

Abstract
In the past decade, numerous advances in the study of the human brain were fostered by successful applications of blind source separation (BSS) methods to a wide range of imaging modalities. The main focus has been on extracting “networks” represented as the underlying latent sources. While the broad success in learning latent representations from multiple datasets has promoted the wide presence of BSS in modern neuroscience, it also introduced a wide variety of objective functions, underlying graphical structures, and parameter constraints for each method. Such diversity, combined with a host of datatype-specific know-how, can cause a sense of disorder and confusion, hampering a practitioner’s judgment and impeding further development.
We organize the diverse landscape of BSS models by exposing its key features and combining them to establish a novel unifying view of the area. In the process, we unveil important connections among models according to their properties and subspace structures. Consequently, a high-level descriptive structure is exposed, ultimately helping practitioners select the right model for their applications. Equipped with that knowledge, we review the current state of BSS applications to neuroimaging.
The gained insight into model connections elicits a broader sense of generalization, highlighting several directions for model development. In light of that, we discuss emerging multi-dataset multidimensional (MDM) models and summarize their benefits for the study of the healthy brain and disease-related changes.
Index Terms: BSS, neuroimaging, unimodal, multimodality, multiset data analysis, overview, subspace, unify, modeling
I. Introduction
Blind source separation (BSS) methods [1] have been widely used in the study of the brain. They can be adapted and made compatible with a number of brain imaging, genetics, and non-imaging modalities, fueling applications to neurophysiological measurements such as magnetic resonance imaging (MRI)—both structural (sMRI) [2] and functional (fMRI) [3], [4]—magnetoencephalography (MEG) [5], electroencephalography (EEG) [6], diffusion weighted MRI (DWI) [7], copy-number variation (CNV) [8], single nucleotide polymorphism (SNP) [9], methylation [10], [11], metabolomics [12], and questionaires [13], [14] among others. Continued technological advancements in brain structure and function assessment [15]–[18] have fostered the development of a growing collection of BSS methods and tools. Their applications range from the study of human brain deficits associated with certain mental disorders to the neurophysiological associations with cognitive and behavioral measures.
Despite such wide application range, selecting the right BSS tool for a given problem—or developing a new one—can quickly turn into a daunting task if an understanding of the underlying structure of the area is missing. Our work addresses this issue. It highlights fundamental connections among BSS models and offers a novel, intuitive taxonomy, organizing BSS problems into specialized subproblems. Also, our investigation of various assumptions embedded within BSS models refines this structure, revealing hidden connections and differences.
To achieve that, we let BSS refer to any method for simultaneous model (or system) inversion of one or multiple datasets that uses only the observed measurements (or outputs). Then, we put a number of methods originating from different areas in perspective, focusing on three key properties: the number of datasets allowed, the grouping of sources within a dataset, and the use of second-, higher-, or all-order statistics. As a result, unanticipated connections and differences among seemingly unrelated methods are revealed, culminating in a new unified framework for BSS model selection and development. A hierarchy of increasing model complexity ensues, providing a sensible guide to practitioners in their domain-specific contexts. Model weaknesses and strengths, as well as key differences and shared features, stand out, exposing a high-level descriptive structure useful for researchers either interested in pursuing new, unexplored directions, or simply trying to identify candidate models for an application. These properties are finally summarized in a set of systematic, yet simple, modeling choices, exposing new insight into future directions for the area and advancing a novel unifying view.
Our unifying framework describes a new, largely under-investigated class of problems, paving a way for development of new models. These models are anticipated to be highly flexible, combining and expanding key features and subspace structures from existing models. We expect that these models will play a key role in neuroimaging research and improve how we understand the intricacies of the human brain, laying out a promising new path for future research developments that could easily extend beyond neuroimaging applications.
We introduce the unifying framework in section II. We then describe how the unifying framework specializes to different models and methods in section III. We discuss future directions in section IV and provide concluding remarks in section V.
II. A Unified Framework for Subspace Modeling and Development
The wide range of applications utilizing BSS methods to capture and analyze brain networks requires a fairly broad understanding of the area by the average researcher. The terminology and notation from different fields where methods have originally been developed makes it an even harder task. Not surprisingly, the use of a BSS tool for a certain application is often unintentionally limited to what has already been applied to a certain datatype or disease. Our belief is that users and developers of BSS tools can largely benefit from a clear and intuitive description of the underlying structure among BSS methods. This is our guiding motivation throughout.
A. The Structure of BSS Problems
The BSS problem is broadly defined as “recovering unobservable source signals s from measurements x (i.e., data), with no knowledge of the parameters θ of the generative system x = f (s, θ).” It can be organized into subproblems depending on whether x contains either single or multiple datasets, and whether or not subsets of s (within the same dataset) group together to form one or more multidimensional sources. We propose a novel taxonomy to define four general BSS subproblems, as follows:
Single dataset unidimensional (SDU): x consists of a single dataset whose sources are not grouped, e.g., independent component analysis (ICA) [19]–[21] and second order blind identification (SOBI) [22], [23], as in section III-A1;
Multiple dataset unidimensional (MDU): x consists of one or more datasets but no multidimensional sources occur within any of the datasets, although multidimensional sources containing a single source from each dataset may occur, e.g., canonical correlation analysis (CCA) [24], partial least squares (PLS) [25], and independent vector analysis (IVA) [26], [27], discussed in III-A2;
Single dataset multidimensional (SDM): x consists of a single dataset with one or more multidimensional sources, e.g., multidimensional independent component analysis (MICA) [28], [29] and independent subspace analysis (ISA) [30], [31], discussed in III-A3;
Multiple dataset multidimensional (MDM): x contains one or more datasets, each containing one or more multidimensional sources that may group further with single or multidimensional sources from the remaining datasets, e.g., multidataset independent subspace analysis (MISA) [32], [33] and joint independent subspace analysis (JISA) [34], discussed in III-A4.
Under these definitions, subproblems are contained within each other, as described in Fig. 1, revealing a natural hierarchical structure among them. Accordingly, the generative models describing data generation from sources should follow the same hierarchy. Problem specification, therefore, contributes to the description of f (·) itself and some properties of its parameters (θ) and inputs (s) in generative models. This provides a new perspective about basic connections among models following from problem specification.
Fig. 1. Venn diagram of the structure of BSS subproblems.
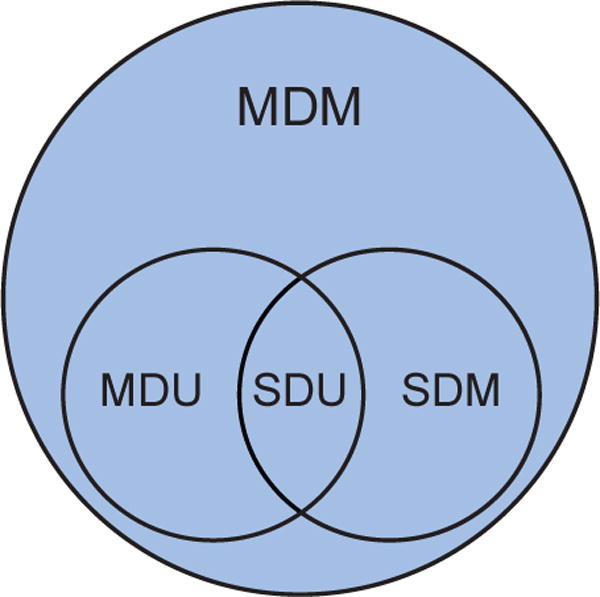
Single dataset unidimensional (SDU) problems are special cases of multiple dataset unidimensional (MDU), single dataset multidimensional (SDM), and multiple dataset multidimensional (MDM) problems, while MDU and SDM problems are special cases of MDM problems.
In the presence of noise, x = f (s, θ) + e, where the sensor noise e is typically Gaussian. Noisy system inversion has been well studied, especially in linear systems, with results such as the Wiener filter, which defines a system inversion ŝ = g(s, θ, x) that minimizes for known s and θ Source estimation strategies for noisy cases are different (see section II-D) and largely tailored to SDU problems. Still, noise-free BSS models are often fairly robust to noise.
B. Assumptions that Drive Model Hierarchy
A generative BSS model is completely defined only when the parameters (θ) and source signals (s) are fully described according to three sets of assumptions. The leading assumption is the presence of latent source signals in the data. Additional assumptions act to counter ill-conditions, allowing sources to be identified from data. These assumptions, combined with the problem hierarchy, induce a set of basic modeling choices, as described below and summarized in Table I.
TABLE I.
Typical choices in BSS modeling. Choices relevant to this work are color-coded to match Fig. 2.
| Model Property | Choice to Make | Options |
|---|---|---|
| Sources | Model order | C ∈ ℕ (per dataset) |
|
| ||
| Mixture | Mapping | linear or non-linear |
|
|
||
| Layout | fully-connected or structured | |
|
|
||
| (optional) | Parameter constraints | Orthogonality, sparsity, match a template, min. total variation |
|
| ||
| Statistical Relationship | (which) | and K ≤ C |
|
|
||
| Interactions (how) | graph (directed or not, acyclic/cyclic, tree/hierarchy), and/or sample dependence | |
|
|
||
| Type of Stats. (how) | , , or | |
|
|
||
| (optional) | Source constraints | Sparsity, match a template, min. total variation |
Presence of sources
Given N observations of M ≥ 1 datasets, we wish to identify an unobservable latent source random vector (r.v.) that relates to the observed r.v. via a vector function f (s, θ). Learning both s and f (·, θ) blindly—without prior knowledge of either of them—requires choosing the number of sources Cm in each dataset, with compound and .
Mixture function
The assumptions imposed on the vector function f (·, θ) are characterized by the following properties:
Mapping. Mixture functions are mappings of either a linear or non-linear type. A linear function is any linear transformation by square or rectangular matrices (A) with , and . For quadratic functions, , , .
Layout. The layout is a cross-dataset indication of which elements of s generate which elements of x. It is fully-connected if s in all datasets contribute to all x. Otherwise, it is structured, such as in separable models where f() is either shared (e.g., same A) or dataset-specific (e.g., block-diagonal A). Tensor models, such as parallel factors (PARAFAC), offer further structured layout subtypes [35].
Statistical relationship among sources
This assumption regards which sources are (un)related, and how. Only stochastic relationships are considered since all deterministic relationships can be absorbed in f(·). Sources can also be related to themselves through sample dependence (e.g., autocorrelation).
Subsets. This choice determines which sources are related to each other and which are not. It leads to the notion of source groups (sk, k = 1,…, K), i.e., related sources that go together to form one of K groups, which are broadly referred to as subspaces1. The number of subspaces (K) and their compositions are key choices in S/MDM problems.
Interactions. This specifies directed (possibly causal) and/or undirected relationships among sources. Many graphical structures [36] are possible, including “self-loops” to represent sample dependence. For brevity, this work emphasizes either undirected non-causal instantaneous relations, or those based on sample dependence.
-
Type of statistics. When random variables are statistically related they are said to be dependent. There are two types of statistical dependence to choose from: linear dependence (captured by second-order statistics), and higher-order dependence (captured by higher-order statistics). Unrelated variables, however, are statistically independent, meaning their joint distribution is a product of the marginal distributions, e.g., . Independence implies no grouping and, thus, sources do not interact. Consequently, both second- and higher-order dependencies are absent in that case.
Second-order statistics (SOS): This kind of statistics refers to so-called second moments. The second moment of a zero-mean random variable is E[X2], where E[ ] is the expected value operator. It captures the “scale” (or variability) of X in the form of variance or standard deviation. For pairs of variables, however, second moments become cross-moments E[X1, X2], which capture the level of linear relation between random variables in the form of a correlation coefficient (ρ). In simple terms, SOS measures how well a straight line explains the joint statistical relationship between two random variables. Independence implies all SOS cross-moments are zero for zero-mean sources and, therefore, uncorrelation.
Higher-order statistics (HOS): This kind of statistics refers to higher-order moments. A higher-order moment of a zero-mean random variable is the expected-value of its p-th power, E[Xp], for p > 2. It captures other properties of the distribution of X, like skewness (p = 3) and kurtosis (p = 4). For tuples of C variables, however, higher-order moments become higher-order cross-moments , C ≤ p; Ep[·] is a p-order expectation. Put simply, HOS measures joint relationships among multiple random variables beyond those explained by a single straight line. Independence implies all HOS cross-moments are zero for zero-mean sources.
SOS and HOS are at the core of statistical source relationship modeling, broadly compartmentalizing the landscape of models into those capturing only one or both types of statistics. The latter case is considered more general, as depicted in Fig. 2. Often, all-order statistical information (i.e., both SOS and HOS) can be achieved by simply choosing an effective joint probability density model for the sources/subspaces.
Fig. 2. Hierarchy of linear BSS models.
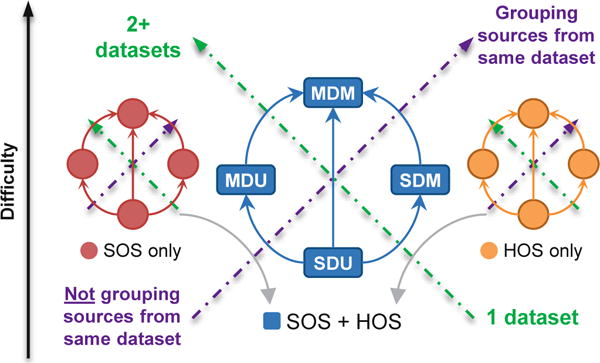
Historically, BSS models have been made more general by: A) increasing the number of datasets which can be jointly analyzed [see Layout and Subsets]; B) moving from isolated sources to groups of sources in the same dataset [see Subsets]; C) exploiting SOS, HOS, or both [see Type of Statistics]. The arrows indicate the directions of increasing difficulty, model complexity, and generality. Highly general models can address MDM problems by incorporating lenient modeling choices.
C. Terminology and Indeterminacies
We intentionally generalize the definition of BSS to include cases of simultaneous system inversion, which attempt to leverage information from multiple systems (via their outputs) to jointly infer their mixture functions and sources. Utilizing multiple datasets to infer each system may lead one to interpret the methods not as “blind” as a single-dataset BSS. However, our view is that, together, all these systems/datasets form a single larger system that needs to be identified only by the outputs provided by each of its parts. This view aligns with prior work coined as joint BSS [37], and even more so with multimodal brain data analysis.
Like seminal works from the SDU literature [38], certain restrictions apply with respect to the identifiability of SDM, SDU, and MDM models. In general, this is a result of how well the modeling choices (see Table I) match the true generative process. For example, the typical scale, sign, and permutation ambiguities from the linear independence-based SDU models [1] generalize to arbitrary invertible linear transformations of the subspaces in SDM models [28]. In linear second-order independence-based MDU models, identifiability is not attainable in cases were two or more subspaces share an identical block correlation structure [39], [40]. Recent initial work [41] developed for linear second-order independence-based MDM models suggests a combination of conditions from SDM and MDU. In the non-linear case, however, independence-based SDU models are unidentifiable if independence is the only assumption [1, Ch.14]. Additional constraints are required and Bayesian approaches offer a nice framework for that. A complete study of the identifiability conditions for each combination of modeling choices, especially in the case of MDM models, is valuable but exceeds the scope of this work. Note, however, that for noisy linear models optimizing for minimal error in s implies WA ≠ I, i.e., W is not identifiable. Conversely, identifiability of W does not guarantee identifiability of s in noisy models [1, Ch.4]. Finally, the number of components C can be estimated by model order selection approaches based on information-theoretic criteria (IC) such as Akaike’s IC (AIC) [42], Bayesian IC (BIC) [43], Kullback-Leibler IC (KIC) [44], Draper’s IC [45], or minimum description length (MDL) [46]. However, we are unaware of methods for direct estimation of the number of subspaces K and their compositions, except for post-hoc approaches using clustering [47] and non-linear correlations [31]. Also, these approaches do not generalize trivially to multiple datasets.
D. Turning Models into Algorithms
After characterizing the model based on the choices outlined above, three additional steps are typically required to translate it into an algorithm (Fig. 3): (i) define an inverse model for s ≈ y = g (x; ϕ) based on the modeling choices made for f(·), s and θ, where ϕ denotes a system inversion parameter, (ii) select a cost function J(ϕ) that is sensitive to the properties of s, and (iii) choose an optimization procedure to estimate ϕ by minimizing/maximizing J(ϕ).
Fig. 3. Steps involved in moving from a model to an algorithm.

The properties of s and θ, selected during the modeling step, impose requirements on the inverse model and cost function. The parameters ϕ of the inverse model are the inputs to the cost function and change according to the selected optimization strategy.
The inverse model results directly from the choices in the generative model. In noise-free linear BSS models, the inverse model must also be linear, in which case ϕ is also a matrix, denoted W, and y = Wx. The cost function is typically one that reflects the desired properties of s, i.e., it attains a minimum or a maximum when such properties are met (e.g. the likelihood function). It also changes with the structure of A. Thus, a numerical optimization strategy [48] is selected to identify the optimal W that approximately attains such minimum/maximum from data. Typical unconstrained optimization algorithms include line search methods, using regular, stochastic, relative [49], or natural [50] gradient descent, Newton or quasi-Newton descent [48], as well as trust-region methods [48]. Some variations allow for constraints on θ, ϕ and/or s (Table I), such as regularized optimization, null-space methods [51], interior point [48], and multiobjective [52] optimization. For example, sparsity constraints on θ = A reduce the number of sources contributing to a sensor, while low total variation of s has a smoothing and denoising effect.
Numerical optimization is key for Bayesian estimation [1, Ch.12] as well. Using priors, Bayesian methods infer the posterior distribution from the likelihood function. This offers a nice, principled strategy to incorporate constraints as prior knowledge. Then, maximization of the posterior (MAP) jointly estimates s and θ from x. Alternatively, maximization after marginalizing s out of the posterior is thought to prevent overfitting by avoiding arbitrary peaks of the joint posterior, leading to a better estimate of the posterior mass concentration. Variational Bayes (VB) approaches, such as ensemble learning [53], [54], carry out marginalization while approximating the joint posterior by a product of factors, each corresponding to a subset of the model (and noise) parameters θ. Marginalization can also simplify to the likelihood function when a “constant” prior is used for θ. When no analytical approximation is imposed on this likelihood, a general expectation-maximization (EM) approach emerges [55]: conditional expectations of s are computed in the E-step and used to update θ in the M-step (maximizing the likelihood). This was shown [56] to be particularly useful in the case of noisy models, using the Wiener filter in the E-step. Marginalization of θ following marginalization of s requires MCMC approaches for approximate integration.
E. Unified Framework
Building on the broad, general view of modeling and development in BSS problems presented above, we propose a unified framework for description of BSS models based on charting the modeling choices made for each of the three sets of assumptions outlined in II-B and the type of problem being addressed. In the following section, we illustrate the scope of this unifying framework by characterizing and reviewing a number of BSS models popular for brain data analysis.
III. Review of BSS Models for Brain Data
Following the proposed framework, in this section we review BSS models and algorithms frequently employed in brain data analysis. Throughout the description, models become progressively stronger by adopting more lenient choices, enabling simultaneous analysis of multiple datasets, allowing multidimensional sources, and exploiting both second- and higher-order statistics. High-level differences and relationships among these models become evident, as shown below. Applications to various brain data modalities are presented last.
A. BSS Models
Here, both classical algorithms and recent models are reviewed through the framework we propose. Following Table I, we first focus our attention on linear mixture models (x = As) with undirected source relationships within subspaces and/or sample dependence, and no optional constraints. In all cases, we assume that sources are zero-mean. The sections are organized by problem, following the structure in Fig. 1.
1) Single Dataset Unidimensional (SDU) Problem
The linear models for the SDU problem assume a single dataset (M = 1) generated by an invertible linear, fully-connected mixture (see Fig. 4). The classical model in this case is principal component analysis (PCA) [57]–[60], which assumes the sources s are uncorrelated, implying a diagonal source covariance matrix Σs. Thus, SOS dependence among estimated sources y = Wx should be zero. Eigenvalue decomposition (EVD) of Σx or singular value decomposition (SVD) of the observed V × N dataset X identify such diagonalizing W, assigning sources to each of the principal axes of the data, i.e., the (orthogonal) directions of maximal variability. The PCA solution is unique only up to sign ambiguities. Also, sources with equal variance are unrecoverable if A is a rotation matrix, since x would then be already uncorrelated. Its focus on the top C sources with largest variability makes it prone to error when the sources of interest have low variance.
Fig. 4. General inverse models for linear SDU, MDU, and SDM problems.
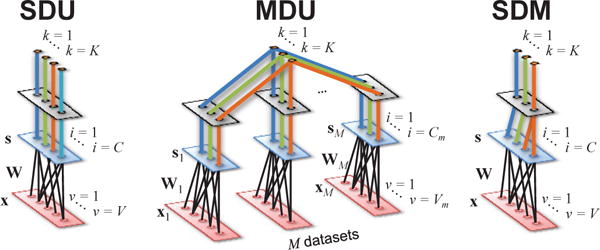
The models are presented as graphical structures where the lower layer corresponds to one 1 × V observation of the input data x. The middle layer represents the C sources s obtained by linear transformation of x through the unmixing matrix W. The top layer establishes the type of interaction between sources as described in Section II-B, forming K subspaces sk. The problems are described in Section II-A.
A very successful model for brain data in this category is independent component analysis (ICA) [3], [7]–[9], [61]–[70]. The ICA model assumes statistical independence among the sources in s and, thus, all HOS and SOS dependence among estimated sources should be zero. Cost functions for dependence assessment are abundant [1], [71]–[73], including negentropy [19] (as in FastICA [21], [74]) and information divergence [75], [76], of which mutual information [26], [77], [78] is an important special case and a natural, general choice:
| (1) |
where h(s) = −E[log p(s)] is the joint differential entropy, and p(s) and p(si) are the joint probability density function (pdf) of all sources and the marginal pdf, respectively. When u ≈ γ(y) = γ(Wx), where γ(·) is an element-wise non-linear transformation representing a fixed cumulative distribution function (cdf), and p(ui) is the Uniform distribution in the [0, 1] domain, h(ui) is zero. In this case, minimizing I(u) is equivalent to maximizing h(u), which is the popular Infomax approach [20] when the sigmoid function is chosen as the cdf.
Another successful method, particularly in the field of EEG-based brain-computer interface (BCI), is called second-order blind identification (SOBI) [22], [79]. SOBI considers the case of independent non-white stochastic source processes si(t), in which sample dependence occurs within each source si through autocorrelation (e.g., lag-correlation , τ ∈ [0, T ]) but not highly among different sources (e.g., , i ≠ j, ∀τ ∈ [0, T ]). This translates to high SOS of a source with itself and low SOS with other sources, i.e, Rs(τ) ≈ I for all τ. Finding W that simultaneously diagonalizes Rx(τ) for all τ is known as joint diagonalization (JD). This principle is shared by many other techniques, such as the algorithm for multiple unknown signals extraction (AMUSE) [80], which pursues exact2 JD between Rx(0) and Rx(τ), for fixed τ ≠ 0, and the time-delays based separation (TDSEP) [81], which uses exact JD on two weighted averages of multiple Rx(τ). Weights-adjusted SOBI (WASOBI) [23] is a variant implementation of the SOBI model that attains better performance by optimally weighting each Rx(τ) and performing approximate JD via weighted least-squares.
Seeking to combine the ICA and SOBI models, COMBI [82] proposes a “wrapper” algorithm that runs both efficient FastICA (EFICA) [83] and WASOBI, selecting the “best” components from each [84]. Recent developments utilizing mutual information rate to combine ICA and SOBI principles have inspired unique algorithms like entropy rate bound minimization (ERBM) [85] and entropy rate minimization using an autoregressive (AR) source model driven by generalized Gaussian distribution (ERM-ARG) [86]. The use of both sample correlation and HOS of sources provides significantly better performance [26], although these have not yet been applied in BCI.
The last model we consider in this category is a simple but effective one, called group ICA (GICA) [4], [87]. GICA is a popular approach for group analysis of resting-state fMRI data [88] that implements “spatial ICA.” An actively growing research area called dynamic resting-state functional network connectivity (rs-FNC) [89]–[92] analysis has been built on top of results produced with this approach. GICA models several datasets as if they were one (by temporal concatenation), assuming the same single set of sources s (the “aggregate” spatial maps) for all M datasets (the subjects): xm = Amsm, s1 = ⋯ = sM = s. Dataset- or subject-specific variations in s are then captured by a process called back-reconstruction [93]. While effective, this assumption is also somewhat restrictive and recent work suggests that MDU-type models may capture subject-specific source variability better than GICA when sm are highly distinct [26], [94] across datasets.
The class of SDU models includes those that extend beyond noise-free linear unconstraint approaches. We go over some of them. Factor analysis (FA) assumes Gaussian sources with uncorrelated sensor noise [95]. Probabilistic ICA (PICA) [96] is a FastICA approach that utilizes a preprocessing step (namely, standardize each observation xn to zero mean and unit variance) to condition the data prior to PCA reduction. This is based on an extended FA [38] to select the number of components, assuming sensor noise is very low. Expanding Bayesian methods for linear ICA [97]–[99], non-linear FA (NFA) and non-linear independent FA (NIFA) approaches [100], [101] have been proposed under a Bayesian framework too.
In tensor ICA (TICA) [102], the PARAFAC tensor model xm = ADms, m = 1M, where Dm is a diagonal matrix, is used to achieve a variation of GICA. Identically to GICA on M datasets, shared sources s are recovered using PICA. However, Am = ADm is obtained in a post-processing step of the concatenated mixing matrices. Thus, the columns of Am are perfectly correlated across datasets (subjects). While this can be useful for task-elicited activation in which the task stimulus timing is identical, in the case of spontaneous activity, such as resting fMRI, a model that does not assume perfectly correlated timecourses across datasets (subjects) is preferred.
The use of tensor representations is also common in cumulant-based SDU methods [103], but does not relate to modeling datasets as tensors. Instead, they seek to diagonalize second- and fourth-order cumulant tensors by applying the same transformation matrix W to all dimensions of the tensor, effectively achieving second- and fourth-order independence by driving cross-moments toward zero. As for constraints, ICA-R [104]–[106] was proposed to allow references to be incorporated and help extract certain specific patterns from data while pursuing independence. The reference “guides” the decomposition, potentially overcoming high noise issues.
2) Multiple Dataset Unidimensional Problem
MDU-type linear models assume M ≥ 1 datasets generated by a linear, structured mixture. As such, the combined mixing matrix A has a block-diagonal structure that confines sources to their respective datasets: xm = Amsm, m = 1 … M. The number of sources is typically the same for all datasets (Cm = C). Although no multidimensional (grouped) sources occur within any single dataset, sources are allowed to group across datasets (see Fig. 4). The properties of these K = C cross-dataset M-dimensional source groupings (or subspaces, sk) mark the major differences among models in this category, particularly their choice of SOS, HOS, or both to describe (un)relatedness.
SOS-only models underly classical algorithms such as canonical correlation analysis (CCA) [24] and partial least squares (PLS) [25], [107], as well as more recent models such as multiset CCA (mCCA) [108] and second-order independent vector analysis (IVA) [26], [27]. Thus, in these models, unrelated sources are linearly independent (uncorrelated) and related sources are linearly dependent (correlated). In the case of CCA and PLS, exactly M = 2 datasets are considered, meaning only corresponding sources from each dataset form related pairs. CCA seeks a particular solution that maximizes the correlation between related source pairs sk=i = [s1i, s2i]T, s1i = W1ix1 and s2i = W2ix2, i = 1 … C, where Wmi is the i-th row of Wm, while PLS maximizes their covariance instead. For i = 1, CCA solves the following constrained optimization [109],
| (2) |
where is the (cross-) covariance matrix between datasets xm and xl, while PLS solves a different constraint [109],
| (3) |
In either case, by Lagrange multipliers, the constrained optimizations reduce to generalized eigenvalue (GEV) problems Evi = λFvi, where
for CCA3, and FPLS = I for PLS, both solvable by the power method (PM) of numerical linear algebra. The structure of FPLS implies W11 and W21 are the left and right singular vectors of the largest singular value of , respectively [109]. It also enables a popular variant of PM called non-linear iteration partial least squares (NIPALS) [111], which converges in a single step when either x1 or x2 is univariate (Vm = 1).
For i > 1, CCA requires additional constraints to enforce diagonal structure on source covariances , , and
meaning all non-corresponding source pairs are uncorrelated. While sequential estimation in CCA simply yields the remaining eigenvectors of the GEV problem [112], the same is not always the case in PLS [109]. This is because different deflation strategies can be employed between iterations i and i+1, giving rise to a wide range of PLS variants [109], [110], [113], [114]:
| Name | Deflation | |
| PLS-SVD |
|
|
| PLS Mode A |
|
|
| PLS1/PLS2 | , |
where , is the m-th Vm × N data matrix, containing N observations of the measurement vector xm at the i-th iteration, and . Alternating the PLS-SVD deflation with the basic PLS optimization in (3), for i > 1, is equivalent to sequential rank-one deflations of [109], or to additional orthogonal constraints , ∀m ∈ {1, 2}, all simply yielding the remaining eigenvectors of the initial GEV problem. As a result, non-corresponding source pairs are uncorrelated in PLS-SVD (as in CCA). This is generally not the case in PLS Mode A, although sources are uncorrelated to each other within the same dataset [110] (since the residual is orthogonal to ). The deflation in PLS Mode A is inspired by least squares [115], seeking to remove the variability in explained by (the m-th 1 × N vector containing N observations of the source smi) at the i-th iteration. PLS-SVD and PLS Mode A are exploratory approaches recommended for modeling unobservable relationships between datasets. PLS1 and PLS2, however, are intended for regression, univariate (V2 = 1) and multivariate (V2 > 1), respectively [113], with X2 acting as the response variable and using the information contained in X1 to make predictions about X2. To that end, s1i is assumed to be a good surrogate for s2i [113], thus replacing it in the deflation of . After C deflations, a “global” multiple regression equation is derived which can be used for prediction of X2 from new observations of X1 [109], [112]:
where P1 and P2 are matrices whose columns are the projections and , respectively, 1 ≤ i ≤ C, and W1 contains W1i at the i-th row.
Overall, for sources s estimated with a known inverse model g(·), [116] suggests that the generative model f() conveying optimal interpretation is the one which minimizes the data reconstruction error ‖(s) − x‖. When the L2-norm is selected, the least squares solution ensues. For separable linear models, , and, thus, . This is quite similar in nature to the PLS Mode A deflation, except that all sources sm contribute simultaneously to the estimation of Am. This idea was explored in source power comodulation (SPoC) [117], which pursued a CCA-type analysis between windowed variance profiles of s1 (in dataset m = 1) and a single known fixed reference source s21 (in dataset m = 2), canonical SPoC (cSPoC) [118], which pursued CCA between “envelope” transformations of sm, and multimodal SPoC (mSPoC) [119], which pursued CCA between s1 and temporally filtered windowed variance profiles of s2. The key differences between CCA and SPoC-type approaches are that s1 and s2 can have different number of observations and at least one set of sources undergoes a non-linear transformation.
Since covariance is , where is correlation between s1i and s2i, and are their standard deviations, respectively, maximizing covariance will not necessarily maximize correlation4. Thus, covariance might not detect sources with high linear dependence (high correlation) if either of their standard deviations is low (possibly the case in genetic data [120]). Because PLS does not prioritize correlation over scale, we consider it “deficient” from an optimization perspective as it will always be biased by the scale of the data. Nevertheless, it may still be advantageous to rely on this property, depending on the importance of scale for a given application, such as regression, where larger scale translates into larger explained variability.
Multiset CCA (mCCA) [108] extends CCA to M ≥ 2 datasets. In this case, sources are organized into K = C subspaces, each one spanning over M datasets, forming K tuples made of one corresponding source from each dataset. The M sources contained in each subspace (sk, k = i) share an M × M correlation matrix . The solution sought in mCCA maximizes the entire correlation structure of each . This is typically achieved by either minimizing its determinant or maximizing some norm . Consequently, sources in the same subspace sk are (potentially) highly linearly related to each other and, therefore, statistically dependent. Typical cost functions for mCCA include sum of squares of all entries of the correlation matrix (SSQCOR) and the generalized variance (GENVAR). For i = 1, SSQCOR mCCA solves the following constrained optimization [37], [108], [121], with , when the constraints are enforced, and k = i:
| (4) |
where, tr(·) is the trace operator, is the cross-covariance among the i-th source from all datasets, Σx is the crosscovariance matrix among all datasets, and W·i is a , block-diagonal matrix whose m-th block contains the row vector Wmi. GENVAR mCCA, on the other hand, solves [108]:
| (5) |
which is a function of the product of eigenvalues of Ri. For i > 1, mCCA also requires additional constraints:
meaning all non-corresponding source pairs are uncorrelated. Multi-block PLS approaches exist [122] but are not common in brain data analysis.
IVA is a model that seeks to minimize the mutual information between subspaces sk [26], [27], similarly to (1):
| (6) |
where K = C, h(s) = −E[log p(s)], and p(s) and p(sk) are the joint probability density function (pdf) of all sources and the marginal subspace pdf, respectively. The choice of distribution for p(sk) distinguishes between different IVA algorithms. In second-order IVA (IVA-G) [123], p(sk) is modeled as multivariate Gaussian, simplifying (6) to:
| (7) |
where λmi are the M eigenvalues of the source covariance matrices , k=i, and e is Napier’s constant. When Wm is constrained to be orthogonal, IVA-G is equivalent to GENVAR mCCA [123].
IVA assumes all sources are independent within each dataset, such that , m = 1 … M. This implies that second- and higher-order cross-moments between non-corresponding sources are driven to zero and, likewise, become potentially non-zero for sources in the same subspace. For IVA-G, only SOS is considered so that independence translates to uncorrelation. Thus, IVA-G shares the same base model as CCA, PLS-SVD, and mCCA, except the latter three seek particular solutions that explicitly maximize some measure of correlation inside each subspace sk. The relationship with IVA becomes clearer when we consider that the cost functions in these algorithms assume zero-correlation among sources in different subspaces. From an optimization theory perspective, this can be achieved, for example, by null-space methods [51], which first project into a space that satisfies the constraints (i.e., uncorrelates non-corresponding sources) and then find a solution within that space. It should be clear that the constraints in CCA, PLS-SVD, and mCCA correspond exactly to IVA-G and that maximization of correlation/covariance gives a particular solution within that space.
IVA-L [27], on the other hand, uses the multivariate Laplace distribution to model HOS dependence within subspaces. Due to its HOS nature, it leads to independence, in addition to uncorrelation, among subspaces. Uncorrelation is imposed within subspaces, however, due to the assumed identity dispersion matrix [107]:
| (8) |
with k = i, , smi = Wmixm, and Γ(·) is the Gamma function. IVA can explicitly pursue independence in each dataset while retaining dependence across corresponding sources. Estimating dataset-specific Wm and dependent, rather than identical, sources sm enables greater flexibility to capture dataset-specific variability. Under similar motivation, GIG-ICA [124] uses the source estimates s from GICA as reference for dataset-specific estimation of Wm and sm via ICA-R, effectively using two SDU approaches to attain an MDU result.
Next, we consider the joint ICA (jICA) model [125], commonly utilized in multimodal data fusion [121], [126] and “temporal ICA” of temporally concatenated fMRI [127], [128]. Originally proposed for (but not limited to) exactly two datasets, jICA’s hallmark assumption is that the same mixing matrix A generates both datasets. It also assumes none of the sources are statistically related, i.e., , and that p(·) is the same for all sources. Comparing to the IVA model, this is equivalent to constraining the block-diagonal structure to Am = A, m = 1 … M, and modeling subspaces with . The key difference between such a variant of IVA and JICA is that the first uses an M-dimensional independent joint pdf for sk while the second combines corresponding sources into a single one-dimensional pdf. Thus, JICA conveniently follows optimization of (1).
In a similar fashion, the approach of common spatial patterns (CSP) [129], [130] assumes the same generative system for two different datasets (typically from the same subject in different conditions). Like exact JD approaches for SDU models, it uses SOS from two covariance matrices, and , to form a generalized eigenvalue problem , , and identify uncorrelated sources s1 and s2 with maximum variance contrast between corresponding sources. That is, for C sources, s11 has maximal variance (eigenvalue) and the corresponding s21 has minimal variance; likewise, s1C has minimal variance and s2C has maximal variance. The motivation for stems from classification: maximizing variance contrast between corresponding sources helps enhance source-based classification of different conditions. Equivalently, maximization of the Jensen-Shannon divergence (or symmetric Kullback-Leibler (KL) divergence) leads to the same CSP solution when the sources are assumed to be uncorrelated Gaussian [131]. Extensions of CSP focus on regularizing the problem with additional constraints [132], [133], leading to GEV problems of the form , , where Kp is a positive definite penalty term representing any undesired properties detected in the data (typically, non-stationarity due to multiple subjects, sessions, or artifacts). A general regularization framework based on divergence measures is also possible, with Beta divergence offering additional robustness against outliers [131]. The benefits of regularization come at a cost: Wmi is different for each dataset and, thus, requires dataset-specific optimization. Consequently, this implies a different generative system per dataset, which places CSP closer to CCA (and mCCA) but not quite since each dataset is optimized separately rather than jointly.
Expanding on the jICA model, linked ICA (LICA) [134] applies Bayesian ICA to a “joint” TICA model, establishing a more flexible structure on the shared A. Specifically, TICA is applied to D groups of Md datasets of equal spatial resolution. For each d = 1..D, xdm = ADdmsd, m = 1..Md. Like jICA, sources sd are assumed independent across the D groups of datasets but, like GICA, they are identical for the Md datasets in the same group, i.e., . Thus, sources are modeled as , finally combining the corresponding sources sk, k = i, into a single one-dimensional pdf that is a weighted average of each source’s pdf: , k = i, where αd is determined by the number of observations in each sd. As a result of the PARAFAC model, the mixing matrices from each dataset share a common structure but are not identical, unlike jICA. However, their columns are perfectly correlated, which may or may not be a benefit depending on the problem. Finally, the Bayesian strategy provides a nice framework to handle noise and employ re-estimation of the source distribution parameters, which is selected as a mixture of Gaussian (MOG) for each sk.
To conclude, a nice example of generalization are the wide class of models contained in the IVA-Kotz family [107] (and a version that includes HOS and sample dependence [135]), which cleverly use the Kotz distribution to capture both SOS and HOS simultaneously.
3) Single Dataset Multidimensional (SDM) Problem
The linear models for the SDM problem assume a single dataset generated by an invertible linear, fully-connected mixture with multidimensional (grouped) sources occurring within the dataset (see Fig. 4), forming K ≤ C subspaces sk. The most common model in this category was originally introduced as multidimensional ICA (MICA) [28] and later investigated under the independent subspace analysis (ISA) [30], [31], [136] nomenclature. In this model, sources in the same subspace sk are related and, thus, statistically dependent. Sources in different subspaces are assumed independent. The simplest ISA approach post-processes ICA results to form subspaces post-hoc as in [28], [31], [47].
A more principled approach is to minimize (6), redefining sk according to user-defined source groupings. Applying this approach, Hyvärinen et al. [136] assume W is orthogonal, using a Laplacian-like multivariate distribution for independence among subspaces and HOS-only dependence within subspaces, enforcing uncorrelation both within and among subspaces. Similarly, Silva et al. [33] use a scale-adjusted multivariate Laplace distribution and introduces reconstruction error constraints to bypass the typical PCA reduction step. Focusing only on SOS among subspaces, Lahat et al. [29] use a multivariate Gaussian distribution to model subspace dependences. Likewise, Silva et al. [137] improve on [33] by not enforcing uncorrelation within subspaces.
Stationary subspace analysis (SSA) is a model designed to find one group of sources whose mean and SOS remain unchanged over time, hence the name. KL-SSA [138] uses an AJD of Σs(τ), accounting for different μs(τ), to identify stationary sources based on KL divergence, very similar to Pham’s AJD criterion [139]. It models each window as a Gaussian source , and the collection of all windows as . Then the sum of divergences between each window and the “aggregate” source is minimized. By definition, K = 2, though only the group of stationary sources is retrieved. Analytic SSA (ASSA) [140] approximates the KL divergence with a “variance of covariance” function, simplifying the optimization to a generalized eigenvalue problem. Like other SDM models, sources within the retrieved subspace are still unmixed. Consequently, SSA is only intended to act as a filtering tool, removing non-stationarities from the data.
4) Multiple Dataset Multidimensional Problem
MDM models were developed only recently. In linear MDM, M ≥ 1, datasets are generated by a linear, structured mixture where the combined mixing matrix A has a block-diagonal structure: xm = Amsm, m = 1 … M. The number of sources Cm is typically not the same for all datasets. Multidimensional (grouped) sources occur within any single dataset and are allowed to group (or not) across datasets (see Fig. 5), forming K dk-dimensional subspaces sk.
Fig. 5. General inverse model for the linear MDM problem.
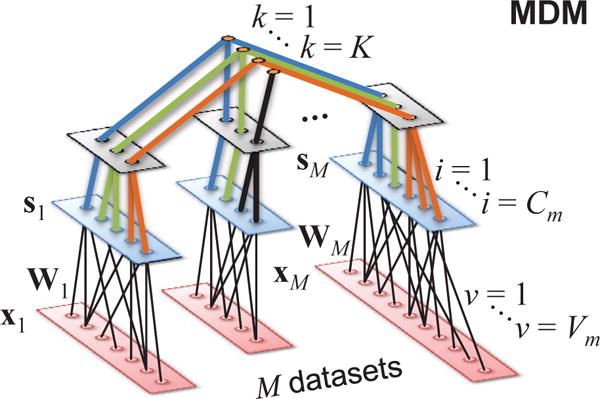
The lower layer corresponds to one Vm × 1 observation of each input data stream xm, reflecting the different intrinsic dimensionality (Vm) of each dataset. The middle layer represents the Cm sources. The top layer establishes the K subspaces sk, which may be dataset-specific (k = K in the figure) or span through many datasets, illustrating the different compositions permitted.
Sources in the same subspace sk are considered statistically dependent, and independent otherwise. Thus, , and minimization of (6) with user-defined source groupings for sk follows. Variations include models that either exploit a) only SOS, like joint independent subspace analysis (JISA) [34], b) only HOS, like multidataset independent subspace analysis (MISA) [32], [33] (emphasizing uncorrelation within subspaces), or c) both, like MISA with SOS [137].
B. Applications and Data Modalities
The “blind” property of BSS models makes them a powerful tool in applications lacking a precise model of the measured system and with data confounded by noise of unknown characteristics. Brain imaging is an area where these properties are especially emphasized. We now briefly review some applications of BSS models to brain imaging data. The first case focuses on data from a single imaging modality (unimodal) while the other considers current attempts to identify common motifs from two or more imaging modalities (multimodal).
1) Unimodal
First we consider the analysis of a single dataset. If it contains data from a single subject, the model captures subject-specific information. If instead it contains subject-specific summaries from a certain population, then the model characterizes underlying group patterns. Both cases resort to SDU models. The second example regards the processing of two or more datasets simultaneously. When each dataset contains information from a single subject, shared or similar patterns across subjects are identified and group trends derived. Although group trends offer useful conclusions about population differences, preserving subject-specific information is crucial for clinical diagnosis and personalized treatment. Both SDU and MDU models have been used to capture inter-subject, and sometimes inter-trial, variability.
a) SDU Problem
ICA has been successfully utilized in a number of exciting applications, especially those that have proven challenging with the standard regression-type approaches [141], [142]. For fMRI [4], [143] and EEG [6], [144]–[146], ICA reveals dynamics for which a temporal model is not available [147], finding largely non-overlapping, temporally coherent brain regions without constraining the shape of the temporal response. The Infomax algorithm with a sparse prior is particularly well suited for spatial analysis [148]. Besides fMRI, the brain grey [2], [149] and white matter [149], as well as functional near-infrared spectroscopy (fNIRS) [69] have also been analyzed by ICA to study the diseased brain. In addition to its wide use for recovering spatial networks as independent components—in diffusion tensor imaging (DTI) [7], positron emission tomography (PET) [67], and even MEG [150]—ICA is also promising for temporal [128], [151] and spectral (e.g., MR spectroscopic imaging (MRSI) [70]) domains of brain imaging.
ICA was shown to be useful in modalities such as EEG and MEG. It has also been successfully applied to multi-neuronal recordings [68]. Mostly, it is used for artifact reduction [61], [152] or for real-time control in BCI applications [65]. However, for artifact reduction in MEG, SOBI was shown to be superior to other BSS methods available at the time [5] (also see [153], [154] for another comparative study).
GICA [4] of fMRI [3] is one of the most successful BSS tools for neuroimaging analysis, providing a means to handle multi-subject datasets. It enables network identification under task and rest regimes [89]. The connection patterns between these networks is very interesting and useful for differentiation [90], [155]–[157] and neurodiagnostic discovery [87].
b) MDU Problem
Both CCA and mCCA have been successfully utilized in applications ranging from single- [158] and multi-subject analysis of fMRI [159], [160], as well as BCI [161], [162]. PLS, on the other hand, has also been successfully applied to neuropsychological and MRI relationships [163], while temporal ICA was investigated in [127], [128], [151]. Finally, IVA has found great value in leveraging the success of independence-based methods while better characterizing inter-subject variability [94], [164], [165].
2) Multimodal
Multimodal analyses are intended to leverage information contained in multiple data streams by modeling the relationship among modalities. Convergent evidence suggests that combining functional and structural information is useful in clinical research [166]–[168]. Moreover, multi-modal studies often demonstrate some congruent effects across modalities and different brain pathologies [169]–[173]. Any remaining complementary information typically contributes to increased differentiation power among diseases. Unlike multimodal approaches that use one modality to constrain or filter the other, multimodal data fusion seeks hidden shared information underlying the signals from both modalities simultaneously. Multimodal data fusion applications are by and large viewed as MDU-type problems [174], [175]. However, for the most part, current neuroimaging multimodal fusion schemes have focused on pairs of modalities.
IV. Future Directions
A. Emerging Modalities
Improvements in imaging instrumentation and signal acquisition continue to provide researchers with novel and higher quality information about the physiology of the brain. Naturally, the use and combination of such emerging modalities has great potential for producing new findings and applications.
We begin with a summary of promising, emerging modalities. First, high-resolution quantitative MR imaging of tissue-specific parameters such as longitudinal relaxation (T1) provides good indication of cortical myelination [176], with the benefit of allowing direct comparison of images across scanners and sites, as well as longitudinally, for most cortical brain areas [177]. Also, a measure of local variation in grey matter called voxel-based cortical thickness (VBCT) provides higher grey matter sensitivity than typical voxel-based morphometry (VBM) [178]. Following recent breakthroughs in DWI [179], [180], crossing white matter fibers can now be resolved and tracked, providing thrilling details about the orientation and structural connectivity of fiber bundles. Similar improvements have led to ultra-fast fMRI sequences [16] at higher spatial resolution, simplifying the filtering of certain physiological noise sources, such as breathing and cardiac pulsation.
We also highlight the emergence of new devices that combine different imaging modalities. Simultaneous PET/MR devices offer multiple opportunities for multimodal research. Particularly, with the advent of functional PET (fPET) by constant infusion of 2-[(18)F]-fluorodeoxyglucose (FDG), functional changes in glucose utilization by the brain can be observed with better time resolution than traditional PET [181]. Consequently, simultaneous functional imaging using fPET and fMRI (by arterial spin labeling (ASL) and blood oxygen level dependent (BOLD) contrasts) enables the study of neurovascular coupling [182], especially in the study of drug challenges. Also, sMRI scans interleaved with PET acquisition can enable improved PET resolution and SNR following MRI-guided attenuation and partial-volume corrections, motion compensation, and reconstruction [183].
Similarly, recent advances in cap and probe design allow for high-density simultaneous fNIRS and EEG experiments with reduced motion artifacts and for extended periods of time [184], [185]. These could be combined with PET/MR systems, offering a huge opportunity for neurodiscovery, and indicating an impending need for multiple-dataset methods oriented to multimodal fusion.
B. Emerging Applications
The past decade has witnessed a growing interest in multimodal analyses, especially N-way multimodal fusion [33], [186], for their potential to leverage hidden multimodal interactions (i.e., cross-dataset dependence) and construct a more complete view of brain function and structure. More modalities typically means increased confidence in statements about the neural determinants of healthy [187] and disease states. Moreover, multiple-dataset BSS has demonstrated potential to identify endophenotypes from brain imaging data for genetic association studies, eliciting candidate biomarkers for several mental illnesses [188], [189].
While multiple-dataset BSS provides a pristine opportunity for neurodiscovery in multimodal studies of mental disorders [190], the benefits for unimodal studies involving longitudinal or multi-site data can be more immediate, as they may identify recurrent features across time and study location.
Structure-function connectivity analyses [171], [191]–[193] are also expected to largely benefit from continued research in multiple-dataset BSS. For example, graph-oriented BSS may elicit the underlying breakdown of networks into modules and meta-states [194], offering a fresh new look at connectivity.
C. Emerging Techniques
Typically, linear BSS on a V ×N dataset X = AS captures information along the dimension of N. In order to leverage information contained along the other dimension, some approaches have been exploiting the data transpose XT as well. Utilizing a two-step approach, mCCA+jICA [190] computes mCCA among to find with high correlation among corresponding rows, followed by jICA on Sm; conversely, [151] uses temporal ICA on the temporally concatenated AT that results from GICA. On the other hand, approaches like non-negative matrix factorization (NMF) [195] alternate between X and XT at every step of the alternating least-squares (ALS) [196], [197] optimization. This approach generalizes well to the tensor case [198], [199]. Parallel ICA [9], however, alternates between ICA (on X1 and X2, separately) and CCA (between and ) at every step. Such techniques are likely to play an important role in the development of new methods for linear MDM problems.
V. Conclusion
We have presented a unifying view of BSS, providing new insight into the connections among many traditional and modern BSS models. The new perspective leads to a broader sense of generalization, highlighting several directions for further development. Particularly, MDM models emerge as an organic confluence of three major trends: simultaneous multi-dataset analysis, grouping of sources within a dataset, and use of all-order statistics. Therefore, they capture all key features and subspace structures common to their predecessors. Their benefit is in the flexibility to simultaneously model dataset-specific as well as cross-dataset subspace associations.
The demands from advances in multimodal brain imaging technology are likely to propel the development of BSS methods strongly into the direction of N-way multimodal fusion. However, a better and more general solution becomes possible. The availability of such advanced BSS approaches will provide novel ways to investigate inter-subject covariation across multiple populations, sites, and longitudinal inquiries.
Acknowledgments
This work was primarily funded by NIH grant R01EB005846 and NIH NIGMS Center of Biomedical Research Excellent (COBRE) grant 5P20RR021938/P20GM 103472 to Vince Calhoun (PI), and NSF 1539067.
Biographies

Rogers F. Silva (Student Member, IEEE) received the B.Sc. degree in Electrical Engineering in 2003 from the Catholic University (PUCRS), Porto Alegre, Brazil, the M.S. degree in Computer Engineering (with minors in Statistics and in Mathematics) in 2011, and the Ph.D. degree in computer engineering in 2016 (expected), both from The University of New Mexico, Albuquerque, NM, USA. He worked as an engineer, lecturer, and consultant, and is currently a senior graduate research assistant at The Mind Research Network, Albuquerque, NM, USA. As a multidisciplinary research scientist, he develops algorithms for statistical and machine learning, image analysis, numerical optimization, memory efficient large scale data reduction, and distributed analyses, focusing on multimodal, multi-subject neuroimaging data from thousands of subjects. His interests are: multimodal data fusion, statistical and machine learning, image, video and data analysis, multiobjective, combinatorial and constrained optimization, signal processing, and neuroimaging.

Sergey M. Plis received the Ph.D. degree in Computer Science in 2007 from The University of New Mexico, Albuquerque, NM, USA. He is the Director of Machine Learning at the Mind Research Network, Albuquerque, NM, USA. His research interests lie in developing novel and applying existing techniques and approaches to analyzing large scale datasets in multimodal brain imaging and other domains. He develops tools that fall within the fields of machine learning and data science.
One of his key goals is to take advantage of the strengths of imaging modalities and infer structure and patterns that are hard to obtain non-invasively and/or that are unavailable for direct observation. In the long term this amounts to developing methods capable of revealing mechanisms used by the brain to form task-specific transient interaction networks and their cognition-inducing interactions via multimodal fusion at features and interaction levels.
His ongoing work is focused on inferring multimodal probabilistic and causal descriptions of these function-induced networks based on fusion of fast and slow imaging modalities. This includes feature estimation via deep learning-based pattern recognition and learning causal graphical models.

Jing Sui (Senior Member, IEEE) received her B.S. and PhD. Degree in optical engineering with honors from Beijing Institute of Technology in 2002 and 2007 respectively. Then she worked at the Mind Research Network, NM, USA as a postdoctor fellow and got promoted to Research Scientist in 2010 and Assistant Professor of Translational Neuroscience in 2012. She is currently a full professor at the National Laboratory of Pattern Recognition & Brainnetome Center, Institute of Automation, Chinese Academy of Science (CAS). Dr Suis research interests include machine learning, multi-modal data fusion (fMRI, sMRI, DTI, EEG, genetics), pattern recognition and biomarker identification of mental illnesses. Her ongoing work in predictive data mining attempts to meet clinical challenges of making early intervention possible based on fundamental neuroimaging data. She is a recipient of One Hundred Talents plan of CAS and has been program committee member of IEEE BIBM since 2011. Now she serves as grant reviewer for China Natural Science Foundation, China Scholarship Council etc and regular reviewers for more than 30 peer-reviewed journals.

Tülay Adalı (Fellow, IEEE) received the Ph.D. degree in electrical engineering from North Carolina State University, Raleigh, NC, USA, in 1992.
She joined the faculty at the University of Maryland Baltimore County (UMBC), Baltimore, MD, USA, in 1992. She is currently a Distinguished University Professor in the Department of Computer Science and Electrical Engineering at UMBC. Her research interests are in the areas of statistical signal processing, machine learning for signal processing, and biomedical data analysis.
Prof. Adalı assisted in the organization of a number of international conferences and workshops including the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), the IEEE International Workshop on Neural Networks for Signal Processing (NNSP), and the IEEE International Workshop on Machine Learning for Signal Processing (MLSP). She was the General Co-Chair, NNSP (2001–2003); Technical Chair, MLSP (2004–2008); Program Co-Chair, MLSP (2008, 2009, and 2014), 2009 International Conference on Independent Component Analysis and Source Separation; Publicity Chair, ICASSP (2000 and 2005); and Publications Co-Chair, ICASSP 2008. She is Technical Program Co-Chair for ICASSP 2017 and Special Sessions Co-Chair for ICASSP 2018. She chaired the IEEE Signal Processing Society (SPS) MLSP Technical Committee (2003–2005, 2011–2013), served on the SPS Conference Board (1998–2006), and the Bio Imaging and Signal Processing Technical Committee (2004–2007). She was an Associate Editor for the IEEE TRANSACTIONS ON SIGNAL PROCESSING (2003–2006), the IEEE TRANSACTIONS ON BIOMEDICAL ENGINEERING (2007–2013), the IEEE JOURNAL OF SELECTED AREAS IN SIGNAL PROCESSING (2010–2013), and Elsevier Signal Processing Journal (2007–2010). She is currently serving on the Editorial Boards of the PROCEEDINGS OF THE IEEE and Journal of Signal Processing Systems for Signal, Image, and Video Technology, and is a member of the IEEE Signal Processing Theory and Methods Technical Committee. She is a Fellow of the American Institute for Medical and Biological Engineering (AIMBE), a Fulbright Scholar, recipient of a 2010 IEEE Signal Processing Society Best Paper Award, 2013 University System of Maryland Regents’ Award for Research, and an NSF CAREER Award. She was an IEEE Signal Processing Society Distinguished Lecturer for 2012 and 2013.

Marios S. Pattichis (Senior Member, IEEE) received the B.Sc. degree (high and special honors) in Computer Sciences and the B.A. degree (high honors) in Mathematics, both in 1991, M.S. degree in Electrical Engineering in 1993, and the Ph.D. degree in Computer Engineering in 1998, all from the University of Texas at Austin, Austin, TX, USA. He is currently a Professor with the Department of Electrical and Computer Engineering, University of New Mexico (UNM), Albuquerque, NM, USA. He was a founding Co-PI of COSMIAC at UNM, where he is currently Director of the image & video Processing and Communications Lab (ivPCL, ivpcl.org). His current research interests include digital image, video processing, communications, dynamically reconfigurable computer architectures, and biomedical and space image processing applications.
Dr. Pattichis is currently a Senior Associate Editor of the IEEE SIGNAL PROCESSING LETTERS. He has been an Associate Editor for the IEEE TRANSACTIONS ON IMAGE PROCESSING and the IEEE TRANSACTIONS ON INDUSTRIAL INFORMATICS, and has also served as a Guest Associate Editor for the IEEE TRANSACTIONS ON INFORMATION TECHNOLOGY IN BIOMEDICINE. He was the General Chair of the 2008 IEEE Southwest Symposium on Image Analysis and Interpretation. He was a recipient of the 2004 Electrical and Computer Engineering Distinguished Teaching Award at UNM. For his development of the digital logic design labs at UNM he was recognized by the Xilinx Corporation in 2003 and by the UNM School of Engineering’s Harrison faculty excellent award in 2006.

Vince D. Calhoun (Fellow, IEEE & AAAS) received the B.S. degree in electrical engineering from the University of Kansas, Lawrence, KS, USA, in 1991, the M.S. degrees in biomedical engineering and information systems from The Johns Hopkins University, Baltimore, MD, USA, in 1993 and 1996, respectively, and the Ph.D. degree in electrical engineering from the University of Maryland Baltimore County, Baltimore, in 2002.
He worked as a Research Engineer in the Psychiatric Neuroimaging Laboratory, Johns Hopkins, from 1993 until 2002. He then served as the Director of Medical Image Analysis at the Olin Neuropsychiatry Research Center and as an Associate Professor at Yale University. He is currently Executive Science Officer and Director of Image Analysis and MR Research at the Mind Research Network, Albuquerque, NM, USA, and is a Distinguished Professor in the Departments of Electrical and Computer Engineering (primary), Biology, Computer Science, Neurosciences, and Psychiatry at the University of New Mexico, Albuquerque. He is the author of more than 400 full journal articles and over 500 technical reports, abstracts, and conference proceedings. Much of his career has been spent on the development of data-driven approaches for the analysis of brain imaging data. He has won over $85 million in NSF and NIH grants on the incorporation of prior information into ICA for functional magnetic resonance imaging, data fusion of multimodal imaging and genetics data, and the identification of biomarkers for disease, and leads a P20 COBRE center grant on multimodal imaging of schizophrenia, bipolar disorder, and major depression.
Dr. Calhoun is a Fellow of the American Association for the Advancement of Science (AAAS), the American Institute for Medical and Biological Engineering (AIMBE), and the International Society for Magnetic Resonance in Medicine (ISMRM). He is also a member and regularly attends the Organization for Human Brain Mapping, the International Society for Magnetic Resonance in Medicine, the International Congress on Schizophrenia Research, and the American College of Neuropsychopharmacology. He is also a regular grant reviewer for NIH and NSF. He has organized workshops and special sessions at multiple conferences. He is currently chair of the IEEE Machine Learning for Signal Processing (MLSP) technical committee. He is a reviewer for many journals, is on the editorial board of the Brain Connectivity and Neuroimage journals, and serves as an Associate Editor for Journal of Neuroscience Methods and several other journals.
Footnotes
The subspace terminology stems from the linear mixture function case [28] in which the columns of A corresponding to sk form a linear (sub)space.
Exact JD is only attained in the case of two symmetric matrices.
CCA is sometimes referred to as PLS Mode B [110].
The constraint in CCA enforces . Likewise for mCCA.
Contributor Information
Rogers F. Silva, Dept. of ECE at The University of New Mexico, NM USA; The Mind Research Network, LBERI, Albuquerque, New Mexico USA.
Sergey M. Plis, The Mind Research Network, LBERI, Albuquerque, New Mexico USA
Jing Sui, Brainnetome Center & NLPR, Institute of Automation, Chinese Academy of Sciences, Beijing China; The Mind Research Network, LBERI, Albuquerque, New Mexico USA.
Marios S. Pattichis, Calhoun are with the Dept. of ECE at The University of New Mexico, NM USA.
Tülay Adalı, Dept. of CSEE, University of Maryland Baltimore County, Baltimore, Maryland USA.
Vince D. Calhoun, Dept. of ECE at The University of New Mexico, NM USAThe Mind Research Network, LBERI, Albuquerque, New Mexico USA.
References
- 1.Comon P, Jutten C. Handbook of Blind Source Separation. 1st. Oxford, UK: Academic Press; 2010. [Google Scholar]
- 2.Xu L, Groth K, Pearlson G, Schretlen D, Calhoun V. Source-based morphometry: The use of independent component analysis to identify gray matter differences with application to schizophrenia. Hum Brain Mapp. 2009;30(3):711–724. doi: 10.1002/hbm.20540. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 3.Calhoun V, Liu J, Adalı T. A review of group ICA for fMRI data and ICA for joint inference of imaging, genetic, and ERP data. NeuroImage. 2009;45(1 Supplement 1):S163–S172. doi: 10.1016/j.neuroimage.2008.10.057. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 4.Calhoun V, Adalı T, Pearlson G, Pekar J. A method for making group inferences from functional MRI data using independent component analysis. Hum Brain Mapp. 2001;14(3):140–151. doi: 10.1002/hbm.1048. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Tang A, Pearlmutter B, Zibulevsky M, Carter S. Blind source separation of multichannel neuromagnetic responses. Neurocomputing. 2000;3233:1115–1120. [Google Scholar]
- 6.Eichele T, Rachakonda S, Brakedal B, Eikeland R, Calhoun V. EEGIFT: Group independent component analysis for event-related EEG data. Comput Intell Neurosci. 2011;2011:129365. doi: 10.1155/2011/129365. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7.Arfanakis K, Cordes D, Haughton V, Carew J, Meyerand M. Independent component analysis applied to diffusion tensor MRI. Magn Reson Med. 2002;47(2):354–363. doi: 10.1002/mrm.10046. [DOI] [PubMed] [Google Scholar]
- 8.Boutte D, Calhoun V, Chen J, Sabbineni A, Hutchison K, Liu J. Association of genetic copy number variations at 11 q14.2 with brain regional volume differences in an alcohol use disorder population. Alcohol. 2012;46(6):519–527. doi: 10.1016/j.alcohol.2012.05.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Liu J, Demirci O, Calhoun V. A parallel independent component analysis approach to investigate genomic influence on brain function. IEEE Signal Process Lett. 2008;15:413–416. doi: 10.1109/LSP.2008.922513. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Liu J, Morgan M, Hutchison K, Calhoun VD. A study of the influence of sex on genome wide methylation. PLoS ONE. 2010 Apr;5(4):1–8. doi: 10.1371/journal.pone.0010028. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11.Renard E, Teschendorff AE, Absil P-A. Capturing confounding sources of variation in DNA methylation data by spatiotemporal independent component analysis. Proc ESANN 2014. :195–200. [Google Scholar]
- 12.Bartel J, Krumsiek J, Theis FJ. Statistical methods for the analysis of high-throughput metabolomics data. Comput Struct Biotechnol J. 2013;4(5):1–9. doi: 10.5936/csbj.201301009. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Spearman C, Jones L. Human Ability: A Continuation of “The Abilities of Man”. Macmillan; 1950. [Google Scholar]
- 14.Eysenck SBG, Eysenck HJ. The validity of questionnaire and rating assessments of extraversion and neuroticism, and their factorial stability. Brit J Psychol. 1963;54(1):51–62. [Google Scholar]
- 15.Feinberg D, Moeller S, Smith S, Auerbach E, Ramanna S, Glasser M, Miller K, Ugurbil K, Yacoub E. Multiplexed echo planar imaging for sub-second whole brain FMRI and fast diffusion imaging. PLoS ONE. 2010 Dec;5(12):1–11. doi: 10.1371/journal.pone.0015710. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Feinberg D, Setsompop K. Ultra-fast MRI of the human brain with simultaneous multi-slice imaging. J Magn Reson. 2013;229:90–100. doi: 10.1016/j.jmr.2013.02.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Bianciardi M, Toschi N, Edlow B, Eichner C, Setsompop K, Polimeni J, Brown E, Kinney H, Rosen B, Wald L. Toward an in vivo neuroimaging template of human brainstem nuclei of the ascending arousal, autonomic, and motor systems. Brain Connect. 2015 Dec;5(10):597–607. doi: 10.1089/brain.2015.0347. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18.van der Zwaag W, Schfer A, Marques J, Turner R, Trampel R. Recent applications of UHF-MRI in the study of human brain function and structure: a review. NMR Biomed. 2015 doi: 10.1002/nbm.3275. [DOI] [PubMed] [Google Scholar]
- 19.Comon P. Independent component analysis, a new concept? Signal Process. 1994;36(3):287–314. [Google Scholar]
- 20.Bell A, Sejnowski T. An information-maximization approach to blind separation and blind deconvolution. Neural Comput. 1995 Nov;7(6):1129–1159. doi: 10.1162/neco.1995.7.6.1129. [DOI] [PubMed] [Google Scholar]
- 21.Hyvärinen A, Erkki O. A fast fixed-point algorithm for independent component analysis. Neural Comput. 1997;9(7):1483–1492. [Google Scholar]
- 22.Belouchrani A, Abed-Meraim K, Cardoso J-F, Moulines E. Proc ICDSP 1993. Nicosia, Cyprus: 1993. Second-order blind separation of temporally correlated sources; pp. 346–351. [Google Scholar]
- 23.Yeredor A. Blind separation of gaussian sources via second-order statistics with asymptotically optimal weighting. IEEE Signal Process Lett. 2000 Jul;7(7):197–200. [Google Scholar]
- 24.Hotelling H. Relations between two sets of variates. Biometrika. 1936 Dec;28(3/4):321–377. [Google Scholar]
- 25.Wold H. Nonlinear estimation by iterative least squares procedures. In: David F, editor. Research Papers in Statistics Festschrift for J Neyman. New York, NY: Wiley; 1966. pp. 411–444. [Google Scholar]
- 26.Adalı T, Anderson M, Fu G-S. Diversity in independent component and vector analyses: Identifiability, algorithms, and applications in medical imaging. IEEE Signal Process Mag. 2014 May;31(3):18–33. [Google Scholar]
- 27.Kim T, Eltoft T, Lee T-W. Proc ICA 2006. Charleston, SC: Independent vector analysis: An extension of ICA to multivariate components; pp. 165–172. [Google Scholar]
- 28.Cardoso J-F. Proc IEEE ICASSP 1998. Vol. 4. Seattle, WA: 1998. Multidimensional independent component analysis; pp. 1941–1944. [Google Scholar]
- 29.Lahat D, Cardoso J, Messer H. Second-order multidimensional ICA: Performance analysis. IEEE Trans Signal Process. 2012 Sep;60(9):4598–4610. [Google Scholar]
- 30.Hyvärinen A, Köster U. Proc ESANN 2006. Bruges, Belgium: 2006. FastISA: A fast fixed-point algorithm for independent subspace analysis; pp. 371–376. [Google Scholar]
- 31.Szabó Z, Póczos B, Lőrincz A. Separation theorem for independent subspace analysis and its consequences. Pattern Recognit. 2012;45(4):1782–1791. [Google Scholar]
- 32.Silva R, Plis S, Adalı T, Calhoun V. Proc OHBM 2014. Hamburg, Germany: Multidataset independent subspace analysis. Poster 3506. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Silva R, Plis S, Adalı T, Calhoun V. Proc IEEE ICIP 2014. Paris, France: 2014. Multidataset independent subspace analysis extends independent vector analysis; pp. 2864–2868. [Google Scholar]
- 34.Lahat D, Jutten C. Proc LVA/ICA 2015. Liberec, Czech Republic: 2015. Joint independent subspace analysis: A quasi-newton algorithm; pp. 111–118. [Google Scholar]
- 35.Zhou G, Zhao Q, Zhang Y, Adalı T, Xie S, Cichocki A. Linked component analysis from matrices to high-order tensors: Applications to biomedical data. Proc IEEE. 2016 Feb;104(2):310–331. [Google Scholar]
- 36.Koller D, Friedman N. Probabilistic Graphical Models: Principles and Techniques. 1st. Cambridge, MA: MIT Press; 2009. (ser Adaptive computation and machine learning). [Google Scholar]
- 37.Li Y-O, Adalı T, Wang W, Calhoun V. Joint blind source separation by multiset canonical correlation analysis. IEEE Trans Signal Process. 2009 Oct;57(10):3918–3929. doi: 10.1109/TSP.2009.2021636. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Rao C. A decomposition theorem for vector variables with a linear structure. Ann Math Stat. 1969;40(5):1845–1849. [Google Scholar]
- 39.Anderson M, Fu G, Phlypo R, Adalı T. Independent vector analysis: Identification conditions and performance bounds. IEEE Trans Signal Process. 2014 Sep;62(17):4399–4410. [Google Scholar]
- 40.Lahat D, Jutten C. Proc IEEE ICASSP 2016. Shanghai, China: 2016. An alternative proof for the identifiability of independent vector analysis using second order statistics. In Press. [Google Scholar]
- 41.Lahat D, Jutten C. Joint independent subspace analysis using second-order statistics. IEEE Trans Signal Process. 2016 In Press. [Google Scholar]
- 42.Akaike H. A new look at the statistical model identification. IEEE Trans Autom Control. 1974 Dec;19(6):716–723. [Google Scholar]
- 43.Schwarz G. Estimating the dimension of a model. Ann Statist. 1978 Mar;6(2):461–464. [Google Scholar]
- 44.Cavanaugh JE. A large-sample model selection criterion based on Kullback’s symmetric divergence. Stat Probabil Lett. 1999;42(4):333–343. [Google Scholar]
- 45.Draper D. Assessment and propagation of model uncertainty. J Roy Statist Soc Ser B. 1995;57(1):45–97. [Google Scholar]
- 46.Rissanen J. Modeling by shortest data description. Automatica. 1978;14(5):465–471. [Google Scholar]
- 47.Ma S, Li X-L, Correa N, Adalı T, Calhoun V. Proc IEEE ICASSP 2010. Dallas, TX: 2010. Independent subspace analysis with prior information for fMRI data; pp. 1922–1925. [Google Scholar]
- 48.Nocedal J, Wright S. Numerical Optimization. 2nd. New York, NY: Springer; 2006. (ser Springer Series in Operations Research and Financial Engineering). [Google Scholar]
- 49.Cardoso J, Laheld B. Equivariant adaptive source separation. IEEE Trans Signal Process. 1996 Dec;44(12):3017–3030. [Google Scholar]
- 50.Amari S-I. Natural gradient works efficiently in learning. Neural Comput. 1998 Feb;10(2):251–276. [Google Scholar]
- 51.Strang G. Computational Science and Engineering. Wellesley-Cambridge Press; 2007. [Google Scholar]
- 52.Boyd S, Vandenberghe L. Convex Optimization. 1st. Cambridge, UK: Cambridge University Press; 2004. [Google Scholar]
- 53.Honkela A, Valpola H, Ilin A, Karhunen J. Blind separation of nonlinear mixtures by variational bayesian learning. Digit Signal Process. 2007;17(5):914–934. [Google Scholar]
- 54.Choudrey R, Roberts S. Variational mixture of bayesian independent component analyzers. Neural Comput. 2003;15(1):213–252. doi: 10.1162/089976603321043766. [DOI] [PubMed] [Google Scholar]
- 55.Delyon B, Lavielle M, Moulines E. Convergence of a stochastic approximation version of the EM algorithm. Ann Stat. 1999;27(1):94–128. [Google Scholar]
- 56.Delabrouille J, Cardoso J-F, Patanchon G. Multidetector multicomponent spectral matching and applications for cosmic microwave background data analysis. Mon Not R Astron Soc. 2003;346(4):1089–1102. [Google Scholar]
- 57.Pearson K. On lines and planes of closest fit to systems of points in space. Philos Mag. 1901;2(11):559–572. [Google Scholar]
- 58.Friston K, Frith C, Liddle P, Frackowiak R. Functional connectivity: The principal-component analysis of large (PET) data sets. J Cereb Blood Flow Metab. 1993;13(1):5–14. doi: 10.1038/jcbfm.1993.4. [DOI] [PubMed] [Google Scholar]
- 59.Andersen A, Gash D, Avison M. Principal component analysis of the dynamic response measured by fMRI: a generalized linear systems framework. Magn Reson Imaging. 1999;17(6):795–815. doi: 10.1016/s0730-725x(99)00028-4. [DOI] [PubMed] [Google Scholar]
- 60.Leonardi N, Richiardi J, Gschwind M, Simioni S, Annoni J-M, Schluep M, Vuilleumier P, Ville DVD. Principal components of functional connectivity: A new approach to study dynamic brain connectivity during rest. NeuroImage. 2013;83:937–950. doi: 10.1016/j.neuroimage.2013.07.019. [DOI] [PubMed] [Google Scholar]
- 61.Vigário R. Extraction of ocular artefacts from EEG using independent component analysis. Electroencephalogr Clin Neurophysiol. 1997;103(3):395–404. doi: 10.1016/s0013-4694(97)00042-8. [DOI] [PubMed] [Google Scholar]
- 62.Makeig S, Jung T, Bell A, Ghahremani D, Sejnowski T. Blind separation of auditory event-related brain responses into independent components. Proc Natl Acad Sci. 1997;94(20):10979–10984. doi: 10.1073/pnas.94.20.10979. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63.McKeown M, Jung T, Makeig S, Brown G, Kindermann S, Lee T, Sejnowski T. Spatially independent activity patterns in functional MRI data during the stroop color-naming task. Proc Natl Acad Sci. 1998;95(3):803–810. doi: 10.1073/pnas.95.3.803. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64.McKeown M, Makeig S, Brown G, Jung T, Kindermann S, Bell A, Sejnowski T. Analysis of fMRI data by blind separation into independent spatial components. Hum Brain Map. 1998;6(3):160–188. doi: 10.1002/(SICI)1097-0193(1998)6:3<160::AID-HBM5>3.0.CO;2-1. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 65.Makeig S, Enghoff S, Jung T-P, Sejnowski T. A natural basis for efficient brain-actuated control. IEEE Trans Rehabil Eng. 2000 Jun;8(2):208–211. doi: 10.1109/86.847818. [DOI] [PubMed] [Google Scholar]
- 66.Vigário R, Sarela J, Jousmiki V, Hämäläinen M, Oja E. Independent component approach to the analysis of EEG and MEG recordings. IEEE Trans Biomed Eng. 2000 May;47(5):589–593. doi: 10.1109/10.841330. [DOI] [PubMed] [Google Scholar]
- 67.Park H-J, Kim J-J, Youn T, Lee D, Lee M, Kwon J. Independent component model for cognitive functions of multiple subjects using [15O]H2O PET images. Hum Brain Mapp. 2003;18(4):284–295. doi: 10.1002/hbm.10085. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 68.Takahashi S, Anzai Y, Sakurai Y. Automatic sorting for multi-neuronal activity recorded with tetrodes in the presence of overlapping spikes. J Neurphysiol. 2003;89(4):2245–2258. doi: 10.1152/jn.00827.2002. [DOI] [PubMed] [Google Scholar]
- 69.Morren G, Wolf M, Lemmerling P, Wolf U, Choi J, Gratton E, De Lathauwer L, Van Huffel S. Detection of fast neuronal signals in the motor cortex from functional near infrared spectroscopy measurements using independent component analysis. Med Biol Eng Comput. 2004;42(1):92–99. doi: 10.1007/BF02351016. [DOI] [PubMed] [Google Scholar]
- 70.Pulkkinen J, Häkkinen A-M, Lundbom N, Paetau A, Kauppinen R, Hiltunen Y. Independent component analysis to proton spectroscopic imaging data of human brain tumours. Eur J Radiol. 2005;56(2):160–164. doi: 10.1016/j.ejrad.2005.03.018. [DOI] [PubMed] [Google Scholar]
- 71.Cichocki A, Amari SI. Adaptive Blind Signal and Image Processing. Chichester, UK: Wiley; 2003. revised and corrected ed. [Google Scholar]
- 72.Hyvärinen A, Karhunen J, Oja E. Independent Component Analysis. 1st. New York, NY: Wiley; 2002. [Google Scholar]
- 73.Kirshner S, Póczos B. ICA and ISA using Schweizer-Wolff measure of dependence. 2008:464–471. [Google Scholar]
- 74.Haykin S. Neural Networks and Learning Machines. 3rd. Upper Saddle River, NJ: Prentice Hall; 2008. [Google Scholar]
- 75.Cichocki A, Amari S-I. Families of alpha- beta- and gamma-divergences: Flexible and robust measures of similarities. Entropy. 2010;12(6):1532–1568. [Google Scholar]
- 76.Amari S-I, Cichocki A. Information geometry of divergence functions. Bull Pol Acad Sci, Tech Sci. 2010;58(1):183–195. [Google Scholar]
- 77.Cover T, Thomas J. Elements of Information Theory. 2nd. Wiley; 2006. (ser Telecommunications and Signal Processing). [Google Scholar]
- 78.Stögbauer H, Kraskov A, Astakhov S, Grassberger P. Least-dependent-component analysis based on mutual information. Phys Rev E. 2004 Dec;70:066123. doi: 10.1103/PhysRevE.70.066123. [DOI] [PubMed] [Google Scholar]
- 79.Belouchrani A, Abed-Meraim K, Cardoso J-F, Moulines E. A blind source separation technique using second-order statistics. IEEE Trans Signal Process. 1997 Feb;45(2):434–444. [Google Scholar]
- 80.Tong L, Soon V, Huang Y, Liu R. Proc IEEE ISCS 1990. Vol. 3 New Orleans, LA: 1990. AMUSE: a new blind identification algorithm; pp. 1784–1787. [Google Scholar]
- 81.Ziehe A, Müller K-R. Proc ICANN 98. Skövde, Sweden: 1998. TDSEP – an efficient algorithm for blind separation using time structure; pp. 675–680. [Google Scholar]
- 82.Tichavsky P, Koldovsky Z, Doron E, Yeredor A, Gomez-Herrero G. Proc 14h Euro SPC. Florence, Italy: 2006. Blind signal separation by combining two ICA algorithms: HOS-based EFICA and time structure-based WASOBI; pp. 1–5. [Google Scholar]
- 83.Koldovsky Z, Tichavsky P, Oja E. Efficient variant of algorithm FastICA for independent component analysis attaining the Cramer-Rao lower bound. IEEE Trans Neural Netw. 2006 Sep;17(5):1265–1277. doi: 10.1109/TNN.2006.875991. [DOI] [PubMed] [Google Scholar]
- 84.Tichavsky P, Koldovsky Z, Yeredor A, Gomez-Herrero G, Doron E. A hybrid technique for blind separation of non-gaussian and time-correlated sources using a multicomponent approach. IEEE Trans Neural Netw. 2008 Mar;19(3):421–430. doi: 10.1109/TNN.2007.908648. [DOI] [PubMed] [Google Scholar]
- 85.Li X-L, Adalı T. Proc IEEE ICASSP 2010. Dallas, TX: 2010. Blind spatiotemporal separation of second and/or higher-order correlated sources by entropy rate minimization; pp. 1934–1937. [Google Scholar]
- 86.Fu G-S, Phlypo R, Anderson M, Li X-L, Adalı T. Proc IEEE ICASSP 2013. Vancouver, BC: 2013. Algorithms for markovian source separation by entropy rate minimization; pp. 3248–3252. [Google Scholar]
- 87.Calhoun V, Adalı T. Multisubject independent component analysis of fMRI: A decade of intrinsic networks, default mode, and neurodiagnostic discovery. IEEE Rev Biomed Eng. 2012;5:60–73. doi: 10.1109/RBME.2012.2211076. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 88.Allen E, Erhardt E, Damaraju E, Gruner W, Segall J, Silva R, Havlicek M, Rachakonda S, Fries J, Kalyanam R, et al. A baseline for the multivariate comparison of resting-state networks. Front Syst Neurosci. 2011;5 doi: 10.3389/fnsys.2011.00002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 89.Allen E, Damaraju E, Plis S, Erhardt E, Eichele T, Calhoun V. Tracking whole-brain connectivity dynamics in the resting state. Cereb Cortex. 2012 doi: 10.1093/cercor/bhs352. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 90.Yaesoubi M, Allen E, Miller R, Calhoun V. Dynamic coherence analysis of resting fMRI data to jointly capture state-based phase, frequency, and time-domain information. NeuroImage. 2015 Oct;120:133–142. doi: 10.1016/j.neuroimage.2015.07.002. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 91.Calhoun V, Miller R, Pearlson G, Adalı T. The Chronnectome: Time-varying connectivity networks as the next frontier in fMRI data discovery. Neuron. 2014;84(2):262–274. doi: 10.1016/j.neuron.2014.10.015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 92.Hutchison RM, Womelsdorf T, Allen EA, Bandettini PA, Calhoun VD, Corbetta M, Penna SD, Duyn JH, Glover GH, Gonzalez-Castillo J, Handwerker DA, Keilholz S, Kiviniemi V, Leopold DA, de Pasquale F, Sporns O, Walter M, Chang C. Dynamic functional connectivity: Promise, issues, and interpretations. NeuroImage. 2013;80:360–378. doi: 10.1016/j.neuroimage.2013.05.079. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 93.Erhardt E, Rachakonda S, Bedrick E, Allen E, Adalı T, Calhoun V. Comparison of multi-subject ICA methods for analysis of fMRI data. Hum Brain Mapp. 2011;32(12):2075–2095. doi: 10.1002/hbm.21170. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 94.Michael A, Anderson M, Miller R, Adalı T, Calhoun V. Preserving subject variability in group fMRI analysis: Performance evaluation of GICA versus IVA. Front Syst Neurosci. 2014;8(106) doi: 10.3389/fnsys.2014.00106. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 95.Lawley D, Maxwell A. Factor analysis as a statistical method. J R Stat Soc. 1962;12(3):209–229. [Google Scholar]
- 96.Beckmann C, Smith S. Probabilistic independent component analysis for functional magnetic resonance imaging. IEEE Trans Med Imag. 2004 Feb;23(2):137–152. doi: 10.1109/TMI.2003.822821. [DOI] [PubMed] [Google Scholar]
- 97.Attias H. Independent factor analysis. Neural Comput. 1999 May;11(4):803–851. doi: 10.1162/089976699300016458. [DOI] [PubMed] [Google Scholar]
- 98.Choudrey R. PhD dissertation. University of Oxford; 2002. Variational methods for bayesian independent component analysis. [Google Scholar]
- 99.Roberts S, Choudrey R. Proc DSMML Workshop 2004. Sheffield, UK: 2004. Bayesian independent component analysis with prior constraints: An application in biosignal analysis; pp. 159–179. [Google Scholar]
- 100.Lappalainen H, Honkela A. Bayesian non-linear independent component analysis by multi-layer perceptrons. In: Girolami M, editor. Advances in Independent Component Analysis. London, UK: Springer; 2000. pp. 93–121. ch. 6. [Google Scholar]
- 101.Valpola H, Karhunen J. An unsupervised ensemble learning method for nonlinear dynamic state-space models. Neural Comput. 2002 Nov;14(11):2647–2692. [Google Scholar]
- 102.Beckmann C, Smith S. Tensorial extensions of independent component analysis for multisubject FMRI analysis. NeuroImage. 2005;25(1):294–311. doi: 10.1016/j.neuroimage.2004.10.043. [DOI] [PubMed] [Google Scholar]
- 103.Cardoso J, Souloumiac A. Blind beamforming for non-Gaussian signals. IEE Proc F. 1993 Dec;140(6):362–370. [Google Scholar]
- 104.Lu W, Rajapakse J. Proc NIPS2000. Denver, CO: 2000. Constrained independent component analysis; pp. 570–576. [Google Scholar]
- 105.Lu W, Rajapakse J. ICA with reference. Neurocomputing. 2006;69(16–18):2244–2257. [Google Scholar]
- 106.Lin Q-H, Zheng Y-R, Yin F-L, Liang H, Calhoun V. A fast algorithm for one-unit ICA-R. Inform Sciences. 2007;177(5):1265–1275. [Google Scholar]
- 107.Anderson M, Fu G-S, Phlypo R, Adalı T. Proc IEEE ICASSP 2013. Vancouver, BC: 2013. Independent vector analysis, the Kotz distribution, and performance bounds; pp. 3243–3247. [Google Scholar]
- 108.Kettenring J. Canonical analysis of several sets of variables. Biometrika. 1971 Dec;58(3):433–451. [Google Scholar]
- 109.De Bie T, Cristianini N, Rosipal R. Eigenproblems in pattern recognition. In: Corrochano E, editor. Handbook of Geometric Computing: Applications in Pattern Recognition, Computer Vision, Neuralcomputing, and Robotics. 1st. New York, NY: Springer; 2005. pp. 129–167. ch. 5. [Google Scholar]
- 110.Wegelin J. A survey of partial least squares (PLS) methods, with emphasis on the two-block case. Dept. of Statistics, University of Washington; Seattle, WA, 98195, USA: Mar, 2000. (Tech. Rep. 371). [Google Scholar]
- 111.Wold H. Nonlinear iterative partial least squares (NIPALS) estimation procedures. In: Wold H, Lyttkens E, editors. Bulletin of the International Statistical Institute. Vol. 42. London, UK: International Statistical Institute (ISI); 1969. pp. 91–424. [Google Scholar]
- 112.Lu H, Plataniotis K, Venetsanopoulos A. Multilinear Subspace Learning: Dimensionality Reduction of Multidimensional Data. 1st. Boca Raton, FL: CRC Press; Dec, 2013. (ser Machine Learning & Pattern Recognition). [Google Scholar]
- 113.Rosipal R, Krämer N. Proc SLSFS 2005. Bohinj, Slovenia: 2005. Overview and recent advances in partial least squares; pp. 34–51. [Google Scholar]
- 114.Höskuldsson A. PLS regression methods. J Chemometrics. 1988 Jun;2(3):211–228. [Google Scholar]
- 115.Stigler S. Gauss and the invention of least squares. Ann Statist. 1981 May;9(3):465–474. [Google Scholar]
- 116.Haufe S, Meinecke F, Görgen K, Dähne S, Haynes J-D, Blankertz B, Bießmann F. On the interpretation of weight vectors of linear models in multivariate neuroimaging. NeuroImage. 2014;87:96–110. doi: 10.1016/j.neuroimage.2013.10.067. [DOI] [PubMed] [Google Scholar]
- 117.Dähne S, Meinecke F, Haufe S, Höhne J, Tangermann M, Müller K-R, Nikulin V. SPoC: A novel framework for relating the amplitude of neuronal oscillations to behaviorally relevant parameters. NeuroImage. 2014;86:111–122. doi: 10.1016/j.neuroimage.2013.07.079. [DOI] [PubMed] [Google Scholar]
- 118.Dähne S, Nikulin V, Ramírez D, Schreier P, Müller K-R, Haufe S. Finding brain oscillations with power dependencies in neuroimaging data. NeuroImage. 2014;96:334–348. doi: 10.1016/j.neuroimage.2014.03.075. [DOI] [PubMed] [Google Scholar]
- 119.Dähne S, Bießmann F, Meinecke F, Mehnert J, Fazli S, Müller K-R. Integration of multivariate data streams with bandpower signals. IEEE Trans Multimedia. 2013 Aug;15(5):1001–1013. [Google Scholar]
- 120.Chen J, Calhoun V, Liu J. Proc IEEE EMBC 2012. San Diego, CA: 2012. ICA order selection based on consistency: Application to genotype data; pp. 360–363. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 121.Dähne S, Bießmann F, Samek W, Haufe S, Goltz D, Gundlach C, Villringer A, Fazli S, Müller K-R. Multivariate machine learning methods for fusing multimodal functional neuroimaging data. Proc IEEE. 2015 Sep;103(9):1507–1530. [Google Scholar]
- 122.Arteaga F, Gallarza M, Gil I. A new multiblock PLS based method to estimate causal models: application to the post-consumption behavior in tourism. In: Esposito Vinzi V, Chin W, Henseler J, Wang H, editors. Handbook of Partial Least Squares: Concepts, Methods and Applications. 1st. New York, NY: Springer; 2010. pp. 141–169. ch. 6. [Google Scholar]
- 123.Anderson M, Li X-L, Adalı T. Proc LVA/ICA 2010. St Malo, France: 2010. Nonorthogonal independent vector analysis using multivariate gaussian model; pp. 354–361. [Google Scholar]
- 124.Du Y, Fan Y. Group information guided ICA for fMRI data analysis. NeuroImages. 2013;69:157–197. doi: 10.1016/j.neuroimage.2012.11.008. [DOI] [PubMed] [Google Scholar]
- 125.Calhoun V, Adalı T, Kiehl K, Astur R, Pekar J, Pearlson G. A method for multi-task fMRI data fusion applied to schizophrenia. Hum Brain Map. 2006;27(7):598–610. doi: 10.1002/hbm.20204. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 126.Calhoun V, Adalı T. Feature-based fusion of medical imaging data. IEEE Trans Inf Technol Biomed. 2009 Sep;13(5):711–720. doi: 10.1109/TITB.2008.923773. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 127.Calhoun V, Adalı T, Pearlson G, Pekar J. Spatial and temporal independent component analysis of functional MRI data containing a pair of task-related waveforms. Hum Brain Mapp. 2001;13(1):43–53. doi: 10.1002/hbm.1024. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 128.Baker B, Silva R, Calhoun V, Sarwate A, Plis S. IEEE MLSP 2015. Boston, MA: 2015. Large scale collaboration with autonomy: Decentralized data ICA; pp. 1–6. [Google Scholar]
- 129.Koles Z. The quantitative extraction and topographic mapping of the abnormal components in the clinical EEG. Electroen Clin Neuro. 1991;79(6):440–447. doi: 10.1016/0013-4694(91)90163-x. [DOI] [PubMed] [Google Scholar]
- 130.Ramoser H, Muller-Gerking J, Pfurtscheller G. Optimal spatial filtering of single trial EEG during imagined hand movement. IEEE Trans Rehabil Eng. 2000 Dec;8(4):441–446. doi: 10.1109/86.895946. [DOI] [PubMed] [Google Scholar]
- 131.Samek W, Kawanabe M, Müller KR. Divergence-based framework for common spatial patterns algorithms. IEEE Rev Biomed Eng. 2014;7:50–72. doi: 10.1109/RBME.2013.2290621. [DOI] [PubMed] [Google Scholar]
- 132.Lotte F, Guan C. Regularizing common spatial patterns to improve BCI designs: Unified theory and new algorithms. IEEE Trans Biomed Eng. 2011 Feb;58(2):355–362. doi: 10.1109/TBME.2010.2082539. [DOI] [PubMed] [Google Scholar]
- 133.Samek W, Vidaurre C, Müller K-R, Kawanabe M. Stationary common spatial patterns for braincomputer interfacing. J Neural Eng. 2012;9(2):026013. doi: 10.1088/1741-2560/9/2/026013. [DOI] [PubMed] [Google Scholar]
- 134.Groves AR, Beckmann CF, Smith SM, Woolrich MW. Linked independent component analysis for multimodal data fusion. NeuroImage. 2011;54(3):2198–2217. doi: 10.1016/j.neuroimage.2010.09.073. [DOI] [PubMed] [Google Scholar]
- 135.Fu G-S, Anderson M, Adalı T. Proc CISS. Baltimore, MD: 2015. Independent vector analysis by entropy rate bound minimization. [Google Scholar]
- 136.Hyvärinen A, Hurri J, Hoyer P. Natural Image Statistics: A Probabilistic Approach to Early Computational Vision. 1st. Vol. 39 Springer; 2009. (ser Computational Imaging and Vision). [Google Scholar]
- 137.Silva R, Plis S, Pattichis M, Adalı T, Calhoun V. Proc OHBM 2015. Honolulu, HI: Incorporating second-order statistics in multidataset independent subspace analysis. Poster 3743. [Google Scholar]
- 138.von Bünau P, Meinecke FC, Király FC, Müller K-R. Finding stationary subspaces in multivariate time series. Phys Rev Lett. 2009 Nov;103:214101. doi: 10.1103/PhysRevLett.103.214101. [DOI] [PubMed] [Google Scholar]
- 139.Pham DT. Joint approximate diagonalization of positive definite Hermitian matrices. SIAM J Matrix Anal Appl. 2001;22(4):1136–1152. [Google Scholar]
- 140.Hara S, Kawahara Y, Washio T, von Bünau P. Proc ICONIP 2010. Sydney, Australia: 2010. Stationary subspace analysis as a generalized eigenvalue problem; pp. 422–429. [Google Scholar]
- 141.McKeown M, Hansen L, Sejnowski T. Independent component analysis of functional MRI: what is signal and what is noise? Curr Opin Neurobiol. 2003;13(5):620–629. doi: 10.1016/j.conb.2003.09.012. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 142.Calhoun V, Adalı T. Unmixing fMRI with independent component analysis. IEEE Eng Med Biol Mag. 2006 Mar;25(2):79–90. doi: 10.1109/memb.2006.1607672. [DOI] [PubMed] [Google Scholar]
- 143.Biswal B, Ulmer J. Blind source separation of multiple signal sources of fMRI data sets using independent component analysis. J Comput Assist Tomogr. 1999;23(2):265–271. doi: 10.1097/00004728-199903000-00016. [DOI] [PubMed] [Google Scholar]
- 144.Eichele T, Specht K, Moosmann M, Jongsma M, Quiroga R, Nordby H, Hugdahl K. Assessing the spatiotemporal evolution of neuronal activation with single-trial event-related potentials and functional MRI. Proc Natl Acad Sci. 2005;102(49):17798–17803. doi: 10.1073/pnas.0505508102. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 145.Bridwell D, Kiehl K, Pearlson G, Calhoun V. Patients with schizophrenia demonstrate reduced cortical sensitivity to auditory oddball regularities. Schizophr Res. 2014;158(13):189–194. doi: 10.1016/j.schres.2014.06.037. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 146.Onton J, Westerfield M, Townsend J, Makeig S. Imaging human EEG dynamics using independent component analysis. Neurosci Biobehav Rev. 2006;30(6):808–822. doi: 10.1016/j.neubiorev.2006.06.007. [DOI] [PubMed] [Google Scholar]
- 147.Calhoun V, Adalı T, Pearlson G, van Zijl P, Pekar J. Independent component analysis of fMRI data in the complex domain. Magnet Reson Med. 2002;48(1):180–192. doi: 10.1002/mrm.10202. [DOI] [PubMed] [Google Scholar]
- 148.Petersen K, Hansen L, Kolenda T, Rostrup E, Strother S. Proc ICA 2000. Helsinki, Finland: 2000. On the independent components of functional neuroimages; pp. 615–620. [Google Scholar]
- 149.Caprihan A, Abbott C, Yamamoto J, Pearlson G, Perrone-Bizzozero N, Sui J, Calhoun V. Source-based morphometry analysis of group differences in fractional anisotropy in schizophrenia. Brain Connect. 2011;1(2):133–145. doi: 10.1089/brain.2011.0015. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 150.Brookes M, Woolrich M, Luckhoo H, Price D, Hale J, Stephenson M, Barnes G, Smith S, Morris P. Investigating the electrophysiological basis of resting state networks using magnetoencephalography. Proc Natl Acad Sci. 2011;108(40):16783–16788. doi: 10.1073/pnas.1112685108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 151.Smith SM, Miller KL, Moeller S, Xu J, Auerbach EJ, Woolrich MW, Beckmann CF, Jenkinson M, Andersson J, Glasser MF, Van Essen DC, Feinberg DA, Yacoub ES, Ugurbil K. Temporally-independent functional modes of spontaneous brain activity. Proc Natl Acad Sci. 2012;109(8):3131–3136. doi: 10.1073/pnas.1121329109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 152.Makeig S, Bell A, Jung T-P, Sejnowski T. Proc NIPS1995. Denver, CO: 1995. Independent component analysis of electroencephalographic data; pp. 145–151. [Google Scholar]
- 153.Delorme A, Sejnowski T, Makeig S. Enhanced detection of artifacts in EEG data using higher-order statistics and independent component analysis. NeuroImage. 2007;34(4):1443–1449. doi: 10.1016/j.neuroimage.2006.11.004. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 154.Tang A, Sutherland M, McKinney C. Validation of SOBI components from high-density EEG. NeuroImage. 2005;25(2):539–553. doi: 10.1016/j.neuroimage.2004.11.027. [DOI] [PubMed] [Google Scholar]
- 155.Calhoun V, Sui J, Kiehl K, Turner J, Allen E, Pearlson G. Exploring the psychosis functional connectome: aberrant intrinsic networks in schizophrenia and bipolar disorder. Front Psychiatry. 2012;2(75) doi: 10.3389/fpsyt.2011.00075. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 156.Jafri M, Pearlson G, Stevens M, Calhoun V. A method for functional network connectivity among spatially independent resting-state components in schizophrenia. NeuroImage. 2008;39(4):1666–1681. doi: 10.1016/j.neuroimage.2007.11.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 157.Damaraju E, Allen E, Belger A, Ford J, McEwen S, Mathalon D, Mueller B, Pearlson G, Potkin S, Preda A, Turner J, Vaidya J, van Erp T, Calhoun V. Dynamic functional connectivity analysis reveals transient states of dysconnectivity in schizophrenia. NeuroImage: Clin. 2014;5:298–308. doi: 10.1016/j.nicl.2014.07.003. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 158.Friman O, Carlsson J, Lundberg P, Borga M, Knutsson H. Detection of neural activity in functional MRI using canonical correlation analysis. Magn Reson Med. 2001 Feb;45(2):323–330. doi: 10.1002/1522-2594(200102)45:2<323::aid-mrm1041>3.0.co;2-#. [DOI] [PubMed] [Google Scholar]
- 159.Correa N, Adalı T, Li Y-O, Calhoun V. Canonical correlation analysis for data fusion and group inferences. IEEE Signal Process Mag. 2010;27(4):39–50. doi: 10.1109/MSP.2010.936725. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 160.Li Y-O, Eichele T, Calhoun V, Adalı T. Group study of simulated driving fMRI data by multiset canonical correlation analysis. J Signal Process Syst. 2012;68(1):31–48. doi: 10.1007/s11265-010-0572-8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 161.Lin Z, Zhang C, Wu W, Gao X. Frequency recognition based on canonical correlation analysis for SSVEP-Based BCIs. IEEE Trans Biomed Eng. 2006 Dec;53(12):2610–2614. doi: 10.1109/tbme.2006.886577. [DOI] [PubMed] [Google Scholar]
- 162.Zhang Y, Zhou G, Jin J, Wang X, Cichocki A. Frequency recognition in SSVEP-based BCI using multiset canonical correlation analysis. Int J Neural Syst. 2014;24(4):1450013. doi: 10.1142/S0129065714500130. [DOI] [PubMed] [Google Scholar]
- 163.Nestor P, O’Donnell B, McCarley R, Niznikiewicz M, Barnard J, Jen Shen Z, Bookstein F, Shenton M. A new statistical method for testing hypotheses of neuropsychological MRI relationships in schizophrenia: partial least squares analysis. Schizophr Res. 2002 Jan;53(1–2):57–66. doi: 10.1016/s0920-9964(00)00171-7. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 164.Lee J-H, Lee T-W, Jolesz F, Yoo S-S. Independent vector analysis (IVA): Multivariate approach for fMRI group study. NeuroImage. 2008;40(1):86–109. doi: 10.1016/j.neuroimage.2007.11.019. [DOI] [PubMed] [Google Scholar]
- 165.Gopal S, Miller R, Michael A, Adalı T, Cetin M, Rachakonda S, Bustillo J, Cahill N, Baum S, Calhoun V. Spatial variance in resting fMRI networks of schizophrenia patients: An independent vector analysis. Schizophr Bull. 2016;42(1):152–160. doi: 10.1093/schbul/sbv085. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 166.Schlösser R, Nenadic I, Wagner G, Güllmar D, von Consbruch K, Köhler S, Schultz C, Koch K, Fitzek C, Matthews P, Reichenbach J, Sauer H. White matter abnormalities and brain activation in schizophrenia: A combined DTI and fMRI study. Schizophr Res. 2007;89(13):1–11. doi: 10.1016/j.schres.2006.09.007. [DOI] [PubMed] [Google Scholar]
- 167.Wang F, Kalmar J, He Y, Jackowski M, Chepenik L, Edmiston E, Tie K, Gong G, Shah M, Jones M, Uderman J, Constable R, Blumberg H. Functional and structural connectivity between the perigenual anterior cingulate and amygdala in bipolar disorder. Biol Psychiat. 2009;66(5):516–521. doi: 10.1016/j.biopsych.2009.03.023. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 168.Kolb B, Whishaw I. Brain plasticity and behavior. Annu Rev Psychol. 1998;49(1):43–64. doi: 10.1146/annurev.psych.49.1.43. [DOI] [PubMed] [Google Scholar]
- 169.Keightley M, Chen J-K, Ptito A. Examining the neural impact of pediatric concussion: a scoping review of multimodal and integrative approaches using functional and structural MRI techniques. Curr Opin Pediatr. 2012;24(6):709716. doi: 10.1097/MOP.0b013e3283599a55. [DOI] [PubMed] [Google Scholar]
- 170.Toosy A, Ciccarelli O, Parker G, Wheeler-Kingshott C, Miller D, Thompson A. Characterizing functionstructure relationships in the human visual system with functional MRI and diffusion tensor imaging. NeuroImage. 2004;21(4):1452–1463. doi: 10.1016/j.neuroimage.2003.11.022. [DOI] [PubMed] [Google Scholar]
- 171.Bullmore E, Sporns O. Complex brain networks: graph theoretical analysis of structural and functional systems. Nat Rev Neurosci. 2009;10(3):186–198. doi: 10.1038/nrn2575. [DOI] [PubMed] [Google Scholar]
- 172.Camchong J, MacDonald A, Bell C, Mueller B, Lim K. Altered functional and anatomical connectivity in schizophrenia. Schizophrenia Bull. 2011;37(3):640–650. doi: 10.1093/schbul/sbp131. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 173.Sui J, Pearlson G, Caprihan A, Adalı T, Kiehl K, Liu J, Yamamoto J, Calhoun V. Discriminating schizophrenia and bipolar disorder by fusing fMRI and DTI in a multimodal CCA + joint ICA model. NeuroImage. 2011;57(3):839–855. doi: 10.1016/j.neuroimage.2011.05.055. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 174.Lahat D, Adali T, Jutten C. Multimodal data fusion: An overview of methods, challenges, and prospects. Proc IEEE. 2015 Sep;103(9):1449–1477. [Google Scholar]
- 175.Chen X, Wang ZJ, McKeown M. Joint blind source separation for neurophysiological data analysis: Multiset and multimodal methods. IEEE Signal Process Mag. 2016 May;33(3):86–107. [Google Scholar]
- 176.Lutti A, Dick F, Sereno MI, Weiskopf N. Using high-resolution quantitative mapping of R1 as an index of cortical myelination. NeuroImage. 2014;93(Part 2):176–188. doi: 10.1016/j.neuroimage.2013.06.005. [DOI] [PubMed] [Google Scholar]
- 177.Sereno M, Lutti A, Weiskopf N, Dick F. Mapping the human cortical surface by combining quantitative T1 with retinotopy. Cereb Cortex. 2013;23(9):2261–2268. doi: 10.1093/cercor/bhs213. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 178.Hutton C, Draganski B, Ashburner J, Weiskopf N. A comparison between voxel-based cortical thickness and voxel-based morphometry in normal aging. NeuroImage. 2009;48(2):371–380. doi: 10.1016/j.neuroimage.2009.06.043. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 179.Johansen-Berg H, Behrens T. Diffusion MRI. San Diego, CA: Academic Press; 2009. [Google Scholar]
- 180.Li J, Shi Y, Toga AW. Mapping brain anatomical connectivity using diffusion magnetic resonance imaging: Structural connectivity of the human brain. IEEE Signal Process Mag. 2016 May;33(3):36–51. doi: 10.1109/MSP.2015.2510024. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 181.Villien M, Wey H-Y, Mandeville JB, Catana C, Polimeni JR, Sander CY, Zürcher NR, Chonde DB, Fowler JS, Rosen BR, Hooker JM. Dynamic functional imaging of brain glucose utilization using fPET-FDG. NeuroImage. 2014;100:192–199. doi: 10.1016/j.neuroimage.2014.06.025. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 182.Villien M. Simultaneous functional imaging using fPET and fMRI. EJNMMI Physics. 2015;2(1) doi: 10.1186/2197-7364-2-S1-A66. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 183.Zaidi H, Becker M. The promise of hybrid PET/MRI: Technical advances and clinical applications. IEEE Signal Process Mag. 2016;33(3):67–85. [Google Scholar]
- 184.Yücel MA, Selb J, Boas DA, Cash SS, Cooper RJ. Reducing motion artifacts for long-term clinical NIRS monitoring using collodion-fixed prism-based optical fibers. NeuroImage. 2014;85(Part 1):192–201. doi: 10.1016/j.neuroimage.2013.06.054. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 185.Giacometti P, Diamond SG. Correspondence of electroencephalography and near-infrared spectroscopy sensitivities to the cerebral cortex using a high-density layout. Neurophotonics. 2014;1(2):025001. doi: 10.1117/1.NPh.1.2.025001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 186.Sui J, Yu Q, He H, Pearlson G, Calhoun V. A selective review of multimodal fusion methods in schizophrenia. Front Hum Neurosci. 2012;6(27) doi: 10.3389/fnhum.2012.00027. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 187.Hao X, Xu D, Bansal R, Dong Z, Liu J, Wang Z, Kangarlu A, Liu F, Duan Y, Shova S, Gerber A, Peterson B. Multimodal magnetic resonance imaging: The coordinated use of multiple, mutually informative probes to understand brain structure and function. Hum Brain Mapp. 2013;34(2):253–271. doi: 10.1002/hbm.21440. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 188.Liu J, Ghassemi M, Michael A, Boutte D, Wells W, Perrone-Bizzozero N, Macciardi F, Mathalon D, Ford J, Potkin S, Turner J, Calhoun V. An ICA with reference approach in identification of genetic variation and associated brain networks. Front Hum Neurosci. 2012;6(21) doi: 10.3389/fnhum.2012.00021. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 189.Meda S, Narayanan B, Liu J, Perrone-Bizzozero N, Stevens M, Calhoun V, Glahn D, Shen L, Risacher S, Saykin A, Pearlson G. A large scale multivariate parallel ICA method reveals novel imaginggenetic relationships for alzheimer’s disease in the ADNI cohort. NeuroImage. 2012;60(3):1608–1621. doi: 10.1016/j.neuroimage.2011.12.076. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 190.Sui J, He H, Yu Q, Chen J, Rogers J, Pearlson G, Mayer A, Bustillo J, Canive J, Calhoun V. Combination of resting state fMRI, DTI and sMRI data to discriminate schizophrenia by N-way MCCA+jICA. Front Hum Neurosci. 2013;7(235) doi: 10.3389/fnhum.2013.00235. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 191.Rubinov M, Sporns O. Complex network measures of brain connectivity: Uses and interpretations. NeuroImage. 2010;52(3):1059–1069. doi: 10.1016/j.neuroimage.2009.10.003. [DOI] [PubMed] [Google Scholar]
- 192.Yu Q, Allen E, Sui J, Arbabshirani M, Pearlson G, Calhoun V. Brain connectivity networks in schizophrenia underlying resting state functional magnetic resonance imaging. Curr Top Med Chem. 2012;12(21):2415–2425. doi: 10.2174/156802612805289890. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 193.Yu Q, Sui J, Liu J, Plis S, Kiehl K, Pearlson G, Calhoun V. Disrupted correlation between low frequency power and connectivity strength of resting state brain networks in schizophrenia. Schizophr Res. 2013;143(1):165–171. doi: 10.1016/j.schres.2012.11.001. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 194.Miller RL, Yaesoubi M, Turner JA, Mathalon D, Preda A, Pearlson G, Adalı T, Calhoun VD. Higher dimensional meta-state analysis reveals reduced resting fMRI connectivity dynamism in schizophrenia patients. PLoS ONE. 2016 Mar;11(3):1–24. doi: 10.1371/journal.pone.0149849. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 195.Lee D, Seung H. Learning the parts of objects by non-negative matrix factorization. Nature. 1999;401(6755):788–791. doi: 10.1038/44565. [DOI] [PubMed] [Google Scholar]
- 196.Yates F. The analysis of replicated experiments when the field results are incomplete. Empire J Exp Agr. 1933;1(2):129–142. [Google Scholar]
- 197.Leeuw Jde, Young FW, Takane Y. Additive structure in qualitative data: An alternating least squares method with optimal scaling features. Psychometrika. 1976;41(4):471–503. [Google Scholar]
- 198.Bro R. PARAFAC. Tutorial and applications. Chemometr Intell Lab. 1997;38(2):149–171. [Google Scholar]
- 199.Phan AH, Cichocki A. Proc ISNN 2008, Part II. Beijing, China: 2008. Fast and efficient algorithms for non-negative tucker decomposition; pp. 772–782. [Google Scholar]