

Abstract
The definition of heritability has been unique and clear, but its estimation and estimates vary across studies. Linear mixed model (LMM) and Haseman–Elston (HE) regression analyses are commonly used for estimating heritability from genome-wide association data. This study provides an analytical resolution that can be used to reconcile the differences between LMM and HE in the estimation of heritability given the genetic architecture, which is responsible for these differences. The genetic architecture was classified into three forms via thought experiments: (i) coupling genetic architecture that the quantitative trait loci (QTLs) in the linkage disequilibrium (LD) had a positive covariance; (ii) repulsion genetic architecture that the QTLs in the LD had a negative covariance; (iii) and neutral genetic architecture that the QTLs in the LD had a covariance with a summation of zero. The neutral genetic architecture is so far most embraced, whereas the coupling and the repulsion genetic architecture have not been well investigated. For a quantitative trait under the coupling genetic architecture, HE overestimated the heritability and LMM underestimated the heritability; under the repulsion genetic architecture, HE underestimated but LMM overestimated the heritability for a quantitative trait. These two methods gave identical results under the neutral genetic architecture. A general analytical result for the statistic estimated under HE is given regardless of genetic architecture. In contrast, the performance of LMM remained elusive, such as further depended on the ratio between the sample size and the number of markers, but LMM converged to HE with increased sample size.
Introduction
Heritability has been defined under the context of the multiple regression of an infinitesimal sample size.1 Recently, various methods have been developed to search for missing heritability in genome-wide association study (GWAS) data, which is typical high-dimensional data (M>>N; ie, the number of markers is larger than the sample size).2 Variance component methods, such as the modified Haseman–Elston (HE) regression and the linear mixed model (LMM), estimate heritability as being higher than do single-marker association studies.3, 4, 5 For a quantitative trait such as height, the estimated heritability was about 0.5 using variance component methods. Compared with the empirical upper bound of the heritability of height,6, 7 which was thought to be approximately 0.8, the gap of 'missing heritability' has been much narrowed using variance component methods. However, 'true heritability' has not yet been attained. The majority endeavors focused on searching for 'missing heritability' aim to fill the gaps between state-of-the-art (GWAS data; single-marker GWAS provides the lower bound, and variance component GWAS often offers a higher estimate) and old-fashioned designs (such epidemiological data, providing the upper bound of heritability). However, epidemiological and family-based studies are often criticized for potential overestimation of heritability, if not fully justified, due to the shared environment. Similarly, it is unknown whether the variance component will overestimate or underestimate the heritability for GWAS data.
Some researchers showed that LMM provided valid estimate of heritability,8 whereas under various genetic architecture the estimated heritability from GWAS data using maximum likelihood framework may be ambiguous.9 Recently, Golan et al.5 and Chen10 independently discovered the discrepancy between the estimates from LMM and HE for the estimates of heritability for case-control studies (Chen also found a discrepancy in quantitative traits). Of note, a method by Golan et al.5 is called phenotype correlation–genotype correlation (PCGC) regression, when without adjustment for covariates PCGC resembles HE. For convenience, we call both of them HE thereby. For more detailed discussion and controversies on the estimation of heritability please refer to Table 1.
Table 1. A summary of various arguments regarding searching for missing heritability.
| Conclusion | |||
|---|---|---|---|
| Author(s) | Methods | Quantitative traits | Case-control |
| Yang et al.3 | LMM | Unbiased | NA |
| HE | Unbiased | NA | |
| Lee et al.4 | LMM | NA | Unbiased |
| HE | NA | NA | |
| Speed et al.13 | LMM (weights) | Unbiased | Underestimated |
| HE | NA | NA | |
| Lee and Chow8 | LMM | Unbiased | |
| NA | NA | ||
| de los Campos et al.9 | LMM (a Bayesian version) | Biased | NA |
| HE | NA | NA | |
| Golan et al.5 | LMM | Unbiased | Underestimate |
| HE | Unbiased | Unbiased | |
| Chen.10 | LMM | Biased (under- or overestimate) | Biased (under- or overestimate) |
| HE | Biased (under- or overestimate) | Biased (under- or overestimate) | |
Abbreviations: HE, modified Haseman–Elston regression; LMM, linear mixed model; NA, if not mentioned in their reports.
Two common issues should be noted. First, the estimation of heritability is most often treated as a statistical procedure: a parameter is estimated and assumed to be heritability as granted. Second, the effect sizes of QTLs are assumed to be from a random distribution. Estimation of heritability can be influenced by the genetic architecture, such as the genomic locations of causal variants/QTLs or the ranges of their effect sizes.11 As heritability is a genetic architecture parameter, it is reasonable to examine how certain forms of genetic architecture, implicitly or explicitly, will influence the estimation of variance component methods. Although little is known about genetic architecture, the estimation of heritability depends on the genetic architecture.11
This study closely scrutinized the genetic architecture without assuming that QTLs were random along the genome, and addressed this implication in the estimation of heritability. As demonstrated in this study, the estimation of heritability depended on the genetic architecture, which can be classified into three forms, underlying a complex trait. Given the various methods proposed for estimating heritability in GWAS data, LMM, which represents a method that is built on maximum likelihood, and HE, which is built on least squares, were studied in detail; they may differ dramatically in their estimations of heritability and reflect the genetic architecture underlying a complex trait. The following conclusions were made: (1) an increased estimate of heritability via variance component methods can be the result of overestimation under the certain forms of genetic architecture; (2) the difference between the estimated heritability in LMM and that in HE may reveal the genetic architecture underlying a complex trait.
MATERIALS AND METHODS
The linear model of a complex trait
For a quantitative trait, under the Hardy–Weinberg equilibrium the additive genetic variance (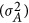 ) is
) is
in which p
l(≤0.5) is the allele frequency for the reference allele at the lth QTL, ql=1−pl the frequency for the alternative allele, 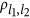 is the correlation measure between the
is the correlation measure between the 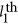 and the
and the 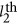 QTLs, and
QTLs, and 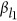 is the additive effect for the
is the additive effect for the 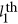 locus. Equation 1 is the classic definition of additive genetic variance, referring to page 102 in Lynch and Walsh.12 For ease of discussion: (i) the phenotype and the genotypes are standardized, and consequently,
locus. Equation 1 is the classic definition of additive genetic variance, referring to page 102 in Lynch and Walsh.12 For ease of discussion: (i) the phenotype and the genotypes are standardized, and consequently, 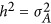 ; (ii) only narrow-sense heritability is discussed here; and (iii) every QTL is perfectly tagged. Due to the context,
; (ii) only narrow-sense heritability is discussed here; and (iii) every QTL is perfectly tagged. Due to the context, 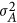 and h2 will be used interchangeably.
and h2 will be used interchangeably.
The decomposition of genetic architecture
The additive variance component expressed in Equation 1 can be decomposed as
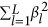 is the within-locus variance, denoted as
is the within-locus variance, denoted as 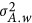 , and
, and 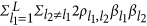 is the between-locus variance/covariance, denoted as
is the between-locus variance/covariance, denoted as 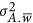 . Analogously,
. Analogously, 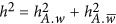 .
.
The unit of 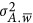 is
is 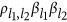 , a three-element product characterizing a pair of QTLs. Given the two possible signs for
, a three-element product characterizing a pair of QTLs. Given the two possible signs for 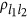 ,
, 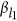 , and
, and 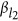 , it generates eight combinations. Thus, for the ease of discussion of this two-QTL scenario, it is presumed that the reference alleles of two QTLs have been aligned such that
, it generates eight combinations. Thus, for the ease of discussion of this two-QTL scenario, it is presumed that the reference alleles of two QTLs have been aligned such that 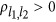 (changing the reference alleles will not change the sign of
(changing the reference alleles will not change the sign of 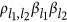 , Supplementary Note I). If
, Supplementary Note I). If 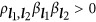 , the genetic unit is called the coupling phase, where QTLs with the same effect sign are clustered together. It is equivalent to argue whether a detected QTL is actually the aggregation of a pair of small-effect QTLs with the same sign. If
, the genetic unit is called the coupling phase, where QTLs with the same effect sign are clustered together. It is equivalent to argue whether a detected QTL is actually the aggregation of a pair of small-effect QTLs with the same sign. If 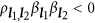 , it is called the repulsion phase, where QTLs with opposite effect signs are clustered together. It is analogous to argue whether a detected QTL is actually the aggregation of two QTLs with opposite signs. If
, it is called the repulsion phase, where QTLs with opposite effect signs are clustered together. It is analogous to argue whether a detected QTL is actually the aggregation of two QTLs with opposite signs. If 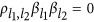 , this is the neutral phase, where QTLs are in linkage equilibrium for the two-QTL scenario.
, this is the neutral phase, where QTLs are in linkage equilibrium for the two-QTL scenario.
Thus, the smallest genetic architecture in this definition has at least two QTLs, and the total between-locus variance 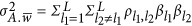 now can be written as the aggregation of the repulsion and coupling phases along the genome,
now can be written as the aggregation of the repulsion and coupling phases along the genome, 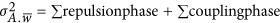 . Depending on if
. Depending on if 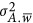 is 0, or greater/smaller than 0, the genetic architecture is split into three forms:
is 0, or greater/smaller than 0, the genetic architecture is split into three forms:
(1) the coupling genetic architecture where 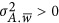 ;
;
(2) the repulsion genetic architecture where 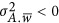 ;
;
(3) and the neutral genetic architecture where 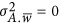 .
.
When the neutral genetic architecture is assumed, the heritability can be simplified as 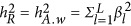 . For almost all recent variance component publications,3, 4, 5, 8, 9, 13 a random distribution of effects, leading to a neutral genetic architecture, along the genome is assumed. Therefore, it is subsequently demonstrated that the coupling/repulsion genetic architecture helps to reconcile the estimation of heritability for GWAS data.
. For almost all recent variance component publications,3, 4, 5, 8, 9, 13 a random distribution of effects, leading to a neutral genetic architecture, along the genome is assumed. Therefore, it is subsequently demonstrated that the coupling/repulsion genetic architecture helps to reconcile the estimation of heritability for GWAS data.
The conventional definition of heritability under the context of multiple regression (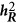 )
)
As argued above, the heritability can be split into two components under the multiple regression of infinitesimal sample size
Before the availability of GWAS data, 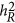 is often estimated from epidemiological data via structural equation or linkage analysis.6, 7 Those estimates are often served as the upper bound in searching 'missing heritability'.
is often estimated from epidemiological data via structural equation or linkage analysis.6, 7 Those estimates are often served as the upper bound in searching 'missing heritability'.
Heritability estimated under LMM (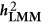 and
and 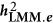 )
)
In LMM, the variance component of a trait is modeled as
Where A is a realized genetic relatedness matrix for samples. Between a pair of individuals i and j, 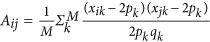 , in which M is the number of markers and xk counts the reference alleles for the kth marker.
, in which M is the number of markers and xk counts the reference alleles for the kth marker. 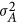 can be estimated via the restricted maximum likelihood estimator.14, 15 It should be noted, as will be shown below, that when
can be estimated via the restricted maximum likelihood estimator.14, 15 It should be noted, as will be shown below, that when 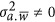 , LMM will give a biased estimate. As discussed by de los Campos et al,9 the actual estimated statistic, which is often taken as heritability, remains a fundamental question for LMM.
, LMM will give a biased estimate. As discussed by de los Campos et al,9 the actual estimated statistic, which is often taken as heritability, remains a fundamental question for LMM. 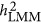 denotes the heritability estimated by LMM, and
denotes the heritability estimated by LMM, and 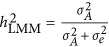 , in which
, in which 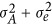 is considered a proxy for
is considered a proxy for 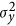 . Alternatively, in this study, an ad hoc estimate of heritability was also defined as
. Alternatively, in this study, an ad hoc estimate of heritability was also defined as
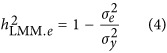 |
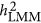 and
and 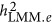 might differ across genetic architectures. Other ad hoc estimates include introducing weights to A matrix as proposed by Speed et al.13
might differ across genetic architectures. Other ad hoc estimates include introducing weights to A matrix as proposed by Speed et al.13
Heritability as defined under the HE regression (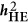 )
)
Using a modified HE (or PCGC as proposed by Golan et al.),5, 10 the variance component can be modeled as 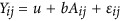 , in which μ is the mean of the model, b is the regression coefficient,
, in which μ is the mean of the model, b is the regression coefficient, 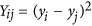 is the squared difference between a pair of individuals, and
is the squared difference between a pair of individuals, and 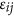 is the residual. A is the realized genetic relatedness matrix for samples, as used for LMM above. Chen10 and Golan et al.5 both adopted this framework. Golan et al. derive the regression coefficient under the assumption that
is the residual. A is the realized genetic relatedness matrix for samples, as used for LMM above. Chen10 and Golan et al.5 both adopted this framework. Golan et al. derive the regression coefficient under the assumption that 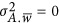 ; when
; when 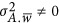 , Golan et al. did not provide a solution. In Chen's work, the mathematical expectation of the regression coefficient was derived regardless of whether
, Golan et al. did not provide a solution. In Chen's work, the mathematical expectation of the regression coefficient was derived regardless of whether 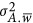 was zero or not.10 After all, Golan et al.5 took the estimate as heritability directly, whereas Chen found a much broad variation of the estimate and discussed the condition it was, or not was, equal to heritability (
was zero or not.10 After all, Golan et al.5 took the estimate as heritability directly, whereas Chen found a much broad variation of the estimate and discussed the condition it was, or not was, equal to heritability (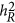 ).
).
Chen's original work is too long to present here; therefore, only partial results are shown.10 Without losing generality, the regression coefficient of HE is as follows (see Equation 1 and Table 1 in Chen's original work)
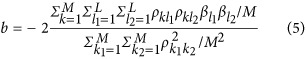 |
The denominator 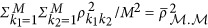 is the averaged linkage disequilibrium (LD) between the markers. The heritability is estimated as
is the averaged linkage disequilibrium (LD) between the markers. The heritability is estimated as 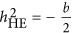 . When there is only one marker in Equation 5,
. When there is only one marker in Equation 5, 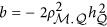 , in which
, in which 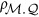 is the correlation between the marker and the QTL;
is the correlation between the marker and the QTL; 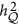 is the heritability of the QTL. An alternative expression for HE regression coefficient is
is the heritability of the QTL. An alternative expression for HE regression coefficient is
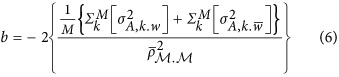 |
which decomposes the numerator to the within-locus variance, 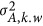 , and the between-locus variance,
, and the between-locus variance, 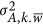 (Supplementary Note II). Equation 6, which resembles Equation 2, indicates how
(Supplementary Note II). Equation 6, which resembles Equation 2, indicates how 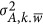 , the covariance, will influence the estimate. The implications of these two components are not trivial in the inference of genetic architecture for complex traits.
, the covariance, will influence the estimate. The implications of these two components are not trivial in the inference of genetic architecture for complex traits.
Scenario 1: When it is the neutral genetic architecture, 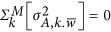 . Equation 5 can be simplified as
. Equation 5 can be simplified as
in which 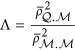 .
. 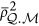 , an unknown parameter, indicates the mean of the LD between a marker and a QTL. When there is no
, an unknown parameter, indicates the mean of the LD between a marker and a QTL. When there is no 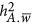 ,
, 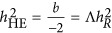 .
. 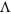 can be 1 when every marker is a QTL, and
can be 1 when every marker is a QTL, and 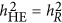 directly leads to an unbiased estimate of heritability.
directly leads to an unbiased estimate of heritability.
Scenario 2: When either the coupling or repulsion genetic architecture is present, the between-locus component contributes to the estimate in Equation 6. 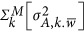 can be positive or negative depending on the underlying genetic architecture. Then there is no simple way to find the heritability (
can be positive or negative depending on the underlying genetic architecture. Then there is no simple way to find the heritability (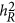 ) for the trait. As demonstrated in the simulation below, a discrepancy was observed between the respective estimates of LMM and HE.
) for the trait. As demonstrated in the simulation below, a discrepancy was observed between the respective estimates of LMM and HE.
In addition, weights can be introduced into the HE regression for Aij, as proposed by Speed et al.13 In general, as long as the weights follow a normal distribution, the estimated heritability will be nearly identical to that without weights (Supplementary Note III).
Results
Simulation I: the genetic unit (two QTLs) of the genetic architecture
In order to demonstrate how genetic architecture affects the estimation of heritability, the smallest genetic architecture, which only has two QTLs, was considered first. We simulated 1000 unrelated individuals, and two equally frequent QTLs, which had identical effect sizes, were tagged perfectly on the genome. The heritability was 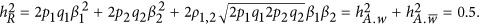 The LD between the pair of two consecutive single-nucleotide polymorphism markers was set to
The LD between the pair of two consecutive single-nucleotide polymorphism markers was set to 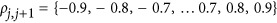 . When
. When 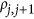 was positive, it led to the coupling genetic architecture; when
was positive, it led to the coupling genetic architecture; when 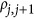 was negative, it led to the repulsion genetic. The number of genetic markers
was negative, it led to the repulsion genetic. The number of genetic markers 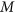 was set to 2, 100, 200, 500, 750, 1000, 2000, and 5000, and the allele frequency was 0.5 for each marker. These two QTLs were always located on the
was set to 2, 100, 200, 500, 750, 1000, 2000, and 5000, and the allele frequency was 0.5 for each marker. These two QTLs were always located on the 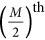 and
and 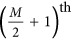 markers. The genetic relatedness matrix A between the individuals was calculated using all M markers. Heritability was estimated using LMM and HE, respectively. For HE, based on Equation 5, it could be predicted that
markers. The genetic relatedness matrix A between the individuals was calculated using all M markers. Heritability was estimated using LMM and HE, respectively. For HE, based on Equation 5, it could be predicted that 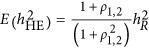 (Appendix). The analytical results for
(Appendix). The analytical results for 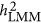 was hardly known due to the likelihood, which maximizes to unpredictable maximization if it is not specified correctly.
was hardly known due to the likelihood, which maximizes to unpredictable maximization if it is not specified correctly.
Figure 1 illustrates the influence of the coupling/repulsion genetic architecture on the estimation of heritability. Under either the coupling or repulsion genetic architecture, neither HE nor LMM gave unbiased estimates of heritability; unbiased estimates were only generated under the neutral genetic architecture (LD=0), regardless of the number of QTLs and the markers. For HE, the influence of genetic architecture was predictable (Appendix), and the estimated heritability agreed well with 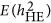 . HE underestimated the true heritability,
. HE underestimated the true heritability, 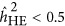 , under the repulsion genetic architecture; HE overestimated the true heritability,
, under the repulsion genetic architecture; HE overestimated the true heritability, 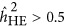 , under the coupling genetic architecture. The whole pattern was consistent for
, under the coupling genetic architecture. The whole pattern was consistent for 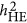 under different M/N ratios. So, the performance of HE should be predictable for the estimation of heritability, at least in the simulated scenarios.
under different M/N ratios. So, the performance of HE should be predictable for the estimation of heritability, at least in the simulated scenarios.
Figure 1.

The influence of the genetic architecture on the estimation of heritability from the Haseman–Elston Regression (HE) and the linear mixed model (LMM) – 2 QTLs. The x axis indicates the genetic architecture as quantified by 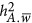 .
. 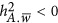 refers to the repulsion genetic architecture,
refers to the repulsion genetic architecture, 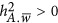 refers to the coupling genetic architecture; and
refers to the coupling genetic architecture; and 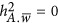 refers to the neutral genetic architecture.
refers to the neutral genetic architecture. 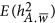 can be derived by Equation 5. The SD of each estimate was calculated from 100 replications of the simulations.
can be derived by Equation 5. The SD of each estimate was calculated from 100 replications of the simulations.
For LMM, the findings were more complicated. The bias of the estimate was not only due to the genetic architecture but also to the ratio of M/N. As observed, when M/N<0.5, 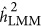 overestimated the true heritability under the repulsion genetic architecture, and underestimated the true heritability under the coupling genetic architecture. It seemed that
overestimated the true heritability under the repulsion genetic architecture, and underestimated the true heritability under the coupling genetic architecture. It seemed that 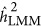 was not influenced by the genetic architecture when
was not influenced by the genetic architecture when 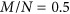 . Nevertheless,
. Nevertheless, 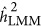 changed its response to the genetic architecture when M/N>0.5. However, the number of markers increased and the performance of
changed its response to the genetic architecture when M/N>0.5. However, the number of markers increased and the performance of 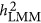 converged with
converged with 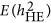 . No known theory can explain the performance of
. No known theory can explain the performance of 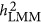 . The heritability estimated by
. The heritability estimated by 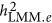 was more precise than that of both
was more precise than that of both 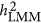 and
and 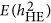 when M<500. When the number of markers was greater than 500, its performance also converged with
when M<500. When the number of markers was greater than 500, its performance also converged with 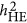 .
.
In addition, weights were introduced to generate genetic relatedness,13 but a nearly identical patterns for both 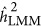 and
and 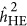 were observed with weights as without weights (Supplementary Figure S1).
were observed with weights as without weights (Supplementary Figure S1).
The scenarios for more QTLs were also considered, but the general pattern remained the same for HE and LMM as observed for the two-QTL scenarios (Supplementary Figure S2).
Simulation II: scenarios for case–control data
In previous works by Chen10 and Golan et al,5 it was demonstrated that HE (or PCGC) was unbiased in estimating heritability for case-control data. However, that conclusion was incomplete. When the base population from which the cases and controls were sampled was characterized by either the coupling or repulsion genetic architecture, HE could also be biased. To demonstrate this phenomenon, 1000 cases and 1000 controls were simulated, M={100, 500, 750, 1000}, and equally frequent biallelic QTLs were simulated. To introduce the repulsion and coupling genetic architectures, the effects of the QTLs were sampled from the standard normal distribution, and furthermore, from the first QTL to the last QTL, the effect assumed a quantity of 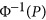 .
. 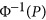 generated a quantity from the normal distribution, given a p-value of P. Here
generated a quantity from the normal distribution, given a p-value of P. Here 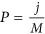 for the jth QTL. The LD between two consecutive QTLs was
for the jth QTL. The LD between two consecutive QTLs was 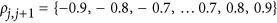 . The total heritability on the liability scale was constrained to 0.5.
. The total heritability on the liability scale was constrained to 0.5.
As illustrated in Figure 2, after transformation to the liability scale,4 a pattern was observed that was similar for quantitative traits: when the base population was under the repulsion genetic architecture, 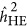 underestimated the heritability, and when it was under the coupling genetic architecture,
underestimated the heritability, and when it was under the coupling genetic architecture, 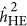 overestimated the heritability. When the base population was under the neutral genetic architecture,
overestimated the heritability. When the base population was under the neutral genetic architecture, 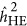 produced an unbiased estimate of the heritability. In contrast,
produced an unbiased estimate of the heritability. In contrast, 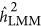 depended on both the number of markers and the genetic architecture. As observed, when M=100 and K=0.1,
depended on both the number of markers and the genetic architecture. As observed, when M=100 and K=0.1, 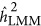 overestimated the heritability when it was under the repulsion genetic architecture, and underestimated the heritability when it was under the coupling genetic architecture. However, the pattern depended upon the number of markers: when the number of markers increased to 1000,
overestimated the heritability when it was under the repulsion genetic architecture, and underestimated the heritability when it was under the coupling genetic architecture. However, the pattern depended upon the number of markers: when the number of markers increased to 1000, 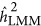 always underestimated the heritability.
always underestimated the heritability. 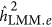 was not as precise in this situation as it was for quantitative traits.
was not as precise in this situation as it was for quantitative traits.
Figure 2.

The simulation results for case-control data with varying prevalence (K) and number of QTLs. The x axis quantifies the genetic architecture for the base population, in which the cases and the controls are sampled. The y axis represents the heritability on the liability scale. The x axis reflects the genetic architecture: negative/positive LD indicates the repulsion/coupling genetic architecture; LD=0 indicates the neutral genetic architecture. Of note, when 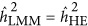 , it was under the repulsion genetic architecture.
, it was under the repulsion genetic architecture.
Of note, the crossover between 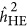 and
and 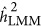 did not occur at the point where there was neutral genetic architecture, but slightly under the repulsion genetic architecture. This was likely because ascertainment would introduce genetic architecture that resembled the coupling genetic architecture, which is known as Bulmer's effect in selection studies.16
did not occur at the point where there was neutral genetic architecture, but slightly under the repulsion genetic architecture. This was likely because ascertainment would introduce genetic architecture that resembled the coupling genetic architecture, which is known as Bulmer's effect in selection studies.16
Weights were also introduced to the genetic relatedness between individuals,13 and the results were nearly identical to those without weighting (Supplementary Figure S3).
Summary: reconciliation of missing heritability in both theory and practice
Table 2 summarizes the theoretical and simulation results presented. The genetic architecture can be classified into coupling, repulsion, and neutral genetic architectures. They reflect the physical features of QTLs along the genome, and heritability is a commonly used statistic to summarize this. Depending upon the genetic architecture, multiple regression 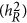 – the standard definition for heritability, LMM (
– the standard definition for heritability, LMM (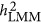 ), and HE (
), and HE (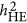 ) estimate heritability differently. As heritability is defined under the context of multiple regression, which leads to
) estimate heritability differently. As heritability is defined under the context of multiple regression, which leads to 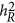 , it may or may not agree with an alternative heritability estimation, such as
, it may or may not agree with an alternative heritability estimation, such as 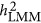 and
and 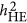 .
.
Table 2. Summary for LMM and HE in the estimation of heritability for genome-wide association data.

Under the neutral genetic architecture, these three statistics may be closely related. In particular, 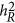 and
and 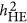 are identical, but via different statistical mechanisms, as described in Equation 6. However, under the coupling or repulsion genetic architecture,
are identical, but via different statistical mechanisms, as described in Equation 6. However, under the coupling or repulsion genetic architecture, 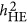 may under- or overestimate
may under- or overestimate 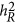 . However, it is not easy to predict the performance of
. However, it is not easy to predict the performance of 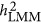 ; under the neutral genetic architecture, its performance should resemble HE, and very likely converges with the performance of
; under the neutral genetic architecture, its performance should resemble HE, and very likely converges with the performance of 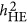 under a wide range of genetic architectures.
under a wide range of genetic architectures.
In application, the difference between 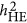 and
and 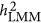 , if observed for a trait, may reflect the underlying genetic architecture of that trait. As demonstrated in Simulation I, given the increasing ratio between M/N,
, if observed for a trait, may reflect the underlying genetic architecture of that trait. As demonstrated in Simulation I, given the increasing ratio between M/N, 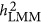 converges with
converges with 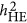 . When these values are close, it does not mean that the estimated heritability is correct; however, this may reflect a condition in which one can presume that the estimated heritability was likely unbiased. It is unclear whether the convergence is also the case in real data analyses. Further investigation is required to examine how often
. When these values are close, it does not mean that the estimated heritability is correct; however, this may reflect a condition in which one can presume that the estimated heritability was likely unbiased. It is unclear whether the convergence is also the case in real data analyses. Further investigation is required to examine how often 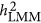 converges with
converges with 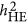 , otherwise many reported heritability from LMM remains to be ad hoc because of its unwarranted outcomes.
, otherwise many reported heritability from LMM remains to be ad hoc because of its unwarranted outcomes.
Discussion
As acknowledging the genetic architecture is important for the estimation of heritability, three possible forms of genetic architecture were introduced. Under these three forms, the performance of LMM and HE could be classified. In previous studies, it was suspected that LMM may underestimate the heritability in case-control data,5, 10 and this study showed that the bias could even occur for quantitative traits. Furthermore, under the coupling genetic architecture, HE overestimated the heritability; under the repulsion genetic architecture, HE underestimated heritability. Under the neutral genetic architecture, HE gave an unbiased estimate. LMM depended on factors other than the genetic architecture, such as the ratio between M and N. Although there was uncertainty in 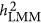 , an approximation of
, an approximation of 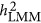 could be archived under the neutral genetic architecture. However, as the density of markers can fluctuate the estimation of
could be archived under the neutral genetic architecture. However, as the density of markers can fluctuate the estimation of 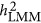 , an increased estimate of heritability may reflect better tagging of QTLs, which may be a good thing, or an overestimation, which is not expected.
, an increased estimate of heritability may reflect better tagging of QTLs, which may be a good thing, or an overestimation, which is not expected.
These three classes of genetic architecture can be naturally translated into a biological question: how do QTLs emerge on a regional scale and do those nearby QTLs resemble each other or not? A GWAS hit is often an aggregation of much smaller signals, such as those observed in the GIANT height study.17 In the future, it should be possible to determine whether a region that harbors a GWAS hit actually has more than one signal. The local clustering of QTLs will lead to the repulsion or coupling genetic architecture on the whole-genome scale, but large sample size is required to observe it.
As argued by Bulmer,16 selection could drive the departure of 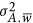 from zero, and consequently lead to the coupling or repulsion genetic architecture. This raises the question of how likely the repulsion or coupling genetic architecture in real data. A departure from the neutral genetic architecture is indicated when a trait's
from zero, and consequently lead to the coupling or repulsion genetic architecture. This raises the question of how likely the repulsion or coupling genetic architecture in real data. A departure from the neutral genetic architecture is indicated when a trait's 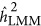 may differ from its
may differ from its 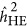 . As HE has been under reported in the literature, assessing which genetic architecture is more likely among the three proposed genetic architectures is not possible now. As
. As HE has been under reported in the literature, assessing which genetic architecture is more likely among the three proposed genetic architectures is not possible now. As 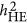 is easy to implement, testing for genetic architecture forms in various species should be possible,5, 10, 18 particularly among beef cattle or chickens, which are often under strong directional selection and whose traits are also likely under strong selection.
is easy to implement, testing for genetic architecture forms in various species should be possible,5, 10, 18 particularly among beef cattle or chickens, which are often under strong directional selection and whose traits are also likely under strong selection.
This study used very simple scenarios to demonstrate the genetic architecture and its impact on estimating heritability. Other factors, such as quality control and population structure, may lead to different estimates of heritability using LMM and HE. After all, the current paradigm used to search for missing heritability favors a higher estimate of heritability; however, one should be careful because a much higher estimate may be an overestimation due to methodological limitations rather than approach the missing heritability.19
Acknowledgments
This article benefited greatly from detailed feedback by the reviewers. I thank Wouter Peyrot and Liyuan Zhou for their helpful discussion. No specific funding was received for this work.
Appendix
Numerical example of a two-QTL scenario
Given p1=p2=0.5 for both QTLs, which had the same effect size, 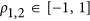 , and the real heritability is
, and the real heritability is 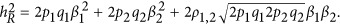 For this case, we set
For this case, we set 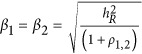 .
.
The numerator of the HE regression coefficient was calculated as 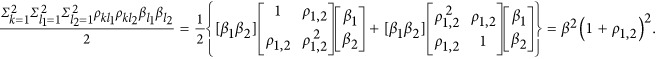 The denominator was calculated as
The denominator was calculated as 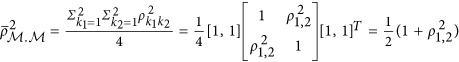 .
.
Therefore, 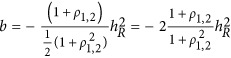 . If taking the heritability as the negative half of the regression coefficient, consequently,
. If taking the heritability as the negative half of the regression coefficient, consequently, 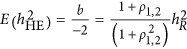 , which is represented in Figure 1. It means that the statistic estimated from HE may or may not be the heritability. When ρ1,2=0, indicating neutral genetic architecture, HE can provide unbiased estimate of heritability.
, which is represented in Figure 1. It means that the statistic estimated from HE may or may not be the heritability. When ρ1,2=0, indicating neutral genetic architecture, HE can provide unbiased estimate of heritability.
The author declares no conflict of interest.
Footnotes
Supplementary Information accompanies this paper on European Journal of Human Genetics website (http://www.nature.com/ejhg)
Supplementary Material
References
- Falconer DS, Mackay TFC: Introduction to Quantitative Genetics. 4th edn. Pearson Education Limited: Harlow, UK, 1996. [Google Scholar]
- Manolio TA, Collins FS, Cox NJ et al: Finding the missing heritability of complex diseases. Nature 2009; 461: 747–753. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yang J, Benyamin B, McEvoy BP et al: Common SNPs explain a large proportion of the heritability for human height. Nat Genet 2010; 42: 565–569. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lee SH, Wray NR, Goddard ME, Visscher PM: Estimating missing heritability for disease from genome-wide association studies. Am J Hum Genet 2011; 88: 294–305. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Golan D, Lander ES, Rosset S: Measuring missing heritability: Inferring the contribution of common variants. Proc Natl Acad Sci USA 2014; 111: E5272–E5281. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Visscher PM, Medland SE, Ferreira MAR et al: Assumption-free estimation of heritability from genome-wide identity-by-descent sharing between full siblings. PLoS Genet 2006; 2: e41. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen X, Kuja-Halkola R, Rahman I et al: Dominant Genetic Variation and Missing Heritability for Human Complex Traits: Insights from Twin versus Genome-wide Common SNP Models. Am J Hum Genet 2015; 97: 708–714. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lee JJ, Chow CC: Conditions for the validity of SNP-based heritability estimation. Hum Genet 2014; 133: 1011–1022. [DOI] [PMC free article] [PubMed] [Google Scholar]
- de los Campos G, Sorensen D, Gianola D: Genomic Heritability: What Is It? PLoS Genet 2015; 11: e1005048. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chen G-B: Estimating heritability of complex traits from genome-wide association studies using IBS-based Haseman-Elston regression. Front Genet 2014; 5: 107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Moser G, Lee SH, Hayes BJ, Goddard ME, Wray NR, Visscher PM: Simultaneous Discovery, Estimation and Prediction Analysis of Complex Traits Using a Bayesian Mixture Model. PLoS Genet 2015; 11: e1004969. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lynch M, Walsh B: Genetics and Analysis of Quantitative Traits. Sinauer Associates, Inc. Sunderland, MA, USA 1998. [Google Scholar]
- Speed D, Hemani G, Johnson MR, Balding DJ: Improved Heritability Estimation from Genome-wide SNPs. Am J Hum Genet 2012; 91: 1011–1021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Patterson HD, Thompson R: Recovery of inter-block information when block sizes are unequal. Biometrika 1971; 58: 545–554. [Google Scholar]
- Gilmour AR, Thompson R, Cullis BR: Average information REML: an efficient in linear mixed models variance parameter estimation in linear mixed models. Biometrics 1995; 51: 1440–1450. [Google Scholar]
- Bulmer MG: The effect of selection on genetic variability. Am Nat 1971; 105: 201–211. [Google Scholar]
- Yang J, Ferreira T, Morris AP et al: Conditional and joint multiple-SNP analysis of GWAS summary statistics identifies additional variants influencing complex traits. Nat Genet 2012; 44: 369–375. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hu Z, Yang R-C: Marker-based estimation of genetic parameters in genomics. PLoS One 2014; 9: e102715. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yang J, Bakshi A, Zhu Z et al: Genetic variance estimation with imputed variants finds negligible missing heritability for human height and body mass index. Nat Genet 2015; 47: 1114–1120. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.