

Abstract
Using novel virtual cities, we investigated the influence of verbal and visual strategies on the encoding of navigation-relevant information in a large-scale virtual environment. In two experiments, participants watched videos of routes through four virtual cities and were subsequently tested on their memory for observed landmarks and on their ability to make judgments regarding the relative directions of the different landmarks along the route. In the first experiment, self-report questionnaires measuring visual and verbal cognitive styles were administered to examine correlations between cognitive styles, landmark recognition, and judgments of relative direction. Results demonstrate a tradeoff in which the verbal cognitive style is more beneficial for recognizing individual landmarks than for judging relative directions between them, whereas the visual cognitive style is more beneficial for judging relative directions than for landmark recognition. In a second experiment, we manipulated the use of verbal and visual strategies by varying task instructions given to separate groups of participants. Results confirm that a verbal strategy benefits landmark memory, whereas a visual strategy benefits judgments of relative direction. The manipulation of strategy by altering task instructions appears to trump individual differences in cognitive style. Taken together, we find that processing different details during route encoding, whether due to individual proclivities (Experiment 1) or task instructions (Experiment 2), results in benefits for different components of navigation relevant information. These findings also highlight the value of considering multiple sources of individual differences as part of spatial cognition investigations.
Keywords: spatial cognition, individual differences, cognitive styles, navigation, strategies
When finding one's way to an unfamiliar destination, such as navigating to a hotel in an unfamiliar city, one can rely on various forms of information including GPS devices, maps, landmarks, or spoken directions. Research on navigation has revealed consequential differences between these information formats and has further revealed a range of individual differences in habits, skills, and strategies for learning about an unfamiliar environment (Etchamendy & Bohbot, 2007; Fields & Shelton, 2006; Hegarty, Montello, Richardson, Ishikawa, & Lovelace, 2006; Hegarty, Richardson, Montello, Lovelace, & Subbiah, 2002; Ishikawa & Montello, 2006; Mellet et al., 2000; Palermo, Iaria, & Guariglia, 2008; Pazzaglia & De Beni, 2001; Richardson, Montello, & Hegarty, 1999; Schinazi, Nardi, Newcombe, Shipley, & Epstein, 2013). A common procedure used in these experiments, as in real-life navigation, is to refer to the names or verbal descriptions of the landmarks (e.g., “walk towards the gray brick office building”) and sometimes to verbally list the route directions as well (e.g., “turn right here”). Although including these verbal cues often add ecological validity, these experiments have, by design, neglected the comparison of verbal versus visual representations of directions and landmarks (but see Pazzaglia & De Beni, 2001, discussed below). It is therefore not fully understood under which circumstances and to what degree the verbal information commonly used during visually guided navigation is beneficial. Likewise, it is not known whether different individuals may habitually rely on verbal versus visual information when navigating new environments. The goal of the present investigation is to examine the influence of verbal versus visual strategies on encoding landmark identity and location, and to examine individual differences in using these strategies.
One relevant measure of individual differences that pertains to verbal and visual strategy use is cognitive style. These self-reported preferences reflect “heuristics an individual uses to process information about his or her environment” (Kozhevnikov, 2007, p. 477). Specifically, visual and verbal cognitive styles are believed to represent tendencies of thought associated with mental imagery or linguistic representations, respectively (Kozhevnikov, 2007; Paivio & Harshman, 1983; Paivio, 1979). These constructs are often measured by self-report questionnaires in which participants report, for example, the degree to which they think in terms of mental pictures and the facility they have in using words to express their thoughts (Blazhenkova & Kozhevnikov, 2008; Kirby, Moore, & Schofield, 1988; Paivio & Harshman, 1983). Conceivably, the strategies associated with verbal and visual cognitive styles may influence one's ability to navigate in an unfamiliar environment, although to our knowledge this hypothesis has not been examined by prior work.
How might visual and verbal cognitive styles, and their respective strategies, influence spatial cognition? To answer this question, we must consider three factors: 1) the processing that an individual engages in during encoding of the visual scene as one moves through the environment (e.g., focusing on visual details or verbally labeling the features of notable landmarks), 2) the type of information being tested for later recall (e.g., individual buildings or the spatial relationship between multiple locations), and 3) the format of the recall test (e.g., pictures or word cues). The vast literature on memory retrieval is informative here, particularly regarding research that falls under the general headings of encoding specificity (Tulving & Thomson, 1973), transfer appropriate processing (Morris, Bransford, & Franks, 1977; Roediger & Blaxton, 1987), and material appropriate processing (McDaniel & Einstein, 1989). Broadly, theoretical models based on the principles of encoding specificity and transfer appropriate processing predict retrieval success as a function of the overlap between cognitive processing that occurs during encoding and that which occurs during retrieval (Roediger, Gallo, & Geraci, 2002). Similarly, models based on material appropriate processing (and the related principle of task appropriate processing) consider the similarity between encoding and retrieval demands, with the additional dimension that the optimal type of processing may vary as a function of the format of the material as well (Einstein, McDaniel, Owen, & Coté, 1990; Hunt & Einstein, 1981; McDaniel & Einstein, 1989; McDaniel & Kearney, 1984). In particular, this work demonstrates that it is important to consider for a given task “whether or not the encoding strategy promotes the encoding of requisite information not activated by the material itself” (McDaniel & Kearney, 1984, p. 371).
In the present study, we measure the effects of verbal and visual processing strategies during encoding, first by exploring naturally occurring individual differences in cognitive style (Experiment 1), and second by varying task instructions (Experiment 2). In both experiments, we test the effects of these processing strategies on the retrieval of two different types of information that are critical components of navigation: landmark identification, and the spatial relationship between landmarks (i.e., relative locations and directions; Lee & Tversky, 2005; Presson & Montello, 1988; Shelton & McNamara, 2001). In the present study we do not manipulate test format (e.g., by using words to probe retrieval of visual information); instead we match as much as possible the information presented during encoding with the cues presented for retrieval at test. In this way, we ensure a cleaner measure of the effects of processing strategy and type of information to be retrieved (landmarks and relative directions between landmarks).
If cognitive styles are indicators of preferred approaches or strategies for processing information (Kozhevnikov, 2007; Kraemer et al., 2009; Paivio & Harshman, 1983; Witkin, Moore, Goodenough, & Cox, 1977), a visual strategy may involve a reliance on one's visuo-spatial skills (e.g., imagery) to assist in spatial integration of landmark locations. Although previous studies have linked visual cognitive styles to a propensity for engaging in mental imagery that is vivid and pictorial (i.e., object imagery; Blazhenkova & Kozhevnikov, 2008; Kozhevnikov, Kosslyn, & Shephard, 2005), and to performance in small-scale spatial tasks such as mental rotation of objects and mental paper folding (i.e., spatial imagery; Blajenkova et al., 2006; Kozhevnikov et al., 2010, 2005; Massa & Mayer, 2006), to our knowledge no study to date has explored the relationship between the visual cognitive style and large-scale spatial navigation. Determining the relative locations and directions between landmarks relies on complex visuo-spatial transformations between perspectives (Fields & Shelton, 2006; Hegarty & Waller, 2004; Kozhevnikov & Hegarty, 2001; Schinazi et al., 2013). This may be particularly true when the environment is novel and experienced through the first-person perspective. Given that these representations are visual in nature and are difficult to verbalize, we predict that the strategy associated with the visual cognitive style (and not the verbal cognitive style) will correlate with performance on a judgment of relative direction (JRD) test. This prediction is in keeping with transfer appropriate processing principles. Specifically, the visual information that is the focus of attention during encoding (for those using a visual strategy) will be similarly available and useful in retrieving the required information at test, whereas the verbal information will not.
In contrast, a verbal strategy may be useful for other important aspects of navigation such as describing and remembering landmarks. The strategy associated with the verbal cognitive style may involve, for example, using verbal descriptions to identify landmarks (e.g., “tall brick office building”), or covertly encoding verbal labels for particular buildings and actions (e.g., “turn left at the skyscraper”). We hypothesize that the verbal cognitive style will be beneficial for landmark memory, but not for JRD, given the finding that the verbal cognitive style is predictive of a tendency to mentally label visual stimuli (Constantinidou & Baker, 2002; Kraemer, Hamilton, Messing, DeSantis, & Thompson-Schill, 2014; Kraemer et al., 2009; Paivio, 1979), and given the evidence that labels facilitate processing of nameable visual stimuli (Constantinidou & Baker, 2002; Johnson, Paivio, & Clark, 1996; Lupyan, Rakison, & McClelland, 2007; Paivio, 1991; Taevs, Dahmani, Zatorre, & Bohbot, 2010). As above, this hypothesis would be in keeping with transfer appropriate processing theories because it highlights the overlap between the processing that one focuses on during encoding and during retrieval. In particular, the focus here is on the verbal labeling strategy, which is a processing approach that adds information during encoding beyond what the stimuli alone provide (Einstein et al., 1990; McDaniel & Kearney, 1984).
In order to test these hypotheses, we conducted two experiments that each measure performance on two critical components of large-scale spatial navigation – landmark identification (assessed by a recognition test) and spatial orientation and integration (assessed by JRD). We used novel realistic virtual navigation environments constructed for this project in our laboratory (see Figure 1). Participants viewed first-person perspective videos of routes through the virtual cities and were then tested on landmark identification and JRD. Due to our focus on encoding the identity and locations of landmarks, the choice of first-person perspective videos (versus user-navigated environments) offered several advantages. Specifically, this method allowed us to match the amount of time each participant viewed each landmark as well as ensure that the perspective viewed during the study phase matched that of the test phase. These were important controls given that we wanted to isolate the effect of individual differences in verbal and visual cognitive styles and avoid potential confounds, such as differences in wayfinding strategy (Wolbers & Hegarty, 2010) or facility maneuvering through a virtual reality environment (Richardson et al., 1999).
Figure 1.

Example virtual intersection with landmark. A) Screen-captured image of an intersection viewed during the route (also seen during the JRD task). B) Isolated landmark as presented during the landmark recognition test.
Experiment 1 tested the hypothesis that individuals who self-report a preference for the verbal cognitive style (measured as a difference between scores on the verbal style dimension minus the visual style dimension) show a relative strength on the landmark memory test, for which there exists a clear verbal strategy – covertly naming or describing the landmarks. Similarly, we hypothesized that those who indicate a preference for the visual cognitive style would perform better on the JRD task, which requires integrating egocentric visual information in a manner that does not seem straightforward to verbalize. Experiment 2 aims to confirm the benefits of attending to visual or verbal information during route encoding by explicitly instructing a new group of participants to engage in either a verbal labeling strategy or a visual depiction strategy when studying the routes. In this experiment we also assess which factor exerts a greater influence over the encoding of relevant material – task instructions or cognitive style.
Experiment 1
Participants
Forty participants (23 female, 17 male; aged 18-30, M = 21) participated in this experiment. Participants were recruited from the University of Pennsylvania community, consented to participate in accordance with the oversight of the internal review board of the University, and were monetarily compensated for their time.
Materials and Procedure
For four virtual cities, participants viewed a route through the city and then, following two viewings of the route, were presented with the landmark memory test and the JRD test, each of which is described in detail below. Pilot testing confirmed that two viewings was sufficient to achieve task performance significantly greater than chance, though still not at ceiling for either of the tasks. Another test that assessed memory for intersections rather than for individual buildings appeared after the landmark test. For space considerations we do not discuss this condition further here. For all tests, subjects were instructed to respond as quickly and as accurately as possible, placing a greater emphasis on accuracy. Presentation order of the cities was counterbalanced across subjects. At the end of the session, participants completed a cognitive style questionnaire (see below) and were debriefed.
Route Videos
On a computer monitor, subjects were shown a first-person-perspective video of a walk through a virtual city. All videos and subsequent tests were presented using Eprime software (www.pstnet.com/eprime.cfm) on a desktop personal computer running Windows 7 and displayed on a 22-inch flat-panel digital LCD monitor. Virtual cities were created using Sketchup software (http://www.sketchup.com/). Cities were composed of virtual 3D buildings with photographic surface renderings that were modeled after real buildings. These were downloaded from Google 3D Warehouse (http://sketchup.google.com/3dwarehouse/), as well as additional objects and materials intended to populate the scene in a realistic manner such as road surface textures, sidewalks, trees, fire hydrants, and bus stops. Buildings were chosen from various cities around the world, with the goal in mind of choosing buildings that are unique enough as to be memorable and distinct, while including no buildings that are famous or otherwise recognizable to the participants outside the context of the experiment. Post-experiment questioning confirmed that this was the case. The virtual cities contained no written words on the buildings or anywhere else in the environment. Using a 3rd-party rendering program (iRender; http://www.renderplus.com), routes were created by drawing a path for a virtual camera through the streets of each city. The height and speed of the camera were chosen to approximate an individual walking down the center of a vacant street. We chose to use the center of the road so that right turns and left turns would require traveling equal distances and thus be viewed onscreen for equivalent times. Each route contained six right-angle turns (with equal numbers of right and left turns across cities) as well as 1-3 additional intersections that were passed straight through. Videos were 4.5-5.5 minutes in length. Figure 1a shows a sample screenshot of one of the cities.
Each subject viewed the same route twice in succession. On the initial viewing, participants were told to pick out one or two buildings at each intersection that they would use as landmarks if they were trying to navigate around the city, and to press spacebar once they had made their choice. For the second viewing, which was played at 75% of the original speed, they were told to try to recall the direction that the route turned or passed through each intersection, and to press the spacebar as the video exited the intersection. These instructions ensured that participants were attentive to the video, as well as focused on information that would be relevant for the subsequent memory tests. Participants watched videos of routes through four different novel cities.
Landmark Memory Test
For the landmark recognition test, subjects were shown an isolated building that was either present in the virtual city or not. The image of the building was taken from a screenshot of the studied route as the camera approaches the intersection with the building. Thus, the building was presented in the same location on the screen as it actually appeared during the video walkthrough (Figure 1b). This format precluded the need for any mental rotation or alignment in order to recognize the familiar buildings. The subject was asked to respond on each trial as to whether or not they recognized the building from the city, pressing separate keyboard buttons with the right hand for “yes” and “no” responses. Feedback was given after every answer. For each city, half of the items appeared in the observed video. Foils were generated in an identical manner from virtual cities that were not previously shown to the participant. For a given observed city, all false trials were drawn from the same unobserved virtual city. Images remained onscreen until the participant responded with a key press. There were twelve trials per city, for a total of forty-eight trials.
All landmarks were situated at decision point intersections (Allen, 2000; Janzen, 2006; Janzen & van Turennout, 2004; Schinazi & Epstein, 2010), defined here as all intersections in which a turn was possible, even when the intended route proceeded straight. Pilot testing was used to confirm the choice of landmarks as salient. For this, fourteen subjects watched the videos and noted which two buildings they would choose as a landmark for each intersection. Buildings that were chosen for the subsequent memory test were ones that had been independently selected as landmarks by all participants in the pilot phase.
Judgment of Relative Direction
For the judgment of relative direction test, participants were shown one intersection from the observed city for four seconds, and then the intersection disappeared and was immediately followed by the appearance of a second intersection. The subjects were asked to respond in which direction they would have to point, if they were standing at the first intersection shown, to indicate the direction of the second intersection. Images of the second intersection remained onscreen until participants indicated a response. Subjects responded using the eight buttons around the circumference of the number pad (Figure 2), approximating the 360° range divided into eight bins of 45° each. We devised a scoring system such that partial credit could be assigned based on the proximity of each response to the correct answer (thus approximating a calculation of angular error by using a keypad rather than a joystick). Specifically, full credit (10) was given for the correct button (i.e., the correct 45°bin), half credit (5) was given for answering one button away from the correct answer in either direction, and minimal partial credit (1) was given for answering two buttons away from the correct answer. No credit was awarded for the other responses. For five items in this task, the correct answer was within 5° of the dividing line between two 45° bins so both responses were awarded full credit. There were twelve items per city, for a total of forty-eight items.
Figure 2.
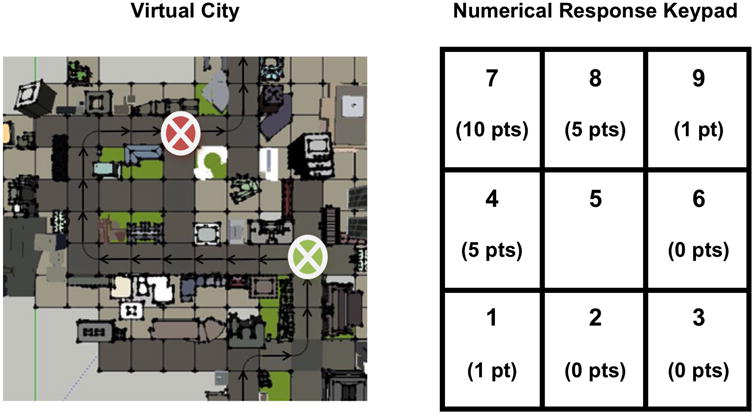
Illustration of the scoring rubric for JRD trials showing aerial perspective of a virtual city (left) and numerical response keypad with button labels and scores for each possible response on the illustrated trial (right). Green and red markers placed on the route indicate the positions of the initial and target locations for the trial, respectively. In this example, the correct response is 7 – i.e., the participant would point to the left and forward to get from the green intersection to the red intersection. Partial credit is awarded for responses near the correct response, as noted on the keypad illustration on the right side of the figure. (Participants never viewed cities from the aerial perspective.)
Object/Spatial Imagery and Verbal Questionnaire
The Object Spatial Imagery and Verbal Questionnaire (OSIVQ; Blazhenkova & Kozhevnikov, 2008) is a 45-item self-report questionnaire designed to assess separately an individual's propensities for three different cognitive style dimensions: object imagery (e.g., “My images are very vivid and photographic”, “I can easily remember a great deal of visual details that someone else might never notice”), spatial processing (e.g., “I can easily imagine and mentally rotate three-dimensional geometric figures”, “I have excellent abilities in technical graphics”), and verbal processing (e.g., “My verbal skills are excellent,” “When explaining something, I would rather give verbal explanations than make drawings or sketches”). A modified form of the questionnaire was used here that replaced the original yes/no form of the questions with a 5-point Likert scale (5 = strongly agree). Two questions were reverse scored, following (Blazhenkova & Kozhevnikov, 2008). Average scores for each dimension as well as difference scores between dimensions were computed for each subject.
Results and Discussion
Task Performance
Table 1 reports the results from Experiment 1. Accuracy (proportion correct) on the landmark task ranged from .63-.96 (M = .81, SD = .08), i.e., 30-46 items correct. Accuracy on JRD (proportion correct out of total possible score) ranged from .25-.77 (M = .41, SD = .10). One subject was removed from all further analysis based on task performance that was greater than three standard deviations above the mean on the JRD task. Accuracy for the remaining 39 participants ranged from .63-.96 (M = .80, SD = .08) for the landmark task and from .25-.68 (M = .40, SD = .08) for the JRD task. Performance was significantly above chance for both measures (Landmark: chance = .50, t(38) = 23.03, p < .0001; JRD: chance = .291, t(38) = 8.45, p < .0001). Accuracy was not significantly correlated between landmark and JRD tasks (r = .27, p = .10).
Table 1. Results from Experiment 1.
| Task | Style | |
|---|---|---|
| Verbal dTASK = 6.36 | Visual dTASK = 4.23 | |
| Landmark dSTYLE = .65 | .83 (.06) | .78 (.09) |
| JRD dSTYLE = .50 | .38 (.08) | .42 (.08) |
Note: Accuracy means (proportion correct) are outside the parentheses and standard deviations are inside the parentheses. Cohen's d values are reported for each pairwise comparison within each task and each style. JRD = judgment of relative direction.
Cognitive Styles
Table 1 and Figure 3 report task performance by cognitive style group for Experiment 1. Cohen's effect size values (landmark d = .65, JRD d = .50) suggest moderate to high practical significance. In order to examine our main hypothesis regarding cognitive styles and encoding of navigation-relevant details, we analyzed the data in two ways: first treating verbal-visual cognitive style preference as a continuous variable (calculated as verbal styles scores minus visual style scores), and second treating verbal-visual style as a categorical variable in order to facilitate the comparison of results between Experiment 1 and Experiment 2 (where instructions vary between groups). To examine the link between cognitive styles and spatial cognition on a continuous scale, we first calculated the correlations between cognitive style (verbal score minus object score) and task performance for both tasks. The correlation between verbal-visual cognitive style preference and accuracy on the JRD task revealed a significant negative relationship (r = -.34, p = .03), favoring the visual strategy over the verbal strategy. In contrast to this result, the correlation between verbal-visual cognitive style preference and accuracy on the landmark recognition task was in the positive direction (r = .30, p = .06), favoring the verbal strategy over the visual (object imagery) strategy. These effect sizes are generally considered moderate in magnitude, according to Cohen's conventions (Cohen, 1988). These correlation values differed significantly from each other (t = -3.75, p = .0006), using Williams's test (i.e., Steiger's preferred method).
Figure 3.
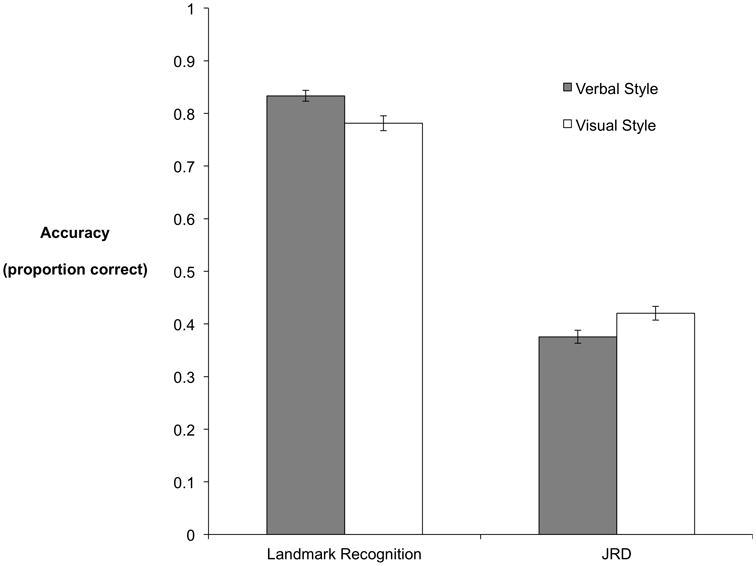
Experiment 1 results. Error bars reflect standard error of the mean (SEM). Chance performance for the landmark recognition task is .50, for JRD it is .29.
In terms of the individual dimensions of cognitive style, the object dimension correlated positively with accuracy on the JRD task (r = .40, p = .01) and negatively with accuracy on the landmark task (r = -.25, p = .12), while all other correlations were non-significant (p-values > .40). Based on the name of the spatial cognitive style dimension, it might appear surprising that performance on a spatial judgment task was correlated not with this dimension, but rather with the object imagery dimension. However, the kind of spatial processing involved in this task is more related to rotating the perspective of oneself in space and not necessarily to mental rotation of objects (Fields & Shelton, 2006; Hegarty & Waller, 2004; Kozhevnikov & Hegarty, 2001; Schinazi et al., 2013), the latter being the ability most closely associated with the spatial cognitive style dimension (Blajenkova et al., 2006; Blazhenkova & Kozhevnikov, 2008; Kozhevnikov et al., 2010, 2005). Moreover, it is the case that in order to accurately complete a JRD, one needs to recall visual details and attend to features of the landmarks that are relevant, such as the appearance of each different face of the building, in order to determine one's heading when viewing a static image of an intersection. Therefore, it is possible that directing attention to such visual features of the landmarks – which are neither captured by words, nor dependent on mental rotation – could bolster performance for JRD. Perhaps it is the case that individuals who score highly on the visual style dimension attend to these features as a matter of habit, but that – if given instructions to do so – every individual could benefit from such a strategy, independent of cognitive style. Experiment 2 directly tests this prediction, as well as the complementary prediction that focusing on verbal descriptions will enhance landmark recognition.
To facilitate comparison of results between experiments 1 and 2, we performed two separate 2(style: verbal, visual) × 2(task: landmark recognition, JRD) mixed-design ANOVAs. In both models, task performance was Z-scored in order to compare both tasks on the same scale. Although not useful for comparing overall group performance between the two tasks, this method allows for the clearest interpretation of the task*style interaction, which is most directly related to our hypothesis. The first model included the object imagery dimension as the visual style measure, and the second model included the spatial imagery dimension of the OSIVQ as the visual style measure. For both models, the verbal group was defined as the subjects who scored higher on their verbal dimension than on their visual dimension, while the visual group scored higher on the visual relative to verbal dimension. (Both ANOVA models were also re-computed by using median-split instead of positive versus negative scores and the pattern of results did not substantially differ.)
For the ANOVA including the object imagery style, results show a significant task*style interaction (F(1,37) = 11.71, p = .002, η2 = .24), in which the more verbal participants performed better on the landmark test and worse on JRD, whereas the more visual participants performed worse on the landmark test and better on JRD. There was no significant main effect of style (F(1,37) = .03, p = .87). Follow up t-tests indicate a significant difference between verbal and visual style groups (see Table 1 for means and effect sizes) on the landmark task (t = 2.12, p = .04) and a smaller difference between groups on the JRD task (t = 1.75, p = .09). For the ANOVA including the spatial imagery style, we found no significant interaction (F(1,37) = .07, p = .79) and no significant main effect of style (F(1,37) = .72, p = .40).
Experiment 2
Participants
Forty-two participants (28 female, 14 male; aged 18-30, M = 20) participated in this experiment. Participants were recruited from the University of Pennsylvania community, consented to participate in accordance with the oversight of the internal review board of the University, and were monetarily compensated for their time.
Materials and Procedure
The videos, test, and surveys used in Experiment 2 were identical to those used in Experiment 1. The only difference in procedure related to the instructions given when the participants were studying the video routes. Specifically, on the initial viewing participants were told to pick out a landmark building as they approached each intersection and to describe its features out loud (verbal strategy) or to quickly sketch an image of the building (visual strategy). For example, verbal descriptions often described building features such as height, width, color, and materials (e.g., “tall bluish glass skyscraper”). Visual depictions consisted mostly of quick line drawings that convey the overall shape of the building and some characteristic features. As with Experiment 1, the second viewing, which was played at 75% of the original speed, was aimed at focusing participants on directional information. Here they were told to try to recall the direction that the route turned or passed through each intersection, and to say the direction – left, right, or straight – out loud (verbal strategy), or to indicate that they have directed their visual attention to the part of the scene towards which the route will turn by pointing onscreen (visual strategy).
Results and Discussion
Task Performance
Table 2 reports the results from Experiment 2. Overall performance was similar to that observed for Experiment 1. Accuracy (proportion correct) on the landmark task ranged from .65-.98 (M = .84, SD = .08). Accuracy on JRD (proportion correct) ranged from .24-.67 (M = .42, SD = .10). Performance was significantly above chance for both measures (Landmark: chance = .50, t(41) = 28.04, p < .0001; JRD: chance = .29, t(41) = 8.45, p < .0001). Accuracy was not significantly correlated between landmark and JRD tasks (r = .26, p = .11).
Table 2. Results from Experiment 2.
| Task | Strategy | Style | ||
|---|---|---|---|---|
| Verbal dTASK = 4.99 | Visual dTASK = 4.75 | Verbal dTASK = 4.64 | Visual dTASK = 4.75 | |
| Landmark dSTRATEGY = .67 dSTYLE = 0 | .86 (.07) | .81 (.08) | .84 (.08) | .84 (.08) |
| JRD dSTRATEGY = .31 dSTYLE = .10 | .40 (.11) | .43 (.08) | .42 (.10) | .41 (.10) |
Note: Accuracy means (proportion correct) are outside the parentheses and standard deviations are inside the parentheses. Cohen's d values are reported for each pairwise comparison within each task and each style. JRD = judgment of relative direction.
Encoding Strategies
Table 2 and Figure 4 report task performance as a function of encoding strategy instructions and cognitive style group for Experiment 2. Cohen's effect size values (landmark d = .67, JRD d = .31) range from low to high practical significance for strategy, and indicate no reliable effect for cognitive style in this experiment. In order to investigate our hypothesis that the verbal strategy would benefit performance on the landmark recognition task and the visual strategy would benefit accuracy on JRD, and also to compare these effects to those of cognitive styles, we performed a 2(instruction: verbal strategy, visual strategy) × 2(task: landmark recognition, JRD) × 2(style: verbal, object) mixed-design ANOVA. As with Experiment 1, task performance was Z-scored for each task across all participants in Experiment 2. The hypothesized interaction between task and strategy instructions was found to be significant (F(1,38) = 8.31, p = .006, η2 = .24). The verbal strategy benefitted performance on the landmark task whereas the visual strategy benefitted performance on the JRD task. No significant main effect of instructions was observed (F(1,38) = .36, p = .56). Follow up t-tests indicate a significant difference between groups receiving verbal and visual instructions (see Table 2 for means and effect sizes) on the landmark task (t = 2.14, p = .04) and a smaller difference between groups on the JRD task (t = 1.20, p = .24).
Figure 4.
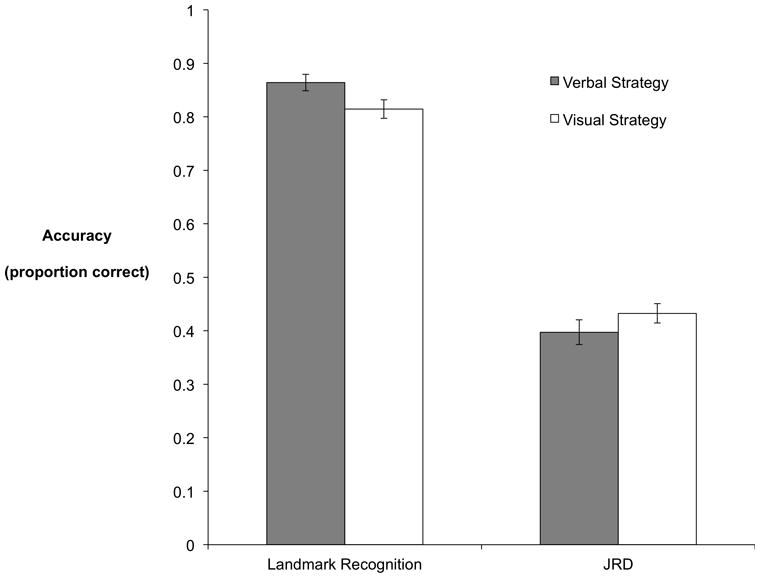
Experiment 2 results. Error bars reflect SEM. Chance performance for the landmark recognition task is .50, for JRD it is .29.
Results of the ANOVA further indicated that cognitive styles did not have a significant impact on task performance in Experiment 2. No significant main effect of style was observed (F(1,38) = .12, p = .74). The interaction between instructions and style was not significant (F(1,38) = 1.56, p = .22), the interaction between task and style was not significant (F(1,38) = .66, p = .42), and the three-way interaction was also not significant (F(1,38) = .13, p = .72).
The present design allowed us to separately observe the effects of verbal and visual strategies on landmark recognition memory and spatial integration. These results are consistent with Experiment 1 and specifically the interpretation that the verbal and visual (object) cognitive styles correlate with preferences for verbal and visual encoding strategies, respectively. The pattern of results we observed here indicates that these strategies are adaptable, as the strategy instructions – and not cognitive style – produced a similar pattern of results as we observed in Experiment 1. If instead cognitive styles were not representative of strategies but were only reflective of abilities, then verbal and visual styles would have interacted with the task conditions as in Experiment 1, or would have modulated the interaction between task and strategy.
General Discussion
We can draw at least two conclusions from the present investigation, which have implications for research on navigation as well as on cognitive styles. First, the results of Experiment 1 demonstrate that individual differences in verbalizing and visualizing tendencies, namely cognitive styles, have a significant influence on the encoding of landmark information in a large-scale environment. This effect is moderate in size, as is the comparable effect of using a verbal versus a visual strategy in Experiment 2. Second, the finding that cognitive styles do not modulate the interaction between strategy instruction and task performance in Experiment 2 confirms that, at least in the present context, verbal and visual cognitive styles are not predominantly reflective of innate abilities or of immutable habits of thought, but rather of cognitive strategies that can be modified (easily in this case) by changes in instruction.
Notably, these results are consistent with the research on memory that considers the overlap of cognitive processes during encoding and retrieval, including the theories of encoding specificity and transfer appropriate processing. Specifically, performance on the landmark and JRD tests can be understood as a function of what information one chooses to focus on during encoding; how that processing is or is not congruent with the information that is cued during retrieval. In this case, the results show that a focus on verbal labels is useful for retrieving information about landmarks (which have easily-verbalized descriptions), but not for retrieving information about the relative spatial locations of those buildings (which is not easy to verbalize).
These results echo earlier findings in the memory literature, which have focused on similar distinctions, such as the differential effects of imagery versus verbal processes on memory retention for various types of word lists and object pictures (Kirchhoff & Buckner, 2006; McDaniel & Kearney, 1984), and the distinction between memory for individual details versus the relationships between items (Einstein et al., 1990; Hunt & Einstein, 1981; McDaniel & Einstein, 1989; Waddill & McDaniel, 1992). For example, McDaniel & Kearney (1984) found that different processing strategies, focusing either on visual imagery, categorization, or verbal elaboration, were effective for different types of word-based tasks. Consistent with the present findings, the strategies that were most effective for each task focused on information that was related to the stimuli but not already provided (e.g., forming a mental image of a word and its meaning for a vocabulary test). Notably, participants naturally varied their strategies across tasks, with most choosing an appropriate task strategy even when left unadvised regarding which strategy to use. However, these natural propensities for strategy choice were easily overridden by instructions to employ a given strategy, even when the assigned strategy was less optimal than another choice of strategy. Similarly, we find here that differing strategy usage during encoding has a varying effect on retrieval performance, depending on the information being retrieved. Likewise, the independent choice of strategy appears to vary across individual participants, however it is also readily amenable to instruction.
How do the current findings inform our understanding of the role of verbal information in spatial cognition? Numerous studies have used verbal labels or verbal route directions in the service of visual navigation tasks, for both virtual environments (Aguirre & D'Esposito, 1997; Fields & Shelton, 2006; Giudice, Bakdash, Legge, & Roy, 2010; Schinazi et al., 2013) and real-world environments (Giudice, Bakdash, & Legge, 2007; Ishikawa & Montello, 2006; Marchette, Yerramsetti, Burns, & Shelton, 2011; Pazzaglia & De Beni, 2001). However, to our knowledge the only prior study that directly compared learning about a novel visual environment with versus without the use of verbal descriptions (Pazzaglia & De Beni, 2001) did so by confounding the presence of words (in the form of a route description) with a change in perspective (in the form of an aerial map). Notably, the results of the comparable route-oriented condition in that study are similar to our present findings, in that they also reveal an association between verbal labels and landmark memory: the verbal descriptions were more effective for those individuals who reported higher reliance on landmarks for navigation (Pazzaglia & De Beni, 2001).
Separately, a rich literature on narrative processing has revealed that verbal descriptions of unobserved environments can be effective for generating accurate mental models of environments and routes (Brunyé, Rapp, & Taylor, 2008;Brunyé, Taylor, & Worboys, 2007; Brunyé & Taylor, 2008a, 2008b; Lee & Tversky, 2005; Mani & Johnson-Laird, 1982; Schneider & Taylor, 1999; Taylor & Tversky, 1992a, 1992b), and for online navigation (Giudice et al., 2007, 2010; Meilinger, 2005; Pazzaglia & De Beni, 2001; Tversky & Lee, 1999; but see Wanet-Defalque, Vanlierde, & Michaux, 2001). Here we demonstrate a complementary phenomenon – that in the course of visually encoding an environment, supplementary verbal information is beneficial for reinforcing landmark memory.
A debate also continues regarding the role of language in the (not-uniquely) human ability to reorient oneself in an environment (Hermer-Vazquez, Spelke, & Katsnelson, 1999; Learmonth, Newcombe, & Huttenlocher, 2001; Pyers, Shusterman, Senghas, Spelke, & Emmorey, 2010; Ratliff & Newcombe, 2008; Wang & Spelke, 2000, 2002). Here, the fact that the verbal strategy produced worse performance on the spatial integration task (relative to the non-verbal strategy) suggests that, at least for the case of JRD, verbal labeling is not a critical component of spatial integration and orienting. These results are consistent with previous findings from studies with aphasic patients (Bek, Blades, Siegal, & Varley, 2010), pre-verbal toddlers (Learmonth et al., 2001), and non-impaired adult participants during verbal suppression tasks (Ratliff & Newcombe, 2008), in which the lack of language ability in all these cases does not impair orienting. As the verbal descriptions of buildings in this experiment tended to be fairly general (e.g., “tall, black skyscraper”), this pattern of results is also consistent with the neuroimaging findings of Epstein and Higgins (2007) that dissociated the contributions of language networks involved in identifying general place categories (e.g., “kitchen”) from a visuo-spatial network including retrosplenial cortex that was more active when identifying specific familiar landmarks that could be localized within an environment. In other words, verbal encoding appears to help identify a landmark, but not to locate it.
Turning to cognitive styles, the present findings support the view that cognitive styles represent processing strategies (Kozhevnikov, 2007; Kraemer et al., 2009; Paivio & Harshman, 1983; Witkin, Moore, Goodenough, & Cox, 1977). Moreover, these results demonstrate the novel finding that the strategies associated with verbal and visual cognitive styles are amenable to changes in task instruction. As for the effects of these strategies on task performance, the finding that the verbal strategy aids memory for nameable visual information is consistent with results from research on cognitive styles and on memory. In particular, we have previously reported results which indicate that individuals tend to mentally convert information that is presented in a non-preferred modality into their preferred modality (Kraemer et al., 2014, 2009). For example, during a picture-based task involving nameable stimuli, the verbal cognitive style correlated with activity in a functionally-defined verbal brain region, consistent with the interpretation that the verbal cognitive style is associated with mentally labeling observed images (Kraemer et al., 2009). Other lines of research have also demonstrated the benefits of using verbal information for processing visual stimuli, such as categorization of novel stimuli (Lupyan et al., 2007). However, drawbacks for such strategies have been reported in other cases when the information is less-verbalizable, such as the verbal overshadowing effect for memory of faces (Schooler & Engstler-Schooler, 1990). This latter type of effect may be a factor in why the verbal strategy was not helpful for the JRD task.
In contrast, the visual strategy did prove beneficial for judging these spatial relationships. What could be the explanation for this finding? The object imagery dimension has been shown to correlate with attention to precise visual features of objects (Blazhenkova & Kozhevnikov, 2008; Kozhevnikov et al., 2010), and it includes statements relating directly to scene imagery and memory (e.g., “I can close my eyes and easily picture a scene that I have experienced”, “When entering a familiar store to get a specific item, I can easily picture the exact location of the target item, the shelf it stands on, how it is arranged and the surrounding articles”, “When reading fiction, I usually form a clear and detailed mental picture of a scene or room that has been described”; Blazhenkova & Kozhevnikov, 2008). Our JRD task used previously-viewed images of intersections to establish landmark location and heading (see Figure 1a). Therefore, memory for scenes is a critical component of this task, as it generally is for real-world judgments of relative direction (Schinazi et al., 2013). Moreover, attending to details such as the shape of the outline of a building and the distinct configurations of details on the façade of the building may help orient oneself to the heading of a given snapshot of a location from the learned environment. Correctly determining this orientation is also critical to successful completion of the JRD. Thus, a strategy that focuses the viewer on these helpful visual cues, whether arrived at by individual preference or through task instruction, is useful for encoding (and retrieving) the relative directions of distinct locations. We therefore conclude that future studies of navigation should take into account the details that subjects attend to during route encoding – both due to task demands as well as due to individual differences in cognitive style.
Acknowledgments
This research was supported by the National Science Foundation through REESE DRL-0910247 and by the National Eye Institute of the National Institutes of Health under award number R01EY021717 (PI: Thompson-Schill).
Footnotes
To calculate a chance score for the JRD task, we first calculated the probability on each trial of obtaining each possible score by random selection, then we multiplied those probabilities by the respective scores to get an expected value for each trial, then we summed those expected values across all trials, and finally divided that sum by the total possible score.
References
- Aguirre GK, D'Esposito M. Environmental knowledge is subserved by separable dorsal/ventral neural areas. Journal of Neuroscience. 1997;17(7):2512–2518. doi: 10.1523/JNEUROSCI.17-07-02512.1997. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Allen GL. Principles and practices for communicating route knowledge. Applied Cognitive Psychology. 2000;14(4):333–359. [Google Scholar]
- Bek J, Blades M, Siegal M, Varley R. Language and spatial reorientation: Evidence from severe aphasia. Journal of Experimental Psychology: Learning, Memory, and Cognition. 2010;36(3):646–658. doi: 10.1037/a0018281. http://doi.org/10.1037/a0018281. [DOI] [PubMed] [Google Scholar]
- Blajenkova O, Kozhevnikov M, Motes MA. Object-spatial imagery: a new self-report imagery questionnaire. Applied Cognitive Psychology. 2006;20(2):239–263. http://doi.org/10.1002/acp.1182. [Google Scholar]
- Blazhenkova O, Kozhevnikov M. The new object-spatial-verbal cognitive style model: Theory and measurement. Applied Cognitive Psychology. 2008;23(5):638–663. http://doi.org/10.1002/acp.1473. [Google Scholar]
- Blazhenkova O, Kozhevnikov M. Visual-object ability: A new dimension of non-verbal intelligence. Cognition. 2010;117(3):276–301. doi: 10.1016/j.cognition.2010.08.021. http://doi.org/10.1016/j.cognition.2010.08.021. [DOI] [PubMed] [Google Scholar]
- Brunyé TT, Rapp DN, Taylor HA. Representational flexibility and specificity following spatial descriptions of real-world environments. Cognition. 2008;108(2):418–443. doi: 10.1016/j.cognition.2008.03.005. http://doi.org/10.1016/j.cognition.2008.03.005. [DOI] [PubMed] [Google Scholar]
- Brunyé TT, Taylor HA. Extended experience benefits spatial mental model development with route but not survey descriptions. Acta Psychologica. 2008a;127(2):340–354. doi: 10.1016/j.actpsy.2007.07.002. http://doi.org/10.1016/j.actpsy.2007.07.002. [DOI] [PubMed] [Google Scholar]
- Brunyé TT, Taylor HA. Working memory in developing and applying mental models from spatial descriptions✩. Journal of Memory and Language. 2008b;58(3):701–729. http://doi.org/10.1016/j.jml.2007.08.003. [Google Scholar]
- Brunyé TT, Taylor HA, Worboys M. Levels of detail in descriptions and depictions of geographic space. Spatial Cognition and Computation. 2007;7(3):227–266. [Google Scholar]
- Cohen J. Statistical power analysis for the behavioral sciences. 2nd. Hillsdale, N.J: L. Erlbaum Associates; 1988. [Google Scholar]
- Constantinidou F, Baker S. Stimulus modality and verbal learning performance in normal aging. Brain and Language. 2002;82(3):296–311. doi: 10.1016/s0093-934x(02)00018-4. [DOI] [PubMed] [Google Scholar]
- Einstein GO, McDaniel MA, Owen PD, Coté NC. Encoding and recall of texts: The importance of material appropriate processing. Journal of Memory and Language. 1990;29(5):566–581. http://doi.org/10.1016/0749-596X(90)90052-2. [Google Scholar]
- Epstein RA, Higgins JS. Differential Parahippocampal and Retrosplenial Involvement in Three Types of Visual Scene Recognition. Cerebral Cortex. 2007;17(7):1680–1693. doi: 10.1093/cercor/bhl079. http://doi.org/10.1093/cercor/bhl079. [DOI] [PubMed] [Google Scholar]
- Etchamendy N, Bohbot VD. Spontaneous navigational strategies and performance in the virtual town. Hippocampus. 2007;17(8):595–599. doi: 10.1002/hipo.20303. http://doi.org/10.1002/hipo.20303. [DOI] [PubMed] [Google Scholar]
- Fields AW, Shelton AL. Individual skill differences and large-scale environmental learning. Journal of Experimental Psychology: Learning, Memory, and Cognition. 2006;32(3):506–515. doi: 10.1037/0278-7393.32.3.506. [DOI] [PubMed] [Google Scholar]
- Giudice NA, Bakdash JZ, Legge GE. Wayfinding with words: spatial learning and navigation using dynamically updated verbal descriptions. Psychological Research. 2007;71(3):347–358. doi: 10.1007/s00426-006-0089-8. http://doi.org/10.1007/s00426-006-0089-8. [DOI] [PubMed] [Google Scholar]
- Giudice NA, Bakdash JZ, Legge GE, Roy R. Spatial learning and navigation using a virtual verbal display. ACM Transactions on Applied Perception. 2010;7(1):1–22. http://doi.org/10.1145/1658349.1658352. [Google Scholar]
- Hegarty M, Montello DR, Richardson AE, Ishikawa T, Lovelace K. Spatial abilities at different scales: Individual differences in aptitude-test performance and spatial-layout learning. Intelligence. 2006;34(2):151–176. [Google Scholar]
- Hegarty M, Richardson AE, Montello DR, Lovelace K, Subbiah I. Development of a self-report measure of environmental spatial ability. Intelligence. 2002;(30):425–447. [Google Scholar]
- Hegarty M, Waller D. A dissociation between mental rotation and perspective-taking spatial abilities. Intelligence. 2004;32(2):175–191. http://doi.org/10.1016/j.intell.2003.12.001. [Google Scholar]
- Hermer-Vazquez L, Spelke ES, Katsnelson AS. Sources of flexibility in human cognition: dual-task studies of space and language. Cognitive Psychology. 1999;39(1):3–36. doi: 10.1006/cogp.1998.0713. http://doi.org/10.1006/cogp.1998.0713. [DOI] [PubMed] [Google Scholar]
- Hunt RR, Einstein GO. Relational and item-specific information in memory. Journal of Verbal Learning and Verbal Behavior. 1981;20(5):497–514. [Google Scholar]
- Ishikawa T, Montello DR. Spatial knowledge acquisition from direct experience in the environment: Individual differences in the development of metric knowledge and the integration of separately learned places. Cognitive Psychology. 2006;52(2):93–129. doi: 10.1016/j.cogpsych.2005.08.003. [DOI] [PubMed] [Google Scholar]
- Janzen G. Memory for object location and route direction in virtual large-scale space. The Quarterly Journal of Experimental Psychology. 2006;59(3):493–508. doi: 10.1080/02724980443000746. http://doi.org/10.1080/02724980443000746. [DOI] [PubMed] [Google Scholar]
- Janzen G, van Turennout M. Selective neural representation of objects relevant for navigation. Nature Neuroscience. 2004;7(6):673–677. doi: 10.1038/nn1257. http://doi.org/10.1038/nn1257. [DOI] [PubMed] [Google Scholar]
- Johnson CJ, Paivio A, Clark JM. Cognitive components of picture naming. Psychological Bulletin. 1996;120(1):113–139. doi: 10.1037/0033-2909.120.1.113. [DOI] [PubMed] [Google Scholar]
- Kirby JR, Moore PJ, Schofield NJ. Verbal and Visual Learning Styles. Contemporary Educational Psychology. 1988;13(2):169–184. [Google Scholar]
- Kirchhoff BA, Buckner RL. Functional-Anatomic Correlates of Individual Differences in Memory. Neuron. 2006;51(2):263–274. doi: 10.1016/j.neuron.2006.06.006. http://doi.org/10.1016/j.neuron.2006.06.006. [DOI] [PubMed] [Google Scholar]
- Kozhevnikov M. Cognitive Styles in the Context of Modern Psychology: Toward an Integrated Framework of Cognitive Style. Psychological Bulletin. 2007;133(3):464–481. doi: 10.1037/0033-2909.133.3.464. http://doi.org/10.1037/0033-2909.133.3.464. [DOI] [PubMed] [Google Scholar]
- Kozhevnikov M, Blazhenkova O, Becker M. Trade-off in object versus spatial visualization abilities: Restriction in the development of visual-processing resources. Psychonomic Bulletin & Review. 2010;17(1):29–35. doi: 10.3758/PBR.17.1.29. http://doi.org/10.3758/PBR.17.1.29. [DOI] [PubMed] [Google Scholar]
- Kozhevnikov M, Hegarty M. A dissociation between object manipulation spatial ability and spatial orientation ability. Memory & Cognition. 2001;29(5):745–756. doi: 10.3758/bf03200477. [DOI] [PubMed] [Google Scholar]
- Kozhevnikov M, Kosslyn S, Shephard J. Spatial versus object visualizers: A new characterization of visual cognitive style. Memory & Cognition. 2005;33(4):710–726. doi: 10.3758/bf03195337. [DOI] [PubMed] [Google Scholar]
- Kraemer DJM, Hamilton RH, Messing SB, DeSantis JH, Thompson-Schill SL. Cognitive style, cortical stimulation, and the conversion hypothesis. Frontiers in Human Neuroscience. 2014;8:1–9. doi: 10.3389/fnhum.2014.00015. http://doi.org/10.3389/fnhum.2014.00015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kraemer DJM, Rosenberg LM, Thompson-Schill SL. The Neural Correlates of Visual and Verbal Cognitive Styles. Journal of Neuroscience. 2009;29(12):3792–3798. doi: 10.1523/JNEUROSCI.4635-08.2009. http://doi.org/10.1523/JNEUROSCI.4635-08.2009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Learmonth AE, Newcombe NS, Huttenlocher J. Toddlers' Use of Metric Information and Landmarks to Reorient. Journal of Experimental Child Psychology. 2001;80(3):225–244. doi: 10.1006/jecp.2001.2635. http://doi.org/10.1006/jecp.2001.2635. [DOI] [PubMed] [Google Scholar]
- Lee PU, Tversky B. Interplay Between Visual and Spatial: The Effect of Landmark Descriptions on Comprehension of Route/Survey Spatial Descriptions. Spatial Cognition & Computation. 2005;5(2-3):163–185. http://doi.org/10.1080/13875868.2005.9683802. [Google Scholar]
- Lupyan G, Rakison DH, McClelland JL. Language is not Just for Talking Redundant Labels Facilitate Learning of Novel Categories. Psychological Science. 2007;18(12):1077–1083. doi: 10.1111/j.1467-9280.2007.02028.x. [DOI] [PubMed] [Google Scholar]
- Mani K, Johnson-Laird PN. The mental representation of spatial descriptions. Memory & Cognition. 1982;10(2):181–187. doi: 10.3758/bf03209220. [DOI] [PubMed] [Google Scholar]
- Marchette SA, Yerramsetti A, Burns TJ, Shelton AL. Spatial memory in the real world: long-term representations of everyday environments. Memory & Cognition. 2011;39(8):1401–1408. doi: 10.3758/s13421-011-0108-x. http://doi.org/10.3758/s13421-011-0108-x. [DOI] [PubMed] [Google Scholar]
- Massa LJ, Mayer RE. Testing the ATI hypothesis: Should multimedia instruction accommodate verbalizer-visualizer cognitive style? Learning and Individual Differences. 2006;16(4):321–335. http://doi.org/10.1016/j.lindif.2006.10.001. [Google Scholar]
- McDaniel MA, Einstein GO. Material-appropriate processing: A contextualist approach to reading and studying strategies. Educational Psychology Review. 1989;1(2):113–145. [Google Scholar]
- McDaniel MA, Kearney EM. Optimal learning strategies and their spontaneous use: The importance of task-appropriate processing. Memory & Cognition. 1984;12(4):361–373. doi: 10.3758/bf03198296. [DOI] [PubMed] [Google Scholar]
- Meilinger T. Wayfinding with maps and verbal directions. Proceedings of the 26th Annual Conference of the Cognitive Science Society. 2005 Retrieved from http://www.kyb.mpg.de/fileadmin/user_upload/files/publications/CogSci-2005-Meilinger.pdf.
- Mellet E, Briscogne S, Tzourio-Mazoyer N, Ghaëm O, Petit L, Zago L, Denis M. Neural correlates of topographic mental exploration: the impact of route versus survey perspective learning. NeuroImage. 2000;12(5):588–600. doi: 10.1006/nimg.2000.0648. http://doi.org/10.1006/nimg.2000.0648. [DOI] [PubMed] [Google Scholar]
- Morris CD, Bransford JD, Franks JJ. Levels of processing versus transfer appropriate processing. Journal of Verbal Learning and Verbal Behavior. 1977;16(5):519–533. [Google Scholar]
- Paivio A. Imagery and Verbal Processes. Hillsdale, NJ: Lawrence Earlbaum Associates; 1979. [Google Scholar]
- Paivio A. Dual coding theory: Retrospect and current status. Canadian Journal of Psychology/Revue Canadienne de Psychologie. 1991;45(3):255–287. http://doi.org/10.1037/h0084295. [Google Scholar]
- Paivio A, Harshman R. Factor analysis of a questionnaire on imagery and verbal habits and skills. Canadian Journal of Psychology/Revue Canadienne de Psychologie. 1983;37(4):461–483. [Google Scholar]
- Palermo L, Iaria G, Guariglia C. Mental imagery skills and topographical orientation in humans: A correlation study. Behavioural Brain Research. 2008;192(2):248–253. doi: 10.1016/j.bbr.2008.04.014. http://doi.org/10.1016/j.bbr.2008.04.014. [DOI] [PubMed] [Google Scholar]
- Pazzaglia F, De Beni R. Strategies of processing spatial information in survey and landmark-centred individuals. European Journal of Cognitive Psychology. 2001;13(4):493–508. http://doi.org/10.1080/09541440125778. [Google Scholar]
- Presson CC, Montello DR. Points of reference in spatial cognition: Stalking the elusive landmark*. British Journal of Developmental Psychology. 1988;6(4):378–381. http://doi.org/10.1111/j.2044-835X.1988.tb01113.x. [Google Scholar]
- Pyers JE, Shusterman A, Senghas A, Spelke ES, Emmorey K. From the Cover: Evidence from an emerging sign language reveals that language supports spatial cognition. Proceedings of the National Academy of Sciences. 2010;107(27):12116–12120. doi: 10.1073/pnas.0914044107. http://doi.org/10.1073/pnas.0914044107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Ratliff KR, Newcombe NS. Is language necessary for human spatial reorientation? Reconsidering evidence from dual task paradigms. Cognitive Psychology. 2008;56(2):142–163. doi: 10.1016/j.cogpsych.2007.06.002. http://doi.org/10.1016/j.cogpsych.2007.06.002. [DOI] [PubMed] [Google Scholar]
- Richardson AE, Montello DR, Hegarty M. Spatial knowledge acquisition from maps and from navigation in real and virtual environments. Memory & Cognition. 1999;27(4):741–750. doi: 10.3758/bf03211566. [DOI] [PubMed] [Google Scholar]
- Roediger HL, Blaxton TA. Effects of varying modality, surface features, and retention interval on priming in word-fragment completion. Memory & Cognition. 1987;15(5):379–388. doi: 10.3758/bf03197728. [DOI] [PubMed] [Google Scholar]
- Roediger HL, Gallo DA, Geraci L. Processing approaches to cognition: The impetus from the levels-of-processing framework. Memory. 2002;10(5-6):319–332. doi: 10.1080/09658210224000144. http://doi.org/10.1080/09658210224000144. [DOI] [PubMed] [Google Scholar]
- Schinazi VR, Epstein RA. Neural correlates of real-world route learning. NeuroImage. 2010;53(2):725–735. doi: 10.1016/j.neuroimage.2010.06.065. http://doi.org/10.1016/j.neuroimage.2010.06.065. [DOI] [PubMed] [Google Scholar]
- Schinazi VR, Nardi D, Newcombe NS, Shipley TF, Epstein RA. Hippocampal size predicts rapid learning of a cognitive map in humans. Hippocampus. 2013;23(6):515–528. doi: 10.1002/hipo.22111. http://doi.org/10.1002/hipo.22111. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Schneider LF, Taylor HA. How do you get there from here? Mental representations of route descriptions. Applied Cognitive Psychology. 1999;13(5):415–441. http://doi.org/10.1002/(SICI)1099-0720(199910)13:5<415∷AID-ACP602>3.0.CO;2-N. [Google Scholar]
- Schooler JW, Engstler-Schooler TY. Verbal overshadowing of visual memories: Some things are better left unsaid. Cognitive Psychology. 1990;22(1):36–71. doi: 10.1016/0010-0285(90)90003-m. [DOI] [PubMed] [Google Scholar]
- Shelton AL, McNamara TP. Systems of Spatial Reference in Human Memory. Cognitive Psychology. 2001;43(4):274–310. doi: 10.1006/cogp.2001.0758. http://doi.org/10.1006/cogp.2001.0758. [DOI] [PubMed] [Google Scholar]
- Taevs M, Dahmani L, Zatorre RJ, Bohbot VD. Semantic Elaboration in Auditory and Visual Spatial Memory. Frontiers in Psychology. 2010;1 doi: 10.3389/fpsyg.2010.00228. http://doi.org/10.3389/fpsyg.2010.00228. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Taylor HA, Tversky B. Descriptions and depictions of environments. Memory & Cognition. 1992a;20(5):483–496. doi: 10.3758/bf03199581. [DOI] [PubMed] [Google Scholar]
- Taylor HA, Tversky B. Spatial mental models derived from survey and route descriptions. Journal of Memory and Language. 1992b;31(2):261–292. [Google Scholar]
- Tulving E, Thomson DM. Encoding specificity and retrieval processes in episodic memory. Psychological Review. 1973;80(5):352–373. http://doi.org/10.1037/h0020071. [Google Scholar]
- Tversky B, Lee PU. Spatial information theory Cognitive and computational foundations of geographic information science. Springer; 1999. Pictorial and verbal tools for conveying routes; pp. 51–64. Retrieved from http://link.springer.com/chapter/10.1007/3-540-48384-5_4. [Google Scholar]
- Waddill PJ, McDaniel MA. Pictorial enhancement of text memory: Limitations imposed by picture type and comprehension skill. Memory & Cognition. 1992;20(5):472–482. doi: 10.3758/bf03199580. [DOI] [PubMed] [Google Scholar]
- Wanet-Defalque MC, Vanlierde A, Michaux G. Mental Representation of Spaces and Objects in a Historic Site: Influence of Visual Impairment. Journal of Visual Impairment & Blindness. 2001;95(3):172–75. [Google Scholar]
- Wang RF, Spelke ES. Updating egocentric representations in human navigation. Cognition. 2000;77(3):215–250. doi: 10.1016/s0010-0277(00)00105-0. [DOI] [PubMed] [Google Scholar]
- Wang RF, Spelke ES. Human spatial representation: Insights from animals. Trends in Cognitive Sciences. 2002;6(9):376–382. doi: 10.1016/s1364-6613(02)01961-7. [DOI] [PubMed] [Google Scholar]
- Witkin HA, Moore CA, Goodenough DR, Cox PW. Field-dependent and field-independent cognitive styles and their educational implications. Review of Educational Research. 1977;47(1):1–64. [PubMed] [Google Scholar]
- Wolbers T, Hegarty M. What determines our navigational abilities? Trends in Cognitive Sciences. 2010;14(3):138–146. doi: 10.1016/j.tics.2010.01.001. http://doi.org/10.1016/j.tics.2010.01.001. [DOI] [PubMed] [Google Scholar]