

Abstract
Background
Spaced seeds, also named gapped q-grams, gapped k-mers, spaced q-grams, have been proven to be more sensitive than contiguous seeds (contiguous q-grams, contiguous k-mers) in nucleic and amino-acid sequences analysis. Initially proposed to detect sequence similarities and to anchor sequence alignments, spaced seeds have more recently been applied in several alignment-free related methods. Unfortunately, spaced seeds need to be initially designed. This task is known to be time-consuming due to the number of spaced seed candidates. Moreover, it can be altered by a set of arbitrary chosen parameters from the probabilistic alignment models used. In this general context, Dominant seeds have been introduced by Mak and Benson (Bioinformatics 25:302–308, 2009) on the Bernoulli model, in order to reduce the number of spaced seed candidates that are further processed in a parameter-free calculation of the sensitivity.
Results
We expand the scope of work of Mak and Benson on single and multiple seeds by considering the Hit Integration model of Chung and Park (BMC Bioinform 11:31, 2010), demonstrate that the same dominance definition can be applied, and that a parameter-free study can be performed without any significant additional cost. We also consider two new discrete models, namely the Heaviside and the Dirac models, where lossless seeds can be integrated. From a theoretical standpoint, we establish a generic framework on all the proposed models, by applying a counting semi-ring to quickly compute large polynomial coefficients needed by the dominance filter. From a practical standpoint, we confirm that dominant seeds reduce the set of, either single seeds to thoroughly analyse, or multiple seeds to store. Moreover, in http://bioinfo.cristal.univ-lille.fr/yass/iedera_dominance, we provide a full list of spaced seeds computed on the four aforementioned models, with one (continuous) parameter left free for each model, and with several (discrete) alignment lengths.
Keywords: Spaced seeds, Dominant seeds, Bernoulli, Hit Integration, Heaviside, Dirac, Counting semi-ring, Polynomial form, DFA
Background
Optimized spaced seeds, or best gapped q-grams, have independently been proposed in PatternHunter [3] and by Burkhardt and Karkkainen [4]. The primary objective was either to improve the sensitivity of the heuristic but efficient hit and extend BLAST-like strategy (without using the neighborhood word principle 1), or to increase the selectivity for lossless filters on alignments of size under a given Hamming distance of k.
Several extensions of the spaced seed model have then been proposed on the two aforementioned problems: vector seeds [5], one gapped q-grams [6] or indel seeds [7, 8], neighbor seeds [9, 10], transition seeds [11–15], multiple seeds [16–19], adaptive seeds [20] and related work on the associated indexes [21–26], just to mention a few.
Unfortunately, spaced seeds are known to produce hard problems, both on the seed sensitivity computation [27] or the lossless computation [28], and moreover on the seed design [29]. But the choice of the right seed pattern has a significant impact on genomic sequence comparison [3, 12, 16, 20, 30–38], on oligonucleotide design [39–44], as well as on amino acid sequence comparison [45–53]; this has led to several effective methods to (possibly greedily) select spaced seeds [54–61] with elaborated alignment models and their associated algorithms [62–70].
Another less frequently mentioned problem is that the seed design is mostly performed on a fixed and already fully parameterized alignment model (for example, a Bernoulli model where the probability of a match p is set to 0.7). There is not so much choice for the optimal seed, when, for example, the scoring system is changed, and thus the expected distribution of alignments.
We note that several recent works mention the use of spaced seeds in alignment-free methods [71–73] with applications in phylogenetic distance estimation [74], metagenomic classification [75, 76], just to cite a few.
Finally, we also noticed that several recent studies use the overlap complexity [54, 56, 57, 77–79] which is closely linked to the variance of the number of spaced-word matches [80] and is known to provide an upper/lower bound for the expectation of the length preceding the first seed hit [27, 66, 81]. We mention here that a similar parameter-free approach could also be applied for the variance induced selection of seeds, but an interesting question remains in that case: to find a dominance equivalent criterion associated with the selection of candidate seeds.
The paper is organized as follows. We start with an introduction to the spaced seed model and its associated sensitivity or lossless aspect, and show how semi-rings on DFA can help determining such features. Section “Semi-rings and number of alignments” restricts the description to counting semi-rings that are applied on a specific DFA to perform an efficient dynamic programming algorithm on a set of counters. This is a prerequisite for the two next sections that present respectively continuous models and discrete models. Section “Continuous models” is divided into two parts : the first one outlines the polynomial form of the sensitivity proposed by [1] to compute the sensitivity on the Bernoulli model together with the associated dominance principle, whereas the second one extends this polynomial form to the Hit Integration model of [2], and explains why the dominance principle remains valid. Section “Discrete models” describes two new Dirac and Heaviside models, and shows how lossless seeds can be integrated into them. Then, we report our experimental analysis on all the aforementioned models, display and explain several optimal seed Pareto plots for the restricted case of one single seed, and links to a wide range of compiled results for multiple seeds. The last section brings the discussion to the asymptotic problem, and to several finite extensions.
Spaced seeds and seed sensitivity
We suppose here that strings are indexed starting from position number 1. For a given string u, we will use the following notation: u[i] gives the i-th symbol of u, |u| is the length of u, and is the number of symbol letters a that u contains.
Nucleotide sequence alignments without indels can be represented as a succession of match or mismatch symbols, and thus represented as a string x over a binary alphabet .
A spaced seed can be represented as a string over a binary alphabet but with a different meaning for each of the two symbols: indicates a position on the seed where a single match must occur in the alignment x (it is thus called a must match symbol), whereas indicates a position where a single match or a single mismatch is allowed (it is thus called a don’t-care symbol).
The weight of a seed (denoted by w or ) is defined as the number of must match symbols (): the weight is frequently set constant or with a minimal value, because it is related to the selectivity of the seed. The span or length of a seed (denoted by ) is its full length (). We will also frequently use for the length of the alignment ().
The spaced seed hits at position i of the alignment x where iff
For example, the seed hits the alignment twice, at positions 2 and 9. 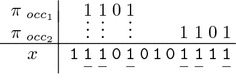
Naturally, the shape of the seed, i.e. possible placement of a set of don’t-care symbols between any consecutive pair of the w must match symbols, plays a significant role and must be carefully controlled. Requiring at least one hit for a seed, on an alignment x, is the most common (but not unique) way to select a good seed.
However, depending on the context and the problem being solved, even measuring this simple feature can easily take one of the two (previously briefly mentioned) forms:
When considering that any alignment x is of given length , and each symbol is generated by a Bernoulli model (so there is no restriction on the number of match or mismatch symbols an alignment must contain, but with some configurations more probable than others), the problem is to select a good seed (respectively the best seed) as the one that has a high probability (respectively the best probability) to hit at least once.
When considering that any alignment x is of given length , and contains at most k mismatch symbols, a classical requirement for a good seed is to guarantee that all the possible alignments, obtained by any placements of k mismatch symbols on the alignment symbols, will all be detected by at least one seed hit each: when this distinctive feature occurs, the seed is considered lossless or -lossless.
The two problems can be solved by first considering the language recognized by the seed , in this context the at least one hit regular language, and its associated DFA. As an illustration, Fig. 1 displays the at least one hit DFA for the spaced seed : this automaton recognizes the associated regular language , or less formally, any binary alignment sequence x that has at least one occurrence of or as a factor.
Fig. 1.
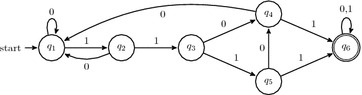
Spaced seed DFA. We represent the at least one hit DFA for the spaced seed . This automaton recognizes any alignment sequence with at least one occurrence of or
The second step consists in computing, by using a simple dynamic programming (DP) procedure set for any states of the DFA and for each step ,
Either, the probability to reach any of the automaton states.
Otherwise, the minimal number of mismatch symbols 0 that have been crossed to reach any state.
For example, considering the probability problem (a) on a Bernoulli model where a match has a probability p set to 0.7, we show it can be computed—by first “replacing”, on the automaton of Fig. 1, the transition symbols 0 and 1 by their respective probabilities 0.3 and 0.7—then, on each step i, it is possible to compute the probability to reach each of the states q by applying a recursive formula that uses the probability to be at any of its preceding states on step . For the automaton of Fig. 1, this gives  on step , the probability to reach the final state can be computed to ( ), as a logical (and first non-null) probability for the seed to detect alignments of length —on step , the probability to reach can be computed to ( to detect alignments of length .
on step , the probability to reach the final state can be computed to ( ), as a logical (and first non-null) probability for the seed to detect alignments of length —on step , the probability to reach can be computed to ( to detect alignments of length .
Another example, considering now the lossless property (b) for the spaced seed : we can show that this seed is lossless for one single mismatch, when (but computational details are left to the reader, after a remark on tropical semi-rings in the next paragraph): the seed is thus -lossless ; however, this seed is not -lossless, since reading the consistent sequence leads to a non-final state.
Finally, we simply mention that this second computational step involves the implicit use of semi-rings,
Either probability semi-rings: ; the final state(s) of the DFA give(s) the probability of having at least one hit after steps of the DP algorithm,
Otherwise tropical semi-rings: . The seed is -lossless iff all the non-final states of the DFA have a minimal number of mismatches that is strictly greater than k, after steps of the DP algorithm.2
Semi-rings and number of alignments
Semi-rings are a flexible and powerful tool, employed for example to compute probabilities, scores, distances, counts (to name a few) in a generic dynamic programming framework [82, 83]. The first problem involved, mentioned at the end of the previous section, is the right choice of the semi-ring, adapted to the question being addressed. Sometimes, selecting an alternative semi-ring to count elements, may turn out to be a flexible choice that solves more involved problems (for example computing probabilities is one of them, and will be described in next section).
Counting semi-rings [84] are adapted for this task: when applied on the right language and its right automaton, they can report the number of alignments that are at the same time detected by the seed while having m matches out of alignment symbols. The main idea that enables the computation of these counting coefficients (illustrated on Fig. 2 as the intersection product) is first to intersect the language recognized by the seed (the at least one hit language of ) with the classes of alignments that have exactly m matches: the automaton associated with all of these classes of alignments with m matches has a very simple linear form with states, where several distinct final states are defined according to all the possible values of . Finally, since the intersection of two regular languages is regular [Theorem 4.8 of the timeless 85], it can thus be represented by a conventional DFA, while keeping the feature of having several distinct final states.
Fig. 2.
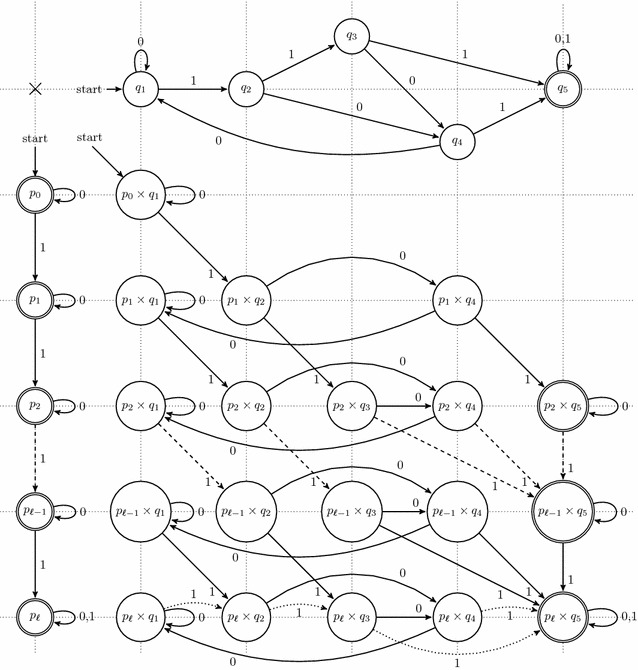
DFA intersection product. We represent the resulting intersection product of the at least one hit DFA for the seed (top horizontal automaton), with the -counting DFA (left vertical automaton). The dashed transitions represent ellipsis in the construction between and , while the dotted transitions at the bottom of the resulting automaton make it complete
As an illustration, Fig. 2 displays the at least one hit DFA for the spaced seed (on the top), the linear -counting DFA (on the vertical left part) to isolate alignments with exactly m matches, and finally their intersection product, that represent the intersecting language as a new DFA (itself obtained by crossing synchronously the two previous DFAs). Note that each of the final states (for ) of the resulting DFA is reached by alignment sequences with exactly m matches that are also detected by the seed (unless for the last state , where matches may have been detected).
Then, starting with the empty word (counted once from the initial state ), it is then possible to count the number of words of size one (two words 0 and 1 on a binary alphabet) by following transitions from the initial state to and , respectively; from the (two) states already reached, it is then possible to count words of size two (four words on a binary alphabet), and so on, while keeping, for each DFA state and on each step i, a single count record, which represents the size of the subset of the partition of the words that reach .
Note that, for a seed of weight and span (thus with don’t-care symbols), the at least one hit automaton size is in , so the intersection with the classes of alignments that have m matches out of leads to a full size in : the computational complexity of the algorithm can thus be estimated in in time and in space. As shown by [1], it can be processed incrementally for all the alignment lengths up to , with the only restriction that the numbers of alignments per state () fit inside an integer word (64 or 128bits).
We first mention that a breadth-first construction of the intersection product can be used to limit the depth of the reached states to . We have already noticed that several authors have performed equivalent tasks with a matrix for the full automaton [86], or with a vector for each automaton state [1], probably because contiguous memory performance is better. An advantage of such lazy automaton product evaluation may be that, besides the fact that it is a generic automaton product, we avoid sparse data-structures combined with many non-reachable states (for example, and will never be reached on any sequences of size : since two mismatches are needed to reach them, then must always have its associated number of matches ).
We finally mention that a similar method was used in [87] to compute correlation coefficients between the seed number of hits or the seed coverage, and the true alignment Hamming distance.3
In the following sections, we will use the (m-matches counting) coefficients to compute, either probabilities on continuous models, or frequencies on discrete models.
Continuous models
Bernoulli polynomial form and dominance between seeds
Once the coefficients (the number of alignments of length with m matches that are detected by the seed ) are determined, the probability to hit an alignment of length under a Bernoulli model (where the probability of having a match is p) can be directly computed as a polynomial over p of degree at most :
| 1 |
The expression (1) was first proposed by [1] for spaced seeds, noticing that each alignment with m match symbols and mismatch symbols, “no matter how arranged”, has the same probability to occur. The coefficient then gives the number of such (obviously independent) alignments that are detected by the seed . This leads, for all the possible number of match/mismatch symbols in an alignment of length , to the expression (1) of the sensitivity for . At first sight, we would conclude that this formula might be numerically unstable without any adapted computation, due to large coefficients, opposed to rather small probability values. But we will see that this expression (1) is not so frequently evaluated, and when it is, requires more involved tools than a classical numerical computation.
Mark and Benson [1] also include in their paper an elegant and simple partial order named dominance between seeds: suppose that two spaced seeds and have to be compared according to their respective and coefficients: now, assume that, (with at least a single difference on at least one of the coefficients), then we can conclude that dominates , and thus that can be discarded from the possible set of optimal seeds. Indeed, the sensitivity, defined by the formula (1) as a sum of same positive terms , each term being respectively multiplied by a seed-dependent positive coefficient , guarantee that the sensitivity of will never be better than the sensitivity of , whatever parameter is chosen.
In practice, from the initial set of all the possible seeds of given weight w and maximal span s, several seeds can be discarded using this dominance principle, reducing the initial set to a small subset of candidate seeds to optimality. But this dominance principle is a partial order between seeds: this signifies that some seeds cannot be compared.
As an illustration, Table 1 lists the coefficients of two single seeds, the contiguous seed (11111111111), and the Patternhunter I spaced seed (111010010100110111), for the alignment length . Note that comparing only the pairs of coefficients and does not help in choosing/discarding any of the two seeds by the dominance principle, since when , or otherwise (with a strict inequality when ). Actually, both seeds are included in the set of the dominant seeds of weight found on alignments of length , as mentioned by [1], and verified in our experiments.
Table 1.
Polynomial coefficients

Number of alignments of length with exactly m matches that are hit, by the contiguous seed (first column), by the Patternhunter I spaced seed (second column), and their respective difference (third column). The fourth column indicates the maximal number of alignments of length with exactly m matches that could have been detected: when equality occurs with the first or the second column, the seed is then considered to be lossless: when this occurs, the background of the cell is pink
Surprisingly, according to the experiments of [1], very few single seeds are overall dominant in the class of seeds of same weight w and fixed or restricted span s (e.g. ) : this dominance criterion was thus used as a filter for the pre-selection of optimal seeds. In the section “Experiments” , we show that the dominance selection also scales reasonably well for selecting multiple seeds candidates.
Hit Integration and its associated polynomial form
Hit Integration (HI) for a given seed was proposed by [2] as for a given interval (with ), where is the probability for the seed to hit an alignment of length generated by a Bernoulli model of parameter p, as mentioned at the beginning of the previous part.
The main idea behind this integral formula is that, to cope with a “once set” and “single” p value that gives higher probabilities to alignments with percent identities close to p, a given interval is more suitable. In terms of the generative process, can be interpreted as choosing uniformly a value for the Bernoulli parameter p in the range , each time and once per alignment sequence, before running the Bernoulli model to generate this full alignment sequence x of length .
An illustration of the full probability mass function for the Hit Integration compared with the Bernoulli and the Heaviside distributions (the latter is defined in the next section) is given in Fig. 3 for alignments of length .
Fig. 3.
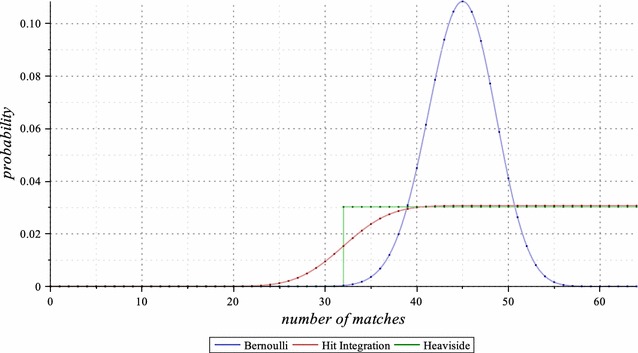
Bernoulli, Hit Integration, and Heaviside models. The Bernoulli (for ), the Hit Integration, and the Heaviside probability mass functions of the number of matches, on alignments of length . Highlighted dots indicate the weights given for each alignment class with a given number of matches m out of alignment symbols, under each of the three models. Note that, since the sum of the weights is always 1 for any model, and since the class of alignments with exactly matches out of is fully included in Heaviside model but only half-included in Hit Integration model, there is a thin difference between the two resulting lines
Chung and Park [2] pointed out that designed spaced seeds were of different shapes, and that several seeds obtained on or were in practice better (compared with three other criteria tested in their paper). We also noticed that the method of [2] was modeled on the [27] recursive decomposition, and is based on a very careful and non-trivial analysis of the terms defined by :
with i: position along alignment, b: alignment suffix that is also π-prefix hitting, over the parameter , and their relationship: this leads to their recurrence formula computed with the [27] algorithm scheme, using an additional internal loop layer for , and a non-obvious ordering of the computed terms on k vs |b| to remain DP-tractable.
Even if the algorithm we propose to compute the Hit Integration (in the next paragraph) has the same theoretical worst case complexity, its advantages are twofold:
We propose a dynamic programming algorithm that is strictly equivalent to the one previously proposed for the the Bernoulli model : in fact, both model-dependent algorithms can even pool their most time-consuming part. Moreover, the automaton used by the dynamic programming algorithm can be previously minimized: this reduction is greatly appreciated when multiple seeds are processed.
We propose a parameter-free approach for the or parameters: it is therefore possible to compute, on any interval, how far a seed is optimal; moreover, we will show that the dominance criterion can be applied as a pre-processing step.
The Hit Integration can be rewritten by applying the polynomial formula (1) into:
| 2 |
Two interesting features can then be deduced from this trivial rewriting.
First, for any constant integers u and v, since the integral of the polynomial part can be easily computed (as a larger degree polynomial), the integral of the right part of the formula (2) can be pre-computed independently of the counting coefficients , and thus independently of the seed . Thus, only coefficients characterize the seed for both the Bernoulli model and the Hit Integration model.
Moreover, we can see that, for and for all , the integral of the right part of the formula (2) is always positive. Therefore, the dominance between seeds also can be directly applied on the coefficients to select dominant seeds before computing the Hit Integration (for any range ) by applying the formula (2), thereby saving computation time for the optimal set of seeds.
As a consequence, even if the optimal seeds selected from the Bernoulli and the Hit Integration models may have different shapes, all such optimal seeds are guaranteed to be dominant 4 in the sense of [1]. Note that the dominance of a seed can be computed independently of any parameter p, or here, any parameters : the dominance criterion can thus be used to pre-select seeds using exactly the same process proposed at the end of the previous part.
As an illustration, Fig. 4 plots the Bernoulli (left) and the Hit Integration (right) polynomials of two seeds: the contiguous seed (11111111111) and the Patternhunter I spaced seed (111010010100110111) which are the two already mentioned out of the forty dominant seeds of weight on alignments of length . Note that the Patternhunter I spaced seed, when compared to the contiguous seed, turns out to be better, if we consider the Bernoulli criterion only when (dark red dashed line)5, or if we consider the Hit Integration criterion only when (dark red dashed line). However, if one wants to consider, not the , but the Hit Integration criterion (data not shown), then the Patternhunter I spaced seed will always outperform the contiguous seed, even if both seeds are dominant in terms of coefficients and cannot be directly compared at first with this partial order dominance.
Fig. 4.
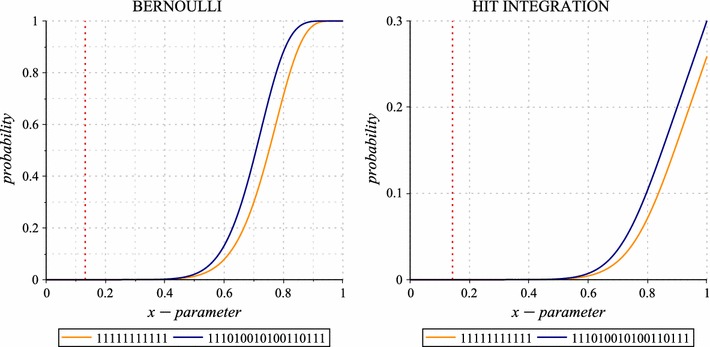
Bernoulli and Hit Integration polynomials. The Bernoulli and Hit Integration polynomials plots for the contiguous seed and the Patternhunter I spaced seed, on alignments of length . The two polynomials have been plotted according to their respective formulas (1) and (2). A vertical mark indicates where they cross each other in the range : the contiguous seed is better under this marked value; otherwise, the Patternhunter I spaced seed is better
We finally mention that, for alignments of length , both the contiguous seed and the Patternhunter I seed are in the set of the twelve optimal seeds found for the Bernoulli model6 (they are reported by symbols  and
and  in Fig. 5, top line of the first plot). Both are also in the set of the eight optimal seeds for the Hit Integration model. But, quite surprisingly, neither of the two is in the set of the four optimal seeds for the Hit Integration model (reported in Fig. 6, top line of first plot). In fact, for the Hit Integration model, the spaced seed 111001011001010111 (reported by a symbol
in Fig. 5, top line of the first plot). Both are also in the set of the eight optimal seeds for the Hit Integration model. But, quite surprisingly, neither of the two is in the set of the four optimal seeds for the Hit Integration model (reported in Fig. 6, top line of first plot). In fact, for the Hit Integration model, the spaced seed 111001011001010111 (reported by a symbol  in Fig. 6, top line of first plot) is optimal7 on a wide range of x () before being surpassed by three other seeds (
in Fig. 6, top line of first plot) is optimal7 on a wide range of x () before being surpassed by three other seeds ( ,
,  and
and  in Fig. 6, top line of the first plot).
in Fig. 6, top line of the first plot).
Fig. 5.
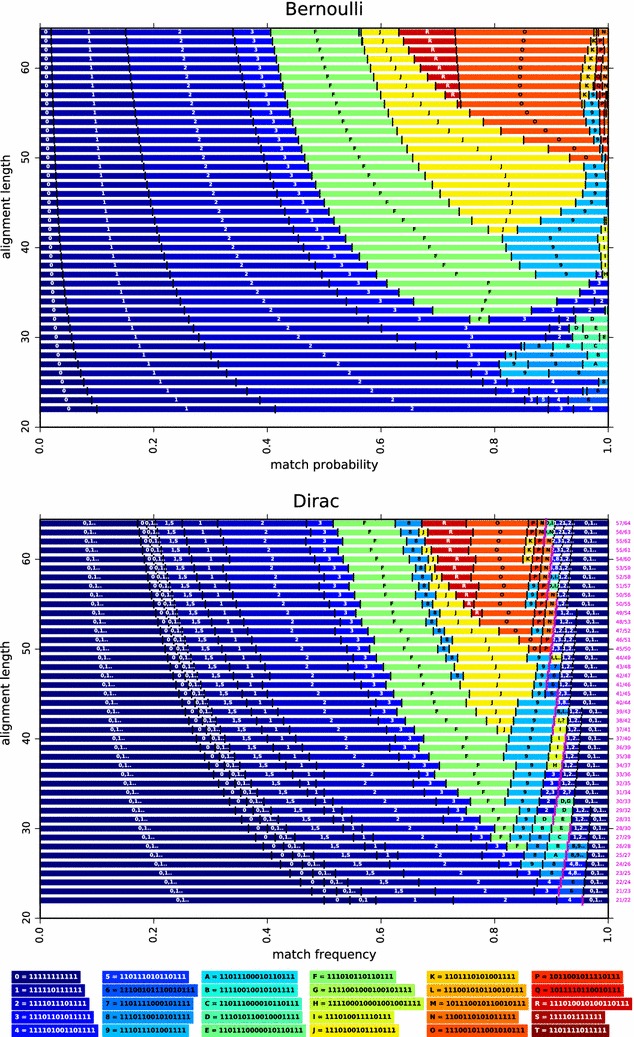
Bernoulli and Dirac optimal seeds. The Bernoulli and Dirac optimal seeds, for single seeds of weight 11 and span , over the match probability or the match frequency of each model (x-axis), and on any alignment length (y-axis). On both Figs. 5 and 6, we choose to represent the same seeds with the same label and with the same background color. On discrete models, a pink mark is set. Seeds on the right of this mark are lossless for the two parameters indicated on the right margin: the minimum number of matches m over the alignment length
Fig. 6.
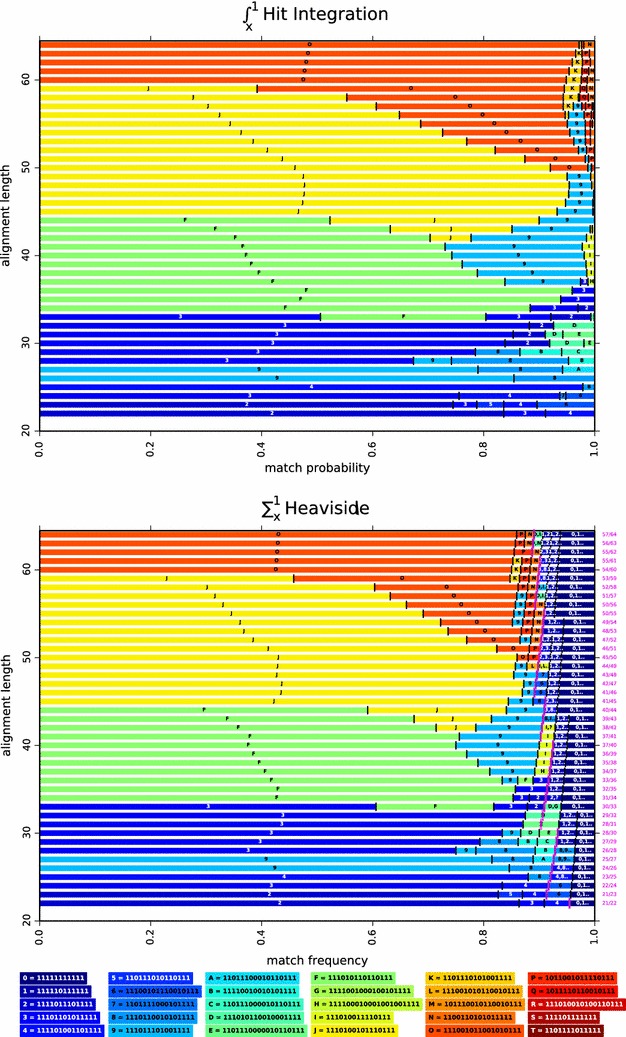
Hit Integration and Heaviside optimal seeds. The Hit Integration and Heaviside optimal seeds, for single seeds of weight 11 and span , over the match probability or the match frequency of each model (x-axis), and on any alignment length (y-axis). On both Figs. 5 and 6, we choose to represent the same seeds with the same label and with the same background color. On discrete models, a pink mark is set. Seeds on the right of this mark are lossless for the two parameters indicated on the right margin: the minimum number of matches m over the alignment length
Discrete models and lossless seeds
In this section, we propose two additional models for selecting seeds. We will name them Dirac and Heaviside. These models can be seen as the discrete counterparts of the Bernoulli and the Hit Integration models, and are simply defined by:
, to give the ratio between the number of alignments detected by the seed over all the alignments of length with exactly m matches,
, to give the average ratio, over any number of matches m between and (out of ) of the previously defined Dirac model. The Heaviside full distribution has already been illustrated in Fig. 3, together with the Hit Integration distribution with similar parameters.
As long as we allow the possible loss of some of the strictly equivalent 8 seeds in terms of sensitivity defined by the Dirac and Heaviside functions, the dominance criterion can be applied to filter out many candidate seeds.
In addition, the Dirac and Heaviside functions are based on rational number computations/comparisons: they are thus one or two orders of magnitude faster and lighter to compute and store, compared to the polynomial forms given by the continuous models of the previous section.
Finally, an interesting feature of the , also true for the specific , is that, when the number of match symbols m is large enough, one seed (or sometime several seeds) can meet the equality for all . Such seeds are thus lossless since they can detect all the alignments of length with at least m matches (or with at most mismatches), and obviously the best lossless ones are retained in the set of dominant seeds, when the equality occurs. As a side consequence, the best lossless seeds are also in the set of dominant seeds and will be reported in the experiments.
Note that, to keep a symmetric notation with the Hit Integration, and also have the same range for the domain of definition (), we will use the “frequency” notation Heaviside to designate . We will also rescale the Dirac function on the Bernoulli’s domain of definition, by using the frequency f () to designate .
Experiments
Single spaced seeds () and multiple co-designed spaced seeds () of weight and span s at most have been considered. Note that, for single seeds of large weight (), or for multiple seed, the full enumeration is respectively burdensome or intractable, so we prefer to apply the hill-climbing algorithm of Iedera [88]: selected dominant spaced seeds are thus locally dominant, since it would be computationally unfeasible to guarantee their overall dominance. All the spaced seeds are evaluated on alignments of length .
The main idea during the evaluation, also used by [1] but only for the single Bernoulli criterion and on a single spaced seed, is to split the computation in two distinct stages:
Selecting the set of dominant seeds is the first stage: it provides a reduced set of candidate seeds. Note that the dominant selection can be applicable without prior knowledge of the sensitivity criterion being used, provided that this sensitivity criterion is established on i.i.d sequence alignments (this last requirement is true for the Bernoulli, the Hit Integration, the Dirac, and the Heaviside models).
- Comparing each of the seeds from the set of dominant seeds with a sensitivity criterion is the second stage: it usually depends on at least one parameter (for example, for the Bernoulli model: the probability p to generate a match) which has different consequences on continuous and discrete models:
- For the Bernoulli and the Hit Integration continuous models, this implies comparing p-parametrized or -parametrized polynomials: we follow the idea proposed in [1] for the Bernoulli model and also apply it on the Hit Integration model where we compute the HI and the HI respectively. Let us concentrate on the Bernoulli model with a (single) free parameter p: For two dominant seeds and and a given length , we compute their respective polynomials and and their difference (an example of its associated coefficients is illustrated on the third column of Table 1), from which zeros in the range are numerically extracted using solvers from maple or maxima. Using the p-intervals between these zeros, it is then possible to determine whether is positive or negative, and thus which of the two seeds or is better according to p. Finally, the Pareto envelope (optimal seeds) can be extracted from the initial set of dominant seeds.
- For the Dirac and the Heaviside discrete models, this implies comparing, instead of real-valued polynomials, integer numbers for the Dirac model (and respectively rational numbers for the Heaviside model), which is an easier and lighter process. The Pareto envelope can then be easily extracted from these discrete models to select the optimal seeds from the set of dominant seeds. We have also extracted the lossless part for the Dirac and the Heaviside criteria.
In the aforementioned experiments, we noticed that the size of the set of dominant seeds was at most (with a median size of 57 and an average size of 303 for all the experiments). To briefly illustrate this point, a list of each maximum size in our experiments is provided on Table 2.
Table 2.
Maximum size of the set of dominant seeds
| w | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| n | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 1 | 2 | 7 | 8 | 13 | 15 | 26 | 23 | 32 | 40 | 45 | 46 | 48 | 74 | 84 |
| (64) | (64) | (62) | (64) | (64) | (61) | (60) | (62) | (64) | (63) | (64) | (59) | (64) | (64) | |
| 2 | 5 | 12 | 35 | 41 | 52 | 99 | 128 | 197 | 231 | 207 | 350 | 320 | 439 | 376 |
| (64) | (63) | (63) | (61) | (64) | (64) | (60) | (62) | (61) | (59) | (63) | (64) | (64) | (41) | |
| 3 | 6 | 26 | 85 | 84 | 204 | 320 | 391 | 485 | 854 | 932 | 1103 | 1449 | 1508 | 1812 |
| (60) | (64) | (64) | (62) | (64) | (60) | (56) | (56) | (62) | (64) | (64) | (41) | (64) | (63) | |
| 4 | 7 | 29 | 124 | 190 | 254 | 535 | 811 | 1041 | 1450 | 1908 | 1775 | 2364 | 3125 | 3359 |
| (64) | (64) | (64) | (64) | (64) | (59) | (64) | (58) | (63) | (64) | (62) | (39) | (63) | (37) | |
For n seeds of weight w, we indicate the maximum size of the dominant set found in our experiments on all the alignment lengths . We also give the largest alignment length where this maximum has been reached
So far, we restricted the span of our designed seeds to , and also did not consider one single fixed probability p during the optimization process. These restrictive conditions could be of course alleviated, but we mention here that computed sensitivities are close to (even if not strictly speaking “better than”) the top ones mentioned in several publications [56, 77, 78, 80] where the emphasis was on the heuristic being used for designing seed, the speed of the optimization algorithm, and the best seed for a fixed probability p. Table 3 has been extracted from the Table 1 of recently published paper [80] and summarizes known optimal sensitivities.
Table 3.
Sensitivity comparison of different programs
| w | p | SpEED | AcoSeed | FastHC | MuteHC | Rasbhari | Current sensitivity () |
|---|---|---|---|---|---|---|---|
| 10 | 0.75 | 90.9098 | 90.9513 | 90.7312 | 92.6812 | 90.9614 | 90.8753 (1.8059%) |
| 0.80 | 97.8337 | 97.8521 | 97.7625 | 98.3836 | 97.8554 | 97.8203 (0.5633%) | |
| 0.85 | 99.7569 | 99.7614 | 99.7431 | 99.8356 | 99.7618 | 99.7568 (0.0788%) | |
| 11 | 0.75 | 83.3793 | 83.4728 | 83.3068 | 83.4127 | 83.4679 | 83.4297 (0.0431%) |
| 0.80 | 94.9861 | 95.037 | 94.9453 | 95.0194 | 95.0386 | 95.0127 (0.0259%) | |
| 0.85 | 99.2431 | 99.2478 | 99.2250 | 99.2486 | 99.2506 | 99.2452 (0.0054%) | |
| 12 | 0.80 | 90.5750 | 90.6328 | 90.4735 | 90.5820 | 90.6648 | 90.5571 (0.1077%) |
| 0.85 | 98.1589 | 98.1766 | 98.1199 | 98.1670 | 98.1824 | 98.1591 (0.0233%) | |
| 0.90 | 99.8821 | 99.8853 | 99.8771 | 99.8836 | 99.8864 | 99.8840 (0.0024%) | |
| 16 | 0.85 | 84.8212 | 84.9829 | 84.6558 | 84.8764 | 84.969 | 84.9668 (0.0161%) |
| 0.90 | 97.4321 | 97.4712 | 97.3556 | 97.4460 | 97.5035 | 97.4730 (0.0305%) | |
| 0.95 | 99.9388 | 99.9419 | 99.9347 | 99.9424 | 99.9441 | 99.9414 (0.0027%) |
Italic values indicate the best sensitivity
The reported sensitivity for seeds of weight w on alignments of length under a Bernoulli model with a match probability p. All the reported results are extracted from the Table 1 of [80], but the last column that corresponds to our current public seeds, with a difference to the optimal seed
Note that we did not use any Overlap Complexity/Covariance heuristic optimisation here (to stay in a generic framework), and simply apply the very simple hill-climbing algorithm of Iedera. We also mention that our seeds are not definitely the best ones, but since they are published, their sensitivity can be checked using other software, as mandala [63], SpEED [56], or rasbhari [80] ([43, 57] did the same with the seeds obtained with the SpEED software).
Finally, to show a typical output of this generalized parameter-free approach, optimal single () seeds of weight have been plotted according to the main parameter of each model (horizontal axis) and the length of the alignment (vertical axis) in Figs. 5 and 6. On discrete models, a pink mark represents the lossless border: seeds on the right of this border are by essence lossless for the set of parameters. On the right margin of the discrete models, we indicate the fraction of the minimum number of matches m over the alignment length to be lossless.
We provide the scripts and the whole set of single and multiple seeds, in http://bioinfo.cristal.univ-lille.fr/yass/iedera_dominance in the hope this will be useful to alignment software and spaced seeds alignment-free metagenomic classifiers.
Discussion
In this paper, we have presented a generalization of the usage of dominant seeds, first on the Hit integration model with a parameter-free approach, and also on two new discrete models (named Dirac and Heaviside) that are related to lossless seeds. In this parameter-free context, we show that all these models can be computed with help of a method for counting alignments of particular classes, themselves represented by regular languages, and a counting semi-ring to perform an efficient set size computation.
We open the discussion with the complementary asymptotic problem, before going to finite but multivariate model extensions.
Complementary asymptotic problem
So far, we only have considered a set of finite alignment lengths to design seeds. But limiting the length is far from satisfactory, so the next problem deserves consideration too: the asymptotic hit probability of seeds [63, 89–91].
As an example, if we consider the Bernoulli model where we choose p in the interval ]0, 1[, and then consider the probability for to hit an alignment of length (noted to simplify), then it can be shown that the complementary probability [see for example 91, equation (3)] follows
Here is the largest (positive) eigenvalue of the sub-stochastic matrix of where final states have been removed, this matrix computing thus the distribution when powered to (see section 3.1 and of [63]).
As an example, for and for the Patternhunter I spaced seed, we have (with help of a Maple script) , that can be compared with the contiguous seed of same weight . [63] have proven that, in the class of seeds with the same weight, contiguous seeds have the largest value and thus are the asymptotic worst-case in terms of hit probability, a trait shared with the uniformly spaced seeds of same weight (e.g. 101010101010101010101 or 1001001001001001001001001001001).
Comparing seeds asymptotically can thus be done easily by comparing their respective eigenvalue, or their when equality occurs, but it seems to be computationally possible 9 only if p is set numerically before the analysis.
Moreover dominant seeds’ extracted from this paper on a limited alignment length (here ) would not always be optimal for any : such seeds can, however, be justified as “good” candidates for seeds of restricted span (e.g. ), but definitely not the optimal ones, unless dominance is computed on a wider range of alignment length values.
For example, the best (smallest) for any dominant seed of weight and span at most , on alignments of length is 0.98714 for the seed 1110010100110010111. Surprisingly, even if this seed reaches the smallest out of its dominant class, it never occurred in the optimal seeds, in any of our experiments. Moreover, we have checked that another seed 1110010100100100010111 has an even smaller : this last seed was not dominant for , but would be in the class of seeds of span at most if larger values of were selected.
Finally, a parameter-free analysis implying both p and seems difficult to apply for large seeds. It is interesting to notice that several of our preliminary experiments suggest that, asymptotically, and only10 for a restricted set of seeds (e.g. of weight and span at most ), one seed is optimal whatever the value of p. This remains to be confirmed experimentally and theoretically because it might be possible that special cases exist, where at least two (or even more) seeds share the p partition.
Models and multivariate analysis
As far as i.i.d sequences are considered, the full framework of [1], including the dominant seed selection, can be applied on any extended spaced seed model (such as transition constrained seeds, vector seeds, indel seeds,...). However, additional free-parameters (such as the transition/transversion rate, the indel/mismatch rate, ...) lead to an increase in the number of alignment classes (for example, alignments of length , with i indels, v transversion errors, t transitions errors, and remaining m matches, such that ) that have to be considered by the dominance selection. Moreover, it involves a much more complex multivariate polynomial analysis, if more than one parameter is, at this point, left free.
In a more general way, if i.i.d sequences are ignored, and dominant seed selection thus abandoned in its original form, one could mix several numerically-fixed models: for example, mixing a given HMM representing coding sequences, with a numerically-fixed Bernoulli model. The idea is here to use a free probability parameter to create a balance between the two models: either initially before generating the alignment, to choose each of the two models; or along the alignment generation process, to switch between each of the two models. Seeds designed could thus be two-handed for analyzing both coding and non-coding genomic sequences at the same time, but with an additional control parameter that helps to change the known percentage of such genomic sequences. To compute the sensitivity in this model, a simple idea is to apply a polynomial semi-ring (with at least one parameter-free variable: here the one used to create the balance) on the automaton, and perform, not a numeric, but a symbolic computation.
Finally, as a logical consequence of the two previous remarks, we mention that any HMM with one (or possibly several) free probability parameter(s) could always be analysed with a (multivariate) polynomial semi-ring, increasing thus the scope of the method to applications that depend on Finite State Machines : such parameter-free pre-processing can, at some point, be applied; moreover if several equivalence classes are established in term of probability, it may be possible to use equivalent dominance method to filter out candidates when comparing several elements.
Acknowledgments and funding
Donald E. K. Martin provided substantive comments on an earlier version of this manuscript. The author would like to thank the second reviewer for his/her thorough review which significantly contributed to improving the quality of the paper. The publication costs were covered by the French Institute for Research in Computer Science and Automation (inria).
Competing interests
The author declare that he has no competing interests.
Availability of data and materials
All data and source code are freely available and may be downloaded from: http://bioinfo.cristal.univ-lille.fr/yass/iedera_dominance/
Consent for publication
Not applicable. The manuscript does not contain any data from any individual person.
Ethical approval
The manuscript does not report new studies involving any animal or human data or tissue.
Footnotes
We mention an interesting analysis in [92].
The opposite is equivalent to say that at least one string of length with mismatches is not hit by the seed; in other words, that the seed is not -lossless. Note that k does not need to be initially set: it can be estimated using this requirement, even after the DP run.
Technical details at http://bioinfo.cristal.univ-lille.fr/yass/iedera_coverage/index_additional.html.
This side result is not discussed in [2], probably because they were more interested by the seed rank and not necessary the “optimal seed”, which they sometime called “dominant”.
As already observed by [63].
As already mentioned by [1].
As already mentioned by [2], but for the non-parametrized and Hit Integration model.
To give a quick and intuitive example, we consider an extreme case : an alignment of fixed length without any mismatch symbol. Any seed of weight and span obviously detects this alignment, whatever its shape is, so and reach their maximal sensitivity of 1. For a given weight w, the restriction of all these seeds to dominant seeds implies that many are lost when dominance selection is applied to keep the best representatives.
At least to the author, but this parametrized problem is intrinsically interesting in itself.
This restricted set of seeds condition is necessary: if removed, best seeds span will increase along , see [18].
References
- 1.Mak DYF, Benson G. All hits all the time: parameter free calculation of seed sensitivity. Bioinformatics. 2009;25(3):302–308. doi: 10.1093/bioinformatics/btn643. [DOI] [PubMed] [Google Scholar]
- 2.Chung WH, Park SB. Hit integration for identifying optimal spaced seeds. BMC Bioinform. 2010;11(1):S37. doi: 10.1186/1471-2105-11-S1-S37. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Ma B, Tromp J, Li M. PatternHunter: faster and more sensitive homology search. Bioinformatics. 2002;18(3):440–445. doi: 10.1093/bioinformatics/18.3.440. [DOI] [PubMed] [Google Scholar]
- 4.Burkhardt S, Kärkkäinen J. Better filtering with gapped -grams. Fund Inform. 2002;56(1—-2):51–70. [Google Scholar]
- 5.Brejová B, Brown DG, Vinař T. Vector seeds: an extension to spaced seeds. J Comput Syst Sci. 2005;70(3):364–380. doi: 10.1016/j.jcss.2004.12.008. [DOI] [Google Scholar]
- 6.Burkhardt S, Kärkkäinen J. One-gapped -gram filters for Levenshtein distance. Proceedings of the 13th symposium on combinatorial pattern matching (CPM), vol 2373, Lecture Notes in Computer Science Fukuoka (Japan). Berlin: Springer; 2002. p. 225–34.
- 7.Mak DYF, Gelfand Y, Benson G. Indel seeds for homology search. Bioinformatics. 2006;22(14):341–349. doi: 10.1093/bioinformatics/btl263. [DOI] [PubMed] [Google Scholar]
- 8.Chen K, Zhu Q, Yang F, Tang D. An efficient way of finding good indel seeds for local homology search. Chin Sci Bull. 2009;54(20):3837–3842. doi: 10.1007/s11434-009-0531-6. [DOI] [Google Scholar]
- 9.Csűrös M, Ma B. Rapid homology search with neighbor seeds. Algorithmica. 2007;48(2):187–202. doi: 10.1007/s00453-007-0062-y. [DOI] [Google Scholar]
- 10.Ilie L, Ilie S. Fast computation of neighbor seeds. Bioinformatics. 2009;25(6):822–823. doi: 10.1093/bioinformatics/btp054. [DOI] [PubMed] [Google Scholar]
- 11.Chen W, Sung WK. On half gapped seed. Genome Inform. 2003;14:176–185. [PubMed] [Google Scholar]
- 12.Noé L, Kucherov G. Improved hit criteria for DNA local alignment. BMC Bioinform. 2004;5:149. doi: 10.1186/1471-2105-5-149. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Yang J, Zhang L. Run probabilities of seed-like patterns and identifying good transition seeds. J Comput Biol. 2008;5(10):1295–1313. doi: 10.1089/cmb.2007.0209. [DOI] [PubMed] [Google Scholar]
- 14.Zhou L, Stanton J, Florea L. Universal seeds for cDNA-to-genome comparison. BMC Bioinform. 2008;9:36. doi: 10.1186/1471-2105-9-36. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Frith MC, Noé L. Improved search heuristics find 20 000 new alignments between human and mouse genomes. Nucleic Acids Res. 2014;42(7):59. doi: 10.1093/nar/gku104. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Li M, Ma B, Kisman D, Tromp J. PatternHunter II: highly sensitive and fast homology search. J Bioinform Comput Biol. 2004;2(3):417–439. doi: 10.1142/S0219720004000661. [DOI] [PubMed] [Google Scholar]
- 17.Sun Y, Buhler J. Designing multiple simultaneous seeds for DNA similarity search. J Comput Biol. 2005;12(6):847–861. doi: 10.1089/cmb.2005.12.847. [DOI] [PubMed] [Google Scholar]
- 18.Kucherov G, Noé L, Roytberg MA. Multiseed lossless filtration. IEEE/ACM Trans Comput Biol Bioinform. 2005;2(1):51–61. doi: 10.1109/TCBB.2005.12. [DOI] [PubMed] [Google Scholar]
- 19.Farach-Colton M, Landau GM, Cenk Sahinalp S, Tsur D. Optimal spaced seeds for faster approximate string matching. J Comput Syst Sci. 2007;73(7):1035–1044. doi: 10.1016/j.jcss.2007.03.007. [DOI] [Google Scholar]
- 20.Kiełbasa SM, Wan R, Sato K, Horton P, Frith MC. Adaptive seeds tame genomic sequence comparison. Genome Res. 2011;21(3):487–493. doi: 10.1101/gr.113985.110. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Peterlongo P, Pisanti N, Boyer F, Sagot MF. Lossless filter for finding long multiple approximate repetitions using a new data structure, the bi-factor array. In: Consens M, Navarro G, editor. Proceedings of the 12th international conference, on string processing and information retrieval (SPIRE). Lecture Notes in Computer Science, vol 3772. Buenos Aires; 2005. p. 179–190.
- 22.Crochemore M, Tischler G. The gapped suffix array: a new index structure for fast approximate matching. In: Chavez E, Lonardi S, editors. Proceedings of the 17th international—symposium on string processing and information retrieval (SPIRE) Los Cabos: Springer; 2010. pp. 359–364. [Google Scholar]
- 23.Onodera T, Shibuya T. An index structure for spaced seed search. In: Asano T, Nakano S-I, Okamoto Y, Watanabe O, editors. Proceedings of the 22nd international symposium on algorithms and computation (ISAAC) Yokohama (Japan): Springer; 2011. pp. 764–772. [Google Scholar]
- 24.Gagie T, Manzini G, Valenzuela D. Compressed spaced suffix arrays. In: Proceedings of the 2nd international conference on algorithms for big data (ICABD). CEUR-WS, vol 1146. Palermo; 2014. p. 37–45.
- 25.Shrestha AMS, Frith MC, Horton P. A bioinformatician’s guide to the forefront of suffix array construction algorithms. Brief Bioinform. 2014;15(2):138–154. doi: 10.1093/bib/bbt081. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Birol I, Chu J, Mohamadi H, Jackman SD, Raghavan K, Vandervalk BP, Raymond A, Warren RL. Spaced seed data structures for de novo assembly. Int J Genom. 2015;2015:196591. doi: 10.1155/2015/196591. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Keich U, Li M, Ma B, Tromp J. On spaced seeds for similarity search. Discret Appl Math. 2004;138(3):253–263. doi: 10.1016/S0166-218X(03)00382-2. [DOI] [Google Scholar]
- 28.Nicolas F, Rivals É. Hardness of optimal spaced seed design. J Comput Syst Sci. 2008;74(5):831–849. doi: 10.1016/j.jcss.2007.10.001. [DOI] [Google Scholar]
- 29.Ma B, Yao H. Seed optimization for i.i.d. similarities is no easier than optimal Golomb ruler design. Inf Process Lett. 2009;109(19):1120–1124. doi: 10.1016/j.ipl.2009.07.008. [DOI] [Google Scholar]
- 30.Schwartz S, Kent WJ, Smit A, Zhang Z, Baertsch R, Hardison RC, Haussler D, Miller W. Human-mouse alignments with BLASTZ. Genome Res. 2003;13:103–107. doi: 10.1101/gr.809403. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Darling AE, Treangen TJ, Zhang L, Kuiken C, Messeguer X, Perna NT. Procrastination leads to efficient filtration for local multiple alignment. Proceedings of the 6th international workshop on algorithms in bioinformatics (WABI), vol 4175. Lecture notes in bioinformatics. Zürich: Springer; 2006. p. 126–37.
- 32.Harris RS. Improved pairwise alignment of genomic dna. Ph.d. thesis, The Pennsylvania State University; 2007
- 33.Lin H, Zhang Z, Zhang MQ, Ma B, Li M. ZOOM! Zillions Of Oligos Mapped. Bioinformatics. 2008;24(21):2431–2437. doi: 10.1093/bioinformatics/btn416. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Rumble SM, Lacroute P, Dalca AV, Fiume M, Sidow A, Brudno M. SHRiMP: accurate mapping of short color-space reads. PLoS Comp Biol. 2009;5(5):1000386. doi: 10.1371/journal.pcbi.1000386. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 35.Chen Y, Souaiaia T, Chen T. PerM: efficient mapping of short sequencing reads with periodic full sensitive spaced seeds. Bioinformatics. 2009;25(19):2514–2521. doi: 10.1093/bioinformatics/btp486. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Giladi E, Healy J, Myers G, Hart C, Kapranov P, Lipson D, Roels S, Thayer E, Letovsky S. Error tolerant indexing and alignment of short reads with covering template families. J Comput Biol. 2010;17(10):1397–1411. doi: 10.1089/cmb.2010.0005. [DOI] [PubMed] [Google Scholar]
- 37.David M, Dzamba M, Lister D, Ilie L, Brudno M. SHRiMP2: Sensitive yet practical short read mapping. Bioinformatics. 2011;27(7):1011–1012. doi: 10.1093/bioinformatics/btr046. [DOI] [PubMed] [Google Scholar]
- 38.Sović I, Šikić M, Wilm A, Fenlon SN, Chen S, Nagarajan N. Fast and sensitive mapping of nanopore sequencing reads with GraphMap. Nat Commun. 2016;7:11307. doi: 10.1038/ncomms11307. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Preparata FP, Oliver JS. DNA sequencing by hybridization using semi-degenerate bases. J Comput Biol. 2005;11(4):753–765. doi: 10.1089/cmb.2004.11.753. [DOI] [PubMed] [Google Scholar]
- 40.Tsur D. Optimal probing patterns for sequencing by hybridization. Proceedings of the 6th international workshop on algorithms in bioinformatics (WABI), vol 4175. Lecture notes in bioinformatics. Zürich: Springer; 2006. p. 366–75.
- 41.Feng S, Tillier ERM. A fast and flexible approach to oligonucleotide probe design for genomes and gene families. Bioinformatics. 2007;23(10):1195–1202. doi: 10.1093/bioinformatics/btm114. [DOI] [PubMed] [Google Scholar]
- 42.Chung W-H, Park S-B. An empirical study of choosing efficient discriminative seeds for oligonucleotide design. BMC Genom. 2009;10(Suppl 3):3. doi: 10.1186/1471-2164-10-S3-S3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43.Ilie L, Ilie S, Khoshraftar S, Mansouri Bigvand A. Seeds for effective oligonucleotide design. BMC Genom. 2011;12:280. doi: 10.1186/1471-2164-12-280. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Ilie L, Mohamadi H, Brian Golding G, Smyth WF. BOND: Basic Oligo Nucleotide Design. BMC Bioinform. 2013;14:69. doi: 10.1186/1471-2105-14-69. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Kisman D, Li M, Ma B, Li W. tPatternhunter: gapped, fast and sensitive translated homology search. Bioinformatics. 2005;21(4):542–544. doi: 10.1093/bioinformatics/bti035. [DOI] [PubMed] [Google Scholar]
- 46.Brown DG. Optimizing multiple seeds for protein homology search. IEEE/ACM Trans Comput Biol Bioinform. 2005;2(1):23–38. doi: 10.1109/TCBB.2005.13. [DOI] [PubMed] [Google Scholar]
- 47.Roytberg MA, Gambin A, Noé L, Lasota S, Furletova E, Szczurek E, Kucherov G. On subset seeds for protein alignment. IEEE/ACM Trans Comput Biol Bioinform. 2009;6(3):483–494. doi: 10.1109/TCBB.2009.4. [DOI] [PubMed] [Google Scholar]
- 48.Nguyen V-H, Lavenier D. PLAST: parallel local alignment search tool for database comparison. BMC Bioinform. 2009;10:329. doi: 10.1186/1471-2105-10-329. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49.Startek M, Lasota S, Sykulski M, Bułak A, Noé L, Kucherov G, Gambin A. Efficient alternatives to PSI-BLAST. Bull Pol Acad Sci Tech Sci. 2012;60(3):495–505. [Google Scholar]
- 50.Li W, Ma B, Zhang K. Optimizing spaced k-mer neighbors for efficient filtration in protein similarity search. IEEE/ACM Trans Comput Biol Bioinform. 2014;11(2):398–406. doi: 10.1109/TCBB.2014.2306831. [DOI] [PubMed] [Google Scholar]
- 51.Buchfink B, Xie C, Huson DH. Fast and sensitive protein alignment using DIAMOND. Nat Methods. 2014;12:59–60. doi: 10.1038/nmeth.3176. [DOI] [PubMed] [Google Scholar]
- 52.Somervuo P, Holm L. SANSparallel: interactive homology search against Uniprot. Nucleic Acids Res. 2015;43(W1):24–29. doi: 10.1093/nar/gkv317. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Petrov I, Brillet S, Drezen E, Quiniou S, Antin L, Durand P, Lavenier D. KLAST: fast and sensitive software to compare large genomic databanks on cloud. In: Proceedings world congress in computer science, computer engineering, and applied computing (WORLDCOMP). Las Vegas; 2015. p. 85–90.
- 54.Yang IH, Wang SH, Chen YH, Huang PH, Ye L, Huang X, Chao KM. Efficient methods for generating optimal single and multiple spaced seeds. In: Proceedings of the IEEE 4th symposium on bioinformatics and bioengineering (BIBE). Taichung: IEEE Computer Society Press; 2004. p. 411–16.
- 55.Ilie L, Ilie S. Multiple spaced seeds for homology search. Bioinformatics. 2007;23(22):2969–2977. doi: 10.1093/bioinformatics/btm422. [DOI] [PubMed] [Google Scholar]
- 56.Ilie L, Ilie S. SpEED: fast computation of sensitive spaced seeds. Bioinformatics. 2011;27(17):2433–2434. doi: 10.1093/bioinformatics/btr368. [DOI] [PubMed] [Google Scholar]
- 57.Ilie S. Efficient computation of spaced seeds. BMC Res Notes. 2012;5:123. doi: 10.1186/1756-0500-5-123. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Egidi L, Manzini G. Better spaced seeds using quadratic residues. J Comput Syst Sci. 2013;79(7):1144–1155. doi: 10.1016/j.jcss.2013.03.002. [DOI] [Google Scholar]
- 59.Egidi L, Manzini G. Design and analysis of periodic multiple seeds. Theor Comput Sci. 2014;522:62–76. doi: 10.1016/j.tcs.2013.12.007. [DOI] [Google Scholar]
- 60.Egidi L, Manzini G. Spaced seeds design using perfect rulers. Fund Inform. 2014;131(2):187–203. [Google Scholar]
- 61.Egidi L, Manzini G. Multiple seeds sensitivity using a single seed with threshold. J Bioinform Comput Biol. 2015;13(4):1550011. doi: 10.1142/S0219720015500110. [DOI] [PubMed] [Google Scholar]
- 62.Brejová B, Brown DG, Vinař T. Optimal spaced seeds for homologous coding regions. J Bioinform Comput Biol. 2004;1(4):595–610. doi: 10.1142/S0219720004000326. [DOI] [PubMed] [Google Scholar]
- 63.Buhler J, Keich U, Sun Y. Designing seeds for similarity search in genomic DNA. J Comput Syst Sci. 2005;70(3):342–363. doi: 10.1016/j.jcss.2004.12.003. [DOI] [Google Scholar]
- 64.Preparata FP, Zhang L, Choi KP. Quick, practical selection of effective seeds for homology search. J Comput Biol. 2005;12(9):1137–1152. doi: 10.1089/cmb.2005.12.1137. [DOI] [PubMed] [Google Scholar]
- 65.Kucherov G, Noé L, Roytberg MA. A unifying framework for seed sensitivity and its application to subset seeds. J Bioinform Comput Biol. 2006;4(2):553–569. doi: 10.1142/S0219720006001977. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66.Zhang L. Superiority of spaced seeds for homology search. IEEE/ACM Trans Comput Biol Bioinform. 2007;4(3):496–505. doi: 10.1109/tcbb.2007.1013. [DOI] [PubMed] [Google Scholar]
- 67.Kong Y. Generalized correlation functions and their applications in selection of optimal multiple spaced seeds for homology search. J Comput Biol. 2007;14(2):238–254. doi: 10.1089/cmb.2006.0008. [DOI] [PubMed] [Google Scholar]
- 68.Noé L, Gîrdea M, Kucherov G. Designing efficient spaced seeds for SOLiD read mapping. Adv Bioinform. 2010;2010:708501. doi: 10.1155/2010/708501. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 69.Marschall T, Herms I, Kaltenbach H-M, Rahmann S. Probabilistic arithmetic automata and their applications. IEEE/ACM Trans Comput Biol Bioinform. 2012;9(6):1737–1750. doi: 10.1109/TCBB.2012.109. [DOI] [PubMed] [Google Scholar]
- 70.Martin DEK, Noé L. Faster exact distributions of pattern statistics through sequential elimination of states. Ann Inst Stat Math. 2017;69:1–18. doi: 10.1007/s10463-015-0540-y. [DOI] [Google Scholar]
- 71.Horwege S, Lindner S, Boden M, Hatje K, Kollmar M, Leimeister C-A, Morgenstern B. Spaced words and kmacs: fast alignment-free sequence comparison based on inexact word matches. Nucleic Acids Res. 2014;42(W1):7–11. doi: 10.1093/nar/gku398. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 72.Leimeister CA, Boden M, Horwege S, Lindner S, Morgenstern B. Fast alignment-free sequence comparison using spaced-word frequencies. Bioinformatics. 2014;30(14):1991–1999. doi: 10.1093/bioinformatics/btu177. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 73.Ghandi M, Mohammad-Noori M, Beer MA. Robust k-mer frequency estimation using gapped k-mers. J Math Biol. 2014;69(2):469–500. doi: 10.1007/s00285-013-0705-3. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 74.Morgenstern B, Zhu B, Horwege S, Leimeister CA. Estimating evolutionary distances between genomic sequences from spaced-word matches. Algorithms Mol Biol. 2015;10:5. doi: 10.1186/s13015-015-0032-x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 75.Břinda K, Sykulski M, Kucherov G. Spaced seeds improve k-mer based metagenomic classification. Bioinformatics. 2015;31(22):3584–3592. doi: 10.1093/bioinformatics/btv419. [DOI] [PubMed] [Google Scholar]
- 76.Ounit R, Lonardi S. Higher classification sensitivity of short metagenomic reads with CLARK-S. Bioinformatics. 2016. [DOI] [PubMed]
- 77.Duc DD, Dinh HQ, Dang TH, Laukens K, Hoang XH. AcoSeeD: an ant colony optimization for finding optimal spaced seeds in biological sequence search. Proceedings of the 8th international conference on swarm intelligence (ANTS), vol 7461. Lecture notes in computer science. Brussels: Springer; 2012. p. 204–11.
- 78.Do PT, Tran-Thi CG. An improvement of the overlap complexity in the spaced seed searching problem between genomic DNAs. In: Proceedings of the 2nd National Foundation for Science and Technology Development Conference on Information and Computer Science (NICS). Ho Chi Minh City; 2015. p. 271–76.
- 79.Gheraibia Y, Moussaoui A, Djenouri Y, Kabir S, Yin P-Y, Mazouzi S. Penguin search optimisation algorithm for finding optimal spaced seeds. Int J Softw Sci Comput Intell. 2015;7(2):85–99. doi: 10.4018/IJSSCI.2015040105. [DOI] [Google Scholar]
- 80.Hahn L, Leimeister C-A, Ounit R, Lonardi S, Morgenstern B. rasbhari: optimizing spaced seeds for database searching, read mapping and alignment-free sequence comparison. PLoS Comput Biol. 2016;12(10):1005107. doi: 10.1371/journal.pcbi.1005107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 81.Choi KP, Zeng F, Zhang L. Good spaced seeds for homology search. Bioinformatics. 2004;20(7):1053–1059. doi: 10.1093/bioinformatics/bth037. [DOI] [PubMed] [Google Scholar]
- 82.Allauzen C, Riley M, Schalkwyk J, Skut W, Mohri M. OpenFst: a general and efficient weighted finite-state transducer library. In: Holub J, Zdarek J, editors. Proceedings of the 12th international conference on implementation and application of automata (CIAA) Prague: Springer; 2007. pp. 11–23. [Google Scholar]
- 83.Mohri M. Weighted automata algorithms. In: Handbook of weighted automata. Berlin: Springer; 2009. p. 213–54.
- 84.Huang L. Dynamic programming algorithms in semiring and hypergraph frameworks. Technical report, University of Pennsylvania, Philadelphia, USA; 2006.
- 85.Hopcroft JE, Motwani R, Ullman JD. Introduction to automata theory languages and computation. 3. New York: Pearson; 2007. [Google Scholar]
- 86.Aston JAD, Martin DEK. Distributions associated with general runs and patterns in hidden Markov models. Ann Appl Stat. 2007;1(2):585–611. doi: 10.1214/07-AOAS125. [DOI] [Google Scholar]
- 87.Noé L, Martin DEK. A coverage criterion for spaced seeds and its applications to support vector machine string kernels and k-mer distances. J Comput Biol. 2014;21(12):947–963. doi: 10.1089/cmb.2014.0173. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 88.Kucherov G, Noé L, Roytberg MA. Iedera subset seed design tool. http://bioinfo.lifl.fr/yass/iedera.php; 2016.
- 89.Ma B, Li M. On the complexity of spaced seeds. J Comput Syst Sci. 2007;73(7):1024–1034. doi: 10.1016/j.jcss.2007.03.008. [DOI] [Google Scholar]
- 90.Li M, Ma B, Zhang L. Superiority and complexity of the spaced seeds. In: Proceedings of the 17th symposium on discrete algorithms (SODA). Miami: ACM Press; 2006. p. 444–53.
- 91.Nicodème P, Salvy B, Flajolet P. Motif statistics. Theor Comput Sci. 2002;287(2):593–617. doi: 10.1016/S0304-3975(01)00264-X. [DOI] [Google Scholar]
- 92.Myers G. 1. What’s behind blast. Models and algorithms for genome evolution, vol 19. Computational biology. Berlin: Springer; 2013. p. 3–15.
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
All data and source code are freely available and may be downloaded from: http://bioinfo.cristal.univ-lille.fr/yass/iedera_dominance/