

Abstract
Standardization of clinical data element (CDE) definitions is foundational to track, interpret, and analyze patient states, populations, and costs across providers, settings and time – critical activities to achieve the Triple Aim: improving the experience of care, improving the health of populations, and reducing per capita healthcare costs. We defined and implemented two analytical methods to prioritize and refine CDE definitions within electronic health records (EHRs), taking into account resource restrictions to carry out the analysis and configuration changes: 1) analysis of downstream data needs to identify high priority clinical topics, and 2) gap analysis of EHR CDEs when compared to reference models for the same clinical topics. We present use cases for six clinical topics. Pain Assessment and Skin Alteration Assessment were topics with the highest regulatory and non-regulatory downstream data needs and with significant gaps across documention artifacts in our system, confirming that these topics should be refined first.
Introduction
Standardization of clinical data definitions for use in a learning health system is a critical foundation to achieve the Healthcare Triple Aim: 1) Improving the experience of care, 2) Improving the health of populations, and 3) Reducing per capita costs of health care.1 Improving the experience of care requires effective coordination across people, time, and settings, but is effectively enabled only with consistent data to track patient states. Improving the health of populations is dependent on common data definitions to group similar patients across sites and providers, enabling the identification and tracking of patient need and outcome patterns. Reducing per capita costs of health care requires reliable comparisons of clinical data across settings, health professionals, and research databases, particularly considering the need to understand relationships between cost, care complexity, and patient outcomes.
Prospective clinical data collection, even if performed efficiently, is not substantially useful if it is not “reliable” (i.e. collected using inconsistent data definitions), and/or not “computable” (i.e. collected using nonstandard formats and values). Unfortunately, consistent and standards-based data definitions for EHR clinical documentation do not naturally emerge, even within the same clinical information system, without proper clinical governance and technical oversight.2
Background
Definition of standardized data sets for clinical documentation, often operationally known as Minimum Data Sets, have been used to enable effective clinical data analytics, such as nursing care and management across hospitals, and clinical assessment of all residents in Medicare or Medicaid certified nursing homes.3–8 The Nursing Minimum Data Set and Nursing Management Minimum Data Sets have been added to LOINC9,10, an internationally adopted standard terminology. Standard terminologies help ensure that discrete clinical data elements (CDEs) can be aggregated and compared across patients, providers, and care delivery sites. Standardized data sets also identify the specific collection of CDEs necessary to represent a given clinical domain or topic. Each collection of CDEs can be simply characterized as a “reference model,” or more appropriately as a “detailed clinical model”.11–13 A few publically available sources provide ready-to-use clinical reference models, or sometimes preliminary examples that can inform the development of new models for a given clinical topic.14–19
At our organization we leverage these terminology and model resources to refine existing clinical data reference models, or to develop new models, always seeking a direct application to our commercially available EHR.20 We have developed a process to validate reference models based on pre-defined best practices and consensus of interprofessional subject matter experts (SMEs).21 The central deliverable of our process is a reference model that can be effectively implemented using our EHR, ensuring consistent data capture and documentation across settings, professions, and purposes.
Detailed and consistent data capture within commercially available EHRs is critical to building a learning health system. While the need for consistent data is widely recognized11, the required methods and scope definition, particularly the specific steps for identifying EHR data collection tools (e.g. forms and flowsheets) that need refinement and alignment with available standards, remain unclear to many stakeholders and organizations. Critical initiatives are in process, such as the S&I Framework Structured Data Capture Initiative and HL7 Clinical Information Modeling Initiative (CIMI).16,22 However, individual organizations are overwhelmed with the effort required to refine CDE definitons within their EHRs and may ask “where do we start?” or “do we have enough resources to complete the work?”.
To help organizations answer these questions, we have defined practical analytic methods to: 1) identify priorities for the definition of clinical data reference models and, 2) identify and resolve gaps between existing EHR data collection tools and validated reference models. These methods can be applied within and across EHR systems as a systematic and rigorous path to align data definitions within and, eventually, across healthcare organizations.
Methods
We previously published a description of a process for governance and refinement of structured data elements.21 In that publication we outlined a 10-step approach that: 1) identifies clinical topics, 2) creates draft reference models for clinical topics, 3) identifies downstream data needs for clinical topics, 4) prioritizes clinical topics, 5) validates reference models for clinical topics, 6) perform gap analysis of EHR CDEs compared against reference model, 7) communicates validated reference models across project members, 8) requests revisions to EHR CDEs based on gap analysis, 9) evaluates usage of reference models across project, and 10) monitors for new evidence requiring revisions to reference model.
In this paper we focus on a more detailed description of the metrics and analytical processes involved in the scoring of downstream data needs to prioritize clinical topics (steps 3 & 4 above), and the process to identify gaps when EHR documentation artifacts are compared against reference models (step 6 above). Figure 1 illustrates how these criteria combine to help prioritize and direct EHR refinement. We view steps 3, 4, and 6 as the most critical steps from an organizational perspective, since these steps provide a rigorous and repeatable method to identify refinement priorities in the context of limited resources. A detailed description of steps 3, 4, and 6 is not included in our prior publication.21
Figure 1.
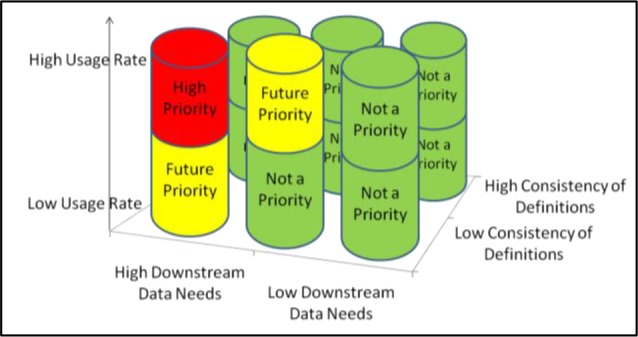
Criteria to Prioritize Clinical Topic Refinement
Downstream data needs
The analysis of downstream data needs begins with an environmental scan for the following types of needs related to the identified clinical topic: 1) regulatory, 2) billing, 3) reporting (via automated extracts), 4) clinical decision support (CDS), 5) reporting (via manual chart review), 6) quality initiatives, 7) past data usage statistics, 8) order sets, 9) plans of care, 10) institutional protocols, and 11) literature (published evidence). The environmental scan may require input from SMEs, such as hospital quality and compliance experts. Since the aim of this analysis is to identify high priority topics, an extensive and exhaustive environmental scan is not always necessary. This approach purposefully exploits the underlying assumption that important downstream data needs are readily and efficiently identified during brief interactions with SMEs and from relatively simple online searches. In exploiting that assumption, the usefulness of this method is tied to expedience and analytical rigor, as well as repeatability for comparisons between topics.
Data needs are categorized in two tiers: “direct data needs” (Tier 1) and “indirect data needs” (Tier 2). A direct data need is defined as requiring a process of automated reuse for data filed within a structured CDE, such as electronic Clinical Quality Measures (eCQMs) to Centers for Medicare and Medicaid Services (CMS) programs.23 An indirect data need is defined as not requiring a process of automated reuse for data filed within a structured CDE. Rather, an indirect data need may be fulfilled using manual chart review processes, such as chart extraction (e.g., quality initiatives), or in the course of clinical care (e.g., reference to protocols). Each identified data need counts as ‘1’ and is applied to the appropriate data need category (see Table 1).
Table 1.
Downstream Data Needs Categories and Weighted Values
| Data Need Category | Weight Symbol | Weight Value |
|---|---|---|
| Tier 1 (direct data needs) | ||
| Regulatory | w1 | 30 |
| Billing | w2 | 25 |
| Reporting (i.e., automated extracts) | w3 | 25 |
| Clinical Decision Support | w4 | 25 |
| Tier 2 (indirect data needs) | ||
| Reporting (i.e., manual chart reviews) | w6 | 20 |
| Quality initiatives | w7 | 20 |
| Usage data | w8 | 15 |
| Order Sets | w9 | 8 |
| Plans of Care | w10 | 8 |
| Protocols | w11 | 7 |
| Literature | w12 | 5 |
Usage data is also an important variable in our model. During the transition phase while implementing a new EHR at our organization, we used usage statistics from our legacy EHR systems in our model. Six months after our new EHR was implemented, we switched to usage statistics from our new EHR system. The usage data statistic is a simple rate of use per month and needs to be normalized for comparison with the other data need counts (which in our experience are typically in single digits). Based on an analysis of the counts of usage per month from our legacy systems for our initial set of clinical topics, we determined a cutoff range of 1,000 data points per month for any CDE to indicate high usage. CDEs that had less than 1,000 data points per month received a score of 0.5, topics with greater than or equal to 1,000 data points per month received a score of 1, and CDEs with no usage per month received a zero. The specific cutoff range and additional scores in the instance of particularly high usage (e.g., score of 2 for 2,000-2,999 data points/month, score 3 for > 3,000 data points per month etc.) may be modified per organization based on typical usage rates taking into account number of EHR users and patient encounters.
The downstream data need ‘count’ for each data need category and the weighted values from Table 1 are applied to the formula in Figure 2 below. The key requirement for this formula was that any topic with regulatory data needs should have a higher score than any topic without any regulatory data needs. In order to accomplish that, the first term in the formula is a regulatory term that includes a factor of the signum function applied to the count of the regulatory data sources. In the event that there are no regulatory data needs, this factor, hence the first term, has a value of zero so that the score value is simply equal to the rest of the formula, which is the nonregulatory part of the score. If there are any regulatory data needs, then the first term has a value which is greater than one and less than two. This property of the first term being greater than one is needed in order to exceed the value of the rest of the formula, or the nonregulatory component, which has a value greater than or equal to zero and less than one. This situation guarantees that a topic with even a single regulatory data need has a higher score than a topic with no regulatory data needs, even if such a topic has many nonregulatory data needs. The inverse square root function was chosen for the formula for more even scaling than an exponential or simple inverse function would allow, so that differences among topics could be better pronounced and visually distinguishable. It was also desired that the formula for this score gracefully scale with added data needs and across topics having different numbers of data needs. Using the inverse square root function in this way allows for this in order to confine the score value to a finite range, rather than allowing an unbounded score value as the number of data sources increases.
Figure 2.

Formula to calculate weighted Downstream Data Need Score per Clinical Topic
Using results from this formula we produce a scorecard summarizing Tier 1 data needs that can be easily disseminated among stakeholders. Regulatory data needs are given the highest weight due to their significance for healthcare institutions. The formula results in a weighted score between 0 and 3. Scores in the range of 0-1 indicate there is a non-regulatory data need only; scores in the range of 1-2 indicate there is a regulatory data need; and scores in the range of 2-3 indicate there are regulatory and non-regulatory downstream data needs. These scores are used to rank topics by their identified downstream data needs.
Gap analysis of EHR Clinical Data Elements compared against Reference Model
The development of reference models loses significance if the subsequent implementation of those models within an EHR system becomes too onerous and is deferred for a later date when implementation resources are available. The purposes of quantifying the gap between current state and the reference model are: 1) to estimate the effort required to close the gap for particular documentation artifacts, 2) to rank the documentation artifacts that should be prioritized for refinement based on estimated effort, and 3) to achieve reliability in alignment with the reference model across documentation artifacts.
Table 2 outlines our adaption of the MUC-5 (Fifth Message Understanding Conference) Evaluation Metrics, which were originally used to express error rates as part of a scoring system for template instances produced by information extraction systems when compared to manual extraction by humans.24 Each documentation artifact being evaluated is compared to the reference model by assigning to each CDE one of the following codes: match, partial match, conflicting, extra, or missing. Next, the four metrics are calculated for each documentation artifact: total mismatch, undergeneration, overgeneration, substitution. Each score is on a scale of 0 to 100, with higher scores for greater discrepancies. The total mismatch score is useful for a gross estimate and ranking of the effort required for aligning documentation artifacts with the reference model. The undergeneration score identifies CDEs that are not included on documentation artifacts. The substitution score identifies CDEs from the reference model that are inconsistently implemented in EHR documentation artifacts. This score is useful to identify changes that are slightly more complex than fixing undergeneration scores by simply adding new CDEs, but likely can be completed without further SME input. The overgeneration score identifies CDEs that may be irrelevant to the clinical topic, i.e. truly spurious, and that require additional review by SMEs for possible inclusion.
Table 2.
Calibration Metrics for Gap Analysis
| Metric | Calculation |
|---|---|
| Total Mismatch (Total Error) | wrong/total = (incorrect + partial/2 + missing + spurious)/(correct + partial+ incorrect+ missing + spurious) |
| Undergeneration | missing/possible = missing/(correct + partial+ incorrect + missing) |
| Overgeneration | spurious/actual = spurious/(correct + partial + incorrect + spurious) |
| Substitution | (incorrect + partial/2)/(correct + partial + incorrect) |
Codes and Definitions:
| |
We view these metrics as useful to compare any reference model (i.e. set of standardized CDEs) to existing clinical documentation artifacts to identify gaps and work toward alignment. These metrics are also useful to directly estimate the level of effort, time, and expertise to align current documentation artifacts to the reference model and can be useful for readiness assessments at sites with limited resources (see Table 3). For example, based on estimates provided by analysts that implement changes to documentation artifacts in our EHR system, we can use the above described results to calculate the total amount of time required to make the necessary changes, including relevant EHR configuration details that might increase the complexity of the change.
Table 3.
Calculations to Estimate Resources for EHR Refinement Based on Calibration Metrics
| Change Process | Applicable Calibration Metric Categorization | Time Estimate |
|---|---|---|
| EHR Configuration Build | Not Complex: High undergeneration rate indicating need to add missing clinical data elements (CDEs) | 5 min/ CDE |
| Average Complexity: High substitution or overgeneration indicating need to swap out CDEs or delete superfluous CDEs | 25 min/ CDE | |
| Highly Complex: High rate of at least two of three (undergeneration, substitution, overgeneration) indicating need to redesign artifacts | 200 min/ CDE | |
| Subject Matter Expert Review (as needed) | Not Complex: no communication or review required | 0 hours |
| Average Complexity: communication that change occurred | 1 - 2.5 hours/DF | |
| Highly Complex: review of changes to ensure clinical appropriateness | 2.5 - 5 hours/DF | |
| EHR Unit Testing | Not Complex: High undergeneration rate indicating need to add missing CDEs | 10 min/CDE |
| Average Complexity: High substitution or overgeneration indicating need to swap out CDEs or delete superfluous CDEs | 50 min/CDE | |
| Highly Complex: High rate of at least two of three (undergeneration, substitution, overgeneration) indicating need to redesign artifacts | 400 min/CDE |
Results
Downstream Data Needs
We display our results of the downstream data analyses for 6 clinical topics: 1) Pain assessment, 2) Skin Alteration assessment, 3) Lung assessment, 4) Mental Status assessment, 5) Gait assessment, and 6) Living Situation assessment (see Figure 3). We also present the detailed ScoreCard for the two highest priority clinical topics: Pain assessment (see Table 4) and Skin Alteration assessment (see Table 5). The clinical topic Pain Assessment resulted in the highest weighted score for downstream data needs with a score of 2.76 out of 3. Skin Alteration Assessment was the second highest weighted score at 2.70 out of 3.0. Lung Exam, Mental Status, Gait, and Living Situation assessments were 2.56, 2.48, 2.42, and 2.2, respectively.
Figure 3.

Weighted Score Indicating Clinical Topics with Non-Regulatory Data Needs Only (Green), Regulatory Data Needs Only (Yellow), Regulatory and Non-Regulatory Data Needs (Red)
Table 4.
Weighted Score Card for Pain Assessment
| Total Weighted Data Need Score for Clinical Topic: Pain Assessment = 2.76* | ||||||||
|---|---|---|---|---|---|---|---|---|
| Reason Data is Needed | High Priority Data Needs | Data Need Tallies for selected Clinical Data Elements** | ||||||
| Pain Location | Pain Duration | Pain Severity | Pain Course | Pain Periodicity | Temporal Pattern | Alleviating Factors | ||
| Regulatory | TJC1 Standards for assessing and treating pain | 1 | 1 | 1 | 1 | 1 | 1 | |
| NDNQI2 Pediatric Pain Assessment | 1 | 1 | 1 | 1 | ||||
| Billing | Identified by SME3 | 1 | 1 | 1 | 1 | 1 | ||
| Quality | QM MU PQRS4 Oncology Results Report | 1 | ||||||
| CDS | Pain indicated add to Plan of Care | 3 | 2 | |||||
| Weighted score per clinical data element | 2.23 | 2.27 | 2.4 | 2.05 | 1.73 | 1.97 | 2.49 | |
Weighted Score Key: 0-1 non-regulatory data need only, 1-2 regulatory data needs, 2-3 non-regulatory and regulatory data needs.
Table only displays the clinical data elements with weighted score > 1.0;
TJC: The Joint Commission;
NDNQI: National Database of Nursing Quality Indicators;
SME: Subject Matter Expert;
QM MU PQRS: Quality Measures Meaningful Use Physician Quality Reporting System
Table 5.
Weighted Score Card for Skin Alteration Assessment
| Total Weighted Data Need Score for Clinical Topic: Skin Alteration = 2.69* | |||||||
|---|---|---|---|---|---|---|---|
| Reason Data is Needed | High Priority Data Needs | Data Need Tallies for selected Clinical Data Elements** | |||||
| Skin Alteration Type | Healing Progress | Wound Bed Appearance | Pressure Ulcer Preexisting | Pressure Ulcer Start Date | Pressure Ulcer Stage | ||
| Regulatory | CMS1 Pressure Ulcers Acquired After Admission | 1 | 1 | 1 | |||
| AHRQ2 Patient Safety Indicators | 1 | 1 | 1 | ||||
| TJC Surgical Care Improvement Project | 1 | ||||||
| Billing | Identified by SME | 1 | 1 | 1 | 1 | 1 | |
| CDS | Pressure Ulcer Present on Admission; Plan of Care Problem | 1 | 2 | ||||
| Weighted score per clinical data element | 2.11 | 2.1 | 1.68 | 2.09 | 2.14 | 2.12 | |
Weighted Score Key: 0-1 non-regulatory data need only, 1-2 regulatory data needs, 2-3 non-regulatory and regulatory data needs.
Table only displays the clinical data elements with weighted score > 1.0;
CMS: Center for Medicare and Medicaid Services;
AHRQ: Agency for Healthcare Research and Quality;
TJC: The Joint Commission
These results demonstrate that all six topics include regulatory requirements, indicating they are all high priority topics, and can be ranked in order of highest priority. The weighted score allowed for continuous updates to the score and ranking of these high priority topics as new needs were identified. For example, our initial list of topics did not include mental status assessment and lung assessment, but as usage data from our EHR became available, these two topics were identified as frequently documented and added to the analysis. This approach allows for an iterative process to identify and analyze downstream data needs with continuous updating of the prioritized list for selection of the next topic to devote resources for refinement.
Calculation of Gap Analyses of EHR and EDC Compared Against Reference Model
We present the gap analyses for CDEs from each reference model that were identified by SMEs as important to be present on all clinical documentation artifacts in our EHR. We found that the total mismatch rate ranged from 26% to 82% for Pain Assessment CDEs on documentation artifacts. In comparison, the total mismatch rate ranged from 58% to 98% for Skin Alteration Assessment CDEs. Based on these calibration metrics and resources available a threshold should be selected and refinement efforts targeted at any CDEs above that threshold (higher scores = greater discrepancies). For example, we could establish a threshold of 60% for our data set. The undergeneration rate for the CDE ‘Pain Location Qualifier’ was 64% and the substitution rate was 67% across documentation artifacts analyzed. These rates were based on 20 documentation artifacts in which the CDE ‘Pain Location Qualifier’ was missing and 11 documentation artifacts in which the CDE ‘ Pain Location Qualifier’ was a partial match. We can calculate (based on Table 3) that the 20 missing CDEs require a total of 100 minutes of EHR configuration (5minutes/CDE), 0 hours for SME review, and 200 minutes for unit testing (10 minutes/CDE). The 11 partial match CDEs require 275 minutes (25 minutes/CDE), 1-2.5 hours for SME review, and 550 minutes for unit testing (50 min/CDE). Therefore to optimize the clinical data capture of the CDE ‘Pain Location Qualifier’ throughout our EHR will require a total of about 20 hours of effort. These estimates are intended to be realistic with time allotted for troubleshooting and team communication as needed.
Discussion
Refinement of EHR CDEs and documentation artifacts is a continuous process that requires consistent effort, yet is often delayed due to a lack of resources, competing deadlines, and difficulty identifying “where to start”. We found that analyzing downstream data needs at the clinical topic level, and calibrating how well documentation artifacts for that topic matched CDEs from a validated reference model was an effective and productive exercise to initiate and direct refinement efforts for our EHR. This approach is both rigorous and flexible. The metrics provide rigorous comparisons while the ranking and selection of clinical topics and CDEs in which to focus our efforts can consider contextual organization factors such as available resources, strategic quality and safety initiatives, and usage statistics. We believe this approach is useful for topic prioritization and re-prioritization as priorities shift. For example, ‘Pain Assessment’ may be shifting in priority and/or management approach due the Opioid Epidemic.25
One of the strengths of the downstream data scoring system is that the scoring is performed at the individual CDE level to identify priorities within clinical topics. The clinical topics serve to scope and group the work to catch inconsistencies in CDE definitions within the context of that topic. For example, inconsistencies may not be detected if only the CDEs that address regulatory requirements were selected for analysis and refinement. For example, a Pain Assessment Scale may appropriately capture data to meet a regulatory need; however, if the other CDEs on that documentation artifact are inconsistently defined it will be challenging for an organization to use sets of data from that documentation artifact in a useful way, besides meeting that isolated regulatory requirement.
To our knowledge, this is the first publication to propose a prescribed, rigorous process and metrics to use for prioritizing work to optimize EHR structured CDEs. We believe the initial time investment required to conduct these analytic activities is realistic and is particularly critical for organizations with limited resources. As expected, we found a high rate of mismatch between a number of CDEs from the reference models and their implementation on EHR documentation artifacts. We used these metrics to highlight which CDEs have the greatest need for alignment with EHR documentation artifacts and the resources required to achieve that alignment. As one example, we quantified that 20 hours of resources was required to optimize one CDE throughout the EHR system. These estimates assume that work is conducted to refine only one CDE at a time. In the instances when refinements can be scaled (a set of CDEs can be refined on one or more documentation artifacts together) there is likely a decrease in total resources required. From a governance perspective, the ability to quantify the resources needed to refine a constrained set of high priority clinical topics is important for organizations hoping to realize a return on investment from the interoperability and data analytics capability of their EHR implementation. The priorities and estimates that result from our analytics can be used to prioritize refinement work to fit allotted resource hours or to request resource hours based on refinement work that is a high priority for an organization.
Limitations
This work has been performed at one integrated health care system during, and immediately after, implementation of a vendor-based enterprise-wide EHR. These metrics and processes should be applied at other institutions to understand how to best apply and integrate them across different operational clinical informatics governance structure and resources. Evaluation of the use of these metrics and processes is needed to quantify their added value in the context of enabling analytics and secondary use of structured data as well as prioritizing work and resources. Finally, the work described is limited by the topics identified and the scope of those topic areas. Topic identification could be enhanced through mining or Natural Language Processing of EHR data for topic areas that are highly used.
Conclusion
Refinement of CDE definitions on documentation artifacts across an enterprise EHR system can be an overwhelming task. We propose a set of metrics that can prioritize and direct this work as part of continuous refinement activities and alignment of EHR data. We presented use cases of high priority topics. In the use cases presented, we found high rates of mismatch between CDEs from our validated reference models and documentation artifacts, indicating the need to move forward with refinement of these artifacts. EHR refinement is an iterative process that requires insightful expertise and motivated individuals. These metrics can illuminate priorities and gaps to focus efforts. We believe these analytical steps are practical and generalizable across organizations and should be shared as a critical collaborative step toward continuous EHR refinement and alignment.
Figure 4.

Mismatch of Clinical Data Elements in Documentation Artifacts Compared to Pain Reference Model
Figure 5.

Mismatch of Clinical Data Elements in Documentation Artifacts Compared to Skin Reference Model
Acknowledgements
We would like to acknowledge the Structured Clinical Data Element Workgroup from the Partners eCare project and members of the subject matter expert panels that contributed to this work.
References
- 1.Institute for Healthcare Improvement. The IHI Triple Aim. IHI Triple Aim Initiat. 2014. http://www.ihi.org/Engage/Initiatives/TripleAim/Pages/default.aspx.
- 2.Collins S, Bavuso K, Zuccotti G, Rocha RA. Lessons Learned for Collaborative Clinical Content Development. Appl Clin Inf. 2013;4(2) doi: 10.4338/ACI-2013-02-CR-0014. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Ahn H, Garvan C, Lyon D. Pain and Aggression in Nursing Home Residents With Dementia: Minimum Data Set 3.0 Analysis. Nurs Res. 64(4):256–263. doi: 10.1097/NNR.0000000000000099. [DOI] [PubMed] [Google Scholar]
- 4.Delaney CW, Westra BL. Minneapolis, MN: 1991. USA Nursing Minimum Data Set (USA NMDS) [Google Scholar]
- 5.Delaney CW, Westra BL, Pruinelli L. Minneapolis, MN: 2015. Implementation Guide for the Nursing Management Minimum Data Set: NMMDS(c) [Google Scholar]
- 6.Ranegger R, Hackl WO, Ammenwerth E. Development of the Austrian Nursing Minimum Data Set (NMDS-AT): The Third Delphi Round, a Quantitative Online Survey. Stud Health Technol Inform. 2015;212:73–80. [PubMed] [Google Scholar]
- 7.Williams CA. The Nursing Minimum Data Set: a major priority for public health nursing but not a panacea. Am J Public Health. 1991;81(4):413–414. doi: 10.2105/ajph.81.4.413. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Werley HH, Devine EC, Zorn CR, Ryan P, Westra BL. The Nursing Minimum Data Set: abstraction tool for standardized, comparable, essential data. Am J Public Health. 1991;81(4):421–426. doi: 10.2105/ajph.81.4.421. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Subramanian A, Westra B, Matney S, et al. Integrating the nursing management minimum data set into the logical observation identifier names and codes system; AMIA Annu Symp Proc; 2008. Jan, p. 1148. [PubMed] [Google Scholar]
- 10.Westra BL, Subramanian A, Hart CM, et al. Achieving “meaningful use” of electronic health records through the integration of the Nursing Management Minimum Data Set. J Nurs Adm. 40(7-8):336–343. doi: 10.1097/NNA.0b013e3181e93994. [DOI] [PubMed] [Google Scholar]
- 11.Moreno-Conde A, Moner D, Dimas W, Santos MR. Clinical information modeling processes for semantic interoperability of electronic health records : systematic review and inductive analysis. J Am Med Informatics Assoc. 2015;22:925–934. doi: 10.1093/jamia/ocv008. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Kim Y, Park H -a. Development and Validation of Detailed Clinical Models for Nursing Problems in Perinatal care. Appl Clin Inform. 2011;2(2):225–239. doi: 10.4338/ACI-2011-01-RA-0007. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Park HA, Min YH, Kim Y, Lee MK, Lee Y. Development of detailed clinical models for nursing assessments and nursing interventions. Healthc Inform Res. 2011;17(4):244–252. doi: 10.4258/hir.2011.17.4.244. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.openEHR Foundation. openEHR. 2016. http://www.openehr.org/home Accessed February 22, 2016.
- 15.Intermountain Healthcare. Clinical Element Model Browser. 2015. http://www.opencem.org/#/Accessed February 22, 2016.
- 16.Health Level 7 International. Clinical Information Modeling Initiative (CIMI) http://www.hl7.org/Special/Committees/cimi/index.cfmAccessed March 7, 2016.
- 17.Hoy D, Hardiker NR, McNicoll IT, Westwell P, Bryans A. Collaborative development of clinical templates as a national resource. Int J Med Inform. 2009;78(1):95–100. doi: 10.1016/j.ijmedinf.2008.06.003. [DOI] [PubMed] [Google Scholar]
- 18.Oniki TA, Zhuo N, Beebe CE, et al. Clinical element models in the SHARPn consortium. J Am Med Inform Assoc. 2015. Nov, [DOI] [PMC free article] [PubMed]
- 19.Pedersen R, Wynn R, Ellingsen G. Semantic Interoperable Electronic Patient Records: The Unfolding of Consensus based Archetypes. Stud Health Technol Inform. 2015;210:170–174. [PubMed] [Google Scholar]
- 20.Gesner E, Collins SA, Rocha R. Pain Documentation: Validation of a Reference Model. Stud Health Technol Inform. 2015;216:805–809. [PubMed] [Google Scholar]
- 21.Collins S, Gesner E, Morgan S, et al. A Practical Approach to Governance and Optimization of Structured Data Elements; MedInfo 2015: 15th World Congress on Health and Biomedical Informatics.; 2015. p. 5. [PubMed] [Google Scholar]
- 22.S&I Framework. Standards & Interoperability (S&I) Framework - Structured Data Capture Charter and Members. S&I wiki. 2016. http://wiki.siframework.org/Structured+Data+Capture+Charter+and+MembersAccessed January 28, 2016.
- 23.Centers for Medicare and Medicaid Services (CMS) CMS eCQM Library for 2014. 2015. https://www.cms.gov/Regulations-and-Guidance/Legislation/EHRIncentivePrograms/eCQM_Library.htmlAccessed March 7, 2016.
- 24.Chinchor N, Sundheim B. MUC-5 Evalution Metrics; Fifth Message Understanding Conference (MUC-5); 1992. pp. 69–78. [Google Scholar]
- 25.The White House Office of the Press Secretary. Fact Sheet: Obama Administration Announces Additional Actions to Address the Prescription Opioid Abuse and Heroin Epidemic. 2016.