

Summary
Prokaryotic adaptive immune systems are composed of clustered regularly interspaced short palindromic repeats (CRISPR) and CRISPR-associated (Cas) proteins. These systems adapt to new threats by integrating short nucleic acids, termed spacers, into the CRISPR array. The functional motifs in the repeat and the mechanism by which a constant repeat size is maintained are still elusive. Here, through a series of mutations within the repeat of the CRISPR-Cas type I-E, we identify motifs that are crucial for adaptation and show that they serve as anchor sites for two molecular rulers determining the size of the new repeat. Adaptation products from various repeat mutants support a model in which two motifs in the repeat bind to two different sites in the adaptation complex that are 8 and 16 bp away from the active site. This model significantly extends our understanding of the adaptation process and broadens the scope of its applications.
Keywords: adaptation, spacer integration, elongated repeat, shortened repeat, anchor site
Graphical Abstract
Highlights
-
•
Inverted repeats in the type I-E CRISPR-Cas system are essential for adaptation
-
•
Each inverted repeat encodes a motif serving as an anchor site for a molecular ruler
-
•
These molecular rulers determine the spacer insertion site regardless of the sequence
-
•
The findings support a model considering all known steps in spacer adaptation
Goren et al. map elements that are essential for adaptation in the E. coli CRISPR-Cas type I-E repeat. Two elements were identified as anchor sites for two molecular rulers that maintain a constant repeat size. Their findings support a comprehensive model for spacer adaptation.
Introduction
Clustered regularly interspaced short palindromic repeats (CRISPR) and CRISPR-associated (Cas) proteins have been identified as central components of prokaryotic immune systems (Barrangou et al., 2007). These intriguing systems are found in up to 90% of archaeal genomes and in ∼50% of bacterial genomes (Sorek et al., 2013) and are analogous to the mammalian immune system (Abedon, 2012, Goren et al., 2012b). Various types of CRISPR-Cas systems (Makarova et al., 2011, Makarova et al., 2015) defend prokaryotes against viruses and horizontally transferred DNA (Barrangou et al., 2007, Brouns et al., 2008, Marraffini and Sontheimer, 2008) and RNA (Abudayyeh et al., 2016, Hale et al., 2009, Staals et al., 2014). The genetic loci of all systems include a CRISPR array—short repeated sequences, called “repeats,” that flank similarly sized sequences, called “spacers.” The spacers are acquired from DNA sequences termed “protospacers.” Their incorporation into the bacterial CRISPR array, termed “adaptation,” enhances the spacer repertoire of the array against foreign elements. The CRISPR array is usually preceded by a “leader” DNA sequence that is located near a cluster of cas genes (Deveau et al., 2010, Marraffini and Sontheimer, 2010, Sorek et al., 2008). RNA transcribed from the CRISPR array (crRNA) is processed by Cas proteins into RNA-based spacers flanked by partial repeats. These RNA spacers specifically direct Cas interference proteins to target and cleave nucleic acids encoding matching protospacers. Thus, the system can adaptively and specifically target invaders.
The adaptation process has been thoroughly characterized for the type I-E CRISPR-Cas system in the model organism Escherichia coli (Sternberg et al., 2016). In vivo, two proteins, Cas1 and Cas2, are both necessary and sufficient for acquiring new spacers in this system (Yosef et al., 2012). Expression of these two proteins from a plasmid results in significant spacer adaptation into CRISPR arrays. Adaptation requiring only Cas1 and Cas2 proteins is termed “naive,” as opposed to “primed” adaptation, which requires additional Cas proteins guided by a targeting spacer (Datsenko et al., 2012). These in vivo findings have been supported in vitro by naive adaptation experiments comprising Cas1, Cas2, a CRISPR array, and a donor spacer (Nuñez et al., 2015b, Rollie et al., 2015).
A single repeat of 28 bp is both necessary and sufficient for adaptation (Goren et al., 2012a, Yosef et al., 2012). The repeat encodes a heptameric palindrome composed of two inverted repeats (IRs) interspaced by 4 nt that can form a stem-loop structure in a single-strand nucleic acid. This secondary structure in the mature crRNA is thought to serve as a “molecular handle” for the interference proteins (Gesner et al., 2011, Sashital et al., 2011). Bioinformatics analysis has shown that the IRs are the most conserved sequences in the type I-E repeat, whereas the sequence connecting the IRs is the least conserved (Kunin et al., 2007). Although the IRs have been shown to be required for the adaptation step (Arslan et al., 2014), a thorough characterization of the entire repeat element has not been reported for the type I-E system.
A recent report did thoroughly characterize the repeat element in Haloarcula hispanica (Wang et al., 2016). However, that study focused solely on primed adaptation, because there is no system for studying naive adaptation in that archaeon (Li et al., 2014). The study showed that certain substitutions in the leader-proximal end of the repeat significantly reduce adaptation efficiency. The leader-proximal IR (IR1) was important for adaptation, as mutating it reduced adaptation significantly. Interestingly, the leader-distal IR (IR2) could be mutated without detrimental effect on adaptation. A second motif between these two IRs was found to be important for adaptation, as mutating it reduced adaptation significantly. This motif was suggested to serve as an anchor site for a molecular ruler that measures a specific distance from which the spacer is inserted. This putative molecular ruler inserted the spacer 8 nt downstream of the end of this motif regardless of the sequence of the downstream nucleotides. Overall, the study showed that in a primed type I-B adaptation system, the adaptation machinery probably recognizes two sites (Wang et al., 2016). One site, at the leader-repeat junction, serves as a docking site for the protein complex, and the other probably serves as an anchor for a molecular ruler that measures a specific length, regardless of the downstream sequence.
In the present study, we searched for motifs in the repeat that are essential for spacer adaptation in the E. coli type I-E system and possibly determine the fidelity of the process and the maintenance of a constant repeat size. We found that the IRs, as well as their orientation, are essential for efficient adaptation, whereas other elements are not. Most significantly, we found that motifs in these IRs are anchor sites from which a constant distance is measured to initiate the leader-distal nucleophilic attack. The differences and similarities between type I-E and I-B systems are discussed and highlight a mechanism for “quality control” of size determination in the adaptation process that ensures a constant repeat size is maintained.
Results
Experimental Setup
To identify motifs in the repeat affecting the efficiency and fidelity of spacer acquisition, we used a plasmid-based adaptation assay. The plasmid encoded a leader-repeat sequence as well as Cas1 and Cas2 expressed from an inducible promoter (Figure S1). The plasmid was transformed into E. coli BL21-AI, lacking the interference cas genes (Brouns et al., 2008) and deleted for one of its endogenous CRISPR arrays. Following Cas1 and Cas2 expression, DNA from a sample of the culture was used as a template for PCR amplification of the adapted region. To determine the extent of adaptation and the size and sequence of the newly inserted repeats, the obtained products were analyzed by high-throughput DNA sequencing, as elaborated in Experimental Procedures. This system thus allowed us to efficiently monitor adaptation under naive conditions.
Determining Motifs Required for Adaptation
Analysis of spacer acquisition into a plasmid encoding a wild-type (WT) repeat indicated that ∼14% of the templates contain new spacer-repeat insertions (Figure 1, WT). We tested repeats having substitution mutations in the leader-proximal end, the region between the IRs, the leader-distal end, and the IRs. Spacer acquisition in all mutants outside the IRs was only up to 3-fold reduced compared to spacer acquisition into the WT repeat (Figure 1, repeats S1–S3). Conversely, mutations in the IRs reduced the adaptation efficiency ∼100-fold compared to the WT repeat (Figure 1, repeat S4). This reduction was also detected when each IR was individually mutated (Figure 1, repeats S5 and S6). Moreover, maintaining the IR sequences but reversing their orientation also significantly reduced adaptation efficiency (Figure 1, repeat S7). These results demonstrated that the IR sequences, as well as their orientation, are major determinants of adaptation, whereas other regions of the repeat are less important for adaptation efficiency.
Figure 1.

Determination of Essential Elements in the Repeat
Adaptation assays were carried out for the different repeat variants as described in Experimental Procedures. Each box represents a nucleotide of the indicated repeat as follows: green, leader-proximal region; red, IRs; orange, region between IRs; blue, leader-distal region; X, substitution mutation. Percentage of adaptation efficiency was determined by analyzing high-throughput DNA sequencing products as described in Experimental Procedures.
Identifying an Anchor Motif for a Molecular Ruler
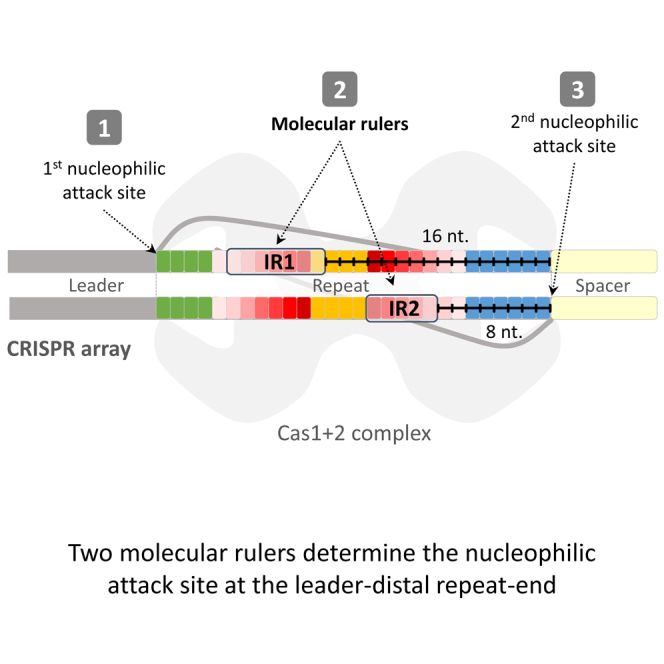
We speculated that at least one of these IRs serves as a docking site for the Cas1–Cas2 integrase, as shown by Xiang and colleagues for the type I-B system (Wang et al., 2016). We therefore generated single-nucleotide deletions across the repeat sequence as shown in Figure 2A. We expected that a deletion upstream of such a docking site would simply be duplicated, resulting in a 27-bp repeat, which is shorter than the WT repeat due to the deleted nucleotide. On the other hand, deletion downstream of the docking site would result in a regular-sized 28-bp repeat, as the molecular ruler would measure a defined distance downstream to this site, regardless of the deletion. Therefore, in these cases, a single nucleotide from the sequence immediately downstream of the repeat would be added to the repeat. Indeed, deletions from the leader-proximal end of the repeat up to the leader-distal IR (IR2) resulted, in over 97% of the cases, in a duplicated 27-bp repeat (Figure 2A, repeats D1–D6). Deletions of nucleotides downstream of a motif in the IR2 resulted almost exclusively (>98%) in a repeat that was extended by a single G nucleotide, the nucleotide found immediately adjacent to the repeat (Figure 2A, repeats D7–D10). These results indicated that the “GCGGG” motif (or some part thereof) in IR2 serves as an anchor site for a molecular ruler. The spacer is inserted 8 nucleotides downstream of the end of this motif, probably as a result of a molecular ruler that dictates nucleophilic attack of the spacer 8 nt downstream of the end of this motif (see also Figure 4 for graphical illustrations of these results).
Figure 2.

Determination of Anchor Sites for a Molecular Ruler
Experiment and representation as described for Figure 1 except that arrowheads represent location of a single nucleotide deletion (A) or insertion (B). Percentage of new repeat length was determined as described in Experimental Procedures.
Figure 4.

Schematic Summary of the Results Leading to a Proposed Model
(A–C) Schematics of the repeats and spacer-insertion sites. Arrows point to 16 and 8 bp from the end of the IR1 and IR2 motifs, respectively, where most spacer insertions were observed.
(D and E) Same as (A)–(C). Thickness of arrows correlates schematically with spacer insertions at the indicated site (not to scale).
(F) A model depicting the two anchor sites (fully colored boxes) for two molecular rulers (black-marked lines). In accordance with the structure, four Cas1 (light blue) and two Cas2 (yellow) form a heteromeric complex binding a protospacer substrate (gray strands). We envision that the complex also binds the repeat (boxed letters) at the two identified anchor sites. The ends of these sites are positioned 8 and 16 bp away from the active site (dark gray half circle) of nucleophilic attack on the repeat.
Identifying an Additional Anchor Motif for a Molecular Ruler
We speculated that single-nucleotide insertions upstream of the newly identified docking site would result in duplicated 29-bp repeats (longer than the 28-bp WT repeats due to the nucleotide insertion), whereas nucleotide insertions downstream of this docking site would result in a regular-sized repeat due to the molecular ruler that measures 8 nucleotides downstream of the motif. Indeed, insertion downstream of the motif resulted in a regular-sized repeat (Figure 2B, repeats I6–I8). Surprisingly however, several nucleotide insertions upstream of this motif also resulted in regular-sized repeats (Figure 2B, repeats I3–I5). These insertions were located between IR2 and the leader-proximal IR1. Insertions upstream of IR1 resulted in mostly (>76%) duplicated 29 bp repeats (Figure 2B, repeats I1 and I2). These results suggested that IR1 also encodes a “CCCCGCG” motif (or some part thereof) that serves as a docking site for another molecular ruler. The distance measured from the end of this motif to the spacer-insertion site was 16 nucleotides. Apparently, the measurement of 16 nt from this motif was masked in the repeat deletion mutants shown in Figure 2A. Thus, the “ruler measurement” of IR1 is masked by the ruler activity of IR2 in cases where the repeat is being lengthened to the regular length but is revealed when the repeat is being shortened to the regular length. The dominant ruler is the one that measures the shorter distance in each case. These results revealed an additional anchor site for a molecular ruler.
Validation of Both Anchor Sites
We hypothesized that a nucleotide deletion between IR1 and IR2 would be processed to a regular-sized repeat if the IR2 molecular ruler is disabled. In this case, IR1 would be the only anchor site for a molecular ruler, and would be unmasked by the molecular ruler of IR2. We therefore constructed a series of substitution mutants in the IR2 motif in repeats having a deletion between IR1 and IR2, and monitored repeat length in the products. As speculated, we observed that some of the mutations disrupted the suspected motif in IR2 and have led to repeats lengthened by 1 bp. Specifically, a single A substitution in the second base of IR2 led to elevation of the percentage of lengthened repeats from 1.31% in the parental repeat to 45.76% in the mutant (Figure 3A, D5S2), suggesting that this base is central to the anchor motif in IR2. In accordance, a mutation that included the same A substitution, in addition to two A substitutions in its flanking bases, resulted in >91% of the new repeats being longer (Figure 3A, D5S6), further suggesting that these mutations disrupted the IR2 anchor motif. These results clearly indicated that, indeed, IR1 is an anchor for a molecular ruler that is masked by the presence of the IR2 molecular ruler.
Figure 3.

Validation of Anchor Sites
Experiment and representation as described for Figure 2.
We further speculated that mutating the IR1 motif in repeats having an insertion between IR1 and IR2 would eliminate the shortening of the repeat to a regular-sized one. This would result because IR1 is the only anchor site for a molecular ruler that is found upstream of this insertion, whereas the downstream IR2 does not “measure” such an insertion. We therefore constructed a mutant having an insertion between IR1 and IR2, in addition to a 3-A substitution in IR1. This mutant significantly increased the proportion of repeats that remained long, as predicted. The percentage of long repeats increased >10-fold from 0.64% in the parental repeat (Figure 3B, repeat I4) to 6.89% in these settings (Figure 3B, repeat I4S1). We hypothesize that the introduced substitutions did not entirely disable the activity of the IR1 ruler, and thus repeat shortening remained relatively high. The importance of this anchor site in adaptation was reflected in the low acquisition detected from this 3-bp-substitution mutant. This result further indicated that motifs in both IR1 and IR2 function as anchors for molecular rulers. Taken together, these results demonstrate the presence of two independent anchor sites for two molecular rulers measuring distinct distances.
Discussion
We studied the requirement for each element in the repeat sequence for efficiency and fidelity of adaptation. We found that the only essential elements in the repeats are the IRs; the other elements could be individually mutated. The most important finding of this study was that both of the IRs encode motifs that serve as anchors for two distinct molecular rulers that determine the distance of the nucleophilic attack on the leader-distal end. These motifs maintain a constant-sized repeat by lengthening or shortening an irregular-sized repeat to the regular size.
Xiang and colleagues characterized the type I-B repeats by substitution, deletion, and insertion mutations in the repeat’s elements followed by Sanger sequencing of several products. Interestingly, they found that the leader-proximal end of the repeat is essential for adaptation. Certain substitutions in this region completely abrogated adaptation, whereas others only mildly impaired it (Wang et al., 2016). IR1 was essential for adaptation and possibly served as a docking site for the protein complex, whereas IR2 was not. In addition, mutating the region between the two IRs resulted in significantly reduced adaptation. Thus, a major difference between type I-B and type I-E is that in the latter, the nucleotides between the IRs are dispensable, whereas both of the IRs are essential. There are also differences in the proteins and spacers required for proper adaptation: currently, type I-B can only be studied in a primed state (Li et al., 2014), whereas type I-E can be studied in both states (Datsenko et al., 2012, Swarts et al., 2012, Yosef et al., 2012). Thus, type I-B strictly requires the presence of the interference proteins and a targeting spacer for adaptation of a new spacer (most likely for generation of spacers, but not for the spacer integration step). In addition, the type I-B adaptation complex probably requires the non-interference protein Cas4 for adaptation, whereas type I-E does not (Li et al., 2014). These differences indicate that systems of the same type exhibit different mechanisms for spacer adaptation.
The most significant difference is that type I-E has two anchor sites for molecular rulers within the IRs, whereas in type I-B, only a single putative site was found between the two IRs (Wang et al., 2016). In all cases in the latter study, insertions and deletions upstream of this type I-B motif resulted in the expected repeat duplication. In addition, in most cases, deletions and insertions downstream of it resulted in lengthened or shortened repeats, respectively, as expected (Wang et al., 2016).
In this work, we found two anchor sites for molecular rulers, each measuring a different distance and eventually coordinating a nucleophilic attack at the repeat-spacer junction in the WT repeat. The existence of two docking sites for molecular rulers may serve as “quality control” for size determination and to maintain a constant repeat size. The first nucleophilic attack is dictated by the position of the leader-repeat junction (Nuñez et al., 2015b, Rollie et al., 2015), and therefore, the rulers determine the distance to the second nucleophilic attack, at the leader-spacer junction. In the WT repeat, both rulers deliver the repeat to the same site, where nucleophilic attack of the spacer takes place (Figure 4A). In repeats encoding a deletion or insertion upstream of both IRs, the two molecular rulers both “miss” the length correction but both deliver the repeat at the same site for spacer nucleophilic attack (Figure 4B). In repeats encoding a deletion or insertion downstream of both IRs, both molecular rulers correct the size by either extending the repeat length in the case of a deletion or shortening it in the case of an insertion (Figure 4C). In repeats encoding a deletion or insertion between the two molecular rulers, the molecular ruler that shortens the repeat dominates (Figure 4D). We speculate that this is because the repeat cannot be delivered for nucleophilic attack at a distance of more than 8 or 16 nt from the anchor site due to tight docking. It is only when one of these docking sites is mutated that the other molecular ruler can take over (Figure 4E). We suppose that in this case, the mutated motif does not dock the repeat, and therefore, the other site is allowed to deliver the repeat for nucleophilic attack at its programmed distance. Mutating the IR2 allows total domination of IR1, whereas mutating IR1 allows increased domination of IR2 rather than total domination. One may speculate that IR1 and the leader-repeat docking site are on the same protein subunit in the complex and thus less flexibility is allowed in IR1 substitution, whereas IR2 is on a different protein subunit in the complex, thus allowing more flexibility in its substitution. Another possibility is that the IR1 anchor helps define the first integration site at the leader-repeat junction, and therefore, its absence is more pronounced on adaptation.
The integration complex has intrinsic symmetry in its structure (Nuñez et al., 2015a, Wang et al., 2015). Despite this symmetry, which suggests that the mechanism of integration would be symmetrical as well, directional adaptation is observed with regard to the protospacer adjacent motif (PAM) sequence (Nuñez et al., 2015a, Wang et al., 2015, Yosef et al., 2012). The asymmetrical mechanism is also reflected in the two molecular rulers measuring two distinct distances in the same direction, rather than similar distance in opposite directions. This directionality is probably dictated by the docking site that is recognized at the leader-repeat junction, dictating that the measurement would be to the other end lacking a distinct docking site. Thus, the asymmetry of the docking sites flanking the repeat probably dictate the asymmetrical mechanism operating in the integration machinery.
What is the mechanism maintaining constant repeat size in other CRISPR-Cas systems? As shown for type I-B, a ruler that is not located in IR1 or IR2, but rather between these two motifs serves as a molecular ruler. Other CRISPR-Cas systems, such as the type II-A in Streptococcus pyogenes, have their IRs in the extreme ends of the repeat. We speculate that in that case, the IRs would serve as direct attachment sites to the integration complex and consequently would be directly involved in the nucleophilic attack. This mechanism would preserve the repeat size without molecular rulers. In cases where there are no IRs in the repeat, we speculate that the leader-repeat junction may serve as one docking site, and another site will serve as a docking site for a molecular ruler, as is the case in the type I-B system. Altogether, we believe that various types of CRISPR-Cas evolved distinct mechanisms but with similar principles to maintain the periodicity of the array.
Our observations of adaptation into mutated repeats are explained by the function of these two motifs, serving as anchor sites, and substantiate the model shown in Figure 4F. This model is based on recent in vitro work and structural studies (Nuñez et al., 2015a, Nuñez et al., 2015b, Rollie et al., 2015, Wang et al., 2015). Those studies revealed that the adaptation proteins Cas1 and Cas2 bind the 5′ and 3′ ends of the newly inserted spacer during the integration process, enabling nucleophilic attack at the integration sites. The structure of these proteins with the repeat and spacer DNAs has not yet been published. Thus, our study is important for elucidating one of the remaining unresolved stages of the adaptation process: the delivery of the repeat to the spacer for nucleophilic attack. A crystal structure containing the repeat and spacer should reveal the exact contact residues of the proteins with the repeats. Rational modification of these residues may produce proteins generating repeats of various lengths, which in turn will extend the repertoire of adaptation products used for different applications (e.g., Shipman et al., 2016). Our results also contribute to such applications as they map the elements that are permutable and can thus significantly extend the repertoire of barcoded functional repeats.
Experimental Procedures
Reagents, Strains, Plasmids, and Plasmid Constructions
The above are described in Supplemental Experimental Procedures.
Adaptation Assay
A single colony from each IYB5283 strain harboring the different pCas1+2R mutant plasmids was inoculated in lysogeny-broth (LB) medium containing 50 μg/ml streptomycin and aerated at 37°C for 16 hr. Each of the overnight cultures was then diluted 1:300 in LB medium containing 50 μg/ml streptomycin with 0.2% (w/v) L-arabinose + 0.1 mM isopropyl β-D-1-thiogalactopyranoside (IPTG) and grown for an additional 10–16 hr at 37°C. This procedure was repeated twice more. A sample from each culture was used as the template in PCR1 (see Supplemental Experimental Procedures).
PCR Products for Deep Sequencing
PCR1 and PCR2 production are described in Supplemental Experimental Procedures.
Determination of Adaptation Efficiency and New Repeat Length
Illumina sequencing libraries were prepared using the PCR1 and PCR2 products. The libraries were sequenced using the Illumina Miseq or NextSeq500 platforms generating 150-bp reads. Sequenced reads were demultiplexed and mapped to the E. coli “BL21-Gold(DE3)pLysS AG” genome (NC_012947.1) and pCas1+2R plasmid using blastn (with parameters: -e 1e-10 -F F). Adaptation efficiency was determined as previously described (Levy et al., 2015), except that new acquisition events were inferred if the read alignment spanned the old repeat and the sequence downstream of it but did not include the leader upstream, meaning that a new sequence had been inserted between the old repeat and the leader. New repeat length was determined using the PCR2 library reads. Reads were identified as representing an acquisition event if they contained two alignments to the repeat sequence, with a sequence in between that maps elsewhere in the genome or the plasmid (the potential spacer). The repeat length was initially determined according to the alignment. Spacers recorded as 34 or 35 nt in length, with the first nucleotide being a G that was not aligned to the genome, were considered as 33- or 34-nt spacers, respectively, derived from a repeat that was 1 bp longer. Spacers that were 32 nt in length with an upstream C in the genome were considered to be 33-nt spacers (with C as their first nucleotide) with a repeat that was shorter by 1 bp. The percentage of new repeat length presented in Figures 2 and 3 is based on acquisitions of 33-nt spacers.
Author Contributions
M.G.G., S.D., R.G., G.A., R.S., and U.Q. conceived and designed the experiments and analyzed the data. M.G.G., R.G., and G.A. performed experiments. U.Q. wrote the manuscript with feedback from all authors. R.S. and U.Q. secured funding.
Acknowledgments
We thank Camille Vainstein for professional language editing and Oren Auster for providing the pCas1+2R plasmid. The study was supported by the European Research Council StG and CoG programs (grant 336079 to U.Q. and grant 681203 to R.S.), the Israel Science Foundation (grant 268/14 to U.Q., grant 1303/12 to R.S., and I-CORE grant 1796 to R.S.) and the Israeli Ministry of Health (grant 9988-3 to U.Q.).
Published: September 13, 2016
Footnotes
Supplemental Information includes Supplemental Experimental Procedures, one figure, and two tables and can be found with this article online at http://dx.doi.org/10.1016/j.celrep.2016.08.043.
Contributor Information
Rotem Sorek, Email: rotem.sorek@weizmann.ac.il.
Udi Qimron, Email: ehudq@post.tau.ac.il.
Accession Numbers
The accession number for the deep-sequencing data reported in this paper is ENA: PRJEB15054.
Supplemental Information
References
- Abedon S.T. Bacterial ‘immunity’ against bacteriophages. Bacteriophage. 2012;2:50–54. doi: 10.4161/bact.18609. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Abudayyeh O.O., Gootenberg J.S., Konermann S., Joung J., Slaymaker I.M., Cox D.B., Shmakov S., Makarova K.S., Semenova E., Minakhin L. C2c2 is a single-component programmable RNA-guided RNA-targeting CRISPR effector. Science. 2016;353:aaf5573. doi: 10.1126/science.aaf5573. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Arslan Z., Hermanns V., Wurm R., Wagner R., Pul Ü. Detection and characterization of spacer integration intermediates in type I-E CRISPR-Cas system. Nucleic Acids Res. 2014;42:7884–7893. doi: 10.1093/nar/gku510. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Barrangou R., Fremaux C., Deveau H., Richards M., Boyaval P., Moineau S., Romero D.A., Horvath P. CRISPR provides acquired resistance against viruses in prokaryotes. Science. 2007;315:1709–1712. doi: 10.1126/science.1138140. [DOI] [PubMed] [Google Scholar]
- Brouns S.J., Jore M.M., Lundgren M., Westra E.R., Slijkhuis R.J., Snijders A.P., Dickman M.J., Makarova K.S., Koonin E.V., van der Oost J. Small CRISPR RNAs guide antiviral defense in prokaryotes. Science. 2008;321:960–964. doi: 10.1126/science.1159689. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Datsenko K.A., Pougach K., Tikhonov A., Wanner B.L., Severinov K., Semenova E. Molecular memory of prior infections activates the CRISPR/Cas adaptive bacterial immunity system. Nat. Commun. 2012;3:945. doi: 10.1038/ncomms1937. [DOI] [PubMed] [Google Scholar]
- Deveau H., Garneau J.E., Moineau S. CRISPR/Cas system and its role in phage-bacteria interactions. Annu. Rev. Microbiol. 2010;64:475–493. doi: 10.1146/annurev.micro.112408.134123. [DOI] [PubMed] [Google Scholar]
- Gesner E.M., Schellenberg M.J., Garside E.L., George M.M., Macmillan A.M. Recognition and maturation of effector RNAs in a CRISPR interference pathway. Nat. Struct. Mol. Biol. 2011;18:688–692. doi: 10.1038/nsmb.2042. [DOI] [PubMed] [Google Scholar]
- Goren M.G., Yosef I., Auster O., Qimron U. Experimental definition of a clustered regularly interspaced short palindromic duplicon in Escherichia coli. J. Mol. Biol. 2012;423:14–16. doi: 10.1016/j.jmb.2012.06.037. [DOI] [PubMed] [Google Scholar]
- Goren M., Yosef I., Edgar R., Qimron U. The bacterial CRISPR/Cas system as analog of the mammalian adaptive immune system. RNA Biol. 2012;9:549–554. doi: 10.4161/rna.20177. [DOI] [PubMed] [Google Scholar]
- Hale C.R., Zhao P., Olson S., Duff M.O., Graveley B.R., Wells L., Terns R.M., Terns M.P. RNA-guided RNA cleavage by a CRISPR RNA-Cas protein complex. Cell. 2009;139:945–956. doi: 10.1016/j.cell.2009.07.040. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kunin V., Sorek R., Hugenholtz P. Evolutionary conservation of sequence and secondary structures in CRISPR repeats. Genome Biol. 2007;8:R61. doi: 10.1186/gb-2007-8-4-r61. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Levy A., Goren M.G., Yosef I., Auster O., Manor M., Amitai G., Edgar R., Qimron U., Sorek R. CRISPR adaptation biases explain preference for acquisition of foreign DNA. Nature. 2015;520:505–510. doi: 10.1038/nature14302. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li M., Wang R., Zhao D., Xiang H. Adaptation of the Haloarcula hispanica CRISPR-Cas system to a purified virus strictly requires a priming process. Nucleic Acids Res. 2014;42:2483–2492. doi: 10.1093/nar/gkt1154. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Makarova K.S., Haft D.H., Barrangou R., Brouns S.J., Charpentier E., Horvath P., Moineau S., Mojica F.J., Wolf Y.I., Yakunin A.F. Evolution and classification of the CRISPR-Cas systems. Nat. Rev. Microbiol. 2011;9:467–477. doi: 10.1038/nrmicro2577. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Makarova K.S., Wolf Y.I., Alkhnbashi O.S., Costa F., Shah S.A., Saunders S.J., Barrangou R., Brouns S.J., Charpentier E., Haft D.H. An updated evolutionary classification of CRISPR-Cas systems. Nat. Rev. Microbiol. 2015;13:722–736. doi: 10.1038/nrmicro3569. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Marraffini L.A., Sontheimer E.J. CRISPR interference limits horizontal gene transfer in staphylococci by targeting DNA. Science. 2008;322:1843–1845. doi: 10.1126/science.1165771. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Marraffini L.A., Sontheimer E.J. CRISPR interference: RNA-directed adaptive immunity in bacteria and archaea. Nat. Rev. Genet. 2010;11:181–190. doi: 10.1038/nrg2749. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nuñez J.K., Harrington L.B., Kranzusch P.J., Engelman A.N., Doudna J.A. Foreign DNA capture during CRISPR-Cas adaptive immunity. Nature. 2015;527:535–538. doi: 10.1038/nature15760. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nuñez J.K., Lee A.S., Engelman A., Doudna J.A. Integrase-mediated spacer acquisition during CRISPR-Cas adaptive immunity. Nature. 2015;519:193–198. doi: 10.1038/nature14237. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rollie C., Schneider S., Brinkmann A.S., Bolt E.L., White M.F. Intrinsic sequence specificity of the Cas1 integrase directs new spacer acquisition. eLife. 2015;4:e08716. doi: 10.7554/eLife.08716. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sashital D.G., Jinek M., Doudna J.A. An RNA-induced conformational change required for CRISPR RNA cleavage by the endoribonuclease Cse3. Nat. Struct. Mol. Biol. 2011;18:680–687. doi: 10.1038/nsmb.2043. [DOI] [PubMed] [Google Scholar]
- Shipman S.L., Nivala J., Macklis J.D., Church G.M. Molecular recordings by directed CRISPR spacer acquisition. Science. 2016;353:aaf1175. doi: 10.1126/science.aaf1175. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sorek R., Kunin V., Hugenholtz P. CRISPR--a widespread system that provides acquired resistance against phages in bacteria and archaea. Nat. Rev. Microbiol. 2008;6:181–186. doi: 10.1038/nrmicro1793. [DOI] [PubMed] [Google Scholar]
- Sorek R., Lawrence C.M., Wiedenheft B. CRISPR-mediated adaptive immune systems in bacteria and archaea. Annu. Rev. Biochem. 2013;82:237–266. doi: 10.1146/annurev-biochem-072911-172315. [DOI] [PubMed] [Google Scholar]
- Staals R.H., Zhu Y., Taylor D.W., Kornfeld J.E., Sharma K., Barendregt A., Koehorst J.J., Vlot M., Neupane N., Varossieau K. RNA targeting by the type III-A CRISPR-Cas Csm complex of Thermus thermophilus. Mol. Cell. 2014;56:518–530. doi: 10.1016/j.molcel.2014.10.005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sternberg S.H., Richter H., Charpentier E., Qimron U. Adaptation in CRISPR-Cas Systems. Mol. Cell. 2016;61:797–808. doi: 10.1016/j.molcel.2016.01.030. [DOI] [PubMed] [Google Scholar]
- Swarts D.C., Mosterd C., van Passel M.W.J., Brouns S.J.J. CRISPR interference directs strand specific spacer acquisition. PLoS ONE. 2012;7:e35888. doi: 10.1371/journal.pone.0035888. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wang J., Li J., Zhao H., Sheng G., Wang M., Yin M., Wang Y. Structural and mechanistic basis of PAM-dependent spacer acquisition in CRISPR-Cas systems. Cell. 2015;163:840–853. doi: 10.1016/j.cell.2015.10.008. [DOI] [PubMed] [Google Scholar]
- Wang R., Li M., Gong L., Hu S., Xiang H. DNA motifs determining the accuracy of repeat duplication during CRISPR adaptation in Haloarcula hispanica. Nucleic Acids Res. 2016;44:4266–4277. doi: 10.1093/nar/gkw260. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yosef I., Goren M.G., Qimron U. Proteins and DNA elements essential for the CRISPR adaptation process in Escherichia coli. Nucleic Acids Res. 2012;40:5569–5576. doi: 10.1093/nar/gks216. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.