

Abstract
We present a natural generalization of the recent low rank + sparse matrix decomposition and consider the decomposition of matrices into components of multiple scales. Such decomposition is well motivated in practice as data matrices often exhibit local correlations in multiple scales. Concretely, we propose a multi-scale low rank modeling that represents a data matrix as a sum of block-wise low rank matrices with increasing scales of block sizes. We then consider the inverse problem of decomposing the data matrix into its multi-scale low rank components and approach the problem via a convex formulation. Theoretically, we show that under various incoherence conditions, the convex program recovers the multi-scale low rank components either exactly or approximately. Practically, we provide guidance on selecting the regularization parameters and incorporate cycle spinning to reduce blocking artifacts. Experimentally, we show that the multi-scale low rank decomposition provides a more intuitive decomposition than conventional low rank methods and demonstrate its effectiveness in four applications, including illumination normalization for face images, motion separation for surveillance videos, multi-scale modeling of the dynamic contrast enhanced magnetic resonance imaging and collaborative filtering exploiting age information.
Index Terms: Multi-scale Modeling, Low Rank Modeling, Convex Relaxation, Structured Matrix, Signal Decomposition
I. INTRODUCTION
Signals and systems often exhibit different structures at different scales. Such multi-scale structure has inspired a wide variety of multi-scale signal transforms, such as wavelets [1], curvelets [2] and multi-scale pyramids [3], that can represent natural signals compactly. Moreover, their ability to compress signal information into a few significant coefficients has made multi-scale signal transforms valuable beyond compression and are now commonly used in signal reconstruction applications, including denoising [4], compressed sensing [5], [6], and signal separation [7]–[9]. By now, multi-scale modeling is associated with many success stories in engineering applications.
On the other hand, low rank methods are commonly used instead when the signal subspace needs to be estimated as well. In particular, low rank methods have seen great success in applications, such as biomedical imaging [10], face recognition [11] and collaborative filtering [12], that require exploiting the global data correlation to recover the signal subspace and compactly represent the signal at the same time. Recent convex relaxation techniques [13] have further enabled low rank model to be adaptable to various signal processing tasks, including matrix completion [14], system identification [15] and phase retrieval [16], making low rank methods ever more attractive.
In this paper, we present a multi-scale low rank matrix decomposition method that incorporates multi-scale structures with low rank methods. The additional multi-scale structure allows us to obtain a more accurate and compact signal representation than conventional low rank methods whenever the signal exhibits multi-scale structures (see Figure 1). To capture data correlation at multiple scales, we model our data matrix as a sum of block-wise low rank matrices with increasing scales of block sizes (more detail in Section II) and consider the inverse problem of decomposing the matrix into its multi-scale components. Since we do not assume an explicit basis model, multi-scale low rank decomposition also prevents modeling errors or basis mismatch that are commonly seen with multi-scale signal transforms. In short, our proposed multi-scale low rank decomposition inherits the merits from both multi-scale modeling and low rank matrix decomposition.
Fig. 1.

An example of our proposed multi-scale low rank decomposition compared with other low rank methods. Each blob in the input matrix is a rank-1 matrix constructed from an outer product of hanning windows. Only the multi-scale low rank decomposition exactly separates the blobs to their corresponding scales and represents each blob as compactly as possible.
Leveraging recent convex relaxation techniques, we propose a convex formulation to perform the multi-scale low rank matrix decomposition. We provide a theoretical analysis in Section V that extends the rank-sparsity incoherence results in Chandrasekaran et al. [17]. We show that the proposed convex program decomposes the data matrix into its multi-scale components exactly under a deterministic incoherence condition. In addition, in Section VI, we provide a theoretical analysis on approximate multi-scale low rank matrix decomposition in the presence of additive noise that extends the work of Agarwal et al. [18].
A major component of this paper is to introduce the proposed multi-scale low rank decomposition with emphasis on its practical performance and applications. We provide practical guidance on choosing regularization parameters for the convex method in Section IV and describe heuristics to perform cycle spinning [19] to reduce blocking artifacts in Section IX. In addition, we applied the multi-scale low rank decomposition on real datasets and considered four applications of the multi-scale low rank decomposition: illumination normalization for face images, motion separation for surveillance videos, compact modeling of the dynamic contrast enhanced magnetic resonance imaging and collaborative filtering exploiting age information. (See Section X for more detail). Our results show that the proposed multi-scale low rank decomposition provides intuitive multi-scale decomposition and compact signal representation for a wide range of applications.
Related work
Our proposed multi-scale low rank matrix decomposition draws many inspirations from recent developments in rank minimization [13], [14], [18], [20]–[24]. In particular, the multi-scale low rank matrix decomposition is a generalization of the low rank + sparse decomposition proposed by Chandrasekaran et al. [17] and Candès et al. [25]. Our multi-scale low rank convex formulation also fits into the convex demixing framework proposed by McCoy et al. [26]–[28], who studied the problem of demixing components via convex optimization. The proposed multi-scale low rank decomposition can be viewed as a concrete and practical example of the convex demixing problem. However, their theoretical analysis assumes that each component is randomly oriented with respect to each other, and does not apply to our setting, where we observe the direct summation of the components. Bakshi et al. [29] proposed a multi-scale principal component analysis by applying principal component analysis on wavelet transformed signals, but such method implicitly constrains the signal to lie on a predefined wavelet subspace. Various multi-resolution matrix factorization techniques [30], [31] were proposed to greedily peel off components of each scale by recursively applying matrix factorization. One disadvantage of these factorization methods is that it is not straightforward to incorporate them with other reconstruction problems as models. Similar multi-scale modeling using demographic information was also used in collaborative filtering described in Vozalis and Margaritis [32].
II. MULTI-SCALE LOW RANK MATRIX MODELING
In this section, we describe the proposed multi-scale low rank matrix modeling in detail. To concretely formulate the model, we assume that we can partition the data matrix of interest Y into different scales. Specifically, we assume that we are given a multi-scale partition of the indices of an M × N matrix, where each block b in Pi is an order magnitude larger than the blocks in the previous scale Pi−1. Such multi-scale partition can be naturally obtained in many applications. For example in video processing, a multi-scale partition can be obtained by decimating both space and time dimensions. Figures 2 and 4 provide two examples of a multi-scale partition, the first one with decimation along two dimensions and the second one with decimation along one dimension. In Section X, we provide practical examples on creating these multi-scale partitions for different applications.
Fig. 2.
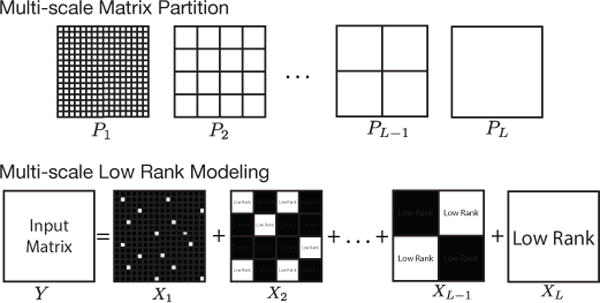
Illustration of a multi-scale matrix partition and its associated multi-scale low rank modeling. Since the zero matrix is a matrix with the least rank, our multi-scale modeling naturally extends to sparse matrices as 1 × 1 low rank matrices.
Fig. 4.
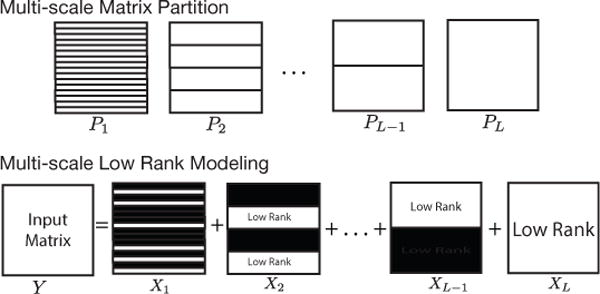
Illustration of another multi-scale matrix partition and its associated multi-scale low rank modeling. Here, only the vertical dimension of the matrix is decimated. Since a 1 × N matrix is low rank if and only if it is zero, our multi-scale modeling naturally extends to group sparse matrices.
To easily transform between the data matrix and the block matrices, we then consider a block reshape operator Rb(X) that extracts a block b from the full matrix X and reshapes the block into an mi × ni matrix (Figure 3), where mi × ni is the ith scale block matrix size determined by the user.
Fig. 3.
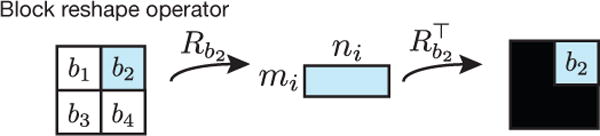
Illustration of the block reshape operator Rb. Rb extracts block b from the full matrix and reshapes it into an mi × ni matrix. Its adjoint operator takes an mi × ni matrix and embeds it into a full-size zero matrix.
Given an M × N input matrix Y and its corresponding multi-scale partition and block reshape operators, we propose a multi-scale low rank modeling that models the M × N input matrix Y as a sum of matrices , in which each Xi is block-wise low rank with respect to its partition Pi that is,
where Ub, Sb, and Vb are matrices with sizes mi ×rb, rb × rb and ni × rb respectively and form the rank-rb reduced SVD of Rb(Xi). Note that when the rank of the block matrix Rb(Xi) is zero, we have {Ub, Sb, Vb} as empty matrices, which do not contribute to Xi. Figure 2 and 4 provide illustrations of two kinds of modeling with their associated partitions.
By constraining each block matrices to be of low rank, the multi-scale low rank modeling captures the notion that some nearby entries are more similar to each other than global entries in the data matrix. We note that the multi-scale low rank modeling is a generalization of the low rank + sparse modeling proposed by Chandrasekaren et al. [17] and Candès et al. [25]. In particular, the low rank + sparse modeling can be viewed as a 2-scale low rank modeling, in which the first scale has block size 1 × 1 and the second scale has block size M × N. By adding additional scales between the sparse and globally low rank matrices, the multi-scale low rank modeling can capture locally low rank components that would otherwise need many coefficients to represent for low rank + sparse.
Given a data matrix Y that fits our multi-scale low rank model, our goal is to decompose the data matrix Y to its multi-scale components . The ability to recover these multi-scale components is beneficial for many applications and allows us to, for example, extract motions at multiple scales in surveillance videos (Section X). Since there are many more parameters to be estimated than the number of observations, it is necessary to impose conditions on Xi. In particular, we will exploit the fact that each block matrix is low rank via a convex program, which will be described in detail in section III.
A. Multi-scale low rank + noise
Before moving to the convex formulation, we note that our multi-scale matrix modeling can easily account for data matrices that are corrupted by additive white Gaussian noise. Under the multi-scale low rank modeling, we can think of the additive noise matrix as the largest scale signal component and is unstructured in any local scales. Specifically if we observe instead the following
| (1) |
where XZ is an independent and identically distributed Gaussian noise matrix. Then we can define a reshape operator RZ that reshapes the entire matrix into an MN × 1 vector and the resulting matrix fits exactly to our multi-scale low rank model with L+1 scales. This incorporation of noise makes our model flexible in that it automatically provides a corresponding convex relaxation, a regularization parameter for the noise matrix and allows us to utilize the same iterative algorithm to solve for the noise matrix. Figure 5 provides an example of the noisy multi-scale low rank matrix decomposition.
Fig. 5.

An example of the multi-scale low rank decomposition in the presense of additive Gaussian noise by solving the convex program (2).
III. PROBLEM FORMULATION AND CONVEX RELAXATION
Given a data matrix Y that fits the multi-scale low rank model, our goal is to recover the underlying multi-scale components using the fact that Xi is block-wise low rank. Ideally, we would like to obtain a multi-scale decomposition with the minimal block matrix rank and solve a problem similar to the following form:
However, each rank minimization for each block is combinatorial in nature. In addition, it is not obvious whether the direct summation of ranks is a correct formulation as a 1-sparse matrix and a rank-1 matrix should intuitively not carry the same cost. Hence, the above non-convex problem is not a practical formulation to obtain the multi-scale decomposition.
Recent development in convex relaxations suggests that rank minimization problems can often be relaxed to a convex program via nuclear norm relaxation [13], [23], while still recovering the optimal solution to the original problem. In particular, Chandrasekaren et al. [17] and Candès et al., [25] showed that a low rank + sparse decomposition can be relaxed to a convex program by minimizing a nuclear norm + ℓ1-norm objective as long as the signal constituents are incoherent with respect to each other. In addition, Candès et al., [25] showed that the regularization parameters for sparsity and low rank should be related by the square root of the matrix size. Hence, there is hope that, along the same line, we can perform the multi-scale low rank decomposition exactly via a convex formulation.
Concretely, let us define ‖·‖nuc to be the nuclear norm, the sum of singular values, and ‖·‖msv be the maximum singular value norm. For each scale i, we consider the block-wise nuclear norm to be the convex surrogate for the block-wise ranks and define ‖·‖(i) the block-wise nuclear norm for the ith scale as
Its associated dual norm is then given by
which is the maximum of all block-wise maximum singular values.
We then consider the following convex relaxation for our multi-scale low rank decomposition problem:
| (2) |
where are the regularization parameters and their selection will be described in detail in section IV.
Our convex formulation is a natural generalization of the low rank + sparse convex formulation [17], [25]. With the two sided matrix partition (Fig. 2), the nuclear norm applied to the 1 × 1 blocks becomes the element-wise ℓ1-norm and the norm for the largest scale is the nuclear norm. With the one sided matrix partition (Fig. 4), the nuclear norm applied to 1 × N blocks becomes the group-sparse norm and can be seen as a generalization of the group sparse + low rank decomposition [21]. If we incorporate additive Gaussian noise in our model as described in Section II-A, then we have a nuclear norm applied to an MN × 1 vector, which is equivalent to the Frobenius norm.
One should hope that the theoretical conditions from low rank + sparse can be generalized rather seamlessly to the multi-scale counterpart. Indeed, in Section V, we show that the core theoretical guarantees in the work of Chandrasekaren et al. [17] on exact low rank + sparse decomposition can be generalized to the multi-scale setting. In section VI, we show that the core theoretical guarantees in the work of Agarwal et al. [18] on noisy matrix decomposition can be generalized to the multi-scale setting as well to provide approximate decomposition guarentees.
IV. GUIDANCE ON CHOOSING REGULARIZATION PARAMETERS
In this section, we provide practical guidance on selecting the regularization parameters . Selecting the regularization parameters is crucial for the convex decomposition to succeed, both theoretically and practically. While theoretically we can establish criteria on selecting the regularization parameters (see Section V and VI), such parameters are not straightforward to calculate in practice as it requires properties of the signal components before the decomposition.
To select the regularization parameters in practice, we follow the suggestions from Wright et al. [33] and Fogel et al. [34], and set each regularization parameter λi to be the Gaussian complexity of each norm‖·‖, which is defined the expectation of the dual norm of random Gaussian matrix:
| (3) |
where ∼ denotes equality up to some constant and G is a unit-variance independent and identically distributed random Gaussian matrix.
The resulting expression for the Gaussian complexity is the maximum singular value of a random Gaussian matrix, which has been studied extensively by Bandeira and Handel [35]. The recommended regularization parameter for scale i is given by
| (4) |
For the sparse matrix scale with 1 × 1 block size, and for the globally low rank scale with M × N block size, . Hence this regularization parameter selection is consistent with the ones recommended for low rank + sparse decomposition by Candès et al. [25], up to a log factor. In addition, for the noise matrix with MN × 1 block size, , which has similar scaling as in square root LASSO [36]. In practice, we found that the suggested regularization parameter selection allows exact multi-scale decomposition when the signal model is matched (for example Figure 1) and provides visually intuitive decomposition for real datasets.
For approximate multi-scale low rank decomposition in the presence of additive noise, some form of theoretical guarantees for the regularization selection can be found in our analysis in Section VI. In particular, we show that if the regularization parameters λi is larger than the Gaussian complexity of in addition to some “spikiness” parameters, then the error between recovered decomposition and the ground truth is bounded by the block-wise matrix rank.
V. THEORETICAL ANALYSIS FOR EXACT DECOMPOSITION
In this section, we provide a theoretical analysis of the proposed convex formulation and show that if satisfies a deterministic incoherence condition, then the proposed convex formulation (2) recovers from Y exactly.
Our analysis follows similar arguments taken by Chandrasekaren et al. [17] on low rank + sparse decomposition and generalizes them to the proposed multi-scale low rank decomposition. Before showing our main result (Theorem V.1), we first describe the subgradients of our objective function (Section V-A) and define a coherence parameter in terms of the block-wise row and column spaces (Section V-B).
A. Subdifferentials of the block-wise nuclear norms
To characterize the optimality of our convex problem, we first look at the subgradients of our objective function. We recall that for any matrix X with {U, S, V} as its reduced SVD representation, the subdifferential of ‖·‖nuc at X is given by [23], [37],
Now recall that we define the block-wise nuclear norm to be . Then using the chain rule and the fact that , we obtain an expression for the subdifferential of ‖·‖(i) at Xi as follows:
To simplify our notation, we define and Ti to be a vector space that contains matrices with the same block-wise row spaces or column spaces as Xi, that is,
where mi ×ni is the size of the block matrices for scale i and rb is the matrix rank for block b. Then, the subdifferential of each ‖·‖(i) at Xi can be compactly represented as,
We note that Ei can be thought of as the “sign” of the matrix Xi, pointing toward the principal components, and, in the case of the sparse scale, is exactly the sign of the entries.
In the rest of the section, we will be interested in projecting a matrix X onto Ti, which can be performed with the following operation:
Similarly, to project a matrix X onto the orthogonal complement of Ti, we can apply the following operation:
where I is an appropriately sized identity matrix.
B. Incoherence
Following Chandrasekaren et al. [17], we consider a deterministic measure of incoherence through the block-wise column and row spaces of Xi. Concretely, we define the coherence parameter for the jth scale signal component Xj with respect to the ith scale to be the following:
| (5) |
Using μij as a measure of incoherence, we can quantitatively say that the jth scale signal component is incoherent with respect to the ith scale if μij is small. In the case of low rank + sparse, Chandrasekaren et al. [17] provides excellent description of the concepts behind the coherence parameters. We refer the reader to their paper for more detail.
C. Main Result
Given the above definition of incoherence, the following theorem states our main result for exact multi-scale low rank decomposition:
Theorem V.1
If we can choose regularization parameters such that
then is the unique optimizer of the proposed convex problem (2).
In particular when the number of scales L = 2, the condition on {μ12, μ21} reduces to μ12μ21 < 1/4 and the condition on {λ1, λ2} reduces to 2μ12 < λ1/λ2 < 1/(2μ21), which is in similar form as Theorem 2 in Chandrasekaren et al. [17].
The proof for the above theorem is given in Appendix A.
VI. THEORETICAL ANALYSIS FOR APPROXIMATE DECOMPOSITION
In this section, we provide a theoretical analysis for approximate multi-scale low rank decomposition when the measurement is corrupted by additive noise as described in Section II-A. Our result follows arguments from Agarwal et al. [18] on noisy 2-scale matrix decomposition and extends it to the multi-scale setting.
Instead of using the incoherence parameter μij defined for the exact decomposition analysis in Section V, we opt for a weaker characterization of incoherence between scales for approximate decomposition, studied in Agarwal et al. [18]. Concretely, we consider spikiness parameters αij between the jth signal component Xj and ith scale norm ‖·‖(i) such that,
for each j ≠ i. Hence, if αij is small, we say Xj is not spiky with respect to the ith norm.
For analysis purpose, we also impose the constraints in the convex program. That is, we consider the solution from the following convex program:
| (6) |
| (7) |
We emphasize that the additional constraints (7) are imposed only for the purpose of theoretical analysis and are not imposed in our experimental results. In particular, for our simulation example in Figure 5, the minimizer of the convex program (2), using the recommended regularization parameters in Section IV, satisfied the constraints (7) even when the constraints were not imposed.
Let us define and ΔZ to be the errors between the ground truth components and XZ and the minimizers of convex program (6). Then, equivalently, we can denote and XZ + ΔZ as the minimizers of the convex program (6). The following theorem states our main result for approximate decomposition.
Theorem VI.1
If we choose such that
| (8) |
and λZ such that
| (9) |
then the error is bounded by
where ≲ denotes inequality up to a universal constant.
Hence, when the spikiness parameters are negligible and XZ = σG, where G is an independent, identically distributed Gaussian noise matrix with unit variance and σ is the noise standard deviation, choosing and ensures the condition is satisfied with high probability. This motivates the recommended regularization selection in Section IV.
The proof for the above theorem is given in Appendix B and follows arguments from Agarwal et al. [18] on noisy matrix decomposition and Belloni et al. [36] on square root LASSO.
VII. AN ITERATIVE ALGORITHM FOR SOLVING THE MULTI-SCALE LOW RANK DECOMPOSITION
In the following, we will derive an iterative algorithm that solves for the multi-scale low rank decomposition via the Alternating Direction of Multiple Multipliers (ADMM) [38]. While the proposed convex formulation (2) can be formulated into a semi-definite program, first-order iterative methods are commonly used when solving for large datasets for their computational efficiency and scalability. A conceptual illustration of the algorithm is shown in Figure 6.
Fig. 6.
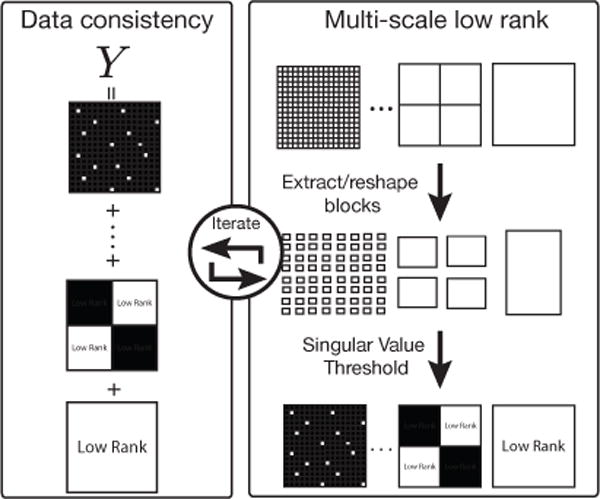
A conceptual illustration of how to obtain a multi-scale low rank decomposition. First, we extract each block from the input matrix and perform a thresholding operation on its singular value to recover the significant components. Then, we subtract these significant components from our input matrix, thereby enabling the recovery of weaker, previously submerged components.
To formally obtain update steps using ADMM, we first formulate the problem into the standard ADMM form with two separable objectives connected by an equality constraint,
| (10) |
where I{·} is the indicator function.
To proceed, we then need to obtain the proximal operators [39] for the two objective functions and . For the data consistency objective , the proximal operator is simply the projection operator to the set. To obtain the proximal operator for the multi-scale nuclear norm objective , we first recall that the proximal operator for the nuclear norm ‖X‖nuc with parameter λ is given by the singular value soft-threshold operator [23],
| (11) |
Since we defined the block-wise nuclear norm for each scale i as , the norm is separable with respect to each block and its proximal function with parameter λi is given by the block-wise singular value soft-threshold operator,
| (12) |
which simply extracts every blocks in the matrix, performs singular value thresholding and puts the blocks back to the matrix. We note that for 1 × 1 blocks, the block-wise singular value soft-threshold operator reduces to the element-wise soft-threshold operator and for 1 × N blocks, the block-wise singular soft-threshold operator reduces to the joint soft-threshold operator.
Putting everything together and invoking the ADMM recipe [38], we have the following algorithm to solve our convex multi-scale low rank decomposition (2):
| (13) |
where ρ is the ADMM parameter that only affects the convergence rate of the algorithm.
The resulting ADMM update steps are similar in essence to the intuitive update steps in Figure 6, and alternates between data consistency and enforcing multi-scale low rank. The major difference of ADMM is that it adds a dual update step with Ui, which bridges the two objectives and ensures the convergence to the optimal solution. Under the guarantees of ADMM, in the limit of iterations, Xi and Zi converge to the optimal solution of the convex program (2) and Ui converges to a scaled version of the dual variable. In practice, we found that ∼ 1000 iterations are sufficient without any visible change for imaging applications. Finally, we note that because the proximal operator for the multi-scale nuclear norm is computationally simple, other proximal operator based algorithms [39] can also be used.
VIII. COMPUTATIONAL COMPLEXITY
Given the iterative algorithm (13), one concern about the multi-scale low rank decomposition might be that it is significantly more computationally intensive than other low rank methods as we have many more SVD’s and variables to compute for. In this section, we show that because we decimate the matrices at each scale geometrically, the theoretical computational complexity of the multi-scale low rank decomposition is similar to other low rank decomposition methods, such as the low rank + sparse decomposition.
For concreteness, let us consider the multi-scale partition with two-sided decimation shown in Figure 2 and have block sizes mi = 2i−1 and ni = 2i−1. Similar to other low rank methods, the SVD’s dominate the per iteration complexity for the multi-scale low rank decomposition. For an M × N matrix, each SVD costs<monospace>#flops</monospace>(M ×N SVD) = O(MN2). The per iteration complexity for the multi-scale low rank decomposition is dominated by the summation of all the SVD’s performed for each scale, which is given by,
| (14) |
Hence, the per-iteration computational complexity of the multi-scale low rank with two-sided decimated partition is on the order of a M × N matrix SVD. In general, one can show that the per-iteration complexity for arbitrary multi-scale partition is at most log(N) times the full matrix SVD.
While theoretically, the computation cost for small block sizes should be less than bigger block sizes, we found that in practice the computation cost for computing the small SVD’s can dominate the per-iteration computation. This is due to the overhead of copying small block matrices and calling library functions repeatedly to compute the SVD’s.
Since we are interested in thresholding the singular values and in practice many of the small block matrices are zero as shown in Section X, one trick of reducing the computation time is to quickly compute an upper bound on the maximum singular value for block matrices before the SVD’s. Then if the upper bound for the maximum singular value is less than the threshold, we know the thresholded matrix will be zero and can avoid computing the SVD. Since for any matrix X, its maximum singular value is bounded by the square root of any matrix norm on X⊤X [40], there are many different upper bounds that we can use. In particular, we choose the maximum row norm and consider the following upper bound,
| (15) |
Using this upper bound, we can identify many below-the-threshold matrices before computing the SVD’s at all. In practice, we found that the above trick provides a modest speedup of 3 ∼ 5×.
IX. HEURISTICS FOR TRANSLATION INVARIANT DECOMPOSITION
Similar to wavelet transforms, one drawback of the multi-scale low rank decomposition is that it is not translation invariant, that is, shifting the input changes the resulting decomposition. In practice, this translation variant nature often creates blocking artifacts near the block boundaries, which can be visually jarring for image or video applications. One solution to remove these artifacts is to introduce overlapping partitions of the matrix so that the overall algorithm is translation invariant. However, this vastly increases both memory and computation especially for large block sizes. In the following, we will describe a cycle spinning approach that we used in practice to reduce the blocking artifacts with only slight increase in per-iteration computation.
Cycle spinning [19] has been commonly used in wavelet denoising to reduce the blocking artifacts due to the translation variant nature of the wavelet transform. To minimize artifacts, cycle spinning averages the denoised results from all possible shifted copies of the input, thereby making the entire process translation invariant. Concretely, let S be the set of all shifts possible in the target application, SHIFTs denote the shifting operator by s, and DENOISE be the denoising operator of interest. Then the cycle spinned denoising of the input X is given by:
| (16) |
In the context of multi-scale low rank decomposition, we can make the iterative algorithm translation invariant by replacing the block-wise singular value thresholding operation in each iteration with its cycle spinning counterpart. In particular, for our ADMM update steps, we can replace the Zi step to:
| (17) |
To further reduce computation, we perform random cycle spinning in each iteration as described in Figueiredo et al. [41], in which we randomly shifts the input, performs block-wise singular value thresholding and then unshifts back:
| (18) |
where s is randomly chosen from the set S.
Using random cycle spinning, blocking artifacts caused by thresholding are averaged over iterations and in practice, reduces distortion significantly. Figure 7 shows an example of the multi-scale low rank decomposition with and without random cycle spinning applied on a simulated data that does not fall on the partition grid. The decomposition with random cycle spinning vastly reduces blocking artifacts that appeared in the one without random cycle spinning.
Fig. 7.

An example of the multi-scale low rank decomposition with and without random cycle spinning. Each blob in the input matrix Y is a rank-1 matrix constructed from an outer product of hanning windows and is placed at random positions. Blocking artifacts can be seen in the decomposition without random cycle spinning while vastly diminished in the random cycle spinned decomposition.
X. APPLICATIONS
To test for practical performance, we applied the multi-scale low rank decomposition on four different real datasets that are conventionally used in low rank modeling: illumination normalization for face images (Section X-A), motion separation for surveillance videos (Section X-B), multi-scale modeling of dynamic contrast enhanced magnetic resonance imaging (Section X-C) and collaborative filtering exploiting age information (Section X-D). We compared our proposed multi-scale low rank decomposition with low rank + sparse decomposition for the first three applications and with low rank matrix completion for the last application. Randomly cycle spinning was used for multi-scale low rank decomposition for all of our experiments. Regularization parameters λi were chosen exactly as for multi-scale low rank and max(mi, ni) for low rank + sparse decomposition. Our simulations were written in the C programming language and ran on a 20-core Intel Xeon workstation. Some results are best viewed in video format, which are available as supplementary materials.
In the spirit of reproducible research, we provide a software package (in C and partially in MATLAB) to reproduce most of the results described in this paper. The software package can be downloaded from: https://github.com/frankong/multi_scale_low_rank.git
A. Multi-scale Illumination Normalization for Face Recognition Pre-processing
Face recognition algorithms are sensitive to shadows or occlusions on faces. In order to obtain the best possible performance for these algorithms, it is desired to remove illumination variations and shadows on the face images. Low rank modeling are often used to model faces and is justified by approximating faces as convex Lambertian surfaces [11].
Low rank + sparse decomposition [25] was recently proposed to capture uneven illumination as sparse errors and was shown to remove small shadows while capturing the underlying faces as the low rank component. However, most shadows are not sparse and contain structure over different lighting conditions. Here, we propose modeling shadows and illumination changes in different face images as block-low rank as illumination variations are spatially correlated in multiple scales.
We considered face images from the Yale B face database [42]. Each face image was of size 192×168 with 64 different lighting conditions. The images were then reshaped into a 32, 256 × 64 matrix and both multi-scale low rank and low rank + sparse decomposition were applied on the data matrix. For low rank + sparse decomposition, we found that the best separation result was obtained when each face image was normalized to the maximum value. For multi-scale low rank decomposition, the original unscaled image was used. Only the space dimension was decimated as we assumed there was no ordering in different illumination conditions. The multi-scale matrix partition can be visualized as in Figure 4.
Figure 8 shows one of the comparison results. Multi-scale low rank decomposition recovered almost shadow-free faces. In particular, the sparkles in the eyes were represented in the 1 × 1 block size and the larger illumination changes were represented in bigger blocks, thus capturing most of the uneven illumination changes. In contrast, low rank + sparse decomposition could only recover from small illumination changes and still contained the larger shadows in the globally low rank component.
Fig. 8.
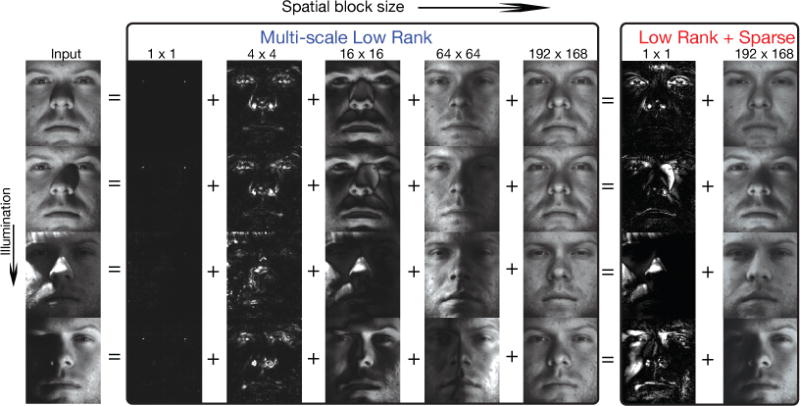
Multi-scale low rank versus low rank + sparse on faces with uneven illumination. Multi-scale low rank decomposition recovers almost shadow-free faces, whereas low rank + sparse decomposition can only remove some shadows.
B. Multi-scale Motion Separation for Surveillance Videos
In surveillance video processing, it is desired to extract foreground objects from the video. To be able to extract foreground objects, both the background and the foreground dynamics have to be modeled. Low rank modeling have been shown to be suitable for slowly varying videos, such as background illumination changes. In particular, if the video background only changes its brightness over time, then it can be represented as a rank-1 matrix.
Low rank + sparse decomposition [25] was proposed to foreground objects as sparse components and was shown to separate dynamics from background components. However, sparsity alone cannot capture motion compactly and often results in ghosting artifacts occurring around the foreground objects as shown in Figure 9. Since video dynamics are correlated locally at multiple scales in space and time, we propose using the multi-scale low rank modeling with two sided decimation to capture different scales of video dynamics over space and time.
Fig. 9.

Multi-scale low rank versus low rank + sparse decomposition on a surveillance video. For the multi-scale low rank, body motion is mostly captured in the 16 × 16 × 16 scale while fine-scale motion is captured in 4 × 4 × 4 scale. Background video component is captured in the globally low rank component and is almost artifact-free. Low rank + sparse decomposition exhibits ghosting artifacts as pointed by the red arrow because they are neither globally low rank or sparse.
We considered a surveillance video from Li et al. [43]. Each video frame was of size 144×176 and the first 200 frames were used. The video frames were then reshaped into a 25, 344×200 matrix and both multi-scale low rank and low rank + sparse decomposition were applied on the data matrix.
Figure 9 shows one of the results. Multi-scale low rank decomposition recovered a mostly artifact free background video in the globally low rank component whereas low rank + sparse decomposition exhibits ghosting artifact in certain segments of the video. For the multi-scale low rank decomposition, body motion was mostly captured in the 16 × 16 × 16 scale while fine-scale motion was captured in 4 × 4 × 4 scale.
C. Multi-scale Low Rank Modeling for Dynamic Contrast Enhanced Magnetic Resonance Imaging
In dynamic contrast enhanced magnetic resonance imaging (DCE-MRI), a series of images over time is acquired after a T1 contrast agent was injected into the patient. Different tissues then exhibit different contrast dynamics over time, thereby allowing radiologists to characterize and examine lesions. Compressed sensing Magnetic Resonance Imaging [44] is now a popular research approach used in three dimensional DCE-MRI to speed up acquisition. Since the more compact we can represent the image series, the better our compressed reconstruction result becomes, an accurate modeling of the dynamic image series is desired to improve the compressed sensing reconstruction results for DCE-MRI.
When a region contains only one type of tissue, then the block matrix constructed by stacking each frame as columns will have rank 1. Hence, low rank modeling [10], and locally low rank modeling [45] have been popular models for DCE-MRI. Recently, low rank + sparse modeling [46] have also been proposed to model the static background and dynamics as low rank and sparse matrices respectively. However, dynamics in DCE-MRI are almost never sparse and often exhibit correlation across different scales. Hence, we propose using a multi-scale low rank modeling to capture contrast dynamics over multiple scales.
We considered a fully sampled dynamic contrast enhanced image data. The data was acquired in a pediatric patient with 20 contrast phases, 1×1.4×2 mm3 resolution, and 8s temporal resolution. The acquisition was performed on a 3T GE MR750 scanner with a 32-channel cardiac array using an RF-spoiled gradient-echo sequence. We considered a 2D slice of size 154×112 were then reshaped into a 17, 248×20 matrix. Both multi-scale low rank and low rank + sparse decomposition were applied on the data matrix.
Figure 10 shows one of the results. In the multi-scale low rank decomposition result, small contrast dynamics in vessels were captured in 4 × 4 blocks while contrast dynamics in the liver were captured in 16 × 16 blocks. The biggest block size captured the static tissues and interestingly the respiratory motion. Hence, different types of contrast dynamics were captured compactly in their suitable scales. In contrast, the low rank + sparse modeling could only provide a coarse separation of dynamics and static tissue, which resulted in neither truly sparse nor truly low rank components.
Fig. 10.
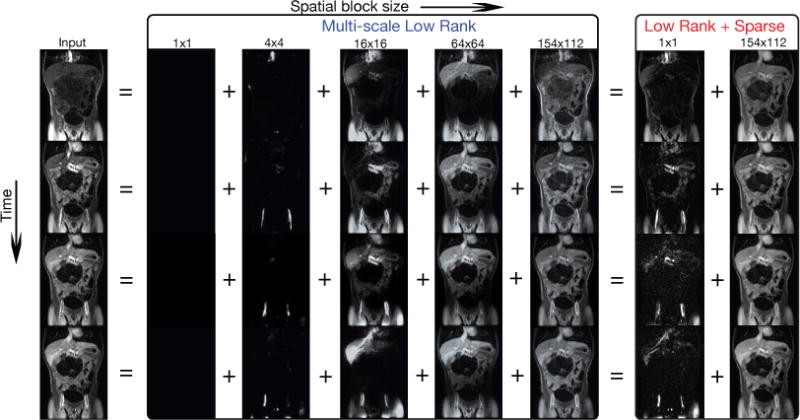
Multi-scale low rank versus low rank + sparse decomposition on a dynamic contrast enhanced magnetic resonance image series. For the multi-scale result, small contrast dynamics in vessels are captured in 4 × 4 blocks while contrast dynamics in the liver are captured in 16 × 16 blocks. The biggest block size captures the static tissues and interestingly the respiratory motion. In contrast, the low rank + sparse modeling could only provide a coarse separation of dynamics and static tissue, which result in neither truly sparse nor truly low rank components.
D. Multi-scale Age Grouping for Collaborative Filtering
Collaborative filtering is the task of making predictions about the interests of a user using available information from all users. Since users often have similar taste for the same item, low rank modeling is commonly used to exploit the data similarity to complete the rating matrix [14], [22], [23]. On the other hand, low rank matrix completion does not exploit the fact that users with similar demographic backgrounds have similar taste for similar items. In particular, users of similar age should have similar taste. Hence, we incorporated the proposed multi-scale low rank modeling with matrix completion by partitioning users according to their age and compared it with the conventional low rank matrix completion. Our method belongs to the general class of collaborative filtering methods that utilize demographic information [32].
To incorporate multi-scale low rank modeling into matrix completion, we change the data consistency constraint in problem (2) to for observed jk entries, and correspondingly, the update step for in equation (13) is changed to for observed jk entries and for unobserved jk entries. We emphasize that our theoretical analysis does not cover matrix completion and the presented collaborative filtering application is mainly of empirical interest.
To compare the methods, we considered the 100K Movie-Lens dataset, in which 943 users rated 1682 movies. The resulting matrix was of size 1682 × 943, where the first dimension represented movies and the second dimension represented users. The entire matrix had 93.7% missing entries. Test data was further generated by randomly undersampling the rating matrix by 5. The algorithms were then run on the test data and root mean squared errors were calculated over all available entries. To obtain a multi-scale partition of the matrix, we sorted the users according to their age along the second dimension and partitioned them evenly into age groups.
Figure 11 shows a multi-scale low rank reconstructed user rating matrix. Using multiple scales of block-wise low rank matrices, correlations in different age groups were captured. For example, one of the scales shown in Figure 11 captures the tendency that younger users rated Star Wars higher whereas the more senior users rated Gone with the Wind higher. The multi-scale low rank reconstructed matrix achieved a root mean-squared-error of 0.9385 compared to a root mean-squared-error of 0.9552 for the low rank reconstructed matrix.
Fig. 11.
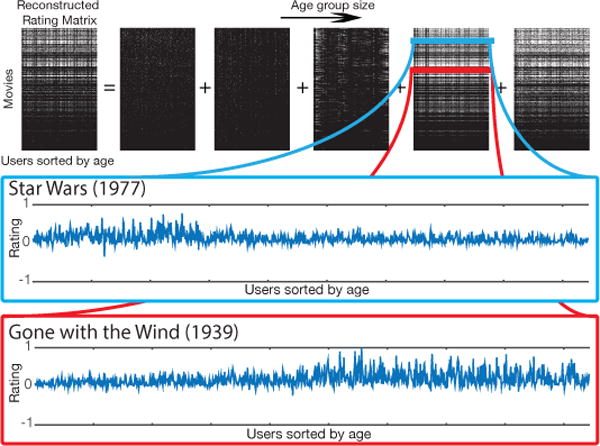
Multi-scale low rank reconstructed matrix of the 100K MovieLens dataset. The extracted signal scale component captures the tendency that younger users rated Star Wars higher whereas the more senior users rated Gone with the Wind higher.
XI. DISCUSSION
We have presented a multi-scale low rank matrix decomposition method that combines both multi-scale modeling and low rank matrix decomposition. Using a convex formulation, we can solve for the decomposition efficiently and exactly, provided that the multi-scale signal components are incoherent. We provided a theoretical analysis of the convex relaxation for exact decomposition, which extends the analysis in Chandrasekaren et al. [17], and an analysis for approximate decomposition in the presence of additive noise, which extends the analysis in Agarwal et al. [18]. We also provided empirical results that the multi-scale low rank decomposition performs well on real datasets.
We would also like to emphasize that our recommended regularization parameters empirically perform well even with the addition of noise, and hence in practice does not require manual tuning. While some form of theoretical guarantees for the regularization parameters are provided in the approximate decomposition analysis, complete theoretical guarentees are not provided, especially for noiseless situations, and would be valuable for future work.
Our experiments show that the multi-scale low rank decomposition improves upon the low rank + sparse decomposition in a variety of applications. We believe that more improvement can be achieved if domain knowledge for each applications is incorporated with the multi-scale low rank decomposition. For example, for face shadow removal, prior knowledge of the illumination angle might be able to provide a better multi-scale partition. For movie rating collaborative filtering, general demographic information and movie types can be used to construct multi-scale partitions in addition to age information.
Supplementary Material
Acknowledgments
This work is supported by NIH grants R01EB019241, R01EB009690, and P41RR09784, Sloan research fellowship, Okawa research grant and NSF GRFP.
Biographies

Frank Ong is currently pursuing the Ph.D. degree in the department of Electrical Engineering and Computer Sciences at the University of California, Berkeley. He received his B.Sc. at the same department in 2013. His research interests lie in signal processing, medical image reconstruction, compressed sensing and low rank methods.

Michael (Miki) Lustig is an Associate Professor in EECS. He joined the faculty of the EECS Department at UC Berkeley in Spring 2010. He received his B.Sc. in Electrical Engineering from the Technion, Israel Institute of Technology in 2002. He received his Msc and Ph.D. in Electrical Engineering from Stanford University in 2004 and 2008, respectively. His research focuses on medical imaging, particularly Magnetic Resonance Imaging (MRI), and very specifically, the application of compressed sensing to rapid and high-resolution MRI, MRI pulse sequence design, medical image reconstruction, inverse problems in medical imaging and sparse signal representation.
APPENDIX A PROOF OF THEOREM V.1
In this section, we provide a proof of Theorem V.1 and show that if satisfies a deterministic incoherence condition, then the proposed convex formulation (2) recovers from Y exactly. Our proof makes use of the dual certificate common in such proofs. We will begin by proving a technical lemma collecting three inequalities.
Lemma A.1
For i = 1,…, L, the following three inequalities hold,
| (19) |
| (20) |
| (21) |
Proof
To show the first inequality (19), we recall that . Then, using the variational representation of the maximum singular value norm, we obtain,
where col and row denote the column and row spaces respectively.
Similarly, we obtain the second inequality (20):
The third inequality (21) follows from the incoherence definition that for any non-zero Nj.■
Next, we will show that if we can choose some parameters to “balance” the coherence between the scales, then the block-wise row/column spaces are independent, that is is a direct sum. Consequently, each matrix N in the span of has a unique decomposition , where Ni ∈ Ti.
Proposition A.2
If we can choose some positive parameters such that
| (22) |
then we have
| (23) |
In particular when L = 2, the condition on {μ12,μ21} reduces to μ12μ21 < 1, which coincides with Proposition 1 in Chandrasekaren et al. [17]. We also note that given μij, we can obtain that satisfies the condition by solving a linear program.
Proof
Suppose by contradiction that there exists such that , but Then there exists such that and not all Ni zero. But this leads to a contradiction because for i = 1,…,L,
| (24) |
| (25) |
| (26) |
where we have used equation (21) for the first inequality (24), Holder’s inequality for second inequality (25) and for the last inequality. Hence, none of is the largest of the set, which is a contradiction. ■
Our next theorem shows an optimality condition of the convex program (2) in terms of its dual solution.
Theorem A.3
(Lemma 4.2 [33]). is the unique minimizer of the convex program (2) if there exists a matrix Q such that for i = 1,…,L,
1)
2)
Proof
Consider any non-zero perturbation to such that stays in the feasible set, that is . We will show that .
We first decompose Δi into orthogonal parts with respect to Ti, that is, . We also consider a specific subgradient of at such that , and . Then, from the definition of subgradient and the fact that , we have,
Applying the orthogonal decomposition with respect to Ti and using , we have,
Using Holder’s inequality and the assumption for the subgradient Gi, we obtain,
■
With Proposition A.2 and Theorem A.3, we are ready to prove Theorem V.1.
Proof of Theorem V.1
Since , by Proposition A.2, for all i. Thus, there is a unique matrix Q in such that . In addition, Q can be uniquely expressed as a sum of elements in Ti. That is, with Qi ∈ Ti. We now have a matrix Q that satisfies the first optimality condition. In the following, we will show that it also satisfies the second optimality condition .
If the vector spaces are orthogonal, then Qi is exactly λiEi. Because they are not necessarily orthogonal, we express Qi as λiEi plus a correction term λi∈i. That is, we express Qi = λi(Ei + ∈i). Putting Qi’s back to Q, we have
| (27) |
Combining the above equation (27) with the first optimality condition (A.3), , we have . Since , rearranging the equation, we obtain the following recursive expression for :
| (28) |
We now obtain a bound on in terms of εi.
| (29) |
| (30) |
| (31) |
where we obtain equation (29) from equation (20), equation (30) from equation (21) and the last inequality (31) from Holder’s inequality.
Similarly, we obtain a recursive expression for using equation (28)
| (32) |
| (33) |
| (34) |
where we obtain equation (32) from equation (19), equation (33) from equation (21) and the last inequality (34) from Holder’s inequality.
Taking the maximum over i on both sides and rearranging, we have
Putting the bound back to equation (31), we obtain
| (35) |
where we used in the last inequality.
Thus, we have constructed a dual certificate Q that satisfies the optimality conditions (A.3) and is the unique optimizer of the convex problem (2).
APPENDIX B PROOF OF THEOREM VI
In this section, we provide a proof of Theorem VI, showing that as long as we can choose our regularization parameters accordingly, we obtain a solution from the convex program (6) that is close to the ground truth .
We will begin by proving a technical lemma collecting three inequalities. Throughout the section, we will assume is non-zero for simplicity, so that the subgradient of is exactly .
Lemma B.1
For i=1,…,L, the following three inequalities hold,
| (36) |
| (37) |
| (38) |
Proof
We will prove the inequalities in order.
Let us choose a subgradient of at Xi such that . Then, from the definition of the subgradient, we have,
| (39) |
where we used Holder’s inequality for the last inequality (39). Re-arranging, we obtain the first result (36).
For the second inequality, we note that since , we have .From the definition of subgradient, we obtain,
| (40) |
| (41) |
| (42) |
where we obtain equation (40) from Holder’s inequality, equation (41) from the condition of (8) and equation (42) from the triangle inequality.
Since and achieves the minimum objective function, we have,
Substituting equation (39) and (42), we obtain,
| (43) |
Cancelling and re-arranging, we obtain the desired inequality (37),
For the third inequality, recall that for any rank-r matrix X, its nuclear norm is upper bounded by . Moreover, the projection of any matrix Y to the column and row space T of a rank r matrix is at most rank-2r, that is rank(PT (Y)) ≤ 2r. Hence, we obtain,
where the last inequality follows from Cauchy-Schwatz inequality and the fact that ■.
With these three inequalities, we now proceed to prove Theorem VI.
Proof of Theorem VI
From the optimality of , we have the following inequality,
Re-arranging, we obtain,
For convenience, let us define and . Then, from Lemma B.1 equation (36), we obtain,
| (44) |
We would like to keep only on the left hand side and cancel . To do this, we multiply both sides of equation (44) with . Then, using (a+b)(a−b) = a2 − b2, we expand the left hand side as:
Recall that , we obtain the following lower bound for the left hand side:
| (45) |
| (46) |
| (47) |
where we used Holder’s inequality for equation (45), the condition for λi for equation (46), and the triangle inequality for (47).
We now turn to upper bound the right hand side. We know from equation (44). Hence, we obtain,
Using Lemma B.1 equation (37), we have,
| (48) |
Combining and simplifying the lower bound (47) and the upper bound (48), we obtain,
| (49) |
We will now lower bound by individual terms:
where we used Holder’s inequality for the last inequality.
Now, using the assumption that both and are bounded by αij. We have,
| (50) |
| (51) |
where we used the triangle inequality for equation (50) and Lemma B.1 equation (37) for equation (51).
Substituting the lower bound back to equation (49), we have
| (52) |
We now turn to upper bound the equation. From Lemma B.1 equation (38), we know that . Hence, we have,
| (53) |
| (54) |
where we used Cauchy-Schwartz’s inequality for equation (53) and the condition for for equation (54). Hence, substituting back to equation (52), rearranging and ignoring constants, we have,
Completing the squares with respect to gives us,
Using the triangle inequality to lower bound the left hand side, we obtain
Using the fact that ℓ1-norm is larger than the ℓ2-norm, and re-arranging give us the desired result,
■
References
- 1.Mallat SG. A theory for multiresolution signal decomposition: the wavelet representation. IEEE Transactions on Pattern Analysis and Machine Intelligence. 1989 [Online]. Available: http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=192463.
- 2.Candes E, Demanet L, Donoho D, Ying L. Fast discrete curvelet transforms. Multiscale Modeling & Simulation. 2006 [Online]. Available: http://epubs.siam.org/doi/abs/10.1137/05064182X.
- 3.Simoncelli EP, Freeman WT, Adelson EH, Heeger DJ. Shiftable multiscale transforms. IEEE Transactions on Information Theory. 1992 Mar;38(2):587–607. [Online]. Available: http://ieeexplore.ieee.org/lpdocs/epic03/wrapper.htm?arnumber=119725. [Google Scholar]
- 4.Donoho DL, Johnstone IM. Ideal spatial adaptation by wavelet shrinkage. Biometrika. 2006 Sep;81(3):1–31. [Online]. Available: http://www.jstor.org/stable/2337118?origin=crossref. [Google Scholar]
- 5.Donoho DL. Compressed sensing. IEEE Transactions on Information Theory. 2006 Apr;52(4):1289–1306. [Online]. Available: http://ieeexplore.ieee.org/lpdocs/epic03/wrapper.htm?arnumber=1614066. [Google Scholar]
- 6.Candes EJ, Romberg J, Tao T. Robust uncertainty principles: exact signal reconstruction from highly incomplete frequency information. IEEE Transactions on Information Theory. 2006;52(2):489–509. [Online]. Available: http://ieeexplore.ieee.org/lpdocs/epic03/wrapper.htm?arnumber=1580791. [Google Scholar]
- 7.Donoho DL, Huo X. Uncertainty principles and ideal atomic decomposition. IEEE Transactions on Information Theory. 2001 Nov;47(7):2845–2862. [Online]. Available: http://ieeexplore.ieee.org/lpdocs/epic03/wrapper.htm?arnumber=959265. [Google Scholar]
- 8.Starck JL, Moudden Y, Bobin J, Elad M, Donoho DL. Morphological component analysis. Optics & Photonics 2005. 2005 Aug;5914:59 140Q-59–140Q-15. [Online]. Available: http://proceedings.spiedigitallibrary.org/proceeding.aspx?articleid=870615. [Google Scholar]
- 9.Chen SS, Donoho DL, Saunders MA. Atomic decomposition by basis pursuit. SIAM Journal on Scientific Computing. 1998;20(1):33–61. [Online]. Available: http://epubs.siam.org/doi/abs/10.1137/S1064827596304010. [Google Scholar]
- 10.Liang ZP. Spatiotemporal imaging with partially separable functions. The Proceedings of the International Symposium of Biomedical Imaging: From Nano to Macro IEEE. 2007:988–991. [Online]. Available: http://ieeexplore.ieee.org/lpdocs/epic03/wrapper.htm?arnumber=4193454.
- 11.Basri R, Jacobs DW. Lambertian reflectance and linear subspaces. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2003 Feb;25(2):218–233. [Online]. Available: http://ieeexplore.ieee.org/lpdocs/epic03/wrapper.htm?arnumber=1177153. [Google Scholar]
- 12.Goldberg K, Roeder T, Gupta D, Perkins C. Eigentaste: A Constant Time Collaborative Filtering Algorithm. Information Retrieval. 2001;4(2):133–151. [Online]. Available: http://link.springer.com/10.1023/A:1011419012209. [Google Scholar]
- 13.Fazel M. Ph D dissertation. Stanford University; Mar, 2002. Matrix rank minimization with applications. [Online]. Available: https://faculty.washington.edu/mfazel/thesis-final.pdf. [Google Scholar]
- 14.Candès EJ, Recht B. Exact Matrix Completion via Convex Optimization. Foundations of Computational Mathematics. 2009 Dec;9(6):717–772. [Online]. Available: http://link.springer.com/10.1007/s10208-009-9045-5. [Google Scholar]
- 15.Fazel M, Pong TK, Sun D, Tseng P. Hankel Matrix Rank Minimization with Applications to System Identification and Realization. SIAM Journal on Matrix Analysis and Applications. 2013 Jul;34(3):946–977. [Online]. Available: http://epubs.siam.org/doi/abs/10.1137/110853996. [Google Scholar]
- 16.Candès EJ, Eldar YC, Strohmer T, Voroninski V. Phase Retrieval via Matrix Completion. SIAM Journal on Imaging Sciences. 2013 Feb;6(1):199–225. [Online]. Available: http://epubs.siam.org/doi/abs/10.1137/110848074. [Google Scholar]
- 17.Chandrasekaran V, Sanghavi S, Parrilo PA. Rank-sparsity incoherence for matrix decomposition. SIAM Journal on Optimization. 2011;21(2):572–596. [Online]. Available: http://epubs.siam.org/doi/abs/10.1137/090761793. [Google Scholar]
- 18.Agarwal A, Negahban S, Wainwright MJ. Noisy matrix decomposition via convex relaxation: Optimal rates in high dimensions. The Annals of Statistics. 2012 Apr;40(2):1171–1197. [Online]. Available: http://projecteuclid.org/euclid.aos/1342625465. [Google Scholar]
- 19.Coifman RR, Donoho DL. Wavelets and Statistics. New York, NY: Springer New York; 1995. Translation-Invariant De-Noising; pp. 125–150. [Online]. Available: http://link.springer.com/10.1007/978-1-4612-2544-7_9. [Google Scholar]
- 20.Recht B, Xu W, Hassibi B. Null space conditions and thresholds for rank minimization. Mathematical Programming. 2010 Oct;127(1):175–202. [Online]. Available: http://link.springer.com/10.1007/s10107-010-0422-2. [Google Scholar]
- 21.Xu H, Caramanis C, Sanghavi S. Robust PCA via outlier pursuit. Advances in Neural Information Processing Systems. 2010;23:2496–2504. [Online]. Available: http://papers.nips.cc/paper/4005-robust-pca-via-outlier-pursuit. [Google Scholar]
- 22.Candes EJ, Tao T. The Power of Convex Relaxation: Near-Optimal Matrix Completion. IEEE Transactions on Information Theory. 2010 May;56(5):2053–2080. [Online]. Available: http://ieeexplore.ieee.org/lpdocs/epic03/wrapper.htm?arnumber=5452187. [Google Scholar]
- 23.Recht B, Fazel M, Parrilo PA. Guaranteed minimum-rank solutions of linear matrix equations via nuclear norm minimization. SIAM Review. 2010 [Online]. Available: http://epubs.siam.org/doi/abs/10.1137/070697835.
- 24.Hsu D, Kakade SM, Zhang T. Robust Matrix Decomposition With Sparse Corruptions. IEEE Transactions on Information Theory. 2011;57(11):7221–7234. [Online]. Available: http://ieeexplore.ieee.org/lpdocs/epic03/wrapper.htm?arnumber=5934412. [Google Scholar]
- 25.Candès EJ, Li X, Ma Y, Wright J. Robust principal component analysis? Journal of the ACM. 2011 May;58(3):1–37. [Online]. Available: http://portal.acm.org/citation.cfm?doid=1970392.1970395. [Google Scholar]
- 26.McCoy MB, Tropp JA. The achievable performance of convex demixing. arXiv preprint arXiv:1309.7478v1. 2013 Sep; [Online]. Available: http://arxiv.org/abs/1309.7478v1.
- 27.McCoy MB, Tropp JA. Sharp recovery bounds for convex demixing, with applications. Foundations of Computational Mathematics. 2014 Jan;14(3):1–51. [Online]. Available: http://link.springer.com/10.1007/s10208-014-9191-2. [Google Scholar]
- 28.McCoy MB, Cevher V, Dinh QT, Asaei A. Convexity in source separation: Models, geometry, and algorithms. IEEE Signal Processing Magazine. 2014;31(3):87–95. [Online]. Available: http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=6784106. [Google Scholar]
- 29.Bakshi BR. Multiscale PCA with application to multivariate statistical process monitoring. AIChE Journal. 1998 Jul;44(7):1596–1610. [Online]. Available: http://doi.wiley.com/10.1002/aic.690440712. [Google Scholar]
- 30.Kondor R, Teneva N, Garg V. Multiresolution Matrix Factorization. in The 31st International Conference on Machine Learning. 2014:1620–1628. [Online]. Available: http://jmlr.org/proceedings/papers/v32/kondor14.html.
- 31.Kakarala R, Ogunbona PO. Signal analysis using a multiresolution form of the singular value decomposition. Image Processing. 2001 doi: 10.1109/83.918566. [Online]. Available: http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=918566. [DOI] [PubMed]
- 32.Vozalis M, Margaritis K. Using SVD and demographic data for the enhancement of generalized Collaborative Filtering. Information Sciences. 2007 Aug;177(15):3017–3037. [Online]. Available: http://linkinghub.elsevier.com/retrieve/pii/S0020025507001223. [Google Scholar]
- 33.Wright J, Ganesh A, Min K, Ma Y. Compressive principal component pursuit. Information and Inference: A Journal of the IMA. 2013 [Online]. Available: http://imaiai.oxfordjournals.org/content/2/1/32.short.
- 34.Foygel R, Mackey L. Corrupted sensing: Novel guarantees for separating structured signals. IEEE Transaction on Information Theory. 2014;60(2):1223–1247. [Online]. Available: http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=6712045. [Google Scholar]
- 35.Bandeira AS, van Handel R. Sharp nonasymptotic bounds on the norm of random matrices with independent entries. arXiv preprint arXiv:1408.6185v3. 2014 Aug; [Online]. Available: http://arxiv.org/abs/1408.6185v3.
- 36.Belloni A, Chernozhukov V, Wang L. Square-root lasso: pivotal recovery of sparse signals via conic programming. Biometrika. 2011 [Online]. Available: http://biomet.oxfordjournals.org/content/98/4/791.short.
- 37.Watson GA. Characterization of the subdifferential of some matrix norms. Linear Algebra and Its Applications. 1992 [Online]. Available: http://www.sciencedirect.com/science/article/pii/0024379592904072.
- 38.Boyd S. Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers. Foundations and Trends® in Machine Learning. 2010;3(1):1–122. [Online]. Available: https://web.stanford.edu/~boyd/papers/pdf/admm_distr_stats.pdf. [Google Scholar]
- 39.Parikh N, Boyd S. Proximal algorithms. Foundations and Trends in optimization. 2013 [Online]. Available: http://web.stanford.edu/~boyd/papers/pdf/prox_algs.pdf.
- 40.Horn RA, Johnson CR. Matrix Analysis. Cambridge University Press; Oct, 2012. [Online]. Available: https://books.google.com/books?id=5I5AYeeh0JUC. [Google Scholar]
- 41.Figueiredo MAT, Nowak RD. An EM algorithm for wavelet-based image restoration. IEEE Transactions on Image Processing. 2003 Aug;12(8):906–916. doi: 10.1109/TIP.2003.814255. [Online]. Available: http://ieeexplore.ieee.org/lpdocs/epic03/wrapper.htm?arnumber=1217267. [DOI] [PubMed] [Google Scholar]
- 42.Georghiades AS, Belhumeur PN, Kriegman DJ. From few to many: illumination cone models for face recognition under variable lighting and pose. IEEE Transactions on Pattern Analysis and Machine Intelligence. 2001;23(6):643–660. [Online]. Available: http://ieeexplore.ieee.org/lpdocs/epic03/wrapper.htm?arnumber=927464. [Google Scholar]
- 43.Li L, Huang W, Gu IYH, Tian Q. Statistical Modeling of Complex Backgrounds for Foreground Object Detection. IEEE Transactions on Image Processing. 2004 Nov;13(11):1459–1472. doi: 10.1109/tip.2004.836169. [Online]. Available: http://ieeexplore.ieee.org/lpdocs/epic03/wrapper.htm?arnumber=1344037. [DOI] [PubMed] [Google Scholar]
- 44.Lustig M, Donoho D, Pauly JM. Sparse MRI: The application of compressed sensing for rapid MR imaging. Magnetic Resonance in Medicine. 2007;58(6):1182–1195. doi: 10.1002/mrm.21391. [Online]. Available: http://doi.wiley.com/10.1002/mrm.21391. [DOI] [PubMed] [Google Scholar]
- 45.Zhang T, Cheng JY, Potnick AG, Barth RA, Alley MT, Uecker M, Lustig M, Pauly JM, Vasanawala SS. Fast pediatric 3D free-breathing abdominal dynamic contrast enhanced MRI with high spatiotemporal resolution. Journal of Magnetic Resonance Imaging. 2015 Feb;41(2):460–473. doi: 10.1002/jmri.24551. [Online]. Available: http://doi.wiley.com/10.1002/jmri.24551. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Otazo R, Candès E, Sodickson DK. Low-rank plus sparse matrix decomposition for accelerated dynamic MRI with separation of background and dynamic components. Magnetic Resonance in Medicine. 2015 Mar;73(3):1125–1136. doi: 10.1002/mrm.25240. [Online]. Available: http://eutils.ncbi.nlm.nih.gov/entrez/eutils/elink.fcgi?dbfrom=pubmed&id=24760724&retmode=ref&cmd=prlinks. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.