

Abstract
The E. coli single strand DNA binding protein (SSB) is essential to viability where it functions in two seemingly disparate roles: it binds to single stranded DNA (ssDNA) and to target proteins that comprise the SSB interactome. The link between these roles resides in a previously under‐appreciated region of the protein known as the intrinsically disordered linker (IDL). We present a model wherein the IDL is responsible for mediating protein–protein interactions critical to each role. When interactions occur between SSB tetramers, cooperative binding to ssDNA results. When binding occurs between SSB and an interactome partner, storage or loading of that protein onto the DNA takes place. The properties of the IDL that facilitate these interactions include the presence of repeats, a putative polyproline type II helix and, PXXP motifs that may facilitate direct binding to the OB‐fold in a manner similar to that observed for SH3 domain binding of PXXP ligands in eukaryotic systems.
Keywords: SSB, RecG, RecO, OB‐fold, SH3 domain, PXXP motif
Abbreviations
- SSB
single stranded DNA binding protein
- ssDNA
single stranded DNA
- IDL
intrinsically disordered linker
- PPII
polyproline type II helix.
Introduction
The Escherichia coli single stranded DNA binding protein (SSB) is essential to all aspects of DNA metabolism. Here it performs two seemingly disparate roles. First, it functions to stabilize single‐stranded DNA (ssDNA) intermediates generated during DNA processing.1, 2, 3, 4, 5 Second, it interacts with as many as 14 proteins in temporal and spatial fashion, to both store and target enzymes to the DNA when needed.6, 7 How these roles are linked mechanistically is currently not known.
The protein, like the majority of eubacterial SSBs, exists as a stable homo‐tetramer with a monomer MW of 18,843 Da.8 Each 178 amino acid length monomer can be divided into two general domains defined by proteolytic cleavage: an N‐terminal portion comprising approximately the first 115 residues and a C‐terminal domain that includes residues 116–178.9 The N‐terminal domain contains elements critical to tetramer formation and the oligonucleotide/oligosaccharide binding‐fold (OB‐fold) required for binding to ssDNA.10 DNA binding occurs via the wrapping of ssDNA around the SSB tetramer using an extensive network of electrostatic and base‐stacking interactions with the phosphodiester backbone and nucleotide bases, respectively.10, 11, 12
The C‐terminal domain can be further subdivided into two additional regions: a sequence of ∼50 amino acids that has been called the intrinsically disordered linker (IDL) and the last 8–10 residues which are known as the acidic tip or C‐peptide and which is very well conserved among eubacterial proteins.1, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23 While there is extensive knowledge of the N‐terminal domain, there are only a limited number of studies of the C‐terminus. This is due in part to the fact that it is highly disordered even when the protein is bound to ssDNA.24 Recent studies have focused on the acidic tip only as it is thought to be critical for mediating interactions with SSB interactome partner proteins.1
The IDL is the least conserved region among prokaryotic SSB proteins.1, 5 Initially, it was proposed to be non‐essential, as a mutant ssb with residues 116‐167 deleted was able to complement an ssb deletion.9 However, truncated ssb genes terminating at residues 117 or 152 were unable to complement the same ssb deletion. This led to the proposal that the last 20–50 residues of SSB are essential for protein–protein interactions.9 Subsequent in vitro studies showed that deletion of the C‐terminal 15–20 residues eliminated interactions with the psi and chi subunits of the DNA polymerase III complex.18, 25 Further work both in vivo and in vitro using the ssbΔC8 gene and SSBΔC8 protein respectively, have shown that the last eight residues are critical, but not solely responsible, for target protein binding.7, 22 One interpretation is that the acidic tip residues contact target proteins directly.23, 26, 27, 28 An alternative proposal suggests that these last eight residues play a regulatory role and that target protein binding utilizes another region of SSB.29
We propose that this other region is the intrinsically disordered linker. This proposal makes sense because the IDL is unique to each bacterium, and may explain species specificity in interactome function.6, 22 What is known about the IDL is limited. As alluded to above, early studies suggested that it is a non‐essential part of the protein.9 Recently, the Lohman group found that when the linker is deleted or its sequence altered, cooperative ssDNA binding by SSB is affected.23 They proposed a model wherein the linkers could self‐associate so that the linker of one tetramer binds to that of an adjacent one and, this would facilitate interactions between acidic tips and OB cores. This model has at its core, interactions between the acidic tip and OB‐folds of adjacent proteins. The current data show that this interaction is at its best, only transient.29, 30 Furthermore, recent crystal structures of part of the acidic tip bound to interactome partners reveal that the tip does not bind to OB‐folds but instead binds to a hydrophobic pocket that contains a prominent basic residue.26, 27, 28, 31
To begin to understand how the linker region of SSB may link the seemingly disparate activities of cooperative ssDNA and protein binding, a combinatorial strategy was employed. First a series of linker deletion mutants containing the acidic tip was created, and then utilized in an in vivo binding assay to monitor the interaction between small (RecO; 27 kDa) and large (RecG; 76 kDa) interactome partners.22, 32 Results show that a full length linker is required to bind RecG whereas shorter linker SSBs can still bind to RecO. We then compared the binding results of our mutants to that of a naturally occurring short‐linker protein, the Thermotoga maritima SSB and also to E. coli–Mycobacterium tuberculosis hybrid SSB proteins. Collectively, these results reveal novel insights into the role of the linker in target protein binding as well as insight into subdomains within the linker which are critical to IDL function. These include a section that could adopt a polyproline type II helix, repeats that impart flexibility and tensile strength and also PXXP motifs to facilitate binding specificity.
Consequently, a model is proposed whereby the linker(s) of an SSB tetramer bind to the OB‐folds present in either a neighboring SSB or a member of the interactome. The common feature in these interactions are the PXXP motifs in the intrinsically disordered linker of SSB and the OB‐fold of the target protein. Here binding occurs in a manner analogous to eukaryotic SH3 domains binding PXXP‐containing protein ligands. When binding of a linker to the OB‐fold of another SSB occurs, this results in rapid and cooperative ssDNA binding, producing a stable complex that can resist displacement by a variety of enzymes that might otherwise damage the exposed portion of the genome. When the IDLs bind to a protein such as RecG, the helicase is loaded onto the DNA, leading to the rescue of stalled replication forks. Therefore, the linker domain of SSB connects the seemingly disparate roles of ssDNA and target protein binding by SSB using a common mechanism.
Results
RecO and SSB bind in vivo
The RecO interaction with SSB in vitro has been demonstrated previously.32, 33 To determine whether binding also occurs in vivo, as shown previously for PriA and RecG, an identical approach was employed.7 To test this, expression strains were made by transforming high copy number plasmids expressing either wild type or N‐terminally his‐tagged SSB into E. coli strains. Then, high copy number plasmids expressing his‐ or wild type RecO were transformed separately into wild type and his‐SSB cells, respectively. One liter cultures of cells expressing both proteins were grown, lysed and the cleared cell lysates subjected to Ni‐sepharose chromatography. After extensive washing, proteins were eluted using a linear, imidazole gradient as described in the Materials and Methods. The results show that both SSB and his‐RecO coeluted from the column [Fig. 1(A)]. When the tag was present on the C‐terminus of RecO (i.e., RecO‐his), coelution was not observed, suggesting that this end of the protein being involved in binding to SSB [Fig. 1(B)32, 33]. A vanishingly small amount of SSB could be detected and the resulting analysis shows that binding decreased 67‐fold compared to his‐RecO [Fig. 1(E)]. Coelution of SSB and RecO was observed when the histidine tag was present on the N‐terminus of either protein [Figs. 1(A,C)]. Analysis of the gels shows that when his‐RecO was used, the ratio of RecO to SSB was 1.7 ± 0.5 [Fig. 1(A,E)]. When the tag was on SSB, the ratio of RecO:SSB in the eluted fractions was 1.4 ± 0.4 [Fig. 1(C,E)]. Our previous work with RecG and PriA demonstrates that the SSB‐partner complexes exist in vivo and do not form following cell lysis.7 Therefore, the data presented in Figure 1 show that RecO binds to SSB in vivo.
Figure 1.
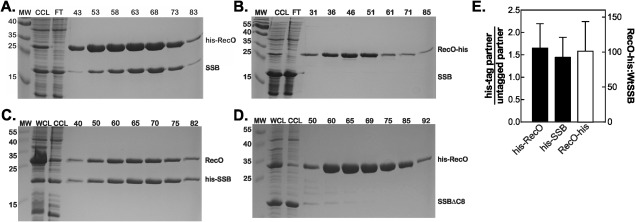
SSB binds to RecO in vivo. The 1‐L cultures of cells expressing RecO and SSB were grown to early log phase, IPTG added to 500 µM and growth continued until early stationary phase. Cells were harvested by centrifugation, lysed and the cleared cell lysate applied to a 5‐mL nickel column as described in the Materials and Methods. Proteins were then eluted using an imidazole gradient following extensive washing to remove unbound proteins. Aliquots from various fractions throughout the purification were subjected to electrophoresis. The resulting Coomassie stained, 15% SDS‐PAGE gels of the purifications are presented. (A), hisRecO binds to SSB; (B), RecO‐his does not bind to SSB; (C), RecO binds to hisSSB; (D), formation of the RecO‐SSB complex requires the highly conserved and acidic SSB tip.; (E), Analysis of the gels in panels A–C. For each analysis, only the five central lanes of the peak were analyzed and the ratios averaged. MW, molecular weight marker; WCL, whole cell lysate; CCL, cleared cell lysate; FT, flow through; numbers, indicate fraction numbers from the peak elution profile. Proteins were eluted using a linear imidazole gradient from 30 to 500 mM.
RecO‐SSB complex formation requires the presence of the SSB C‐terminus
In vitro studies show that SSBΔC8, a mutant which lacks the last eight residues of SSB, does not form a complex with RecO.32 Previous work has shown that binding to the RecG and PriA helicases in vivo requires the presence of the C‐terminal eight residues of SSB.7 To determine whether these residues are also required for complex formation between SSB and RecO in vivo, we made dual‐expression strains, replacing wild type SSB with SSBΔC8. One liter cultures of cells expressing SSBΔC8 and his‐RecO were grown, lysed and the cleared cell lysates subjected to Ni Sepharose chromatography as before. The results show that his‐RecO eluted off the column as expected, but that these fractions contained little or no SSBΔC8 [Fig. 1(D)]. There is however, a small amount of SSBΔC8 found in the fractions eluted from the column at the front end of the peak. This indicates that there is a weak interaction between RecO and SSBΔC8, similar to what was observed with RecG.7 Therefore, and as shown previously for RecG and PriA, binding of RecO requires that the last 8 amino acids of the acidic tip of SSB be present.7
SSB linker length appears to be critical for binding to interactome partners
As the binding of SSB to interactome partners in vivo is essential to facilitating many DNA metabolic processes, we wanted to understand the role of the linker region in target protein binding.7 To do this, we constructed a series of SSB linker mutants, designated SSB125, SSB133, SSB145, and SSB155 [Fig. 2(A,B), Supporting Information Fig. S1]. These are similar to those of the Lohman group, but differ in the deletion points and the length of the C‐terminal tip retained.23 For the proteins described herein, the subscript refers to the number of residues in each protein, counting the first methionine as position 1. Each protein contains the N‐terminal 115 residues of the protein responsible for tetramer formation and DNA binding, followed by various length linker regions and the C‐terminus (the last 10 amino acids; 5′‐PMDFDDDIPF‐3′). Wild type SSB has a linker 54 residues in length while that of mutants is 31 (SSB155; SSBΔ146–167); 21 (SSB145; SSBΔ135–167); 6 (SSB133; SSBΔ124–167); and 0 (SSB125; SSBΔ115–167). Next, we coexpressed his‐RecO separately with each of the mutants, and subjected the cleared cell lysates to nickel column chromatography.
Figure 2.
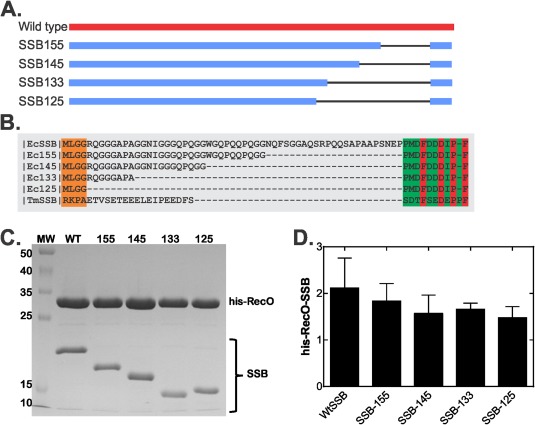
SSB linker length affects binding to RecO. (A), Schematic of the wild type and linker domain mutants. The black line demarcates the region deleted in each mutant. (B), Sequence alignment of full length and linker domain mutants of E. coli SSB with T. maritima SSB. The alignment was done using PRALINE multiple sequence alignment and the result shows residues 112–178 (E. coli numbering)66. The green boxed region indicates the C‐terminal tail with invariant residues in red. (C) SSB linker domain mutants co‐elute with his‐RecO. The 100 mL cultures were grown to early log phase and expression induced with 500 µM IPTG. Cells were harvested in early stationary phase by centrifugation and the resulting pellets lysed. The cleared cell lysates were applied to 1mL nickel columns, extensively washed and eluted with elution buffer as described in the Materials and Methods. A Coomassie stained, 15% SDS‐PAGE gel with the apex fraction of each coelution is shown. To allow direct comparison, each lane was normalized to the amount of RecO loaded. (D), Quantification of SDS‐PAGE gels such as those shown in (C).
The results show co‐elution of his‐RecO with each SSB protein consistent with in vivo complex formation [Fig. 2(C)]. In the gel shown, we have normalized each lane to the amount of his‐RecO eluted in the peak fractions from each purification. When presented in this manner, it is clear that the average ratio of RecO to SSB is 2.2 for wild type. This ratio decreases in almost linear fashion as length of the linker decreases to zero, reaching a minimum of 1.3 ± 0.4 for SSB125. Thus complete binding to RecO requires a fully intact linker.
Full length SSB binds to RecG whereas linker mutants do not
Recent work demonstrates that RecG (MW = 76,430 Da) and SSB, bind to each other in vivo in the absence of DNA.7 The mass of the RecO protein is 27,391 Da, approximately one third that of RecG. It is conceivable that the truncated SSB proteins bind to RecO due to its small size but perhaps binding to the larger RecG requires a longer linker.
To test this, we co‐expressed the histidine tagged version of each of the SSB mutants with RecG. As a positive control for the linker mutants, we repeated the experiment with full length SSB and RecG. As expected, both his‐SSB and RecG eluted from the column [Fig. 3(A,D)]. In contrast, when the linker mutants replaced full length SSB, co‐elution to the level of wild type was not observed [Fig. 3(B,C)]. In fact, binding to RecG was diminished 10‐fold for SSB155 and 26‐fold for the SSB125 mutant. A simple interpretation of these data is that longer linkers are required to bind larger interactome partner proteins. However, and as explained below, this turns out not to be the case.
Figure 3.
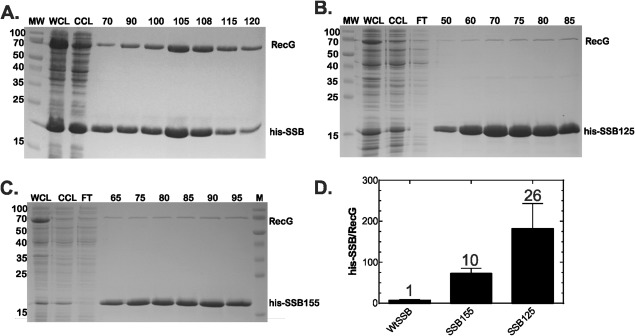
Alterations in the SSB linker eliminate binding to RecG. The 1‐L cultures of cells expressing RecG and SSB or linker mutants were grown to early log phase, IPTG added to 500 µM and growth continued until early stationary phase. Cells were harvested by centrifugation, lysed and the cleared cell lysate applied to a 5‐mL nickel column as described in the Materials and Methods. Proteins were then eluted using an imidazole gradient following extensive washing to remove unbound proteins. Aliquots from various fractions throughout the purification were subjected to electrophoresis. The resulting Coomassie stained, 12% SDS‐PAGE gels of the purifications are presented. (A) RecG binds to full‐length SSB as shown previously.7 (B) RecG does not bind appreciably to SSB125. (C) RecG does not bind appreciably to SSB155. MW, molecular weight marker; WCL, whole cell lysate; CCL, cleared cell lysate; FT, flow through; numbers, indicate fraction numbers from the peak elution profile.
Key components of the linker are required for optimal function
To understand why the linker mutants bind to RecO but not to RecG, two separate sequence analyses were done. First, we examined the primary amino acid sequence of SSB focusing on the C‐terminal 69 residues. This analysis shows that this region is over‐represented for Gly 24.6%, Gln 17.4%, Pro 14.5%, and to a lesser extent, Ala and Ser [8.7 and 5.8%, respectively; Fig. 4(A)]. The presence and spacing of these residues in the N‐terminal half of this region, ending at residues 148 and 149 (Phe and Ser, respectively), is consistent with the formation of polyproline II helices (PPII) found in proteins such as collagen.34 However, the spacing of the proline residues in collagen occurs at every fourth position which is not the case for SSB. Instead, we observed that glycine, glutamine and arginine occur in those positions in SSB. A recent study has shown that these amino acids can substitute for proline without disrupting a model PPII helix.35 As one strand of a collagen fiber is essentially a PPII helix, we wanted to determine whether this region of SSB could be modeled on a collagen‐like peptide.36, 37 Indeed, the SSB sequence can adopt a PPII helix that superimposes well with the peptide, with an RMSD = 0.8 Angstroms for the backbone atoms (Supporting Information Fig. S3). In contrast, the C‐terminal 30 residues of SSB downstream of F148/S149 could not be modeled on the collagen peptide using the same approach (data not shown).
Figure 4.
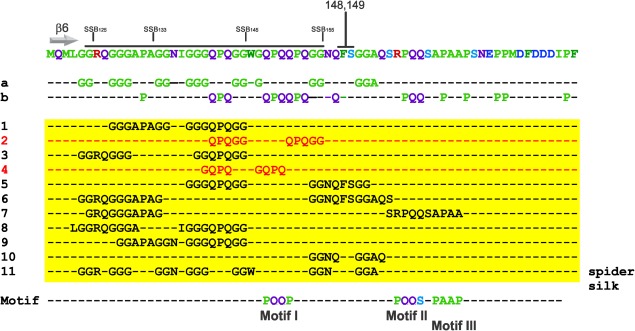
The linker of EcSSB has a specialized sequence composition. The sequence of the C‐terminal 69 residues of EcSSB (top line) contains repetitive elements consisting of glycine, proline and glutamine. Sequence analysis of the protein was done using REPRO at http://www.ibi.vu.nl/programs/.38 The position of beta sheet 6 is indicated.34, 43 Lines a and b illuminate the over‐represented residues in the SSB C‐terminus (explained in the next). Lines 1–11 (yellow box) show a subset of the repeated sequence elements identified using REPRO.35, 38 The PXXP motifs were identified by eye. The amino acids spanning the putative PPII‐helix are indicated by the black line and the positions of the deletions in the linker mutants are also shown.
Second, and as the gly, pro and gln residues appear in clusters in the SSB C‐terminal domain (Fig. 4, lines a and b), we analyzed the entire 69 residue region for repeats using REPRO, which identifies protein sequence repeats using a graph‐based iterative clustering procedure.38 Eleven of the identified repeats are shown in Figure 4 (lines 1–11; yellow box). Some are these are identical (highlighted in red), while the remaining identified repeats possess a high degree of similarity with one another (quasi‐repeats), for example, repeats 1 and 10. We also noticed the presence of seven hydrophilic GGX repeats (line 11). In addition, of the first ten repeats, nine cluster in the N‐terminal half of the IDL sequence upstream of F148. Likewise, six of the seven GGX repeats also occur in this region of the protein.
Similar repeats containing G, P, and Q have been identified in several eukaryotic proteins such as the X‐type HMW subunit of wheat gluten, spider silk protein and ω‐protein where they have been shown to confer important structural features and special functions in addition to conferring elastomeric properties to that region of the protein.39 The over‐representation of gly, gln, pro, and ser residues and the presence of the repeats, may impart similar elastomeric properties to the C‐terminus of SSB, enabling it to interact with a large range of partners of different sizes.
Finally, we also identified three PXXP motifs: PQQP, PAAP and the similar, PQQS (Fig. 4, motif). Two of these are deleted in SSB155 and all three are absent in SSB145. In summary, these analyses suggest that in addition to length, the sequence composition of the SSB linker is critical to protein–protein interactions.
TmSSB binds to EcRecO in vivo
To understand whether linker length or sequence composition is more critical to binding, we decided to test these independently. First, to evaluate the role of linker length in protein binding, we selected an SSB that had a naturally occurring short linker region relative to the E. coli protein. For this purpose, we selected the Thermotoga maritima SSB (TmSSB) which has a linker 22 residues in length, approximately the same as that of SSB145 [Fig. 2(B), Supporting Information Fig. S1]. In addition, the last six residues of TmSSB are 50% identical to that of EcSSB. Correspondingly, we cloned the Thermotoga RecG protein, which is similar to EcRecG, but has additional N‐terminal residues of unknown function.40
To test binding, the TmRecG and his‐TmSSB proteins were expressed in E. coli and the resulting cleared cell lysate subjected to nickel column chromatography. The results show that as for the E. coli proteins, Thermotoga RecG and SSB coelute although the amount of RecG eluted is significantly lower [Fig. 5(A)]. The ratio of TmSSB:TmRecG is on average, 25 whereas for Ec proteins, the average was 7 [Fig. 5(D)]. Next, we tested binding of TmSSB to EcRecG. As before, cleared cell lysates were subjected to nickel column chromatography and proteins eluted with a linear imidazole gradient. The resulting SDS‐PAGE gel shows a significant level of TmSSB eluted and only a small, but detectable level of EcRecG [Fig. 5(B)]. The ratio of TmSSB: EcRecG eluted is 39 ± 3 and this is comparable to what we observed for SSB155 where the ratio was 70 ± 10 (Fig. 3). This suggests that binding of TmSSB to EcRecG is impaired.
Figure 5.
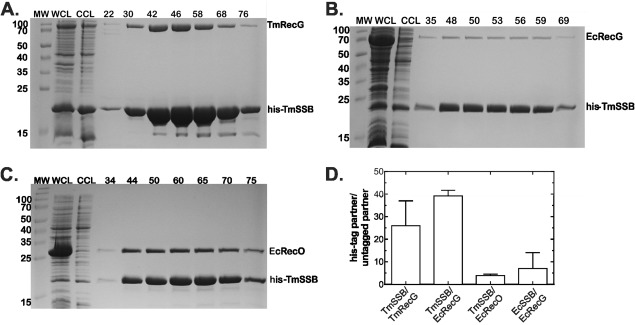
TmSSB forms stable complexes with TmRecG and EcRecO but not EcRecG. The 1‐L cultures of cells expressing RecG (Ec or Tm) with his‐TmSSB were grown to early log phase, IPTG added to 500 µM and growth continued until early stationary phase. Cells were harvested by centrifugation, lysed and the cleared cell lysate applied to a 5‐mL nickel column as described in the Materials and methods. Proteins were then eluted using an imidazole gradient following extensive washing to remove unbound proteins. Aliquots from various fractions throughout the purification were subjected to electrophoresis. Coomassie stained, 15% SDS‐PAGE gels showing various stages during the purification are presented. (A) TmRecG binds to TmSSB. (B) EcRecG does not bind appreciably to TmSSB. (C) TmSSB binds to EcRecO. (D), Analysis of the gels in panels A–C. The data for EcSSB/EcRecG are from column 1, Figure 3(D) and are presented here for comparison. MW, molecular weight marker; WCL, whole cell lysate; CCL, cleared cell lysate; numbers indicate fraction numbers from the peak elution profile.
Next, to test binding to the smaller RecO protein and as the T. maritima genome does not contain recO, EcRecO had to be used instead. The results from the nickel column show that the EcRecO coeluted with TmSSB and the ratio of SSB:RecO was 3.9 ± 0.6 [Fig. 5(C)]. However, the amount of SSB was in excess of RecO indicating that binding was not stoichiometric as we observed for full length E. coli proteins [Fig. 1(E)]. This ratio is twofold higher than what was observed for the SSB145 linker mutant [Fig. 2(D)]. Because the sequences of the linkers in the TmSSB and SSB145 proteins are different while the lengths are similar [Fig. 2(B)], these data suggest that the sequence of the linker is more important than length for target protein binding, as suggested by the sequence analyses.
Binding of SSB to EcRecO requires more than the acidic tip
To further understand the role of sequence composition of the linker region in target protein binding, we utilized a series of five hybrid SSB proteins and determined their ability to bind EcRecO in vivo. These hybrid SSBs are combinations of the E. coli and Mycobacterium tuberculosis proteins and are shown schematically in Figure 6(A).41, 42 The sequences of each hybrid aligned to full length E. coli SSB are shown in Supporting Information Figure S2. In both instances, MtSSB is shown for comparison only and was not studied here. We selected MtSSB as the protein has been well studied in vivo and in vitro, its N‐terminal core is similar to that of EcSSB and the last six residues of the acidic tip are 67% identical. The hybrid proteins are designated EM followed by a number. EM‐1 and 2 are control proteins with altered core domains and otherwise E. coli linker and C‐termini, while the test proteins EM‐3, 4, and 5 have chimeric linker regions as explained below.
Figure 6.
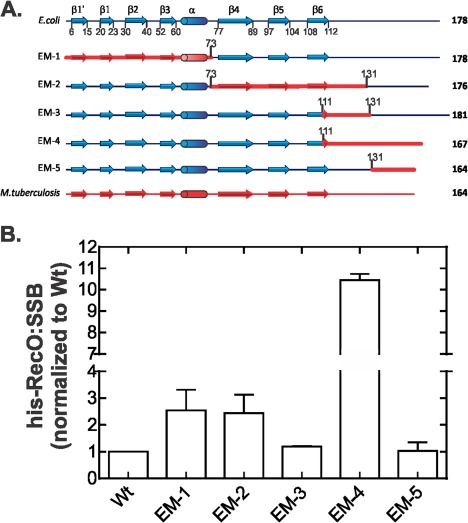
The sequence composition of the EcSSB linker influences binding to RecO. (A) Schematic of EcSSB, five Mt‐Ec‐SSB hybrid proteins and MtSSB is shown. Residue numbering is from the E. coli sequence with methionine as 1. Numbers immediately above the hybrid proteins demarcates where the sequence changes from E. coli to M. tuberculosis. (B) Some hybrid proteins bind to EcRecO while others do not. Quantification of the Coomassie‐stained gels of apex fractions from each coelution of his‐RecO and the five hybrid SSB proteins is shown. The 100 mL cultures of his‐RecO and each of the five hybrid were grown separately to early log phase and expression induced with 500 µM IPTG. Cells were harvested in early stationary phase by centrifugation and the resulting pellets lysed. The cleared cell lysates were applied to 1‐mL nickel columns, extensively washed and eluted with elution buffer as described in the Materials and methods. Eluted fractions were subjected to electrophoresis in 15% SDS‐PAGE gels.
Hybrid proteins EM‐1 and EM‐2 each have an E. coli C‐terminus and split core domains [Fig. 6(A)]. For EM‐1, the N‐terminal 73 residues are Mycobacterial in origin with the remainder of the protein from E. coli. In contrast, for EM‐2, the C‐terminal part of the core, corresponding to residues 73–131, is from MtSSB. EM‐3 is an otherwise E. coli protein with only part of beta sheet 6 and the downstream sequence from the Mycobacterium protein replacing the corresponding region. EM‐4 has part of beta sheet 6 as well as the C‐terminus from M. tuberculosis. Finally, EM‐5 is an E. coli protein with only its C‐terminal 33 amino acids replaced with the Mycobacterial sequence. Each of the hybrids selected forms homotetramers, retains binding to ssDNA and with the exception of EM‐2, are functional when expressed in E. coli.41, 42
To test whether these hybrid proteins could bind to EcRecO, separate strains expressing his‐RecO and the five hybrid proteins were made, grown, lysed, and subjected to nickel column chromatography as before. Analysis of the resulting gels reveals some surprising results [Fig. 6(B)]. First, binding of the EM‐1 and EM‐2 proteins to RecO is reduced 2.5‐fold. This was surprising given that EM‐2 is inactive in vivo.41, 42 Second, and perhaps the most surprising result is that the efficiency of binding of EM‐4 is reduced 10‐fold, while EM‐3 and EM‐5 bind as well as wild type E. coli SSB. The failure of EM‐4 to bind is not simply due to a length change because the EM‐5 hybrid is three residues shorter and it retains wild type levels of binding. Nor is it the presence of the Mycobacterial terminal eight residues replacing the E. coli acidic tip, as EM‐5 binds well. Instead, residues 111–131 from MtSSB in combination with the Mycobacterial C‐terminus provide insight into how the linker may be involved in protein‐protein interactions.
Perturbation of the putative PPII helix‐like region eliminates binding
To gain further insight into the contributing factors affecting binding in the hybrids, sequence analysis for composition and repetitive elements was done. Analysis of the MtSSB sequence reveals it to be over‐represented for Ser (19%), Gly (18%), Ala (14%), and Pro (12%). Furthermore, and not surprisingly, the REPRO analysis identified repeats that were different from that of EcSSB and, in contrast to E. coli, these repeats are clustered in the C‐terminal half of the sequence (Supporting Information Fig. S4). The clustering within this region of the C‐terminus, prompted us to ascertain whether a model could be built using collagen as a template. Surprisingly, we were able to build a model of the C‐terminal 33 residues of MtSSB using the collagen‐like peptide (Supporting Information Fig. S5). In contrast, a model of the core‐proximal region of the linker of this SSB could not be built (data not shown).
Next we analyzed hybrid proteins 3, 4, and 5. Replacement of residues 114–130 as in the EM‐3 protein does not significantly alter the over‐representation of amino acids but eliminates five of the ten repeats identified in EcSSB and only repeats similar to 2 and 4–7 are retained. In addition, and in contrast to the wild type protein, the clusters identified occur in the C‐terminal half of the sequence (data not shown). In addition, while the region corresponding to the proposed PPII‐like helix is perturbed, the PXXP motifs are retained. Analysis of EM‐4, shows a reduction in Gln to only 2 residues, Gly and Pro are reduced while Alanine and Serine are increased. In addition, all of the repeats present in the wild type E. coli SSB C‐terminal 69 residues are eliminated (not shown). Finally, EM‐5 retains the PPII‐like region but the sequences of the PXXP motifs are all different. In summary, these data suggest that when the sequence and/or position of the proposed PP‐II helix are altered it has profound effects on SSB‐protein interactions.
To understand how the changes in sequence in each of the hybrids relative to wild type E. coli SSB could lead to the elimination of binding to RecO, we performed homology modeling of the intact hybrid proteins using Swiss‐model.36, 37 In each case, models of each hybrid were built using subunit 1 of 1QVC as a template as in this structure, residues 2–145 are visible.43 The resulting Connolly surface representations for residues 112 to the C‐terminal residue of each model are shown in Figure 7 with the same region from subunit 1 from the SSB structure 1QVC as a reference. When viewed in this way, it is evident that the N‐terminal part of this region presents as a PPII‐like helix with minimal additional secondary structure for the EcSSB and EM‐3 proteins (Fig. 7, yellow shaded region). Even though this region of SSB can adopt different conformations, residues 112–130 still present as a PPII‐like helix with minimal additional secondary structure. In contrast, the same region in the EM‐4protein does not present as a PPII‐like helix but has increased secondary structure. This results in this region being more compact and possibly more rigid, stabilized by hydrogen binding (not shown), resulting in a protein that cannot bind to RecO. Even though these are models, they suggest that the changes in primary amino acid sequence of residues 112–130 leading to disruption of the putative PPII helix, has profound effects on the ability of EcSSB to interact with target proteins.
Figure 7.
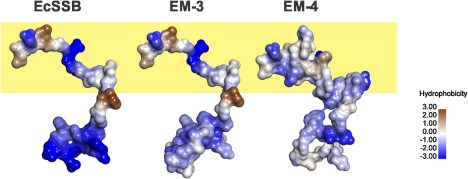
The proposed PPII helix region is important to EcSSB function. Homology modeling of the EM‐3 and 4 proteins was done at Swiss‐model in automated mode using PDB file 1QVC as a template.37, 39, 43 Models were built on the first subunit of 1QVC. As residues 1–111 in each model are identical to 1QVC they are not displayed. Instead, the Connolly surfaces of residues 110 to the C‐terminus of each model are shown with the N‐termini at the top left of each image.44, 67 For EcSSB this is to residue 145; for EM‐3 it extends to position 149, and for EM‐4 to amino acid 161. Colouring is done according to hydrophobicity as indicated and the orientation of each region is approximately the same. A sequence alignment of the hybrids to EcSSB is shown in Supporting Information Figure S2.
Discussion
The primary conclusion of this article is that the intrinsically disordered linker (IDL) connects ssDNA binding and protein–protein interactions of SSB using a common mechanism. This mechanism involves binding of the IDL of an SSB tetramer to the OB‐fold of a nearby protein as explained below.
The importance of the IDL became clear when sequence analysis revealed several previously unidentified features that impart specificity, tensile strength, and flexibility. These properties are conferred on SSB in the following ways. First, for the linker region to function correctly, either all, or a subset, of the amino acids present must be able to adopt a PPII‐like helix conformation. This may impart tensile strength when SSB tetramers associate with one another along a stretch of ssDNA or when bound to a target protein. Second, the primary amino acid sequence of the C‐terminal 69 residues arranged in various repeats, imparts flexibility possibly in a similar fashion to that observed in proteins such as wheat gluten. This enables SSB to bind to all interactome partners, regardless of their size or the position within multi‐subunit complexes and also between SSB tetramers. Finally, the presence of PXXP motifs suggests that this region of SSB is directly involved in protein‐protein interactions: either between SSB tetramers during cooperative binding to ssDNA or between SSB and interactome partners. These interactions involve binding between the PXXP regions of SSB and the OB‐fold in the target protein, either another SSB or an interactome partner.
The in vivo binding studies revealed that SSB binds to RecO in vivo, similar to what was observed previously for PriA and RecG.7 Binding was not observed when SSBΔC8 replaced wild type and when the histidine tag was present on the C‐terminus of RecO, consistent with previous work showing that this region was involved in SSB binding.32 The in vivo binding assay was subsequently used to determine the effects of deletions of residues within the linker on binding to RecO and separately, to RecG. Results show that the deletion of 21 residues eliminated binding to RecG, whereas binding to RecO was only affected when 42 or more residues were removed. To determine whether linker length is critical or whether sequence may be important, we used the Thermotoga maritima SSB. The IDL in this protein is 16–18 residues in length, comparable to that in the SSB145 mutant. In vivo binding to EcRecO was observed but this was reduced compared to full length EcSSB, and more importantly, to SSB145 as well. Surprisingly, TmSSB bound to TmRecG but not to EcRecG. T m/T m binding was reduced compared to E c/E c binding, but this was not surprising given these are thermostable proteins. Collectively, these results suggested that while the length of the linker is important for protein–protein interactions, the sequence is more critical, as illuminated below.
The analysis of the sequence of the C‐terminal 69 residues of EcSSB revealed an over‐representation of glycine, glutamine, proline, serine, and alanine. Further analysis with REPRO showed the presence of repeats of the over‐represented residues in various combinations [Fig. 4(A)]. Similar sequence composition and repeats have been found in a large number of eukaryotic proteins where they have been shown to confer elastomeric properties to that region of each protein.39 These include the flagelliform silk proteins (repeats of GPGGx), spider silk proteins (GGX), the X‐type HMW subunit of wheat gluten and ω‐protein (repeats of PGQGQQ and GQQ) and dragline protein (repeats of GPGQQ).44 Each of these repeats occurs in the linker region of E. coli SSB with most being repeated once and GGX seven times [Fig. 4(A)]. In the eukaryotic proteins, the same sequence is typically repeated many times. The presence of this collection of repeats confers elastomeric properties such as those observed in the eukaryotic proteins enabling the C‐terminal 69 residues to adopt different conformations thereby facilitating a larger range of partner proteins with which SSB can bind. This sequence composition likely contributes to the movements of the C‐terminal domain of the protein associated with ssDNA binding.45
Our analysis of the linker region of EcSSB suggests that the amino acids present in the region from Q117 to Q147 have a propensity to form a PPII‐like helix.46, 47, 48 This is supported by modeling which showed that this region could adopt a structure resembling a collagen monomer. While this analysis does not prove the existence of a PPII‐helix (experiments are underway to determine this possibility experimentally), it provides some insight into what this region of SSB could be doing. First, PP‐II helices are known to bind nucleic acids and to be involved in protein–protein interactions.34, 48, 49 Our results showing that perturbations in the sequence of this region, as well as in changes in its position relative to the core of SSB, severely impaired target protein binding is consistent with a role in protein–protein interactions. Second, the accessibility of PPII helices is greatly enhanced by the fact that they are frequently found either at the amino‐ or carboxyl termini of proteins where they form extended structures that have been described as “sticky arms.”46, 47, 48 Third, PPII‐helices are flexible, and this has been suggested to be the major feature underlying its function in protein interactions.50
However, this is not the only important component of the linker region. The identification of PXXP motifs in the C‐terminus of SSB suggests a possible mechanism for binding specificity. PXXP motifs are most well known for their ability to bind structurally conserved Src homology 3 (SH3) domains. These domains are ∼50 residue modules that are ubiquitous in biological systems and which often occur in signaling and cytoskeletal proteins in eukaryotes.48, 51, 52, 53 The SH3 domain has a characteristic fold which consists of five or six beta‐strands arranged as two tightly packed anti‐parallel beta sheets and is similar in structure to the OB‐fold.54 SH3‐like domains have been identified in several E. coli proteins, including Exonuclease I, an SSB‐interactome partner.14, 55 This prompted us to look at the crystal structures available of SSB interactome partners to determine whether they contained an OB‐fold. Indeed, each structure examined contains an OB‐fold (not shown and P.Bianco, manuscript in preparation).
Therefore, since SSB has PXXP motifs and each partner as well as SSB has an OB‐fold, we propose the following model, shown in schematic fashion in Figure 8. The linker(s) from one SSB tetramer bind to the OB‐fold of the interaction partner. When the partner is another SSB tetramer, cooperative binding to ssDNA results with multiple interactions forming a stable complex wherein the ssDNA is extremely well protected. In similar fashion, when the nearby protein is a member of the SSB interactome, storage or loading of that protein on to the DNA results, as shown for the fork rescue DNA helicase RecG.22, 56 While the OB‐fold is most well‐known for its ability to bind oligosaccharides and single stranded nucleic acids, peptide binding by an OB‐fold is not without precedent. A scan of the PDB reveals more than fifteen instances including matrix metalloproteinases, Staphylococcal enterotoxin B, and yeast RNA polymerase II.15, 57, 58, 59
Figure 8.
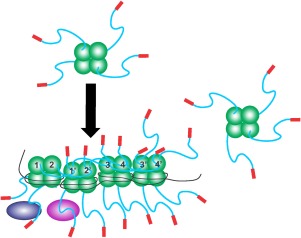
SSB linkers mediate all protein–protein interactions. Schematics of wild type SSB proteins binding to ssDNA and to partners. The colouring of SSB monomers is as follows the core domain in green, linker in blue and acidic tip in red. Here tetramers have their functional C‐terminal domains exposed in solution. Upon binding to ssDNA the IDLs of monomers 1 and 2, bind to the OB‐folds of monomers 1′ and 2′, respectively. Concurrently, the linkers of monomers 1′ and 2′ bind to the OB‐folds of monomers 3 and 4, and their IDLs bind to monomers 3′and 4′, respectively. The C‐termini of subunits 3′ and 4′ are available to bind to an incoming tetramer as shown on the right. On the opposite side of each tetramer, C‐termini are available for binding to interactome partners such as RecG or RecO (purple and blue ovals). For simplicity, SSB–SSB interactions are shown in the top subunits only, and SSB interactome partners binding in the lower subunits.
If the model suggested above is correct, then there are some obvious predictions. First, loss of these motifs should eliminate binding to interactome partners. This was clearly the case for RecG but not for RecO, indicating that other parts of the IDL may be important for binding as well. Second, removal of these motifs should negatively impact cooperative binding to ssDNA. This is exactly what was observed by the Lohman group.23 Third, mutation of the PXXP motifs should negatively impact. Preliminary data where the motifs were interrupted or replaced eliminated binding (P. Bianco, manuscript in preparation). Finally, elimination of the OB‐fold in an interacting partner should eliminate binding. Consistent, removal of the corresponding regions in both RecO and RecG eliminate binding entirely (P. Bianco, unpublished).60
In summary, we propose that the linker region of E. coli SSB is essential for optimal functioning of the protein. While previously thought of as being unimportant, our results show that this is no longer the case. SSB has two seemingly disparate roles: it binds rapidly and cooperatively to ssDNA and it binds to partner proteins that constitute the SSB interactome (Fig. 8). These two roles are not disparate but are instead, intimately linked. They are linked by the properties identified in the IDL that facilitate protein‐protein interactions. When these interactions occur between an SSB tetramer and an interactome partner, loading of that protein onto DNA takes place. When the interactions take place between SSB tetramers, cooperative ssDNA binding occurs. When these key elements—the putative PPII‐helix, the repeats and the PXXP motifs are perturbed, SSB no longer functions correctly.23
Materials and Methods
Chemicals and reagents
All chemicals were reagent grade and were made up in Nanopure water and passed through 0.2‐µm pore size filters. Ampicillin, IPTG, NaCl, Na2HPO4, tryptone, and yeast extract were from Fisher Scientific (NJ). Coomassie brilliant blue R‐250, kanamycin, lysozyme, sucrose, tris‐base, triton x‐100, sodium dodecyl sulfate were from AMRESCO (OH). EDTA, NaH2PO4, and nickel sulfate were from J.T. Baker (NJ). Sodium deoxycholic acid and imidazole were from Acros Organics (NJ). The infusion kit was from Clontech (CA). Nonidet P40 was from USB (OH). Protease and phosphatase inhibitor mini tablets were from Thermo Scientific (IL). PMSF was from Omnipur (NJ). The 1 and 5 mL HisTrap FF crude columns, Ni Sepharose 6 Fast Flow were from GE Healthcare Life Sciences (NJ). Oligonucleotides were purchased from IDT (Coralville, IA) and are listed in Supporting Information Table SI.
Cloning
A pET21a+ plasmid containing the E. coli ssb gene was obtained from Dr. James Keck (UW‐Madison). The ssb gene was amplified by PCR and subcloned into pET15b to produce his‐SSB. Positive clones were identified by restriction enzyme mapping and verified by DNA sequencing. All oligonucleotides used are listed in Supporting Information Table SI.
To create a series of truncated C‐terminal linker domain SSBs, the region comprising amino acids 113–168 was deleted in separate reactions by infusion cloning. In these reactions, a single forward primer (PB513) was used in combination with four reverse primers (PB514‐517) in separate reactions. PCR was done using the various primer combinations and Infusion to create the final construct. The mutants contain the SSB N‐terminal domain (residues 1–112), various length linker regions (residues 113–168) and the C‐terminal tail (residues 169–178). The linker domain mutants constructed were: SSB125 (53 residues deleted; final length: 125aa), SSB133 (48 residues deleted; final length: 130aa), SSB145 (33 residues deleted; final length: 145aa) and SSB155 (23 residues deleted; final length: 155aa). Positive clones were identified by restriction enzyme mapping and verified by DNA sequencing. The resulting plasmids created were: pET21a+‐SSB125, pET21a+‐SSB133, pET21a+‐SSB145, and pET21a+‐SSB155. Next, each mutant was cloned using Infusion technology into pET15b to create histidine‐tagged fusion proteins. Positive clones were identified by restriction enzyme mapping and verified by DNA sequencing.
To construct N‐terminal his6 tagged truncated SSBs, primers (PB549 and 550) were used to amplify truncated ssb genes from the vectors described above followed by Infusion cloning of the PCR fragments into pET15b at NdeI and BamHI sites.pET15b‐wt‐recO was made by amplifying genomic E. coli recO from MG1655 using primers (PB458 and 459) and inserted into pET15b at NcoI and EcoRI sites via Infusion Cloning. To create C‐terminal histidine tagged recO, the recO gene was amplified using primers (PB462 and 463) and then inserted into pET28a+ at NcoI and HindIII sites using Infusion Cloning. Positive clones were identified by restriction enzyme mapping and verified by DNA sequencing. The resulting plasmid was pET28a+ ‐his‐rec0.pUC57 plasmids containing the Thermotoga maritima (Tm) ssb and recG genes were purchased from Genescript. The original Thermotoga sequences were codon optimized for expression in E. coli to produce SSB (Q9WZ73); and RecG (Q9WY48). To create N‐terminal his‐TmSSB, the pUC57 Tmssb gene was amplified by PCR using primers (PB523 and 525) and inserted into NdeI and BamHI sites of the pET15b vector (Novagen) using Infusion cloning (Clontech). To create a pET28a+ plasmid expressing TmRecG, pUC57 containing TmrecG gene was amplified by PCR using (PB526 and 528) and inserted into NcoI and EcoRI sites of the pET28a+ vector using Infusion cloning. Positive clones were identified by restriction enzyme mapping and DNA sequencing. The resulting clones were: pET15b‐his‐Tmssb, and pET28a+‐TmrecG.
Construction of the E. coli–M. tuberculosis hybrid genes was described previously.41, 42, 43 These genes were amplified by PCR and cloned by Infusion into pET15b. Positive clones were identified by restriction enzyme mapping and DNA sequencing. The resulting plasmids and strains are listed in Supporting Information Tables SII and SIII, respectively.
Dual plasmid expression
To facilitate coexpression of his‐RecO with potential binding partners, pET28a+‐his‐recO was transformed into Tuner (λDE3) cells. A colony in which high levels of expression of his‐RecO was observed was selected and made competent. Next, these cells were transformed separately with test plasmids encoding wtSSB, SSB125, SSB133, SSB145, and SSB155. Next, expression of his‐RecO and the SSB proteins were determined using 5‐mL cultures. Fresh overnights were used to inoculate LB+ antibiotics (ampicillin and kanamycin, 250 and 25 μg mL−1, respectively) and cells grown at 37°C for 3 h. IPTG was added to either 100 μM, 500 μM, or 1 mM final, followed by an additional 2 h of growth. Protein expression levels were assessed using SDS‐PAGE. A colony in which high levels of both his‐RecO and the SSBs were observed was selected and grown overnight in LB+ antibiotics and 0.2% glucose. The overnights were used to inoculate 0.1 and 2 L cultures the following day at a 1:100 ratio.
To facilitate coexpression of TmhisSSB with potential binding partners, Tuner (λDE3) cells that expressed his‐Tmssb from the pET15b plasmid were made competent and transformed separately with pET28a+‐TmrecG, pET28a+‐EcrecG, or pET28a+‐EcrecO plasmids. Next, expression was determined as described above except IPTG was used at 500μM. Protein expression levels were assessed using SDS‐PAGE. A colony in which overexpression of both his‐TmSSB and the target binding proteins was observed was selected and grown overnight as described above. The overnights were used to inoculate 1‐ and 2‐L cultures the following day at a 1:100 ratio.
0.1, 1, and 2 liters cell growth
The 1, 10, and 20 mL of fresh overnight cultures were added to 100 mL, 1 L, and 2 L of LB, respectively. LB contained ampicillin (250 μg mL−1) and kanamycin (25 μg mL−1). Cells were grown at 37°C with vigorous shaking. When the OD600 was between 0.4 and 1, IPTG was added to 500 μM final, and growth continued for an additional 3 h. Cells were harvested by centrifugation at 4°C and cell pellets were resuspended in lysis buffer (50 mM Tris‐HCl (pH 8.0), 20% sucrose) using 2.05 mL g−1 of wet cell weight. Resuspended cells were frozen at −20°C or stirred at 4°C overnight for lysis the following day.
Elution of proteins using an imidazole gradient
The 100 mL, 1 L, and 2 L cultures were lysed and the cleared cell lysate was subjected to affinity chromatography using a 1 mL or 5 mL HisTrap FF crude column. To lyse the cells, lysozyme (1 mg mL−1 final), benzonase 5 μL, Mg(OAc)2 (4 mM final), CaCl2 (2 mM final), PMSF (1 mM final), protease inhibitor mini tablets (50 mL cells/tablet) were added and mixture stirred for 30 min at 4°C. Deoxycholate (0.5% final) and triton x‐100 (0.1% final) were added slowly followed by stirring for 40 min. Imidazole and NaCl were then added to 30 and 600 mM final, respectively, and stirred for 5 min. The whole cell lysate of each was centrifuged at 35,000g at 4°C for 30 min. The cleared cell lysate was loaded onto a nickel column equilibrated in Binding Buffer (20 mM sodium phosphate; 600 mM NaCl; 30 mM Imidazole; pH 7.4). The column was sequentially washed with 400 mL binding buffer, 350 mL binding buffer with 0.2% NP40 and 250 mL binding buffer only. A linear gradient of 30–500 mM of Imidazole was used to elute bound proteins from the column. Proteins were assessed by SDS‐PAGE. Following electrophoresis, gels were stained with Coomassie brilliant blue, destained, and photographed. Protein fractions were pooled and then precipitated in 70% ammonium sulfate for short term storage or further processing.
Small scale, step‐elution of proteins
Cell lysis, centrifugation and buffers were identical to that of larger cultures with volumes adjusted accordingly. The cleared cell lysate was loaded onto the 1 mL HisTrap FF crude column. The column was washed with 45 mL binding buffer. Proteins were eluted using 6 mL of Elution buffer containing 500 mM Imidazole. The 1 mL fractions were collected and aliquots subjected to SDS‐PAGE. The majority of protein(s) eluted in the third fraction.
Analysis of coomassie stained gels
Photographs of stained, SDS‐PAGE gels were analyzed using the Gels Analysis function in Fiji.61, 62 Here, the area under each peak was determined from the densitometric trace of each lane. This value was then divided by the molecular weight of each protein to correct for the different amounts of Coomassie dye being present in bands, assuming each protein stained equally well with Coomassie. The ratio of protein A: protein B was then determined as is displayed in various graphs throughout the article. Each coelution experiment was repeated two to five times, with a minimum of three lanes per gel analyzed and combined to yield the resulting graphs.
Supporting information
Supporting Information
References
- 1. Shereda RD, Kozlov AG, Lohman TM, Cox MM, Keck JL (2008) SSB as an organizer/mobilizer of genome maintenance complexes. Crit Rev Biochem Mol Biol 43:289–318. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2. Chase JW, Williams KR (1986) Single‐stranded DNA binding proteins required for DNA replication. Annu Rev Biochem 55:103–136. [DOI] [PubMed] [Google Scholar]
- 3. Meyer RR, Laine PS (1990) The single‐stranded DNA‐binding protein of Escherichia coli . Microbiol Rev 54:342–380. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4. Kowalczykowski SC, Dixon DA, Eggleston AK, Lauder SD, Rehrauer WM (1994) Biochemistry of homologous recombination in Escherichia coli . Microbiol Rev 58:401–465. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5. Lohman T, Ferrari M (1994) Escherichia coli single‐stranded DNA‐binding protein: multiple DNA‐binding modes and cooperativities. Ann Rev Biochem 63:527–570. [DOI] [PubMed] [Google Scholar]
- 6. Costes A, Lecointe F, McGovern S, Quevillon‐Cheruel S, Polard P (2010) The C‐terminal domain of the bacterial SSB protein acts as a DNA maintenance hub at active chromosome replication forks. PLoS Genet 6:e1001238. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7. Yu C, Tan HY, Choi M, Stanenas AJ, Byrd AK, K DR, Cohan CS, Bianco PR (2016) SSB binds to the RecG and PriA helicases in vivo in the absence of DNA. Genes Cells 21:163–184. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8. Sancar A, Williams KR, Chase JW, Rupp WD (1981) Sequences of the ssb gene and protein. Proc Natl Acad Sci USA 78:4274–4278. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9. Curth U, Genschel J, Urbanke C, Greipel J (1996) In vitro and in vivo function of the C‐terminus of Escherichia coli single‐stranded DNA binding protein. Nucleic Acids Res 24:2706–2711. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10. Raghunathan S, Kozlov A, Lohman T, Waksman G (2000) Structure of the DNA binding domain of E. coli SSB bound to ssDNA. Nat Struct Biol 7:648–652. [DOI] [PubMed] [Google Scholar]
- 11. Chrysogelos S, Griffith J (1982) Escherichia coli single‐strand binding protein organizes single‐stranded DNA in nucleosome‐like units. Proc Natl Acad Sci USA 79:5803–5807. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12. Kuznetsov S, Kozlov A, Lohman T, Ansari A (2006) Microsecond dynamics of protein–DNA interactions: direct observation of the wrapping/unwrapping kinetics of single‐stranded DNA around the E. coli SSB tetramer. J Mol Biol 359:55–65. [DOI] [PubMed] [Google Scholar]
- 13. Umezu K, Kolodner RD (1994) Protein interactions in genetic recombination in Escherichia coli. Interactions involving RecO and RecR overcome the inhibition of RecA by single‐stranded DNA‐binding protein. J Biol Chem 269:30005–30013. [PubMed] [Google Scholar]
- 14. Genschel J, Curth U, Urbanke C (2000) Interaction of E. coli single‐stranded DNA binding protein (SSB) with exonuclease I. The carboxy‐terminus of SSB is the recognition site for the nuclease. Biol Chem 381:183–192. [DOI] [PubMed] [Google Scholar]
- 15. Handa P, Acharya N, Varshney U (2001) Chimeras between single‐stranded DNA‐binding proteins from Escherichia coli and Mycobacterium tuberculosis reveal that their C‐terminal domains interact with uracil DNA glycosylases. J Biol Chem 276:16992–16997. [DOI] [PubMed] [Google Scholar]
- 16. Kantake N, Madiraju MV, Sugiyama T, Kowalczykowski SC (2002) Escherichia coli RecO protein anneals ssDNA complexed with its cognate ssDNA‐binding protein: a common step in genetic recombination. Proc Natl Acad Sci USA 99:15327–15332. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17. Glover B, McHenry C (1998) The chi psi subunits of DNA polymerase III holoenzyme bind to single‐stranded DNA‐binding protein (SSB) and facilitate replication of an SSB‐coated template. J Biol Chem 273:23476–23484. [DOI] [PubMed] [Google Scholar]
- 18. Witte G, Urbanke C, Curth U (2003) DNA polymerase III chi subunit ties single‐stranded DNA binding protein to the bacterial replication machinery. Nucleic Acids Res 31:4434–4440. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19. Cadman CJ, McGlynn P (2004) PriA helicase and SSB interact physically and functionally. Nucleic Acids Res 32:6378–6387. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20. Shereda RD, Bernstein DA, Keck JL (2007) A central role for SSB in Escherichia coli RecQ DNA helicase function. J Biol Chem 282:19247–19258. [DOI] [PubMed] [Google Scholar]
- 21. Suski C, Marians KJ (2008) Resolution of converging replication forks by RecQ and topoisomerase III. Mol Cell 30:779–789. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22. Buss J, Kimura Y, Bianco P (2008) RecG interacts directly with SSB: implications for stalled replication fork regression. Nucleic Acids Res 36:7029–7042. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23. Kozlov AG, Weiland E, Mittal A, Waldman V, Antony E, Fazio N, Pappu RV, Lohman TM (2015) Intrinsically disordered C‐terminal tails of E. coli single‐stranded DNA binding protein regulate cooperative binding to single‐stranded DNA. J Mol Biol 427:763–774. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24. Savvides SN, Raghunathan S, Futterer K, Kozlov AG, Lohman TM, Waksman G (2004) The C‐terminal domain of full‐length E. coli SSB is disordered even when bound to DNA. Protein Sci 13:1942–1947. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25. Kelman Z, Yuzhakov A, Andjelkovic J, O'Donnell M (1998) Devoted to the lagging strand‐the subunit of DNA polymerase III holoenzyme contacts SSB to promote processive elongation and sliding clamp assembly. EMBO J 17:2436–2449. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26. Bhattacharyya B, George NP, Thurmes TM, Zhou R, Jani N, Wessel SR, Sandler SJ, Ha T, Keck JL (2014) Structural mechanisms of PriA‐mediated DNA replication restart. Proc Natl Acad Sci USA 111:1373–1378. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27. Marceau AH, Bahng S, Massoni SC, George NP, Sandler SJ, Marians KJ, Keck JL (2011) Structure of the SSB‐DNA polymerase III interface and its role in DNA replication. EMBO J 30:4236–4247. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 28. Shereda RD, Reiter NJ, Butcher SE, Keck JL (2009) Identification of the SSB binding site on E. coli RecQ reveals a conserved surface for binding SSB's C terminus. J Mol Biol 386:612–625. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29. Su XC, Wang Y, Yagi H, Shishmarev D, Mason CE, Smith PJ, Vandevenne M, Dixon NE, Otting G (2014) Bound or free: interaction of the C‐terminal domain of Escherichia coli single‐stranded DNA‐binding protein (SSB) with the tetrameric core of SSB. Biochemistry 53:1925–1934. [DOI] [PubMed] [Google Scholar]
- 30. Shishmarev D, Wang Y, Mason CE, Su XC, Oakley AJ, Graham B, Huber T, Dixon NE, Otting G (2014) Intramolecular binding mode of the C‐terminus of Escherichia coli single‐stranded DNA binding protein determined by nuclear magnetic resonance spectroscopy. Nucleic Acids Res 42:2750–2757. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31. Lu D, Keck JL (2008) Structural basis of Escherichia coli single‐stranded DNA‐binding protein stimulation of exonuclease I. Proc Natl Acad Sci USA 105:9169–9174. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32. Ryzhikov M, Koroleva O, Postnov D, Tran A, Korolev S (2011) Mechanism of RecO recruitment to DNA by single‐stranded DNA binding protein. Nucleic Acids Res 39:6305–6314. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33. Ryzhikov M, Korolev S (2012) Structural studies of SSB interaction with RecO. Methods Mol Biol 922:123–131. [DOI] [PubMed] [Google Scholar]
- 34. Adzhubei AA, Sternberg MJ, Makarov AA (2013) Polyproline‐II helix in proteins: structure and function. J Mol Biol 425:2100–2132. [DOI] [PubMed] [Google Scholar]
- 35. Brown AM, Zondlo NJ (2012) A propensity scale for type II polyproline helices (PPII): aromatic amino acids in proline‐rich sequences strongly disfavor PPII due to proline‐aromatic interactions. Biochemistry 51:5041–5051. [DOI] [PubMed] [Google Scholar]
- 36. Schwede T, Kopp J, Guex N, Peitsch MC (2003) SWISS‐MODEL: an automated protein homology‐modeling server. Nucleic Acids Res 31:3381–3385. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37. Biasini M, Bienert S, Waterhouse A, Arnold K, Studer G, Schmidt T, Kiefer F, Cassarino TG, Bertoni M, Bordoli L, Schwede T (2014) SWISS‐MODEL: modelling protein tertiary and quaternary structure using evolutionary information. Nucleic Acids Res 42:W252–W258. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38. George RA, Heringa J (2000) The REPRO server: finding protein internal sequence repeats through the Web. Trends Biochem Sci 25:515–517. [DOI] [PubMed] [Google Scholar]
- 39. Matsushima N, Yoshida H, Kumaki Y, Kamiya M, Tanaka T, Izumi Y, Kretsinger RH (2008) Flexible structures and ligand interactions of tandem repeats consisting of proline, glycine, asparagine, serine, and/or threonine rich oligopeptides in proteins. Curr Protein Pept Sci 9:591–610. [DOI] [PubMed] [Google Scholar]
- 40. Singleton MR, Scaife S, Wigley DB (2001) Structural analysis of DNA replication fork reversal by RecG. Cell 107:79–89. [DOI] [PubMed] [Google Scholar]
- 41. Rex K, Bharti SK, Sah S, Varshney U (2014) A genetic analysis of the functional interactions within Mycobacterium tuberculosis single‐stranded DNA binding protein. PLoS One 9:e94669. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42. Bharti SK, Rex K, Sreedhar P, Krishnan N, Varshney U (2011) Chimeras of Escherichia coli and Mycobacterium tuberculosis single‐stranded DNA binding proteins: characterization and function in Escherichia coli . PLoS One 6:e27216. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43. Matsumoto T, Morimoto Y, Shibata N, Kinebuchi T, Shimamoto N, Tsukihara T, Yasuoka N (2000) Roles of functional loops and the C‐terminal segment of a single‐stranded DNA binding protein elucidated by X‐Ray structure analysis, J Biochem 127, 329–335. [DOI] [PubMed] [Google Scholar]
- 44. Tatham AS, Shewry PR (2000) Elastomeric proteins: biological roles, structures and mechanisms, Trends Biochem Sci 25, 567–571. [DOI] [PubMed] [Google Scholar]
- 45. Green M, Hatter L, Brookes E, Soultanas P, Scott DJ (2016) Defining the Intrinsically Disordered C‐Terminal Domain of SSB Reveals DNA‐Mediated Compaction, J Mol Biol 428, 357–364. [DOI] [PubMed] [Google Scholar]
- 46. Matsushima N, Creutz CE, Kretsinger RH (1990) Polyproline, beta‐turn helices. Novel secondary structures proposed for the tandem repeats within rhodopsin, synaptophysin, synexin, gliadin, RNA polymerase II, hordein, and gluten, Proteins 7, 125–155. [DOI] [PubMed] [Google Scholar]
- 47. Adzhubei AA, Sternberg MJ (1993) Left‐handed polyproline II helices commonly occur in globular proteins, J Mol Biol 229, 472–493. [DOI] [PubMed] [Google Scholar]
- 48. Kay BK, Williamson MP, Sudol M (2000) The importance of being proline: the interaction of proline‐rich motifs in signaling proteins with their cognate domains, FASEB‐J 14, 231–241. [PubMed] [Google Scholar]
- 49. Hicks JM, Hsu VL (2004) The extended left‐handed helix: a simple nucleic acid‐binding motif, Proteins 55, 330–338. [DOI] [PubMed] [Google Scholar]
- 50. Bochicchio B, Ait‐Ali A, Tamburro AM, Alix AJ (2004) Spectroscopic evidence revealing polyproline II structure in hydrophobic, putatively elastomeric sequences encoded by specific exons of human tropoelastin, Biopolymers 73, 484–493. [DOI] [PubMed] [Google Scholar]
- 51. Dalgarno DC, Botfield MC, Rickles RJ (1997) SH3 domains and drug design: ligands, structure, and biological function, Biopolymers 43, 383–400. [DOI] [PubMed] [Google Scholar]
- 52. Sudol M (1998) From Src Homology domains to other signaling modules: proposal of the ‘protein recognition code', Oncogene 17, 1469–1474. [DOI] [PubMed] [Google Scholar]
- 53. Ponting CP, Aravind L, Schultz J, Bork P, Koonin EV (1999) Eukaryotic signalling domain homologues in archaea and bacteria. Ancient ancestry and horizontal gene transfer, Journal of Molecular Biology 289, 729–745. [DOI] [PubMed] [Google Scholar]
- 54. Agrawal V, Kishan RK (2001) Functional evolution of two subtly different (similar) folds, BMC Struct Biol 1, 5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55. Breyer WA, Matthews BW (2000) Structure of Escherichia coli exonuclease I suggests how processivity is achieved, Nat Struct Biol 7, 1125–1128. [DOI] [PubMed] [Google Scholar]
- 56. Sun Z, Tan HY, Bianco PR, Lyubchenko YL (2015) Remodeling of RecG Helicase at the DNA Replication Fork by SSB Protein, Sci Rep 5, 9625. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57. Papageorgiou AC, Tranter HS, Acharya KR (1998) Crystal structure of microbial superantigen staphylococcal enterotoxin B at 1.5 A resolution: implications for superantigen recognition by MHC class II molecules and T‐cell receptors, J Mol Biol 277, 61–79. [DOI] [PubMed] [Google Scholar]
- 58. Fernandez‐Catalan C, Bode W, Huber R, Turk D, Calvete JJ, Lichte A, Tschesche H, Maskos K (1998) Crystal structure of the complex formed by the membrane type 1‐matrix metalloproteinase with the tissue inhibitor of metalloproteinases‐2, the soluble progelatinase A receptor, EMBO J 17, 5238–5248. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59. Cramer P, Bushnell DA, Kornberg RD (2001) Structural basis of transcription: RNA polymerase II at 2.8 angstrom resolution, Science 292, 1863–1876. [DOI] [PubMed] [Google Scholar]
- 60. Lu D, Windsor MA, Gellman SH, Keck JL (2009) Peptide inhibitors identify roles for SSB C‐terminal residues in SSB/exonuclease I complex formation, Biochemistry 48, 6764–6771. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61. Kozlov AG, Jezewska MJ, Bujalowski W, Lohman TM (2010) Binding specificity of Escherichia coli single‐stranded DNA binding protein for the chi subunit of DNA pol III holoenzyme and PriA helicase., Biochemistry 49, 3555–3566. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62. Schindelin J, Arganda‐Carreras I, Frise E, Kaynig V, Longair M, Pietzsch T, Preibisch S, Rueden C, Saalfeld S, Schmid B, Tinevez JY, White DJ, Hartenstein V, Eliceiri K, Tomancak P, Cardona A (2012) Fiji: an open‐source platform for biological‐image analysis, Nat Methods 9, 676–682. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63. Sievers F, Wilm A, Dineen D, Gibson TJ, Karplus K, Li W, Lopez R, McWilliam H, Remmert M, Soding J, Thompson JD, Higgins DG (2011) Fast, scalable generation of high‐quality protein multiple sequence alignments using Clustal Omega, Mol Syst Biol 7, 539. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64. Robert X, Gouet P (2014) Deciphering key features in protein structures with the new ENDscript server, Nucleic Acids Res 42, W320–324. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 65. Bella J, Eaton M, Brodsky B, Berman HM (1994) Crystal and molecular structure of a collagen‐like peptide at 1.9 A resolution, Science 266, 75–81. [DOI] [PubMed] [Google Scholar]
- 66. Simossis VA, Heringa J (2005) PRALINE: a multiple sequence alignment toolbox that integrates homology‐extended and secondary structure information., Nucleic Acids Res 33, W289–294. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67. Connolly ML (1983) Solvent‐accessible surfaces of proteins and nucleic acids. Science 221, 709–713. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supporting Information