

Abstract
Simulation experiments were used to show the impact of varying extraction efficiency, aliquot proportion, and PCR efficiency on the heterozygote balance of a range of diploid and haploid cells. Reducing either parameters introduces variance. It is well-known that the variance in heterozygote balance increases as the amount of DNA is reduced. Surprisingly the distribution is in fact diamond shaped — the variance start to decrease at very low amounts of DNA. Simulations suggest that pristine diluted DNA is an acceptable approximation in validations to infer heterozygote balance. However, the difference in distribution of the variance between diploid and haploid cell types may, under some circumstances, need to be considered in statistical models. Finally, we exemplify how simulations can be used to predict the outcome of PCR for degraded samples. Visualizing the predicted DNA profile as an electropherogram can help to identify the best approach for sample processing.
Electronic supplementary material
The online version of this article (doi:10.1007/s00414-016-1453-x) contains supplementary material, which is available to authorized users.
Keywords: PCR, Heterozygote balance, Simulation, Degradation, Validation
Introduction
The typical forensic DNA analysis process consists of sample recovery, extraction, quantification, amplification, and capillary electrophoresis. Depending on the laboratory’s instrumentation and workflow, there can be additional purification of the DNA extract or PCR product. Forensic laboratories seek to optimize each step of the process to maximize the chance to retrieve DNA evidence. Interpretation of DNA evidence within the likelihood ratio framework has made significant progress in recent years [1, 2] and several software solutions are available [3–5]. Different models, e.g. qualitative, semi-continuous (without peak height), and continuous (with peak height, stutter, etc), have been implemented. The only assumptions of the qualitative model are the estimated allele frequencies. Usually, unrelatedness between the contributors to the DNA evidence is also assumed, although recently, it has been possible to specify relatedness in some software (e.g. LRmix Studio [4]). Semi-continuous models include drop-in and drop-out parameters, estimated either from laboratory experiments or from the observed DNA evidence and simulations. Continuous models (with peak height) may require additional parameters to be estimated experimentally, although this is largely circumvented by gamma models [6] which automatically determine parameters from the crime stain profile itself. Typically a number of known single-source samples are analysed to estimate key characteristics like stutter ratios and heterozygote balance. Each extraction method, STR kit, PCR protocol, and capillary electrophoresis (CE) instrument may result in different estimates of the parameters. To ensure validity, the experiments may need to be repeated if there are significant changes to protocols or equipment (e.g. major service of the CE instrument).
In the laboratory, there is always a loss of DNA during the DNA extraction process [7–9]. Although there is limited published information on the absolute efficiency, NIST studies indicate an absolute DNA extraction efficiency of 1–37 %.1
The PCR process is not 100 % efficient, [10] estimated the PCR efficiency to be approximately 82–97 % using real-time PCR. Gill et al. [11] created a graphical simulation model of the entire DNA process using a binomial selection of molecules, as suggested by [12], in order to simulate each step of the process. The model was used to predict the behaviour of heterozygote balance and the probability of allelic drop-out for low-template samples.
This paper explores the effect of different parameters (such as PCR efficiency and aliquot) on the heterozygote balance for diploid and haploid cells. Diploid cells contain two copies of each chromosome, while haploid cells (i.e. sperm cells) contain only one copy. Simulation was used to predict the stochastic behaviour of sub-cell (pg) levels of DNA, which was compared to observed experimental data. Finally, implications to casework relative to assumptions used in continuous models are discussed.
Material, methods, and models
Parameters and definitions
Extraction efficiency (e x e): The probability that a given DNA molecule survives the DNA extraction process.
PCR aliquot (p c r a): A proportion of the DNA extract is transferred to the PCR tube. Therefore, there is a probability that a given DNA molecule will be selected for PCR amplification.
PCR cycles (p c r c): Number of PCR cycles.
PCR efficiency (p c r e): During each PCR cycle, there is a probability that a given DNA molecule will be amplified.
Stutter probability (s t u t t e r p): During each PCR cycle, there is a probability that a given DNA molecule will be amplified as a stutter one repeat shorter than the allele.
Aliquot to capillary electrophoresis (c e a): A proportion of the PCR product is transferred to the capillary electrophoresis injection plate.
Capillary electrophoresis peak height threshold (c e T): The number of fluorescent labelled DNA molecules required to trigger a signal described by the intercept (c e Ti), slope (c e Ts), and the residual standard error (c e Tσ).
Capillary electrophoresis peak height scaling (c e S): Conversion of the number of DNA molecules into relative fluorescent molecules (RFU) described by the intercept (c e Si) and slope (c e Ss).
Limit of detection threshold (LDT): Signals above this peak height threshold (RFU) is considered to be reliably caused by actual alleles rather than instrument noise.
Degradation parameter (P(d e g)): The probability of degradation per base pair. If a DNA fragment is degraded at one or more bases the amplification of that fragment fails.
Degradation index (DI): The ratio of the low molecular weight target to the high molecular weight target provides a qualitative measure of the degradation.
Simulated data
Simulation was performed using the R package pcrsim 2 version 1.0. The package was developed based on the simulation functions in forensim [13]. Both packages are implementations of ‘A graphical simulation model of the entire DNA process’ [11]. In pcrsim the PCR efficiency is assumed to be constant across cycle number, which has previously been demonstrated to be true for the first 10 to 15 cycles [12, 14]. In reality PCR efficiency declines towards the plateau phase mainly because of product inhibition of the DNA polymerase enzyme [15]. However, for STR analysis of low-template samples, the plateau phase is in practice never reached [16]. Hedell et al. [16] showed that for each increase in number of PCR cycles from 30 to 35, the allele peak height increase was approximately constant, coinciding with ideal amplification. Hence, the application of a constant PCR efficiency per cycle is a realistic approximation. Some published values of the PCR efficiency are 0.82 [11], 0.85 [17], and 0.82–0.97 [10]. We will use a PCR efficiency p c r e=0.90 to simulate crime stains. Specific simulation parameters are given under the respective simulation experiment. If direct PCR was used, then the extraction efficiency e x e=1.00 and the PCR aliquot p c r a=1.00 since none of the DNA is lost using this method.
In order to maximize the data collection for simulations with sub-cellular amounts of DNA, the capillary electrophoresis peak height threshold was set to c e T=0 with a peak height scaling of c e S=1. Consequently, there is no drop-out dependant on low peak height, only due to complete absence of template molecules in the PCR reaction.
Serial dilutions vs. crime stains
Parameters for comparison between simulated dilutions and simulated crime stains were as follows: the original experiment was a 2-fold serial dilution of a NIST human DNA quantitation standard (SRM 2372A) as outlined by [18]. In this simulation, the series was extended at the lower end with three more dilutions to produce a final range of 1.65 to 845 pg in the PCR reaction (equivalent to 0.25–128 diploid cells assuming 6.6 pg per cell). Stock solution of the quantitation standard was 57 ng/μl and dilution was performed with large transfer volumes (450 μl) to avoid stochastic effects. The comparison was made between 1000 replicate simulations of the same serial dilution, simulation of 1000 diploid crime stains with target 0.25-128 cells in the PCR reaction, and 1000 haploid crime stains with target 0.50–256 cells in the PCR reaction.
The extraction efficiency was set to e x e=0.30 (the higher end of previously reported values).1
The PCR aliquot was p c r a=0.35 (the higher end of commonly used proportions).3
A PCR efficiency of p c r e=0.90, approximately in the middle of a previously reported range of 0.82−0.97 [10], was used. The number of cycles was p c r c=28.
CE aliquot c e a=1.0.
CE detection threshold was set to c e Ti=14.03744, c e Ts=0.82254, c e Tσ=0.1319579 based on a previous 3500xL calibration.4
CE peak height scaling was set to: c e Si=−14.38233, c e Ss=1.173163 based on a previous 3500xL calibration.4
Limit of detection threshold L D T=200 RFU.
The crime stain samples were simulated using four settings (other parameters were the same as for the simulated dilution):
e x e=0.30 and p c r a=0.35, emulating a realistic process where a relatively efficient extraction method1 is combined with a relatively high aliquot proportion.3
e x e=0.30 and p c r a=1.00, emulating a relatively efficient extraction method1 combined with PCR of the entire DNA extract.
e x e=1.00 and p c r a=0.35, emulating single tube extraction combined with a relatively high aliquot proportion.3
e x e=1.00 and p c r a=1.00, emulating direct PCR.
Heterozygote balance and the ‘diamond’ effect
For comparison with observations from experimental data, simulation parameters were used that emulated the experimental conditions as closely as possible. For comparison to [16], the following parameters were used.
The extraction efficiency was set to e x e=1.00 to mimic one tube Chelex extraction.
The aliquot forwarded to PCR was set to p c r a=0.05.
For each simulated sample p c r c=30−35 PCR cycles with PCR efficiency p c r e=0.90, approximately in the middle of a previously reported range of 0.82−0.97 [10], was used.
Stutters were simulated by multinomial selection with s t u t t e r p=0.005 [19].
CE detection threshold was set to c e Ti=15.4653, c e Ts=0.9044, and c e Tσ=0.364 based on a previous 3130xL calibration.4
CE peak height scaling was set to c e Si=−13.66131 and c e Ss=1.0047, c e Sσ=0.3836 based on a previous 3130xL calibration.4
The limit of detection threshold was set to L D T=50 RFU.
Possible stutter-allele pairs, when the actual partner allele has dropped out, were excluded from the calculations by removing alleles separated with 1 repeat unit. Loci with mean peak heights >10,000 RFU were removed to mimic the saturation threshold of the 3130xL instrument.
Degraded samples
See on-line supplement Section C for details of simulation parameters for degraded samples.
Table 2.
Concentrations (ng/μl), degradation index (DI), and estimated degradation parameter (P(d e g)) for nine degraded tissue samples based on quantification by Quantifiler®; Trio DNA Quantification Kit (QT) and PowerQuantTM System (PQ). Target amplicon size in base pairs is 80 and 84 for the small targets, and 214 and 294 for the large targets. A degradation index DI is calculated by dividing the small autosomal target DNA concentration by the large autosomal target DNA concentration (Eq. 2)
| Sample | QT:80 | PQ:84 | QT:214 | PQ:294 | QT:DI | PQ:DI | QT:P(deg) | PQ:P(deg) |
|---|---|---|---|---|---|---|---|---|
| D1 | 119.710 | 127.850 | 83.6300 | 27.7100 | 1.4 | 4.6 | 0.0027 | 0.0073 |
| D2 | 0.058 | 0.003 | 0.0009 | NA | 64.9 | NA | 0.0307 | NA |
| D3 | 45.605 | 59.950 | 1.5170 | 1.8600 | 30.1 | 32.2 | 0.0251 | 0.0164 |
| D4 | 0.437 | 0.547 | 0.1357 | 0.0540 | 3.2 | 10.1 | 0.0087 | 0.0110 |
| D5 | 0.256 | 0.333 | 0.0111 | 0.0042 | 23.1 | 79.2 | 0.0231 | 0.0206 |
| D6 | 0.098 | 0.119 | 0.0079 | 0.0024 | 12.4 | 49.5 | 0.0186 | 0.0184 |
| D7 | 0.284 | 0.292 | 0.0036 | 0.0034 | 78.8 | 86.0 | 0.0321 | 0.0210 |
| D8 | 1.437 | 1.712 | 0.0900 | 0.0859 | 16.0 | 19.9 | 0.0205 | 0.0141 |
| D9 | 31.510 | 55.710 | 0.0565 | 0.0077 | 557.7 | 7235.1 | 0.0461 | 0.0414 |
Empirical data
Heterozygote balance
Empirical data used by [16] was kindly provided by the authors. Their experimental set-up was as follows. A dilution series was prepared, by mixing 5 μl whole blood together with 1245 μl of 0.9 % NaCl (commonly referred to as physiological saline). The volume of diluted blood transferred in each subsequent step was at least 400 μl to avoid potential stochastic effects. The use of physiological saline prevented cell lysis; hence, the integrity of complete genomes was conserved. Quantification was performed in triplicate using the Quantifiler®; Human DNA Quantification Kit (Life Technologies). Only three out of twelve samples produced results within the range of the standard curve. Two were negative and the remaining were extrapolated from the standard curve. Therefore [16] estimated the concentrations for the three lower concentrations based on the sample with the highest concentration. See reference [16] for further details on the experimental set-up. The actual quantification results are reproduced in Table 4 (online supplement Section A).
Degraded samples
Anonymous DNA extracts from nine presumably degraded tissue samples were used. The extraction method was the BioRobot EZ1 (Qiagen) using the EZ1 DNA Tissue Kit (Qiagen) according to manufacturers recommendations. The extracts had been stored for about two years in a freezer prior to quantification and analysis. The Quantifiler®; Trio DNA Quantification Kit (Applied Biosystems), with an 80 bp small autosomal target and 214 bp large autosomal target, and PowerQuantTM System (Promega), with an 84 bp small autosomal target and 294 bp large autosomal target, were used for quantification. Both kits confirmed that the tissue samples were degraded to different degrees (degradation index in Table 2). The PowerPlex®; ESX 17 Fast System (Promega) was used for STR amplification.
Analysis of data
The free R statistical software5. was used to analyse data. Specifically the package strvalidator [20] version 1.4 was used to calculate heterozygote balance according to Eq. 1:
| 1 |
where H b is the heterozygote balance, Ø HMW and Ø LMW are the simulated number of amplicons (if no scaling is used) and simulated peak height (if scaling is used) of the high and low molecular weight allele, respectively.
The R packages data.table 6. and plyr 7. were used for some calculations for performance reasons. ggplot2 8. was used to create figures.
Results and discussion
The effect of PCR efficiency
Theoretical simulations to explore the effect of PCR efficiency on the heterozygote balance were performed (Fig. 1). Direct PCR was simulated at three efficiencies; p c r e=0.20, p c r e=0.80, and p c r e=1.00. Low PCR efficiency may be caused by inhibition (refer to the exhaustive review by [21] and [22] for details on mechanisms and solutions to overcome inhibition).
Fig. 1.
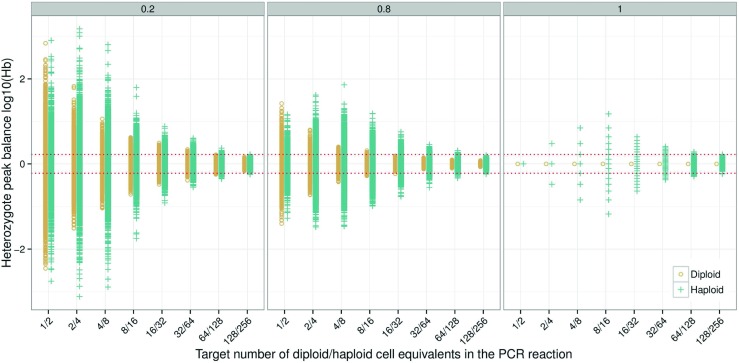
Simulation of 500 samples for diploid and haploid cells with PCR efficiencies of p c r e=0.20, p c r e=0.80 and p c r e=1.00, respectively. Stutters were not simulated. In this example, the heterozygote balance is affected only by the cell type and the PCR efficiency. This was achieved by setting all other parameters to one (e x e = p c r a = c e a=1.00). To obtain observations at low PCR efficiency for low-template, the detection threshold was set to zero (c e T=0), and no peak height scaling was applied (c e S=1), i.e. the number of molecules was used to calculate H b. Circles are diploid, crosses are haploid, and the red dotted lines denote the 0.6<H b<1.67 thresholds
Simulations show increased heterozygote imbalance as the template DNA is reduced from optimal amounts (usually 0.5 to 1 ng). This has been shown in numerous publications, e.g. [23]. Conversely, increased template decreases the heterozygote imbalance until a minimum is reached. Adding more template beyond this point will not improve the balance further. Increased PCR efficiency also reduces the imbalance. Both alleles for diploid cells are perfectly balanced when the p c r e=1.00 (Fig. 1). However, this is not true for haploid cells [24].
If allelic copies are randomly drawn from a pool of haploid alleles that comprises equal number of (a, b) alleles at a heterozygous locus, this leads to a discrete distribution of possible ratios. For example, consider a DNA extract with four haploid genome copies with alleles a and b. There are only three possible copy number ratios that can be randomly drawn for a heterozygous (ab) locus: 1/3, i.e. one a and three bs, 2/2, and 3/1, with probabilities of 0.25, 0.375, and 0.25, respectively. A ratio 0/4 and 4/0, each with a probability of 0.0625, is also possible but will give rise to +- infinity when l o g 10 is taken (for these combinations, alleles a and b, respectively, have dropped out, giving the appearance of a homozygote). This is further elaborated in the online supplement, Section B. For a mathematical model, simulations, and risk assessment of false homozygotes for diploid cells refer to [25]. The discrete or multi-modal nature of haploid peak height ratios is clearly visible at p c r e=1.00 with a small number of cells. As the PCR efficiency is reduced the multi-modality is smoothed as previously shown by [12]. As the number of haploid cells increases, the imbalance reaches a maximum at approximately 8–16 haploid cells. We call this the ‘diamond’ effect. The diamond effect is clearly visible at p c r e=1.00 and, to a lesser extent, at p c r e=0.80 (Fig. 1). The distribution for diploid cells has a funnel shape. This is also true for haploid cells at p c r e=0.20 (Fig. 1 left facet). With >16 cells and p c r e=1.00, the number of discrete possibilities becomes so tightly packed that the distribution can be considered continuous. Furthermore, the distribution for haploid cells converges towards the diploid distribution. A general threshold that is used by laboratories to denote a balanced locus is 0.6<H b<1.67 [26] (using Eq. 1).
For haploid cells, the probability of observing H b within the range accepted as ‘balanced’ (0.6<H b<1.67) and perfectly balanced (H b=1) is listed in Table 1. As the number of haploid cells increase, the probability of perfect balance reduces, while the probability of ‘accepted’ balance increases. [27] calculated the number of haploid cells needed to recover perfect balance with different values for the standard error.
Table 1.
Theoretical probabilities of heterozygote balance within the accepted range (0.60≤H b≤1.67) and in perfect balance of different numbers of haploid cells as modelled by the Poisson distribution.
| Haploid cells | P(accepted) | P(balanced) |
|---|---|---|
| 2 | 0.500 | 0.500 |
| 4 | 0.375 | 0.375 |
| 8 | 0.711 | 0.273 |
| 16 | 0.790 | 0.196 |
| 32 | 0.890 | 0.140 |
| 64 | 0.967 | 0.099 |
| 128 | 0.997 | 0.070 |
| 256 | 1.000 | 0.050 |
The effect of low PCR efficiency is most noticeable for diploid cells, as the distribution of peak height ratios approaches the distribution for haploid cells. However, the distributions of heterozygote balance for diploid and haploid cells never converge completely. Not even when the PCR efficiency is reduced to p c r e=0.20 (Fig. 1).
The effect of PCR aliquot
Pre-PCR random sampling of alleles is the main source of stochastic effects in low template samples [11, 18]. The aliquot forwarded to PCR is usually in the range 0.05 to 0.35 of the DNA extract3. Common reasons for a small aliquot is 1) the extraction method utilised requires a relatively large final volume, 2) to allow multiple PCR amplifications, or 3) a combination of these factors. To explore the effect of PCR aliquot proportions on heterozygote balance, theoretical simulations with fixed numbers of cells (1–128 diploid cells, and 2–256 haploid cells) in the DNA extract were performed (Fig. 2). Simulations of direct PCR p c r a=1.00, and aliquot proportions of p c r a=0.05 and p c r a=0.35 were compared. The difference in H b variance between p c r a=0.05 and p c r a=0.35 is large at the two highest DNA concentrations (64 and 128 diploid cells equivalent to 384 and 768 pg in the source DNA extract). However, the difference between distributions from diploid and haploid cells are small, and at p c r a=0.05, they are practically identical. Smaller aliquot proportions spread the possible outcomes of randomly selected alleles in diploid cells to the point where the distributions converge. The diamond effect is clearly visible for p c r a=0.35 (Fig. 2) where the average amount in the PCR tube approaches sub-cell levels. The variance is self-limiting because there is a limited number of possible copy number ratios for heterozygous loci at very small concentrations (as explained in ‘3The effect of PCR 3efficiency’).
Fig. 2.
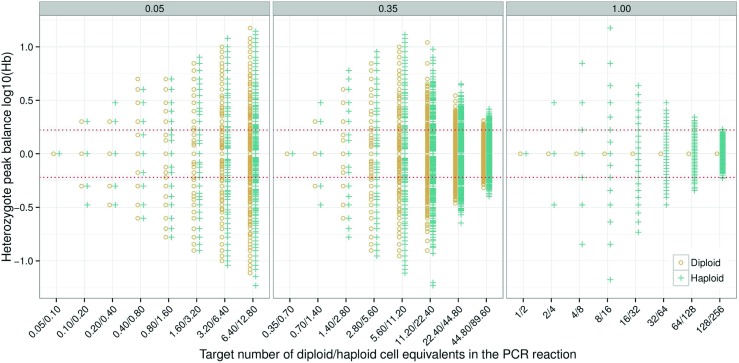
Simulation of 1500 samples for diploid and haploid cells with PCR aliquots of p c r a=0.05, p c r a=0.35 and p c r a=1.00, respectively. Stutters were not simulated. The heterozygote balance is affected only by the cell type and the PCR aliquot proportion. This was achieved by setting all other parameters to one (e x e = p c r e = c e a=1.00). To obtain observations at low PCR efficiency for low-template, the detection threshold was set to zero (c e T=0), and no peak height scaling was applied (c e S=1), i.e. the number of molecules was used to calculate H b. Circles are diploid, crosses are haploid, and the red dotted linesdenote the 0.6<H b<1.67 thresholds
The effect of extraction efficiency
The DNA extraction process contributes to the pre-PCR random sampling of alleles. Loss of DNA during the extraction process is unavoidable. The loss can be caused by transfer steps, incomplete cell lysis [28], incomplete cell elution [29], or other reasons mentioned in [30]. For one-tube extraction methods like Chelex [31], there is no loss of DNA due to transfer steps. For simplicity, in this paper we assumed that pure samples with small number of cells have an extraction efficiency of 100 %. Hence, the PCR aliquot proportion will be the only source of pre-PCR allele sampling. To explore the effect of extraction efficiency on H b, simulations were performed using e x e=0.30, e x e=0.60, and e x e=1.00 (Fig. 3). At e x e=1.00 (i.e. direct PCR) all alleles from diploid cells are in perfect balance, while alleles from haploid cells form discrete distributions. At e x e=0.30, the diploid and haploid H b distributions are roughly equal. However, at e x e=0.60, the difference between diploid and haploid cells are quite large implying that cell type has an effect on H b at high extraction efficiencies. As with changes in PCR efficiency (Fig. 1), it is observed that as the extraction efficiency decreases, the diamond shape widens at the lower end to become more funnel shaped (Fig. 3).
Fig. 3.

Simulation of 1000 samples for diploid and haploid cells with extraction efficiencies of e x e=0.30, e x e=0.60, and e x e=1.00, respectively. Stutters were not simulated. The heterozygote balance is affected only by the cell type and the extraction efficiency. This was achieved by setting all other parameters to one (p c r a = p c r e = c e a=1.00). To obtain observations at low PCR efficiency for low-template the detection threshold was set to zero (c e T=0), and no peak height scaling was applied (c e S=1), i.e. the number of molecules was used to calculate H b. Circles are diploid, crosses are haploid, and the red dotted lines denote the 0.6<H b<1.67 thresholds
Very low amounts of DNA lead to reduced heterozygote imbalance
Previous authors have determined that the variance for heterozygote imbalance increases as the amount of DNA decreases [18, 23, 32–35]. We have shown that this is only partially true. In fact, the reverse happens when the DNA concentration reaches a lower threshold. The theoretical reasoning and independent simulations to verify this is elaborated in the online supplement, Section B. The reason that it has not been previously noted is that the experimental design at very low levels of DNA is very difficult to accommodate. This is where simulation methods not only complement experiments, but can be used to inform experimental design by providing information about predicted behaviour.
Serial dilutions vs. crime stains
For convenience, many laboratory experiments and validations are carried out using highly concentrated stock solutions of extracted DNA which is diluted in several steps to the desired target concentrations [18]. Then, the laboratory applies the measured characteristics (H b, stutter, etc.) to crime stains that are run routinely. However, dilution experiments do not strictly emulate the conditions in crime stains [36]. The purpose of the following simulations was to determine whether dilution experiments could be used instead of a much more complex experimental design that carries out assessments according to cell type while varying the number of cells per stain. We simulated serial dilutions according to [18] and compared them to simulated diploid and haploid crime stain samples (see ‘3Serial dilutions vs. 3crime stains’).
The 5th and 95th percentiles of H b are shown in Fig. 4. The simulated dilution reaches its maximum at two to four diploid cell equivalents of DNA (i.e. 13.2 to 26.4 pg). In comparison to simulated diploid crime stains (Fig. 4, top) the serial dilution appears to have roughly the same variance distribution, with the exception of direct PCR - a serial dilution from pristine and highly concentrated DNA does not accurately reflect direct PCR. Direct PCR has a very narrow funnel shaped distribution with a maximum at 1 diploid cell. The serial dilution more closely resembles the distributions from simulated haploid crime stains (Fig. 4, bottom). This has previously been pointed out in [27]. Down to approximately four haploid cell equivalents of DNA there is practically no difference between the simulated methods. The exception is a very low amount (<4) of haploid cells for direct PCR where the difference becomes larger with a decreasing number of haploid cells.
Fig. 4.

The 5th and 95th percentile H b of simulated serial dilution and simulated crime stains. Diploid crime stains (top) and haploid crime stains (bottom)
The difference between serial dilutions and crime stain samples, amplified using non-direct PCR methods to infer H b distributions is relatively small. This suggests that the use of serial dilutions is a reasonable approximation, which was also concluded in [34]. The exceptions are methods where both the extraction efficiency and the aliquot proportion are high, e.g. direct PCR, and the cell type is diploid. The ‘diamond’ effect is observed in the simulated data and suggests that the H b variance starts to decrease below two diploid, or four haploid, cell equivalents of DNA.
Compromised crime stains
Degraded DNA is a common complication with forensic samples. Environmental factors such as humidity, bacteria, and ultraviolet light break down the DNA [37]. Longer DNA fragments are affected more than shorter DNA fragments causing increased imbalance [38] (see ‘3The effect of 3degradation’). The degradation can be modelled by an exponential curve [39]. Given two measurements of the DNA concentration in a single sample, using qPCR targets of different lengths, the probability of degradation per base pair P(d e g) can be calculated (Eq. 8). Inhibition of the Taq polymerase reduces PCR efficiency and increases the imbalance, the effect is greatest on high molecular weight fragments [40, 41]. Therefore the effect of inhibition is the same as degradation. Consequently, both inhibition and degradation can be modelled using the PCR efficiency and degradation parameters together. There are also other modes of inhibition e.g. DNA sequence specific inhibition, which are currently not modelled in pcrsim.
The effect of degradation
DNA extracts from degraded tissue samples were quantified using two quantification kits with capability to measure degradation (i.e. the DNA concentration using two different target sizes). The result was used to estimate P(d e g), the probability that a single base pair is degraded, for each sample (derivation is explained later in this section). Table 2 shows the estimated probabilities, together with the DNA concentrations and the degradation index (DI) which is calculated according to Eq. 2:
| 2 |
where C small and C large is the DNA quantity of the small and large target respectively. The degradation index is a useful indicator of size dependent quantities that are present in a crime sample. After calibration against the generated DNA profiles the DI, can be used to decide how to process the sample. The calculated DI differs between Quantifiler®; Trio and PowerQuantTM because the target sizes are different. However the estimated P(d e g) parameter is reasonably similar, suggesting that it is kit independent. It is likely that only one calibration to EPGs is required for all quantification kits able to measure degradation if P(d e g) is used rather than DI. The degradation parameter can potentially be used as a standardized measure of degradation which would facilitate collaboration and inter-laboratory information exchange even if different kits are used.
The estimated P(d e g) was plugged into the PCR simulator. Figure 5 shows observed and simulated EPG’s of a degraded sample. The overall characteristics of the degraded DNA profile are very similar.
Fig. 5.
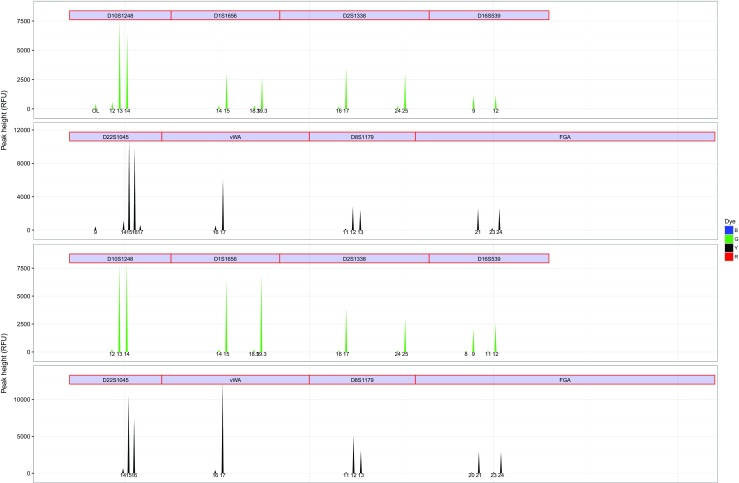
Comparison of an observed (top) and simulated (bottom) degraded ESX 17 Fast profile. Only the green and yellow dye is shown for visibility. A degradation parameter of P(d e g)=0.0023 was used
Degradation is a consequence of random DNA cleavage (refer to the exhaustive review by [37] for details on mechanisms and consequences of degradation). Consider a fragment of DNA that is x bases long. It makes no difference whether 1 or more cleavages occur within the fragment of interest, as the fragment will fail to amplify no matter where the DNA was cleaved. As a result the fragment will not be visualized.
Usually, there are multiple copies of DNA. Degradation can be related to drop-out. Allele drop-out occurs either because no copies are amplified (i.e. no molecules present in the PCR reaction), or because the fluorescence signal fails to reach the threshold value of the CCD detector of the capillary electrophoresis machine (i.e. insufficient number of molecules present in the PCR reaction).
We can generalize that the chance of drop-out is related to the number of template DNA copies - the fewer the number of copies the lower the fluorescence after PCR. Thus probability of drop-out of a single copy of DNA can be characterized by Eq. 3, assuming independence between the base pairs of the copy, to estimate the chance of cleavage of a molecule of x bases:
| 3 |
where P(d r o p 1) is probability of drop-out. We can write the probability that a fragment of size x is intact (i.e. not degraded) and available for amplification (Eq. 4):
| 4 |
However, it is necessary to evaluate the probability of cleavage of DNA as a function of n copies of DNA. This is defined by the binomial probability in Eq. 5:
| 5 |
We make the same assumptions as [42] and use a constant probability of cleavage across the fragment sequence. Similar to [42], we assume a log-linear relationship between concentration c(x), fragment length x, and the probability of no degradation, i.e. Eq. 6:
| 6 |
From this follows Eqs. 7 and 8:
| 7 |
| 8 |
where x 1<x 2 and c(x 2)≤c(x 1). We can formalize this as the probability of 5 cleavage of the affected base. Therefore, given P(d e g) the number of intact fragments of any fragment length can be estimated. Figure 6 shows the probability of intact fragments as a function of fragment length, for different values of the degradation parameter using Eq. 4.
Fig. 6.

Probability of intact fragment available for amplification as a function of fragment length for different values of the degradation parameter (0.0005–0.0170)
Modern human real-time DNA quantification kits (e.g. Quantifiler®; Trio DNA Quantification Kit and PowerQuantTM System) often come with the ability to measure the degree of degradation for each sample. This is accomplished by adding a second longer target to measure the total human DNA. Usually a 200–300 base pair fragment (x 2) is generated from the longer target, while the shorter generates a 70–150 base pair fragment (x 1).
To simulate degradation, the probabilities that each allele (i.e. fragment length) is complete, and thereby available for amplification, is calculated. Then a binomial selection of molecules with the previously calculated probabilities is applied ‘post PCR’ (Eq. 9):
| 9 |
where N molecules is the number of molecules of each allele after PCR amplification, and N intact is the number of intact molecules. To illustrate, we simulate degradation of a fragment of 300 bases, 1 ng total DNA, corresponding to 167 haploid copies (Fig. 7) using the binomial distribution B i n(N=167,P=0.05).
Fig. 7.

1000 simulations N=167 copies of a 300 bp fragment with P(!d r o p)=0.05 probability of being intact, corresponding to approximately P(d e g)=0.0099. The range of intact fragments is 1–19, which may fail to produce sufficient PCR product to trigger a signal
This results in a population of intact fragments that can be amplified, but with this particular example, where P(!d r o p)=0.05, there are between 1 and 19 undegraded copies derived from 1 ng. A DNA fragment will only be visualized if there are sufficient molecules present to trigger the capillary electrophoresis machine’s CCD camera. For 28 cycles, approximately 30 haploid copies (ca 90 pg) are required before sufficient PCR product is available to trigger a signal [43], whereas for 34 cycles, just one molecule (ca 3 pg in a haploid cell) is needed to produce sufficient signal [44].
Therefore optimization of systems when degraded DNA is analysed, cannot be considered without a concurrent consideration of the effect of PCR cycle number.
We repeated the simulation with a smaller fragment size of 100 bases (Fig. 8). Using the same degradation parameters, a fragment that is just 100 bases has a chance of 37 % of surviving, thus a nanogram of DNA from diploid cells will have between 44 and 83 intact molecules of each allele (approximately 264 to 498 pg). The threshold is always exceeded even at 28 cycles.
Fig. 8.

1000 simulations N=167 copies of a 100 bp fragment with P(!d r o p)=0.37 probability of being intact, corresponding approximately to P(d e g)=0.0099. The range of intact fragments is 44–83, which normally result in sufficient PCR product to trigger a signal
Heterozygote balance and the ‘diamond effect’
Real data were analysed to verify the ‘diamond effect’ predicted by simulations. Previous experiments showed that heterozygote balance was mainly affected by the amount of DNA rather than the number of PCR cycles or the CE injection time [16]. This has also been confirmed in for example [45]. Based on this knowledge, observations from different injection times and different number of PCR cycles were combined for each target amount of DNA. This increased the number of observations for the lowest amount to allow meaningful comparisons. Heterozygote balance from simulated (expected) compared with real (observed) data is shown in Fig. 9. The data visually support the contention that the variance decreases for very low amounts of DNA, as predicted. The simulation was performed using average amounts of approximately 2.4, 19.5, 31.7, and 63.3 pg of DNA in the PCR reaction. A range of different amounts were tried in order to find the input amounts giving the best fit to observed data (further described in online supplement, Section A). The uncertainty in experimental quantification results are large since they are also subject to stochastic effects and this is probably the main reason that adjusted input amounts were required to provide good fit. The adjusted amounts predicted by the ‘fitted’ models are all within the range of the quantification results and are near the median values (Table 4 in online supplement, Section A). It is possible that H b may be a useful aid to determine quantity of DNA. However, this is not pursued further here as more work is required to verify a useful method. Other parameters which will influence the simulations are the assumed PCR efficiency, the CE detection threshold and peak height scaling. Calibration of pcrsim using the same CE instrument that produced the data would likely improve the accuracy as there is variation between instruments.
Fig. 9.
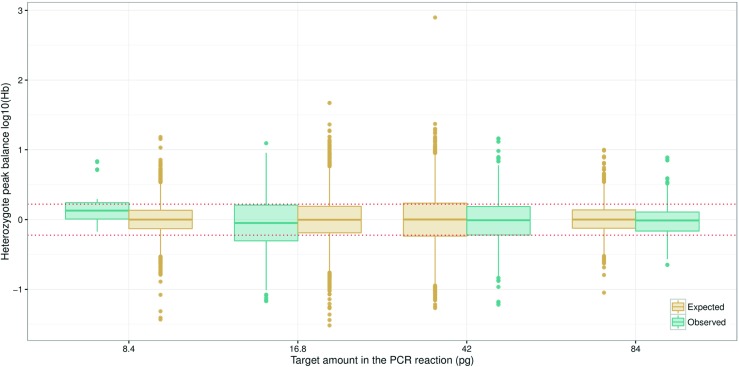
Heterozygote balance from a total of 200 simulated ESX16 samples compared to observed data from another laboratory. The average amount was estimated to 8.4, 16.8, 42, and 84 pg, respectively (Table 4 in online supplement, Section A). The simulation was performed with average amounts of approximately 2.4, 19.5, 31.7, and 63.3 pg of DNA in the PCR reaction. Those amounts gave the best fit to observed data using the approach described in the online supplement, Section A
Implications for casework
Maximizing the chance to obtain a complete profile
[24] calculated that at least 15 haploid cells are required for a complete DNA profile (≥99.9 % confidence) at 15 loci and indeed [46] confirmed that it is possible to produce complete Identifiler®; profiles from only 15 sperm cells using Laser Capture Microdissection (LCM). For robust LCM approximately 30 sperm cells are needed [47] (refer to Vandewoestyne et. al. for a review of LCM techniques [48]). For a specific DNA extract, the aliquot proportion determine the amount of DNA forwarded to PCR and, hence, the chance to obtain a complete DNA profile. Table 3 shows the theoretical numbers of cells required in DNA extracts, before the aliquot is taken, to result in a given amount of DNA in the PCR reaction. Theoretically, provided enough diploid cells are selected to pass the fluorescence detection threshold, this will always result in a complete DNA profile for direct PCR (i.e. p c r a=1.00). When an aliquot of an extract is used, a random selection of alleles takes place (because of dissociated chromosomes), resulting in reduced chance to obtain a complete profile. In essence, this is similar to samples of haploid cells.
Table 3.
Theoretical number of cells (rounded up) required in the DNA extract, before an aliquot (of 5, 35, and 100 %) is taken, to obtain a certain average amount (pg) in the PCR reaction.
| 5 % | 35 % | 100 % | Amount |
|---|---|---|---|
| 20 | 3 | 1 | 6 |
| 40 | 6 | 2 | 12 |
| 80 | 12 | 4 | 24 |
| 160 | 23 | 8 | 48 |
| 320 | 46 | 16 | 96 |
| 640 | 92 | 32 | 192 |
| 1280 | 183 | 64 | 384 |
| 2560 | 366 | 128 | 768 |
Inhibiting substances increase heterozygote imbalance
[49] used LCM to collect 15 to 150 FISH labelled diploid cells for direct PCR, using 28 cycles and the Identifiler®; PCR Amplification Kit, and investigated the heterozygote balance. Although one-tube extraction and direct PCR (i.e. e x e = p c r a=1.00) should minimise stochastic effects, it was concluded that there was no improvement9 in peak height balance compared to single-source crime scene samples analysed in a study conducted by [50]. Further comparison with ‘Christmas Tree’ stained cells indicated that the FISH process has a negative impact on peak balance.
Haploid versus diploid cells
Concurrently varying extraction efficiency and PCR aliquot proportion (Fig. 10) shows that for normal casework (with extraction efficiencies of up to at least 30 % and aliquot proportions up to 35 %) the distributions of heterozygote balance for diploid and haploid cells are practically identical. Haploid cells then represent the worst case scenario for diploid cells (consider Figs. 1, 2, and 3). However if the extraction efficiency and the aliquot proportion are both relatively large, i.e. direct PCR, differences in haploid/diploid heterozygote balance distributions should be considered in models that evaluate complex DNA evidence.
Fig. 10.
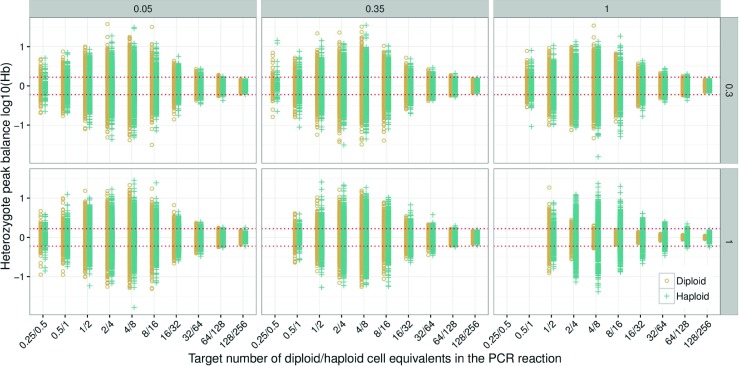
Heterozygote balance from 250 simulated samples with e x e=0.30 and e x e=1.00, and p c r a=0.05, p c r a=0.35, and p c r a=1.00 in combination. PCR parameters were p c r c=30 and p c r e=0.90. Stutters were not simulated. Capillary electrophoresis parameters were c e a=1.00, c e T=0, c e S=1, i.e. the number of molecules was used to calculate H b. The red dotted lines denotes the 0.6<H b<1.67 thresholds
Conclusions
It has long been established that the variance in heterozygote balance increases as the amount of DNA is reduced. Using simulations, we have shown that the distribution is in fact diamond shaped. As the amount of DNA decreases, the variance increases until a maximum is reached. The variance starts to decrease at very low amounts of DNA (50 pg or less, depending on PCR efficiency, aliquot proportion, and extraction efficiency) and the distributions become multi-modal rather than continuous. This was also confirmed by experimental data. In theory, under optimal conditions, the alleles in amplified diploid cells will be in perfect balance. However the extraction process, aliquot proportion, and amplification efficiency introduces variance. Direct PCR is preferred for optimal allele balance and sensitivity and has been successfully implemented for certain casework samples [51, 52]. Simulations show that for direct PCR, haploid and diploid cells have different heterozygote balance distributions. This may need to be accounted for in some statistical models that are used to evaluate DNA evidence. However, direct PCR is not widely implemented (and may not always be suitable). With realistic extraction efficiencies and aliquot proportions the difference between H b variances is negligible. Consequently, diploid cells can be used in validation to determine characteristics of H b also for haploid cells. Simulations also suggest that diluted DNA extracts, which are commonly used in validations exercises are an acceptable approximation to crime stain samples (provided that care is taken to use large volumes) except for direct PCR methods or very low levels of DNA. Our results suggest that simulations of crime stains are preferred over dilutions when the average amount of DNA in the PCR reaction approaches sub-cellular amounts.
We have exemplified that the number of PCR cycles is a key factor to consider when degraded DNA is analysed. If the probability of degradation per base pair is used as a metric, rather than degradation indexes, the measure becomes kit independent. With knowledge of the degradation parameter the resulting characteristics of the DNA profiles can be predicted by simulation.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Acknowledgments
The work leading to these results has received funding from the European Union seventh Framework Programme (FP7/2007-2013) under Grant Agreement No. 285487 (EUROFORGEN-NoE). The authors thank two anonymous referees that greatly improved this manuscript. We thank Ronny Hedell and Charlotte Dufva at the Biology Section (Swedish National Forensic Centre, NFC) for access to the raw data analysed in their paper [16]. We are also grateful to our colleagues Ingebjørg Heitmann for performing all the quantification work in the laboratory, and Thore Egeland and Øyvind Bleka for deriving the formulae to calculate the degradation parameter. Special thanks to Johannes Hedman (NFC and Applied Microbiology, Lund University) for valuable discussions and input to this paper.
Footnotes
“Evaluation of DNA Extraction Efficiency” presented by Erica L.R. Butts, 65th American Academy of Forensic Sciences (February 2013)
http://cran.r-project.org/web/packages/pcrsim/index.html, accessed 08.04.2016
Personal communication with 5 European laboratories.
For details see ‘Calibrate pcrsim 1.0.0’ at https://sites.google.com/site/forensicapps/pcrsim.
http://www.r-project.org/, accessed 08.04.2016
https://github.com/Rdatatable/data.table/wiki, accessed 08.04.2016
http://plyr.had.co.nz/,accessed08.04.2016
http://ggplot2.org/,accessed 08.04.2016
The metric used was the average peak height where the central 0.95 quantile crosses the 60 % threshold.
References
- 1.Haned H, Slooten K, Gill P. Exploratory data analysis for the interpretation of low template DNA mixtures. Forensic Sci Int Genet. 2012;6:762–774. doi: 10.1016/j.fsigen.2012.08.008. [DOI] [PubMed] [Google Scholar]
- 2.Gill P, Haned H. A new methodological framework to interpret complex DNA profiles using likelihood ratios. Forensic Sci Int Genet. 2013;7:251–263. doi: 10.1016/j.fsigen.2012.11.002. [DOI] [PubMed] [Google Scholar]
- 3.Perlin MW, Legler MM, Spencer CE, Smith JL, Allan WP, Belrose JL, Duceman BW, Validating TrueAllele DNA. Mixture interpretation. J Forensic Sci. 2011;56:1430–1447. doi: 10.1111/j.1556-4029.2011.01859.x. [DOI] [PubMed] [Google Scholar]
- 4.Haned H, Gill P. Analysis of complex DNA mixtures using the Forensim package. Forensic Sci Int Genet Suppl Ser. 2011;3:e79–e80. doi: 10.1016/j.fsigss.2011.08.039. [DOI] [Google Scholar]
- 5.Mitchell AA, Tamariz J, O’Connell K, Ducasse N, Budimlija Z, Prinz M, Caragine T. Validation of a DNA mixture statistics tool incorporating allelic drop-out and drop-in. Forensic Sci Int Genet. 2012;6:749–761. doi: 10.1016/j.fsigen.2012.08.007. [DOI] [PubMed] [Google Scholar]
- 6.Bleka Ø, Storvik G, Gill P. Euroformix: An open source software based on a continuous model to evaluate STR DNA profiles from a mixture of contributors with artefacts. Forensic Sci Int Genet. 2016;21:35–44. doi: 10.1016/j.fsigen.2015.11.008. [DOI] [PubMed] [Google Scholar]
- 7.Colussi A, Viegas M, Beltramo J, Lojo M. Efficiency of DNA IQ System in recovering semen DNA from cotton swabs. Forensic Sci Int Genet Suppl Ser. 2009;2:87–88. doi: 10.1016/j.fsigss.2009.09.031. [DOI] [Google Scholar]
- 8.Kishore R, Reef Hardy W, Anderson VJ, Sanchez NA, Buoncristiani MR. Optimization of DNA extraction from low-yield and degraded damples using the BioRobot EZ1 and BioRobot M48. J Forensic Sci. 2006;51:1055–1061. doi: 10.1111/j.1556-4029.2006.00204.x. [DOI] [PubMed] [Google Scholar]
- 9.Swaran YC, Welch L. A comparison between direct PCR and extraction to generate DNA profiles from samples retrieved from various substrates. Forensic Sci Int Genet. 2012;6:407–412. doi: 10.1016/j.fsigen.2011.08.007. [DOI] [PubMed] [Google Scholar]
- 10.Hudlow WR, Chong MD, Swango KL, Timken MD, Buoncristiani MR. A quadruplex real-time qPCR assay for the simultaneous assessment of total human DNA, human male DNA, DNA degradation and the presence of PCR inhibitors in forensic samples: a diagnostic tool for STR typing, Forensic Science International. Genetics. 2008;2:108–125. doi: 10.1016/j.fsigen.2007.09.001. [DOI] [PubMed] [Google Scholar]
- 11.Gill P, Curran J, Elliot K. A graphical simulation model of the entire DNA process associated with the analysis of short tandem repeat loci. Nucleic Acids Res. 2005;33:632–643. doi: 10.1093/nar/gki205. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Stolovitzky G, Cecchi G. Efficiency of DNA replication in the polymerase chain reaction. Proc Natl Acad Sci. 1996;93:12947–12952. doi: 10.1073/pnas.93.23.12947. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Haned H. Forensim: an open-source initiative for the evaluation of statistical methods in forensic genetics. Forensic Sci Int Genet. 2011;5:265–268. doi: 10.1016/j.fsigen.2010.03.017. [DOI] [PubMed] [Google Scholar]
- 14.Lee JY, Lim H-W, Yoo S-I, Zhang B-T, Park TH. Simulation and real-time monitoring of polymerase chain reaction for its higher efficiency. Biochem Eng J. 2006;29:109–118. doi: 10.1016/j.bej.2005.02.023. [DOI] [Google Scholar]
- 15.Kainz P. The PCR plateau phase — towards an understanding of its limitations. Biochim et Biophys Acta (BBA) - Gene Struct and Expression. 2000;1494:23–27. doi: 10.1016/S0167-4781(00)00200-1. [DOI] [PubMed] [Google Scholar]
- 16.Hedell R, Dufva C, Ansell R, Mostad P, Hedman J. Enhanced low-template DNA analysis conditions and investigation of allele dropout patterns. Forensic Sci Int Genet. 2015;14:61–75. doi: 10.1016/j.fsigen.2014.09.008. [DOI] [PubMed] [Google Scholar]
- 17.Shinde D, Lai Y, Sun F, Arnheim N. Taq DNA polymerase slippage mutation rates measured by PCR and quasi-likelihood analysis: (CA/GT)n and (A/T)n microsatellites. Nucleic Acids Res. 2003;31:974–980. doi: 10.1093/nar/gkg178. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Timken MD, Klein SB, Buoncristiani MR. Stochastic sampling effects in STR typing: implications for analysis and interpretation. Forensic Sci Int Genet. 2014;11:195–204. doi: 10.1016/j.fsigen.2014.03.015. [DOI] [PubMed] [Google Scholar]
- 19.Weusten J, Herbergs J. A stochastic model of the processes in PCR based amplification of STR DNA in forensic applications. Forensic Sci Int Genet. 2012;6:17–25. doi: 10.1016/j.fsigen.2011.01.003. [DOI] [PubMed] [Google Scholar]
- 20.Hansson O, Gill P, Egeland T. STR-Validator: An open source platform for validation and process control. Forensic Sci Int Genet. 2014;13:154–166. doi: 10.1016/j.fsigen.2014.07.009. [DOI] [PubMed] [Google Scholar]
- 21.Alaeddini R. Forensic implications of PCR inhibition—a review. Forensic Sci Int Genet. 2012;6:297–305. doi: 10.1016/j.fsigen.2011.08.006. [DOI] [PubMed] [Google Scholar]
- 22.Hedman J, Knutsson R, Ansell R, Rådström P, Rasmusson B. Pre-PCR processing in bioterrorism preparedness: improved diagnostic capabilities for laboratory response networks. Biosecurity and Bioterrorism: Biodefense Strategy, Practice, and Sci 11 Suppl. 2013;1:S87–101. doi: 10.1089/bsp.2012.0090. [DOI] [PubMed] [Google Scholar]
- 23.Kelly H, Bright J-A, Curran JM, Buckleton J. Modelling heterozygote balance in forensic DNA profiles. Forensic Sci Int Genet. 2012;6:729–734. doi: 10.1016/j.fsigen.2012.08.002. [DOI] [PubMed] [Google Scholar]
- 24.Lucy D, Curran JM, Pirie AA, Gill P. The probability of achieving full allelic representation for LCN-STR profiling of haploid cells. Sci Justice. 2007;47:168–171. doi: 10.1016/j.scijus.2007.10.001. [DOI] [PubMed] [Google Scholar]
- 25.Taberlet P, Griffin S, Goossens B, Questiau S, Manceau V, Escaravage N, Waits LP, Bouvet J. Reliable genotyping of samples with very low DNA quantities using PCR. Nucleic Acids Res. 1996;24:3189–3194. doi: 10.1093/nar/24.16.3189. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Gill P, Sparkes R, Fereday L, Werrett DJ. Report of the European Network of Forensic Science Institutes (ENSFI): formulation and testing of principles to evaluate STR multiplexes. Forensic Sci Int. 2000;108:1–29. doi: 10.1016/S0379-0738(99)00186-3. [DOI] [PubMed] [Google Scholar]
- 27.Haned H, Egeland T, Pontier D, Pn̄e L, Gill P. Estimating drop-out probabilities in forensic DNA samples: a simulation approach to evaluate different models. Forensic Sci Int Genet. 2011;5:525–531. doi: 10.1016/j.fsigen.2010.12.002. [DOI] [PubMed] [Google Scholar]
- 28.Miller DN, Bryant JE, Madsen EL, Ghiorse WC. Evaluation and optimization of DNA extraction and purification procedures for soil and sediment samples. Appl Environ Microbiol. 1999;65:4715–4724. doi: 10.1128/aem.65.11.4715-4724.1999. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 29.Adamowicz MS, Stasulli DM, Sobestanovich EM, Bille TW. Evaluation of methods to improve the extraction and recovery of DNA from cotton swabs for forensic analysis. PLOS ONE. 2014;9:e116351. doi: 10.1371/journal.pone.0116351. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 30.Templeton JEL, Taylor D, Handt O, Skuza P, Linacre A. Direct PCR improves the recovery of DNA from various substrates. J Forensic Sci. 2015;60:1558–1562. doi: 10.1111/1556-4029.12843. [DOI] [PubMed] [Google Scholar]
- 31.Walsh PS, Metzger DA, Higuchi R. Chelex 100 as a medium for simple extraction of DNA for PCR-based typing from forensic material. BioTechniques. 1991;10:506–513. [PubMed] [Google Scholar]
- 32.Tvedebrink T, Mogensen HS, Stene MC, Morling N. Performance of two 17 locus forensic identification STR kits - Applied Biosystems’s ampflSTR NGMSElect and Promega’s PowerPlex ESI17 kits. Forensic Sci Int Genet. 2012;6:523–531. doi: 10.1016/j.fsigen.2011.12.006. [DOI] [PubMed] [Google Scholar]
- 33.Bright J-A, Neville S, Curran JM, Buckleton JS. Variability of mixed DNA profiles separated on a 3130 and 3500 capillary electrophoresis instrument. Australian J Forensic Sci. 2014;46:304–312. doi: 10.1080/00450618.2013.851279. [DOI] [Google Scholar]
- 34.Bright J-A, McManus K, Harbison S, Gill P, Buckleton J. A comparison of stochastic variation in mixed and unmixed casework and synthetic samples. Forensic Sci Int Genet. 2012;6:180–184. doi: 10.1016/j.fsigen.2011.04.010. [DOI] [PubMed] [Google Scholar]
- 35.Bright J-A, Huizing E, Melia L, Buckleton J. Determination of the variables affecting mixed MiniFiler DNA profiles. Forensic Sci Int Genet. 2011;5:381–385. doi: 10.1016/j.fsigen.2010.08.006. [DOI] [PubMed] [Google Scholar]
- 36.Budowle B, Eisenberg AJ, van Daal A. Validity of low copy number typing and applications to forensic science. Croat Med J. 2009;50:207–217. doi: 10.3325/cmj.2009.50.207. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Alaeddini R, Walsh SJ, Abbas A. Forensic implications of genetic analyses from degraded DNA—a review. Forensic Sci Int Genet. 2010;4:148–157. doi: 10.1016/j.fsigen.2009.09.007. [DOI] [PubMed] [Google Scholar]
- 38.Chung DT, Drb̈ek J, Opel KL, Butler JM, McCord BR. A study on the effects of degradation and template concentration on the amplification efficiency of the STR Miniplex primer sets. J Forensic Sci. 2004;49:733–740. doi: 10.1520/JFS2003269. [DOI] [PubMed] [Google Scholar]
- 39.Bright J-A, Taylor D, Curran JM, Buckleton JS. Degradation of forensic DNA profiles. Australian J Forensic Sci. 2013;45:445–449. doi: 10.1080/00450618.2013.772235. [DOI] [Google Scholar]
- 40.Funes-Huacca ME, Opel K, Thompson R, McCord BR. A comparison of the effects of PCR inhibition in quantitative PCR and forensic STR analysis. Electrophoresis. 2011;32:1084–1089. doi: 10.1002/elps.201000584. [DOI] [PubMed] [Google Scholar]
- 41.Thompson RE, Duncan G, McCord BR. An investigation of PCR inhibition using Plexor-based quantitative PCR and short tandem repeat amplification. J Forensic Sci. 2014;59:1517–1529. doi: 10.1111/1556-4029.12556. [DOI] [PubMed] [Google Scholar]
- 42.Tvedebrink T, Eriksen PS, Mogensen HS, Morling N. Statistical model for degraded DNA samples and adjusted probabilities for allelic drop-out. Forensic Sci Int Genet. 2012;6:97–101. doi: 10.1016/j.fsigen.2011.03.001. [DOI] [PubMed] [Google Scholar]
- 43.Meredith M, Bright J-A, Cockerton S, Vintiner S. Development of a one-tube extraction and amplification method for DNA analysis of sperm and epithelial cells recovered from forensic samples by laser microdissection. Forensic Sci Int Genet. 2012;6:91–96. doi: 10.1016/j.fsigen.2011.02.007. [DOI] [PubMed] [Google Scholar]
- 44.Kloosterman AD, Kersbergen P. Efficacy and limits of genotyping low copy number DNA samples by multiplex PCR of STR loci. Int Congr Ser. 2003;1239:795–798. doi: 10.1016/S0531-5131(02)00514-9. [DOI] [PubMed] [Google Scholar]
- 45.Forster L, Thomson J, Kutranov S. Direct comparison of post-28-cycle PCR purification and modified capillary electrophoresis methods with the 34-cycle “low copy number” (LCN) method for analysis of trace forensic DNA samples. Forensic Sci Int Genet. 2008;2:318–328. doi: 10.1016/j.fsigen.2008.04.005. [DOI] [PubMed] [Google Scholar]
- 46.Li C-x, Han J-p, Ren W-y, Ji A-q, Xu X-l, Hu L. DNA Profiling of Spermatozoa by Laser Capture Microdissection and Low Volume-PCR. PLoS ONE. 2011;6:e22316. doi: 10.1371/journal.pone.0022316. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Vandewoestyne M, Van Hoofstat D, Van Nieuwerburgh F, Deforce D. Automatic detection of spermatozoa for laser capture microdissection. Int J Legal Med. 2009;123:169–175. doi: 10.1007/s00414-008-0271-1. [DOI] [PubMed] [Google Scholar]
- 48.Vandewoestyne M, Deforce D. Laser capture microdissection in forensic research: a review. Int J Legal Med. 2010;124:513–521. doi: 10.1007/s00414-010-0499-4. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Lynch L, Gamblin A, Vintiner S, Simons JL. STR Profiling of epithelial cells identified by x/y-FISH labelling and laser microdissection using standard and elevated PCR conditions. Forensic Sci Int Genet. 2015;16:1–7. doi: 10.1016/j.fsigen.2014.10.017. [DOI] [PubMed] [Google Scholar]
- 50.Bright J-A, Turkington J, Buckleton J. Examination of the variability in mixed DNA profile parameters for the Identifiler multiplex. Forensic Sci Int Genet. 2010;4:111–114. doi: 10.1016/j.fsigen.2009.07.002. [DOI] [PubMed] [Google Scholar]
- 51.Gray K, Crowle D, Scott P. Direct amplification of casework bloodstains using the Promega PowerPlex 21 PCR Amplification System. Forensic Sci Int Genet. 2014;12:86–92. doi: 10.1016/j.fsigen.2014.05.003. [DOI] [PubMed] [Google Scholar]
- 52.Verheij S, Harteveld J, Sijen T. A protocol for direct and rapid multiplex PCR amplification on forensically relevant samples. Forensic Sci Int Genet. 2012;6:167–175. doi: 10.1016/j.fsigen.2011.03.014. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.