

Abstract
Biological systems are increasingly being studied by high throughput profiling of molecular data over time. Determining the set of time points to sample in studies that profile several different types of molecular data is still challenging. Here we present the Time Point Selection (TPS) method that solves this combinatorial problem in a principled and practical way. TPS utilizes expression data from a small set of genes sampled at a high rate. As we show by applying TPS to study mouse lung development, the points selected by TPS can be used to reconstruct an accurate representation for the expression values of the non selected points. Further, even though the selection is only based on gene expression, these points are also appropriate for representing a much larger set of protein, miRNA and DNA methylation changes over time. TPS can thus serve as a key design strategy for high throughput time series experiments. Supporting Website: www.sb.cs.cmu.edu/TPS
DOI: http://dx.doi.org/10.7554/eLife.18541.001
Research Organism: Mouse
Introduction
Time series experiments are very commonly used to study a wide range of biological processes. Examples include various developmental processes (Roy et al., 2010), stem cell differentiation (Sperger et al., 2003), immune responses (Yosef and Regev, 2011), stress responses (Gitter et al., 2013) and several others. Indeed, analysis of the largest repository of gene expression experiments, the Gene Expression Omnibus (GEO), determined that roughly a third of these datasets come from experiments profiling dynamic processes over time (Zinman et al., 2013).
While mRNA gene expression data have been the primary source of high-throughput time series data, more recently several other genomic regulatory features are profiled over time. These include miRNA expression data (Schulz et al., 2013), ChIP-Seq studied to determine TF targets (Chang et al., 2013) and several types of epigenetic markers including DNA methylation (Singer et al., 2014), histone modifications (Paige et al., 2012) and more. In fact, with the rise in our ability to perform such high-throughput time series analysis, many researchers are now combining a few or several of these time series profiling experiments in a single experiment (Chang et al., 2013; Buenrostro et al., 2015) and then integrate these datasets to obtain a better understanding of cellular activity.
While integrated analysis of high-throughput genomic datasets can greatly improve our ability to model biological processes and systems, it comes at a cost. From the monetary point of view, these costs include the increased number of Seq experiments required to profile all types of genomic features. While such costs are common to all types of studies utilizing high-throughput data, they can be prohibitively high for time series based studies since they are multiplied by the number of time points required, the number of repeats performed for each time point and the number of different types of data being profiled. Importantly, even if the budget is not an issue, the ability to obtain enough samples for profiling all genomic features at all time points may be challenging, if not completely prohibitive.
One of the key determinants of the experimental and sample acquisition costs associated with time series studies is the number of time points that are being profiled. In most studies, the first and last time point can usually be determined by the researcher (for example, the time from birth to full lung structural development and maturation in mice). However, the number of samples required between these two points and the sampling frequency (given a fixed budget) are often hard to determine based on phenotypic observations since the molecular events of interest may precede such phenotypic events. To date, sampling rates have largely been determined using one of two ad-hoc protocols. The first utilized uniform sampling across the duration of the study (Li et al., 2013) with the number of samples constrained by the available budget and samples. The second relied on some (conceived or real) knowledge of the process, often based on phenotypic observations. These studies, especially for responses though also for development, have often used nonuniform sampling (Schulz et al., 2013; Bar-Joseph et al., 2003a) though it is hard to determine if such sampling misses important molecular events between the sampled points.
Relatively, little work has focused so far on the selection of time points to sample in high throughput time series studies. Singh et al (Singh et al., 2005) and Rosa et al (Rosa et al., 2012) presented an iterative process which starts with profiling a small number of time points and then selects the next time point either based on an Active Learning method (Singh et al., 2005) or based on using prior related experiments (Rosa et al., 2012). Next the selected point is profiled and the process is repeated until a stopping criteria has been reached. Both of these methods require several iterations until the final time series is profiled, which can drastically lengthen the experiment time and can introduce additional biases making them less useful in practice. In addition, these methods employ a stopping criteria that does not take into account the full profile and also require that related time series expression experiments be used to select the point, which may be problematic when studying new processes or treatments.
Here, we propose the first non iterative method to address the issue of sampling rates across all different genomic data types. Our method starts by selecting a small set of genes that are known to be associated with the process being studied (while the full set is often unknown, for most processes a small set is usually known in advance). Next, we use a cheap array-based technology to sample these genes at a high, uniform rate across the duration of the study. Note that unlike standard curve fitting algorithms, a method for selecting time points for these experiments is required to accommodate over a hundred curves (for all genes) simultaneously, and we discuss various ways to formulate this as an optimization problem. To solve this optimization problems, we developed the Time Points Selection method (TPS), an algorithm that uses spline based analysis and combinatorial search to select a subset of the points that, when combined, provide enough information for reconstructing the values for all genes across all time points. The number of points selected can either be set in advance by the user (for example, based on budget constraints) or can be defined as a function of the reconstruction error. The selected time points are then used for the larger, genome-wide experiments across the different types of data being profiled.
To test and evaluate the method we applied it to study lung development in mice. Normal development of lung alveoli through the process of alveolar septation is a dynamic, coordinated process that requires the accurate spatial and temporal integration of signals. We currently lack a comprehensive understanding of the dynamic networks that govern normal alveolar septation. Thus, lung development can serve as an ideal test case for TPS since a variety of different time series genomic datasets are needed to enable accurate reconstruction of networks regulating this process. As we show, TPS was able to successfully identify time points for reconstructing the mRNA profiles of selected genes and these points improved upon uniform based sampling for such points. Further, we show that the set of points selected based on the analysis of this limited set of highly sampled mRNAs is also appropriate for sampling a much larger, unbiased, set of miRNA profiles as well as to determine the temporal protein levels of over 1000 proteins. Finally, we show that the mRNA samples can also be used to determine the optimal sampling points for a DNA methylation study of the same developmental process.
Results
The time points selection (TPS ) method
We developed TPS to select a subset of time points from an initial larger set of points such that the selected subset provides an accurate, yet compact, representation of the temporal trajectory. Figure 1 presents an overview of the method. TPS utilizes splines to represent temporal profiles and implements a cross-validation strategy to evaluate potential sets of points. Following initialization which is based on the expression values, we employ a greedy search procedure that adds and removes points until a local minima is reached (Materials and methods). The resulting set is then used for the larger genomic and epigenetic experiments.
Figure 1. The TPS method.
Clockwise from top left. Given a dense sampling of a selected subset of genes (a) we select an initial set of points (b) using the initialization method described in the text. Next, we fit a spline to the selected points for each gene (c) and evaluate the error on all other points. We perform a greedy search process (d) which iteratively removes and adds points to improve the test data fit resulting in the final set of points (e). The reconstructed curves are fitted to all genes (f) and an overall error is computed and compared to the theoretical limit (noise) to determine the ability of the selected number of points to fit the data.

Figure 1—figure supplement 1. Comparison of performance between TPSand a previous method Singh et al.

Figure 1—figure supplement 2. Comparison of initialization methods to each other by their final error.

Figure 1—figure supplement 3. Comparison of initialization method by their final error compared to selecting random points.

To test the usefulness of TPS , we used it to determine time points for a lung development study in mice. We first profiled the expression of 126 genes known or suspected to be involved in lung development using NanoString (See Appendix Methods for a list of the selected genes and the reason each was selected). We then used TPS analysis of these experiments to select a subset of time points for profiling the expression of a larger, unbiased, set of miRNAs. Finally, we have used TPS to design time series experiments to study DNA methylation patterns for a subset of the genes.
TPS identifies subset of important time points across multiple genes
We have tested the performance of TPS by using it to select subsets of points ranging from 3 to 25 and evaluating how well these can be used to determine the values of non-sampled points. To determine the accuracy of the reconstructed profiles using the selected points, we computed the average mean squared error for points that were not used by the method (Materials and methods). The results are presented in Figure 2. The figure includes a comparison of our method with two baseline methods: a random selection of the same number of points and uniform sampling of points within the range being studied, a method that is commonly used for time series expression profiling as discussed above. We have also compared the performance of the different strategies for initializing the set of points as discussed in Appendix Method (sorting by absolute differences or by equal partition) and between different methods for searching for the optimal subset (simulated annealing, weighting genes by cluster size, and adding/removing multiple time points per iteration, Appendix Methods). Finally, Figure 2 also presents the repeat noise values which is the theoretical limit for the performance of any profile reconstruction method.
Figure 2. Performance of TPS using different sizes for the selected points.
Error comparisons of TPS variants to uniform selection of points and noise. Absolute difference - Greedy iterative addition with absolute difference initialization (Algorithm 1, Appendix Methods). Simulated annealing - Iterating using simulated annealing with absolute difference initialization. Weighted error - Selection based on cluster rather than individual gene errors. See Appendix Methods for details.

Figure 2—figure supplement 1. Average noise in each mRNA expression time point.
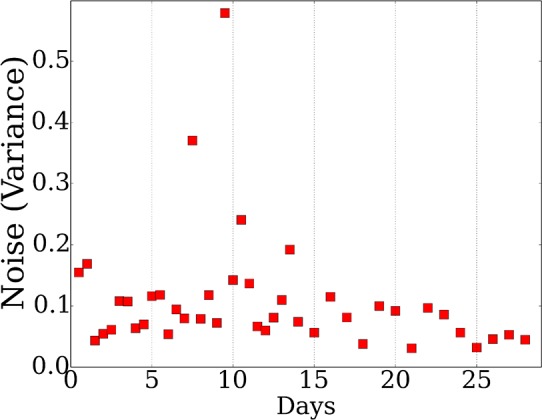
Figure 2—figure supplement 2. Comparison of error for the TPS algorithm on full data, 75% random data, and random points chosen on the full data.

Figure 2—figure supplement 3. Comparison of TPS and piecewise linear fitting over genes (a) Pdgfra, (b)Eln, (c) Lrat.

Figure 2—figure supplement 4. Comparison of the reconstruction error when using the points selected by TPS and when using the same number of random points from the overall set of sampled points.

As expected, we find significant performance improvement when using TPS when compared to randomly selected points. Importantly, we also see a significant and consistent improvement (for all sizes of selected time points) over uniform sampling highlighting the advantage of condition-specific sampling decisions. Sorting initial points by absolute values further improves the performance highlighting the importance of initialization when searching large combinatorial spaces. Simulated annealing, weighting, and multiple point selection improve performance as well. As the number of points used by TPS increases, it leads to results that are very close to the error represented by noise in the data (0.108) ( Figure 2—figure supplement 1).
Figure 3 presents the reconstructed and measured expression values when using TPS to select time points (less than a third of the points that were profiled). Note that even though each of these genes has distinct trajectory and inflection points, the selected set of time points enable TPS to fit all quite accurately without overfitting (See Figure 3—figure supplement 1 and Figure 3—figure supplement 2 for figures of several other genes and for figures reconstructed by using the best 8 time points as determined by TPS , respectively).
Figure 3. Reconstructed expression profiles for selected genes.
(a). Pdgfra. , (b). Eln. , (c). Inmt.

Figure 3—figure supplement 1. Expression profiles over several genes (a) Esr2, (b) Nme3, (c) Polr2a.

Figure 3—figure supplement 2. Reconstructed expression proles by eight points over genes (a) Pdgfra, (b) Eln, (c) Inmt.

Identified time points using mRNA data are appropriate for miRNA profiling
To test the usefulness of our method for predicting the correct sampling rates for other genomic datasets, we next profiled mouse miRNAs for the same developmental process. miRNAs have been known to regulate lung development (Sessa and Hata, 2013) and several miRNAs are differentially expressed during this developmental process (Williams et al., 2007). Several of these are also coordinately activated with various TFs to control specific transitions during development (Schulz et al., 2013). Thus, any large scale effort to model lung development would require the profiling of miRNAs as well. Unlike the mRNA dataset, which utilized prior knowledge to profile less than 1% of all genes, the miRNA dataset contained a much larger number of miRNAs (). Thus, the miRNA data represent an unbiased sample providing information on whether using one type of genomic data can be helpful for determining rates for other types. In our analysis, we normalized miRNA values by variance mean normalization (Bolstad et al., 2003).
To test TPS on this dataset, we used the mRNA expression data to select time points and then used the miRNA expression values for the selected time points to reconstruct the complete trajectories for each miRNA. The results are presented in Figure 4. As can be seen, when using the points selected based on the mRNA data we achieve a much lower error when compared to the error resulting from using the same number of uniform or random points ( for random based on randomization analysis) highlighting the relationship between the two datasets and the ability to use one to determine points for the other. More generally, even though the noise in the miRNA data is higher than for the mRNA dataset, relative ordering of the performance of each of the methods is similar to the mRNA results in Figure 2. This serves as a strong indication that mRNAs can serve as a general proxy for selecting time points for other genomic datasets. Figure 4b presents the error achieved when using the miRNA data itself to select the set of points (evaluated on the miRNA data). As expected, the performance when using the miRNA data itself is better than when using the mRNA data. However, when taking into account the inherent noise in the data the differences are not large. For example, when using the 13 selected mRNA points, the average mean squared error is 0.4312 whereas when using the optimal points based on the miRNA data itself the error is 0.4042.
Figure 4. Performance of TPS by on the miRNA data.
(a) TPS reconstruction error when using the mRNA data to select time points for the miRNA experiments. Results of random and uniform selection as well as repeat noise error are also presented for comparison. TPS variants shown are the same two presented in Figure 2. (b) Error of splines with points selected by training TPS on the actual miRNA data itself, using the maximum absolute difference initialization.

Figure 4—figure supplement 1. Observed and reconstructed expression proles for miRNAs (a) mmu-miR-100, (b) mmu-miR-136,c) mmu-miR-152, (d) mmu-miR-219.

Figure 4—figure supplement 2. 8 stable miRNA clusters.

Figure 4—figure supplement 3. TPS performance for the proteomics data using different number of time points.

Figure 4—figure supplement 1 presents the reconstructed and measured expression values for a few miRNAs based on time points identified using the mRNA dataset. As with the mRNA data, the ability to accurately reconstruct different miRNA profiles highlights the importance of selecting a global set of points that can fit all genes and miRNAs in our study.
We have also analyzed the performance of TPS when using the mRNA data to select sampling time points for profiling the levels of more than 1000 proteins. We observed results that are very similar to the results obtained for the miRNA time point selection. Specifically, the points selected by TPS lead to reconstruction errors that are lower than those observed for uniform sampling or for a random set of the same number of points further demonstrating the general applicability of our method. See Appendix Results for details.
Using TPS to select time points for DNA methylation analysis
In addition to mRNA and miRNA expression data, epigenetic data have been increasingly studied in time series experiments (Talens et al., 2010; Schneider et al., 2010). To test the ability of the mRNA data to determine the appropriate points for DNA methylation analysis, we used targeted bisulfite sequencing to profile three CpG-enriched regions for genes at of the time points used for the mRNA and miRNA studies (Materials and methods). We next applied TPS to the mRNA data of these points to select the best subest of points and compared the selected points to those that would have been selected using the methylation data itself. The points identified using the mRNA data (, , , ) were exactly the same as the ones selected using the methylation data indicating again that mRNA data is a good proxy for the dynamics of the epigenetic data as well. Figure 5—figure supplement 1 presents the reconstructed splines over the identified points for several genomic methylation loci. Figure 5 presents the methylation and expression curves for genes: Akt,1 Cdh11, and Tnc. These were the genes with the strongest negative correlation between their methylation and expression. As can be seen, in several cases we observed strong negative or positive correlations between the two datasets in the time points we used serving as another indication for the ability to use one dataset to select the sampling points for the other. See Figure 5—figure supplement 2 for correlation of all genes.
Figure 5. Comparison of gene expression and methylation data for selected genes.
(a). Akt1. , (b). Cdh11. , (c). Tnc.

Figure 5—figure supplement 1. Reconstructed methylation proles over several loci (chromosome, position) with corresponding genes.

Figure 5—figure supplement 2. Bootstrap analysis of Pearson correlation r between expression and methylation datasets over eight time points for each gene.

Discussion
Time series gene expression experiments are widely used in several studies. More recently, advances in sequencing and proteomics are enabling the profiling of several other types of genomic data over time. Here we focused on lung development in mice with the goal of identifying an optimal set of time points for profiling various genomic and proteomic data types for this process.
An important question is: Whether a better selection of time points really leads to observations that are missed when using an inferior set of points (even if the number of points is the same)? To answer this question we looked at several prior studies that profiled mouse lung development over time using various high throughput assays. Table 1 presents representative studies and lists the biological data that was profiled and the time points that were used. As can be seen, while certain time points seem to be widely used across studies (for example, 7d) others were profiled in only one or two of the studies (2d, 10d, three weeks). This raises several issues. First, it is very hard to compare or combine these datasets (for example, protein levels were not profiled on day (Cox et al., 2007) whereas all mRNA levels were). It also makes it hard to determine if differences between DE genes or miRNAs between these studies are the result of differences in the underlying conditions studied (for example, when testing for mutants or treatments) or simply the result of different sampling. Finally, each of these studies may have missed key genes, proteins or miRNAs because of the sampling used restricting the ability of downstream analysis to use the data to model causal and regulatory events in lung development.
Table 1.
Summary of prior high throughput lung development studies.
| Reference | Data types | Selected time points (Days) |
|---|---|---|
|
mRNA expression |
E9, E4, E17, 0, 7, 14, 28 |
|
|
mRNA expression |
E16, E18, 0, 7, 14, 28 |
|
|
microRNA expression |
E16, E19, E21, 0, 6, 14, 60 |
|
|
mRNA and microRNA expression |
E12, E14, E16, 0, 2, 10 |
|
Protein expression levels |
E12, E14, E18, 2, 14, 56 |
|
|
mRNA and miRNA expression |
0, 4, 7, 14, 42 |
|
|
mRNA expression |
0, 7, 14, adult |
|
|
mRNA expression |
E15, E17, E19, E21, 1, 14, 84 |
|
|
mRNA expression |
E18, 1, 4, 7, 10, 14, 21, adult |
To illustrate these problems we compared the resulting curves using three of the sampling rates from Table 1 to the reconstructed curves obtained by using TPS to select the optimal and time points. For example, the points selected by Schulz et al. (2013) are 0, , , and (since is last day in our analysis we used it instead of ). In contrast, TPS selects , , , and . As can be seen in Figure 6, important expression changes in key genes are missed by using the arbitrary points while the TPS points are able to correctly reconstruct these profiles even though the total number of points is the same (). More globally, the error for the arbitrary set of selected points is much higher on average (Appendix 2—Table 4). Similar results are obtained for the other sampling rates used in the past (Figure 6, Appendix 2—Table 4) and when comparing TPS to iterative methods previously suggested for selecting the set of points to profile (Figure 1—figure supplement 1). This indicates that accurate selection of time points can have a large impact on the ability of the study to identify key genes and events. See also Appendix Results for a discussion about the importance of the differences between the TPS and prior work results for selected genes.
Figure 6. Comparison of TPS with sampling rates used in previous studies.
Dark green curves are the reconstructed profiles based on the points profiled by prior studies. Light green and red curves are based on the points selected by TPS . As can be seen, even when comparing results from using the same number of points, TPS can identify key events for some of the genes that are missed when using the phenotype based sampling rates. Subfigures a,b, and c are a piecewise linear fit over points 0.5, 7.0, 14.0, 28.0 . Subfigures d,e, and f are a piecewise linear fit over points 0.5, 2.0, 14.0, 28.0. Subfigures g,h, and i are a piecewise linear fit over points 0.5, 4.0, 7.0, 14.0, 28.0.

Figure 6—figure supplement 1. Comparison of gene expression and protein abundance for selected gene protein pairs.

Our method relies on a very small subset of genes that are known to be involved in the process studied for the initial (highly sampled) set of experiments. While such set is known for several processes, there may be cases where very little is known about the biological process and so it may be hard to obtain such set. TPS can still be applied to determine sampling rates for such processes using a small random set of genes. To illustrate this we repeated the analysis presented in Results using only the measured values of 25% of genes in our original set and replacing the values for the other genes with random profiles. As we show in Figure 2—figure supplement 2, even when using such set, the time points selected by TPS greatly improve upon an arbitrary set of the same number of time points. Since in most time series experiments at least 25% of the genes are differentially expressed (and in several cases a much larger fraction, (Zhou et al., 2009; Shi et al., 2015) a random selection of genes is likely to exhibit similar results even for poorly understood processes.
Beyond the analysis of a specific type of data, several studies have now been profiling multiple types of genomic data over time. Such studies need to agree on a set of time points which would be common to all experiments so that these diverse types can be integrated to form a unified model (Chang et al., 2013; Roy et al., 2010). To date, the selection of such points relied on ad-hoc methods. The processes being studied were either sampled uniformly or based on prior knowledge. However, known properties of such systems were often been based on phenotypic observations which may not necessarily agree with the timing of molecular events. In addition, in many case studies of the same, or similar processes differed with respect to the time points that have been profiled. For example, early work on the analysis of cell cycle data in yeast utilized both uniform and nonuniform sampling (Spellman et al., 1998) and recent studies of circadian rhythms have followed a similar pattern (Storch et al., 2002; Ueda et al., 2002). Similarly, more recent analysis of responses to flu diverged widely in the (nonuniform) sampling rates that were used (Shapira et al., 2009; Li et al., 2011).
TPS addresses these problems by using a principled method for determining sampling rates. An important goal in the development of TPS was to enable it to be successfully applied to different types of biological datasets. As we show, a relatively inexpensive, gene centric, method provides a very good solution for RNA expression profiling as well as other types of data including miRNAs and DNA methylation. Thus, a combined experiment can be fully designed using our method.
While we evaluated TPS on several types of high throughput data, we have only tested it so far on data for a specific biological process (lung development in mice). While we believe that such data is both challenging and representative and thus provides a good test case for the method, analysis of additional datasets may identify new challenges that we have not addressed and we leave it to future work to address these.
TPS, including all initialization methods discussed, is implemented in Python and is available on the supporting website. We hope that as sequencing technology continues to advance, more and more studies would integrate diverse types of time series data and will utilize TPS in the design pipeline of their studies.
Materials and methods
mRNA and miRNA used in the study
To select the list of 126 genes used in the NanoString profiling we searched the literature for genes that have been linked to the following processes: (a) Cell type specification genes (e.g. alveolar type I epithelial, alveolar type II epithelial, any epithelial, basal, endothelial, mesenchymal, pericyte, fibroblast, monocyte), (b) genes known to be up or down regulated during septation, (c) genes known to be altered in DNA methylation during development, (d) genes known to be involved in septation, (e) genes known to be regulated by miRNA involved in septation, and (f) genes known to be regulated by DNA methylation during fibrosis. Appendix 2—Table 1 contains a list of the selected genes and the process for which they were selected.
For the miRNA set we used a commercially available, unbiased, array (the nCounter Mouse miRNA Expression Assay Kit, NanoString).
mRNA and miRNA profiling and analysis
A total of 240 samples were isolated by Laser Capture Microscopy (LCM) from murine lung at multiple time points (E16.5, P.05 to P14 every 12 hr, and P15 to P28 every 24 hr). The samples were used to prepare total RNA. RNA extraction was performed by miRNeasy MicroKit (Qiagen) following the manufacturer’s protocol. RNA concentration and integrity were measured by using NanoDrop ND-2000 and 2200 Tape Station. A custom NanoString probe set (Reporter Code set and Capture Probe set) for 126 genes was designed and the nCounter Gene Expression Assay was performed using 50 ng total RNA. The data files produced by the nCounter Digital Analyzer were exported as a Reporter Code Count (RCC) file and data normalization was performed using the nSolver, the analysis software provided by Nanostring.
DNA methylation analysis
Mouse alveolar lung tissues attached to LCM caps were stored at −80°C until processing. DNA was extracted using the ZR Genomic DNA-Tissue MicroPrep kit (Zymo Research). Incubation with Digestion buffer and proteinase K was done overnight at 55°C in inverted tubes. 13 genes were chosen for targeted NextGen bisulfite sequencing (NGBS): Igfbp3, Wif1, Cdh11, Eln, Sox9, Tnc, Dnmt3a, Akt, Vegfa, Lox, Foxf2, Zfp536 and Src, based on published data (Cuna et al., 2015). Targeted NGBS was done on samples collected at: E16.5, E18.5, P0.5, P1.5, P2.5, P5, P10, P15, P19 and P26. Multiplex PCR was performed using 0.5 units of TaKaRa EpiTaq HS (Takara Bio, Kusatsu, Japan) in 2x master mix. FASTQ files were aligned using open source Bismark Bisulfite Read Mapper using Bowtie2. Methylation levels were calculated in Bismark. Sites where the difference in methylation was less than 5% over the entire time period, those where there was a difference of >20% at a single time point and those with less than non zero values were removed from the analyses.
Problem statement
Our goal is to identify a (small) subset of time points that can be used to accurately reconstruct the expression trajectory for all genes or other molecules being profiled. We assume that we can efficiently and cheaply obtain a dense sample for the expression of a very small subset of representative genes (here we use nanostring to profile less than 0.5% of all genes) and attempt to use this subset to determine optimal sampling points for the entire set of genes.
Formally, let be the set of genes we have profiled in our dense sample, be the set of all sampled time points. We assume that for each time point we have repeats for all genes. We denote by be the expression value for gene at time in the ’th repeat for that time point. We define as the complete data for gene over all replicates and time points .
To constrain the set of points we select, we assume that we have a predefined budget for the maximum number of time points we can sample in the complete experiment (i.e. for profiling all genes, miRNAs, epigenetic marks etc. using high-throughput seq experiments). We are interested in selecting time points from which, when using only the data collected at these points, minimizes the prediction error for the expression values of the unused points. To evaluate such a selection, we use the selected values to obtain a smoothing spline (De Boor, 1978; Bar-Joseph et al., 2003a; Wahba, 1990) function for each gene and compare the predicted values based on the spline to the measured value for the non-selected points to determine the error. In our problem, and define the first and end points, so they are always selected. The rest of the points are selected to maximize the following objective 1:
Problem statement: Given for genes , the number of desired time points , identify a subset of time points in which minimizes the prediction error for the expression values of all genes in the remaining time points.
Spline assignments
Before discussing the actual procedure we use to select the set of time points, we discuss the method we use to assign splines based on a selected subset of points for each gene. There are two issues that need to be resolved when assigning such smoothing splines: (1) The number of knots (control points) and (2) their spacing. Past approaches for using splines to model time series gene expression data have usually used the same number of control points for all genes regardless of their trajectories (Subhani et al., 2010; Bar-Joseph et al., 2003b), and mostly employed uniform knot placements. However, since our method needs to be able to adapt to any size of as defined above, we also attempt to select the number of knots and their spacing. We do this by using a regularization parameter for the fitted cubic smoothing spline where number of knots is increased until the smoothing condition is satisfied (Wahba, 1990). The regularization parameter is estimated by leave-one-out cross-validation (LOOCV).
TPS : Iterative process to select points
Because of the highly combinatorial nature of the time points, we rely on a greedy iterative process to select the optimal points as summarized in Figure 1 (See Appendix Methods for pseudocode).
There are three key steps in this algorithm which we discuss in detail below.
Selecting the initial set of points: When using an iterative algorithm to solve non-convex problems with several local minima, a key issue is the appropriate selection of the initial solution set (Hartigan, 1975; McLachlan and Peel, 2004)]. We have tested a number of methods for performing such initializations and results for some of these are presented in Figure 1—figure supplement 2. Since the goal of the method is to optimize a specific function (error on the left out set of expression values measured at time points not used), all initialization methods can be tested for each dataset and the solution minimizing the left out error can be used. See Appendix Methods for details.
-
Iterative improvement step: After selecting the initial set, we begin the iterative process of refining the subset of selected points. In this step we repeat the following analysis in each iteration. We exhaustively remove all points from the existing solution (one at a time) and replace it with all points that were not in the selected set (again, one at a time). For each pair of such point, we compute the error resulting from the change (using the splines computed based on the current set of points evaluated on the left out time points), and determine if the new point reduces the error or not. Formally, let and be set of points for iteration . We are interested in finding a point pair which minimizes the following error ratio for the next iteration :
(1) where is our spline based estimate of the expression of gene at time by fitting smoothing spline over points . If there are pairs which lead to an error ratio of less than in the above function, we select the best (lowest error), assign it to and continue the iterative process. Otherwise we terminate the process and output as the optimal solution. While the process is guaranteed to converge, given the large combinatorial search space convergence can be slow. This makes adequate initialization an important issue which we have focused on. In practice we find that the search usually converges very fast (within 10 – 15 iterations).
Fitting smoothing spline: The third key step of our approach is fitting a smoothing spline to every gene independently for the selected subset of time points. As discussed above, this is done by using a regularized version of approximating splines which allow us to determine a unique number of control points and spacing for each of the genes. See Appendix Methods for more details.
Individual vs. cluster-based evaluation
So far, we assumed that error of each gene has the same contribution to the overall error. However, this assumption ignores the fact that the expression profiles of genes are correlated with the expression of other genes. To take the correlation between gene profiles into account, we also performed cluster based evaluation of genes where we analyzed the error by weighting each gene in terms of inverse of the numbers of genes in the cluster it belongs. This scheme ensures that each cluster contributes equally to the resulting error rather than each gene. We find clusters by k-means algorithm over time series-data by treating each gene as a point in space as well as over a vector of randomly sampled time points on fitted spline (Bishop, 2006). We use Bayesian Information Criterion (BIC) to determine the optimal number of clusters (Schwarz, 1978).
Acknowledgement
We thank the LungMAP consortium for useful comments regarding the methods and analysis presented in this paper. Work supported in part by NIH grant U01 HL122626.
Appendix 1 Methods
Selecting the set of 126 genes
Table 1 provides the list of genes used for the nanostring analysis and the rational for their inclusion.
DNA Methylation analysis
Mouse alveolar lung tissues attached to LCM caps were stored at −80°C until processing. DNA was extracted using the ZR Genomic DNA-Tissue MicroPrep kit (Zymo Research). Incubation with Digestion buffer and proteinase K was done overnight at 55°C in inverted tubes. 13 genes were chosen for targeted NextGen bisulfite sequencing (NGBS): Igfbp3, Wif1, Cdh11, Eln, Sox9, Tnc, Dnmt3a, Akt, VEGF, Lox, FoxF2, ZFP536 and Src, based on published data (Cuna et al., 2015). The presence of CpG islands in 5-UTR, gene body and 3-UTR was interrogated using NCBI Epigenomics database, as well as CpG island searcher (Takai and Jones, 2002), and EMBOSS Cpgplot (Rice et al., 2000). Targeted NGBS was done by Epigendx Inc. Gene sequences from selected regions were acquired from the Ensembl database. Gene IDs, transcript IDs, simplex PCR IDs, and target regions for each gene are listed in Appendix 2—Table 3. A total of target PCRs were designed by PyroMark Assay Design Software (Qiagen).
Targeted NGBS was done on samples collected at the following time points: E16.5, E18.5, P0.5, P1.5, P2.5, P5, P10, P15, P19 and P26. Mouse genomic DNA (200–500 ng) was bisulfite treated using the EZ DNA Methylation Kit (Zymo Research). Multiplex PCR was performed using 0.5 units of TaKaRa EpiTaq HS (Takara Bio) in 2x master mix.
FASTQ files were aligned using open source Bismark Bisulfite Read Mapper using Bowtie2. Methylation levels were calculated in Bismark by dividing the number of methylated reads by the number of total reads, considering all CpG sites covered by a minimum of total reads. Sites where the difference in methylation was less than over the entire time period, those where there was a difference of at a single time point and those with less than non zero values were removed from the analyses.
TPS Algorithm
A pseudocode for the TPS algorithm is presented in Algorithm 1.3.
Algorithm 1. TPS : Iterative -point selection |
|---|
|
1: Procedure Iterative–Temporal–Selection 2: select initial time points by absolute difference sorting 3: error of remaining points by fitting splines to 4: 5: do 6: for each pair do 7: 8: estimate error by fitting smoothing spline to where regularization parameter is estimated by LOOCV 9: if then 10: 11: 12: end if 13: 14: end for 15: While 16: Output and 17: end procedure |
Selecting the initial set of points
When using an iterative algorithm to solve non-convex problems with several local minima, a key issue is the appropriate selection of the initial solution set. We have tested a number of methods for performing such initializations. The simplest method we tried is to uniformly select a subset of the points (so if we use each 4’th point). Another method we tested is to partition the set of all time points into intervals of almost equal size. This method determines these boundaries by estimating the cumulative number of points until each time point and selecting time points with cumulative values respectively. Then, it uses interval boundaries including and as initial solution. We also tested a method that relies on the changes between consecutive time points to select the most important ones for our initial set. Specifically, we sort all points except and by average absolute difference with respect to its predecessor and successor time points by computing:
| (2) |
where is the median expression for gene at time . We then select the points with maximum as the initial solution.
Finally, we developed an alternative initialization method, based on dyanmic recalculation of a metric on each time point. Metric A is same equal to the equation shown above. Metric B of a time point is the difference absolute difference with respect to its predecessor and successor time points. Metric C of a time point is absolute difference with respect to only its predecessor. The alternative initialization algorithm calculates the given metric on each time point other than the first and last and then places those points in a min heap based on the metric. The top(minimum) point in the heap is removed. The metric is recalculated for the point’s predeccesor and succesor based on thier neighboring points, using only the points remaining in the heap. This process is repated until only k-2 time points remain in the heap. Then the first time point, last time point and the points remaind in the heap are chosen.
| (3) |
| (4) |
| (5) |
Algorithm 2: Init TPS: Iterative initial point selection |
|---|
|
1: Procedure Iterative–Initial Point–Selection 2: Empty min heap 3: matrix where rows are genes and columns are time points, values are expression measurements 4: for each time point (other than the first and last) do 5: 6: 7: 8: Add to 9: end for 10: While do 11: Remove minimum time point from 12: 13: 14: Remove from 15: Remove from 16: Remove from 17: 18: 19: Add 20: Add 21: end while 22: Ouput all left as in + first time point + last time point 23: end procedure |
We found that for our particular dataset, the dynamic initialization with performed best for selections of time points smaller than one third of the the initial dense time series, while the non dynamic method works best for selections of time points between one third and and one half of the initial time series. The dyanmic metric and non dynamic metrics can be compared in their performance on our data in Figure 1—figure supplement 2. However, all of the metrics performed much better than a selection of random points as shown in Figure 1—figure supplement 3.
Further improvements to the iterative points selection procedures
We tested the following possible search strategies to improve the iterative points removal and addition in TPS.
We add and remove time points in each iteration instead of a single point. This increases the complexity of each iteration from to where is the complexity of fitting a smoothing spline.
We use simulated annealing to escape from local minima (Kirkpatrick et al., 1983). In this case, we do not always move to a pair of points with the minimum error in each iteration, but instead move to a solution with random pair of points with probability if its error is lower than error of current solution whereas we move to a solution with probability if . Here, is the temperature that increases by increasing number of iterations and the probability of moving to a solution with larger error decreases over time.
In practice, even though both approaches should in theory be better able to escape local minima than the greedy approach described above, for the data we analyzed they do not perform significantly better as Figure 2 in the main text demonstrates.
Fitting smoothing spline
TPS uses splines for fitting expression curves. Regularized smoothing spline satisfies the piecewise cubic polynomial for as shown in Wahba (1990). Then, according to (Reinsch, 1967; De Boor, 1978), regularized smoothing spline objective can also be expressed as in:
| (6) |
where , , and is a tridiagonal symmetric matrix with entries , where . The continuity restrictions imply that:
| (7) |
where is an tridiagonal matrix with entries , and . Thus, we may write Equation 6 as:
| (8) |
where can be derived as in:
| (9) |
Once is estimated, , , are estimated by corresponding Equations in Reinsch (1967).
For our specific setting, we also introduce a regularization parameter to enable us to determine the number of control points. Let , and be the spline we are interested in fitting, smoothing spline can be found by the following optimization problem which minimizes penalized least-squares error:
| (10) |
where is the regularization parameter which prevents overfitting by affecting the number of knots selected. We estimated by leave-one-out cross-validation (LOOCV) in our experiments (See Appendix Methods for details of smoothing spline fitting).
Proteomics analysis
Proteins were extracted using tissue protein extraction reagent (T-PER, Thermo) as per manufacturer’s instructions, carried out directly on the micro-dissection cap. Protein concentrations was determined with the EZQ protein assay (Life Sciences). The proteins were digested overnight at 37C, followed by acidification to pH with formic acid (FA), and extracted as per manufacturer’s instructions, then concentrated to near completion using a Savant SpeedVac Concentrator (Thermo) and diluted with FA to a final concentration of ng \uL for analysis by LCMS. The LCMS data were converted to a universal MzXML file format prior to being searched using SEQEST (Thermo) against a Mouse subset of the UniRef100 database. These data were then uploaded to Scaffold (Proteome Software) in order to filter and group each peptide ID to specific proteins with peptide probability scores set at , and protein probability scores set at . Using only proteins presenting with or more peptides per protein, the confidence interval was set to with and FDR . Quantification was carried out using Scaffold Q + using normalized spectral counts.
Appendix 2 Results
Example of a TPS run
Here we discuss a specific setting for TPS that allows us to discuss the set of points selected and their relevance. Specifically, to test TPS , we fixed three set points in advance (first (’th day) and last (’th day), which are required for any setting and day which was previously determined to be of importance to lung development. Next, we have asked TPS to further select more points (for a total of ). For this setting, the method selected the following points: , , , , , , , , , , , , . While we do not know the ground truth, the larger focus on the earlier time points determined by the method (with of the points for the first days) makes sense in this context as several aspects of lung differentiation are determined in the first week (Guilliams et al., 2013). The other weeks were more or less uniformly sampled by our TPS . This highlights the usefulness of an unbiased approach to sampling time points rather than just uniformly sampling through the time window.
TPS identifies subset of important time points across multiple genes
To understand whether gene-expression profiles over time has a simple trend, we also compare the reconstruction performance of TPS with fitting piecewise linear curves between initial and middle time points and between middle and last time points. The reconstruction error by TPS is significantly better than the piecewise linear reconstruction for genes out of genes. We have plotted the comparison of reconstruction for several of these genes as in Figure 2—figure supplement 3. The distribution of error difference between these methods looks significantly different than normal distribution ( by Shapiro-Wilk test).
miRNA clusters are enriched for several biological processes
While the mRNA datasets includes only a handful of genes (less than 0.5% of all genes) the miRNA data includes more profiles and so further analysis of this data can be perfromed. We have performed clustering of the miRNA data using k-means (Hartigan, 1975) where the number of clusters is selected by Bayesian Information Criteria (Schwarz, 1978) leading to stable miRNA clusters Figure 4—figure supplement 2. Next, we mapped miRNA’s to predicted targets using TargetScan (Agarwal et al., 2015), and performed gene-enrichment analysis by FuncAssociate (Berriz et al., 2003). We find clusters to be enriched for several Gene Ontology biological processes (Ashburner et al., 2000). For instance, cluster is enriched for single-organism cellular process, positive regulation of biological process, regulation of metabolic process, etc. See Supporting Website for complete results.
miRNA reconstruction
Figure 4—figure supplement 1 presents the reconstructed and measured expression values for a few miRNAs based on time points identified using the mRNA dataset. Several of these miRNAs are known to be involved in regulation of lung development. For example, mmu-miR-100 is known to regulate Fgfr3 and Igf1r, mmu-miR-136 targets Tgfb2, mmu-miR-152 targets Meox2, Robo1, Fbn1, Nfya (Popova et al., 2014). Additional figures for all miRNAs and mRNAs are avialable on the supporting website.
TPS application to select time points for proteomics analysis
We used mass spectrometry to profile the levels of proteins over the optimal time points determined by TPS (using the mRNA expression data): ). To test the ability of TPS to determine the optimal time points for the proeomics data (based only on the mRNA data) we performed a similar analysis to the analysis performed for the miRNA data. Specifically, we used TPS to select subset of to of these points based on the mRNA data and compared the error using these points to random and uniform selection of the same number of points. The results are presented in . In addition to comparing TPS to random and uniform we have also compared different strategies for initializing the set of points as discussed in Method. Finally, the figure also presents the repeat noise values which is the theoretical limit for the performance of any profile reconstruction method.
As for the miRNA data, we see a significant and consistent improvement (for all number of selected time points) over uniform sampling highlighting the advantage of condition specific sampling decisions. Again, as the number of points used by TPS increases, it leads to results that are very close to the error represented by noise in the data ().
Analysis of methylation data
Methylation data included repeats for time points , , , , , , , for loci belonging to genes. Among these genes all except Zfp536 were also profiled in our nanostring mRNA analysis. Appendix 2—Table 2 summarizes the number of loci for each gene in the methylation dataset. We used shifted percentage of methylation at each time point in our analysis which is obtained by subtracting the median percentage of methylation at initial time point (baseline) from all data points for each gene. Figure 5—figure supplement 2 presents the best positive or negative correaltion observed between the methylation data and the gene expression data for these genes (note that we do not expect all up stream regions to show a correlated profile since it is likely that only a subset, or even a single, region is responsible for the changes in expression observed which is why we look for the most correlated or anti-correlated region).
Importance of correct determination of expression profiles
As shown in Figure 6 in the main text, TPS results differ from prior methods when reconstructing expression profiles for several genes. Below we discuss the significance of these differences and their impact on the ability to correctly assign function to that gene:
Nol3: Nucleolar protein 3 (apotosis repressor with CAR domain) gene (also called ARC) encodes a protein that inhibits apoptosis, by decreasing activities of Caspases 2 and 8 and tumor protein p53. Evaluation of the TPS profile suggests that the increase in Nol3 correlates with postnatal lung development, with a rapid increase from birth until 2 weeks of age, followed by stabilization, while the prior sampling rates show only an initial peak and then decrease. While the exact role of Nol3 in lung development has not been established, it is known that Nol3 protects pulmonary arterial smooth muscle cells from hypoxia-induced death and facilitates growth factor-induced proliferation and hypertrophy, and is probably involved in human pulmonary hypertension (Turi et al., 1990). Nol3 is a regulator of myogenic differentiation (Hunter et al., 2007) and its pattern of expression suggests that it may be important in regulating pulmonary airway and vascular smooth muscle development and differentiation.
Esr2: The gene estrogen receptor beta encodes a receptor for estrogen, and is important in regulating lung development and modulating differences in lung development between males and females (Gortner et al., 2013). Evaluation of the TPS profile suggests that the Esr2 decreases briefly after birth, followed by an increase from around day 5 until day 20 whereas non-optimized profile suggests a relatively flat profile. While fetal mouse lungs express both Esr2 alpha and beta, adult mouse lungs express only Esr2 beta consistent with the TPSresults (Carvalho and Goncalves, 2012).
Igfbp3: Insulin-like growth factor binding protein 3 ( Igfbp3) belongs to the Igfbp family and has a Igfbp domain and a thyroglobulin type-I domain (http://www.ncbi.nlm.nih.gov/gene/3486). The TPS profile for Igfbp3 is very different from the non-optimized profile, suggesting that important biological information is lost when not using the TPS profile. Igfbp3 regulates the induction of TNC by TGF-beta (Brissett et al., 2012) and both these molecules are critical in lung alveolar septation.
Wif1: Wnt inhibitory factor 1 ( WIF1) inhibits Wnt proteins, that are well known to be critical in many stages of lung development. The TPS profile is very different from the non-optimized profile, as the TPS profile indicates a much earlier and higher peak of WIF1 during postnatal lung development that may be critical in alveolar septation. WIF1 is a target gene for Smad1, one of the BMP receptor proteins important in lung development and maturation. A regulatory loop of Bmp4-Smad1-Wif1-Wnt/beta-catenin may coordinate BMP and Wnt pathways to control lung development (Xu et al., 2011), and dysregulation of the Smad1/Wif1 axis is associated with lung hypoplasia (Fujiwara et al., 2012).
Inmt: Indolethylamine N-methyl transferase (Inmt) gene encodes an enzyme that N-methylates indoles such as tryptamine (http://www.ncbi.nlm.nih.gov/gene/11185). The TPS profile for Inmt is very different from the non-optimized profile, as the TPS profile indicates a much lower and prolonged reduction of Inmt during postnatal lung development. Methyl conjugation is an important pathway in the metabolism of many drugs, neurotransmitters, and xenobiotic compounds (Thompson and Weinshilboum, 1998). While it is known that Inmt expression varies over the course of human lung development (Kopantzev et al., 2008), its exact role in lung development is not known.
Fgf18: Fibroblast growth factor 18 (Fgf18) is a member of the fibroblast growth factor family, and the Fgfs are well known to be critical in multiple stages of lung development. The non-optimized profile indicates a smaller and later peak, and is not similar to the TPS profile which suggests a much more improtant role.Fgf18 is a pleiotropic growth factor that stimulates proliferation in a number of tissues (http://www.ncbi.nlm.nih.gov/gene/8817). Fgf18 is highly expressed in the developing lung as the TPS profile indicates (Ohbayashi et al., 1998), and Fgfr3 is important in postnatal alveolar development (Weinstein et al., 1998). The role of Fgf18 in regulating fibroblast proliferation (Hu et al., 1999) may be important in alveolar septation, as Fgf18 increases after birth with a peak around P10, with reduction after completion of alveolar septation.
Appendix 2—table 1.
List of genes used for the Nanostring analysis and the rational for their inclusion.
| Ensembl gene ID | Accession number | Gene name | Rationale |
|---|---|---|---|
| ENSMUSG00000024130 | NM_001039581.2 | Abca3 | Alveolar Type II cell marker |
| ENSMUSG00000031378 | NM_007435.1 | Abcd1 | important in other processes (IPF, COPD etc) |
| ENSMUSG00000029802 | NM_011920.3 | Abcg2 | Mesenchymal cell marker |
| ENSMUSG00000035783 | NM_007392.3 | Acta2 | Fibroblast cell marker |
| ENSMUSG00000029580 | NM_007393.1 | Actb | Common house-keeping gene |
| ENSMUSG00000036040 | NM_029981.1 | Adamtsl2 | Altered DNA methylation during septation |
| ENSMUSG00000015452 | NM_007425.2 | Ager | Alveolar Type I cell marker |
| ENSMUSG00000001729 | NM_001165894.1 | Akt1 | Altered DNA methylation during septation |
| ENSMUSG00000053279 | NM_013467.3 | Aldh1a1 | Important for septation |
| ENSMUSG00000013584 | NM_009022.3 | Aldh1a2 | Potentially important for septation |
| ENSMUSG00000022244 | NM_008537.4 | Amacr | important in other processes (IPF , COPD etc) |
| ENSMUSG00000044217 | NM_009701.4 | Aqp5 | Alveolar Type I cell marker |
| ENSMUSG00000026576 | NM_009721.5 | Atp1b1 | Lung fluid clearance |
| ENSMUSG00000060802 | NM_009735.3 | B2m | Common house-keeping gene |
| ENSMUSG00000102037 | NM_009742.3 | Bcl2a1a | Apoptosis regulator |
| ENSMUSG00000056216 | NM_009884.3 | Cebpg | Important for lung development |
| ENSMUSG00000029084 | NM_007646.4 | Cd38 | Airway smooth muscle cell functional responses |
| ENSMUSG00000018774 | NM_009853.1 | Cd68 | Monocyte cell marker |
| ENSMUSG00000031673 | NM_009866.4 | Cdh1 | Epithelial cell marker |
| ENSMUSG00000064246 | NM_007695.2 | Chil1 | Monocyte cell marker |
| ENSMUSG00000040809 | NM_009892.1 | Chil3 | Increased during septation |
| ENSMUSG00000022512 | NM_016674.3 | Cldn1 | Tight junction protein |
| ENSMUSG00000070473 | NM_009902.4 | Cldn3 | Tight junction protein (mostly epithelial) |
| ENSMUSG00000041378 | NM_013805.4 | Cldn5 | Tight junction protein |
| ENSMUSG00000018569 | NM_016887.6 | Cldn7 | Tight junction protein (mostly epithelial) |
| ENSMUSG00000001506 | NM_007742.3 | Col1a1 | Fibroblast cell marker |
| ENSMUSG00000063063 | NM_009819.2 | Ctnna2 | Altered DNA methylation during septation |
| ENSMUSG00000031360 | NM_001168571.1 | Ctps2 | important in other processes (IPF , COPD etc) |
| ENSMUSG00000040856 | NM_010052.4 | Dlk1 | Decreased during septation |
| ENSMUSG00000020661 | NM_007872.4 | Dnmt3a | Altered DNA methylation during septation |
| ENSMUSG00000046179 | NM_001013368.5 | E2f8 | Altered DNA methylation during septation |
| ENSMUSG00000000303 | NM_009864.2 | Cdh1 | Epithelial cell marker |
| ENSMUSG00000020122 | NM_207655.2 | Egfr | Important for lung development |
| ENSMUSG00000029675 | NM_007925.3 | Eln | Altered DNA methylation during septation |
| ENSMUSG00000045394 | NM_008532.2 | Epcam | Epithelial cell marker |
| ENSMUSG00000052504 | NM_010140.3 | Epha3 | Involved in lung development |
| ENSMUSG00000028289 | NM_001122889.1 | Epha7 | Involved in lung cancer, potential role in development |
| ENSMUSG00000021055 | NM_010157.3 | Esr2 | Important regulator of multiple processes |
| ENSMUSG00000061731 | NM_010162.2 | Ext1 | Altered DNA methylation during septation |
| ENSMUSG00000039109 | NM_001166391.1 | F13a1 | Involved in lung injury , cancer |
| ENSMUSG00000057967 | NM_008005.1 | Fgf18 | Important for septation |
| ENSMUSG00000030849 | NM_010207.2 | Fgfr2 | Important regulator of multiple processes |
| ENSMUSG00000078302 | NM_008242.2 | Foxd1 | Pericyte cell marker |
| ENSMUSG00000042812 | NM_010426.1 | Foxf1 | Involved in lung development |
| ENSMUSG00000038402 | NM_010225.1 | Foxf2 | Altered DNA methylation during fibrosis |
| ENSMUSG00000001020 | NM_011311.1 | S100a4 | Fibroblast cell marker |
| ENSMUSG00000057666 | NM_001001303.1 | Gapdh | Common house-keeping gene |
| ENSMUSG00000005836 | NM_010258.3 | Gata6 | Important regulator of multiple processes |
| ENSMUSG00000029992 | NM_013528.3 | Gfpt1 | important in other processes (IPF, COPD etc) |
| ENSMUSG00000041624 | NM_001033322.2 | Gucy1a2 | Important for septation |
| ENSMUSG00000025534 | NM_010368.1 | Gusb | Common house-keeping gene |
| ENSMUSG00000021109 | NM_010431.2 | Hif1a | Hypoxia signaling |
| ENSMUSG00000058773 | NM_020034.1 | Hist1h1b | Decreased during septation |
| ENSMUSG00000061615 | NM_175660.3 | Hist1h2ab | Decreased during septation |
| ENSMUSG00000032126 | NM_013551.2 | Hmbs | Common house-keeping gene |
| ENSMUSG00000029919 | NM_019455.4 | Hpgds | important in other processes (IPF, COPD etc) |
| ENSMUSG00000025630 | NM_013556.2 | Hprt | Common house-keeping gene |
| ENSMUSG00000020053 | NM_001111274.1 | Igf1 | Regulating miRNA altered during septation |
| ENSMUSG00000020427 | NM_008343.2 | Igfbp3 | Altered DNA methylation during septation, fibrosis |
| ENSMUSG00000003477 | NM_009349.3 | Inmt | Increased during septation |
| ENSMUSG00000026768 | NM_001001309.2 | Itga8 | Involved in lung development |
| ENSMUSG00000040029 | NM_001081113.1 | Ipo8 | important in other processes (IPF, COPD etc) |
| ENSMUSG00000030786 | NM_001082960.1 | Itgam | Monocyte cell marker |
| ENSMUSG00000030789 | NM_021334.2 | Itgax | Monocyte cell marker |
| ENSMUSG00000090122 | NM_021487.1 | Kcne1l | important in other processes (IPF, COPD etc) |
| ENSMUSG00000063142.10 | XM_006518608.1 | Kcnma1 | Altered DNA methylation during septation |
| ENSMUSG00000079852 | NM_010649.3 | Klra4 | Increased during septation |
| ENSMUSG00000023043 | NM_010664.2 | Krt18 | Epithelial cell marker |
| ENSMUSG00000061527 | NM_027011.2 | Krt5 | Basal cell marker |
| ENSMUSG00000029570 | NM_008494.3 | Lfng | Important for septation |
| ENSMUSG00000024529 | NM_010728.2 | Lox | Altered DNA methylation during fibrosis |
| ENSMUSG00000028003 | NM_023624.4 | Lrat | Increased during septation |
| ENSMUSG00000027070 | NM_001081088.1 | Lrp2 | Altered DNA methylation during septation |
| ENSMUSG00000061068 | NM_010779.2 | Mcpt4 | Decreased during septation |
| ENSMUSG00000026110 | NM_173870.2 | Mgat4a | Involved in acute lung injury |
| ENSMUSG00000043613 | NM_010809.1 | Mmp3 | Increased during septation |
| ENSMUSG00000018623 | NM_010810.4 | Mmp7 | Important in lung fibrosis |
| ENSMUSG00000066108 | XM_006508653.1 | Muc5b | Important in lung fibrosis |
| ENSMUSG00000037974 | NM_010844.1 | Muc5ac | Epithelial cell marker |
| ENSMUSG00000024304 | NM_007664.4 | Cdh2 | Tight Junction/Adhesion |
| ENSMUSG00000054008 | NM_008306.4 | Ndst1 | Involved in pathologic airway remodeling |
| ENSMUSG00000031902 | NM_010901.2 | Nfatc3 | Important for lung development |
| ENSMUSG00000073435 | NM_019730.2 | Nme3 | Apoptosis-related gene |
| ENSMUSG00000026575 | NM_138314.3 | Nme7 | Important for stem cell renewal |
| ENSMUSG00000014776 | NM_030152.4 | Nol3 | Regulating miRNA altered during septation |
| ENSMUSG00000051048 | NM_177161.4 | P4ha3 | Important in lung fibrosis |
| ENSMUSG00000068039 | NM_013686.3 | Tcp1 | Basal cell marker |
| ENSMUSG00000029998 | NM_025823.4 | Pcyox1 | important in other processes (IPF , COPD etc) |
| ENSMUSG00000029231 | NM_011058.2 | Pdgfra | Important for septation |
| ENSMUSG00000024620 | NM_008809.1 | Pdgfrb | Pericyte cell marker |
| ENSMUSG00000028583 | NM_010329.2 | Pdpn | Alveolar Type I cell marker |
| ENSMUSG00000062070 | NM_008828.2 | Pgk1 | important in other processes (IPF , COPD etc) |
| ENSMUSG00000053398 | NM_016966.3 | Phgdh | important in other processes (IPF, COPD etc) |
| ENSMUSG00000005198 | NM_009089.2 | Polr2a | important in other processes (IPF, COPD etc) |
| ENSMUSG00000071866 | NM_008907.1 | Ppia | Common house-keeping gene |
| ENSMUSG00000024997 | NM_007452.2 | Prdx3 | Mitochondrial oxidative stress regulator |
| ENSMUSG00000026134 | NM_008922.2 | Prim2 | Expressed in placenta and crucial for mammalian growth. |
| ENSMUSG00000033491 | NM_178738.3 | Prss35 | Decreased during septation |
| ENSMUSG00000032487 | NM_011198.3 | Ptgs2 | Regulating miRNA altered during septation |
| ENSMUSG00000056458 | NM_011973.2 | Mok | Alveolar Type I cell marker |
| ENSMUSG00000037992 | NM_001177302.1 | Rara | Important for septation |
| ENSMUSG00000022883 | NM_019413.2 | Robo1 | Altered DNA methylation during septation |
| ENSMUSG00000025508 | NM_026020.6 | Rplp2 | |
| ENSMUSG00000066361 | NM_008458.2 | Serpina3c | Increased during septation |
| ENSMUSG00000022097 | NM_011359.1 | Sftpc | Alveolar Type II cell marker |
| ENSMUSG00000021795 | NM_009160.2 | Sftpd | Alveolar Type II cell marker |
| ENSMUSG00000050010 | NM_001033415.3 | Shisa3 | Altered DNA methylation during septation |
| ENSMUSG00000032402 | NM_016769.3 | Smad3 | Important for septation |
| ENSMUSG00000042821 | NM_011427.2 | Snai1 | Important for lung development and injury |
| ENSMUSG00000000567 | NM_011448.4 | Sox9 | Altered DNA methylation during septation |
| ENSMUSG00000027646 | NM_001025395.2 | Src | Altered DNA methylation during septation |
| ENSMUSG00000014767 | NM_013684.3 | Tbp | Common house-keeping gene , involved in multiple processes |
| ENSMUSG00000000094 | NM_172798.1 | Tbx4 | Altered DNA methylation during septation |
| ENSMUSG00000032228 | NM_011544.3 | Tcf12 | Involved in multiple developmental processes |
| ENSMUSG00000022797 | NM_011638.3 | Tfrc | Common house-keeping gene |
| ENSMUSG00000002603 | NM_011577.1 | Tgfb1 | Important for septation |
| ENSMUSG00000045691 | NM_153083.5 | Thtpa | important in other processes (IPF, COPD etc) |
| ENSMUSG00000032011 | NM_009382.3 | Thy1 | Fibroblast cell marker |
| ENSMUSG00000028364 | NM_011607.1 | Tnc | Altered DNA methylation during septation |
| ENSMUSG00000044986 | NM_009437.4 | Tst | important in other processes (IPF, COPD etc) |
| ENSMUSG00000026803 | NM_009442.2 | Ttf1 | Important for lung development |
| ENSMUSG00000008348 | NM_019639.4 | Ubc | Common house-keeping gene |
| ENSMUSG00000023951 | NM_001025250.3 | Vegfa | Angiogenesis; Altered DNA methylation during septation |
| ENSMUSG00000026728 | NM_011701.4 | Vim | Mesenchymal cell marker |
| ENSMUSG00000020218 | NM_011915.1 | Wif1 | Altered DNA methylation during septation |
| ENSMUSG00000022285 | NM_011740.2 | Ywhaz | Common house-keeping gene |
Appendix 2—table 2.
Summary of methylation dataset
| Gene | Number of loci | Gene | Number of loci | |
|---|---|---|---|---|
| Cdh11 | 14 | Zfp536 | 16 | |
| Src | 11 | Igfbp3 | 34 | |
| Sox9 | 16 | Wif1 | 21 | |
| Dnmt3a | 41 | Vegfa | 20 | |
| Eln | 20 | Tnc | 4 | |
| Foxf2 | 41 | Lox | 17 | |
| Akt1 | 11 |
Appendix 2—table 3.
Target regions for each gene for methylation analysis
| Gene | Ensembl gene ID | Ensembl transcript ID | Assay ID | Target location | Fwd Tm | Rev Tm | % GC | Coordinates (GRCm38/mm10) |
|---|---|---|---|---|---|---|---|---|
| Akt1 | ENSMUSG00000001729 | ENSMUST00000001780 | ADS3333 | 3’ UTR | 68 | 65.5 | 31.5 | chr12:112654548–112654709 |
| Akt1 | ENSMUSG00000001729 | ENSMUST00000001780 | ADS3332 | Intron 9/Exon 10 | 68.3 | 69.8 | 38.3 | chr12:112657120–112657273 |
| Cdh11 | ENSMUSG00000031673 | ENSMUST00000075190 | ADS3308 | Intron 3 | 66.8 | 68.3 | 36.9 | chr8:102677609–102677766 |
| Cdh11 | ENSMUSG00000031673 | ENSMUST00000075190 | ADS3318 | Intron 1 | 64.1 | 69.7 | 37 | chr8:102784569–102784722 |
| Cdh11 | ENSMUSG00000031673 | ENSMUST00000075190 | ADS3307 | Promoter | 69.1 | 71.3 | 29.9 | chr8:102785456–102785649 |
| Dnmt3a | ENSMUSG00000020661 | ENSMUST00000020991 | ADS3326 | Promoter | 68.6 | 67.7 | 47.1 | chr12:3806505–3806659 |
| Dnmt3a | ENSMUSG00000020661 | ENSMUST00000020991 | ADS632 | Intron 1 | 64 | 64.7 | 32.2 | chr12:3834382–3834592 |
| Dnmt3a | ENSMUSG00000020661 | ENSMUST00000020991 | ADS3328 | Exon 6/Intron 6 | 64.7 | 64 | 31.8 | chr12:3901545–3901764 |
| Dnmt3a | ENSMUSG00000020661 | ENSMUST00000020991 | ADS3329 | Intron 6 | 66.8 | 66.1 | 25.4 | chr12:3907514–3907765 |
| Eln | ENSMUSG00000029675 | ENSMUST00000015138 | ADS3319 | Intron 16 | 67.1 | 67.9 | 47.8 | chr5:134721191–134721447 |
| Eln | ENSMUSG00000029675 | ENSMUST00000015138 | ADS3309 | Intron 7/Exon 8/Intron 8 | 64.1 | 67.4 | 37.8 | chr5:134729221–134729526 |
| Eln | ENSMUSG00000029675 | ENSMUST00000015138 | ADS024 | Promoter | 65 | 67.4 | 42.6 | chr5:134747412–134747606 |
| Foxf2 | ENSMUSG00000038402 | ENSMUST00000042054 | ADS4505 | Promoter | 63.1 | 65 | 42.5 | chr13: 31625470–31625556 |
| Foxf2 | ENSMUSG00000038402 | ENSMUST00000042054 | ADS4506 | 5-UTR | 65.1 | 64.8 | 37.9 | chr13:31625904–31626093 |
| Foxf2 | ENSMUSG00000038402 | ENSMUST00000042054 | ADS4507 | 3-Downstream | 68 | 68.9 | 28.1 | chr13:31632481–31632716 |
| Igfbp3 | ENSMUSG00000020427 | ENSMUST00000020702 | ADS5134 | 3-Downstream | 69.3 | 69.6 | 32.1 | chr11:7203969–7204208 |
| Igfbp3 | ENSMUSG00000020427 | ENSMUST00000020702 | ADS3301 | Exon 4/Intron 4 | 70.5 | 70 | 33 | chr11:7208306–7208481 |
| Igfbp3 | ENSMUSG00000020427 | ENSMUST00000020702 | ADS5133 | Intron 1 | 68.3 | 68.5 | 26.1 | chr11:7212803–7213043 |
| Igfbp3 | ENSMUSG00000020427 | ENSMUST00000020702 | ADS5132 | Promoter | 67.8 | 69.2 | 28.7 | chr11:7214210–7214499 |
| Lox | ENSMUSG00000024529 | ENSMUST00000171470 | ADS4512 | Exon 2 | 69 | 70.9 | 31.3 | chr18: 52529184–52529315 |
| Lox | ENSMUSG00000024529 | ENSMUST00000171470 | ADS4513 | Exon 4 | 65.7 | 64.8 | 28.5 | chr18:52526887–52527023 |
| Lox | ENSMUSG00000024529 | ENSMUST00000171470 | ADS4511 | Promoter | 64.7 | 66.4 | 21.2 | chr18:52530080–52530216 |
| Sox9 | ENSMUSG00000000567 | ENSMUST00000000579 | ADS796 | Promoter | 61 | 66.1 | 31.4 | chr11:112781641–112781811 |
| Sox9 | ENSMUSG00000000567 | ENSMUST00000000579 | ADS3311 | Intron 1 | 69.7 | 68.5 | 34.7 | chr11:112783358–112783605 |
| Sox9 | ENSMUSG00000000567 | ENSMUST00000000579 | ADS3310 | Exon 3 | 66.4 | 63.1 | 26.2 | chr11:112784760–112784885 |
| Src | ENSMUSG00000027646 | ENSMUST00000109533 | ADS4514 | Intron 1 | 64.8 | 65.9 | 35.9 | chr2:157423925–157424027 |
| Src | ENSMUSG00000027646 | ENSMUST00000109533 | ADS4515 | Intron 4 | 66.5 | 68.8 | 37.6 | chr2:157457351–157457520 |
| Src | ENSMUSG00000027646 | ENSMUST00000109533 | ADS4516 | Exon 14 | 65.5 | 65.6 | 33.7 | chr2:157469741–157469912 |
| Tnc | ENSMUSG00000028364 | ENSMUST00000107377 | ADS3324 | Intron 14 | 63.3 | 62.2 | 23 | chr4:63982645–63982818 |
| Tnc | ENSMUSG00000028364 | ENSMUST00000107377 | ADS3325 | Intron 14 | 62.5 | 61.6 | 20.2 | chr4:63982799–63982986 |
| Tnc | ENSMUSG00000028364 | ENSMUST00000107377 | ADS3323 | Exon 3 | 65 | 67.5 | 35.2 | chr4:64017478–64017721 |
| Tnc | ENSMUSG00000028364 | ENSMUST00000107377 | ADS3322 | Promoter | 62.7 | 63.9 | 26.7 | chr4:64047034–64047149 |
| Vegfa | ENSMUSG00000023951 | ENSMUST00000071648 | ADS3336 | 3-UTR | 67.2 | 66.9 | 32.6 | chr17:46018598–46018735 |
| Vegfa | ENSMUSG00000023951 | ENSMUST00000071648 | ADS3335 | Intron 2/Exon 3 | 64.6 | 63.8 | 29.5 | chr17:46025336–46025620 |
| Wif1 | ENSMUSG00000020218 | ENSMUST00000020439 | ADS3302 | Promoter | 69.4 | 68.7 | 31.3 | chr10:121033395–121033691 |
| Wif1 | ENSMUSG00000020218 | ENSMUST00000020439 | ADS3303 | Intron 4/Exon 5/Intron 5 | 60.9 | 60.1 | 31.8 | chr10:121083800–121083997 |
| Wif1 | ENSMUSG00000020218 | ENSMUST00000020439 | ADS3304 | Exon 10/3-UTR | 66.6 | 67.5 | 24.8 | chr10:121099752–121099973 |
| Zfp536 | ENSMUSG00000043456 | ENSMUST00000056338 | ADS4510 | 3-Downstream | 65.4 | 67.4 | 35.9 | chr7:37473451–37473606 |
| Zfp536 | ENSMUSG00000043456 | ENSMUST00000056338 | ADS4509 | Exon 4 | 68.4 | 69.9 | 35.4 | chr7:37567973–37568130 |
Appendix 2—table 4.
Mean and standard deviation of mean squared error over all genes by TPS selecting points and piecewise linear fits over sets of points identified heuristically in the literature.
| Method | Mean | Std dev |
|---|---|---|
| TPS (, , , and ) | 0.40306335962 | 0.2206665163 |
| Piecewise linear over , , , | 0.594072719494 | 0.399642079492 |
| Piecewise linear over , , , | 0.710967061349 | 0.721681860787 |
| Piecewise linear over , , , , | 0.560990230501 | 0.364739525724 |
Funding Statement
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Funding Information
This paper was supported by the following grant:
National Institutes of Health U01 HL122626 to Ziv Bar-Joseph.
Additional information
Competing interests
The authors declare that no competing interests exist.
Author contributions
MK, Software, Formal analysis, Validation, Investigation, Visualization, Methodology, Writing—original draft, Writing—review and editing.
ES, Conceptualization, Formal analysis, Validation, Investigation, Visualization, Methodology, Writing—original draft.
TN, Resources, Data curation, Investigation.
CE, Resources, Data curation, Investigation.
DC, Resources, Data curation, Investigation.
JSH, Resources, Data curation, Investigation.
NK, Resources, Data curation, Investigation.
NA, Resources, Data curation, Investigation.
ZB-J, Conceptualization, Resources, Supervision, Funding acquisition, Investigation, Methodology, Writing—original draft, Project administration, Writing—review and editing.
Ethics
Animal experimentation: This study was performed in strict accordance with the recommendations in the Guide for the Care and Use of Laboratory Animals of the National Institutes of Health. All of the animals were handled according to approved institutional animal care and use committee (IACUC) protocols (APN 10042) of the University of Alabama at Birmingham. All lungs were isolated immediately following euthanasia using approved protocols.
Additional files
Major datasets
The following dataset was generated:
Kleyman M,Sefer E,Nicola T,Espinoza C,Chhabra D,Hagood JS,Kaminski N,Ambalavanan N,Joseph ZB,2016,miRNA Data of Mouse Lung Developement,http://sb.cs.cmu.edu/TPS/data.html,Publicly available at the Systems Biology Group, School of Computer Science, Carnegie Mellon University website
References
- Agarwal V, Bell GW, Nam J-W, Bartel DP. Predicting effective microRNA target sites in mammalian mRNAs. eLife. 2015;4:e05005. doi: 10.7554/eLife.05005. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ashburner M, Ball CA, Blake JA, Botstein D, Butler H, Cherry JM, Davis AP, Dolinski K, Dwight SS, Eppig JT, Harris MA, Hill DP, Issel-Tarver L, Kasarskis A, Lewis S, Matese JC, Richardson JE, Ringwald M, Rubin GM, Sherlock G. Gene ontology: tool for the unification of biology. Nature Genetics. 2000;25:25–29. doi: 10.1038/75556. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bar-Joseph Z, Gerber GK, Gifford DK, Jaakkola TS, Simon I. Continuous representations of time-series gene expression data. Journal of Computational Biology. 2003a;10:341–356. doi: 10.1089/10665270360688057. [DOI] [PubMed] [Google Scholar]
- Bar-Joseph Z, Gerber G, Simon I, Gifford DK, Jaakkola TS. Comparing the continuous representation of time-series expression profiles to identify differentially expressed genes. PNAS. 2003b;100:10146–10151. doi: 10.1073/pnas.1732547100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Berriz GF, King OD, Bryant B, Sander C, Roth FP. Characterizing gene sets with FuncAssociate. Bioinformatics. 2003;19:2502–2504. doi: 10.1093/bioinformatics/btg363. [DOI] [PubMed] [Google Scholar]
- Bhaskaran M, Wang Y, Zhang H, Weng T, Baviskar P, Guo Y, Gou D, Liu L. MicroRNA-127 modulates fetal lung development. Physiological Genomics. 2009;37:268–278. doi: 10.1152/physiolgenomics.90268.2008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Bishop CM. Pattern recognition and machine learning. Springer; 2006. [Google Scholar]
- Bolstad BM, Irizarry RA, Astrand M, Speed TP. A comparison of normalization methods for high density oligonucleotide array data based on variance and bias. Bioinformatics. 2003;19:185–193. doi: 10.1093/bioinformatics/19.2.185. [DOI] [PubMed] [Google Scholar]
- Bonner AE, Lemon WJ, You M. Gene expression signatures identify novel regulatory pathways during murine lung development: implications for lung tumorigenesis. Journal of Medical Genetics. 2003;40:408–417. doi: 10.1136/jmg.40.6.408. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Brissett M, Veraldi KL, Pilewski JM, Medsger TA, Feghali-Bostwick CA. Localized expression of tenascin in systemic sclerosis-associated pulmonary fibrosis and its regulation by insulin-like growth factor binding protein 3. Arthritis & Rheumatism. 2012;64:272–280. doi: 10.1002/art.30647. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Buenrostro JD, Wu B, Litzenburger UM, Ruff D, Gonzales ML, Snyder MP, Chang HY, Greenleaf WJ. Single-cell chromatin accessibility reveals principles of regulatory variation. Nature. 2015;523:486–490. doi: 10.1038/nature14590. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Carvalho O, Gonçalves C. Expression of oestrogen receptors in foetal lung tissue of mice. Anatomia, Histologia, Embryologia. 2012;41:1–6. doi: 10.1111/j.1439-0264.2011.01096.x. [DOI] [PubMed] [Google Scholar]
- Chang KN, Zhong S, Weirauch MT, Hon G, Pelizzola M, Li H, Huang SS, Schmitz RJ, Urich MA, Kuo D, Nery JR, Qiao H, Yang A, Jamali A, Chen H, Ideker T, Ren B, Bar-Joseph Z, Hughes TR, Ecker JR. Temporal transcriptional response to ethylene gas drives growth hormone cross-regulation in arabidopsis. eLife. 2013;2:e00675. doi: 10.7554/eLife.00675. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cormack M, Lin M, Fedulov A, Mentzer SJ, Tsuda A. Age-dependent changes in gene expression profiles of postnatally developing rat lungs exposed to nano-size and micro-size cuo particles. The FASEB Journal. 2010;24:612–618. [Google Scholar]
- Cox B, Kislinger T, Wigle DA, Kannan A, Brown K, Okubo T, Hogan B, Jurisica I, Frey B, Rossant J, Emili A. Integrated proteomic and transcriptomic profiling of mouse lung development and nmyc target genes. Molecular Systems Biology. 2007;3:109. doi: 10.1038/msb4100151. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Cuna A, Halloran B, Faye-Petersen O, Kelly D, Crossman DK, Cui X, Pandit K, Kaminski N, Bhattacharya S, Ahmad A, Mariani TJ, Ambalavanan N. Alterations in gene expression and DNA methylation during murine and human lung alveolar septation. American Journal of Respiratory Cell and Molecular Biology. 2015;53:60–73. doi: 10.1165/rcmb.2014-0160OC. [DOI] [PMC free article] [PubMed] [Google Scholar]
- De Boor C. Mathematics of Computation. New York: Springer, NY; 1978. A practical guide to splines. [Google Scholar]
- Dong J, Sutor S, Jiang G, Cao Y, Asmann YW, Wigle DA. c-Myc regulates self-renewal in bronchoalveolar stem cells. PLoS One. 2011;6:e23707. doi: 10.1371/journal.pone.0023707. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Fujiwara N, Doi T, Gosemann JH, Kutasy B, Friedmacher F, Puri P. Smad1 and WIF1 genes are downregulated during saccular stage of lung development in the nitrofen rat model. Pediatric Surgery International. 2012;28:189–193. doi: 10.1007/s00383-011-2987-0. [DOI] [PubMed] [Google Scholar]
- Gitter A, Carmi M, Barkai N, Bar-Joseph Z. Linking the signaling cascades and dynamic regulatory networks controlling stress responses. Genome Research. 2013;23:365–376. doi: 10.1101/gr.138628.112. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gortner L, Shen J, Tutdibi E. Sexual dimorphism of neonatal lung development. Klinische Pädiatrie. 2013;225:64–69. doi: 10.1055/s-0033-1333758. [DOI] [PubMed] [Google Scholar]
- Guilliams M, De Kleer, Henri S, Post S, Vanhoutte L, De Prijck S, Deswarte K, Malissen B, Hammad H, Lambrecht BN. Alveolar macrophages develop from fetal monocytes that differentiate into long-lived cells in the first week of life via GM-CSF. The Journal of Experimental Medicine. 2013;210:1977–1992. doi: 10.1084/jem.20131199. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hartigan JA. Clustering Algorithms. Hoboken, NJ: John Wiley & Sons, Inc; 1975. [Google Scholar]
- Hu MC, Wang YP, Qiu WR. Human fibroblast growth factor-18 stimulates fibroblast cell proliferation and is mapped to chromosome 14p11. Oncogene. 1999;18:2635–2642. doi: 10.1038/sj.onc.1202616. [DOI] [PubMed] [Google Scholar]
- Hunter AL, Zhang J, Chen SC, Si X, Wong B, Ekhterae D, Luo H, Granville DJ. Apoptosis repressor with caspase recruitment domain (ARC) inhibits myogenic differentiation. FEBS Letters. 2007;581:879–884. doi: 10.1016/j.febslet.2007.01.050. [DOI] [PubMed] [Google Scholar]
- Kirkpatrick S, Gelatt CD, Vecchi MP. Optimization by simulated annealing. Science. 1983;220:671–680. doi: 10.1126/science.220.4598.671. [DOI] [PubMed] [Google Scholar]
- Kopantzev EP, Monastyrskaya GS, Vinogradova TV, Zinovyeva MV, Kostina MB, Filyukova OB, Tonevitsky AG, Sukhikh GT, Sverdlov ED. Differences in gene expression levels between early and later stages of human lung development are opposite to those between normal lung tissue and non-small lung cell carcinoma. Lung Cancer. 2008;62:23–34. doi: 10.1016/j.lungcan.2008.02.011. [DOI] [PubMed] [Google Scholar]
- Li C, Bankhead A, Eisfeld AJ, Hatta Y, Jeng S, Chang JH, Aicher LD, Proll S, Ellis AL, Law GL, Waters KM, Neumann G, Katze MG, McWeeney S, Kawaoka Y. Host regulatory network response to infection with highly pathogenic H5N1 avian influenza virus. Journal of Virology. 2011;85:10955–10967. doi: 10.1128/JVI.05792-11. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li JZ, Bunney BG, Meng F, Hagenauer MH, Walsh DM, Vawter MP, Evans SJ, Choudary PV, Cartagena P, Barchas JD, Schatzberg AF, Jones EG, Myers RM, Watson SJ, Akil H, Bunney WE. Circadian patterns of gene expression in the human brain and disruption in major depressive disorder. PNAS. 2013;110:9950–9955. doi: 10.1073/pnas.1305814110. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Mager EM, Renzetti G, Auais A, Piedimonte G. Growth factors gene expression in the developing lung. Acta Paediatrica. 2007;96:1015–1020. doi: 10.1111/j.1651-2227.2007.00332.x. [DOI] [PubMed] [Google Scholar]
- Mariani TJ, Reed JJ, Shapiro SD. Expression profiling of the developing mouse lung: insights into the establishment of the extracellular matrix. American journal of respiratory cell and molecular biology. 2002;26:541–548. doi: 10.1165/ajrcmb.26.5.2001-00080c. [DOI] [PubMed] [Google Scholar]
- McLachlan G, Peel D. Finite Mixture Models. Hoboken, NJ: John Wiley & Sons; 2004. [Google Scholar]
- Melén E, Kho AT, Sharma S, Gaedigk R, Leeder JS, Mariani TJ, Carey VJ, Weiss ST, Tantisira KG. Expression analysis of asthma candidate genes during human and murine lung development. Respiratory Research. 2011;12:86. doi: 10.1186/1465-9921-12-86. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ohbayashi N, Hoshikawa M, Kimura S, Yamasaki M, Fukui S, Itoh N. Structure and expression of the mRNA encoding a novel fibroblast growth factor, FGF-18. Journal of Biological Chemistry. 1998;273:18161–18164. doi: 10.1074/jbc.273.29.18161. [DOI] [PubMed] [Google Scholar]
- Paige SL, Thomas S, Stoick-Cooper CL, Wang H, Maves L, Sandstrom R, Pabon L, Reinecke H, Pratt G, Keller G, Moon RT, Stamatoyannopoulos J, Murry CE. A temporal chromatin signature in human embryonic stem cells identifies regulators of cardiac development. Cell. 2012;151:221–232. doi: 10.1016/j.cell.2012.08.027. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Popova AP, Bentley JK, Cui TX, Richardson MN, Linn MJ, Lei J, Chen Q, Goldsmith AM, Pryhuber GS, Hershenson MB. Reduced platelet-derived growth factor receptor expression is a primary feature of human bronchopulmonary dysplasia. AJP: Lung Cellular and Molecular Physiology. 2014;307:L231–L239. doi: 10.1152/ajplung.00342.2013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Reinsch CH. Smoothing by spline functions. Numerische Mathematik. 1967;10:177–183. doi: 10.1007/BF02162161. [DOI] [Google Scholar]
- Rice P, Longden I, Bleasby A. EMBOSS: the european molecular biology open software suite. Trends in Genetics. 2000;16:276–277. doi: 10.1016/S0168-9525(00)02024-2. [DOI] [PubMed] [Google Scholar]
- Rosa BA, Zhang J, Major IT, Qin W, Chen J. Optimal timepoint sampling in high-throughput gene expression experiments. Bioinformatics. 2012;28:2773–2781. doi: 10.1093/bioinformatics/bts511. [DOI] [PubMed] [Google Scholar]
- Roy S, Ernst J, Kharchenko PV, Kheradpour P, Negre N, Eaton ML, Landolin JM, Bristow CA, Ma L, Lin MF, Washietl S, Arshinoff BI, Ay F, Meyer PE, Robine N, Washington NL, Di Stefano L, Berezikov E, Brown CD, Candeias R, Carlson JW, Carr A, Jungreis I, Marbach D, Sealfon R, Tolstorukov MY, Will S, Alekseyenko AA, Artieri C, Booth BW, Brooks AN, Dai Q, Davis CA, Duff MO, Feng X, Gorchakov AA, Gu T, Henikoff JG, Kapranov P, Li R, MacAlpine HK, Malone J, Minoda A, Nordman J, Okamura K, Perry M, Powell SK, Riddle NC, Sakai A, Samsonova A, Sandler JE, Schwartz YB, Sher N, Spokony R, Sturgill D, van Baren M, Wan KH, Yang L, Yu C, Feingold E, Good P, Guyer M, Lowdon R, Ahmad K, Andrews J, Berger B, Brenner SE, Brent MR, Cherbas L, Elgin SC, Gingeras TR, Grossman R, Hoskins RA, Kaufman TC, Kent W, Kuroda MI, Orr-Weaver T, Perrimon N, Pirrotta V, Posakony JW, Ren B, Russell S, Cherbas P, Graveley BR, Lewis S, Micklem G, Oliver B, Park PJ, Celniker SE, Henikoff S, Karpen GH, Lai EC, MacAlpine DM, Stein LD, White KP, Kellis M, modENCODE Consortium Identification of functional elements and regulatory circuits by drosophila modENCODE. Science. 2010;330:1787–1797. doi: 10.1126/science.1198374. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schneider E, Pliushch G, El Hajj N, Galetzka D, Puhl A, Schorsch M, Frauenknecht K, Riepert T, Tresch A, Müller AM, Coerdt W, Zechner U, Haaf T. Spatial, temporal and interindividual epigenetic variation of functionally important DNA methylation patterns. Nucleic Acids Research. 2010;38:3880–3890. doi: 10.1093/nar/gkq126. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schulz MH, Pandit KV, Lino Cardenas CL, Ambalavanan N, Kaminski N, Bar-Joseph Z. Reconstructing dynamic microRNA-regulated interaction networks. PNAS. 2013;110:15686–15691. doi: 10.1073/pnas.1303236110. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schwarz G. Estimating the dimension of a model. The Annals of Statistics. 1978;6:461–464. doi: 10.1214/aos/1176344136. [DOI] [Google Scholar]
- Sessa R, Hata A. Role of microRNAs in lung development and pulmonary diseases. Pulmonary Circulation. 2013;3:315. doi: 10.4103/2045-8932.114758. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shapira SD, Gat-Viks I, Shum BO, Dricot A, de Grace MM, Wu L, Gupta PB, Hao T, Silver SJ, Root DE, Hill DE, Regev A, Hacohen N. A physical and regulatory map of host-influenza interactions reveals pathways in H1N1 infection. Cell. 2009;139:1255–1267. doi: 10.1016/j.cell.2009.12.018. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Shi W, Liao Y, Willis SN, Taubenheim N, Inouye M, Tarlinton DM, Smyth GK, Hodgkin PD, Nutt SL, Corcoran LM. Transcriptional profiling of mouse B cell terminal differentiation defines a signature for antibody-secreting plasma cells. Nature Immunology. 2015;16:663–673. doi: 10.1038/ni.3154. [DOI] [PubMed] [Google Scholar]
- Singer ZS, Yong J, Tischler J, Hackett JA, Altinok A, Surani MA, Cai L, Elowitz MB. Dynamic heterogeneity and DNA methylation in embryonic stem cells. Molecular Cell. 2014;55:319–331. doi: 10.1016/j.molcel.2014.06.029. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Singh R, Palmer N, Gifford D, Berger B, Bar-Joseph Z. Active learning for sampling in time-series experiments with application to gene expression analysis. Proceedings of the 22nd International Conference on Machine Learning (ICML-05); 2005. pp. 832–839. [Google Scholar]
- Spellman PT, Sherlock G, Zhang MQ, Iyer VR, Anders K, Eisen MB, Brown PO, Botstein D, Futcher B. Comprehensive identification of cell cycle-regulated genes of the yeast saccharomyces cerevisiae by microarray hybridization. Molecular Biology of the Cell. 1998;9:3273–3297. doi: 10.1091/mbc.9.12.3273. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Sperger JM, Chen X, Draper JS, Antosiewicz JE, Chon CH, Jones SB, Brooks JD, Andrews PW, Brown PO, Thomson JA. Gene expression patterns in human embryonic stem cells and human pluripotent germ cell tumors. PNAS. 2003;100:13350–13355. doi: 10.1073/pnas.2235735100. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Storch KF, Lipan O, Leykin I, Viswanathan N, Davis FC, Wong WH, Weitz CJ. Extensive and divergent circadian gene expression in liver and heart. Nature. 2002;417:78–83. doi: 10.1038/nature744. [DOI] [PubMed] [Google Scholar]
- Subhani N, Rueda L, Ngom A, Burden CJ. Multiple gene expression profile alignment for microarray time-series data clustering. Bioinformatics. 2010;26:2281–2288. doi: 10.1093/bioinformatics/btq422. [DOI] [PubMed] [Google Scholar]
- Takai D, Jones PA. Comprehensive analysis of CpG islands in human chromosomes 21 and 22. PNAS. 2002;99:3740–3745. doi: 10.1073/pnas.052410099. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Talens RP, Boomsma DI, Tobi EW, Kremer D, Jukema JW, Willemsen G, Putter H, Slagboom PE, Heijmans BT. Variation, patterns, and temporal stability of DNA methylation: considerations for epigenetic epidemiology. The FASEB Journal. 2010;24:3135–3144. doi: 10.1096/fj.09-150490. [DOI] [PubMed] [Google Scholar]
- Thompson MA, Weinshilboum RM. Rabbit lung indolethylamine N-methyltransferase. cDNA and gene cloning and characterization. Journal of Biological Chemistry. 1998;273:34502–34510. doi: 10.1074/jbc.273.51.34502. [DOI] [PubMed] [Google Scholar]
- Turi ZG, Rezkella S, Campbell CA, Kloner RA. Left main percutaneous transluminal coronary angioplasty with the autoperfusion catheter in an animal model. Catheterization and Cardiovascular Diagnosis. 1990;21:45–50. doi: 10.1002/ccd.1810210112. [DOI] [PubMed] [Google Scholar]
- Ueda HR, Chen W, Adachi A, Wakamatsu H, Hayashi S, Takasugi T, Nagano M, Nakahama K, Suzuki Y, Sugano S, Iino M, Shigeyoshi Y, Hashimoto S. A transcription factor response element for gene expression during circadian night. Nature. 2002;418:534–539. doi: 10.1038/nature00906. [DOI] [PubMed] [Google Scholar]
- Wahba G. Spline Models for Observational Data, Vol. 59. Philadelphia, PA: SIAM: Society for Industrial and Applied Mathematics; 1990. [Google Scholar]
- Weinstein M, Xu X, Ohyama K, Deng CX. FGFR-3 and FGFR-4 function cooperatively to direct alveogenesis in the murine lung. Development. 1998;125:3615–3623. doi: 10.1242/dev.125.18.3615. [DOI] [PubMed] [Google Scholar]
- Williams AE, Moschos SA, Perry MM, Barnes PJ, Lindsay MA. Maternally imprinted microRNAs are differentially expressed during mouse and human lung development. Developmental Dynamics. 2007;236:572–580. doi: 10.1002/dvdy.21047. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Xu B, Chen C, Chen H, Zheng SG, Bringas P, Xu M, Zhou X, Chen D, Umans L, Zwijsen A, Shi W. Smad1 and its target gene Wif1 coordinate BMP and wnt signaling activities to regulate fetal lung development. Development. 2011;138:925–935. doi: 10.1242/dev.062687. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Yosef N, Regev A. Impulse control: temporal dynamics in gene transcription. Cell. 2011;144:886–896. doi: 10.1016/j.cell.2011.02.015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zhou L, Mideros SX, Bao L, Hanlon R, Arredondo FD, Tripathy S, Krampis K, Jerauld A, Evans C, St Martin SK, Maroof MAS, Hoeschele I, Dorrance AE, Tyler BM. Infection and genotype remodel the entire soybean transcriptome. BMC Genomics. 2009;10:1. doi: 10.1186/1471-2164-10-49. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Zinman GE, Naiman S, Kanfi Y, Cohen H, Bar-Joseph Z. ExpressionBlast: mining large, unstructured expression databases. Nature Methods. 2013;10:925–926. doi: 10.1038/nmeth.2630. [DOI] [PubMed] [Google Scholar]