

Abstract
The little Grothendieck problem consists of maximizing Σij Cijxixj for a positive semidef-inite matrix C, over binary variables xi ∈ {±1}. In this paper we focus on a natural generalization of this problem, the little Grothendieck problem over the orthogonal group. Given C ∈ ℝdn × dn a positive semidefinite matrix, the objective is to maximize restricting Oi to take values in the group of orthogonal matrices , where Cij denotes the (ij)-th d × d block of C.
We propose an approximation algorithm, which we refer to as Orthogonal-Cut, to solve the little Grothendieck problem over the group of orthogonal matrices and show a constant approximation ratio. Our method is based on semidefinite programming. For a given d ≥ 1, we show a constant approximation ratio of αℝ(d)2, where αℝ(d) is the expected average singular value of a d × d matrix with random Gaussian i.i.d. entries. For d = 1 we recover the known αℝ(1)2 = 2/π approximation guarantee for the classical little Grothendieck problem. Our algorithm and analysis naturally extends to the complex valued case also providing a constant approximation ratio for the analogous little Grothendieck problem over the Unitary Group .
Orthogonal-Cut also serves as an approximation algorithm for several applications, including the Procrustes problem where it improves over the best previously known approximation ratio of . The little Grothendieck problem falls under the larger class of problems approximated by a recent algorithm proposed in the context of the non-commutative Grothendieck inequality. Nonetheless, our approach is simpler and provides better approximation with matching integrality gaps.
Finally, we also provide an improved approximation algorithm for the more general little Grothendieck problem over the orthogonal (or unitary) group with rank constraints, recovering, when d = 1, the sharp, known ratios.
Keywords: Approximation algorithms, Procrustes problem, Semidefinite programming
1 Introduction
The little Grothendieck problem [AN04] in combinatorial optimization is written as
| (1) |
where C is a n × n positive semidefinite matrix real matrix.
Problem (1) is known to be NP-hard. In fact, if C is a Laplacian matrix of a graph then (1) is equivalent to the Max-Cut problem. In a seminal paper in the context of the Max-Cut problem, Goemans and Williamson [GW95] provide a semidefinite relaxation for (1):
| (2) |
It is clear that in (2), one can take m = n. Furthermore, (2) is equivalent to a semidefinite program and can be solved, to arbitrary precision, in polynomial time [VB96]. In the same paper [GW95] it is shown that a simple rounding technique is guaranteed to produce a solution whose objective value is, in expectation, at least a multiplicative factor of the optimum.
A few years later, Nesterov [Nes98] showed an approximation ratio of for the general case of an arbitrary positive semidefinite C ⪰ 0 using the same relaxation as [GW95]. This implies, in particular, that the value of (1) can never be smaller than times the value of (2). Interestingly, such an inequality was already known from the influential work of Grothendieck on norms of tensor products of Banach spaces [Gro96] (see [Pis11] for a survey on this).
Several more applications have since been found for the Grothendieck problem (and variants), and its semidefinite relaxation. Alon and Naor [AN04] showed applications to estimating the cut-norm of a matrix; Ben-Tal and Nemirovski [BTN02] showed applications to control theory; Briet, Buhrman, and Toner [BBT11] explored connections with quantum non-locality. For many more applications, see for example [AMMN05] (and references therein).
In this paper, we focus on a natural generalization of problem (1), the little Grothendieck problem over the orthogonal group, where the variables are now elements of the orthogonal group , instead of {±1}. More precisely, given C ∈ ℝdn × dn a positive semidefinite matrix, we consider the problem
| (3) |
where Cij denotes the (i, j)-th d × d block of C, and is the group of d × d orthogonal matrices (i.e., if and only if OOT = OT O = Id×d).
We will also consider the unitary group variant, where the variables are now elements of the unitary group (i.e., if and only if UUH = UH U = Id×d). More precisely, given C ∈ ℂdn×dn a complex valued positive semidefinite matrix, we consider the problem
| (4) |
Since C is Hermitian positive semidefinite, the value of the objective function in (4) is always real. Note also that when d = 1, (3) reduces to (1). Also, since is the multiplicative group of the complex numbers with unit norm, (4) recovers the classical complex case of the little Grothendieck problem. In fact, the work of Nesterov was extended [SZY07] to the complex plane (corresponding to , or equivalently, the special orthogonal group ) with an approximation ratio of for C ⪰ 0. As we will see later, the analysis of our algorithm shares many ideas with the proofs of both [Nes98] and [SZY07] and recovers both results.
As we will see in Section 2, several problems can be written in the forms (3) and (4), such as the Procrustes problem [Sch66, Nem07, So11] and Global Registration [CKS15]. Moreover, the approximation ratio we obtain for (3) and (4) translates into the same approximation ratio for these applications, improving over the best previously known approximation ratio of in the real case and in the complex case, given by [NRV13] for these problems.
Problem (3) belongs to a wider class of problems considered by Nemirovski [Nem07] called QO-OC (Quadratic Optimization under Orthogonality Constraints), which itself is a subclass of QC-QP (Quadratically Constrainted Quadratic Programs). Please refer to Section 2 for a more detailed comparison with the results of Nemirovski [Nem07]. More recently, Naor et al. [NRV13] proposed an efficient rounding scheme for the non commutative Grothendieck inequality that provides an approximation algorithm for a vast set of problems involving orthogonality constraints, including problems of the form of (3) and (4). We refer to Section 1.2 for a comparison between this approach and ours.
Similarly to (2) we formulate a semidefinite relaxation we name the Orthogonal-Cut SDP:
| (5) |
Analogously, in the unitary case, we consider the relaxation
| (6) |
Since C is Hermitian positive semidefinite, the value of the objective function in (6) is guaranteed to be real. Note also that we can take m = dn as the Gram matrix does not have a rank constraint for this value of m. In fact, both problems (5) and (6) are equivalent to the semidefinite program
| (7) |
for respectively ℝ and ℂ, which are generally known to be computationally tractable1 [VB96, Nes04, AHO98]. At first glance, one could think of problem (5) as having d2n variables and that we would have to take m = d2n for (5) to be tractable (in fact, this is the size of the SDP considered by Nemirovski [Nem07]). The savings in size (corresponding to number of variables) of our proposed SDP relaxation come from the group structure of (or ).
One of the main contributions of this paper is showing that Algorithm 3 (Section 1.1) gives a constant factor approximation to (3), and its unitary analog (4), with an optimal approximation ratio for our relaxation (Section 6). It consists of a simple generalization of the rounding in [GW95] applied to (5), or (4).
Theorem 1
Let C ⪰ 0 and real. Let be the (random) output of the orthogonal version of Algorithm 3. Then
where αℝ(d) is the constant defined below.
Analogously, in the unitary case, if are the (random) output of the unitary version of Algorithm 3, then for C ⪰ 0 and complex,
where αℂ(d) is defined below.
Definition 2
Let Gℝ ∈ ℝd×d and Gℂ ∈ ℂd×d be, respectively, a Gaussian random matrix with i.i.d real valued entries and a Gaussian random matrix with i.i.d complex valued entries . We define
where σj(G) is the jth singular value of G.
Although we do not have a complete understanding of the behavior of αℝ(d) and αℂ(d) as functions of d, we can, for each d separately, compute a closed form expression (see Section 4). For d = 1 we recover the sharp and results of, respectively, Nesterov [Nes98] and So et al. [SZY07]. One can also show that , for both and . Curiously,
Our computations strongly suggest that αℝ(d) is monotonically increasing while its complex analog αℂ(d) is monotonically decreasing. We find the fact that the approximation ratio seems to get, as the dimension increases, better in the real case and worse in the complex case quite intriguing. One might naively think that the problem for a specific d can be formulated as a degenerate problem for a larger d, however this does not seem to be true, as evidenced by the fact that is increasing. Another interesting point is that αℝ(2) ≠ αℂ(1) which suggests that the little Grothendieck problem over is quite different from the analog in (which is isomorphic to ). Unfortunately, we were unable to provide a proof for the monotonicity of (Conjecture 8). Nevertheless, we can show lower bounds for both and that have the right asymptotics (see Section 4). In particular, we can show that our approximation ratios are uniformly bounded below by the approximation ratio given in [NRV13].
In some applications, such as the Common Lines problem [SS11] (see Section 5), one is interested in a more general version of (3) where the variables take values in the Stiefel manifold , the set of matrices O ∈ ℝd×r such that OOT = Id×d. This motivates considering a generalized version of (3) formulated as, for r ≥ d,
| (8) |
for C ⪰ 0. The special case d = 1 was formulated and studied in [BBT11] and [BFV10] in the context of quantum non-locality and quantum XOR games. Note that in the special case r = nd, (8) reduces to (5) and is equivalent to a semidefinite program.
We propose an adaption of Algorithm 3, Algorithm 9, and show an approximation ratio of αℝ(d, r)2, where αℝ(d, r) is also defined as the average singular value of a Gaussian matrix (see Section 5). For d = 1 we recover the sharp results of Briet el al. [BFV10] giving a simple interpretation for the approximation ratios, as α(1, r) is simply the mean of a normalized chi-distribution with r degrees of freedom. As before, the techniques are easily extended to the complex valued case.
In order to understand the optimality of the approximation ratios αℝ(d)2 and αℂ(d)2 we provide an integrality gap for the relaxations (5) and (6) that matches these ratios, showing that they are tight. Our construction of an instance having this gap is an adaption of the classical construction for the d = 1 case (see, e.g., [AN04]). As it will become clear later (see Section 6), there is an extra difficulty in the d > 1 orthogonal case which can be dealt with using the Lowner-Heinz Theorem on operator convexity (see Theorem 13 and the notes [Car09]).
Besides the monotonicity of (Conjecture 8), there are several interesting questions raised from this work, including the hardness of approximation of the problems considered in this paper (see Section 7 for a discussion on these and other directions for future work).
Organization of the paper
The paper is organized as follows. In Section 1.1 below we present the approximation algorithm for (3) and (4). In Section 1.2, we compare our results with the ones in [NRV13]. We then describe a few applications in Section 2 and show the analysis for the approximation ratio guarantee in Section 3. In Section 4 we analyze the value of the approximation ratio constants. Section 5 is devoted to a more general, rank constrained, version of (4). We give an integrality gap for our relaxation in Section 6 and discuss open problems and future work in Section 7. Finally, we present supporting technical results in the Appendix.
1.1 Algorithm
We now present the (randomized) approximation algorithm we propose to solve (3) and (4).
Algorithm 3
Compute X1, …, Xn ∈ ℝd×nd (or Y1, …, Yn ∈ ℂd×nd) a solution to (5) (or (6)). Let R be a nd × d Gaussian random matrix whose entries are real (or complex) i.i.d. . The approximate solution for (3) (or (4)) is now computed as
where , for any X ∈ ℝd×d (or Y ∈ ℂd×d) and is the Frobenius norm.
Note that (5) and (6) can be solved with arbitrary precision in polynomial time [VB96] as they are equivalent to a semidefinite program (followed by a Cholesky decomposition) with a, respectively real and complex valued, matrix variable of size dn × dn, and d2n linear constraints. In fact, this semidefinite program has a very similar structure to the classical Max-Cut SDP. This may allow one to adapt specific methods designed to solve the Max-Cut SDP such as, for example, the row-by-row method [WGS12] (see Section 2.4 of [Ban15]).
Moreover, given X a d × d matrix (real or complex), the polar component is the orthogonal (or unitary) matrix part of the polar decomposition, that can be easily computed via the singular value decomposition of X = UΣVH as (see [FH55, Kel75, Hig86]), rendering Algorithm 3 efficient. The polar component is the analog in high dimensions of the sign in and the angle in and can also be written as .
1.2 Relation to non-commutative Grothendieck inequality
The approximation algorithm proposed in [NRV13] can also be used to approximate problems (3) and (4). In fact, the method in [NRV13] deals with problems of the form
| (9) |
where M is a N × N × N × N real valued 4-tensor.
Problem (3) can be encoded in the form of (9) by taking N = dn and having the d × d block of M, obtained by having the first two indices range from (i − 1)d + 1 to id and the last two from (j − 1)d + 1 to jd, equal to Cij, and the rest of the tensor equal to zero [NRV13]. More explicitly, the nonzero entries of M are given by M(i−1)d+r,(i−1)d+r,(j−1)d+s,(j−1)d+s = [Cij]rs, for each i, j and r, s = 1, …, d. Since C is positive semidefinite, the supremum in (9) is attained at a pair (X, Y) such that X = Y.
In order to describe the relaxation one needs to first define the space of vector-valued orthogonal matrices where XXT and XTX are N × N matrices defined as and .
The relaxation proposed in [NRV13] (which is equivalent to our relaxation when M is specified as above) is given by
| (10) |
and there exists a rounding procedure [NRV13] that achieves an approximation ratio of . Analogously, in the unitary case, the relaxation is essentially the same and the approximation ratio is . We can show (see Section 4) that the approximation ratios we obtain are larger than these for all d ≥ 1. Interestingly, the approximation ratio of , for the complex case in [NRV13], is tight in the full generality of the problem considered in [NRV13], nevertheless αℂ(d)2 is larger than this for all dimensions d.
Note also that to approximate (3) with this approach one needs to have N = dn in (10). This means that a naïve implementation of this relaxation would result in a semidefinite program with a matrix variable of size d2n2 × d2n2, while our approach is based on semidefinite programs with matrix variables of size dn × dn. It is however conceivable that when restricted to problems of the type of (3), the SDP relaxation (10) may enjoy certain symmetries or other properties that facilitate its solution.
2 Applications
Problem (3) can describe several problems of interest. As examples, we describe below how it encodes a complementary version of the orthogonal Procrustes problem and the problem of Global Registration over Euclidean Transforms. Later, in Section 5, we briefly discuss yet another problem, the Common Lines problem, that is encoded by a more general rank constrained version of (3).
2.1 Orthogonal Procrustes
Given n point clouds in ℝd of k points each, the orthogonal Procrustes problem [Sch66] consists of finding n orthogonal transformations that best simultaneously align the point clouds. If the points are represented as the columns of matrices A1, …, An, where Ai ∈ ℝd×k then the orthogonal Procrustes problem consists of solving
| (11) |
Since , (11) has the same solution as the complementary version of the problem
| (12) |
Since C ∈ ℝdn×dn given by is positive semidefinite, problem (12) is encoded by (3) and Algorithm 3 provides a solution with an approximation ratio guaranteed (Theorem 1) to be at least αℝ(d)2.
The algorithm proposed in Naor et al. [NRV13] gives an approximation ratio of , smaller than αℝ(d)2, for (12). As discussed above, the approach in [NRV13] is based on a semidefinite relaxation with a matrix variable of size d2n2 × d2n2 instead of dn × dn as in (5) (see Section 1.2 for more details).
Nemirovski [Nem07] proposed a different semidefinite relaxation (with a matrix variable of size d2n × d2n instead of dn × dn as in (5)) for the orthogonal Procrustes problem. In fact, his algorithm approximates the slightly different problem
| (13) |
which is an additive constant (independent of O1, …, On) smaller than (12). The best known approximation ratio for this semidefinite relaxation, due to So [So11], is . Although an approximation to (13) would technically be stronger than an approximation to (12), the two quantities are essentially the same provided that the point clouds are indeed perturbations of orthogonal transformations of the same original point cloud, as is the case in most applications (see [NRV13] for a more thorough discussion on the differences between formulations (12) and (13)).
Another important instance of this problem is when the transformations are elements of (the special orthogonal group of dimension 2, corresponding to rotations of the plane). Since is isomorphic to we can encode it as an instance of problem (4), in this case we recover the previously known optimal approximation ratio of [SZY07].
Note that, since all instances of problem (3) can be written as an instance of orthogonal Procrustes, the integrality gap we show (Theorem 14) guarantees that our approximation ratio is optimal for the natural semidefinite relaxation we consider for the problem.
2.2 Global Registration over Euclidean Transforms
The problem of global registration over Euclidean rigid motions is an extension of orthogonal Procrustes. In global registration, one is required to estimate the positions x1, …, xk of k points in ℝd and the unknown rigid transforms of n local coordinate systems given (perhaps noisy) measurements of the local coordinates of each point in some (though not necessarily all) of the local coordinate systems. The problem differs from orthogonal Procrustes in two aspects: First, for each local coordinate system, we need to estimate not only an orthogonal transformation but also a translation in ℝd. Second, each point may appear in only a subset of the coordinate systems. Despite those differences, it is shown in [CKS15] that global registration can also be reduced to the form (3) with a matrix C that is positive semidefinite.
More precisely, denoting by Pi the subset of points that belong to the i-th local coordinate system (i = 1 … n), and given the local coordinates
of point xl ∈ Pi (where Oi denotes an unknown orthogonal transformation, ti an unknown translation and ξil a noise term). The goal is to estimate the global coordinates xl. The idea is to minimize the function
over xl, ti ∈ ℝd, . It is not difficult to see that the optimal and can be written in terms of O1, …, On. Substituting them back into ε, the authors in [CKS15] reduce the previous optimization to solving
| (14) |
where L is a certain (n + k) × (n + k) Laplacian matrix, L† is its pseudo inverse, and B is a (dn) × (n + k) matrix (see [CKS15]). This means that BL†BT ⪰ 0, and (14) is of the form of (3).
3 Analysis of the approximation algorithm
In this Section we prove Theorem 1. As (5) and (6) are relaxations of, respectively, problem (3) and problem (4) their maximums are necessarily at least as large as the ones of, respectively, (3) and (4). This means that Theorem 1 is a direct consequence of the following theorem.
Theorem 4
Let C ⪰ 0 and real. Let X1, …, Xn be a feasible solution to (5). Let be the output of the (random) rounding procedure described in Algorithm 3. Then
where αℝ(d) is the constant in Definition 2. Analogously, if C ⪰ 0 and complex and Y1, …, Yn is a feasible solution of (6) and the output of the (random) rounding procedure described in Algorithm 3. Then
where αℂ(d) is the constant in Definition 2.
In Section 6 we show that these ratios are optimal (Theorem 14).
Before proving Theorem 4 we present a sketch of the proof for the case d = 1 (and real). The argument is known as the Rietz method (See [AN04])2:
Let X1, …, Xn ∈ ℝ1×n be a feasible solution to (5), meaning that . Let R ∈ ℝn×1 be a random matrix with i.i.d. standard Gaussian entries. Our objective is to compare with . The main observation is that although is not a linear function of , the expectation is. In fact — which follows readily by thinking of Xi and Xj as vectors in the two dimensional plane that they span. We use this fact (together with the positiveness of C) to show our result. The idea is to build the matrix S ⪰ 0,
Since both C and S are PSD, tr(CS) ≥ 0, which means that
Combining this with the observation above and the fact that , we have
Proof
[of Theorem 4] For the sake of brevity we restrict the presentation of the proof to the real case. Nevertheless, it is easy to see that all the arguments trivially adapt to the complex case by, essentially, replacing all transposes with Hermitian adjoints and αℝ(d) with αℂ(d).
Let R ∈ ℝnd×d be a Gaussian random matrix with i.i.d entries . We want to provide a lower bound for
Similarly to the d = 1 case, one of the main ingredients of the proof is the fact given by the lemma below.
Lemma 5
Let r ≥ d. Let M, N ∈ ℝd×nd such that MMT = NNT = Id×d. Let R ∈ ℝnd×d be a Gaussian random matrix with real valued i.i.d entries . Then
where αℝ(d) is constant in Definition 2.
Analogously, if M, N ∈ ℂd×nd such that MMH = NNH = Id×d, and R ∈ ℂnd×r is a Gaussian random matrix with complex valued i.i.d entries , then
where αℂ(d) is constant in Definition 2.
Before proving Lemma 5 we use it to finish the proof of Theorem 4.
Just as above, we define the positive semidefinite matrix S ∈ ℝdn×dn whose (i, j)-th block is given by
We have =
By construction S ⪰ 0. Since C ⪰ 0, tr(CS) ≥ 0, which means that
Thus,
□
We now present and prove an auxiliary lemma, needed for the proof of Lemma 5.
Lemma 6
Let G be a d × d Gaussian random matrix with real valued i.i.d. entries and let αℝ(d) as defined in Definition 2. Then,
Furthermore, if G is a d × d Gaussian random matrix with complex valued i.i.d. entries and αℂ(d) the analogous constant (Definition 2), then
Proof
We restrict the presentation to the real case. All the arguments are equivalent to the complex case, replacing all transposes with Hermitian adjoints and αℝ(d) with αℂ(d).
Let G = UΣVT be the singular value decomposition of G. Since GGT = UΣ2UT is a Wishart matrix, it is well known that its eigenvalues and eigenvectors are independent and U is distributed according to the Haar measure in (see e.g. Lemma 2.6 in [TV04]). To resolve ambiguities, we consider Σ ordered such that Σ11 ≥ Σ22 ≥ … ≥ Σdd.
Let . Since
we have
Note that .
Denoting u1, …, ud the rows of U, since U is distributed according to the Haar measure, we have that uj and −uj have the same distribution conditioned on Σ and ui, for any i ≠ j. This implies that if i ≠ j, is a symmetric random variable, and so . Also, ui ~ uj implies that Yii ~ Yjj. This means that for some constant c. To obtain c,
which shows the lemma.
Proof
[of Lemma 5] We restrict the presentation of proof to the real case. Nevertheless, as before, all the arguments trivially adapt to the complex case by, essentially, replacing all transposes with Hermitian adjoints and αℝ(d) with αℂ(d).
Let A = [MT NT] ∈ ℝdn×2d and A = QB be the QR decomposition of A with Q ∈ ℝnd×nd an orthogonal matrix and B ∈ ℝnd×2d upper triangular with non-negative diagonal entries; note that only the first 2d rows of B are nonzero. We can write
where B11 ∈ ℝd×d and B22 ∈ ℝd×d are upper triangular matrices with non-negative diagonal entries. Since
B11 = (QTMT)11 is an orthogonal matrix, which together with the non-negativity of the diagonal entries (and the fact that B11 is upper-triangular) forces B11 to be B11 = Id×d.
Since R is a Gaussian matrix and Q is an orthogonal matrix, QR ~ R which implies
Since and ,
where R1 and R2 are the first two d × d blocks of R. Since these blocks are independent, the second term vanishes and we have
The Lemma now follows from using Lemma 6 to obtain and noting that B12 = (QTMT) (QTNT) = MNT.
The same argument, with Q’B’ the QR decomposition of A’ = [NTMT] ∈ ℝdn×2d instead, shows
□
4 The approximation ratios αℝ(d)2 and αℂ(d)2
The approximation ratio we obtain (Theorem 1) for Algorithm 3 is given, in the orthogonal case, by αℝ(d)2 and, in the unitary case, by αℂ(d)2. αℝ(d) and αℂ(d) are defined as the average singular value of a d × d Gaussian matrix G with, respectively real and complex valued, i.i.d entries. These singular values correspond to the square root of the eigenvalues of a Wishart matrix W = GGT, which are well-studied objects (see, e.g., [She01] or [CD11]).
For d = 1, this corresponds to the expected value of the absolute value of standard Gaussian (real or complex) random variable. Hence,
meaning that, for d = 1, we recover the approximation ratio of , of Nesterov [Nes98] for the real case, and the approximation ratio of of So et al. [SZY07] in the complex case.
For any d ≥ 1, the marginal distribution of an eigenvalue of the Wishart matrix W = GGT is known [LV11, CD11, Lev12] (see Section B). Denoting by the marginal distribution for and , we have
| (15) |
In the complex valued case, can be written in terms of Laguerre polynomials [CD11, Lev12] and αℂ(d) is given by
| (16) |
Where Ln(x) is the nth Laguerre polynomial. In Section B we give a lower bound to (16). The real case is more involved [LV11], nevertheless we are able to provide a lower bound for αℝ(d) as well.
Theorem 7
Consider αℝ(d) and αℂ(d) as defined in (2). The following holds,
Proof
These bounds are a direct consequence of Lemmas 20 and 21.
One can easily evaluate (without using Theorem 7) by noting that the distribution of the eigenvalues of the Wishart matrix we are interested in, as d → ∞, converges in probability to the Marchenko-Pastur distribution [She01] with density
for both and . This immediately gives,
We note that one could also obtain lower bounds for from results on the rate of convergence to mp(x) [GT11]. However this approach seems to not provide bounds with explicit constants and to not be as sharp as the approach taken in Theorem 7.
For any d, the exact value of can be computed, by (15), using Mathematica (See table below). Figure 1 plots these values for d = 1, …, 44. We also plot the bounds for the real and complex case obtained in Theorem 7, and the approximation ratios obtained in [NRV13], for comparison.
Figure 1.
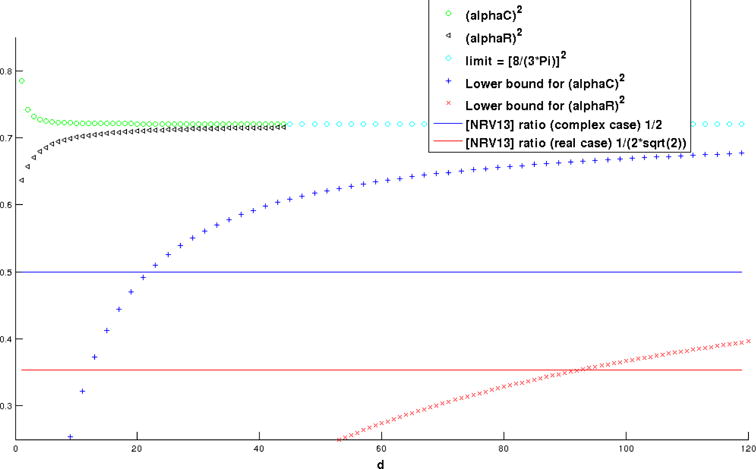
Plot showing the computed values of , for d ≤ 44, the limit of as d → ∞, the lower bound for given by Theorem 7 as function of d, and the approximation ratio of and obtained in [NRV13].
| d | αℝ(d) | αℂ(d) | αℝ(d) ≈ | αℝ(d)2 ≈ | αℂ(d) ≈ | αℂ(d)2 ≈ | ||
|
| ||||||||
| 1 |
|
|
0.7979 | 0.6366 | 0.8862 | 0.7854 | ||
| 2 |
|
|
0.8102 | 0.6564 | 0.8617 | 0.7424 | ||
| 3 |
|
|
0.8188 | 0.6704 | 0.8554 | 0.7312 | ||
| ∞ |
|
|
0.8488 | 0.7205 | 0.8488 | 0.7205 | ||
The following conjecture is suggested by our analysis and numerical computations.
Conjecture 8
Let αℝ(d) and αℂ(d) be the average singular value of a d × d matrix with random i.i.d., respectively real valued and complex valued, entries (see Definition 2). Then, for all d ≥ 1,
5 The little Grothendieck problem over the Stiefel manifold
In this section we focus on a generalization of (3), the little Grothendieck problem over the Stiefel manifold , the set of matrices O ∈ ℝd×r such that OOT = Id×d. In this exposition we will restrict ourselves to the real valued case but it is easy to see that the ideas in this Section easily adapt to the complex valued case.
We consider the problem
| (17) |
for C ⪰ 0. The special case d = 1 was formulated and studied in [BBT11] and [BFV10] in the context of quantum non-locality and quantum XOR games.
Note that, for r = d, problem (17) reduces to (3) and, for r = nd, it reduces to the tractable relaxation (5). As a solution to (3) can be transformed, via zero padding, into a solution to (17) with the same objective function value, Algorithm 3 automatically provides an approximation ratio for (17), however we want to understand how this approximation ratio can be improved using the extra freedom (in particular, in the case r = nd, the approximation ratio is trivially 1). Below we show an adaptation of Algorithm 3, based on the same relaxation (5), for problem (17) and show an improved approximation ratio.
Algorithm 9
Compute X1, …, Xn ∈ ℝd×nd a solution to (5). Let R be and × r Gaussian random matrix whose entries are real i.i.d. . The approximate solution for (17) is now computed as
where , for any X ∈ ℝd×r, is a generalization of the polar component to the Stiefel manifold .
Below we show an approximation ratio for Algorithm 9.
Theorem 10
Let C ⪰ 0. Let be the (random) output of Algorithm 9. Then,
where αℝ(d, r) is the defined below (Definition 11).
Definition 11
Let r ≥ d and G ∈ ℝd×r be a Gaussian random matrix with i.i.d real entri . We define
where σj(G) is the jth singular value of G.
We investigate the limiting behavior of αℝ(d, r) as r → ∞ and as r, d → ∞ at a proporitional rate in Section 6.2.
The proof of Theorem 10 follows the same line of reasoning as that of Theorem 1 (and Theorem 4). We do not provide the proof in full, but state and prove Lemmas 17 and 18 in the Appendix, which are the analogous, to this setting, of Lemmas 6 and 5.
Besides the applications, for d = 1, described in [BBT11] and [BFV10], Problem (17) is also motivated by an application in molecule imaging, the common lines problem.
5.1 The common lines problem
The common lines problem arises in three-dimensional structure determination of biological molecules using Cryo-Electron Microscopy [SS11], and can be formulated as follows. Consider n rotation matrices . The three columns of each rotation matrix form a orthonormal basis to ℝ3. In particular, the first two columns of each rotation matrix span a two-dimensional subspace (a plane) in ℝ3. We assume that no two planes are parallel. Every pair of planes intersect at a line, called the common-line of intersection. Let bij ∈ ℝ3 be a unit vector that points in the direction of the common-line between the planes corresponding to Oi and Oj. Hence, there exist unit vectors cij and cji with vanishing third component (i.e., cij = (xij, yij, 0)T) such that Oicij = Ojcji = bij. The common lines problem consists of estimating the rotation matrices O1, …, On from (perhaps noisy) measurements of the unit vectors cij and cji. The least-squares formulation of this problem is equivalent to
| (18) |
However, since cij has zero in the third coordinate, the common-line equations Oicij = Ojcji do not involve the third columns of the rotation matrices. The optimization problem (18) is therefore equivalent to
| (19) |
where Π: ℝ3 → ℝ2 is a projection discarding the third component (i.e., Π(x, y, z) = (x, y)) and . The coefficient matrix in (19), Cij = Π(cij)Π(cji)T, is not positive semidefinite. However, one can add a diagonal matrix with large enough values to it in order to make it PSD. Although this does not affect the solution of (19) it does increase its function value by a constant, meaning that the approximation ratio obtained in Theorem 10 does not directly translate into an approximation ratio for Problem (19); see Section 7 for a discussion on extending the results to the non positive semidefinite case.
5.2 The approximation ratio αℝ(d, r)2
In this Section we attempt to understand the behavior of αℝ(d, r)2, the approximation ratio obtained for Algorithm 9. Recall that αℝ(d, r) is defined as the average singular value of G ∈ ℝd×r, a Gaussian random matrix with i.i.d. entries .
For d = 1 this simply corresponds to the average length of a Gaussian vector in ℝr with i.i.d. entries . This means that αℝ(1, r) is the mean of a normalized chi-distribution,
In fact, this corresponds to the results of Briet el al [BFV10], which are known to be sharp [BFV10].
For d > 1 we do not completely understand the behavior of αℝ(d, r), nevertheless it is easy to provide a lower bound for it by a function approaching 1 as r → ∞.
Proposition 12
Consider αℝ(d, r) as in Definition 11. Then,
| (20) |
Proof
Gordon’s theorem for Gaussian matrices (see Theorem 5.32 in [Ver12]) gives us
where smin(G) is the smallest singular value. The bound follows immediately from noting that the average singular value is larger than the expected value of the smallest singular value.
As we are bounding αℝ(d, r) by the expected value of the smallest singular value of a Gaussian matrix, we do not expect (20) to be tight. In fact, for d = 1, the stronger bound holds [BFV10].
Similarly to αℝ(d), we can describe the behavior of αℝ(d, r) in the limit as d → ∞ and . More precisely, the singular values of G correspond to the square root of the eigenvalues of the Wishart matrix [CD11] . Let us set r = ρd, for ρ ≥ 1. The distribution of the eigenvalues of a Wishart matrix , as d → ∞ are known to converge to the Marchenko Pastur distribution (see [CD11]) given by
where .
Hence, we can define ε(ρ) as
Although we do not provide a closed form solution for ε(ρ) the integral can be easily computed numerically and we plot it below. It shows how the approximation ratio improves as ρ increases.
6 Integrality Gap
In this section we provide an integrality gap for relaxation (5) that matches our approximation ratio αℝ(d)2. For the sake of the exposition we will restrict ourselves to the real case, but it is not difficult to see that all the arguments can be adapted to the complex case.
Our construction is an adaption of the classical construction for the d = 1 case (see, e.g., [AN04]). As it will become clear below, there is an extra difficulty in the d > 1 orthogonal case. In fact, the bound on the integrality gap of (5) given by this construction is , defined as
| (21) |
where G is a Gaussian matrix with i.i.d. real entries .
Fortunately, using the notion of operator concavity of a function and the Lowner-Heinz Theorem [Car09], we are able to show the following theorem.
Theorem 13
Let d ≥ 1. Also, let αℝ(d) be as defined in Definition 2 and as defined in (21). Then,
Proof
We want to show that
where G is a d × d matrix with i.i.d. entries . By taking V = D2, and recalling the definition of singular value, we obtain the following claim (which immediately implies Theorem 13)
Claim 6.1
Proof
We will proceed by contradiction, suppose (6.1) does not hold. Since the optimization space is compact and the function continuous it must have a maximum that is attained by a certain V ≠ Id×d. Out of all maximizers V, let V(*) be the one with smallest possible Frobenius norm. The idea will be to use concavity arguments to build an optimal V(card) with smaller Frobenius norm, arriving at a contradiction and hence showing the theorem.
Since V(*) is optimal we have
Furthermore, since V(*) ≠ Id×d, it must have two different diagonal elements. Let V(**) be a matrix obtained by swapping, in V(*), two of its non-equal diagonal elements. Clearly, ‖V(**)‖F = ‖V(*)‖F and, because of the rotation invariance of the Gaussian, it is easy to see that
Since V(*) ⪰ 0, these two matrices are not multiples of each other and so
has a strictly smaller Frobenius norm than V(*). It is also clear that V(card) is a feasible solution. We conclude the proof by showing
| (22) |
By linearity of expectation and construction of V(card), (22) is equivalent to
This inequality follows from the stronger statement: Given two d × d matrices A ⪰ 0 and B ⪰ 0, the following holds
| (23) |
Finally, (23) follows from the Lowner-Heinz Theorem, which states that the square root function is operator concave (See these lecture notes [Car09] for a very nice introduction to these inequalities).
Theorem 13 guarantees the optimality of the approximation ratio obtained in Section 3. In fact, we show the theorem below.
Theorem 14
For any d ≥ 1 and any ɛ > 0, there exists n for which there exists C ∈ ℝdn×dn such that C ⪰ 0, and
| (24) |
We will construct C randomly and show that it satisfies (24) with positive probability. Given p an integer we consider n i.i.d. matrix random variables Vk, with k = 1, …, n, where each Vk is a d × dp Gaussian matrix whose entries are . We then define C as the random matrix with d × d blocks . The idea now is to understand the typical behavior of both
For wc, we can rewrite
If
then . The idea is that, given a fixed (direction unit frobenius-norm matrix) , converges to the expected value of one of the summands and, by an ε-net argument (since the dimension of the space where is depends only on d and p and the number of summands is n which can be made much larger than d and p) we can argue that the sum is close, for all simultaneously, to that expectation. It is not hard to see that we can assume that where D is diagonal and non-negative d × d matrix with . In that case (see (21)),
where G is a Gaussian matrix with i.i.d. real entries . This, together with Theorem 13, gives . All of this is made precise in the following lemma
Lemma 15
For any d and ɛ > 0 there exists p0 and n0 such that, for any p > p0 and n > n0,
with probability strictly larger than 1/2.
Proof
Let us define
We have
For D with ‖D‖F = 1, we define
We proceed by understanding the behavior of AD(V) for a specific D.
Let , where Σ is a d × d non-negative diagonal matrix, be the singular value decomposition of D. For each i = 1, …, n, we have (using rotation invariance of the Gaussian distribution):
where G is a d × d Gaussian matrix with entries.
This means that
with Xi i.i.d. distributed as .
Since , by (21), we get
This, together with Theorem 13, gives
| (25) |
In order to give tail bounds for we will show that Xi is subgaussian and use Hoeffding’s inequality (see Vershynin’s notes [Ver12]). In fact,
Note that is a subgaussian random variable as ‖G‖F is smaller than the entry wise ℓ1 norm of G which is the sum of d2 half-normals (more specifically, the absolute value of a random variable). Since half-normals are subgaussian and the sum of subgaussian random variables is a subgaussian random variable with subgaussian norm at most the sum of the norms (see the Rotation invariance Lemma in [Ver12]) we get that Xi is subgaussian. Furthermore, the subgaussian norm of Xi, which we define as , is bounded by , for some universal constant C.
Hence, we can use Hoeffding’s inequality (see [Ver12]) and get, since ,
where ci are universal constants.
To find an upper bound for we use a classicl ε-net argument. There exists a set of matrices Dk ∈ ℝd×pd satisfying ‖Dk‖F = 1, such that for any D ∈ ℝd×pd with Frobenius norm 1, there exists an element such that . is called an ε-net, and it’s known (see [Ver12]) that there exists such a set with size
By the union-bound, with probability at least
all the Dk’s in satisfy
If D is not in , there exists such that ‖D − Dk‖F ≤ ε. This means that
We can globally bound by Hoeffding’s inequality as well (see [Ver12]). Using the same argument as above, it is easy to see that ‖Vi‖F has subgaussian norm bounded by , and an explicit computation shows its mean is , where the inequality follows from lemma 20.
This means that by Hoeffding’s inequality (see [Ver12])
with ci universal constants.
By union-bound on the two events above, with probability at least
we have
Choosing and we get
with probability at least
which can be made arbitrarily close to 1 by taking n large enough.
This means that
with high probability, proving the lemma. □
Regarding wr, we know that it is at least the value of for . Since, for p large enough, we essentially have which should approximate . This is made precise in the following lemma:
Lemma 16
For any d and ɛ > 0 there exists p0 and n0 such that, for any p > p0 and n > n0,
with probability strictly larger than 1/2.
Proof
Recall that is the d × dp matrix polar component of Vi, meaning that
Hence,
We proceed by using a lower bound for the expected value of the smallest eigenvalue (see [Ver12]), and get
Since , it has subgaussian norm smaller than Cd, with C an universal constant (using the same argument as in Lemma 15). Therefore, by Hoeffding’s inequality (see [Ver12]),
where ci are universal constants.
By setting , we get
with probability at least proving the Lemma.
Theorem 14 immediately follows from these two lemmas.
We note that these techniques are quite general. It is not difficult to see that these arguments, establishing integrality gaps that match the approximation ratios obtained, can be easily adapted for both the unitary case and the rank constrained case introduced in Section 5. For the sake of exposition we omit the details in these cases.
7 Open Problems and Future Work
Besides Conjecture 8, there are several extensions of this work that the authors consider to be interesting directions for future work.
A natural extension is to consider the little Grothendieck problem (3) over other groups of matrices. One interesting extension would be to consider the special orthogonal group and the special unitary group , these seem more difficult since they are not described by quadratic constraints.3
In some applications, like Synchronization [BSS13, Sin11] (a similar problem to Orthogonal Procrustes) and Common Lines [SS11], the positive semidefiniteness condition is not natural. It would be useful to better understand approximation algorithms for a version of (3) where C is not assumed to be positive semidefinite. Previous work in the special case d = 1, [NRT99, CW04, AMMN05] for and [SZY07] for , suggest that it is possible to obtain an approximation ratio for (3) depending logarithmically on the size of the problem. Moreover, for , the logarithmic term is known to be needed in general [AMMN05].
It would also be interesting to understand whether the techniques in [AN04] can be adapted to obtain an approximation algorithm to the bipartite Grothendieck problem over the orthogonal group; this would be closer in spirit to the non commutative Grothendieck inequality [NRV13].
Another interesting question is whether the approximation ratios obtained in this paper correspond to the hardness of approximation of the problem (perhaps conditioned on the Unique-Games conjecture [Kho10]). Our optimality conditions are restricted to the particular relaxation we consider and do not exclude the existence of an efficient algorithm, not relying on the same relaxation, that approximates (3) with a better approximation ratio. Nevertheless, Raghavendra [Rag08] results on hardness for a host of problems matching the integrality gap of natural SDP relaxations suggest that our approximation ratios might be optimal (see also the recent results in [BRS15]).
Figure 2.
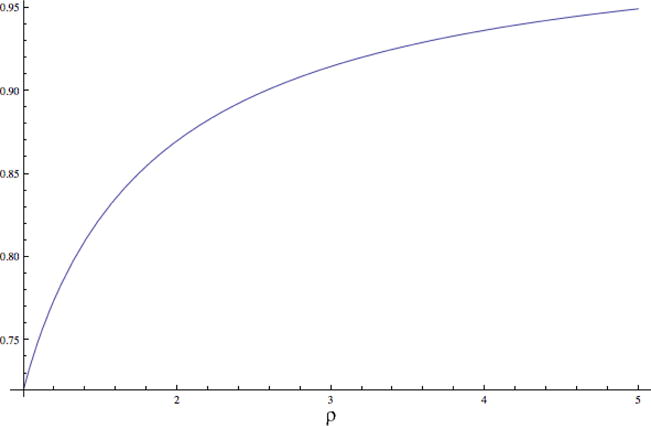
Plot of ε(ρ) = limd → ∞ αℝ(d, ρd) for ρ ∈ [1, 5].
Acknowledgments
The authors would like to thank Moses Charikar for valuable guidance in context of this work and Jop Briet, Alexander Iriza, Yuehaw Khoo, Dustin Mixon, Oded Regev, and Zhizhen Zhao for insightful discussions on the topic of this paper. Special thanks to Johannes Trost for a very useful answer to a Mathoverflow question posed by the first author. Finally, we would like to thank the reviewers for numerous suggestions that helped to greatly improve the quality of this paper.
A. S. Bandeira was supported by AFOSR Grant No. FA9550-12-1-0317. A. Singer was partially supported by Award Number FA9550-12-1-0317 and FA9550-13-1-0076 from AFOSR, by Award Number R01GM090200 from the NIGMS, and by Award Number LTR DTD 06-05-2012 from the Simons Foundation. Parts of this work have appeared in C. Kennedy’s senior thesis at Princeton University.
A Technical proofs – analysis of algorithm for the Stiefel Manifold setting
Lemma 17
Let r ≥ d. Let G be a d × r Gaussian random matrix with real valued i.i.d. entries and let αℝ(d, r) as defined in Definition 11. Then,
Furthermore, if G is a d × r Gaussian random matrix with complex valued i.i.d. entries and αℂ(d, r) the analogous constant (Definition 11), then
The proof of this Lemma is a simple adaptation of the proof of Lemma 6.
Proof
We restrict the presentation to the real case. As before, all the arguments are equivalent to the complex case, replacing all transposes with Hermitian adjoints and αℝ(d, r) with αℂ(d, r).
Let G = U[Σ 0]VT be the singular value decomposition of G. Since GGT = UΣ2UT is a Wishart matrix, it is well known that its eigenvalues and eigenvectors are independent and U is distributed according to the Haar measure in (see e.g. Lemma 2.6 in [TV04]). To resolve ambiguities, we consider Σ ordered such that Σ11 ≥ Σ22 ≥ … ≥ Σdd.
Let . Since
we have
Note that .
Since , where u1, …, ud are the rows of U, and U is distributed according to the Haar measure, we have that uj and −uj have the same distribution conditioned on any ui, for i ≠ j, and Σ. This implies that, if i ≠ j, is a symmetric random variable, and so . Also, ui ~ uj implies that Yii ~ Yjj. This means that for some constant c. To obtain c,
which shows the lemma. □
Lemma 18
Let r ≥ d. Let M, N ∈ ℝd×nd such that M MT = N NT = Id×d. Let R ∈ ℝnd×r be a Gaussian random matrix with real valued i.i.d. entries . Then
where αℝ(d, r) is the constant in Definition 11.
Analogously, if M, N ∈ ℂd×nd such that MMH=N NH = Id×d, and R ∈ ℂnd×r is a Gaussian random matrix with complex valued i.i.d. entries , then
where αℂ(d, r) is the constant in Definition 11.
Similarly to above, the proof of this Lemma is a simple adaptation of the proof of Lemma 5.
Proof
We restrict the presentation of proof to the real case. Nevertheless, all the arguments trivially adapt to the complex case by, essentially, replacing all transposes with Hermitian adjoints and αℝ(d) and αℝ(d, r) with αℂ(d) and αℂ(d, r).
Let A = [MT NT] ∈ ℝdn×2d and A = QB be the QR decomposition of A with Q ∈ ℝnd×nd an orthogonal matrix and B ∈ ℝnd×2d upper triangular with non-negative diagonal entries; note that only the first 2d rows of B are nonzero. We can write
where B11 ∈ ℝd×d and B22 ∈ ℝd×d are upper triangular matrices with non-negative diagonal entries. Since
B11 = (QT MT)11 is an orthogonal matrix, which together with the non-negativity of the diagonal entries (and the fact that B11 is upper-triangular) forces B11 to be B11 = Id×d.
Since R is a Gaussian matrix and Q is an orthogonal matrix, QR ~ R which implies
Since and ,
where R1 and R2 are the first two d × r blocks of R. Since these blocks are independent, the second term vanishes and we have
The Lemma now follows from using Lemma 17 to obtain and nothing that .
The same argument, with Q′B′ the QR decomposition of A′ = [NTMT] ∈ ℝdn×2d instead, shows
B Bounds for the average singular value
Lemma 19
Let be a Gaussian random matrix with i.i.d. complex valued entries and define . We have the following bound
Proof
We express as sums and products of Gamma functions and then use classical bounds to obtain our result.
Recall that from equation (16),
| (26) |
where
and Ln(x) is the nth Laguerre polynomial,
This integral can be expressed as (see [GR94] section 7.414 equation 4(1))
| (27) |
where (x)m is the Pochhammer symbol
The next lemma states a couple basic facts about the Gamma function that we will need in the subsequent computations.
Lemma 20
The Gamma function satisfies the following inequalities:
Proof
See [AS64] page 255.
We want to bound the summation in (27), which we rewrite as
For simplicity define
so that (27) becomes
The first term we can compute explicitly (see [GR94]) as
For the second term we use the fact that to get
Using the first inequality in Lemma 20 and the multiplication formula for the Gamma function,
so we have
For the third term, we use the formula to deduce
Using the second bound in Lemma 20,
and also
so that
If we multiply top and bottom by and use the fact that
then
Combining our bounds for (I), (II) and (III),
and by (26),
The term is the main term and can be bounded below by
The other error terms are at most
Combining the main and error term bounds, the lemma follows.
Lemma 21
For a Gaussian random matrix with i.i.d. valued (0, d−1) entries, define . The following holds
Proof
To find an explicit formula for αℝ(d), we need an expression for the spectral distribution of the wishart matrix , which we call , given by equation (16) in [LV11]:
where
κ = d mod 2 and is the incomplete Gamma function.
This means that
Recall that (see section 5)
which implies
| (28) |
We are especially interested in the following terms which appear in the full expression for αℝ(d):
| (29) |
From [GR94] section 7.414 equation 4(1), we have
The following lemma deals with bounds on sums involving Q(m, k) terms.
Lemma 22
For Q(m, k) as defined in (29) we have the following bounds
| (30) |
| (31) |
Proof
Note that in (30),
since m ≥ k.
For 0 < i < 2k − 1, the ith term in the summation of Q(2m, 2k) can be bounded above by
This means that
We bound the sum from i = 1 to 2k − 3 by
so that for k ≥ 1,
For k = 0, Q(2m, 0) < 0 except for the term which also becomes negative in the full sum, so we ignore these terms.
We now turn our attention to the full sum . As before, we define for clarity
Using the bounds in lemma 20,
Finally,
To deduce the inequality (31), we use the previously derived bounds to show that
so that Q(2m − 1; 2k − 1) ≤ Q(2m, 2k). Now it suffices to note that in the full sum, and we get
We now return our focus to finding a bound on the expression for αℝ (d) given in (28). Since ψ1, ψ2 depend on the parity of d, we split in to two cases.
Odd d = 2m + 1
From (see [GR94] section 7.414 equation 6),
thus equation (28) becomes
and using the first bound in Lemma 22,
Even d = 2m
For d = 2m, we have
We split the integral into two parts,
Expanding from the definition of ψ1 above, we have
so by Lemma 22,
The other part of the integral is
where we use the fact that for odd 2m − 1 (see [GR94] section 7.414 equation 6),
We can bound the first integral in the expression of (II) by
so finally
Combining the above bounds we see that in the case of even d = 2m,
Footnotes
We also note that these semidefinite programs satisfy Slater’s condition as the identity matrix is a feasible point. This ensures strong duality, which can be exploited by many semidefinite programming solvers.
These ideas also play a major role in the unidimensional complex case treated by So et al [SZY07].
The additional constraint that forces a matrix to be in the special orthogonal or unitary group is having determinant equal to 1 which is not quadratic.
Contributor Information
Afonso S. Bandeira, Email: bandeira@mit.edu.
Christopher Kennedy, Email: ckennedy@math.utexas.edu.
Amit Singer, Email: amits@math.princeton.edu.
References
- [AHO98].Alizadeh F, Haeberly JPA, Overton ML. Primal-dual interior-point methods for semidefinite programming: convergence rates, stability and numerical results. SIAM Journal on Optimization. 1998;8(3):746–768. [Google Scholar]
- [AMMN05].Alon N, Makarychev K, Makarychev Y, Naor A. Quadratic forms on graphs. Invent Math. 2005;163:486–493. [Google Scholar]
- [AN04].Alon N, Naor A. Proc of the 36 th ACM STOC. ACM Press; 2004. Approximating the cut-norm via Grothendieck’s inequality; pp. 72–80. [Google Scholar]
- [AS64].Abramowitz M, Stegun IA. Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables. Dover; New York: 1964. [Google Scholar]
- [Ban15].Bandeira AS. PhD thesis. Princeton University; 2015. Convex relaxations for certain inverse problems on graphs. (Program in Applied and Computational Mathematics). [Google Scholar]
- [BBT11].Briet J, Buhrman H, Toner B. A generalized Grothendieck inequality and nonlocal correlations that require high entanglement. Communications in Mathematical Physics. 2011;305(3):827–843. [Google Scholar]
- [BFV10].Briet J, Filho FMO, Vallentin F. Automata, Languages and Programming, volume 6198 of Lecture Notes in Computer Science. Springer; Berlin Heidelberg: 2010. The positive semidefinite Grothendieck problem with rank constraint; pp. 31–42. [Google Scholar]
- [BRS15].Briet J, Regev O, Saket R. Tight hardness of the non-commutative Grothendieck problem. FOCS 2015, to appear. 2015 [Google Scholar]
- [BSS13].Bandeira AS, Singer A, Spielman DA. A Cheeger inequality for the graph connection Laplacian. SIAM J Matrix Anal Appl. 2013;34(4):1611–1630. [Google Scholar]
- [BTN02].Ben-Tal A, Nemirovski A. On tractable approximations of uncertain linear matrix inequalities affected by interval uncertainty. SIAM Journal on Optimization. 2002;12:811–833. [Google Scholar]
- [Car09].Carlen EA. Trace inequalities and quantum entropy: An introductory course. 2009 available at http://www.ueltschi.org/azschool/notes/ericcarlen.pdf.
- [CD11].Couillet R, Debbah M. Random Matrix Methods for Wireless Communications. Cambridge University Press; New York, NY, USA: 2011. [Google Scholar]
- [CKS15].Chaudhury KN, Khoo Y, Singer A. Global registration of multiple point clouds using semidefinite programming. SIAM Journal on Optimization. 2015;25(1):126–185. [Google Scholar]
- [CW04].Charikar M, Wirth A. Proceedings of the 45th Annual IEEE Symposium on Foundations of Computer Science, FOCS ’04. Washington, DC, USA: IEEE Computer Society; 2004. Maximizing quadratic programs: Extending Grothendieck’s inequality; pp. 54–60. [Google Scholar]
- [FH55].Fan K, Hoffman AJ. Some metric inequalities in the space of matrices. Proceedings of the American Mathematical Society. 1955;6(1):111–116. [Google Scholar]
- [GR94].Gradshteyn IS, Ryzhik IM. Table of Integrals, Series, and Products. Fifth. Academic Press; Jan, 1994. 5th edition. [Google Scholar]
- [Gro96].Grothendieck A. Resume de la theorie metrique des produits tensoriels topologiques (french) Reprint of Bol Soc Mat Sao Paulo. 1996:179. [Google Scholar]
- [GT11].Gotze F, Tikhomirov A. On the rate of convergence to the Marchenko–Pastur distribution. 2011 arXiv:1110.1284 [math.PR] [Google Scholar]
- [GW95].Goemans MX, Williamson DP. Improved apprximation algorithms for maximum cut and satisfiability problems using semidefine programming. Journal of the Association for Computing Machinery. 1995;42:1115–1145. [Google Scholar]
- [Hig86].Higham NJ. Computing the polar decomposition – with applications. SIAM J Sci Stat Comput. 1986 Oct;7:1160–1174. [Google Scholar]
- [Kel75].Keller JB. Closest unitary, orthogonal and hermitian operators to a given operator. Mathematics Magazine. 1975;48(4):192–197. [Google Scholar]
- [Kho10].Khot S. Proceedings of the 2010 IEEE 25th Annual Conference on Computational Complexity, CCC ’10. Washington, DC, USA: IEEE Computer Society; 2010. On the unique games conjecture (invited survey) pp. 99–121. [Google Scholar]
- [Lev12].Leveque O. Random matrices and communication systems: Wishart random matrices: marginal eigenvalue distribution. 2012 Available at: http://ipg.epfl.ch/~leveque/Matrix/
- [LV11].Livan G, Vivo P. Moments of Wishart-Laguerre and Jacobi ensembles of random matrices: application to the quantum transport problem in chaotic cavities. Acta Physica Polonica B. 2011;42:1081. [Google Scholar]
- [Nem07].Nemirovski A. Sums of random symmetric matrices and quadratic optimization under orthogonality constraints. Math Program. 2007;109(2–3):283–317. [Google Scholar]
- [Nes98].Nesterov Y. Semidefinite relaxation and nonconvex quadratic optimization. Opti-mization Methods and Software. 1998;9(1–3):141–160. [Google Scholar]
- [Nes04].Nesterov Y. Introductory lectures on convex optimization: A basic course, volume 87 of Applied optimization. Springer; 2004. [Google Scholar]
- [NRT99].Nemirovski A, Roos C, Terlaky T. On maximization of quadratic form over intersection of ellipsoids with common center. Mathematical Programming. 1999;86(3):463–473. [Google Scholar]
- [NRV13].Naor A, Regev O, Vidick T. Proceedings of the 45th annual ACM symposium on Symposium on theory of computing, STOC ’13. New York, NY, USA: ACM; 2013. Efficient rounding for the noncommutative Grothendieck inequality; pp. 71–80. [Google Scholar]
- [Pis11].Pisier G. Grothendieck’s theorem, past and present. Bull Amer Math Soc. 2011;49:237323. [Google Scholar]
- [Rag08].Raghavendra P. Optimal algorithms and inapproximability results for every CSP. Proc 40 th ACM STOC. 2008:245–254. [Google Scholar]
- [Sch66].Schonemann PH. A generalized solution of the orthogonal procrustes problem. Psychometrika. 1966;31(1):1–10. [Google Scholar]
- [She01].Shen J. On the singular values of gaussian random matrices. Linear Algebra and its Applications. 2001;326(13):1–14. [Google Scholar]
- [Sin11].Singer A. Angular synchronization by eigenvectors and semidefinite programming. Appl Comput Harmon Anal. 2011;30(1):20–36. doi: 10.1016/j.acha.2010.02.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [So11].So AC. Moment inequalities for sums of random matrices and their applications in optimization. Mathematical Programming. 2011;130(1):125–151. [Google Scholar]
- [SS11].Singer A, Shkolnisky Y. Three-dimensional structure determination from common lines in Cryo-EM by eigenvectors and semidefinite programming. SIAM J Imaging Sciences. 2011;4(2):543–572. doi: 10.1137/090767777. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [SZY07].So A, Zhang J, Ye Y. On approximating complex quadratic optimization problems via semidefinite programming relaxations. Math Program Ser B. 2007 [Google Scholar]
- [TV04].Tulino AM, Verdú S. Random matrix theory and wireless communications. Commun Inf Theory. 2004 Jun;1(1):1–182. [Google Scholar]
- [VB96].Vanderberghe L, Boyd S. Semidefinite programming. SIAM Review. 1996;38:49–95. [Google Scholar]
- [Ver12].Vershynin R. In: Introduction to the non-asymptotic analysis of random matrices. Chapter 5 of: Compressed Sensing, Theory and Applications. Eldar Y, Kutyniok G, editors. Cambridge University Press; 2012. [Google Scholar]
- [WGS12].Wen Z, Goldfarb D, Scheinberg K. Handbook on Semidefinite, Conic and Polynomial Optimization, volume 166 of International Series in Operations Research & Management Science. Springer; US: 2012. Block coordinate descent methods for semidefinite programming; pp. 533–564. [Google Scholar]