PubMed] [Google Scholar]
- 21.Innocenti F, Schilsky RL, Ramirez J, Janisch L, Undevia S, House LK, et al. Dose-finding and pharmacokinetic study to optimize the dosing of irinotecan according to the UGT1A1 genotype of patients with cancer. J Clin Oncol. 2014;32:2328–2334. doi: 10.1200/JCO.2014.55.2307. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22.Brauch H, Schwab M. Prediction of tamoxifen outcome by genetic variation of CYP2D6 in post-menopausal women with early breast cancer. Br J Clin Pharmacol. 2014;77:695–703. doi: 10.1111/bcp.12229. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Relling MV, Klein TE. CPIC: Clinical Pharmacogenetics Implementation Consortium of the Pharmacogenomics Research Network. Clin Pharmacol Ther. 2011;89:464–467. doi: 10.1038/clpt.2010.279. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Fernandez-Rozadilla C, Cazier JB, Moreno V, Crous-Bou M, Guino E, Duran G, et al. Pharmacogenomics in colorectal cancer: a genome-wide association study to predict toxicity after 5-fluorouracil or FOLFOX administration. Pharmacogenomics J. 2013;13:209–217. doi: 10.1038/tpj.2012.2. [DOI] [PubMed] [Google Scholar]
- 25.Cao S, Wang S, Ma H, Tang S, Sun C, Dai J, et al. Genome-wide association study of myelosuppression in non-small-cell lung cancer patients with platinum-based chemotherapy. Pharmacogenomics J. 2016;16:41–46. doi: 10.1038/tpj.2015.22. [DOI] [PubMed] [Google Scholar]
- 26.Feinberg AP. The epigenetic basis of common human disease. Trans Am Clin Climatol Assoc. 2013;124:84–93. [PMC free article] [PubMed] [Google Scholar]
- 27.Hunter P. The second coming of epigenetic drugs: a more strategic and broader research framework could boost the development of new drugs to modify epigenetic factors and gene expression. EMBO Rep. 2015;16:276–279. doi: 10.15252/embr.201540121. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28.Tang J, Xiong Y, Zhou HH, Chen XP. DNA methylation and personalized medicine. J Clin Pharm Ther. 2014;39:621–627. doi: 10.1111/jcpt.12206. [DOI] [PubMed] [Google Scholar]
- 29.Guengerich FP. Cytochrome p450 and chemical toxicology. Chem Res Toxicol. 2008;21:70–83. doi: 10.1021/tx700079z. [DOI] [PubMed] [Google Scholar]
- 30.Zanger UM, Turpeinen M, Klein K, Schwab M. Functional pharmacogenetics/genomics of human cytochromes P450 involved in drug biotransformation. Anal Bioanal Chem. 2008;392:1093–1108. doi: 10.1007/s00216-008-2291-6. [DOI] [PubMed] [Google Scholar]
- 31.Fisel P, Schaeffeler E, Schwab M. DNA methylation of ADME genes. Clin Pharmacol Ther. 2016;99:512–527. doi: 10.1002/cpt.343. [DOI] [PubMed] [Google Scholar]
- 32.Iorio F, Knijnenburg TA, Vis DJ, Bignell GR, Menden MP, Schubert M, et al. A landscape of pharmacogenomic interactions in cancer. Cell. 2016;166(3):740–754. doi: 10.1016/j.cell.2016.06.017. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Motsinger-Reif AA, Jorgenson E, Relling MV, Kroetz DL, Weinshilboum R, Cox NJ, Roden DM. Genome-wide association studies in pharmacogenomics: successes and lessons. Pharmacogenet Genom. 2013;23:383–394. doi: 10.1097/FPC.0b013e32833d7b45. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Price MJ, Carson AR, Murray SS, Phillips T, Janel L, Tisch R, et al. First pharmacogenomic analysis using whole exome sequencing to identify novel genetic determinants of clopidogrel response variability: results of the genotype information and functional testing (GIFT) exome study. J Am Coll Cardiol. 2012;59(13s1):E9. doi: 10.1016/S0735-1097(12)60010-2. [DOI] [Google Scholar]
- 35.Wagle N, Grabiner BC, Van Allen EM, Hodis E, Jacobus S, Supko JG, Stewart M, et al. Activating mTOR mutations in a patient with an extraordinary response on a phase I trial of everolimus and pazopanib. Cancer Discov. 2014;4:546–553. doi: 10.1158/2159-8290.CD-13-0353. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Relling MV, Evans WE. Pharmacogenomics in the clinic. Nature. 2015;526:343–350. doi: 10.1038/nature15817. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Vogel C, Abreu Rde S, Ko D, Le SY, Shapiro BA, Burns SC, et al. Sequence signatures and mRNA concentration can explain two-thirds of protein abundance variation in a human cell line. Mol Syst Biol. 2010;6:400. doi: 10.1038/msb.2010.59. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Ezkurdia I, Juan D, Rodriguez JM, Frankish A, Diekhans M, Harrow J, et al. Multiple evidence strands suggest that there may be as few as 19,000 human protein-coding genes. Hum Mol Genet. 2014;23:5866–5878. doi: 10.1093/hmg/ddu309. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Jain KK. Role of pharmacoproteomics in the development of personalized medicine. Pharmacogenomics. 2004;5:331–336. doi: 10.1517/phgs.5.3.331.29830. [DOI] [PubMed] [Google Scholar]
- 40.Wang Z, Gerstein M, Snyder M. RNA-Seq: a revolutionary tool for transcriptomics. Nat Rev Genet. 2009;10(1):57–63. doi: 10.1038/nrg2484. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Haider S, Pal R. Integrated analysis of transcriptomic and proteomic data. Curr Genom. 2013;14(2):91–110. doi: 10.2174/1389202911314020003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Chapal N, Molina L, Molina F, Laplanche M, Pau B, Petit P. Pharmacoproteomic approach to the study of drug mode of action, toxicity, and resistance: applications in diabetes and cancer. Fundam Clin Pharmacol. 2004;18:413–422. doi: 10.1111/j.1472-8206.2004.00258.x. [DOI] [PubMed] [Google Scholar]
- 43.Witzmann FA, Grant RA. Pharmacoproteomics in drug development. Pharmacogenomics J. 2003;3:69–76. doi: 10.1038/sj.tpj.6500164. [DOI] [PubMed] [Google Scholar]
- 44.Meister W. Pharmacogenomics/pharmacoproteomics Europe. Pharmacogenomics. 2002;3:449–452. doi: 10.1517/14622416.3.4.449. [DOI] [PubMed] [Google Scholar]
- 45.Hay M, Thomas DW, Craighead JL, Economides C, Rosenthal J. Clinical development success rates for investigational drugs. Nat Biotechnol. 2014;32:40–51. doi: 10.1038/nbt.2786. [DOI] [PubMed] [Google Scholar]
- 46.Nomura DK, Dix MM, Cravatt BF. Activity-based protein profiling for biochemical pathway discovery in cancer. Nat Rev Cancer. 2010;10:630–638. doi: 10.1038/nrc2901. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Rix U, Superti-Furga G. Target profiling of small molecules by chemical proteomics. Nat Chem Biol. 2009;5:616–624. doi: 10.1038/nchembio.216. [DOI] [PubMed] [Google Scholar]
- 48.Willems LI, Overkleeft HS, van Kasteren SI. Current developments in activity-based protein profiling. Bioconjug Chem. 2014;25:1181–1191. doi: 10.1021/bc500208y. [DOI] [PubMed] [Google Scholar]
- 49.Ong SE, Blagoev B, Kratchmarova I, Kristensen DB, Steen H, Pandey A, Mann M. Stable isotope labeling by amino acids in cell culture, SILAC, as a simple and accurate approach to expression proteomics. Mol Cell Proteom. 2002;1:376–386. doi: 10.1074/mcp.M200025-MCP200. [DOI] [PubMed] [Google Scholar]
- 50.Beck M, Schmidt A, Malmstroem J, Claassen M, Ori A, Szymborska A, et al. The quantitative proteome of a human cell line. Mol Syst Biol. 2011;7:549. doi: 10.1038/msb.2011.82. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51.Nagaraj N, Wisniewski JR, Geiger T, Cox J, Kircher M, Kelso J, et al. Deep proteome and transcriptome mapping of a human cancer cell line. Mol Syst Biol. 2011;7:548. doi: 10.1038/msb.2011.81. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52.Prieto DA, Johann DJ, Jr, Wei BR, Ye X, Chan KC, Nissley DV, et al. Mass spectrometry in cancer biomarker research: a case for immunodepletion of abundant blood-derived proteins from clinical tissue specimens. Biomark Med. 2014;8:269–286. doi: 10.2217/bmm.13.101. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Klammer M, Kaminski M, Zedler A, Oppermann F, Blencke S, Marx S, et al. Phosphosignature predicts dasatinib response in non-small cell lung cancer. Mol Cell Proteom. 2012;11:651–668. doi: 10.1074/mcp.M111.016410. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Kingsmore SF. Multiplexed protein measurement: technologies and applications of protein and antibody arrays. Nat Rev Drug Discov. 2006;5(4):310–320. doi: 10.1038/nrd2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55.Ong SE, Schenone M, Margolin AA, Li X, Do K, Doud MK, et al. Identifying the proteins to which small-molecule probes and drugs bind in cells. Proc Natl Acad Sci U S A. 2009;106:4617–4622. doi: 10.1073/pnas.0900191106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 56.Colzani M, Noberini R, Romanenghi M, Colella G, Pasi M, Fancelli D, et al. Quantitative chemical proteomics identifies novel targets of the anti-cancer multi-kinase inhibitor E-3810. Mol Cell Proteom. 2014;13:1495–1509. doi: 10.1074/mcp.M113.034173. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.Kronke J, Udeshi ND, Narla A, Grauman P, Hurst SN, McConkey M, et al. Lenalidomide causes selective degradation of IKZF1 and IKZF3 in multiple myeloma cells. Science. 2014;343:301–305. doi: 10.1126/science.1244851. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Raj L, Ide T, Gurkar AU, Foley M, Schenone M, Li X, et al. Selective killing of cancer cells by a small molecule targeting the stress response to ROS. Nature. 2011;475:231–234. doi: 10.1038/nature10167. [DOI] [PMC free article] [PubMed] [Google Scholar] [Retracted]
- 59.Moellering RE, Cravatt BF. How chemoproteomics can enable drug discovery and development. Chem Biol. 2012;19:11–22. doi: 10.1016/j.chembiol.2012.01.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60.Goldstein RL, Yang SN, Taldone T, Chang B, Gerecitano J, Elenitoba-Johnson K, et al. Pharmacoproteomics identifies combinatorial therapy targets for diffuse large B cell lymphoma. J Clin Invest. 2015;125:4559–4571. doi: 10.1172/JCI80714. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61.Ning MM, Lopez M, Sarracino D, Cao J, Karchin M, McMullin D, et al. Pharmaco-proteomics opportunities for individualizing neurovascular treatment. Neurol Res. 2013;35:448–456. doi: 10.1179/1743132813Y.0000000213. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62.Ohtsuki S, Hirayama M, Ito S, Uchida Y, Tachikawa M, Terasaki T. Quantitative targeted proteomics for understanding the blood-brain barrier: towards pharmacoproteomics. Expert Rev Proteom. 2014;11:303–313. doi: 10.1586/14789450.2014.893830. [DOI] [PubMed] [Google Scholar]
- 63.Wetmore BA, Merrick BA. Toxicoproteomics: proteomics applied to toxicology and pathology. Toxicol Pathol. 2004;32:619–642. doi: 10.1080/01926230490518244. [DOI] [PubMed] [Google Scholar]
- 64.Rabilloud T, Lescuyer P. Proteomics in mechanistic toxicology: history, concepts, achievements, caveats, and potential. Proteomics. 2015;15:1051–1074. doi: 10.1002/pmic.201400288. [DOI] [PubMed] [Google Scholar]
- 65.Van Summeren A, Renes J, van Delft JH, Kleinjans JC, Mariman EC. Proteomics in the search for mechanisms and biomarkers of drug-induced hepatotoxicity. Toxicol In Vitro. 2012;26:373–385. doi: 10.1016/j.tiv.2012.01.012. [DOI] [PubMed] [Google Scholar]
- 66.Kaddurah-Daouk R, Weinshilboum RM, Pharmacometabolomics Research N Pharmacometabolomics: implications for clinical pharmacology and systems pharmacology. Clin Pharmacol Ther. 2014;95:154–167. doi: 10.1038/clpt.2013.217. [DOI] [PubMed] [Google Scholar]
- 67.Hao D, Sarfaraz MO, Farshidfar F, Bebb DG, Lee CY, Card CM, et al. Temporal characterization of serum metabolite signatures in lung cancer patients undergoing treatment. Metabolomics. 2016;12:58. doi: 10.1007/s11306-016-0961-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 68.Miolo G, Muraro E, Caruso D, Crivellari D, Ash A, Scalone S, et al. Phamacometabolomics study identifies circulating spermidine and tryptophan as potential biomarkers associated with the complete pathological response to trastuzumab-paclitaxel neoadjuvant therapy in HER-2 positive breast cancer. Oncotarget. 2016. [DOI] [PMC free article] [PubMed]
- 69.National Cancer Institute Clinical Proteomic Tumor Analysis Consortium. http://proteomics.cancer.gov/programs/cptacnetwork. Accessed 29 July 2016.
- 70.Mertins P, Mani DR, Ruggles KV, Gillette MA, Clauser KR, Wang P, et al. Proteogenomics connects somatic mutations to signalling in breast cancer. Nature. 2016;534:55–62. doi: 10.1038/nature18003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 71.Zhang H, Liu T, Zhang Z, Payne SH, Zhang B, McDermott JE, et al. Integrated proteogenomic characterization of human high-grade serous ovarian cancer. Cell. 2016;166:755–765. doi: 10.1016/j.cell.2016.05.069. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 72.Pharmacogenomics Research Network. http://www.pgrn.org. Accessed 29 July 2016.
- 73.Pharmacometabolomics Research Network. https://pharmacometabolomics.duhs.duke.edu/home. Accessed 29 July 2016.
- 74.Neavin D, Kaddurah-Daouk R, Weinshilboum R. Pharmacometabolomics informs pharmacogenomics. Metabolomics. 2016;12:121. doi: 10.1007/s11306-016-1066-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 75.Kaddurah-Daouk R, Weinshilboum R, Pharmacometabolomics Research Network Metabolomic signatures for drug response phenotypes: pharmacometabolomics enables precision medicine. Clin Pharmacol Ther. 2015;98:71–75. doi: 10.1002/cpt.134. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 76.U.S. Food and Drug Administration. Table of pharmacogenomic biomarkers in drug labeling. http://www.fda.gov/Drugs/ScienceResearch/ResearchAreas/Pharmacogenetics/ucm083378.htm (2016). Accessed 29 July 2016.
- 77.Tutton R. Pharmacogenomic biomarkers in drug labels: what do they tell us? Pharmacogenomics. 2014;15:297–304. doi: 10.2217/pgs.13.198. [DOI] [PubMed] [Google Scholar]
- 78.U.S. Food and Drug Administration. Nucleic acid based tests. http://www.fda.gov/MedicalDevices/ProductsandMedicalProcedures/InVitroDiagnostics/ucm330711.htm. Accessed 29 July 2016.
- 79.Draft Guidance for Industry, Food and Drug Administration Staff, and Clinical Laboratories: Framework for regulatory oversight of laboratory developed tests (LDTs). U.S. Department of Health and Human Services Food and Drug Administration, Docket no. FDA-2011-D-0360; 2014.
- 80.Levy KD, Pratt VM, Skaar TC, Vance GH, Flockhart DA. FDA’s draft guidance on laboratory-developed tests increases clinical and economic risk to adoption of pharmacogenetic testing. J Clin Pharmacol. 2015;55:725–727. doi: 10.1002/jcph.492. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 81.Fuzery AK, Levin J, Chan MM, Chan DW. Translation of proteomic biomarkers into FDA approved cancer diagnostics: issues and challenges. Clin Proteom. 2013;10:13. doi: 10.1186/1559-0275-10-13. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 82.Tabb DL, Vega-Montoto L, Rudnick PA, Variyath AM, Ham AL, Bunk DM, et al. Repeatability and reproducibility in proteomic identifications by liquid chromatography—tandem mass spectrometry. J Proteome Res. 2010;9(2):761. doi: 10.1021/pr9006365. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 83.Addona TA, Abbatiello SE, Schilling B, Skates SJ, Mani DR, Bunk DM, et al. Multi-site assessment of the precision and reproducibility of multiple reaction monitoring-based measurements of proteins in plasma. Nat Biotechnol. 2009;27:633–641. doi: 10.1038/nbt.1546. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 84.Marioni JC, Mason CE, Mane SM, Stephens M, Gilad Y. RNA-seq: an assessment of technical reproducibility and comparison with gene expression arrays. Genome Res. 2008;18:1509–1517. doi: 10.1101/gr.079558.108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 85.NIH Cancer Genome Atlas. http://cancergenome.nih.gov. Accessed 8 Sept 2016.
- 86.The International Cancer Genome Consortium. http://www.icgc.org. Accessed 8 Sept 2016.
- 87.Ferreira CR, Yannell KE, Jarmusch AK, Pirro V, Ouyang Z, Cooks RG. Ambient ionization mass spectrometry for point-of-care diagnostics and other clinical measurements. Clin Chem. 2016;62:99–110. doi: 10.1373/clinchem.2014.237164. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
Data sharing is not applicable to this article as no datasets were generated or analyzed for this manuscript.