

Abstract
Individuals from pancreatic cancer families are at increased risk, not only of pancreatic cancer, but also of melanoma, breast, ovarian, and colon cancers. While some of the increased risk may be due to mutations in high-penetrance genes (i.e. BRCA2, PALB2, ATM, p16/CDKN2A or DNA mismatch-repair genes), common genetic variants may also be involved. In a high-risk population of cases with either a family history of pancreatic cancer or early-onset pancreatic cancer (diagnosis before age 50), we examined the role of genetic variants previously associated with risk of pancreatic, breast, ovarian, or prostate cancer. We genotyped 985 cases (79 early-onset cases, 906 cases with a family history of pancreatic cancer) and 877 controls for 215,389 SNPs using the iCOGS array with custom content. Logistic regression was performed using a log-linear additive model. We replicated several previously reported pancreatic cancer susceptibility loci, including recently identified variants on 2p13.3 and 7p13 (2p13.3, rs1486134: OR=1.36, 95%CI (1.13-1.63), p=9.29×10-4; 7p13, rs17688601: OR =0.76, 95%CI (0.63-0.93), p=6.59×10-3). For the replicated loci, the magnitude of association observed in these high-risk patients was similar to that observed in studies of unselected patients. In addition to the established pancreatic cancer loci, we also found suggestive evidence of association (p<5×10-5) to pancreatic cancer for SNPs at HDAC9 (7p21.1) and COL6A2 (21q22.3). Even in high-risk populations, common variants influence pancreatic cancer susceptibility.
Keywords: pancreatic cancer, GWAS, iCOGS, genetic epidemiology, familial pancreatic cancer
Introduction
Pancreatic cancer has a five-year survival rate of 7%. It is currently the fourth leading cause of cancer death in the United States(1) and projected to be second by 2030(2). Approximately 5-10% of individuals with pancreatic cancer have a family history of the disease(3). Familial pancreatic cancer (FPC) is defined as a kindred with at least two first-degree relatives (FDRs) diagnosed with pancreatic cancer. Population-based studies have estimated that having a single FDR with pancreatic cancer increases ones risk 1.7 to 13-fold(4, 5). Prospective studies of FPC have shown a 6.5 to 18-fold risk of pancreatic cancer for individuals with two or more affected FDRs(6, 7).
Age is a strong predictor of pancreatic cancer risk with the median age at diagnosis of pancreatic cancer in the United States being 72(8). However, 5-10% of all pancreatic cancer cases present with Early Onset Pancreatic Cancer (EOPC) defined as the occurrence of a cancer before age 50(8). While it has been suggested that this group of patients may have an underlying genetic predisposition to pancreatic cancer(9), not all studies report an increased risk of pancreatic cancer among the relatives of EOPC patients (7,10).
Individuals with inherited mutations in genes including BRCA2, BRCA1, PALB2,ATM, STK11, CDKN2A, PRSS1 and DNA mismatch repair genes(11-15) are at increased risk of pancreatic cancer. We have shown that FDRs of FPC probands have an increased risk of dying from breast (weighted standardized mortality ratio(wSMR)=1.36, 95% CI 1.02-1.79) and ovarian (wSMR=1.66, 95% CI 1.04-2.53) cancers(16). Relatives of EOPC probands have an increased risk of mortality due to cancers of the breast (wSMR=1.98, 95% CI 1.01-3.52), colon (wSMR=2.31, 95% CI 1.30-3.81), or prostate (wSMR=2.31, 95% CI 1.14-4.20) (16). These findings suggest the possibility of an overlapping genetic etiology among breast, ovarian, prostate, colon, and pancreatic cancers, only a fraction of which are likely explained by mutations in established hereditary cancer genes.
Genome-wide association studies (GWAS) have been successful in identifying common genetic variants (single nucleotide polymorphisms, SNPs) associated with many cancers. In a series of three GWAS studies the Pancreatic Cancer Case-Control Consortium (PanC4, PanScan II) and the Pancreatic Cancer Cohort Consortium (PanScan I-III) identified SNPs associated with pancreatic cancer at the following loci in the non-Hispanic white population: rs505922 on 9q34(ABO)(17), rs9543325 on 13q21(18), rs3790844 on 1q31(18), at least two independent loci on 5p15.33 (rs401681(CLPTM1L)(18) and rs2736098(TERT)(19)), rs6971499 on 7q32.3(19), rs7190458 on 16q23.1(BCAR1/CTRB1/CTRB2)(19), rs9581943 on 13q12.12(PDX1)(19), and rs16986825 on 22q12.1 (ZNRF3)(19). PanC4 recently identified additional significantly associated loci (rs1486134 on 2p13.3(near ETAA1), rs9854771 on 3q29(TP63), rs17688601 on 7p13(SUGCT), and rs11655237 on 17q25.1(LINC00673))(20).
Genome wide association studies have identified many loci that harbor common susceptibility alleles for common cancers such as breast, colon, ovarian and prostate cancer(21). The iCOGS array(22) was designed to capture genetic variation associated with risk for breast, ovarian and prostate cancer as well as all regions found to have highly suggestive evidence of association with other phenotypes(as indicated in the NHGRI genome browser as of May 2010).
Because individuals with EOPC or with a strong family history of pancreatic cancer may differ in underlying genetic susceptibility to pancreatic cancer, we sought to examine the role of common pancreatic cancer-associated variants in our high-risk population using samples from the Pancreatic Cancer Genetic Epidemiology (PACGENE) Consortium(23). We further sought to identify novel pancreatic cancer candidate loci by interrogating genomic regions with known associations to other cancers.
Materials and Methods
Subjects
1,862 individuals (985 pancreatic cancer cases and 877 controls) from six PACGENE study sites(23) were included(Supplementary Table 1). Cases were eligible if they had either a family history of pancreatic cancer or were diagnosed with pancreatic cancer at age 50 or younger. PACGENE sites include Dana-Farber Cancer Institute (Boston, MA), Johns Hopkins Hospital (Baltimore, MD; www.nfptr.org), Karmanos Cancer Institute (Detroit, MI), Mayo Clinic (Rochester, MN), M.D. Anderson Cancer Center (Houston, TX), and University of Toronto (Ontario, Canada). Controls were kindred-based unrelated individuals (i.e., spouse or other unrelated individual in the kindred) from each of the participating sites. All participants completed risk factor and family history questionnaires and provided a blood or saliva sample from which DNA was extracted for genotyping. Informed consent was obtained from each study participant and each study site received its respective Institutional Review Board approval.
Genotyping
Samples were genotyped at the Johns Hopkins Genetic Resource Genotyping Core using the iCOGS Illumina genotyping array, consisting of 211,155 SNPs plus custom content of 4,234 SNPs. The iCOGS array (22), designed as part of the Collaborative Oncological Gene-Environment Study, is a custom Illumina iSelect genotyping array Our custom SNP content included 1,283 SNPs selected for prior evidence of association with pancreatic cancer (based on p-values<0.001 in PanScan I(17) or PanScan II(18)). We also included SNPs found to be highly correlated with these target SNPs, based on r2 values greater than 0.4 in Hapmap2, Hapmap3, or 1000 Genomes Pilot 1 data, for a total of 4,234 custom SNPs. Genotyping quality was excellent with a blind duplicate reproducibility rate of 99.99% (based on 23 duplicate sample pairs) and a concordance rate of 99.65% from HapMap control samples that were genotyped on this array along with our samples. No individuals had a missing call rate greater than 2%.
Quality control metrics were applied to all samples and SNPs prior to statistical analyses (See Supplementary Figures 1A and 1B). Samples were removed if their reported sex did not match genetic sex. If identity-by-descent(IBD) sharing analysis determined that a pair of samples shared more alleles than expected by chance (>0.185), the sample with the largest missing call rate was removed. SNPs with minor allele frequencies less than 0.02, missing call rate greater than 5%, evidence of departure from Hardy-Weinberg Equilibrium (p<5.7×10-7), or a missing rate that differed significantly between cases and controls (p<1×10-5) were excluded. After quality control 199,677 SNPs (195,720 iCOGS SNPs and 3,957 custom SNPs) and 1,825 samples (963 cases and 862 controls) remained for analyses.
Statistical Analysis
Logistic regression using an additive genetic model was performed with PLINKv.1.07(24) for each SNP. Sex and the first three eigenvectors from principal components analysis were included as covariates to control for population structure (Supplementary Figure 2). A Bonferroni threshold of p<2.5×10-7 (.05/199,677) was used to assess statistical significance.
SNPs with significant evidence of association (p< 5×10-8) in prior GWAS were tested for association in the PACGENE samples. In order to identify any overlapping or related individuals between PACGENE and prior GWAS (PanScan I(17), PanScan II(18), and PanC4(20)), IBD sharing was carried out to identify pairs of individuals who share more of their genome than would be expected by chance. For any pair that shared greater than 0.185, the PACGENE individual was excluded from analysis. PanScan I and PanScan II data were downloaded from dbGAP(dbGaP study accession: phs000206.v4.p3). Z-tests were used to determine if the effect size in our study was statistically different from the effect size estimates identified in prior GWAS for the same SNP.
Results
A total of 1,862 samples (985 cases, 877 controls) were available for genotyping (Table 1). Of these 985 cases, 79 were EOPC cases (age<50 at diagnosis) and 906 cases had a family history of pancreatic cancer, averaging 2.44 affected family members. Among these 906 cases, 684 were from kindreds that met the definition of FPC. Mean age at onset was 40.6 in the EOPC cases and 64.3 in the cases with a family history. Individuals were predominantly non-Hispanic white based on self-reported ancestry. Approximately 50% of cases were male and 44% of controls were male.
Table 1. Description of Cases with Early-Onset Pancreatic Cancer, Family History, and Unrelated Controls from the PACGENE Consortium.
| Subseta | N | Ageb (SD) | Familial Casesc | Average Number of Affected Family Members (range) | % Male | % Non-Hispanic White | |
|---|---|---|---|---|---|---|---|
| Cases | Early-Onset | 79 | 40.56 (3.93) | 0 | 1 (1-1) | 54 | 95 |
| Family History | 906 | 64.31 (10.82) | 685 | 2.44 (2-11) | 50 | 93 | |
| All | 985 | 62.62 (12.13) | 685 | 2.33 (1-11) | 50 | 93 | |
| Controls | 877 | 62.24 (10.96) | 0 | 0.0046 (0-1) | 44 | 96 |
Early-Onset: diagnosed with pancreatic cancer before age 50. Family History: has a family history of pancreatic cancer.
Average age of onset for cases; average age at study enrollment for controls
Cases belonging to a familial pancreatic cancer kindred, defined as a confirmed diagnosis of pancreatic cancer in a pair of first-degree relatives.
195,720 SNPs genotyped on the iCOGS array passed quality control and were analyzed using a logistic regression model with an additive genetic effect (Supplementary Figure 3, Supplementary Figure 4). No loci were significant after Bonferroni correction (p<2.5×10-7). Two novel regions showed suggestive evidence of association to pancreatic cancer (p<5×10-5) and merit further study: 7p21.1(HDAC9, rs12531908, OR=1.43, 95%CI:1.23-1.66, p=3.88×10-6) and 21q22.3(COL6A2, rs4458293, OR=0.75, 95%CI:0.65-0.86,p=3.33×10-5) (see Figure 1).
Figure 1.
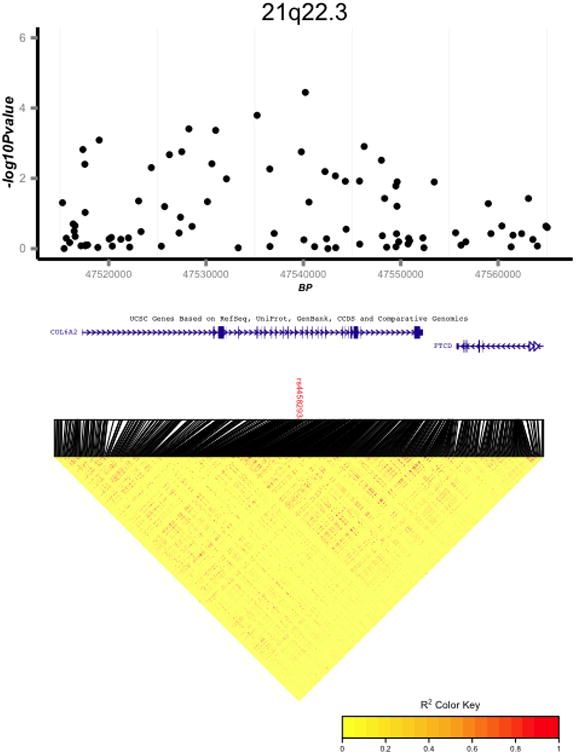
Regional association and linkage disequilibrium (LD) plots for two regions suggestive for association with pancreatic cancer: 7p21.1 (A); 21q22.3 (B). LD plots are based on 1,000 Genomes European samples.
By design, the 4 SNPs that reached genome-wide significance from PanScan I(17) and PanScan II(18) were included on the custom panel. Results from PanScan III(19) and PanC4(20) were not available at the time of SNP selection, therefore not all genome-wide significant SNPs in PanScan III and PanC4 were genotyped on the custom panel. Of the 9 SNPs on the custom panel that were previously associated with pancreatic cancer risk at the genome-wide level, 6 were significantly associated with pancreatic cancer in this high-risk population (P<0.05) (see Table 2, Supplementary Figure 5): 9q34(17) (ABO, rs505922, OR=1.29, 95% CI:1.12-1.48, p=4.37×10-4), 13q21.32(18) (KLF5, rs9543325, OR=1.25, 95%CI:1.08-1.45, p=3.58×10-3), 5p13.33(18) (CLPTM1L, rs401681, OR=1.31, 95%CI:1.14-1.52, p=2.26×10-4), 7q32.3(19) (LINC-PINT, rs6971499, OR=0.72, 95%CI:0.58-0.88, p=1.73×10-3), 2p13.3(20) (ETAA1, rs1486134, OR=1.36, 95%CI:1.13-1.63, p=9.88×10-4), and 7p13(20) (SUGCT, rs17688601, OR=0.77, 95%CI:0.64-0.94, p=1.05×10-2). For the 3 remaining SNPs, the point estimates and direction of effect were consistent with the previously reported association: 1q32.1(18) (NR5A2, rs3790844, OR=0.87, 95%CI:0.73-1.03, p=9.48×10-2), 13q12.12(19) (PDX1-AS1, rs9581943, OR=1.11, 95%CI:0.96-1.29, p=1.50×10-1) and 3q29 (TP63, rs9854771, OR=0.92, 95%CI:0.77-1.09, p=3.14×10-1). For all 9 SNPs, the Z-tests were not significant (p>0.05), confirming that the observed effect sizes in our cohort do not differ significantly from those observed in prior GWAS. The control allele frequencies in our study population were consistent with those reported in the prior studies (p-values>0.1). We also observed strong evidence supporting association to SNPs at 16q23.1 (BCAR1/CTRB1/CTRB2)(19) (rs7202877, OR=1.72, 95%CI:1.40-2.11,p=2.3×10-7) which was identified as a pancreatic cancer susceptibility locus by PanScan III. Two sensitivity analyses were conducted: (1) the analysis was repeated using only non-Hispanic white samples; and (2) PACGENE study site was included as an additional covariate in the analysis. For both sensitivity analyses, results were essentially unchanged (results not shown).
Table 2. Association results for 9 previously reported pancreatic cancer susceptibility loci and current PACGENE data.
| Chromosomea SNPb Genec Positiond |
Studye | Publishedf | PACGENEg | |||||
|---|---|---|---|---|---|---|---|---|
| Odds Ratio (95% CI) | p | MAFg (Cases; Controls) | OR(95%CI) | p | Ni | MAFf (Cases; Controls) | ||
| 9q34.3 rs505922 (C/T) ABO 136,149,229 |
PanScan I (17) | 1.20 (1.12-1.28) | 5.37×10-8 | 0.39;0.35 | 1.29 (1.12 - 1.48) | 4.37×10-4 | 903 cases, 847 controls | 0.40; 0.342 |
| 13q21.32 rs9543325(C/T) KLF5 73,916,628 |
PanScan II (18) | 1.26 (1.18-1.35) | 3.27×10-11 | 0.42;0.37 | 1.25 (1.08 - 1.45) | 3.58×10-3 | 863 cases, 707 controls | 0.44;0.38 |
| 1q32.1 rs3790844(C/T) NR5A2 200,007,432 |
PanScan II (18) | 0.77 (0.71-0.84) | 2.45×10-10 | 0.20;0.24 | 0.87 (0.73 - 1.03) | 9.48×10-2 | 863 cases, 707 controls | 0.22;0.25 |
| 5p15.33 rs401681(T/C) CLPTM1L 1,322,087 |
PanScan II (18) | 1.19 (1.11-1.27) | 3.66×10-7 | 0.49;0.45 | 1.31 (1.14-1.52) | 2.26×10-4 | 863 cases, 707 controls | 0.50;0.43 |
| 7q32.3 rs6971499(C/T) LINC-PINT 130,680,521 |
PanScan III (19) | 0.79 (0.74-0.84) | 2.98×10-12 | 0.12;0.15 | 0.72 (0.58 - 0.88) | 1.73×10-3 | 803 cases, 693 controls | 0.12;0.16 |
| 13q12.12 rs9581943(A/G) PDX1-AS1 28,493,997 |
PanScan III (19) | 1.15 (1.10-1.20) | 2.35×10-9 | 0.43;0.41 | 1.11 (0.96 - 1.29) | 1.50×10-1 | 803 cases, 693 controls | 0.42;0.40 |
| 2p13.3 rs1486134(G/T) ETAA1 67,639,769 |
PanC4(20) | 1.14 (1.09-1.19) | 3.36×10-9 | 0.30;0.28 | 1.36 (1.13 - 1.63) | 9.88×10-4 | 564 cases, 606 controls | 0.31; 0.26 |
| 7p13 rs17688601(A/C) SUGCT 40,866,663 |
PanC4(20) | 0.88 (0.84-0.92) | 1.41×10-8 | 0.24;0.27 | 0.77 (0.64 - 0.94) | 1.05×10-2 | 564 cases, 606 controls | 0.22;0.28 |
| 3q29 rs9854771 (A/G) TP63 189,508,471 |
PanC4(20) | 0.89 (0.85-0.92) | 2.35×10-8 | 0.33;0.36 | 0.92 (0.77 - 1.09) | 3.14×10-1 | 564 cases, 606 controls | 0.33;0.35 |
Cytogenetic region according to NCBI genome build 37 and NCBI's Map Viewer
Effect Allele/Reference Allele
The closest RefSeq gene
SNP Position according to NCBI genome build 37 (Hg19)
The study where the association was originally identified and published.
The odds ratio and p-value reported in the publication referred to in the Study column.
MAF: Minor Allele Frequency
The odds ratio and p-value observed in the PACGENE study
The number of individuals included for each association test. Since individuals that were present in PACGENE and the prior studies were removed, the number of individuals analyzed varies.
Discussion
Our findings support a role for common genetic variants that increase pancreatic cancer risk among a cohort of patients with a family history or early onset of the disease. Understanding the full spectrum of genetic changes that predispose to pancreatic cancer may improve our understanding of the biology of the disease and lead to strategies for its early detection and treatment. Our results confirm a role for variation at 9q34(ABO), 13q21.32(KLF5), 5p13.33(CLPTM1L), 7q32.3(LINC-PINT), 16q23.1(BCAR1/CTRB1/CTRB2), 2p13.3(ETAA1), and 7p13(SUGCT) in the development of pancreatic cancer, specifically among high-risk patients. Our study represents the first independent report to replicate association at 7p13 and 2p13.3(20), providing further evidence supporting a role for variation at these two loci in the development of pancreatic cancer.
Our study suggests that variation at 7p21.1, driven by SNP rs12531908 intronic to HDAC9(histone deacetylase 9) (Figure 1a), may be associated with pancreatic cancer. HDACs play a role in regulation of acetylation of histone proteins and several HDAC inhibitors are currently being studied in pre-clinical or clinical studies for pancreatic cancer(26).
Our study was underpowered to detect associations of modest effect sizes. A power analysis for our discovery stage where 963 cases and 862 controls were analyzed across 200,158 SNPs showed our study to have >80% power to detect an effect size of 1.5 at a locus with a MAF of 0.4. When replicating the previously identified SNPs, our smallest sample size of 565 cases and 606 controls had >80% power to detect an effect of 1.3 for a SNP with a MAF > 0.25. In our study, we were therefore insufficiently powered to detect most of the SNPs with reported modest effect sizes (∼1.15). Additionally, the sparse genome coverage of the iCOGS array prevented us from addressing important questions related to polygenic risk scores and heritability; these questions are better left for a study with genome-wide coverage.
We analyzed a high-risk population of pancreatic cancer patients including subjects with either early onset diagnosis (<age 50) or a family history of the disease. SNPs associated with pancreatic cancer in prior GWAS are associated in this high-risk population, and the effect sizes do not differ significantly. This does not rule out the likely possibility of separate, unique, genetic risk factors and/or gene-by-environment interactions in this specific population. Our work supports a role for common variants in pancreatic cancer susceptibility, even among defined high-risk subgroups.
Supplementary Material
Acknowledgments
Financial support for each author: This work was supported by NIH grants R01 CA97075 (K.G. Chaffee, S. Gallinger, S. Syngal, A.G. Schwartz, M.L. Cote, R.H. Hruban, D.N. Rider, M.G. Goggins, G.M. Petersen, A.P. Klein) and R01 CA154823 (E.J. Childs, K.G. Chaffee, S. Gallinger, H.A. Risch, M.G. Goggins, G.M. Petersen, A.P. Klein) and NIH Specialized Programs of Research Excellence P50 CA062924 (R.H. Hruban, M.G. Goggins, A.P. Klein) and P50 CA102701 (K.G. Chaffee, D.N. Rider, G.M. Petersen), the Lustgarten Foundation for Pancreatic Cancer Research (R.H. Hruban, M.G. Goggins, A.P. Klein), the Michael Rolfe Foundation (R.H. Hruban, M.G. Goggins), Susan Wojcicki and Dennis Troper (R.H. Hruban, M.G. Goggins, A.P. Klein) and the Sol Goldman Pancreatic Cancer Research Center(R.H. Hruban, M.G. Goggins, A.P. Klein). B.M. Wolpin was supported by NIH grant K07 CA140790. The development of the iCOGS array was supported by the European Community's Seventh Framework Programme under grant agreement 223175 (HEALTH-F2-2009-223175) and Cancer Research UK (C1287/A10710).
Footnotes
Conflicts of interest: Under a licensing agreement between Myriad Genetics, Inc., and the Johns Hopkins University, M. G. Goggins, R H Hruban and A.P. Klein are entitled to a share of royalties received by the university on sales of products related to PALB2. The terms of this arrangement are being managed by the Johns Hopkins University in accordance with its conflict-of-interest policies
References
- 1.Siegel R, Ma J, Zou Z, Jemal A. Cancer statistics, 2014. CA Cancer J Clin. 2014;64:9–29. doi: 10.3322/caac.21208. [DOI] [PubMed] [Google Scholar]
- 2.Rahib L, Smith BD, Aizenberg R, Rosenzweig AB, Fleshman JM, Matrisian LM. Projecting cancer incidence and deaths to 2030: the unexpected burden of thyroid, liver, and pancreas cancers in the United States. Cancer Res. 2014;74:2913–21. doi: 10.1158/0008-5472.CAN-14-0155. [DOI] [PubMed] [Google Scholar]
- 3.Klein AP. Genetic susceptibility to pancreatic cancer. Molecular Carcinogenesis. 2012;51:14–24. doi: 10.1002/mc.20855. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Ghadirian P, Liu G, Gallinger S, Schmocker B, Paradis AJ, Lal G, et al. Risk of pancreatic cancer among individuals with a family history of cancer of the pancreas. Int J Cancer. 2002;97:807–10. doi: 10.1002/ijc.10123. [DOI] [PubMed] [Google Scholar]
- 5.Jacobs EJ, Chanock SJ, Fuchs CS, Lacroix A, McWilliams RR, Steplowski E, et al. Family history of cancer and risk of pancreatic cancer: a pooled analysis from the Pancreatic Cancer Cohort Consortium (PanScan) Int J Cancer. 2010;127:1421–8. doi: 10.1002/ijc.25148. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6.Klein AP, Brune KA, Petersen GM, Goggins M, Tersmette AC, Offerhaus GJA, et al. Prospective risk of pancreatic cancer in familial pancreatic cancer kindreds. Cancer Research. 2004;64:2634–8. doi: 10.1158/0008-5472.can-03-3823. [DOI] [PubMed] [Google Scholar]
- 7.Brune KA, Lau B, Paimisano E, Canto M, Goggins MG, Hruban RH, et al. Importance of Age of Onset in Pancreatic Cancer Kindreds. Journal of the National Cancer Institute. 2010;102:119–26. doi: 10.1093/jnci/djp466. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Raimondi S, Maisonneuve P, Lowenfels AB. Epidemiology of pancreatic cancer: an overview. Nat Rev Gastroenterol Hepatol. 2009;6:699–708. doi: 10.1038/nrgastro.2009.177. [DOI] [PubMed] [Google Scholar]
- 9.Raimondi S, Maisonneuve P, Löhr JM, Lowenfels AB. Early onset pancreatic cancer: evidence of a major role for smoking and genetic factors. Cancer Epidemiol Biomarkers Prev. 2007;16:1894–7. doi: 10.1158/1055-9965.EPI-07-0341. [DOI] [PubMed] [Google Scholar]
- 10.Piciucchi M, Capurso G, Valente R, Larghi A, Archibugi L, Signoretti M, et al. Early onset pancreatic cancer: risk factors, presentation and outcome. Pancreatology. 2015;15:151–5. doi: 10.1016/j.pan.2015.01.013. [DOI] [PubMed] [Google Scholar]
- 11.Goggins M, Schutte M, Lu J, Moskaluk CA, Weinstein CL, Petersen GM, et al. Germline BRCA2 gene mutations in patients with apparently sporadic pancreatic carcinomas. Cancer Res. 1996;56:5360–4. [PubMed] [Google Scholar]
- 12.Hahn SA, Greenhalf B, Ellis I, Sina-Frey M, Rieder H, Korte B, et al. BRCA2 germline mutations in familial pancreatic carcinoma. J Natl Cancer Inst. 2003;95:214–21. doi: 10.1093/jnci/95.3.214. [DOI] [PubMed] [Google Scholar]
- 13.Jones S, Hruban RH, Kamiyama M, Borges M, Zhang X, Parsons DW, et al. Exomic sequencing identifies PALB2 as a pancreatic cancer susceptibility gene. Science. 2009;324:217. doi: 10.1126/science.1171202. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Giardiello FM, Welsh SB, Hamilton SR, Offerhaus GJ, Gittelsohn AM, Booker SV, et al. Increased risk of cancer in the Peutz-Jeghers syndrome. N Engl J Med. 1987;316:1511–4. doi: 10.1056/NEJM198706113162404. [DOI] [PubMed] [Google Scholar]
- 15.Lynch HT, Fusaro RM, Lynch JF, Brand R. Pancreatic cancer and the FAMMM syndrome. Fam Cancer. 2008;7:103–12. doi: 10.1007/s10689-007-9166-4. [DOI] [PubMed] [Google Scholar]
- 16.Wang L, Brune KA, Visvanathan K, Laheru D, Herman J, Wolfgang C, et al. Elevated cancer mortality in the relatives of patients with pancreatic cancer. Cancer Epidemiol Biomarkers Prev. 2009;18:2829–34. doi: 10.1158/1055-9965.EPI-09-0557. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Amundadottir L, Kraft P, Stolzenberg-Solomon RZ, Fuchs CS, Petersen GM, Arslan AA, et al. Genome-wide association study identifies variants in the ABO locus associated with susceptibility to pancreatic cancer. Nat Genet. 2009;41:986–90. doi: 10.1038/ng.429. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.Petersen GM, Amundadottir L, Fuchs CS, Kraft P, Stolzenberg-Solomon RZ, Jacobs KB, et al. A genome-wide association study identifies pancreatic cancer susceptibility loci on chromosomes 13q22.1, 1q32.1 and 5p15.33. Nat Genet. 2010;42:224–8. doi: 10.1038/ng.522. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19.Wolpin BM, Rizzato C, Kraft P, Kooperberg C, Petersen GM, Wang Z, et al. Genome-wide association study identifies multiple susceptibility loci for pancreatic cancer. Nat Genet. 2014;46:994–1000. doi: 10.1038/ng.3052. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Childs EJ, Mocci E, Campa D, Bracci PM, Gallinger S, Goggins M, et al. Common variation at 2p13.3, 3q29, 7p13 and 17q25.1 associated with susceptibility to pancreatic cancer. Nat Genet. 2015;47:911–6. doi: 10.1038/ng.3341. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Manolio TA. Genomewide association studies and assessment of the risk of disease. N Engl J Med. 2010;363:166–76. doi: 10.1056/NEJMra0905980. [DOI] [PubMed] [Google Scholar]
- 22.Eeles RA, Olama AA, Benlloch S, Saunders EJ, Leongamornlert DA, Tymrakiewicz M, et al. Identification of 23 new prostate cancer susceptibility loci using the iCOGS custom genotyping array. Nat Genet. 2013;45:385–91. 91e1–2. doi: 10.1038/ng.2560. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Petersen GM, de Andrade M, Goggins M, Hruban RH, Bondy M, Korczak JF, et al. Pancreatic cancer genetic epidemiology consortium. Cancer Epidemiology Biomarkers & Prevention. 2006;15:704–10. doi: 10.1158/1055-9965.EPI-05-0734. [DOI] [PubMed] [Google Scholar]
- 24.Purcell S, Neale B, Todd-Brown K, Thomas L, Ferreira MA, Bender D, et al. PLINK: a tool set for whole-genome association and population-based linkage analyses. Am J Hum Genet. 2007;81:559–75. doi: 10.1086/519795. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Wolpin BM, Rizzato C, Kraft P, Kooperberg C, Petersen GM, Wang Z, et al. Genome-wide association study identifies multiple susceptibility loci for pancreatic cancer. Nat Genet. 2014 doi: 10.1038/ng.3052. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Damaskos C, Karatzas T, Nikolidakis L, Kostakis ID, Karamaroudis S, Boutsikos G, et al. Histone Deacetylase (HDAC) Inhibitors: Current Evidence for Therapeutic Activities in Pancreatic Cancer. Anticancer Res. 2015;35:3129–35. [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.