

Abstract
While almost everyone discounts the value of future rewards over immediate rewards, people differ in their so-called delay-discounting. One of the several factors that may explain individual differences in delay-discounting is reward-processing. To study individual-differences in reward-processing, however, one needs to consider the heterogeneity of neural-activity at each reward-processing stage. Here using EEG, we separated reward-related neural activity into distinct reward-anticipation and reward-outcome stages using time-frequency characteristics. Thirty-seven individuals completed a behavioral delay-discounting task. Reward-processing EEG activity was assessed using a separate reward-learning task, called a reward time-estimation task. During this task, participants were instructed to estimate time duration and were provided performance feedback on a trial-by-trial basis. Participants received monetary-reward for accurate-performance on Reward trials, but not on No-Reward trials. Reward trials, relative to No-Reward trials, enhanced EEG activity during both reward-anticipation stage (including, cued-locked delta power during cue-evaluation and pre-feedback alpha suppression during feedback-anticipation) and at the reward-outcome stage (including, feedback-locked delta, theta and beta power). Moreover, all of these EEG indices correlated with behavioral performance in the time-estimation task, suggesting their essential roles in learning and adjusting performance to maximize winnings in a reward-learning situation. Importantly, enhanced EEG power during Reward trials for 1) pre-feedback alpha suppression, 2) feedback-locked theta and 3) feedback-locked beta was associated with a greater preference for larger-but-delayed rewards. Results highlight the association between a stronger preference toward larger-but-delayed rewards and enhanced reward-processing. Moreover, our reward-processing EEG indices detail the specific stages of reward-processing where these associations occur.
Keywords: delay discounting, reward-processing, pre-stimulus alpha suppression, frontal midline theta, feedback-locked beta
1. Introduction
Choosing between receiving $400 today or $800 today is easy. Most people, if not everyone, will select $800 today. However, choosing between receiving $400 today or $800 in three years is more difficult, and different people will choose differently. This latter decision becomes harder and requires a stronger computational demand (Rangel, Camerer, & Montague, 2008) because the subjective value of $800 is devalued, or discounted, over time. For decades, economists, psychologists, and, more recently, cognitive neuroscientists have studied this so-called delay-discounting phenomenon (also known as temporal discounting or inter-temporal choices; Ainslie, 1975; Frederick, Loewenstein, & O’Donoghue, 2003; Kalenscher & Pennartz, 2008; Peters & Büchel, 2011; Samuelson, 1937; Schultz, 2010). While the phenomenon is well documented, it is clear that people vary in how much they discount future rewards. In fact, individual differences in delay-discounting are stable over time and are sometimes considered a personality trait (Kirby, 2009; Odum, 2011). Recently personality and cognitive-neuroscience research has shown that these individual differences in delay-discounting are correlated with several trait affective and cognitive variables (Civai, Hawes, DeYoung, & Rustichini, 2016; Hirsh, Morisano, & Peterson, 2008; Mahalingam, Stillwell, Kosinski, Rust, & Kogan, 2014). Among these variables is reward-processing (Benningfield et al., 2014; Boettiger et al., 2007; Hariri et al., 2006), which relates to the value an individual places on potential rewards during both the expectation and receipt of that reward (McClure, York, & Montague, 2004; Schultz, Tremblay, & Hollerman, 2000). Yet, the exact nature of the relationship between delay-discounting tendencies and individual differences in reward-processing is still unclear, perhaps due to the multifaceted nature of reward-processing.
1.1 Reward-Processing and Individual Differences in Delay-Discounting Responses
An early study by Hariri and colleagues (2006) reported that individuals with elevated reward-related neural activation in the ventral striatum (VS) during an incentivized fMRI card-guessing task had a stronger preference toward smaller-but-immediate rewards, as indexed by a subsequent behavioral delay-discounting task. This finding suggests that enhanced reward-processing is related to a stronger preference toward smaller-but-immediate rewards. However, recent data suggests the opposite pattern, indicating that elevated reward-processing is associated with a preference for larger-but-delayed (as opposed to smaller-but-immediate) rewards. In line with this view, a recent fMRI study using the Monetary Incentive Delay (MID) task reported that elevated VS activation during reward-anticipation among adolescents was associated with a stronger preference for larger-but-delayed rewards on a subsequent behavioral delay-discounting task (Benningfield et al., 2014). This finding is consistent with other recent fMRI studies reporting that elevated activation in the VS is associated with a stronger preference toward larger-but-delayed rewards (Ballard & Knutson, 2009; Samanez-Larkin et al., 2011). This relationship is also in line with animal research showing that lesions to the VS lead to a preference for smaller-but-immediate choices (Cardinal et al., 2001). In addition to the VS, enhanced activity in another neural region implicated in reward processing, the lateral orbitofrontal cortex (L-OFC), has been associated with a stronger preference toward larger-but-delayed rewards during an fMRI delay-discounting task (Boettiger et al., 2007). Next, there is indirect evidence from research involving the Val158Met polymorphism of the catechol-O-methyltransferase (COMT) gene. The Met-allele of the COMT gene is associated with higher synaptic dopamine levels and carriers of this allele display enhanced VS activation in an fMRI reward task (Chen et al., 2004; Yacubian et al., 2007). Critically, Met-allele carriers also show a preference toward larger-but-delayed rewards (Boettiger et al., 2007; Gianotti, Figner, Ebstein, & Knoch, 2012; Smith & Boettiger, 2012). More recently, research with Parkinson patients suggests that medications designed to elevate dopamine signaling are associated with a heightened preference for larger-but-delayed rewards (Foerde et al., 2016). Thus, taken as a whole, evidence from fMRI, animal, genetic, and pharmacological studies suggest that individuals with elevated reward-processing have a tendency to wait for larger rewards and forgo smaller-but-immediate rewards.1
The current study aimed to further test and substantiate the relationship between a stronger preference toward larger-but-delayed rewards and enhanced reward-processing by investigating the relationship at different temporal stages of reward-processing via electroencephalogram (EEG). Reward-processing is thought be comprised of two temporal stages that are mediated by distinct neurobiological systems: reward-anticipation and reward-outcome (Berridge, 1996; Wise, 2008). The superior temporal resolution of EEG, compared to fMRI, allows researchers to more accurately dissociate neural-cognitive states that occur close to each other in time (Cohen, 2014; Luck, 2014), such as reward-anticipation and reward-outcome stages, as well as between different sub-stages within reward-anticipation itself (Brunia, Hackley, van Boxtel, Kotani, & Ohgami, 2011; Goldstein et al., 2006; McAdam & Seales, 1969). EEG, for instance, has been used to dissociate reward-anticipation from motor-preparation (Brunia et al., 2011; Hughes, Mathan, & Yeung, 2013), which has been a challenge in previous fMRI research on the relationship between reward-processing and delay discounting tendencies. As noted by Benningfield and colleagues (2014), for example, the fMRI MID task does not isolate motor-preparation processes from reward-anticipation processes. Moreover, recent advancements in EEG time-frequency analyses allows researchers to investigate neural processes in ways that may not be available in other techniques, such as examining changes in neural activation (power) at a specific time windows and frequency bands (Cohen, 2014; Makeig, Debener, Onton, & Delorme, 2004).
1.2 The Reward Time Estimation Task
To identify different stages of reward-processing, we adapted a feedback-learning task (called the reward time estimation task) (e.g., Damen & Brunia, 1987; Kotani et al., 2003; Luft, 2014; Pornpattananangkul & Nusslock, 2015). Here participants were asked to estimate a specific time duration by pressing a button 3.5 s after the onset of a Reward or No-Reward cue. The Reward/No-Reward cue indicated whether the current trial was a Reward- or No-Reward trial. Participants received monetary-reward for accurate-performance (pressing close to 3.5 s) on Reward trials, but not on No-Reward trials. Two seconds after making the button press, participants received feedback regarding the accuracy of their time-estimation. This paradigm allowed us to parse EEG related to reward-processing into reward-anticipation and reward-outcome phases (i.e., before and after feedback onset, respectively). Within reward-anticipation, we further separated EEG activity into 1) a cue-evaluation stage, involving a period immediately following the Reward/No-Reward cue, and 2) a feedback-anticipation stage, involving a period right before the feedback while participants were waiting to see if their recent action was considered accurate (i.e., close to 3.5 s). In addition to EEG indices, the improvement of time-estimation accuracy as the task proceeds can also be used as a behavioral index for the effectiveness in learning through feedback (Luft, Nolte, & Bhattacharya, 2013). When the task provides rewards based on performance, then this behavioral index may reflect motivated-learning, or how motivated people are in learning to improve their performance in order to maximize reward earning (Luft, 2014). This motivated-learning behavioral index can be used 1) in corroborating EEG activity as indices of reward processing, and 2) in and of itself as an indirect, behavioral measure for individual-differences in reward-processing.
1.3 EEG Indices at Each Stage of Reward-Processing
During cue-evaluation, participants evaluated whether their immediate future action could lead to a reward. In previous research, a cue signaling the possibility of receiving a reward was associated with a stronger P3 ERP component (compared to a cue in No-Reward trials) (Broyd et al., 2012; Goldstein et al., 2006; Ramsey & Finn, 1997; Santesso et al., 2012). More recently, Cavanagh (2015) found an enhancement of EEG power (or synchronization) in the delta band (~ 1 – 3 Hz, called cue-locked delta) to reward-related cues. This cue-locked delta power at parietal sites approximately 100 – 500 ms following cue onset is relevant to the P3 ERP component. Moreover, Cavanagh (2015) showed that enhanced cue-locked delta power to reward-related cues predicted behavioral adjustments in a reinforcement learning task, suggesting an important role of cue-locked delta power in the cue evaluation stage
As for feedback-anticipation, the suppression (or desynchronization) of alpha (~8–13 Hz) EEG power at parieto-occipital sites prior to stimulus onset appears to index anticipation-related processes toward upcoming visual stimuli. For instance, using a time-estimation task, Bastiaansen and colleagues (2002; 1999; 2001) provided either visual or auditory feedback regarding the accuracy of time-estimation to participants. The authors reported alpha power suppression immediately preceding both types of feedback, but this alpha suppression was strongly distributed to occipital sites for the visual, but not auditory, feedback. This suggests the role of pre-stimulus alpha suppression in modality-specific anticipation processes. Given that alpha power reflects the functional inhibition of neural activity (Jensen & Mazaheri, 2010), alpha suppression during the pre-stimulus anticipatory period likely reflects the dis-inhibition of neural activity in sensory cortices to facilitate attentional allocation to the upcoming stimulus. Additionally, this pre-stimulus suppression of parieto-occipital alpha to visual stimuli has been found to track the location of where people anticipate the stimuli to appear (Thut, Nietzel, Brandt, & Pascual-Leone, 2006). Stronger suppression of pre-stimulus alpha power is also associated with how well people perceive the preceding near-threshold stimulus (Hanslmayr et al., 2007). Collectively, these findings suggest a relationship between alpha-suppression and anticipatory attention. More recently, stronger alpha suppression has been reported following monetary-reward cues and preceding monetary-reward feedback (Hughes et al., 2013). This additional suppression of alpha power by reward motivational cues suggests that alpha suppression indexes enhanced attentional processes during the anticipation of reward-related stimuli/feedback. Consistent with this idea, van den Berg and colleague (2014) recently investigated the role of reward-related cues in a Stroop task, and demonstrated an inter-individual relationship. Specifically, individuals who had particularly strong alpha suppression following reward-related cues were more likely to have better behavioral performance on reward trials. Therefore, pre-feedback alpha suppression should serve as a reliable index for individual differences in reward-processing during the feedback-anticipation stage of reward-anticipation.
The reward-outcome period in our time-estimation task involved participants receiving feedback for that particular trial. We focused on two types of feedback evaluation: reward-evaluation and performance-evaluation. During reward-evaluation, individuals evaluate the motivational value of the feedback (Luft, 2014). That is, regardless of whether their performance outcome is good or bad, people should be more motivated to learn the outcome of their performance when this performance can lead to monetary reward (i.e., during Reward trials compared to No-Reward trials). During performance-evaluation, individuals assess whether their prior action was good or bad in meeting their performance goal, e.g., whether or not their time-estimation was accurate (Cavanagh & Shackman, 2015; Miltner, Braun, & Coles, 1997). The concept of performance evaluation has been related to both prediction error and conflict resolution. Unfortunately, many EEG studies have lumped these two aspects of feedback evaluation (i.e., reward-evaluation and performance evaluation) together, making it difficult to interprete the specific cognitive processes underlying their EEG findings. Here we separate reward-evaluation and performance evaluation. Furthermore, we examine three separate EEG indices during the reward-outcome stage, each occurring at distinct frequency bands: feedback-locked delta, feedback-locked theta and feedback-locked beta. As outlined next, we argue that each of these feedback-locked EEG profiles index individual differences in reward-processing during the reward-outcome stage.
First, similar to cue-locked delta, recent studies have started to document changes in feedback-locked delta (1–3 Hz) power at parietal sites during reward-outcome approximately 100–500 ms following feedback onset (Cavanagh, 2015; Foti, Weinberg, Bernat, & Proudfit, 2015; Leicht et al., 2013). Cavanagh (2015) reported that feedback-locked delta was associated with prediction error in a reinforcement-learning task. Foti and colleagues (2015) reported that feedback-locked delta activity was stronger to feedbacks indicating monetary gains, compared to losses. Nonetheless, because monetary-gain feedback in these previous studies indicated both good performance and a positive reward outcome, it remains unclear whether enhancement in feedback-locked delta activity to gain feedback is driven by performance-evaluation or reward-evaluation. In the present study, we use the time estimation task to dissociate neural processes associated with reward and performance evaluation, and we examine their respective relationships with individual differences in delay-discounting.
Next, the enhancement of feedback-locked theta (~4–7 Hz) power at frontal-midline sites (i.e., frontal-midline theta, FMT) approximately 200–400 ms following feedback onset has been implicated in feedback/outcome evaluation (Cohen, Wilmes, & van de Vijver, 2011). Thought to be generated from the anterior-cingulate cortex (Cavanagh & Frank, 2014), enhanced feedback-locked theta has been associated with cognitive-control processes that incorporate feedback/outcome information to facilitate behavioral adjustment on subsequent trials in order to maximize performance (van de Vijver, Ridderinkhof, & Cohen, 2011). Feedback-locked theta appears sensitive to both performance-evaluation and reward-evaluation (Luft, 2014). In contrast to feedback-locked delta, feedback-locked theta is reliably stronger for bad-performance (compared to good-performance) feedback (Cohen, Elger, & Ranganath, 2007; for a review see Luft, 2014). Additionally, such enhancement to bad-performance feedback predicts behavioral adjustment on a subsequent trial (Cavanagh & Shackman, 2015). As for reward-evaluation, Van den Berg and colleagues (2012) employed the time-estimation task and focused on the Feedback-Related Negativity (FRN), an event-related potential (ERP) thought to reflect the phase/time-locked feature of feedback-locked theta (Cavanagh, Zambrano-Vazquez, & Allen, 2012). They found an enhanced FRN to feedback during Reward-trials where Good-performance led to monetary reward, compared to feedback during No-Reward trials where performance had no monetary consequences. Similar to the FRN, other studies have shown the influence of reward-evaluation on feedback-locked theta. For instance, feedback-locked theta is modulated by reward expectation (Cohen et al., 2007) and is stronger following feedback indicating a higher magnitude of monetary reward (Leicht et al., 2013). Thus, we expected feedback-locked theta to be modulated by both reward and performance evaluation.
Lastly, in addition to feedback-locked delta and theta, several recent studies have focused on feedback-locked EEG in the beta band (~15–25 Hz) (for review, see Luft, 2014). Similar to feedback-locked delta (but opposite to feedback-locked theta), researchers have consistently found stronger beta power to positive feedback (e.g., monetary gains), compared to negative feedback (e.g., monetary losses) (Cohen et al., 2007; De Pascalis, Varriale, & Rotonda, 2012; HajiHosseini, Rodríguez-Fornells, & Marco-Pallarés, 2012; Marco-Pallares et al., 2008; Marco-Pallarés et al., 2009). Given that a similar pattern of enhanced beta power has been reported in the ventral striatum of animals during a reward-processing task (Berke, 2009; Courtemanche, Fujii, & Graybiel, 2003), it has been proposed that feedback-locked beta power represents reward-related signals from this region. Parietal feedback-locked beta power is reduced in humans following feedback during reward-learning tasks, such as the time estimation task (Luft, Nolte, et al., 2013; Luft, Takase, & Bhattacharya, 2013; van de Vijver et al., 2011). This reduction in feedback-locked beta power (desynchronization) is less pronounced when feedback indicates good performance, compared to bad performance. Additionally, a greater enhancement of feedback-locked beta power (i.e., less reduction/desynchronization) predicts more rapid learning of a time duration in the time estimation task (Luft, Nolte, et al., 2013). Nonetheless, similar to feedback-locked delta, most previous studies of feedback-locked beta have either lumped performance evaluation and reward evaluation feedback together (e.g., monetary gain indicating both good performance and reward associated with the performance) or focused solely on performance-evaluation, making it hard to interpret the psychological meaning of the effects. The current study separated the two aspects of feedback evaluation, and assessed their relationships with delay-discounting tendencies.
1.4 Current Study
In the present study, participants completed a behavioral delay-discounting task and then a separate EEG reward time-estimation task.2 Drawing on existing research (Benningfield et al., 2014; Boettiger et al., 2007; Foerde et al., 2016), we predict that enhanced reward-related neural activity will be associated with a greater preference for larger-but-delayed rewards. An important contribution of this study is that we examined the relationship between reward-related neural activity and delay discounting tendencies at different temporal stages of reward-processing based on EEG time-frequency characteristics. Within the reward-anticipation stage, elevated reward-processing was operationalized as 1) greater cued-locked delta activity during cue-evaluation and 2) greater pre-feedback alpha suppression during feedback-anticipation. Within the reward-outcome stage, elevated reward-processing was operationalized as greater feedback-locked delta, theta and beta activity. To help corroborate these EEG variables as indices of reward processing, we examined the relationship between EEG-related data and behavioral learning performance during the reward time estimation task, which reflects motivated learning (Luft, Nolte, et al., 2013). We also expect this behavioral index for motivated learning to correlate with individual differences in delay-discounting in a manner that is similar to reward-processing EEG indices.
2. Methods
2.1 Participants
Thirty-seven right-handed (< 18, Chapman Handedness Scale; Chapman and Chapman (1987) native English speakers (21 females; age M = 19.05 years, SD = 1.22) at Northwestern University received partial course credit for their participation. Participants also earned additional monetary bonus based on their performance in the reward time estimation task (see below). Data from nine additional participants were discarded due to an EEG equipment problem (n = 1), excessive EEG slow-frequency (i.e., sweat artifact; n = 2) or high-frequency noise (i.e., muscle artifact; n = 1), giving the same answer throughout the Delay-Discounting task (n = 2), or a model-fit index on the Delay-Discounting task (R-square, see below) that was 1.5 inter-quartile ranges (IQRs) away from the nearer quartile (n = 3). Participants had no neurological history of head injury and were not taking psychotropic medications at the time of the study. Participants provided informed consent before the experiment. Northwestern Institutional Review Board approved the study.
2.2 Behavioral Measure of Delay-Discounting Responses: The Delay-Discounting Task
Before EEG setup, participants completed a computer-adaptive version of the Delay-Discounting task (Figure 1a) to assess individual differences in delay-discounting tendencies (Ahn et al., 2011; Rachlin, Raineri, & Cross, 1991). Given previous studies reporting a similar pattern of responses in delay-discounting between hypothetical and real monetary rewards (M. W. Johnson & Bickel, 2002; Lagorio & Madden, 2005), we used hypothetical rewards in this task to allow us to assess a wide range of delay periods and reward amounts.
Figure 1. The delay-discounting task.

Figure 1a. An example of one trial in the delay-discounting task.
Figure 1b. Mean subjective values of a larger-but-delayed choice ($800) as a function of delays (in weeks). Error bars represent ± standard error.
For each trial in the delay-discounting task, participants were told to choose between a smaller-but-immediate (e.g., “$400 now”) or larger-but-delayed (e.g., “$800 in one year”) reward (see Figure 1 for an example of a trial). There were six blocks of trials. Each block involved the same distribution of six different delay periods: two weeks, one month, six months, one year, three years or ten years. The order of blocks was fully randomized across participants. During the first trial of each block, participants made a choice between “$400 now” vs. “$800 at a given delay.” A mean of the upper and lower bounds according to the choice made on the current trial were used as a smaller-but-immediate choice on the subsequent trial (Ahn et al., 2011; Du, Green, & Myerson, 2002; Green & Myerson, 2004). The larger-but-delayed choice was always fixed at $800 regardless of the choice made on the previous trial. For example, if “$400 now” was chosen over “$800 in one year”, then the smaller-but-immediate choice on the next trial would have been $200 (i.e., the mean of upper ($400) and lower ($0) bounds). This is because, based on the current-trial choice, “$800 in one year” had a lower subjective value than “$400 now”, which means that the subjective value of “$800 in one year” was between “$0 now” and “$400 now”. Thus, the subsequent trial would assess whether “$800 in one year” had a lower or higher subjective value than “$200 now.” Conversely, if “$800 in one year” was chosen over $400, the next smaller-but-immediate choice would have been “$600 now” (i.e., the mean of upper ($800) and lower ($400) bounds). Following procedures conventionally used in studies focusing on individual-differences (Ahn et al., 2011; Du et al., 2002), we continued the adaptation of the smaller-but-immediate choice to the sixth trial of each block. Accordingly, the mean of the upper and lower bounds of the sixth trial was considered participants’ subjective value of $800 at a given delay (Ahn et al., 2011; Du et al., 2002). The subjective values of $800 at every delay from all of the blocks were then fit into a hyperbolic model, which represented individual differences in delayed-discounting tendencies (Green & Myerson, 2004; Mazur, 1987). The steepness of the slope within this hyperbolic model (known as the discounting rate, or k value) reflects the extent to which people prefer smaller-but-immediate (compared to larger-but-delayed) rewards (see data analyses below).
2.3 EEG Measure of Reward-Processing: The Reward Time-Estimation Task
The reward time-estimation task, adapted from a previous EEG paradigm (e.g., Damen & Brunia, 1987; Kotani et al., 2003), was used to assess individual differences in reward-related EEG activity. Participants were instructed to press a button with their right index finger 3.5 s after seeing a cue (see Figure 2 for a schematic representation of the task). During Reward Trials, participants earned 20 cents for accurate time estimations and received no monetary reward for inaccurate estimates. During No-Reward trials, participants received no monetary reward irrespective of their performance. Thus, the difference in EEG activity between Reward trials and No-Reward trials was considered an index of reward-related neural activity and reward-processing more generally. Each trial began with a Reward/No-Reward anticipation cue that signaled whether the trial was a Reward or No-Reward trial. This cue was presented for 300 ms and involved either circle or square shapes (counterbalanced across participants). The circle and square shapes were matched for luminance, contrast, and spatial frequency using Shine toolbox (Willenbockel et al., 2010) in Matlab.
Figure 2. Diagram of the time estimation task during the experimental blocks.

Note: The image representations for Reward-Anticipation and No-Reward-Anticipation Cues were counter-balanced across subjects. A Good-Performance feedback corresponds to an accurate response, or a response within the correct time-window, and is indicated by a “=“ sign on the top line. A Bad-Performance feedback corresponds to a response slower than 2 s and faster than 5 s, but not within the correct time-window, and is indicated by a “<3.5” or “>3.5” sign on the top line, respectively. An extremely fast/slow feedback corresponds to a response faster than 2 s or slower than 5 s and is indicated by a “<2” or “>5” sign on the top line, respectively. The task during the Control blocks used a different image representation for the cue that carried no reward-related meaning, and only provided extremely fast/slow feedbacks (see text). ITI = Inter Trial Interval.
We considered accurate responses as estimations that fell within the correct time-window. To control for variance in time-estimation ability among participants, two procedures were used to determine the correct time window. First, the correct time window on a given trial was shortened (or lengthened) by 20 ms if the response on the previous trial was (or was not) within the correct time-window (Kotani et al., 2003; Ohgami et al., 2006). This method has been found to generate an accuracy-rate of approximately 50%. Second, we included three Control blocks, each comprised of 36 trials, which were administered prior to the Experimental blocks. During these Control blocks, participants were instructed to button-press 3.5 s after seeing a triangle-shaped cue. There was no reward involved during these Control blocks, and participants were not informed about any of the reward contingencies in the time estimation task until after they finished these blocks. Moreover, unlike the Experimental blocks, participants received no performance feedback during the Control blocks, except if they made an extremely fast (a response faster than 2 s, indicated by a “<2” sign) or slow (a response slower than 5 s, indicated by a “>5” sign) response. These Control blocks allowed us to generate a correct response time window that was then calibrated to each individual participant and to measure participant’s initial time-estimation ability prior to them learning through reward/performance feedback in the Experimental blocks (see below). The initial time window for a correct response during the Control blocks was +/− 500 ms, centered at 3500 ms. Following the Control blocks, participants completed 30 practice trials. These practice trials resembled trials during the Experimental blocks, except there were no earnings. The individualized time window for a correct response obtained from the Control blocks was used in the first practice trial.
The Experimental blocks consisted of six blocks of 36 trials. Within each block, there was a random distribution of Reward and No-Reward trials with a 50/50 split for each trial type. During the Experimental blocks, two lines of feedback text appeared two seconds following the button-press in the middle of the screen for 1000 ms (see Figure 2). The top-line indicated performance feedback information, which was separated into three categories: Good-Performance, Bad-Performance and extremely fast/slow. Good-Performance corresponded to an accurate response, or a response within the correct time-window, and was indicated by a “=“ sign on the top line. Bad-Performance corresponded to a response slower than 2 s and faster than 5 s, but not within the correct time-window, and was indicated by a “<3.5” (for a response between 2 s and the lower end of the correct time-window) or “>3.5” (for a response between the higher end of the correct time-window and 5s) sign on the top line. Extremely fast/slow feedback corresponded to a response faster than 2 s or slower than 5 s and was indicated by a “<2” (for a response faster than 2 s) or “>5” (for a response slower than 5 s) sign on the top line.
The bottom line of the feedback text indicated whether or not participants won money for that particular response and included the following: “$” indicated the participant won money (20 cents) for that trial, and “0” indicated the participant did not win money for that trial. Thus, during Reward trials, participants would see “$”for Good-Performance, and see “0” for both Bad-Performance and Extremely fast/slow estimation. For No-Reward trials, participants would see “0” regardless of their performance. Trials were terminated with a randomly distributed ITI between 1000–1150 ms. To incentivize participants’ continued attention on both Reward and No-Reward trials, they were told they would receive no earnings if they saw feedback indicating extremely fast/slow responses (i.e., “<2” or “>5”) more than 15 times. This ensured that they avoided extremely fast or slow responses.
2.4 Procedure
Following consent, participants completed the delay-discounting task. EEG electrodes were then applied and participants next completed the Time-Estimation Task. To help familiarize participants with the time duration of 3.5-s, participants first listened to two beep sounds 3.5-s apart as many times as they desired. Participants then completed the Control blocks for the Time-Estimation Task with no knowledge of the upcoming Experimental blocks. Participants were then given instructions regarding the Experimental blocks and corresponding Reward and No-Reward cues and the different kinds of feedbacks for the Time-Estimation Task. Participants were tested on their comprehension of these cues and feedbacks. Each block was separated by breaks of participant-determined length. During these breaks, participants were informed of their earnings and reminded of the meaning of the Reward/No-Reward Cues.
2.5 Electrophysiological Recording
Continuous EEG data with a sampling rate at 500 Hz (DC to 100 Hz on-line, Neuroscan Inc.) were collected from inside an electro-magnetic shielded booth. Twenty-four Ag/AgCl scalp electrodes were used (F7/3/z/4/8, FC3/z/4, C3/z/4, T3/4, CP3/z/4, P3/z/4, T5/6, O1/z/2). HEOG and VEOG were recorded with four separate eye electrodes. Recordings were referenced on-line to a left mastoid and re-referenced offline to linked mastoids. Impedance was kept below 5 kΩ and 10 kΩ for scalp and eye electrodes, respectively. During offline analyses, eye movement artifacts were first corrected with PCA algorithms implemented in NeuroScan EDIT (Neuroscan Inc.). Movement-related artifacts were removed manually. EEG data were offline highpass-filtered at .01 Hz.
2.6 Data Analyses for the Delay-Discounting Task
Each participants’ subjective value of $800 at every delay were fit to the hyperbolic model in the form of V = A/(1 + kD) (Green & Myerson, 2004; Mazur, 1987) using the Curve Fitting Toolbox in Matlab. V was the subjective value, A was a larger-but-delayed reward amount ($800), D was the delay interval in weeks, and k was a free parameter, reflecting a discounting rate. The smaller the k, the stronger preference toward larger-but-delayed rewards. To normalize its distribution, the natural log of k, ln(k), was used as an index for individual-differences in delay-discounting responses. R-square as a model-fit index was also calculated. R-square indicates the proportion of variance accounted for by the hyperbolic model, ranging from 0 to 1 (perfect fit).
2.7 Data Analyses for the Reward Time-Estimation Task
2.7.1 Manipulation Check
We computed an Inaccurate Estimation index as the standard deviation of the absolute difference between participants’ actual estimations (in milliseconds, ms) and the target time interval (3500 ms) (Luft, Nolte, et al., 2013). Thus, higher Inaccurate Estimation reflects worse time estimation performance. To normalize the Inaccurate Estimation distribution, a natural-log (In) transformation was applied. As a manipulation check for whether participants were more motivated during Reward trials, we compared Inaccurate Estimation during 1) Reward trials from all of the Experimental blocks, 2) No-Reward trials from all of the Experimental blocks and 3) Control trials from all of the Control blocks. We predicted lower Inaccurate Estimation during Reward (compared to No-Reward and Control) trials.
2.7.2 Behavioral Indices for Individual-Differences in Motivated Learning
In addition to being used as a manipulation check, Inaccurate Estimation was also employed as a behavioral index for individual-differences in motivated learning. Specifically, Inaccurate Estimation during the Control blocks (referred to as Control Inaccurate Estimation) served as an index for individual differences in estimation ability prior to learning in the Experimental blocks. Inaccurate Estimation during the last (i.e., 6th) Experimental block (referred to as Motivated-Learning Inaccurate Estimation) served as an index for how motivated participants were to learn through feedback over the course of the experiment (for a similar approch, see Luft, Nolte, et al., 2013). For individual differences in Motivated-Learning Inaccurate Estimation, we collapsed across Reward and No-Reward trials during the last experiment block. This is because, in the context of the current time-estimation task, learning about their estimation performance through feedbacks during the No-Reward trials also helped participants to earn more rewards during the Reward trials. Thus, toward the end of the experiment (i.e., 6th block), people who were more motivated to obtain rewards in the task would perform better in both Reward and No-Reward trials. Additionally, combing both Reward and No-Reward trials during the last experiment block led to more trials to be computed, thus increasing stability of Motivated-Learning Inaccurate Estimation as a measure for individual differences. This is important, given that we only had 36 trials (Reward and No-Reward trials combined) in each block. We then examined whether both ln(k) and EEG indices have relationship with Control Inaccurate Estimation and Motivated-Learning Inaccurate Estimation.
2.7.3 EEG Data
Extremely fast (less than 2 s, “<2”) or slow (more than 5 s, “>5”) trials were excluded from the EEG analyses as they may reflect a lack of attention to the task. EEGlab (Delorme & Makeig, 2004) was used to analyze EEG data. After a linear detrend was applied to EEG epochs, any epoch containing artifacts (±75 μV) were rejected. Time-frequency decomposition was then performed to compute event-related spectral perturbation (ERSP). ERSP refers to changes in EEG power from the baseline period at specific frequency and time (Makeig et al., 2004). We used a linear space for both frequency (at every 1 Hz) and time (at every 2 ms).
We separated EEG activity into three phases of reward-processing: 1) cue-locked EEG corresponding to cue-evaluation during the reward-anticipation stage (i.e., cue evaluation during Reward vs. No-Reward trials), 2) pre-feedback EEG corresponding to feedback-anticipation during the reward-anticipation stage (i.e., anticipation during the wait for feedback outcome during Reward vs. No-Reward trials), and 3) feedback-locked EEG corresponding to the reward-outcome stage (i.e., evaluation of feedback that revealed Reward and Performance information). For cue-locked and feedback-locked EEG activity, we focused on ERSP power following the onset of the cue and feedback, respectively. Here, EEG data were epoched from −2500 to 3500 ms relative to cue/feedback onset. This relatively long epoch allowed us to investigate ERSPs from a low (1 Hz) to a relatively high (50 Hz) frequency, which covered EEG frequency bands of interest during these time periods (delta, theta and beta). A modified complex sinusoidal wavelet was used with a sliding window of 3342-ms wide (leading to 3 cycles at 1 Hz) and a wavelet factor of .92. To reduce the potential edge effects, we removed half of the sliding window (1671 ms) at the edges (i.e., the beginning and the end) of each epoch, leaving an epoch between −829 and 1927 ms after edge removal. The baseline for cue- and feedback-locked EEG was between −300 to −100 ms before the stimulus onset.
For pre-feedback EEG activity, we focused on ERSP power prior to feedback onset. Specifically, pre-feedback EEG activity was epoched from −2557 to 2557 ms relative to the button-press. Given that our focus during this period was specifically on the Alpha band (8–13 Hz), we computed pre-feedback ERSP at a narrower frequency range of 3 to 30 Hz. Because the lowest frequency (3 Hz) for pre-feedback EEG was higher than it was in the cue-/feedback-locked EEG (1 Hz), we used a shorter sliding window of 1114-ms wide (leading to 3 cycles at 3 Hz) and a wavelet factor of .5. The removal of epoch edges (557 ms or half of a sliding window) shortened the epoch to be between −2000 to 2000 ms relative to each button-press, which ended at the onset of the feedback. EEG power during this period from −2000 to −1500 ms before the button-press was used as baseline. This early baseline period was selected in order to avoid movement-related activity near the time of the button-press.
Two-tailed paired parametric tests were performed on ERSP time-frequency and topographic maps, as implemented in EEGlab. Multiple comparisons were corrected using False Discovery Rate (FDR) (Benjamini & Yekutieli, 2001). P-values based on these statistical tests were shown on time-frequency and topographic maps. These maps of p values indicate times, frequencies and electrodes at which there was a significant effect. For cue-locked and pre-feedback EEG activity, the statistical tests were used to assess whether there was an effect of reward condition (Reward-trial vs. No-Reward-trial) on ERSP power. For feedback-locked EEG activity, we separated feedbacks based on evaluation types: Reward Evaluation (Reward-trial vs. No-Reward-trial) × Performance Evaluation (Bad-Performance vs. Good-Performance). The main effects and interaction between evaluation types were tested on ERSP power.
2.7.4 Reward-Processing ERSPs as indices for individual differences
We focused individual differences analyses on ERSPs that significantly varied between Reward and No-Reward trials according to main-effect analyses (see Results). Specifically, for cue-locked EEG, individual-differences analyses were centered at cue-locked delta (1–3 Hz) between 100 and 500 ms following the cue onset at the parietal CPz site, similar to a recent study on reward-processing to the cue (Cavanagh, 2015). For pre-feedback EEG, we used alpha (8–13 Hz) power within the 500-ms window right before feedback onset at Oz. Occipital pre-feedback alpha suppression (i.e., lower power) is related to anticipation processes toward upcoming visual stimuli (Bastiaansen et al., 1999; Hughes et al., 2013). Thus, the more negative the alpha-suppression, the stronger the anticipation-related processes. For feedback-locked EEG, we focused on three different ERPSs from three different frequency bands: feedback-locked delta, theta and beta. Similar to cue-locked delta, feedback-locked delta (1–3 Hz) was quantified as averaged EEG power between 100 and 500 ms following the feedback onset at CPz. This is similar to previous research on feedback-locked delta power (Foti et al., 2015). As for feedback-locked theta (4–7 Hz), we employed averaged EEG power between 200 and 400 ms after feedback onset at Fz, following previous research on frontal-midline theta and outcome/feedback-processing (Cohen et al., 2007; Marco-Pallares et al., 2008). Lastly, feedback-locked beta (15–25 Hz) was quantified through averaged EEG power between 400 and 600 ms after feedback onset at CPz following a recent time-estimation study (Luft, Nolte, et al., 2013).
In addition to examining ERSPs at separate conditions (i.e., Reward-Trial and No-Reward-Trial ERSPs for cue-locked and pre-feedback EEG; Reward-Trial, No-Reward-Trial, Good-Performance and Bad-Performance ERSPs for feedback-locked EEG), we also computed ERSP difference scores by subtracting ERSP power during No-Reward trials from that during Reward trials (collapsing across Bad- and Good-Performance feedback for feedback-locked EEG). Referred to as ΔReward ERSPs, these difference scores allowed us to focus in on reward-processing EEG activity. For feedback-locked EEG, we also computed ΔPerformance ERSP difference scores by subtracting ERSP power during Good-Performance trials from that during Bad-Performance trials, collapsing across Reward-and No-Reward trials. The ΔPerformance ERSPs reflect individual differences in performance evaluation.
3. Results
3.1 Delay-Discounting Responses
Figure 1b shows how subjective values were discounted as a function of delays. The mean of ln(k) was −4.72 (SD = 1.45). R-square, as a model-fit index for the hyperbolic model used, had the median of .89 (IQR = .94 – .81), similar to previous studies (de Wit, Flory, Acheson, McCloskey, & Manuck, 2007; Hariri et al., 2006).
3.2 Reward Time-Estimation Behavior
3.2.1 Manipulation Check
During the time-estimation task, behavioral data from one participant was lost due to a technical error, leaving data from 36 (as opposed to 37) participants. Overall, during the Experimental blocks, participants estimated 3.5 s quite well (MRT = 3.52 s, SD = .11), and rarely made extremely fast (less than 2 s) or slow (more than 5 s) responses (M = 2.58 trials out of 216 trials, SD = 2.15). Given that the accuracy rate (M = 50.3%, SD = 3.06) closely matched 50%, it is clear that the time-window adaptation algorithm worked effectively. Across blocks, there were differences in Inaccurate Estimation (i.e., SD of the absolute difference between actual estimations and the target time interval) among Reward and No-Reward trials during all of the Experimental blocks and Control trials during all of the Control blocks, F(1.14, 39.90) = 84.33, p < .001, Greenhouse-Geisser corrected. As expected, Inaccurate Estimation was lower during Reward trials (M = 5.44 ln(ms), SD = .38) compared to No-Reward trials (M = 5.54 ln(ms), SD = .39, p < .001), which was lower than Control trials (M = 6.22 ln(ms), SD = .33, p < .001).
3.2.2 Relationship between Motivated Learning Inaccurate Estimation and Delay-Discounting Responses
Motivated-Learning Inaccurate Estimation (i.e., collapsing across all Reward and No-Reward trials during the last experimental block,) was positively correlated with ln(k), while Control Inaccurate Estimation (i.e., during the Control blocks) was not (see Table 1 and Figure 3). Thus, participants with poorer estimation performance after learning throughout the task (i.e., higher Motivated-Learning Inaccurate Estimation) had higher k values (i.e., stronger preference toward small-but-immediate rewards). In other words, people who were more motivated to learn through feedbacks throughout the task were more likely to prefer larger-but-delayed rewards.
Table 1.
Zero-order correlations between ERSPs, behavioral indices and ln(k).
| ERSPs & Behavioral Indices |
Motivated-Learning Inaccurate Estimation |
Control Inaccurate Estimation |
Delay-Discounting Tendencies Ln(k) |
|
|---|---|---|---|---|
| Cue-locked | Reward-Trial Delta | −.377* | .047 | −.076 |
| No-Reward-Trial Delta | −.069 | .125 | −.143 | |
| ΔReward Delta | −.359* | −.090 | .080 | |
| Pre-feedback | Reward-Trial Alpha Suppression | .375* | .209 | .441** |
| No-Reward-Trial Alpha Suppression | .327† | .237 | .254 | |
| ΔReward Alpha Suppression | .196 | .035 | .400* | |
| Feedback-locked Reward-Evaluation | Reward-Trial Delta | −.507** | −.185 | −.264 |
| No-Reward-Trial Delta | −.321† | −.178 | −.194 | |
| ΔReward Delta | −.466** | −.052 | −.191 | |
| Reward-Trial Theta | −.536** | −.117 | −.407* | |
| No-Reward-Trial Theta | −.302† | −.131 | −.293† | |
| ΔReward Theta | −.563** | −.043 | −.344* | |
| Reward-Trial Beta | −.377* | .071 | −.427** | |
| No-Reward-Trial Beta | −.302† | .061 | −.361* | |
| ΔReward Beta | −.237 | .038 | −.246a | |
| Feedback-locked Performance-Evaluation | Bad-Performance Delta | −.480** | −.205 | −.196 |
| Good-Performance Delta | −.338* | −.14 | −.242 | |
| ΔPerformance Delta | −.16 | −.075 | .079 | |
| Bad-Performance Theta | −.470** | −.15 | −.354* | |
| Good-Performance Theta | −.454** | −.076 | −.400* | |
| ΔPerformance Theta | −.217 | −.191 | −.051 | |
| Bad-Performance Beta | −.254 | .149 | −.303† | |
| Good-Performance Beta | −.365* | −.013 | −.436** | |
| ΔPerformance Beta | .109 | .202 | .138 | |
| Performance | Experimental Inaccurate Estimation | - | .266 | .393* |
| Control Inaccurate Estimation | - | - | .014 |
Note. For feedback-locked Reward-Evaluation ERSPs, ERSPs were collapsing across Bad-Performance and Good-Performance feedbacks. ΔReward ERSPs were calculated by subtracting No-Reward-Trial ERSPs from Reward-Trial ERSPs. Similarly, for feedback-locked Performance-Evaluation ERSPs, ERSPs were collapsing across Reward- and No-Reward-Trial feedbacks. ΔPerformance ERSPs were calculated by subtracting Good-Performance ERSPs from Bad-Performance ERSPs. More negative values of ΔReward Alpha-Suppression reflect the greater suppression of alpha activity during Reward trials (relative to No-Reward trials). Inaccurate Estimation refers to the deviation from the goal of estimating time (3.5 s), and therefore high values reflect worse performance. Motivated-Learning Inaccurate Estimation and Control Inaccurate Estimation refer to Inaccurate Estimation indices during the last block of the experimental session, and during the control blocks (i.e., before the learning occurred), respectively.
p < .01,
p < .05,
p < .10 (2-tailed).
became significant (r(35) = −.36, p = .03), after a bivariate outlier was removed (see Figure 11).
Figure 3. Scatterplot of the correlations between delay-discounting tendencies [ln(k)] and Control Inaccurate Estimation (i.e., during the control blocks) and Motivated-Learning Inaccurate Estimation (i.e., during the last (6th) experimental block).
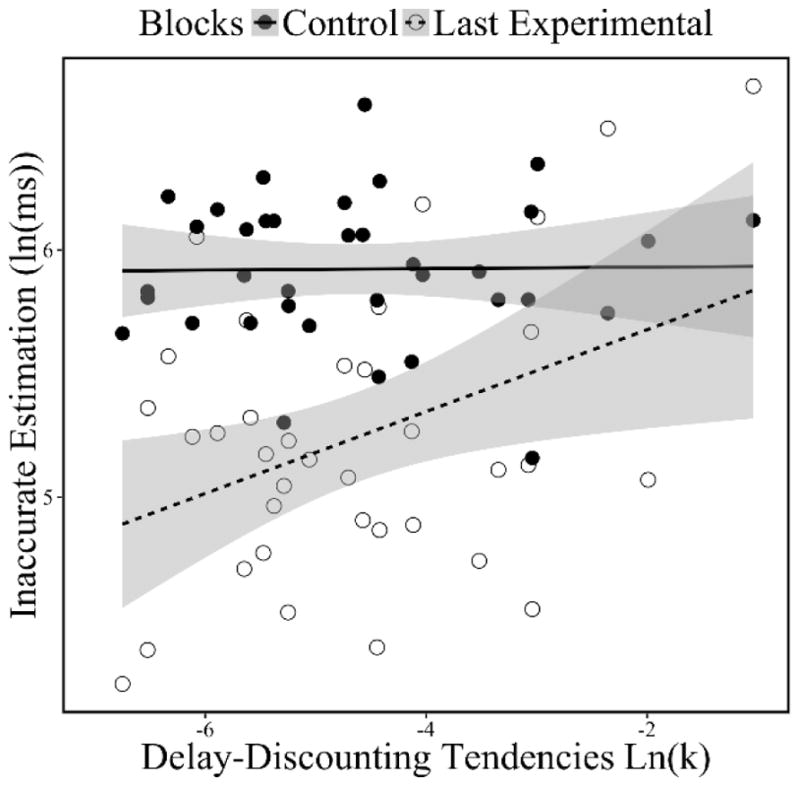
Note: Delay-Discounting Tendencies ln(k) was significantly correlated with Motivated-Learning Inaccurate Estimation (during the last (6th) experimental block) (r(34) = .39, p = .02), but not with Control Inaccurate Estimation (during the control blocks) (r(34) = .01, p = .94). Inaccurate Estimation is the standard deviation from the goal of estimating 3.5 s. Hence, higher Inaccurate Estimation values reflect worse time-estimation performance. Control Inaccurate Estimation reflects participant’ time estimation ability prior to the experimental session, during when participants could not learn about their performance through feedback. Motivated-learning Inaccurate Estimation during the last block of the experimental session reflects how well participants had been motivated to learn through feedback over the course of the experimental session. Gray areas indicate the confident interval of 95% around the linear regression line.
3.3 Cue-Locked EEG Activity
Figure 4a and 4b show ERSP time-frequency and topographic maps of cue-locked EEG. Overall, following cue onset, there was an increase in ERSP power at delta (1–3 Hz) and theta (4–7 Hz) bands and a decrease in ERSP power at the alpha/beta (8–25 Hz) band. More importantly, cue-locked ERSP power at the delta (but not theta or beta) band was significantly stronger for Reward trials than for No-Reward trials approximately 100 ms to 500 ms following cue onset at parietal sites (for p values, FDR corrected, see Figure 4a). This EEG pattern is similar to the profile of the parietal delta during reward-related cue evaluation reported in previous research (Cavanagh, 2015). Thus, for cue-locked EEG, we employed delta power during this window at CPz as an EEG index for individual differences in cue evaluation during the reward-anticipation stage.
Figure 4. Cue-locked Parietal Delta.

Figure 4a shows event-related spectral perturbation (ERSP) time-frequency maps at the electrode CPz (Top) and topographic maps (the grand-average of delta ERSP power (1–3 Hz) at the 100 – 500 ms window following cue onset) (Bottom) depicting cue-locked reward-anticipation EEG activity. Specifically, ERSP activity during Reward and No-Reward trials is depicted in the left and middle columns, respectively. The right column depicts paired t-tests’ (df = 36) p values (FDR corrected) for which Reward trial ERSP power was significantly different from No-Reward trial ERSP power. For these p-value maps, the time-frequency map shows p values at each time and frequency at CPz, while the bottom topo map shows p values at the delta (1–3 Hz) band at the 100 – 500 ms window following cue onset at every electrode. The time scale in the time-frequency maps is relative to the cue onset. Note that we computed time-frequency maps from −830 to 1828 ms (see text). However, for visual proposes, we only show −300 to 1000 ms relative to the cue onset here, given our focus on the time period right after cue onset. Note also that heat-map scales for time-frequency and topographic maps are different. Figure 4b depicts ERSP at the delta band (1–3 Hz) at CPz. Figure 4c shows a scatterplot between Motivated-Learning Inaccurate Estimation (i.e., during the last experimental block) and cue-locked delta ERSP (1–3 Hz between 100 – 500 ms) at CPz. In this scatterplot, cue-locked delta ERSP is separated to the ERSP during Reward Trials and No-Reward Trials. Gray areas indicate the confident interval of 95% around the regression line.
We found that cue-locked delta during Reward trials (but not during No-Reward trials) was negatively correlated with Motivated-Learning Inaccurate Estimation (see Table 1, Figure 4c). Similarly, ΔReward (Reward minus No-Reward-trial) cue-locked delta was also negatively correlated with Motivated-Learning Inaccurate Estimation (see Table 1, Figure 9a). Control Inaccurate Estimation, however, was not predicted by any cue-locked delta indices (see Table 1). Altogether, this suggests that enhanced delta power to Reward-trial cues (compared to No-Reward-trial cues) was related to how well participants adjusted their time-estimation performance. Nonetheless, none of the cue-locked delta indices significantly predicted ln(k) (see Table 1).
Figure 9. Scatterplots of the correlation between Motivated-Learning Inaccurate Estimation (i.e., during the last experimental block) and ΔReward ERSPs (Reward-trial ERSPs minus No-Reward-trial ERSPs).

Note that higher Motivated-Learning Inaccurate Estimation values reflect worse time-estimation performance during the last experimental block. Potentials bivariate outliers were detected using Minimum Covariance Determinant (MCD), and represented by red data points. Ellipses contain non-outlying data. Pink shaded areas represent 95% bootstrapped confident intervals around the linear regression line after the potential bivariate outliers were removed. Importantly, all of the correlations presented below remain significant, with or without bivariate outlier removal, suggesting the robustness of the relationship. Figure 9a represents the correlation between Motivated-Learning Inaccurate Estimation and ΔReward cue-locked delta (Reward-trial cue-locked delta minus No-Reward-trial cue-locked delta). The correlation coefficient was significant both before (r(34) = −0.36, p=0.03) and after (r(32) = −0.39, p=0.02) bivariate outliers removal. Figure 9b represents the correlation between Motivated-Learning Inaccurate Estimation and ΔReward feedback-locked delta (Reward-trial cue-locked delta minus No-Reward-trial cue-locked delta, collapsing across Bad- and Good-Performance feedbacks). The correlation coefficient was significant both before (r(34) = −0.47, p=0.004) and after (r(31) = −0.65, p<0.001) bivariate outliers removal. Figure 9c represents the correlation between Motivated-Learning Inaccurate Estimation and ΔReward feedback-locked theta (Reward-trial cue-locked theta minus No-Reward-trial cue-locked theta, collapsing across Bad- and Good-Performance feedbacks). The correlation coefficient was significant both before (r(34) = −0.56, p<0.001) and after (r(33) = −0.45, p = 0.007) bivariate outliers removal.
3.4 Pre-Feedback EEG Activity
Figure 5a and 5b show ERSP time-frequency and topographic maps during a period prior to feedback onset. There was a clear pattern of alpha (8–13 Hz) suppression (i.e., reduction in ERSP power) at parieto-occipital sites, peaking at the period right before feedback onset. This EEG pattern is similar to the profile of occipital alpha suppression during anticipation-related activity reported in previous studies (Bastiaansen et al., 1999; Hughes et al., 2013; B. van den Berg et al., 2014). As predicted, alpha suppression was significantly stronger (i.e., higher reduction in alpha power) for Reward trials than for No-Reward trials starting approximately 500 ms before feedback onset. This effect was primarily significant at parieto-occipital sites (for p values, FDR corrected, see Figure 5a). Thus, we employed pre-feedback alpha power during the 500-ms window prior to feedback onset at Oz as an EEG index for individual differences in feedback anticipation during the reward-anticipation stage.
Figure 5. Pre-feedback occipital alpha suppression.

Figure 5a shows event-related spectral perturbation (ERSP) time-frequency maps at the electrode Oz (Top) and topographic maps (the grand-average of alpha (8–13 Hz) ERSP power at the 500-ms window prior to feedback onset) (Bottom) depicting pre-feedback reward-anticipation EEG activity. Specifically, ERSP activity during Reward and No-Reward trials is depicted in the left and middle columns, respectively. The right column depicts paired t-tests’ (df = 36) p-values (FDR corrected) for which Reward trial ERSP power was significantly different from No-Reward trial ERSP power. For these p-value maps, the time-frequency map shows p values at each time and frequency at Oz, while the bottom topo map shows p values at the alpha (8–13 Hz) band at the 500-ms window prior to feedback onset at every electrode. The time scale in the time-frequency maps is relative to button-presses: 0 ms is when a button was pressed, and 2000 ms is when the feedback was presented. Note that we computed time-frequency maps from −2000 to 2000 ms (see text). However, for visual proposes, we only show 0 to 2000 ms here, given our focus on the time period right before feedback onset. Note also that heat-map scales for time-frequency and topographic maps are different. Figure 5b depicts ERSP at the alpha band (8–13 Hz) at Oz. Figure 5c shows a scatterplot between Motivated-Learning Inaccurate Estimation (i.e., during the last experimental block) and pre-feedback alpha ERSP (8–13 Hz at the 500-ms window pre-feedback) at Oz. In this scatterplot, pre-feedback alpha ERSP is separated to the ERSP during Reward Trials and No-Reward Trials. Gray areas indicate the confident interval of 95% around the regression line.
Motivated-Learning Inaccurate Estimation had a significant, positive correlation with pre-feedback alpha during Reward trials, and a marginally significant, positive correlation with this ERSP during No-Reward trials (see Table 1, Figure 5c). Nonetheless, Motivated-Learning Inaccurate Estimation was not correlated with the ΔReward (Reward minus No-Reward-trial) pre-feedback alpha (see Table 1). Additionally, Control Inaccurate Estimation was not correlated with any pre-feedback alpha indices (see Table 1). This suggests that enhanced alpha suppression (i.e., lower alpha power) prior to the feedback onset was related to better adjustment of time-estimation performance (i.e., lower Inaccurate Estimation) throughout the task. However, the relationship between alpha suppression and time-estimation performance may not be limited to Reward trials.
With respect to delay-discounting tendencies, pre-feedback alpha power during Reward trials (but not during No-Reward trials) had a positive relationship with ln(k) (see Table 1). Moreover, there was a significant positive relationship between ΔReward pre-feedback alpha and ln(k) (see Table 1, Figure 10). These correlations suggest that participants who had stronger alpha suppression (i.e., lower power) during Reward (compared to No-Reward) trials (i.e., more negative ΔReward pre-feedback alpha) had smaller k values. In other words, individuals who had stronger feedback anticipation during Reward trials had a stronger preference toward larger-but-delayed, compared to smaller-but-immediate, rewards.
Figure 10. Scatterplot of the correlation between delay-discounting tendencies [ln(k)] and Δalpha-suppression (Reward-trial Alpha activity minus No-Reward-trial Alpha activity) prior to the feedback onset.
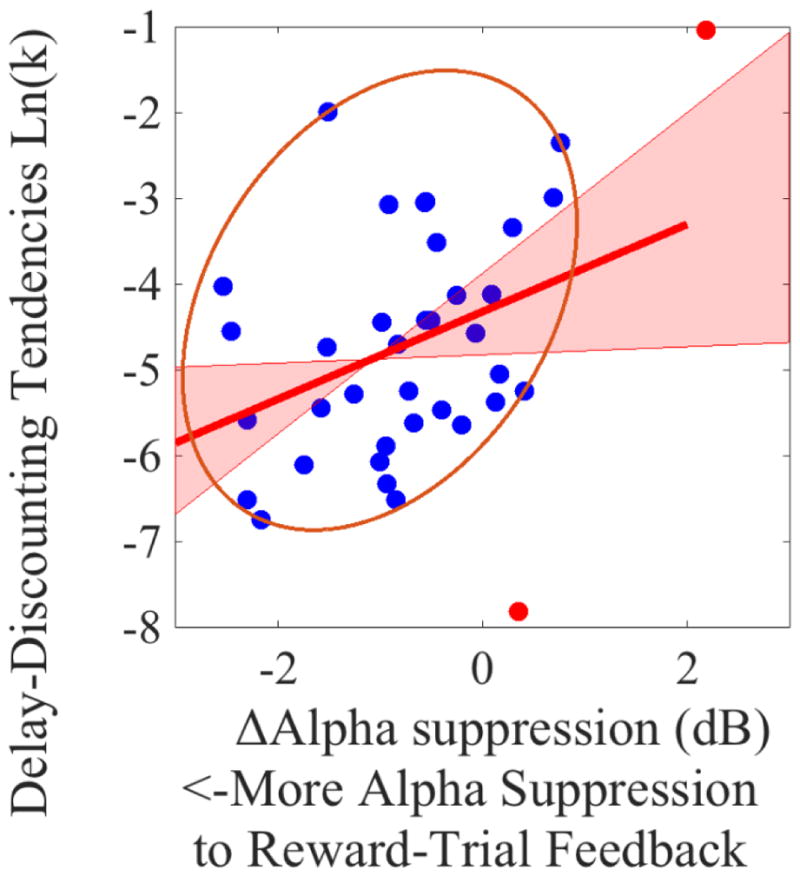
Note that, the more negative the Δalpha-suppression, the greater the suppression of alpha activity during Reward trials (relative to No-Reward trials). Potentials bivariate outliers were detected using Minimum Covariance Determinant (MCD), and represented by red data points. Ellipse contains non-outlying data. Pink shaded areas represent 95% bootstrapped confident intervals around the linear regression line after the potential bivariate outliers were removed. The correlation coefficient was significant both before (r(35) = 0.40, p=0.01) and after (r(33) = 0.36, p=0.03) bivariate outliers removal. This suggests that the potential outliers did not drive the correlation.
3.5 Feedback-Locked EEG Activity
ERSP time-frequency and topographic maps following feedback onset are shown in Figures 5–7. Overall, following feedback onset, EEG power was increased at the delta (1–3 Hz) and theta (4–7 Hz) bands and decreased at the alpha/beta (8–25 Hz) band. Moreover, the effect of Reward-Evaluation (Reward-trial vs. No-Reward-trial feedbacks) on feedback-locked EEG power was found at delta, theta and beta bands (for p values, FDR corrected, see Figure 6b, 7b, 8b).
Figure 7. The influence of reward-evaluation and performance-evaluation on frontal-midline theta ERSP following feedback onset.

Figure 7a show ERSP time-frequency maps at the electrode Fz and topographic maps (the grand-average of theta ERSP power at 4–7 Hz, 200 – 400 ms window following feedback onset). ERSP activity locked to feedback onset is separated into reward evaluation (Reward-Trial vs. No-Reward Trial feedbacks) and performance evaluation (Bad-Performance vs. Good-Performance feedbacks). Note that we computed time-frequency maps from −830 to 1828 ms (see text). However, for visual proposes, we only show −300 to 1000 ms relative to the feedback onset here. Note also that heat-map scales for time-frequency and topographic maps are different. Figure 7b depicts p-values (FDR corrected) showing the main effect of Reward Evaluation (Reward Trial vs. No-Reward Trial), main effect of Performance Evaluation (Bad- vs. Good-Performance) and their interaction. For these p-value maps, the time-frequency map shows p values at each time and frequency at Fz, while the topographic map shows p values at the theta (4–8 Hz) band at the 200 – 400 ms window following feedback onset at every electrode. Figure 7c shows grand-average of theta power (4–7 Hz) at CPz during 200 – 400 ms window following feedback onset, separated by conditions. Error bars represent standard error of the mean, corrected for repeated-measure comparison. Figure 7d shows a scatterplot between Motivated-Learning Inaccurate Estimation (i.e., during the last experimental block) and feedback-locked theta ERSP (4–7 Hz, 200 – 400 ms window following feedback onset). In this scatterplot feedback-locked theta ERSP was separated to the ERSP during the Reward Trials and No-Reward Trials, collapsing across Bad- and Good-Performance. Gray areas indicate the confident interval of 95% around the regression line.
Figure 6. The influence of reward-evaluation and performance-evaluation on parietal delta ERSP following feedback onset.

Figure 6a show ERSP time-frequency maps at the electrode CPz and topographic maps (the grand-average of delta ERSP power at 1–3 Hz, 100 – 500 ms window following feedback onset). ERSP activity locked to feedback onset is separated into reward evaluation (Reward-Trial vs. No-Reward Trial feedbacks) and performance evaluation (Bad-Performance vs. Good-Performance feedbacks). Note that we computed time-frequency maps from −830 to 1828 ms (see text). However, for visual proposes, we only show −300 to 1000 ms relative to the feedback onset here. Note also that heat-map scales for time-frequency and topographic maps are different. Figure 6b depicts p-values (FDR corrected) showing the main effect of Reward Evaluation (Reward Trial vs. No-Reward Trial), main effect of Performance Evaluation (Bad- vs. Good-Performance) and their interaction. For these p-value maps, the time-frequency map shows p values at each time and frequency at CPz, while the topographic map shows p values at the delta (1–3 Hz) band at the 100 – 500 ms window following feedback onset at every electrode. Figure 6c shows grand-average of delta power (1–3 Hz) at CPz during 100 – 500 ms window following feedback onset, separated by conditions. Error bars represent standard error of the mean, corrected for repeated-measure comparison. Figure 6d shows a scatterplot between Motivated-Learning Inaccurate Estimation (i.e., during the last experimental block) and feedback-locked delta ERSP (1–3 Hz, 100 – 500 ms window following feedback onset). In this scatterplot feedback-locked delta ERSP was separated to the ERSP during the Reward Trials and No-Reward Trials, collapsing across Bad- and Good-Performance. Gray areas indicate the confident interval of 95% around the regression line.
Figure 8. The influence of reward-evaluation and performance-evaluation on parietal beta ERSP following feedback.

Figure 8a show ERSP time-frequency maps at the electrode CPz and topographic maps (the grand-average of beta ERSP power at 15–25 Hz, 400 – 600 ms window following feedback onset). ERSP activity locked to feedback onset is separated into reward evaluation (Reward-Trial vs. No-Reward Trial feedbacks) and performance evaluation (Bad-Performance vs. Good-Performance feedbacks). Note that we computed time-frequency maps from −830 to 1828 ms (see text). However, for visual proposes, we only show 300 to 700 ms relative to the feedback onset here. This is to highlight beta activity (15–25 Hz) between 400 – 600 ms. To further highlight ERSP power at the beta band, we also constrains the heat-map scales for the time-frequency maps to −2 to 2 dB. Note also that heat-map scales for the time-frequency and topographic maps are different. Figure 8b depicts p-values, FDR corrected, showing the main effect of Reward Evaluation (Reward Trial vs. No-Reward Trial), main effect of Performance Evaluation (Bad- vs. Good-Performance) and their interaction. For these p-value maps, the time-frequency map shows p values at each time and frequency at CPz, while the topographic map shows p values at the beta (15–25 Hz) band at the 400 – 600 ms window following feedback onset at every electrode. Figure 8c shows grand-average of beta power (15–25 Hz) at CPz during 400 – 600 ms window following feedback onset, separated by conditions. Error bars represent standard error of the mean, corrected for repeated-measure comparison. Figure 8d shows a scatterplot between Motivated-Learning Inaccurate Estimation (i.e., during the last experimental block) and feedback-locked theta ERSP (15–25 Hz) during 400 – 600 ms window following feedback onset at CPz. The feedback-locked theta ERSP is separated into the ERSP during the Reward Trials and No-Reward Trials, collapsing across Bad- and Good-Performance. Gray areas indicate the confident interval of 95% around the regression line.
3.5.1 Feedback-Locked Delta
Similar to cue-locked delta, feedback-locked delta (1–3 Hz) was enhanced approximately 100 – 500 ms following feedback onset at parietal sites. There were main effects of both Reward Evaluation and Performance Evaluation on feedback-locked delta (see Figure 6a, 6c for ERSP power and 6b for p values, FDR corrected). Specifically, for Reward Evaluation, feedback-locked delta was stronger for Reward-trial, than No-Reward-trial, feedback at CPz and other parietal sites. For Feedback Evaluation, feedback-locked delta was significantly stronger for Good-Performance, than Bad-Performance, feedback at parietal sites. There was also a significant interaction. Yet, while the effect of Reward Evaluation (i.e., stronger feedback-locked delta during Reward trials than during No-Reward trials) was numerically larger for Good-Performance (than for Bad-Performance) feedback, the Reward Evaluation effect was significant for both Good-Performance and Bad-Performance feedback. Thus, we collapsed across Good-Performance and Bad-Performance feedback when employing the feedback-locked delta as an index for individual differences in Reward Evaluation of the feedback.
Motivated-Learning Inaccurate Estimation had a significant, negative correlation with feedback-locked delta during Reward trials, and a marginally significant, positive correlation with this ERSP during No-Reward trials (see Table 1, Figure 6d). Similar to ΔReward cue-locked delta, ΔReward (Reward minus No-Reward-trial) feedback-locked delta was also negatively correlated with Motivated-Learning Inaccurate Estimation (see Table 1, Figure 9b). Motivated-Learning Inaccurate Estimation, however, had no relationship with ΔPerformance (Bad minus Good-Performance) feedback-locked delta. Similarly, Control Inaccurate Estimation was not correlated with any feedback-locked delta indices (see Table 1). Altogether, this suggests that enhanced feedback-locked delta power to Reward-trial (compared to the No-Reward-trial) feedback was related to a better behavioral adjustment of time-estimation performance (reflected by smaller Motivated-Learning Inaccurate Estimation). Nonetheless, similar to cue-locked delta indices, feedback-locked delta indices did not significantly predict ln(k) (see Table 1).
3.5.2 Feedback-Locked Theta
ERSP power in the theta frequency (4–7 Hz) was enhanced during the 200 – 400 ms window following feedback onset at frontal-midline sites. This EEG pattern is similar to the profile of frontal-midline theta (FMT) during outcome-processing reported in previous studies (Cohen et al., 2007; Luft, 2014). As expected, there was a main effect of both Reward Evaluation and Performance Evaluation (see Figure 7a, 7c for ERSP power and 7b for p values, FDR corrected). At Fz and other frontal-midline sites, feedback-locked theta was significantly stronger for Reward-trial, than No-Reward-trial, feedback. In contrast to feedback-locked delta, feedback-locked theta was significantly stronger for Bad-Performance, than Good-Performance, feedback at Fz and other frontal-midline sites. There was no interaction between Reward Evaluation and Performance Evaluation on feedback-locked theta at any frontal-midline sites (for p values, FDR corrected, see Figure 7b).
Similar to feedback-locked delta, Motivated-Learning Inaccurate Estimation was negatively correlated with feedback-locked theta during Reward trials, and there was a marginally significant negative correlation between Motivated-Learning Inaccurate Estimation and feedback-locked theta during No-Reward trials (see Table 1, Figure 7d). Similar to ΔReward cue-locked and feedback-locked delta, ΔReward feedback-locked (Reward minus No-Reward-trial) theta was also negatively correlated with Motivated-Learning Inaccurate Estimation (see Table 1, Figure 9c). There was, however, no relationship between ΔPerformance (Bad minus Good-Performance) feedback-locked theta and Motivated-Learning Inaccurate Estimation. Control Inaccurate Estimation was not predicted by any of the feedback-locked theta indices (see Table 1). Together, this suggests that enhanced feedback-locked theta power to Reward-trial (compared to the No-Reward-trial) feedback was associated with a better adjustment of time-estimation performance (reflected by smaller Motivated-Learning Inaccurate Estimation).
In contrast to cue-locked and feedback-locked delta, but similar to pre-feedback alpha, feedback-locked theta was related to delay-discounting tendencies. Specifically, ln(k) was negatively correlated with feedback-locked theta during Reward trials, and there was a marginally significant negative correlation between ln(k) and feedback-locked theta during No-Reward trials (Table 1). Moreover, while the relationship between the ΔPerformance feedback-locked theta and ln(k) was not significant, there was a significant negative relationship between the ΔReward feedback-locked theta and ln(k) (Table 1). Thus, participants with stronger feedback-locked theta power following Reward-trial, compared to No-Reward-trial, feedback (i.e., more positive ΔReward feedback-locked theta) had smaller k values (i.e., stronger preference toward larger-but-delayed rewards). To investigate the specificity of this relationship, we examined correlations between ln(k) and the ΔReward feedback-locked theta following Bad-Performance feedback separately from ΔReward feedback-locked theta following Good-Performance feedback. Ln(k) was negatively correlated with the ΔReward feedback-locked theta following Good-Performance feedback, r(35) = −.44, p = .006 (Figure 11), but not with the ΔReward feedback-locked theta following Bad-Performance feedback, r(35) = −.14, p = .39.
Figure 11. Scatterplot of the correlation between delay-discounting tendencies [ln(k)] the ΔReward feedback-locked theta (Reward-trial feedback-locked theta minus No-Reward-trial feedback-locked theta) following Good-Performance feedback.
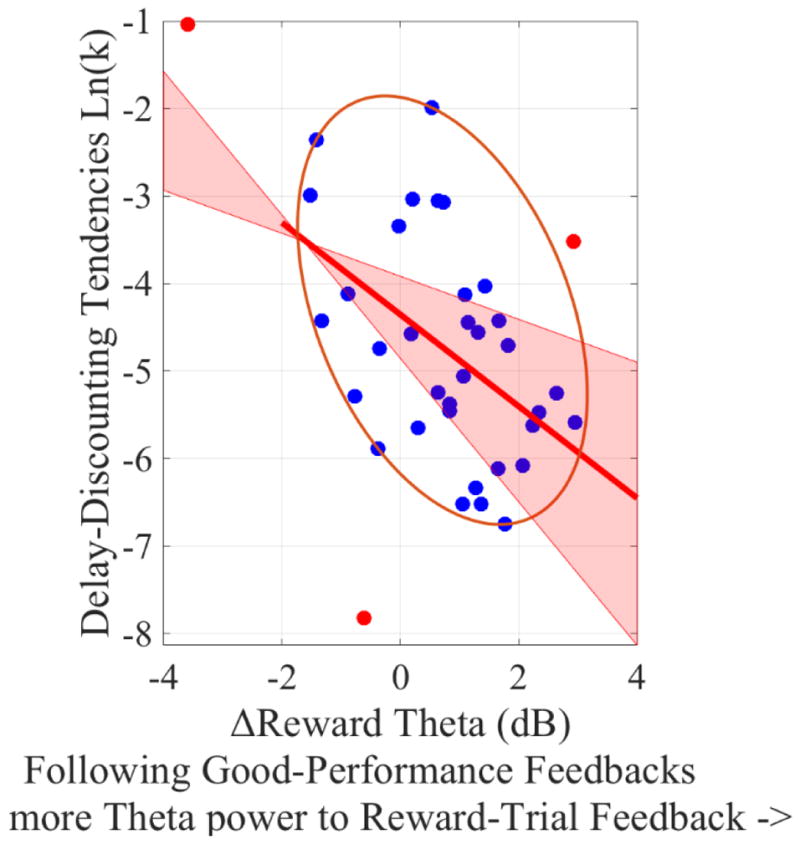
Note that, the more positive the ΔReward feedback-locked theta, the stronger the theta power during Reward trials (relative to No-Reward trials). Potentials bivariate outliers were detected using Minimum Covariance Determinant (MCD), and represented by red data points. Ellipse contains non-outlying data. Pink shaded areas represent 95% bootstrapped confident intervals around the linear regression line after the potential bivariate outliers were removed. The correlation coefficient was significant both before (r(35) = −.44, p=0.006) and after (r(32) = −.49, p=0.003) bivariate outliers removal. This suggests that the potential outliers did not drive the correlation.
3.5.3 Feedback-Locked Beta
Feedback-locked beta power (15–25 Hz) was reduced starting approximately 200 ms after feedback onset at parietal sites (see Figure 8a, 8c for ERSP power). This is similar to a pattern of beta desyncronization found in a recent time-estimation study (Luft, Nolte, et al., 2013). Significant main effects of both Reward Evaluation and Performance Evaluation on feedback-locked beta were found at approximately 400 – 600 ms following feedback onset (see Figure 8b for p values, FDR corrected). Specifically, for Reward Evaluation, feedback-locked beta was less reduced during Reward trials than No-Reward trials. Moreover, for Feedback Evaluation, feedback-locked beta was less reduced following Good-Performance feedback, compared to following Bad-Performance feedback. There was a trend for the Reward Evaluation by Performance Evaluation interaction, but this interaction did not survive FDR correction. Thus, we collapsed across Good-Performance and Bad-Performance feedback when employing feedback-locked beta as an index for individual differences in Reward Evaluation at this frequency band.
Similar to feedback-locked delta and theta, Motivated-Learning Inaccurate Estimation was negatively correlated with feedback-locked beta during Reward trials, and was marginally correlated with feedback-locked beta during No-Reward trials (see Table 1, Figure 8d). Nonetheless, neither ΔReward feedback-locked (Reward minus No-Reward-trial) beta or ΔPerformance feedback-locked (Bad- minus Good-Performance) beta was correlated with Motivated-Learning Inaccurate Estimation (see Table 1). Additionally, Control Inaccurate Estimation was not predicted by any feedback-locked beta indices (see Table 1). Similar to pre-feedback alpha, this suggests that a smaller reduction in feedback-locked beta was related to better adjustment of time-estimation performance (i.e., smaller Motivated-Learning Inaccurate Estimation). However, the relationship between feedback-locked beta and Motivated-Learning Inaccurate Estimation does not appear to be unique to Reward trials.
Similar to pre-feedback alpha and feedback-locked theta, there was a relationship between feedback-locked beta and delay-discounting tendencies (see Table 1). Specifically, Ln(k) was negatively correlated with feedback-locked beta during both Reward and No-Reward trials. Thus, participants with stronger (i.e., less of a reduction in) feedback-locked beta power had smaller k values (i.e., stronger preference toward larger-but-delayed rewards), regardless of whether it was a Reward-trial or No-Reward-trial feedback. Moreover, while the correlation coefficient between Ln(k) and ΔReward (Reward-trial minus No-Reward-trial) feedback-locked beta was not significant, r(35) = −.25, p = .13, the correlation became significant after one bivariate outlier was removed, r(34) = −.36, p = .03 (see Figure 12). We employed the Minimum Covariance Determinant (MCD) estimator (Rousseeuw & Driessen, 1999) to detect this bivariate outlier, using the Robust Correlation and LIBRA toolboxes in Matlab (Pernet, Wilcox, & Rousselet, 2012; Verboven & Hubert, 2005). This so-called skipped correlation method is a robust statistical for controlling for outliers while preserving statistical power compared to non-parametric statistics (Rousseeuw, 1984; Wilcox, 2012). Thus, participants with less of a reduction in feedback-locked beta power following Reward-trial, compared to No-Reward-trial, feedback (i.e., more positive ΔReward feedback-locked beta) had smaller k values. To investigate the specificity of this relationship, we removed the outlier and examined correlations between ln(k) and the ΔReward feedback-locked beta following Bad-Performance feedback separately from the ΔReward feedback-locked beta following Good-Performance feedback. Ln(k) was marginally correlated with the ΔReward feedback-locked beta following Good-Performance feedbacks, r(34) = −.30, p = .07, but not with the ΔReward feedback-locked beta following Bad-Performance feedbacks, r(34) = −.11, p = .53. Additionally, the correlation between ΔPerformance (Bad- minus Good-Performance) feedback-locked beta and ln(k) was not significant.
Figure 12. Scatterplot of the correlation between delay-discounting tendencies [ln(k)] the ΔReward feedback-locked beta (Reward-trial feedback-locked beta minus No-Reward-trial feedback-locked beta), collapsing across Bad- and Good-Performance feedbacks.

Note that, the more positive the ΔReward feedback-locked beta, the stronger the theta power during Reward trials (relative to No-Reward trials). Potentials bivariate outliers were detected using Minimum Covariance Determinant (MCD), and represented by red data points. Ellipses contain non-outlying data. Pink shaded areas represent 95% bootstrapped confident intervals around the linear regression line after the potential bivariate outliers were removed. While the Pearson zero-order correlation coefficient was not significant (r(35) = −.25, p=0.13), the correlation became significant after one bivariate outlier was removed (r(34) = −.36, p=0.03).
3.6 Delay-Discounting Responses as Predicted by Multiple Reward-Processing EEG Activity
Because multiple ΔReward (Reward- minus No-Reward-trial) EEG indices were correlated with ln(k), an additional multiple-regression analysis was used to assess for shared versus unique effects of these EEG indices (see Table 2). The ΔReward EEG indices included in this multiple-regression analysis were ΔReward pre-feedback alpha, ΔReward feedback-locked theta following Good-Performance feedback and ΔReward feedback-locked beta (collapsing across Bad- and Good-Performance feedback). First, we examined the correlations among these indices (see Table 3), and found that ΔReward pre-feedback alpha and ΔReward feedback-locked theta following Good-Performance feedback were correlated with each other. However, ΔReward feedback-locked beta was not correlated with either ΔReward pre-feedback alpha or ΔReward feedback-locked theta following Good-Performance feedback. Then, the three ΔReward EEG indices were entered as simultaneous predictors with ln(k), as a criterion. In this model, while ΔReward pre-feedback alpha was not significant, ΔReward feedback-locked theta following Good-Performance feedback was significant, and ΔReward feedback-locked beta was marginally significant (p = .06). Because ΔReward pre-feedback alpha and ΔReward feedback-locked theta following Good-Performance feedback were correlated with each other (but not with ΔReward feedback-locked beta), these two EEG indices may account for similar variance in ln(k). However, this variance in ln(k) was unique from that of ΔReward feedback-locked beta.
Table 2.
Multiple Regression Analyses for ΔReward (Reward-Trial minus No-Reward-Trial) EEG indices predicting ln(k)
| B | SE B | β | P | Tolerance | VIF | |
|---|---|---|---|---|---|---|
| Constant | −3.87 | .32 | <.001 | |||
| ΔReward pre-feedback alpha | .30 | .25 | .21 | .23 | .71 | 1.41 |
| ΔReward feedback-locked theta following Good-Performance feedback | −.37 | .18 | −.36 | .04 | .71 | 1.42 |
| ΔReward feedback-locked beta (collapsing across Bad- and Good-Performance feedback) | −.75 | .39 | −.28 | .06a | .99 | 1.01 |
Note. R2 = .31 (p = .006); Collinearity statistics (Tolerance and VIF) indicate that multicollinearity between the predictors was not a concern.
became significant (p = .03) after a bivariate outlier was removed (see Figure 12).
Table 3.
Zero-order correlations among ΔReward (Reward-Trial minus No-Reward-Trial) EEG indices that predicted ln(k)
| 1) | 2) | 3) | |
|---|---|---|---|
| 1) ΔReward pre-feedback alpha | - | −.54*** | .003 |
| 2) ΔReward feedback-locked theta following Good-Performance feedback | - | - | −.10 |
| 3) ΔReward feedback-locked beta (collapsing across Bad- and Good-Performance feedback) | - | - | - |
Note.
p < .001 (2-tailed).
4. Discussion
The current study tested the relationship between individual differences in delay-discounting tendencies and reward-processing at specific temporal stages. To operationalize individual differences in reward-processing, we examined EEG activity during a reward time estimation task. Our use of time- and frequency-specific EEG measures allowed us to separately investigate individual differences in reward-processing at the reward-anticipation stage (including, cued-locked delta during cue-evaluation and pre-feedback alpha suppression during feedback-anticipation) and at the reward-outcome stage (including, feedback-locked delta, theta and beta). All of our EEG indices were elevated during Reward, compared to No-Reward, trials. Moreover, these EEG indices significantly predicted behavioral performance during the time estimation task (reflected by smaller Motivated-Learning Inaccurate Estimation), highlighting their essential roles in modulating performance during motivated-learning situation.
4.1 Reward-Processing and Individual Differences in Delay-Discounting Responses
Overall, results supported our primary hypotheses regarding the relationship between enhanced reward-processing and a stronger preference toward larger-but-delayed, over smaller-but-immediate, rewards (i.e., smaller ln(k) or less delay-discounting). Behaviorally, people who were motivated to learn through feedback over the course of the experiment (reflected by having smaller Motivated-Learning Inaccurate Estimation) had a stronger preference toward larger-but-delayed. Neurally, people whose EEG activity was particularly enhanced during Reward trial at various stages (reflected by having stronger pre-feedback alpha-suppression during feedback-anticipation in the reward-anticipation stage, and stronger feedback-locked theta and beta during the reward-outcome stage) also expressed a stronger preference toward larger-but-delayed rewards. More specifically, from multiple-regression results, it appears that two sets of EEG indices (pre-feedback alpha-suppression and feedback-locked theta vs. feedback-locked beta) independently modulate individual differences in delay-discounting responses. This suggests that different neural-cognitive mechanisms during reward processing are related to delay-discounting tendencies.
The observed bias toward larger-but-delayed rewards among individuals with elevated reward-processing is consistent with a number of previous studies (although see Hariri et al., 2006 for contradictory finding). First, a recent fMRI study reported a bias toward larger-but-delayed rewards among adolescents with elevated ventral striatal (VS) activation during reward anticipation using the MID task (Benningfield et al., 2014). Other fMRI studies have also found a relationship between elevated activation in the VS and other reward-related areas, such as the lateral orbitofrontal cortex (L-OFC), and a stronger preference toward larger-but-delayed rewards (Ballard & Knutson, 2009; Boettiger et al., 2007; Samanez-Larkin et al., 2011). Second, animal research has shown that lesions to the VS, resulting in reduced reward-related neural activation, leads to a preference for smaller-but-immediate rewards (Cardinal et al., 2001). Third, psychiatric and health-related research has shown that dampened reward sensitivity and reduced reward-related brain function is a risk factor for high-risk and poor health related behaviors (P. M. Johnson & Kenny, 2010; Stice, Spoor, Bohon, & Small, 2008). These data have been conceptualized within the Reward Deficiency Model of addiction, which proposes that persons with low reward sensitivity self-medicate negative emotions and/or attempt to elevate positive emotions through pursuing high-risk, short-term rewards (e.g., drugs, alcohol, high-fat diets) (Blum et al., 2000; Volkow, Wang, Fowler, Tomasi, & Baler, 2012). The logic of the Reward Deficiency Model is consistent with our results given that participants with reduced reward-related EEG activity in the present study had a stronger preference for smaller-but-immediate rewards. Additionally, individuals with the Met-allele of the COMT-gene, which has been associated with elevated reward-related brain function (Chen et al., 2004; Yacubian et al., 2007), show a preference for larger-but-delayed reward (Boettiger et al., 2007; Gianotti et al., 2012; Smith & Boettiger, 2012; Yacubian et al., 2007). Similarly, a recent study also found a stronger preference toward larger-but-delayed rewards as a result of medications designed to increase dopamine signaling in patients with Parkinson’s disease (Foerde et al., 2016). Thus, combined with results from the present study, we argue that there is growing evidence that elevated reward-processing is associated with a higher propensity to forgo smaller-but-immediate rewards, in favor of larger-but-delayed rewards.
4.2 EEG Indices at Each Stage of Reward-Processing
Our use of EEG extends previous fMRI findings (Benningfield et al., 2014) by providing a more time-sensitive index of reward-related neural activity, allowing us to demonstrate the nature of the relationship between delay-discounting and reward-processing at specific temporal stages (e.g., during feedback-anticipation and reward outcome, but not cue-evaluation). Owing to the time-frequency decomposition of the EEG data, we also were able to show that these relationships were quite sensitive to specific neural frequency bands (e.g., theta, alpha and beta, but not delta).
4.2.1 Pre-Feedback Alpha-Suppression during the Reward Time Estimation Task
With respect to feedback-anticipation EEG activity, we found a clear pattern of pre-feedback occipital alpha suppression peaking right before feedback onset. This pattern is consistent with previous reports suggesting that occipital alpha suppression prior to upcoming visual stimuli indexes anticipatory processes (Bastiaansen et al., 1999; Hughes et al., 2013; Pfurtscheller & Aranibar, 1977). Also consistent with previous research (Hanslmayr et al., 2007; Hughes et al., 2013; B. van den Berg et al., 2014), occipital alpha suppression was modulated by reward condition, as we observed greater alpha suppression during Reward, compared to No-Reward, trials.3 These findings are in line with the recent perspective that occipital alpha suppression indexes enhanced attentional processes during the anticipation of reward-related stimuli/feedback, and that this enhanced attentional processing is associated with individual differences in reward-processing (B. van den Berg et al., 2014). Moreover, our study is among the first to demonstrate that pre-feedback alpha suppression predicts enhanced motivated-learning during a reward task (reflected by smaller Motivated-Learning Inaccurate Estimation). This suggests enhanced attentional processing prior to feedback facilitates learning and behavioral adjustment to maximize rewards.
4.2.2 Pre-Feedback Alpha-Suppression and Delay-Discounting Responses
Most importantly, however, is the fact that stronger occipital alpha suppression, reflecting elevated feedback-anticipation neural activity was associated with a greater preference toward larger-but-delayed rewards during the delay-discounting task. Given the temporal and frequency precision afforded by our EEG time-estimation paradigm, we were able to dissociate neural activity during reward feedback-anticipation from other reward-anticipation processes (e.g., cue-evaluation and motor-preparation). This degree of temporal precision is not feasible with fMRI studies of reward processing using paradigms such as the MID task (Benningfield et al., 2014), given the slow dynamics of the fMRI BOLD signal. We argue that the neurophysiological index of reward-anticipation neural activity related to delay-discounting responses in the present study (i.e., occipital alpha suppression) reflects the dis-inhibition of neural activity in sensory cortices that facilitate anticipatory attention to reward-related feedbacks (Hughes et al., 2013; Jensen & Mazaheri, 2010; B. van den Berg et al., 2014). Future research with alpha-suppression prior to feedback onset will have important implications for unpacking the nuances of reward-anticipation, particularly when aiming to control for other relevant processes, such as reward cue-evaluation or motor-preparation.
4.2.3 Reward-Outcome EEG Activity
With respect to reward-outcome EEG activity during the reward time-estimation task, we found that EEG activity in two frequency bands (feedback-locked theta and beta) were associated with individual differences in delay-discounting. Importantly, our study is among the first to separate the influence of reward-evaluation from performance-evaluation on individual differences in reward-outcome EEG activity (Leicht et al., 2013). Most studies of individual-differences of reward-outcome EEG data collapse across these two factors (e.g., Bress & Hajcak, 2013; Bress, Smith, Foti, Klein, & Hajcak, 2012; Foti & Hajcak, 2009; I. Van den Berg, Franken, & Muris, 2011). For instance, in several studies, good-performance feedback also indicates the wining of a monetary reward, while bad-performance feedback implies no-wining/losing of monetary reward. This makes it difficult to dissociate whether individual differences in outcome EEG data are driven by variability in reward-feedback evaluation, performance-feedback evaluation, or some combination of the two (Luft, 2014).
4.2.4 Feedback-Locked Theta during the Reward Time Estimation Task
For feedback-locked theta, our findings are in line with previous research suggesting that feedback-locked theta is sensitive to both reward- (Leicht et al., 2013) and performance- (Cohen et al., 2007; Luft, 2014) evaluation. Specifically, for reward evaluation, we observed greater feedback-locked theta during Reward trials (compared to No-Reward trials). For performance evaluation, greater feedback-locked theta was found in response to Bad-Performance (compared to Good-Performance) feedback. These two main effects were independent of each other given the absence of a reward-by-performance evaluation interaction. Consistent with previous studies, feedback-locked theta predicted behavioral performance in our reward-learning task (Cavanagh & Shackman, 2015; van de Vijver et al., 2011). This confirms the role of feedback-locked theta in cognitive-control processes that incorporate feedback/outcome information (Luft, 2014). More importantly, by separating reward from performance evaluation, we demonstrated for the first time that reward evaluation (i.e., ΔReward feedback-locked theta), but not performance evaluation (i.e., ΔPerformance feedback-locked theta) predicted enhanced motivated-learning during a reward task (reflected by smaller Motivated-Learning Inaccurate Estimation). This suggests that the enhancement of cognitive-control during Reward (compared to No-Reward) trials facilitates one’s ability to learn through feedback in a reward situation to maximize reward receipt.
4.2.5 Feedback-Locked Theta and Delay-Discounting Responses
Similarly, reward evaluation (but not performance evaluation) of feedback-locked theta predicted a greater preference to larger-but-delayed rewards. This may indicate that enhanced cognitive-control processes during Reward trials (reflected by reward evaluation), as opposed to prediction error or uncertainty resolution (reflected by performance evaluation), drove the relationship between reward-processing and delay-discounting responses. Moreover, subsequent analyses indicated that the relationship between ΔReward feedback-locked theta and delay-discounting responses was primarily driven by ΔReward feedback-locked to Good-Performance, but not Bad-Performance, feedback. This suggests that a preference toward larger-but-delayed rewards is particularly related to theta activity in the gain, but not the no-gain, domain, highlighting the fact that this relationship is specific to a reward-processing context.
4.2.6 Feedback-Locked Beta during the Reward Time Estimation Task
As for feedback-locked beta, our findings are consistent with studies showing stronger beta power (less reduction/desyncronization) to positive (compared to negative) feedbacks (for review, see Luft, 2014). By separating reward from performance evaluation, we extend previous research on feedback-locked beta power by showing the effect of both reward (stronger during Reward trials) and performance (stronger to Good-Performance feedback) evaluation. Additionally, greater enhancement of feedback-locked beta predicted enhanced motivated-learning during a reward task, replicating a previous time-estimation study (Luft, Nolte, et al., 2013). Altogether, this pattern of feedback-locked beta is in line with the interpretation of this EEG index as a reward-specific signal (Cohen et al., 2007; De Pascalis et al., 2012; HajiHosseini et al., 2012; Marco-Pallares et al., 2008; Marco-Pallarés et al., 2009).
4.2.7 Feedback-Locked Beta and Delay-Discounting Responses
Relating to our main focus on delay discounting, we demonstrate for the first time that reward evaluation (but not performance evaluation) of feedback-locked beta predicted a greater preference to larger-but-delayed rewards. This suggests that individual differences in delay-discounting may be related to the motivational saliency of the feedback (i.e., during Reward trials) as opposed to the positive behavioral performance signal from the feedback (i.e., a Good-Performance feedback).
4.2.8 Cue-Locked and Feedback-Locked Delta during the Reward Time Estimation Task
Although cue-locked delta and feedback-locked delta did not predict delay-discounting tendencies, the present study provides additional insight into to their roles in reward-processing. During cue-evaluation in the reward-anticipation stage, cue-locked delta was stronger in Reward, compared to No-Reward, trials. This pattern is consistent with previous research focusing on a P3 component elicited by reward-related cues at similar time and topography (Broyd et al., 2012; Goldstein et al., 2006; Ramsey & Finn, 1997; Santesso et al., 2012). In line with a recent reinforcement study (Cavanagh, 2015), cue-locked delta predicted enhanced motivated-learning in our reward task (reflected by smaller Motivated-Learning Inaccurate Estimation). More importantly, motivated-learning was predicted by cue-locked delta power to the Reward cue (i.e., ΔReward cue-locked delta), suggesting an essential role of cue-locked delta in reward-processing, not just cue-evaluation in general. As for feedback-locked delta during the reward-outcome stage, similar to feedback-locked beta, we found an effect of both reward evaluation (stronger during Reward trials) and performance evaluation (stronger to Good-Performance feedbacks). This extends previous research that collapsed the two evaluation types together (Cavanagh, 2015; Foti et al., 2015; Leicht et al., 2013). More specifically, reward evaluation (ΔReward feedback-locked delta) of feedback-locked delta (not performance evaluation) predicted motivated-learning during the reward time-estimation task. This suggests that higher sensitivity to the motivational saliency of the feedback (reflected by stronger ΔReward feedback-locked detla) facilitates one’s ability to learn through feedback and adjust their performance to maximize gains. Taken together with other EEG indices, our study provides a comprehensive overview of reward-processing neural activity across specific temporal stages.
4.2.9 Relationship Among Reward-Processing ERSP indices
We also report, for the first time, a relationship between reward-processing during feedback-anticipation (ΔReward pre-feedback alpha) and during reward-outcome (ΔReward feedback-locked theta following Good-Performance feedback) (see Table 3). ΔReward pre-feedback alpha, however, did not correlate with ΔReward feedback-locked beta. This suggests that enhanced attentional processes prior to feedback (pre-feedback alpha suppression) was specifically related to enhanced cognitive-control processes during evaluation of reward-outcome (feedback-locked theta).
4.3 Limitations
This study is not without its limitations. First, similar to previous fMRI research on delay discounting and reward-related neural activity (Benningfield et al., 2014), our reward task did not include a punishment condition. Given that our focus was on individual differences in reward-processing, we were concerned that adding a punishment condition would unnecessarily lengthen the task. Task length is an important issue given fatigue has been shown to attenuate reward-related EEG data (Boksem & Tops, 2008). Future research involving a punishment condition is needed to examine whether the relationship between delay discounting and reward-related neural activity is primarily driven by a sensitivity to rewarding stimuli, or by a more general sensitivity to arousing or motivationally salient stimuli. Second, using undergraduate students may restrict the range of individual differences in impulsivity compared to other populations (Henrich, Heine, & Norenzayan, 2010). This is important, given that individual differences in impulsivity are associated with delay-discounting as well as reward-processing (e.g., Bjork, Knutson, & Hommer, 2008; Hahn et al., 2009; for a review see Plichta & Scheres, 2014). Future research may employ other populations to further investigate whether the relationship between reward-related EEG activity and delay-discounting manifests differently among individuals with high (e.g., hypomania) or low (e.g., depression) in impulsivity.
An important future direction is to examine the relationship between individual differences in reward-processing EEG activity at specific temporal stages to personality indices of reward sensitivity more generally. One of the most wildly used personality theories of reward-sensitivity is Gray’s biopsychological theory of personality (Gray, 1987, 1989). In particular, Gray proposed that the behavioral activation system (BAS) underlies individual differences in appetitive motivation. Later personality researchers have separated the BAS into three subtypes: BAS Drive, Fun Seeking and Reward Responsiveness (Carver & White, 1994). The main difference between Gray’s BAS reward-sensitivity and reward-processing used in the current study is that Gray did not separate BAS into temporal reward-processing stages as is common in contemporary neuroscientific theories (Berridge, 1996; McClure et al., 2004; Schultz et al., 2000; Wise, 2008). Accordingly, it is unclear how Gray’s theory and the three proposed BAS subtypes map onto individual differences in reward-processing across each specific temporal stage of reward processing. Future research is needed to examine these relationships. Additionally, the time-estimation reward task used in the present study only provides immediate rewards, and does not provide delayed rewards. The delay-discounting task, by contrast, involves both immediate and delayed reward choices. Accordingly, we were only able to investigate the relationship between delay-discounting responses and neural activity to immediate-reward stimuli. Future research may wish to vary whether rewards are delivered immediately or following a delay, as in previous research (Cherniawsky & Holroyd, 2013). Similarly, while the delay-discounting task in the present study employed hypothetical monetary rewards, the time-estimation reward task employed real monetary rewards. Although previous studies suggest a similarity between hypothetical and real monetary rewards in the delay-discounting task (M. W. Johnson & Bickel, 2002; Lagorio & Madden, 2005), future research should employ real monetary rewards in both tasks to test the generalizability of our findings.
5. Conclusions
In conclusion, one of the multiple factors that may modulate individual differences in delay-discounting responses is reward-processing. To comprehensively study individual differences in reward-processing, however, one needs to consider its heterogeneity in temporal dynamics. Here using EEG, we were able to separate reward-processing neural activity at each temporal stage into different indices based on time and frequency dimensions. In line with recent research (Benningfield et al., 2014; Boettiger et al., 2007; Foerde et al., 2016), we found that a stronger preference toward larger-but-delayed rewards was associated with enhanced reward-related neural activity at specific stages of reward-processing. Our findings not only substantiates the association between individual differences in delay-discounting responses and reward-processing, but also provides specific details about which stages of reward-processing are driving these associations.
Highlights.
We tested the relationship between reward-processing and delay-discounting responses.
Enhanced reward-anticipation and -outcome EEGs predicted larger-but-delayed choices.
Reward-anticipation EEG refers to pre-feedback occipital alpha-suppression.
Reward-outcome EEG refers to post-feedback frontal-midline theta and parietal beta.
Hence, enhanced reward-processing was related to delay-gratification.
Acknowledgments
This work was supported by NIH grant T32 NS047987 and Graduate Research Grant from The Graduate School, Northwestern University to NP. RN’s contribution to this work was supported by National Institute of Mental Health (NIMH) grant R01 MH100117-01 and R01 MH077908-01A1, as well as a Young Investigator Grant from the Ryan Licht Sang Bipolar Foundation and the Chauncey and Marion D. McCormick Family Foundation. The authors thank Xiaoqing Hu, J. Peter Rosenfeld and Ken Paller for helpful discussion, Sam Reznik, Daniel O’Leary, Storm Heidinger, Michelle Thai, Jonathan Yu and Ajay Nadig for assisting with data collection.
Abbreviations
- ANOVA
analysis of variance
- COMT gene
Catechol-O-methyltransferase gene
- EEG
electroencephalogram
- ERSP
event-related spectral perturbation
- FDR
false discovery rate
- fMRI
functional magnetic resonance imaging
- FMT
frontal-midline theta
- FRN
feedback-related negativity
- HEOG
horizontal electrooculography
- IQR
inter-quartile range
- ITI
inter-trial interval
- L-OFC
left orbitofrontal cortex
- MID task
Monetary Incentive Delay task
- PCA
principle component analysis
- VEOG
vertical electrooculography
- VS
ventral striatum
Footnotes
The relationship between elevated reward-processing and a stronger preference for larger-but-delayed rewards does not necessarily support or contradict one of the most cited theories in delay-discounting, called “the visceral factor perspective” by Loewenstein and colleagues (Frederick et al., 2003; Loewenstein, 1996, 2000). Loewenstein and colleagues proposed that visceral factors, or drive states (such as, hunger, thirst, emotions, moods, craving for drugs, etc.), may explain intra-individual variability in delay-discounting. These visceral factors are endogenous, and can be changed from moment to moment depending on one’s drive state (e.g., hunger level depending on how long ago a person ate food). To support his theory, Loewenstein (1996) highlights research by Mischel and colleagues (Mischel, 1974; Mischel, Shoda, & Rodriguez, 1989) showing that children prefer a smaller-but-immediate reward if the reward object (e.g., marshmallow) is placed in front of them. But children would prefer a larger-but-delayed reward if they see a photograph of the delayed reward object. Loewenstein (1996) interpreted these findings as suggesting that having the reward object in front of you enhances the drive state for the immediate rewards, and seeing the photograph of the delayed reward object enhances drive states for the delayed reward. The focus in the current study, however, is inter-individual relationships between reward-processing and delay-discounting. This is reflecdted in the use of separate reward-processing and delay-discounting tasks, and the fact that we did not manipulate the visceral factors of our delay-discounting task (see Methods).
There are difficulties in interpreting results regarding individual differences from studies that investigated the association between reward-related neural activation and delay-discounting tendencies within the same delay-discounting task (e.g., Ballard & Knutson, 2009; Boettiger et al., 2007). As argued by Benningfield and colleagues (2014), reward-related neural activation in the context of a delay-discounting task is already arbitrarily reduced due to the presence of the delay, and hence should not be used as an individual-difference index for reward-processing. Accordingly, we employed two separate tasks to examine the relationship between reward-related neural activity and delay discounting tendencies.
Based on our design, we argue that stronger alpha-suppression during Reward (compared to No-Reward) trials was driven by the motivationally salient aspects (as opposed to uncertainty aspect) of the upcoming feedback in the Reward trials. Unlike previous studies that manipulated uncertainty and found the modulation of uncertainty on a stimulus-preceding negativity (SPN) ERP component (Catena et al., 2012; Morís, Luque, & Rodríguez-Fornells, 2013), our study controlled for uncertainty. That is, for both Reward and No-Reward trials, the only source of uncertainty during feedback-anticipation facing participants was whether their recent performance would be considered good or bad. Because of our adaptation method, the accuracy rates during Reward trials (M = 52.42%, SD = 5.23) and No-Reward trials (M = 48.07%, SD = 4.75) were closely matched at 50% chance. Hence, the uncertainty between the two reward conditions was controlled at around a chance level. This means that once a participant pressed the time-estimation button, it was equally likely for them to see bad- versus good-performance feedback during both Reward and No-Reward trials. The bad and good-performance feedback, however, were more meaningful and motivationally salient during Reward trials than No-Reward trials, given that performance information during Reward trials indicated monetary-reward earnings.
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- Ahn WY, Rass O, Fridberg DJ, Bishara AJ, Forsyth JK, Breier A, … O’Donnell BF. Temporal discounting of rewards in patients with bipolar disorder and schizophrenia. Journal of Abnormal Psychology. 2011;120(4):911–921. doi: 10.1037/a0023333. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ainslie G. Specious reward: A behavioral theory of impulsiveness and impulse control. Psychological Bulletin. 1975;82(4):463–496. doi: 10.1037/h0076860. [DOI] [PubMed] [Google Scholar]
- Ballard K, Knutson B. Dissociable neural representations of future reward magnitude and delay during temporal discounting. Neuroimage. 2009;45(1):143–150. doi: 10.1016/j.neuroimage.2008.11.004. http://dx.doi.org/10.1016/j.neuroimage.2008.11.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bastiaansen MCM, Böcker KBE, Brunia CHM. ERD as an index of anticipatory attention? Effects of stimulus degradation. Psychophysiology. 2002;39(1):16–28. doi: 10.1111/1469-8986.3910016. [DOI] [PubMed] [Google Scholar]
- Bastiaansen MCM, Böcker KBE, Cluitmans PJM, Brunia CHM. Event-related desynchronization related to the anticipation of a stimulus providing knowledge of results. Clinical Neurophysiology. 1999;110(2):250–260. doi: 10.1016/s0013-4694(98)00122-9. http://dx.doi.org/10.1016/S0013-4694(98)00122-9. [DOI] [PubMed] [Google Scholar]
- Bastiaansen MCM, Brunia CHM. Anticipatory attention: an event-related desynchronization approach. International Journal of Psychophysiology. 2001;43(1):91–107. doi: 10.1016/s0167-8760(01)00181-7. http://dx.doi.org/10.1016/S0167-8760(01)00181-7. [DOI] [PubMed] [Google Scholar]
- Benjamini Y, Yekutieli D. The control of the false discovery rate in multiple testing under dependency. Annals of Statistics. 2001;29(4):1165–1188. doi: 10.1214/aos/1013699998. [DOI] [Google Scholar]
- Benningfield MM, Blackford JU, Ellsworth ME, Samanez-Larkin GR, Martin PR, Cowan RL, Zald DH. Caudate responses to reward anticipation associated with delay discounting behavior in healthy youth. Developmental Cognitive Neuroscience. 2014;7(0):43–52. doi: 10.1016/j.dcn.2013.10.009. http://dx.doi.org/10.1016/j.dcn.2013.10.009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Berke JD. Fast oscillations in cortical-striatal networks switch frequency following rewarding events and stimulant drugs. European Journal of Neuroscience. 2009;30(5):848–859. doi: 10.1111/j.1460-9568.2009.06843.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Berridge KC. Food reward: Brain substrates of wanting and liking. Neuroscience & Biobehavioral Reviews. 1996;20(1):1–25. doi: 10.1016/0149-7634(95)00033-b. http://dx.doi.org/10.1016/0149-7634(95)00033-B. [DOI] [PubMed] [Google Scholar]
- Bjork JM, Knutson B, Hommer DW. Incentive-elicited striatal activation in adolescent children of alcoholics. Addiction. 2008;103(8):1308–1319. doi: 10.1111/j.1360-0443.2008.02250.x. [DOI] [PubMed] [Google Scholar]
- Blum K, Braverman ER, Holder JM, Lubar JF, Monastra VJ, Miller D, … Comings DE. The Reward Deficiency Syndrome: A Biogenetic Model for the Diagnosis and Treatment of Impulsive, Addictive and Compulsive Behaviors. Journal of Psychoactive Drugs. 2000;32(sup1):1–112. doi: 10.1080/02791072.2000.10736099. [DOI] [PubMed] [Google Scholar]
- Boettiger CA, Mitchell JM, Tavares VC, Robertson M, Joslyn G, D’Esposito M, Fields HL. Immediate Reward Bias in Humans: Fronto-Parietal Networks and a Role for the Catechol-O-Methyltransferase 158Val/Val Genotype. The Journal of Neuroscience. 2007;27(52):14383–14391. doi: 10.1523/jneurosci.2551-07.2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Boksem MAS, Tops M. Mental fatigue: Costs and benefits. Brain Research Reviews. 2008;59(1):125–139. doi: 10.1016/j.brainresrev.2008.07.001. http://dx.doi.org/10.1016/j.brainresrev.2008.07.001. [DOI] [PubMed] [Google Scholar]
- Bress JN, Hajcak G. Self-report and behavioral measures of reward sensitivity predict the feedback negativity. Psychophysiology. 2013;50(7):610–616. doi: 10.1111/psyp.12053. [DOI] [PubMed] [Google Scholar]
- Bress JN, Smith E, Foti D, Klein DN, Hajcak G. Neural response to reward and depressive symptoms in late childhood to early adolescence. Biological Psychology. 2012;89(1):156–162. doi: 10.1016/j.biopsycho.2011.10.004. http://dx.doi.org/10.1016/j.biopsycho.2011.10.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Broyd SJ, Richards HJ, Helps SK, Chronaki G, Bamford S, Sonuga-Barke EJS. An electrophysiological monetary incentive delay (e-MID) task: A way to decompose the different components of neural response to positive and negative monetary reinforcement. Journal of Neuroscience Methods. 2012;209(1):40–49. doi: 10.1016/j.jneumeth.2012.05.015. http://dx.doi.org/10.1016/j.jneumeth.2012.05.015. [DOI] [PubMed] [Google Scholar]
- Brunia CHM, Hackley SA, van Boxtel GJ, Kotani Y, Ohgami Y. Waiting to perceive: reward or punishment? Clinical Neurophysiology. 2011;122(5):858–868. doi: 10.1016/j.clinph.2010.12.039. [DOI] [PubMed] [Google Scholar]
- Cardinal RN, Pennicott DR, Lakmali C, Sugathapala, Robbins TW, Everitt BJ. Impulsive Choice Induced in Rats by Lesions of the Nucleus Accumbens Core. Science. 2001;292(5526):2499–2501. doi: 10.1126/science.1060818. [DOI] [PubMed] [Google Scholar]
- Carver CS, White TL. Behavioral inhibition, behavioral activation, and affective responses to impending reward and punishment: The BIS/BAS Scales. Journal of Personality and Social Psychology. 1994;67(2):319–333. doi: 10.1037/0022-3514.67.2.319. [DOI] [Google Scholar]
- Catena A, Perales JC, MegÌas A, Cándido A, Jara E, Maldonado A. The Brain Network of Expectancy and Uncertainty Processing. PLoS ONE. 2012;7(7):e40252. doi: 10.1371/journal.pone.0040252. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cavanagh JF. Cortical delta activity reflects reward prediction error and related behavioral adjustments, but at different times. Neuroimage. 2015;110:205–216. doi: 10.1016/j.neuroimage.2015.02.007. [DOI] [PubMed] [Google Scholar]
- Cavanagh JF, Frank MJ. Frontal theta as a mechanism for cognitive control. Trends in Cognitive Sciences. 2014;18(8):414–421. doi: 10.1016/j.tics.2014.04.012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cavanagh JF, Shackman AJ. Frontal midline theta reflects anxiety and cognitive control: meta-analytic evidence. Journal of Physiology - Paris. 2015;109(1–3):3–15. doi: 10.1016/j.jphysparis.2014.04.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cavanagh JF, Zambrano-Vazquez L, Allen JJ. Theta lingua franca: a common mid-frontal substrate for action monitoring processes. Psychophysiology. 2012;49(2):220–238. doi: 10.1111/j.1469-8986.2011.01293.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chapman LJ, Chapman JP. The measurement of handedness. Brain and Cognition. 1987;6(2):175–183. doi: 10.1016/0278-2626(87)90118-7. http://dx.doi.org/10.1016/0278-2626(87)90118-7. [DOI] [PubMed] [Google Scholar]
- Chen J, Lipska BK, Halim N, Ma QD, Matsumoto M, Melhem S, … Weinberger DR. Functional Analysis of Genetic Variation in Catechol-O-Methyltransferase (COMT): Effects on mRNA, Protein, and Enzyme Activity in Postmortem Human Brain. The American Journal of Human Genetics. 2004;75(5):807–821. doi: 10.1086/425589. http://dx.doi.org/10.1086/425589. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cherniawsky A, Holroyd C. High temporal discounters overvalue immediate rewards rather than undervalue future rewards: An event-related brain potential study. Cognitive, Affective, & Behavioral Neuroscience. 2013;13(1):36–45. doi: 10.3758/s13415-012-0122-x. [DOI] [PubMed] [Google Scholar]
- Civai C, Hawes DR, DeYoung CG, Rustichini A. Intelligence and Extraversion in the neural evaluation of delayed rewards. Journal of Research in Personality. 2016;61:99–108. http://dx.doi.org/10.1016/j.jrp.2016.02.006. [Google Scholar]
- Cohen MX. Analyzing neural time series data: theory and practice. MIT Press; 2014. [Google Scholar]
- Cohen MX, Elger CE, Ranganath C. Reward expectation modulates feedback-related negativity and EEG spectra. Neuroimage. 2007;35(2):968–978. doi: 10.1016/j.neuroimage.2006.11.056. http://dx.doi.org/10.1016/j.neuroimage.2006.11.056. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cohen MX, Wilmes KA, van de Vijver I. Cortical electrophysiological network dynamics of feedback learning. Trends in Cognitive Sciences. 2011;15(12):558–566. doi: 10.1016/j.tics.2011.10.004. http://dx.doi.org/10.1016/j.tics.2011.10.004. [DOI] [PubMed] [Google Scholar]
- Courtemanche R, Fujii N, Graybiel AM. Synchronous, Focally Modulated β-Band Oscillations Characterize Local Field Potential Activity in the Striatum of Awake Behaving Monkeys. The Journal of Neuroscience. 2003;23(37):11741–11752. doi: 10.1523/JNEUROSCI.23-37-11741.2003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Damen EJP, Brunia CHM. Changes in Heart Rate and Slow Brain Potentials Related to Motor Preparation and Stimulus Anticipation in a Time Estimation Task. Psychophysiology. 1987;24(6):700–713. doi: 10.1111/j.1469-8986.1987.tb00353.x. [DOI] [PubMed] [Google Scholar]
- De Pascalis V, Varriale V, Rotonda M. EEG oscillatory activity associated to monetary gain and loss signals in a learning task: effects of attentional impulsivity and learning ability. International journal of psychophysiology : official journal of the International Organization of Psychophysiology. 2012;85(1):68–78. doi: 10.1016/j.ijpsycho.2011.06.005. [DOI] [PubMed] [Google Scholar]
- de Wit H, Flory JD, Acheson A, McCloskey M, Manuck SB. IQ and nonplanning impulsivity are independently associated with delay discounting in middle-aged adults. Personality and Individual Differences. 2007;42(1):111–121. doi: 10.1016/j.paid.2006.06.026. [DOI] [Google Scholar]
- Delorme A, Makeig S. EEGLAB: an open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. Journal of Neuroscience Methods. 2004;134(1):9–21. doi: 10.1016/j.jneumeth.2003.10.009. http://dx.doi.org/10.1016/j.jneumeth.2003.10.009. [DOI] [PubMed] [Google Scholar]
- Du WJ, Green L, Myerson J. Cross-cultural comparisons of discounting delayed and probabilistic rewards. Psychological Record. 2002;52(4):479–492. [Google Scholar]
- Foerde K, Figner B, Doll BB, Woyke IC, Braun EK, Weber EU, Shohamy D. Dopamine Modulation of Intertemporal Decision-making: Evidence from Parkinson Disease. Journal of Cognitive Neuroscience. 2016;28(5):657–667. doi: 10.1162/jocn_a_00929. [DOI] [PubMed] [Google Scholar]
- Foti D, Hajcak G. Depression and reduced sensitivity to non-rewards versus rewards: Evidence from event-related potentials. Biological Psychology. 2009;81(1):1–8. doi: 10.1016/j.biopsycho.2008.12.004. http://dx.doi.org/10.1016/j.biopsycho.2008.12.004. [DOI] [PubMed] [Google Scholar]
- Foti D, Weinberg A, Bernat EM, Proudfit GH. Anterior cingulate activity to monetary loss and basal ganglia activity to monetary gain uniquely contribute to the feedback negativity. Clinical Neurophysiology. 2015;126(7):1338–1347. doi: 10.1016/j.clinph.2014.08.025. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Frederick S, Loewenstein G, O’Donoghue T. Time discounting and time preference: A critical review. In: Loewenstein G, Read D, Baumeister R, editors. Time and decision: Economic and psychological perspectives on intertemporal choice. New York, NY: Russell Sage Foundation; 2003. pp. 13–86.pp. xiiipp. 569 [Google Scholar]
- Gianotti LRR, Figner B, Ebstein RP, Knoch D. Why some people discount more than others: Baseline activation in the dorsal PFC mediates the link between COMT genotype and impatient choice. Frontiers in Neuroscience. 2012:6. doi: 10.3389/fnins.2012.00054. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Goldstein RZ, Cottone LA, Jia Z, Maloney T, Volkow ND, Squires NK. The effect of graded monetary reward on cognitive event-related potentials and behavior in young healthy adults. International Journal of Psychophysiology. 2006;62(2):272–279. doi: 10.1016/j.ijpsycho.2006.05.006. http://dx.doi.org/10.1016/j.ijpsycho.2006.05.006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gray JA. The neuropsychology of emotion and personality. In: Stahl SM, Iversen SD, Goodman EC, editors. Cognitive neurochemistry. New York, NY: Oxford University Press; 1987. pp. 171–190. [Google Scholar]
- Gray JA. Fundamental systems of emotion in the mammalian brain. In: Palermo DS, editor. The Penn State series on child & adolescent development. Hillsdale, NJ, England: Lawrence Erlbaum Associates Inc; 1989. pp. 173–195. [Google Scholar]
- Green L, Myerson J. A Discounting Framework for Choice With Delayed and Probabilistic Rewards. Psychological Bulletin. 2004;130(5):769–792. doi: 10.1037/0033-2909.130.5.769. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hahn T, Dresler T, Ehlis AC, Plichta MM, Heinzel S, Polak T, … Fallgatter AJ. Neural response to reward anticipation is modulated by Gray’s impulsivity. Neuroimage. 2009;46(4):1148–1153. doi: 10.1016/j.neuroimage.2009.03.038. http://dx.doi.org/10.1016/j.neuroimage.2009.03.038. [DOI] [PubMed] [Google Scholar]
- HajiHosseini A, Rodríguez-Fornells A, Marco-Pallarés J. The role of beta-gamma oscillations in unexpected rewards processing. Neuroimage. 2012;60(3):1678–1685. doi: 10.1016/j.neuroimage.2012.01.125. http://dx.doi.org/10.1016/j.neuroimage.2012.01.125. [DOI] [PubMed] [Google Scholar]
- Hanslmayr S, Aslan A, Staudigl T, Klimesch W, Herrmann CS, Bäuml KH. Prestimulus oscillations predict visual perception performance between and within subjects. Neuroimage. 2007;37(4):1465–1473. doi: 10.1016/j.neuroimage.2007.07.011. http://dx.doi.org/10.1016/j.neuroimage.2007.07.011. [DOI] [PubMed] [Google Scholar]
- Hariri AR, Brown SM, Williamson DE, Flory JD, de Wit H, Manuck SB. Preference for Immediate over Delayed Rewards Is Associated with Magnitude of Ventral Striatal Activity. The Journal of Neuroscience. 2006;26(51):13213–13217. doi: 10.1523/jneurosci.3446-06.2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Henrich J, Heine SJ, Norenzayan A. The weirdest people in the world? Behavioral and Brain Sciences. 2010;33(2–3):61–83. doi: 10.1017/s0140525x0999152x. [DOI] [PubMed] [Google Scholar]
- Hirsh JB, Morisano D, Peterson JB. Delay discounting: Interactions between personality and cognitive ability. Journal of Research in Personality. 2008;42(6):1646–1650. http://dx.doi.org/10.1016/j.jrp.2008.07.005. [Google Scholar]
- Hughes G, Mathan S, Yeung N. EEG indices of reward motivation and target detectability in a rapid visual detection task. Neuroimage. 2013;64(0):590–600. doi: 10.1016/j.neuroimage.2012.09.003. http://dx.doi.org/10.1016/j.neuroimage.2012.09.003. [DOI] [PubMed] [Google Scholar]
- Jensen O, Mazaheri A. Shaping functional architecture by oscillatory alpha activity: gating by inhibition. Frontiers in Human Neuroscience. 2010:4. doi: 10.3389/fnhum.2010.00186. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Johnson MW, Bickel WK. Within-subject comparison of real and hypothetical money rewards in delay discounting. Journal of the Experimental Analysis of Behavior. 2002;77(2):129–146. doi: 10.1901/jeab.2002.77-129. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Johnson PM, Kenny PJ. Dopamine D2 receptors in addiction-like reward dysfunction and compulsive eating in obese rats. Nature Neuroscience. 2010;13(5):635–641. doi: 10.1038/nn.2519. http://www.nature.com/neuro/journal/v13/n5/suppinfo/nn.2519_S1.html. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kalenscher T, Pennartz CMA. Is a bird in the hand worth two in the future? The neuroeconomics of intertemporal decision-making. Progress in Neurobiology. 2008;84(3):284–315. doi: 10.1016/j.pneurobio.2007.11.004. http://dx.doi.org/10.1016/j.pneurobio.2007.11.004. [DOI] [PubMed] [Google Scholar]
- Kirby K. One-year temporal stability of delay-discount rates. Psychonomic bulletin & review. 2009;16(3):457–462. doi: 10.3758/PBR.16.3.457. [DOI] [PubMed] [Google Scholar]
- Kotani Y, Kishida S, Hiraku S, Suda K, Ishii M, Aihara Y. Effects of information and reward on stimulus-preceding negativity prior to feedback stimuli. Psychophysiology. 2003;40(5):818–826. doi: 10.1111/1469-8986.00082. [DOI] [PubMed] [Google Scholar]
- Lagorio CH, Madden GJ. Delay discounting of real and hypothetical rewards III: Steady-state assessments, forced-choice trials, and all real rewards. Behavioural Processes. 2005;69(2):173–187. doi: 10.1016/j.beproc.2005.02.003. http://dx.doi.org/10.1016/j.beproc.2005.02.003. [DOI] [PubMed] [Google Scholar]
- Leicht G, Troschütz S, Andreou C, Karamatskos E, Ertl M, Naber D, Mulert C. Relationship between Oscillatory Neuronal Activity during Reward Processing and Trait Impulsivity and Sensation Seeking. PLoS ONE. 2013;8(12):e83414. doi: 10.1371/journal.pone.0083414. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Loewenstein G. Out of control: Visceral influences on behavior. Organizational Behavior and Human Decision Processes. 1996;65(3):272–292. doi: 10.1006/obhd.1996.0028. [DOI] [Google Scholar]
- Loewenstein G. Emotions in Economic Theory and Economic Behavior. The American Economic Review. 2000;90(2):426–432. [Google Scholar]
- Luck SJ. An introduction to the event-related potential technique. MIT press; 2014. [Google Scholar]
- Luft CDB. Learning from feedback: The neural mechanisms of feedback processing facilitating better performance. Behavioural Brain Research. 2014;261(0):356–368. doi: 10.1016/j.bbr.2013.12.043. http://dx.doi.org/10.1016/j.bbr.2013.12.043. [DOI] [PubMed] [Google Scholar]
- Luft CDB, Nolte G, Bhattacharya J. High-Learners Present Larger Mid-Frontal Theta Power and Connectivity in Response to Incorrect Performance Feedback. The Journal of Neuroscience. 2013;33(5):2029–2038. doi: 10.1523/jneurosci.2565-12.2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Luft CDB, Takase E, Bhattacharya J. Processing Graded Feedback: Electrophysiological Correlates of Learning from Small and Large Errors. Journal of Cognitive Neuroscience. 2013;26(5):1180–1193. doi: 10.1162/jocn_a_00543. [DOI] [PubMed] [Google Scholar]
- Mahalingam V, Stillwell D, Kosinski M, Rust J, Kogan A. Who Can Wait for the Future? A Personality Perspective. Social Psychological and Personality Science. 2014;5(5):573–583. doi: 10.1177/1948550613515007. [DOI] [Google Scholar]
- Makeig S, Debener S, Onton J, Delorme A. Mining event-related brain dynamics. Trends in Cognitive Sciences. 2004;8(5):204–210. doi: 10.1016/j.tics.2004.03.008. [DOI] [PubMed] [Google Scholar]
- Marco-Pallares J, Cucurell D, Cunillera T, García R, Andrés-Pueyo A, Münte TF, Rodríguez-Fornells A. Human oscillatory activity associated to reward processing in a gambling task. Neuropsychologia. 2008;46(1):241–248. doi: 10.1016/j.neuropsychologia.2007.07.016. http://dx.doi.org/10.1016/j.neuropsychologia.2007.07.016. [DOI] [PubMed] [Google Scholar]
- Marco-Pallarés J, Cucurell D, Cunillera T, Krämer UM, Càmara E, Nager W, … Rodriguez-Fornells A. Genetic Variability in the Dopamine System (Dopamine Receptor D4, Catechol-O-Methyltransferase) Modulates Neurophysiological Responses to Gains and Losses. Biological Psychiatry. 2009;66(2):154–161. doi: 10.1016/j.biopsych.2009.01.006. [DOI] [PubMed] [Google Scholar]
- Mazur JE. In: An adjusting procedure for studying delayed reinforcement. Commons ML, Mazur JE, Nevin JA, editors. 1987. pp. 55–73. [Google Scholar]
- McAdam DW, Seales DM. Bereitschaftspotential enhancement with increased level of motivation. Electroencephalography & Clinical Neurophysiology. 1969;27(1):73–75. doi: 10.1016/0013-4694(69)90111-4. [DOI] [PubMed] [Google Scholar]
- McClure SM, York MK, Montague PR. The Neural Substrates of Reward Processing in Humans: The Modern Role of fMRI. The Neuroscientist. 2004;10(3):260–268. doi: 10.1177/1073858404263526. [DOI] [PubMed] [Google Scholar]
- Miltner WHR, Braun CH, Coles MGH. Event-related brain potentials following incorrect feedback in a time-estimation task: Evidence for a ‘generic’ neural system for error detection. Journal of Cognitive Neuroscience. 1997;9(6):788–798. doi: 10.1162/jocn.1997.9.6.788. [DOI] [PubMed] [Google Scholar]
- Mischel W. Processes in delay of gratification. Academic Press; 1974. [Google Scholar]
- Mischel W, Shoda Y, Rodriguez M. Delay of gratification in children. Science. 1989;244(4907):933–938. doi: 10.1126/science.2658056. [DOI] [PubMed] [Google Scholar]
- Morís J, Luque D, Rodríguez-Fornells A. Learning-induced modulations of the stimulus-preceding negativity. Psychophysiology. 2013;50(9):931–939. doi: 10.1111/psyp.12073. [DOI] [PubMed] [Google Scholar]
- Odum AL. Delay discounting: Trait variable? Behavioural Processes. 2011;87(1):1–9. doi: 10.1016/j.beproc.2011.02.007. http://dx.doi.org/10.1016/j.beproc.2011.02.007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ohgami Y, Kotani Y, Tsukamoto T, Omura K, Inoue Y, Aihara Y, Nakayama M. Effects of monetary reward and punishment on stimulus-preceding negativity. Psychophysiology. 2006;43(3):227–236. doi: 10.1111/j.1469-8986.2006.00396.x. [DOI] [PubMed] [Google Scholar]
- Pernet CR, Wilcox R, Rousselet GA. Robust correlation analyses: false positive and power validation using a new open source matlab toolbox. Frontiers in Psychology. 2012;3:606. doi: 10.3389/fpsyg.2012.00606. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Peters J, Büchel C. The neural mechanisms of inter-temporal decision-making: understanding variability. Trends in Cognitive Sciences. 2011;15(5):227–239. doi: 10.1016/j.tics.2011.03.002. http://dx.doi.org/10.1016/j.tics.2011.03.002. [DOI] [PubMed] [Google Scholar]
- Pfurtscheller G, Aranibar A. Event-related cortical desynchronization detected by power measurements of scalp EEG. Electroencephalography and clinical neurophysiology. 1977;42(6):817–826. doi: 10.1016/0013-4694(77)90235-8. http://dx.doi.org/10.1016/0013-4694(77)90235-8. [DOI] [PubMed] [Google Scholar]
- Plichta MM, Scheres A. Ventral striatal responsiveness during reward anticipation in ADHD and its relation to trait impulsivity in the healthy population: A meta-analytic review of the fMRI literature. Neuroscience & Biobehavioral Reviews. 2014;38(0):125–134. doi: 10.1016/j.neubiorev.2013.07.012. http://dx.doi.org/10.1016/j.neubiorev.2013.07.012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Pornpattananangkul N, Nusslock R. Motivated to win: Relationship between anticipatory and outcome reward-related neural activity. Brain and Cognition. 2015;100:21–40. doi: 10.1016/j.bandc.2015.09.002. http://dx.doi.org/10.1016/j.bandc.2015.09.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rachlin H, Raineri A, Cross D. Subjective probability and delay. Journal of the Experimental Analysis of Behavior. 1991;55(2):233–244. doi: 10.1901/jeab.1991.55-233. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ramsey SE, Finn PR. P300 from men with a family history of alcoholism under different incentive conditions. Journal of Studies on Alcohol and Drugs. 1997;58(6):606–616. doi: 10.15288/jsa.1997.58.606. [DOI] [PubMed] [Google Scholar]
- Rangel A, Camerer C, Montague PR. A framework for studying the neurobiology of value-based decision making. Nat Rev Neurosci. 2008;9(7):545–556. doi: 10.1038/nrn2357. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rousseeuw PJ. Least Median of Squares Regression. Journal of the American Statistical Association. 1984;79(388):871–880. doi: 10.1080/01621459.1984.10477105. [DOI] [Google Scholar]
- Rousseeuw PJ, Driessen KV. A Fast Algorithm for the Minimum Covariance Determinant Estimator. Technometrics. 1999;41(3):212–223. doi: 10.1080/00401706.1999.10485670. [DOI] [Google Scholar]
- Samanez-Larkin GR, Mata R, Radu PT, Ballard IC, Carstensen LL, McClure SM. Age differences in striatal delay sensitivity during intertemporal choice in healthy adults. Frontiers in Neuroscience. 2011:5. doi: 10.3389/fnins.2011.00126. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Samuelson PA. Some Aspects of the Pure Theory of Capital. The Quarterly Journal of Economics. 1937;51(3):469–496. doi: 10.2307/1884837. [DOI] [Google Scholar]
- Santesso DL, Bogdan R, Birk JL, Goetz EL, Holmes AJ, Pizzagalli DA. Neural responses to negative feedback are related to negative emotionality in healthy adults. Social Cognitive and Affective Neuroscience. 2012;7(7):794–803. doi: 10.1093/scan/nsr054. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schultz W. Subjective neuronal coding of reward: temporal value discounting and risk. European Journal of Neuroscience. 2010;31(12):2124–2135. doi: 10.1111/j.1460-9568.2010.07282.x. [DOI] [PubMed] [Google Scholar]
- Schultz W, Tremblay L, Hollerman JR. Reward Processing in Primate Orbitofrontal Cortex and Basal Ganglia. Cerebral Cortex. 2000;10(3):272–283. doi: 10.1093/cercor/10.3.272. [DOI] [PubMed] [Google Scholar]
- Smith C, Boettiger C. Age modulates the effect of COMT genotype on delay discounting behavior. Psychopharmacology. 2012;222(4):609–617. doi: 10.1007/s00213-012-2653-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stice E, Spoor S, Bohon C, Small DM. Relation Between Obesity and Blunted Striatal Response to Food Is Moderated by TaqIA A1 Allele. Science. 2008;322(5900):449–452. doi: 10.1126/science.1161550. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Thut G, Nietzel A, Brandt SA, Pascual-Leone A. α-Band Electroencephalographic Activity over Occipital Cortex Indexes Visuospatial Attention Bias and Predicts Visual Target Detection. The Journal of Neuroscience. 2006;26(37):9494–9502. doi: 10.1523/jneurosci.0875-06.2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- van de Vijver I, Ridderinkhof KR, Cohen MX. Frontal Oscillatory Dynamics Predict Feedback Learning and Action Adjustment. Journal of Cognitive Neuroscience. 2011;23(12):4106–4121. doi: 10.1162/jocn_a_00110. [DOI] [PubMed] [Google Scholar]
- van den Berg B, Krebs RM, Lorist MM, Woldorff MG. Utilization of reward-prospect enhances preparatory attention and reduces stimulus conflict. Cognitive, Affective & Behavioral Neuroscience. 2014;14(2):561–577. doi: 10.3758/s13415-014-0281-z. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Van den Berg I, Franken IHA, Muris P. Individual differences in sensitivity to reward: Association with electrophysiological responses to monetary gains and losses. Journal of Psychophysiology. 2011;25(2):81–86. doi: 10.1027/0269-8803/a000032. [DOI] [Google Scholar]
- Van den Berg I, Shaul L, Van der Veen FM, Franken IHA. The role of monetary incentives in feedback processing: Why we should pay our participants. NeuroReport: For Rapid Communication of Neuroscience Research. 2012;23(6):347–353. doi: 10.1097/WNR.0b013e328351db2f. [DOI] [PubMed] [Google Scholar]
- Verboven S, Hubert M. LIBRA: a MATLAB library for robust analysis. Chemometrics and Intelligent Laboratory Systems. 2005;75(2):127–136. http://dx.doi.org/10.1016/j.chemolab.2004.06.003. [Google Scholar]
- Volkow ND, Wang GJ, Fowler JS, Tomasi D, Baler R. Food and Drug Reward: Overlapping Circuits in Human Obesity and Addiction. In: Carter CS, Dalley JW, editors. Brain Imaging in Behavioral Neuroscience. Vol. 11. Springer; Berlin Heidelberg: 2012. pp. 1–24. [DOI] [PubMed] [Google Scholar]
- Wilcox R. Introduction to Robust Estimation and Hypothesis Testing. 3. Boston: Academic Press; 2012. Chapter 9 - Correlation and Tests of Independence; pp. 441–469. [Google Scholar]
- Willenbockel V, Sadr J, Fiset D, Horne G, Gosselin F, Tanaka J. The SHINE toolbox for controlling low-level image properties. Journal of Vision. 2010;10(7):653. doi: 10.1167/10.7.653. [DOI] [PubMed] [Google Scholar]
- Wise R. Dopamine and reward: The anhedonia hypothesis 30 years on. Neurotoxicity Research. 2008;14(2–3):169–183. doi: 10.1007/BF03033808. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yacubian J, Sommer T, Schroeder K, Glascher J, Kalisch R, Leuenberger B, … Buchel C. Gene-gene interaction associated with neural reward sensitivity. Proceedings of the National Academy of Sciences. 2007;104(19):8125–8130. doi: 10.1073/pnas.0702029104. [DOI] [PMC free article] [PubMed] [Google Scholar]