

Abstract
Species from the genus Talaromyces produce useful biomass-degrading enzymes and secondary metabolites. However, these enzymes and secondary metabolites are still poorly understood and have not been explored in depth because of a lack of comprehensive genetic information. Here, we report a 36.51-megabase genome assembly of Talaromyces pinophilus strain 1–95, with coverage of nine scaffolds of eight chromosomes with telomeric repeats at their ends and circular mitochondrial DNA. In total, 13,472 protein-coding genes were predicted. Of these, 803 were annotated to encode enzymes that act on carbohydrates, including 39 cellulose-degrading and 24 starch-degrading enzymes. In addition, 68 secondary metabolism gene clusters were identified, mainly including T1 polyketide synthase genes and nonribosomal peptide synthase genes. Comparative genomic analyses revealed that T. pinophilus 1–95 harbors more biomass-degrading enzymes and secondary metabolites than other related filamentous fungi. The prediction of the T. pinophilus 1–95 secretome indicated that approximately 50% of the biomass-degrading enzymes are secreted into the extracellular environment. These results expanded our genetic knowledge of the biomass-degrading enzyme system of T. pinophilus and its biosynthesis of secondary metabolites, facilitating the cultivation of T. pinophilus for high production of useful products.
Introduction
Talaromyces pinophilus, formerly designated Penicillium pinophilum, is a fungus that produces biomass-degrading enzymes such as α-amylase1, cellulase2, endoglucanase3, xylanase2, laccase4 and α-galactosidase2. In one study, a blended enzyme cocktail produced by T. pinophilus and Chrysoporthe cubensis improved the efficiency of hydrolysis of glucan and xylan in sugarcane bagasse for glucose and xylose production, compared with enzymes from a single strain2. A relatively high level of β-glucosidase activity is observed in T. pinophilus under solid state fermentation5. Therefore, T. pinophilus is considered a potential alternative to Trichoderma reesei for cellulase production and efficient biomass hydrolysis. T. pinophilus produces a variety of medically useful metabolites such as 3-O-methylfunicone, which is used to inhibit mesothelioma cell motility6, and talaromycolides 1–3, 5 and 11, which inhibit the growth of the human pathogen methicillin-resistant Staphylococcus aureus 7.
The fungal strain T. pinophilus 1–95 was isolated from the soil of a dried, ploughed field in Wuzhou, China. This strain produces a highly efficient, calcium-independent α-amylase1. Application of calcium-independent α-amylase in starch conversion avoids problems caused by addition of calcium ions8. Additionally, we found that T. pinophilus 1–95 produces 1.21 ± 0.30 U/mL of filter-paper cellulase, 10.72 ± 0.74 U/mL of carboxymethylcellulose cellulase, 0.71 ± 0.02 U/mL of p-nitrophenyl-β-cellobioside cellulase, 0.27 ± 0.01 U/mL of p-nitrophenyl-β-glucopyranoside cellulase and 41.93 ± 2.84 U/mL of xylanase activities in submerged flask cultivation (data not shown). However, a comprehensive understanding of the biomass-degrading enzyme system in this fungus is still lacking.
We describe the de novo whole-genome assembly of T. pinophilus strain 1–95, a nearly complete genome sequence of a high biomass-degrading enzyme-producing species in the genus Talaromyces. Carbohydrate-active enzyme (CAZyme) genes and secondary metabolism gene clusters were observed in the sequenced genome. Comparative genomic analysis suggested that T. pinophilus harbors more biomass-degrading enzymes and secondary metabolites than other related filamentous fungi. In addition, the predicted secretory protein patterns of T. pinophilus 1–95 were analyzed.
Results
Genome sequencing, assembly and annotation
Genome sequencing of the fungal strain T. pinophilus 1–95 (CGMCC No. 2645), isolated from soil in a dried, ploughed field in Wuzhou, China, was performed using a combination of single molecule real-time (SMRT) DNA sequencing and next generation sequencing technology. A high-quality genome sequence of T. pinophilus 1–95 was generated on the PacBio RS II platform. Approximately 1.94 Gb of clean subreads, with sequences from a single pass of a polymerase on a single strand of an insert within a SMRTbell template and no adapter sequences with an N50 size of 10,045 bp and average length 8,102 bp were generated. Additionally, a paired-end (PE) library with a 500-bp average insert size was constructed using the Illumina HiSeq 4000 platform, and 3.88 Gb clean, short-sequence PE reads were generated with a length of 125 bp. Reads were used to correct wrong bases in the assembled genome sequence on the PacBio RS II platform. Finally, a 36.51-Mb genome of T. pinophilus 1–95 was generated with 159-fold coverage. This size was in accordance with the estimated genome size of 28–36 Mb for three Talaromyces species9–11. The genome was covered by nine scaffolds, including eight large scaffolds (accession number CP017344-CP017351 in GenBank) without gaps (Fig. 1) and a smaller circular scaffold (accession number CP017352 in GenBank). The N50 and N90 sizes of the scaffolds were, respectively, 4.80 Mb and 2.99 Mb (Table 1). Telomeric repeats (primarily 5ʹ-TTAGGG-3′) were found at both ends of all large scaffolds except for scaffold number 2, for which a telomeric repeat was only found at one end, possibly due to incompleteness of the scaffold sequence data. We inferred that the T. pinophilus 1–95 genome consisted of eight chromosomes (Fig. 1). Additionally, a smaller circular scaffold of 31.73 kb was assembled as a mitochondrial genome (Table 1). Several sequenced Penicillium and Aspergillus species such as P. oxalicum 114-212 and Aspergillus niger ATCC 101513 are also predicted to have eight chromosomes. The overall GC content of the T. pinophilus 1–95 genome was 46.23%. The GC content was 50.08% for the coding sequences and 24.84% for the mitochondrial genome. Other general features of the T. pinophilus 1–95 genome are in Table 1.
Figure 1.
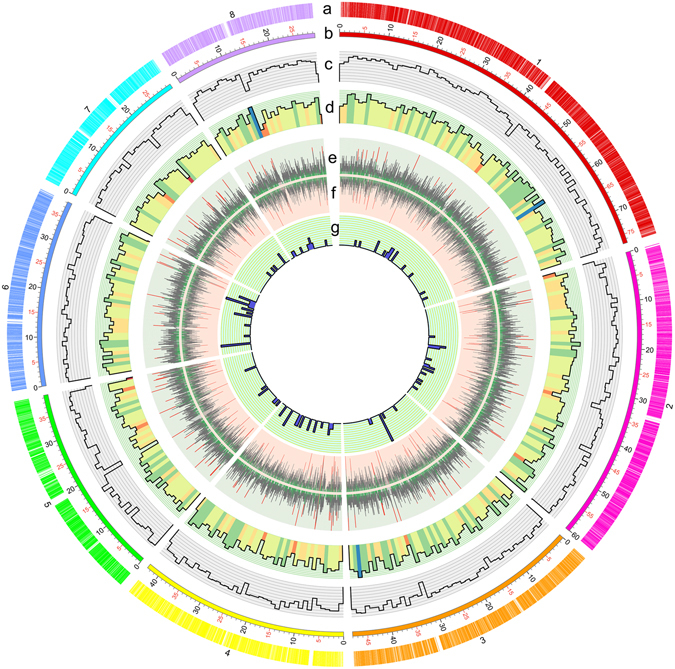
Circular map of genomic features of the T. pinophilus 1–95 genome. (a) Location of predicted genes. Numbers represent predicted chromosomes. (b) Schematic representation of genomic characteristics of T. pinophilus pseudogenome (Mb scale). (c) Gene density represented by number of genes in 100-kb nonoverlapping windows. (d) Gene density of genes annotated by the GO database in each 100-kb window. (e) Exon positions of protein-coding genes (circle). Red, exon number (>10) in a gene; green, one exon included. (f) Intron positions of protein-coding genes (circle). Red, exon number (>10) in a gene; green, no intron included. (g) The tRNA density represented by number of tRNAs in 100-kb nonoverlapping windows.
Table 1.
Genome features of Talaromyces pinophilus 1–95.
| Genome features | Value |
|---|---|
| Nuclear genome | |
| Size of assembled genome (Mbp) | 36.51 |
| GC content of assembled genome (%) | 46.25 |
| N50 Length (bp) | 4,804,168 |
| N90 Length (bp) | 2,993,891 |
| Maximum length (bp) | 7,684,667 |
| Minimum length (bp) | 2,941,929 |
| All protein-coding genes | 13,472 |
| Protein-coding genes (≥60 aa) | 13,450 |
| Average gene length (bp) | 1,602.97 |
| Average number of introns per gene | 2.07 |
| Average intron length (bp) | 75.36 |
| Average exons per gene | 3.07 |
| Average exon length (bp) | 470.18 |
| tRNA genes | 107 |
| Mitochondrial genome | |
| Size (bp) | 31,729 |
| GC content (%) | 24.84 |
| tRNA genes | 25 |
In total, 13,472 protein-coding genes were predicted from the genome assembly using five ab initio gene prediction programs: Augustus (http://bioinf.uni-greifswald.de/augustus/), GeneMark-ES (http://exon.gatech.edu/GeneMark/), Genewise (http://www.ebi.ac.uk/Tools/psa/genewise/), SNAP14 and an unsupervised learning system program Glean version 1 (https://sourceforge.net/projects/glean-gene/). The number of coding genes was significantly higher than other filamentous fungi that produce biomass-degrading enzymes (see Supplementary Table S1). Of the T. pinophilus coding genes, 8162 (60.58%), were annotated in the Gene Ontology (GO) database (http://geneontology.org/), 12,828 (95.21%) in the UniProt database (http://www.uniprot.org/), 12,946 (96.09%) in the NCBI non-redundant (NR) protein sequences database (ftp://ftp.ncbi.nlm.nih.gov/blast/db/) and 4437 (32.93%) in the Clusters of Orthologous Groups of proteins database (http://www.ncbi.nlm.nih.gov/COG/). A total of 6817 (50.6%) genes belonging to 331 pathways were also annotated in the Kyoto Encyclopedia of Genes and Genomes (KEGG) database (http://www.kegg.jp/) (see Supplementary Fig. S1). The coding regions of the predicted genes constituted almost 53.37% of the genome, with an average length of 1446.5 bp. BUSCO15 and CEGMA16 were used to evaluate the integrity of the genome assembly and prediction of gene sets. A BUSCO set for fungi comprising 1438 single-copy ortholog genes from more than 100 fungal strains was used to evaluate the genome assembly and gene sets of T. pinophilus 1–95. More than 98% of the orthologous genes matched with genes in the genome and gene sets of T. pinophilus 1–95 (see Supplementary Table S2). Using CEGMA, 238 of 248 core eukaryotic genes for fungi were completely identified by evaluating the genome assembly, and 427 of 437 eukaryotic clusters of orthologous groups were identified with an overlap rate > 0.5 when predicted gene sets were assessed (see Supplementary Table S1). These results indicated that our genome assembly and prediction of gene sets for T. pinophilus 1–95 were of high quality and confidence.
Overall genome and proteome comparison
The genome size and number of protein-encoding genes of T. pinophilus 1–95 were comparable to other sequenced filamentous fungi (see Supplementary Table S1). A phylogenetic tree constructed based on 2082 single-copy orthologs (see Supplementary Dataset S1) indicated that T. pinophilus 1–95 was most closely related to T. cellulolyticus Y-94 (Fig. 2a). Analyzing the top hits of a BLASTp (https://blast.ncbi.nlm.nih.gov/Blast.cgi) search of all-vs.-all findings showed that T. pinophilus 1–95 and T. cellulolyticus Y-94 shared 10,260 orthologous proteins, accounting for 76.16% of the total proteome, with an average amino acid sequence identity of 98.28%. In contrast, low identity was observed to other sequenced Talaromyces species17, Trichoderma sp.18, Penicillium sp.19, 20 and Aspergillus sp.13, 21, 22, ranging from 70% to 88% (see Supplementary Table S3).
Figure 2.
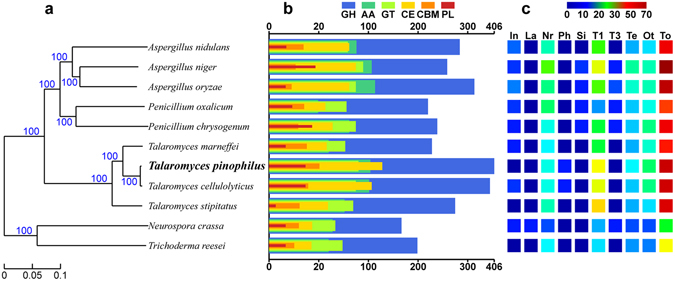
Comparative genomic analysis of T. pinophilus and other fungal species. (a) Maximum-likelihood phylogenetic tree of T. pinophilus and 10 fungal species. (b) Comparative analysis of carbohydrate-active enzyme (CAZyme) numbers. GH, glycoside hydrolase; AA, auxiliary activity; GT, glycosyl transferase; CE, carbohydrate esterase; CBM, carbohydrate-binding module; PL, polysaccharide lyase. (c) Comparative analysis of secondary metabolite gene cluster numbers. In, Indole and Indole-Nrps; La, Lantipeptide; Nr, Nrps, Nrps-Indole, Nrps-T1pks and Nrps-Terpene; Ph, Phosphonate; Si, Siderophore; T1, T1pks, T1pks-Indole and T1pks-Nrps; T3, T3pks; Te, Terpene-Nrps, Terpene-Nrps-Indole and Terpene-T1pks; Ot, Others; To, total number of secondary metabolite gene clusters. Vertical axes in (b) and (c) correspond to fungal species in (a).
The predicted proteome of T. pinophilus 1–95 was 23.84% larger than the proteome of T. cellulolyticus Y-949, whereas the genome size of 1–95 was similar to Y-94 (see Supplementary Table S1). The reason for this finding was that the genome sequencing and assembly of T. pinophilus 1–95 were of high quality (see Supplementary Table S2), partly due to the lack of gaps in the scaffolds. A comparative analysis of proteins annotated by the GO database between T. pinophilus 1–95 and T. cellulolyticus Y-94 showed functional differences between the proteins mostly for “biological regulation”, “cellular process” and “metabolic process” in the biological process category and “binding”, “catalytic activity” and “nucleic acid binding transcription factor activity” in the molecular function category (see Supplementary Fig. S2).
We used data from the PE library with an average insert size of 500 bp from T. pinophilus 1–95 to map the entire genome sequence of T. cellulolyticus Y-947. The PE reads covered 35 scaffolds with 32.06 Mb of sequence from the T. cellulolyticus Y-94 genome, resulting in 88% average coverage and 83-times average depth (see Supplementary Table S4). We found 489 genes from T. cellulolyticus Y-94 contained insertion-deletion mutations when mapping PE reads from the T. pinophilus 1–95 to the genome of T. cellulolyticus Y-94; 257 of these occurred in coding sequence regions. Only 33 of the mutated genes showed no similarity with genes in the T. pinophilus 1–95 proteome, and approximately half were annotated by the GO database as related to “oxidation-reduction”, “binding” and “catalytic activity”.
Biomass degrading machinery in T. pinophilus 1–95
Among the 13,472 unique proteins of T. pinophilus 1–95, 803 were annotated as encoding CAZymes using carbohydrate-active enzyme annotations from dbCAN23. The putative CAZymes included 72 families of glycoside hydrolases (GHs), 35 families of glycosyl transferases (GTs), 13 families of carbohydrate esterases (CEs), 10 families of auxiliary activities (AAs), 5 families of polysaccharide lyases (PLs) genes and 19 families of carbohydrate-binding modules (CBMs) (Fig. 2b). Further analysis revealed that 156 CAZymes were predicted to be plant cell wall-degrading enzymes (CWDEs), specifically 42 cellulolytic enzymes, 97 hemicellulases and 17 pectinases (Fig. 3; see Supplementary Table S5).
Figure 3.
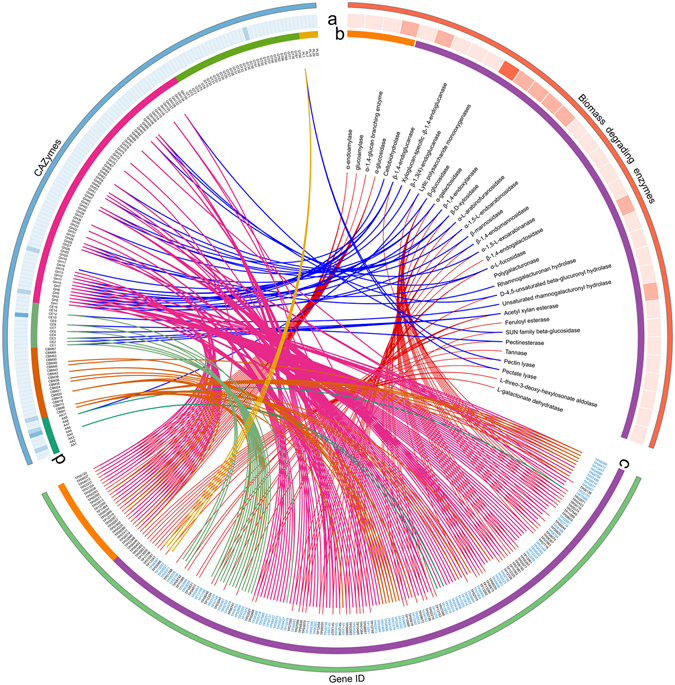
Carbohydrate-active enzyme (CAZymes) genes in T. pinophilus 1–95 including plant cell wall-degrading enzymes (CWDEs) and starch-degrading enzymes (SDEs). Blue gene IDs, secreted CWDEs and SDEs. (a) Heatmap of different enzyme types. (b,c) Orange, starch-degrading enzymes; purple, plant CWDEs. (d) Colors represent different CAZyme families.
Among the cellulolytic enzymes, 2 cellobiohydrolases (CBHs, EC 3.2.1.91), 8 β-1,4-endoglucanases (EGs, EC 3.2.1.4) and 29 β-glucosidases (BGLs, EC 3.2.1.21) were included as cellulases. Of these, the known cellulases included Cel7A-2 (TP09412), Cel5A (TP03457), Cel5B (TP07499), Cel7B (TP08514) and Bgl3A (TP09042). Compared with known filamentous fungi used for cellulase production, i.e., T. cellulolyticus Y-94 and P. oxalicum HP7-1, larger numbers of BGLs were classified into GH families 1 and 3 in the T. pinophilus 1–95 genome (see Supplementary Table S5). We examined lytic polysaccharide monooxygenases (LPMO) that catalyze the initial oxidative cleavage of recalcitrant cellulose, resulting in the slow release of oxidized oligosaccharides into solution. LPMO-cellulase synergy is beneficial for degradation of large and highly resistant crystalline cellulose24, 25. Only one, TP03971, an ortholog of Cel61A from P. oxalicum HP7–1, was identified, which was fewer than in P. oxalicum HP7–1 (see Supplementary Table S5).
The T. pinophilus 1–95 genome was rich in hemicellulose-degrading enzymes (97 genes) assigned into 29 predicted CAZyme families; this finding was compared to 77 genes in T. cellulolyticus Y-94 and 80 genes in P. oxalicum HP7–1, which includes Xyn11A (TP00436) and Xyn10A (TP06900), encoding the important β-1,4-endoxylanases. This result supports the high xylanase activity of T. pinophilus 1–95. The predicted hemicellulases in T. pinophilus 1–95 were divided into 19 types by substrate specificities. The large differences among T. pinophilus 1–95, T. cellulolyticus Y-94 and P. oxalicum HP7–1 broadly covered most of the listed hemicellulase types (see Supplementary Table S5). For instance, T. pinophilus 1–95 possessed more β-D-xylosidases (EC 3.2.1.37), acetyl xylan esterases (EC 3.1.1.72) and feruloyl esterases (EC 3.1.1.73) than the two others. β-D-xylosidases hydrolyze xylobiose or linear xylooligosaccharides to the monomer xylose. Acetyl xylan esterases liberate acetic acid esterifying position 2 and 3 on mono- and di-O-acetylated β-1,4-linked D-xylopyranosyl residues in xylan chains. Feruloyl esterases liberate trans-ferulic acid from 5-O-feruloylated L-arabinofuranosyl residues. These enzymes facilitate the hydrolysis of hemicellulose26. In contrast, the T. pinophilus 1–95 genome possessed a similar number of pectin-degrading enzymes as T. cellulolyticus Y-94 and P. oxalicum HP7–1 (see Supplementary Table S5).
T. pinophilus 1–95 produces a highly efficient, calcium-independent α-amylase1. Application of this enzyme in starch conversion might avoid the drawbacks of calcium ion addition8. Among 803 CAZymes, 24 were involved in starch degradation, while 5 to 21 were found in the other 10 investigated filamentous fungi (see Supplementary Table S6). These 24 enzymes were composed of 5 α-amylases (EC 3.2.1.1), which mainly break internal α-1,4-glucosidic linkages and some branched α-1,6-glycosidic linkages from the inner starch chain; 13 α-glucosidases (EC 3.2.1.20), which break α-1,4-linkages in mainly maltose and short maltooligosaccharides to release glucose at nonreducing ends27; 5 glucoamylases (EC 3.2.1.3), which mainly hydrolyze α-1,4-glucosidic linkages from the nonreducing ends of starch chains with the release of β-D-glucose28; and a 1,4-α-glucan branching enzyme (EC 2.4.1.18) that cleave α-1,4 glucosidic linkages of glucan chain, and then transfer the cut end to 6-position of glucose residue within the cleaved or another glucan chain, resulting the generation of an α-1,6 glucosidic linkage27, 29. Comparative analysis indicated that T. pinophilus 1–95 had more α-glucosidases and glucoamylases than the other investigated fungi (see Supplementary Table S6), supporting that it has a high capacity for starch hydrolysis1. Proteomic mass spectrometry and proteome prediction analyses indicated that TP04014 may encode a highly efficient, calcium-independent α-amylase, as reported in Xian et al.1, but this result needs to be further confirmed experimentally.
Transcription factor prediction
Transcription factors (TFs) are essential for modulating diverse biological processes by regulating gene expression. In total, 943 TFs were found in the predicted proteome of T. pinophilus 1–95. The largest family was proteins (716 members) containing zinc-finger structures, such as the Zn2Cys6 type, the C2H2 type and CCHC type, followed by the winged helix repressor DNA-binding family (97 members) (Fig. 4). TFs are used in genetic engineering to improve biomass-degrading enzyme yields. We carried out an orthology search of known TFs involved in regulation of lignocellulolytic genes in filamentous fungi against the translated proteins in the T. pinophilus 1–95 genome using an identity of 40% and an E-value threshold of 1E-10. Orthologs of most known TFs were identified in T. pinophilus 1–95, including the carbon catabolite repressor CreA (TP09972), the cellulase transcription activator CLR-2 (TP10486), the starch degradation regulator AmyR (TP09286) and the xylan degradation regulator XlnR (TP02627) (Table 2). Several related proteins include ACEII, Xpp1, ClrC and BglR, had no ortholog in T. pinophilus 1–95.
Figure 4.
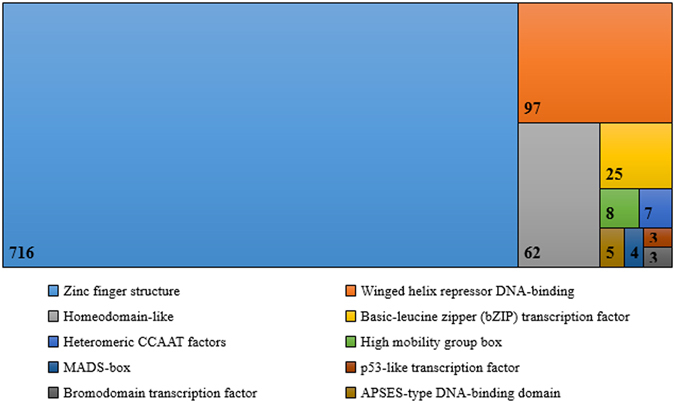
Top 10 types of predicted transcription factors in T. pinophilus 1–95.
Table 2.
Orthologs of known transcription factors involved in regulation of biomass-degrading enzyme genes in T. pinophilus 1–95.
| Protein name | Species | Accession No. | Protein ID in T. pinophilus |
|---|---|---|---|
| AceA | Penicillium oxalicum 12 | EPS27047.1 | TP12581 |
| AceII | Trichoderma reesei 50 | AAK69383.1 | Not found |
| AreA | Aspergillus nidulans 51 | CAA36731 | TP08849 |
| AraR | A. niger 52 | A2QJX5.1 | TP07534 |
| AmyR | P. oxalicum 53 | EPS29018.1 | TP09286 |
| BglR | T. reesei 54 | EGR44729.1 | Not found |
| BrlA | P. oxalicum 55 | EPS25156.1 | TP04848 |
| Clr-1 | Neurospora crassa 56 | ESA42840 | Not found |
| ClrB | P. oxalicum 53 | EPS31045.1 | TP10486 |
| ClrC | P. oxalicum 53 | EPS34061.1 | Not found |
| CreA | P. oxalicum 53 | EPS28222.1 | TP09972 |
| Hap2 | P. oxalicum 12 | EPS31428.1 | TP13257 |
| Hap3 | P. oxalicum 12 | EPS27888.1 | TP07843 |
| Hap5 | P. oxalicum 12 | EPS26080.1 | TP12862 |
| PacC | N. crassa 57 | Q7RVQ8.2 | Not found |
| FlbC | P. oxalicum 53 | EPS33410.1 | TP08156 |
| Rca1 | N. crassa 58 | XP_961398.1 | TP08385 |
| Vib1 | N. crassa 59 | XP_011394570.1 | TP06351 |
| XlnR | P. oxalicum 53 | EPS32714.1 | TP02627 |
| Xpp1 | T. reesei 60 | EGR46848.1 | Not found |
A repertoire of secondary metabolism gene clusters
We found that T. pinophilus 1–95 had a wealth of secondary metabolites using the AntiSMASH web service30. A total of 68 secondary metabolism gene clusters harboring 401 putative genes were identified. The predicted products of 52 secondary metabolism gene clusters were classified into 8 different types: 28 T1 polyketide synthase (T1PKS) gene clusters, 9 non-ribosomal peptide synthase (NRPS) gene clusters, 9 terpene gene clusters, 2 Nrps-T1pks gene clusters, 1 phosphonate gene cluster, 1 T1pks-Indole gene cluster, 1 T1pks-Nrps gene cluster and 1 Terpene-T1pks gene cluster; the remaining 16 gene clusters synthesized other unknown secondary metabolites (Fig. 2c; see Supplementary Table S7). When compared with known gene clusters for secondary metabolites, eight were predicted to produce emericellin, pestheic acid, azanigerone and azaphilone (data not shown).
The transporter and secretory system
Transporters are important in microbial growth and reproduction because they assist microbes in the uptake of nutrients and energy from the surrounding environment. In total, 1,238 genes encoding putative transporters belonging to seven superfamilies were identified in the T. pinophilus 1–95 genome (see Supplementary Dataset S2). Of these, members of the electrochemical potential-driven transporters (EPTs) were the most abundant, accounting for 54.7%, followed by primary active transporters (18.3%). Among the EPTs, 431 members of a major facilitator superfamily were selected; these are involved in the transport of substances including sugar, drugs and peptides. Of these EPTs, TP13272 and TP06909, respectively, were orthologs of the cellodextrin transporters Cdt-C and Cdt-D, which are crucial for induction of cellulase gene expression by insoluble cellulose31.
Many proteins are commonly secreted into extracellular regions, including enzymes involved in biomass degradation. A comprehensive pipeline was designed to predict the T. pinophilus 1–95 secretome. T. pinophilus 1–95 potentially secreted 1,203 extracellular proteins (8.9% of predicted total proteins), comprising 831 classical and 372 nonclassical secretory proteins (see Supplementary Dataset S3). Using KEGG annotation, 546 putatively secreted proteins were assigned, indicating that these abundant secretory proteins were mainly involved in metabolism, especially carbohydrate metabolism and xenobiotic biodegradation and metabolism (see Supplementary Fig. S3). We found that 323 of these, including 35 nonclassical secreted proteins, were present in the CAZyme database, accounting for 26.8% of the total secretome. The repertoire of secreted CAZymes consisted of 54 GH families, 18 GT families, 12 CE families, 8 AA families, 4 PL families and 13 CBM families. The most common GH family, comprising 188 enzymes, contributed to 58.2% of total secreted CAZymes, followed by the AA families (14.9%). The most prevalent GH CAZyme classes were GH7, GH3, GH5, GH10-13 and GH31, which represent cellulases, endoxylanases and amylases, all of which are required for biomass degradation. The most abundant CBM family was CBM1, accounting for 43.8% of total CBMs, which are known to bind to crystalline cellulose and aid in its enzymatic hydrolysis32.
Further analysis indicated that 82 of 323 predicted secretory CAZymes including two nonclassical proteins and six non-CAZymes were identified as CWDEs. Of these, 18 cellulases consisting of two CBHs, seven EGs and nine BGLs were investigated. These cellulases included the major CWDEs for cellulose degradation Cel7A-2 (TP09412), Cel7B (TP08415), Cel5A (TP13457), Cel5B (TP07499), Cel5C (TP08784), Cel45A (TP06957) and Bgl3A (TP09042). We also identified 62 hemicellulose-degrading enzymes and 6 pectin-degrading enzymes, including eight β-1,4-endoxylanases, nine acetyl xylan esterases, four α-galactosidases, 10 α-L-arabinofuranosidases, five α-L-fucosidases, one endo-1,4-β-mannanase and four feruloyl esterases, as well as two pectin esterases, two tannases, one pectate lyase and one pectin lyase (see Supplementary Dataset S3). In addition to CWDEs, 10 starch-degrading enzymes were found in the predicted secretome of T. pinophilus 1–95: four α-amylases, one glucoamylase and five α-glucosidases (see Supplementary Dataset S3).
Discussion
A systematic genetic investigation of filamentous fungi would contribute to genetic engineering of more diverse and productive industrial microbial strains for improving cellulolytic enzyme production. We sequenced, assembled and analyzed the entire T. pinophilus 1–95 genome in detail. T. pinophilus is a promising filamentous fungus for the industrial production of biomass-degrading enzymes. This study describes the nearly complete genome sequence of a member of the genus Talaromyces. The total assembled genome size was 36.51 Mb, which was within the range of filamentous fungi that produce cellulolytic enzymes, including Penicillium, Aspergillus, Trichoderma and Neurospora species.
Comparative genome analysis indicated that the most closely related species to T. pinophilus 1–95 was T. cellulolyticus Y-94. T. cellulolyticus Y-94 was identified as T. pinophilus based on only an internal transcribed spacer sequence33. It was proposed as the new species T. cellulolyticus in the genus based on morphological and phenotypic differences from T. pinophilus 34. The reported genome sequence of Y-94 is a draft with a number of gaps9. In this study, a nearly complete genome sequence of T. pinophilus 1–95 was obtained. The number of protein-encoding genes in T. pinophilus was higher than in other investigated fungal strains. This result may be because of the presence of more genes or the result of high-quality SMRT DNA sequencing technology and a different methodology for gene prediction. In particular, a large inventory of CAZymes was found, including CWDEs and starch-degrading enzymes. This result supported the high capacity of this species to degrade biomass, comparable to T. cellulolyticus Y-9435 and P. oxalicum HP7-120. Of note, T. pinophilus 1–95 possessed the most BGLs (29 coding genes), glucoamylases (5 coding genes) and α-glucosidases (13 coding genes) among species we compared. BGLs are important for releasing inhibition of cellulase activity36. Furthermore, the predicted secretome of T. pinophilus 1–95 showed that approximately 50% of CWDEs and starch-degrading enzymes were secreted into the extracellular region, including major cellulases, hemicellulases and amylases. This result indicated a promising application of T. pinophilus in biorefining. These results also demonstrated that T. pinophilus 1–95 is more excellent cellular machinery for biomass-degrading enzymes than that of P. oxalicum HP7–1 and T. cellulolyticus Y-94 as previously observed20, 35, meriting further study.
Comparative analysis to 10 filamentous fungi from four genera, Talaromyces, Trichoderma, Penicillium and Aspergillus, indicated that T. pinophilus 1–95 possessed the most secondary metabolism gene clusters except for A. niger and A. oryzae. T. pinophilus 1–95 had more T1PKs than Trichoderma sp., Penicillium sp. and Aspergillus sp., and fewer NRPS than Aspergillus species. These results suggested that T. pinophilus 1–95 has potential for producing bioactive secondary metabolites. Although thus far, several bioactive secondary metabolites have been extracted and characterized from T. pinophilus 6, 7, according to the genomic data, additional secondary metabolites could be generated using this species.
In summary, this study provided a nearly complete genome sequence for the genus Talaromyces. The result provided new insights for a comprehensive understanding of the biomass-degrading enzyme system of Talaromyces at the genome level. Detailed comparative genomic analysis revealed a complex biomass-degrading enzyme system in T. pinophilus, indicating its promising application in biomass biorefineries. This study provides a genome-sequence basis for developing strategies that use T. pinophilus as a microbial cell factory for production of high-value enzymes and secondary metabolites.
Materials and Methods
Culture conditions and genomic DNA extraction
T. pinophilus 1–95 was isolated from soil in a dried, ploughed paddy field in Wuzhou, China1 and was deposited at the China General Microbiological Culture Collection Center (CGMCC) under accession number CGMCC No. 2645. Total DNA extraction from mycelia was performed using a phenol-chloroform method with some modifications37. Mycelia were ground in liquid nitrogen and put in 1 mL lysate reagent (40 mM Tris-HCl, 20 mM sodium acetate, 10 mM ethylenediaminetetraacetic acid, and 1% sodium dodecyl sulfate, pH 8.0) per 100 mg mycelia powder. Genomic DNA was collected by centrifugation at 11,300 × g for 10 min.
Genome sequencing and assembly
The T. pinophilus strain 1–95 genome was sequenced using a PacBio RS II platform and Illumina HiSeq 4000 platform at the Beijing Genomics Institute (BGI, Shenzhen, China). Four SMRT cells zero-mode waveguide arrays of sequencing, were used by the PacBio platform to generate the subreads set. PacBio subreads (length < 1 kb) were removed. The program Pbdagcon (https://github.com/PacificBiosciences/pbdagcon) was used for self-correction. Draft genomic unitigs, which are uncontested groups of fragments, were assembled using the Celera Assembler38 against a high-quality corrected circular consensus sequence subreads set. Order, distance and orientation of unitigs and combined scaffolds were generated using software SSPACE39. An upgraded draft genome was obtained after filling or reducing as many captured gaps as possible using software PBJelly40. To improve the accuracy of the genome sequences, GATK (https://www.broadinstitute.org/gatk/) and SOAP tool packages (SOAP2, SOAPsnp, SOAPindel)41, 42 were used to make single-base corrections.
A DNA library of 500 bp inserts was constructed and PE sequenced. For generated HiSeq reads, Q20, representing the probability of the incorrectness of the corresponding base call, was detected. If Q20 reads accounted for less than 60%, they were discarded. Software Pilon43 used reasonable PE sequence data from Illumina libraries to perform comprehensive variant detection and improve genome assembly.
Gene detection and functional annotation
Protein-coding genes in the T. pinophilus 1–95 genome were predicted independently with the gene prediction programs Augustus (http://bioinf.uni-greifswald.de/augustus/), GeneMark-ES (http://exon.gatech.edu/GeneMark/), Genewise (http://www.ebi.ac.uk/Tools/psa/genewise/), SNAP14, and the unsupervised learning system program Glean (https://sourceforge.net/projects/glean-gene/) version 1. Augustus and SNAP, using default parameters, were trained on gene models for A. oryzae, P. oxalicum, T. marneffei and T. stipitatus (see Supplementary Table S1). Programs GeneWise and GeneMark-ES were used to obtain different gene sets and worked in a self-training manner. Finally, all prediction gene sets were integrated by Glean.
For functional annotation of translated proteins in the T. pinophilus 1–95 genome, a BLASTp version 2.2.28+ search against the NCBI NR database (update 05, 2015) and Swiss-Prot and TrEMBL databases (http://www.mrc-lmb.cam.ac.uk/genomes/madanm/pres/swiss2.htm) (update 01, 2016) and KEGG database (http://www.kegg.jp/) version 76, were used to assign general protein function profiles. We used cut-off E-value ≤ 1e-5, overlap 0.4 and identity 30. InterProScan5 (http://www.ebi.ac.uk/interpro/), stand-alone version 55, and GO (http://geneontology.org/) were also used to annotate the predicted proteome. TFs were predicted based on InterPro IDs in the Fungal Transcription Factor Database (http://ftfd.snu.ac.kr/). The hmmsearch program in the HMMER 3.1b2 package (http://hmmer.org/), was used to search all predicted proteomes with the family-specific hidden Markov model profiles of CAZymes from the dbCAN database26. Primary results were processed with an E-value threshold of 1E-7. Protein kinases and phosphatases were detected using hmmsearch based on the Eukaryotic Kinase and Phosphatase Database (http://ekpd.biocuckoo.org/). Membrane transport proteins were classified and identified by a BLASTp search against the transport classification database44, with E-value threshold 1E-10, overlap 0.4 and identity of 30. AntiSMASH30 was used to annotate secondary metabolism gene clusters.
Phylogenetic analysis
An all-against-all pairwise BLASTp similarity search was performed using proteomes from 11 filamentous fungi (see Supplementary Table S2) with E-value cutoff 1E-7, according to the method described previously45. We selected 2,082 single-copy genes from 118,099 genes in 11 fungal genomes. MUSCLE (http://www.ebi.ac.uk/Tools/msa/muscle/) version 3.7 with default parameters was used to perform multiple sequence alignment of single-copy genes. A neighbor-joining tree was calculated using TreeBeST46 with bootstrapping set to 100. The phylogenetic tree was visualized using SVGKit (http://svgkit.sourceforge.net/) and PERL scripts.
Secretome prediction
The total set of 13,472 proteins of T. pinophilus strain 1–95 was analyzed using Secretome P47 v1.0 and SignalP48 v4.0 for ab initio prediction of classical and nonclassical secretory proteins, except for 11 proteins with more than 4,000 amino acid residues. All proteins containing signal peptides were selected, with proteins without signal peptides chosen as candidates in cases of neural network score ≥ 0.6. All selected proteins were analyzed by TargetP49 v1.1 with localization = secretory pathway and RC≤ 4 as screening criteria. Protein sets were scrutinized for the presence of transmembrane domains using TMHMM v2.0 (http://www.cbs.dtu.dk/services/TMHMM/) and for glycosylphosphatidyl inositol anchors use web server PredGPI (http://gpcr.biocomp.unibo.it/predgpi/). Software tRNAscan-SE (http://lowelab.ucsc.edu/tRNAscan-SE/) version 1.3 was used for transfer RNA prediction using the T. pinophilus 1–95 genome with option C and other default parameters.
Electronic supplementary material
Supplementary Infromation for SREP-16-39329
Acknowledgements
This work was financially supported by grants from the Guangxi BaGui Scholars Program Foundation (grant number 2011A001), the ‘One Hundred Person’ Project of Guangxi, and Excellent Teaching Program of Guangxi High Education-Program of Advantageous and Characteristic Specialty (Excellent Undergraduate Major). We thank the Beijing Genomics Institute (Shenzhen, China) for physical sequencing of Talaromyces pinophilus 1–95 genome and the software support.
Author Contributions
J.X.F. designed and supervised the research, involved in data analysis, and prepared the manuscript. S.Z. prepared the manuscript and involved in data analysis. C.X.L. sequenced and analyzed genome data. T.Z. and L.S.L. extracted genomic DNA and assayed the enzyme activity. L.X. and J.L.L. were involved in data analysis. All the authors have approved the manuscript.
Competing Interests
The authors declare that they have no competing interests.
Footnotes
Cheng-Xi Li and Shuai Zhao contributed equally to this work.
Electronic supplementary material
Supplementary information accompanies this paper at doi:10.1038/s41598-017-00567-0
Accession Codes: This Whole Genome Shotgun project has been deposited at DDBJ/ENA/GenBank under the accession LSFK00000000.1, and the 8 chromosomes and the mitochondrial genome have been assigned accession numbers CP017344-CP017352. The BioProject ID in GenBank is PRJNA310372.
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
References
- 1.Xian L, Wang F, Luo X, Feng YL, Feng JX. Purification and characterization of a highly efficient calcium-independent alpha-amylase from Talaromyces pinophilus 1–95. PLoS One. 2015;10:e0121531. doi: 10.1371/journal.pone.0121531. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2.Visser EM, Falkoski DL, de Almeida MN, Maitan-Alfenas GP, Guimarães VM. Production and application of an enzyme blend from Chrysoporthe cubensis and Penicillium pinophilum with potential for hydrolysis of sugarcane bagasse. Bioresour Technol. 2013;144:587–594. doi: 10.1016/j.biortech.2013.07.015. [DOI] [PubMed] [Google Scholar]
- 3.Pol D, Laxman RS, Rao M. Purification and biochemical characterization of endoglucanase from Penicillium pinophilum MS 20. Indian J Biochem Biophys. 2012;49:189–194. [PubMed] [Google Scholar]
- 4.Dhakar K, Jain R, Tamta S, Pandey A. Prolonged laccase production by a cold and pH tolerant strain of Penicillium pinophilum (MCC 1049) isolated from a low temperature environment. Enzyme Res. 2014;2014:120708. doi: 10.1155/2014/120708. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Elnaggar EA, Haroun SA, Oweis EA, Sherief AA. Identification of newly isolated Talaromyces pinophilus and statistical optimization of glucosidase production under solid-state fermentation. Prep Biochem Biotech. 2014;45:712–729. doi: 10.1080/10826068.2014.943375. [DOI] [PubMed] [Google Scholar]
- 6.Buommino E, et al. Cell-growth and migration inhibition of human mesothelioma cells induced by 3-O-Methylfunicone from Penicillium pinophilum and cisplatin. Invest New Drug. 2012;30:1343–1351. doi: 10.1007/s10637-011-9698-1. [DOI] [PubMed] [Google Scholar]
- 7.Zhai MM, et al. Talaromycolides A-C, novel phenyl-substituted phthalides isolated from the green chinese onion-derived fungus Talaromyces pinophilus AF-02. J Agr Food Chem. 2015;63:9558–9564. doi: 10.1021/acs.jafc.5b04296. [DOI] [PubMed] [Google Scholar]
- 8.Haki GD, Rakshit SK. Developments in industrially important thermostable enzymes: a review. Bioresour Technol. 2003;89:17–34. doi: 10.1016/S0960-8524(03)00033-6. [DOI] [PubMed] [Google Scholar]
- 9.Fujii T, Koike H, Sawayama S, Yano S, Inoue H. Draft genome sequence of Talaromyces cellulolyticus strain Y-94, a source of lignocellulosic biomass-degrading enzymes. Genome Announc. 2015;3:e00014–15. doi: 10.1128/genomeA.00014-15. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10.Hu L, et al. Draft genome sequence of Talaromyces verruculosus (“Penicillium verruculosum”) strain TS63-9, a fungus with great potential for industrial production of polysaccharide-degrading enzymes. J Biotechnol. 2016;219:5–6. doi: 10.1016/j.jbiotec.2015.12.017. [DOI] [PubMed] [Google Scholar]
- 11.Schafhauser T, et al. Draft genome sequence of Talaromyces islandicus (“Penicillium islandicum”) WF-38-12, a neglected mold with significant biotechnological potential. J Biotechnol. 2015;211:101–102. doi: 10.1016/j.jbiotec.2015.07.004. [DOI] [PubMed] [Google Scholar]
- 12.Liu G, et al. Genomic and secretomic analyses reveal unique features of the lignocellulolytic enzyme system of Penicillium decumbens. PLoS One. 2013;8:e55185. doi: 10.1371/journal.pone.0055185. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13.Andersen MR, et al. Comparative genomics of citric-acid-producing Aspergillus niger ATCC 1015 versus enzyme-producing CBS 513.88. Genome Res. 2011;21:885–897. doi: 10.1101/gr.112169.110. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14.Korf I. Gene finding in novel genomes. BMC Bioinformatics. 2004;5:1–9. doi: 10.1186/1471-2105-5-59. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 15.Sim AFO, Waterhouse MR, Ioannidis P, Kriventseva VE, Zdobnov ME. BUSCO: assessing genome assembly and annotation completeness with single-copy orthologs. Bioinformatics. 2015;31:3210–3212. doi: 10.1093/bioinformatics/btv351. [DOI] [PubMed] [Google Scholar]
- 16.Parra G, Bradnam K, Ning Z, Keane T, Korf I. Assessing the gene space in draft genomes. Nucleic Acids Res. 2009;37:289–297. doi: 10.1093/nar/gkn916. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17.Nierman, W. C., Fedorovaabrams, N. D. & Andrianopoulos, A. Genome sequence of the AIDS-associated pathogen Penicillium marneffei (ATCC18224) and its Near taxonomic relative Talaromyces stipitatus (ATCC10500). Genome Announc3 (2015). [DOI] [PMC free article] [PubMed]
- 18.Martinez D, et al. Genome sequencing and analysis of the biomass-degrading fungus Trichoderma reesei (syn. Hypocrea jecorina) Nat Biotechnol. 2008;26:553–560. doi: 10.1038/nbt1403. [DOI] [PubMed] [Google Scholar]
- 19.Specht T, Dahlmann TA, Zadra I, Kürnsteiner H, Kück U. Complete sequencing and chromosome-scale genome assembly of the industrial progenitor strain P2niaD18 from the penicillin producer Penicillium chrysogenum. Genome Announc. 2014;2:e00577–14. doi: 10.1128/genomeA.00577-14. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20.Zhao S, et al. Comparative genomic, transcriptomic and secretomic profiling of Penicillium oxalicum HP7-1 and its cellulase and xylanase hyper-producing mutant EU2106, and identification of two novel regulatory genes of cellulase and xylanase gene expression. Biotechnol Biofuel. 2016;9:203. doi: 10.1186/s13068-016-0616-9. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Galagan JE, et al. Sequencing of Aspergillus nidulans and comparative analysis with A. fumigatus and A. oryzae. Nature. 2005;438:1105–1115. doi: 10.1038/nature04341. [DOI] [PubMed] [Google Scholar]
- 22.Zhao G, et al. Draft genome sequence of Aspergillus oryzae strain 3.042. Eukaryot Cell. 2012;11:1178–1178. doi: 10.1128/EC.00160-12. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23.Yin Y, et al. dbCAN: a web resource for automated carbohydrate-active enzyme annotation. Nucleic Acids Res. 2012;40:W451. doi: 10.1093/nar/gks479. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24.Eibinger M, et al. Cellulose surface degradation by lytic polysaccharide monooxygenase and its effect on cellulase hydrolytic efficiency. J Biol Chem. 2014;289:35929–35938. doi: 10.1074/jbc.M114.602227. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25.Kracher D, et al. Extracellular electron tranfer systems fuel cellulose oxidative degradation. Science. 2016;352:1098–1101. doi: 10.1126/science.aaf3165. [DOI] [PubMed] [Google Scholar]
- 26.Biely P, Singh S, Puchart V. Towards enzymatic breakdown of complex plant xylan structures: state of the art. Biotechnol Adv. 2016;34:1260–1274. doi: 10.1016/j.biotechadv.2016.09.001. [DOI] [PubMed] [Google Scholar]
- 27.Møller MS, Svensson B. Structural biology of starch-degrading enzymes and their regulation. Curr Opin Struc Biol. 2016;40:33–42. doi: 10.1016/j.sbi.2016.07.006. [DOI] [PubMed] [Google Scholar]
- 28.Marín-Navarro J, Polaina J. Glucoamylases: structural and biotechnological aspects. Appl Microbiol Biotechnol. 2011;89:1267–1273. doi: 10.1007/s00253-010-3034-0. [DOI] [PubMed] [Google Scholar]
- 29.Li WW, et al. Retrogradation behavior of corn starch treated with 1,4-α-glucan branching enzyme. Food Chem. 2016;203:308–313. doi: 10.1016/j.foodchem.2016.02.059. [DOI] [PubMed] [Google Scholar]
- 30.Weber T, et al. antiSMASH 3.0-a comprehensive resource for the genome mining of biosynthetic gene clusters. Nucleic Acids Res. 2015;43:237–243. doi: 10.1093/nar/gkv437. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 31.Li J, et al. Cellodextrin transporters play important roles in cellulase induction in the cellulolytic fungus Penicillium oxalicum. Appl. Microbiol Biotechnol. 2013;97:10479–10488. doi: 10.1007/s00253-013-5301-3. [DOI] [PubMed] [Google Scholar]
- 32.Duan CJ, Feng YL, Cao QL, Huang MY, Feng JX. Identification of a novel family of carbohydrate-binding modules with broad ligand specificity. Sci Rep. 2016;6:19392. doi: 10.1038/srep19392. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 33.Houbraken, J., de Vries, R. P. & Samson, R. A. Modern taxonomy of biotechnologically important Aspergillus and Penicillium species (ed. Sima Sariaslani, S. & Gadd, G. M.) 86, 199-249 (Elsevier, 2014). [DOI] [PubMed]
- 34.Fujii T, Hoshino T, Inoue H, Yano S. Taxonomic revision of the cellulose-degrading fungus Acremonium cellulolyticus nomen nudum to Talaromyces based on phylogenetic analysis. FEMS Microbiol Lett. 2014;351:32–41. doi: 10.1111/1574-6968.12352. [DOI] [PubMed] [Google Scholar]
- 35.Inoue H, Decker SR, Taylor LE, 2nd, Yano S, Sawayama S. Identification and charaterization of core cellulolytic enzymes from Talaromyces cellulolyticus (formerly Acremonium cellulolyticus) critical for hydrolysis of lignocellulosic biomass. Biotechnol Biofuel. 2014;7:151. doi: 10.1186/s13068-014-0151-5. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 36.Gusakov AV. Alternatives to Trichoderma reesei in biofuel production. Trends Biotechnol. 2011;29:419–425. doi: 10.1016/j.tibtech.2011.04.004. [DOI] [PubMed] [Google Scholar]
- 37.Sun X, Liu Z, Qu Y, Li X. The effects of wheat bran composition on the production of biomass-hydrolyzing enzymes by Penicillium decumbens. Appl Biochem Biotechnol. 2008;146:119–128. doi: 10.1007/s12010-007-8049-3. [DOI] [PubMed] [Google Scholar]
- 38.Myers EW, et al. A whole-genome assembly of Drosophila. Science. 2000;287:2196–2204. doi: 10.1126/science.287.5461.2196. [DOI] [PubMed] [Google Scholar]
- 39.Boetzer M, Pirovano W. SSPACE-LongRead: scaffolding bacterial draft genomes using long read sequence information. BMC Bioinformatics. 2014;15:211. doi: 10.1186/1471-2105-15-211. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40.English AC, et al. Mind the gap: upgrading genomes with Pacific Biosciences RS long-read sequencing technology. PLoS One. 2012;7:e47768–e47768. doi: 10.1371/journal.pone.0047768. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41.Li R, et al. SNP detection for massively parallel whole-genome resequencing. Genome Res. 2009;19:545–552. doi: 10.1101/gr.089789.108. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42.Li R, et al. SOAP2: an improved ultrafast tool for short read alignment. Bioinformatics. 2009;25:1966–1967. doi: 10.1093/bioinformatics/btp336. [DOI] [PubMed] [Google Scholar]
- 43.Walker BJ, et al. Pilon: an integrated tool for comprehensive microbial variant detection and genome assembly improvement. PLoS One. 2014;9:e112963. doi: 10.1371/journal.pone.0112963. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44.Jr SM, Reddy VS, Tamang DG, Västermark A. The transporter classification database. Nucleic Acids Res. 2014;42:251–258. doi: 10.1093/nar/gkt1097. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Kim EB, et al. Genome seqeucing reveals insights into physiology and longevity of the naked mole rat. Nature. 2011;479:223–227. doi: 10.1038/nature10533. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46.Vilella AJ, et al. EnsemblCompara GeneTrees: complete, duplication-aware phylogenetic trees in vertebrates. Genome Res. 2009;19:327–335. doi: 10.1101/gr.073585.107. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47.Bendtsen JD, Jensen LJ, Blom N, Von HG, Brunak S. Feature-based prediction of non-classical and leaderless protein secretion. Protein Eng Des Sel Peds. 2004;17:349–356. doi: 10.1093/protein/gzh037. [DOI] [PubMed] [Google Scholar]
- 48.Petersen TN, Brunak S, Von HG, Nielsen H. SIGNALP 4.0: discriminating signal peptides from transmembrane regions. Nat Methods. 2011;8:785–786. doi: 10.1038/nmeth.1701. [DOI] [PubMed] [Google Scholar]
- 49.Emanuelsson O, Nielsen H, Brunak S, Heijne GV. Predicting subcellular localization of proteins based on their N-terminal amino acid sequence. J Mol Biol. 2000;300:1005–1016. doi: 10.1006/jmbi.2000.3903. [DOI] [PubMed] [Google Scholar]
- 50.Aro N, Saloheimo A, Ilmen M, Penttila M. ACEII, a novel transcriptional activator involved in regulation of cellulase and xylanase genes of Trichoderma reesei. J Biol Chem. 2001;276:24309–24314. doi: 10.1074/jbc.M003624200. [DOI] [PubMed] [Google Scholar]
- 51.Lockington RA, Rodbourn L, Barnett S, Carter CJ, Kelly JM. Regulation by carbon and nitrogen sources of a family of cellulases in Aspergillus nidulans. Fungal Genet Biol. 2002;37:190–196. doi: 10.1016/S1087-1845(02)00504-2. [DOI] [PubMed] [Google Scholar]
- 52.Battagliae E, et al. Regulation of pentose utilisation by AraR, but not XlnR, differs in Aspergillus nidulans and Aspergillus niger. Appl Microbiol Biotechnol. 2011;91:387–397. doi: 10.1007/s00253-011-3242-2. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 53.Li ZH, et al. Synergistic and dose-controlled regulation of cellulase gene expression in Penicillium oxalicum. PLoS Genet. 2015;11:e1005509. doi: 10.1371/journal.pgen.1005509. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 54.Nitta M, et al. A new Zn(II)(2)Cys(6)-type transcription factor BglR regulates beta-glucosidase expression in Trichoderma reesei. Fungal Genet Biol. 2012;49:388–397. doi: 10.1016/j.fgb.2012.02.009. [DOI] [PubMed] [Google Scholar]
- 55.Qin Y, et al. Penicillium decumbens BrlA extensively regulates secondary metabolism and functionally associates with the expression of cellulase genes. Appl Microbiol Biotechnol. 2013;97:10453–10467. doi: 10.1007/s00253-013-5273-3. [DOI] [PubMed] [Google Scholar]
- 56.Coradetti ST, et al. Conserved and essential transcription factors for cellulase gene expression in ascomycete fungi. P Natl Acad Sci USA. 2012;109:7397–7402. doi: 10.1073/pnas.1200785109. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57.Tilburn J, et al. The Aspergillus PacC zinc finger transcription factor mediates regulation of both acid- and alkaline-expressed genes by ambient pH. EMBO J. 1995;14:779–790. doi: 10.1002/j.1460-2075.1995.tb07056.x. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58.Wang B, et al. A transcriptomic analysis of Neurospora crassa using five major crop residues and the novel role of the sporulation regulator rca-1 in lignocellulase production. Biotechnol Biofuel. 2015;8:21. doi: 10.1186/s13068-015-0208-0. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59.Xiong Y, Sun JP, Glass NL. VIB1, a link between glucose signaling and carbon catabolite repression, is essential for plant cell wall degradation by Neurospora crassa. PLoS Genet. 2014;10:e1004500. doi: 10.1371/journal.pgen.1004500. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60.Mach-Aigner AR, Grosstessner-Hain K, Pocas-Fonseca MJ, Mechtler K, Mach RL. From an electrophoretic mobility shift assay to isolated transcription factors: a fast genomic-proteomic approach. BMC Genomics. 2010;11:644. doi: 10.1186/1471-2164-11-644. [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supplementary Infromation for SREP-16-39329