

The understanding of where and how auditory scene analysis is accomplished is of broad interest to neuroscientists. In this paper, we systematically investigated neuronal coding of multiple vocalizations degraded by two distinct noises at various signal-to-noise ratios in nonhuman primates. In the process, we uncovered heterogeneity of single-unit representations for different auditory scenes yet homogeneity of responses across the population.
Keywords: primary auditory cortex, vocalizations, noise interference, signal-to-noise ratio, single unit
Abstract
Robust auditory perception plays a pivotal function for processing behaviorally relevant sounds, particularly with distractions from the environment. The neuronal coding enabling this ability, however, is still not well understood. In this study, we recorded single-unit activity from the primary auditory cortex (A1) of awake marmoset monkeys (Callithrix jacchus) while delivering conspecific vocalizations degraded by two different background noises: broadband white noise and vocalization babble. Noise effects on neural representation of target vocalizations were quantified by measuring the responses' similarity to those elicited by natural vocalizations as a function of signal-to-noise ratio. A clustering approach was used to describe the range of response profiles by reducing the population responses to a summary of four response classes (robust, balanced, insensitive, and brittle) under both noise conditions. This clustering approach revealed that, on average, approximately two-thirds of the neurons change their response class when encountering different noises. Therefore, the distortion induced by one particular masking background in single-unit responses is not necessarily predictable from that induced by another, suggesting the low likelihood of a unique group of noise-invariant neurons across different background conditions in A1. Regarding noise influence on neural activities, the brittle response group showed addition of spiking activity both within and between phrases of vocalizations relative to clean vocalizations, whereas the other groups generally showed spiking activity suppression within phrases, and the alteration between phrases was noise dependent. Overall, the variable single-unit responses, yet consistent response types, imply that primate A1 performs scene analysis through the collective activity of multiple neurons.
NEW & NOTEWORTHY The understanding of where and how auditory scene analysis is accomplished is of broad interest to neuroscientists. In this paper, we systematically investigated neuronal coding of multiple vocalizations degraded by two distinct noises at various signal-to-noise ratios in nonhuman primates. In the process, we uncovered heterogeneity of single-unit representations for different auditory scenes yet homogeneity of responses across the population.
in natural settings, behaviorally relevant acoustic signals usually co-occur with other acoustic sources. Therefore, the auditory system's ability to process multiple competing sound sources is closely linked with our ability to perceive individual sounds. Although humans and animals exhibit reliable auditory detection against substantial amounts of noise, the underlying neural representation of sound in such contexts is still not well understood.
Individual auditory neurons are believed to represent behaviorally relevant, natural sounds effectively, particularly animal vocalizations and human speech. Animal call/song-selective neurons have been discovered in multiple sensory system models, such as crickets, frogs, songbirds, guinea pigs, and nonhuman primates (Feng et al. 1990; Grace et al. 2003; Grimsley et al. 2012; Libersat et al. 1994; Newman and Wollberg 1973; Wang et al. 1995). To cope with distortion induced by noise, mammalian auditory cortex appears to be actively involved in recovering the disrupted upstream neural representation (Anderson et al. 2010). Neurons in primary auditory cortex (A1) have been found to be sensitive to the masking component of complex stimuli (Bar-Yosef and Nelken 2007), and neuronal adaptation to stimulus statistics has been identified to be responsible for building noise-invariant responses (Rabinowitz et al. 2013; Willmore et al. 2014). In the auditory cortex of humans, low-frequency (<4 Hz) neural activity has been suggested to provide neural cues for stable speech recognition against both energetic and informational masking (Ding and Simon 2012, 2013). This line of research is more advanced in avian models: individual neurons in higher avian auditory brain regions have been identified with robust encoding of noisy vocalizations (Moore et al. 2013; Schneider and Woolley 2013). Furthermore, multiple complex background maskers affect neuronal discriminability differently, but behavioral discriminability is degraded to the same degree regardless of masking type (Narayan et al. 2007).
Relatively few studies, however, have investigated reliable single-neuron discrimination of complex sounds in noise in nonhuman primates. One study has explored neural coding of degraded marmoset twitter calls in anesthetized marmosets, showing robust neural responses to vocalizations at medium signal-to-noise ratios (SNRs) (Nagarajan et al. 2002). How noisy vocalizations are encoded in awake marmoset auditory cortex remains uncertain. In addition, only one type of vocalization in a single type of noise was studied with limited levels of SNR; therefore, no generalized conclusions can be drawn for the quantitative effects of noise on the neural representation of natural calls.
Marmoset vocalizations contain acoustic information over distributed frequencies and a wide range of time scales (Agamaite et al. 2015; DiMattina and Wang 2006). Neurons in marmoset A1 exhibit multiple encoding strategies (Barbour and Wang 2003b; Wang 2007; Watkins and Barbour 2011), with a majority of them responsive to vocalizations. Here, we evaluate the effects of white Gaussian noise (WGN) and four-marmoset-talker babble (Babble) on the auditory cortical representation of conspecific vocalizations in awake, adult common marmoset monkeys. Babble noise covers a similar frequency range as natural vocalizations, whereas WGN has considerably different statistics and has historically been considered to be a poor stimulus for driving neurons in higher auditory areas (Miller and Schreiner 2000; Theunissen et al. 2000; Valentine and Eggermont 2004). We predicted that Babble noise would generally result in more disruption of the neural representation of targeted vocalizations than WGN and that a subclass of vocalization-responsive neurons would preferentially be responsible for robust vocalization encoding in the face of both types of noise. In particular, we predicted that neurons robustly encoding vocalizations across intensity might also encode them robustly across noise classes. Whereas we did discover clear evidence of robust vocalization encoding in awake marmoset A1, the form that this encoding takes appears to be considerably more complex than originally anticipated.
MATERIALS AND METHODS
Surgery and recording.
Two female adult (7 yr old) common marmoset monkeys (Callithrix jacchus) were used as subjects. All training, recording, and surgical procedures complied with U.S. National Institutes of Health Guide for the Care and Use of Laboratory Animals and were approved by the Animal Studies Committee of Washington University in St. Louis. Subjects were initially trained to sit upright in a custom, minimally restraining primate chair inside a double-walled, sound-attenuation booth (120a-3; IAC Acoustics, Bronx, NY) for the same duration as would be used for physiology recording. After they had become accustomed to this setup, a head cap for recording was surgically affixed to the skull of each subject. The location of the vasculature running within the lateral sulcus was marked indelibly on the skull. The animals were allowed to take sufficient time following surgery to recover their normal behavior, and postoperative analgesia was provided. With the use of the lateral sulcus as a guide, microcraniotomies (<1 mm diameter) were drilled one at a time through the skull over the temporal lobe with a custom drill. All physiology experiments were conducted through these microcraniotomies, which enabled extremely stable recordings. After each recording session, the active recording hole was partially filled with ointment and dental cement to prevent excess tissue growth and infections. Each microcraniotomy was permanently sealed with dental cement before the next craniotomy was drilled. In this way, we largely preserved the intactness of the bone and the landmarks. The animal's awake state was monitored with a camera throughout the recording session by observing its eye movement. Recording was paused as soon as any drowsiness was observed during the passive paradigm, which was signaled by frequent eye blinking and eyelid drooping. Recording restarted after the animal had resumed the awake state. The location of A1 was identified anatomically based on lateral sulcus and bregma landmarks and confirmed with physiological mapping (Stephan et al. 2012).
Within each microcraniotomy, a single, high-impedance, tungsten-epoxy, 125-μm electrode (∼5 MΩ at 1 kHz; FHC, Bowdoin, ME) was advanced perpendicularly to the cortical surface by a hydraulic system. Microelectrode signals were amplified using an alternating current differential amplifier (Model 1800; A-M Systems, Sequim, WA), with the differential lead attached to a grounding screw. Single-unit action potentials were sorted online using manual, template-based, spike-sorting hardware and software (Alpha Omega Engineering, Nazareth, Israel). Each single unit was confirmed by its consistent, distinctive action-potential shape. The median SNR for single units recorded with this preparation is 24.5 dB. When a template match occurred, the spike-sorting hardware relayed a transistor–transistor logic pulse to the digital signal processor system (RX6; Tucker-Davis Technologies, Alachua, FL) that temporally aligned recorded spike times (2.5 μs accuracy) with stimulus delivery. Our single units were collected at depths between 400 and 2,000 μm below the dural surface, which in our experience, includes superficial supragranular and deep granular layers. Recording locations within the head cap were varied daily, eventually covering all regions of interest.
Acoustic stimulation.
Two types of noise—WGN and Babble—were mixed individually with five natural marmoset-conspecific vocalizations from distinct acoustic classes (Trillphee, Peeptrill, Trilltwitter, Tsikstring, and Peepstring) in MATLAB (MathWorks, Natick, MA) to generate noisy vocalizations at eight different SNRs (−15 to 20 dB at 5 dB intervals, plus pure noise and pure vocalizations). The five vocalizations were selected from a vocalization repertoire of 20 vocalizations; these vocalizations were recorded from the marmoset colony maintained at The Johns Hopkins University School of Medicine (Baltimore, MD). The average spectral power of noise at each SNR level Pnoise(SNR) was calculated relative to the average spectral power of pure vocalization Pvoc, as in Eq. 1. The waveform of noise at each SNR Anoise(SNR) was further scaled and added to the waveform of clean vocalization Avoc to generate the acoustic waveform of noisy vocalization ASNR at each SNR level in Eqs. 2 and 3. The resulting ASNR was normalized between −1 and 1, stored on disk, and then delivered at the appropriate absolute sound-pressure level using an amplifier and programmable attenuator
| (1) |
| (2) |
| (3) |
The five calls were selected to represent most of the acoustic features of the marmoset vocalization repertoire (Agamaite et al. 2015). Among the five vocalizations, Trillphee, Trilltwitter, and Peepstring have durations ∼1,000 ms; Peeptrill and Tsikstring are two relatively shorter calls, with duration ∼400 ms. In terms of complexity, Trillphee is a simple call, as it contains no temporal gaps. Peeptrill, Trilltwitter, Tsikstring, and Peepstring are all considered compound calls, composed of multiple acoustic elements separated by gaps of <100 ms. Because of the acoustical variety of these calls, results in common among them are likely to be reflective of the repertoire as a whole.
To distinguish the onset responses induced by the components of noise and vocalization in the synthesized stimuli, a 250-ms interval of noise alone was concatenated to either end of each noisy vocalization. Babble sharing certain acoustic attributes of vocalizations was created by shuffling superimposed, 50 ms-long pieces of four different, randomly selected vocalization instances (Trillpeep, Peeptrill, Twitterpeep, and Trillphee), which were different from the five test vocalizations. Both WGN and Babble were synthesized with durations equivalent to the longest vocalization—the Trillphee. For the other four vocalizations, WGN and Babble were truncated to the same length as each vocalization.
Frozen WGN and Babble noises were used on each trial and for each single unit. The overall sound level for all noisy vocalization representations was fixed by an initial probe to identify the sound levels at which each unit was most responsive. The noise level decreased as SNR increased because signal power was held constant. The noise and vocalization level at each SNR for overall sound level at 75 dB sound pressure level (SPL) is displayed in Table 1.
Table 1.
Noise and vocalization level at each SNR for overall sound level at 75 dB SPL
| SNR | Vocalization, dB SPL | Noise, dB SPL | Vocalization + SNR, dB SPL |
|---|---|---|---|
| Vocalization | 75 | 75 | |
| 20 dB | 74.96 | 54.96 | 75 |
| 15 dB | 74.86 | 59.86 | 75 |
| 10 dB | 74.59 | 64.59 | 75 |
| 5 dB | 73.81 | 68.81 | 75 |
| 0 dB | 71.99 | 71.99 | 75 |
| −5 dB | 68.81 | 73.81 | 75 |
| −10 dB | 64.59 | 74.59 | 75 |
| −15 dB | 59.86 | 74.86 | 75 |
| Noise | 75 | 75 |
Experimental procedure.
Acoustic stimuli were delivered in free field through a loudspeaker (601 S3 series; Bowers & Wilkens, Worthing, West Sussex, UK), located 1 m along the midline of and in front of the animal's head. The output of the speaker was calibrated so that the maximum sound level delivered was ∼105 dB SPL with a flat frequency response from 60 Hz to 32 kHz (Watkins and Barbour 2011). Single-unit activities in A1 were recorded from two awake, adult marmoset monkeys while they passively listened to the playback of natural and synthesized conspecific vocalizations. Auditory neurons were detected based on their responses, evoked by pure tones and vocalizations. Once an auditory neuron was isolated, its characteristic frequency was estimated using random spectrum stimuli (Barbour and Wang 2003a) and/or pure tones to confirm that the response field of the neuron overlapped with at least some vocalization energy. Next, the rate-level function of each of the five vocalizations was measured with intensities ranging from 15 to 75 dB SPL in 20 dB SPL steps and in random order for 10 repetitions. The sound level evoking the highest firing rate (within each vocalization) to more than one-half of the vocalizations was selected to deliver noisy vocalizations, which were also randomly delivered at between 5 and 10 repetitions.
Analysis.
Because rate driven by vocalizations in A1 does not necessarily surpass mean spontaneous rate, we implemented a relatively loose criterion for defining responsive neurons in our dataset. Neurons generating at least one spike in the presence of a clean vocalization in at least 50% of the trials were defined to be responsive. A total of n = 326 single units were extracellularly isolated from A1 of two marmosets. After applying the responsiveness criterion for each of the five vocalizations—216 (Trillphee), 191 (Peeptrill), 222 (Trilltwitter), 200 (Tsikstring), and 224 (Peepstring)—single units were included for further data analysis. The lenient criterion is an effort to include as many well-isolated neurons into analysis while excluding extremely low-spiking (i.e., nonresponsive) neurons. A stricter responsive criterion, which requires that the vocalization-driven response rate be 1 or 2 SD above the spontaneous response rate, yielded very similar results as the lenient criterion for every analysis that we performed. All data analyses were conducted in MATLAB R2014a (MathWorks).
For each unit in the dataset, mean spontaneous rates and mean discharge rates (excluding the 2 concatenated noise portions) were measured for each stimulus. We adopted a correlation metric proposed by Schreiber et al. (2003) to evaluate neuronal response reliability across repetitions. Spike trains of neural responses to the same stimulus, presented n times, were first convolved with a Gaussian filter having a window length of 50 ms to obtain vectors (i = 1, …, n). Correlations between all pairs of filtered spike-train vectors and were computed and normalized by the norms of these two vectors, and the resulting average correlation value was defined as response reliability of that single unit to a particular stimulus, as displayed in Eq. 4. If either or was empty, then the correlation between them was set to zero. This correlation value ranges from zero to one, with higher values denoting more consistent responses across trials
| (4) |
To evaluate the influence of noise upon neural representation of vocalizations, we quantified the amount of vocalization encoded by single neurons at a particular SNR level by calculating an extraction index (EI) adapted from a similar study in songbirds (Schneider and Woolley 2013). This metric is based on the repetition-averaged peristimulus time histogram (PSTH) of neural response with a time bin of 50 ms. Different window bins of 5, 10, 20, and 100 ms were also evaluated, which yielded qualitatively similar results. In this manuscript, we only report results based on 50 ms time bins. The initial and final 250-ms-long noise segments were again excluded from the PSTH during this analysis. EI was computed as in Eqs. 5 and 6
| (5) |
| (6) |
where Dn-snr is the distance between PSTH of noise and PSTH snr of vocalization at a particular SNR, whereas Dv-snr is the distance between PSTH of pure vocalization and PSTH snr of vocalization at a particular SNR. EI is bounded between −1 and 1: a positive value indicates that the neural response to noisy vocalization is more vocalization like, and a negative value implies that the neural response is more noise like. The EI profile for each single unit was determined by computing EI at every SNR level. The normalized inner product was used to compute distance between and snr, as shown in Eq. 6. For computational purposes, empty PSTHs were replaced by a vector generated from a Gaussian distribution with a mean rate of 0 and SD of 0.001 so that we could report the distance between 2 empty PSTHs as 0. To reduce the artifact introduced by using an artificial PSTH vector, while calculating distance between an empty PSTH and nonempty PSTH, the nonempty PSTH was augmented with the same artificial vector used to replace the empty PSTH. We calculated slope and SNR threshold at EI = 0 to describe each EI profile quantitatively. Slope was defined as the change in the EI values divided by the change in the SNR levels (between −10 and 15 dB). The threshold was estimated using interpolation based on the SNR levels, where maximum and minimum EI values occurred, excluding noise and vocalization alone.
To probe the response patterns of individual neurons, we further implemented an exploratory analysis based on the calculated EI profiles. By applying k-means clustering on the blended EI profiles from both noise conditions together, we obtained subgroups of EI profiles, which divided single units into clusters according to the similarity of their EI profiles. Similarity was quantified by Euclidean distance. The number of clusters was determined by the mean-squared error (MSE) of clustering, as in Eq. 7, where n is the number of neurons, EIPi is the EI profile of a single neuron, and EĪP̄cluster−i is the mean EI profile of the cluster into which this neuron is categorized
| (7) |
The number of clusters was selected based on two criteria. First, the overall number of clusters was narrowed down to those where the decrease of MSE flattens, according to the elbow method (Tibshirani et al. 2001). The appropriate number of clusters was further selected from the candidates, which yielded response groups with distinct functionality in terms of their resistance to noise. This analysis was performed by pooling EI profiles from all five vocalizations together for each unit. Hierarchical clustering was also implemented and yielded very similar results; therefore, we report the results of k-means clustering only.
To examine if a link exists between neurons' intensity-invariance and noise resistance, discriminative analysis of single units responding to vocalizations at varied intensities was implemented to compute an intensity-invariance index (Billimoria et al. 2008). This value represents the discriminability of neural representations of a particular vocalization at multiple intensities from all of the other vocalization-intensity instances. Neural responses to five vocalizations at four intensity levels (15, 35, 55, and 75 dB SPL) were truncated to the same length as the vocalization with the shortest duration. To calculate the intensity-invariance index for a particular vocalization, a single trial of neural responses at 75 dB SPL was randomly selected for each of five vocalizations as master templates, and all of the remaining trials were classified into the vocalization type as the most similar master trial based on cosine similarity, an angular distance metric. The process was repeated 100 times. Classification accuracies—the proportions of correctly classified trials—were obtained for the investigated vocalization at each intensity level. The deviation of the classification accuracies Ci (i = 15, 35, and 55 dB SPL) was measured at all tested intensities from the classification accuracy Cmaster (master = 75 dB SPL) of the intensity of the master template, denoted as I in Eq. 8, where NAtten is the number of tested intensities. I was linearly scaled so that it takes values between zero and one and therefore represents an intensity-invariance index.
| (8) |
The alteration in the number of spiking activities induced by noisy vocalizations relative to clean vocalizations was quantified by measuring the firing rates within and between vocalization phrases. For each vocalization, manual segmentation marked the temporal boundaries of phrases and gaps between phrases according to their spectrograms. Although Trillphee is a complete call without temporal gaps between call phrases, there is an ∼30-ms silent period before the onset of the vocalization. That silent period was used as the “gap” for the Trillphee vocalization. The firing-rate change within each phrase and gap was computed for noisy vocalizations at 20 dB SNR relative to clean vocalizations. The resulting differences in firing rates within and between phrases were averaged across trials, phrases/gaps, and vocalizations.
The clustering of individual neuron response types to noisy vocalizations was also conducted upon a subset of neurons with intensity-invariance indices above 0.7. The resulting response types were very similar to that using all of the available neurons without additional intensity-invariance criterion (data not shown).
Normality was verified by the Lilliefors test. Unless otherwise indicated, hypothesis testing was conducted using a two-sided Wilcoxon signed-rank test. The significance criterion was set to 0.05.
RESULTS
In this study, we investigated the impact of two types of noise—WGN and Babble—on the neural encoding of marmoset-conspecific vocalizations. We recorded the responses of 326 marmoset A1 single units to 5 vocalizations degraded by WGN and marmoset Babble, and units were selected for further analysis, according to the response criterion for each vocalization. Power spectra of vocalizations and noises are shown in Fig. 1A. Spectrograms of vocalization Trillphee at all of the tested SNR levels under two noise conditions that we studied are also displayed in Fig. 1B. For each vocalization, we only included responsive neurons to that particular vocalization in the analysis. To measure the degree of degradation that noise contributed to the neural representation of vocalizations, we calculated the amount of vocalization encoded by each unit as a function of SNR.
Fig. 1.

Acoustic stimuli used to investigate auditory cortex. A: power spectra of 5 vocalizations (Voc; solid lines), WGN (gray lines), and Babble noise (dashed lines). Background noises were truncated to have the same duration as each vocalization. The temporal waveform of each vocalization is displayed above each power spectrum. B: example spectrogram of vocalization Trillphee in noise at 10 different SNR levels, including pure noise and pure vocalization. The first column is Trillphee with WGN as background noise, and the second column is with Babble as background noise. The temporal waveforms of WGN and Babble are shown below each column.
Mean discharge rate and response reliability both decrease as SNR decreases.
We recorded single-unit responses in A1 to five vocalizations embedded within the two different background noises at multiple SNR levels (−15 to 20 dB, at 5 dB intervals). Figure 2A shows an example of a typical neuronal response. For this example unit, all vocalizations presented alone evoked neural responses that were locked to particular acoustic features, which can be observed from the temporal patterns formed by aligned spikes in the raster plots. Neural encoding of vocalizations was particularly susceptible to the presence of Babble noise, given that spikes corresponding to the acoustic features of target vocalizations started to diminish even at 20 dB SNR, where the noise component was quite small. Responses at lower SNR values appeared to be mainly dominated by the Babble noise component. In comparison, this particular unit's responses to WGN were not as strong as responses to vocalizations. As a result, the temporal firing patterns in response to vocalization components were maintained at lower WGN SNR levels. Additionally, response nonlinearities can be discerned. For example, responses to vocalization Peepstring between −5 and −15 dB SNR under the WGN condition elicited stronger activity than in response to vocalization or WGN present alone.
Fig. 2.

Clean vocalizations generally elicit the most spiking and the most reliable spiking. A: example spike raster plots of 1 unit's responses to 5 noisy vocalizations under 2 different noise conditions. Each point denotes an action potential generated by this unit. Black dots with white background are the neural activities in silence. Black dots with light-blue background are neural activities occurring during 2 concatenated noise presentations. Red dots with light-blue background are spikes driven by noisy vocalizations. Responses to vocalizations and noises alone are highlighted with dark-gray background for distinction. B: mean discharge rates to 5 vocalizations at multiple SNRs (means ± SE). Lines with filled circles are discharge rates of vocalizations in Babble. Lines with open circles are discharge rates of vocalizations in WGN. W*/B* indicates mean discharge rate to WGN/Babble (W/B; respectively) alone is significantly lower than vocalization alone (see text). C: mean response reliabilities to 5 vocalizations at multiple SNRs (means ± SE). The same color and line type denotations as in B are depicted. W*/B* indicates mean response reliability to WGN/Babble (W/B; respectively) alone is significantly lower than vocalization alone (see text).
To quantify noise effects on noisy vocalization-induced discharge rates as a function of SNR, we calculated the mean discharge rate (i.e., absolute spiking rate) evoked during noisy vocalizations, averaged over all single units, in Fig. 2B. Generally, mean discharge rates of single neurons in response to vocalizations masked with both noises decreased as SNR decreased. Discharge rates of pure WGN were significantly lower than discharge rates of all pure vocalizations (Trillphee: Z = −5.31, P = 1.10 × 10−7; Peeptrill: Z = −7.88, P = 3.40 × 10−15; Trilltwitter: Z = −8.91, P = 5.10 × 10−19; Tsikstring: Z = −7.95, P = 1.84 × 10−15; Peepstring: Z = −9.09, P = 9.04 × 10−22). With regard to Babble, the same trend was observed for four out of five vocalizations (Trillphee: Z = −0.438, P = 0.661; Peeptrill: Z = −5.71, P = 1.10 × 10−8; Trilltwitter: Z = −5.37, P = 7.74 × 10−8; Tsikstring: Z = −3.91, P = 9.10 × 10−5; Peepstring: Z = −4.28, P = 1.83 × 10−5). It is noteworthy that under Babble noise conditions, more spikes were evoked, on average, by 20 dB SNR rather than by clean vocalizations. One extreme case is vocalization Trillphee, to which the neural responses were as strong as or even stronger at all SNR levels than the vocalization component alone. In addition, the mean responses to WGN alone were relatively weaker than responses to Babble but were still comparable. This is somewhat surprising, given the traditional view that WGN is a poor stimulus for activating auditory neurons at higher processing levels (Miller and Schreiner 2000; Theunissen et al. 2000; Valentine and Eggermont 2004).
Due to the stochastic nature of neural spike timing, neurons produce varied spike trains in response to a stimulus presented multiple times (de Ruyter van Steveninck et al. 1997; Oram et al. 1999). We also examined the noise-induced alteration in response reliability of neurons to vocalizations. By computing the mean value of pairwise correlation between individual spike trains, we quantified stability of single-neuron response as a function of SNR in Fig. 2C. In the WGN condition, more noise resulted in decreased neural response reliability for all five vocalizations. Additionally, pure WGN induced significantly lower response reliability than pure vocalizations (Trillphee: Z = −7.15, P = 8.60 × 10−13; Peeptrill: Z = −9.05, P = 1.50 × 10−19; Trilltwitter: Z = −10.3, P = 4.46 × 10−25; Tsikstring: Z = −9.53, P = 1.54 × 10−21; Peepstring: Z = −10.6, P = 5.04 × 10−26). Although the response reliability degradation induced by Babble noise was weaker, the resulting values were still significantly lower than those of most pure vocalizations except Trillphee (Trillphee: Z = −1.88, P = 0.0608; Peeptrill: Z = −4.46, P = 8.34 × 10−6; Trilltwitter: Z = −5.69, P = 1.26 × 10−8; Tsikstring: Z = −4.97, P = 6.54 × 10−7; Peepstring: Z = −5.08, P = 3.81 × 10−7).
To summarize, vocalizations generally elicited more spikes and more reliable spikes than either noise alone in this neuronal population. A more prominent increase in neuronal discharge rate and response reliability was observed as SNR increased in the WGN case compared with Babble. Finally, rates and reliability elicited by WGN were both higher than anticipated at this high level of auditory processing.
Low correlation between single units' resistance to different noises.
We next studied the ability of single units to encode vocalizations consistently despite the influence of background noises by calculating an EI profile for each neuron as a function of SNR. The EI measurement was previously implemented in a songbird study and was demonstrated to be able to reflect single neurons' vocalization-coding ability more accurately than average discharge rate, given that both vocalization and noise components elicited strong responses in that study (Schneider and Woolley 2013). Essentially, EI is designed to quantify whether a trial-averaged response is more vocalization evoked or more noise evoked. For example, an EI of 1 suggests that the evaluated response is evoked by vocalization alone, and an EI of −1 suggests that the response is evoked by noise alone. By calculating EI at each SNR level, we obtained an EI profile for each neuron. A mean EI profile value was further computed at SNR levels ranging from −15 to 20 dB SNR to obtain an overall picture of the pairwise relationship between single-neuron responses to vocalizations mixed with WGN and Babble. The results are shown in Fig. 3.
Fig. 3.

Babble tends to disrupt vocalization encoding more than WGN. A: scatterplot of mean of EI profile values under WGN and Babble conditions. Neuron counts are indicated above each plot. Filled dots and open dots indicate data from 2 monkeys. B: boxplots of EI profile mean values under WGN (W) and Babble (B) conditions. Neuron counts are the same as in A. Boxplots with dotted, open circles display distribution of mean EI values under WGN condition, and boxplots with filled circles display distribution of mean EI values with background of Babble noise. Open, black circles and dotted, open, black circles denote outliers. *Mean EI values under WGN and Babble are significantly different (see text).
We visualized the data in two ways. In Fig. 3A, EI profile mean values of single units under WGN and Babble were first scattered so that the pairwise relationship can be better observed and quantified by Pearson R correlation. This analysis indicates that a weak but significant positive correlation exists between single units' rejection of WGN and Babble for vocalization Trillphee, Trilltwitter, and Tsikstring (Trillphee: R = 0.413, P = 3.09 × 10−10; Trilltwitter: R = 0.424, P = 5.03 × 10−11; Tsikstring: R = 0.332, P = 2.41 × 10−6), whereas the correlation is low for vocalization Peeptrill and Peepstring (Peeptrill: R = 0.191, P = 8.70 × 10−3; Peepstring: R = 0.130, P = 4.41 × 10−2). This result implies that a relatively large variability exists in the relationship of individual neurons' resistance to disruption by WGN and Babble. In other words, the ability to predict a single unit's responses to vocalizations in WGN based on its responses to vocalizations in Babble is limited and vice versa.
Additionally, Fig. 3A demonstrates that more points are located below the diagonal than above. We can better observe this trend in Fig. 3B across vocalizations, where medians of population EI mean values are mostly positive in WGN, whereas medians of population EI mean values are mostly negative in Babble. A paired Wilcoxon signed-rank test shows that the mean EI values under the two noises are significantly different for four out of five vocalizations (Trillphee: Z = 7.43, P = 1.13 × 10−13; Peeptrill: Z = 5.04, P = 4.55 × 10−7; Trilltwitter: Z = 7.27, P = 3.59 × 10−13; Tsikstring: Z = 1.69, P = 0.0900; Peepstring: Z = 5.67, P = 1.39 × 10−8). Therefore, whereas there is large variability among single-unit responses to vocalizations under different noise conditions, a majority of neurons is more resistant to vocalization degradation by WGN than by Babble.
Intensity invariance is insufficient to account for noise resistance.
Acoustic signals can be varied in terms of a rich set of parameters. Previous evidence points to the existence of intensity-invariant neurons that retain neural responses to natural stimuli delivered at multiple intensities (Billimoria et al. 2008; Sadagopan and Wang 2008; Schneider and Woolley 2010; Watkins and Barbour 2011). Single units with rate-level functions measured using vocalizations were included in this portion of analysis. Neural responses were truncated to the length of the shortest vocalization to determine the intensity-invariance index, which was scaled for each vocalization separately and was bounded between zero and one. The higher the index value, the better the unit is at discriminating vocalizations in an intensity-invariant manner. We associated the intensity-invariance index of single units with their noise resistance as reflected by mean EI profile values using Pearson correlation in Fig. 4. Generally, a weak but significant positive correlation between intensity invariance and noise resistance exists in the WGN condition (Trillphee: R = 0.376, P = 3.72 × 10−8; Peeptrill: R = 0.198, P = 7.60 × 10−3; Trilltwitter, R = 0.370, P = 3.81 × 10−8; Tsikstring: R = 0.198, P = 6.00 × 10−3; Peepstring: R = 0.349, P = 1.90 × 10−7). On the other hand, no significant correlation exists between intensity invariance and noise resistance in the Babble situation (Trillphee: R = 0.00860, P = 0.904; Peeptrill: R = −0.142, P = 0.0569; Trilltwitter, R = 0.0328, P = 0.638; Tsikstring: R = 0.0542, P = 0.455; Peepstring: R = 0.0626, P = 0.364). The relatively low correlations in both noise cases imply that intensity invariance and noise resistance reflect two mostly separate processes. The weak but significant correlations for WGN raise the possibility that these processes are related and perhaps overlap in some way, at least under the conditions evaluated by WGN.
Fig. 4.

Intensity invariance correlates poorly with noise resistance. A: intensity invariance vs. noise resistance in WGN condition. Filled circles and open circles indicate data from 2 different monkeys. B: intensity invariance vs. noise resistance in Babble condition. Filled circles and open circles indicate data from 2 different monkeys.
Selecting the number of neural response groups.
Babble noise was demonstrated to induce more distortion in neural responses to vocalizations than WGN in terms of EI values. Next, we examined each single unit's EI profile more closely to elucidate in detail the large variability of neural responses to vocalizations in noise. To investigate the potential patterns embedded within EI profiles, we implemented unsupervised k-means clustering on the raw EI profiles across SNR levels from −15 to 20 dB SNR. EI profiles with similar shapes were grouped together automatically by this method to minimize the distance between group centroids and individual profiles. According to the MSE values for different numbers of clusters in Fig. 5A, two, three, and four numbers of clusters all appear to be potential candidates.
Fig. 5.

Selecting the number of response groups. A: mean squared error of EI profile clustering as a function of number of clusters for each vocalization under 2 noise conditions. B: population-averaged EI profile clusters of Trillphee vocalization with a different number of response groups. Numbers of response groups vary between 2 and 5 from left to right.
To select the appropriate number of clusters for further analysis, we first examined cluster numbers of two, three, four, and five. The resulting population-averaged EI profiles for vocalization Trillphee are displayed in Fig. 5B. In all cases, this analysis revealed two clusters that appeared to encode either the vocalization or the noise preferentially. Higher cluster numbers revealed intermediate responses that appeared to encode neither. Given that five clusters exposed two nearly redundant clusters—both tending to encode the noise—and visual inspection of raster plots revealed that the four clusters corresponded to easily discernible spiking patterns, we completed further analysis with four clusters. All of the findings that follow were replicated for all of the other cluster numbers that we considered, with similar findings (data not shown).
Constant response groups with dynamic neuron membership.
The clustering methodology described above yielded constant EI profile groups across all five vocalizations under both noise conditions. As exhibited in Fig. 6A, single units' EI profiles were sorted based on their group identity to form a matrix for each vocalization and noise combination. The four groups of responses can be identified by the color transition in the matrix, which reflects their noise-resistance ability. The first group exhibits positive EI values down to the lowest SNR. Neurons in this group can individually encode more vocalization than noise, as long as even a small vocalization component exists in the auditory scene. We refer to this group as robust. The second group appears to have a more varied pattern in the EI profile matrix, given that high EI values occupy the upper half of SNR values and low EI values dominate the lower half of SNR values. This trend indicates that neural responses in this group encode either noise or vocalization, depending on which is more prominent in the auditory scene. We refer to this second group as balanced. The third group is the least varied group in the EI profile matrix. Instead of being dominated by either high or low EI values, this group contains EI values near 0, indicating little preference for either vocalization or noise. We refer to this group as insensitive. The fourth group exhibits a matrix mostly dominated by low EI values. Neural responses in this group thus are more susceptible to the presence of noise, and they are more likely to encode noise predominantly, even if only a small amount of noise exists in the stimulus. We refer to this group as brittle. It is a challenge to determine the optimal cluster number for such a rich dataset. Figures 5 and 6 provide enough details to show the complexity. In Fig. 6A, some of the cluster boundaries appear less distinct than others. These were always the intermediate clusters in all of the clustering regimes that we studied; the robust and brittle clusters were always more distinct.
Fig. 6.

All noisy vocalization responses fall into a consistent set of group clusters. A: raw EI profiles of single units are sorted in the order of clusters into which they were classified. Four similar EI profile clusters were identified automatically in all 5 vocalizations. Each row is an EI profile of a single unit. Four stacked colors on the right of each panel indicate the identity of the neurons under each noise condition, with the top indicating the WGN condition and the bottom indicating the Babble condition. The robust group is in blue (cluster 1), balanced group in gray (cluster 2), insensitive group in purple (cluster 3), and brittle group in red (cluster 4). B: population-averaged EI profile of each cluster (means ± SE). The relative numbers of neurons classified into each group are displayed at the bottom right of each panel. The cluster identities are indicated with the same color denotations as in A.
These four distinctive encoding patterns are summarized graphically in Fig. 6B, where EI profiles of individual neurons were averaged with others sharing the same group identity. Robust profiles can be identified by predominantly positive EI, brittle profiles can be distinguished by predominantly negative EI values, balanced profiles can be recognized by near-equal-positive and -negative EI values, and insensitive profiles show EI around zero. The fractions of profiles classified into one of the four groups are depicted in each panel. Generally, >30% of EI profiles were classified into the insensitive group, irrespective of the vocalization–noise combination. The fraction of profiles categorized into the robust and brittle groups was vocalization dependent. Consistent with the observation from the mean values of EI profiles in Fig. 3B, more EI profiles were classified into the robust group in the WGN condition than Babble condition for all vocalizations. Still, considerable variance can be observed in the distribution of EI profiles across the four groups.
Four groups can be well distinguished by the corresponding threshold and slope combination in Fig. 7, where slopes and thresholds were averaged within each response group across vocalizations. The balanced group has the steepest slope and a threshold value ∼0 dB SNR. The robust group is represented by the lowest threshold value and a shallower slope. The brittle group shares a similar slope as the robust group but with the highest threshold. Lastly, the insensitive group can be recognized by a similar threshold as the balanced group and the shallowest slope.
Fig. 7.

EI profile slope and threshold for different response groups under WGN and Babble conditions. EI profile slope and threshold were averaged across vocalizations within response groups (means ± SE). Color denotations of the bar plots are the same as in Fig. 6A.
One single unit from each response group with distinct response patterns to Trilltwitter in WGN/Babble is displayed in Fig. 8A. Shown are spike raster plots of four single-unit responses to Trilltwitter degraded by WGN, and they were classified into robust, balanced, insensitive, and brittle groups, respectively, as indicated by the panel frames' colors. The corresponding neural responses of the same four neurons to Trilltwitter degraded by Babble are also displayed in Fig. 8A (as insensitive, robust, brittle, and balanced, respectively). It is worth noting that these neurons' response memberships were not the same in the WGN condition as in Babble. This phenomenon can be more easily observed directly from EI profiles corresponding to each raster plot, as shown in Fig. 8B.
Fig. 8.

Exemplar neurons for each response groups. A: exemplar units are displayed for each of the 4 groups of robust, balanced, insensitive, and brittle. Top: raster plots of 4 different single units' responses to the Trilltwitter call in WGN; bottom: same units' responses to the Trilltwitter call in Babble. Color denotations of dots in raster plots are the same as in Fig. 2A. The same color indicators as in Fig. 6A are used for raster plot outlines. B: EI profiles corresponding to the same 4 exemplar neural responses shown in A. W1–W4/B1–B4 indicate neural response group under WGN/Babble condition as robust, balanced, insensitive, and brittle, respectively.
The previous observation in Fig. 6B of consistent response-group formations under all stimulus conditions tested, yet individual units' inconsistent response-group identities in Fig. 8B, led us to ask whether the majority of units retains their group identities under different noise conditions. To address this question, we evaluated the proportional distribution of constituent units in the four response groups with Babble masking given the neurons' group identity in WGN condition in Fig. 9A. Two possible scenarios might be predicted, as illustrated in Fig. 9A. One is an invariant model, in which all units completely retain their response-group identities across the two noise types. For example, units falling into the robust group under the WGN condition (as W1) fully preserve their group-response identity in Babble (as B1). In a similar way, W2–W4 and B2–B4 share the same subgroup of units (balanced, insensitive, and brittle, respectively). This model predicts a diagonal group-switching matrix. Another model is a random model, in which all units randomly change their response-group identities under different noise conditions. This model predicts a uniform group-switching matrix.
Fig. 9.

Noisy vocalization response types are not consistent for individual units. A: group-switching matrices of unit membership in response clusters under WGN and Babble conditions. Top: two hypothetical models are depicted: the invariant model and the random model; bottom: group-switching matrices of 5 vocalizations are displayed. For each matrix, the abscissa indicates cluster identity in the Babble condition (B1–B4), and the ordinate represents cluster identity in the WGN condition (W1–W4). The grayscale value in each unit square denotes the proportion of units originally falling into a particular cluster identity in the WGN condition, being reclassified into a particular cluster identity in the Babble condition. B: scatterplots of mean discharge rate elicited by pure vocalizations and pure WGN noises (top) or Babble (bottom). Mean discharge rates of single units are colored with their corresponding cluster identity, as determined by their EI profiles. Color conventions are the same as those used in Fig. 6. Filled and open circles indicate data from 2 different monkeys. C: cluster-averaged mean discharge rate of noise alone and vocalization alone across all vocalization types (means ± SE).
The group-switching matrices of our neuronal population can also be seen in Fig. 9A. These matrices lie between the invariant and random models, although considerably closer to random. Bin sizes of 20 and 100 ms yielded very similar group-switching matrices (data not shown). As a consequence, units appear to change their response-group identities as background noise is altered, and <40% (mean = 0.37, SD = 0.04) of neurons in general retain the same response group when the background noise shifts from WGN to Babble. For example, with vocalization Tsikstring, we might naively expect that a majority of units in the brittle group under the WGN condition would still be classified into the same group under the Babble situation, given that Babble noise has a more disruptive effect upon vocalization encoding, as seen in Fig. 3. In actuality, however, >50% of neurons in the WGN brittle group have response-group identities as balanced, insensitive, or even robust in the Babble condition. The proportion of neurons that retained their response-group identity across masking noises was considerably less than expected, indicating strong noise-dependent response properties in A1. Under both noise conditions, ∼5% of the 163 single units responsive to all 5 tested vocalizations retained their response-group identity across all vocalizations. Most of that small number of neurons retained their identity as insensitive or brittle. Approximately 80% of single units fell into two or three different response groups across vocalizations, and the remainder covered all four response-group identities across vocalizations. Therefore, despite four consistent clusters of neural responses for all vocalization–noise combinations tested, the individual units constituting each of these groups differed substantially.
We further examined the mean discharge rates of single units in response to pure vocalizations and noises with units' response groups being specified in colors in Fig. 9B. We found that a majority of units belonging to robust groups in both noise scenarios was situated below the diagonal, indicating that units with stronger responses elicited by pure vocalization rather than pure noise are more likely to encode vocalizations at lower SNR values. The discharge rates of units belonging to other response groups, however, were more blended without a clear boundary. To summarize the information across vocalizations, mean discharge rates of single units in response to vocalization/noise alone were averaged within response groups (Fig. 9C). At the response-cluster level, the robust group exhibits a stronger response to vocalization than noise, whereas the brittle group shows the opposite trend. Both the balanced group and the insensitive group display more nearly equivalent responses to vocalization and noise, and the insensitive group shows a smaller response magnitude. Neuronal response reliability to noise alone and vocalization alone was also compared in terms of response groups, and a similar trend was observed (data not shown). However, neither discharge rate nor response reliability alone is sufficient to explain individual neuronal response type in the face of noise interference.
Suppression and addition of spiking activity within and between vocalization phrases.
To investigate how the addition of noise affected the spiking activity elicited by vocalizations in terms of acoustic features, we measured the discharge rate within vocalization phrases and between gaps of vocalization phrases in Fig. 10. By comparing vocalizations at 20 dB SNR with clean vocalizations, the brittle response group showed increased spiking activity both within and between vocalization phrases under both noise conditions. This finding serves as strong evidence for the existence of a group of neurons that can detect a barely audible noise stream once it is present in the auditory scene. In contrast to the brittle response group, the robust response group, along with balanced and insensitive groups, showed suppression of neural activity within vocalization phrases under both noise conditions, indicating that the response patterns to vocalizations might be largely preserved but with smaller amplitude. Whereas the robust response group also showed suppression of activities in gaps between vocalization phrases in both noise conditions, the activities of less robust groups (i.e., balanced and insensitive) during the gaps are more subject to interference by noise under the Babble condition than the WGN.
Fig. 10.
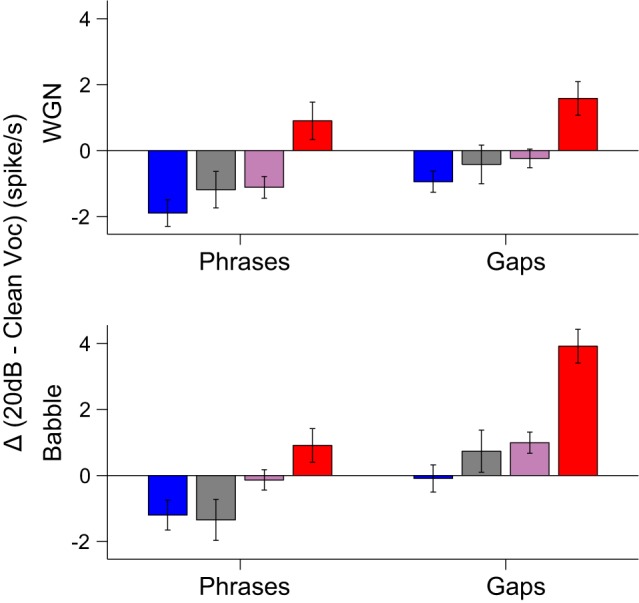
Difference (Δ) of discharge rates to phrases and gaps of vocalizations. Changes in discharge rates at 20 dB SNR within and between gaps of vocalization phrases relative to clean vocalizations are displayed for each neural response type (means ± SE). The same color denotations as in Fig. 6A are used.
DISCUSSION
The introduction of either WGN or Babble noise reduced mean vocalization-induced discharge rates in A1 neurons. Similar observations were made in other preparations under different stimulus conditions (Gai and Carney 2006; Schneider and Woolley 2013). Both noise types also reduced mean reliability, which correlated with the decreases in mean discharge rates. Higher mean discharge rates alone are not the source of higher response reliability, however, because reliability calculations were based on correlation of neuron responses across trials, unaffected by the absolute firing rate.
Nagarajan et al. (2002) observed that 15% of barbiturate-anesthetized A1 neurons respond more strongly to calls in white noise than to pure calls alone. Similar neural responses were also noticed in our awake animals, such that, on average, 13% of units exhibited responses stronger than 1.5 times the response to pure vocalizations at 20 dB SNR in the WGN condition and 19% in the Babble condition. Therefore, similar phenomena appear to take place in awake subjects as well. One potential explanation might be the widespread nonmonotonic, rate-level functions of marmoset A1 (Sadagopan and Wang 2008; Watkins and Barbour 2011). A nonmonotonic, vocalization-selective neuron with best intensity somewhat lower than the one at which the noisy vocalizations were delivered might respond better as some noise is added in a power-normalized fashion, thereby reducing the intensity of the vocalization component. Another possible explanation is that these neurons might dynamically adjust their contrast gains under this specific combination of acoustic signal and noise (Barbour and Wang 2003b; Willmore et al. 2014).
We found that the single-unit neural representation of communication sounds in marmoset A1 is also context dependent (Narayan et al. 2007). Four consistent response groups were identified by their responses to noisy vocalizations. We first determined that the group identity of a neuron's responses to a vocalization in WGN poorly predicted its responses to the same vocalization in Babble. A small subset of neurons demonstrated sustained, high responsiveness to WGN but suppressed responses to Babble, implying complex spectrotemporal integration. The responses of many A1 neurons to a sound mixture were dominated by the stimulus that more effectively induced a response when delivered alone, which is consistent with the “strong signal capture” observed with pure tones masked with broadband noise and bird chips mixed with multiple background components (Bar-Yosef and Nelken 2007; Phillips and Cynader 1985). Strong signal capture has also been described at the level of the auditory nerve (Geisler and Sinex 1980).
It is worth explicitly mentioning that both thresholds and slopes of EI profiles tended to fall along a continuum instead of a multimodal distribution and that the full range of this continuum was maintained across all conditions tested. The distribution of slopes was unimodal, but the distribution of thresholds differed. With the elimination of the highest and lowest thresholds, which represent threshold extremes that cannot be attributed to the actual SNR indicated, threshold distribution is nearly uniform. Finally, the individual contribution of slope and threshold appears to combine independently in the joint distribution (data not shown). The consistent unsupervised clusters formed from the EI profiles matched spiking characteristics clearly visible in many raster plots and provided an objective method of subdividing neuronal responses into verifiable patterns. The four clusters turn out to be readily differentiable by combinations of EI profile threshold and slope. It is possible that these types of responses may correlate to fundamental neuronal response properties, bearing in mind that intermediate response types exist that could be classified as either one of two adjacent clusters. We did not attempt to measure this correlation, however, for two reasons: one philosophical and one practical.
From our own previous studies of higher-order auditory neurons and from those of other groups, we observe that many, if not most, such neurons can be highly responsive to vocalizations but not return clearly interpretable response fields as a result of traditional reductionist analysis methods attributing neuronal response patterns to specific acoustical stimulus features. In the current study, we designed a methodology to accept as many neurons into analysis as possible so as not to omit neurons poorly accessible to particular analytical methods. Given that population-level response patterns emerged instead of neuron-level patterns, this may have ultimately been a more fruitful exercise. Nevertheless, there are likely to be correlations between the observed responses and fundamental neuronal properties, although a practical consideration made a thorough evaluation of this hypothesis challenging in this case.
Methods to assess responsiveness to specific stimulus features require the delivery of many similar yet slightly different features to probe the stimulus space sufficiently. To study robustness, however, we need to deliver identical stimuli for many repetitions to attribute all observed response variability to the neural system in question. The retainment of individual single units for the hours required to acquire all of the necessary data for both of these goals is extremely challenging. Armed with the findings of the current study, however, an informative subsequent study quantifying the correlation between robustness and fundamental response properties could be carried out efficiently.
One critical question for auditory-scene analysis is where the auditory segmentation initially occurs (Shamma and Micheyl 2010). Formation of auditory objects has been widely studied both at cortical and subcortical levels using multiple recording techniques (Bar-Yosef and Nelken 2007; Fishman et al. 2001, 2004; Pressnitzer et al. 2008). A unifying principle from previous studies is that auditory-streaming processing exists at least as late as A1 and possibly begins as early as cochlear nucleus. In our study, the presence of four noisy vocalization response groups supports A1 as a source of stream segregation processing.
Regarding functionality, the robust group represents a neural signature of the vocalization stream, whereas the brittle group represents a neural signature of the noise stream. The balanced group provides another coding dimension reflecting the SNR between two auditory streams (i.e., indicating which stream is relatively more intense). The insensitive group responds equally to both streams and is not particularly useful for segregating either of them but may have other coding functions. Given that these response groups emerged consistently under every signal and noise condition tested, we speculate that this organization may represent a general coding mechanism for representing sounds. It is worth emphasizing again that individual A1 neurons can generate responses that fall into any of these classes depending on stimulus context. It is possible that individual neurons in other core auditory cortex areas may demonstrate greater resistance to noise degradation of vocalization-induced responses given those areas' different response properties relative to A1 (Bendor and Wang 2008). Noise degradation may also be less pronounced in the belt areas (Rauschecker and Tian 2004; Rauschecker et al. 1995).
How can A1 project to downstream areas so that noise-invariant responses to sounds become possible? Feedforward suppression is suggested to be the underlying mechanism of noise-invariant responses (Schneider and Woolley 2013). In the context of our dataset, the readout from the robust group would be strengthened, whereas the readout from the brittle group would be suppressed. Top-down regulation is probably needed for such enhancement (Jäncke et al. 1999; Tervaniemi et al. 2009), and this control signal would also need to be contextually dependent and possibly under attentional control. Explicit involvement of top-down processing in an active experimental paradigm might also lead to different observations than the present study. Attention could facilitate resistance of neural responses to noise degradation. One possibility is that most neurons in A1 would be more noise resistant and have more consistent response types under different noise conditions. However, songbird forebrain studied under an active paradigm revealed neurons with various degrees of noise resistance, as well. Therefore, top-down processing might not affect individual neurons' contextual-dependent effect in A1. It is still possible that downstream neurons may generate robust neural responses regardless of noise type under the top-down modulation of attention.
No evidence of a strong positive relationship between intensity invariance and noise resistance exists in our dataset. One potential explanation is our observation that if a neuron is very responsive to vocalizations alone, then it is also likely to be actively driven by noise alone. When these two stimuli are combined, we often see sensitivity to both. Alternatively, we tested a limited range of intensity levels, which may be insufficient to capture neurons' full intensity invariance. Combinations of different auditory objects evoke some A1 neurons to respond predominantly to the weaker object (Bar-Yosef and Nelken 2007; Bar-Yosef et al. 2002). This type of response may be reflected in our brittle group; nevertheless, this response pattern in the population would lower the probability that simple, context-independent, rate-level response features induced by single stimuli can explain the present results.
By segmenting the neural activities based on the spectrotemporal phrases of vocalizations, we revealed the underlying firing-rate alteration of different response groups at 20 dB SNR relative to the firing rates in response to clean vocalizations. This analysis explicitly shows the distinctive difference between the robust and brittle group. The robust group suppressed spiking activities both within and between phrases, and the brittle group behaved oppositely. A previous songbird study reported suppression of neural activities within song syllables and addition of spikes between song syllables on a population level (Narayan et al. 2007). Our results, however, further indicated that the influence of noise on the neural activities varies among different types of neural response groups, and the suppression/addition of spikes was dominated by different subgroups of neurons. The emergence of different response groups that preferentially encode individual auditory streams in A1 provides evidence of the underlying neural processing for auditory scene analysis.
We have studied neural encoding of vocalizations presented in conjunction with two types of background noises in marmoset monkey A1. Subsets of single units with high discrimination performance existed under both noise conditions. The dynamic role of single units indicates that there are relatively few individual neurons in A1 that can robustly encode stimuli in the presence of different noises. Robust encoding clearly exists in A1 when considering population responses, however, and future studies should consider evaluating integrated population responses and the effects of top-down influences mediated by attention.
GRANTS
Support for this work was provided by the National Institute on Deafness and Other Communication Disorders (Grant R01-DC009215).
DISCLOSURES
No conflicts of interest, financial or otherwise, are declared by the authors.
AUTHOR CONTRIBUTIONS
R.N., D.A.B., A.M.S., and J.R.G. performed experiments; R.N., A.M.S., and J.R.G. analyzed data; R.N., A.M.S., and D.L.B. interpreted results of experiments; R.N. prepared figures; R.N. drafted manuscript; R.N., D.A.B., and D.L.B. edited and revised manuscript; R.N., D.A.B., A.M.S., J.R.G., and D.L.B. approved final version of manuscript.
ACKNOWLEDGMENTS
The authors thank Kim Kocher for valuable assistance with animal training and data collection. Thanks also go to Wensheng Sun for her help with neurophysiology experiment preparation.
REFERENCES
- Agamaite JA, Chang CJ, Osmanski MS, Wang X. A quantitative acoustic analysis of the vocal repertoire of the common marmoset (Callithrix jacchus). J Acoust Soc Am 138: 2906, 2015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Anderson S, Skoe E, Chandrasekaran B, Kraus N. Neural timing is linked to speech perception in noise. J Neurosci 30: 4922–4926, 2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bar-Yosef O, Nelken I. The effects of background noise on the neural responses to natural sounds in cat primary auditory cortex. Front Comput Neurosci 1: 3, 2007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bar-Yosef O, Rotman Y, Nelken I. Responses of neurons in cat primary auditory cortex to bird chirps: effects of temporal and spectral context. J Neurosci 22: 8619–8632, 2002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Barbour DL, Wang X. Auditory cortical responses elicited in awake primates by random spectrum stimuli. J Neurosci 23: 7194–7206, 2003a. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Barbour DL, Wang X. Contrast tuning in auditory cortex. Science 299: 1073–1075, 2003b. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bendor D, Wang X. Neural response properties of primary, rostral, and rostrotemporal core fields in the auditory cortex of marmoset monkeys. J Neurophysiol 100: 888–906, 2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Billimoria CP, Kraus BJ, Narayan R, Maddox RK, Sen K. Invariance and sensitivity to intensity in neural discrimination of natural sounds. J Neurosci 28: 6304–6308, 2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- de Ruyter van Steveninck RR, Lewen GD, Strong SP, Koberle R, Bialek W. Reproducibility and variability in neural spike trains. Science 275: 1805–1808, 1997. [DOI] [PubMed] [Google Scholar]
- DiMattina C, Wang X. Virtual vocalization stimuli for investigating neural representations of species-specific vocalizations. J Neurophysiol 95: 1244–1262, 2006. [DOI] [PubMed] [Google Scholar]
- Ding N, Simon JZ. Adaptive temporal encoding leads to a background-insensitive cortical representation of speech. J Neurosci 33: 5728–5735, 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ding N, Simon JZ. Emergence of neural encoding of auditory objects while listening to competing speakers. Proc Natl Acad Sci USA 109: 11854–11859, 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Feng AS, Hall JC, Gooler DM. Neural basis of sound pattern recognition in anurans. Prog Neurobiol 34: 313–329, 1990. [DOI] [PubMed] [Google Scholar]
- Fishman YI, Arezzo JC, Steinschneider M. Auditory stream segregation in monkey auditory cortex: effects of frequency separation, presentation rate, and tone duration. J Acoust Soc Am 116: 1656–1670, 2004. [DOI] [PubMed] [Google Scholar]
- Fishman YI, Reser DH, Arezzo JC, Steinschneider M. Neural correlates of auditory stream segregation in primary auditory cortex of the awake monkey. Hear Res 151: 167–187, 2001. [DOI] [PubMed] [Google Scholar]
- Gai Y, Carney LH. Temporal measures and neural strategies for detection of tones in noise based on responses in anteroventral cochlear nucleus. J Neurophysiol 96: 2451–2464, 2006. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Geisler CD, Sinex DG. Responses of primary auditory fibers to combined noise and tonal stimuli. Hear Res 3: 317–334, 1980. [DOI] [PubMed] [Google Scholar]
- Grace JA, Amin N, Singh NC, Theunissen FE. Selectivity for conspecific song in the zebra finch auditory forebrain. J Neurophysiol 89: 472–487, 2003. [DOI] [PubMed] [Google Scholar]
- Grimsley JM, Shanbhag SJ, Palmer AR, Wallace MN. Processing of communication calls in Guinea pig auditory cortex. PLoS One 7: e51646, 2012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Jäncke L, Mirzazade S, Shah NJ. Attention modulates activity in the primary and the secondary auditory cortex: a functional magnetic resonance imaging study in human subjects. Neurosci Lett 266: 125–128, 1999. [DOI] [PubMed] [Google Scholar]
- Libersat F, Murray JA, Hoy RR. Frequency as a releaser in the courtship song of two crickets, Gryllus bimaculatus (de Geer) and Teleogryllus oceanicus: a neuroethological analysis. J Comp Physiol A 174: 485–494, 1994. [DOI] [PubMed] [Google Scholar]
- Miller LM, Schreiner CE. Stimulus-based state control in the thalamocortical system. J Neurosci 20: 7011–7016, 2000. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Moore RC, Lee T, Theunissen FE. Noise-invariant neurons in the avian auditory cortex: hearing the song in noise. PLoS Comput Biol 9: e1002942, 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Nagarajan SS, Cheung SW, Bedenbaugh P, Beitel RE, Schreiner CE, Merzenich MM. Representation of spectral and temporal envelope of twitter vocalizations in common marmoset primary auditory cortex. J Neurophysiol 87: 1723–1737, 2002. [DOI] [PubMed] [Google Scholar]
- Narayan R, Best V, Ozmeral E, McClaine E, Dent M, Shinn-Cunningham B, Sen K. Cortical interference effects in the cocktail party problem. Nat Neurosci 10: 1601–1607, 2007. [DOI] [PubMed] [Google Scholar]
- Newman JD, Wollberg Z. Multiple coding of species-specific vocalizations in the auditory cortex of squirrel monkeys. Brain Res 54: 287–304, 1973. [DOI] [PubMed] [Google Scholar]
- Oram MW, Wiener MC, Lestienne R, Richmond BJ. Stochastic nature of precisely timed spike patterns in visual system neuronal responses. J Neurophysiol 81: 3021–3033, 1999. [DOI] [PubMed] [Google Scholar]
- Phillips DP, Cynader MS. Some neural mechanisms in the cat's auditory cortex underlying sensitivity to combined tone and wide-spectrum noise stimuli. Hear Res 18: 87–102, 1985. [DOI] [PubMed] [Google Scholar]
- Pressnitzer D, Sayles M, Micheyl C, Winter IM. Perceptual organization of sound begins in the auditory periphery. Curr Biol 18: 1124–1128, 2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rabinowitz NC, Willmore BD, King AJ, Schnupp JW. Constructing noise-invariant representations of sound in the auditory pathway. PLoS Biol 11: e1001710, 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rauschecker JP, Tian B. Processing of band-passed noise in the lateral auditory belt cortex of the rhesus monkey. J Neurophysiol 91: 2578–2589, 2004. [DOI] [PubMed] [Google Scholar]
- Rauschecker JP, Tian B, Hauser M. Processing of complex sounds in the macaque nonprimary auditory cortex. Science 268: 111–114, 1995. [DOI] [PubMed] [Google Scholar]
- Sadagopan S, Wang X. Level invariant representation of sounds by populations of neurons in primary auditory cortex. J Neurosci 28: 3415–3426, 2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schneider DM, Woolley SM. Discrimination of communication vocalizations by single neurons and groups of neurons in the auditory midbrain. J Neurophysiol 103: 3248–3265, 2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schneider DM, Woolley SM. Sparse and background-invariant coding of vocalizations in auditory scenes. Neuron 79: 141–152, 2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schreiber S, Fellous JM, Whitmer D, Tiesinga P, Sejnowski TJ. A new correlation-based measure of spike timing reliability. Neurocomputing 52–54: 925–931, 2003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shamma SA, Micheyl C. Behind the scenes of auditory perception. Curr Opin Neurobiol 20: 361–366, 2010. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Stephan H, Baron G, Schwerdtfeger WK. The Brain of the Common Marmoset (Callithrix jacchus): A Stereotaxic Atlas. Berlin; Heidelberg, Germany: Springer Science + Business Media, 2012. [Google Scholar]
- Tervaniemi M, Kruck S, De Baene W, Schroger E, Alter K, Friederici AD. Top-down modulation of auditory processing: effects of sound context, musical expertise and attentional focus. Eur J Neurosci 30: 1636–1642, 2009. [DOI] [PubMed] [Google Scholar]
- Theunissen FE, Sen K, Doupe AJ. Spectral-temporal receptive fields of nonlinear auditory neurons obtained using natural sounds. J Neurosci 20: 2315–2331, 2000. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Tibshirani R, Walther G, Hastie T. Estimating the number of clusters in a data set via the gap statistic. J R Stat Soc Series B Stat Methodol 63: 411–423, 2001. [Google Scholar]
- Valentine PA, Eggermont JJ. Stimulus dependence of spectro-temporal receptive fields in cat primary auditory cortex. Hear Res 196: 119–133, 2004. [DOI] [PubMed] [Google Scholar]
- Wang X. Neural coding strategies in auditory cortex. Hear Res 229: 81–93, 2007. [DOI] [PubMed] [Google Scholar]
- Wang X, Merzenich MM, Beitel R, Schreiner CE. Representation of a species-specific vocalization in the primary auditory cortex of the common marmoset: temporal and spectral characteristics. J Neurophysiol 74: 2685–2706, 1995. [DOI] [PubMed] [Google Scholar]
- Watkins PV, Barbour DL. Rate-level responses in awake marmoset auditory cortex. Hear Res 275: 30–42, 2011. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Willmore BD, Cooke JE, King AJ. Hearing in noisy environments: noise invariance and contrast gain control. J Physiol 592: 3371–3381, 2014. [DOI] [PMC free article] [PubMed] [Google Scholar]