

Abstract
Background:
Despite the risk associated with nocturnal hypoglycemia (NH) there are only a few methods aiming at the prediction of such events based on intermittent blood glucose monitoring data. One of the first methods that potentially can be used for NH prediction is based on the low blood glucose index (LBGI) and suggested, for example, in Accu-Chek® Connect as a hypoglycemia risk indicator. On the other hand, nowadays there are other glucose control indices (GCI), which could be used for NH prediction in the same spirit as LBGI. In the present study we propose a general approach of combining NH predictors constructed from different GCI.
Methods:
The approach is based on a recently developed strategy for aggregating ranking algorithms in machine learning. NH predictors have been calibrated and tested on data extracted from clinical trials, performed in EU FP7-funded project DIAdvisor. Then, to show a portability of the method we have tested it on another dataset that was received from EU Horizon 2020-funded project AMMODIT.
Results:
We exemplify the proposed approach by aggregating NH predictors that have been constructed based on 4 GCI associated with hypoglycemia. Even though these predictors have been preliminary optimized to exhibit better performance on the considered dataset, our aggregation approach allows a further performance improvement. On the dataset, where a portability of the proposed approach has been demonstrated, the aggregating predictor has exhibited the following performance: sensitivity 77%, specificity 83.4%, positive predictive value 80.2%, negative predictive value 80.6%, which is higher than conventionally considered as acceptable.
Conclusion:
The proposed approach shows potential to be used in telemedicine systems for NH prediction.
Keywords: aggregation, prediction of nocturnal hypoglycemia, prediction from glycemic control indices, type 1 diabetes
Nocturnal hypoglycemia (NH) is the most feared type of hypoglycemia in patients with type 1 diabetes treated by insulin. Despite the danger of NH, there is still a lack of methods aiming at the prevention of such cases. NH problem is less worrisome for the patients equipped with continuous glucose monitors (CGM), but, according to GBI Research, Diabetes Landscape, Market, Technology and Intellectual Property, May 2012, only about 2-3% of insulin-treated patients use such systems.
On the other hand, intermittent monitoring performed from finger sticks remains the most widely used blood glucose monitoring method (BGM). This type of BGM is marketed at very low prices compared to CGM and provides fairly accurate results of BG concentration. Therefore, it is attractive to develop a method for predicting NH which uses only limited discrete information on blood glucose level during daytime hours.
One of the first methods that aims at the prediction of severe hypoglycemia, and also can potentially be used for prediction of NH, is based on the low blood glucose index (LBGI).1,2 The value of LBGI index cumulates all daily measurements of blood glucose and may provide a risk indicator for NH. For example, in Blood Glucose Index3 the LBGI-values above 2.5 are interpreted as to be at risk of hypoglycemia.
On the other hand, nowadays there are other glucose control indices (GCI), which could be used for NH-prediction in the same spirit as LBGI. Namely, a particular index, say I, needs to be accompanied with a suitable threshold value , and then the values of the index I above the threshold could be interpreted as to be at risk of NH. In the present study we illustrate this idea using some indices discussed in the survey.4
At the same time, as mentioned in that survey, there has been no consensus as to which of the discussed indices is best. Therefore, in the present study we propose a general approach of combining NH predictors constructed from different GCI. The approach is based on a recently developed strategy for aggregating ranking algorithms.5,6 The approach has been tested on 2 different clinical datasets and exhibited a secure level of predictive accuracy outperforming previously known results.
Performance Metrics
In this paper we use the standard metrics for measuring the performance of classifiers, that is, predictors predicting the “yes” or “no” answer. These metrics count the numbers or percentage of true positive (TP), true negative (TN), false positive (FP), and false negative (FN) predictions. In the present context TP and TN mean respectively the cases when NH appearance or absence was correctly predicted. FP means that NH was predicted, but did not occur, and FN means the opposite scenario.
Sensitivity defined as SE = TP/(TP+FN) and Specificity as SP = TN/(TN+FP) measure respectively the proportion of positives and negatives that were correctly identified as such.
The positive and negative predictive values, defined as PPV = TP/(TP+FP) and NPV = TN/(TN+FN), respectively, are the proportions of positive and negative predictions that were true.
For measuring the accuracy of classifiers the so-called f-scores are also used, since they represent a weighted average of the precision (PPV) and recall (SE). In the present study we use the traditional f-measure or balanced f-score (f1 score = 2TP/(2TP+FN+FP)) that is the harmonic mean of precision and recall. In addition, we measure the f2 score = 5TP/(5TP+4FN+FP), which weights recall higher than precision. The importance of the latter one can be explained by the patient’s desire to be sure that the predictions of no hypoglycemia will be correct (SE is more important).
Method Description
NH Prediction From GCI
Let be a vector of daily blood glucose (BG) measurements (in mg/dL), where for instance, is the last before-bed (LBB) measurement that was used for NH prediction in Whincup and Milner7 and Davies.8
Glucose control indices4 considered in this paper are the functions assigning the values to each vector of BG measurements Then NH prediction for the night succeeding the day, on which the measurements were performed, can be made in the following way
where is a suitable threshold value, and means the positive NH forecast (ie, NH is expected), while means the opposite case.
For example, as we mentioned, in Blood Glucose Index3 a predictor based on the low blood glucose index
is suggested, where is the so-called quadratic risk function, and
Moreover, combining the idea of the quadratic risk function with the observation7 that LBB measurement is an important NH indicator, we can consider one more NH predictor Such predictor can be seen as an analog of the predictors7,8 in terms of LBGI.
At the same time, it is clear that the construction (1) admits the use of other GCI. Below we recall the definition of GCI that will be used as examples in (1).
Hypoglycemic Index (HI)
where LLTR denotes lower limit of target range BG value, a default value of LLTR is 95 mg/dL.
GRADE Hypoglycemic Index (GHI)
Aggregation of NH Predictors Based on GCI
Let be NH predictors of the form (1), which are based on different indices
Assume that we can access clinical records of diabetic patients, which contain historical data such as daily BG measurements collected within different days, and retrospective NH detections for the corresponding succeeding nights, such that the real case of NH in the night after the day is coded as , while the night without NH corresponds to The set of pairs will further be called “training set”.
Having an ensemble of NH predictors l = 1,2,…,m, one can consider a linear combination
Note that NH predictors are in fact classifiers taking the values -1 and 1, while the combination may take other values as well. At the same time, in the spirit of (1), the value can be used for constructing NH predictor
where is a certain threshold with a default value
Following Kriukova et al,5 we choose the vector of coefficients in (2) by solving the linear system
with the matrix and the vector such that
where form a dataset denoted above as
From Kriukova et al5 (see Theorem 10 there) it follows that under rather general assumptions and for sufficiently large number of training set pairs the choice (4), (5) gives rise to the predictor (3) that is close to the minimizer of a misclassification error. Note that there is a theoretical justification5 that with a high probability the prediction should be at the level of the accuracy of the best prediction among
Thus, to construct NH predictor which is based on a linear combination of given predictors one needs to perform calculations (4), (5) using the data from a dataset
Datasets
In the current study we used datasets DIAdvisor and ChildrenData. Both datasets contain BG measurements of patients with type 1 diabetes. Further details are given below.
DIAdvisor
DIAdvisor dataset containing the data of 34 patients with diabetes was collected within the framework of the European FP7-funded project DIAdvisor. The considered subjects have been treated with insulin for at least 12 months before data collection; their ages were between 18 and 65 years, with a BMI< 35 kg/m2. During the study, the CGM-values were sampled every 5-10 min using continuous glucose monitoring (CGM) sensor. These data were not used for a prediction, but allow a detection of NH during the nights. Only confirmed hypoglycemia by finger stick measurements were used to qualify for NH. At the same time, 4 true BG measurements were performed daily in parallel with CGM estimations, and these BG data were used for training and testing the considered NH predictors.
A total number of n = 150 days has been chosen to test the proposed approach. NH has been confirmed in 40 cases.
ChildrenData
This dataset was collected during 3 and a half months in children hospitals of the Kyiv city, Ukraine, according to a protocol that is similar to Whincup and Milner.7 The access to this dataset has been provided within the framework of the European Horizon 2020-funded MSC-project AMMODIT.
The dataset contains information about 179 children. Each of n = 476 records of this dataset contains 9 BG measurements, which were performed at the following time points of a 24-hour cycle: 08:00, 11:30, 13:30, 16:00, 18:00, 21:00, 00:00, 03:00 and 06:00. The measurements at 00:00, 03:00 and 06:00 were used to identify the occurrence of NH, while the measurements of other time points of the 24-hour cycle form the input for NH prediction. In this dataset the number of records with NH is 222.
Method Testing
To illustrate our aggregation approach, we consider NH predictors of the form (1), which are based on the indices discussed in Rodbard4 and recalled above. The corresponding threshold values in (1) can be taken to optimize the performance of the predictors with respect to the chosen performance metrics on the DIAdvisor dataset, for example. For this purpose one can use, for instance, the so-called receiver operating characteristic (ROC) curve created by plotting SE of a predictor against its false positive rate (calculated as 1-SP) at various threshold values . The MATLAB routine perfcurve was used to select a threshold value , which is optimal in ROC-sense. In our illustrations below we use NH predictors with thresholds calibrated to optimize performance on the DIAdvisor dataset.
NH predictors are aggregated into a predictor by performing the calculations (4), (5) with the data from DIAdvisor dataset. Figure 1 illustrates a scheme of prediction, and we use a default threshold value Table 1 reports the performance of NH predictors and on DIAdvisor dataset. As it can be seen from this table, even though NH predictors have been optimized in the sense of performance on the considered dataset, our aggregation approach allows a further performance improvement.
Figure 1.
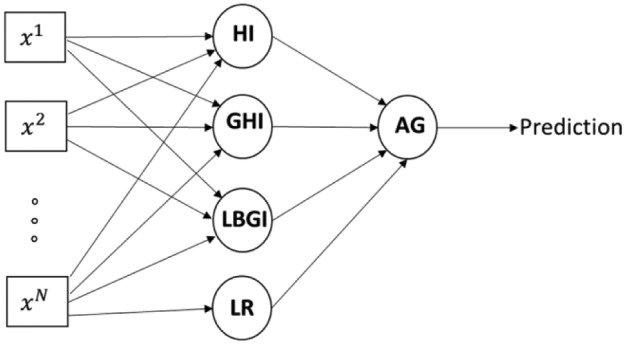
Scheme of prediction by means of an aggregation of the considered GCI-based NH predictors.
Table 1.
Performance of NH Predictors Based on GCI and Their Aggregator on DIAdvisor Dataset (Values Are Percentages).
| NH Predictor based on | SE | SP | PPV | NPV | f1 | f2 |
|---|---|---|---|---|---|---|
| HypoIndex | 80 | 89.09 | 72.73 | 92.45 | 76.19 | 78.43 |
| GRADEHypoIndex | 77.5 | 90 | 73.81 | 91.67 | 75.61 | 76.73 |
| LR | 55 | 98.18 | 91.67 | 85.71 | 68.75 | 59.78 |
| LBGI | 62.5 | 98.18 | 92.59 | 87.8 | 74.63 | 66.84 |
| Aggregation | 80 | 96.36 | 88.89 | 92.98 | 84.21 | 81.63 |
In view of possible application in Telemedicine, a desirable feature of a NH predictor is its portability from individual to individual without readjustment. This means that an algorithm, which was constructed with the use of clinical data of one group of patients, can be used by other patients without recalibration and essential loss of prediction performance.
To illustrate that the proposed aggregation of NH predictors potentially allows the above mentioned portability, the predictor constructed with the use of DIAdvisor dataset is applied without any adjustment to ChildrenData described above. The first row of Table 2 reports the values of the corresponding performance metrics. The second row of this table reports the performance achieved on the same dataset by NH predictor6 that aggregates and another 6 NH predictors proposed in Whincup and Milner7 and Davies,8 which are based only on the LBB BG measurement. Table 2 allows a conclusion that an extension of the ensemble of GCI-based predictors leads to an aggregation with reduction of false negatives, which is in agreement with the patient’s desire to be sure that the predictions of no hypoglycemia will be correct.
Table 2.
Comparative Performance of Aggregations of Different Ensembles of NH Predictors (Values Are Percentages).
| SE | SP | PPV | NPV | f1 | f2 | |
|---|---|---|---|---|---|---|
| Aggregation | 77.03 | 83.46 | 80.28 | 80.61 | 78.62 | 77.66 |
| Aggregation6 | 73.4 | 87.8 | 84.0 | 79.0 | 78.4 | 75.3 |
Note that, as has been pointed in Skladnev et al,9 a NH prevention method may achieve market acceptance at SE of 70% with SP of 65%. Then the performance reported in Table 2 is higher than conventionally considered as acceptable.
Conclusions
We have discussed an extension of the idea1,2 of using GCI for NH prediction. Our results also demonstrate the advantages of aggregating several GCI-based NH predictors instead of choosing a single one. Although the construction of an aggregator requires training, the obtained predictor can further be used without modifications.
It is also worth to note that all our tests have been performed with data acquired from patients with type 1 diabetes, but the predictors considered in the present study are dealing with GCI that can be used for both patients with type 1 and type 2 diabetes patients. Therefore, a similar performance could potentially be expected for patients with type 2 diabetes. At the same time, a challenge is that patients with type 2 diabetes usually perform a lower number of daily BG measurements.
Note that in contrast to DIAdvisor the ChildrenData dataset contains BG measurements at discrete time moments only. Therefore, a validation of hypoglycemia cases on these datasets has been performed similar to Whincup and Milner7 and Davies8 by examining BG measurements collected during the night period. Of course, in this way some asymptomatic nocturnal hypos may be missed. Therefore, the results reported above should be considered as a proof of concept only.
Another limitation is that the considered predictors take into account only daily glucose variability. However, it is clear that there are other important factors that need to be considered in understanding development of hypoglycemia during the night, including intensity and duration of daily physical activity, meals, basal and bolus insulin doses. Therefore, further investigations are necessary for more accurate NH prediction.
As a summary, we would like to mention, that, in contrast to majority of publications on blood glucose prediction, the current study uses 2 independently collected clinical datasets for validating prediction performances. The main message of the presented study is that the incorporation of more and more new predictors into the proposed aggregation procedure leads to the improvement of prediction reliability. This conclusion follows from present study (see Table 2) and previous publications.5,6 At the same time, we understand that to bring the proposed tool closer to patients a new clinical trial entirely devoted to its testing would be desirable, and we hope that our research provides a motivation for such a trial. The design of this future trial should shed light on the following issues.
The use of CGM as “gold standard” for NH detection. This is the issue because it is known (see Baysal et al10 and references therein) that CGM is not very reliable especially during the night and may produce false hypoglycemia scenarios. Hence only confirmed hypoglycemia by finger stick measurement is expected to be considered.
Dependence of prediction reliability on the number and the time of SMBG measurements. Note that here we may check whether this issue can be resolved by aggregating NH-predictors that use different input data.
Actions toward NH-prevention, when NH has been predicted. Of course, an obvious solution would be to take an additional snack followed by one more SMBG measurement reversing the prediction. But the time, at which the above mentioned SMBG measurement should be performed, is an open issue (see the previous issue). Moreover, the amount of additional carbohydrate intake should not drastically increase the mean overnight glucose. Nevertheless the development of decision algorithms following a predicted NH will definitely add value of predictor use to the patient.
Acknowledgments
This work was done while the first author was visiting Johann Radon Institute and he gratefully acknowledges the hospitality at Linz. The visit was supported by EU-Horizon 2020 MSC-RISE project AMMODIT.
Footnotes
Abbreviations: BG, blood glucose; BGM, blood glucose monitoring method; CGM, continuous glucose monitors; FN, false negative; FP, false positive; GCI, glycemic control indices; GRADE, Glycemic Risk Assessment Diabetes Equation; LBB, last before-bed; LBGI, low blood glucose index; LLTR, lower limit of target range BG value; NH, nocturnal hypoglycemia; NPV, negative predictive values; PPV, positive predictive values; ROC, receiver operating characteristic; SE, sensitivity; SP, specificity; TN, true negative; TP, true positive.
Declaration of Conflicting Interests: The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding: The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors affiliated with Johann Radon Institute gratefully acknowledge the support of the Austrian Science Fund (FWF): projects P25424 and I1669.
References
- 1. Kovatchev BP, Cox DJ, Gonder-Frederick LA, Young-Hyman D, Schlundt D, Clarke W. Assessment of risk for severe hypoglycemia among adults with IDDM: validation of the low blood glucose index. Diabetes Care. 1998;21 (11):1870-1875. [DOI] [PubMed] [Google Scholar]
- 2. Cox DJ, Gonder-Frederick L, Ritterband L, Clarke W, Kovatchev BP. Prediction of severe hypoglycemia. Diabetes Care. 2007;30:1370-1373. [DOI] [PubMed] [Google Scholar]
- 3. Blood Glucose Index. Available at: http://hcp.accu-chek.co.uk/gbconnect/blood-glucose-index.html. Accessed February 15, 2016.
- 4. Rodbard D. Interpretation of continuous glucose monitoring data: glycemic variability and quality of glycemic control. Diabetes Technol Ther. 2009;11:55-67. [DOI] [PubMed] [Google Scholar]
- 5. Kriukova G, Panasiuk O, Pereverzyev SV, Tkachenko P. A linear functional strategy for regularized ranking. Neural Networks. 2016;73:26-35. [DOI] [PubMed] [Google Scholar]
- 6. Tkachenko P, Kriukova G, Aleksandrova M, Chertov O, Renard E, Pereverzyev S. Prediction of nocturnal hypoglycemia by an aggregation of previously known prediction approaches: proof of concept for clinical application. RICAM Report; June 2016. [DOI] [PubMed] [Google Scholar]
- 7. Whincup G, Milner R. Prediction and management of nocturnal hypo-glycaemia in diabetes. Arch Dis Child. 1987;62(4):333-337. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8. Davies A. Prediction and management of nocturnal hypo-glycaemia in diabetes. Arch Dis Child. 1987;62(10):1085. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9. Skladnev V, Ghevondian N, Tarnavskii S, Paramalingam N, Jones T. Clinical evaluation of a noninvasive alarm system for nocturnal hypo-glycemia. J Diabetes Sci Technol. 2010;4(1):67-74. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10. Baysal N, Cameron F, Buckingham BA, et al. A novel method to detect pressure-induced sensor attenuations (PISA) in an artificial pancreas. J Diabetes Sci Technol. 2014;8(6):1091-1096. [DOI] [PMC free article] [PubMed] [Google Scholar]