

Abstract
In order to improve the detection accuracy of pulmonary nodules in CT image, considering two problems of pulmonary nodules detection model, including unreasonable feature structure and nontightness of feature representation, a pulmonary nodules detection algorithm is proposed based on SVM and CT image feature-level fusion with rough sets. Firstly, CT images of pulmonary nodule are analyzed, and 42-dimensional feature components are extracted, including six new 3-dimensional features proposed by this paper and others 2-dimensional and 3-dimensional features. Secondly, these features are reduced for five times with rough set based on feature-level fusion. Thirdly, a grid optimization model is used to optimize the kernel function of support vector machine (SVM), which is used as a classifier to identify pulmonary nodules. Finally, lung CT images of 70 patients with pulmonary nodules are collected as the original samples, which are used to verify the effectiveness and stability of the proposed model by four groups' comparative experiments. The experimental results show that the effectiveness and stability of the proposed model based on rough set feature-level fusion are improved in some degrees.
1. Introduction
Lung cancer is a malignant tumor with the highest morbidity and mortality rate in the world, posing a serious threat to human life and health [1, 2]. The ability to estimate the risk of lung cancer is important in two common clinical models [3]: pulmonary nodules management and risk prediction model. Identification of early symptomatic in lung cancer is very important to improve early survival and reduce emergency presentations. Early detection is the most popular method to improve the effectiveness of the treatment of patients with lung cancer. Since pulmonary nodules are the early form of lung cancer [4], the detection of pulmonary nodules plays a critical role in the early diagnosis and treatment of lung cancer. Recent advances in computed tomography (CT) have a progressively increased spatial resolution and decreased acquisition times, making it possible for high resolution, multiangle, 3-dimensional, isotropic image of the whole lung to be acquired in less than 10 seconds. This has expanded capabilities for the early detection of small pulmonary nodules [4]. It is believed that early detection of lung cancer will result in earlier treatment at lower stages of the disease, thereby improving the 5-year survival rate, which has remained relatively constant at 15% for the last 30 years. However, with the wide application of CT in the lung imaging, the issues of CT data overloading and subjective interpretation of images result in a high clinical misdiagnosis rate [5].
Computer-Aided Diagnosis (CAD) systems provided a beneficial support and enhance the diagnostic accuracy. CAD is capable of performing the preliminary screen of the vast amounts of CT image and marking suspicious lesions, thereby helping radiologists to carry out the quadratic discrimination to reduce the workload and improve the accuracy rate of cancer diagnosis [6, 7].
Pulmonary nodule detection technology is one of the hot topics in the field of CAD in recent years. For example, ROI segment is a key problem, Xia et al. [8] using local variational Gaussian mixture models to segment brain MRI image Based on Learning Local Variational Gaussian Mixture Models, segmentation of breast ultrasound images are discussed by Xian [9, 10] and Santos et al. [11] segment the lung parenchyma based on region growing algorithm. Magalhães Barros Netto et al. [12] use growing neural gas (GNG) to segment the lung parenchyma, the obtained pulmonary nodules are then separated from tissues containing blood vessels and bronchi according to the 3D distance transform, and finally SVM is used to carry out the effective identification of pulmonary nodules with shape and texture features. Ye et al. [13] firstly segment and extract region of interest (ROI) with fuzzy threshold in combination with Gaussian matrix, mean curvature, and Hessian matrix, then choose the local shape information and local intensity dispersion as the feature expression of ROI, and finally use the weighted SVM for recognition of pulmonary nodules. Tan et al. [14] segment pulmonary nodules based on the blood vessels and nodule enhancement filter proposed by Li et al. [15], then locate the clustering center of pulmonary nodules based on the divergence calculated by Gaussian template and achieve ROI extraction, and finally use the classifier based on genetic model, artificial neural network (ANN), and SVM for comparative analysis of the detection effectiveness of pulmonary nodules; Cascio et al. [16] use regional growth model and morphological operation to extract the ROI firstly, then reconstruct B-spline surface based on 3D spring model in order to extract the related 3D gray features and shape features, and detect the pulmonary nodules using ANN. Although the above literature explores the methods of detecting pulmonary nodules, overall, these are still two disadvantages of these methods in feature structure design and feature set expression as follows.
When extracting and quantifying feature for ROI, the feature structure design is irrational, reflected by the fact that the combination of global features and local features and the combination of two-dimensional and three-dimensional features are not fully considered.
When fusing feature data, the compactness of feature expression is a difficult problem. Therefore, feature redundancy is usually not eliminated. Moreover, the feature-level fusion method without prior knowledge is rarely used.
Rough set theory was developed by Zdzislaw Pawlak in the early 1980s and can be regarded as a new mathematical tool for feature selection, feature extraction, and decision rule generation without prior knowledge. Rough sets provide the mechanism to find the minimal set of attributes required to classify the training samples. This minimal set of attributes is called reduct and contains the same knowledge as the original set of attributes in a given information system. Therefore, reducts can be used to obtain different classifiers. Wang et al. [17] present a framework for a systematic study of the rough set theory. Various views and interpretations of the theory and different approaches to study the theory are discussed. The relationships between the rough sets and other theories, such as fuzzy sets, evidence theory, granular computing, formal concept analysis, and knowledge spaces, are examined. Cost of disease prediction and diagnosis can be reduced by applying machine learning and data mining methods. Disease prediction and decision-making play a significant role in medical diagnosis. Udhaya Kumar and Hannah Inbarani [18] put forward a novel neighborhood rough set classification approach to deal with medical datasets. Experimental result of the proposed classification algorithm is compared with other existing approaches such as rough set, Kth-nearest neighbor, support vector machine, BP NN, and multilayer perceptron to conclude that the proposed approach is a cheaper way for disease prediction and decision-making. Feature Selection (FS) is a solution that involves finding a subset of prominent features to improve predictive accuracy and to remove the redundant features. Thus, the learning model receives a concise structure without forfeiting the predictive accuracy built by using only the selected prominent features. Therefore, nowadays, FS is an essential part of knowledge discovery. Inbarani et al. [19] proposed new supervised feature selection methods based on hybridization of Particle Swarm Optimization (PSO), PSO based Relative Reduct (PSO-RR), and PSO based Quick Reduct (PSO-QR) presented for the diseases diagnosis, in order to seek to investigate the utility of a computer-aided diagnosis in the task of differentiating malignant nodules from benign nodules based on single thin-section CT image data. In Shah et al. [20], CT images of solitary pulmonary nodules were contoured manually on a single representative slice by a thoracic radiologist. Two separate contours were created for each nodule, one including only the solid portion of the nodule and one including any ground-glass components. For each contour, 75 features were calculated that measured the attenuation, shape, and texture of the nodule. These features were then input into a feature selection step and four different classifiers to determine if the diagnosis could be predicted from the feature vector. Hassanien [21] discuss a hybrid scheme that combines the advantages of fuzzy sets and rough sets in conjunction with statistical feature extraction techniques. An application of breast cancer imaging has been chosen and hybridization scheme have been applied to see their ability and accuracy to classify the breast cancer images into two outcomes: cancer or noncancer.
Based on the above reasons, a pulmonary nodule detection model based on rough set (RS) feature-level fusion and SVM is proposed in this paper. To overcome the first aforementioned disadvantage, the shape feature, intensity feature and texture feature are extracted. For shape feature, three new 3-dimensional features, namely, External Spherical Volume (ESV), Surface-Center Distance Standard Deviation (SCDSTD), and External Rectangle Cross Line Distance (ERCLD) are proposed. For intensity feature, three new 3-dimensional features, namely intensity gradient (from inside to outside), Laplace Divergence Mean (LDM), and Laplace Divergence Distance (LDD) are proposed. Regarding feature description, two-dimensional texture feature, three-dimensional shape feature, and intensity feature are used for quantification. With regard to the second aforementioned disadvantage, rough set feature-level fusion is adopted since it can fully retain the properties of the features without prior knowledge. Finally, a grid optimization model is employed to optimize the kernel function of support vector machine (SVM), which is used to conduct the recognition and detection of pulmonary nodules. In order to verify the validity and stability, advantages of the model, four groups of comparative experiments are performed in this paper, that is, model validation experiments before and after rough set reduction, model stability experiments before and after rough set reduction, validation experiments of the superiority of the rough set feature-level fusion model, and comparative experiments with other pulmonary nodule detection models to compare the performance. The experimental results show that the method proposed in this paper can improve, to a certain extent, the rationality of feature structure and compactness of feature expression, thereby improving the detection accuracy of pulmonary nodules.
2. Related Theory
The description of ROI features is determined by both its comprehensiveness (features cannot be “observed” with “multiperspective” approach if the features amount is too little) and the accuracy of characterization (more quantized values diverged from the real information will cause a low feature discrimination). A large number of noise information sets will reduce the ROI feature extraction accuracy and affect the final results of detection. Therefore, for comprehensive and accurate expression of the morphological structure of ROI and local features, six new 3-dimensional features are proposed based on the analysis of ROI for lung CT image. These new 3-dimensional features are used to qualitatively analyze and quantitatively characterize the lesions from 2-dimensional and 3-dimensional perspectives in combination with other shape features, intensity features, texture features.
2.1. Pulmonary Nodules Features in CT Image
2.1.1. Shape Characteristics
Shape characteristics analyze the spatial distribution of gray values, by computing local features at each point in the image. Shape feature is the most intuitive visual feature, which can be used to describe the main medical signs of CT image of pulmonary nodule ROI, such as nodule sign, lobulation sign, spinous process sign, vacuole sign, and spicule sign, from the perspectives of geometric shape, edge roughness, and topology structure. In this paper the extracted components of the shape features mainly include perimeter, area, volume, roundness, rectangularity, elongation, Euler number, Harris, Hu moment, ESV, SCDSTD, and ERCLD. Here some features are given [22]:
(1) Area
| (1) |
where f(x, y) is the pixels of the target and M and N are the length and width, respectively.
(2) Perimeter
| (2) |
where p(i, j) is the pixels of the target edge and M and N are the length and width, respectively.
(3) Circularity
| (3) |
Circularity describes object shape that is close to the degree of circular, where S is the area of the target region and C is circumference of the target region. 0 < R 0 < 1 and R 0 value reflects the complexity of the measurement boundary; the shape is more complex and the R 0 value is more smaller.
(4) Rectangularity
| (4) |
where S is the area of the target region and H and, W are the length and width, respectively.
(5) Elongation
| (5) |
Elongation can distinguish different shapes of the images (such as circle, square, ellipse, thin and long, and short and wide), where H and W are the length and width, respectively.
(6) Euler Number
| (6) |
where C is the number of connection parts and H is the number of holes.
(7) External Spherical Volume (ESV). ESV is the ratio of each ROI A i (maximum diameter is dim(A i)) to the External Spherical Volume VS(A i) extracted from three-dimensional CT image, which reflects the similarity between the region and the sphere, as shown in Figure 1(b).
| (7) |
Figure 1.

Three-dimensional character sketch.
(8) Surface-Center Distance STandard Deviation (SCDSTD). SCDSTD is the coordinate distance standard deviation of each individual element C(S i) and regional center C cen(A i) from the surface of each ROI; its value also describes the similarity with sphere of ROI. If the value is 0, E 2(A i) is a standard sphere. With the increase in E 2(A i) value, the magnitude of the deviation from the sphere in the region increases, as shown in Figure 1(c).
| (8) |
(9) External Rectangle Cross Line Distance (ERCLD). ERCLD is the distance from center voxel C cen(A i) of ROI to the center dim(L i) (i = 1,2,…, 12) of its 12 intersecting lines, which may indicate that the regional voxel is evenly distributed in the rectangular body, as shown in Figure 1(d).
| (9) |
2.1.2. Hu Moment Characteristics
Moments and the related invariants have been extensively analyzed to characterize the patterns in images. The moment invariants are independent of position, size, and orientation but also independent of parallel projection. Hu [23] was the first person to prove the central moment invariants. The central geometric moment invariants are derived based upon algebraic invariants, including six absolute orthogonal invariants and one skew orthogonal invariant. The moment invariants have been proved to be the adequate measures for tracing image patterns about the images translation, scaling, and rotation.
Hu moment invariants define seven values, computed by normalizing central moments through order three, which are invariant to object scale, position, and orientation, and a large number of papers that have significant contribution to the application of Hu moment. Two-dimensional moments of a digitally sampled M∗N image that has gray function f(x, y) (x = 1,2,…, M, y = 1,2,…, N) are given as
| (10) |
The moments f(x, y) translated by an amount (a, b) are defined as
| (11) |
When a scaling normalization is applied, the central moments change as
| (12) |
In terms of the central moments, the seven moments are given as
| (13) |
Hu 7-moment invariants vary widely, in order to compare, using logarithmic function to compress data, and hence the actual invariants moment features are C K′:
| (14) |
The amended moment invariant features possess translation invariance, rotational invariance, and scale invariance.
2.1.3. Texture Characteristics
Tamura texture features, Tamura texture based on human visual perception in psychological research, are proposed by Tamura in 1978. Six components of Tamura texture feature correspond with 6 properties in psychology, three of them are coarseness, contrast, and directionality, which have the good application value in the texture synthesis, image recognition, and so on.
Texture is the gray distribution which appears repeatedly in the space position, so there are some relationships between two pixels at some distance from each other in image space, called gray spatial correlation properties in gray image. GLCM is a common method by studying the relevant relationship of gray image.
2.1.4. Intensity Features
Gray statistical feature is a quantitative method to describe the basic features of two-dimensional image region; it is called intensity feature from three-dimensional perspective [16]. In this paper, the extracted components of intensity features include the mean intensity, intensity variance, maximum and minimum intensity difference, skewness, kurtosis, intensity gradient (from inside to outside), Laplace Divergence Mean (LDM), and Laplace Divergence Distance (LDD).
(1) Intensity Gradient (from Inside to Outside). For ROI A i with the voxel S i volume greater than 0, morphological erosion processing is performed continuously and the ratio of the mean of the excluded area of each erosion processing to the mean of the last operation (initial value is 0) is calculated until the ratio is zero. Consider the following equation where n is the number of operations.
| (15) |
(2) Laplace Divergence Mean (LDM). According to the Laplacian convolution results with the original CT image, it is found that the nodule surrounding area with smaller gray value difference has a significant different divergence. Therefore, calculation of Laplace divergence is helpful to distinguish pulmonary nodules from interfering impurities.
| (16) |
(3) Laplace Divergence Distance (LDD). The difference between the maximum and minimum values of the Laplace divergence values is used to describe the range of regional divergence.
| (17) |
Table 1 shows the feature set of 42 features based on the above feature description of ROI. To facilitate subsequent tests, features are numbered in the order as showed in Table 1; that is, the shape features are numbered fs1–fs18, the intensity features are numbered fi1–fi8, and texture features are numbered ft1–ft16, respectively.
Table 1.
ROI feature set.
| Feature type | Feature vectors | Dimensionality |
|---|---|---|
| Shape features (fs) | Perimeter, area, volume, roundness, rectangularity, length, Euler's number, ESV, SCDSTD, ERCLD, Hu moment | 18 |
|
| ||
| Intensity features (fi) | Mean intensity, intensity standard variance, maximum-minimum intensity difference value of variance, skewness, kurtosis, intensity gradient (from inside to outside), LDM, LDD | 8 |
|
| ||
| Texture features (ft) | Tamura texture features (contrast, direction, roughness), GLCM (angular second moment, moment of inertia, torque deficit, sum mean, variance, sum variance, difference variance, entropy, sum entropy, differential entropy, information measure, correlation coefficient, maximum correlation coefficient) | 16 |
2.2. Rough Set and Attribute Reduction
Rough set theory (RST), proposed by Pawlak in 1982, is one of the effective mathematical tools for processing fuzzy and uncertainty knowledge. Nowadays, RST has been applied to a variety of fields such as artificial intelligence, data mining, pattern recognition, and knowledge discovery. Rough set is founded on the assumption that with every object of the universe of discourse some knowledge is associated. Objects characterized by the same information are similar in view of the available information about them. The indiscernibility relation generated in this way is the mathematical basis of rough set theory. Any set of all indiscernible objects are called an elementary set and form a basic granule of knowledge about the universe. Any union of some elementary sets is referred to as a crisp set, otherwise the set is rough set.
Definition 1 . —
An information system S is a quadruple S = (U, A, V, f), where U is a nonempty and finite set of objects, A is a nonempty and finite set of attributes, V≔⋃V a with V a being the domain of attribute a, and f is an information function such that f(x, a) ∈ V a for every x ∈ U and every a ∈ A. A decision system is an information system (U, C ∪ D, V, f) with C∩D = Ф, where C and D are called the conditional and decision attribute sets, respectively.
For a subset P of A, let us define the corresponding equivalence relation as
| (18) |
and denote the equivalence class of IND(P) which contains the object x ∈ U by [x]P; that is,
| (19) |
The factor set of all equivalence classes of IND(P) is denoted by U/P; that is, U/P = {[x]P∣x ∈ U}.
As well known, attribute reduction is one of the key issues in RST. It is performed in information systems by means of the notion of a reduct based on a specialization of the notion of independence due to Marczewski. Up to now, much attention has been paid to this issue and many different methods of attribute reduction have been proposed for decision systems. For example, the reduction approaches are, respectively, based on partition, discernibility matrix, conditional information entropy, positive region, and ant colony optimization approach.
Definition 2 . —
Let S = (U, A, V, f) be an information system and P⊆A. For a subset X of U, R P(X) = {x ∈ U∣[x]P⊆X} and R P(X) = {x ∈ U∣[x]P∩X ≠ Ф} are called P-lower and P-upper approximations of X, respectively.
Definition 3 . —
Let S = (U, A, V, f) be an information system and let P and Q be two subsets of A. Then, POSP(Q) = ⋃X∈U/Q R P(X) is called P-positive region of Q, where R P(X) is the P-lower approximation of X.
Definition 4 . —
Let S = (U, A, V, f) be a decision system, a ∈ C, and P⊆C. If POSC(Q) = POSC∖{a}(Q), a is said to be D-dispensable in C; otherwise, a is said to be D-indispensable in C. The set of all the D-indispensable attributes is called the core of S and denoted by Core(S). Furthermore, if POSP(Q) = POSC(Q) and each of the attributes of P is D-indispensable, then P is called a reduct of S.
2.3. SVM and Its Optimization
SVM is a pattern recognition method developed from statistical learning theory based on the idea of structural risk minimization principle. In the case of ensuring classification accuracy, SVM can improve the generalization ability of the learning machine by maximizing the classification interval. The biggest advantage of SVM is that it overcomes the overlearning and high dimension both of which lead to computational complexity and local extremum problems. A reliable classification model based on SVM is urgently needed for the study of hospitalization expenses of patients with gastric cancer.
SVM deals with linearly separable data (Figure 2); the assumption is that there are data sets S = {x 1,…, x n} and data marker G = {y 1,…, y n}, where x i is the input space vector of the data sample and y i records the category of the sample.
Figure 2.
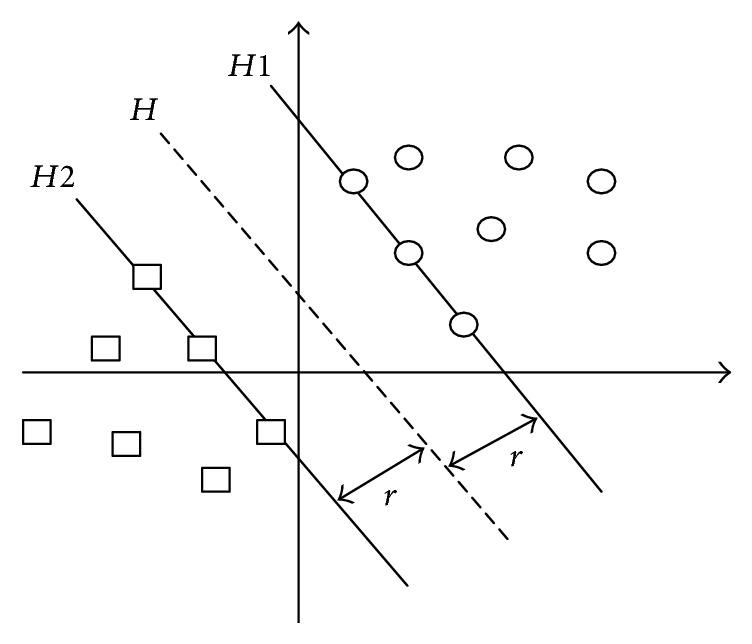
Optimal hyper plane.
The aim of SVM is to find an optimal hyper plane H to separate these two samples and make the largest interval. The optimal hyper plane H is expressed as
| (20) |
where w is the weight vector and b is the threshold.
This problem is transformed into the optimal problem of w and b:
| (21) |
In order to simplify the formula, the Lagrange dual is introduced to meet the requirements of KKT (Karush-Kuhn-Tucker). The objective function is transformed into
| (22) |
As for the linearly inseparable data, the penalty parameter C and relaxation variable ξ are introduced in the constraint condition, thus the generalization ability of SVM is increased, and the function is transformed into
| (23) |
where C is the artificial setting parameter. According to the practical experience, the bigger C, the greater separation interval. At the same time, it will increase the risk of generalization.
The final classification function is
| (24) |
For nonlinear classification data, SVM transforms them into linearly separable data in a high-dimensional space via nonlinear mapping of kernel function, and the optimal hyper plane is found in high-dimensional space. The kernel function which meets the mercer kernel condition corresponding to the transvection of a spatial transformation is used to realize the nonlinear transformation of linear classification.
The corresponding kernel function is defined as
| (25) |
At this point the final classification function is
| (26) |
Penalty factor C and parameter g of the kernel function play an extremely important role in the performance of SVM classification. In order to obtain the optimal classification results, grid optimization model is used for optimization in this paper. In grid optimization model, the parameters to be searched are expressed in the form of grids in a certain space, and the optimal parameters are selected by traversing all the grids. Therefore, grid optimization model has the advantages of simplicity, convenience, good stability, and easiness to get the global optimal solution [24]. In the learning process of SVM, 10-fold cross-validation is used to calculate the kernel function parameters and penalty coefficient with the optimal classification performance, which are then applied to the SVM classifier for recognition and detection of pulmonary nodules. Finally, sensitivity, specificity, accuracy, and processing time are used as indexes to evaluate the detection of relevant experiments.
3. Pulmonary Nodule Detection Model
In this paper, CT images of 70 cases of patients with pulmonary nodules are used. The images are firstly segmented [7] to three different types of pulmonary nodules (solitary pulmonary nodules or SPN, vascular adhesion pulmonary nodules or VAPN, and pleural adhesion pulmonary nodules or PAPN), which are marked by radiologists, as well as a large number of nonnodular areas, including blood vessels, bones, and alveoli. Forty-two feature components characterizing ROI are extracted from the 2-dimensional and 3-dimensional perspectives, including six new 3-dimensional features proposed in this paper. They are composed of 18 shape features, 8 intensity features, and 16 texture features. The extracted feature set (identified as the FS) is discretized and normalized. Feature-level fusion of the improved feature data is performed for five times using rough set model (since the reduction of rough set feature subset is not unique, in this paper, the extracted feature sets are reduced for five times and are identified as RS1, RS2, RS3, RS4, and RS5). Feature subset RS1 is used for comparative experiment. Finally, SVM parameters are optimized using grid optimization model, and the improved SVM is used in the following four sets of comparative experiments: comparative analysis of the effectiveness and stability of classification before and after rough set reduction of features; comparative analysis of the recognition performance before and after feature-level fusion based on rough set or PCA; comparative analysis of the recognition performance of our proposed method and other methods. Based on the above views, we present a flow chart of pulmonary nodule detection model as shown in Figure 3.
Figure 3.

Flow chart of pulmonary nodule detection model.
4. Results and Discussion
4.1. Experimental Environments
In this paper, the hardware and software environments are as follows.
Software Environments. Windows 7 OS, the Matlab R2014b, ImageJ 1.48 u, and LibSVM.
Hardware Environments. Intel Core i5 4670-3.4 GHz, 8.0 GB of memory, and 500 GB hard disk.
Experimental Data. CT images of 70 cases of patients with pulmonary nodules are collected as experimental samples, which are marked by radiologists, with a size of 512 × 512 and a thickness of 2 mm. They are composed of 2232 CT images from 38 cases of patients with solitary pulmonary nodules (SPN), 17 cases of patients with vascular adhesion pulmonary nodules (VAPN), and 15 cases of patients with pleural adhesion pulmonary nodules (PAPN), respectively. Figure 4 shows the representatives of each type of pulmonary nodules and the corresponding segmentation results.
Figure 4.

Pulmonary nodule segmentation results.
In this paper, 42-dimensional features of 70 marked pulmonary nodular areas and 70 randomly selected nonnodular areas are extracted. Table 2 shows the 42-dimensional feature values of the lung nodular and nonnodular areas. shape features are identified as the fs, intensity features are identified as the fi, and texture features are identified as the ft. In order to intuitively understand the distribution of different feature values and the discrimination comparison, external sphere volume (ESV) ratio and the standard deviation of surface-center distance (SCD) are calculated and plotted as box diagram as shown in Figure 5.
Table 2.
Feature values of pulmonary nodular areas and nonnodular areas.
| Shape features (fs) | Intensity features (fi) | Texture features (ft) | |||
|---|---|---|---|---|---|
| Nodular areas | Nonnodular areas | Nodular areas | Nonnodular areas | Nodular areas | Nonnodular areas |
| 95 | 78 | 59.06 | 91.0987 | 8.3104 | 5.4016 |
| 159 | 128 | 14.06 | 4.4872 | 12.041 | 12.5216 |
| 284 | 178 | 0.5956 | −0.39568 | 0.4303 | 0.0067 |
| 0.6517 | 0.211 | 2.7348 | 1.8669 | 0.7709 | 0.7275 |
| 0.6961 | 2.1587 | 55.1865 | 14.3481 | 0.7169 | 0.9865 |
| 0.3529 | 0.7778 | 0.5 | 1 | 0.8059 | 5.3894 |
| 0 | 1 | 13.9598 | 20.6044 | 0.1942 | 0.0487 |
| 0.3186 | 1.0295 | 729.905 | 354.6389 | 0.7708 | 0.7273 |
| 0.0686 | 1.0197 | 0.8059 | 5.3498 | ||
| 0.0042 | 0.0458 | 3.5042 | 5.0971 | ||
| 0.0021 | 0.0295 | 0.6514 | 0.8453 | ||
| 0.0013 | 0.0268 | 0.0971 | 0.6143 | ||
| 0.0005 | 0.0011 | 4.4033 | 82.1862 | ||
| 0 | 1 | 0.0691 | 5.0061 | ||
| 14 | 9 | −0.5785 | −0.4245 | ||
| 0.5356 | 0.5571 | 2.307 | 3.2239 | ||
| 0.3072 | 0.501788 | ||||
| 0.1738 | 0.207122 | ||||
Figure 5.

Pulmonary nodule area and the pulmonary nodules boxplot. “+” refers to upper and lower bounders of ESV value and SCDSTD value.
4.2. Feature-Level Fusion Based on Rough Set
In order to avoid the attribute value of small range of values dominated by that of large range of values and reduce the complexity of the statistical computation process, the extracted feature sets are firstly preprocessed by normalizing data with bigger difference and linearly mapping the data to [0, 1]. The preprocessed feature data are then fused for five times using rough set model. The fusion results are shown in Table 3.
Table 3.
Feature reduction based on rough sets.
| Feature subset | Reduction results | Dimensionality |
|---|---|---|
| RS1 | fs4, fs16, fs17, fs18, fi2, fi4, fi6, fi7, fi8, ft2, ft4, ft5, ft6, ft7, ft8, ft9, ft10, ft11, ft13, ft14, ft15, ft16 | 21 |
| RS2 | fs4, fs9, fs16, fs18, fi1, fi2, fi5, ft2, ft5, ft6, ft8, ft9, ft10, ft11, ft12, ft13, ft15 | 17 |
| RS3 | fs9, fs17, fs18, fi1, fi2, fi5, fi7, fi8, ft2, ft6, ft7, ft8, ft9, ft10, ft11, ft12, ft14, ft15, ft16 | 19 |
| RS4 | fs9, fs16, fs18, fi1, fi2, fi5, fi7, fi8, ft5, ft6, ft7, ft8, ft9, ft10, ft11, ft12, ft14, ft15, ft16 | 19 |
| RS5 | fs9, fs16, fs17, fs18, fi1, fi2, fi4, fi5, fi7, fi8, ft2, ft5, ft6, ft7, ft8, ft9, ft10, ft12, ft15, ft16 | 20 |
4.3. Pulmonary Nodule Detection with SVM Based on Grid Optimization
4.3.1. The Model Effectiveness Experiment
Tenfold cross-validation is used to calculate the accuracy, sensitivity, specificity, and processing time of classification before and after rough set reduction (RS1(70 × 21) obtained from experiment one is used as the data set after reduction), and the recognition performance of classifier is compared before and after reduction. The results are shown in Table 4.
Table 4.
Statistics of effectiveness before and after rough set reduction.
| Serial number | Accuracy (%) | Sensibility (%) | Specificity (%) | Processing time (s) | |
|---|---|---|---|---|---|
| Before reduction | 1 | 96.42 | 92.86 | 100 | 1.0610 |
| 2 | 91.96 | 83.93 | 100 | 0.6170 | |
| 3 | 95.54 | 100 | 91.07 | 0.5490 | |
| 4 | 89.28 | 100 | 78.57 | 0.5630 | |
| 5 | 95.54 | 91.07 | 100 | 0.5470 | |
| 6 | 98.21 | 96.43 | 100 | 0.5460 | |
| 7 | 94.64 | 89.29 | 100 | 0.5460 | |
| 8 | 95.53 | 91.07 | 100 | 0.5460 | |
| 9 | 91.96 | 83.93 | 100 | 0.5460 | |
| 10 | 97.32 | 100 | 96.64 | 0.5300 | |
|
| |||||
| Mean | 94.64 | 92.86 | 96.43 | 0.6051 | |
|
| |||||
| After reduction (Rs1) | 1 | 100 | 100 | 100 | 0.9370 |
| 2 | 100 | 100 | 100 | 0.4360 | |
| 3 | 100 | 100 | 100 | 0.3870 | |
| 4 | 100 | 100 | 100 | 0.4210 | |
| 5 | 100 | 100 | 100 | 0.4210 | |
| 6 | 100 | 100 | 100 | 0.3900 | |
| 7 | 100 | 100 | 100 | 0.4060 | |
| 8 | 91.67 | 100 | 83.33 | 0.4060 | |
| 9 | 100 | 100 | 100 | 0.3740 | |
| 10 | 100 | 100 | 100 | 0.3930 | |
|
| |||||
| Mean | 99.17 | 100 | 98.33 | 0.4571 | |
|
| |||||
| Increase after reduction | 4.53 | 7.14 | 1.9 | 0.148 | |
Experimental results show that pulmonary nodule detection accuracy is increased significantly after feature-level fusion, with a decrease in the missed diagnosis rate, reflected by the increased sensitivity, and the misdiagnosis rate, reflected by the increased specificity. The processing time is also shorter after reduction. These results indicate that the feature-level fusion of the extracted feature set with 42 dimensionalities based on rough set model is effective, which not only improves the compactness of the feature set (to eliminate redundancy and low degree of differentiation features component), but also corrects the abnormal data of the feature set, thereby further improving the performance of pulmonary nodule detection. Table 5 shows the effectiveness of the five rough set reduction subsets.
Table 5.
Effectiveness of rough set reduction subsets.
| Subset | Average accuracy (%) | Average sensitivity (%) | Average specificity (%) | Processing time (s) |
|---|---|---|---|---|
| RS1 | 99.17 | 100 | 98.33 | 0.4571 |
| RS2 | 97.5 | 96.67 | 98.33 | 0.4650 |
| RS3 | 99.17 | 100 | 98.33 | 0.4656 |
| RS4 | 100 | 100 | 100 | 0.4731 |
| RS5 | 98.33 | 98.33 | 98.33 | 0.4850 |
|
| ||||
| Mean | 98.83 | 99 | 98.66 | 0.4672 |
4.3.2. The Model Stability Experiment
The feature data of pulmonary nodules are tested with RS1(70∗21) as the dataset for classification for five rounds with a different ratio of training set over testing set of 50/20, 40/30, 35/35, 35/35, or 20/50. Each round of test is carried out with a randomly selected ratio of training set over testing set and the mean of 10 test results is used as the corresponding accuracy, sensitivity, specificity, and running time of the model. The results are shown in Table 6.
Table 6.
Stability statistics of rough set reduction subsets.
| Training set/testing set | Accuracy (%) | Sensitivity (%) | Specificity (%) | Running time (s) | |
|---|---|---|---|---|---|
| Before fusion | 50/20 | 97.35 | 94.71 | 100 | 0.4873 |
| 40/30 | 96.53 | 93.08 | 98.32 | 0.3846 | |
| 35/35 | 95.83 | 92.39 | 97.79 | 0.4254 | |
| 30/40 | 96.16 | 95.58 | 96.74 | 0.3560 | |
| 20/50 | 94.88 | 94.63 | 95.86 | 0.4236 | |
|
| |||||
| Mean | 96.15 | 94.08 | 97.742 | 0.4154 | |
|
| |||||
| After fusion (Rs1) | 50/20 | 99.71 | 99.41 | 100 | 0.2684 |
| 40/30 | 98.96 | 99.58 | 98.46 | 0.2568 | |
| 35/35 | 98.65 | 99.23 | 98.08 | 0.2382 | |
| 30/40 | 98.37 | 98.60 | 98.14 | 0.2646 | |
| 20/50 | 98.25 | 97.67 | 98.84 | 0.2636 | |
|
| |||||
| Mean | 98.79 | 98.84 | 98.70 | 0.2583 | |
The experimental results show that, with the decrease in the ratio of training set over testing set, the decrease in the classification accuracy of feature subset after rough set reduction is not obvious, whereas that of feature set before rough set reduction is fluctuating to certain extent (Figure 6 is more intuitive). These results indicate that the classification stability of the feature level fusion model based on rough set is higher and is less susceptible to the interference of sample data. Table 7 shows the stability of 5 groups feature subset after rough set reduction.
Figure 6.
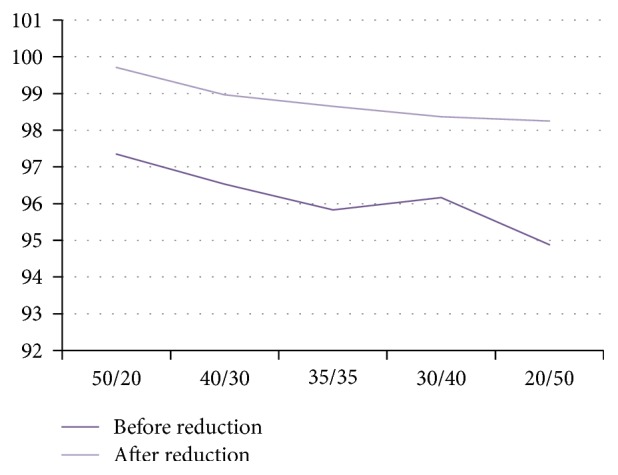
Comparative results of feature subsets before and after rough set reduction.
Table 7.
Classification performance of rough set reduction subset.
| Subset | Average accuracy (%) | Average sensitivity (%) | Average specificity (%) | Running time (s) |
|---|---|---|---|---|
| RS1 | 99.17 | 100 | 98.33 | 0.2583 |
| RS2 | 97.5 | 96.67 | 98.33 | 0.2870 |
| RS3 | 99.17 | 100 | 98.33 | 0.2560 |
| RS4 | 100 | 100 | 100 | 0.2531 |
| RS5 | 98.33 | 98.33 | 98.33 | 0.2656 |
|
| ||||
| Mean | 98.834 | 99 | 98.66 | 0.2620 |
4.3.3. The Superiority of Feature-Level Fusion Model Based on Rough Set
Since PCA is a well-developed model, characterized by simple calculation and easy programming, it has become the preferred dimension reduction method for most of the feature-level fusion model in order to analyze comparatively two types of feature-level fusions. In this paper, PCA-based feature-level fusion of the extracted feature sets is performed at the same time, and the tenfold cross-validation results are shown in Table 8. Figure 7 shows the classification performance of the two types of feature-level fusion methods (feature subset RS1 from Table 3 is used, and the running time is 100 × actual time).
Table 8.
Classification performance of feature reduction based on PCA.
| Serial number | Accuracy (%) | Sensitivity (%) | Specificity (%) | 10 × running time (s) |
|---|---|---|---|---|
| 1 | 91.67 | 83.33 | 100 | 0.9970 |
| 2 | 96.74 | 93.48 | 100 | 0.4830 |
| 3 | 96.74 | 93.48 | 100 | 0.4880 |
| 4 | 98.91 | 100 | 97.83 | 0.4950 |
| 5 | 93.48 | 86.96 | 100 | 0.4950 |
| 6 | 96.74 | 100 | 93.48 | 0.5140 |
| 7 | 96.74 | 100 | 93.48 | 0.5120 |
| 8 | 94.57 | 89.13 | 100 | 0.4890 |
| 9 | 97.83 | 95.65 | 100 | 0.4990 |
| 10 | 95.65 | 93.48 | 97.83 | 0.5180 |
|
| ||||
| Mean | 95.91 | 93.55 | 98.26 | 0.5490 |
Figure 7.
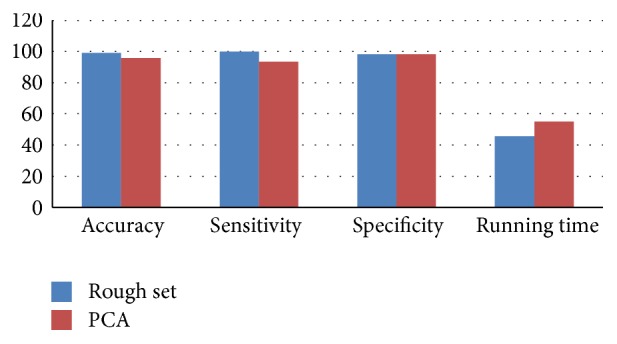
Comparison of two feature-level fusion models.
Experimental results show that various performance indicators of the feature-level fusion model based on rough set are better than those based on PCA, indicating that the rough set is more suitable than PCA to eliminate redundant information.
4.3.4. Comparison with Other Pulmonary Nodule Detection Methods
Pulmonary nodule detection accuracy and False Positives per scan (FP/s) are used as the evaluation indexes of pulmonary nodule detection methods to compare and analyze the method proposed in this paper and other five detection methods of pulmonary nodules (the optimal detection accuracy is used for all detection methods). The results are shown in Table 9 (Pr: private database; L: LIDC).
Table 9.
Comparison of the performance of different lung nodule detection methods.
Experimental results show that the proposed method is superior to the other pulmonary nodule detection methods to a certain extent, indicating that this method not only improves the comprehensiveness and accuracy of the feature description of ROI by supplementing and improving the feature components, but also improves the firmness of the feature set by integrating the concept of feature-level fusion based on rough set to exclude the redundant features and data with irregular information, thereby improving the overall pulmonary nodule detection performance.
5. Conclusions
In this paper the research status quo of pulmonary nodule detection methods is analyzed and a pulmonary nodule detection model is proposed based on rough set based feature-level fusion. To address the issues that the feature description is insufficient and the characterization is inaccurate in the process of feature extraction, six new 3D features, in combination with other 2D and 3D features, are proposed to extract and quantify the feature information of ROI in this model. A rough set based feature-level fusion is employed to reduce the dimensionality of the feature sets since there is redundant information in the extracted high-dimensional features. In addition, a grid optimization model is adopted to optimize the SVM kernel function, which is used as the classifier for detection and recognition of pulmonary nodule. Finally, the pulmonary nodule detection performance of the proposed method is verified with four groups of comparative experiments. The experimental results show that the proposed pulmonary nodule detection method based on rough set based feature-level fusion is effective, with the classification accuracy that can basically meet the requirements of medical imaging for the detection of pulmonary nodules and therefore is of great value for the detection of pulmonary nodules and auxiliary diagnosis of lung cancer.
Acknowledgments
The work is partially supported by National Natural Science Foundation of China (Grant No. 61561040), Natural Science Foundation of Ningxia (Grant No. NZ16067), and Scientific Research Fund of Ningxia Education Department (Grant No. NGY2016084).
Competing Interests
The authors declare that they have no competing interests.
References
- 1.Riaz S. P., Lüchtenborg M., Coupland V. H., Spicer J., Peake M. D., Møller H. Trends in incidence of small cell lung cancer and all lung cancer. Lung Cancer. 2012;75(3):280–284. doi: 10.1016/j.lungcan.2011.08.004. [DOI] [PubMed] [Google Scholar]
- 2.Ferlay J., Soerjomataram I., Dikshit R., et al. Cancer incidence and mortality worldwide: sources, methods and major patterns in GLOBOCAN 2012. International Journal of Cancer. 2015;136(5):E359–E386. doi: 10.1002/ijc.29210. [DOI] [PubMed] [Google Scholar]
- 3.Baldwin D. R. Prediction of risk of lung cancer in populations and in pulmonary nodules: significant progress to drive changes in paradigms. Lung Cancer. 2015;89(1):1–3. doi: 10.1016/j.lungcan.2015.05.004. [DOI] [PubMed] [Google Scholar]
- 4.Diciotti S., Picozzi G., Falchini M., Mascalchi M., Villari N., Valli G. 3-D segmentation algorithm of small lung nodules in spiral CT images. IEEE Transactions on Information Technology in Biomedicine. 2008;12(1):7–19. doi: 10.1109/titb.2007.899504. [DOI] [PubMed] [Google Scholar]
- 5.Theodoridis S., Koutroumbas K. Pattern Recognition. 4th. The Associated Press; 2010. [Google Scholar]
- 6.Sahiner B., Chan H.-P., Hadjiiski L. M., et al. Effect of CAD on radiologists' detection of lung nodules on thoracic CT scans: analysis of an observer performance study by nodule size. Academic Radiology. 2009;16(12):1518–1530. doi: 10.1016/j.acra.2009.08.006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Xia Y., Lu S., Wen L., Eberl S., Fulham M., Feng D. D. Automated identification of dementia using FDG-PET imaging. BioMed Research International. 2014;2014:8. doi: 10.1155/2014/421743.421743 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Xia Y., Ji Z., Zhang Y. Brain MRI image segmentation based on learning local variational Gaussian mixture models. Neurocomputing. 2016;204:189–197. doi: 10.1016/j.neucom.2015.08.125. [DOI] [Google Scholar]
- 9.Xian M., Zhang Y., Cheng H. D. Fully automatic segmentation of breast ultrasound images based on breast characteristics in space and frequency domains. Pattern Recognition. 2015;48(2):485–497. doi: 10.1016/j.patcog.2014.07.026. [DOI] [Google Scholar]
- 10.Xian M., Zhang Y., Cheng H.-D., Xu F., Ding J. Neutro-connectedness cut. IEEE Transactions on Image Processing. 2016;25(10):4691–4703. doi: 10.1109/tip.2016.2594485. [DOI] [PubMed] [Google Scholar]
- 11.Santos A. M., de Carvalho Filho A. O., Silva A. C., et al. Automatic detection of small lung nodules in 3D CT data using Gaussian mixture models, Tsallis entropy and SVM. Engineering Applications of Artificial Intelligence. 2014;36:27–39. doi: 10.1016/j.engappai.2014.07.007. [DOI] [Google Scholar]
- 12.Magalhães Barros Netto S., Corrĉa Silva A., Acatauassú Nunes R., Gattass M. Automatic segmentation of lung nodules with growing neural gas and support vector machine. Computers in Biology and Medicine. 2012;42(11):1110–1121. doi: 10.1016/j.compbiomed.2012.09.003. [DOI] [PubMed] [Google Scholar]
- 13.Ye X., Lin X., Dehmeshki J., Slabaugh G., Beddoe G. Shape-based computer-aided detection of lung nodules in thoracic CT images. IEEE Transactions on Biomedical Engineering. 2009;56(7):1810–1820. doi: 10.1109/TBME.2009.2017027. [DOI] [PubMed] [Google Scholar]
- 14.Tan M., Deklerck R., Jansen B., Bister M., Cornelis J. A novel computer-aided lung nodule detection system for CT images. Medical Physics. 2011;38(10):5630–5645. doi: 10.1118/1.3633941. [DOI] [PubMed] [Google Scholar]
- 15.Li Q., Li F., Doi K. Computerized Detection of Lung Nodules in Thin-Section CT Images by Use of Selective Enhancement Filters and an Automated Rule-Based Classifier. Academic Radiology. 2008;15(2):165–175. doi: 10.1016/j.acra.2007.09.018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Cascio D., Magro R., Fauci F., Iacomi M., Raso G. Automatic detection of lung nodules in CT datasets based on stable 3D mass-spring models. Computers in Biology and Medicine. 2012;42(11):1098–1109. doi: 10.1016/j.compbiomed.2012.09.002. [DOI] [PubMed] [Google Scholar]
- 17.Wang G. Y., Yao Y. Y., Yu H. A survey on rough set theory and applications. Chinese Journal of Computers. 2009;32(7):1229–1246. doi: 10.3724/sp.j.1016.2009.01229. [DOI] [Google Scholar]
- 18.Udhaya Kumar S., Hannah Inbarani H. A novel neighborhood rough set based classification approach for medical diagnosis. Procedia Computer Science. 2015;47:351–359. [Google Scholar]
- 19.Inbarani H. H., Azar A. T., Jothi G. Supervised hybrid feature selection based on PSO and rough sets for medical diagnosis. Computer Methods and Programs in Biomedicine. 2014;113(1):175–185. doi: 10.1016/j.cmpb.2013.10.007. [DOI] [PubMed] [Google Scholar]
- 20.Shah S. K., McNitt-Gray M. F., Rogers S. R., et al. Computer-aided diagnosis of the solitary pulmonary nodule. Academic Radiology. 2005;12(5):570–575. doi: 10.1016/j.acra.2005.01.018. [DOI] [PubMed] [Google Scholar]
- 21.Hassanien A. Fuzzy rough sets hybrid scheme for breast cancer detection. Image and Vision Computing. 2007;25(2):172–183. doi: 10.1016/j.imavis.2006.01.026. [DOI] [Google Scholar]
- 22.Guo Z., Li Y., Wang Y., Liu S., Lei T., Fan Y. A method of effective text extraction for complex video scene. Mathematical Problems in Engineering. 2016;2016:11. doi: 10.1155/2016/2187647.2187647 [DOI] [Google Scholar]
- 23.Hu M.-K. Visual pattern recognition by moment invariants. IRE Transactions on Information Theory. 1962;8(2):179–187. doi: 10.1109/tit.1962.1057692. [DOI] [Google Scholar]
- 24.Chorowski J., Wang J., Zurada J. M. Review and performance comparison of SVM- and ELM-based classifiers. Neurocomputing. 2014;128:507–516. doi: 10.1016/j.neucom.2013.08.009. [DOI] [Google Scholar]