

Researchers propose sparse regression for identifying governing partial differential equations for spatiotemporal systems.
Keywords: data-driven discovery, dynamical systems, partial differential equations, sparse regression
Abstract
We propose a sparse regression method capable of discovering the governing partial differential equation(s) of a given system by time series measurements in the spatial domain. The regression framework relies on sparsity-promoting techniques to select the nonlinear and partial derivative terms of the governing equations that most accurately represent the data, bypassing a combinatorially large search through all possible candidate models. The method balances model complexity and regression accuracy by selecting a parsimonious model via Pareto analysis. Time series measurements can be made in an Eulerian framework, where the sensors are fixed spatially, or in a Lagrangian framework, where the sensors move with the dynamics. The method is computationally efficient, robust, and demonstrated to work on a variety of canonical problems spanning a number of scientific domains including Navier-Stokes, the quantum harmonic oscillator, and the diffusion equation. Moreover, the method is capable of disambiguating between potentially nonunique dynamical terms by using multiple time series taken with different initial data. Thus, for a traveling wave, the method can distinguish between a linear wave equation and the Korteweg–de Vries equation, for instance. The method provides a promising new technique for discovering governing equations and physical laws in parameterized spatiotemporal systems, where first-principles derivations are intractable.
INTRODUCTION
Data-driven discovery methods, which have been enabled in the past decade by the plummeting cost of sensors, data storage, and computational resources, have a transformative impact on the sciences, facilitating a variety of innovations for characterizing high-dimensional data generated from experiments. Less well understood is how to uncover underlying physical laws and/or governing equations from time series data that exhibit spatiotemporal activity. Traditional theoretical methods for deriving the underlying partial differential equations (PDEs) are rooted in conservation laws, physical principles, and/or phenomenological behaviors. These first-principles derivations lead to many of the canonical models ubiquitous in physics, engineering, and the biological sciences. However, there remain many complex systems that have eluded quantitative analytic descriptions or even characterization of a suitable choice of variables (for example, neuroscience, power grids, epidemiology, finance, and ecology). We propose an alternative method to derive governing equations based solely on time series data collected at a fixed number of spatial locations. Using innovations in sparse regression, we discover the terms of the governing PDE that most accurately represent the data from a large library of potential candidate functions. Measurements can be made in an Eulerian framework, where the sensors are fixed spatially, or in a Lagrangian framework, where the sensors move with the dynamics. We demonstrate the success of the method by rediscovering a broad range of physical laws solely from time series data.
Methods for data-driven discovery of dynamical systems (1) include equation-free modeling (2), artificial neural networks (3), nonlinear regression (4), empirical dynamic modeling (5, 6), normal form identification (7), nonlinear Laplacian spectral analysis (8), modeling emergent behavior (9), and automated inference of dynamics (10–12). In this series of developments, seminal contributions leveraging symbolic regression and an evolutionary algorithm (13, 14) were capable of directly determining nonlinear dynamical system from data. More recently, sparsity (15) has been used to robustly determine, in a highly efficient computational manner, the governing dynamical system (16, 17). Both the evolutionary (14) and sparse (16) symbolic regression methods avoid overfitting by selecting parsimonious models that balance model accuracy with complexity via Pareto analysis. The method we present is able to select, from a large library, the correct linear, nonlinear, and spatial derivative terms, resulting in the identification of PDEs from data. Only those terms that are most informative about the dynamics are selected as part of the discovered PDE. The innovation presented here is critically important because it efficiently handles spatiotemporal data, which is a fundamental characteristic of many canonical models. Previous sparsity-promoting methods are able to identify ordinary differential equations (ODEs) from data but are not able to handle spatiotemporal data or high-dimensional measurements (16). Our novel methodology has several advantageous practical characteristics: Measurements can be collected in either a fixed or moving frame (Eulerian or Lagrangian), allowing for a broad application to a variety of experimental data; the algorithm can also efficiently handle high-dimensional data through innovative sampling strategies. The algorithm, PDE functional identification of nonlinear dynamics (PDE-FIND), is applied to a wide range of canonical models.
RESULTS
We consider a parameterized and nonlinear PDE of the general form
| (1) |
where the subscripts denote partial differentiation in either time or space, and N(∙) is an unknown right-hand side that is generally a nonlinear function of u(x, t), its derivatives, and parameters in μ. Our objective is to construct N(∙) given time series measurements of the system at a fixed number of spatial locations in x. A key assumption is that the function N(∙) consists of only a few terms, making the functional form sparse relative to the large space of possible contributing terms. As an example, Burgers’ equation (N = −uux + μuxx) and the harmonic oscillator (N = −iμx2 − iℏuxx/2) each have two terms. Thus, given the large collection of candidate terms for constructing PDEs, we use sparse regression methodologies to determine which right-hand-side terms are contributing to the dynamics without an intractable (np-hard) combinatorial brute-force search across all possible term combinations.
Upon discretization, the right hand side of Eq. 1 can be expressed as a function of U, which is the discrete version of u(x, t) and its derivatives, through the matrix Θ(U, Q), where the column vector Q contains any additional input terms to the right hand side. Each column of the library Θ(U, Q) corresponds to a specific candidate term for the governing equation, as shown in Fig. 1 (1b). The PDE evolution can be expressed in this library as follows
| (2) |
Each nonzero entry in ξ corresponds to a term in the PDE, and for canonical PDEs, the vector ξ is sparse, meaning that only a few terms are active. We explicitly show in Materials and Methods how to construct Θ(U, Q) and solve for the vector ξ, thus identifying the terms in the PDE.
Fig. 1. Steps in the PDE functional identification of nonlinear dynamics (PDE-FIND) algorithm, applied to infer the Navier-Stokes equations from data.
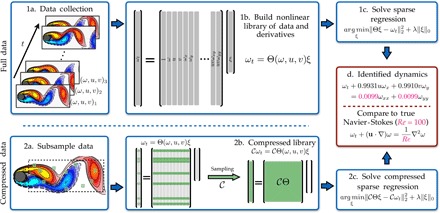
(1a) Data are collected as snapshots of a solution to a PDE. (1b) Numerical derivatives are taken, and data are compiled into a large matrix Θ, incorporating candidate terms for the PDE. (1c) Sparse regressions are used to identify active terms in the PDE. (2a) For large data sets, sparse sampling may be used to reduce the size of the problem. (2b) Subsampling the data set is equivalent to taking a subset of rows from the linear system in Eq. 2. (2c) An identical sparse regression problem is formed but with fewer rows. (d) Active terms in ξ are synthesized into a PDE.
Discovering the Navier-Stokes equations
Figure 1 demonstrates the algorithmic procedure for successfully identifying the correct PDE dynamics for a given set of measurements from a physical system. Specifically, fluid flow around a cylinder is simulated at a given Reynolds, and measurements of the vorticity and velocity can be densely or sparsely sampled to correctly reconstruct the well-known Navier-Stokes equations. Remarkably, the coefficients of the PDE and Reynolds number are identified within a fraction of a percent accuracy. This figure represents our innovative mathematical structure that combines sparse regression, a library of potential functional forms, and parsimonious model selection.
Figure 1 also demonstrates that, for large data sets, such as those generated from two- and three-dimensional problems, PDE-FIND can be effectively used on subsampled data. This distinction is fundamentally important because full-state measurements are often computationally and experimentally prohibitive to collect and may also make the regression needlessly expensive. We randomly select a set of spatial points and uniformly subsample in time, resulting in the use of only a fraction of the data set. Mathematically, this amounts to ignoring a fraction of the rows in the linear system Ut = Θ(U, Q)ξ, as illustrated in Fig. 1 (2a and 2b). Although we only use a small fraction of the spatial points in the linear system, nearby points are needed to evaluate the derivative terms in the library. The derivatives are computed using a small number of spatially localized points near each measurement position via polynomial interpolation. Therefore, whereas subsampling uses only a small fraction of the points in the regression, we are using local information around each measurement.
Previous sparse identification algorithms (16) faced a number of challenges: They were not able to handle subsampled spatial data, and the algorithm did not scale well to high-dimensional measurements. Standard model reduction techniques such as proper orthogonal decomposition (POD) were used to overcome the high-dimensional measurements, allowing for a lower-order ODE model to be constructed on energetic POD modes. This procedure resembles the standard Galerkin projection onto POD modes (18). In contrast, the PDE-FIND algorithm identifies a PDE directly from subsampled measurement data.
Sensors moving with the dynamics
As a second demonstration of the method, we consider one of the fundamental results of the early 20th century concerning the relationship between random walks (Brownian motion) and diffusion. The theoretical connection between these two was first made by Einstein in 1905 (19) and was part of the Annus Mirabilis papers, which lay the foundations of modern physics. We use the method proposed here to sample the movement of a random walker, which is effectively a Lagrangian measurement coordinate, to verify that it can reproduce the well-known diffusion equation. By biasing the random walk, we can also produce the generalization of advection-diffusion in one dimension. Figure 2 shows the success of the method in identifying the correct diffusion model from a random walk trajectory. Given a sufficiently long time series with high enough resolution, the method produces the heat equation that describes the temporal evolution of the probability distribution function. It remains an open question how one might estimate the length of time series necessary to derive the underlying PDE. However, Fig. 2C suggests that a Pareto analysis, where the error drops sharply, may serve as a practical guide.
Fig. 2. Inferring the diffusion equation from a single Brownian motion.
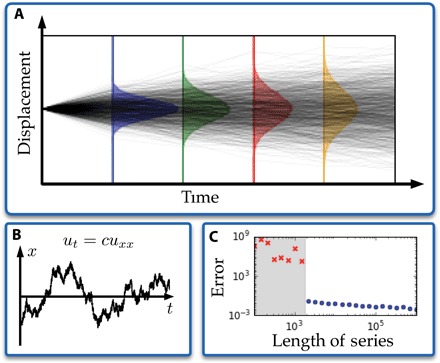
(A) Time series is broken into many short random walks that are used to construct histograms of the displacement. (B) Brownian motion trajectory following the diffusion equation. (C) Parameter error versus length of known time series. Blue symbols correspond to correct identification of the structure of the diffusion model ut = cuxx.
This example is important in that the measurements are now moving with the dynamics of the underlying governing equations. Specifically, measurements are made in the frame of the random walker. For many physical and engineering systems, fixed measurement locations may be impractical to achieve. This is relevant for applications such as ocean monitoring, where the change in spatial location of buoys due to ocean currents can be informative about the underlying dynamical properties of the system. These systems represent a Lagrangian framework for sensor placement and data-driven discovery of dynamics.
Disambiguating dynamical systems
A third canonical example is the Korteweg–de Vries (KdV) equation modeling the unidirectional propagation of small-amplitude, long or shallow-water waves. Discovered first by Boussinesq in 1877 and later developed by Korteweg and de Vries in 1895, it was one of the earliest models known to have soliton solutions. One potential viewpoint of the equation is as a dispersive regularization of Burgers’ equation. The KdV evolution is given by
| (3) |
with soliton solutions , which propagate with a speed proportional to their amplitude c. If one observes a single propagating soliton, it would be indistinguishable from a solution to the one-way wave equation ut + cux = 0. Hence, it presents a challenge to PDE-FIND, which would select the sparsest representation, in this case, the one-way wave equation. This ambiguity in selecting the correct PDE is rectified by constructing time series data for more than a single initial amplitude. Figure 3 demonstrates the evolution of two KdV solitons of differing amplitudes, which enables the unique determination of the governing PDE (Eq. 3).
Fig. 3. Inferring nonlinearity via observing solutions at multiple amplitudes.
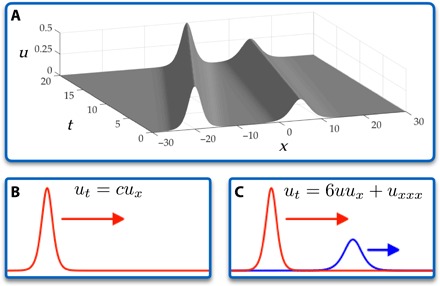
(A) Example two-soliton solution to the KdV equation. (B) Applying our method to a single soliton solution determines that it solves the standard advection equation. (C) Looking at two completely separate solutions reveals nonlinearity.
Discovery for canonical PDE models
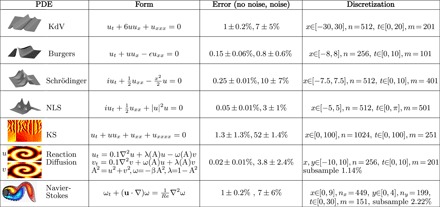
Table 1 applies the methodology proposed to a wide range of canonical models from mathematical physics and engineering sciences. The PDEs selected represent a wide range of physical systems, displaying both Hamiltonian (conservative) dynamics and dissipative nonlinear dynamics along with periodic to chaotic behavior. Aside from the quantum oscillator (third row), all the dynamics observed are strongly nonlinear. Each example is also identified after the addition of Gaussian noise to the data set, which significantly complicates accurate differentiation and library building. Remarkably, the method is able to discover each physical system even if significantly subsampled spatially. The space and time sampling used (data set in ), along with the accuracy in recovering the PDE parameters with and without noise, are detailed in Table 1. This highlights the broad applicability of the method and the success of the technique in discovering governing PDEs. Moreover, it demonstrates that a wide range of distinct physical observations can be captured by the regression framework, thus allowing the method to be broadly applied across the sciences, where spatiotemporal activity dominates.
Table 1. Summary of regression results for a wide range of canonical models of mathematical physics.
In each example, the correct model structure is identified using PDE-FIND. The spatial and temporal sampling of the numerical simulation data used for the regression is given along with the error produced in the parameters of the model for both no noise and 1% noise. In the reaction-diffusion system, 0.5% noise is used. For Navier-Stokes and reaction-diffusion, the percent of data used in subsampling is also given. NLS, nonlinear Schrödinger; KS, Kuramoto-Sivashinsky.
DISCUSSION
PDE-FIND is a viable, data-driven tool for modern applications, where first-principles derivations may be intractable (for example, neuroscience, epidemiology, and dynamical networks) but where new data recordings and sensor technologies are revolutionizing our understanding of physical and/or biophysical processes on spatial domains. To our knowledge, this is the first data-driven regression technique that explicitly accounts for spatial derivatives in discovering physical laws, thus significantly broadening the applicability to a wide variety of complex systems. Traditional approaches, such as reducing the model to a local linear embedding based on collected data, fall short in achieving the fundamental goal of research scientists: to construct a nonlinear model from observations, which characterizes the observed dynamics and generalizes to unsampled areas of parameter space. For instance, we can discover the Navier-Stokes equations at Re = 100 and a particular boundary condition and use this knowledge to accurately simulate new boundary conditions where no data were collected. As in the study of Brunton et al. (16), it may also be possible to sample the dynamics at a range of parameter values and discover the fully parameterized system. The goal would be to collect data at a range of flow conditions corresponding to different Reynolds numbers, and infer both the parameterized Navier-Stokes equations and the Reynolds number, which is an exciting avenue of future research.
The Kuramoto-Sivashinsky equation is particularly challenging to identify with low error on the coefficients and illustrates a limitation of the method. Although the correct terms are identified, there is substantial coefficient error in the case with noise. The true and identified models are given by
The high precision but substantial underestimation of the coefficients indicates significant error in numerical differentiation.
The success of this methodology suggests that many concepts from statistical learning can be integrated with traditional scientific computing and dynamical systems theory to discover dynamical models from data. This integration of nonlinear dynamics and machine learning opens the door for principled versus heuristic methods for model construction, nonlinear control strategies, and sensor placement techniques.
MATERIALS AND METHODS
The innovations presented here were built upon three key ideas: (i) overcomplete libraries of candidate functions to represent the dynamics, (ii) sparse regression for selecting a small number of terms, and (iii) parsimonious selection of the governing equations via Pareto analysis. The architecture is enabled by the ability to accurately compute derivatives even when noise is present in the measurements. Each method is detailed below.
Building libraries of candidate terms
The sparse regression and discovery method (see Fig. 1) begins by first collecting all the spatial time series data into a single column vector , representing data collected over m time points and n spatial locations. We also consider any additional input such as a known potential for the Schrödinger equation, or the magnitude of complex data, in a column vector . Next, a library of D candidate linear and nonlinear terms and partial derivatives for the PDE is constructed. Derivatives are taken either using finite differences for clean data or when noise is added with polynomial interpolation. The candidate linear and nonlinear terms and partial derivatives are then combined into a matrix Θ(U, Q), which takes the form, for example
| (4) |
Each column of Θ contains all of the values of a particular candidate function across all of the mn space-time grid points on which data are collected. Therefore, if we have data on an n × m grid (for example, a 256 × 100 grid represents 256 spatial measurements at 100 time points) and have 50 candidate terms in the PDE, then . The time derivative Ut was also computed and reshaped into a column vector. Figure 1 demonstrates the data collection and processing. As an example, a column of Θ(U, Q) may be q2uxx.
If we assume that Θ is an overcomplete library, meaning Θ has a sufficiently rich column space that the dynamics will be in its range, then the PDE should be well represented by Eq. 2 with a sparse vector of coefficients ξ. This is equivalent to picking enough candidate functions that the full PDE may be written as a weighted sum of library terms. For an unbiased representation of the dynamics, we would simply solve the least-squares problem for ξ. However, even with the only error coming from numerical roundoff, the least-squares solution may be inaccurate. In particular, ξ will have predominantly nonzero values, suggesting a PDE with every functional form contained in the library. Regression problems similar to Eq. 2 result in least-squares problems that are poorly conditioned. Error in computing the derivatives (already an ill-conditioned problem with noise) will be magnified by numerical errors when inverting Θ. Thus, a least-squares regression radically changes the qualitative nature of the inferred dynamics.
Sparse regression
In general, we require the sparsest vector ξ that satisfies Eq. 2 with a small residual. Instead of an intractable combinatorial search through all possible sparse vector structures, a common technique was to relax the problem to a convex ℓ1 regularized least squares (15); however, this tends to perform poorly with highly correlated data. Instead, we approximate the problem using candidate solutions to a ridge regression problem with hard thresholding, which we call sequential threshold ridge regression (STRidge in Algorithm 1). For a given tolerance and λ, this gives a sparse approximation to ξ. We iteratively refined the tolerance of Algorithm 1 to find the best predictor based on the selection criteria
| (5) |
where κ(Θ) is the condition number of the matrix Θ, indicating stronger regularization for ill-posed problems. Penalizing ‖ξ‖0 discourages overfitting by selecting from the optimal position in a Pareto front.
Other methods for finding sparse solutions to least-squares problem exist. Greedy algorithms were shown to exhibit good performance on sparse optimization problems including PDE-FIND but, in some cases, were less reliable than STRidge (20). Although STRidge with normalization works well on almost all of the examples we tested, we do not make the claim that it is optimal. If additional information regarding the PDE is known (for instance, if we know that one of the terms is nonzero), then this may be incorporated into the penalty on the coefficients.
Numerical evaluation of derivatives
Proper evaluation of the numerical derivatives is the most challenging and critical task for the success of the method. This is particularly true when the discretized solution contains measurement noise. Given the well-known accuracy problems with finite-difference approximations, we experimented with a number of more robust numerical differentiation methods. Smoothing with a Gaussian kernel and Tikhonov differentiation were both investigated but were difficult to implement because of the difficulty in controlling the bias-variance trade-off. Spectral differentiation with thresholding for high-frequency terms was also considered but not used because of its restriction to periodic domains and the difficulty in implementing an appropriate thresholding function. The most reliable and robust method for computing derivatives from noisy data was polynomial interpolation (21). For each data point where we compute a derivative, a polynomial of degree P was fit to greater than P points, and derivatives of the polynomial were taken to approximate those of the numerical data. Points close to the boundaries, where it was difficult to fit a polynomial, were not used in the regression. This method is far from perfect; data close to the boundaries were difficult to differentiate, and we discovered that this could strongly influence the results of PDE-FIND. For a more principled but involved approach to polynomial differentiation, see the study of Bruno and Hoch (22).
Supplementary Material
Acknowledgments
Funding: J.N.K. acknowledges support from the Air Force Office of Scientific Research (FA9550-15-1-0385). S.L.B. and J.N.K. acknowledge support from the Defense Advanced Research Projects Agency (DARPA contract HR0011-16-C-0016). J.L.P. would like to thank Bill and Melinda Gates for their active support of the Institute for Disease Modeling and their sponsorship through the Global Good Fund. Author contributions: S.H.R. developed the sparse selection algorithms. S.H.R. and J.N.K. developed simulation codes for the example problems considered. All authors participated in designing the study and discussing and writing the results. Competing interests: The authors declare that they have no competing interests. Data and materials availability: All data needed to evaluate the conclusions in the paper are present in the paper and/or the Supplementary Materials. Additional data related to this paper may be requested from the authors. All data and codes used in this manuscript are publicly available on GitHub at https://github.com/snagcliffs/PDE-FIND.
SUPPLEMENTARY MATERIALS
Supplementary material for this article is available at http://advances.sciencemag.org/cgi/content/full/3/4/e1602614/DC1
Introduction
PDE-FIND
Examples
Limitations
fig. S1. Steps in the PDE functional identification of nonlinear dynamics (PDE-FIND) algorithm, applied to infer the Navier-Stokes equations from data.
fig. S2. The numerical solution to the KdV equation plotted in space-time.
fig. S3. The numerical solution to the Burgers’ equation plotted in space-time.
fig. S4. The magnitude of the numerical solution to the Schrödinger’s equation plotted in space-time.
fig. S5. The magnitude of the numerical solution to the nonlinear Schrödinger’s equation plotted in space-time.
fig. S6. The numerical solution to the Kuramoto-Sivashinsky equation plotted in space-time.
fig. S7. The numerical solution to the reaction-diffusion equation plotted in space-time.
fig. S8. A single snapshot of the vorticity field is illustrated for the fluid flow past a cylinder.
fig. S9. A single stochastic realization of Brownian motion.
fig. S10. Five empirical distributions, illustrating the statistical spread of a particle’s expected location over time, are presented.
fig. 11. Five empirical distributions, illustrating the statistical spread of a particle’s expected location over time, are presented.
fig. S12. The numerical solution to the misidentified Kuramoto-Sivashinsky equation.
fig. S13. The numerical solution to the misidentified nonlinear Schrödinger equation.
fig. S14. Results of PDE-FIND applied to Burgers’ equation for varying levels of noise.
table S1. Summary of regression results for a wide range of canonical models of mathematical physics.
table S2. Summary of PDE-FIND for identifying the KdV equation.
table S3. Summary of PDE-FIND for identifying Burgers’ equation.
table S4. Summary of PDE-FIND for identifying the Schrödinger equation.
table S5. Summary of PDE-FIND for identifying the nonlinear Schrödinger equation.
table S6. Summary of PDE-FIND for identifying the Kuramoto-Sivashinsky equation.
table S7. Summary of PDE-FIND for identifying reaction-diffusion equation.
table S8. Summary of PDE-FIND for identifying the Navier-Stokes equation.
table S9. Accuracy of PDE-FIND on Burgers’ equation with various grid sizes.
REFERENCES AND NOTES
- 1.Crutchfield J., McNamara B., Equations of motion from a data series. Complex Syst. 1, 417–452 (1987). [Google Scholar]
- 2.Gear C. W., Hyman J. M., Kevrekidis P. G., Kevrekidis I. G., Runborg O., Theodoropoulos C., Equation-free, coarse-grained multiscale computation: Enabling mocroscopic simulators to perform system-level analysis. Commun. Math. Sci. 1, 715–762 (2003). [Google Scholar]
- 3.González-García R., Rico-Martínez R., Kevrekidis I. G., Identification of distributed parameter systems: A neural net based approach. Comput. Chem. Eng. 22, S965–S968 (1998). [Google Scholar]
- 4.Voss H. U., Kolodner P., Abel M., Kurths J., Amplitude equations from spatiotemporal binary-fluid convection data. Phys. Rev. Lett. 83, 3422 (1999). [Google Scholar]
- 5.Sugihara G., May R., Ye H., Hsieh C.-h., Deyle E., Fogarty M., Munch S., Detecting causality in complex ecosystems. Science 338, 496–500 (2012). [DOI] [PubMed] [Google Scholar]
- 6.Ye H., Beamish R. J., Glaser S. M., Grant S. C. H., Hsieh C.-h., Richards L. J., Schnute J. T., Sugihara G., Equation-free mechanistic ecosystem forecasting using empirical dynamic modeling. Proc. Natl. Acad. Sci. U.S.A. 112, E1569–E1576 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Majda A. J., Franzke C., Crommelin D., Normal forms for reduced stochastic climate models. Proc. Natl. Acad. Sci. U.S.A. 106, 3649–3653 (2009). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 8.Giannakis D. Majda A. J., Nonlinear Laplacian spectral analysis for time series with intermittency and low-frequency variability. Proc. Natl. Acad. Sci. U.S.A. 109, 2222–2227 (2012). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.A. J. Roberts, Model Emergent Dynamics in Complex Systems (SIAM, 2014). [Google Scholar]
- 10.Schmidt M. D., Vallabhajosyula R. R., Jenkins J. W., Hood J. E., Soni A. S., Wikswo J. P., Lipson H., Automated refinement and inference of analytical models for metabolic networks. Phys. Biol. 8, 055011 (2011). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Daniels B. C. Nemenman I., Automated adaptive inference of phenomenological dynamical models. Nat. Commun. 6, 8133 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 12.Daniels B. C. Nemenman I., Efficient inference of parsimonious phenomenological models of cellular dynamics using S-systems and alternating regression. PLOS ONE 10, e0119821 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Bongard J. Lipson H., Automated reverse engineering of nonlinear dynamical systems. Proc. Natl. Acad. Sci. U.S.A. 104, 9943–9948 (2007). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Schmidt M. Lipson H., Distilling free-form natural laws from experimental data. Science 324, 81–85 (2009). [DOI] [PubMed] [Google Scholar]
- 15.Tibshirani R., Regression shrinkage and selection via the lasso. J. R. Stat. Soc. B 58, 267–288 (1996). [Google Scholar]
- 16.Brunton S. L., Proctor J. L., Kutz J. N., Discovering governing equations from data by sparse identification of nonlinear dynamical systems. Proc. Natl. Acad. Sci. U.S.A. 113, 3932–3937 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Mangan N. M., Brunton S. L., Proctor J. L., Kutz J. N., Inferring biological networks by sparse identification of nonlinear dynamics. IEEE Trans. Mol. Biol. Multi-Scale Commun. 2, 52–63 (2016). [Google Scholar]
- 18.P. Holmes, J. L. Lumley, G. Berkooz, C. W. Rowley, Turbulence, Coherent Structures, Dynamical Systems and Symmetry (Cambridge Univ. Press, ed. 2, 2012). [Google Scholar]
- 19.Einstein A., Über die von der molekularkinetischen Theorie der Wärme geforderte Bewegung von in ruhenden Flüssigkeiten suspendierten Teilchen. Ann. Phys. 322, 549–560 (1905). [Google Scholar]
- 20.T. Zhang, Adaptive forward-backward greedy algorithm for sparse learning with linear models, in Advances in Neural Information Processing Systems 21, D. Koller, D. Schuurmans, Y. Bengio, L. Bottou, Eds. (Curran Associates Inc., 2009), pp. 1921–1928. [Google Scholar]
- 21.Knowles I., Renka R. J., Methods for numerical differentiation of noisy data. Electron. J. Differ. Eq. 235–246 (2014). [Google Scholar]
- 22.Bruno O., Hoch D., Numerical differentiation of approximated functions with limited order-of-accuracy deterioration. SIAM J. Numer. Anal. 50, 1581–1603 (2012). [Google Scholar]
- 23.Bai Z., Wimalajeewa T., Berger Z., Wang G., Glauser M., Varshney P. K., Low-dimensional approach for reconstruction of airfoil data via compressive sensing. AIAA J. 53, 920–933 (2014). [Google Scholar]
- 24.Berkooz G., Holmes P., Lumley J. L., The proper orthogonal decomposition in the analysis of turbulent flows. Annu. Rev. Fluid Mech. 25, 539–575 (1993). [Google Scholar]
- 25.Brunton S. L., Brunton B. W., Proctor J. L., Kaiser E., Kutz J. N., Chaos as an intermittently forced linear system. arXiv:1608.05306 (2016). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 26.Brunton S. L., Tu J. H., Bright I., Kutz J. N., Compressive sensing and low-rank libraries for classification of bifurcation regimes in nonlinear dynamical systems. SIAM J. Appl. Dyn. Syst. 13, 1716–1732 (2014). [Google Scholar]
- 27.Budišić M., Mohr R., Mezić I., Applied Koopmanism. Chaos 22, 047510 (2012). [DOI] [PubMed] [Google Scholar]
- 28.Cole J. D., On a quasi-linear parabolic equation occurring in aerodynamics. Quart. Appl. Math. 9, 225–236 (1951). [Google Scholar]
- 29.Colonius T., Taira K., A fast immersed boundary method using a nullspace approach and multi-domain far-field boundary conditions. Comput. Methods Appl. Mech. Eng. 197, 2131–2146 (2008). [Google Scholar]
- 30.Cross M. C., Hohenberg P. C., Pattern formation out of equilibrium. Rev. Mod. Phys. 65, 851–1112 (1993). [Google Scholar]
- 31.C. Gardiner, Stochastic Methods (Springer, 2009). [Google Scholar]
- 32.Gavish M., Donoho D. L., The optimal hard threshold for singular values is . IEEE Trans. Inf. Theory 60, 5040–5053 (2014). [Google Scholar]
- 33.Hopf E., The partial differential equation ut + uux = μuxx. Commun. Pure App. Math. 3, 201–230 (1950). [Google Scholar]
- 34.J. N. Kutz, Data-Driven Modeling & Scientific Computation: Methods for Complex Systems & Big Data (Oxford Univ. Press, 2013). [Google Scholar]
- 35.R. J. LeVeque, Finite Difference Methods for Ordinary and Partial Differential Equations: Steady-State and Time-Dependent Problems, Vol. 98 (SIAM, 2007). [Google Scholar]
- 36.Mackey A., Schaeffer H., Osher S., On the compressive spectral method. Multiscale Model. Simul. 12, 1800–1827 (2014). [Google Scholar]
- 37.Mezić I., Spectral properties of dynamical systems, model reduction and decompositions. Nonlinear Dyn. 41, 309–325 (2005). [Google Scholar]
- 38.Mezić I., Analysis of fluid flows via spectral properties of the Koopman operator. Annu. Rev. Fluid Mech. 45, 357–378 (2013). [Google Scholar]
- 39.K. P. Murphy, Machine Learning: A Probabilistic Perspective (MIT Press, 2012). [Google Scholar]
- 40.Noack B. R., Afanasiev K., Morzyński M., Tadmor G., Thiele F., A hierarchy of low- dimensional models for the transient and post-transient cylinder wake. J. Fluid Mech. 497, 335–363 (2003). [Google Scholar]
- 41.Ozoliņš V., Lai R., Caflisch R., Osher S., Compressed modes for variational problems in mathematics and physics. Proc. Natl. Acad. Sci. U.S.A. 110, 18368–18373 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.R. Pinnau, Model reduction via proper orthogonal decomposition, in Model Order Reduction: Theory, Research Aspects and Applications (Springer, 2008) pp. 95–109. [Google Scholar]
- 43.Proctor J. L., Brunton S. L., Brunton B. W., Kutz J. N., Exploiting sparsity and equation- free architectures in complex systems. Eur. Phys. J. Spec. Top. 223, 2665–2684 (2014). [Google Scholar]
- 44.Schaeffer H., Caflisch R., Hauck C. D., Osher S., Sparse dynamics for partial differential equations. Proc. Natl. Acad. Sci. U.S.A. 110, 6634–6639 (2013). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Taira K., Colonius T., The immersed boundary method: A projection approach. J. Comput. Phys. 225, 2118–2137 (2007). [Google Scholar]
- 46.Tran G., Ward R., Exact recovery of chaotic systems from highly corrupted data. arXiv:1607.01067 (2016). [Google Scholar]
- 47.L. N. Trefethen, Spectral Methods in MATLAB, Vol. 10 (SIAM, 2000). [Google Scholar]
- 48.L. N. Trefethen, D. Bau III, Numerical Linear Algebra, Vol. 50 (SIAM, 1997). [Google Scholar]
- 49.Wang W.-X., Yang R., Lai Y.-C., Kovanis V., Grebogi C., Predicting catastrophes in non-linear dynamical systems by compressive sensing. Phys. Rev. Lett. 106, 154101 (2011). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50.Zou H., Hastie T., Regularization and variable selection via the elastic net. J. R. Stat. Soc. B 67, 301–320 (2005). [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supplementary material for this article is available at http://advances.sciencemag.org/cgi/content/full/3/4/e1602614/DC1
Introduction
PDE-FIND
Examples
Limitations
fig. S1. Steps in the PDE functional identification of nonlinear dynamics (PDE-FIND) algorithm, applied to infer the Navier-Stokes equations from data.
fig. S2. The numerical solution to the KdV equation plotted in space-time.
fig. S3. The numerical solution to the Burgers’ equation plotted in space-time.
fig. S4. The magnitude of the numerical solution to the Schrödinger’s equation plotted in space-time.
fig. S5. The magnitude of the numerical solution to the nonlinear Schrödinger’s equation plotted in space-time.
fig. S6. The numerical solution to the Kuramoto-Sivashinsky equation plotted in space-time.
fig. S7. The numerical solution to the reaction-diffusion equation plotted in space-time.
fig. S8. A single snapshot of the vorticity field is illustrated for the fluid flow past a cylinder.
fig. S9. A single stochastic realization of Brownian motion.
fig. S10. Five empirical distributions, illustrating the statistical spread of a particle’s expected location over time, are presented.
fig. 11. Five empirical distributions, illustrating the statistical spread of a particle’s expected location over time, are presented.
fig. S12. The numerical solution to the misidentified Kuramoto-Sivashinsky equation.
fig. S13. The numerical solution to the misidentified nonlinear Schrödinger equation.
fig. S14. Results of PDE-FIND applied to Burgers’ equation for varying levels of noise.
table S1. Summary of regression results for a wide range of canonical models of mathematical physics.
table S2. Summary of PDE-FIND for identifying the KdV equation.
table S3. Summary of PDE-FIND for identifying Burgers’ equation.
table S4. Summary of PDE-FIND for identifying the Schrödinger equation.
table S5. Summary of PDE-FIND for identifying the nonlinear Schrödinger equation.
table S6. Summary of PDE-FIND for identifying the Kuramoto-Sivashinsky equation.
table S7. Summary of PDE-FIND for identifying reaction-diffusion equation.
table S8. Summary of PDE-FIND for identifying the Navier-Stokes equation.
table S9. Accuracy of PDE-FIND on Burgers’ equation with various grid sizes.